
Abstract
The algorithm derived in this article, which builds upon the original paper, takes a holistic view of the handedness of an orthonormal eigenvector matrix so as to transfer what would have been labeled as a reflection in the original algorithm into a rotation through a major arc in the new algorithm. In so doing, the angular wrap-around on the interval \(\pi \) that exists in the original is extended to a \(2\pi \) interval for primary rotations, which in turn provides clean directional statistics. The modified algorithm is detailed in this article and an empirical example is shown. The empirical example is analyzed in the context of random matrix theory, after which two methods are discussed to stabilize eigenvector pointing directions as they evolve in time. The thucyd Python package and source code, reported in the original paper, has been updated to include the new algorithm and is freely available.
Similar content being viewed by others


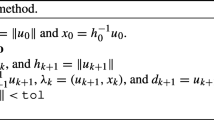
Avoid common mistakes on your manuscript.
1 Overview
A model-free algorithm to consistently orient the eigenvectors returned from an svd or eig software call was detailed in an earlier article, and the Python package thucyd that was made freely available is now used in industry [7]. To consistently orient a matrix V of eigenvectors is to replace V with \(\mathcal {V}\) such that the latter is only a pure rotation R away from the identity matrix. To produce \(\mathcal {V}\), the algorithm first sorts the eigenvectors by their associated eigenvalues in descending order, and then decides, one by one and from top to bottom, whether the sign of an eigenvector needs to be flipped. In the context of running linear regressions on the eigenbasis \(\mathcal {V}\) over an evolving data stream, the original article demonstrated that the signs of regression weights \(\varvec{\beta }\) are stabilized by regressing on \(\mathcal {V}\) rather than V, which in turn leads to good interpretability of the evolving system. One of the consequences of the algorithm is that the rotation angles \(\varvec{\theta }\) embedded within V are calculated.Footnote 1 As detailed then, the angles were limited to a \([-\pi /2, \pi /2]\) interval and calculated using an arcsin approach. It was natural to extend the angular interval to \([-\pi , \pi ]\) by using an arctan2 method, but it was shown that edge cases break the algorithm.
This article extends the original algorithm so that \(N-1\) angles embedded in a space of \(\mathbb {R}^N\) are able to cover a full \(2\pi \) interval. To do so requires the realization that only the first rotation upon entry into a new subspace of V requires a \(2\pi \) rotation range, whereas the remaining angles in the subspace are inherently bound to a \(\pi \) interval. This leads to a modified arctan2 algorithm that will not break on the aforementioned edge cases. As a consequence, the revised algorithm avoids unnecessary angular wrap-around on the \(\pi \) interval, a wrap-around that can be seen with the original. And yet, it also turns out that there is a trade-off that is made between the original algorithm and its revision: sign flips in the original can be replaced by rotations on a \(2\pi \) range (although not in a one-to-one manner), and as a consequence, the revised algorithm is better suited to problems that need full angular disambiguation while the original algorithm is better suited to problems like regression where a flip of a sign in V has a knock-on effect to other parameters, such as \(\varvec{\beta }\) above.
In either case, the orientation algorithm uses sequences of Givens rotations. The use of Givens rotations is far from new, and the original article cited Dash [8] who spoke of calculating the embedded angles in matrix V, and Golub and Van Loan [9]. Since that publication, I have become aware of the work of Cao et al. [5], Tsay and Pourahmadi [18], and Potters and Bouchaud [16], all of whom use Givens rotations. However, the interest of Potters and Bouchaud is to calculate the Vandermonde determinant by perturbing the rotations, and the approaches of Cao and Tsay and colleagues can lead to loss of positive definiteness. In the end, what is important here is the specification and solution to a system of transcendental equations, a sample of which appears in Eq. (11). Golub and Van Loan come close to articulating this system with the second (unnumbered) equation in Section 5.2.2, “Householder QR,” and the unnumbered equations in Section 5.2.6, “Hessenberg QR via Givens,” (4th edition), but they do not solve the equations. In effect, the algorithm in my original article solves the equations in one way and the revised algorithm detailed below solves the equations in another way. What is learned, in part, is that handedness, which is either left- or righthanded in 3D, does not generalize well in higher dimensions, but what can be said is whether the determinant of an orthonormal basis is \(+1\), which indicates a pure rotation and an even number of reflections, or is \(-1\), which indicates that there is an odd number of embedded reflections along with a rotation.
The body of this article reviews the original algorithm, details the revision, then applies the new tools to an empirical dataset, and connects the results to random matrix theory. Lastly, methods to stabilize eigenvectors as they evolve in time are demonstrated.
2 Review of the original algorithm
Following Eq. (7) in the original paper, the central equation for the consistent orientation of an eigenvector matrix V is
where R, S, and I are rotation, reflection, and identity matrices, respectively. In the case where V has embedded reflections, S, which is defined by \(S = \prod S_k\) and
where \(s_k = \pm 1\), is designed to rectify them. With this design, the VS product produces
where \(\mathcal {V}\) is the oriented eigenvector matrix that is only a rotation \(R^T\) away from the identity. The algorithm that finds matrices \((R, S)\) starts in the space of \(V \in \mathbb {R}^N\) and visits its \(N-1\) subspaces so that all N eigenvectors are analyzed. (The spaces are indexed by the eigenvalues associated with the eigenvectors, sorted in descending order.) At each subspace level, beginning from the entire space, the algorithm determines whether an embedded reflection exists and if so, applies a reflection to the associated eigenvector. After this step, the rotation required to align that eigenvector to a constituent axis is calculated. The pattern that develops is
which leads to the expansion of (1) according to
For later convenience, let us define the partially oriented eigenvector \(V_k\) matrix as
It is important to observe that reflections lie solely to the right of V, whereas rotations lie solely to the left.
To breathe life into the structure above, let us work through an example in \(\mathbb {R}^3\) that is taken from Fig. 3 in the original paper and reproduced in the top row of Fig. 1. Pane (a) shows a lefthanded basis \(\textbf{v}\) that is to be oriented into the righthanded basis \(\varvec{\pi }\). At the first subspace (the entire space itself), the focus is on eigenvector \(v_1\) and constituent axis \(\pi _1\). As drawn, \(v_1\) lies in the front hemisphere with respect to \(\pi _1\), which is to say, \(v_1 \cdot \pi _1 > 0\), and so no reflection of \(v_1\) is required; thus \(s_1 = 1\). Rotation \(R_1^T\) is then found to swing \(v_1\) onto \(\pi _1\); observe that \(R_1^T\) rotates the entire basis \(\textbf{v}\), as pictured in pane (b).
The next subspace, orthogonal to \(\pi _1\), is spanned by vectors \(R_1^T[v_2, v_3]\). The algorithm begins again by constructing \(S_2\) first and then \(R_2^T\). As drawn, \(R_1^Tv_2\) lies in the back hemisphere with respect to \(\pi _2\), that is, \((R_1^Tv_2) \cdot \pi _2 < 0\), which indicates the existence of an embedded reflection within V. The \(R_1^T\)-rotated eigenvector \(v_2\) therefore requires reflection, so \(s_2 = -1\), leading to the righthanded basis orientation seen in pane (c). The orientation \(R_1^TV S_1 S_2\) requires a rotation \(R_2^T\) about \(\pi _1\) to align \(v_2\) with \(\pi _2\); this leads to pane (d).
The first and second subspaces are reducible because a rotation can align the associated eigenvector to a constituent axis, reducing the dimension of the nonaligned space by one. The last subspace, the third subspace in this example, is irreducible: no axes remain about which a rotation can be applied; only reflection is possible. As drawn in pane (c), \(R_2^TR_1^Tv_3\) lies in the front hemisphere with respect to \(\pi _3\), so no reflection is required. To maintain symmetry in (5), \(R_3\) exists and is simply the identity matrix.
The pattern of working down the subspaces of V can be seen in matrix form. Writing V of any dimension as
where W represents a working matrix and index n denotes the size of the subspace, the first two subspace reductions can be written as
Observe that rotation by \(R_k^T\) leads to partial diagonalization of enclosing space \(W_{(n-k+1)}\) such that a 1 appears on the kth diagonal entry. This can be seen above as \(V_1\) becomes \(V_2 = R_2^TV_1 S_2\). The partial diagonalization continues for all reducible subspaces.

Two methods to orient a lefthanded basis in \(\mathbb {R}^3\) onto the righthanded identity matrix \(I\). The top row shows the orientation sequence reported in the original article wherein \(v_2\) as it appears in pane (b) is reflected in order to have it point in the direction of \(\pi _2\). The bottom rows show the new orientation sequence wherein rotation through a major angle replaces reflection in reducible subspaces while reflection is reserved for the last subspace, which is irreducible
It is this pattern that leads to the governing equation to compute the angles of rotation. Let us label the entries of \(W_{(n-k)}\) by the triplet \(w_{n-k, i, j}\).Footnote 2 The first two rotations require
where the w columns naturally have unit \(\ell ^2\) norms. Rotations \(R_k^T\) are then composed from a cascade of \(n-k\) Givens rotations, each Givens rotation operating within a two-dimensional plane. For instance, \(R_1 \in \mathbb {R}^4\) can be composed as
The application of \(R_1^T\) to the first column of \(W_{(4)}\) leads to the composition shown figuratively as
where, for instance,
and \(\{s_3|c_3\} = \{\sin |\cos \}(\theta _{1,3})\). Multiplying through the lefthand side of (9) and equating it to the righthand side leads to the system of transcendental equations
where \(a_i\) is a simpler symbolic substitute for \(w_{4,,1}\). An alternative solution to this equation than the solutions found in the original article is central to this paper.
The original solution uses the arcsin method. Here, the entries in the columns are taken pairwise from the bottom up, leading to the system (again in \(\mathbb {R}^4\))
Systems like this are composed for all reducible subspaces and the collection of angles \(\varvec{\theta }\) are recorded. In all, there are \(N(N-1)/2\) angles embedded in \(V\in \mathbb {R}^N\).
Now, the issue with the arcsin method is that angles are minor, that is, those restricted to a \(\pi \) interval such as \(\theta \in [-\pi /2, \pi /2]\). This in turn means that the apparent pointing direction of all N eigenvectors is limited to a hyper/hemisphere rather than a full hypersphere. In systems with a good mixture of states, the vectors tend to point toward the centers of their respective orthants, but in other systems, vectors can point near the equator of their respective hyper/hemispheres. In the presence of noise in an evolving system, vector wobble can lead to an angular wrap-around such that \(v(t_2)\) and \(v(t_1)\) appear on opposite sides of the hyper/hemisphere even when these vectors are in proximity on a hypersphere.
With this in mind, the original article proposed an arctan2 method to span the major angular range of \(2\pi \). However, it was shown that edge cases exist for this method that break the orientation algorithm, and so the arctan2 method could not be used. The first version of the thucyd Python package was implemented with the arcsin method.
3 Handedness in high dimensions
This section revisits the analysis of Eq. (1) and does so by considering the handedness of an orthogonal basis holistically. This approach contrasts with the “opportunistic” approach taken in the original article. The resulting modified arctan2 method is not simply a tweak to the existing algorithm but instead relies on insight about handedness and partially oriented eigenvectors.

The orientation of a 4D vector via the three Givens rotations in (17). The blue vector in pane (a) shows the orientation of \((a_1, a_2)\) in the \((\pi _1, \pi _2)\) plane. This vector is rotated into \(\pi _1\), annihilating the \(\pi _2\) component. Subsequent rotations, panes (b) and (c), annihilate the \(\pi _3\) and \(\pi _4\) components. Only in pane (a) does the vector point into the back hemisphere with respect to \(\pi _1\)
To begin, eigenvector matrix V and rotation matrix R are unitary in that
and yet the individual matrices have different determinant possibilities: Footnote 3
The reason for this difference is that V can contain embedded reflections along with its rotations, whereas R is by nature a pure rotation. Therefore, V belongs to the orthogonal group \(\text {O}(N)\) while R belongs to the special orthogonal group \(\text {SO}(N) \subset \text {O}(N)\). The problem statement is then one of squeezing V into \(\text {SO}(N)\) so that the squeezed version of V is only a pure rotation away from \(I\). To accomplish this, the auxiliary matrix S is introduced to impart pure reflections. Moving R to the righthand side of (1) and taking determinants leads to
In the original scheme, the reflection matrix goes as
where the signs of the elements are determined as the subspaces are visited in descending order. The solution leads to an even number of negative entries (reflections) when \(\det (V) = 1\) and to an odd number of reflections otherwise, and no global constraint is placed on the number of elements of either sign. But in light of (15), it is clear that no reflections are inherently required when \(\det (V) = 1\), and only a single reflection is necessary otherwise. To achieve the minimum reflection count, we need a workable method for major-angle rotation; this is the starting point for the revised algorithm.
Consider again the lefthanded \(\mathbb {R}^3\) basis shown in Fig. 1 top. The diagonal entries were found to be \(\mathop {\mathrm {\text {diag}}}\limits (S) = \left( 1, -1, 1\right) \), and indeed, being lefthanded, V requires at least one reflection to become righthanded. But where the reflection is introduced can be adjusted. The original algorithm is “opportunistic” because the hyper/hemisphere in which the kth eigenvector lies (after prior rotations) is forced via reflection (if required) to lie in the direction of constituent axis \(\pi _k\); the reflection is imposed by setting \(s_k = -1\). The key way forward is to recognize that this reflection can be replaced by a rotation of \(\pi \) when in a reducible subspace.
To illustrate this alternative approach, Fig. 1 bottom again aligns a lefthanded \(\mathbb {R}^3\) basis. Panes (a) and (a\('\)) are the same, since \(v_1\) already points in the direction of \(\pi _1\), so no reflection is necessary; only a minor-angle rotation is required to align the vectors. But while pane (b) reflects \(v_2\) to point in the direction of \(\pi _2\), the operation in pane (b\('\)) rotates \(v_2\) through a major angle to align directly with \(\pi _2\). Pane (c\('\)) shows that \(v_3\) is counterdirectional to \(\pi _3\), and that there are no more rotations available with which to align these vectors—the system is irreducible. The only recourse is to reflect \(v_3\) into \(\pi _3\), and this is done to go from pane (c\('\)) to (d\('\)). The resulting reflection matrix is \(\mathop {\mathrm {\text {diag}}}\limits (S') = \left( 1, 1, -1\right) \). Observe that the embedded reflection is now handled in the one irreducible dimension. There is in fact a pattern in how S transforms into \(S'\) as the subspaces are visited, and this is discussed below.
Moving on to higher dimensions, one way to draw an N-dimensional system is to plot the entries of a vector pairwise in a 2D plane across a series of panes. An example appears in Fig. 2. What is shown here is the evolution of a 4D vector as it is rotated into alignment with \(\pi _1\) according to the rotations that appear in a reorganization of (9):
Let us call the vector on the left \(\textbf{a}\). As pictured in pane (a), \(\textbf{a}\) points into the back hyper/hemisphere with respect to \(\pi _1\). The original algorithm would reflect \(\textbf{a}\) into the front hyper/hemisphere and then rotate, but here, rotation \(R_{1,2}^T\) through major angle \(\theta _{1,2}\) is used instead. The rotation is only within the \((\pi _1, \pi _2)\) plane and applies only to the \((a_1, a_2)\) entries. The figure inset shows that the \(\pi _2\) component of \(R_{1,2}^T\, \textbf{a}\) vanishes. Next, the \(R_{1,2}^T\)-rotated \((a_1, a_3)\) vector, shown in green in pane (b), is rotated by \(R_{1,3}^T\) in the \((\pi _1, \pi _3)\) plane so that the \(\pi _3\) component is annihilated. Likewise, the \(R_{1,3}^TR_{1,2}^T\)-rotated \((a_1, a_4)\) vector, the copper vector in pane (c), is rotated by \(R_{1,4}^T\) so as to annihilate the \(\pi _4\) component. To recapitulate the main point: a rotation through a major angle has substituted for a reflection and subsequent rotation through a minor angle.
Now, let us examine the signs of the entries. At the start, elements \((a_1, a_2)\) can possess either sign: their vector direction can point into any quadrant in the \((\pi _1, \pi _2)\) plane, and the arctan2 function is powerful enough to determine the major angle \(\theta _{1,2}\) required to align the vector to \(\pi _1\). However, once the \(a_1\) entry is rotated to align with \(\pi _1\), subsequent values of the top element of the vector are guaranteed to be positive. As pane (b) shows, the third vector entry can be either positive or negative, but the angle \(\theta _{1,3}\) is only ever minor. The same holds for \(\theta _{1,4}\) in pane (c). Put another way, the vectors that lie in the \((\pi _1, \pi _3)\) and \((\pi _1, \pi _4)\) planes, prior to their orienting rotations, always point into the front hyper/hemisphere with respect to \(\pi _1\). This observation lies at the heart of the modified arctan2 method.
The modified arctan2 solution to (11), for four dimensions, is
where the arguments follow an arctan2(y, x) call style. To avoid overflow, the latter equations can be rewritten in the form
In contrast to Eq. (25) of the original article, only the first angle is calculated from all four quadrants; subsequent angles are calculated by enforcing the nonnegative nature of the vector as projected onto the \(\pi _1\) axis. As a side effect, the catastrophic edge case discussed in the original article is avoided because a signed zero cannot appear in the x argument.
In the special case when the column vector \(\textbf{a}\) is sparse, the indexing in (18) requires adjustment. To see this, consider \(\textbf{a} = \left( a_1, a_2, 0, a_4 \right) ^T\). Using (18) as written, \(a_3 = 0\) leads to \(\theta _{1,3} = 0\), which in turn leads to \(\theta _{1,4} = {{\,\textrm{arctan2}\,}}(a_4 \cdot |0|, |0|) = 0\). What has happened is that the algorithm, as written, has stalled, and the resulting “solution” to (11) is incorrect. To correct for sparsity, let us first refer back to the original setup (17): having \(a_3 = 0\) is tantamount to skipping the \(R_{1,3}^T\) rotation. With this in mind, all that needs to change is the indexing of the prior entry; that is,
where \(a_{k-j}\) points to the first nonzero entry behind \(a_k\). There is one more edge case when \(a_2 = 0\). Here,
where k is the first nonzero entry in \(\textbf{a}\) after \(a_1\). The sine term is absent here, which is a consequence of its absence in the first row of (11) and \(\theta _{\cdot , j} = 0\) for \(j < k\).
All of the Givens rotation angles associated with the reducible subspaces of V can be calculated in this way, leaving only a final potential reflection for the one irreducible subspace that remains. The central equation to orient V into \(I\), Eq. (1), is still
in structure, but the angles \(\varvec{\theta _\text {tan}}\) differ from the arcsin method, and the reflection matrix is simply
In particular, \(\varvec{\theta _\text {tan}}\) can now contain major angles for the first rotation of each new subspace.
To emphasize the point made in the original article, the sequence of Givens rotations to align a vector to a particular constituent axis is arbitrary and does not affect the ability to orient. Therefore, a convenient sequence and subsequent consistency are all that is required. It turns out that the Givens sequence for the arcsin method works just as well for the modified arctan2 method.
The final topic of this section is the relationship between reflection matrix S from the arcsin method, Eq. (16), and the modified arctan2 method, Eq. (22). One way to do this is to augment the \(\textbf{a}\) vector in (17) to write
Although \(\textbf{a} \cdot \textbf{b} = 0\) by construction, the entries that lie in the \((\pi _1, \pi _2)\) plane are in general not orthogonal. An example is pictured in Fig. 3a. Consider now the rotation by \(R_{1,2}^T\) through a major angle. Although the two vectors, projected onto the \((\pi _1, \pi _2)\) plane, are not orthogonal, their angle is preserved under rotation, as shown in pane (b). And while \(\textbf{a}\) and \(\textbf{a}'\) point in opposite hyper/hemispheres, the same holds true for vectors \(\textbf{b}\) and \(\textbf{b}'\) with respect to the hyper/hemisphere associated with axis \(\pi _2\). This observation does not extend to further augmented vectors, say \(\textbf{c}\) and \(\textbf{d}\), because Givens rotations \(R_{1,3}^T\) and \(R_{1,4}^T\) subtend only minor angles. A rule can be deduced from this observation: a rotation through a major angle in subspace k flips the sign of both \(s_k\) and \(s_{k+1}\). Reflection vectors \(\mathop {\mathrm {\text {diag}}}\limits (S_{\text {sin}})\) can now be “untwisted,” at least as a thought experiment.

Rotation of a vector \(\textbf{a}\) through a major angle, as projected onto the \((\pi _1, \pi _2)\) plane, changes the hyper/hemisphere in which the vector points. The same rotation also reorients the next vector in the system, here labeled \(\textbf{b}\). This effect can be summarized as modifying two adjacent entries in reflection matrix S
To simplify the notation, let \(\mathcal {S} = \mathop {\mathrm {\text {diag}}}\limits (S)\). Then, from the example of Fig. 1, we found that \(\mathcal {S_\text {sin}} = (1, -1, 1)\). Rather than applying a reflection in the second subspace, we can instead apply a major-angle rotation. This flips the sign of the second and third entries, yielding \(\mathcal {S_\text {tan}} = (1, 1, -1)\). As another example, start with the system where \(\mathcal {S_\text {sin}} = (-1, -1, -1, 1)\). Rotation in the first subspace by a major angle leads to \(\mathcal {S} = (1, 1, -1, 1)\), after which only a minor rotation is needed in the second subspace. Another major-angle rotation in the third subspace gives \(\mathcal {S_\text {tan}} = (1, 1, 1, -1)\), leaving a final reflection in the irreducible subspace. Observe that when \(\det (V) = +1\) and \(\mathcal {S}_{\text {sin}}\) has an even number of negative signs, no reflection is needed for orientation using the modified arctan2 method.
4 Reference implementation
The Python package thucyd is freely available from PyPi and Conda-Forge and can be used directly once installed. The source code is available on GitLab. See Sect. 8 for link details.

Pseudocode implementation of the orient_eigenvectors function for the modified arctan2 method in the absence of sparsity. Functions whose names are colored differ from the original algorithm. Matrix and vector indexing follows Python Numpy notation. Consult the source code in the thucyd package for the details around sparsity.
There are two functions exposed on the interface of thucyd.eigen:
-
orient_eigenvectors implements both the arcsin and modified arctan2 methods. The pseudocode listing of Algorithm 1 outlines the latter method. The function takes the keyword argument method that defaults to arcsin (for backward compatibility) but arctan2 can be chosen and is now preferred.
-
generate_oriented_eigenvectors is the same as detailed in the original article.
In certain application-specific scenarios, one may anticipate that the first eigenvector points into the first orthant, which is when all elements of the first eigenvector are positive. However, the sign returned from an eig or svd call may well be negative. Rather than accepting the major rotation that the modified arctan2 method will impart, the orient_eigenvectors function accepts an OrientToFirstOrthant flag that, when true, records a reflection at the top-level dimension, or \(s_1 = -1\). The general case for the S matrix when this flag is true is
With \(s_1 = -1\), rotation \(R_{1,2}^T\) is always minor.
5 Empirical example and random matrix theory
The techniques of the previous sections are now applied to a dataset of quotes and trades from the financial markets in order to demonstrate the significance of unwrapping the \(\pi \) interval of the arcsin method into the full \(2\pi \) interval of the modified arctan2 method. The consequent eigenvector pointing directions are then connected to the eigenvalue distribution of random matrix theory. The main results are 1) unwrapping the angular interval from \(\pi \) to \(2\pi \), as seen by comparing Fig. 4 with Figs. 5 and 6, allows for a distinction to be made between informative and uninformative eigenmodes; and 2) this distinction coincides well with what can be inferred from the eigenvalue spectra, as seen in Fig. 7. These results then motivate static and dynamic methods to temporally stabilize eigenvectors, methods which are discussed in the following section.
The centered, standardized data panels P that are constructed below are analyzed via singular-value decomposition to produce
where U represents the projection of the data onto eigenvectors V and \(\Lambda \) is a diagonal matrix of eigenvalues \(\lambda \). The eigendecomposition of the corresponding correlation matrix is
At issue is the estimation of V and \(\Lambda \) from the data in P. The domain of classical statistics is asymptotically approached when the number of records T for a fixed number of features N goes to infinity: in this case, the Central Limit Theorem applies and estimation variance devolves to Gaussian. But in the real world, T is finite and we can only hope to be in the \(T > N\) regime, for otherwise P is singular. Sample noise always exists with finite T, and so the question becomes one of distinguishing between real information and sample noise in P. The field of random matrix theory (RMT) addresses this question [6, 12, 16].

Hemispherical angles for quote and trade eigenvectors over 23 days and the six reducible modes. The angles were calculated using the arcsin method, and therefore they are all minor angles. The radii indicate the participation scores of the associated eigenvectors for each day: larger radii indicate better participation among the elements of an eigenvector

Spherical angles of the quote eigenvectors over 23 days and the six reducible modes. The modified arctan2 method was used to calculate the rotation angles. The first rotation angle of each mode spans the circle, whereas subsequent angles are bound to the right hemisphere. Observe that the eigenvectors in mode 1 are highly directed, whereas those in modes 4–6 are well scattered. Modes 2 and 3 remain somewhat directed but with lower participation scores. The red circle highlights an apparent outlier that is discussed in the text

Spherical angles of the trade eigenvectors. Observe that the first mode is clearly directed into the first orthant whereas the other modes randomly scatter
The majority of the RMT literature until the early 2000s dealt with the probability density of the eigenvalues of a Gaussian random matrix, and within the universe of all random matrix types, the real positive-definite matrix is relevant here. A principal result is that, in the limits \(T\rightarrow \infty \) and \(N / T \rightarrow q > 0\), the eigenvalues \(\lambda \) of such a random matrix follow the Marčenko–Pastur (MP) distribution
where \(\lambda \in [\lambda _-, \lambda _+]\). Had N been fixed, then \(q\rightarrow 0\) and the density reduces to \(\rho (\lambda ) = \delta (\lambda - 1)\), which is to say, all eigenvalues are unity and so the eigenbasis is isotropic regardless of its orientation. When empirical eigenvalues fall outside of the MP distribution then they are not entirely corrupted by sample noise, but for those that fall within the distribution, the eigenvalues are indistinguishable from such noise.
As for eigenvectors V, it is well established that the probability of drawing random matrix \(E = P^TP / T\) is invariant under the similarity transform \(V' = O V O^T\), where O is a pure rotation matrix. The consequence is that eigenvectors \(v_k\) of such random matrices point uniformly across the surface of a hypersphere; this is known as the Haar measure. More recent advances in random matrix theory include the interaction between informative eigenvectors, known as rank-1 perturbations, to the eigenvectors that lie within the sample-noise bulk (see, for instance, [4, 10]). However, research along this vein seldom speaks of adjusting the pointing direction(s) of informative eigenvectors (but see Bartz et al. [1, 2]); the main theme is how to better shrink empirical eigenvalues given the additional information available from the overlap between informative and randomly oriented eigenvectors. And so, there is an opportunity to use the techniques from Sect. 3 to distinguish between informative eigenvectors and those corrupted by noise, and to reorient the eigenvectors based on this distinction.
To begin the empirical example, Chicago Mercantile Exchange (CME) futures quote and trade data were obtained from the CME for seven foreign exchange contracts for May 2023. The FX pairs were EURUSD, USDJPY, GPBUSD, USDCHF, AUDUSD, NZDUSD, and CADUSD. The data covers 23 business days, some of which fall on regional holidays. The June 2023 contract was the most liquid during May and was therefore the focus. The daily datasets were sliced to retain records that fell between 00:00 and 16:00 Chicago time, which is generally the most liquid period. The quotes were for the best bid and offer and the trades were signed. A mid-price was generated from the quote data (ignoring changes in liquidity for the same price), and the mid-prices were processed to reduce the microstructure noise. Since the quote and trade data arrive asynchronously from contract to contract and from quote to trade, a common panel of records was created using time arbitration, one panel for each day. The panels had 14 columns, seven each for quotes and trades. The columns were then filtered with causal linear filters configured to a common timescale. The (log) quotes were filtered to measure price change, while the (signed) trades were filtered to measure directionality. The panel was then downsampled in order to remove the autocorrelation imparted by the filters, leaving between 500–1000 records for non-holiday days. Empirical study showed that each column was Student-t distributed, so the dispersion and shape parameters were estimated, after which the columns were each mapped through the copula to a zero mean, unit variance Gaussian distribution, see [14]. As a result, the final panel was multivariate Gaussian. This is the starting point for the eigenanalysis. Although the processing details have been only briefly summarized, they will be expanded upon in another publication.
While the panels were constructed with quotes and trades together in order to account for their relative update frequency, they can now be separated into two panels of 7 columns to inspect their inherent structure. Eigenanalysis was performed via SVD as in (25) on the quote and trade panels, a separate analysis for each day. The rest of this section is devoted to the analysis of the eigenvalues \(\Lambda \) and eigenvectors V.Footnote 4 Next, the orient_eigenvectors function was called with V and \(\Lambda \) using both arcsin and arctan2 methods. Recall from Eq. (21) of the original paper that the embedded angles can be organized into the upper triangle of a square matrix. For the panels in this example, the \(\varvec{\theta }\) matrix looks like

The diagonal color stripes highlight the common rotation order for the modes. For instance, the long green stripe indicates major angles, all of the other angles being minor. Observe that the number of angles required for alignment decreases as the mode index increases: \(N-1\) rotations are required for mode 1, which spans the entire space \(\mathbb {R}^N\); \(N-2\) rotations are required for mode 2, which spans \(\mathbb {R}^{N-1}\); and so on. The eigenvector with the smallest eigenvalue lies in an irreducible space: it cannot be rotated because there are no axes that remain. As a consequence, the polar plots have fewer independent rotations (samples with different colors) as the angles for modes 1 through 6 are plotted.
To complement the angular information that appears in the plots, the radial coordinate plots the participation score (PS). The participation score is a simple variation on the inverse participation ratio (IPR), defined as
where \(v_i\) is the ith entry of an eigenvector in V, and \(\textbf{v}^T\textbf{v} = 1\) because V is orthonormal [15, 17]. The lower bound of the IPR is attained when all entries \(v_i\) participate equally, \(v_i = 1/\sqrt{N}\), and the upper bound is attained when only one entry is nonzero, leaving \(v_k = 1\) for some k. In order to score higher participation above lower, the participation score goes as
When all elements participate equally, \(\text {PS} = 1\). Now that the radial coordinate is defined we can move on to study the eigenvector systems.
Figure 4 plots the quote and trade angles on half-circles using on the arcsin method for the 23 days available. It is evident that mode 1 for quotes and trades is highly directed into the first orthant. Quote modes 2 and 3 appear somewhat directed, although with lower participation scores, and with a question mark on mode 3 because of the appearance of samples toward the south pole of the plot: have these been wrapped around from the north? Trade modes 2–6 have their angles fully scattered across \(\pi \), and the participation scores are small and rather unstable. Quote mode 4 has randomly scattered angles and persistently low scores; it is hard to tell what to say about modes 5 and 6.
Figures 5 and 6 replot the quote and trade eigensystems after the angles were calculated using the modified arctan2 method. The green points have been expanded into major angles. It is now evident that quote mode 4 truly points in random directions, and that is probably the case for modes 5 and 6. The full-circle plots for modes 2 and 3 are also more revealing: the modes are indeed directed, albeit less so. For mode 3, the points that had appeared in the south now all point to the north except for an outlier, and this highlights the benefit of moving from the arcsin method to the arctan2 method. The outlier, which is encircled in the graphs for modes 2 and 3, can only be discerned after switching to the arctan2 method. This outlier is not an artifact of the orientation algorithm but is an actual outlier in the data: the monthly update of the US Consumer Price Index (CPI) was released on May 10, 2023. Market participants were following the CPI closely in order to assess whether the US Federal Reserve would curtail their rate hikes. There was a price jump at the time of the announcement for all of the FX pairs considered, but EURUSD responded anomalously. (Removal of this pair from the panel construction restored the outlining point to the north-facing cluster.) In practice, the quantitative analyst would likely split the data into times outside of scheduled economic events from those times around the events, and then analyze the split-out data separately. In this way, “normal” market behavior is separated from times when the markets often jump to new levels, but for the purpose here it is more interesting to show that the arctan2 can reveal an outlier.
The trade eigensystems shown in Fig. 6 show how the major angle scatters uniformly over the full circle for modes 2–6 while the minor angles continue to scatter in the right hemisphere. Only mode 1 is highly directed and exhibits high participation scores.
These observations can now be compared to the traditional RMT eigenvalue analysis. Figure 7 plots empirical eigenvalues and participation scores as points on a Cartesian graph, and plots an average of the associated rescaled Marčenko–Pastur distributions. As discussed above, almost any analysis of empirical data panels is corrupted by noise induced by the finite length of the panels. For instance, eigenmodes whose eigenvalues fall within the MP distribution, while produced from real data, are indistinguishable from noise. The top and bottom panes show that quote modes 1–3 and trade mode 1 fall outside of the (average) MP distribution; the other modes fall within the distribution. This is a very good match to the conclusions made above.

Overlay of empirical eigenvalue spectra with averaged Marčenko–Pastur distributions. (The colors here are used to distinguish the eigenmodes but do not correspond to the colors in the previous figures.) Top, modes 1–3 fall outside of the averaged MP distribution, indicating that their content has not been corrupted by sample noise. Bottom, only mode 1 falls well outside of the MP distribution while the rest lies firmly within the eigenvalue range that is indistinguishable from noise
However, this eigenvalue analysis is not absolute, and it is here where the analysis of pointing directions can be leveraged: a rescaling of the MP distribution was performed, and while there is no question that rescaling is necessary, the results can be somewhat self-fulfilling. This is what is going on: the MP distribution applies to purely random matrices, but here we have a mixture of informative and random modes. For trades, there is only one informative mode, so really there are \(N-1\) modes that are indistinguishable from noise. The q value needs to be adjusted to read \(q' = (N - 1) / T\); this change is simple. In addition, eigenvalue \(\lambda _1\) has contributed to the scaling of the multivariate Gaussian distribution, so this needs correction [13, 16]. With
the rescaled MP distribution reads
It is the average (over the 23 days) of these rescaled distributions that are plotted in the trades pane of the figure. For quotes, three modes were deemed to be informative, leaving four modes to generate noise (the irreducible mode has to be included). Every time an eigenmode is excluded from the noise, the remaining distribution shifts to the left, leading to a potentially subjective line between modes to include or exclude. It is here where the analysis of pointing directions introduces new information to cross-validate the traditional RMT eigenvalue approach.
6 Eigenvector stabilization
The empirical eigenvector pointing directions studied in the last section exhibit two different ways in which they evolve in time. Informative modes are at least somewhat directed, and so their average direction is meaningful. Noninformative modes, in contrast, scatter randomly on the hypersphere, and so their average, which is not meaningful, can be replaced by a fixed direction, thereby exchanging variance for bias. Let us call these two methods of stabilization dynamic and static. These methods could be used in future work to help clean empirical correlation matrices. For now, Figs. 10 and 11 show examples of how the stabilization of the eigenvectors in turn stabilizes the evolution of the correlation matrix. But first, these methods are quantified.

The average pointing direction \(\tilde{\theta }\) in \(\mathbb {R}^2\) over five wobbling vectors is found by stacking the vectors end-to-end and then measuring the resultant vector \(\textbf{v}\). Applying weights to the vectors is equivalent to scaling the vector lengths, as illustrated here
With respect to dynamic stabilization, it is evident from Figs. 5 and 6 that the pointing directions of the informative modes wobble in time, whereas, in contrast, the eigenvectors of the random modes scatter uniformly. A causal local average of the latest pointing directions can be estimated by applying a simple filter, but how shall this be performed? Recall from Sect. 9.2 of the original article that the angular inclination of a collection of vectors is correctly computed by stacking the vectors together end-to-end and then calculating the angle of the resultant vector, such as pictured in Fig. 8. This stands in contrast to simply averaging the angles directly. In analogy to Eq. (31) in the original article, we can write more generally
and then renormalize via
where
What is happening here is that a time series of orientated eigenbases \(\mathcal {V}[n]\) is convolved with impulse response h[n] to yield \(M_h[n]\), and to make sense in this context, the weights of h[n] are all positive. For any n, \(M_h\) is no longer orthonormal, for this property is not guaranteed under basis addition. Subsequent normalization into M[n] is done in (34). To orthogonalize, the orientation algorithm can be used by computing the sequence

Angular distributions after five-point filtering of the directed quote and trade eigenvectors. To the left are the angles of quote modes 1–3, and to the right lie the angular distributions of the trade mode 1. The filter weights were \(h[n] =[1,2,3,2,1]/9\), which is the result of convolving a three-point box filter with itself. The average delay for this h[n] is two samples, or 2 days here. Observe the stabilization of the eigenvector wobble and the concentration of the participation scores, especially for quote and trade modes 1
where calls to orient_eigenvectors and generate_ oriented_eigenvectors are using in turn. From these intermediate steps we can ultimately write
Let us denote by \(\tilde{\varvec{\theta }}[n]\) the matrix of embedded angles associated with \(\bar{\mathcal {V}}[n]\), where the tilde on \(\varvec{\theta }\), rather than a bar, emphasizes that the average here is not over angles but eigenvectors.
For consistency with the eigenvector treatment, the eigenvalues are also filtered; we have
The rank order of eigenvalues does not change upon convolution with positive h[n], so there is no disruption in the map between eigenvalues to eigenvectors.
Figure 9 shows the result of filtering the quote and trade eigenvectors for the informative modes. A five-point causal filter was applied, so each point represents the local average of five contiguous days. The caption covers the filter details. A statistical analysis would require the downsampling of the filtered points, but here all filtered points were plotted because there are so few points in this dataset. As expected, the scatter of filtered pointing directions is reduced. In addition, the participation scores have tightened and slightly increased. Quote mode 2 continues to have a curiously low participation score, but the vectors remain directed. All in all, eigenvector wobble has been demonstrably reduced by applying a filter. Increasing the filter length would add further stability but at the expense of adding more delay into the system.
With respect to static stabilization, we have already seen that quote modes 3–6 and trade modes 2–6 scatter randomly, so taking their local average is meaningless. An evident way to statically reorient the eigenvectors is to fix the angles of the random modes, and in the absence of a better alternative, the angles can simply be set to zero. In doing so, an angular bias is put in place in order to reduce out-of-sample error. For the quotes, angle matrix \(\varvec{\theta }\) that appears in (28) is rewritten as
where \(\varvec{\theta }_{\text {modal}}\) only retains nonrandom modes. Static stabilization can be applied to either daily oriented matrices \(\mathcal {V}[n]\) or their averages \(\bar{\mathcal {V}}[n]\). A statically stabilized matrix \(\mathcal {V}\) is then reconstructed by calling generate_ oriented_eigenvectors with \(\varvec{\theta }_{\text {modal}}\). Static stabilization has the flavor of principal component analysis (PCA) but it is not. With PCA, informative eigenmodes are retained while the others are discarded, but with static stabilization, all modes remain present in \(\mathcal {V}\). Geometrically, what is going on is that \(\mathcal {V}_{\text {modal}}\) is “closer” to identity matrix \(I\) than \(\mathcal {V}\) itself. For the six reducible modes in this example, expanding (3) leads to
since we have \(R_{4,5,6} = I\).
We are now in a position to study the correlation structure as the stabilization steps are applied. A correlation matrix is calculated according to
where \(\mathbf {\varsigma }^2 = \mathop {\mathrm {\text {diag}}}\limits \left( \bar{\mathcal {V}} \bar{\Lambda } \bar{\mathcal {V}}^T\right) \). Note that while \(\mathcal {V}\Lambda \mathcal {V}^T\) produces a proper correlation matrix, being positive definite with ones along the diagonal, \(\bar{\mathcal {V}} \bar{\Lambda } \bar{\mathcal {V}}^T\) does not. The latter product is positive definite, but the diagonal entries have small deviations from unity. Such imperfections arise from the processing used to produce \(\bar{\mathcal {V}}\) and \(\bar{\Lambda }\), and are removed by the two end terms in (40).

Quote and trade correlation matrices, raw through fully stabilized, for a single day. The original correlation matrices (left) contain a lot of structure. The dynamically stabilized correlations (center) have less structure. Lastly, the dynamically and statically stabilized correlations (right) have the least structure and are the most persistent over time
Figure 10 shows a progression of matrix stabilization from the original to dynamically stabilized to both dynamically and statically stabilized. The correlation matrices in the figure are for 1 day, a single day for the original, and a single 5-day average for the dynamically filtered. What is apparent as the eigenvectors are stabilized is that structure in the correlation matrix is removed; this is especially true for the trade correlations. Although the effect of static stabilization is somewhat apparent for this progression of matrices, the benefit of filtering the eigenvector directions cannot be shown from a single snapshot.

Pairwise correlation scatter for each element of the correlation matrices in Fig. 10. Observe the reduction in correlation dispersion as the eigensystem is stabilized, first by filtering the eigenvector pointing directions (gray circles) followed by retaining the angular structure of only the informative modes (orange circles)
To better investigate the effect of the stabilization, the correlation scatter of each entry in the correlation matrices can be plotted over the population, which in this case is 23 days less the 5 day filter window, or 18 available samples. This analysis appears in Fig. 11. Overall, correlations (gray circles) that result from filtering the eigenvectors to create local averages fall within the range of the original correlations (blue circles). This is the consequence of wobble reduction. However, the randomly oriented modes still have an effect. The second stabilizing stage, where only the angles of the informative modes are retained, further decreases the dispersion of the correlations (orange circles).
Static stabilization brings us close to the topic of shrinkage of a correlation matrix subject to corruption from finite-sample noise. Recall that Ledoit–Wolf shrinkage, being the matrix generalization of James–Stein shrinkage, blends an empirical matrix with an identity matrix of the same size,
where \(\alpha \in [0, 1]\) is the shrinkage factor [11]. However, this estimator applies to empirical correlation matrices that have no informative modes. Informative modes (often called “spikes” in the literature; see, for instance, [3]) cannot simply be dropped from a matrix of eigenvectors (in the manner that PCA drops uninformative modes) because the remaining vectors still include all N entries, but we can rotate them away in order to isolate the remaining uninformative modes. With the quote panel in mind, we figuratively have
which is admissible into (41), after which the shrunk matrix is rotated back. Only the noise-related eigenvalues should be included when calculating \(\alpha \). Since the shrinkage weight for static stabilization is \(\alpha = 0\) and applying no such stabilization is associated with \(\alpha = 1\), the concept of static stabilization gives the two bounds within which linear Ledoit–Wolf shrinkage resides.
To summarize this section, directional analysis has been applied twice to the eigenanalysis of quote and trade data as it evolves in time. In the first instance, the pointing directions of the eigenvectors have been filtered to reduce wobble. In the second instance, the orientation of randomly oriented modes was stabilized by setting their embedded angles to zero in order to trade off out-of-sample error with bias. The effects of this type of matrix “cleaning” were demonstrated by taking several types of views of the data, from angular to correlation to pairwise correlation dispersion. When a correlation matrix contains a mixture of informative and noise-corrupted modes, one can rotate away the informative modes, apply proper shrinkage, and then rotate the system back Table 1.
7 Conclusions
Two methods now exist to solve the system of transcendental equations necessary to rotate an eigenbasis into the identity matrix: In the original article, which introduced the arcsin method, rotations and reflections were combined to scan for, and rectify, reflections that could be embedded in an eigenvector matrix V returned from software calls to svd or eig. This article introduced the modified arctan2 method that can defer the rectification of reflections embedded in V until the last subspace. In doing so, \(N-1\) angles within \(V \in \mathbb {R}^{N}\) can span a \(2\pi \) interval rather than the single \(\pi \) interval of the arcsin method. This in turn allows for the disambiguation of angular wrap-around on the \(\pi \) interval for these rotations, and the empirical example showed the importance of observing the full sweep of eigenvector pointing directions in an evolving system. The arcsin and modified arctan2 methods serve different purposes: the former is better for uses such as regression where the instability of eigenvector signs along an evolving datastream corrupts downstream interpretability, and the latter is better for determining the degree of eigenvector directedness over time.
Data availability
The CME data used to generate the panel data cannot be republished. However, the eigensystems, which are the focus of this paper, are available at thucyd-eigen-working-examples. Follow the project’s Readme.md file for details.
Code availability
The Python package thucyd is available on PyPi and Conda-Forge at https://pypi.org/project/thucyd/pypi.org/project/thucydgithub.com/conda-forge/thucyd-feedstock. This paper covers thucyd version 0.2.5+. The code is covered by the Apache 2.0 license and is freely available. In addition, the source code for the reference implementation is freely available at gitlab.com/thucyd-dev/thucyd.
Notes
The angles are not unique, but given a fixed rotation order they can at least be standardized.
The original paper uses different indexing of the triplet. The indexing scheme here is cleaner.
The statement that \(\det (V) = +1\) on page four of the original article erroneously omits the potential for a negative sign.
See Sect. 8 for a link the \(\Lambda \) and V data used in this work.
References
Bartz, D.: Advances in High-dimensional Covariance Matrix Estimation. Technische Universitaet, Berlin (2016)
Bartz, D., Müller, K.R., Hatrick, K., Hesse, C.W., Lemm, S.: Directional Variance Adjustment: A Novel Covariance Estimator for High Dimensional Portfolio Optimization (2011)
Benaych-Georges, F., Nadakuditi, R.R.: The eigenvalues and eigenvectors of finite, low rank perturbations of large random matrices. Adv. Math. 227(1), 494–521 (2011)
Bun, J., Bouchaud, J.P., Potters, M.: Overlaps between eigenvectors of correlated random matrices. Phys. Rev. E 98(5), 052145 (2018)
Cao, G., Bachega, L.R., Bouman, C.A.: The sparse matrix transform for covariance estimation and analysis of high dimensional signals. IEEE Trans. Image Process. 20(3), 625–640 (2011)
Couillet, R., Liao, Z.: Random Matrix Methods for Machine Learning. Cambridge University Press, New York (2022)
Damask, J.: A consistently oriented basis for eigenanalysis. Int. J. Data Sci. Anal. (2020). https://doi.org/10.1007/s41060-020-00227-z
Dash, J.W.: Quantitative Finance and Risk Management. World Scientific, River Edge, NJ (2004). See chapter 22, Correlation Matrix Formalism: the \({\cal{N}}\)-Sphere
Golub, G.H., Van Loan, C.F.: Matrix Computations, 4th edn. Johns Hopkins University Press, Baltimore (2013)
Ledoit, O., Péché, S.: Eigenvectors of some large sample covariance matrix ensembles. Probab. Theory Relat. Fields 151(1–2), 233–264 (2011)
Ledoit, O., Wolf, M.: A well-conditioned estimator for large-dimensional covariance matrices. J. Multivar. Anal. 88(2), 365–411 (2004)
Mehta, M.L.: Random Matrices. Elsevier, Amsterdam (2004)
Meucci, A.: Correlation shrinkage: random matrix theory. In: Advanced Risk and Portfolio Management. https://www.arpm.co/lab/redirect.php?permalink=correlation-shrinkage-random-matrix-theory
Meucci, A.: Risk and Asset Allocation. Springer, New York (2007)
Monasson, R., Villamaina, D.: Estimating the principal components of correlation matrices from all their empirical eigenvectors. Europhys. Lett. 112(5), 50001 (2015)
Potters, M., Bouchaud, J.P.: A first course in random matrix theory: for physicists. In: Engineers and Data Scientists. Cambridge University Press, New York (2021)
Potters, M., Bouchaud, J.P., Laloux, L.: Financial applications of random matrix theory: old laces and new pieces. arXiv:physics/0507111 (2005)
Tsay, R.S., Pourahmadi, M.: Modelling structured correlation matrices. Biometrika 104(1), 237–242 (2017)
Acknowledgements
I am grateful for my conversations with Dr. A. Meucci about the distribution mapping through the copula; this led to a cleaner application of random matrix theory. Thank you also to Professor J. Gama, Editor of this Journal, and my anonymous reviewers for their helpful suggestions.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
I declare that I have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Damask, J. A consistently oriented basis for eigenanalysis: improved directional statistics. Int J Data Sci Anal (2024). https://doi.org/10.1007/s41060-024-00570-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s41060-024-00570-5