
Abstract
Recently, with graph neural networks (GNNs) becoming a powerful technique for graph representation, many excellent GNN-based models have been proposed for processing heterogeneous graphs, which are termed Heterogeneous graph neural networks (HGNNs). However, existing HGNNs tend to aggregate information from either direct neighbors or those connected by short metapaths, thereby neglecting the higher-order information and global feature similarity information in heterogeneous graphs. In this paper, we propose a Multi-View Heterogeneous graph neural network (MV-HGNN) to aggregate these information. Firstly, two auxiliary views, specifically a global feature similarity view and a graph diffusion view, are generated from the original heterogeneous graph. Secondly, MV-HGNN performs two message-passing strategies to get the representation of different views. Subsequently, a transformer-based aggregator is used to get the semantic information. Subsequently, the representations of the three views are fused into a final composite representation. We evaluate our method on the node classification task over three commonly used heterogeneous graph datasets, and the results demonstrate that our proposed MV-HGNN significantly outperforms state-of-the-art baselines.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Various human social data, such as citation networks, movie networks, and user-product networks, are apt to be modeled as graphs for analytical analysis. Heterogeneous graphs [1], consisting of multiple types of nodes and edges, are suitable for modeling semantic relationships in the real world. Accordingly, Graph Neural Networks (GNNs) [2, 3], a powerful tool for mining graph data [4, 5], have achieved exciting results in several tasks [6,7,8,9,10,11,12]. Recently, researchers have begun to investigate the potential of GNNs on heterogeneous graphs and design models that specifically deal with heterogeneous graphs, which are called heterogeneous graph neural networks (HGNNs) [13,14,15].
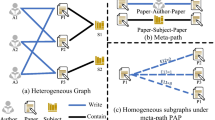
When modeling realistic systems as heterogeneous graphs, due to various limitations, some important information is discarded. Taking the IMDBFootnote 1 movie information network shown in Fig. 1a and b as an example, it contains only four types of nodes: movie, director, actor, and keyword. Based solely on nodes of these four types, it is insufficient to determine the genre of a movie. Because actors usually appear in different types of movies, and directors are the same. Due to the limited node types, some other information, such as the duration of the movie, the number and the type of background music (BGM), cannot be represented in the graph. When modeling movie heterogeneous graphs, these important information is modeled in higher-order nodes and node features. This modeling approach can result in two similar movie nodes being far away from each other in the modeled heterogeneous graph. Therefore, it is necessary to mine important information from the features and higher-order nodes.

Illustration of the heterogeneous movie graph IMDB. a Four types of nodes, namely movie, director, actor and keyword. b A heterogeneous graph consisting of four types of nodes and three types of relations. c Three metapaths, namely Movie-Director-Movie & Movie-Keyword-Movie & Movie-Actor-Movie-Keyword
Existing HGNNs [16] process low-order and high-order information in the same way. In addition, feature information is exclusively used for aggregation. It is essential to design a HGNN that specially processes higher-order information and feature information. Recent works in the field of homogeneous graph research [17,18,19,20] have generated auxiliary views through various forms of augmentation to learn higher-order information more effectively. However, due to the limitation of multiple types of nodes and edges, these models cannot be directly used in heterogeneous graphs. In this paper, considering the heterogeneity, we propose a Multi-View Heterogeneous Graph Neural Network (MV-HGNN) to fuse higher-order information and global feature information. Firstly, we generate two auxiliary views from the original heterogeneous graph, namely the global feature similarity view and the graph diffusion view. Specifically, the global feature similarity view is use to calculate the feature similarity between nodes, while the graph diffusion view is utilized to mine the higher-order structure information. Secondly, we design two lightweight message passing methods for generating representations from neighbors. Thirdly, we employ a transformer-based semantic aggregator to fuse the semantics in heterogeneous graphs. Finally, MV-HGNN uses MLP to obtain the representations of different views and achieve the final comprehensive representation.
The main contributions of this paper are as follows:
-
(1)
To the best of our knowledge, this is the first work to perform global feature similarity computation and graph diffusion in heterogeneous graphs. These two techniques are used to generate two separate auxiliary views.
-
(2)
We introduce the MV-HGNN model, which employs a dual-view generation mechanism to synthesise a comprehensive representation from three distinct perspectives, each representing a different graph structure. The auxiliary views establish direct connections between target nodes and significant nodes.
-
(3)
We conduct experiments on heterogeneous graph datasets. The experiment results demonstrate that our proposed MV-HGNN significantly outperforms the state-of-the-art methods.
The rest of this paper is organized as follows. In Sect. 2, we briefly review the related work. In Sect. 3, the preliminaries are introduced. In Sect. 4, the proposed model is described in detail. In Sect. 5, we conduct extensive experiments to confirm the effectiveness of the proposed model MV-HGNN. Finally, we end with some conclusions in Sect. 6.
2 Related Work
2.1 Graph Neural Network
Benefiting from the widespread application of graph data, GNNs [21,22,23,24] have experienced significant growth in recent years. To overcome the limitation that GNNs can only utilize one-hop neighbors, Graph Diffusion Networks [17, 18, 25] have been introduced as a generalized graph diffusion technique. This technique enables the inclusion of higher-order neighbors during the message-passing process. MAGNA [26] combined attention mechanisms with graph diffusion techniques, calculating the attention scores of multi-hop neighbors to capture long-range interactions between nodes. [18] focused on learning node-level and graph-level representations through contrasting encodings from direct neighbors with those from neighbors after the graph diffusion process.
However, these methods were primarily designed for homogeneous graphs and cannot be directly applied to heterogeneous graphs.
2.2 Heterogeneous Graph Neural Network
Recently, researchers have designed GNNs that extract semantic information from heterogeneous graphs. HAN [27] employed both node-level and semantic-level attention mechanisms to aggregate information from neighbors across diverse metapaths. MAGNN [28] incorporated diverse input features and aggregates information from intermediate nodes along metapaths, thereby capturing the semantics of heterogeneous graphs, whereas HAN overlooks this information. GTN [29] incorporated an attention mechanism to autonomously identify advantageous meta-paths, facilitating the generation of a novel graph structure optimized for the computation of node embeddings. HGB established a novel benchmark for heterogeneous graphs and shows that optimized Graph Attention Network [23] surpass the performance of most HGNNs. HGT [31] employed meta-relations to characterize heterogeneous edges, leveraging this representation to transform matrices for attention computation. This approach effectively facilitates the automatic and implicit discovery of useful metapaths. THAN [32] employed a transformer-like aggregator to capture the topological structure, focusing on performing a temporal link prediction task instead of a node classification task. Furthermore, it calculated node-level attention directly, as opposed to metapath-level or type-level attention, thereby avoiding the learning of an excessive number of parameters.
However, none of the aforementioned HGNNs considered creating auxiliary views to forge a more comprehensive representation for the nodes.
3 Preliminaries
The main notations used in this paper are summarized in Table 1. Before introducing the MV-HGNN, we provide formal definitions for certain key terms relevant to this paper.
3.1 Heterogeneous Graph
A heterogeneous graph, denoted as \({\mathcal {G}}\), is defined as a directed graph with the form \({\mathcal {G}}=({\mathcal {V}}, {\mathcal {E}}, {\mathcal {A}}, {\mathcal {R}}, \phi , \varphi )\). Here \({\mathcal {V}}\) and \({\mathcal {E}}\) denote the set of nodes and edges, \({\mathcal {A}}\) and \({\mathcal {R}}\) denote the set of node types and edge types. Additionally, the condition \(|{\mathcal {A}}|+|{\mathcal {R}}|\>2\) must be satisfied. It is associated with a node type mapping function \(\phi : {\mathcal {V}} \rightarrow {\mathcal {A}}\) and a edge type mapping function \(\varphi : {\mathcal {E}} \rightarrow {\mathcal {R}}\). When \(|{\mathcal {A}}|= |{\mathcal {R}}|=1\), the graph is converted to a homogeneous graph. Additionally, \({\mathcal {V}}_t \subseteq {\mathcal {V}}\) is the set of target nodes, and \({\mathcal {Y}}\) is the label set of target nodes.
As shown in Fig. 1b, an example of the heterogeneous movie graph IMDB consists of four types of nodes (Movie, Director, Actor, Keyword) and six types of relations (directing and directed relations between movies and directors, starred and starring relations between movies and actors, having and related relations between movies and keywords). All the nodes of the type Movie are designed as the target nodes.
3.2 Metapath
Metapaths are instrumental in extracting higher-order semantic information from heterogeneous graphs. A metapath, denoted by \({\mathcal {P}}\), follows the form \({\mathcal {P}} \triangleq c_{1} {\mathop {\longrightarrow }\limits ^{r_{1}}} c_{2} {\mathop {\longrightarrow }\limits ^{r_{2}}} \ldots {\mathop {\rightarrow }\limits ^{r_{l}}} c_{l+1}\) (abbreviated as \(c_{1}c_{2}\ldots c_{l+1}\)), where each \(c_{i} \in {\mathcal {A}}\) (for \(i=1,...,l+1\)) denotes a node type, and each \(r_{j} \in {\mathcal {R}}\) (for \(j=1,...,l\)) denotes a relation type. The composite relation associated with a metapath is defined as \(r=r_{1} \circ r_{2} \circ \cdots \circ r_{l}\), where \(\circ\) is the composition operator. Metapaths usually start with the type c of the target nodes. Target nodes are the task-related nodes of a certain type \(c \in {\mathcal {A}}\).
For example, as shown in Fig. 1c, three of the metapaths of the heterogeneous movie graph IMDB are used to capture semantic information of varying length. Note that metapaths used in this paper are not limited to symmetric metapaths.
4 The Proposed Method
In this section, we introduce MV-HGNN for node classification in heterogeneous graphs. As shown in Fig. 2, MV-HGNN has four main components: view generation, message passing, semantic aggregation and representation fusion. Its idea is to generate two auxiliary views to obtain important information, including feature similarity information and higher order information, which is challenging to obtain on the original view. After performing message passing and semantic aggregation, the features obtained from the three views are fused into a final representation that is used for downstream tasks.

The overview of the proposed framework
4.1 View Generation
4.1.1 Global Feature Similarity View
View generation can be considered as the augmentation on the graphs. The initial heterogeneous graph, known as the original view, represents the primary heterogeneous structure and semantic information. However, the number of node types in a heterogeneous graph is limited. Consequently, some information that should be modeled as graph structure remains embedded within features. For example, in the IMDB movie dataset, only a few attributes like directors, actors and keywords are modeled as nodes. This approach leaves a substantial portion of the remaining attribute information in the features, which leads to two nodes with similar features, but possibly being far apart in the graph.
We aim to break the limitations of heterogeneous graphs. Experiments in [28] demonstrated that that in many datasets, only certain types of features prove beneficial for the task, and [27] showed that the node features corresponding to the type of target nodes are useful. In addition, [33] suggested that the features of a node can be learned from its heterogeneous neighbors. Therefore, for the target nodes, we retain the original features. However, for nodes of other types, we discard their original features in favor of generating new features through feature propagation. As shown in Fig. 3, all author-type nodes are determined as target nodes. Original features of nodes categorized as author and subject are discarded, with new features being generated through feature propagation from the target nodes. In the process of feature generation, we compute the features of neighbors through direct averaging, avoiding the introduction of learnable parameters. In this paper, we only aggregate features from 1-hop or 2-hop neighbors for feature propagation.
Given a set of target node \({\mathcal {V}}_t\), let \({\mathcal {V}}^+\) denotes the set of nodes with complete original features, and let \({\mathcal {V}}^-\) denotes the set of nodes with discarded features. Only the target nodes have features, i.e. \({\mathcal {V}}^+ \iff {\mathcal {V}}_t\). If aggregating features from 1-hop neighbors, for a node \(v \in {\mathcal {V}}^-\), we generate the features of node v by aggregating the features from the neighbor set \({\mathcal {N}}_v\):
where \(x_u\) is the features of neighbor u, \(x_v\) is the features of v. If aggregating features from 2-hop neighbors, the process described in Eq. (1) is performed twice in succession, propagating features from higher-order neighbors to lower-order nodes.
The new features \(\textrm{x}_v\) encapsulate the local structural of the heterogeneous neighbors. Since the features are generated by nodes with the same type, we ignore the node heterogeneity when calculating the feature similarity. Given a target node u within the set \({\mathcal {V}}_t\), we compute the cosine similarity between the feature vector of the target node u and the feature vector the node v, \(v \in {\mathcal {V}}\):
where \(\cos \left( a, b\right) =\frac{a \cdot b}{\left\| a\right\| \cdot \left\| b\right\| }\). Subsequently, node similarities are represented in the form of several heterogeneous adjacency matrices, and the matrices are normalized and sparsified. For any target nodes \(\textrm{u} \in {\mathcal {V}} _t\), we select the top-k nodes whose features are most similar to their features and establish direct connections between u and these nodes. Then we obtain a set of heterogeneous matrices \({S^{f e a t}}\) = \(\{{A}^{f e a t}_{c, c_1}, {A}^{f e a t}_{c, c_2}, \ldots , {A}^{f e a t}_{c, c_l} \}\), which represents all the nodes and edges of the global feature similarity view.
It is important to note that the generated features shown in Fig. 3 are only used for feature similarity calculation. In the subsequent modules, all nodes use the original features.

Nodes of the same type as the target node retain the original features(the paper nodes), nodes of a different type than the target node (the author nodes and the subject nodes) discard the original features and generate features from the aggregation of neighbors that retain the original features
4.1.2 Graph Diffusion View
Similar to the global feature similarity view, we consider the structural similarity of the target nodes globally and regenerate the links as another view for the heterogeneous graph. Personalized PageRank (PPR) [34] and Heat Kernel(HK) [35] are prevalent techniques used to obtain the diffusion matrices that encapsulate the global structure. However, our empirical investigations demonstrate that HK cannot generate a good representation for the target nodes. Therefore, we only introduce PPR for generating the diffusion matrices.
In a homogeneous graph, the adjacency matrix, which is a normalized symmetric matrix, describes the relationships between between different types of nodes. In order to perform PPR on a heterogeneous graph, all adjacency matrices of the heterogeneous graph need to be represented as a symmetric normalized form of the homogeneous graph. The PPR closed-form solution is represented as follows:

Separating multiple heterogeneous matrices from a homogeneous global structural similarity matrix
where \(\alpha\) denotes the transition probability in a random walk, \(I_n\) is an identity matrix, and D is the degree matrix of A. The global structural similarity matrix \(A^{p p r}\) needs to be transformed into the form of a heterogeneous adjacency matrix set \({S^{p p r}}\) = \(\{{A}^{p p r}_{c, c_1}, {A}^{p p r}_{c, c_2}, \ldots , {A}^{p p r}_{c, c_l} \}\). Figure 4 shows an example of the process of separating a homogeneous matrix into two heterogeneous matrices. Similarly, for every \({A}_{c, c_l}\) in \({S^{p p r}}\), \(l\in \{1,2,3 \ldots \}\), we perform matrix sparsification. We consider the new adjacency relationships generated by graph diffusion as another view, termed the graph diffusion view. The graph diffusion view represents the higher-order structural similarity of the target nodes.
Consistent with the two generated views, the original view is also represented as a set of heterogeneous matrices \({S^{ori}}\) = \(\{{A}^{ori}_{c, c_1}, {A}^{ori}_{c, c_2}, \ldots , {A}^{ori}_{c, c_l} \}\).
4.2 Message Passing
4.2.1 Metapath-based Message Passing
The original view comprises multiple types of nodes and edges. To mine these complex relationships, we utilize metapaths. Short metapaths are able to capture local relationships, and long metapaths are able to aggregate higher-order information. To minimize the parameters during training, we aggregate the representation of neighbors by metapaths in the preprocessing stage. Given a metapath set \({\mathcal {F}} = \{{\mathcal {P}}_1, \ldots , {\mathcal {P}}_n\}\), where each metapath \({\mathcal {P}}_i \in {\mathcal {F}}\) is denoted as \({\mathcal {P}}_i = c c_1 c_2 \ldots c_l\), the simplified neighbor aggregation is expressed as:
where \({A}^{ori}_{c, c_i}\) is the heterogeneous adjacency matrix between type of target node c and type \(c_l\). \(X_{c_l}\) is the feature matrix of node type \(c_l\).
4.2.2 Type-based Message Passing
Since the two auxiliary views generate direct links between the target nodes and their neighbors with important information, in both views, we no longer perform matrix multiplication to obtain higher-order relationships. However, due to the specificity of heterogeneous graphs, we aggregate the different types of nodes separately:
where \(c_i \in {\mathcal {A}}\). Equation (5) can be considered as information about the metapath \(c c_l\) with 2-length aggregation.
4.3 Semantic Aggregation
4.3.1 Feature Projection
In heterogeneous graphs, nodes with varying types are typically possess differing feature dimensions. Even if the dimensions are equal, the feature spaces are different. When aggregating semantics, it is impractical to use a uniform framework to deal with features originating from disparate vector space. Therefore, we first project features generated from different metapaths or different types into the same vector space. The process of feature projection is presented as:
where \(W_{{\mathcal {P}}}\) is the parametric weight matrix.
where \(W^{feat}_{c_i}\) and \(W^{ppr}_{c_i}\) are the parametric weight matrices.
4.3.2 Transformer-based Aggregator
Given the pre-defined node type set \({\mathcal {A}} =\left\{ c_1, \ldots , c_n\right\}\) and metapath set \({\mathcal {F}} = \{{\mathcal {P}}_1, \ldots , {\mathcal {P}}_n\}\), the semantic sets of the three views after projection are \(\Psi ^{ori} = \left\{ H^{ori}_{{\mathcal {P}}_1}, \ldots , H^{ori}_{ {\mathcal {P}}_n}\right\}\), \(\Psi ^{feat} = \left\{ H^{feat}_{c_1}, \ldots , H^{feat}_{ c_n}\right\}\) and \(\Psi ^{ppr} = \left\{ H^{ppr}_{c_1}, \ldots , H^{ppr}_{ c_n}\right\}\). Semantic aggregation refers to the integrated fusion of the aforementioned semantic representations. We introduce an attention mechanism that assigns variable weights to each semantic element. We employ a transformer [36]-based semantic aggregator to compute the significance of various semantics. Taking the original view as an example, to get the query matrix \(Q^{ori}_{{\mathcal {P}}_i}\), the key matrix \(K^{ori}_{{\mathcal {P}}_i}\) and value matrix \(V^{ori}_{{\mathcal {P}}_i}\), we introduce three specific weight matrices \(W^{ori}_Q\), \(W^{ori}_K\), \(W^{ori}_V\) shared for all semantics. The process of semantic aggregation is as follows:
Subsequently, the attention scores are calculated by applying the softmax function to the scaled dot products of the query and key vectors.
where \({\textsf{T}}\) is the matrix transition. Furthermore, we aggregates and updates the node representation for a specific metapath:
Clearly, the aggregator output of the original view is represented as \(\hat{\Psi }^{ori} = \left\{ \hat{H}^{ori}_{{\mathcal {P}}_1}, \ldots , \hat{H}^{ori}_{ {\mathcal {P}}_n}\right\}\).
Since the target nodes in the two auxiliary views are directly connected to important high-order or low-order nodes, the reliance on metapaths becomes unnecessary. However, these two auxiliary views make no distinction between node types, when fusing semantics, we calculate the attention scores of different types. Taking global feature similarity view as an example to calculate the importance between different types of nodes, for any \(c_i \in {\mathcal {A}}\):
The attention score is
Similarly, we also implement Eqs. (11), (12), (13) in graph diffusion view. The aggregator outputs for the global feature similarity view and the graph diffusion view are \(\hat{\Psi }^{feat} = \left\{ \hat{H}^{feat}_{c_1}, \ldots , \hat{H}^{feat}_{ c_n}\right\}\) and \(\hat{\Psi }^{ppr} = \left\{ \hat{H}^{ppr}_{c_1}, \ldots , \hat{H}^{ppr}_{ c_n}\right\}\).
4.4 Representation Fusion
To generate the output of the different views, we concatenate the outputs of the transformer-based semantic aggregator and pass them through one layer of \(\textrm{MLP}\). Given the input feature vector \(\textrm{X} \in {\mathbb {R}}\), the sequence of operations in \(\textrm{MLP}\) can be described as follows:
The one-dimensional convolution operation with a kernel size of \(1\times 1\) is applied to transform the input features:
Layer Normalization is then applied to the convolution output:
A PReLU activation function processes the layer normalized output:
Lastly, a Dropout operation is applied to reduce overfitting:
Based on the \(\textrm{MLP}\) described above, the representation of the original view is expressed as follows:
The representation of the global feature similarity view is expressed as follows:
The representation of the graph diffusion view is expressed as follows:
Similarly, we use concatenation and pass through a layer of \(\textrm{MLP}\) to generate a final representation for the target nodes that fuses the three views:
Finally, MV-HGNN employs an additional linear transformation with a nonlinear function to project the node embeddings to the vector space with the desired output dimension:
where \(\sigma (\cdot )\) is a PReLU activation function, and \(\textrm{W}_o\) is a weight matrix.
4.5 Loss
To maximize the mutual information between views, we design the following constraints:
where D is the distance function, \(D(a, b)=\Vert a-b\Vert ^2\).
The task loss is
where \(y_i \in {\mathcal {Y}}\).
The final loss is
where \(\lambda\) is a hyperparameter.
The overall training process of MV-HGNN is summarized in Algorithm 1.

The overall training process of MV-HGNN
5 Experiment
5.1 Experimental Setup
5.1.1 Datasets
To evaluate the performance of the proposed model MV-HGNN, we use three heterogeneous graph datasets DBLP, ACM, IMDB, which are provided by [30]. The simple statistics of these datasets are summarized in Table 2.
-
(1)
DBLPFootnote 2 is a bibliography website for computer science. We employ a subset that comprises 4,057 authors (target nodes), 14,328 papers, 7,723 terms, and 20 venues. The features of author nodes are generated using a bag-of-words model based on keywords, with the dimension of 334.
-
(2)
ACMFootnote 3 is a citation network in which papers are published in KDD, SIGMOD, VLDB, SIGCOMM, and MobiCOMM. We employ a subset that comprises 3025 papers (target nodes), 5959 authors, 56 subjects. The features of paper nodes are generated using a bag-of-words model based on keywords, with the dimension of 1902.
-
(3)
IMDB is a website about movies and television programs, and we employ a common subset with 4932 movies(target nodes), 2393 directors, 6124 actors and 7971 keywords. The features of movie nodes are generated using a bag-of-words model based on keywords, with the dimension of 3489.
5.1.2 Baseline
We compare the performance of MV-HGNN with the following methods.
-
GCN [22]: A homogeneous GNN. This model simplifies graph convolutions to efficiently aggregate neighborhood information, enhancing feature representation without the need for complex mechanisms.
-
GAT [23]: A homogeneous GNN. This model implicitly computes node attention values within and between types when aggregating neighbors.
-
RGCN [7]: A heterogeneous GNN. This model performs multiple graph convolutions based on the number of edge types before conducting a weighted sum calculation.
-
HetGNN [37]: A heterogeneous GNN. This model employs random walks to generate neighbors of the same number but of different types and then aggregates content embeddings based on a Bi-LSTM.
-
HAN [27]: A heterogeneous GNN. This model uses predefined metapaths to capture semantic information of heterogeneous graphs, it also employs a hierarchical attention mechanism to obtain node representations.
-
MAGNN [28]: A heterogeneous GNN. Based on HAN, this model takes into account the intermediate nodes of each metapath and designs multiple encoder functions to further enhance the performance.
-
RSHN [38]: A heterogeneous GNN. Instead of using metapaths, this model constructs a coarsened line graph to address heterogeneity, and designs a message-passing module to integrate information from both nodes and edges.
-
HetSANN [39]: A heterogeneous GNN. This model directly encodes heterogeneous graph structures and leverages attention mechanisms to aggregate information of different relationships.
-
HGT [31]: A heterogeneous GNN. This model focuses on processing large and dynamic graphs, using meta-relations to address heterogeneity.
-
HGB [30]: A heterogeneous GNN. This model can be regarded as an enhanced version of GAT, incorporating edge information, employing residual connections, and utilizing normalization for improved performance.
5.2 Implementation Details
All experiments in this paper are conducted on an NVIDIA GeForce RTX 2080. It come with 8 GB of GDDR6 memory. The Adam [40] optimizer is used to optimize the proposed model MV-HGNN with all of the parameters being initialized at random. For all datasets, the model configuration is summarized in Table 3. The two important hyperparameters, l and k, are analyzed in detail in Sect. 5.5.
It is important to note that some types of nodes have no features. Moreover, due to the heterogeneity of heterogeneous graphs, the dimensions of node features are generally inconsistent. Even if the dimensions are consistent, the features may not in the same space. Therefore, all features are projected into the same space as that of the target node. Additionally, all compared models are executed on the same split and all of their parameters will be also optimized using the validation set to achieve best performance. It is worth mentioning that nodes of some types are featureless. Therefore, for nodes without features, we assign them with randomly initialized features, the dimensions of which match those of the given features.
Metapaths are able to captures the complex semantics of heterogeneous graphs and enhances interpretability. The number and quality of metapaths play a decisive role in the effectiveness of the model. As mentioned above, MV-HGNN utilizes all the metapaths up to length l in the original graph, and the importance of these metapaths is calculated by the transformer-based semantic aggregator. This approach not only accounts for the heterogeneity of the graphs but also makes the model interpretable. For homogeneous GNNs GCN and GAT, the default two-layer encoder is equivalent to aggregating all homogeneous neighbors of the second-order, but these neighbors are not classified, which is not interpretable. Heterogeneous GNNs RGCN, HetGNN, RSHN and HetSANN consider the heterogeneity of heterogeneous graphs in the aggregation process and perform simple aggregation based on different node types, but they cannot process complex semantics. Heterogeneous GNNs HAN and MAGNN use predefined symmetric metapaths to aggregate neighbor information. However, the number of these metapaths is limited, ignoring a large number of information in undefined metapaths. And this approach requires expert knowledge. Heterogeneous GNNs HGT uses multiple asymmetric metapaths, but the matrix stacking strategy brings huge resource consumption. Heterogeneous GNNs HGB affirms the superiority of GAT for processing heterogeneous graphs and optimizes GAT. but it is not possible to explain which types are more importance.
5.3 Node Classification
We compare MV-HGNN with the existing state-of-the-art models in the node classification task. In the following experiments, all results are the average from 10 times of training and we report both the Macro-F1 and Micro-F1 scores. Only labeled target nodes are evaluated and and reported.
The results are shown in Tables 4 and 5. The best-performing values are indicated in bold, and the second-best values are underlined. As can be seen, among all datasets, MV-HGNN outperforms all baselines. The results show the strength of MV-HGNN for node classification and illustrate the great potential of fused multi-view representations. Traditional GNNs designed for homogeneous graphs were underestimated, especially GAT, whose performance is even better than many HGNNs specially designed for heterogeneous graphs. This shows that the method of homogeneous graphs can also mine potential heterogeneous information. Another reason is we directly convert the original heterogeneous graph into a homogeneous graph, instead of using a symmetric metapath to generate a homogeneous graph like the process in HAN and MAGNN, which can maximize the information of the graph. The strategy of RGCN is the superposition of convolution in multiple homogeneous graphs, which also achieves good results. HetGNN is ineffective as it fails to distinguish the importance of nodes when aggregating different types and tends to aggregate neighbors that are ineffective or even harmful. HAN and MAGNN capture the semantic information of heterogeneous graphs using symmetric metapaths, achieving stable results across three datasets. However, relying solely on a limited number of predefined symmetric metapaths can lead to information loss, thus preventing the attainment of optimal results. RSHN handles the heterogeneity of heterogeneous graphs by constructing line graphs. This message passing method has achieved good results in IMDB and DBLP. HetSANN encodes the heterogeneous graph structure and combines the attention mechanism. This method fails in DBLP and IMDB and is only effective in ACM. HGT addresses the issue in HAN and MAGNN, where metapaths need to be predefined, by employing a stacking metapath approach. This method effectively captures semantic information within heterogeneous graphs, leading to improved results across all three datasets. However, it significantly increases both the computational time and power required. HGB optimizes GAT by integrating edge information and adding residual links, and performs well in all three datasets, but not as well as MV-HGNN. In contrast, among all compared methods, MV-HGNN employs the largest number of metapaths and assigns appropriate attention scores to these metapaths. It utilizes short metapaths to aggregate lower-order neighbors and leverages long metapaths to capture higher-order information. These two auxiliary views generate a new graph structure based on the original view respectively. The global feature similarity view captures the feature similarity of the target nodes, while the graph diffusion view captures the global structural similarity of the target nodes. And the newly graph structures help the target nodes directly link to effective high-order heterogeneous nodes as a supplement to the original graph.
Thus we conclude that our proposed MV-HGNN is able to mine more useful information from the heterogeneous graph. Furthermore, we observe that both homogeneous GNNs outperform some HGNNs, suggesting that GNN models designed for homogeneous graphs are underestimated. Nonetheless, utilizing metapaths remains a reliable method for enhancing model performance. Both quantity and quality of metapaths play a critical role in determining the performance of a model. Accordingly, the model needs to automatically select metapaths by assigning appropriate importance to different metapaths.
As shown in Tables 4 and 5, we observe that while MV-HGNN achieves the best results across all three datasets, its classification performance in the citation networks of DBLP and ACM is significantly better compared to the movie network IMDB. For the DBLP dataset, authors are as target nodes, alongside papers, terms, and venues, making up a total of four different node types. The main classification labels are aligned with the research fields of authors, creating a strong connection between these node types and the classification labels. This connection results in the exceptional performance of MV-HGNN on this dataset, as the nodes in DBLP are inherently linked to the research domains of authors, providing a detailed context for precise classification. Likewise, the ACM dataset contains papers as target nodes, authors, and subjects, with classification labels that correspond to the research areas of papers. Similar to the DBLP dataset, there is a significant relationship between the node types and the classification labels, reinforcing the MV-HGNN to classify the data accurately based on these closely related attributes. Conversely, the IMDB dataset offers a varied landscape. It includes movies as target nodes, directors, actors, and keywords. The labels denote the movie genres. However, the link between the nodes and the labels is not as pronounced or direct as seen in the DBLP and ACM datasets. A director might direct films across various genres, actors can partake in movies of different types, and similar keywords could be found across diverse genres (for instance, the keyword “family” might feature in both romance and action movies). This diluted correlation might influence the classification capabilities of the MV-HGNN model on the IMDB dataset, evident in the Macro-f1 and Micro-f1 scores.
5.4 Ablation Study
In this subsection, we perform a series of ablation studies to better show the effectiveness of our multi-view strategies and the transformer-based semantic aggregator. Specifically, we introduce three different variants of MV-HGNN include variant w/o FS, variant w/o D and variant w/o Trans to verify the effectiveness of each component. To evaluate the effectiveness of neighbors obtained by calculating global feature similarity, variant w/o FS does not fuse the representation from the global feature similarity view. To evaluate the effectiveness of higher-order neighbors obtained by graph diffusion strategy, variant w/o D does not fuse the representation of the graph diffusion view. In order to verify whether the semantic information generated by different metapaths needs to be assigned weights through the attention mechanism, variant w/o Trans doesn’t perform semantic aggregation. The results are shown in Fig. 5.
The results on w/o FS and w/o D show that fusing the representations of different views brings performance improvements, with the graph diffusion view contributing more significantly than the feature similar view. This is because neighbors with similar features are lower-order neighbors that can be easily captured by short metapaths. In contrast, higher-order neighbors with similar graph structures are more challenging to learn through metapaths, and without explicit emphasis, the contributions from useful high-order neighbors might be overshadowed. The results on w/o Trans highlight the substantial performance boost provided by transformer-based semantic aggregation. Through our strategy of generating metapaths, a large number of metapaths are generated, it becomes crucial to assign more attentional weights to the more important metapaths.

Effectiveness of each component of MV-HGNN
5.5 Analysis of Hyperparameters
In this section, we systematically investigate the sensitivity of two main parameters: the length of metapath l, the number of neighbors k of target nodes in the two auxiliary views. We conduct node classification on the ACM and DBLP datasets and report the Micro-F1 scores.

Analysis of the lenth of metapath
Analysis of l. l is the length of metapath in original view. We change its value and the corresponding results are shown in Fig. 6. As l increases, the performance of the model on the ACM dataset rises and then falls, with the optimal point is at 4. As l increases, the model is less sensitive to l on DBLP, with an optimal point of 5. Due to resource limitation, the maximum l on ACM is 5, and on DBLP is 7.
Analysis of k. k is the number of neighbors in the two auxiliary views after sparsification the importance. The results are shown in Fig. 7. On the ACM dataset, as we gradually increase the value of k, the classification effectiveness first improves and then tends to stabilize, with \(k=84\) being the optimal point. On the DBLP dataset, as k increases, the classification effect first improves and then decreases, achieving the best result when \(k=60\).

Analysis of the number of target node neighbors in diffusion view and feature similar view

Visualization of embedding on ACM
5.6 Visualization
To provide a more intuitive comparison, we visualize the embeddings of nodes with their respective labels. Based on above results, we select representative baselines for an embedding visualization comparison alongside MV-HGNN. Firstly, we get the final embeddings of the selected models. Specifically, we take the logits before the output layer of GNN models as the node embedding and then project these embedding into a 2-dimensional space. The popular t-SNE algorithm to visualize the embedding of target nodes on ACM. The visualization graph contains all the test set nodes in the ACM dataset, and we color the nodes according to their respective classes. It should be noted that the visualizations of the models designed for homogeneous graphs such as GCN and GAT, are similar. Therefore, we only present the visualization of the GAT model. HAN and HGB are currently the most classic and best-performing models for heterogeneous graphs respectively.
As shown in Fig. 8, MV-HGNN achieves the best visualization performance with clear demarcation lines between nodes of the three classes and nodes of the same class converge together. GAT exhibits poor performance, especially in distinguishing the class denoted by the purple color. HAN struggles to separate these three types of nodes effectively, leading to a suboptimal clustering performance due to the information loss from symmetric metapaths. The visualization of HGB shows two classes of nodes intermixing without a definitive clear demarcation line.
6 Conclusion
We propose a multi-view heterogeneous graph neural network that is capable of generating two auxiliary views from the original view to capture more structural information for the classification task of target nodes. These views consist of the global feature similarity view and the graph diffusion view. The global feature similarity view establishes direct connections to nodes with global similar features, while the graph diffusion view builds direct links to nodes with similar global structure. These auxiliary views allow the target nodes to easily aggregate critical information, including that from higher-order nodes, through its first-order neighbors. To effectively capture the representations of these views, we have designed various lightweight message-passing methods and a transformer-based aggregator. Integrating multi-view representations significantly improves node classification performance on three heterogeneous graph datasets. Ablation study results further demonstrate the effectiveness of our distinct views and components.
For future work, we aim to develop HGNN models for the unsupervised node classification task, which will be capable of fusing multi-view representations.
References
Shi C, Li Y, Zhang J, Sun Y, Philip SY (2016) A survey of heterogeneous information network analysis. IEEE Trans Knowl Data Eng 29(1):17–37
Zhou J, Cui G, Hu S, Zhang Z, Yang C, Liu Z, Wang L, Li C, Sun M (2020) Graph neural networks: a review of methods and applications. AI Open 1:57–81
Wu Z, Pan S, Chen F, Long G, Zhang C, Philip SY (2020) A comprehensive survey on graph neural networks. IEEE Trans Neural Netw Learn Syst 32(1):4–24
Dong Y, Ma J, Wang S, Chen C, Li J (2023) Fairness in graph mining: a survey. IEEE Trans Knowl Data Eng 35:10583–10602
Nie M, Chen D, Wang D (2023) Reinforcement learning on graphs: A survey. IEEE Trans Emerg Topics Comput Intell 7(4):1065–1082. https://doi.org/10.1109/TETCI.2022.3222545
Kipf TN, Welling M (2016) Variational graph auto-encoders. arXiv preprint arXiv:1611.07308
Schlichtkrull M, Kipf TN, Bloem P, Van Den Berg R, Titov I, Welling M (2018) Modeling relational data with graph convolutional networks. In: European semantic web conference, Springer, pp 593–607
Berg Rvd, Kipf TN, Welling M (2017) Graph convolutional matrix completion. arXiv preprint arXiv:1706.02263
Zhang J, Shi X, Zhao S, King I (2019) Star-gcn: stacked and reconstructed graph convolutional networks for recommender systems. In: Proceedings of the 28th international joint conference on artificial intelligence, pp 4264–4270
Cheng F, Zhou C, Liu X, Wang Q, Qiu J, Zhang L (2023) Graph-based feature selection in classification: structure and node dynamic mechanisms. IEEE Trans Emerg Topics Comput Intell 7(4):1314–1328. https://doi.org/10.1109/TETCI.2022.3225550
Takiddin A, Atat R, Ismail M, Boyaci O, Davis KR, Serpedin E (2023) Generalized graph neural network-based detection of false data injection attacks in smart grids. IEEE Trans Emerg Topics Comput Intell 7(3):618–630. https://doi.org/10.1109/TETCI.2022.3232821
Zhang Z, Jia Y, Hou Y, Yu X (2024) Explicit behavior interaction with heterogeneous graph for multi-behavior recommendation. Data Sci Eng 19:1–19
Yang C, Pal A, Zhai A, Pancha N, Han J, Rosenberg C, Leskovec J (2020) Multisage: empowering gcn with contextualized multi-embeddings on web-scale multipartite networks. In: Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pp 2434–2443
Tian Y, Dong K, Zhang C, Zhang C, Chawla NV (2023) Heterogeneous graph masked autoencoders. In: Proceedings of the AAAI conference on artificial intelligence, vol. 37, pp 9997–10005
Chen M, Huang C, Xia L, Wei W, Xu Y, Luo R (2023) Heterogeneous graph contrastive learning for recommendation. In: Proceedings of the 16th ACM international conference on web search and data mining, pp 544–552
Wang X, Bo D, Shi C, Fan S, Ye Y, Philip SY (2022) A survey on heterogeneous graph embedding: methods, techniques, applications and sources. IEEE Trans Big Data 9(2):415–436
Klicpera J, Weißenberger S, Günnemann S (2019) Diffusion improves graph learning. arXiv preprint arXiv:1911.05485
Hassani K, Khasahmadi AH (2020) Contrastive multi-view representation learning on graphs. In: International Conference on machine learning, PMLR, pp 4116–4126
You Y, Chen T, Sui Y, Chen T, Wang Z, Shen Y (2020) Graph contrastive learning with augmentations. Adv Neural Inf Process Syst 33:5812–5823
Chen M-S, Lin J-Q, Li X-L, Liu B-Y, Wang C-D, Huang D, Lai J-H (2022) Representation learning in multi-view clustering: a literature review. Data Sci Eng 7(3):225–241
Defferrard M, Bresson X, Vandergheynst P (2016) Convolutional neural networks on graphs with fast localized spectral filtering. Adv Neural Inf Process Syst 29:3844–3852
Kipf TN, Welling M (2016) Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907
Velickovic P, Cucurull G, Casanova A, Romero A, Lio P, Bengio Y et al (2017) Graph attention networks. stat 1050(20):10–48550
Hamilton WL, Ying R, Leskovec J (2017) Inductive representation learning on large graphs. In: Proceedings of the 31st international conference on neural information processing systems, pp 1025–1035
Tsitsulin A, Mottin D, Karras P, Müller E (2018) Verse: versatile graph embeddings from similarity measures. In: Proceedings of the 2018 world wide web conference, pp 539–548
Wang G, Ying R, Huang J, Leskovec J (2020) Multi-hop attention graph neural network. arXiv preprint arXiv:2009.14332
Wang X, Ji H, Shi C, Wang B, Ye Y, Cui P, Yu PS (2019) Heterogeneous graph attention network. In: The world wide web conference, pp 2022–2032
Fu X, Zhang J, Meng Z, King I (2020) Magnn: Metapath aggregated graph neural network for heterogeneous graph embedding. In: Proceedings of the web conference 2020, pp 2331–2341
Yun S, Jeong M, Kim R, Kang J, Kim HJ (2019) Graph transformer networks. Adv Neural Inf Process Syst 32:11983–11993
Lv Q, Ding M, Liu Q, Chen Y, Feng W, He S, Zhou C, Jiang J, Dong Y, Tang J (2021) Are we really making much progress? revisiting, benchmarking and refining heterogeneous graph neural networks. In: Proceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining, pp 1150–1160
Hu Z, Dong Y, Wang K, Sun Y (2020) Heterogeneous graph transformer. In: Proceedings of the web conference 2020, pp 2704–2710
Li L, Duan L, Wang J, He C, Chen Z, Xie G, Deng S, Luo Z (2023) Memory-enhanced transformer for representation learning on temporal heterogeneous graphs. Data Sci Eng 8(2):98–111
Jin D, Huo C, Liang C, Yang L (2021) Heterogeneous graph neural network via attribute completion. In: Proceedings of the web conference 2021, pp 391–400
Page L, Brin S, Motwani R, Winograd T (1999) The pagerank citation ranking: bringing order to the web. Technical report, Stanford InfoLab
Kondor RI, Lafferty J (2002) Diffusion kernels on graphs and other discrete structures. In: Proceedings of the 19th international conference on machine learning, vol 2002, pp 315–322
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I (2017) Attention is all you need. Advances in Neural Information Processing Systems 30
Zhang C, Song D, Huang C, Swami A, Chawla NV (2019) Heterogeneous graph neural network. In: Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pp 793–803
Zhu S, Zhou C, Pan S, Zhu X, Wang B (2019) Relation structure-aware heterogeneous graph neural network. In: 2019 IEEE international conference on data mining (ICDM), IEEE, pp 1534–1539
Hong H, Guo H, Lin Y, Yang X, Li Z, Ye J (2020) An attention-based graph neural network for heterogeneous structural learning. In: Proceedings of the AAAI conference on artificial intelligence, vol 34, pp 4132–4139
Kingma DP, Ba J (2014) Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980
Acknowledgements
This work was partly supported by the Guangdong Provincial Key Laboratory Project of Intellectual Property and Big Data (2018B030322016), the National Natural Science Foundation of China (U1701266), Special Projects for Key Fields in Higher Education of Guangdong (2020ZDZX3077), Key Discipline Research Capacity Improvement Project of Guangdong Province (2022ZDJS013).
Author information
Authors and Affiliations
Contributions
Xi Zeng: Original draft writing; model design; visualization. Fangyuan Lei: Review and editing; validation. Changdong Wang: Review and Editing; project administration. Qingyun Dai: Supervision; funding acquisition.
Corresponding author
Ethics declarations
Conflict of interest
I declare that I have no conflict of interest.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zeng, X., Lei, FY., Wang, CD. et al. Multi-view Heterogeneous Graph Neural Networks for Node Classification. Data Sci. Eng. (2024). https://doi.org/10.1007/s41019-024-00253-y
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s41019-024-00253-y