
Abstract
Emotions remain a fertile field of research. Thanks to newly available technology, investigating people’s preferences, emotions and feelings is relevant for different purposes and perspectives. Consequently, the exploration of emotion has stimulated specialised software development. This paper presents a snapshot of currently available computational tools for analysing emotions. We also explore and compare their contributions and use them complementarily to characterise a corpus. The study presented here combines several emotion analysis tools to examine and characterise a corpus of political debates. Specifically, 34 British House of Commons debates on the war in Ukraine have been examined to identify the lexicon associated with the emotions articulated by parliamentarians in a situation of maximum political conflict, such as war, and to provide a global overview of the most common terms used, to express emotion and feeling. Using corpus pragmatics, a comprehensive overview of the corpus is obtained, as it allows the analysis of considerable amounts of data, studied from a pragmatics perspective, for the characterisation of emotion in terms of meaning and use.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Emotions are a complex area of research, as they are influenced by their contexts of use (interculturality) and lexical constraints (ethnopragmatics). Their study is relevant for different purposes (psychological, neurological, linguistic, computer science, etc.) and has been approached from several perspectives: Natural Language Processing, Discourse Analysis, etc. To examine large amounts of data, texts are often mined from social networks and the internet (Periñan Pascual, 2017, 2018, 2019; Sailunaz et al., 2018).
Emotions are expressed in different settings that shape them; for instance, in governmental contexts, emotions are readily appealed to by political opponents and audiences (Crabtree et al., 2020; Mestre-Mestre, 2021). In this sense, political discourse has been described as conveying passionate emotions based on confrontation and power (Chilton & Schäffner, 1997; van Dijk, 2005, 2010).
This is even more obvious in times of extreme conflict, when mixed feelings of anger, solidarity, and fear are emphasised and spread in the political arena, which also opens the ground for populist discourse (Rico et al., 2017). The current confrontation in political debate, exacerbated by the crisis in Ukraine, invites an examination of the political discussion traditionally characterised by notions of power, conflict, and subordination (Bourdieu, 1991; Giddens, 1991; van Dijk, 2003, 2010).
A valuable approach for discourse analysis is corpus pragmatics, which allows analysing large amounts of data with the accuracy and precision of pragmatics (Romero-Trillo, 2008), thus enabling the researcher to conduct in-depth studies of corpora. Some tools that support this type of study are analysed here, as newly developed software to analyse emotion allows the combination of available computational tools to address more complete studies. Four tools have been used to complete the analysis; two software packages (Linguistic Inquiry and Word Count (LIWC) (2001), Sentiment Analysis and Social Cognition Engine (SEANCE) based on existing databases (SenticNet)), and two lexicons (NRC Word-Emotion Association Dictionary (Emolex), (2010) and Merriam-Webster Learner Dictionary).
The broad research question is how can several existing tools be combined to complete an analysis of emotions expressed in a corpus of political discourse. For this, what pragmatic data can be extracted with the existing technological tools in an emotion corpus analysis? Are results obtained by using these tools coincidental and/or complementary so that they can provide a global characterisation of the corpus from a pragmatic point of view? Additionally, regarding the corpus, how is political debate characterised in terms of emotion, and what are the most common emotions expressed in the parliamentary discussion in England referring to the war between Ukraine and Russia?
So, the derived objectives are to explore the tools that can be used for a corpus pragmatic analysis of emotions expressed in political debate, to evaluate individually the results each emotion analysis instrument can provide; and to combine all the tools for a global characterisation and to identify any inconsistencies.
The paper is organised as follows: after this introduction, the state of the art is explained, providing a characterisation of political debate, corpus pragmatics and emotion, as well as a brief mention of the tools used for the examination. The methodology section then describes the corpus and the tools used for the study. This is followed by the results and conclusions sections.
State of the Art
The theoretical background in this section includes the grounding of the investigation and stretches from the subject matter analysed, political discourse, to the theorisation of corpus pragmatics and its use to analyse emotion, as the specific subject of interest, each addressed in a different subsection. A brief description of the tools used for the analysis concludes it.
Political Discourse. Parliamentary Debate
Power, ideology, dominance and conflict have been highlighted as core to the political discussion (Giddens, 1991; Bourdieu, 1991; Fairclough, 1995; Chilton & Schäffner, 1997; van Dijk, 1993, 1997, 2003, 2005, 2010; Ferrer Garcia, 2016; Wilson, 1990, 1991). However, it has been argued (Chilton, 2004; Fairclough & Fairclough, 2012) that the relationship between cooperation and conflict is at the core of politics, as debate and discussion are structured around political ideology. Hence, politics is a fight for power but also cooperation to resolve divergence, looking for empathy and support. Regarding this, some works signal the recurrent use of emotions as a rhetorical tool in political contexts. Cislaru (2012) highlights fear and anger as the two basic emotions used to stimulate political debate, consistent with Brader’s (2005) claim of the use of emotion to influence citizens and stir vote.
Van Dijk’s characterisation of political discourse (1997) relates it directly to its context of production: discourse issued by politicians outside a political context is not to be considered political discourse. In our present circumstance, the irruption of extreme-right ideology in many European parliaments is metamorphosing political discourse, which is becoming more hostile and normalising negative emotions and reactions (Valentim & Widmann, 2021, 2021; Widmann, 2021). This phenomenon also occurs in times of severe gravity, marked by an armed conflict. In times of war, because of extreme situations and questionable acts on the side of authorities, emotions can be made more explicit in political arenas, where representatives position themselves and express their views more vehemently.
New circumstances derived from technology and other causes (political confrontation, post-pandemic conditions, economic crisis, unique needs or new political proposals) are changing how politicians communicate. On top of this, we face moments of great political enervation due to war in a neighbouring country. After many years of peace in Europe, military conflict has made it necessary for the other countries in the continent and surrounding area to position themselves regarding political, economic or military support. Indeed, a critical framework that conditions political discourse is dissemination. Political debate is undeniably shaped by the recording of sessions, worldwide broadcasting and transcribing, and massive distribution through media and social media, which makes asynchronous and repeated access possible. When they debate, politicians consider the broader audience that can see or hear them in the last moments (Albalat-Mascarell and Carrió-Pastor, 2019; Stier et al., 2017; Druckman et al., 2010; Brader, 2005). Some studies point to the breaking of communication maxims to achieve a more significant effect (Hess-Lüttich, 2007; Cuenca & Marín, 2006; Marín Jordà, 2006).
In general terms, Pragmatics studies communication processes, considering the contexts of interaction and mainly focusing on functions, not forms. It has traditionally endorsed a universalist paradigm aimed at finding norms and rules that could be used for all languages and settings. Two main approaches exist to study emotion from a pragmatic perspective: the cross-cultural (ethnopgragmatic) perspective (Ekman, 2003; Gladkova & Romero-Trillo, 2014; Goddard, 2014; Romero-Trillo & Fuentes, 2017; Wierzbicka, 2004), which pursues the finding of lexical universals; and the intercultural perspective (Taguchi, 2017; Kecskes, 2014; Wierzbicka, 1994), which searches common norms of conduct for interaction between interlocutors considered ‘members of a social community’ (Kecskes, 2015:43).
The emotional dimensions of language have traditionally been addressed from a functional perspective (Halliday, 1975; Jakobson, 1960). Apart from pragmatics, other linguistic perspectives have looked into emotion, such as discourse analysis and expression (Bamberg, 1997; Caffi & Janney, 1994; Fitzgerald & Austin, 2008) or literature (Guy et al., 2018; Lynch, 2022; Oatley, 2022). Pepin (2008) claims that emotions have a public character, and are resources for actions as well as co-constructed social phenomena. However, a robust conceptualisation of the notion of emotion is still necessary, as most studies look into one particular issue related to the expression of emotion: conversation, other-repetition, etc., or given interactional settings.
Due to their complexity, detailed explanations of the concept of emotion have also been elaborated from other perspectives. In psychology, emotions involve physiological changes, cognitive processes, action tendencies, and subjective feelings. Different approaches look into their dimensions (Planalp, 1999), components, acquired expressions (Damasio, 2003), categorisation (Schwarz-Friesel, 2015), etc.
Corpus studies manage large amounts of linguistic data. One of the main theoretical and philosophical developments in Corpus Linguistics is its combination with Pragmatics. This approach prompts the compilation and analysis of large quantities of data with the contextualised scrutiny of Pragmatics. The theoretical development of the approach was presented in the seminal volume edited by Romero-Trillo (2008), who asserts that "corpus linguistics and pragmatics are two versions of the same linguistic phenomenon: mechanics and its interpretation" (Romero-Trillo, 2008: 5–6). Corpus Pragmatics has grounded thought-provoking studies on many subjects, such as varietal communication (Avila-Ledesma, 2019; Degenhardt & Bernaisch, 2022), interculturality and identity (Hathaway, 2021; Lee, 2019), multi-modality (Knight & Adolphs, 2008; Huang, 2021), or second language (Romero-Trillo, 2018) or lingua franca use (Mestre-Mestre & Díez-Bedmar, 2022), to cite but a fiew.
Technological Tools to Study Emotion
Analyses of emotion data have also been completed from non-linguistic perspectives. For instance, the automatic (machine) extraction of semantic information, which is categorised under different approaches: subjectivity (Lyons, 1981), opinion mining and sentiment analysis (Pang & Lee, 2008), or affect (Batson et al., 1992). From a computer science perspective, sentiment analysis has proposed different views to analyse enormous amounts of text. In natural language processing coexist proposals based on statistics—frequentist or Bayesian (Navigli & Velardi, 2004; Sclano & Velardi, 2007), text processing (named entity recognition, segmentation, part-of-speech tagging, parsing, etc.), feature extraction, or the classification algorithm (rule-based and machine learning-based methods, etc.).
Some sentiment analysis tools use vector representations to characterise collections of words and phrases that occur in a corpus, using machine-learning algorithms that find patterns of use based on polarity (positive or negative texts). The two basic approaches for developing these vectors are domain-dependent (text classification approach), where the vectors are designed and tested within a specific corpus drawn from a particular domain, or domain-independent (lexical-based approach), in which vectors are developed from general lists of sentiment words and phrases that can be applied to numerous disciplines (Hogenboom et al., 2010). Although domain-dependent approaches can support more detailed studies when used for a particular domain, their reliability drops when working with broader dictionaries or general word lists without a specific reference domain.
As a detailed description of the tools used for the analysis is provided in the methodology section, we will merely mention four tools used for our analysis; Linguistic Inquiry and Word Count (LIWC), by Pennebaker et al., (2001), accessible at https://liwc.wpengine.com/, Mohammad & Turney’s, 2010 Word-Emotion Association Lexicon (NRC), in https://saifmohammad.com/WebPages/NRC-Emotion-Lexicon.htm, Sentiment Analysis and Social Cognition Engine (SEANCE), by Crossley et al. (2017), accessible at https://www.linguisticanalysistools.org/seance.html, and the Merriam-Webster Learner Dictionary (https://www.merriam-webster.com).
Materials and Method
Four tools to study emotion have been used to examine discourse in political debate using a corpus pragmatics approach. The interest of the study was the expression of emotion in a time of war in Ukraine and Russia. The particularities of the corpus compiled for analysis and the method used to investigate it are described below.
Corpus
The corpus compiled for the study consists of 34 parliamentary sessions of the House of Commons of Great Britain held between January 1st, 2022 and April 07th, 2022. They were obtained from Hansard, the official account of Parliamentary debates in the UK. The site collects all interventions in Parliament dating back over 200 years. Sessions are recorded and edited to avoid repetitions or errors and subsequently published. Hansard also reports on the votes of the MP. All sessions can be downloaded from the site, which displays them in two separate publications, one for each House of the Parliament: Commons Hansard and Lords Hansard. The sessions analysed in the present study represent a corpus of 308,888 tokens and 11617 types. Sessions vary in length, ranging from around 200 to a little over 29,000 words. The texts have been analysed in a combined form.
Tools Used in the Analyses
Technological tools have supported and expanded the study of linguistic data from different perspectives. In this sense, studying emotions in various contexts has boosted the development of new software as an emerging area of interest. A snapshot of the tools available for the computer-aided analysis of emotion presents proposals based on Natural Language Processing and just available for corpus analysis.
After examination, the ones useful for the present study are four. One of the first tools developed to study linguistic data was Linguistic Inquiry and Word Count (LIWC),Footnote 1 by Pennebaker et al., (2001). Originally based on the English language, it has been translated to other languages (Spanish, German, or Portuguese, for instance). LIWC is based on lists that employ rating scales for emotion, affect and personal concerns. Writings are classified according to text types, and emotions are identified correspondingly. The database is populated with the introduction of texts fed for evaluation. This nurturing allows both re-rating texts and improving lists of emotions, affects and concerns. The LIWC-22 version allows the analysis of words, word stems, and emoticons. It claims to make a finer distinction between broad sentiment and more targeted emotion, compared to previous versions where all affect dictionaries were labelled as “affect” or “emotion”. It analyses over 100 validated dimensions of text. It includes three instruments: dictionaries (both internal and external, at choice), category lists (for the selection of particular sets), and a segmentation tool to design the text size aimed for analysis. Most LIWC-22 output variables are percentages of total words within a text, supported by robust descriptive statistical analyses based on the 15 text types used (ranging from movies to Twitter entries). Each word is compared to the existing dictionaries, and subsequent standard deviations are calculated. In the present study, all words in the corpus have been analysed to determine first the number of terms related to emotion and affection, and then some particular categories more specifically linked to emotion: ‘emotion: positive’, ‘emotion: negative’, ‘anxiety’, ‘anger’, and ‘sad’.
The second tool chosen for the analysis is the Sentiment Analysis and Social Cognition Engine (SEANCE)Footnote 2, by Crossley et al. (2017). As LIWC, it only operates with English, but unlike it, it is freely available. The tool includes a negation feature based on Hutto and Gilbert (2014), which checks for negation words in the three terms preceding a target word and part-of-speech identification features. SEANCE is based on previous dictionaries and word-vectors taken from pre-existing databases, such as SenticNet (Cambria et al., 2010; Cambria et al., 2012) or Emolex (Mohammad & Turney, 2010, 2013). Twenty component scores related to sentiment, social cognition, and social order are the foundation of this tool. SEANCE version 1.2.0 includes the spaCy NLP framework for part-of-speech (POS) tagging. Table 1 provides an overview of the categories reported in SEANCE and the source databases that document each category.
At the outset of this tool, after a significant data collection process of thousands of texts, all the words contained within were categorised according to the criteria of 3–4 judges to fit into those set categories. The number of words per category varies and depends on the existing terms in the pre-elaborated dictionary. Table 2 displays the categories used for our study, as well as the number of words (stop word lists) each contains for identification.
The third resource utilised in the present research is an enormous glossary; Mohammad & Turney’s, 2010 Word-Emotion Association Lexicon (NRC)Footnote 3. This is an inventory of English words associated with eight basic emotions (anger, fear, anticipation, trust, surprise, sadness, joy, and disgust) and two sentiments (negative and positive). Manual annotations by crowdsourcing feed this lexicon. A particularity of this tool is that it Google translates an English database of words to other languages. The latest version, used for the present study, contained 14,182 unigrams (words), and approximately 25,000 word senses.
Finally, the Merriam-Webster Learner Dictionary is a reference lexicon of 72 basic emotion words. This is a universalisation of Oatley’s, 1989 list of emotion words, which he initially divided into seven groups, depending on their semantic classification: (a) generic emotions, (b) basic emotions, (c) emotional relations, (d) caused emotions, (e) causatives, (f) emotional goals, (g) complex emotions. Adding on this, the list collects words that reflect Cowen & Keltner’s, 2017 inventory of 27 disaggregated emotions. The list of words used for the analysis is displayed in Table 3:
Results
In this section, the results of the successive analyses will be displayed, detailing and comparing the contribution of each tool to the final overview. This allows for a global visualisation of outcomes, permitting an exhaustive relation of complementary results and conclusions. First of all, to identify positive and negative emotions mentioned by MPs in their debates, a corpus-based analysis (Tognini-Bonelli, 2001) was completed using the Merriam Webster lexicon. The purpose was to identify utterances coincidental with the list of 72 basic emotion words proposed in the dictionary. Laurence Anthony’s (2015) (8.5.15) AntConc was used for this. The outcome of this first analysis is displayed in Fig. 1.

Positive and negative emotion words in the corpus
As seen in the graph, most emotions expressed in the corpus are positive, mainly related to feelings of joy (209 occurrences) and generosity (55). In their debates, MPs also expressed, to a lesser extent, some negative emotions, such as “fear” (43) or “horror” (18). Considering all emotion words uttered, two-thirds of emotions spotted are positive, and the remaining one-third are negative.
We then proceeded to compare these with the results available after using SEANCE, which, as mentioned above, uses pre-existing databases for corpus analysis. In our case, the dictionary list of Harvard IV-4 used by The General Inquirer (GI; Stone et al., 1966) was selected. Here, semantic categories are identified from different perspectives, linguistic, sociologic, political and psychologic. An example of the results obtained for the corpus analysed is given in Table 4.
Here too, positive and negative emotions are grouped, taking the classification proposed by SEANCE: Positive, Negative, Hostile, Strong, Power, Weak, Pleasure, Pain and Feel. In this case, the categories consider the eigenvalues obtained for each component analysed, based on vector representation, so that the results are representative. Figure 2 displays their specific distribution.

Distribution of emotion using SEANCE as analysis tool
This was also a corpus-based analysis (Tognini-Bonelli, 2001), but based on a different set of words. Looking at the results, 71% of emotions expressed in the corpus are positive. These results are strikingly similar to the ones obtained with the previous tool. However, it must be pointed out that the dictionary lists SEANCE utilises for analysis vary considerably in the number of words included within. Indeed, as can be seen in Table 5, there exists a significant disparity between the number of words analysed in each category. Also, in some cases, the exclusion criteria are specified (for instance, the category “feeling” excludes “pain” and “pleasure”), identifying less fierce emotions; in others, the emotions included in the lists are made explicit (pleasure includes interest and involvement). Although SEANCE claims that it contains all words related to each category, no exhaustive list of terms included in the analysis is provided. A total of 1915 positive words are included in the database, while the number of negative words is 2291. The words that appear in the corpus are identified, but not their exact percentages and proportions. In addition, regarding the number of positive and negative words and looking at the specific components of the groups, it is observed that in the first analysis, the most commonly used positive terms are hope and generosity, but in the second analysis, the terms identified are related to strength. Comparing such dissimilar classifications seems problematic.
To complement the two previous corpus-based examinations, a corpus-driven (Tognini-Bonelli, 2001) analysis of the corpus was completed. In this examination, positive and negative emotion words were identified, departing from the existing categories: “emo_pos”, “emo_neg”, “emo_anx”, “emo_anger”, “emo_sad” (positive emotion, negative emotion, anger, sadness, and anxiety). Of the proposed initial five categories, only words in the positive and negative emotion groups were identified. In particular, 1349 tokens referring to 225 negative emotions and 1257 tokens identifying 104 terms for positive emotions. In these results, percentages for both groups near 50%, which enlightens us about the variety of terms, but not so much about their frequency or intensity.
For this, another analysis was completed with LWIC, which permits the usual relative frequency rating, establishing the precise percentage of words that appear in the texts, allowing for a general vision of the emotion words used, as well as their distribution. LWIC also displays the percentage of terms compared to the global amount, and in raw counts of terms, which permits the identification of words with exceptional weight in the texts analysed. As for the meaning extraction method used by this tool, after pre-processing, word categories are organised hierarchically (Chung & Pennebaker, 2008). Hence, for instance, words belonging to the category “anger” are categorised as negative emotion words, pertaining, in turn, to the class emotion words (Markowitz, 2021). Results are obtained in word clouds, which allow an upfront view of outstanding words in the contexts analysed, as seen in Fig. 3 and the positioning of emotion words in the general context, as compared to other kinds of terms, allowing for the interpretation of the global significance of such words as compared to the bulk of the corpus.

Word cloud of the corpus using LWIC-22.
As seen in the image, emotion words play little role in the global count. Very few terms can be identified in the word cloud: “hope”, “aggression”, “grateful”, “threat”, and “vulnerable”. Here, it is difficult to see whether the number of positive and negative occurrences are balanced globally. However, besides the expected words related to politics (“government”, “minister”, “secretary”, “house”, etc.), additional terms related to feelings and views, such as “solidarity”, “support”, or “humanitarian” outstand. This could be related to the term “generosity”, obtained in a previous study. In Table 5 are displayed words with at least 14 occurrences in the corpus, in order of magnitude:
The range of words is thought-provoking, as the MPs use different degrees of intensity to express emotion. Clearly, although a greater range of terms is used to talk about negative emotions, positive words are more generally used. Indeed, the most commonly used term in the entire corpus is related to positive emotion: “hope”, which almost doubles the second one, “good”.
Considering that political discourse only occurs in political arenas (Van Dijk, 1997), an analysis of the narrative arch of the texts was completed using LWIC. Based on claims that narrators use a distinctive account of their stories, utilising unique patterns and structures to communicate orally (Boyd et al., 2020). According to these authors, communicators use “staging” language to introduce their speeches; once they have gained the floor, their speech is transformed to introduce “plot progression” words, meant to engage audiences in their stories, and, towards the climax of their story, words which produce “cognitive tension” are chosen. These three ideas are used in LIWC-22 to map out in the discourses staging, plot progression and cognitive tension, to characterise the texts analysed in terms of positivity and negativity. The outcome relative to the narrative arch of the corpus points to a weak degree of narrative along both the positive and negative dimensions. On the contrary, the corpus rates quite below average (− 27.35 for positive emotion and − 24.94 for negative, when the average score is 30.53).
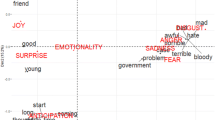
Once the terms that refer to positive and negative emotions are identified, from the corpus-based and corpus-driven analyses, one last tool, Emolex, allows us to look into their degree of intensity, as not all express emotions with the same strength. Indeed, one of the features of this tool is the emotion-intensity score, which relates all words identified in the corpus to eight basic emotions (anger, fear, anticipation, trust, surprise, sadness, joy, and disgust), and calculates for each term the degree of likelihood to the emotion(s) they represent. That is, calculations are carried out for each expression to provide the specific normalised quotient of proximity to the emotion it expresses. Estimates are normalised to 1. Some examples are provided in Table 6, where it can be seen that some terms, such as “courage”, only refer to the emotion “trust”, with a high quotient of belonging (almost 0.7), whereas “shame” can be referred to “fear” to a lesser degree (0.3), and more clearly to “disgust” (0.5), and “sadness” (0.6). This information is visually represented in Fig. 4, where a combination of all variables has been used to describe the degree of likelihood of one term to one particular emotion, different emotions conveyed by the same term and how these are distributed along the continuum representing all eight emotions analysed by the tool, in a widespread manner, but expressing, in general, quite average numbers.

Negative emotion-intensity score using EMOLEX
For instance, “confusion” falls near “frustration”, as a representation of “anger”, but embodies it to a lower degree. The paramount representative of this emotion in the corpus is “horror”, which also expresses “fear”, “disgust”, or “sadness”. According to the calculations completed using this tool, the emotion best described by the term “horror” is “fear”. In this sense, it can be observed in Fig. 5 that positive words used by the politicians are more exact in expressing the positive emotions they try to project since their quotients display much higher numbers.

Positive emotion-intensity score using EMOLEX
Indeed, the degree of proximity of these terms to the emotions they represent ranges higher than the terms in the previous graph. However, the terms seem to be less polysemic or less able to convey more than one emotion in the debates, appearing that the words chosen to express positive emotion are more precise. The variety of terms is less common than the variety found in negative emotion.
All through the research, an issue which seems to present a certain inconsistency is the way emotion words are grouped into categories. Similarly, two categories, sentiment vs emotion, seem to be used in a somewhat flexible way. In the distribution proposed by SEANCE, the results are unbalanced towards the use of emotion words in a much more consistent way than those used to express sentiment. This is not surprising, as they use 49 words to spot feeling and 311 to identify emotion. Unclear boundaries between the uses of the concepts of sentiment and emotion seem to be used depending on the tool utilized. Indeed, LWIC refers to positive and negative emotions and emotion categories, while Emolex refers to them as positive and negative sentiments derived from given emotions.
Finally, although the interest of the study does not fall on the particular issues discussed in the sessions, dwelling on the debates allows the identification of the concerns of politicians about the situation in Ukraine due to the war, and the contexts in which these emotion words were pronounced. This was completed with the word categories provided by SEANCE, in this case “Econ_2_GI”, “Milit_GI”, “Polit_GI”, and “Coll_GI”. Fig. 6 displays the information obtained.

Main issues discussed in Parliament during the sessions, using SEANCE
The majority of words used during the sessions (more than half of the entire corpus) were related to politics themselves, to the political debate, and not necessarily to the exceptionality of the war, military issues, or problems related to human groups and logistics, which might also explain the narrative arch of the sessions.
Conclusions
Four different linguistic analysis tools have been used to complete a Corpus Pragmatics study of a corpus, consisting of 34 sessions carried out in the House of Commons of the UK Parliament. The consecutive analyses shed light on the types of emotions that can be identified in political discussion. Conclusions derived relate to the type of analysis that can be completed with these tools, the complementarity of such analyses, and the characterisation of the corpus analysed.
Regarding the types of analysis, the consecutive studies offer some interesting outcomes. On the one hand, although the tools are helpful to analyse corpora, they focus on different aspects and utilise dissimilar analysis parameters, which can obstruct a comparison of the results obtained and, even more, a complementary analysis of results. Indeed, the Merriam-Webster list permits a corpus-based analysis of the corpus, while SEANCE uses extensive semantic categories. However, results obtained relative to the percentage of positive and negative emotion words used are similar.
Also, following the semantic category analysis and vector representation, positive words used in the debates triple the negative (based on the Harvard IV dictionary), mainly for terms related to power and strength, which is consistent with the analysis based on the Merriam-Webster list, which identifies two-thirds of positive emotion words in all the words analysed.
In this sense, LWIC clarifies the results by showing that, although the tokens detected are similar in number, they are not so in the frequency of use. The contribution of this tool is that it permits a corpus-based analysis, useful to identify the most salient terms in any given corpus. Interestingly, looking at the analyses based on the word frequencies (both raw and relative), it seems clear that politicians express a larger range of negative emotions and use greater variety of terms to voice them.
Finally, Emolex permits the identification of the degree of proximity or belonging of each emotion word to eight identified emotions and positive or negative sentiments by calculating the normalised quotient of the likelihood of such emotion words. This way, it is possible to identify the emotion words used and the intensity of the choice of words. However, considering the analysis completed to identify the degree of likelihood of the terms expressed, it seems clear that the positive emotion terms uttered are much more intense and much more deeply related to the emotions they signify than the negative terms. Also, it seems that the degree of variation used to express positive emotion is lesser than that used to express negative emotion since a smaller number of words is used globally.
Contrary to what could be expected, considering the type of text and how it is organised, the narratives included in the debates are slightly marked from an emotional perspective. In the discussions examined, the aim pursued by politicians was not to raise emotional attachments or appeal to passion through the use of emotion words but to develop a structured, politically armed chronicle, as most communications show a small proportion of emotion words and a narrative of the speeches below average in terms of positive or negative emotion. Consistent with this, most terms used in the debate fall into the category of politics.
Finally, regarding the results for terms considered as emotions or feelings, whereas emotions can be defined as complex psychological states, sentiments can be defined as mental attitudes and thoughts influenced by emotion. It is not the purpose of the present paper to contribute to the description and clarification of “emotion”. However, in some cases, the uncertainty in using the terms “emotion” and “sentiment” in the different tools contrasted obstructs a global understanding of results, since classifications are not coincidental and sometimes lead to ceretain contradiction. Also, some interpretations of the use of terms are possible. The category Feel includes 49 words describing particular feelings, including gratitude, apathy, and optimism, but not those of pain or pleasure. Some tools define sentiments as positive or negative; in others, emotions are used interchangeably with feelings. Moreover, in some cases, the interpretation depends on the context of use of a given term, which can express positive and negative polarities depending on the position, or the intention of the speaker. Further studies related to emotion and feeling are necessary, as well as studies which take context into consideration to identify nuisances and polarities.
Notes
Accessible at: https://www.liwc.app/.
Accessible at: https://www.linguisticanalysistools.org/seance.html.
Accessible at: https://saifmohammad.com/WebPages/NRC-Emotion-Lexicon.htm).
References
Albalat-Mascarell, A., & Carrió-Pastor, M. L. (2019). Self-representation in political campaign talk: A functional metadiscourse approach to self-mentions in televised presidential debates. Journal of Pragmatics, 147, 86–99. https://doi.org/10.1016/j.pragma.2019.05.011
Anthony, L. (2015). AntConc (8.5.15) [Computer Software]. Waseda University. Available from https://www.laurenceanthony.net/software
Avila-Ledesma, N. E. (2019). “Believe my word dear father that you can’t pick up money here as quick as the people at home thinks it”: Exploring migration experiences in irish emigrants’ letters. Corpus Pragmatics, 3, 101–121. https://doi.org/10.1007/s41701-018-00051-8
Bamberg, M. (1997). Language, concepts and emotions: The role of language in the construction of emotions. Language Sciences, 19(4), 309–340. https://doi.org/10.1016/S0388-0001(97)00004-1
Batson, C. D., Shaw, L. L., & Oleson, K. C. (1992). Differentiating affect, mood, and emotion: Toward functionally based conceptual distinctions. Sage.
Bourdieu, P. (1991). Language and symbolic power. Polity.
Boyd, R. L., Blackburn, K. G., & Pennebaker, J. W. (2020). The narrative arc: Revealing core narrative structures through text analysis. Science Advances, 6(32), 1–9. https://doi.org/10.1126/sciadv.aba2196
Brader, T. (2005). Striking a responsive chord: How political ads motivate and persuade voters by appealing to emotions. American Journal of Political Science, 49(2), 388–405.
Caffi, C., & Janney, R. W. (1994). Toward a pragmatics of emotive communication. Journal of Pragmatics, 22, 325–373.
Cambria, E., Havasi, C., & Hussain, A. (2012). SenticNet 2: A semantic and affective resource for opinion mining and sentiment analysis. In G. M. Youngblood, & P.M. Mcarthy (Eds.), Proceedings of the 25th Florida artificial intelligence research society conference (202–207). AAAI Press
Cambria, E., Speer, R., Havasi, C., & Hussain, A. (2010). SenticNet: A publicly available semantic resource for opinion mining. In C. Havasi, D. Lenat, & B. Van Durme (Eds.), Commonsense knowledge: Papers from the AAAI fall symposium (pp. 14–18). AAAI Press.
Chilton, P. (2004). Analysing political discourse. London: Routledge.
Chilton, P., & Schäffner, C. (1997). Discourse and politics. In T. van Dijk (Ed.), Discourse as social interaction (pp. 206–230). Sage.
Chung, C. K., & Pennebaker, J. W. (2008). Revealing dimensions of thinking in open-ended self-descriptions: An automated meaning extraction method for natural language. Journal of Research in Personality, 42(1), 96–132. https://doi.org/10.1016/j.jrp.2007.04.006
Cislaru, G. (2012). Emotions as a rhetorical tool in political discourse. In M. Zaleska (Ed.), Rhetoric and politics (pp. 107–126). Cambridge University Press.
Cowen, A. S., & Keltner, D. (2017). Self-report captures 27 distinct categories of emotion bridged by continuous gradients. Proceedings of the national academy of sciences USA, 19, 114(38), E7900–E7909. https://doi.org/10.1073/pnas.1702247114.
Crabtree, C., Golder, M., Gschwend, T., & Indridason, I. H. (2020). It is not only what you say, it is also how you say it: The strategic use of campaign sentiment. The Journal of Politics, 82(3), 1044–1060.
Crossley, S. A., Kyle, K., & McNamara, D. S. (2017). Sentiment analysis and social cognition engine (SEANCE): An automatic tool for sentiment, social cognition, and social-order analysis. Behavior Research Methods, 49(3), 803–821. https://doi.org/10.3758/s13428-016-0743-z
Cuenca, M. J., & Marín, M. J. (2006). Estratègies d’inici de torn en el debat electoral. Journal of Catalan Studies, 20–47
Damasio, A. (2003). Looking for Spinoza: Joy, sorrow and the feeling brain. Harcourt Brace.
Degenhardt, J., & Bernaisch, T. (2022). Apologies in South Asian varieties of English: A corpus-based study on Indian and Sri Lankan English. Corpus Pragmatics, 6, 201–223. https://doi.org/10.1007/s41701-022-00117-8
Van Dijk, T. (2010). Political identities in parliamentary debates. In C. Ilie (Ed.) European parliaments under scrutiny. Discourse strategies and interaction practices (pp. 29–56). John Benjamins
Druckman, J. N., Kifer, M. J., & Parkin, M. (2010). Timeless strategy meets new medium: Going negative on congressional campaign web sites, 2002–2006. Political Communication, 27(1), 88–103. https://doi.org/10.1080/10584600903502607
Ekman, P. (2003). Emotions revealed. Recognizing faces and feelings to improve communication and emotional life. Times Books.
Fairclough, N. (1995). Critical discourse analysis. Longman.
Fairclough, I., & Fairclough N. (2012). Political discourse analysis: A method for advanced students. London: Routledge.
Ferrer García, D. (2016). Anàlisi crítica dels topoi en el discurs polític. Fòrum De Recerca, 2, 383–404.
Fitzgerald, R., & Austin, H. (2008). Accusation, mitigation and resisting guilt in talk. The Open Communication Journal, 2, 93–99.
Giddens, A. (1991). Modernity and self identity. Polity.
Gladkova, A., & Romero-Trillo, J. (2014). Ain’t it beautiful? The conceptualization of beauty from an ethnopragmatic perspective. Journal of Pragmatics, 60, 140–159.
Goddard, C. (2014). Interjections and emotion with special reference to “surprise” and “disgust.” Emotion Review, 6, 53–63.
Guy, J. M., Conklin, K., & Sanchez-Davies, J. (2018). Literary stylistics, authorial intention and the scientific study of literature: a critical overview. Language and Literature, 27(3), 196–217.
Halliday, M. A. K. (1975). Learning how to mean. Edward Arnold.
Hathaway, Y. (2021). “They made us into a race. We made ourselves into a people”: A corpus study of contemporary black American group identity in the non-fictional writings of Ta-Nehisi Coates. Corpus Pragmatics, 5, 313–334. https://doi.org/10.1007/s41701-021-00101-8
Hess-Lüttich, E. W. B. (2007). (Pseudo-)Argumentation in TV-debates. Journal of Pragmatics, 39(8), 1360–1370. https://doi.org/10.1016/j.pragma.2007.04.008
Hogenboom, A., Hogenboom, F., Kaymak, U., Wouters, P., & De Jong, F. (2010). Mining economic sentiment using argumentation structures. Advances in conceptual modeling—Applications and challenges (200–209). Springer.
Huang, L. (2021). Toward multimodal corpus pragmatics: Rationale, case, and agenda. Digital Scholarship in the Humanities, 36(1), 101–114.
Hutto, C. J., & Gilbert, E. (2014). Vader: A parsimonious rule-based model for sentiment analysis of social media text. In E. Adar, & P. Resnick (Eds.), Proceedings of the eighth international AAAI conference on weblogs and social media (216–225). AAAI Press
Jakobson, R. (1960). Closing statements: Linguistics and poetics. In Th. A. Seboek (Ed.), Style in language (pp. 350–377). MIT Press.
Kecskes, I. (2014). Intercultural pragmatics. New York: Oxford University Press.
Kecskes, I. (2015). Intercultural impoliteness. Journal of Pragmatics, 86, 43–47. https://doi.org/10.1016/j.pragma.2015.05.023
Knight, D., & Adolphs, S. (2008). Multi-modal corpus pragmatics: The case of active listenership. Pragmatics and corpus linguistics, 175–190
Lee, C. (2019). Current issues in intercultural pragmatics. Corpus Pragmatics, 3, 205–209. https://doi.org/10.1007/s41701-018-00047-4
Lynch, A. (2022). The history of emotions and literature. In P. C. Hogan, B. J. Irish, & L. Pandit Hogan (Eds.), The Routledge companion to literature and emotion. Routledge Literature Companions. Taylor and Francis Ltd.
Lyons, J. (1981). Language and linguistics. Cambridge University Press.
Marín Jordá, M. J. (2006). Cortesia lingüística i debat electoral”. In J. L. Blas Arroyo, Á. M. Casanova, & M. Velando Casanova (Eds.), Discurso y sociedad: contribuciones al estudio de la lengua en contexto social (pp. 677–686). Universitat Jaume I.
Markowitz, D. M. (2021). The meaning extraction method: An approach to evaluate content patterns from large-scale language data. Frontiers in Communication. https://doi.org/10.3389/fcomm.2021.588823
Mestre-Mestre, E. M. (2021). Emotion and sentiment polarity in parliamentary debate: A pragmatic comparative study. Corpus Pragmatics, 5, 359–377. https://doi.org/10.1007/s41701-021-00103-6
Mestre-Mestre, E., & Díez-Bedmar, B. (2022). Expressing emotion: A pragmatic analysis of L1 German and L1 Brazilian Portuguese English as a lingua franca users. Revista española de lingüística aplicada, 35(2), 675–705.
Mohammad, S. M., & Turney, P. D. (2010). Emotions evoked by common words and phrases: Using mechanical Turk to create an emotion lexicon. In Proceedings of the NAACL HLT 2010 workshop on computational approaches to analysis and generation of emotion in text (26–34). Association for Computational Linguistics
Mohammad, S. M., & Turney, P. D. (2013). Crowdsourcing a word–emotion association lexicon. Computational Intelligence, 29, 436–465.
Navigli, R., & Velardi, P. (2004). Learning domain ontologies from document warehouses and dedicated web sites. Computational Linguistics, 30(2), 151–179.
Oatley, K. (1989). The language of emotions: An analysis of a semantic field. Cognition and Emotion, 3(2), 81–123.
Oatley, K. (2022). Character and emotion in fiction. In P. C. Hogan, B. J. Irish, & L. Pandit Hogan (Eds.), The Routledge companion to literature and emotion. Routledge Literature Companions. Taylor and Francis Ltd.
Pang, B., & Lee, L. (2008). Opinion mining and sentiment analysis. Foundations and trends. Information Retrieval, 2, 1–135.
Periñán Pascual, C. (2017). A knowledge-based approach to social sensors for environmentally-related problems. In 1st international workshop on intelligent systems for agriculture production and environment protection
Periñán Pascual, C. (2018). The analysis of tweets to detect natural hazards. In 2nd international workshop on intelligent systems for agriculture production and environment protection
Periñán Pascual, C. (2019). Detecting environmentally-related problems on Twitter. Biosystems Engineering, 177, 31–48.
Pennebaker, J. W., Francis, M. E., & Booth, R. J. (2001). Linguistic inquiry and word count. Mahwah: Erlbaum Publishers.
Pepin, N. (2008). Studies on emotions in social interactions. Bulletin Suisse de Linguistique Appliquée (VALS-ASLA) (Swiss association of applied linguistics), 88, 1–18.
Planalp, S. (1999). Communicating emotion: Social. Cambridge (Cambridge University Press).
Rico, G., Guinjoan, M., & Anduiza, E. (2017). The emotional underpinnings of populism: How anger and fear affect populist attitudes. Swiss Political Science Review, 23(4), 444–461.
Romero-Trillo, J. (2008). Introduction: Pragmatics and corpus linguistics-a mutualistic entente. In J. Romero-Trillo (Ed.), Pragmatics and corpus linguistics: A mutualistic entente. Mouton de Gruyter
Romero-Trillo, J. (2018). Corpus pragmatics and second language pragmatics: A mutualistic entente in theory and practice. Corpus Pragmatics, 2, 113–127. https://doi.org/10.1007/s41701-018-0031-5
Romero-Trillo, J., & Fuentes, V. (2017). What is pretty cannot be beautiful? A corpus-based analysis of the aesthetics of nature. In J. Blochowiak, C. Grisot, S. Durrleman-Tame, & C. Laenzlinger (Eds.), Formal models in the study of language (pp. 415–430). Springer.
Sailunaz, K., Dhaliwal, M., Rokne, J., & Alhajj, R. (2018). Emotion detection from text and speech: A survey. Social Network Analysis and Mining. https://doi.org/10.1007/s13278-018-0505-2
Schwarz-Friesel, M. (2015). Language and emotion.https://doi.org/10.1075/ceb.10.08sch
Sclano, F., & Velardi, P. (2007). TermExtractor: A web application to learn the shared terminology of emergent web communities. In: Proceedings of the 3rd international conference on interoperability for enterprise software and applications I-ESA 2007
Stier, S., Posch, L., Bleier, A., & Strohmaier, M. (2017). When populists become popular: Comparing Facebook use by the right-wing movement Pegida and German political parties. Information, Communication and Society, 20(9), 1365–1388.
Stone, P., Dunphy, D. C., Smith, M. S., Ogilvie, D. M., & Associates. (1966). The general inquirer: A computer approach to content analysis. Cambridge: MIT Press.
Taguchi, N. (2017). Interlanguage pragmatics. In A. Barron, P. Grundy, & G. Yueguo (Eds.), The Routledge handbook of pragmatics (pp. 153–167). Oxford/New York: Routledge.
Tognini-Bonelli, E. (2001). Corpus linguistics at work. John Benjamins.
Valentim, V., & Widmann, T. (2021). Does radical-right success make the political debate more negative? Evidence from emotional rhetoric in German State Parliaments. Political Behavior. https://doi.org/10.1007/s11109-021-09697-8
Van Dijk, T. (1993). El poder y los medios de comunicación. Periodística, 6, 11–38.
Van Dijk, T. (1997). What is political discourse analysis? Belgian Journal of Linguistics, 11(1), 11–52.
Van Dijk, T. (2003). Political discourse and ideology. Doxa, 1, 2017–2025.
Van Dijk, T. (2005). War rhetoric of a little ally: Political implicatures and Aznar’s legitimatization of the war in Iraq. Journal of Language and Politics, 4(1), 65–91.
Widmann, T. (2021). How emotional are populists, really? Factors explaining emotional appeals in the communication of political parties. Political Psychology, 42(1), 163–181.
Wierzbicka, A. (1994). Emotion, language, and cultural scripts. In S. Kitayama & H. R. Marcus (Eds.), Emotion and culture (pp. 133–196). American Psychological Association.
Wierzbicka, A. (2004). Preface: Bilingual lives, bilingual experience. Journal of Multilingual and Multicultural Development, 25(2–3), 94–104.
Wilson, J. (1990). Politically speaking. The pragmatic analysis of political language. Blackwell.
Wilson, J. (1991). The linguistic pragmatics of terrorist acts. Discourse and Society, 2(1), 29–45.
Funding
Open Access funding provided thanks to the CRUE-CSIC agreement with Springer Nature.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflicts of interest
Ethical Approval
The authors declare the article has been written and sent on compliance with ethical standards.
Human and Animal Rights
This article does not contain any studies involving animals or humans
Informed Consent
Informed consent was obtained from all individual participants involved in the study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mestre-Mestre, E.M. Emotion in Politics in Times of War: A Corpus Pragmatics Study. Corpus Pragmatics 7, 323–344 (2023). https://doi.org/10.1007/s41701-023-00147-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41701-023-00147-w