
Abstract
Random forests are currently one of the most popular algorithms for supervised machine learning tasks. By taking into account for many trees instead of a single one the resulting forest model is no longer easy to understand and also often denoted as a black box. The paper is dedicated to the interpretability of random forest models using tree-based explanations. Two different concepts, namely most representative trees and surrogate trees are analyzed regarding both their ability to explain the model and to be understandable by humans. For this purpose explanation trees are further extended to groves, i.e. small forests of few trees. The results of an application to three real world data sets underline the inherent trade of between both requirements. Using groves allows to control for the complexity of an explanation while simultaneously analyzing their explanatory power.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Random forests (Breiman 2001) are currently one of the most popular algorithms for supervised machine learning tasks. A reason for their popularity may result from the intuitive idea of bootstrapping single trees which themselves are intuitive and well understood.
Moreover it turned out that random forests are of comparatively high predictive accuracy in many situations (Fernández-Delgado et al. 2014) and quite insensitive to hyperparameter tuning of e.g. the number of trees or the number of randomly selected candidate variables for each split (Probst et al. 2021). In consequence, they are easy to apply and attractive for many users.
In turn, by taking into account for many trees instead of a single one the resulting forest model is no longer easy to understand. For this reason the resulting models are also often denoted as black box models.
The increasing use of complex black box machine learning models has raised the discussion on model interpretability and an expert group by the European Commission has worked out guidelines for trustworthy artificial intelligence (European Commission 2020). One important aspect within these guidelines consists in transparency of models and during the recent years there has been increasing research activity in the field of interpretable machine learning (for an overview, cf. e.g. Bücker et al. 2021).
The paper is dedicated to the interpretability of random forest models. In Sect. 2 two existing concepts for tree-based explanations are presented, namely most representative trees (MRT) (Sect. 2.1) and surrogate trees (Sect. 2.3). In the remainder of the section both concepts are extended to groves, i.e. small forests of few trees.
In order to analyze the ability of these concepts to explain random forest models the measure of explainability is used as described in Sect. 2.5.
Note that a good model explanation not only should be as close as possible to the original model but it should also understandable for the user. Humans cognitive memory capacities are limited (cf. e.g. Miller 1956; Cowan 2010), thus an explanation must not be too complex.
In Sect. 3 the presented methodology is examined with regard to both aspects: explainability and complexity. For this purpose a case study conducted using the publicly available South German credit data (Groemping 2019). In addition, two further real world data sets are analyzed: the bank marketing data as well as the famous Titanic data. In conclusion it turns out (Sect. 4) that there is an inherent trade of between both requirements.
2 Explaining random forests
2.1 Most representative tree
The difficulties in the interpretability of random forest originate in the large number of trees while single trees themselves are interpretable. Banerjee et al. (2012) have suggested strategies, to identify the most representative one from an ensemble of trees given by a random forest.
To do so, they define different (dis)similarity measures \(d(T_j, T_k)\) between any two trees \(T_j\) and \(T_k\) and propose to consider the most representative tree \(T_*\) to be the one with the lowest average dissimilarity to all other trees:
where N is the number of trees in the forest.
Different dissimilarity measures are proposed:
and
the average squared difference over all n observations in the sample in prediction between the two trees. An implementation can be found in the R package timbR (Laabs von Holt 2020).
Note that the intuition behind random forests is to average out the variance of many deep low-bias-high-variance trees. Depending on the total number of variables and the number of observations in the data there may many trees that use the same subset of variables (but with at different stages of the tree or with different splits). In such situations trees have the same distance \(d_1\) to all other trees and the result may not be unique. In order to circumvent shortcomings of \(d_1\) (Laabs von Holt et al. 2022) suggest a weighted version of \(d_1\):
with variable index q and \(U_{T}(X_q)\) the weight of variable \(X_q\) in tree T that takes into account for its relevance in the tree via the the level (i.e. depth) where it occurs:
2.2 Most representative grove
An natural question from Sect. 2.1 is whether it is sufficient to select one single representative tree. In particular as the matrix of all mutual distances between any two trees are computed a subsequent hierarchical clustering of the trees can be applied to answer this question (Murtagh and Contreras 2017). The resulting Dendrogram can be used to select as few trees as possible to ensure a small intra cluster heterogeneity. For the remainder of the paper a small set of representative trees for the purpose of model explanation will be called a grove.
2.3 Surrogate tree
As an alternative tree-based explanation surrogate trees (Molnar 2022, ch. 8.6) can be used. For this purpose an interpretable decision tree model is trained on the data, e.g. using the rpart package (Therneau and Atkinson 2015). But instead of the original target variable now the predictions of the random forest model to be interpreted denote target variable, here. The resulting model is a single tree and can thus be interpreted more easy.
2.4 Surrogate grove
Just like groves of most representative trees in Sect. 2.2 it may also be an idea to construct more than one surrogate tree for model explanation. A natural way to do this is given by gradient boosting (Friedman 2001), as e.g. implemented in the gbm package (Ridgeway 2020). For boosting, a sequence of small trees is trained. In case of stumps with only one split the number of boosting iterations directly corresponds to the number of rules in the resulting explanation model. Just as it is done for the surrogate trees from Sect. 2.3 the predictions of the original random forest model are used as target variable.
Note that as opposed to representative trees both surrogate trees as well as surrogate groves are model agnostic not limited to random forest explanations.
2.5 Explainability
As it has been outlined in the introduction an explanation should be not only (I) understandable for the user (i.e. must not be too complex) but at the same time (II) cover all important aspects of the original model (i.e. it should neither oversimplify things). To address (II) the measure of explainability \(\Upsilon\) has been proposed (Szepannek and Lübke 2022):
The explainability \(\Upsilon\) relates the deviations of the random forest predictions \(\textrm{RF}(X)\) from those of the explanation model T(X) as computed by
to those from the naive average prediction \(E_X(\textrm{RF}(X))\) of the random forest:
For a good explanation, the predictions of the explanation model T should be close to the original random forest RF. Ideally, if the predictions of both models are identical for all observations, \(\textrm{ESD}(T)\) will be 0 which will result in an upper bound of \(1 \ge \Upsilon (T)\). Further details on \(\Upsilon (T)\) can be found in (Szepannek and Lübke 2023). There it is also outlined that that the explainability increases with increasing dimension of the explanation. Requirement (I) originates from the fact that human cognitive memory capacities are limited (Miller 1956; Cowan 2010). For this reason, in addition the complexity of an explanation model is considered as the number of rules the the user has to remember. This number is given by the number of splits in the trees.
3 Application to data
3.1 Case study using the South German Credit data
South German Credit data: The explainability of a random forest by the different explanation methods of the previous section is compared in combination with the complexity of the respective explanation. For this purpose a popular real world data set, the German Credit data are used. The data are used in a corrected version named the South German Credit data (Groemping 2019) (for a summary of the changes cf. also Szepannek and Lübke 2021) and publicly available in the UCI machine learning repository (Dua and Graff 2017). The data have 1000 observations and three numeric as well as 17 categorical explanatory variables. The goal constitutes in the prediction of a binary default event of credit customers. For the case study the data is randomly split into 70% training and 30% test data. For performance evaluation the AUC on the validation data is computed as this measure is commonly used in the context of credit scoring (Szepannek 2022).
Creating baseline models:
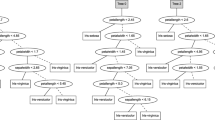
Initially, a random forest model has been trained using the ranger package (Wright et al. 2017). Compared with other machine learning algorithms random forests are quite insensitive to tuning of their hyperparameters (Bischl et al. 2021). For this reason and in line with the results observed in Szepannek (2017) no additional hyperparameter tuning is done and the default parameters are used (500 trees and \(\left\lfloor \sqrt{20} \right\rfloor = 4\) randomly selected split candidate variables for each split). As a reference baseline in addition a default decision tree using the rpart package (Therneau and Atkinson 2015) has been grown. The results in Table 1 illustrate the superior performance of the forest. Bootstrap samples of the validation data are used to compare the AUC difference of both models (DeLong et al. 1988). As it can be seen in Fig. 1 (left) the kernel density does not include 0 which confirms a significant performance increase by the forest.

Distribution of the differences in AUC on the validation data for the random forest and the decision tree on the model bootstrap samples (left). The decision tree model is shown in the right plot
In turn, the random forest model uses a total of 40272 rules which is of course no longer interpretable. The competitive decision tree model uses only 16 rules and is shown in Fig. 1 (right).
Most representative trees: Most representative trees are identified for the different dissimilarity measures. Note that for computation of \(d_2\) already for the small data set under consideration \(700 \atopwithdelims ()2\) pairs of observations will result in a dissimilarity matrix with 59.9 billion entries. For this reason, despite its intuitive definition, \(d_2\) is rather of theoretical interest and only \(d_1\), \(d_3\) and \(d_4\) have been computed.
As it has been outlined in Sect. 2.1 the definition of \(d_1\) bears the risk to end up in several equally representative trees such that there is no unique solution. In our case there are 151 (out of 500) such trees. For these trees the average number of rules and the average explainability \(\Upsilon\) on the validation data have been computed.
As it can be seen in Table 2 (column 2–4) the results for the MRTs are unsatisfying for all three dissimilarity measures: not only their explainability is low (\(< 0\)) but also the number \(\approx 80\) rules means that the MRTs are far from being easily interpretable. The scatterplot of the random forest predictions vs. the predictions of the explanation model in Fig. 2 (left) illustrates the bad explainability for the MRT based on \(d_e\): If the explanations by the MRT (ordinate) would perfectly match the predictions from the original random forest model (abscissa), all observations (points) would be exactly on the diagonal. This would correspond to an explainability \(\Upsilon = 1\) (Szepannek and Lübke 2023). For the MRT the resulting graph is far from looking like that. A reason for both the low explainability as well as the high complexity may be given by the design principle of random forests which consists in building many deep trees of high variance (cf. Sect. 2.1).

Scatterplot of the explanations (ordinate) of the most representative tree based on \(d_2\) (left) and the grove of 24 trees (right) vs. the predictions of the original forest model (abscissa). The horizontal grey line denotes the average prediction of the random forest

Dendrogram (left) and screeplot (right) of the hierarchical cluster analysis of the tree dissimilarities
In addition, three groves of three, ten and 24 trees have been grown. These numbers have been chosen after hierarchical clustering of the dissimilarity matrix \(d_2\) based on the dendrogram and the screeplot (Fig. 3). For the resulting groves, the explainability improves fastly as it can be seen in Table 2 (column 5–7). With as few as 24 trees \(\Upsilon = 0.87\) is obtained. The corresponding prediction-vs-explanation scatterplot (Fig. 2, right) illustrated the improvement of the explanation.
On the other hand of course, the complexity becomes even worse, and thus most representative groves turn out to be neither suitable for random forest explanation.
Surrogate trees: In addition a surrogate tree has been trained on the random forest predictions using the rpart package (Therneau and Atkinson 2015). The resulting model is shown in Fig. 1 (left) and reaches an explainability of \(\Upsilon = 0.59\) for a complexity of only 15 rules. These results indicate that a surrogate tree is much more suited for model explanation than most representative trees. But the explainability is not yet close to the ideal value of one for a perfect explanation and that it remains questionable whether the explanation as provided by the surrogate tree is sufficient. For this purpose also a sequence of rules from decision stumps has been built using the gradient boosting by the gbm package (Ridgeway 2020). The rules for the surrogate grove of 9 trees are given in Table 3 where the final predicted posterior probability is obtained as a sum over the \(\hat{p}_0\) and the \(\Delta _*\) increments of the respective rules. It can be seen that even several rules for the categorical variable status are identical which may result from shrinkage of the weights (Ridgeway 2020). Rows with identical splits can be in Table 3 can be further aggregated, so that the effective complexity is five rules in this case (cf. Table 4).
As it can be seen in Table 4: the explainability of 0.403 for this grove is not sufficient. Moreover, interpretable groves of uo to eleven rules yield bad explanations of \(\Upsilon\) close to 0.5 while for a grove of 100 trees and 56 rules an \(\Upsilon = 0.801\) is obtained.

Surrogate tree (left) and visualization of the trade-off between explainability and complexity of an explanation (right)
Figure 1 (right) summarizes the results of our case study: For explanation models of low complexity (grey vertical line) only small explainability is obtained while for an explanation of at least \(\Upsilon \ge 0.8\) the corresponding grove consists of >50 rules which can be hardly called interpretable anymore.
3.2 Analysis on further real world data sets
Data: An additional analysis is undertaken on two additional publicly available data sets: The bank marketing data (Moro et al. 2014) as given by ID 1461 of the OpenML project (Vanschoren et al. 2013) denote a binary classification problem to predict subscription on a term deposit based on seven numeric and nine categorical variables. The data consist of 45,211 clients where for computational reasons a random subsample of 10% of the data are used. Furthermore, another data set is used that is commonly used in interpretable machine learning research: the data from the Titanic disaster where the target variable is the binary survival status. The data consists of 2207 individuals and five numeric and three categorical predictors. For the analyses an imputed version of the data is used as provided by the DALEX R package (Biecek 2018). As in the previous subsection both data sets are split into 70% training and 30% validation data.
Results: Robnik-Šikonja and Bohanec (2018) distinguish different aspects of the quality of an explanation. The aforementioned explainability \(\Upsilon\) measures the aspect of fidelity while the number of rules measures the comprehensibility of a given explanation.
While the consistency of an explanation describes whether different models result in similar explanations the stability addresses whether similar explanations are obtained for similar observations. For the purpose of this work only one model (the random forest one) per data set is under investigation and thus the aspect of stability is of more relevance. In order to analyze the stability, in a first step similar observations are created as it is done by the SMOTE algorithm (Chawla et al. 2002): for each observation \(x_i\) the five most similar observations [based on Gower distance (Gower 1971) as implemented in the R package clusterMaechler et al. 2022] are identified. One of these observations is randomly selected (\(z_i\)) and a new synthetic observation is created as convex combination \(\lambda * x_i + (1-\lambda ) * z_i\) for the numeric variables and for the categorical variables a level drawn from a Bernoulli distribution with parameter \(\lambda\). The stability of an explanation is computed as average squared difference between the predictions for two similar observations (as described above), related to the average squared difference to the mean prediction over all observations. A small value close to 0 denotes a high stability of the explanation.
For completeness, also the predictive power of the explanation in terms of the AUC on the validation data will also be computed. Note that different from the original model the intention of an explanation is not to provide accurate predictions but to make the original model understandable.
In the previous subsection representative trees turned out to provide no useful explanations, therefore in this analysis only surrogate trees and groves are considered. The results are given in Table 5.
3.3 Discussion of the results
As it is nicely illustrated by the results given in Tables 4 and 5 as well as Fig. 4 in general, the explainability increases with the complexity of the explanation. But in order to obtain an appropriate model explanation (grey horizontal line in Fig. 4) the explanation models may become pretty complex in terms of the number of rules and will no longer remain interpretable. In conclusion, there is an inherent trade-off between explainability and complexity.
The idea of finding the most representative tree of a forest can be improved in terms of the explainability \(\Upsilon\) by considering small groves consisting of few trees instead of single trees. Nonetheless, by construction of random forests themselves neither most representative trees nor representative groves are well suited in terms of the complexity of resulting explanation. Future research could be devoted to identifying more interpretable representative trees of small depth.
The results on the bank marketing data show a similar trade-off between both explainability as well as stability and complexity (# of rules) of the explanation model.
In contrast, for the Titanic data there is a high stability for all explanation models. Further, for this data an explainability \(\Upsilon = 0.88\) is already obtained for a surrogate tree of only six rules. In this case surrogate explanation models are available that both provide appropriate explanations and that are understandable for humans. As a conclusion from our results, the suitability of an explanation should be carefully analyzed in terms of the trade-off between its complexity and the corresponding value of \(\Upsilon\).
For both the bank marketing as well as the Titanic data for well-interpretable explanation models of only few rules a drop in predictive power (AUC) is observed compared to the original model. This supports the claim of Bücker et al. (2021) to analyze the benefit of using a more complex model during the model selection process.
It can be further noted that in our case the surrogate (regression) tree even outperforms the original (classification) tree trained on the target variable which might be due to the fact that both models optimize criteria different than AUC within training.
4 Summary
Decision trees are popular and well-understood. In addition, they provide a set of rules that is easy to understand by humans. For this purpose, tree-based explanations bear the potential to be well-suited for explanations of machine learning models. In the paper, different tree-based model explanations are analyzed concerning their ability to explain a random forest model trained on three different real world data sets: the South German credit data, the bank marketing data as well as the Titanic data. The idea of explanatory trees is extended to groves, i.e. sets of few trees.
Both representative trees and groves turn out to be not suitable with regard to the quality aspect of human comprehensibility of the provided explanation and future research activities could be devoted to circumvent this issue. Surrogate groves allow to control for the complexity of an explanation while simultaneously analyzing their explanatory power. In addition they are model agnostic and are thus not restricted to random forest explanations which may be another direction for future research in this field.
In general, by an increasing grove size the explainability can be enhanced where at the same time the complexity of the explanation increases. The results of the case study underline the trade off between both requirements. But is has to be noticed that for one of the data sets under investigation there exists an explanation model that provides accurate explanations and at the same time good comprehensibility.
In conclusion our results support the conclusion from Bücker et al. (2021) to carefully analyze the benefits of using complex machine learning models which may result in a lack of explainability. But in addition it should be analyzed whether there exists an explanation that is both accurate and understandable for humans.
All codes as well as a corresponding R package xgrove are available in a GitHub repository of the first author.Footnote 1
Data availability
The data are publicly available under: https://archive.ics.uci.edu/dataset/522/south+german+credit.
References
Banerjee M, Ding Y, Noone AM (2012) Identifying representative trees from ensembles. Stat Med 31(15):1601–16. https://doi.org/10.1002/sim.4492
Biecek, P.: Dalex (2018) Explainers for complex predictive models in r. J Mach Learn Res 19(84):1–5. https://jmlr.org/papers/v19/18-416.html
Bischl B, Binder M, Lang M, Pielok T, Richter J, Coors S, Thomas J, Ullmann T, Becker M, Boulesteix AL, Deng D, Lindauer M (2021) Hyperparameter optimization: Foundations, algorithms, best practices and open challenges. CoRR arXiv:2107.05847
Breiman L (2001) Random forests. Mach Learn 45(1):5–32. https://doi.org/10.1023/A:1010933404324
Bücker M, Szepannek G, Gosiewska A, Biecek P (2021) Transparency, Auditability and explainability of machine learning models in credit scoring. J Oper Res Soc. https://doi.org/10.1080/01605682.2021.1922098
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP (2002) SMOTE: synthetic minority over-sampling technique. J Artif Int Res 16(1):321–357
Cowan N (2010) The magical mystery four: How is working memory capacity limited, and why? Curr Dir Psychol Sci 19(1):51–57. https://doi.org/10.1177/0963721409359277
DeLong ER, DeLong DM, Clarke-Pearson DL (1988) Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics 44(3):837–845. https://doi.org/10.2307/2531595
Dua D, Graff C (2017) UCI machine learning repository. http://archive.ics.uci.edu/ml. Accessed 20 Nov 2022
European Commission (2020) On artificial intelligence—a European approach to excellence and trust. https://ec.europa.eu/info/sites/info/files/commission-white-paper-artificial-intelligence-feb2020_en.pdf. Accessed 20 Nov 2022
Fernández-Delgado M, Cernadas E, Barro S, Amorim D (2014) Do we need hundreds of classifiers to solve real world classification problems? J Mach Learn Res 15(1):3133–3181
Friedman J (2001) Greedy function approximation: a gradient boosting machine. Ann Stat 29:1189–1232
Gower JC (1971) A general coefficient of similarity and some of its properties. Biometrics 27(4):857–871. https://doi.org/10.2307/2528823
Groemping U (2019) South German credit data: correcting a widely used data set. Technical report 4/2019, Department II, Beuth University of Applied Sciences Berlin. http://www1.beuth-hochschule.de/FB_II/reports/Report-2019-004.pdf. Accessed 20 Nov 2022
Laabs von Holt BH (2020) timbR: Tree interpretation methods based on range, r package version 0.1.0. https://github.com/imbs-hl/timbR. Accessed 20 Nov 2022
Laabs von Holt BH, Westenberger A, König IR (2022) Identification of representative trees in random forests based on a new tree-based distance measure. biorXiv. https://doi.org/10.1101/2022.05.15.492004
Maechler M, Rousseeuw P, Struyf A, Hubert M, Hornik K (2022) Cluster: cluster analysis basics and extensions. R package version 2.1.4. https://CRAN.R-project.org/package=cluster. Accessed 20 Nov 2022
Miller G (1956) The magical number seven, plus or minus two: some limits on our capacity for processing information. Psychol Rev 63(2):81–97. https://doi.org/10.1037/h0043158
Molnar C (2022) Interpretable machine learning, 2nd edn. https://christophm.github.io/interpretable-ml-book. Accessed 20 Nov 2022
Moro S, Cortez P, Rita P (2014) A data-driven approach to predict the success of bank telemarketing. Decis Support Syst 62:22–31. https://doi.org/10.1016/j.dss.2014.03.001
Murtagh F, Contreras P (2017) Algorithms for hierarchical clustering: an overview, ii. WIREs Data Min Knowl Discov. https://doi.org/10.1002/widm.1219
Probst P, Boulesteix AL, Bischl B (2021) Tunability: importance of hyperparameters of machine learning algorithms. J Mach Learn Res 20(1):1934–1965
Ridgeway G (2020) Generalized boosted models: a guide to the gbm package. https://cran.r-project.org/web/packages/gbm/vignettes/gbm.pdf. Accessed 20 Nov 2022
Robnik-SŠikonja M, Bohanec M (2018) Perturbation-based explanations of prediction models. Springer International Publishing, Cham, pp 159–175
Szepannek G (2017) On the practical relevance of modern machine learning algorithms for credit scoring applications. WIAS Rep Ser 29:88–96. https://doi.org/10.20347/wias.report.29
Szepannek G (2022) An overview on the landscape of r packages for open source scorecard modelling. Risks. https://doi.org/10.3390/risks10030067
Szepannek G, Lübke K (2021) Facing the challenges of developing fair risk scoring models. Front Artif Intell 4:117. https://doi.org/10.3389/frai.2021.681915
Szepannek G, Lübke K (2022) Explaining artificial intelligence with care. KI Künstliche Intelligenz. https://doi.org/10.1007/s13218-022-00764-8
Szepannek G, Lübke K (2023) How much do we see? on the explainability of partial dependence plots for credit risk scoring. Argum Oecon. https://doi.org/10.15611/aoe.2023.1.07
Therneau TM, Atkinson EJ (2015) An introduction to recursive partitioning using the rpart routines. https://www.biostat.wisc.edu/~kbroman/teaching/statgen/2004/refs/therneau.pdf. Accessed 20 Nov 2022
Vanschoren J, van Rijn JN, Bischl B, Torgo L (2013) OpenML: networked science in machine learning. SIGKDD Explor 15(2):49–60. https://doi.org/10.1145/2641190.2641198
Wright MN, Ziegler A (2017) ranger: A fast implementation of random forests for high dimensional data in c++ and r. J Stat Softw 77(1):1–17. https://doi.org/10.18637/jss.v077.i01
Funding
Open Access funding enabled and organized by Projekt DEAL. No funding was received to assist with the preparation of the manuscript.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states assist with the preparation of the manuscript.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

Cite this article
Szepannek, G., Holt, BH.v. Can’t see the forest for the trees. Behaviormetrika 51, 411–423 (2024). https://doi.org/10.1007/s41237-023-00205-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41237-023-00205-2