
Abstract
Within the context of topological data analysis, the problems of identifying topological significance and matching signals across datasets are important and useful inferential tasks in many applications. The limitation of existing solutions to these problems, however, is computational speed. In this paper, we harness the state-of-the-art for persistent homology computation by studying the problem of determining topological prevalence and cycle matching using a cohomological approach, which increases their feasibility and applicability to a wider variety of applications and contexts. We demonstrate this approach on a wide range of real-life, large-scale, and complex datasets. We extend existing notions of topological prevalence and cycle matching to include general non-Morse filtrations. This provides the most general and flexible state-of-the-art adaptation of topological signal identification and persistent cycle matching, which performs comparisons of orders of ten for thousands of sampled points in a matter of minutes on standard institutional HPC CPU facilities.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Persistent homology, one of the cornerstones of topological data analysis, studies the lifespan of the topological features in a nested sequence of topological spaces by tracking the changes in its homology groups. It provides a robust statistical summary of data, capturing its “shape” and “size” and has been been applied to many scientific disciplines in recent years with great success. The diagram consisting of the homology groups of the filtration connected by the maps induced by the inclusions is called the persistence module. From this, the persistence barcode (or simply, barcode) is derived—a canonical summary of the aforementioned lifespans as a set of half-open intervals.
A natural question is whether it is possible to compare the barcodes obtained from different filtrations, which would, for instance, provide a correspondence between some of their intervals. Several solutions have been proposed. Gonzalez-Diaz and Soriano-Trigueros (2020) derive a basis-independent partial matching for ladder modules and zigzag persistence. A different method of persistent extension to find analogous bars—especially interesting if there is no known mapping between the persistence modules—was very recently introduced by Yoon et al. (2022). Bauer and Lesnick (2015) match intervals of barcodes using a known mapping between the persistence modules. This notion was recently reinterpreted in statistical terms by Reani and Bobrowski (2021b), who propose a similar interval matching using image-persistence, which was first introduced by Cohen-Steiner et al. (2009). This matching is applied to define a prevalence score—a measure of the significance of a given interval in a barcode. Typically, persistence (i.e., the length of the interval) is interpreted as topological significance or signal: longer intervals correspond to “true” features, while short ones are attributed to topological noise. However, this practice can be misleading since persistence is highly affected by the distance of sampling points and usually has a higher value for cycles created at a larger scale. The prevalence score proposed by Reani and Bobrowski (2021b) bypasses this shortcoming by taking into account the statistical heuristics of the problem: it is obtained by matching persistence intervals across diagrams of several resamplings of the data.
A limitation common to all previously proposed barcode comparison techniques is that they are all computationally very expensive, which significantly limits their practicality in many applications and to many real datasets. In this paper, we address this specific issue by leveraging the current state-of-the-art in persistent homology computation, Ripser (Bauer 2021), which studies the dual perspective and computes persistent cohomology, thus taking advantage of its equivalence to persistent homology (de Silva et al. 2011a). Furthermore, recently, Ripser was adapted to the setting of image-persistence via Ripser-image (Bauer and Schmahl 2022). We apply this technology to the interval matching approach proposed by Reani and Bobrowski (2021b), as well as specialize and extend their definitions to allow for greater flexibility and applicability. The final result of our contributions is state-of-the-art software for interval matching, executable in a matter of minutes using only standard institutional high performance computing facilities, which we showcase on a wide variety of complex and large-scale datasets, such as static and time-lapse imaging and video data from biomedical and astrophysical applications.
1.1 Contributions
-
We specialize the definition of interval matching proposed by Reani and Bobrowski (2021b) to simplex-wise filtrations (see Definition 15), making it compatible with the output of Ripser-image (Bauer and Schmahl 2022) and more widely applicable.
-
We present a comprehensive case study of different definitions for a matching affinity score that extends the original score proposed by Reani and Bobrowski (2021b).
-
We provide state-of-the-art code for interval matching, freely available at https://github.com/inesgare/interval-matching.
-
We comprehensively showcase and demonstrate representative applications of our specialized definitions and code to complex and large-scale datasets.
1.2 Outline
We begin by introducing the fundamentals of persistent homology and set relevant notations in Sect. 1. We also review image-persistence and use it to present interval matching as proposed in Reani and Bobrowski (2021b). In Sect. 2, we adapt the definition of image-persistence to the various homology settings and study how these frameworks are related. Here, we propose our specialized definition of interval matching and revisit the notion of matching affinity by Reani and Bobrowski (2021b) in a case study of alternative formulations. In Sect. 3, we present applications of the notion of cycle matching to a variety of data sets diverse in nature and aimed at different objectives. We close with a discussion of our contributions and proposals for future work in Sect. 4.
2 Preliminaries
In this section we introduce the fundamental concepts underlying our work and establish some relevant notations that we will use throughout the rest of the paper.
2.1 The four standard persistence modules
A filtration is a family of nested subspaces \(\{X_t: t \in T\}\) of some space X
where \(T \subset \mathbb {R}\) is a totally ordered indexing set. In this paper, we work with filtered complexes, specifically, we further assume that X is a finite simplicial complex and the spaces \(X_t\) are simplicial subcomplexes of X. Filtered complexes can also be interpreted as diagrams \(X_\bullet : T \rightarrow \mathbf {\textrm{Simp}}\) of simplicial complexes indexed over some finite totally ordered set \(T\), such that all maps in the diagram are inclusions.
A re-indexing of a filtration changes the indexing set \(T\) to another totally ordered set \(I\) using some monotonic map \(r: I \rightarrow T\) so that \(X_{r(i)} = X_t\). For instance, if \(\{X_t: t \in T\}\) is a filtered complex, \(T = \{t_1,\ldots ,t_n\}\) is finite and we have the re-indexing \(r(i) = t_i\) that allows for a reparameterization of the filtration over the natural numbers \(\{X_i: 1\le i \le n\}\).
Applying the corresponding homology functor to the simplicial complexes in a filtered complex and the inclusions \(X_i \subset X_{i+1}\) between consecutive spaces gives us the following diagrams
Following de Silva et al. (2011a), we will call these the four standard persistence modules. The first persistence module (1) corresponds to absolute homology and is the one most often used. The expressions following are the persistence modules for absolute cohomology (2), relative homology (3), and relative cohomology (4). Unless otherwise stated, homology and cohomology will have field coefficients, so that these persistence modules are made up of vector spaces and linear maps.
The assumption of field coefficients allows us to invoke the structure theorem (Zomorodian and Carlsson 2005). This is one of the foundational results in persistent homology and ensures that, up to isomorphism, any persistence module, such as the ones above, can be decomposed in a direct sum of interval modules. An interval module consists of copies of the field of coefficients over an interval range of indices; these copies are connected by the identity map and the trivial vector space outside of that interval. This allows for the interpretation that some (co)cycle is born at the beginning of the interval and dies at the end of it. For instance, for the absolute homology module,
where the sub-index denotes the range of indices over which the interval module is nontrivial.
The collection of intervals that appears in the decomposition of the structure theorem is an invariant of the isomorphism type of the persistence module. This collection is the persistence barcode of the filtration
The intervals from the barcode are called persistence intervals and the start and end points of the intervals are the persistence pairs.
The persistence barcode provides a summary of the lifespans of the topological features of the filtration. Persistence pairs are often interpreted with real indices \(t_{b_m}\) and \(t_{d_m}\) associated to the natural indices \(b_m\) and \(d_m\) via re-indexing. In this case, the convention dictates that the barcode be represented by half-open intervals. These intervals exclude the real-valued death time of the subsequent step of the filtration, in relation to when the feature was last designated “alive” using natural indices:
This convention also involves setting \(t_0 = -\infty \)—notice that the index \(i=0\) might appear in the barcodes of relative (co)homology—and \(t_{M+1} = \infty \). It is also customary to discard intervals where \(t_{b_m} = t_{d_{m}+1}\).

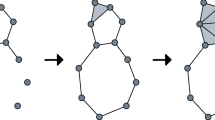
Filtration of a triangle indexed with natural numbers
Example 1
Consider the filtration in Fig. 1, where our filtered complex is a triangle with vertices at \((0,0),\, (1,0)\), and \((\sqrt{3}/2,\sqrt{3}/2)\), where we add edges of increasing length and finally fill in the triangle.
The barcodes for such a filtration for the \(0\)- and \(1\)-dimensional homologies are
Considering the re-indexing given by the diameter of the larger simplex in the complex \(t_i=\max \{ \textrm{diam}\,(\sigma ): \sigma \in X_i\}\), the previous barcodes would then become
so that we may discard the \(1\)-dimensional persistent homology.
The four standard persistence modules carry the same information: the barcode of the setting of absolute (or relative) homology setting is the same as the barcode of the setting of absolute (or relative) cohomology. We can also find a bijection between the bars in the barcodes of the relative setting and the bars in the corresponding absolute setting. For further the details on this equivalence, see de Silva et al. (2011a).
2.2 Image-persistence and interval matching
The idea underlying image-persistence is to study the persistent homology of some filtered complex inside another larger filtered complex. Let \(X\) and \(Z\) be finite simplicial complexes and \( f : X \rightarrow Z\) an injective map between them. Let \(\{X_i : 1 \le i \le n\}\) and \(\{Z_i: 1 \le i \le n\}\) be filtrations associated to the previous complexes and denote the restrictions to the steps in the filtrations by
Note that these are also injective maps, which gives rise to the following commutative diagram for all \(1\le i\le n-1\):

where \(\iota _i^X\) and \(\iota _i^Z\) are the corresponding inclusion maps between consecutive steps in the corresponding filtration.
Applying the homology functor to the previous diagram gives rise to another commutative diagram:

which now involves the homology groups and the induced linear maps. The commutativity of this diagram allows for the following definition.
Definition 2
(Image-persistent homology) The persistence module
given by the subspaces \(\textrm{Im}(\textrm{H}_*(f_i))\subset \textrm{H}_*(Z_i)\) and the restrictions of the maps \(\textrm{H}_*(\iota _i^Z)\) is called image-persistent homology.
The elements in \(\textrm{Im} \,(\textrm{H}_*(f_i))\) can be seen as cycles in \(X_i\) up to boundaries in \(Z_i\), which we gain by studying one filtration inside another.
Remark 3
Since \(\textrm{Im} \,\textrm{H}_*(f_i)\) is a subspace of \(\textrm{H}_*(Z_i)\), a death in the image-persistence module implies a death in the persistent homology of the space \(Z\). At a topological level, this implication can be linked to the fact that every cycle from an image-persistence module is in fact a cycle in the codomain of the function used to define the image-persistence module. This cycle may have been born before as a cycle of the codomain, however, it gets bounded at the same time for both the image-persistence and the persistence module of the codomain. On the other hand, a birth in the image-persistence module implies a birth in the persistent homology of the space \(X\). This is a result from the fact that every cycle in the image persistence corresponds to a cycle of the domain, which may get bounded in the image-persistence module at an earlier time as it is studied within the “larger” codomain. See Cohen-Steiner et al. (2009) for further details on the relations between these three modules.
The definition of interval matching introduced by Reani and Bobrowski (2021b) is based on image-persistence to compare the persistence bars of two diagrams and is restricted to Morse filtrations.
Definition 4
(Morse filtration) A filtration \(\{X_t:t\in \mathbb {R}\}\) is a Morse filtration if there exists a finite set \(T= \{t_1,...,t_n\}\subset \mathbb {R}\) such that the following are satisfied:
-
1.
For all \(t\notin T\), there exists \(\epsilon >0\) small enough such that for every \(0<\epsilon '<\epsilon \) the map
$$\begin{aligned} \textrm{H}_*(i) : \textrm{H}_*(X_{t-\epsilon '}) \rightarrow \textrm{H}_*(X_{t+\epsilon '}) \end{aligned}$$induced by inclusion is an isomorphism for every homology group. Equivalently, the homology does not change at t.
-
2.
For all \(t\in T\), there exists \(\epsilon >0\) small enough so that for any \(0<\epsilon '<\epsilon \) either
-
(a)
\( \textrm{H}_*(i) : \textrm{H}_*(X_{t-\epsilon '}) \rightarrow \textrm{H}_*(X_{t+\epsilon '}) \) is injective and the dimension of the vector space increases by one, or
-
(b)
\( \textrm{H}_*(i) : \textrm{H}_*(X_{t-\epsilon '}) \rightarrow \textrm{H}_k(X_{t+\epsilon '}) \) is surjective and the dimension decreases by one.
Equivalently, the homology changes allowed are either the creation of a single new cycle or the termination of a single existing cycle.
-
(a)
We now review how to match the persistence intervals of two filtered complexes inside a third comparison space. Let X, Y, Z be finite simplicial complexes with Morse filtrations \(\{X_i: 1 \le i \le n\}\), \(\{Y_i: 1 \le i \le n\}\), and \(\{Z_i: 1 \le i \le n\}\). Assume we have injective maps
for every \(1\le i\le n\) such that \(f_j\vert _{X_i} = f_i\) and \(g_j\vert _{Y_i} = g_i\) for every \(i\le j\). With these assumptions, Reani and Bobrowski (2021b) match persistence intervals as follows.
Definition 5
(Matching intervals, Reani and Bobrowski (2021b)) Let \(\alpha \in \textrm{Pers}(\textrm{H}_*(X_\bullet ))\) and \(\beta \in \textrm{Pers}(\textrm{H}_*(Y_\bullet ))\). The intervals \(\alpha \) and \(\beta \) are matching intervals via \(Z_\bullet \) if there exist \(\tilde{\alpha } \in \textrm{Pers}(\textrm{Im} \,\textrm{H}_*(f_\bullet ))\) and \(\tilde{\beta } \in \textrm{Pers}(\textrm{Im} \,\textrm{H}_*(g_\bullet ))\) such that
The intuition behind these criteria for matching intervals stems from Remark 3: every bar in the barcode of the image-persistence module \(\textrm{H}_*(f_\bullet )\) arises from a bar in the barcode of the persistence module \(\textrm{H}_*(X_\bullet )\) so that both share the same birth time; we have the same respective coincidence for the modules \(\textrm{H}_*(g_\bullet )\) and \(\textrm{H}_*(Y_\bullet )\). This justifies our procedure to first match a bar \( \alpha \in \textrm{Pers}(\textrm{H}_*(X_\bullet ))\) and a bar \(\beta \in \textrm{Pers}(\textrm{H}_*(Y_\bullet ))\) with the bars \( \tilde{\alpha } \in \textrm{Pers}(\textrm{H}_*(f_\bullet ))\) and \(\tilde{\beta } \in \textrm{Pers}(\textrm{H}_*(g_\bullet ))\) when their birth times coincide. Similarly, the death of a bar in an image-persistence module implies that there is a bar in the barcode of \(\textrm{H}_*(Z_\bullet )\) sharing that same death time. Consequently, once we have identified the bars \(\tilde{\alpha }\) and \(\tilde{\beta }\), the rule to match them is that they both share the same death time, and thus are related to the same persistence interval of the module \(H_*(Z_\bullet )\).
Remark 6
The Morse assumption is crucial in order for the notion in Definition 5 to be well-defined. Having Morse filtrations for \(X\) and \(Y\) ensures that there is at most one birth at each time in \(\textrm{H}_*(X_\bullet )\) and \(\textrm{H}_*(Y_\bullet )\). From the definition of image-persistence, this also holds in the respective image-persistence modules. Recall that a birth in the image-persistence module means a birth in the corresponding persistent homology module of \(X\) or \(Y\). This allows each bar from the image-persistence module to have the same birth time as exactly one bar in the associated persistent homology.
From the death perspective, recall that a death happening in any of the image-persistence modules means a death in \(\textrm{H}_*(Z_\bullet )\). Thus, there is also at most one bar in each image-persistence diagram dying at any given time. Consequently, each bar from an image-persistence module can share the same death time with at most one bar from the other image-persistence module. These notions of uniqueness induced by assuming Morse filtrations guarantee that there are no ambiguous matchings.
2.3 Matching affinity and prevalence score
The prevalence score was proposed by Reani and Bobrowski (2021b) as an alternative measure to persistence—in the sense of interval length—as an indicator for topological significance in noisy data. It takes inspiration from bootstrapping techniques, which is a well-known and powerful subsampling with replacement method, originally proposed in the statistical literature by Efron (1982).
The formulation of the prevalence score takes into account the inherent tendency that as the sample size grows, noisy generators tend to reappear frequently. Due to this tendency, the affinity of a match must first be discussed before prevalence may be considered. Affinity is a score assigned to every match that considers the lifetimes of the persistent cycles and image-persistent cycles involved in the definition of interval matching. Recall that the Jaccard index of two intervals \(I\) and \(J\) is given by
where \(\Vert {\cdot } \Vert \) denotes the length of an interval.
Definition 7
(Matching affinity, Reani and Bobrowski (2021b)) The matching affinity of two bars \(\alpha , \beta \) matching through their image-bars \(\tilde{\alpha }, \tilde{\beta }\) is defined as the product
With this definition, the prevalence score may now be formally introduced.
Definition 8
(Prevalence score, Reani and Bobrowski (2021b)) Given some reference space \(X = X_{\textrm{ref}}\) and resampling spaces \(X^{(1)},\ldots ,X^{(K)}\) , any \(\alpha \in \textrm{Pers}(H_*(X_\bullet ))\) has a prevalence score defined by
where \(\beta _k(\alpha )\) is the unique bar in \(X^{(k)}\), for \(1\le k\le K\), matched to \(\alpha \) using \(Z = X_{\textrm{ref}}\cup X^{(k)}\) as a comparison space and the inclusions into the union as the connecting maps \(f: X_{\textrm{ref}} \rightarrow Z\) and \(g: X^{(k)} \rightarrow Z\) (if a matching does not exist, set \(\rho = 0\)).
2.4 Clearing algorithm and cohomology
The basic algorithm to compute the persistent homology of a filtered complex is based on reducing each column of the matrix of the boundary operator on the complex by adding columns on its left, from left to right, to obtain a reduced matrix. From this reduced matrix, the barcode can be readily attained.
Chen and Kerber (2011) proposed an optimization of this process called the clearing algorithm, based on the observation that since the matrix to reduce comes from a boundary operator, some columns in the reduced matrix must be null after the reduction and do not play a role in the reduction process. The clearing algorithm then reduces the boundary matrix in blocks from right to left so that it becomes possible to detect these null columns beforehand and set them directly to \(0\). In that way, it is possible to avoid reducing these columns and thereby accelerate the computation. However, the increase in speed is burdened by the large number of columns in the first block that must be reduced in the boundary matrix.
In an application to compute circular coordinates, de Silva et al. (2011b) observed that computing persistent cohomology was generally faster than computing persistent homology. This phenomenon was later confirmed by Bauer et al. (2017), who also realized that this increase in speed was coming from an implicit use of the clearing algorithm to compute persistent cohomology by de Silva et al. (2011b). One of the contributions of Ripser (Bauer 2021), which also implements this optimization, is to provide a formal argument for this increase in speed: the advantage of using the clearing algorithm in persistent cohomology stems from the fact that in the relative coboundary matrix, the first block to reduce is significantly smaller. From the reduced coboundary matrix, the barcode for the relative cohomology setting (4) is read off, which is equivalent to the barcode for the homology setting (1) as established by de Silva et al. (2011a).
We note in particular that Ripser only considers Vietoris–Rips persistent homology, which is based on the Vietoris–Rips filtration, and does not compute other filtrations. The Vietoris–Rips filtration is a standard filtration often considered in computational applications and settings. Recall that the Vietoris–Rips filtration of a finite metric space \((\mathcal {P},d)\) is \(\textrm{VR}_\bullet (\mathcal {P}, d)\) where the simplicial complex at filtration value \(\epsilon \) is
By applying the homology functor, we obtain the Vietoris–Rips persistent homology \(\textrm{H}_*(\textrm{VR}_\bullet (\mathcal {P}, d))\).
3 Cycle matching in the setting of cohomology
In this section, we present our theoretical contributions. Specifically, we address the current gaps in the literature by providing a comprehensive account of the extension of image-persistence to the outstanding settings of the four standard persistence modules and the relations between such modules. Subsequently, we specialize the definition of interval matching to simplex-wise filtrations and outline how to implement our specialization using Ripser-image. We finish the section with a case study of alternative definitions of the matching affinity.
3.1 The four image-persistence modules
We only need functoriality applied to the following commutative diagram

for \(1\le i\le n-1\) to define image-persistence, which can then be easily extended to obtain four image-persistence modules as parallels to the four standard persistence modules presented previously in Sect. 1.1.
In the setting of absolute cohomology, applying the corresponding homology functor gives us the following commutative diagram

for every \(1\le i \le n-1\). Since we are working with field coefficients, the objects with superscripts are dual to the objects with subscripts from the diagram for homology. The commutativity of the diagram allows for the following definition.
Definition 9
(Image-persistent cohomology) The image-persistent cohomology is defined as the persistence module
given by the subspaces \(\textrm{Im}(\textrm{H}^*(f_i)) \subset \textrm{H}^*(X_i)\) and the restrictions of the maps \(\textrm{H}^*(\iota _i^X)\).
We now consider the relative settings. Recall that we have a map \(f: X \rightarrow Z\) such that \(f(X_i) \subset Z_i\); we denote this by
for every \(1 \le i \le n\). Since we also have \(X_i \subset X_{j} \subset X\), for \(i\le j\), we can write
for the identity in \(X\). The same can be written for the identity \(\iota ^Z\)
This gives us the following commutative diagram

for \(1 \le i \le n-1\). Using functoriality in the relative setting we obtain the subsequent commutative diagrams

where again, the subscripts and superscripts mean duality. Observe the notation of the homology functor applied to \(f : (X, X_i) \rightarrow (Z, Z_i)\). Commutativity again allows for the following definitions.
Definition 10
(Image-persistent relative homology) The image-persistent relative homology is the persistence module
given by the vector spaces \(\textrm{Im}(\textrm{H}_*(f, f_i)) \subset \textrm{H}_*(Z,Z_i)\) and the restrictions of the linear maps \(\textrm{H}_*(\iota ^Z)\).
Definition 11
(Image-persistent relative cohomology) The image-persistent relative cohomology is the persistence module
given by the vector spaces \(\textrm{Im}(\textrm{H}^*(f,f_i)) \subset \textrm{H}^*(X,X_i)\) and the restrictions of the linear maps \(\textrm{H}^*(\iota ^X)\).
Remark 12
The four image-persistence modules above currently appear in Bauer and Schmahl (2021) as an example of application of a broader theory of lifespan functors, i.e., endofunctors in the category of persistence modules and matching diagrams—equivalent to barcodes—which are related to boundedness properties of the intervals. Their work is precisely motivated by the extension of the duality results by de Silva et al. (2011a) to the setting of image-persistence. A version of a result from Bauer and Schmahl (2021) is then revisited in Bauer and Schmahl (2022) in Proposition 3.12 in order to implement Ripser-image, which plays a central role in our work. This result will be further explained in Sect. 2.2 and is fully referenced in Proposition .
3.2 Equivalence among the four image-persistence settings
A natural question to ask after introducing the four image-persistence modules is whether we can expect equivalences among them akin to the ones proved by de Silva et al. (2011a) for the standard persistence modules. In search of a first immediate answer to this question, we check directly whether the persistence modules of homology and cohomology provide the same information.
Proposition 13
The following equalities hold:
Proof
It is sufficient to prove that the maps naturally induced between the images,
and
for all \(i \le j\) have the same rank. This is true since
where the second equality (5) is given by duality and the third equality (6) is given by the commutativity of the diagram in absolute cohomology. Since persistence barcodes are uniquely determined by dimensions and ranks, we have shown that the image-persistent absolute homology and image-persistent cohomology barcodes are the same. The same proof applies to prove equality of the barcodes in the relative setting. \(\square \)
As for equivalence between the absolute and relative settings, the arguments used in de Silva et al. (2011a) are not directly applicable for image-persistence. However, if \(\textrm{Pers}_0\) denotes the finite intervals and \(\textrm{Pers}_\infty \) the infinite intervals of a given persistence barcode, we have the following correspondence.
Proposition 14
(Bauer and Schmahl (2022), Proposition 3.12) We have
Additionally, the map \(I \rightarrow T \setminus I\) defines the bijections
This result means that in order to determine the barcode of \(\textrm{Im} \,\textrm{H}_*(f_\bullet )\), it suffices to compute \(\textrm{Pers}_\infty (\textrm{H}^*(X,X_\bullet ))\) and \(\textrm{Pers}_0(\textrm{Im} \,\textrm{H}^*(f, f_\bullet ))\). Both of these persistence diagrams may be computed applying a matrix reduction algorithm to appropriate boundary matrices. Bauer and Schmahl (2022) also show that the clearing algorithm implemented in Ripser (see Sect. 1.4) can be applied to compute image-persistence. In this way, the code for Ripser can be fully adapted to this setting to achieve state-of-the-art computations for image-persistence.
3.3 Matching intervals in non-Morse filtrations
Ripser-image provides the barcode of the image-persistent homology for Vietoris–Rips filtrations. As noted previously in Remark 6, this presents a significant obstacle to implement efficient interval matching using Ripser-image: Vietoris–Rips filtrations are not Morse filtrations. To overcome this limitation, we introduce a specialization of Definition 5 that resolves the matches between bars with shared birth or death time. We first recall the definition of simplex-wise filtration.
Definition 15
A filtered complex \(\{X_i : i \in I\}\) is essential if \(i\ne j\) implies \(X_i \ne X_j\). Additionally, it is a simplex-wise filtration if for every \(i\in I\) such that \(X_i \ne \emptyset \) there is some simplex \(\sigma _{i}\) and some index \(j<i\), such that \(X_i \smallsetminus X_j = \{\sigma _i\}\).
Observe that in simplex-wise filtrations, there is a bijection between the indices of the filtration and the simplices of the complex \(X\). Consequently, the persistence pairs in the intervals of the barcode can be associated with particular simplices. We call the simplices corresponding to birth times positive simplices and those corresponding to death times negative simplices; we say that an interval is created by its positive simplex and destroyed by the negative simplex.
In addition, simplex-wise filtrations are Morse filtrations, which allows us to directly apply the definition of interval matching proposed by Reani and Bobrowski (2021b) (Definition 5): given the correspondence between birth (resp. death) times and positive (resp. negative) simplices, we can rephrase Definition 5 in the following manner. Let X, Y, Z be finite simplicial complexes with simplex-wise filtrations \(\{X_i: i \in I\}\), \(\{Y_i: i \in I\}\), and \(\{Z_i:i \in I\}\). Assume we have injective maps \(f:X \rightarrow Z\) and \(g: Y \rightarrow Z\) with the usual notation for the restrictions
for every \(i \in I\).
Definition 16
(Interval matching for simplex-wise filtrations) Let \(\alpha \in \textrm{Pers}(\textrm{H}_*(X_\bullet ))\) and \(\beta \in \textrm{Pers}(\textrm{H}_*(Y_\bullet ))\). The intervals \(\alpha \) and \(\beta \) are matching intervals via \(Z_\bullet \), if there exist \(\tilde{\alpha } \in \textrm{Pers}(\textrm{Im} \,\textrm{H}_*(f_\bullet ))\) and \(\tilde{\beta } \in \textrm{Pers}(\textrm{Im} \,\textrm{H}_*( g_\bullet ))\) such that the following conditions are satisfied:
-
\(\alpha \) and \(\tilde{\alpha }\) are created by the same simplex (seen in \(X\) and in \(f(X)\), respectively);
-
\(\beta \) and \(\tilde{\beta }\) are created by the same simplex (seen in \(Y\) and in \(g(Y)\), respectively);
-
\(\tilde{\alpha }\) and \(\tilde{\beta }\) are destroyed by the same simplex in \(Z\).
In Definition 16, the use of the phrase “by the same simplex” in relation to intervals \(\alpha \) and \(\tilde{\alpha }\) means that if \(\sigma \) is the positive simplex associated to \(\alpha \), then \(f(\sigma )\) is the positive simplex associated to \(\tilde{\alpha }\); this meaning also applies to the bars \(\beta \) and \(\tilde{\beta }\) with their positive simplices connected by the function \(g\). Notice that this association is well defined since both \(f\) and \(g\) are assumed to be injective. Similarly, the notion of \(\tilde{\alpha }\) and \(\tilde{\beta }\) being destroyed by the same simplex means that the negative simplices associated to these intervals are precisely represented by a single simplex within the larger complex \(Z\).
Again, many constructions of filtered complexes do not comply with Definition 15, in particular, Vietoris–Rips filtrations are not simplex-wise in general. However, for any filtered complex we can always find a re-indexing that refines the filtration and turns it into an essential simplex-wise filtration. This can be done by finding a partial ordering of the simplices in each of the steps of the original filtration that extends to a total ordering in the whole complex. For instance, Ripser uses a lexicographic refinement of the Vietoris–Rips filtration, which orders the simplices by dimension, diameter and a combinatorial system (see Bauer (2021) for further detail).
Consequently, restricting the matching to simplex-wise filtrations does not introduce any additional difficulties; rather, it enables the application of cycle matching to general filtrations. The process described above is a standard procedure in persistent homology solvers (i.e., algorithms that compute persistent homology barcodes), which compute the barcode for the refined simplex-wised filtration and then retrieve the barcode of the original filtration by relabelling the endpoints of the intervals as explained in Sect. 1.1. This process can be extended to interval matching in a similar manner: given a general filtration, we refine it to a simplex-wise filtration, compute the interval matching following Definition 16, and then recover the interval matching for the original filtration. This approach addresses a gap in the work of Reani and Bobrowski (2021b) and thus makes their ideas more general and widely applicable, increasing their practical utility.
Remark 17
Notice that to implement the interval matching in Definition 16 for general filtrations, we need to further assume that underlying simplex-wise refinements are compatible in the three filtrations. This means that the simplices are added to the persistence modules \(\textrm{H}_*(X_\bullet )\) and \(\textrm{H}_*(Y_\bullet )\) and to their image-persistence modules \(\textrm{Im} \,\textrm{H}_*(f_\bullet )\) and \(\textrm{Im} \,\textrm{H}_*(g_\bullet )\) in the same order. This can always be achieved by first setting the orders in \(X\) and \(Y\) and then in \(Z\) accordingly.
3.4 Implementing cycle matching with Ripser-image
The input to Ripser-image consists of two Vietoris–Rips filtrations
where the two metrics \(d, d'\) on a finite set \(\mathcal {P}\) satisfy \(d(p,q) \ge d'(p,q)\) for all \(p, q \in \mathcal {P}\). However, the setting for interval matching is slightly different.
From Sect. 1.2, to implement interval matching on finite point clouds \(\mathcal {X}\) and \(\mathcal {Y}\) living in the same ambient space, we can consider their union \(\mathcal {P} = \mathcal {X} \cup \mathcal {Y}\) and any metric \(d'\) on \(\mathcal {P}\) induced from that ambient space. This will induce metrics \(d_X := d'\vert _{\mathcal {X}} \) and \(d_Y :=d'\vert _{\mathcal {Y}}\) on the smaller point clouds as well. Consider the extension
such that the metric \(d_X'\) is obtained by setting a very large distance between any point in \(\mathcal {X}\) and any point in \(\mathcal {Y}\), and any pair of points in \(\mathcal {Y}\), all seen in the union. Then, up to a threshold corresponding to that large distance and up to the points in \(\mathcal {P}\setminus \mathcal {X} = \mathcal {Y}\), we have
which puts us in the setting of Ripser-image. Notice that in the matrix representation of \(d_X\) there are rows and columns corresponding to points in \(\mathcal {Y}\). This construction can be also applied to \((\mathcal {Y}, d_Y)\), preserving the same order as before in rows and columns to ensure compatibility. In this manner, we obtain the three Vietoris–Rips filtrations
and we consider the inclusions as the connecting functions for the matching.
The code for Ripser and Ripser-image assigns a unique index to any simplex of the input filtered complex using a lexicographic refinement. However, it does not provide the indices associated to the positive and negative simplices of the persistence intervals of the barcode in its output. These values can be readily retrieved with a slight change the original code. By arranging the matrices representing the finite metric spaces as explained above, these indices allow for the implementation of Definition 16 without affecting the computational runtime of both programs.
It is crucial to observe at this point that a change in the order of the columns and rows within the distance matrices used as input for Ripser-image, which are in correspondence with the points of \(\mathcal {X}\) and \(\mathcal {Y}\) in the setting described above, will alter the indices assigned to simplices through the lexicographic refinement. This could, in principle, alter the outcome of the interval matching using Ripser-image as described thus far. Nonetheless, as long as we are consistent with the ordering in all of the three matrices involved in the computations, this observation poses no problem for the implementation of the interval matching. In our code, the points in \(\mathcal {X}\) occupy the foremost positions, preserving the same order in all three matrices, and the points in \(\mathcal {Y}\) assume the terminal positions, also preserving their order across matrices.
A Note on Terminology: Cycle Matching.
Reani and Bobrowski (2021b) refer to this framework of matching intervals in persistent homology as cycle registration. In this paper, whenever we use the term “cycle matching,” we assume that there is a way of finding cycles in the final simplicial complex of the filtration that correspond to the intervals in its barcode. Note that, in general, these representative cycles are not unique—in fact, the persistence intervals are associated to homology classes, i.e., equivalence classes of cycles. However, there are methods to uniquely determine the representative cycles. One such method considers the columns of the reduced boundary matrix corresponding to the killing simplices, which provides the simplices that make up a cycle killed by that simplex.
Further on in Sect. 3, we implement cycle matching by using the version ripser-tight-representative-cycles of Ripser. This feature provides the representative cycles corresponding to the intervals in the barcode computed by Ripser. Note that Ripser does not reduce the boundary matrix but the relative coboundary matrix (see the previous discussion from Sect. 1.4), and thus we cannot implement the aforementioned method directly. However, Čufar and Virk (2021) develop an adaptation of this idea to obtain state-of-the-art computations of barcodes and representatives. The method proposed in Čufar and Virk (2021) uses persistent cohomology to obtain the persistence pairs and reduces the boundary matrix only using the columns corresponding to death indices. This is the technique that ripser-tight-representative-cycles implements.
Processing Multiple Jobs in Parallel.
A computational advantage of the bootstrapping approach proposed by Reani and Bobrowski (2021b) is that this technique is parallelizable, despite the inherently non-parallelizable nature of persistent homology computations. Recall that once the barcode of the reference sample is computed, to obtain the prevalence score of its intervals, these intervals are matched with the intervals in the barcodes of \(K\)-many resamplings. These matchings can be processed in parallel jobs using a high performance computer cluster (HPC) with a workload manager and job scheduling system, such as SLURM or OpenPBS. In each of these jobs, first, the barcode of the corresponding resampling and the barcodes of the image-persistence modules involved are computed, then the generalized interval matching is implemented. This allows for a dramatic increase in efficiency in the computational runtime, with respect to a sequential execution of the code: the total computational time corresponds to the one of the slowest job, instead of the sum of the computational times of the individual jobs.
3.5 Revisiting matching affinity
The matching affinity introduced in Definition 7 relies on a particular choice of pairs of intervals to compare through their Jaccard index. In principle, other selections are also valid to obtain different definitions of the matching affinity. We now study the behavior of four such affinities in the example of two circles with same radius but diverging centers. This will allow us to conclude that only one of these definitions exhibits a significant difference with respect to the others.
From now on, we refer to the matching affinity of Definition 7 as matching affinity A
where \(\alpha , \beta \) denote two bars matched through their image-bars \(\tilde{\alpha }, \tilde{\beta }\). This score involves the comparison of \(\alpha \) and \(\beta \) but also of each bar with its corresponding image-bar. Considering multiple ways to compare persistence bars and image-bars, we also have:
-
the matching affinity B as
$$\rho _B(\alpha ,\beta ) := \textrm{Jac}(\tilde{\alpha },\tilde{\beta }) \cdot \textrm{Jac}(\alpha , \tilde{\alpha })\cdot \textrm{Jac}(\beta ,\tilde{\beta });$$ -
the matching affinity C as
$$\rho _C(\alpha ,\beta ) := \textrm{Jac}(\alpha ,\beta ) \cdot \textrm{Jac}(\tilde{\alpha },\tilde{\beta }) \cdot \textrm{Jac}(\alpha , \tilde{\alpha })\cdot \textrm{Jac}(\beta ,\tilde{\beta }),$$ -
the matching affinity D as
$$\rho _D(\alpha ,\beta ) := \textrm{Jac}(\alpha ,\beta ) \cdot \textrm{Jac}(\tilde{\alpha }, \tilde{\beta }).$$
The following concrete example provides an intuition on how the different affinities behave. Consider two circles of radius \(1\) and centers shifted by a distance \(s\). We expect that the matching affinity decreases as the center-to-center distance \(s\) increases, until reaching 0 (i.e., no match) beyond a certain value. The result of this experiment is displayed in Fig. 2, where we see that all matching affinities decrease with respect to s and that the cutoff value is 1. Affinities A, B, and C follow very similar decreasing behaviors in a linear fashion, whereas affinity D has a distinct plateau-like behavior. We now further investigate this phenomenon.

Mean and standard deviation of the affinities of the matches between two circles of radius 1 with centers shifted according to the horizontal axis. The circles were sampled with \(N = 100\) points without noise added. We considered 15 equidistant distances between 0 and 1 and took 15 samples at each step
Assume that we have two persistence bars \(\alpha \) and \(\beta \) matched via their image-bars \(\tilde{\alpha }\) and \(\tilde{\beta }\). We know that the birth times of \(\alpha \) and \(\tilde{\alpha }\), and \(\beta \) and \(\tilde{\beta }\) coincide, respectively, and that the bars \(\tilde{\alpha }\) and \(\tilde{\beta }\) also have the same death time. Thus, having high affinity A, for instance, depends on the two following phenomena. Firstly, the bars \(\alpha \) and \(\beta \) must have similar birth and death times. This means that the cycles in \(X\) and \(Y\) that generated them should be similar in size. Secondly, the death time of the image-bars should also be similar to the death time of the original bars. Geometrically, this means that the cycles that generated the bars should have high overlapping surface when considered in the union of the point clouds. These ideas are illustrated in Fig. 3, where the affinity A of a match of two circles decreases significantly when the circles have different centers or radii.

Three matches between samples of 100 points of two circles with Gaussian noise of magnitude 0.1 added. In Fig. 3a; the circles have the same radii and centres; in Fig. 3b the circles have the same radii and centres 0.7 units of length apart; and in Fig. 3c, the circles have coinciding centres and radii 1 and 1.5
Returning to Fig. 2 with these ideas in mind, we see that there are few noticeable but not fundamental differences between the affinities A, B, and C. Indeed, the Jaccard indices \(\textrm{Jac}(\alpha , \beta )\) and \(\textrm{Jac}(\tilde{\alpha }, \tilde{\beta })\) have similar magnitude—if a pair of cycles are similar in size in the spaces \(X\) and \(Y\), the cycles corresponding to their image-bars in the union will also have similar sizes. This implies that the affinities A and B are very similar. Affinity \(C\) is slightly lower than affinities \(A\) and \(B\) only because it has an extra multiplicative factor with magnitude less than one.
It also makes sense that the matching affinities A, B, and C drop when the spatial overlap between cycles decreases. This happens because these affinities include the Jaccard indices between bars and image-bars, which are influenced by this overlap. The matching affinity \(D\) does not consider such a comparison, and thus, remains at a higher value until there is no match anymore, when it drops abruptly. Such a behavior could be useful in certain situations. In real-life applications, it might happen that we are interested in matching topological features that shrink or enlarge significantly, or which appear misplaced in the samples. Matching affinity D would then be more sensitive to these matches, by assigning a higher prevalence score to them. However, this feature could be undesirable in other contexts, as we discuss in the next observation.
We now need to check whether the four affinities are consistent with the original motivation, which is the condition proposed in Reani and Bobrowski (2021b). Namely, random cycles that appear in resamplings and get matched several times should be assigned a low prevalence score. Similar to Reani and Bobrowski (2021b), we consider a uniform sampling of the unit square with \(N_{\textrm{ref}} = 1000\) points and compute the prevalence scores of its bars by finding matches with \(K = 20\) different resamplings of \(N =1000\) points from that same distribution. The results of this experiment are given in Fig. 4. For affinity D, some random cycles are assigned quite high prevalence scores in the range 0.6–0.7. This must be taken into account when interpreting the affinity scores for applications using affinity D.

Most matched intervals in resamplings of \(N=1000\) points of the uniform distribution in the unit square. Top left: Frequency of reappearance of the 15 most frequently matched intervals. Remainder of the figure: Cycles representing the persistence intervals of \(X_{\textrm{ref}}\) stained by their prevalence score using the affinity specified above of the image
4 Applications
In this section, we demonstrate with numerous examples that cycle matching can be applied to real-life, large-scale, complex datasets from biology and astrophysics. Several applications motivate the usage of cycle matching and prevalence. First, we can identify common topological features shared by two spaces as a direct application of cycle matching. We can use this to track features both spatially and over time, on consecutive slices of an object or on consecutive time frames. We demonstrate both of these applications in this section.
Second, the most prevalent features in data can be identifed by applying cycle matching repeatedly after resampling from the same distribution. By doing this, we can detect prevalent cycles in large-scale and complex data. Here prevalence is computed using Affinity A exclusively. We demonstrate this on cosmic web data and cell actin network data. Prevalence gives rise to an enriched visualization via the prevalence-augmented barcode, where length corresponds to persistence while thickness and color both correspond to prevalence.
Comparison with Classical Computer Vision Tools for Feature Tracking. It is important to note at this point that the application we are suggesting here differs from existing algorithms for tracking features in computer vision, such as those implemented in OpenCV (Bradski 2000; OpenCV 2014). These algorithms take images of an object of interest as input and use different methods to track the object through subsequent frames, identifying an area in the frame in which the object is located. The technique we are proposing fundamentally differs from the procedure above in four aspects. First, we track topological features, which are structures that are inherently different from objects and object locations in images. Moreover, we do not need any prior knowledge of what to track: persistent homology directly detects the topological features of the image, and our only input is the video or stack of images where the topological features are present. In addition, our output is the chain of features from the persistent homology of the images that are matched in subsequent frames, which we can represent through cycle representatives as explained above, but which is not in principle related to any specific area in the image, as is the case of the output of the feature tracking algorithms. Lastly, notice that we can track several features concurrently, without needing to re-run the whole algorithm, which is what usually happens in feature tracking algorithms in computer vision.
4.1 Tunneling: tracking intervals over slices
As a first application of cycle matching, we tracked intervals over two-dimensional slices of three-dimensional objects. In biomedical imaging, for instance, it is common that data are made up of spherical or tubular elements, such as in vessels and other biological organs with channeling functions. Using cycle matching, we can match the closed contours delimiting the spherical or tubular elements across slices.
Data: Lateral Line in Zebrafish.
To demonstrate this application, we used a biological imaging dataset, in particular the dataset with image ID 9836972 provided in Hartmann et al. (2020). This is a stack of two-dimensional confocal images from the zebrafish posterior lateral line primordium (pLLP). The pLLP is a primitive expression of the lateral line—an organ in fish that allows them to detect the pattern of water flow over their body surface. It appears at the embryonic stage in the form of a rosette-shaped cluster of cells. The circular contours that we can see in the images of the dataset (see Fig. 5) are precisely these cells; we will track these along the height of the stack.

Cycle matching to track cell contours on images of slices of the posterior Lateral Line Primordium (pLLP) of the zebrafish. We applied an Otsu threshold and took samples of \(N = 1000\) points on the images. Cycles matched across consecutive slices can be grouped into tunnels, each stained with a different color. Data courtesy of Hartmann et al. (2020)
We considered a stack of \(15\) images with a \(0.66\,\upmu {\textrm{m}}\) gap and size of \(300 \times 300\) pixels in each image, with a resolution of 0.1 \(\,\upmu {\textrm{m}}\) per pixel. We thresholded the images with the Otsu method and uniformly sampled them with \(N = 1000\) points. We matched persistent intervals between pairs of Vietoris–Rips filtrations on consecutive slices. Some features were matched on consecutive frames and formed a tunnel: we were able to detect 32 such tunnels, each stained with a different color. We computed the geometric generators drawn here to represent the persistence intervals that were matched using the ripser-tight-representative-cycles module of Ripser (Bauer 2021). The results are shown in Fig. 5. As a byproduct of this approach, we can identify slices on which a cell appears then disappears.
4.2 Video data: tracking features over time
Cycle matching can be used to track topological features over time, by matching the barcodes of consecutive frames in a video, or, in a biological context, at different stages of disease development. This method detects common topological patterns surviving across consecutive time points and quantifies the quality of the match through the affinity scores.
Data: Heart Valves in Zebrafish.
To illustrate this application, we analyzed a video of the atrioventricular valve (AVV) of a wild-type AB zebrafish, from Scherz et al. (2008). This video is taken 76 h post fecundation and at a rate of 50 ms. The specimen studied comes from a transgenic line that allows the monitoring of the two chambers that make up the primitive heart of the zebrafish embryo, and how its contraction over time generates embryonic heartbeats. The contraction is especially pronounced for the right chamber, as can be seen from Fig. 6.

Cycle matching on 10 frames from a video courtesy of Scherz et al. (2008). We took samples of \(N = 500\) points and applied a threshold based on the mean of the gray-scale values before sampling. The intervals matched are stained in the same color. Below each image we display the affinity of the match between the interval in the image and the corresponding interval in the subsequent image
We selected 10 frames capturing one contraction and matched cycles on consecutive frames (Fig. 6). We sampled \( N = 500\) points on each of the images after applying a thresholding technique based on the mean of gray-scale values. We successfully detected the persistent intervals delimiting the two chambers, and tracked them on all consecutive frames. We also tracked their size variation. Note that the matching affinities are much more variable for the cycle on the right (in red), which is expected since the right chamber changes abruptly in shape. As before, we show on each frame of Fig. 6 the generator associated to each persistence interval, obtained with the ripser-tight-representative-cycles module of Ripser, while using the same color to stain matched cycles.
Data: Time-Lapse Images of Human Embryos.
As another example to demonstrate feature tracking over time, we tracked intervals on 10 consecutive frames of time-lapse embryo data from Gomez et al. (2022) (Fig. 7). A time-lapse imaging (TLI) system with a special camera captures images of a human embryo every 50 to 100 minutes and features different stages of cellular division. We matched samples of \(N =500\) points on the images after applying a Sato operator and a threshold using the Otsu method. We were able in particular to detect cell division as the appearance of a new topological feature (in red).

Cycle matching on the time-lapse embryo dataset (Gomez et al. 2022) between samples of \(N = 500\) points in the images after applying a Sato operator and a threshold using the Otsu method. Cycles that get matched are stained in the same color. Below each image one can find the affinity of the match between the interval in the image and the corresponding interval in the previous image
4.3 Prevalent cycles
Our next application is to find prevalent cycles in order to reveal significantly organized topological patterns in data. We will demonstrate this on cosmic web data (Fig. 8) and cell actin data. Recall that this consists of comparing multiple resamplings \(X^{(1)},\ldots ,X^{(K)}\) to a reference space \(X_\textrm{ref}\) and finding all possible matching pairs of persistence intervals between \(X_{\textrm{ref}}\) and any \(X^{(k)}\) for \(1\le k\le K\).

Prevalent cycles in the cosmic web. Cycle representatives are stained by prevalence score and galaxies (from the original BOSS CMASS data) are shown as blue dots. We formed the reference space by sampling the galaxies with \(N_\textrm{ref} = 1000\) perturbed points and performed \(K = 20\) comparisons to spaces formed by sampling with \(N = 300\) perturbed points each
This approach becomes especially useful in situations where the initial (unknown) distribution has high topological complexity, and for which we only have access to point cloud samplings. In other situations, the distribution may be partially or even entirely known already—for instance if we are given an image from which to sample points. Oftentimes, an image may suffer from noise or contrast variations, but we can recover the true cycles of the object. Even in the absence of noise, brighter and weaker signals may still capture interesting information (for instance, depth in 2D images)—prevalence takes this into account. We can also study the profile of prevalence scores corresponding to an image to characterize its topological structure in comparison to another image. We may visualize this using prevalence-augmented persistence barcodes, where the length of a bar still represents persistence in the usual sense, while its thickness and color represents prevalence.
Data: The Cosmic Web.
First, we identified prevalent cycles in the cosmic web, based on the point distribution of galaxies from the BOSS CMASS database (Dawson et al. 2013). Matter in the universe is arranged along an intricate pattern involving filamentary structures (de Lapparent et al. 1986; York et al. 2000). However, the reconstruction of these filaments is still challenging; multiple methods to address this reconstruction problem have been proposed (Malavasi et al. 2020). Instead of detecting filaments with an uncertainty score (e.g., Duque et al. 2022, ), we propose to detect cycles with a prevalence score.
The final version of the BOSS CMASS dataset used here is included in the current data release SDSS DR17 (Abdurro’uf et al. 2022) and was released in SDSS DR12 (Alam et al. 2015). We selected galaxies with right ascension \(170< \textrm{RA} < 190\), declination \(30< \textrm{dec} < 50\) and redshift range \(0.564< z < 0.57\) and projected the points onto the \((\textrm{RA},\, \textrm{dec})\) 2D space.
We sampled the reference space \(X_{\textrm{ref}}\) using \(N_\textrm{ref} = 1000\) points and resampled the dataset \(K = 20\) times with 300 points in each resampling \(X^{(k)}\), by adding Gaussian noise of magnitude 0.1 to each point. The noise scale, required for the prevalence score bootstrapping technique, is determined based on both the data magnitude and the width of the filaments present in the original sample that we want to detect. We performed 20 comparisons of barcodes to find matching cycles. The results are shown in Fig. 8, where cycles with different prevalence scores can be visualized.
Data: Cell Actin.
Next, we computed the prevalence of cycles in biological imaging data of cell actin. Actin networks are essential in scaffolding the inner structure of cells, enabling in particular cell motility and reshaping. Figure 9, featuring data from Svitkina and Borisy (1999), shows significant loss of actin filaments in the rear of the lamellipodium network due to the absence of some stabilizing chemicals during extraction. We selected three crops I, II and III, to study from this image, where the actin filaments are sparse, half-sparse and half-dense, and dense, respectively. We then thresholded each cropped image using the Otsu thresholding method to segment filaments, and restricted the original image pixel intensities to these filaments to finally obtain a discrete probability distribution. Points were sampled from this distribution and their spatial coordinates were perturbed with a Gaussian noise of standard deviation \(10\%\) of a pixel side.

Electron micrograph of actin network in Xenopus keratocyte lamellipodium, whose rear part disassembled in the course of unprotected extraction and front part remained dense as in control cells. Selected crops I, II, III (from left to right) are shown as red rectangles. Original image CIL:24800 is from the Cell Image Library database (Ellisman et al. 2021), available under CC BY-NC-SA 3.0 License, corresponding to Figure 6b of Svitkina and Borisy (1999)

Prevalent cycles of reference space X with \(N_\textrm{ref} = 1200\) points (shown as blue dots), based on \(K = 30\) resampling spaces of \(N = 500\) points. Cycle representatives are stained by prevalence score. From left to right: crops I, II, III. Colorbar describes prevalence scores


Persistence barcodes of reference space X. Values on the horizontal axis correspond to birth time and length of a bar to persistence. From left to right: crops I, II, III
We show the results of our computations in Figs. 10, 11, 12, 13, 14, and 15. We found that larger voids in the structure of the actin mesh led to larger cycles of higher prevalence, such as in crop I, whereas small voids in denser parts led to smaller cycles of lower prevalence, such as in crop III. As seen in Figs. 10 and 11, we correctly identified large cycle representatives in crop I, small ones in crop III, and a mix of small and large ones in crop II, at the transitional region between rear and front of the lamellipodium. The usual persistence barcodes (Fig. 12) show numerous short-lived bars in crop III, but some longer-lived features for crops I and II. This barcode information can be enriched by visualizing the prevalence as the thickness and color of a bar (Fig. 13). It is interesting to note that the highest prevalence scores throughout selected data were found in crop II, corresponding to two highly prevalent cycles (see Fig. 14). Their scores are higher than those from crop I, due to contrast variations of larger amplitude along filaments of crop II. Indeed, prevalence can be interpreted as a certainty measure of topological features. Finally, a scatter plot of prevalence versus persistence scores (Fig. 15) confirmed that prevalence is not monotonous with respect to persistence and longer intervals do not necessarily correspond to more prevalent features.

Prevalence-augmented persistence barcodes of reference space X. Thickness and color of a bar correspond to prevalence score. Values on the horizontal axis correspond to birth time and length of the bars to persistence. From left to right: crops I, II, III. Colorbar describes prevalence scores

Prevalence scores, sorted by birth time of the persistence interval. One dot stands for one interval. From left to right: crops I, II, III

Persistence versus prevalence scores in the augmented barcode of the reference space X. One dot stands for one persistence interval. From left to right: crops I, II, III
4.4 A note on computational runtime
As mentioned previously in Sect. 2.4, the advantage of the framework proposed by Reani and Bobrowski (2021b) is that the procedure of matching is easily parallelizable. With access to standard institutional high performance computing (HPC) resources requiring simply CPU processing, use of a single node, one CPU per task, and max 30 GB of memory per CPU, the problem of identifying prevalent cycles or matching intervals in spaces with a range of 100–1000 points generally reduces to a matter of minutes, ranging from seconds to a few hours for the applications showcased here.
We present in Table 1 the runtimes corresponding to the real datasets from Sects. 3.1 and 3.2, where we track topological features over a set of frames. We include the number of points in the samples \(N\) and the number of subsamples \(K\). In Table 2, we exhibit the runtimes associated to the real datasets shown in Sect. 3.3, where we compute prevalent features. We include the number of points on the reference space \(N_\textrm{ref}\), the number of points in the resamples \(N\), and the number of resamples \(K\). Table 3 collects runtimes for computing prevalent features on synthetic datasets that consist of point clouds uniformly sampled in the unit square of the plane. Note that we took \(N_\textrm{ref} = N\) in the synthetic examples.
In Table 1, one runtime corresponds to the computation of
-
(i)
the barcodes of the two samplings on consecutive frames;
-
(ii)
the two image-barcodes of those samplings in their union; and
-
(iii)
the matching itself, which compares the barcodes.
In Tables 2 and 3, step (i) only covers the computation of the barcode on the resampling \(X^{(k)}\) corresponding to that job, and in step (ii), we compute the image-persistence of the reference space \(X_\textrm{ref}\) and the resampling \(X^{(k)}\) in their union. The runtime needed to compute the barcode of the reference space \(X_\textrm{ref}\), which is just a few seconds and is computed once before the parallel jobs, is not included in Tables 2 and 3.

Median runtime versus number of sampling points N for the synthetic examples of Table 3. Median runtime increases as a power law \(T \sim \textrm{cst} \, N^{3.266}\) with respect to N (a linear regression on the logarithmic scale gave a score of 0.996, coefficient 3.266 and intercept \(-14.087\) with respect to the data points of Table 3). Left: linear-linear scale. Right: log–log scale. The dashed line corresponds to the result of the linear regression on the log-log scale
The computational bottleneck here is not the number of matchings K but the number of points N and \(N_\textrm{ref}\) sampled in the respective spaces for each matching instead. The number of matchings could be increased arbitrarily (up to the capacity of the HPC) without affecting the computational runtime while maintaining it on the order of minutes or a few hours. Increasing it here allows for more precise estimations of, for instance, the average runtime needed to find all possible matchings between two spaces. However, median runtime increases following a power law \(T \sim \textrm{cst} \cdot N^p\) where \(\textrm{cst}\) is a constant and \(p \simeq 3.266\) (see Fig. 16), so that increasing the number of sampled points N by a factor of 10 would result in increasing runtime by a factor of \(10^p \simeq 1845\).
4.5 Software and data availability
The code used to perform all experiments here is freely and publicly available at our project GitHub repository https://github.com/inesgare/interval-matching. It is fully adaptable for individual user customization.
Where possible, the data we have used in this section are also provided on the same GitHub repository so that all experiments and examples in our paper are fully reproducible. Note that some of the data we have used here required an institutional materials transfer agreement, so these data were not made available on our repository.
5 Discussion
In this paper, we studied the problem of identifying topologically significant features in noisy data where the usual measure of persistence in the sense of the length of an interval in a persistence barcode is unsatisfactory. We also studied the problem of comparing barcodes over different filtrations and identifying correspondences between persistence intervals. To date, the various existing proposals to these problems have faced significant computational limitations. The main contribution of our work is an extension of existing notions of topological significance and cycle matching to provide the most general and flexible definitions, which we then implement using the dual perspective of cohomology to achieve the fastest available identification of prevalent cycles as well as cycle matching. Our implementation now makes these approaches practical and applicable to real-life, large-scale, complex datasets with execution times ranging from a matter of minutes to a few hours for 100–1000 sampled points, using only standard institutional HPC facilities. Our work inspires several directions for future research, which we now discuss.
First, one natural question is to understand the behavior of the prevalence-augmented barcodes as the number of resampling spaces K and the number of sampling points N for each space increase to infinity. It will be important to understand how at the limit augmented barcodes are related to the original distribution, quantify the rate and type of convergence, and study how the choice of filtration [Rips, Čech, coupled-Alpha (Reani and Bobrowski 2021a)] and of affinity (A, B, C, D) affects the convergence, if at all. This would then allow us to design probabilistically-founded statistical tests, for example, to determine whether a collection of point clouds has been sampled from a specific distribution with known barcode, or not, based on some confidence intervals. Developing such a framework would provide a practical approach to choosing a threshold to identify “true” cycles in the original data as bars whose prevalence are higher than \(1 - \epsilon \). This could also have practical implications on certain applications, for example, by directly extracting “true” topological signal in complex settings such as imaging data, and perhaps even bypassing the need for computationally expensive procedures, such as image segmentation.
Another theoretical question of interest is the study of the new metric \(d_{\textrm{IM}_p}\) on persistence modules introduced by Reani and Bobrowski (2021b) in section 6.2. This metric involves comparing matched intervals between two modules directly, and not comparing birth–death times between persistence diagrams which discards important information about spatial correspondence, as explained previously. It is reasonable to expect that as N increases, the distance between two persistence modules converges to zero if the point clouds are drawn from the same distribution. Likewise, this could be an alternative approach towards the design of a (non-parametric) statistical test to determine whether two points clouds were sampled from a same distribution.
References
Abdurro’uf et al.: The seventeenth data release of the sloan digital sky surveys: complete release of MaNGA, MaStar, and APOGEE-2 data. Astrophys. J. Suppl. Ser. 259(2), 35 (2022). https://doi.org/10.3847/1538-4365/ac4414
Alam, S., et al.: The eleventh and twelfth data releases of the Sloan digital sky survey: final data from sdss-iii. Astrophys. J. Suppl. Ser. 219(1), 12 (2015). https://doi.org/10.1088/0067-0049/219/1/12
Bauer, U.: Ripser: efficient computation of Vietoris–Rips persistence barcodes. J. Appl. Comput. Topol. 5(3), 391–423 (2021). https://doi.org/10.1007/s41468-021-00071-5
Bauer, U., Kerber, M., Reininghaus, J., Wagner, H.: Phat-persistent homology algorithms toolbox. J. Symb. Comput. 78, 76–90 (2017). https://doi.org/10.1016/j.jsc.2016.03.008
Bauer, U., Lesnick, M.: Induced matchings and the algebraic stability of persistence barcodes. J. Comput. Geom. 21, 162–191 (2015). https://doi.org/10.20382/jocg.v6i2a9
Bauer, U., Schmahl, M.: Lifespan Functors and Natural Dualities in Persistent Homology (2021). arXiv:2012.12881 [cs, math]
Bauer, U., Schmahl, M.: Efficient Computation of Image Persistence (2022). arXiv:2201.04170 [cs, math]
Bradski, G.: The OpenCV Library. Dr. Dobb’s journal of software tools (2000)
Chen, C., Kerber, M.: Persistent homology computation with a twist. In: 27th European workshop on computational geometry (EuroCG 2011), pp. 1–4 (2011)
Cohen-Steiner, D., Edelsbrunner, H., Harer, J., Morozov, D.: Persistent homology for kernels, images, and cokernels. In: Proceedings of the twentieth annual ACM-SIAM symposium on discrete algorithms, SODA ’09, USA, pp. 1011–1020. Society for Industrial and Applied Mathematics (2009)
Čufar, M., Virk, Ž.: Fast computation of persistent homology representatives with involuted persistent homology. (2021). arXiv:2105.03629 [math]
Dawson, K.S., et al.: The Baryon oscillation spectroscopic survey of SDSS-III. Astron. J. 145, 10 (2013). https://doi.org/10.1088/0004-6256/145/1/10
de Lapparent, V., Geller, M.J., Huchra, J.P.: A slice of the universe. Astrophys. J. Lett. (1986). https://doi.org/10.1086/184625
de Silva, V., Morozov, D., Vejdemo-Johansson, M.: Dualities in persistent (co)homology. Inverse Prob. 27(12), 124003 (2011a). https://doi.org/10.1088/0266-5611/27/12/124003
de Silva, V., Morozov, D., Vejdemo-Johansson, M.: Persistent cohomology and circular coordinates. Discrete Comput. Geom. 45(4), 737–759 (2011b). https://doi.org/10.1007/s00454-011-9344-x
Duque, J.C., Migliaccio, M., Marinucci, D., Vittorio, N.: A novel cosmic filament catalogue from SDSS data. Astron. Astrophys. 659, A166 (2022). https://doi.org/10.1051/0004-6361/202141538
Efron, B.: The Jackknife, the Bootstrap and Other Resampling Plans. SIAM, New York (1982)
Ellisman, M., Peltier, S., Orloff, D., Wong, W.: Cell image library. Type: dataset (2021)
Gomez, T., Feyeux, M., Boulant, J., Normand, N., David, L., Paul-Gilloteaux, P., Fréour, T., Mouchère, H.: A time-lapse embryo dataset for morphokinetic parameter prediction. Data Brief 42, 108258 (2022). https://doi.org/10.1016/j.dib.2022.108258
Gonzalez-Diaz, R., Soriano-Trigueros, M.: Basis-independent partial matchings induced by morphisms between persistence modules (2020). arXiv:2006.11100 [math]
Hartmann, J., Wong, M., Gallo, E., Gilmour, D.: An image-based data-driven analysis of cellular architecture in a developing tissue. eLife 9, e55913 (2020). https://doi.org/10.7554/eLife.55913
Malavasi, N., Aghanim, N., Douspis, M., Tanimura, H., Bonjean, V.: Characterising filaments in the SDSS volume from the galaxy distribution. Astron. Astrophys. 642, 19 (2020). https://doi.org/10.1051/0004-6361/202037647
OpenCV.: The OpenCV Reference Manual (2.4.13.7 ed.). OpenCV (2014)
Reani, Y., Bobrowski, O.: A Coupled Alpha Complex (2021a). arXiv:2105.08113 [cs, math]
Reani, Y., Bobrowski, O.: Cycle Registration in Persistent Homology with Applications in Topological Bootstrap (2021b). arXiv:2101.00698 [cs, math, stat]
Scherz, P.J., Huisken, J., Sahai-Hernandez, P., Stainier, D.Y.R.: High-speed imaging of developing heart valves reveals interplay of morphogenesis and function. Development 135(6), 1179–1187 (2008). https://doi.org/10.1242/dev.010694
Svitkina, T.M., Borisy, G.G.: Arp2/3 complex and actin depolymerizing factor/cofilin in dendritic organization and treadmilling of actin filament array in lamellipodia. J. Cell Biol. 145(5), 1009–1026 (1999)
Yoon, H.R., Ghrist, R., Giusti, C.: Persistent Extension and Analogous Bars: Data-Induced Relations Between Persistence Barcodes (2022). arXiv:2201.05190 [cs, math]
York, D.G., et al.: The Sloan digital sky survey. Tech. Summ. 120(3), 1579–1587 (2000). https://doi.org/10.1086/301513
Zomorodian, A., Carlsson, G.: Computing persistent homology. Discrete Comput. Geom. 33(2), 249–274 (2005). https://doi.org/10.1007/s00454-004-1146-y
Acknowledgements
We wish to thank Omer Bobrowski, Dominique Bonnet, Vin de Silva, Bernhard Kainz, Yohai Reani, Wojciech Reise, Marc Glisse, and Iris Yoon for helpful conversations. We also wish to thank two anonymous referees for their insightful comments and help with improving the paper. I.G.R. is funded by a London School of Geometry and Number Theory–Imperial College London PhD studentship, which is supported by the Engineering and Physical Sciences Research Council [EP/S021590/1], EPSRC Centre for Doctoral Training in Geometry and Number Theory (The London School of Geometry and Number Theory), University College London. A.S. is funded by a joint Imperial College London–Francis Crick Institute PhD studentship. We wish to acknowledge The Francis Crick Institute, London, and the Information and Communication Technologies resources at Imperial College London for their computing resources which were used to implement the experiments and data applications in this paper. We would like to thank the projects involved in Hartmann et al. (2020), Scherz et al. (2008) and Gomez et al. (2022) for these datasets and their public accessibility. We are grateful to the contributors of the Cell Image Library (CIL) (Ellisman et al. 2021), located at http://www.cellimagelibrary.org, for making their data repository and resources available for public access. Funding for SDSS-III has been provided by the Alfred P. Sloan Foundation, the Participating Institutions, the National Science Foundation, and the U.S. Department of Energy Office of Science. The SDSS-III web site is http://www.sdss3.org/. SDSS-III is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSS-III Collaboration including the University of Arizona, the Brazilian Participation Group, Brookhaven National Laboratory, Carnegie Mellon University, University of Florida, the French Participation Group, the German Participation Group, Harvard University, the Instituto de Astrofisica de Canarias, the Michigan State/Notre Dame/JINA Participation Group, Johns Hopkins University, Lawrence Berkeley National Laboratory, Max Planck Institute for Astrophysics, Max Planck Institute for Extraterrestrial Physics, New Mexico State University, New York University, Ohio State University, Pennsylvania State University, University of Portsmouth, Princeton University, the Spanish Participation Group, University of Tokyo, University of Utah, Vanderbilt University, University of Virginia, University of Washington, and Yale University.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interests
The authors have no relevant financial or non-financial interests to disclose. The authors have no competing interests to declare that are relevant to the content of this article. All authors certify that they have no affiliations with or involvement in any organization or entity with any financial interest or non-financial interest in the subject matter or materials discussed in this manuscript. The authors have no financial or proprietary interests in any material discussed in this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
García-Redondo, I., Monod, A. & Song, A. Fast topological signal identification and persistent cohomological cycle matching. J Appl. and Comput. Topology (2024). https://doi.org/10.1007/s41468-024-00179-4
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s41468-024-00179-4