
Abstract
Background and Objective
Mapping algorithms can be used for estimating quality-adjusted life years (QALYs) when studies apply non-preference-based instruments. In this study, we estimate a regression-based algorithm for mapping between the World Health Organization Disability Assessment Schedule (WHODAS 2.0) and the preference-based instrument SF-6D to obtain preference estimates usable in health economic evaluations. This was done separately for the working and non-working populations, as WHODAS 2.0 discriminates between these groups when estimating scores.
Methods
Using a dataset including 2258 participants from the general Swedish population, we estimated the statistical relationship between SF-6D and WHODAS 2.0. We applied three regression methods, i.e., ordinary least squares (OLS), generalized linear models (GLM), and Tobit, in mapping onto SF-6D from WHODAS 2.0 at the overall-score and domain levels. Root mean squared error (RMSE) and mean absolute error (MAE) were used for validation of the models; R2 was used to assess model fit.
Results
The best-performing models for both the working and non-working populations were GLM models with RMSE ranging from 0.084 to 0.088, MAE ranging from 0.068 to 0.071, and R2 ranging from 0.503 to 0.608. When mapping from the WHODAS 2.0 overall score, the preferred model also included sex for both the working and non-working populations. When mapping from the WHODAS 2.0 domain level, the preferred model for the working population included the domains mobility, household activities, work/study activities, and sex. For the non-working population, the domain-level model included the domains mobility, household activities, participation, and education.
Conclusions
It is possible to apply the derived mapping algorithms for health economic evaluations in studies using WHODAS 2.0. As conceptual overlap is incomplete, we recommend using the domain-based algorithms over the overall score. Different algorithms must be applied depending on whether the population is working or non-working, due to the characteristics of WHODAS 2.0.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Preference-based measures play an important role in health economic evaluations by enabling the conversion of utility scores to quality-adjusted life years. |
A function for deriving SF-6D from WHODAS 2.0 was developed. |
The derived domain-level functions can be used for mapping, but it needs to be considered whether the populations are working or non-working. |
1 Introduction
Preference-based measures (PBMs) play an important role in health economic evaluations. The utility scores generated by PBMs are used for calculating quality-adjusted life years (QALYs) [1]. QALYs are, in Sweden as well as in many other countries, the recommended outcome measure in health economic evaluations [2]. QALYs combine a patient’s estimated life expectancy and health-related quality of life, and it is calculated by multiplying the length of the time period by the utility weight of the HRQoL in each period [3]. Generic PBMs, such as the six-dimensional Health-State Short Form (SF-6D) [4], the EuroQol five-dimensional questionnaire (EQ-5D) [5], and the Health Utilities Index (HUI) [6], are the most widely used measures. Governmental agencies in many countries suggest or require the use of such instruments when evaluating the cost-effectiveness of new treatments [7].
In clinical studies, a non-preference-based outcome measure (non-PBM), often disease specific, is used to capture aspects of health. For these non-PBMs, the preference-based scoring system needed to estimate QALYs is unavailable. In these cases, mapping (also called cross-walking or transfer-to-utility) the non-PBM onto a generic PBM can bridge the gap between different clinical outcomes and preference estimates. Mapping uses a dataset including both the non-PBM and a PBM to estimate the statistical relationships between the two outcome measures. A regression-based algorithm is created that can be used to derive preference estimates in studies when PBMs are unavailable.
The World Health Organization Disability Assessment Schedule (WHODAS) 2.0 is a generic patient-reported outcome measure (PROM) used to assess disability and health in adults who have any disease or injury, regardless whether that disability is based on somatic, mental, or substance-use disorders [8]. People sometimes experience disability in a way that is contrary to the expectations of, for example, health care professionals; they may also report a good or excellent quality of life despite limitations in their functioning [9]. By using WHODAS 2.0, systematic knowledge regarding patients’ own perspectives on health or health-related concerns can be obtained. WHODAS 2.0 is used worldwide, but its lack of preference-based scoring limits its use in health economic evaluations.
Using a dataset including about 2000 participants from the general Swedish population, we aim to estimate a regression-based algorithm for mapping between the non-utility-based WHODAS 2.0 and the utility-based SF-6D for the working and non-working populations respectively, to obtain preference estimates that can be used in health economic evaluations. To our knowledge, this is the first mapping study of WHODAS 2.0 aiming to estimate utility weights, but a recent study mapped WHODAS 2.0 onto disability weights [used to estimate disability-adjusted life years (DALYs)] [10]. Although disability weights are sometimes used to indirectly estimate utility weights, which is preferred from a decision-maker perspective, this is associated with uncertainty, which is pointed out by the authors [10].
2 Methods
2.1 Study Design
This paper presents a mapping study using population-based data. The original study, the Mid-Swed Health Survey [11,12,13], was a cross-sectional postal survey with an assessment at one timepoint. The purpose of the project was to validate three self-report instruments, i.e., the Stigma-related Social Problems scale, RAND-36, and WHODAS 2.0, and collect reference data for the general population. In addition, the survey included demographic questions covering, for example, sex, occupation, and education. More information on the study design can be found elsewhere [11,12,13]. The study was ethically approved by the Regional Ethical Review Board of Uppsala, Sweden (reference number 2015/071). The reporting of the analysis here is based on the MAPS reporting statement for Studies Mapping onto Generic Preference-Based Outcome Measures [14].
2.2 Study Sample
In a first step, a random sample of adults from the general population in Region Örebro County, a central region of Sweden, was invited to participate in the study (N = 4040). The invited population was stratified according to sex and age. To ensure representativeness of the entire adult population, 800 persons were invited from the 20–29-year and 30–39-year age groups, as a lower response rate is commonly expected in younger age groups [15]. From all other age groups, 340–480 persons were invited. Because of a low response rate at the first postal invitation in September 2015, participants (N = 4100) was also invited in March 2016. The same stratification principles were applied at both times [12]. From a total of 8140 invitations, 3482 individuals responded, corresponding to a response rate of close to 43%. Only complete cases (n = 2258) were included in this study, as recommended by the MAPS reporting statement [14]. The following cases were excluded: those who returned the questionnaire without completing it (n = 60); those who had not answered the question about occupation (n = 323); and those who had not responded to the RAND-36 items needed to estimate SF-6D quality-of-life scores and/or WHODAS 2.0 items (n = 841).
2.3 Instruments
WHODAS 2.0 is a generic instrument developed by the World Health Organization (WHO) for assessing health and disability [8]. It was developed to reflect the International Classification of Functioning, Disability and Health (ICF) and can be used in both clinical and general adult populations in different settings and cultures. Six domains of functioning are covered: cognition (domain 1), mobility (domain 2), self-care (domain 3), getting along (domain 4), life activities divided into two domains concerning household (domain 5.1) and work/study (domain 5.2), and participation (domain 6). There are three versions of WHODAS 2.0, i.e., 36-, 12-, and 12 + 24-item versions, asking about difficulties during the previous 30 days. The Swedish 36-item self-administered version was used in this study; it has 36 items for those working (including those studying) and 32 items for those not working/studying (henceforth; non-working) [16]. The 32-item version of WHODAS 2.0 for the non-working is considered comparable to the full 36-item version. The items are scored on a common five-point response scale ranging from no difficulty to extreme difficulty or impossibility, so a higher score indicates a higher level of disability [17]. Domain scores for all domains except the work/study part of the life activities domains are needed to compute a total score.
SF-6D [4] is a generic preference-based instrument calculated from the SF-36 health survey [18] or the version called RAND-36 [19]. These versions have identical items and response options. The Swedish RAND-36 [12, 20, 21] was used here. SF-6D consists of a multi-attribute health status classification system with six dimensions: physical functioning, role limitation, social functioning, pain, mental health, and vitality. These domains are measured using 11 items from SF-36/RAND-36. The classification system consists of four to six levels for each of the six domains, giving 18,000 potential health states. The scoring model was developed on the basis of 836 respondents from the general population of the UK using the standard gamble technique. The UK tariff is the one commonly applied also to a Swedish population as there are no Swedish tariffs available. On the common scale for health state preference values, where dead is 0.0 and full health is 1.0, the worst state in the SF-6D system has a value of 0.20.
2.4 Mapping Process
The following steps were performed for the mapping process. The analyses in steps IV and V were performed separately for those who worked (36 items) and those who did not (32 items). Statistical analyses were carried out using Stata software version 16.1 (StataCorp LP, College Station, TX).
-
I.
On the basis of the RAND-36 data, collected in the Mid-Swed Health Survey [12, 13], SF-6D scores were calculated using a nonparametric Bayesian approach [22]. In the mapping analysis, both the overall score and domain-level scores for WHODAS 2.0 were used, while the overall utility score was used for SF-6D.
-
II.
The next step was to assess the conceptual overlap between WHODAS 2.0 and SF-6D. A qualitative content assessment of the overlap was first conducted by two of the authors (A.P. and L.R.) and was then discussed in the author group, which included experts on both WHODAS 2.0 (Li.H.) and SF-6D (J.K.). As both WHODAS 2.0 and SF-6D cover generic aspects of disability, functioning, and well-being, conceptual overlap was assumed. The qualitative assessment of the content overlap supported by Pearson’s correlations between the WHODAS 2.0 domain scores and the RAND-36 scale scores [11] indicated that the two instruments could conceivably be mapped (Table 1).
-
III.
The next step considered what type of mapping method to choose. Here we used direct mapping, meaning that WHODAS 2.0 was mapped onto the SF-6D health-state utility weights. The alternative method, not used here and less common, is response mapping (i.e., indirect mapping). Response mapping needs responses at all levels in each domain/dimension, while direct mapping needs responses across the full range of disease severity [23].
-
IV.
Furthermore, three regression methods were chosen to develop an algorithm for predicting utility weights for SF-6D based on WHODAS 2.0: ordinary least squares (OLS), generalized linear models (GLM), and Tobit. The choice of regression methods was based on their occurrence of use in similar studies and their applicability to our data. OLS requires normally distributed data with constant variance and is the most common regression method used for mapping to SF-6D [24]. GLM is more flexible and considered a better alternative than OLS for handling skewed or heteroscedastic data [25]. Utility measures are characterized by data with large spikes in the distribution, skewness, multimodality, and gaps in the range of feasible values [23], which makes the use of simple regression methods challenging if one is to avoid bias. Tobit regressions combine the probit model with OLS, and are suitable when the dependent variable is bounded, is normally distributed, and does not contain negative values [25]. In the first model, the SF-6D utility score was regressed on the WHODAS 2.0 overall score. In the second model, the SF-6D utility score was regressed on the domains of WHODAS 2.0. Stepwise regression with forward selection (with the significance level at 0.05) was used to choose the best combination of predictors from the six/seven domains. This was done separately for the working and non-working populations, as WHODAS 2.0 discriminates between these groups when estimating scores. In addition, three socioeconomic parameters (i.e., age, sex, and education) were included in each model.
-
V.
We used two validation measures: root mean squared error (RMSE), i.e., the root of the average of the squared differences between observed and predicted SF-6D values, and mean absolute error (MAE), i.e., the average of the roots of the squared differences between the observed and predicted utility scores of all individuals. RMSE and MAE are the most common validation measures [24], and lower values indicate better model performance. For model fit, we used R2, which shows the proportion of the variance of a dependent variable that is explained by an independent variable or variables in a regression model. Whereas correlation explains the strength of the relationship between an independent and dependent variable, R2 explains to what extent the variance of one variable (the independent variable) explains the variance of the second variable (the dependent variable). The higher the R2 value, the better the model fit. As recommended, the best-performing models were selected on the basis of those with the lowest RMSE [14]. This is because the RMSE is measured in the same units as the data, is representative of the size of a “typical” error, and is more sensitive than other measures to occasional large errors [26]. The performance of the selected models was then based on the MAE between the observed and predicted index scores, and on the model fit determined using R2. Currently, there are no guidelines for the threshold values of RMSE or MAE for model acceptance, but a systematic review of mapping studies has reported RMSEs ranging from 0.084 to 0.2 and MAEs from 0.0011 to 0.19 [27]. Uncertainty was illustrated using the standard error and distribution of the residuals.
3 Results
3.1 Descriptive Characteristics
3.1.1 Working Sample
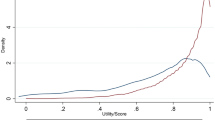
The working sample comprised 1298 cases, the mean age was 44.6 years [standard deviation (SD) 13.0], and 56.2% were women. The mean score for SF-6D was 0.74 (SD 0.12), the minimum score was 0.34, and the maximum score was 0.95. The mean WHODAS 2.0 score was 10.4 (SD 13.1), the minimum score was 0, and the maximum score was 73.58 (Table 2). For SF-6D, 65 unique health states were reported, while 55 unique health states were observed for WHODAS 2.0. A left-skewed distribution was seen for SF-6D (−0.23) and a right-skewed distribution for WHODAS 2.0 (1.88), indicating ceiling and floor effects (Fig. 1).

Distribution of scores for SF-6D and WHODAS 2.0, workers and non-workers, respectively. SF-6D six-dimensional Health-State Short Form, WHODAS World Health Organization Disability Assessment Schedule
3.1.2 Non-working Sample
The non-working sample comprised 960 cases, the mean age was 71.2 years (SD 13.4), and 47.4% were women. The mean score for SF-6D was 0.67 (SD 0.13), the minimum score was 0.20, and the maximum score was 0.95. The mean WHODAS 2.0 score was 19.8 (SD 19.0), the minimum score was 0, and the maximum score was 92.39 (Table 2). For SF-6D, 76 unique health states were reported, while 63 unique health states were observed for WHODAS 2.0. A left-skewed distribution was seen for SF-6D (−0.12) and a right-skewed distribution for WHODAS 2.0 (1.04), indicating ceiling and floor effects (Fig. 1).
3.2 Model Selection
3.2.1 Working Sample
In general, GLM had a slightly lower RMSE than did OLS and Tobit (Supplementary Table 1). The best-performing GLM model, when using the overall WHODAS 2.0 score, also included sex, giving an RMSE of 0.087 and an MAE of 0.070 (Table 3). Using domain levels, the best-performing GLM model included mobility, life activities (both household and work/study activities), participation, and sex. This model had an RMSE of 0.086 and an MAE of 0.069.
On the basis of these results, using the best-performing models, the algorithm to derive SF-6D scores from the WHODAS 2.0 overall score would be: SF-6D utility score = −0.2286844 + (−0.010465 × WHODAS total score) + (0.0175029 × SEX) (dummy variable, 1 = female, 0 = male).
The algorithm to derive SF-6D scores based on WHODAS 2.0 domain scores would be: SF-6D utility score = −0.2237245 + (−0.0013802 × WHODAS 2.0 Domain 2) + (−0.0008823 × WHODAS 2.0 Domain 5.1) + (−0.0020473 × WHODAS 2.0 Domain 5.2) + (−0.0049122 × WHODAS 2.0 Domain 6-score) + (0.0156483 × SEX) (dummy variable, 1 = female, 0 = male).
3.2.2 Non-working Sample
In general, GLM had a slightly lower RMSE than did OLS and Tobit (Supplementary Table 2). The best-performing GLM model when using the overall WHODAS 2.0 score also included sex. This gave an RMSE of 0.088 and an MAE of 0.071 (Table 4). Using domain levels, the best-performing GLM model included mobility, life activities (household), participation, and education. This model had an RMSE of 0.084 and an MAE of 0.068.
On the basis of these results, using the best-performing models, the algorithm to derive SF-6D scores from the WHODAS 2.0 overall score would be: SF-6D utility score = −0.2645313 + (−0.0087997 × WHODAS 2.0 total score) + (0.0193317 × SEX) (dummy variable, 1 = female, 0 = male).
The algorithm to derive SF-6D scores based on WHODAS 2.0 domain scores would be: SF-6D utility score = −0.2495337 + (−0.002078 × WHODAS 2.0 Domain 2) + (−0.0014517 × WHODAS 2.0 Domain 5.1) + (−0.0041913 × WHODAS 2.0 Domain 6-score) + (0.0082603 × education) (dummy variable, 1 = mandatory school, 2 = high-school, 3 = university, and 4 = other).
3.3 Uncertainty
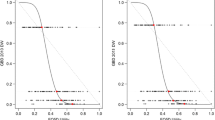
The best-performing models underestimated the lower level of SF-6D but performed well at the higher level (Fig. 2). This is also indicated by a moderately skewed distribution of the residuals, with the residual means being 0.7 (standard error 0.002) for both the overall- and domain-level algorithms, regardless of whether the population was working or non-working.

Mapped and actual SF-6D score for workers and non-workers on overall and domain levels, respectively. SF-6D six-dimensional Health-State Short Form, WHODAS World Health Organization Disability Assessment Schedule
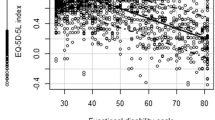
The most important source of uncertainty follows from how well the instruments correspond to each other conceptually. According to WHODAS 2.0, almost 40% of the sample scored full health, while SF-6D scores in this subsample did not correspond to full health (Fig. 3); instead, there was substantial variation in the reported scores.

Distribution of SF-6D scores for workers and non-workers reporting full health in WHODAS 2.0 (first row) and distribution of WHODAS 2.0 scores for workers and non-workers reporting 0.9 or higher in SF-6D (second row). SF-6D six-dimensional Health-State Short Form, WHODAS World Health Organization Disability Assessment Schedule
4 Discussion
The measurement and valuation of health-related quality of life (HRQoL) are important components of economic evaluations of healthcare interventions. WHODAS 2.0 and SF-6D are valid instruments for measuring health status in the general population and clinical samples across countries. In an extensive review of publications between 1999 and 2015, Federici et al. [28] identified 810 studies from 94 countries, in 27 areas of research using WHODAS 2.0. On the basis of these findings they concluded that there is an increasing interest in the WHODAS 2.0 for assessing individuals in different settings and individual health conditions; however, WHODAS 2.0 is not preference based. This study developed mapping algorithms that can predict SF-6D utility scores from WHODAS 2.0 scores; these utility scores can be used to derive QALYs for use in cost-utility analysis when a preference-based HRQoL instrument is not included. To the best of our knowledge, mapping WHODAS 2.0 scores onto utility scores has not been done before. However, WHODAS 2.0 was recently mapped onto disability weights [10], but these cannot be directly used to derive QALYs.
We developed four algorithms to map WHODAS 2.0 onto SF-6D using OLS, GLM, and Tobit regressions based on data from the Mid-Swed Health Survey [12, 13]. Algorithms were developed separately for the working and non-working populations since WHODAS 2.0 includes different numbers of questions depending on the respondent work status. The final algorithms were not the same, which justifies the division of the sample. RMSE, MAE, and R2 were used for the validation and valuation of the fit of the models. RMSE and MAE were on average 0.09 and 0.07, respectively, for the four different models, which is particularly low according to a review of mapping studies conducted by Brazier et al. [27], indicating a good fit. In addition, all models had an R2 above 0.5, which is considered high according to previous literature [27]. For all the models, GLM was the best-performing regression method. However, all regression models developed here tended to be less precise for the lower utility scores, which might be explained by fewer individuals reporting low utility or by the ability of the instruments to discriminate at the high versus low ends of the scales. According to these findings, the algorithms presented here can serve as a practical solution and a basis for health economic evaluation when WHODAS 2.0 is used in a study, but no preference-based instrument is included.
The overall mean scores for SF‐6D were 0.71 (SD 0.12) for workers and 0.67 (SD 0.13) for non-workers, in the lower range compared with SF-6D population norms from other countries [29,30,31,32,33,34]. The WHODAS 2.0 scores were 10.40 (SD 13.06) for workers and 19.82 (SD 18.99) for non-workers, well above the population norms [35]. Given these comparisons, the overall health seems to be lower in the population included in this study versus in the general population. The use of data from the general population is uncommon in mapping studies [24] and is a strength, as these data can be used widely; however, patient populations are more suitable in terms of demographic characteristics and illness severity [23]. Despite this, the low overall health found in our sample might indicate that the mapping algorithms created here could be used in different disease-specific groups. Using general population data might also result in relatively fewer respondents with bad health states, as was the case in this study, leading to less precise estimates in that end of the scale.
The use of mapping is common in health economic studies, but it has been declared that mapping is the second-best alternative, meaning use of preference-based instruments directly in studies is preferred [24]. Mapping has been criticized, and it does have several pitfalls, especially as concerns validation. Round and Hawton [36] have stated that it is not enough to define that it is possible to predict values of one instrument from the values of another; one also must be confident that the two instruments measure the same thing, which is a weakness of many mapping studies. Previous studies have shown correlations of varying strength between WHODAS 2.0 and RAND- or SF-36 [11, 37,38,39,40,41,42]. Moreover, Round and Hawton [36] draw attention to the conceptual overlap between generic and condition-specific instruments and their ability to capture different aspects of health. They have also discussed how sensitive to changes the instruments are, and the problems encountered when the same health domains are measured but the number of items differs. In summary, these authors believe that these shortcomings may lead to systematic bias in health preferences and overall they are skeptical of the use of mapping [36]. A substantial degree of overlap is therefore required in mapping studies, and this was also analyzed before the present study and judged to be satisfactory. This qualitative conceptual overlap harmonized well with the final model, since the domains cognition, self-care, and getting along, which were excluded from the final model, were also judged to have low conceptual overlap before the study. However, it was shown that full health was captured in different ways in the two instruments with a greater proportion scoring low (i.e., good health) according to WHODAS 2.0 than according to SF-6D, which is more normally distributed. This might be explained by the fact that WHODAS 2.0 focuses more on disability, while SF-6D focuses on a broader concept of health that includes both functional status and well-being. Hence, it may be justified to use the algorithm at domain level instead of the overall-score level, and further mapping studies in patient populations may be more useful in some contexts.
This study is also affected by other limitations. First, as there are no specific Swedish tariffs available, preference weights for estimating QALYs are based on UK tariffs. This is standard procedure when using SF-6D in Sweden but might be a limitation due to potential cultural differences. Second, one might consider more advanced regression models, such as Betamix and ALDVMM, for the mapping. Based on our literature search of mapping studies for SF-6D, we noted that these models had not been used for SF-6D although being quite common for EQ-5D. We found one study testing the Betamix and ALDVMM for SF-6D data, but these models were not chosen over OLS [43].
Given these concerns, it is clear that one must be careful with regard to both context and choice of method when creating, using, and comparing mapping preferences. However, it is still a fact that many clinical studies do not include any preference-based instruments, which creates a demand for mapping in order to perform health economic evaluations.
5 Conclusions
The use of mapping studies is common in health economic evaluations. In this study, WHODAS 2.0 was mapped onto SF-6D. We conclude that it is possible to apply the derived mapping algorithm, preferably at the domain level, in studies in which WHODAS 2.0 has been used. Different algorithms must be applied depending on whether the population is working or non-working. As full health is captured in different ways in WHODAS 2.0 and SF-6D, mapping at the domain level seems to be a more reliable approach.
References
Drummond M. Methods for the economic evaluation of health care programmes, Fourth edition. In: Michael FD, Mark JS, Karl C, Greg S, George WT (eds) Oxford: Oxford University Press; 2015.
Sanders GD, Neumann PJ, Basu A, Brock DW, Feeny D, Krahn M, et al. Recommendations for conduct, methodological practices, and reporting of cost-effectiveness analyses: second panel on cost-effectiveness in health and medicine. JAMA. 2016;316(10):1093–103.
Brazier J, Ratcliffe J, Saloman J, Tsuchiya A. Measuring and valuing health benefits for economic evaluation. 2nd ed. Oxford: Oxford University Press; 2016.
Brazier J, Roberts J, Deverill M. The estimation of a preference-based measure of health from the SF-36. J Health Econ. 2002;21(2):271–92.
The EuroQol Group. EuroQol—a new facility for the measurement of health-related quality of life. Health Policy. 1990;16(3):199–208.
Horsman J, Furlong W, Feeny D, Torrance G. The Health Utilities Index (HUI): concepts, measurement properties and applications. Health Qual Life Outcomes. 2003;1:54.
Sharma D, Aggarwal AK, Downey LE, Prinja S. National healthcare economic evaluation guidelines: a cross-country comparison. Pharmacoeconomics. 2021;5(3):349–64.
Ustun TB, Chatterji S, Kostanjsek N, Rehm J, Kennedy C, Epping-Jordan J, et al. Developing the World Health Organization Disability Assessment Schedule 20. Bull World Health Organ. 2010;88(11):815–23.
Albrecht GL, Devlieger PJ. The disability paradox: high quality of life against all odds. Soc Sci Med. 1999;48(8):977–88.
Lokkerbol J, Wijnen BFM, Chatterji S, Kessler RC, Chisholm D. Mapping of the World Health Organization’s Disability Assessment Schedule 20 to disability weights using the Multi-Country Survey Study on Health and Responsiveness. Int J Methods Psychiatr Res. 2021;30(3): e1886.
Norén P, Karlsson J, Ohlsson-Nevo E, Möller M, Hermansson L. Psychometric evaluation of the WHODAS 20 and prevalence of disability in a Swedish general population. J Patient Rep Outcomes. 2023;7(1):36.
Ohlsson-Nevo E, Hiyoshi A, Norén P, Möller M, Karlsson J. The Swedish RAND-36: psychometric characteristics and reference data from the Mid-Swed Health Survey. J Patient-Rep Outcomes. 2021;5(1):1–11.
Ohlsson-Nevo E, Karlsson J. Impact of health-related stigma on psychosocial functioning in the general population: Construct validity and Swedish reference data for the Stigma-related Social Problems scale (SSP). Res Nurs Health. 2019;42(1):72–81.
Petrou S, Rivero-Arias O, Dakin H, Longworth L, Oppe M, Froud R, et al. The MAPS reporting statement for studies mapping onto generic preference-based outcome measures: explanation and elaboration. Pharmacoeconomics. 2015;33(10):993–1011.
Mindell JS, Giampaoli S, Goesswald A, Kamtsiuris P, Mann C, Männistö S, et al. Sample selection, recruitment and participation rates in health examination surveys in Europe—experience from seven national surveys. BMC Med Res Methodol. 2015;5(15):78.
Socialstyrelsen. Mätning av hälsa och funktionshinder: manual till WHO:s formulär för bedömning av funktionshinder WHO Disability Assessment Schedule WHODAS 2.0. . Stockholm: The National Board of Health and Welfare.; 2015.
Üstün T, Kostanjsek N, Chatterji S, Rehm J. Measuring health and disability : manual for WHO Disability Assessment Schedule WHODAS 2.0. Geneva: World Health Organization; 2010.
Ware JE Jr, Sherbourne CD. The MOS 36-item short-form health survey (SF-36). I. Conceptual framework and item selection. Med Care. 1992;30(6):473–83.
Hays RD, Sherbourne CD, Mazel RM. The RAND 36-Item Health Survey 10. Health Econ. 1993;2(3):217–27.
Orwelius L, Nilsson M, Nilsson E, Wenemark M, Walfridsson U, Lundström M, et al. The Swedish RAND-36 Health Survey—reliability and responsiveness assessed in patient populations using Svensson’s method for paired ordinal data. J Patient Rep Outcomes. 2017;2(1):4.
Sydöstra Registercentrum. RAND-36. 2021 [cited 2021 June 22]; Available from: https://sydostrasjukvardsregionen.se/samverkansgrupper/kvalitetsregister/registercentrum-sydost/bestall-rand-36-kostnadsfritt/
Kharroubi SA, Brazier JE, Roberts J, O’Hagan A. Modelling SF-6D health state preference data using a nonparametric Bayesian method. J Health Econ. 2007;26(3):597–612.
Wailoo AJ, Hernandez-Alava M, Manca A, Mejia A, Ray J, Crawford B, et al. Mapping to estimate health-state utility from non-preference-based outcome measures: an ISPOR good practices for outcomes research task force report. Value Health. 2017;20(1):18–27.
Mukuria C, Rowen D, Harnan S, Rawdin A, Wong R, Ara R, et al. An updated systematic review of studies mapping (or cross-walking) measures of health-related quality of life to generic preference-based measures to generate utility values. Appl Health Econ Health Policy. 2019;17(3):295–313.
Deb P, Norton EC, Manning WG. Health econometrics using Stata. TX: Stata Press; 2017.
Browne C, Brazier J, Carlton J, Alavi Y, Jofre-Bonet M. Estimating quality-adjusted life years from patient-reported visual functioning. Eye (Lond). 2012;26(10):1295–301.
Brazier JE, Yang Y, Tsuchiya A, Rowen DL. A review of studies mapping (or cross walking) non-preference based measures of health to generic preference-based measures. Eur J Health Econ. 2010;11(2):215–25.
Federici S, Bracalenti M, Meloni F, Luciano JV. World Health Organization Disability Assessment Schedule 2.0: An international systematic review. Disabil Rehabil. 2017;39(23):2347–80.
Wong CKH, Mulhern B, Cheng GHL, Lam CLK. SF-6D population norms for the Hong Kong Chinese general population. Qual Life Res. 2018;27(9):2349–59.
Garcia-Gordillo MA, Collado-Mateo D, Olivares PR, Adsuar JC. Chilean population norms derived from the health-related quality of Life SF-6D. Eur J Health Econ. 2018;19(5):675–86.
Shiroiwa T, Fukuda T, Ikeda S, Igarashi A, Noto S, Saito S, et al. Japanese population norms for preference-based measures: EQ-5D-3L, EQ-5D-5L, and SF-6D. Qual Life Res. 2016;25(3):707–19.
Ciconelli RM, Ferraz MB, Kowalski S, Pinheiro Gda R, Sato EI. Brazilian urban population norms derived from the health-related quality of life SF-6D. Qual Life Res. 2015;24(10):2559–64.
Ferreira PL, Ferreira LN, Pereira LN. SF-6D Portuguese population norms. Eur J Health Econ. 2015;16(3):235–41.
Norman R, Church J, van den Berg B, Goodall S. Australian health-related quality of life population norms derived from the SF-6D. Aust N Z J Public Health. 2013;37(1):17–23.
Andrews G, Kemp A, Sunderland M, Von Korff M, Ustun TB. Normative data for the 12 item WHO Disability Assessment Schedule 20. PLoS ONE. 2009;4(12): e8343.
Round J, Hawton A. Statistical alchemy: conceptual validity and mapping to generate health state utility values. Pharmacoecon Open. 2017;1(4):233–9.
Baron M, Schieir O, Hudson M, Steele R, Kolahi S, Berkson L, et al. The clinimetric properties of the World Health Organization Disability Assessment Schedule II in early inflammatory arthritis. Arthritis Rheum. 2008;59(3):382–90.
Chwastiak LA, Von Korff M. Disability in depression and back pain: evaluation of the World Health Organization Disability Assessment Schedule (WHO DAS II) in a primary care setting. J Clin Epidemiol. 2003;56(6):507–14.
Garin O, Ayuso-Mateos JL, Almansa J, Nieto M, Chatterji S, Vilagut G, et al. Validation of the “World Health Organization Disability Assessment Schedule, WHODAS-2” in patients with chronic diseases. Health Qual Life Outcomes. 2010;19(8):51.
Hudson M, Steele R, Taillefer S, Baron M. Quality of life in systemic sclerosis: psychometric properties of the World Health Organization Disability Assessment Schedule II. Arthritis Rheum. 2008;59(2):270–8.
Moen VP, Drageset J, Eide GE, Klokkerud M, Gjesdal S. Validation of World Health Organization Assessment Schedule 20 in specialized somatic rehabilitation services in Norway. Qual Life Res. 2017;26(2):505–14.
Pösl M, Cieza A, Stucki G. Psychometric properties of the WHODASII in rehabilitation patients. Qual Life Res. 2007;16(9):1521–31.
Flint I, Medjedovic J, Drogon O’Flaherty E, Alvarez-Baron E, Thangavelu K, Savic N, et al. Mapping analysis to predict SF-6D utilities from health outcomes in people with focal epilepsy. Eur J Health Econ. 2022;2:25.
Acknowledgements
The authors would like to thank all the respondents in the Mid Swed Health Survey, and Paulina Norén for research assistance with the data acquisition.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors have no conflicts of interest to declare.
Financial disclosure
The Mid Swed Health survey was supported by the Research Committee of Örebro County Council, grant number OLL-506801. The funders had no role in the design or implementation of the study; the collection, management, analysis, or interpretation of the data; the preparation, review, or approval of the manuscript; or the decision to submit the manuscript for publication.
Ethics approval
This study was approved by the Regional Ethical Review Board in Uppsala, Sweden (reference number 2015/071).
Consent to participate
Respondents agreed to participate by sending in the survey.
Consent for publication
Respondents were informed at the assessment that the findings were to be published, hence sending in the survey meant agreeing to this.
Materials and/or code availability
Data and program codes are available upon reasonable request.
Author Contributions
Concept and design: Philipson, Hagberg, and Ryen. Acquisition of data: Hermansson, Karlsson, and Ohlsson-Nevo. Analysis and interpretation of data: Philipson and Ryen. Drafting of the manuscript: Philipson. Critical revision of the paper for important intellectual content: Philipson, Hagberg, Hermansson, Karlsson, Ohlsson-Nevo, and Ryen. Obtaining funding: Ohlsson-Nevo.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License, which permits any non-commercial use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc/4.0/.
About this article

Cite this article
Philipson, A., Hagberg, L., Hermansson, L. et al. Mapping the World Health Organization Disability Assessment Schedule (WHODAS 2.0) onto SF-6D Using Swedish General Population Data. PharmacoEconomics Open 7, 765–776 (2023). https://doi.org/10.1007/s41669-023-00425-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41669-023-00425-y