
Abstract
To achieve an objective and reasonable judgment on slope stability, the partially ordered set (Poset) theory is applied to the slope stability evaluation against the engineering background of an open pit slope. From the four aspects of rock mass structural characteristics, slope morphology, environment conditions and engineering conditions, 24 typical evaluation indices such as cohesion, internal friction angle, elastic modulus and Poisson’s ratio are selected. Based on the Poset theory, a Poset evaluation model is established. According to the slope stability evaluation indices and the risk grade classification criteria, the slope stability risk grade is divided into four grades: stable (Grade I), generally stable (Grade II), slightly stable (Grade III) and unstable (Grade IV). The index data are normalized and the weight ranking information is used. Implicit weighting is carried out by means of accumulation. The comparison relation matrix, the Hasse matrix and the Hasse diagram are constructed for each factor layer and comprehensive index layer, respectively. This method was utilized to evaluate the risk grade of an engineering example, determine the slope risk grade, and compare with the actual situation. The results show that the slope to be evaluated is generally stable (Grade II) under the comprehensive evaluation indices of various factors, and the assessed stability condition is consistent with the actual situation. These verify the rationality and applicability of the proposed method and provide a new insight for accurately identifying the stability condition of open-pit slopes.
Article highlights
-
(1)
The poset theory is innovatively applied to the stability evaluation of open-pit slope.
-
(2)
The evaluation model of poset based on poset theory is established.
-
(3)
The multi-factor risk identification and evaluation system for open-pit slope is established, and the factors affecting slope stability are considered comprehensively.
-
(4)
The weight is embedded into the evaluation method in the way of implicit weighting, which does not require the specific weight value to participate in the calculation, and avoids the weighting dispute.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Increasing attention has been paid on the issue of slope failure in open pit mining. In recent years, more than 30 open-pit coal mines in Chinese Baiyinhua coalfield, Shengli coalfield, Baorixile coalfield and Huolinhe coalfield have encountered large deformation and landslide disasters. It is extremely difficult to prevent and control landslides, the number and scale of which are usually large and the loss caused by which is extremely severe. For instance, at Baorixile Open-pit Coal Mine (Ju and Li 2009), a total of 8 large-scale soft rock landslides were recorded as of the end of 2016. Among them, the landslide occurred at the western end of the stope in October 2008 had a volume of about 3.5 million m3 and the direct economic loss was nearly 100 million yuan. Another case is Datang Shengli East II Open-pit Coal Mine (Jiang 2022) whose non-working end slopes suffered two huge landslides in July 2012 and August 2013, and it is as yet unable to conduct the coal production normally. Such landslide accidents have seriously impeded the safe production, economic and social sustainable development of open-pit coal mines in China. Therefore, the analysis and assessment of slope stability is the primary problem to be solved in open pit mining and also the premise and foundation of slope engineering projects (Zou and Wei 2006). Scientific evaluation of slope stability is able to provide guidance on reasonable control measures in mining engineering.
At present, scholars have proposed a variety of methods to evaluate the slope stability. These methods can be divided into two types, i.e., deterministic and non-deterministic methods. The former ones mainly consist of the limit equilibrium method, the numerical analysis method, the probabilistic method, the graphic method, the engineering analogy method, the natural history analysis method, etc. (Deng and Li 2012; Chang et al. 2016; Sun et al. 2019; Pan et al. 2019; Zhang et al. 2020). However, traditional methods on slope stability assessment have some limitations. No matter the limit equilibrium method or the numerical analysis method, it requires a large amount of geological investigation in the early stage, resulting in a great amount of workload and high economic cost (Zhang 2008; Hong et al. 2019). Non-deterministic methods relate to a number of basic theories in different disciplines, including the Chaos theory, the Fuzzy theory, the Stochastic theory, the Mutation theory, the Artificial Neural Network theory, the Grey System theory, etc. (He et al. 2019; Li et al. 2011; Yang et al. 2020; Nabila et al. 2021; Yuan and Li 2021). With the deepening study of slope stability, modern mathematical theories and methods are introduced into the slope stability evaluation, such as the Fuzzy Comprehensive Evaluation method, the TOPSIS evaluation method, the Grey Relational analysis, the Principal Component analysis, the Reliability analysis, the Measurement Uncertainty theory, the Least Square Support Vector Machine method, the Matter-element Extension theory, the Game theory-Cloud model, and so on (Chen et al. 2008; Yuan et al. 2013; He et al. 2014; Tian et al. 2016; Chen et al. 2019; Jena et al. 2020; Huang et al. 2020; Wang et al. 2021; Zhang et al. 2022). Hence, the evaluation system is greatly enriched. Zhou et al. (1995) applied a fuzzy evaluation model to the slope stability evaluation and considered it as an applicable model suitable for promotion. Chen and Yang (2005) built a new intelligent model for slope stability evaluation by introducing the genetic algorithm into the artificial neural network (ANN) and constructing a T-S type reasoning system. Li et al. (2011) established a landslide database based on 31 typical landslide cases in history and compared the slope to be evaluated with the database to achieve the evaluation results. Ren (2017) employed the ideal point method to assess the slope stability, used an improved entropy weight method to determine the weight coefficient of each index, and established an early warning system of slope landslides. Wang and Xu (2011) developed an evaluation model of slope stability based on the projection pursuit optimized by the particle swarm (PSO-PP). The evaluation model was proved to have good feasibility and high accuracy. Qin et al. (2022) proposed an single-valued neutrosophic number-based adaptive neuro fuzzy inference system (SVNN-ANFIS) approach to evaluate the slope stability of an open-pit mine. Traditional deterministic methods have the following deficiencies: (1) the evaluation method has strong randomness. For example, the limit equilibrium method is difficult to determine the position of the sliding surface for the rock and soil slope with complex structure. The numerical analysis method is greatly influenced by the selection of physical parameters. (2) The evaluation method is dependent on experience. For instance, both the graphic method and the engineering analogy method require a certain degree of experience. (3) The evaluation method has a small scope of application. For example, the natural history analysis method needs to trace the evolution process of the slope and is mainly used to assess natural slopes. Non-deterministic methods also have some shortcomings. (1) There is an imbalance between subjective and objective factors. For example, the fuzzy comprehensive evaluation method is more subjective while the support vector machine method is more objective. (2) Specific weight values are needed for calculation in the evaluation process. Yue et al. (2018) and Zhao (2022) used Game theory to solve the weight of the same evaluation index system, but the obtained weight values of each index were not only numerically different, but even the weight orders of some indices were different, indicating that the use of specific weight values for risk assessment is unstable. (3) The evaluation method is dependent on the number of samples. For example, the reliability analysis method requires a large number of samples to obtain the distribution and statistical parameters of random variables, but the actual number of samples is limited.
To overcome the above shortcomings and evaluate slope stability effectively and economically, the Poset decision-making theory is applied in this work to establish a multi-factor risk assessment system based on an open-pit slope of Yuanbaoshan Open-pit Coal Mine. The importance degree and data information contained in the index itself is fully considered. The weights are embedded into the evaluation method by means of implicit weighting, without requiring specific weight values to participate in the calculation. This avoids the controversy about the weight assignment. The Poset evaluation model is constructed to evaluate the slope stability and its accuracy and rationality are verified with the actual situation, which provides a new feasible method for slope stability evaluation.
2 Partially ordered set (Poset) theory
A partially ordered set (A, ≤) refers to the set A equipped with the partial order relation ≤ , where the partial order relation ≤ is a binary relation satisfying reflexivity, antisymmetry and transitivity on the nonempty set A. When this binary relation is used for decision making, it should be noted that the evaluation value and the evaluation relation are essentially different. Yue et al. (2018) provided their conversion relation. For ∀x,y ∈ A, then
where x and y are evaluation objects, cj represents the jth evaluation index, cj(x) is the normalized value of x on the index cj, and cj(y) is the normalized value of y on the index cj.
Under the premise that the weights of the indices meet ω11 ≥ ω12 ≥ ··· ≥ ω1n, Chen et al. (2019) realized the implicit weighting in the form of a matrix for decision making with multiple objects and indices.
where D is the cumulative transformation matrix, X is the evaluation matrix, and E is the upper triangular matrix, \(E = \left( {\begin{array}{*{20}c} 1 & 1 & \cdots & 1 \\ 0 & 1 & \cdots & 1 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & 1 \\ \end{array} } \right)\).
In the matrix D, if each value in the row m − 1 is greater than or equal to the value in the corresponding position of the row m, the evaluation object m− 1 is better than or equal to the evaluation object m. For a given poset (A, ≤), ∀x,y ∈ A, if x is better than or equal to y, sxy = 1. Otherwise, sxy = 0, and S = (sxy)m×m is called the comparison relation matrix of (A, ≤).
However, when the index weight does not satisfy the ranking of ω11 ≥ ω12 ≥ ··· ≥ ω1n, the above calculation cannot be carried out. Aiming at the situation that the weight order of some evaluation indices cannot be determined, Gao et al. expressed the weight relation among the indices in terms of weight sets, namely, ω11 ≥ ··· ≥ ω1i−1 ≥ {ω1i, ω1i+1, ···ω1j} ≥ ω1j+1 ≥ ··· > ω1n. Among them, the weight values of any two indices in the set {ω1i, ω1i+1, ···ω1j} cannot be ascertained, and ω1i−1 ≥ max{ω1i, ω1i+1,···ω1j} ≥ min{ω1i, ω1i+1, ···ω1j} ≥ ω1j+1. In other words, if the weight order of some evaluation indices cannot be determined, the corresponding indices are added as a new index, and then its weight is ranked with other index weights. In this way, the Poset theory can be reapplied.
The comparison relation matrix cannot visually reflect the partial order relation, so it is necessary to depict a relation diagram. A Hasse matrix can be obtained by the conversion calculation of the comparison relation matrix, and then a Hasse diagram can be plotted. The Hasse diagram is a special directed graph, visually showing the partial order results of the evaluation objects. It is a powerful tool to exhibit the transitive and structural relations among the evaluation objects. Fan (2003) illustrated the conversion relation between the comparison relation matrix S and the Hasse matrix by the following expression,
where S is the comparison relation matrix, Hs is the Hasse matrix, I is the unit matrix, and (S − I)2 indicates the Boolean operation (i.e. 1 + 1 = 1, 1 + 0 = 1, 0 + 0 = 0, 1 × 1 = 1, 1 × 0 = 0, 0 × 0 = 0).
For any poset (A, ≤), the set F(x) = {y ∈ A|x ≤ y} is the upper set of A, the set O(x) = {y ∈ A|x ≥ y} is the lower set of A, and the set U(x) is the incomparable set of A. For any x ∈ A, the average height (Brüggemann and Patil 2011) of the evaluation object on the poset (A, ≤) is
In the equation of U(x) = A-O(x)-F(x), |F(x)|, |O(x)|, and |U(x)| is the number of elements in the set of F(x), O(x), and U(x), respectively.
The entire scheme sets can be ordered according to hav(x).
3 Evaluation process
3.1 Establishment of the poset evaluation model
To construct the poset evaluation model, firstly, each index and grade interval of the target samples are determined, then the values of left and right endpoints of the grade intervals are used as the index values to construct grade samples, and the risk degree is determined by the comparison and ranking of the sample to be evaluated and the grade samples on each index (Zhang et al. 2022). If a target sample is sandwiched between the left endpoint and the right endpoint of the grade interval, this sample belongs to the risk level.
Based on the actual data of the engineering background, combined with field experience and related research results, the evaluation indices of the slope stability are comprehensively selected. The risk classification criteria and the influence degrees of the selected indices on the slope stability are determined. The classification criteria are constructed as the grade samples to insert into the sample group and participate in the overall ranking to reflect the risk degree of the target sample. The evaluation indices are ordered according to the importance of their weights, and the most important index is put at the first place, then second and then again. The new index data is obtained by adding the processed index data by column. This accumulative process is a way of implicit weighting. Each scheme is compared on each index one by one and the comparison relation matrix is obtained through calculation. According to Eq. (3), the Hasse matrix is converted and is used to draw a Hasse diagram. The clustering among the samples is visually illustrated in the graph. By using Eq. (4) to calculate the average height, the better and worse relation within the layer set can be clarified. The Hasse diagram can be interpreted structurally, and the risk grade of the target sample can be finally determined. The flow chart of the poset evaluation model is shown in Fig. 1.

Flow chart of the poset evaluation model
3.2 Quantitative processing of qualitative indices
Not all evaluation indices of slope stability are quantitative and some qualitative indices cannot be calculated in the evaluation matrix. Therefore, qualitative indices are quantitatively processed in a hierarchical way according to the research results of Zhang et al. (2022). That is, the qualitative indices are divided into four grades according to the risk grade classification criteria of slope stability: stable (0.2), generally stable (0.4), slightly stable (0.6) and unstable (0.8). The processing results are shown in Table 1.
4 Poset evaluation model of slope stability
4.1 Evaluation indices and grade classification criteria of slope stability
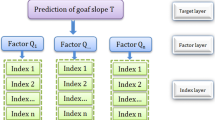
Slope failure is often caused by multiple factors, so the evaluation index of slope stability is not unique. The evaluation indices alter with different situations, and the weights of the evaluation indices and the risk grades are also different. By analyzing the factors influencing slope stability (Wang and Xu 2011) and combining with practical situations of open-pit slopes, from the four perspectives of rock mass structural characteristics, slope morphology, environment conditions and engineering conditions, 24 evaluation objects are selected in the present study as the evaluation indices of slope stability, i.e., cohesion (weak layer), internal friction angle (weak layer), elastic modulus, Poisson’s ratio, dip angle of the down-dip weak layer, joint length, joint condition, filling condition, cohesion (fault), internal friction angle (fault), relative distance to the free face, included angle between strata strike and slope strike, dip angle of the down-dip fault, transmissivity, slope angle, slope height, slope contour, slope section, maximum rainfall, in-slope groundwater or confined water head, seismic intensity, weathering degree, blasting particle vibration velocity and vehicle vibration intensity. Based on the above analysis, the index system of slope stability evaluation is established, as shown in Fig. 2. Four risk grades of slope stability are determined by linear distribution, i.e., stable (Grade I), generally stable (Grade II), slightly stable (Grade III) and unstable (Grade IV). The risk grade classification criteria are given in Table 1.

Hierarchy structure of the slope stability evaluation index system
4.2 Normalization processing of index data
Dimensional difference often exists in the data of different indices. To eliminate the dimensional influence and make the data comparable, it is necessary to normalize the data. Normalization processing of index data includes the benefit type and the cost type:
The index’s influence on the results determines the choice of the processing method. For the classification criteria of slope stability risk grades in this paper, cohesion, internal friction angle, elastic modulus, relative distance to the free face and dip angle of the down-dip fault are positive indicators. Larger values indicate lower risk of a slope landslide. Hence, Eq. (5) is used for processing these indices. The other evaluation indices are inverse indicators. Larger values imply higher risk of a slope landslide, so the Eq. (6) is applied for data processing.
4.3 Ranking the weights of the evaluation indices
Index weights are crucial for any weight-based evaluation model. In the poset evaluation model, there is no need to calculate specific weights, but accurate prediction of samples can be achieved by ranking the weights (Jia et al. 2021). According to practical engineering experience and the methods of solving the weights of the influencing factors and evaluation indices in the literatures (Zhu et al. 2018; Wei et al. 2019; Wang et al. 2021; Zhao 2022), after comparative analysis, the weight ranking of the evaluation indices is carried out by using the improved CRITIC-G2 weighting method.
(1) Determine the weights of the objective indices of the improved CRITIC method
The improved CRITIC weighting method is a difference-driven objective weighting method that can reflect both the variation degree of each evaluation index and the influence degree between the evaluation indices (Zhu et al. 2018). Firstly, the improved CRITIC information is employed to reflect the real information of the data and the mean deviation of the evaluation indices is introduced. Secondly, instead of the decision-makers’ subjective conclusion, the ratio of the improved CRITIC information of each evaluation index and the least important evaluation index is used to determine the importance degree. The main steps of weight calculation are as follows.
① Calculate the information contained in each index by
where Ck is the improved CRITIC information amount of the kth evaluation index, σk is the standard deviation of the kth evaluation index, uk is the mean value of the kth index, \(\sum\nolimits_{i = 1}^{m} {(1 - \left| {t_{ik} } \right|)}\) is the quantified value of the influence degree between the kth index and the other indices, and tik is the correlation coefficient of the evaluation indices i and k.
② Determine the weight of each index by
where Wk is the weight of the kth index.
(2) Determine the weights of the subjective indices in the G2 method
The G2 weighting method is a function-driven subjective weighting method that assigns a score range to an evaluation index according to the relative importance of each evaluation index under the condition of uncertain information and risk. It calculates the weight of each evaluation index in the group decision-making process through quantitative calculation (Yan et al. 2010). The weight calculation of the G2 weighting method is as follows.
Based on the experts’ experience and their preferred coefficients, the m indices in the original index set {ui} are reordered as {ui1, ui2, … uik, …, uim} according to the importance degree. ui1 is the most important index while uim is the least important index. The experts make a rational judgment on the ratio (rkm) of the importance degree of uik to uim.
However, in certain cases, due to the lack of some information, the experts cannot give an exact value of ak, so they have to assign it a range of values [d1k, d2k]. The bounded, closed, real number is considered as an interval number consisting of d1 and d2, and is denoted as Dk, where Dk = [d1k, d2k].
In the above equations, e(Dk) is the interval length, n(Dk) is the midpoint of the interval, φ(Dk) is the interval mapping function of the experts’ risk attitude, and ε is risk attitude factor (ε ≤ 0.5). − 0.5 ≤ ε ≤ 0 means a conservative attitude. When ε = 0, it is neutral. 0 ≤ ε ≤ 0.5 indicates a risk. For a specified expert, ε is a definite number.
If the assignment of {Dk} is accurate, the weight of the k-th index in the G2 method (WG) is calculated by the following equation,
(3) Determine the comprehensive weights in the improved CRITIC-G2 method
To take into account the decision-makers’ intuitive understanding of the evaluation indices and the objective survey data that truly reflect the slope instability characteristics, the confidence interval of the observed values of Ck is denoted as [C1k, C2k], where k = 1, 2, …, m. Based on the ratio of the upper bounds to the lower bounds of the confidence interval of the improved CRITIC information, the interval of the ratio of the importance degrees of the two indices is calculated and then substituted into the rational judgement interval artificially given in the G2 method, namely
The assigned weight (WZ) of the kth evaluation index in the improved CRITIC-G2 interval is obtained by
The CRITIC method is adopted to reorder the evaluation indices of slope stability. After the reordering, relevant experts are invited to score the factor layer and the index layer with the score range of [0, 1]. Considering the experts’ inability to give an exact number, the probability of slope instability caused by each index is replaced by an interval number. According to the experts’ scoring interval, the improved G2 method based on the improved CRITIC is used to calculate the weight of each evaluation index. The risk attitude factor (ε) of the experts is known to be 0.25. The scores of each index at factor level and index level are substituted into Eq. (16). The results are shown in Tables 2 and 3, and the weight values of each evaluation index are obtained.
The weight order at the factor layer is ω1 > ω2 > ω3 > ω4. At the index layer, the weight orders are ω11 > ω12 > ω13 > ω14 > ω15 > ω19 > ω110 > ω111 > ω113 > ω112 > ω114 > ω16 > ω17 > ω18 for the indices of rock mass stractural characteristics, ω22 > ω21 > ω23 > ω24 for the indices of slope morphnolgy, ω32 > ω33 > ω34 > ω31 for the indices of environment conditions, and ω41 > ω42 for the inices of engineering conditions. Figure 3 shows the distributions of the index weights.

Factor and index weight distributions
4.4 Application example
To verify the feasibility of the comprehensive evaluation model based on the Poset theory for the stability evaluation of the open-pit slope, the east end slope at Yuanbaoshan Open-pit Coal Mine is taken as the research background. The slope height is 200 m. The slope angle is 20°. There is a weak bedding layer with a dip angle of about 12° in the slope. The cohesion is 21.5 kPa and the internal friction angle is 16.86°. There is a large normal fault at the east side, which is 35° away from the slope strike. The dip angle of the fault is 50°. The relative distance to the free face is 108 m. The rock mass has loose structure and poor integrity, which is considered as broken loose rock masses. The specific parameters are listed in Table 4.
4.5 Comparison relation matrix
Risk grade samples of slope stability are constructed. A1, A2, A3 and A4 are grade sets constructed according to the endpoint values of the risk grade interval, that is, A1 = (25, 25, 10, 0.25, 5, 1, 0.2, 0.2, 500, 25, 200, 30, 65, 0.2, 15, 100, 0.2, 0.2, 0.2, 20, 20, 3, 5 0.2), A2 = (25, 20, 10, 0.3, 10, 3, 0.4, 0.4, 500, 25, 200, 45, 55, 0.4, 30, 250, 0.4, 0.4, 0.4, 50, 40, 5, 15, 0.4), A3 = (10, 10, 5, 0.35, 15, 20, 0.6, 0.6, 300, 15, 140, 60, 45, 0.6, 45, 400, 0.6, 0.6, 0.6, 100, 100, 8, 25, 0.6), and A4 = (4, 5, 1, 0.5, 15, 20, 0.8, 0.8, 100, 10, 30, 90, 30, 0.8, 45, 400, 0.8, 0.8, 0.8, 100, 100, 12, 25, 0.8). The cohesion (weak layer), internal friction angle (weak layer), elastic modulus, Poisson’s ratio, dip angle of the down-dip weak layer, joint length, joint condition, filling condition, cohesion (fault), internal friction angle (fault), relative distance to the free face, included angle between strata strike and slope strike, dip angle of the down-dip fault, water transmissivity, slope angle, slope height, slope contour and slope section, maximum rainfall, in-slope groundwater or confined water head, seismic intensity, weathering degree, blasting particle vibration velocity and vehicle vibration intensity are used to constructed the sample to be evaluated (A5), and are inserted into the sample group of empirical data to participate in the ranking, as shown in Table 5. By integrating the experts’ experience, this method is able to improve subjectivity, balance subjective factors and objective factors, and reflect the importance of indices themselves and the data information of the indices (Lebanon and Lafferty 2002; Silan et al. 2021).
The evaluation index data is normalized based on Eqs. (5) and (6), hence, the sample data are all in the interval of [0, 1]. After data processing, the evaluation matrices of the four factors are adjusted in the order of index weights as follows:
Then, according to Eq. (2), the evaluation matrix of the evaluation index set of various factors is accumulated, and the cumulative transformation matrices containing the weights are obtained as follows,
If each value in the row of m − 1 is greater than or equal to the value at the corresponding position of the mth row, sxy = 1 is recorded; otherwise, sxy = 0 is recorded. As a result, the comparison relation matrices of the evaluation index sets of various factors are obtained, i.e.
The evaluation matrixes of the above 4 types of evaluation index sets are arranged in a descending order of weights and integrated into the evaluation matrix with comprehensive factors and indices as
The cumulative transformation matrix and comparison relation matrix containing weight information under comprehensive factors and indices can be obtained by repeating the operation steps under single factor,
4.6 Hasse matrix and Hasse diagram
There is a conversion relationship between the comparison relation matrix and the Hasse matrix. Equation (3) is adopted to convert the comparison relation matrix into the Hasse matrix:
According to the method in the literature (Yue et al. 2018), the Hasse matrix is used to draw the Hasse diagram of the poset, as shown in Fig. 4. The Hasse diagram can directly exhibit the ranking relationship among the samples. It is divided into different layer sets. Samples in the same layer set have their advantages and disadvantages, and it is difficult to tell them apart. As illustrated in Fig. 5, the samples inside the layer set can be sorted again by comparing the average height. Equation (5) is employed to calculate the average height (Carlsen and Bruggemann 2008; Li et al. 2018). Poset ranking involves the concept of linear expansion (Bruggemann and Annoni 2014). For a poset, if all possible linear extensions are found, it is possible to calculate the average height of the individual element. Comparison and order ranking are carried out according to the obtained height (Winkler 1982).

Hasse diagrams

Distributions of average height values
Through calculation, it is found that, as shown in Fig. 4a, the risk grade of A5 is laid between the samples A2 and A3 under the condition of rock mass structural characteristics. The ranking order is A1 > A2 > A5 > A3 > A4 and the average height values can be seen in Fig. 5a. Thus, the risk grade of A5 belongs to Grade II (generally stable). From Fig. 4b, under the condition of slope contour, the risk grade of A5 is worse than that of the sample A1 and better than that of the sample A3. The height values are presented in Fig. 5b, and the ranking order is A1 > A2 = A5 > A3 > A4, so the risk grade of A5 is Grade II (generally stable). The risk grade of A5 under the factor of environment conditions is between A2 and A3 (seen Fig. 4c), and the height values are shown in Fig. 5c. The ranking order is A1 > A2 > A5 > A3 > A4. Hence, the risk grade of A5 is Grade II (generally stable). As can be seen in Fig. 4d, the risk grade of A5 under the factor of engineering conditions is between A2 and A3 as well. The height values are presented in Fig. 5d. The ranking order is A1 > A2 > A5 > A3 > A4, so the risk grade of A5 is Grade II (generally stable). Under comprehensive factors, as illustrated in Fig. 4e, the risk grade of A5 lies between the samples A2 and A3. The height values are provided in Fig. 5e. The ranking order is A1 > A2 > A5 > A3 > A4, therefore, the risk grade of A5 is Grade II (generally stable).
To sum up, the risk grade of A5 is Grade II (generally stable) in the evaluation sets of various factors, and the structural characteristics of rock masses have the greatest impact on the slope stability, and the slope under the evaluation of comprehensive factors is generally stable (Grade II). As a result, considering the weight orders of all indices and the evaluation results of comprehensive factors, the slope is generally stable (Grade II). The evaluation result obtained by the poset evaluation method is consistent with the actual situation, indicating that the Poset theory is applicable to the evaluation of slope stability in open pit mines.
5 Conclusions
-
(1)
The poset evaluation method is applied to judge the stability of an open-pit slope. It is able to eliminate the influence of the variation of index weights on the judgment. The evaluation results show that after normalized processing of the evaluation index data under various factors, the importance of rock mass structural characteristics is in the first place. The grade samples A1, A2, A3 and A4 are constructed according to the endpoint values of the risk grade intervals. The comparison relation matrix is established with the evaluation index set A5. By using the conversion relation between the comparison relation matrix and the Hasse matrix, it is concluded that the risk grade of A5 lies between the samples A2 and A3, and the slope is in a generally stable state (Grade II) under the comprehensive evaluation of various factors, which is consistent with the actual situation of the engineering project and verifies the rationality and feasibility of the Poset theory.
-
(2)
The poset evaluation method can be used to classify and cluster the risk degree of an open-pit slope, which can accurately assess the slope stability and facilitate a rational slope design. Moreover, prevention and control measures can be determined according to the main factors affecting the slope stability so as to avoid landslides.
-
(3)
For the evaluation of the open-pit slope stability, 24 influencing factors are selected as the evaluation indices from four aspects, namely rock mass structural characteristics, slope contour, environment conditions and engineering conditions. However, owing to the fact that a great number of factors influence the slope stability, the integrity of the evaluation system needs to be further improved.
Data availability
All data generated or analysed during this study are included in this published article.
References
Bruggemann R, Annoni P (2014) Average heights in partially ordered sets. MATCH Commun Math Comput Chem 71:117–142
Brüggemann R, Patil GP (2011) Ranking and prioritization for multi-indicator systems: introduction to partial order applications. Springer
Carlsen L, Bruggemann R (2008) Accumulating partial order ranking. Environ Model Softw 23(8):986–993. https://doi.org/10.1016/j.envsoft.2007.12.001
Chang J, Song S, Feng H (2016) Analysis of loess slope stability considering cracking and shear failures. J Fail Anal Prev 16(6):982–989. https://doi.org/10.1007/s11668-016-0174-2
Chen C, Yang Y (2005) Fuzzy reasoning system driven by HGA-ANN for estimation of slope stability. Chin J Rock Mech Eng 24(19):3459–3464
Chen G, Lu Y, Cheng S-G (2008) Principal Component analysis of influencing Factors of slope stability. Metal Mine 04:123–125+154
Chen J, Wang J, Yue L (2019) Evaluation model on possibility of coal spontaneous combustion in goaf based on partially ordered set. Journal of Safety Science and Technology 15(2):89–93
Chen X, Zeng Y, Liu W et al (2019) Research on classification of rock mass basic quality based onfuzzy comprehensive evaluation method. J Wuhan Univ (eng Edn) 52(06):511–522. https://doi.org/10.14188/j.1671-8844.2019-06-006
Deng D, Li L (2012) Analysis of slop stability and research of calculation method under horizontal slice method. Rock Soil Mech 33(10):3179–3188. https://doi.org/10.16285/j.rsm.2012.10.020
Fan Y (2003) An analytic method about Hasse chart. J Shanghai Polytech Univ 01:17–22. https://doi.org/10.19570/j.cnki.jsspu.2003.01.003
Fang Q, Shang L (2019) Analysis of the rock slope stability for the open-pit mine based on the game theory and the cloud model. J Saf Environ 19(01):8–13. https://doi.org/10.13637/j.issn.1009-6094.2019.01.002
He Y, Sun S (2014) Comprehensive evaluation of slope stability based on matter element and extension model. Saf Coal Mines 45(03):206–208. https://doi.org/10.13347/j.cnki.mkaq.2014.03.061
He Y, Li Q, Zhang N et al (2019) Application of RBF neural network reliability analysis method in slope stability research. J Saf Sci Technol 15(7):130–136
Hong B, Luo S, Hu S et al (2019) Calculation of critical liquid injection range in full clad ion-absorbed rare earth mine. Chin J Nonferrous Metals 29(7):1509–1518. https://doi.org/10.19476/j.ysxb.1004.0609.2019.07.19
Huang S, Chen Z, Zheng D (2020) Sensitivity analysis of factors influencing slope stability based on grey correlation and strength reduction method. Chin J Geol Hazard Control 31(03):35–40. https://doi.org/10.16031/j.cnki.issn.1003-8035.2020.03.05
Jena R, Pradhan B (2020) Integrated ANN-cross-validation and AHP-TOPSIS model to improve earthquake risk assessment. Int J Disaster Risk Reduct 50:101723. https://doi.org/10.1016/j.ijdrr.2020.101723
Jia B, Cheng Y, Chen J, Wang Z, Bai X (2021) Study on spontaneous combustion risk of coal based on poset evaluation model. J Saf Environ 21(03):977–983. https://doi.org/10.13637/j.issn.1009-6094.2019.1448
Jiang L (2022) Research on stability prevention and control of south slope in Shengli East No. 2 Open-pit Coal Mine. Opencast Min Technol 37(2):88–90. https://doi.org/10.13235/j.cnki.ltcm.2022.02.024
Ju X, Li L (2009) Study on treatment measures of landslide area at the west end-slope of Baorixile Open-pit Mine. Opencast Min Technols 121(05):17–19
Juqian Z, Chuan T (1995) Application of fuzzy evaluation model in slope stability evaluation. J Nat Disasters 03:73–82
Lebanon G, Lafferty J (2002) Conditional models on the ranking Poset. Adv Neural Inf Process Syst 2003:15. https://doi.org/10.5555/2968618.2968672
Li C, Jiang QH, Zhou CB et al (2011) Research on early warning criterion of landslides using case-based reasoning. Rock Soil Mech 32(4):1069–1076. https://doi.org/10.16285/j.rsm.2011.04.009
Li M, Yue L, Jin S (2018) Method of applying relation matrix to express the average height of posets. J Liaoning Tech Univ (nat Sci) 37(1):216–220. https://doi.org/10.11956/j.issn.1008-0562.2018.01.038
Li X, Jiang C, Xu R et al (2021) Combining forecast of landslide displacement based on chaos theory. Arab J Geosci 14(3):202. https://doi.org/10.1007/S12517-021-06514-8
Lidie WANG, Kepeng HOU, Huafen SUN et al (2021) Evaluation of slope stability theory-variable weight based on improved game extension model. Nonferrous Met Eng 11(9):100–106
Nabila H, Mohammed IK, Samir B (2021) Learner modeling in educational games based on fuzzy logic and gameplay data. Int J Game Based Learn IJGBL 11(2):38–39. https://doi.org/10.4018/IJGBL.2021040103
Pan Q, Qu X, Wang X (2019) Probabilistic seismic stability of three-dimensional slopes by pseudo-dynamic approach. J Cent S Univ. https://doi.org/10.1007/s11771-019-4125-4
Qin J, Du S, Ye J et al (2022) SVNN-ANFIS approach for stability evaluation of open-pit mine slopes. Expert Syst Appl 198:116816. https://doi.org/10.1016/j.eswa.2022.116816
Ren S (2017) Evaluation model for slop stability and its application. Road Mach Constr Mech 34(03):118–122
Silan M, Boccuzzo G, Arpino B (2021) Matching on poset-based average rank for multiple treatments to compare many unbalanced groups. Stat Med 40(28):6443–6458. https://doi.org/10.1002/sim.9192
Sun Z, Shu X, Dias D (2019) Stability analysis for nonhomogeneous slopes subjected to water drawdown. J Cent S Univ 26(7):1719–1734. https://doi.org/10.1007/s11771-019-4128-1
Tian M (2016) Dam safety evaluation cloud model based on game theory and its application. Hydropower Energy Sci 34(3):94–97
Wang D (2011) Study on movement rule and stability analysis of counter-tilt slope under combined surface and underground mining. Liaoning Technical University
Wang K, Xu F (2011) Slope stability evaluation based on PSO-PP. Appl Mech Mater 580–583:486–489. https://doi.org/10.4028/www.scientific.net/AMM.580-583.486
Wang J, Hu B, Li J et al (2021) Slope stability evaluation and application of open-pit mine based on uncertainty measurement theory. Chin J Nonferrous Met 31(5):1388–1394
Wei W, Jia B, Qi Y (2019) Prediction model of spontaneous combustion risk of extraction drilling based on improved CRITIC modified G2-TOPSIS method and its application. China Saf Sci J 29(11):26. https://doi.org/10.16265/j.cnki.issn1003-3033.2019.11.005
Winkler P (1982) Average height in a partially ordered set. Discrete Math 39(3):337–341. https://doi.org/10.1016/0012-365X(82)90157-1
Yan D, Chi G, He Y (2010) Study on index weighting method based on improved group-G2. J Syst Eng 25(4):540–546
Yang Y, Zhu Y, Zhao X (2020) Portfolio research based on mean-realized variance-CVaR and random matrix theory under high-frequency data. J Financ Risk Manag 9(04):480. https://doi.org/10.4236/jfrm.2020.94026
Yongxing Z (2008) Slope engineering. China Building and Construction Press, Beijing
Yuan Y, Li J (2021) A cusp catastrophe theory model for evaluation of rock slope stability. Geol Explor 57(1):183–189
Yuan JW, Wang K, Jiang XG (2013) Prediction of gas emission quantity based on least square support vector machine. Adv Mater Res 619:572–576. https://doi.org/10.4028/www.scientific.net/AMR.619.572
Yue L, Zhijie Z, Yan Y (2018) Multi criteria decision making method of Poset with weight. Oper Res Manag Sci 27(2):26. https://doi.org/10.12005/orms.2018.0031
Zhang T, Zeng P, Li T et al (2020) System reliability analyses of slopes based on active-learning radial basis function. Rock Soil Mech 41(09):3098–3108. https://doi.org/10.16285/j.rsm.2019.1695
Zhang L, Bai J, Hou R et al (2021) Application research of reliability theory in slope engineering. J Hubei Univ Technol 36(01):94–99
Zhang C, Chen J, Wu X et al (2022) Poset-based risk identification method for rockburst-induced coal and gas outburst. Process Saf Environ Prot 168:872–882. https://doi.org/10.1016/j.psep.2022.10.059
Zhao B (2022) A combinatorial weighted game theory Yunde element model for slope stability evaluation. Min Res Dev 42(06):60–67. https://doi.org/10.13827/j.cnki.kyyk.2022.06.025
Zhiguo L, Bo H, Wengang Y (2020) Reliability prediction for factory casualty using grey system theory. Int J Perform Eng 16(6):25. https://doi.org/10.23940/ijpe.20.06.p5.866874
Zhu Z, Zhang G, Zhang J (2018) Modified-G2 weighting method based on improved CRITIC and its solid evidence. Stat Decis 34(18):33–38. https://doi.org/10.13546/j.cnki.tjyjc.2018.18.007
Zou G, Wei R (2006) Study of theory and method for numerical solution of general limit equilibrium method. Chin J Rock Mech Eng 25(2):363–370
Funding
This study was funded by the National Natural Science Foundation of China (52204135, 52204136); Natural Science Foundation of Liaoning Province (2022-BS-327). The authors are very grateful to the financial contribution and convey their appreciation for supporting this basic research.
Author information
Authors and Affiliations
Contributions
JJ: conceptualization, methodology, analysis and writing-review; JS: conceptualization, writing-review, editing and revision; DW and LW: Visualization, Investigation, Resources, Supervision; LC and MC: performed resource acquisition, supervision, investigation and validation.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
The authors confirms that the described work has not been published before, and its publication has been approved by all co-authors.
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jiang, J., Sun, J., Wang, D. et al. An evaluation method of open-pit slope stability based on Poset theory. Geomech. Geophys. Geo-energ. Geo-resour. 10, 11 (2024). https://doi.org/10.1007/s40948-023-00708-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40948-023-00708-y