
Abstract
Coal-rock interface identification technology was pivotal in automatically adjusting the shearer’s cutting drum during coal mining. However, it also served as a technical bottleneck hindering the advancement of intelligent coal mining. This study aimed to address the poor accuracy of current coal-rock identification technology on comprehensive working faces, coupled with the limited availability of coal-rock datasets. The loss function of the SegFormer model was enhanced, the model’s hyperparameters and learning rate were adjusted, and an automatic recognition method was proposed for coal-rock interfaces based on FL-SegFormer. Additionally, an experimental platform was constructed to simulate the dusty environment during coal-rock cutting by the shearer, enabling the collection of coal-rock test image datasets. The morphology-based algorithms were employed to expand the coal-rock image datasets through image rotation, color dithering, and Gaussian noise injection so as to augment the diversity and applicability of the datasets. As a result, a coal-rock image dataset comprising 8424 samples was generated. The findings demonstrated that the FL-SegFormer model achieved a Mean Intersection over Union (MIoU) and mean pixel accuracy (MPA) of 97.72% and 98.83%, respectively. The FL-SegFormer model outperformed other models in terms of recognition accuracy, as evidenced by an MIoU exceeding 95.70% of the original image. Furthermore, the FL-SegFormer model using original coal-rock images was validated from No. 15205 working face of the Yulin test mine in northern Shaanxi. The calculated average error was only 1.77%, and the model operated at a rate of 46.96 frames per second, meeting the practical application and deployment requirements in underground settings. These results provided a theoretical foundation for achieving automatic and efficient mining with coal mining machines and the intelligent development of coal mines.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
1 Introduction
Coal is the predominant energy source in China, and safe, efficient, and intelligent coal mining is the only pathway for sustainable development of the coal industry (Xie et al. 2021; Yang et al. 2023; Wang et al. 2023). Coal-rock interface identification, as a cutting-edge technology for intelligent mining in comprehensive working faces, enabled the shearer to perform cutting operations close to the coal seam boundary. It improves the coal recovery rate, reduces rock cutting from the roof and floor to reduce the content of raw coal gangue, and inhibits the strong vibration of the shearer (Wang et al. 2021, 2022a; Zhang et al. 2023a). However, the existing coal mining methods rely heavily on manual intervention, and the safety situation of coal mines is still grim. Mutations in the coal-rock further add to the difficulty of mining. Moreover, the wear of the cutting drum of the shearer increased, resulting in frequent failures of the shearer. At the same time, the increase in the proportion of rocks led to an increase in the workload of subsequent sorting, reducing the efficiency of coal mining. Applying coal-rock interface identification technology could quickly and accurately locate the position of coal seam and rock formation, thus guiding the shearer to adaptively adjust the cutting drum height and traction speed. This was of great significance for improving the service life and coal mining efficiency of the shearer. Therefore, the coal-rock interface identification had become one of the effective ways for intelligent mining. The traditional coal-rock interface identification technology (vibration test method, pick force measurement method, acoustic wave detection method, and so forth) have problems, such as high cost of transformation, easy damage to equipment, and significant effects of the actual working conditions on the identification results (Liu et al. 2018; Wang et al. 2019; Jiang et al. 2022). Addressing the above issues, this study proposed an image-based coal-rock interface identification technology, which aimed to improve the mining efficiency and ensure the coal quality, thereby providing technical support for the intelligent mining of coal mining machines.
The development of graphics processing units in recent years has led to extensive use of image recognition technology based on digital image processing for identifying coal-rock interfaces (Sun et al. 2013; Liu et al. 2020; Wei et al. 2021; Zhang et al. 2021), which had the advantages of high efficiency, speed, accuracy, and safety. Several deep learning studies have been performed, achieving good results (Wang et al. 2022b; Yu et al. 2021; Gorai et al. 2021; Yuan et al. 2023). Zhang et al. (2021b) proposed machine vision coal-rock-type recognition based on similar quantitative discrimination, which improved the accuracy of coal-rock recognition and provided a theoretical basis for the intelligent adjustment of shearer-cutting drums. Wang et al. (2022c) proposed a model using active excitation infrared characterization and PSPNet to realize accurate identification of the coal-rock interface. Actively stimulated infrared images of the coal-rock interface were tested under different excitation times, distances, and intensities using the coal-rock interface identification testbed. Sun et al. (2022) proposed an improved coal-rock interface image recognition model based on the CLBP and receptive field theory. The proposed model balanced the accuracy and efficiency of coal-rock interface image recognition. Yang et al. (2022) proposed a convolutional neural network coal-rock identification method based on the hyperspectral data. The coal-rock interface spectral data were collected using a near-infrared spectrometer, and a convolutional neural network classifier for coal-rock interface identification was built. Gao et al. (2021) established a new coal-rock image classification network model by combining the spatial pyramid pooling structure with convolutional neural network, which had good test results in the dynamic video obtained from the mining and heading face. Based on the U-net network model, Si et al. (2021) designed a coal-rock recognition method for fully mechanized coal mining face, which reduced the training speed and improved the accuracy of image segmentation. Combining the advantages of a convolutional neural network and random forest classifier, Zhang et al. (2023b) designed the RFCNN coal-rock cutting interface identification network model and verified the feasibility of the coal-rock cutting interface model through laboratory field experiments. In addition, a large number of vision technologies were applied to intelligent working faces (Jonathon et al. 2014; Barnewold et al. 2020). Yuan et al. (2022) proposed a cross-joint trace detection algorithm based on digital image processing using the characteristics of typical images of cross-joints in coal roadway excavation faces. This algorithm could filter out the influence of weaving minerals, clay mineral fillings, and cut traces, and extract the cross joints in the heading face. Moridi et al. (2015) introduced an integrated system based on WSN and GIS to realize the automation of underground mine monitoring and communication. This system provided multiuser ground operations and 3D visualization to truly understand the underground environment and miners conditions. The existing studies applied the convolutional neural network model to coal-rock interface identification. Although the coal-rock extraction method based on deep learning had high identification accuracy, the problem of convolutional neural network information loss was not improved. The algorithm model used in the image recognition of coal-rock interface was large, and the amount of calculation was redundant. Thus, it was difficult to meet the real-time identification requirements. In addition, the coal-rock image datasets were affected by multiple factors such as data acquisition, imaging conditions, and environment. Hence, research on coal-rock interface identification datasets was relatively scarce, and further research was urgently needed.
Given the above, the present study was conducted to solve the problems of low recognition accuracy and lack of coal-rock datasets in the existing coal-rock interface identification model. An FL-SegFormer method for coal-rock interface identification in the comprehensive working face was proposed in the present study. An experimental platform for coal-rock interface identification was built to simulate the coal-rock cutting surface during the cutting process of the coal shearer in a dusty environment, so as to obtain images of the coal-rock interface. Then, the morphology-based algorithm was used to perform the same data augmentation on the images and labels in the coal-rock image datasets and dehaze the datasets. Finally, the recognition accuracy and practical applicability of the coal-rock interface identification model were verified taking the comprehensive working face of the test mine as the engineering background. The real-time automatic identification of the coal-rock interface during coal mining was realized, and the distribution characteristics of the coal-rock interface in the working face were determined. The research results provided a scientific theoretical basis for improving coal mining efficiency and quality, and promoting the development of intelligent mines.
2 Coal-rock interface identification model of the comprehensive working face based on SegFormer
2.1 SegFormer semantic segmentation model
SegFormer is a transformer-based image semantic segmentation model capable of automatically categorizing each pixel within an image. Unlike traditional convolutional neural networks, SegFormer incorporates the transformer block to facilitate contextual information processing. The model adopts an encoder-decoder structure, as shown in Fig. 1. The encoder module extracts the high-level semantic information of the images through down-sampling operation, and the decoder restores the high-level semantic features acquired by the encoder to the original image resolution through an upsampling operation, so as to predict the feature map restored to the original resolution. The model performs pixel-level identification on the coal seam and rock formation in the input coal-rock interface image, not only could the classification and location of coal seams and rock formations be completed but also coal-rock regions with detailed boundaries be generated.
The SegFormer model uses a layered transformer to construct a feature extraction network with a larger receptive field than the traditional backbone network based on a convolutional neural network. The feature extraction network significantly improves the identification accuracy and running speed while maintaining the same number of parameters. A lightweight decoder structure is adopted, the layered features obtained by the transformer are effectively used, and excessive calculation and complicated parameter adjustment are avoided.

Encoder-decoder network structure
2.2 Loss function
The loss function is used in machine learning to evaluate the difference between the model’s predicted value and the true value. During the training process, the optimization algorithm adjusts the model parameters according to the value of the loss function, gradually improving the approximation of the model to the true value. Generally speaking, the smaller the loss function, the better the model training. The loss function is mainly used in the training phase of the model. The model generates the predicted value through the forward propagation of the input data of each training batch, and the loss function calculates the difference between the predicted value and the real value. Subsequently, each parameter of the model is updated through back propagation to reduce the loss between the real value and the predicted value, so that the predicted value generated by the model is closer to the real value, so as to achieve the purpose of learning.
2.2.1 Cross-entropy loss function
The cross-entropy loss function is a commonly used loss function for classification problems, which can be used to evaluate the difference between the model’s predicted value and the real value.
Let the real label be y, and the predicted label of the model be ŷ, then the cross-entropy loss function is defined as:
where n represents the number of labels. The cross-entropy loss function can be regarded as the information difference between the real label and the predicted label, and the model parameters can be adjusted by minimizing the loss function, so that the model can predict the label more accurately.
The cross-entropy loss function is widely used in deep learning, especially in training neural networks. The cross-entropy loss not only can effectively reflect the mathematical nature of the classification problem but also has continuity and differentiability. Optimization algorithms such as gradient descent can be used to minimize the loss, thereby training a better classification model.
2.2.2 Dice loss
Dice loss is a loss function widely used in image segmentation tasks, for the purpose of minimizing the difference between the model’s predicted and true values. This ensures that the model can more accurately predict the location of the target object. The formula is as follows:
In the formula, y represents the real label, ŷ represents the predicted label of the model, and n represents the number of labels.
The denominator part represents the area size of the target object, and the numerator part represents the intersection size of the predicted label and the real label, that is, the number of pixels that exist in both the predicted and real labels. The value range of Dice Loss is [0,1]. When the predicted value is exactly the same as the real value, the value of the loss function is 0, otherwise, the value of the loss function will gradually increase. Therefore, minimizing Dice Loss allows the model to more accurately predict the location of the target object.
2.2.3 Focal loss
Focal loss is a loss function for solving class imbalance problems. In deep learning, it can alleviate the problem of low prediction accuracy of classification models on minority categories. The class imbalance problem refers to the fact that some categories have far fewer samples than others. This makes the model pay too much attention to categories with many samples during training, while ignoring categories with a few samples.
Focal loss was proposed by Lin et al. (2017). It mainly alleviates the category imbalance problem by introducing a focusing factor. Focusing factor is an adjustable parameter used to control the weight of difficult and easy samples. For samples that are easy to classify, the focusing factor is close to 0 and does not have much impact on the loss function. For samples that are difficult to classify, the focusing factor is close to 1, which can make it occupy a greater weight in the loss function.
The design idea of focal loss is to reduce the weight of easy-to-classify samples while increasing the weight of difficult-to-classify samples. The approach encourages the model to pay more attention to the learning of difficult-to-classify samples. Specifically, focal loss rebalances the sample distribution by introducing an adjustable parameter γ to reduce the weight of easy-to-classify samples and increase the weight of difficult-to-classify samples. The expression of Focal Loss is as follows:
Among them, Pt represents the probability value predicted by the model, αt represents the category weight factor, and γ represents the adjustment factor.
In practical applications, αt can be set to a small number, such as 0.25, 0.50, etc., to reduce the weight of easy-to-classify samples; γ can be set to a larger number, such as 2, 3, etc., to increase the weight of difficult samples. When γ = 0, Focal Loss is equivalent to the standard cross entropy loss function. The advantage of Focal Loss is that it can effectively solve the problem of category imbalance and improve the prediction accuracy of the model on a few categories.
2.3 Coal-rock image dataset expansion algorithm
The connection between deep learning and intelligent mining of coal mines has become increasingly close. This has further promoted the development of image segmentation technology in the field of coal-rock interface identification. However, the identification accuracy is limited by the number of training samples, and collecting coal-rock interface images requires high manpower and time. Working face coal-rock interface images not only are difficult to obtain but also require manual labeling. This results in insufficient diversity of training images. In this case, the trained coal-rock interface identification model has serious overfitting problems. The coal-rock image datasets should be first expanded before training the model to obtain an identification model with better performance.
Hence, this study proposed an expansion method of geometric transformation to process the coal-rock image datasets. The expansion principle was as follows: the difference between the original and expanded images was determined using geometric transformation operations such as rotation, color jitter, and Gaussian noise processing to expand the coal-rock image datasets. Meanwhile, the specificity and accuracy of the coal-rock interface identification model were improved by increasing the diversity of the datasets. Figure 2 depicts the image dataset expansion method.

Geometric transformation diagram. a Original images b Color jitter processing c Gaussian noise processing d Random rotation pro-cessing
2.3.1 Image rotation
Rotation transformation can be realized by rearranging the pixels of the original image. Commonly used image rotation algorithms include nearest-neighbor interpolation, bilinear interpolation, and bicubic interpolation. Bicubic interpolation is one of the interpolation algorithms provided in the PIL library for image rotation and scaling. The algorithm calculates the rotated or scaled pixel value by taking a weighted average of the surrounding 16 pixels to produce a smoother, clearer image. The affine transformation formula for the rotation operation is as follows:
Among them, x and y represent the pixel coordinates in the original image, x′ and y′ represent the rotated pixel coordinates, and θ represents the angle of rotation.
The affine transformation formula uses a rotation matrix, where cos(θ) and sin(θ) represent the cosine and sine of the rotation angle, 0 represents the displacement, and 1 represents the scaling ratio. The rotated pixel coordinates can be calculated by multiplying the original pixel coordinates and the rotation matrix.
The image rotation operation used a random function to randomly select an angle (90°, 180°, 270°, and 360°) as the rotation angle and rotate the image and label. The bicubic interpolation algorithm was used when rotating, so that the coal-rock interface identification model could better learn the characteristics of different angles.
2.3.2 Color jitter
Color dithering usually refers to a series of color transformations on the image, such as adjusting the saturation, brightness, contrast, and so forth, of the image to generate new training samples. The samples in the training set can be more diverse through color dithering, making it easier for the model to adapt to different scenarios and conditions. In addition, color dithering can also enhance the model’s applicability to factors such as lighting and white balance, thereby improving the accuracy and stability of the model. Commonly used color dithering methods in practical applications include random color transformation, random brightness, random contrast, random hue, and so forth. These methods can generate different training samples by making certain adjustments to the image pixel values.
The image color dithering operation implemented in this study included the following steps:
-
Step 1: Set a random integer as a random factor to adjust the color of the coal-rock image.
-
Step 2: Adjust the saturation of the coal-rock image.
-
Step 3: Adjust the brightness of the coal-rock image after the saturation is changed.
-
Step 4: Adjust the contrast of the coal-rock image after brightness adjustment.
-
Step 5: Adjust the sharpness of the coal-rock image after contrast adjustment.
2.3.3 Gaussian noise processing
Gaussian noise is a common image noise mainly caused by circuit noise of the image sensor, environmental electromagnetic interference, and transmission signal interference. In image processing, Gaussian noise is usually added to generate more training data so as to increase the diversity and applicability of images.
The generation of Gaussian noise can be described as follows: adding a random noise that obeys a normal distribution to each pixel value. The probability density function of a normal distribution can be expressed as:
Among them, µ represents the mean of a normal distribution, and σ represents the standard deviation.
2.4 FL-SegFormer coal-rock interface identification model
Considering the complex environment of the comprehensive working face in the coal mining process, an automatic coal-rock identification model was urgently needed to improve the recognition accuracy of coal-rock in the coal mining process. The purpose was to accurately determine the distribution characteristics of the coal-rock interface in front of the working face and provide a basis for the adaptive adjustment of the cutting drum height and traction speed of the shearer. The traditional convolutional neural networks to recognize coal-rock interface images often had problems such as poor identification accuracy for coal-rock interfaces, false recognition, discontinuous recognition, and high model complexity, which limited their flexible and efficient deployment in actual scenarios.
Hence, this study proposed an FL-SegFormer coal-rock interface image recognition method to address the aforementioned issues. The model adopted the structure of encoding and decoding as shown in Fig. 3.

Improved Segformer network architectur
The SegFormer model consists of a hierarchical transformer encoder and a lightweight ALL-MLP decoder. The encoder part consists of four transformer blocks stacked. Each transformer block consists of overlapped patch merging (OPM), efficient multi-head self-attention (EMSA), and a mix feed-forward network (Mix-FFN). In the SegFormer model, the original coal-rock interface image underwent feature extraction through the four transformer blocks. The resolution of the feature map generated by each transformer block was 1/4, 1/8, 1/16, and 1/32 of the original image, and the feature maps of these different resolutions were fused in the decoder part. The OPM module performed feature extraction and downsampling on the input coal-rock interface image through feature merging and then inputted the obtained features into the EMSA module for self-attention calculation and feature enhancement. Finally, the Mix-FFN module was used to alleviate the accuracy drop caused by the introduction of positional encoding when predicting images. The decoder part linearly transformed and upsampled the feature maps from four different resolutions. The purpose was to fuse the feature maps of different resolutions in the channel position. Then, the spliced feature map was restored to the size of the input image through linear transformation, and the final recognition result map of the model was output.
3 Establishing an experimental platform for coal-rock interface identification and obtaining coal-rock image datasets
3.1 Building an experimental platform for coal-rock interface identification in comprehensive working face
The coal-rock image datasets were affected by factors such as data acquisition, imaging conditions, and dust environment in comprehensive working face. Hence, collecting many coal-rock interface images in real time was difficult. Therefore, this study built a coal-rock interface identification experiment platform based on the distribution characteristics of the underground coal seam and the roof and floor to simulate the coal-rock interface formed after the coal shearer cut the coal-rock interface. The experimental platform was mainly composed of image acquisition equipment and a coal-rock interface identification system. The image acquisition equipment included an image acquisition device and a device for simulating the cutting surface. The coal-rock interface identification experimental platform built is illustrated in Fig. 4.

Coal-rock identification platform of mining working face
The main purpose of this experiment was to obtain a coal-rock test image dataset. To this end, a 200-W Jinbei lamp was used as the light source, and a Qianyanlang high-speed camera model 5F04 was used as the acquisition device. Researchers constructed the cutting surface from bottom to top using the physical similarity simulation method. Further, materials such as coal powder and water were evenly mixed and laid on the physical similarity simulation experiment platform. The mixing was continued, and 200-mesh granite powder, water, and other materials were laid evenly above the coal seam. Considering that the actual underground environment was affected by dust, the fan and fly ash were combined to simulate dust and other external conditions so as to make the simulated environment more realistic. When building each group of coal-rock cutting surfaces, it was necessary to ensure that the boundary shape. This boundary lies between the laid coal seam and the rock layer. The aim was to obtain coal-rock interface images with different changing characteristics. Finally, a model with a length, width, and height of 1.5 m, 0.1 m, and 0.9 m, respectively, was built in a way that conformed to the evolution law of the coal seam. The height of each group of coal-rock cutting surfaces was 0.3 m. The material composition, strength, and other mechanical parameters of the produced coal-rock mass was not much different from the actual coal-rock mass to make the simulated coal-rock mass more realistic.
3.2 Coal-rock test image dataset defogging
The identification of the coal-rock interface was greatly affected by dust in the coal mining process of the working face. This test focused on dust factors and used fans and fly ash to create a dust environment while the coal shearer cut the coal-rock interface. However, in this environment, the collected coal-rock cutting interface was affected by the dense fog caused by dust, which affected the model identification effect. Therefore, defogging was used to solve the blurred effect of shooting due to the dense fog caused by dust.
Defogging usually refers to an image noise reduction algorithm used in digital image processing for eliminating the problems of reduced visibility and image distortion caused by interference, such as dust particles in the image. It can better improve the applicability of the model. As shown in Fig. 5, the use of defogging reduced the blur caused by dust and made the recognition accuracy more accurate.

Defogging treatment method
3.3 Expansion and production of coal-rock test image datasets
In deep learning, data augmentation was a commonly used data preprocessing method to increase the diversity of datasets. The accuracy of the coal-rock recognition model needed the datasets to meet the requirements of small images and multiple samples. A total of 200 original images with a size of 4032 × 3024 pixels were taken from the coal-rock recognition experimental platform. Therefore, two schemes of manual cropping and geometric transformation were used in this study to expand the collected images. Further, different sizes of datasets were used to reflect the impact of different data volumes on identification accuracy. The coal-rock image datasets of different schemes are shown in Table 1.
Option 1 used manual cropping to process the original image. Each original image could generate five to six small-sized images, thus obtaining five times more data. Finally, 1030 images that met the requirements as the datasets were selected.
Option 2 used the expansion method based on geometric transformation described in Sect. 2.3 to expand the original coal-rock image datasets. Meanwhile, image rotation, color dithering, and Gaussian noise injection were used to process the coal-rock interface image and labels at the same time. The final datasets contained 8424 coal-rock interface images by further increasing the diversity and quantity of the datasets.
For the datasets obtained after data expansion, the open-source software Labelme was used to label samples and the expanded datasets were converted into JSON format. In the coal mining process, the shearer was close to the coal seam boundary for cutting operations, which increased the coal recovery rate. The primary task of coal-rock interface image recognition was to accurately identify the coal seam structure and boundary. Therefore, except for the coal seam, the rest was designated as rock formations.
The datasets in this study were divided into two types, one for coal seams and the other for rock formations. Each image in the datasets had a corresponding JSON annotation file that provided object outlines and corresponding classification labels for each image. Finally, the datasets in JSON format were batch converted into a color image with a resolution of 516 × 516 and a depth of 8 bits, where the value of each pixel was the category to which the pixel belonged.
3.4 Coal-rock interface image recognition method and training strategy
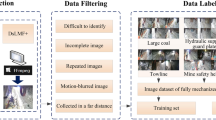
This study proposed an FL-SegFormer automatic identification method of the coal-rock interface in the comprehensive working face. The overall process was divided into three stages. The technical route of the automatic identification of the coal-rock cutting interface is shown in Fig. 6.

Technology roadmap
First, a SegFormer coal-rock interface identification model was built, the loss function was improved, the convergence effect and identification accuracy of the model were tested under different loss functions, and the model hyperparameters and learning rate were adjusted. Second, the method based on morphology was used to expand the coal-rock image datasets, including image rotation, color jitter, Gaussian noise introduction, datasets dehazing, and marking of training and verification sets, through the self-built coal-rock recognition experimental platform to collect coal-rock interface images in the coal mining process. Finally, the FL-SegFormer model was used to train the coal-rock test image datasets with the idea of transfer learning, and the image recognition results were compared and analyzed. Thus, the optimal model for coal-rock interface identification with high recognition accuracy and flexible deployment was obtained.
The experiment adopted the idea of transfer learning and used the weight file trained on the VOC datasets as the pretraining weight of the SegFormer model experiment. The training was divided into two stages: freezing and unfreezing. Setting the freezing stage could make up for the lack of machine performance and improve the applicability of the coal-rock interface identification model for different working faces. The total training epoch was set to 200 and the freezing stage epoch to 100. The settings of the experimental parameters are shown in Table 2.
4 Results and analysis
4.1 Experimental evaluation index
The mean pixel accuracy (MPA), mean intersection over union (MIoU), parameters, and detection frames per second (FPS) were used as evaluation indicators to evaluate the recognition accuracy of the FL-SegFormer model in coal-rock interface identification from multiple perspectives. MPA and MIoU evaluated the overall accuracy and recognition accuracy of the model. The parameter quantity and FPS of the model were important indicators to measure its complexity and identification efficiency. The larger the value of MPA and MIoU, the more accurate the recognition result. The higher the FPS, the smoother and clearer the visual effect. The smaller the number of parameters, the smaller the weight file generated, which could be portably deployed to embedded devices for better application in actual mines.
-
1)
MPA is the average value of the ratio of the number of correctly classified pixels to the total number of pixels in each class, and the calculation method is as follows:
-
2)
MIoU is the ratio of the intersection and union of the predicted value and the real value in each category, the result of summing and averaging, the calculation method is as follows.
In the above formula, n represents the number of categories of the label (coal seam, rock formation), n + 1 represents the number of categories including the background; i represents the real value, j represents the predicted value, and pii represents the number of pixels actually predicted to be class i for class i, pij represents the number of pixels actually predicted as class j for class i, and pji represents the number of pixels actually predicted as class i for class j.
4.2 FL-SegFormer model improvement analysis
The algorithm in this study was mainly based on the original model SegFormer. The loss function was optimized to reduce the gap between the model output and the real label, which helped shorten the training time of the model and improve the convergence speed of the model. The data expansion technology was used to increase the number and diversity of samples in the training set, improve the applicability of the model, and ensure more accurate coal-rock interface identification boundary information. The efficiency of this model was verified by conducting comparative experiments on different coal-rock image datasets using different loss function optimization strategies and different models.
4.2.1 Performance comparison of different loss functions
In semantic segmentation tasks, the loss function was the objective function of the optimized model that measured the gap between the model output and the real label. An appropriate loss function could guide the model to learn better feature extraction and thus improve its applicability. Improving the loss function could speed up the training speed of the model and make the model converge faster. Therefore, it was considered to replace the loss function of the SegFormer model. A total of three sets of comparative experiments were carried out on the coal-rock test image dataset DS3 to test the performance of loss functions such as cross-entropy loss, Dice loss, and focal loss based on the SegFormer model. The experimental results are shown in Fig. 7 and Table 3.

Comparison of different loss functions
As shown in Fig. 7 and Table 3, the focal loss function had a faster convergence speed and less obvious oscillation compared with the two loss functions of CE loss and Dice loss. The loss curves of the first 2 loss functions fluctuated violently when the number of model training rounds reached 135, confirming that the model training was unstable. After improving the loss function from CE loss to Dice loss, the MIoU decreased but the fluctuation of the loss curve increased. When focal loss was selected as the loss function, MIoU reached 97.72%, which was more accurate than the other loss functions, which proved the effectiveness of the loss function proposed in this study. After a comprehensive analysis, it was finally determined to use the focal loss in the coal-rock interface identification experiment. While maintaining the same accuracy, the focal loss could significantly reduce the parameter scale and improve the running speed, which was more advantageous for deployment to actual working conditions.
4.2.2 Comparative experiments on different datasets
In Sect. 2.3, it was pointed out that the recognition accuracy of the coal-rock interface was limited by the number of training samples. The working face coal-rock interface images not only were difficult to obtain but also needed to be manually labeled, resulting in an insufficient diversity of training images. Therefore, the recognition accuracy could be improved through the amount of coal-rock interface image data. Datasets of different scales were used to train the model based on SegFormer. MIoU and accuracy were used as evaluation indicators. The experimental results are shown in Table 4.
Table 4 reveals that the MIoU of the three improved Segformer sample sets was 95.70%, 96.46%, and 97.72%, respectively, which was higher than the MIoU based on the three classic models during the same period. Compared with the identification results of the Dice SegFormer model, the average MIoU of the focal SegFormer model increased by 0.34% and the average accuracy rate increased by 0.33%, which proved that the improvement in the loss function in this study significantly improved the identification accuracy. In addition, the recognition accuracy of different datasets under the same identification model was different, and the datasets after data augmentation had the best recognition performance on the FL-SegFormer model.
4.2.3 Comparative experiments between different models
The coal-rock image dataset DS3 was selected for data training of different models to further verify the excellent recognition effect of the FL-SegFormer model. The model proposed in this study was compared with classic semantic segmentation models such as PSPNet, HRNet, U-Net, and DeepLabV3+. The specific results are shown in Table 5.
Table 5 reveals that, in terms of MIoU, the recognition effect of the FL-SegFormer (DS1) model and the DeepLabV3 + model was not much different, whereas the FL-SegFormer (DS3) model in this study had the highest MIoU, reaching 97.72%. At the same time, MPA and accuracy were the highest among all models. Although PSPNet had obvious advantages over the algorithm in this study in terms of model parameters, the FL-SegFormer (DS3) model in this study increased MIoU only by 5.48% at the cost of loss parameters. The comprehensive analysis showed that, compared with other classical semantic segmentation models, the FL-SegFormer model proposed in this study achieved better recognition results. Not only did the accuracy improve by 2.45% compared with the DeepLabV3 + model, but the model size and parameters were reduced by 93%, the inference speed increased by 88%, and the FPS increased eight times. Hence, the FL-SegFormer model could better meet the actual working conditions.
4.3 Analysis of FL-SegFormer model recognition results
The trained FL-SegFormer model was used to detect the images in the test set. Four groups of coal-rock interface images in the test set were randomly compared and analyzed visually to intuitively compare the recognition accuracy of SegFormer before and after improvement, as shown in Table 6.
Table 6 shows that the U-Net model had the worst identification performance on the coal-rock image datasets in this study. Several instances of missed identification were noted, and the identification accuracy was low. The DeepLabV3 + model had a higher recognition accuracy for the coal-rock interface, and the interface identification was smoother. However, a large number of misidentifications occurred. The image segmentation model based on the convolutional neural network had a large degree of misidentification when applied to coal-rock interface images. Meanwhile, the coal-rock interfaces were coarsely identified, and the coal seams and rock formations could not be distinguished well. The SegFormer model was trained on the unexpanded DS2 datasets. Although the identification was accurate after color dithering and Gaussian processing, some misidentification was observed for the rotated image model, and the coal-rock interfaces were rough. The DS3 datasets after loading data expansion had high identification accuracy, the coal-rock interface identification was more continuous, and the identification effect was similar to the real label map. The problem of category imbalance in the coal-rock interface identification model could be alleviated, the adaptability of the model could be improved, and an identification model with superior performance could be obtained by increasing the number and diversity of samples in the training set through data augmentation technology.
The loss value curve of the FL-SegFormer model proposed in this study trained on the coal-rock test image datasets is shown in Fig. 8. The red straight line represents the loss curve of the training set, and the dark blue dotted line represents the loss curve of the verification set.

Loss function diagram
Figure 8 shows that the loss functions of both the training set and the verification set gradually tended to be stable with the increase in training times. After the first epoch training, the learning rate was adjusted to a value smaller than the initial learning rate to achieve good convergence of the model. The model training process included a freezing phase and an unfreezing phase. The epoch of the freezing phase was 100. When the freezing phase ended, the learning rate was readjusted. Consequently, the loss curve dropped again. Meanwhile, the model deviated from the local optimum and began to converge to the global optimum, indicating that the FL-SegFormer model could effectively reduce the loss of feature information and improve the identification effect. When entering the unfreezing stage, the loss curve decreased slowly and tended to be stable with the increase in the number of training sessions. The loss curve of the verification set was higher than the loss curve of the training set, and the curve trend was good. When the epoch reached 180, the loss of the verification set did not change and the model basically converged. The difference in the loss of the final training set and that of the verification set was 0.003, indicating that the FL-SegFormer model had a better convergence effect on the coal-rock image datasets.
The MIoU curves obtained by comparing and training three different datasets (original dataset DS1, dataset DS2 after artificial cropping and expansion, and dataset DS3 after geometric transformation) based on the coal-rock image expansion technology discussed in Sect. 2.3 are illustrated in Fig. 9.

MIOU curve
Figure 9 shows that, when the training data was in the initial epoch, the MIoU obtained by training the original dataset DS1 without data expansion was about 73.93%. The training MIoU of the expanded datasets DS2 and DS3 was 79.81% and 76.52%, respectively. At the beginning of the training iteration, the datasets after data expansion were obviously better than the original captured image in the model training process. The model converged rapidly after 5–10 times of epoch, indicating that a reliable and effective model was obtained after iteration. When the epoch reached 100 times, the MIoU in the training process increased again due to the end of the freezing phase and the adjustment of the learning rate. Meanwhile, the model deviated from the local optimum and began changing to the global optimum. After the epoch reached 200 times, the MIoU in the training process of the 3 different datasets was 95.70%, 96.47%, and 97.72%, respectively. Considering the epoch of the model, the accuracy of the model, and the size of the model, the model identification performance after geometric transformation data expansion was better.
The comprehensive analysis showed that the FL-SegFormer model had the smallest and fastest decreasing training loss and the highest identification accuracy after training on the data augmented test datasets. The real-time automatic identification of the coal-rock interface during coal mining was achieved, and the distribution characteristics of coal-rock interfaces in the working face were determined.
5 Engineering applications
The measured image was used for experiments to verify the FL-SegFormer automatic identification method of the coal-rock interface in the comprehensive working face proposed in this study. In the model established in this study, the original coal-rock image from No. 15205 working face of the Yulin test mine in northern Shaanxi was recognized. The original coal-rock image is shown in Fig. 10. At the same time, it was verified whether this algorithm could be used as a benchmark for the coal shearer to distinguish the position information of coal seam and rock formations. A total of 10 coal-rock images collected at the working face were randomly selected for image identification. The identification results are shown in Fig. 11.

Original coal-rock image of mining working face
Figure 11 shows that the coal seam and rock layer in the recognized image presented different colors, the coal-rock interface identification accuracy was high, the interfaces identified were smooth, and the comparison with the original image was extremely similar after the original coal-rock image was recognized by the model in this study. The pixels in the original and identified images of coal seams and rock formations were further counted to better prove that the algorithm in this study could meet the needs of actual working conditions. The error analysis of the pixels proved that the identification accuracy of the model in this study was high. Figure 12 shows the pixel point error map.

Coal-rock image segmentation results of mining working face
Figure 12 and Table 7 show that the average error after identification of randomly collected coal-rock images on the site was only 1.77%, and the error of each coal-rock image sample did not exceed 7%. It well reflected the excellent identification accuracy of the coal-rock image identification algorithm proposed in this study in practical application. At the same time, the inference time and FPS were used as evaluation indicators to test the randomly selected coal-rock images. The results are shown in Table 7. The average inference time of a single coal-rock image was 21.31 ms, and the FPS was 46.96 fps.

The error diagram of predicted coal seam proportion and actual coal seam proportion
In summary, the FL-SegFormer coal-rock identification model proposed in this study had an accurate identification algorithm and high identification accuracy, and could be flexibly and efficiently deployed in test mines. The expansion of intelligent coal mining technology was of great significance to promote the intelligent construction of coal mines and the modernization of the coal energy industry.
6 Conclusions
-
(1)
This study proposed an automatic recognition method of coal-rock interface based on FL-SegFormer by improving the loss function and adjusting the model hyperparameters and learning rate. The MIoU and MPA of the improved Segformer model were 97.72% and 98.83%, respectively, and the model size was 14 M. Meanwhile, the identification accuracy was better than other models (U-Net; DeepLabV3+).
-
(2)
An experimental platform for distributing the coal-rock interface in comprehensive working face in simulated dust environment was built. The platform included image acquisition equipment and a coal-rock interface identification system. It was used to collect coal-rock image datasets in the comprehensive working face.
-
(3)
The method of dehazing processing and dataset expansion was proposed to improve the identification reliability of the FL-SegFormer model. The diversity and quantity of the datasets were further increased to alleviate the problem of category imbalance. Finally, the accuracy of the identification model was promoted to increase by 1.69%.
-
(4)
The FL-SegFormer model proposed in this study was applied to No. 15205 working face of Yulin test mine in northern Shaanxi. The average error of coal-rock image identification obtained at random was only 1.77%, and accurate identification results were obtained. The number of transmission FPS was 46.96 fps, which proved that the method could be applied to the actual mine.
References
Barnewold L, Lottermoser BG (2020) Identification of digital technologies and digitalisation trends in the mining industry. Int J Min Sci Technol 30(6):747–757
Gao F, Yin X, Liu Q et al (2021) Coal-rock image recognition method for mining and heading face based on spatial pyramid pooling structure. J China Coal Soc 46(12):4088–4102
Gorai AK, Raval S, Patel AK et al (2021) Design and development of a machine vision system using artificial neural network-based algorithm for automated coal characterization. Int J Coal Sci Technol 8:737–755
Jiang K, Wan L, Zeng Q et al (2022) New effective method for identification of coal and roof interface based on cutting performance. Arab J Sci Eng 48:11351–11362
Jonathon R, David R, Chad H et al (2014) Sensing for advancing mining automation capability: a review of underground automation technology development. Int J Min Sci Technol 24(3):305–310
Lin T, Goyal P, Girshick R et al (2017) Focal Loss for Dense Object Detection. IEEE Transactions on Pattern Analysis and Machine Intelligence 42(2):318-327
Liu Y, Hou L, Qin D et al (2018) Self-adaptive control of shearer based on cutting resistance recognition. Int J Adv Manuf Technol 94:3553–3561
Liu Y, Dhakal S, Hao B (2020) Coal and rock interface identification based on wavelet packet decomposition and fuzzy neural network. J Intell Fuzzy Syst 38(4):3949–3959
Moridi MA, Kawamura Y, Sharifzadeh M et al (2015) Development of underground mine monitoring and communication system integrated ZigBee and GIS. Int J Min Sci Technol 25(5):811–818
Si L, Wang Z, Xiong X et al (2021) Coal-rock recognition method of fully-mechanized coal miningface based on improved U-net network model. J China Coal Soc 46(S1):578–589
Sun J, Su B (2013) Coal–rock interface detection on the basis of image texture features. Int J Min Sci Technol 23(5):681–687
Sun C, Xu R, Wang C et al (2022) Coal rock image recognition method based on improved CLBP and receptive field theory. Deep Undergr Sci Eng 1(2):165–173
Wang S, Wang S (2022b) Longwall mining automation horizon control: coal seam gradient identification using piecewise linear fitting. Int J Min Sci Technol 32(4):821–829
Wang H, Zhang Q (2019) Dynamic identification of coal-rock interface based on adaptive weight optimization and multi-sensor information fusion. Inform Fusion 51:114–128
Wang G, Xu Y, Zhang J et al (2021) New development of intelligent mining in coal mines. Coal Sci Technol 49(1):1–10
Wang H, Liu L, Zhao X (2022c) Pre-perception and accurate recognition of coal–rock interface based on active excitation infrared characterization. J Comput Des Eng 9(5):2040–2054
Wang J, Pan W, Zhang G et al (2022a) Principles and applications of image-based recognition of with drawn coal and intelligen control of draw opening in longwall top coal caving face. J China Coal Soc 47(1):87–101
Wang G, Zhang L, Li S et al (2023) Progresses in theory and technology development of unmanned smart mining system. J China Coal Soc 48(1):34–53
Wei W, Li L, Shi W et al (2021) Ultrasonic imaging recognition of coal-rock interface based on the improved variational mode decomposition. Measurement 170:108728
Xie H, Ren S, Xie Y et al (2021) Development opportunities of the coal industry towards the goal of carbon neu-trality. J China Coal Soc 46(7):2197–2211
Yang J, Chang B, Zhang Y et al (2022) CNN coal and rock recognition method based on hyperspectral data. Int J Coal Sci Technol 9(63)
Yang Y, Lai X, Zhang Y et al (2023) Strength deterioration and energy dissipation characteristics of cemented backfill with different gangue particle size distributions. J Mater Res Technol 25:5122–5135
Yu J, Wang X, Ding E (2021) A novel method of on-line coal-rock interface characterization using THz-TDs. IEEE Access 9:25898–25910
Yuan Y, Zhang N, Han C et al (2022) Digital image processing-based automatic detection algorithm of cross joint trace and its application in mining roadway excavation practice. Int J Min Sci Technol 32(6):1219–1231
Yuan Y, Zhang N, Han C et al (2023) Automated identification of fissure trace in mining roadway via deep learning. J Rock Mech Geotech Eng 15(8):2039–2052
Zhang M, Zhao L, Wang Y (2021a) Recognition system of coal-rock cutting state based on CPS perception analy-sis. J China Coal Soc 46(12):4071–4087
Zhang Q, Gu J, Liu J (2021b) Research on coal and rock type recognition based on mechanical vision. Shock Vib 2021:1–10
Zhang Y, Liu Y, Lai X et al (2023a) Transport mechanism and control technology of heavy metal ions in gangue backfill materials in short-wall block backfill mining. Sci Total Environ 895:165139
Zhang M, Zhao L, Shi B (2023b) Analysis and construction of the coal and rock cutting state identification system in coal mine intelligent mining. Sci Rep 13(3489)
Acknowledgements
We would like to extend my gratitude to the College of Energy Engineering Xi’an University of Science and Technology China for providing us the platforms to complete this project.
Funding
This research was funded by the National Natural Science Foundation of China (52004201; 52274143; 52204153), and China Postdoctoral Science Foundation (2021T140551).
Author information
Authors and Affiliations
Contributions
Yun Zhang and Liang Tong conceived of the research. Yun Zhang analyzed the data and wrote the paper. Xingping Lai, Shenggen Cao, Baoxu Yan, Yanbin Yang, Yongzi Liu and Wei He participated in the design of the study and verified the results. All authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
All the authors of this manuscript have approved the article’s submission for publication. This paper has not been published elsewhere and is not under consideration by another journal. There has been no improper falsifcation or tampering of data. After accepting the manuscript, we promise not to change the author’s identity and author sequence by adding or removing the author.
Competing interests
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, Y., Tong, L., Lai, X. et al. Research on coal-rock identification method and data augmentation algorithm of comprehensive working face based on FL-Segformer. Int J Coal Sci Technol 11, 48 (2024). https://doi.org/10.1007/s40789-024-00704-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40789-024-00704-x