
Abstract
The economic implications of high-speed rail (HSR) cannot be overlooked in China. This paper studies the impact of HSR on the advancement and rationalization of industrial structure and the tertiary industry aggregation through theoretical derivation and multi-period difference-in-differences (DID) by improving the theoretical framework and empirical methods according to the characteristics of China's HSR and economic development. From analyses on urban heterogeneity and inter-industry spillover effects, the transmission mechanism and expressions of the industrial structure are also discussed. The findings show that HSR promotes tertiary industry aggregation and contributes to the transformation of the industrial structure from the primary to secondary and tertiary industry sectors, as well as realizing industrial structure advancement but irrationalization. Furthermore, HSR has a more significant influence on tertiary industry aggregation in large cities and high-density cities. Additionally, the aggregation of the transportation, warehousing, and postal sectors has been reduced, with a significant spillover effect on neighboring cities, proving the siphon effect and conduction mechanism, resulting in a structural shift in the tertiary industry, from basic to advanced sectors. The movement of human resources is a key mediator in the economic impact of HSR.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
With a total length of 37,900 kilometers in 2020, high-speed railways (HSR) can be found in more than 80% of China's cities. Since the opening of high-speed rail in China in 2008, the economy of the regions along the line has developed rapidly. Represented by Beijing-Guangzhou and Beijing-shanghai, as shown in Fig. 1 and Fig. 2, provinces along the Beijing-Shanghai and Beijing-Guangzhou HSR routes overlapped with provinces with high GDP in 2021, with the tertiary industry accounting for more than half of GDP. Spiekerman (1994) found that the space-time distance is compressed after the opening of HSR [1]. However, the HSR's impact on the economy is not always positive. This might result in a siphon effect, suffocating the development of small and medium-sized cities [2]. The Beijing–Shanghai HSR, for example, establishes a 1-hour shuttle between Beijing, Tianjin, and Hebei, while simultaneously enabling Beijing to absorb Tianjin and Hebei's vast resources. Without a doubt, HSR's economic effect is significant, but how does HSR transform the industrial structure? What sectors will be affected as a result of this? Is HSR going to have a siphon effect? Theoretical and empirical studies are needed to better investigate these concerns.

GDP of provinces in China in 2021

Proportion of tertiary industry of provinces in China in 2021
With the advancement of modern transportation networks, more papers on the effect of transportation infrastructure on economic growth [3,4,5]. Since China's HSR launched late, related study on China has gradually gained significance until recent years. The summary of the literature on HSR’ impact on economic growth is shown in Appendix A. In reality, China's HSR development and policy differ from those of other countries, and there is a knowledge gap that applies to China's HSR. Few analyses of China's HSR system take into consideration industry heterogeneity, which is the focus of research on industrial structure issues. Chandra and Thompson [6] found that certain industries profit from US interstates because of lower transportation costs, while others have migrated as a result of economic activity [6]. Holl [7] studied the effects of road investment and the aggregation effect on enterprises in 13 industrial and 9 service sectors in Portugal, and found significant differences across industries [7]. Western research material and methodologies about economic effects of HSR are numerous since it was the first to realize the industrial revolution [8,9,10]. Chen and Silva [11], Ahlfeldt and Feddersen [12], Chen and Haynes [13], Guirao et al. [14], Guirao et al. [15], Cascetta et al. [16] studied the impact of HSR’s opening in Spain, German, China, France and Italy, and the positive impact is acknowledged. The recent papers on the economic consequences of HSR concentrate on individual industries and production factors including regional labor mobility, economic development, and urbanization [17,18,19,20]. Zheng et al. [21] and Pan et al. [22] measured the spatial spillover effect of HSR stations in China, and found that HSR spur the agglomeration of various economic activities from being near and far from the station. About empirical methods, DID (Differences-in-Differences) model is used widely. Wang et al. [23] used anti-gravity and gravity bias models to study how the urban structure of the Yangtze River Delta evolved after the opening of the HSR. Liu et al. [24] used a time-varying DID model to study the spatial integration and industrial development of the Yangtze River Economic Belt, and explained the relationship between the spatial integration of urban aggregations and the characteristics of industrial development after the opening of the HSR. Liang et al. [25] and Wang et al. [28] used the PSM-DID model to analyze the economic development along the HSR line based on the panel data of prefecture-level cities. Li et al. [26] used synthetic control methods (SCM) to investigate the economic effect of HSR, and the results show that the economic effect of HSR had strong disparity [26]. Li et al. [27] used both the DID model and threshold regression and found that the opening of HSR had a significant threshold effect on improving the efficiency of the service sector [27]. Meng et al. [29] constructs an HSR operation network (HSRON) model to study the impact of network position (NP) on service industry agglomeration (SIA) by employing complex network analysis and panel regression methods [29]. Melo et al. [30] discovered that estimates of transportation infrastructure's productivity impact differed by major industry groups, with estimates for the US economy averaging higher than estimates for European countries, and estimates for highways averaging higher than estimates for other modes of transportation [30]. In the empirical analysis on HSR in China, there have been few papers focus on the quantification of transportation costs. It becomes clear that a well-established theoretical framework for analyzing the impact of HSR in China is desperately required. This paper is devoted to a more in-depth assessment of conditions based on previous research.
The contribution of this paper is to improve the theoretical and empirical framework regarding the economic impact of HSR in China on the basis of previous papers. On the one hand, the mathematical economic geography theory of the impact of the opening of the HSR on the industrial structure was proposed, which comprehensively complemented the hypotheses on the economic effects of HSR. The empirical analysis, on the other hand, was in line with the reality in China. In contrast to other studies, we chose appropriate control and treatment groups to avoid cross-influence of lines within the area. In addition to verifying the hypotheses, the mechanism and heterogeneity of HSR on the industrial structure were explored, revealing the manifestations of economic transformation in China.
The remainder of this paper is structured as follows. Section 2 presents the theoretical framework. Section 3 describes the data set. Our empirical results are presented in Sect. 4. Our main conclusions are then summarized in Sect. 5.
2 Theoretical and Analytical Framework
The enhancement of accessibility is a direct result of the opening of HSR [10, 31]. In addition to decreasing distances in time and space, the HSR indirectly increases the flow of factors such as labor, social capital, and technology, thereby reshaping the market structure [1, 5]. Moreover, the opening of HSR facilitates the establishment of economies of scale, which further alters market competition patterns, as seen by the clustering of urban tertiary sectors and the expansion of cities not on the route [8, 32]. The rationality of the industrial structure will be influenced by the advancement of the industrial structure [14]. As the cycle progresses, the advantageous industries will cluster, and the industrial structure will shift as well, both of which are manifestations of indirect impacts. The impact of the introduction of HSR on the industrial structure is seen in Fig. 3.

The direct and indirect effect of the opening of HSR on the industrial structure
The theories and hypotheses proposed in this paper for the impact of HSR on the industrial structure are built using the core–periphery concept. Footnote 1 Area A and area B are the two economic zones. Assume there are no costs or restrictions to labor mobility in both places; consumers are rational, and they consume tradable product x and product y to maximize their utility with wages.
where \(0<\mu <1<\sigma\), \({C}_{Ax}\) is the product \(x\) consumed in area \(A\), \({C}_{Ay}\) is the product \(y\) consumed in area \(A\). \({P}_{Ax}\) and \({P}_{Ay}\) are the corresponding prices, following the form of the D-S model. \({C}_{Ax}\) is expressed by constant elasticity of substitution (CES). \({W}_{A}\) is a consumer's income in area \(A\). If consumer indifference curves are continuous, then:
where \({p}_{i}\) is the price of the \(i\)-th product. After optimization, the indirect utility function is:
where \(\mu\) is the payment’s share for the \(i\)-th product. With the optimization conditions of suppliers, we define \({W}_{B}\) to be the income of consumers in area \(B\), and \({s}_{n}\) to be the proportion of product \(x\) in area \(A\) among all product \(x\) (\({S}_{n}={n}_{i}/n\) where \(n\) is the total of \(x\)). This paper introduces the theory of “iceberg transportation cost” proposed by Samuelson, which holds that there is a cost, represented by \(T\), and only \(1/T (1/T<1)\) of products can be reached in the process of transporting products from area \(A\) to area \(B\). Then, (4) can be transformed into the following:
where \(\sigma\) is the elasticity of substitution, and \(T\) is the product’s transportation cost between area \(A\) and area \(B\). Substituting (6) into (5), we get:
where \(\alpha =\mu /(\sigma -1)\), similarly, we get:
The “accessibility” between locations has improved after the opening of the HSR. Assume \(T={e}^{\tau \times t(H)}\), where \(H\) is a dummy variable for whether \(HSR\) is opened, \(\tau\) is time attenuation, and \(t\) is the average travel time from area \(A\) to area \(B\) after the opening of \(\mathrm{HSR}\). According to the location selection of the long-term equilibrium, the comparative utility function is as follows:
Note \({({e}^{\tau \times t(H)})}^{\alpha \sigma -\alpha }=\lambda\). If we substitute the bivariable Taylor series expansion of \(\frac{{s}_{n}}{1-{s}_{n}}\) , \(\frac{{W}_{A}}{{W}_{B}}\) and \(\mathit{ln}[1-\frac{\alpha }{\lambda }(1-{\lambda }^{2})\frac{{s}_{n}}{1-{s}_{n}}]\) into (9) and take the logarithm, we get:
The consumer utilities in two areas are equal in the long-term equilibrium, that is:
Note \(\frac{{S}_{n}}{{1-S}_{n}}=S\), then we get:
\(\frac{\partial S}{\partial H}\) is the impact of \(HSR\) on the industrial structure. Take the derivative of (12) with respect to \(H\):
It can be concluded that \(0<\frac{\partial \lambda }{\partial H}<1\). \(\frac{\partial S}{\partial H}\) can be determined by (13).
If \(\frac{\partial S}{\partial H}>0\), the behavior is “aggregation,” but if \(\frac{\partial S}{\partial H}<0\) then behaves as “dispersion.” Calculate the second derivative of (12) as follows:
It is not difficult to determine that \(\frac{-4\lambda ({\lambda }^{2}-1-\mathit{ln}\lambda -{\lambda }^{2}\mathit{ln}\lambda )}{({\lambda }^{2}-1{)}^{3}}\) and \(\frac{2\lambda -2\lambda \mathit{ln}\lambda -\lambda -1/\lambda }{({\lambda }^{2}-1{)}^{2}}\) are always negative within the domain. Next, we conclude the following:
(1) \([\mathit{ln}\frac{{W}_{A}}{{W}_{B}}+(1-\mu )\mathit{ln}\frac{{P}_{Ay}}{{P}_{By}}]>0\), then \(\frac{{\partial }^{2}S}{\partial {H}^{2}}<0, \forall \lambda \in (\mathrm{0,1})\) and \(\frac{\partial S}{\partial H}>0, \forall \lambda \in (\mathrm{0,1})\). Fig. 4a shows that the opening of the HSR can boost the number of industries, but the pace of growth will slow at the periphery.

Forms of industrial aggregation and diffusion of HSR
(2) \([\mathit{ln}\frac{{W}_{A}}{{W}_{B}}+(1-\mu )\mathit{ln}\frac{{P}_{Ay}}{{P}_{By}}]\le 0\). Fig. 4b shows \(\frac{{\partial }^{2}S}{\partial {H}^{2}}<0\) at the beginning, \(\frac{{\partial }^{2}S}{\partial {H}^{2}}>0\) at the end, and only one zero point. There are two possible situations. Within the domain, \(\partial S/\partial H>0\) is identical. The HSR is always in an “aggregating state” when it is opened; the pace of aggregation, however, varies. (2) \(\partial S/\partial H>0\) is observed. The aggregation effect of the HSR improves with time until it reaches its peak. The dispersion effect comes later, forcing suppliers with lower competitiveness to migrate to the outskirts. Finally, industries pool their resources to establish higher-quality tertiary industrial conglomerates.
The following hypotheses are proposed according to the derivation:
Hypothesis I:
Once the HSR opens, the number of tertiary industry businesses will increase and higher-grade industries will continue to aggregate. In the short term, it encourages tertiary industry aggregation in cities along the route, but in the long run, the aggregation is dependent on the initial circumstances.
Hypothesis II:
Once the HSR opens, the industrial structure advances steadily, resulting in a structural shift in the tertiary industry, from basic to advanced sectors.
3 Data
3.1 Objects
This paper chooses Beijing–Shanghai and Beijing–Guangzhou HSR as the objects (see Appendix B for details). On the one hand, they are being built at an early stage. The Beijing–Shanghai HSR is China's first dedicated long-distance passenger route, and it goes through some of China's most densely inhabited and economically developed districts. The Beijing–Guangzhou HSR is a watershed moment in China's HSR development and the world's longest HSR. Their construction, on the other hand, is rather quick, which helps to eliminate cross-effects caused by other factors. The Beijing–Shanghai and Beijing–Guangzhou HSR run through a total of 131 prefecture-level cities and municipalities. We omitted cities with other HSR lines passing through, prefecture-level cities that were demoted and divided during the sample period, such as Chaohu, cities with poor accessible data, such as Enshi and Shennongjia forest area, and so on in order to obtain unbiased estimates. The control group consists of 40 cities, with a total of 82 prefecture-level cities as samples.
3.2 Variables
3.2.1 Dependent Variable
The dependent variables are the location entropy of the tertiary industry (\(\mathrm{LQ}\_\mathrm{ third}\)), the rationalization of industrial structure (\(\mathrm{SR}\)) and the advancement of industrial structure (\(\mathrm{SA}\)). Location entropy is a commonly used index to measure the distribution of elements, and the location entropy of industry \(i\) in area \(j\) in the country \(({\mathrm{LQ}}_{ij})\) is as follows:
where \({q}_{ij}\) is the indicator of industry \(i\) in area \(j\), \(q\) is the indicator of all industries in the country; \({q}_{j}\) is the indicator of all industries in area \(j\); \({q}_{i}\) is the indicator of industry \(i\) in the country. The larger the \({LQ}_{ij}\) value, the higher the aggregation degree of the tertiary industry, implying that industry \(i\) has a competitive advantage in area \(j\).
The advancement of the industrial structure (\(\mathrm{SA}\)) is affected by multiple factors, and its definition is currently neither standard nor rigid. We generated an index to quantify \(SA\) using the molar structure change value calculation technique. A set of three-dimensional vectors \({X}_{0}=({x}_{\mathrm{1,0}},{x}_{\mathrm{2,0}},{x}_{\mathrm{3,0}})\) is constructed using the share of three industries in GDP as the spatial vector. The angles between \({X}_{0}\) and \({X}_{1}=(\mathrm{1,0},0)\), \({X}_{0}\) and \({X}_{2}=(\mathrm{0,1},0)\), \({X}_{0}\) and \({X}_{3}=(\mathrm{0,0},1)\) are, respectively, \({\theta }_{1}\), \({\theta }_{2}\) and \({\theta }_{3}\).
\(SA\) is thus defined as follows:
The rationalization of the industrial structure \((\mathrm{SR})\) measures whether the proportion of industries is appropriate. The following is a regularly used measuring form for assigning weights to the significance of each of the three industries:
where \(\mathrm{GDP}\) is the city's gross product, \({GDP}_{i}/{L}_{i}\) is labor productivity, \({GDP}_{i}/GDP\) is the output structure, and \({L}_{i}/L\) is the industry structure. Primary, secondary, and tertiary industries are represented by \(i=\mathrm{1,2},3\). The industrial structure deviation is \(0\) when the output structure matches the employment structure, which is the most appropriate situation. It should be noted that the lower this ratio is, the more the industrial structure has been rationalized.
3.2.2 Independent Variable
The treatment group (\({treated}_{c}\), set to \(1\)) is cities along the HSR, whereas the control group (\({controlled}_{c}\), set to \(0\)) is cities outside the HSR. There is also a time dummy variable, which is \(0\) before the HSR's opening or 1 after the HSR's opening. The core independent variable \({HSR}_{i}\) is the interaction term of the product of the aforementioned two. The Beijing–Shanghai HSR was opened in 2011, with data from 2001 to 2010 as pre-opening data, and data from 2011 to 2017 as post-opening data. The Beijing–Wuhan segment of the Beijing–Guangzhou HSR opened in 2012, while the Wuhan-Guangzhou section opened in 2009. The Beijing–Guangzhou HSR is valued in the same manner. The particular expression is as follows:
where \({Z}_{i}\) denotes the city-level fixed effects that do not change over time, \({X}_{it}\) are the time-varying control variables, and \({\varepsilon }_{it}\) is the residual term. The difference induced by \(HSR\) is represented by \({\beta }_{1}\), and the difference between cities is represented by \({\beta }_{2}\).
4 Summary Statistics
Openness (\(lfdi\)), Economy (\(lgdp\_average\)), Wage (\(lwage\_average\)), Government interference (\(lfee\)), Human capital (\(lhuman\_capital\)), Informatization (\(ltele\_pop\), Transportation (\(lroad\_average\)) and Infrastructure (\(lbooks\_average\) and \(lhospital\_num\)) are the control variables. The sample period is 2003–2017, and the data come from the China City Statistical Yearbook and the China Statistical Yearbook. We use the logarithm of the data throughout the paper and provide the summary descriptive statistics in Table 1. Obviously, with the opening of the HSR, the location entropy of the tertiary industry and the advancement and rationalization of industrial structure are greater, and more empirical study is necessary.
5 Empirical Strategy
5.1 Time-Varying DID Regression
5.1.1 Parallel Trend Test
The parallel trend test, as described by Shao [17], is used to determine whether trends in the treatment and control groups are consistent:
where \(t\) is the first HSR year of operation. The year before the opening is \(m (m=\mathrm{1,2},3)\), while the year following is \(n (n=\mathrm{0,1},\mathrm{2,3},\mathrm{4,5})\). \(FirstHS{R}_{i,t}\), \(FirstHS{R}_{i,t-m}\), \(FirstHS{R}_{i,t+n}\) are dummy variables that return \(1\) if city \(i\) 's HSR is operational in the specified year. The initial 4 years \((year=-4,-3,-2,-1)\) and the latter 4 years \((year=\mathrm{5,6},\mathrm{7,8})\) x are both significant, as shown in Fig. 5. As a result, the opening of HSR has a large delayed impact on the aggregation of tertiary industries, and this conclusion is consistent with Shao [17]. And before \(year=4\), \({\beta }_{m}\) increases year by year, which can be explained by the fact that the corporation made strategic planning after getting the news ahead of time [5, 33]. It may be inferred that there is no significant difference in trend between the treatment and control groups before HSR’s opening. By repeating the steps, it is confirmed that both industrial structure advancement and rationalization satisfy the hypothesis of a parallel trend.

The parallel trend test of \({\varvec{L}}{\varvec{Q}}\_{\varvec{t}}{\varvec{h}}{\varvec{i}}{\varvec{r}}{\varvec{d}}\)
5.1.2 Baseline Regression
The opening of \(HSR\) can be regarded as a quasi-natural experiment.Footnote 2Footnote 3 Multi-period DID is used as the identification model, in the form:
where \(du\) is the entity fixed effect. \(dt\) is the time fixed effect. \({\delta }_{1}\) is the coefficient of double differences, which is also the value of interest in this paper. The coefficients of \(HSR\) remain significant and positive when control variables from models (1) to (6) are included in Table 2. Specifically, ceteris paribus, \(LQ\_third\) and \(SA\) increased by 0.029 and 0.021 respectively after \(HSR\) opened. This supports Hypothesis I and Hypothesis II of this paper, namely, that the \(HSR\) has a significant positive impact on tertiary industry aggregation and industrial structure advancement. The deviation from equilibrium in industrial structure is shown by the significant positive coefficient of \(SR\). The findings also show that the opening of the \(HSR\) causes an imbalance in the local industrial structure and a lack of coordination in resource allocation. Wang (2019) studied the Yangtze River Delta region and discovered that HSR boosted the proportion of tertiary industry added value and improved the quality of urbanization by stimulating industrial structure upgrading [21]. Liang (2020) performed research on the Guangdong–Guangxi–Guizhou HSR and discovered that by altering the industrial structure of the area, the HSR may promote the development of undeveloped regions [25]. Wang (2019) and Liang (2020) came to similar conclusions as this paper's findings.
5.2 Robustness Test
5.2.1 Changes in the Sample
The robustness test includes sample change, instrumental variables, and a placebo test. The changes in the sample come from adjusting the period scope [Model (1) to (3)] and excluding provincial capitals and municipalities [Model (4) to (6)]. The \(HSR\) coefficients remain significantly positive in Table 3, except for model (5)Footnote 4. Model (5)'s insignificance might be due to endogenous recognition across cities, and a heterogeneous effect will be discussed later. As a result, the positive effect of \(HSR\) is consistent across samples, and the conclusion in this paper is robust.
5.2.2 Instrumental Variables (IV)
To test for endogeneity owing to omitted variables, instrumental variables (IV) was used in this paper. The IV of transportation infrastructure commonly mentioned in previous papers are landslides, geographic slope, ancient postal services and historical passenger traffic, historical planning information, and so on [34,35,36]. Referred to Dong [18], this paper uses China's historical railway network in 1961 as the IV of the opening of the HSR. The Beijing–Shanghai and Beijing–Guangzhou HSR construction is based on the railways constructed in 1961, and railways built in 1961 have no direct impact on the present industrial structure. Exogeneity and correlation are both satisfied using the railway network in 1961 as IV. The results in Table 4 show that the significant effect of \(HSR\) on \(SH\) is \(0.0822\), which is consistent with the baseline regression in Table 2. The correlation between instrumental and explanatory variables is also verified (\(old\_railway\) on \(HSR\) is \(0.2198\)), and the assumption of weak instrumental variables was rejected (\(F-\mathrm{Statistic }> 10\)).
5.2.3 Placebo Test
To ensure that the results are not the result of chance or randomness, a placebo test is utilized, in which the treatment group is generated at random. The estimated coefficient of interaction in (22) is as follows:
where \(z\) is the control variables. When \(\gamma =0\), the estimator \({\widehat{\beta }}_{1}\) is unbiased. If \({treated}_{c}\times {time}_{t}\) is replaced by other variables that do not affect explained variables (\({\beta }_{1}=0\)), and \({\widehat{\beta }}_{1}=0\) is obtained by estimation, then \(\gamma =0\) can be realized. Following this line of reasoning, we make the event of the opening of \(HSR\) random, so it has no effect on \({LQ\_third}_{ct}\), \({SA}_{ct}\) and \({SR}_{ct}\), i.e., \({\beta }^{random}=0\). The distribution of \({\widehat{\beta }}^{random}\) is obtained by repeating the above preceding technique as shown in Fig. 6, and t-statistics are distributed U-shaped, with peaks around zero.

Placebo test of LQ_third, SA and SR
5.3 Heterogeneity Test
5.3.1 Socioeconomic Characteristics Among Cities
The effect of HSR is varied across different regions due to differences in endowment [37,38,39]. This paper takes 3 million people and 0.5 million people per square kilometer as the classification for city size and population density, respectively. Footnote 5 Table 5 shows that the economic effects of metropolises and cities with low population density are statistically more significant than those of other cities, implying a link between socioeconomic characteristics and the impact of \(HSR\) on the industrial structure. This is to be expected, since megacities and cities with low population density have better market conditions and a greater effect on factor flows, making them more likely to achieve industrialization and structural upgrading.
5.3.2 Spillover and Aggregation Effects Across Industries
The spatial weight matrix is used to determine the spatial correlation by whether two economic units are geographically located adjacent to each other. With the modernization of transportation infrastructure, this paper uses the queen adjacency matrix to generate an 82*82 adjacency matrix (\({w}_{ij}\)). The spatial matrix and Moran's I are expressed as follows:
where \({x}_{i}\) is the value of unit \(i\), \({x}_{j}\) is the value of unit \(j\), \({x}_{m}\) is the average value of the grid cells in the area, \(n\) is the total number of cell grids, and \({W}_{ij}\) is the spatial weight matrix. Z (Moran's I) is used to test the significance of Moran's I, and the null hypothesis is that there is no spatial autocorrelation.
Moran's I was calculated for 18 subsectors except for agriculture, forestry, animal husbandry, and fishery, and the results and Industry Classification Standard are shown in. Despite the fact that the majority of the \(L{Q}_{X}\) in the sample is not statistically significant at the 1% level each year, the spatial correlation is still worth researching given the delayed impact of the \(HSR\) opening seen in Fig. 5. Footnote 6 According to the results of the spatial autocorrelation test, this paper obtains the spatially relevant industries as follows: mining \((L{Q}_{2})\), electricity, gas, and water production and supply \((L{Q}_{4})\), transportation warehousing and postal \((L{Q}_{7})\), accommodation and catering \((L{Q}_{8})\), financial \((L{Q}_{10})\), real estate \((L{Q}_{11})\), scientific research and technical services \((L{Q}_{13})\), education \((L{Q}_{16})\), health and social security \((L{Q}_{17})\) and public management and social organizations \((L{Q}_{19})\).
Spatial lag models (SAR), spatial error models (SEM), and spatial Durbin models (SDM) are examples of spatial econometric models. SAR and SEM assume spatial autocorrelation between dependent variables and error terms, respectively, whereas SDM considers both. To obtain SAR and SEM, the Kronecker product is employed to integrate the spatial matrix across time. The following are their expressions:
Spatial lag model (SAR):
Spatial error model (SEM):
Spatial Durbin model (SDM):
where \({\beta }_{0}\) is a constant, \(\beta\) is the matrix of the variable coefficients, \(X\) is the matrix of the independent variables, and \({W}_{ij}\) is the weight matrix. \(\rho\) is the spatial autoregressive coefficient, \(\lambda\) is the spatial autocorrelation coefficient, and \(\theta\) is the spatial spillover effect. \({\alpha }_{i}\) and \({\gamma }_{t}\) are used to measure spatial fixed effects and time fixed effects, respectively. \({\varepsilon }_{it}\) is the error term that is subject to normal distribution. This paper uses the approach described by Pace (2009) to separate the estimation of direct and indirect effects from SAR and SDM [40], and it takes the following form:
The partial derivatives with regard to the \({k}^{th}\) independent variable are as follows from area \(1\) to area \(N\):
where \({w}_{ij}\) is the element \((i,j)\) of the matrix \({W}_{ij}\). The direct effect is the average of the sum of the diagonal elements of the matrix (32). The indirect effect is the average of the sum of all row and column elements of the non-diagonal elements, which is also the spillover effect. The spatial panel models are estimated by maximum likelihood estimation (MLE) to avoid biased estimators. When LM-err is significant, the criterion for deciding the optimal spatial model is SEM, and when LM-lag is significant, SAR. The robustness of LM-err and LM-lag are compared if they are both substantial. The results are shown in the Tables 14 to 16 in Appendix D, indicating that SDM is the model with the best explanatory power. The aggregation of the transportation, warehousing, and postal sectors is significantly reduced as a consequence of the HSR's opening, as can be seen in Table 6, and they have a significant spillover impact on neighboring cities. Because HSR boosts urban housing costs, relatively low-end transportation and warehousing in the tertiary sector will be shifted to distant locations, with nearby cities being suitable places to accept them, leading to an increase in the industrial aggregation of these industries. This phenomenon is called the siphon effect [2]. Furthermore, since the opening of HSR, there has been a structural shift in the tertiary industry, from basic to advanced sectors. By analyzing the heterogeneity of HSR in the industrial structure from the effects of HSR on the industry, HSR has an overall positive effect on most sectors, showing that the opening of HSR has fostered the aggregation of the tertiary industry as a whole. Debrezion (2007) [41], He (2020) [42], Huang (2020) [43], Shao (2017) [17], and Wang (2018) [44] studied the impact of HSR on real estate, automobiles, services, and finance, respectively, and found heterogeneity in the impact of HSR across industries, which is consistent with the findings in this paper.
5.4 Human Capital's Mediation Effect
Following the demonstration of the heterogeneity in the impact of \(HSR\) on various cities, it should be determined whether the impact is produced by the flow of human resources. In this paper, the number of college students is utilized as a variable to quantify human resources. If the coefficients of the three regressions are significant but \({c}^{\prime}\) is minor, then the human resource has an intermediary effect on the impact of \(HSR\) on industrial structure. Using the steps below:
where \(X\) is \(HSR\), \(Y\) are dependent variables, and \(M\) is the mediator variable. The significance of \(HSR\)’s coefficients in Models (1), (3), and (5) in Table 7 demonstrates its explanatory power for \(Y\) and \(M\). In Model (2), the partial intermediary effect of human resources is shown with a value of \(ab/c=0.0723\) for \(LQ\_third\) as the explanatory variable. Because the \(lwrdxs\) coefficients in Model (4) are insignificant, the bootstrap test is required to obtain a distribution that is close to the population, and the results for SA are reported in Table 8. The sign of the coefficient in Table 8 is significantly positive, suggesting that human resources have only an indirect effect. Combining Tables 7 and 8, it can be concluded that human resources serve as a complete intermediary in the impact of \(HSR\) on the industrial structure.
6 Discussion and Conclusion
With China's fast expansion of HSR, how to accurately quantify the impact of HSR on the industrial structure is of great concern to many scholars. In light of China's current state of the economy, the theoretical framework and hypothesis of the impact of HSR on the industrial structure are derived using the core–periphery model. This demonstrates that the impact of HSR on industrial structure aggregation includes decreasing-speed and U-shaped-speed aggregation, while the impact of HSR on industrial structure rationalization is uncertain. A series of empirical studies are based on the three hypotheses given in this paper.
The findings show that, first, HSR promotes tertiary industry aggregation and contributes to the transformation of the industrial structure from primary to the secondary and tertiary industry sector, as well as realizing the industrial structure advancement but not rationalization. Next, the impact of HSR on tertiary industry aggregation in major cities and high-density cities is greater than that in other cities, whereas the impact on the industrial structure advancement is smaller. Moreover, following the HSR's opening, the aggregation of the transportation, warehousing, and postal sectors has been greatly reduced, with a significant spillover effect on neighboring cities, proving the siphon effect and conduction mechanism of the HSR on industrial structure. There has also been a structural shift in the tertiary industry, from basic to advanced sectors. Finally, it has been confirmed that HSR decreases human resource flow costs and plays a partial intermediate function in the aggregation of tertiary industry, and the advanced industrial structure's intermediary role is clearer.
The primary contribution of this paper is the selection of appropriate research objects. The impacts of newly built stations and the rehabilitation of existing stations will overlap if all HSR in the area is evaluated, and the cross-effects will lead to skewed results. This study determines the suitable control and treatment groups for improving recognition accuracy after extensive comparison. The second contribution is that this research creates a mathematical economic geography model of the influence of HSR opening on the industrial structure based on Nobel laureate in Economics Krugman's core–periphery model. Samuelson's iceberg transportation cost notion is introduced, which is supplemented to provide a reference for follow-up research. The third contribution is that, unlike previous research, this work takes into account the heterogeneity of HSR's economic impacts across sectors, examines the direct and indirect heterogeneity of HSR on various industries in the city, and investigates the “siphon effect” of HSR.
As urbanization and the establishment of HSR progress, China should continue to boost investment in HSR development and make active use of resource allocation tools to aid in the transformation of the industrial structure. Simultaneously, it should not pursue tertiary industry growth blindly, in order to prevent the establishment of the siphon effect. The shortcomings of this paper, on the one hand, the data used are prefecture-level, not county-level units, potentially resulting in inadequate precision. This work, on the other hand, uses the whole railway line as the research object to prevent cross-influence, potentially resulting in a self-selection dilemma, which could be solved by segmenting the line to form a control group.
Data Availability
The data were collected from the China Statistical Yearbook and the China City Statistical Yearbook.
Notes
The core–periphery model is based on Nobel laureate Krugman's Dixit-Stiglitz (D-S) model, which first proposed that the link between transportation costs and economies of scale is the basis of industrial agglomeration in 1991.
According to the principles of China's railway network planning, the location of \(HSR\) is determined by the “natural force” of the geographical location, the “government force” of the \(HSR\) strategic planning, and the competition and cooperation of local governments and the “market force” of the first-mover advantage of developed regions. As a result, local governments have little control in whether HSR lines go through their jurisdictions.
A series of tests shown in Appendix C conducted before regression revealed no multicollinearity, heteroscedasticity, or model identification error.
The finding is still robust (P>|t|=0.125) if the significance level is increased to 20%.
The reference is the scale classification standard of the State Council of China for large cities (type I) and small and medium-sized cities (type II), and the population density standard of the State Council of China for the construction of metro cities.
The economic effects of the high-speed rail's opening are numerous, but it is impossible to cover everything at this time. We correctly decrease the significance limit to 20% and delete Moran's I insignificant indications.
References
Spiekermann K, Wegener M (1994) The shrinking continent: new time–space maps of Europe. Environ Plann B Plann Des 21(6):653–673. https://doi.org/10.1068/b210653
Niu F, Xin Z, Sun D (2021) Urban land use effects of high-speed railway network in China: a spatial spillover perspective. Land Use Policy 105. https://doi.org/10.1016/j.landusepol.2021.105417
Donaldson D (2010) Railroads of the raj: estimating the impact of transportation infrastructure. Lse Res Online Doc Econ 32(2):16487. https://doi.org/10.1257/aer.20101199
Alexander K (2015) Improving transport infrastructure in Russia. OECD Econ Dep Work Pap 1193:1–22. https://doi.org/10.1787/5js4hmcs3mxp-en
Fageda X, Gonzalez-Aregall M (2017) Do all transport modes impact on industrial employment? Empirical evidence from the Spanish regions. Transp Policy 55:70–78. https://doi.org/10.1016/j.tranpol.2016.12.008
Chandra A, Thompson E (2000) Does public infrastructure affect economic activity? Evidence from the rural interstate highway system. Reg Sci Urban Econ 30(4):457–490. https://doi.org/10.1016/S0166-0462(00)00040-5
Holl A (2004) Transport infrastructure, agglomeration economies, and firm birth: empirical evidence from Portugal. J Reg Sci 44(4):693–712. https://doi.org/10.1111/j.0022-4146.2004.00354.x
Aschauer DA (1989) Is public expenditure productive? J Monet Econ 23(2):177–200. https://doi.org/10.1016/0304-3932(89)90047-0
Chen CL, Hall P (2011) The impacts of high-speed trains on British economic geography: a study of the UK’s intercity 125/225 and its effects. J Transp Geogr 19(4):689–704. https://doi.org/10.1016/j.jtrangeo.2010.08.010
Levinson DM (2012) Accessibility impacts of high-speed rail. J Transp Geogr 22:288–291. https://doi.org/10.1016/j.jtrangeo.2012.01.029
Chen G, Silva J (2014) Estimating the provincial economic impacts of high-speed rail in Spain: an application of structural equation modeling. Soc Behav Sci 111:157–165. https://doi.org/10.1016/j.sbspro.2014.01.048
Ahlfeldt GM, Feddersen A (2017) From periphery to core: measuring agglomeration effects using high-speed rail. Serc Discuss Pap. https://doi.org/10.1093/jeg/lbx005
Chen Z, Haynes KE (2017) Impact of high-speed rail on regional economic disparity in China. J Transp Geogr 65:80–91. https://doi.org/10.1016/j.jtrangeo.2017.08.003
Guirao B, Lara-Galera A, Campa JL (2017) High speed rail commuting impacts on labour migration: the case of the concentration of metropolis in the Madrid functional area. Land Use Policy Int J Cover All Aspects Land Use 66:131–140. https://doi.org/10.1016/j.landusepol.2017.04.035
Guirao B, Campa JL, Casado-Sanz N (2018) Labour mobility between cities and metropolitan integration: the role of high-speed rail commuting in Spain. Cities 78:140–154. https://doi.org/10.1016/j.cities.2018.02.008
Cascetta E, Cartenì A, Ih A, Henke I (2020) Economic growth, transport accessibility and regional equity impacts of high-speed railways in Italy: ten years ex post evaluation and future perspectives. Transp Res Part A: Policy Pract 139:412–428. https://doi.org/10.1016/j.tra.2020.07.008
Shao S, Tian Z, Yang L (2017) High speed rail and urban service industry agglomeration: evidence from China's Yangtze River Delta region. J Transp Geogr 64:174–183. https://doi.org/10.1016/j.jtrangeo.2017.08.019
Dong X (2018) High-speed railway and urban sectoral employment in China. Transp Res Part A Policy Pract 116:603–621. https://doi.org/10.1016/j.tra.2018.07.010
Meng X, Lin S, Zhu X (2018) The resource redistribution effect of high-speed rail stations on the economic growth of neighbouring regions: evidence from China. Transp Policy 68:178–191. https://doi.org/10.1016/j.tranpol.2018.05.006
Wang F, Wei X, Liu J, He L, Gao M (2019) Impact of high-speed rail on population mobility and urbanisation: a case study on Yangtze river delta urban agglomeration, China. Transp Res Part A Policy Pract 127(SEP.):99–114. https://doi.org/10.1016/j.tra.2019.06.018
Zheng L, Long F, Chang Z, Ye J (2019) Ghost town or city of hope? the spatial spillover effects of high-speed railway stations in China. Transp Pol 81(SEP.):230–241. https://doi.org/10.1016/j.tranpol.2019.07.005
Pan H, Cong C, Zhang X (2020) How do high-speed rail projects affect the agglomeration in cities and regions? Transp Res Part D: Transp Environ 88:102561. https://doi.org/10.1016/j.trd.2020.102561
Wang S, Wang J, Liu X (2019) How do urban spatial structures evolution in the high-speed rail era? Case study of Yangtze River Delta, China. Habitat Int 93:102051. https://doi.org/10.1016/j.habitatint.2019.102051
Liu Y, Zhang X, Pan X, Ma X, Tang M (2020) The spatial integration and coordinated industrial development of urban agglomerations in the Yangtze River economic belt China. Cities 104. https://doi.org/10.1016/j.cities.2020.102801
Liang Y, Zhou K, Li X, Zhou Z, Sun W, Zeng J (2020) Effectiveness of high-speed railway on regional economic growth for less developed areas. J Transp Geogr. https://doi.org/10.1016/j.jtrangeo.2019.102621
Li X, Wu Z, Zhao X (2020) Economic effect and its disparity of high-speed rail in China: a study of mechanism based on synthesis control method. Transp Policy 99:262–274. https://doi.org/10.1016/j.tranpol.2020.09.003
Li Y, Chen Z, Wang P (2020) Impact of high-speed rail on urban economic efficiency in China. Transp Policy 97:220–231. https://doi.org/10.1016/j.tranpol.2020.08.001
Wang C, Meng W, Hou X (2020) The impact of high-speed rails on urban economy: an investigation using night lighting data of Chinese cities. Res Transp Econ. https://doi.org/10.1016/j.retrec.2020.100819
Meng TA, Tl A, Xy B, Hz A, Xia MA (2021) The impact of high-speed rail on service industry agglomeration in peripheral cities. Transp Res Part D: Transp Environ. https://doi.org/10.1016/j.trd.2021.102745
Melo PC, Graham DJ, Brage-Ardao R (2013) The productivity of transport infrastructure investment: a meta-analysis of empirical evidence. Reg Sci Urban Econ 43(5):695–706. https://doi.org/10.1016/j.regsciurbeco.2013.05.002
Hansen WG (1959) How accessibility shapes land-use. J Am Inst Plann 25(1):73–76
Guy M, Ferdinand R, Redding SJ (2008) Urbanization and structural transformation. Quart J Econ 2:535–586. https://doi.org/10.1016/10.2139/ssrn.1281691
Pagliara F, Mauriello F, Garofalo A (2017) Exploring the interdependences between high-speed rail systems and tourism: some evidence from Italy. Transp Res Part A: Policy Pract 106:300–308. https://doi.org/10.1016/j.tra.2017.09.022
Duflo E, Pande R (2007) Dams. Q J Econ 122(2):601–646. https://doi.org/10.1162/qjec.122.2.601
Durarnton G, Turner MA (2011) The fundamental law of road congestion: evidence from US cities. Am Econ Rev 101(6):2616–2652. https://doi.org/10.1257/aer.101.6.2616
Turner G (2012) Urban growth and transportation. Cepr Discuss Pap 79(4):1407–1440. https://doi.org/10.2307/23355076
Melitz MJ (2003) The impact of trade on intra-industry reallocations and aggregate industry productivity. Econometrica 71(6):1695–1725. https://doi.org/10.1111/1468-0262.00467/
Richard EB et al (2006) Heterogeneous firms, agglomeration and economic geography: spatial selection and sorting. J Econ Geogr 6(3):323–346. https://doi.org/10.1093/jeg/lbi020
Melitz MJ, Ottaviano G (2008) Market size, trade, and productivity. Rev Econ Stud 75(1):295–316. https://doi.org/10.1111/j.1467-937x.2007.00463.x
Pace RK, Lesage JP (2009) A sampling approach to estimate the log determinant used in spatial likelihood problems. J Geogr Syst 11(3):209–225. https://doi.org/10.1007/s10109-009-0087-7
Debrezion G, Pels E, Rietveld P (2007) The impact of railway stations on residential and commercial property value: a meta-analysis. J Real Estate Financ Econ 35(2):161–180. https://doi.org/10.1007/s11146-007-9032-z
He SY (2020) Regional impact of rail network accessibility on residential property price: modelling spatial heterogeneous capitalisation effects in Hong Kong. Transp Res Part A Policy Pract. https://doi.org/10.1016/j.tra.2020.01.025
Huang Z, Du X (2020) How does high-speed rail affect land value? Evidence from China. Land Use Policy 101. https://doi.org/10.1016/j.landusepol.2020.105068
Wang L, Yuan F, Duan X (2018) How high-speed rail service development influenced commercial land market dynamics: a case study of Jiangsu Province, China. J Transp Geogr 72:248–257. https://doi.org/10.1016/j.jtrangeo.2018.09.010
Author information
Authors and Affiliations
Contributions
Conceptualization, MH and JX; methodology, MH; software, MH; validation, MH and JX; formal analysis, MH and JX; investigation, MH and JX; resources, MH; data curation, MH and JX; writing—review and editing, JX and MH; visualization, MH; supervision, JX. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Additional information
Communicated by Chun Zhang.
Supplementary Information
Below is the link to the electronic supplementary material.
Appendices
Appendix
1.1 Appendix A: The Review of the Literature on High-Speed Rail and Economic Growth
See Table 9.
1.2 Appendix B: The list of HSR and cities along and outside the Beijing–Shanghai and Beijing–Guangzhou HSR
1.3 Appendix C: Tests in heteroscedasticity, multicollinearity, and RESET
See Table 12.
1.3.1 Heteroscedasticity Test
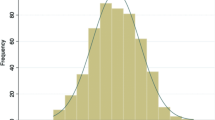
Considering the possible influence of heteroscedasticity, the BP test was performed on the heteroscedasticity of the data. The basic principle of the BP test is to test whether there is heteroscedasticity through auxiliary regression, as shown in Fig. 7. The results show that the null hypothesis is accepted, indicating that there is no obvious heteroscedasticity effect in the data set, and further discussion can be continued. The verified industry-advanced SH and industrial structure rationalization SR have also passed the BP test.

The results of the BP test
1.3.2 Multicollinearity Test
The variance inflation factor is a measure of the severity of multicollinearity in a multiple linear regression model, and it represents the ratio of the variance of the regression coefficient estimator compared with the variance assuming non-linear correlations among the independent variables. A rule of thumb for judging whether there is multicollinearity is that the VIF of the independent variable should not exceed 10, otherwise multicollinearity may become a problem. B.1 shows that the VIF of all variables does not exceed 10, that is, there is no obvious multicollinearity for the variables in this paper.
1.3.3 RESET Test
Considering the effect of possible omitted interactions of higher-order terms and other variables, a regression set error test (RESET) was performed. It is a general method for testing functional form in multiple regression models. Its rationale is a joint significance F-test of squared, cubic, and possibly higher powers of the fitted values derived from the original OLS estimate. Fig. 8 Accepting the null hypothesis means that the model does not obviously miss the need to include complex interaction terms between all independent variables and higher-order terms of the respective variables, and the next in-depth analysis can be carried out.

Regression setting error test
Appendix D: Division standard of industries and test results of spatial correlation
See Tables 13, 14, 15, and 16.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hu, My., Xu, J. How Does High-Speed Rail Impact the Industry Structure? Evidence from China. Urban Rail Transit 8, 296–317 (2022). https://doi.org/10.1007/s40864-022-00175-w
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40864-022-00175-w
Keywords
- High-speed rail
- Industrial aggregation
- Industrial structure advancement
- Industrial structure rationalization
- Siphon effect
- Spillover effect