
Abstract
Steel surface defect detection is crucial in manufacturing, but achieving high accuracy and real-time performance with limited computing resources is challenging. To address this issue, this paper proposes DFFNet, a lightweight fusion network, for fast and accurate steel surface defect detection. Firstly, a lightweight backbone network called LDD is introduced, utilizing partial convolution to reduce computational complexity and extract spatial features efficiently. Then, PANet is enhanced using the Efficient Feature-Optimized Converged Network and a Feature Enhancement Aggregation Module (FEAM) to improve feature fusion. FEAM combines the Efficient Layer Aggregation Network and reparameterization techniques to extend the receptive field for defect perception, and reduce information loss for small defects. Finally, a WIOU loss function with a dynamic non-monotonic mechanism is designed to improve defect localization in complex scenes. Evaluation results on the NEU-DET dataset demonstrate that the proposed DFFNet achieves competitive accuracy with lower computational complexity, with a detection speed of 101 FPS, meeting real-time performance requirements in industrial settings. Furthermore, experimental results on the PASCAL VOC and MS COCO datasets demonstrate the strong generalization capability of DFFNet for object detection in diverse scenarios.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Steel, as one of the most important materials in the industry, is widely used in construction, automotive, aerospace, shipbuilding, energy, machinery, and other fields [1]. It plays a vital role in the development and operation of modern industry. With the advancement driven by the country and society, the dimensional characteristics, shape, and mechanical properties of steel have been greatly improved. However, industries such as electronics, automotive, aerospace, and machinery, which require high precision, have stricter requirements for the surface quality of steel. During the manufacturing, processing, and transportation of steel, various surface defects inevitably occur. These surface defects, as shown in Fig. 1, include pitted surface, inclusion, patches, crazing, rolled-in scale, scratches, and more. They not only affect the appearance of steel but also have adverse effects on its performance, safety, and service life [2]. Therefore, surface defect detection is an indispensable and crucial step in steel production. Rigorous surface defect detection enables quick determination of defect location and nature, preventing further development and spread, and effectively enhancing product quality. At the same time, early detection of surface defects and timely measures such as repair or elimination of non-compliant products can reduce product scrap rates and unnecessary material waste, thereby lowering production costs and enhancing the competitiveness and market share of enterprises [3].

Example diagram of steel surface defects. (a) Pitted surface. (b) Inclusion. (c) Patches. (d) Crazing. (e) Rolled-in scale. (f) Scratches
Traditional surface inspection methods for steel rely heavily on manual visual inspection, which is inefficient, labor-intensive, and lacks consistency in detection standards, limiting its application. Consequently, an increasing number of steel manufacturing companies are turning to automated detection methods to improve production efficiency and detection accuracy [4]. In this regard, machine vision-based surface defect detection methods have been widely adopted in the industrial sector. These methods utilize traditional computer vision techniques to extract defect-related features from images. Machine learning algorithms are then used to classify and recognize these features, thereby achieving steel surface defect detection. However, these traditional methods rely on manually designed features that are often based on domain knowledge and experience, which have limitations and subjectivity. Particularly, for diverse and unknown defects, handcrafted features may not effectively discriminate them, leading to poor robustness and generalization of the detection methods. In recent years, with the rapid development of deep learning, Convolutional Neural Networks (CNN) have overcome the limitations of traditional methods by automatically learning features from raw data. They have shown remarkable achievements in surface defect detection. For instance, Wang et al. [5] proposed an automated defect detection method to optimize industrial quality inspection. The network enhances defect detection accuracy through automatic positive and negative sample allocation strategies, loss fusion pooling, and a soft-weighted attention detection head. Zhang et al. [6] introduced a lightweight printed circuit board defect detection network, the algorithm combines a lightweight feature extraction network, efficient attention module, and lightweight decoupled head to improve the model’s representational capacity and defect detection performance. These studies offer valuable references for utilizing deep learning techniques in surface defect detection. In addition, renowned research works [7,8,9] respectively investigate the security framework in smart healthcare, the sustainable growth assessment of road traffic systems, and the decision-making methodology for sustainable supplier selection. Although the application areas of these studies differ from defect detection, they provide some methods and ideas regarding data security, sustainability, quality control, and decision-making, which are closely related to the challenges of defect detection in industrial applications. Therefore, they also provide inspiration for our research.
However, the application of CNNs in industrial inspection still faces certain limitations. One major limitation is that training large-scale object detection networks requires significant computational resources and time, which may not be feasible for real-time defect detection in production environments. Additionally, only a few industrial production lines can afford the expensive costs of high-performance computing resources required by large-scale neural networks. Therefore, to be applicable in practical production environments, it is necessary to develop lightweight detection models that can run on low-cost hardware devices such as CPUs, enabling fast and accurate defect detection [10].
At the same time, the task of detecting steel surface defects faces certain challenges. Firstly, there is a mixed and extensive variety of steel surface defects, and a general-purpose object detector may not be optimal for the defect detection task. The complex features, sizes, shapes, and textures of different surface defects can also impact the accuracy of detection. Secondly, in the defect detection scenario, the presence of complex backgrounds can overshadow certain defects that are closely associated with the background, thereby significantly interfering with the detection of less prominent defects. Furthermore, some subtle and extremely unevenly scaled surface defects are particularly difficult to detect, requiring optimization of effective feature information in small-sized defects to further improve the accuracy and robustness of the detector [11].
To address the aforementioned issues, this paper introduces a lightweight efficient feature-optimized fusion anchorless detector, named DFFNet (Defect Feature Fusion Network), for quick and accurate detection of steel surface defects. Initially, LDD (Lightweight Dilated DenseNet) is designed with fewer parameters and faster computational speed to efficiently extract image features, thereby enhancing feature representation. Secondly, to improve the sensitivity and accuracy of the defect detector for small-sized defects and mitigate the influence of the background, we propose an EFO module to interact and fuse the information between different scale feature layers. This fusion generates a feature representation with richer semantic information and high spatial resolution, where the fused feature module layers features from different semantic levels and utilizes structural aggregation to enhance the global information of the shallow feature map and effectively learn scale-sensitive features. Finally, the WIOU loss function is employed as the bounding box regression loss to further enhance the performance of the defect detector in accurately localizing defects. The effectiveness of the proposed method is verified through extensive experiments conducted on the NEU-DET defect dataset. To further evaluate the generalization capability of DFFNet, we also introduce the PASCAL VOC and MS COCO datasets for comprehensive testing.
In summary, this paper presents DFFNet, a lightweight defect detection model designed to address the limitations of deploying large models in practical scenarios. DFFNet enables quick and accurate detection of steel surface defects while utilizing limited computational resources. The main contributions of this work are as follows:
-
1.
A lightweight efficient backbone network architecture called LDD is proposed. It incorporates the fast and efficient convolutional PConv(partial convolution), which effectively reduces the model parameters and computational redundancy. This enables better utilization of computational resources on devices.
-
2.
The feature fusion network EFO is redesigned to facilitate dense information exchange across different levels of latent semantics and spatial scales. This allows for more efficient transfer of information for multi-scale features. The FEAM feature fusion block enhances feature fusion through finer-grained aggregated network connections, effectively preventing the loss of small target features and eliminating interference from background information.
-
3.
The WIOU loss function is employed to mitigate overfitting of low-quality samples. This improves the capture of high-quality samples, enhancing the target localization ability and overall robustness of the detector.
-
4.
Experimental results on the NEU-DET, PASCAL VOC, and MS COCO public datasets demonstrate that the proposed method achieves a significant performance improvement and exhibits good generalization to meet real-time detection requirements.
Related works
In this section, we present a comprehensive review of existing defect detection methods, encompassing traditional approaches as well as deep learning-based techniques. We carefully examine their individual strengths and weaknesses, while also highlighting the limitations of the current research in this field.
Traditional defect detection methods
Traditional surface defect detection methods commonly include image preprocessing, edge feature extraction, and threshold segmentation. Image preprocessing encompasses operations such as grayscale transformation, histogram equalization, filtering, and other techniques, which enhance image contrast, reduce noise, and highlight defect areas. Edge feature extraction methods utilize classical edge detection operators like Canny, Prewitt, and Sobel to extract prominent edge information associated with the defective target. Threshold-based segmentation aims to classify pixels in the image using various grayscale thresholds to separate the defective target from the background [12,13,14].
Although the methods mentioned in the references offer advantages such as speed and simplicity, they also have limitations. These methods exhibit poor adaptability to different types of surface defects as they rely on local image features, which makes achieving accurate detection in complex backgrounds challenging. Moreover, they are often sensitive to noise and lighting variations, leading to interference, false detection, and missed detection.
Deep learning-based defect detection methods
In recent years, the advancements in deep learning technology have greatly accelerated the progress of defect detection methods. Compared to traditional approaches, object detection methods based on neural networks harness the capabilities of feature extraction to comprehend defects from both local and global perspectives. This enables accurate detection, precise localization, and offers advantages such as better robustness, accuracy, and efficiency. In the field of defect detection, researchers have proposed a variety of deep learning-based methods. For instance, Addressing fabric defect detection tasks, Chen et al. [15] proposed an effective model called Gabor Faster R-CNN. This model leveraged genetic algorithms for adaptive parameter selection and integrated Gabor filters to suppress textures, thereby enhancing the effectiveness of fabric defect detection. While this study focuses on textile materials, the methods and techniques employed can provide valuable insights for detecting surface defects in steel. Liu et al. [16] developed a defect detection network named Multi-Scale Context Detection Network (MSC-DNet), which employed Auxiliary Image-level Supervision (AIS) to enhance discriminative features for target defects. This approach achieved outstanding defect detection performance with a mean average precision (mAP) of 79.4%. This research provides an effective method for improving feature discrimination and detection accuracy in steel surface defect detection.
However, due to the efficiency challenges associated with the above two-stage detection models, meeting real-time requirements becomes difficult. Consequently, research based on single-stage detection models has gained increasing attention. For example, Hou et al. [17] proposed an enhanced YOLOv5s algorithm for ceramic tile surface defect detection. This algorithm leverages two novel structures, Res-Head and Drop-CA, to enhance information exchange between different layers and alleviate the model’s tendency to overly focus on defect targets. This work is of reference significance for improving methods of information propagation and attention allocation in steel surface defect detection models. Chen et al. [18] proposed a novel hybrid detection method for pipeline defects, which combines YOLOv5 and the Vision Transformer (ViT) in a cascaded manner for detecting and localizing pipeline defects. This method achieved high accuracy and real-time detection capability on their custom dataset, providing valuable insights for meeting the real-time requirements of steel surface defect detection. Wu et al. [19] proposed an adaptive loss-weighted multi-task network with attention-guided proposal generation. This network utilizes object attention to enhance the confidence of small-sized defects, thereby generating more high-quality region proposals to improve defect detection accuracy. This method provides an effective attention mechanism for detecting surface defects in steel. Zhang et al. [20] proposed an enhanced multi-scale feature fusion method for small object detection of multiscale defects. They employed feature enhancement to devise a more efficient feature fusion network and embedded attention mechanisms to optimize lightweight implementation. This approach exhibited outstanding performance on a public printed circuit board defect detection dataset, achieving a mAP of 95.8%. This research provides an effective technical approach in the field of steel surface defect detection, offering significant reference value for our study. Wang et al. [21] addressed the limitations of CNNs and Transformers in defect detection by developing an efficient hybrid Transformer architecture. This architecture is instructive for distinguishing surface pseudo defects in cluttered backgrounds. Zhao et al. [22] proposed an improved RDD-YOLO model based on yolov5 for detecting steel surface defects. The model integrated Res2Net backbone components, a dual-feature pyramid network, and a decoupled head structure, resulting in enhanced detection accuracy. It achieved 81.1 mAP and 57.8 FPS (Frames Per Second) detection speed on NEU-DET dataset. This study provides valuable insights for the model design and performance optimization sections of this paper, particularly in the aspect of model optimization for defect handling.
In previous defect detection studies, although accuracy has been emphasized, there has been a lack of balance between accuracy, speed, and computational complexity, particularly in industrial applications. This imbalance has resulted in challenges such as high costs for training and deployment, slow processing speeds, and excessive consumption of computational resources during practical implementation. To address these issues while maintaining excellent detection performance and real-time capability, this study focuses on the development of a lightweight defect detection network.
Methods
In this section, we first discuss the reasoning behind choosing YOLOv8 as the baseline model. We then present a detailed overview of the enhanced algorithm, DFFNet, along with its key components. These components consist of the LDD, the EFO, the FEAM, and the WIoU loss function.
Baseline model YOLOv8
In the task of strip surface defect detection, traditional anchor-based models have certain drawbacks due to significant variations in morphological characteristics among different types of defects. These drawbacks can be summarized as follows: (1) Complex design: The anchor-based model requires manual selection and design of appropriate anchor frames. However, defects come in diverse sizes and shapes, and the detection effectiveness varies for defects of different scales and aspect ratios. Designing optimal anchor frames that cater to all types of defects becomes challenging, often resulting in unreasonable and inconsistent defect designs in terms of scale. Consequently, this can lead to a decrease in defect detection accuracy. (2) Large computational overhead: In the anchor-based model, each anchor frame requires target detection and classification, which involves computationally intensive operations. This can significantly slow down model training and inference, which is not desirable for real-time defect detection tasks [23]. To address these issues and improve detection accuracy, reduce hyperparameters, and increase computational efficiency, this paper adopts anchorless detectors as the baseline model. Figure 2 illustrates YOLOv8 [24], the latest version of the anchor-free model in the YOLO series, which incorporates key innovations in several aspects. These innovations include adopting a C2f structure with richer gradient flow, a decoupled head structure, Anchor-Free technology, and tuning the number of channels for different scale models. Furthermore, to optimize target detection during the training process, additional instance segmentation annotations are introduced. For loss calculation, YOLOv8 adopts the Task Aligned Assigner positive sample assignment strategy and introduces the Distribution Focal Loss. This strategy focuses more on the detection of rare objects and addresses the long-tail distribution problem in network training, enhancing the model’s generalization ability across different images.
While YOLOv8 is used as the baseline network for DFFNet, there are inherent challenges in defect detection. These challenges include potential detection errors for objects with significant shape variations, less satisfactory performance in detecting small-sized defects, and limitations in detecting defects in complex backgrounds. To address these challenges, this paper presents the DFFNet target detector, which enhances the capabilities of YOLOv8 for strip steel surface defect detection.

The architecture diagram of the baseline model YOLOv8
Overall network architecture
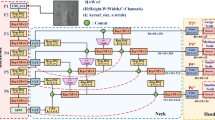
The proposed method, DFFNet, is depicted in detail in Fig. 3. In contrast to conventional target detectors that typically employ a heavy backbone and a light neck model, DFFNet adopts a novel design paradigm consisting of a light backbone and a heavy neck. This design choice effectively addresses the challenge of large-scale variation in targets. Firstly, in DFFNet, the backbone network of YOLOv8 is designed as a lightweight feature extractor. It utilizes PConv [25] to reduce computational redundancy and optimize high-frequency memory access, enabling efficient extraction of defect features. Next, to facilitate efficient information transfer and interaction across different scales, DFFNet introduces the efficient feature-optimized converged network(EFO) structure. Additionally, the FEAM feature aggregation module is employed to fuse the multi-scale features obtained from different stages of the backbone. By leveraging the Efficient Layer Aggregation Network (ELAN) [26] connection and reparameterization(Rep) techniques [27], dense information aggregation between features at different scales is enhanced. This approach effectively captures diverse levels of potential semantics, enabling the detector to effectively handle defects at various scales, particularly small-sized defects. Finally, the decoupled detection head is responsible for target classification and position prediction. By incorporating the WIOU loss function in the regression branch, we enhance the fitting capability of the bounding box regression (BBR) loss function.

The overall structure of the proposed DFFNet
Lightweight dilated DenseNet
The original YOLOv8 model employs the C2f module as its backbone network, which achieves good accuracy. However, it comes with high computational overhead and operations that are not optimized for specific hardware deployments. This limits its ability to balance accuracy and speed in industrial application scenarios. In real production environments, factors like cost constraints and limited computational resources necessitate the design of lightweight models to reduce resource consumption and improve operational efficiency for deployment on various devices.
To address these challenges, we have redesigned the backbone of YOLOv8 and introduced a fast and efficient convolution method called PConv. Our goal was to reduce model computation and memory consumption while achieving efficient model representation. Unlike existing lightweight networks such as Mobileone [28], ShuffleNetV2 [29], and GhostNetV2 [30], utilize deep convolution (DWConv) and/or group convolution (GConv) to extract spatial features. Although these methods significantly reduce parameters and floating point operations (FLOPs), they often involve additional data operations such as cascading, shuffling, and pooling. These operations result in frequent memory accesses and a decrease in the overall inference speed of the model. Experimental results presented in Table 1 demonstrate the advantages of PConv. It has lower parameters and FLOPs compared to regular Convolutional layers. When compared to previous lightweight convolution methods like DWConv [31], GhostConv [32], and GSConv [33], PConv performs well in terms of parameters and FLOPs while achieving the fastest inference speed. This means that PConv can better utilize the computational power on the device, making it a promising choice for efficient and effective model deployment.
The working principle of PConv is visually illustrated in the bottom right corner of Fig. 4. It demonstrates how PConv selectively performs convolution operations on a specific portion of the input channels during spatial feature extraction, while keeping the remaining channels unaltered. Compared to conventional convolution, PConv can significantly reduce computational complexity (FLOPs) and memory access. For an input size of \(\text{c}\times{\text{h}}\times{\text{w}}\) feature map, the FLOPs of the regular Convolution are \(\text{h}\times\text{w}\times{\text{k}}^{\text{2}}\times{\text{c}}^{\text{2}}\). In contrast, the FLOPs of a PConv are significantly reduced to \(\text{h}\times\text{w}\times{\text{k}}^{\text{2}}\times{\text{c}}_{\text{p}}^{\text{2}}\), where “h” and “w” respectively represent the height and width of the feature map, k represents the size of the convolutional kernel, c represents the number of channels in the input feature map. For a typical r = 1/4, it means that the partial channel number (\({\text{c}}_{\text{p}}\)) is one-fourth of the total channel number (c). Therefore, the FLOPs of PConv are only 1/16 of the regular convolution. Additionally, the PConv requires less memory access, i.e.,\(\text{h}\times\text{w}\times2{\text{c}}_{\text{p}}\text{+}{\text{k}}^{\text{2}}\times{\text{c}}_{\text{p}}^{\text{2}}\approx\text{h}\times\text{w}\times2{\text{c}}_{\text{p}}\), which is only 1/4 of a regular Conv for r = 1/4. Leveraging the computational and memory advantages of PConv, we adopt it as the primary operator and introduce the LDD_Block module to construct the LDD, as illustrated in Fig. 4, The LDD_Block module exhibits a dual-branch structure and incorporates a Shortcut connection to reuse the input features. Firstly, one branch applies a 1×1 convolutional layer for channel compression, where the compression factor is denoted by the module compression coefficient “e”. Subsequently, when the input tensor is passed to the “LiteBlock” module if the channel count of the input feature map does not match the target dimension “dim,“, another 1×1 convolution layer is utilized to adjust the number of channels. Then, spatial blending is performed using PConv to enable selective convolutional processing on different regions, thereby enhancing the flexibility and expressive power of the feature representation. Next, the processed feature map undergoes nonlinear transformations through an MLP module consisting of two 1×1 convolutional layers, facilitating dimensionality transformation and feature fusion. Finally, the output features of the MLP module are subjected to selective dropout using the Dropout Path layer to enhance the model’s robustness.
The other branch exclusively consists of a Conv layer, which is responsible for adapting the channel count. Finally, the outputs of the two branches are fused to obtain the final output of the module. This design ensures that the model retains a portion of the original features while incorporating the features that have undergone nonlinear operations. As a result, the module can extract and capture more diverse and meaningful feature representations, leading to enhanced semantic understanding of the input images.

Detailed structure diagram of the fundamental component, LDD_block, in LDDNet
Efficient feature-optimized converged network
In the field of object detection, FPN has emerged as a widely adopted feature fusion network for capturing complementary multi-scale features through a one-way information flow [34]. Various variants of FPN have been proposed to enhance its performance. For instance, PANet [35] introduces an additional bottom-up path aggregation network, but it comes at the cost of increased computational complexity. NAS-FPN [36] leverages Neural Architecture Search techniques to find optimal connection patterns at each node. BiFPN [37] incorporates learnable weights to fuse skip connections from the same level, enhancing internal feature representations. However, these feature fusion methods encounter a common challenge: a semantic gap between features extracted at different levels. This results in limited direct interaction between cross-level features. As a consequence, low-level features fail to fully exploit the rich semantic information for accurate object classification, while high-level features are unable to directly leverage precise localization information from low-level features for improved object localization. Moreover, for small-scale targets, their proportion within large-scale feature maps is relatively small, which can lead to suboptimal detection results due to the scale variation of features and information loss during feature processing.
To tackle the challenges mentioned above, we propose an innovative method called EFO for cross-scale feature fusion, as illustrated in Fig. 5 (a). EFO incorporates a bidirectional pyramid structure, where C3, C4, and C5 represent the feature maps of the backbone network at three different scales (1/8, 1/16, 1/32). P1, P2, P3, and P4 denote the aggregated features on each pathway, while N1, N2, and N3 represent the final output features. Firstly, to mitigate information loss in low-resolution features during fusion, we apply a 1×1 convolution operation before upsampling C5. This step enhances the expressive capability of deep features, eliminates redundant information, and captures more detailed feature information. Secondly, although the shallow feature C3 preserves fine boundary details of defects, distinguishing features of small targets becomes challenging due to scale confusion. To address this, we employ a 3 × 3 convolution to separate and extract information from C3, resulting in more discriminative features. Moreover, cascaded FEAM modules are utilized for multi-scale feature fusion to effectively capture detailed information in the images. Next, to enhance feature reuse and fusion, we merge the upsampled P2, laterally connected P3, and C5 feature maps. Prior to merging, a 3 × 3 convolution operation is performed on {P2, P3} to mitigate the overlap effect introduced during upsampling. Finally, we obtain the efficiently fused feature maps N, which comprise N1, N2, and N3, representing the refined and optimized feature representations.
Equations (1–5) describes the specific flow of the EFO network:
where C3, C4, and C5 represent the feature maps at three different scales (1/8, 1/16, and 1/32) in the backbone network. P1, P2, P3, and P4 denote the aggregated features from each pathway. FEAM stands for the Feature Enhancement Aggregation Module, while N (including N1, N2, and N3) represents the final output features.
The following provides a detailed description of the FEAM module’s specific design. It achieves feature fusion from different layers in a hierarchical manner while addressing conflicts between multi-level feature maps through pre-filtering, minimizing the loss of subtle information. In addition, this module generates a single fused feature map with enhanced multi-scale information representation from lower-level features, combining high-level semantic information with fine-grained spatial details, further enhancing the integration capability of the features.
As depicted in Fig. 5 (b), the FEAM is structured into three key phases: feature reduction, channel focus, and feature fusion. In the feature reduction phase, the input feature map is divided into two branches to extract features. Each branch applies a 1×1 convolution to reduce the spatial dimension while preserving essential feature information. This step effectively reduces the computational complexity of subsequent operations and facilitates the fusion of feature maps across different scales. In the channel focus phase, one branch incorporates the ELAN cascade join and RepConv structure. During inference, multiple branches of convolution layers are reparameterized into a single branch 3×3 convolution. This design optimally leverages hardware computation to enhance the efficiency of feature fusion without compromising accuracy. This approach is particularly advantageous for real-time applications. Simultaneously, it ensures the capture of regionally relevant feature details, minimizing feature loss during the compression phase. Furthermore, low-level feature maps are fused with high-level feature maps through efficient aggregation connections, thereby enhancing the network’s perceptual field size and representational power. Finally, in the feature expansion phase, the reduced feature maps from all branches are stitched combined to obtain more comprehensive and diverse feature information.

The specific configuration of the neck in DFFNet: (a) the architecture of the Efficient feature-optimized converged network, (b) the design of the Feature Enhancement Aggregation Module
Loss function
In defect detection, it is inevitable to encounter low-quality samples, such as uneven illumination, varying defect size and shape, and blurred images. These challenging samples can have a negative impact on model training, making it difficult for the model to accurately identify and locate defects. However, although existing IoU loss (such as GIOU [38], EIOU [39], and SIOU [40]) improve model accuracy by incorporating penalty terms for geometric factors like distance and aspect ratio, they tend to penalize low-quality samples more severely, which hampers the model’s generalization performance.
To address this issue, the WIoU function provides a more accurate evaluation of anchor frames by assessing the outlier degree of the anchor box instead of IOU. It introduces a dynamic non-monotonic focal mechanism, where a small outlier represents a high-quality anchor frame with a small gradient gain. This approach focuses the bounding box regression on an average quality anchor frame. By assigning a smaller gradient gain to anchor frames with high outliers, low-quality examples are prevented from generating large and detrimental gradients. The WIoU function is defined as follows [41]:
In the above formula, the variable “r” represents the non-monotonic focusing coefficient, while “β” denotes the outlier degree of the anchor box. “α” and “δ” are symbols for hyperparameters. “\({\text{L}}_{\text{IOU}}^{\text{*}}\)” refers to the gradient gain, and “\(\overline{{\text{L}}_{\text{IOU}}}\)” represents the sliding average with momentum “m”. Additionally, “Rwiou” represents the normalized distance between the center points of two bounding boxes. The coordinates (x, y) represent the center point of the predicted box, while (xgt, ygt) represent the center point of the ground truth box. The symbol “*” indicates a graph separation operation, which converts the variables “WG” and “HG” with gradients into constants, thus preventing gradient hindrance during convergence.
In order to accommodate the dynamic nature of the \(\overline{{\text{L}}_{\text{IOU}}}\) value, the quality classification criterion for anchor frames is also dynamically adjusted. To prevent low-quality anchor frames from lagging behind in the initial stages of training, we initialize \(\overline{{\text{L}}_{\text{IOU}}}\text{=1}\), ensuring that anchor frames with \({\text{L}}_{\text{IOU}}\text{=1}\) receive the highest gradient gain. To maintain this strategy throughout training, a small momentum value, denoted as “m,” is introduced. This momentum factor delays the convergence of \(\overline{{\text{L}}_{\text{IOU}}}\) towards the real value, \({\text{L}_{\text{IOU}}}\_\text{real}\). This delay ensures that in the middle and later stages of training, the WIoU function assigns a smaller gradient gain to low-quality anchor frames, thereby reducing the impact of detrimental gradients. Simultaneously, it directs more attention towards normal-quality anchor frames, leading to enhanced localization performance of the model. this formulation can be expressed as follows:
where “tn” represents the number of backpropagation gradients of the detection network.
Equation 11 presents the total loss function, which consists of two branches: the classification branch and the regression branch.
where the classification branch, \({\text{loss}}_{\text{cls.}}\), utilizes Binary Cross-Entropy (BCE) Loss. The regression branch, \({\text{loss}}_{\text{Bbox.}}\), employs a combination of Distribution Focal Loss (DFL) and WIOU Loss. DFL loss facilitates the network in quickly focusing on the distribution of neighboring regions around the target location.
Experiments and result analysis
In order to validate the effectiveness of the proposed method in this paper, we conducted ablation experiments primarily using the NEU-DET defective dataset. The obtained results were then compared with several other state-of-the-art methods. Furthermore, we extended our evaluation to two widely-used public benchmark datasets, namely the PASCAL VOC dataset (2007 + 2012) and the MS COCO dataset, to assess the generalization capability of our model.
Datasets
NEU-DET
The NEU-DET dataset comprises 1,800 grayscale images of hot rolled steel strips, containing six common types of defects: rolled-in scale (Rs), patches (Pa), crazing (Cr), pitted surface (Ps), inclusion (In), and scratches (Sc). Each defect category consists of 300 samples. The dataset is split into training and test sets with an 8:2 ratio.
PASCAL VOC (The pascal visual object classification)
The PASCAL VOC dataset is extensively employed in computer vision research and consists of two subsets: PASCAL VOC 2007 and PASCAL VOC 2012. Each subset encompasses 20 object classes, such as people, animals, vehicles, and everyday objects. For training, we utilize the combined train + val set from VOC2007 and VOC2012, which comprises a total of 16,551 samples. The testing is performed on a separate test set from VOC2007, which contains 4,952 samples.
MS COCO (Microsoft common objects in context)
MS COCO is a widely-used large dataset for various tasks including target detection, image segmentation, and pose detection. It comprises over 330,000 images and 2.5 million annotated frames, encompassing 80 object classes. For this experiment, the dataset is divided into 118,287 training samples and 5,000 validation samples.
Implementation details
The experimental setup used in this paper is summarized in Table 2. During the training process, the model undergoes a warm-up phase for 3 epochs, starting with an initial learning rate of 0.1 and a momentum of 0.8 to ensure model stability. A linear learning rate scheme is employed with the stochastic gradient descent (SGD) optimizer. The initial learning rate is set to 0.01, weight decay is set to 0.0005, and learning rate momentum is set to 0.937. For the small sample neu-det dataset, the training is conducted for 200 epochs, while for the PASCAL VOC and MS COCO datasets, the training is extended to 300 epochs. To maintain experimental consistency, all input images are resized to a dimension of 640×640. The data augmentation technique used is initial mosaic data augmentation, which is disabled in the last 10 epochs.
In this paper, several metrics are utilized to evaluate the performance of the model, including mAP, number of parameters, GFLOPs, and FPS. Among these metrics, mAP is considered the most crucial metric for assessing the model’s performance. The number of parameters and GFLOPs are employed to gauge the size and complexity of the model, while FPS is used to evaluate the efficiency of model inference. In resource-constrained scenarios, such as those with limited computational resources, the number of parameters, GFLOPs, and FPS become particularly important. mAP is defined as follows [42]:
where TP signifies the count of accurately identified defective samples, FP signifies the count of identified non-defective samples, and FN signifies the count of erroneously identified defective samples. P and R represent precision and recall, correspondingly. c denotes the number of defect categories. mAP@0.5 denotes the mean average precision across all categories with an IoU threshold of 0.5, while mAP@0.5:0.95 denotes the average mAP across various IoU thresholds ranging from 0.5 to 0.95 with an increment of 0.05.
Ablation study
To gain a comprehensive understanding of the contributions and effects of the model’s components, we conducted a series of incremental performance tests and comparisons on the NEU-DET dataset. Specifically, we focused on evaluating the proposed improvement points, namely LDD, EFO, FEAM, and WIOU, while setting the baseline model consistently as YOLOv8s.
Comparison of Different Lightweight Backbone Networks
To enable real-time defect detection on resource-constrained devices like embedded and mobile devices, we propose a lightweight backbone network architecture that achieves high performance while significantly reducing computational resource requirements. We demonstrate the superiority of LDD by comparing its resource consumption and performance with other current lightweight backbone networks, as illustrated in Table 3.
The table clearly demonstrates that while other lightweight frameworks (Mobileone, ShuffleNetV2, GhostNetV2) employ DWConv to effectively reduce computational burden, they suffer from compromised performance and FPS compared to our proposed framework, LDD. LDD offers significant advantages in terms of detection accuracy, computational volume, and inference speed when compared to the baseline model. We achieve an accuracy improvement of 1.8% and a speed gain of 7 f/s, while also reducing the number of parameters by 1.7 M and the computation volume by 6.3 GFLOPs. The effectiveness of our framework can be attributed primarily to the efficient utilization of Pconv. Pconv plays a crucial role in minimizing latency discrepancies arising from frequent access to low FLOPS operations. This optimization improves both memory access and computational efficiency, resulting in enhanced spatial feature extraction capability. Consequently, the experimental results demonstrate that LDD is a highly efficient and lightweight backbone framework, better suited for industrial defect detection tasks with high real-time requirements.
The impact of EFO
Since different defect types and sizes can result in uneven distribution of information in images, the existing FPN architecture-based approach merely performs basic feature fusion among different layers, overlooking more intricate feature interactions and enhancements. Consequently, this operation falls short in fully exploiting the information from different layers, resulting in the loss and blurring of fine-grained features. In contrast, the proposed EFO architecture effectively resolves this contradiction.
The effectiveness of the EFO network is further validated by evaluating the performance of different architectures in the Neck netwrok. The comparison results in Table 4 demonstrate that both FPN and BiFPN exhibit lower detection accuracy compared to the default PANet. In contrast, the EFO architecture achieves the best recognition performance, with a 73.9% mAP. Particularly, it significantly improves the detection effect of Cr and Rs defects, with an 8.6% and 6.2% increase in AP values, respectively. This outcome highlights the capability of EFO to achieve cross-layer feature fusion by effectively integrating feature information at different scales. It filters out noisy background information, mitigates imbalances in feature importance, overcomes limitations in feature fusion, represents detailed information more accurately, and enhances the efficiency of feature reuse and fusion.
The impact of FEAM
Based on the aforementioned EFO, we have further developed the FEAM as a multi-scale feature fusion module. The objective of this module is to enhance the capture of detailed features associated with small-scale defects by mitigating information loss and providing diverse feature representations. This is achieved through an efficient layer-by-layer aggregation method and the introduction of reparameterization.
In Table 5, we present the results of our ablation experiments on EFO. It is observed that replacing either EFO or FEAM alone in the baseline model leads to a significant improvement in model performance. Specifically, EFO and FEAM individually achieve a mAP gain of 2.0% and 1.8%, respectively. Notably, when EFO and FEAM are combined, the results demonstrate the highly effective interaction and fusion of feature information at different scales within the EFO architecture by FEAM. This combination yields a mAP gain of 4.2% compared to YOLOv8s and a mAP gain of 2.2% compared to replacing EFO alone. Importantly, despite its small number of parameters and low computational requirements, FEAM significantly enhances the performance of the detector.
To visually demonstrate the effectiveness of FEAM in EFO, we employed heatmaps to visualize the output feature maps, as depicted in Fig. 6. Subfigures (b), (c), (d), and (e) represent the visual results of the baseline model, EFO replacement alone, FEAM alone, and the combined EFO and FEAM, respectively. By observing the images, we draw the following conclusions: When utilizing the baseline model, the feature maps exhibit vague activation regions, indicating that the learned feature representations have limited influence on defect recognition. However, upon employing either EFO or FEAM, the feature maps display significantly pronounced regions in the areas corresponding to the defect objects. This enhancement suggests an intensified focus on specific semantic information, thereby improving the perception of semantic details across different image positions. Importantly, after undergoing multi-scale feature aggregation and enhancement (depicted in image (e)), the feature maps become more sparse, showcasing more distinct semantic representations. In comparison to images (b), (c), and (d), the feature map (e) encompasses multiple scales of defect regions, effectively highlighting the defect areas while suppressing the background regions. Consequently, it enables more accurate identification of small defect regions and exhibits superior representativeness.

The heatmap visualization of the output feature maps from the FEAM module in the EFO structure
Comparison of different IOU loss functions
The effectiveness of the WIOU loss function is further demonstrated through a comparison of different IOU loss functions in terms of detection performance. Table 6 presents the results of the comparison, clearly indicating that WIOU achieves the highest mAP of 74.1%. It particularly excels in defect detection for Pa and Rs, with significant advantages and AP values of 97.1% and 54.6%, respectively. On the other hand, other IOU variants such as GIOU, EIOU, and SIOU show a decrease in mAP compared to the initial CIOU. This decrease can be attributed to the fact that these IOU variants primarily focus on penalizing based on distance measurement, without effectively addressing the impact of low-quality examples on the BBR loss. As a result, these variants lead to inferior detection performance. In contrast, the WIOU loss function proposed in this paper overcomes these limitations by utilizing a dynamic non-monotonic focal mechanism to assign gradient gains strategically. This approach effectively mitigates the adverse gradient effects caused by poorer anchor frames, resulting in an overall improvement in the model’s performance.
Ablation experiments of integrated modules
The results of ablation experiments for each integrated module are presented in Table 7. It can be observed that replacing the backbone network in the baseline model with LDD led to a 15% reduction in model parameters, a 1.3% increase in mAP, and a 7.0% increase in FPS. These findings demonstrate the effectiveness of the proposed PConv operator in reducing parameters and GFLOPs compared to static convolution, while enhancing feature extraction capabilities. Subsequently, a new feature fusion network called EFO was introduced on top of the lightweight backbone, resulting in a 2.0% increase in mAP. This result highlights the effectiveness of the EFO structure, which incorporates cross-scale connectivity to facilitate better feature integration for large-scale differences. This addresses the inherent feature misalignment problem in the FPN structure. Furthermore, incorporating the lightweight FEAM module from EFO to enhance features at the transition layer further improved the model’s performance in terms of parameters and efficiency. This enhancement yielded a substantial accuracy gain of 2.2% mAP at a lower cost. The FEAM module, by aggregating multi-scale features, enhances the perception of fine details in deep features and incorporates semantic information from shallow features. It effectively complements global information at different semantic levels, thereby enhancing the detection performance of small targets. Finally, the introduction of the WIOU function optimized the model’s learning ability for low-quality samples, aiding in defect localization and improving the network’s detection capability. The accuracy performance, with an improvement of 2.1% in mAP, confirms the importance of the detector in weighing the learning of low-quality samples against high-quality samples.
Overall, the integration of our proposed method into the baseline model achieves substantial improvements in accuracy while reducing computational complexity. It is important to note that this improvement comes at the cost of a slightly slower inference speed.
Comparison with the state-of-the-art methods in various datasets
To evaluate the performance of our proposed DFFNet algorithm, we conducted comparisons with various methods using the publicly available NEU-DET dataset. Furthermore, to assess its generalization ability and practicality on diverse datasets, we tested DFFNet on the widely-used PASCAL VOC and MS COCO datasets.
Detection performance on NEU-DET
The comparison results of the proposed DFFNet model with various methods on the NEU-DET dataset are presented in the Table 8. The findings demonstrate that the DFFNet model exhibits remarkable advantages, including the lowest number of model parameters (10.3 M) and computational effort (24.5GFLOPs). Additionally, it achieves a faster inference speed of 101fps while maintaining a highly competitive accuracy of 80.2% mAP.
When compared to two-stage models such as Faster R-CNN (71.3% mAP), MSC-DNet (79.4% mAP), CANet (75.4% mAP), and DNN (82.3% mAP), the DFFNet model demonstrates a noteworthy improvement in mAP by 8.9%, 0.8%, and 4.8%, respectively. Although there remains a 2.1% difference in mAP compared to the highest-performing DNN model, it is crucial to highlight that the inference speed of two-stage methods falls short of real-time requirements, not exceeding 30fps. In contrast, the DFFNet model achieves a significantly faster inference speed of 101fps, making the slight difference in accuracy compared to the DNN model negligible due to its superior speed. When compared to popular one-stage models such as SSD and YOLO frameworks (e.g., YOLOv3, YOLOv4, YOLOv5, YOLOX, YOLOv7, YOLOv8), DFFNet demonstrates a remarkable advantage in model accuracy, outperforming them by 5%, 6%, 7%, 8%, 9%, and 10% in mAP, respectively. This indicates that DFFNet achieves a substantial accuracy gain with only a minor speed loss, highlighting its practicality as an efficient and accurate one-stage method that maintains efficiency despite the significant increase in accuracy. Furthermore, our method exhibits a more balanced performance across all metrics compared to other state-of-the-art methods (e.g., ES-Net, DCAM-Net, CS-YOLO, RDD-YOLO, etc.). While many frameworks solely focus on improving detection accuracy, they often overlook the limitation of computational resources, making it challenging to apply them in real industrial production platforms. Although the DFFNet model does not reach the state-of-the-art in terms of mAP, it still achieves a competitive result of 80.2 mAP, which is significantly higher than previous methods.
It is worth emphasizing that DFFNet is specifically designed as a lightweight network, prioritizing the reduction of computational complexity while ensuring high accuracy and real-time performance. This focus on efficiency greatly enhances its suitability for industrial scenarios.
Figure 7 showcases the visualized detection results of DFFNet on the NEU-DET dataset, highlighting its exceptional performance in accurately detecting various types of defects. Each column in the figure corresponds to a specific defect type. Benefiting from the efficient multi-scale fusion technique of DFFNet and its powerful localization capability, this method demonstrates remarkable accuracy in identifying small defects located at the edges or those with indistinct contours, even amidst complex backgrounds. Notably, columns 2, 3, and 6 exemplify the method’s ability to accurately detect fuzzy and small defects, further affirming the reliability and efficiency of our approach in defect detection.

Visualization of DFFNet inspection examples. (a) crazing, (b) inclusion, (c) patches, (d) pitted surface, (e) rolled-in scale, and (f) scratches
Generalization experiments
To further evaluate the effectiveness and generalization capability of the proposed method, DFFNet, we conducted training and testing on two widely used benchmark datasets: PASCAL VOC and MS COCO. Comparing the results with the baseline test results on the respective datasets (see Table 9; Fig. 8). The findings presented in Table 9 clearly demonstrate the it is evident that our method achieved commendable performance even without optimizing the dataset. Notably, on the PASCAL VOC dataset, our proposed enhancement strategies led to significant accuracy gains at low computational costs. Compared to the baseline YOLOv8s, our method achieved a remarkable increase in mAP@0.5 from 78.5 to 81.1% and mAP @0.5:0.95 from 57.7 to 59.8%. This result highlights the superiority of our method and emphasize the effectiveness of the introduced refinements in enhancing the overall framework. Meanwhile, a certain performance improvement was also achieved on the publicly available MS COCO dataset. By incorporating the proposed optimization techniques, DFFNet outperformed YOLOv8s with a 10% increase in mAP @0.5, a 4% increase in mAP @0.5:0.95, and a 5% increase in APs metrics. These results validate the reliability and efficiency of our feature fusion approach, especially for accurate detection of small-sized objects.
Moreover, Fig. 8 visually compares the detection results between DFFNet and YOLOv8s on the PASCAL VOC and MS COCO datasets, highlighting the superior performance of DFFNet in detecting small objects within diverse and complex scenes. These results serve as compelling evidence of the robust generalization capability of our method, showcasing its effectiveness in challenging general scenarios.

Detection results of Yolov8s and our method on PASCAL VOC and MS COCO val set
Discussion
Trade-off among model parameters, detection accuracy, and real-time performance
Figure 9 provides a comprehensive evaluation of the overall performance of the DFFNet model on the NEU-DET dataset, revealing the trade-off relationship between model parameters, detection accuracy, and real-time capability. In the left subplot of Fig. 9, it can be observed that DFFNet achieves a clear trade-off between parameters and accuracy. It achieves an optimal detection accuracy of 80.2% mAP with the fewest parameters, outperforming the high-accuracy MSC-DNet two-stage method, which uses nearly one-third of its parameters to achieve a similar accuracy level. Meanwhile, compared to the one-stage SOTA method DCAM-Net, DFFNet demonstrates good accuracy performance even with lower model parameters, highlighting its excellent trade-off between parameters and accuracy.
Moreover, the right subplot of Fig. 9 illustrates the trade-off between detection accuracy and inference speed. It can be observed that DFFNet achieves the fastest inference speed (101 FPS) among other state-of-the-art methods while maintaining good accuracy performance. This demonstrates the outstanding real-time performance of DFFNet, meeting the requirements of practical applications. In summary, DFFNet achieves a good trade-off between computational complexity, detection accuracy, and real-time performance. This indicates its capability for real-time and efficient defect detection in situations with limited computational resources, providing strong support for practical industrial applications.

Trade-off between model parameters, detection accuracy and inference speed for DFFFNet and state-of-the-art methods
Analysis for failure cases
After testing DFFNet on the NEU-DET dataset, we generated the precision-recall (PR) curve, as shown in Fig. 10. The obtained results indicate notable challenges in accurately detecting certain difficult-to-detect categories, such as crazing and rolled-in-scale, which exhibit relatively low detection accuracy and high failure rates. To gain deeper insights into the reasons behind these detection failures, we analyzed some failure cases of DFFNet on the NEU-DET dataset, as illustrated in Fig. 11. Our observations reveal that DFFNet encounters difficulties when dealing with extreme background interference and irregularly shaped defects, resulting in false detections and missed detections. The primary contributing factors to these challenges lie in the small size, dispersed distribution, and unclear boundaries of these defects. The confusion between the background and defects often leads to adjacent defects being erroneously detected as a single defect region, further complicating the detection task.
To address the aforementioned challenges, future work can consider the following strategies:
-
1.
Implement more efficient preprocessing techniques, such as advanced image enhancement and denoising methods, to enhance image clarity and quality. This can effectively accentuate defect contours and improve the accuracy of defect detection.
-
2.
Incorporate data augmentation using generative models to generate synthetic defect images with diverse backgrounds and appearances. By expanding the dataset in this manner, the algorithm’s robustness can be strengthened, enabling it to perform well under various background conditions.
-
3.
Reduce the dependency on labeled samples by incorporating semi-supervised learning techniques. By leveraging partially labeled data, the algorithm can learn the relationships and interactions between defect and background regions, leading to improved generalization capabilities in defect detection.

The precision-recall (PR) curve plotted based on the test results of DFFNet on the NEU-DET dataset

The instances of detection failure in DFFNet. In the image, (a) represents the actual bounding box, (b) shows the detection result of the model, and (c) visualizes the true positives (TP), false positives (FP), and false negatives (FN). The visualization adopts a color scheme: a green border signifies correct detection by the model, a red border indicates missed detection, and a blue border represents incorrect detection
Conclusion
In this study, we propose DFFNet, a novel lightweight and high-performance approach for accurate and rapid surface defect detection in steel strips, especially in scenarios with limited computational resources. The network utilizes PConv for the design of the backbone network structure, which effectively reduces computational complexity while capturing comprehensive defect feature representations. To enhance the interaction between feature fusion information flows, we incorporate an efficient feature-optimized converged network and a feature enhancement aggregation module during the feature fusion stage. This promotes diversity and effectiveness in capturing multi-scale features, mitigating the impact of complex background interference and the loss of small-sized features. Additionally, we adopt the WIoU loss function to enhance bounding box fitting capability and improve defect localization performance.
Experimental results on the NEU-DET dataset demonstrate that DFFNet offers advantages such as low computational complexity, high detection accuracy, and real-time performance compared to state-of-the-art methods, making it suitable for deployment in industrial settings with limited resources. Furthermore, evaluation on the PASCAL VOC and MS COCO datasets confirms the method’s strong generality and generalization ability. However, we also observed issues of false detection and missed detection when dealing with extreme background interference and irregular-shaped defects. To further enhance defect detection performance, our future work will focus on exploring image preprocessing techniques to improve contrast and reduce noise interference. Additionally, we plan to investigate data augmentation strategies and semi-supervised algorithms to reduce data sample requirements and enhance the model’s generalization performance.
References
Zhang S, Su L, Gu J, Li K, Wu W, Pecht M (2024) Category-level selective dual-adversarial network using significance-augmented unsupervised domain adaptation for surface defect detection. Expert Syst Appl 238:121879
Pang W, Tan Z (2024) A steel surface defect detection model based on graph neural networks. Meas Sci Technol 35:046201
Shen T, Li B (2024) Digital twins in additive manufacturing: a state-of-the-art review. Int J Adv Manuf Technol, 1–30
Liu J, Xie G, Wang J, Li S, Wang C, Zheng F, Jin Y (2024) Deep industrial image anomaly detection: a survey. Mach Intell Res 21:104–135
Wang C, Wei X, Jiang X (2024) An automated defect detection method for optimizing industrial quality inspection. Eng Appl Artif Intell 127:107387
Zhang L, Chen J, Chen J, Wen Z, Zhou X (2024) LDD-Net: Lightweight printed circuit board defect detection network fusing multi-scale features. Eng Appl Artif Intell 129:107628
Alenizi J, Alrashdi I (2023) SFMR-SH: Secure framework for mitigating ransomware attacks in smart healthcare using blockchain technology
Mohamed Z, Ismail M, Abd El-Gawad A (2023) Sustainable supplier selection using neutrosophic multi-criteria decision making methodology. Sustain Mach Intell J, 3
Nabeeh N (2023) Assessment and contrast the sustainable growth of various road transport systems using intelligent neutrosophic multi-criteria decision-making model
Liang Y, Li J, Zhu J, Du R, Wu X (2023) B.J.I.T.o.I. Chen, Measurement, a Lightweight Network for Defect Detection in Nickel-plated. Punched Steel Strip Images
Lu H, Fang M, Qiu Y, Xu WJIToI (2022) Measurement, an Anchor-Free defect detector for complex background based on Pixelwise Adaptive Multiscale Feature Fusion. 72:1–12
Saberironaghi A, Ren J, El-Gindy M (2023) Defect detection methods for industrial products using deep learning techniques: a review. Algorithms 16:95
Singh SA, Kumar AS, Desai K (2023) Comparative assessment of common pre-trained CNNs for vision-based surface defect detection of machined components. Expert Syst Appl 218:119623
Tang B, Chen L, Sun W, Lin Zk (2023) Review of surface defect detection of steel products based on machine vision. IET Image Proc 17:303–322
Chen M, Yu L, Zhi C, Sun R, Zhu S, Gao Z, Ke Z, Zhu M, Zhang YJCiI (2022) Improved faster R-CNN for fabric defect detection based on Gabor filter with genetic algorithm optimization. 134:103551
Liu R, Huang M, Gao Z, Cao Z, Cao PJM (2023) MSC-DNet: an efficient detector with multi-scale context for defect detection on strip steel surface, 112467
Hou W, Jing H (2024) RC-YOLOv5s: for tile surface defect detection. Visual Comput 40:459–470
Chen P, Li R, Fu K, Zhong Z, Xie J, Wang J, Zhu J (2024) A cascaded deep learning approach for detecting pipeline defects via pretrained YOLOv5 and ViT models based on MFL data. Mech Syst Signal Process 206:110919
Wu H, Li B, Tian L, Feng J, Dong C (2024) An adaptive loss weighting multi-task network with attention-guide proposal generation for small size defect inspection. Visual Comput 40:681–698
Zhang Y, Zhang H, Huang Q, Han Y, Zhao M (2024) An anchor-free network with DsPAN for small object detection of multiscale defects. Expert Syst Appl 241:122669
Wang J, Xu G, Yan F, Wang J, Wang ZJM (2023) Defect transformer: an efficient hybrid transformer architecture for surface defect detection. 211:112614
Zhao C, Shu X, Yan X, Zuo X, Zhu FJM (2023) RDD-YOLO: a modified YOLO for detection of steel surface defects. 214:112776
Terven J (2023) D.J.a.p.a. Cordova-Esparza, A comprehensive review of YOLO: From YOLOv1 to YOLOv8 and beyond
Ju R-Y (2023) W.J.a.p.a. Cai, Fracture Detection in Pediatric Wrist Trauma X-ray Images Using YOLOv8 Algorithm
Chen J, Kao S-h, He H, Zhuo W, Wen S, Lee C-H, Chan S-HG (2023) Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12021–12031
Wang C-Y, Liao H-YM (2022) I.-H.J.a.p.a. Yeh. Designing Network Design Strategies Through Gradient Path Analysis
Ding X, Zhang X, Ma N, Han J, Ding G, Sun J (2021) Repvgg: Making vgg-style convnets great again, Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 13733–13742
Vasu PKA, Gabriel J, Zhu J, Tuzel O, Ranjan A (2023) MobileOne: An Improved One Millisecond Mobile Backbone, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7907–7917
Ma N, Zhang X, Zheng H-T, Sun J (2018) Shufflenet v2: Practical guidelines for efficient cnn architecture design, Proceedings of the European conference on computer vision (ECCV), pp. 116–131
Tang Y, Han K, Guo J, Xu C, Xu C (2022) Y.J.a.p.a. Wang, GhostNetV2: Enhance Cheap Operation with Long-Range Attention
Li J, Hassani A, Walton S, Shi H (2023) Convmlp: Hierarchical convolutional mlps for vision, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6306–6315
Sunkara R, Luo TJPR (2023) Deep object detection in the wild with lightweight feature learning and multiscale attention. 139:109451
Li H, Li J, Wei H, Liu Z, Zhan Z (2022) Q.J.a.p.a. Ren, Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles
Gong Y, Yu X, Ding Y, Peng X, Zhao J, Han Z (2021) Effective fusion factor in FPN for tiny object detection, Proceedings of the IEEE/CVF winter conference on applications of computer vision, pp. 1160–1168
Liu S, Qi L, Qin H, Shi J, Jia J (2018) Path aggregation network for instance segmentation, Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 8759–8768
Ghiasi G, Lin T-Y, Le QV (2019) Nas-fpn: Learning scalable feature pyramid architecture for object detection, Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 7036–7045
Tan M, Pang R, Le QV, Efficientdet (2020) Scalable and efficient object detection, Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10781–10790
Rezatofighi H, Tsoi N, Gwak J, Sadeghian A, Reid I, Savarese S (2019) Generalized intersection over union: A metric and a loss for bounding box regression, Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 658–666
Zhang Y-F, Ren W, Zhang Z, Jia Z, Wang L, Tan TJN (2022) Focal and efficient IOU loss for accurate bounding box regression. 506:146–157
Z.J.a.p.a. Gevorgyan, SIoU loss: More powerful learning for bounding box regression, (2022)
Tong Z, Chen Y, Xu Z (2023) R.J.a.p.a. Yu, Wise-IoU. Bounding Box Regression Loss with Dynamic Focusing Mechanism
Hu X, Li X, Huang Z, Chen Q, Lin S (2023) Detecting tea tree pests in complex backgrounds using a hybrid architecture guided by transformers and multi-scale attention mechanism. J Sci Food Agric
Zheng Z, Wang P, Liu W, Li J, Ye R, Ren D (2020) Distance-IoU loss: Faster and better learning for bounding box regression, Proceedings of the AAAI conference on artificial intelligence, pp. 12993–13000
Xing J, Jia MJM (2021) A convolutional neural network-based method for workpiece surface defect detection. 176:109185
Hou X, Liu M, Zhang S, Wei P, Chen BJPR (2023) CANet: Contextual Information and Spatial Attention Based Network for Detecting Small Defects in Manufacturing Industry. 140:109558
Wang W, Mi C, Wu Z, Lu K, Long H, Pan B, Li D, Zhang J, Chen P, Wang B (2022) A Real-Time Steel Surface Defect Detection Approach with High Accuracy. IEEE Trans Instrum Meas 71:1–10
Kou X, Liu S, Cheng K, Qian YJM (2021) Development of a YOLO-V3-based model for detecting defects on steel strip surface. 182:109454
Redmon J (2018) A.J.a.p.a. Farhadi, Yolov3: An incremental improvement
Bochkovskiy A, Wang C-Y (2020) H.-Y.M.J.a.p.a. Liao, vol 4. Optimal speed and accuracy of object detection, Yolov
Zhu X, Lyu S, Wang X, Zhao Q, TPH-YOLOv5 (2021) : Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios, Proceedings of the IEEE/CVF international conference on computer vision, pp. 2778–2788
Ge Z, Liu S, Wang F, Li Z (2021) J.J.a.p.a. Sun, Yolox: Exceeding yolo series in 2021
Wang C-Y, Bochkovskiy A, Liao H-YM (2023) YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7464–7475
Cheng X, Yu JJIToI, Measurement (2020) RetinaNet with difference channel attention and adaptively spatial feature fusion for steel surface defect detection. 70:1–11
Tian R, Jia MJM (2022) DCC-CenterNet: a rapid detection method for steel surface defects. 187:110211
Yu J, Cheng X, Li QJIToI (2021) Measurement, surface defect detection of steel strips based on anchor-free network with channel attention and bidirectional feature fusion. 71:1–10
Yu X, Lyu W, Zhou D, Wang C (2022) W.J.I.T.o.I. Xu, Measurement, ES-Net: efficient scale-aware network for tiny defect detection. 71:1–14
Qian X, Wang X, Yang S, Lei JJIA (2022) LFF-YOLO: a YOLO Algorithm with Lightweight Feature Fusion Network for Multi-scale defect detection. 10:130339–130349
Wang Y, Wang H, Xin ZJIA (2022) Efficient Detection Model of Steel Strip Surface defects based on YOLO-. V7:133936–133944
Chen H, Du Y, Fu Y, Zhu J, Zeng HJIToI (2023) Measurement, DCAM-Net: a Rapid Detection Network for Strip Steel Surface defects based on deformable convolution and attention mechanism. 72:1–12
Yu X, Lyu W, Wang C, Guo Q, Zhou D (2023) K.-B.S. Xu, Progressive refined redistribution pyramid network for defect detection in complex scenarios. 260:110176
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hu, X., Lin, S. DFFNet: a lightweight approach for efficient feature-optimized fusion in steel strip surface defect detection. Complex Intell. Syst. (2024). https://doi.org/10.1007/s40747-024-01512-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40747-024-01512-1