
Abstract
As a practical and challenging task, deep learning-based methods have achieved effective results for fabric defect detection, however, most of them mainly target detection accuracy at the expense of detection speed. Therefore, we propose a fabric defect detection method called PEI-YOLOv5. First, Particle Depthwise Convolution (PDConv) is proposed to extract spatial features more efficiently while reducing redundant computations and memory access, reducing model computation and improving detection speed. Second, Enhance-BiFPN(EB) is proposed based on the structure of BiFPN to enhance the attention of spatial and channel feature maps and the fusion of information at different scales. Third, we improve the loss function and propose IN loss, which improves the problem that the original IOU loss is weak in detecting small targets while speeding up the convergence of the model. Finally, five more common types of defects were selected for training in the GuangDong TianChi fabric defect dataset, and using our proposed PEI-YOLOv5 with only 0.2 Giga Floating Point Operations (GFLOPs) increase, the mAP improved by 3.61%, reaching 87.89%. To demonstrate the versatility of PEI-YOLOv5, we additionally evaluated this in the NEU surface defect database, with the mAP of 79.37%. The performance of PEI-YOLOv 5 in these two datasets surpasses the most advanced fabric defect detection methods at present. We deployed the model to the NVIDIA Jetson TX2 embedded development board, and the detection speed reached 31 frames per second (Fps), which can fully meet the speed requirements of real-time detection.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Textiles are an integral part of people's daily lives. As a basic industry, the textile industry occupies an important position in the world industry, so it is vital to ensure the quality of cloth production. In the actual production of cloth, the surface of cloth suffers from many defects due to material quality, mechanical factors, dye type, yarn size, and human factors. Common cloth defect samples are shown in Fig. 1. The resulting defects will not only affect the quality of the product but also cause huge waste [1, 2]. Fabric surface defect detection has become one of the key processes in industrial production, but many factories still use manual inspection, which is costly, inefficient, and subjective, long time the inspection will make workers' eyes fatigue, increase the length of inspection, reduce accuracy, and very easy to have a wrong inspection and missed inspection. Therefore, a real-time fabric defect detection system needs to be developed to improve detection efficiency, reduce labor costs, and increase business benefits.

Five common types of fabric defects (a) Broken hole; (b) Flower board; (c) Pulp spot; (d) Three threads; (e) Stain
As neural networks have been proposed, more and more problems can be solved by various neural networks and their variants, such as nonlinear problems [3,4,5], target detection [6], target segmentation [7], dynamical system control [8,9,10,11], prediction of complex systems [12, 13], natural language processing [14], etc. The continuous development of neural networks also provides an important tool in the field of fabric defect detection. At present, object detection models are divided into two main categories: (1) two-stage. The well-known one is the Region-CNN(R-CNN) [15] model, which generates a large number of candidate frames by selective search [16], followed by classification and regression of the candidate frames by CNN. Compared with the traditional methods, R-CNN significantly improves the accuracy of detection but brings a huge amount of computation. Although subsequent faster methods such as FastR-CNN [17] and FasterR-CNN [18] have been proposed, they still cannot solve the problem that two-stage detection methods cannot achieve real-time detection. (2) One-stage. The well-known one is you only look once (YOLO) model. The one-stage approach does not have a separate proposal generation phase. YOLOv5 is a very popular single-stage object detection method that can achieve a balance between speed and accuracy at the same time. Compared with the two-stage FasterR-CNN, its pair performs classification and regression only once, which greatly reduces the computational complexity and improves the detection efficiency. Improved feature extraction and feature fusion by deeper backbone and Neck. However, it is challenging to directly apply YOLOv5 to fabric defect detection, because there are many defects with similar color and background texture (such as Fig. 1(e)), and the size of the defect is greatly different (such as Fig. 1a, b), and the long The difference in aspect ratio is large (such as Fig. 1d), and there are many small objects (such as Fig. 1a), making it difficult to perform effective detection.
We propose a PEI-YOLOv5 defect detection network to achieve fast and accurate real-time detection, considering the development needs of defect detection models for embedded system deployment and real-time detection in real production. The network has the following features: (a) modifying the backbone network structure by replacing the last C3 module in the original backbone with the PDC3 module proposed in this paper, which can effectively reduce the model FLOPs and improve the feature extraction capability at the same time. (b) Improve the feature fusion part, using the EB-2 and EB-3 modules proposed in this paper enhances the fusion of defect spatial information and channel information, especially for the detection of defects similar to the background and extreme aspect ratio defects. (c) Improving the loss function, IN loss significantly improves the detection ability of small target defects and the model convergence speed through the integration of normalize Wasserstein distance and CIOU.
The contributions of this paper are as follows:
-
(1)
A faster convolution-PDConv is proposed, which can effectively extract spatial features and still obtain accuracy improvement while reducing the number of parameters to improve the detection speed.
-
(2)
The EB module is proposed to enhance the attention to the defective channels and spatial information, making full use of the multi-scale feature information.
-
(3)
IN loss is proposed to improve the detection capability of small targets and effectively accelerate the model convergence speed.
-
(4)
We evaluate the proposed PEI-YOLOv5 on a portion of the GuangDong Tianchi dataset and the NEU surface defect database, respectively. The experimental results exceed the current state-of-the-art target detection algorithms.
-
(5)
PEI-YOLOv5 was deployed to NVIDIA Jetson TX2, and the detection speed reached 31 FPS, which is larger than the 30 FPS required for real-time detection
Related work
Fabric defect detection
Currently, cloth defect detection algorithms are divided into two main categories: traditional algorithms and learning-based algorithms [19, 20] combined saliency image features with an improved anisotropic filter to extract features of fabric defects, considering both local gradient magnitude and a modified saliency map based on the original anisotropic diffusion model, which removes the background information of the fabric while preserving the defect edges. Shi et al. [21] proposed a fabric defect detection method based on gradient low-rank decomposition and structured graph algorithm, which first divides the defective image into non-defective and defective regions, prevents the merging of defective and non-defective regions by setting an adaptive threshold during the merging process, and finally uses the a priori information of the segmentation results to guide the matrix decomposition. In addition, there are methods to achieve fabric defect detection using statistical methods [22, 23], discrete cosine transforms [24, 25], model-based [26, 27].
With the development of computer science, learning-based approaches for fabric defect detection are becoming more and more popular, especially CNN-based methods have attracted many researchers to conduct research and achieve satisfactory results [28]. Wang et al. [29] proposed an adaptively fused attention module for the problem of difficult detection of tiny fabric defects, which enhances the spatial and channel feature maps and the attentional information flow between them, enabling the detector to better capture inconspicuous small targets, and achieves MS-COCO and CioF datasets with excellent performance on MS-COCO and CioF datasets. However, this method only obtained 12.19 FPS on RTX3090, which could not achieve real-time detection. Liu et al. [30] proposed a framework for fabric defect detection via generative adversarial networks, specifically customizing a deep semantic segmentation network for detecting different defect types and training a Multistage GAN to synthesize reasonable defects in new defect-free samples. The method is capable of continuously updating the fabric defect dataset and tuning the semantic segmentation network with good performance on multiple datasets. Chen et al. [31] addressed the problem of fabric texture interference by fusing Gabor kernels into a FasterR-CNN and trained the model using a two-stage training approach to effectively identify various backgrounds, locations, and defects. Although the above methods have made a breakthrough in detection accuracy, they have neglected detection speed. In the actual factory production, the running speed of the fabric on the conveyor is very fast, which requires the detector to have a high detection speed to realize the accurate detection of fabric defects.
Attention Mechanism.
The ability of humans to tend to focus on a certain part of the information they need in complex and diverse scenarios of real life and ignore other unimportant information is a means for humans to quickly obtain valuable information from a large amount of information using their limited information processing power. Attentional mechanisms were introduced into computer vision with the aim of mimicking this aspect of the human visual system [32]. Attention mechanisms currently play a huge role in computer vision, and can greatly improve the ability of models to capture remote information and run faster. Hu et al. [33] proposed channel attention and used it to propose SENet, which is mainly composed of squeeze-and-excitation (SE) blocks, which can effectively acquire global information, model the relationship between channels and adaptively adjust the features of channels accordingly with a computational. The computational complexity is low. However, the overly simple average pooling of SE block, which only considers channel information and ignores location information, makes it difficult to obtain complex global information. To address the problem that the global average pooling of SE block is too simple, Gao et al. [34] used global second-order pooling (GSoP) block to improve it, which enhances the access to global information to some extent, but this also adds many extra computations. Spatial attention is capable of adaptively selecting locations in spatial regions that require attention, and RAM [35], STN [36], and GENet [37] have achieved better results using spatial attention mechanisms. The convolutional block attention module (CBAM) proposed by Woo et al. [38] ties channel attention to spatial attention and introduces global pooling to obtain global information, which can better inform the network of the content and location that needs attention, greatly improving computational efficiency. The method tries to exploit the location information by reducing the channel dimension of the input tensor after large-scale convolution. However, convolution can only capture local relationships. It cannot address the remote dependencies in vision tasks [39]. Therefore, Hou et al. [40] proposed coordinate attention, which fuses location information into channel attention to enable the network to acquire larger important regions with less computation. The coordinate attention structure is very simple, can be flexibly inserted into the classical network with small computational effort, and has achieved good performance on tasks such as classification tasks [41, 42], target detection [43, 44], and semantic segmentation [45].
Multi-scale feature fusion
Convolutional neural networks have a layer-by-layer structure, and the deeper the feature map is, the larger its perceptual field is, so feature maps of different depths in the network constitute a natural multi-scale representation. However, this structure has poor detection results for small targets. The underlying reason is that there is a significant semantic divide with different feature map depths and different feature representation capabilities. To address the above drawbacks, Lin et al. [46] proposed feature pyramid networks (FPN), which can fuse the fine-grained spatial information of shallow feature maps and the semantic information of deep feature maps to improve the detection of multi-scale targets. However, the top-to-bottom layer-by-layer fusion strategy of FPN is not optimal, so many improvements have emerged on top of it. Liu et al. [47] proposed PANet. Starting from the bottom layer of FPN, a bottom-up feature refusion side channel was added to ensure that the prediction of each target fully utilizes the information of all feature layers. Tan et al. [48] proposed BiFPN based on the FPN of PANet to construct EfficientDet. BiFPN removes the node with only one input, adds a connection between the input and output feature maps of the same scale to fuse richer features, and stacks the pyramid structure multiple times to enhance the feature expression ability. Figure 2 shows the structure diagrams of FPN, PANet, and BIFPN, respectively.

Three kinds of feature pyramid structure diagram
Methods
In this section, the overall structure of the proposed fabric defect detection model PEI-YOLOv5 is first introduced, followed by detailed descriptions of PDConv, EB module and IN loss, respectively.
The network structure of PEI -YOLOv5
The YOLO series algorithm is a typical representative of the CNN single-stage algorithm in the field of image target detection. YOLOv5 adopts CSPDarknet53 as the backbone network and converts feature input of arbitrary size into feature output of fixed size by feature map fusion of local features and global features through the SPPF module. By borrowing from PANet [50], a bottom-up path is added to FPN for better integration of semantic information at different scales. YOLOv5 is built with a simple and powerful application programming interface (API) easy to deploy, very developer friendly, and has a series of advantages such as lightweight, speed, and accuracy. However, the YOLOv5 model uses a large number of convolutions with stride of 2 for downsampling, which inevitably causes the loss of semantic information and makes the network ineffective in extracting and fusing defective features in fabric defective species with Brokenhole, Stain, three thread, Flowerboard, Pulpspot and a variety of defects of different sizes, which requires models that can effectively combine shallow and deep semantic information and features.
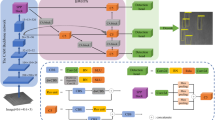
Among the types of fabric defects, there are targets with very small, extreme aspect ratios and large differences in shape, which place high demands on the detection capability of the detector. Therefore, to achieve high accuracy and speed for fabric defect detection, this study proposes the PEI-YOLOv5 detection network. Figure 3 shows the network structure of PEI-YOLOv5. Backbone is mainly responsible for feature extraction, and although it has better feature extraction ability, the large number of parameters will reduce the detection efficiency of the model. Combining PDConv with the last C3 module of backbone, i.e., PDC3 module, not only effectively reduces parameters of Backbone but also improves the detection accuracy. The Neck part uses the structure of FPN + PAN, which mainly fuses the contextual semantic features extracted by the backbone. In this study, EB module is proposed to replace the original PFN + PAN structure on the basis of BiFPN [51]. EB-2 has two inputs, and it uses CARAFE operator for up-sampling to achieve information interaction at different scales and adapt to different scenes and data, while the dimensionality of the feature map can be reduced, thus reducing the computational effort. The up-sampled features are then concatted with branches of the Backbone structure, and finally the CA module is used to enhance the acquisition of channel information and spatial information. The main difference between EB-3 and EB-2 is that the former has three inputs and does not require up-sampling operations. The feature map after the fusion of features in the Neck part needs to be input to the Head part with detection function for the prediction of the final result. The Head part expands the number of channels using 1 × 1 convolution for the multi-scale feature maps respectively, and the final number of channels obtained from the expansion is \(N \times (C + 5)\). Where, N is the number of anchors per detection layer; C represents the number of categories to be identified; 5 represents the information (x, y, w, h) used to detect the target BoundingBox and the confidence level P of the predicted target. The localization loss of YOLOv5 is implemented by IOU, and we find that IOU is very sensitive to the bbox offset of small targets and has limited detection ability for small targets such as Broken hole. Therefore, we propose IN loss, which integrates IOU and NWD, for enhancing the recognition of small targets and also for improving the network convergence speed.

PEI-YOLOv5 overall network structure diagram
Design of PDConv
In order to design neural networks with low computational complexity, reduce the requirement for computing equipment, many researchers have proposed effective methods [52] But these "fast" neural networks are not actually fast enough, and their reductions in floating point operations (FLOPs) do not translate into an exact reduction in latency, and in some cases, do not improve at all, or even lead to worse latency [57]. In our study, we extracted the visualized feature map in the YOLOv5 backbone network, as shown in Fig. 4. We found that there is a high degree of similarity between different channels of the input feature map, which results in high redundancy. Therefore, we propose PDConv. Figure 5a shows how PDConv works, which uses deepwise convolution for spatial feature extraction for only a part of the input channels and keeps the rest of the channels unchanged. Usually, we use the first or the last consecutive \(c_{d}\) channel for calculation as a representative of the whole input feature map. Assuming that the input feature map is \(c \times h \times w\) and the convolution kernel size is \(k \times k\), the number of input and output feature map channels is kept the same, so the FLOPs of PDConv are only:

The larger image in the upper left corner of the figure is the original defect image of the input, and the other images are the visualization results of different channels of the input image

PD Conv and PD block structure diagram
And the FLOPs for a normal Conv are:
In this paper, we take \(c_{d} = \frac{c}{4}\).
Note that the channels other than \(c_{d}\) cannot be removed because this would degrade PDConv to Deepwise Convolution, and we keep the remaining channels because we ensure that the feature information will flow through all channels in the subsequent convolution.
We construct the PD block based on the PDConv. It mainly consists of two paths: (1) A PDConv layer followed by two normal Conv of size \(1 \times 1\), and normalization and activation layers are added between the two \(1 \times 1\) Conv, aiming to keep the diversity of features and reduce the latency; (2) Add the original input to the output of the first path after shortcut operation to make full use of the information extracted from the features and protect the integrity of the information. The module structure is shown in Fig. 5b.
Finally, the PD block is combined with the C3 module of YOLOv5 to form the PDC3 module, whose structure is shown in Fig. 6. We replace the last C3 module in the backbone of YOLOv5 with a PDC3 module, reducing the number of parameters by about 44.1%. The comparison result is shown in Table 1.

PDC3 module structure diagram
EB module
The high level feature map has a deeper abstraction of the target, contains sufficient global information, has a larger perceptual field and a stronger ability to represent contextual semantic information, so the determination of the target location is more accurate; while the spatial resolution of the low level feature map is higher than that of the high level feature map, which can more accurately identify more detailed information such as edges, contours and textures, and make accurate determination of the target class. In order to better fuse multi-scale features, we propose the EB module. Compared with EB-2, EB-3 adds one more input to more effectively fuse different multi-scale features and does not require any more up-sampling operations, and after concat operations, the same attention mechanism is used to enhance the focus on defective information. The specific structure diagram is shown in Fig. 7.

EB structure diagram
Content-Aware ReAssembly of Features
The upsampling operator used in YOLOv5 is nearest neighbor interpolation, which guides the upsampling process by the spatial distance between pixels, and since only subpixel neighborhoods are considered, some semantic information is missing. Therefore, we use the Content-Aware ReAssembly of Features (CARAFE) [49] operator for upsampling operations in the EB-2 module. The CARAFE operator can achieve information interaction at different scales, adapt to different scenes and data, and at the same time can reduce the dimensionality of the feature map, thus reducing the computational effort.
The CARAFE operator consists of two components: the kernel prediction module and the feature Reassembly Module. For the feature map with input shape \(C \times H \times W\), the former firstly compresses the feature map channels to \(C_{m}\) to reduce the computation, secondly generates recombination kernels through the encoder with parameter \(k_{encoder}^{2} \times C_{m} \times C_{up}\), and finally normalizes each recombination kernel; the latter recombines the features within the local area of each kernel through the content-aware recombination module. The CARAFE operator achieves multi-scale information interaction to enhance the accuracy and robustness. In addition to this, while realizing multi-scale information interaction, it reduces the dimensionality of the feature map, decreases the computation, speeds up the network training, and reduces the inference speed.
Coordinate attention and skip layer connection
The attention mechanism can enhance the model's ability to focus on key information and ignore other irrelevant information, which has brought a good performance improvement to the deep neural network. In fabric defect detection, there are stain defects that are similar in color to the background, which are difficult for human eyes to distinguish, and the attention mechanism that determines the attention of the defect region features can attenuate the interference of the background information of stain defects and improve the detection ability of the network for this defect. Coordinate attention enables the network to fully capture the information of a larger region while avoiding huge computational overhead, enhancing the channel, spatial, and global information acquisition capabilities. In our EB module, the number of channels increases after concat operation for different feature maps, and the channels contain semantic information of different levels of input objects, so adding CA module after each concat can effectively use the channel information and spatial information to enhance the attention to the defect location.
Figure 8 shows the network structure of CA module. In order to obtain attention on width and height of the feature maps and encode the exact position, the input feature maps are average pooling in the x and y directions to obtain the feature maps \(z_{c}^{h} (h)\) and \(z_{c}^{w} (w)\) in both directions, respectively.

Coordinate attention module structure diagram
After stitching the feature map, the channels are downscaled to using the convolution module, and the spatial information is encoded by BN and Non-linear activation function \(\delta\), and then obtain the feature map \(f\).
Then \(f\) is decomposed into two independent feature maps \(f^{h}\) and \(f^{w}\), so that their dimensions are consistent with the input feature map. Two others \(1 \times 1\) convolutions and sigmoid functions are used for feature transformation to obtain \(g^{h}\) and \(g^{w}\), respectively.
Finally, the results of each part are combined to obtain the output of the CA module.
Since the maximum pooling of SPPF loses much semantic information and we are more concerned about the defective location information, a new skip layer connection (red dashed line) is added before F4 of Fig. 7. The feature fusion is enhanced while retaining the deep location semantic information.
IN loss function
The loss function is used to measure the distance between the predicted output and the expected output of the model, and the closer the two are the smaller the loss value. The loss function of YOLOv5 is mainly composed of position loss, confidence loss and classification loss. In this paper, the IOU of position loss is improved.
Figure 9 shows the visualization result after normalizing all the defective ground truth in the dataset. In the lower left corner of the figure, we can see that there are obvious dark areas, which indicates that there are more small targets in the dataset. The IOU is very sensitive to the offset of the small target bbox, as shown in Fig. 10. Specifically, for a small target with pixel size of \(5 \times 5\), a few pixels of position deviation will lead to a significant drop in IOU (from 0.39 to 0.03). And for larger size targets of \(40 \times 40\) pixels, the variation of IOU is small (from 0.91 to 0.75) for the same position deviation. Therefore, we propose the use of Normalized Wasserstein Distance (NWD) [58] in combination with IOU to improve the loss function.

Visualization of the results after normalizing all ground truth in the dataset

Sensitivity analysis of CIOU and IN for detecting tiny objects. Each grid represents one pixel, box A denotes the ground truth bounding box; box B, C denote the predicted bounding box with 1 pixel and 4 pixels diagonal deviation, respectively
Since the conventional bbox is represented by a rectangle, its corresponding IOU is more concerned with the fit between boxes, which is not good for the detection of small targets. Small targets are more concerned with localization, i.e., the target center location. The center weight of the two-dimensional projection of the 2D Gaussian distribution is the highest and gradually decreases from the center to both sides, therefore, using the 2D Gaussian distribution to fit the bbox is more consistent with the demand of small targets for bbox. The fitted two-dimensional Gaussian distribution \(N(\mu ,\sum )\) has:
where \(c_{x}\),\(c_{y}\) are the center coordinates of the bbox,\(w\),\(h\) are the length and height. After completing the two-dimensional Gaussian modeling of the bbox, the prediction frame is transformed with the real frame, which obeys \(A = N(\mu_{1} ,\sum_{1} )\) and \(B = N(\mu_{2} ,\sum_{2} )\), respectively. The second-order Wasserstein distance between A and B is defined as:
where \(\|\cdot\|_{F}^{2}\) the Frobenius norm.
However,\(W_{2}^{2} (A,B)\) is a distance metric and cannot be used as a similarity metric. Therefore, it is normalized to obtain NWD, and the expression is shown in Eq. (11).
c is a constant, determined by the average size of the target in the dataset.
The calculation formula of CIOU is as follows:
\(\alpha\) is the weight function;\(v\) is used to measure the similarity of the aspect ratio;\(w\) and \(w^{gt}\) represent the width of the bbox and the ground truth, respectively;\(h\) and \(h^{gt}\) represent the height of the bbox and the ground truth, respectively;\(b\) and \(b_{gt}\) represent the center point of the bbox and the ground truth, respectively;\(\rho\) represents the Euclidean distance between the two center points;\(c_{d}\) represents the diagonal distance of the smallest closure area that can contain both the bbox and the ground truth; \(S_{1}\) and \(S_{2}\) are the intersection area and union area of ground truth and bounding box, respectively.
Why not use NWD to replace CIOU? There are two main reasons: (1) NWD has a slow convergence rate and needs to increase the training epoch, which will lead to an increase in training time. (2) NWD is proposed for small target detection, while our dataset also contains many normal and larger targets, and using a combination of the two will give better results. The improved function is calculated as:
Among them \(r_{i}\) a proportional coefficient, and its value is proportional to the proportion of CIOU, and \(r_{i} = 0.6\) is taken in this paper.
As shown in the comparison in Fig. 10, the sensitivity of IN to small target offsets is much lower than that of CIOU, with a difference of 0.2888 from 0.591 to 0.3022, while the difference of CIOU to small target offsets is 0.363. Therefore, IN loss effectively improves the problem of CIOU being sensitive to small target offsets, enhances the detection ability of small target defects, and has good performance. We provide pseudo-code for PEI-YOLOv5 in Algorithm 1.

The pseudo-code of PEI-YOLOv5 Model
Experiments
Experimental environment and dataset
The experimental platform in this study is divided into two parts: (1) window host, which mainly trains the PEI-YOLOv5; (2) NVIDIA Jetson TX2, to which the trained network will be deployed for actual testing of fabric defect detection, and the environment parameters and training parameters settings are shown in Tables 2 and 3, respectively. Figure 11 shows the fabric defect detection device we used. It mainly consists of CCD industrial camera, HD lens, NVIDIA Jetson TX2, fabric to be tested and standard light source. We selected 5 common types of defects from defective images, namely Broken holes, Stains, Three threads, Flower boards and Pulp spots. 1637 images were selected, each with a resolution of \(2446 \times 1000\), including the location of the defect, each image has a resolution of \(2446 \times 1000\) and contains the specific location and type of defect.

Fabric defect detection device
Data augmentation
Since the number of various types of defects in the original dataset was very unevenly distributed, the number of Three threads was very large while the number of other defects was small. Therefore, we expanded the images other than those containing Three threads by random inversion and scaling to obtain 3253 images, which improved the sample size imbalance to some extent. Table 4 shows each defect category before and after dataset augmentation, and the total number. Although the number of defects in the Flower board category is relatively small compared to the other four categories, after testing we found that the AP of this category has reached 95.85% and no further expansion is needed. The expanded dataset is divided into training set, validation set and test set in the ratio of 8:1:1, and the statistics of the number of images after the division are shown in Table 5. As shown in Table 6, we also did statistics on the number of each defect in the training, validation and test set.
Performance metrics
To verify the effectiveness of PEI-YOLOv5, the model is evaluated using precision, recall, F1, AP, mAP, FPS and FLOPs.
The TP represented the number of positive samples predicted by the model as positive class, FP represented the number of negative samples predicted by the model as positive class and FN represented the number of positive samples predicted by the model as negative class. Precision was based on prediction results, predicting the correct proportions in positive sample. Recall refers to the ratio of samples that can be correctly identified among all positive samples to the entire positive samples. AP refers to the average accuracy rate of defects of the same category at different recall rates. mAP refers to the average AP value of each defect category, where J is the number of defect categories. FPS represents the number of images per second that the model can detect, the larger its value, the faster the detection speed. The full name of FLOPs is floating point operations, and its value is proportional to the complexity of the model.

Comparison chart of three kinds of loss
Loss convergence speed comparison
In "IN Loss function", we mentioned that changing IOU loss to NWD loss slows down the network convergence, while IN loss reduces the loss value and improves the network convergence speed. Figure 12 shows the comparison of loss curves for IOU loss (blue), NWD Loss only (orange) and IN loss (green) using YOLOv5. When using only NWD loss compared to Base, the two loss values are basically the same until about 20 epochs, and after epochs greater than 20 the NWD loss value is significantly larger than Base. The initial loss value of IN loss is significantly lower compared to the other two methods, and the loss value is much lower than Base and NWD throughout the training process, which makes the prediction value of the network closer to the true value and has better prediction ability.
Fabric defect recognition by attention mechanism
In EB module, the defect images are passed through the CA module, which enhances the focus of the model on the defect location. Figure 13 shows the visualization of fabric defect images based on the attention mechanism. The left side of it is the original image with ground truth labels, and the right side is the attention map of the original image. The position with more red color represents the stronger attention of the model to that position. Guided by the attention mechanism, EB module not only learns salient features from defective samples but also can focus more attention on the defective part of the image and ignore other irrelevant regions, thus performing feature fusion more effectively, especially enhancing the Stain defects with similar background color and Three thread defects with extreme aspect ratio detection capability.

Visualization of fabric defects based on attention mechanism
Comparison with other advanced methods
To further verify the effectiveness of PEI-YOLOv5, we compared it with Faster-rcnn, SSD, YOLOv3, YOLOv5n, YOLOX-tiny, YOLOv7-tiny and YOLOv8n. We compared the five fabric defect type AP values, mAP@0.5 and GFLOPs, of the above methods, respectively, as shown in Table 7. It can be seen from the table, our proposed PEI-YOLOv5 has advantages over the other seven methods in terms of accuracy and computation. The two-stage classic method Faster-RCNN achieved only 43.3% of mAP, because the original anchor size of the method is very different from the ground truth of the dataset, especially the category three threads, which is a very slender defect whose ground truth belongs to the extreme aspect ratio. Faster-RCNN only has an AP value of 3.95%. SSD and YOLOv3, which are both one-stage detection methods only obtained 72.95% and 75.09% of mAP with high GFLOPs. YOLOX-tiny and YOLOv7-tiny have similar GFLOPs and obtained 80.34% and 82.36% mAP respectively with reduced number of parameters and improved detection accuracy compared to SSD and YOLOv3. YOLOv8, the most advanced method to date, achieved 82.78% mAP with the further reduction of GFLOPs and obtained the highest AP value of 91.24% for the defective category Broken hole. Our method improves mAP by 3.61%–87.89% compared to YOLOv5n with only 0.2 GFLOPs increase, and the Stain defect category improves up to 7.99%. The best performance was achieved in the comparison experiment, and the highest accuracy was also achieved for all four categories except Broken hole.
We select one image in each defect category and show the results of the comparison of the eight tested models, as shown in Fig. 14, where the white number in the lower right corner of the image represents the AP value predicted by the model for that category. The predictions of the eight methods for the defect category are all correct, but except for YOLOv7-tiny, YOLOX-tiny and PEI-YOLOv5, all other methods do not predict defects. SSD and Faster-RCNN both appear to predict a single anchor box in ground truth as two for the defect categories Flower board and Pulp spot. Our PEI-YOLOv5 not only detects defects and correctly identifies defect categories, but also has high accuracy, demonstrating its good performance.

Detection results of five categories of defects on different models (a) Three threads; (b) Broken hole; (c) Stain; (d) Flower board; (e) Pulp spot
Ablation experiments
Our PEI-YOLOv5 makes three improvements on YOLOv5, and ablation experiments were performed to verify the effectiveness of one improvement, two improvements combined separately, and three improvements combined, as shown in Table 8. Where Base is the original YOLOv5n with 84.28% mAP and 4.1 GFLOPs. By adding PDConv, the parameter is reduced by about 7.4% and the GFLOPs are reduced by 0.1. The highest FPS is obtained on 3060Ti and Jetson TX2 respectively, and the mAP is increased by 1.05% while the speed is improved, but the recall is reduced. With only one improvement, EB has the largest improvement in mAP, reaching 86.09%, which is 1.81% compared to Base. However, this also brings a small improvement in computational parameters. The enhanced attention to spatial and channel feature maps and the fusion of different scale information can effectively improve the detection of fabric defects. We also compared the EB module with the original BiFPN, which achieved the same mAP as PD Conv with the addition of a certain number of parameters, and there is still a gap between the detection effect with the EB module, so that using the original BiFPN does not bring satisfactory results. The addition of PD Conv to EB module improved the mAP by 0.82% and reduced the number of parameters by about 4.9%, indicating that the combination of the two helps to improve the performance of the model for fabric defect detection in a comprehensive manner. The use of IN loss achieved a 1.19% mAP improvement without any additional computational burden, proving that the combined use of IOU loss and NWD loss is very effective for fabric defect detection. Using the three methods at the same time, the optimal performance of mAP, Recall and F1 was obtained, and the FPS of 31 in NVIDIA Jetson TX2 is greater than 30, which can meet the requirements of real-time detection. The GFLOPs of PEI-YOLOv5 increased by only 0.2 and the mAP increased by 3.61%, which not only met the demand for real-time detection but also greatly improved the capability of fabric defect detection.
Experimental results of another dataset
To verify the detection performance of PEI-YOLOv5 for other tasks, we used the NEU surface defect database [59]. The dataset is a hot-rolled strip surface defect dataset with 1800 defect images, the image size is, and there are six defect categories, and we still divide the data according to the ratio of 8:1:1. The performance measures of YOLOv5 and PEI-YOLOv5 are shown in Fig. 15. Our method outperforms YOLOv5 in the prediction accuracy of each category. Table 9 shows the experimental results of our method with 7 other networks of mAP. PEI-YOLOv5 shows the best detection results, outperforming the current advanced YOLOv8, which shows that our method not only outperforms in the area of fabric defect detection but also outperforms existingmethods in other datasets.

Comparative experimental results on NEU surface defect database
Conclusion and discussion
A PEI-YOLOv5 defect detection method is proposed for fabric defects with similar colors and background textures, large differences in defect size and aspect ratio, and many small targets. It significantly improves the mAP of fabric defect detection without significantly increasing computational complexity. Firstly, the structure of backbone is modified by PD block. PDConv enhances the extraction of spatial features and effectively reduces the number of parameters, improving the detection speed while increasing the mAP by 1.05%. Secondly, the Neck part is modified by the EB module. The EB module fully combines spatial information with channel information to realize the interaction of contextual semantic information, which makes the network more focused on the defective target and effectively enhances the fusion of multi-scale semantic information and improves the mAP by 1.81%. Thirdly, we improve the loss function and propose IN loss. Its re-evaluation of loss by normalized Wasserstein distance and CIOU as a metric improves the recognition of small target defects, while significantly accelerating the model convergence speed and improving the mAP by 1.19% without adding any computational parameters. Through experimental comparison in Tianchi dataset and NEU surface defect database, the mAP reached 87.89% and 79.37%, respectively, which is better than the current advanced target detection methods, proving the effectiveness of PEI-YOLOv5. Finally, we deployed PEI-YOLOv5 on NVIDIA Jetson TX2 and achieved a detection speed of 31 FPS, which meets the requirements of real-time factory detection and proves the effectiveness of PEI-YOLOv5.
Although PEI-YOLOv5 effectively enhances the performance of the network with a small increase in computational complexity the network depth and the number of channels are low due to the lightweight model, which leads to a lack of detection capability for the three types of defects, Broken hole, Stain, and Three thread, especially for the Three threads type of defects Weak, as seen in Fig. 14a, is a defect with very small width and high height, which is difficult for the detector to effectively detect defects with extreme aspect ratios. Future research will be conducted on how to improve the detection precision for tiny network, extreme aspect ratio and background color approximation defects while keeping the model lightweight.
Data availability
The GuangDong TianChi fabric defect dataset that support the findings of this study is available at https://tianchi.aliyun.com/dataset/79336. The NEU surface defect database that support the findings of this study is available at http://faculty.neu.edu.cn/songkechen/zh_CN/zdylm/263270/list/.
References
Bullon J, Gonz´alez Arrieta A, Hern´andez Encinas A et al. (2017) Manufacturing processes in the textile industry. Expert Systems for fabrics production. ADCAIJ 6: 15–23. https://doi.org/10.14201/adcaij2017614150
Islam MS, Sadik MS (2014) Report on defects of woven fabrics and their remedies.[Bachelor dissertation, Daffodil International University].
Rajesh Kumar (2022) A Lyapunov-stability-based context-layered recurrent pi-sigma neural network for the identification of nonlinear systems. Appl Soft Comput 122. https://doi.org/10.1016/j.asoc.2022.108836.
Kumar R, Srivastava S, Gupta JRP, Mohindru A (2019) Temporally local recurrent radial basis function network for modeling and adaptive control of nonlinear systems. ISA Trans 87: 88–115. https://doi.org/10.1016/j.isatra.2018.11.027.
Kumar R, Srivastava S, Gupta JRP (2017). Diagonal recurrent neural network based adaptive control of nonlinear dynamical systems using lyapunov stability criterion. ISA Trans 67: 407-427. https://doi.org/10.1016/j.isatra.2017.01.022
Shihai Cao, Ting Wang, Tao Li, Zehui Mao. (2023). UAV small target detection algorithm based on an improved YOLOv5s model. Journal of Visual Communication and Image Representation. 97. https://doi.org/10.1016/j.jvcir.2023.103936.
Kan Ren, Zhuo Chen, Guohua Gu, Qian Chen. (2023). Research on infrared small target segmentation algorithm based on improved mask R-CNN.Optik.272. https://doi.org/10.1016/j.ijleo.2022.170334.
Kumar R, Srivastava S, Gupta JRP (2017) Modeling and adaptive control of nonlinear dynamical systems using radial basis function network. Soft Comput 21:4447–4463. https://doi.org/10.1007/s00500-016-2447-9
Kumar R (2023) Double internal loop higher-order recurrent neural network-based adaptive control of the nonlinear dynamical system. Soft Comput 27:17313–17331. https://doi.org/10.1007/s00500-023-08061-8
Kumar R, Srivastava S, Gupta JRP (2017) Lyapunov stability-based control and identification of nonlinear dynamical systems using adaptive dynamic programming. Soft Comput 21:4465–4480. https://doi.org/10.1007/s00500-017-2500-3
R. Kumar. (2023). Memory Recurrent Elman Neural Network-Based Identification of Time-Delayed Nonlinear Dynamical System. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 753–762. https://doi.org/10.1109/TSMC.2022.3186610.
Gupta T, Kumar R (2023) A novel feed-through Elman neural network for predicting the compressive and flexural strengths of eco-friendly jarosite mixed concrete: design, simulation and a comparative study. Soft Comput. https://doi.org/10.1007/s00500-023-08195-9
Rajesh Kumar, Smriti Srivastava. (2020). Externally Recurrent Neural Network based identification of dynamic systems using Lyapunov stability analysis. ISA Transactions.98. 292–308.https://doi.org/10.1016/j.isatra.2019.08.032.
Mehrdad Rafiepour, Javad Salimi Sartakhti. (2023). CTRAN: CNN-Transformer-based network for natural language understanding. Engineering Applications of Artificial Intelligence.126, Part C. https://doi.org/10.1016/j.engappai.2023.107013.
Girshick, R. , Donahue, J. , Darrell, T. , & Malik, J. . (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. IEEE Computer Society, 580–587.https://doi.org/10.1109/CVPR.2014.81
Uijlings JRR, Sande KEAVD, Gevers T, Smeulders AWM (2013) Selective search for object recognition. Int J Comput Vision 104(2):154–171. https://doi.org/10.1007/s11263-013-0620-5
R. Girshick. (2015). Fast R-CNN. IEEE International Conference on Computer Vision (ICCV). 1440–1448. https://doi.org/10.1109/ICCV.2015.169
Ren S, He K, Girshick RB, Sun J (2015) Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans Pattern Anal Mach Intell 39:1137–1149. https://doi.org/10.1109/TPAMI.2016.2577031
Li C, Li J, Li Y, He L, Fu X, Chen J (2021) Fabric defect detection in textile manufacturing: a survey of the state of the art. Secur Commun Networks 9948808(1–9948808):13. https://doi.org/10.1155/2021/9948808
Gharsallah MB, Braiek EB (2021) A visual attention system based anisotropic diffusion method for an effective textile defect detection. The J Textile Inst 112(12):1925–1939. https://doi.org/10.1080/00405000.2020.1850613
Shi B, Liang J, Di L, Chen C, Hou Z (2021). Fabric defect detection via low-rank decomposition with gradient information and structured graph algorithm. Inform Sci 546: 608–626. https://doi.org/10.1109/ACCESS.2020.2978900
Song L, Li R, Chen S (2020) Fabric defect detection based on membership degree of regions. IEEE Access 8:48752–48760
Gharsallah MB, Braiek EB (2020) A visual attention system based anisotropic diffusion method for an effective textile defect detection. J Text Inst 112(12):1925–1939. https://doi.org/10.1080/00405000.2020.1850613
Chen L, Zeng S, Gao Q et al (2020) Adaptive gabor filtering for fabric defect inspection. J Compurt 31(2):45–55
Zhang J, Li Y, Luo H (2020) Defect detection in textile fabrics with optimal Gabor filter and BRDPSO algorithm. J Phys: Conf Ser 1651(1):012073. https://doi.org/10.1088/1742-6596/1651/1/012073
Shu Y, Zhang L, Zuo D et al (2021) Analysis of texture enhancement methods for the detection of eco-friendly textile fabric defects. J Intell Fuzzy Syst 41(3):4439–4449. https://doi.org/10.3233/JIFS-219268
Shi B, Liang J, Di L et al (2019) Fabric defect detection via LowRank decomposition with gradient information. IEEE Access 546:608–626. https://doi.org/10.1016/j.ins.2020.08.100
Das S, Wahi A, Keerthika S, Thulasiram N (2020). Defect analysis of textiles using artificial neural network. Curr Trends Fashion Technol Textile Eng 6(1): 1–5. https://doi.org/10.19080/CTFTTE.2020.06.555677
Jin W, Jingru Y, Guodong L, Cheng Z, Zhiyong Y, Ying Y (2023). Adaptively fused attention module for the fabric defect detection. Adv Intell Syst 5(2). https://doi.org/10.1002/aisy.202200151
Juhua L, Wang Chaoyue Su, Bo HD, Dacheng T (2019) Multistage GAN for fabric defect detection. IEEE Trans Image Process 29:3388–3400. https://doi.org/10.1109/TIP.2019.2959741
Mengqi C, Lingjie Y, Chao Z, Sun et al. (2022) Improved faster R-CNN for fabric defect detection based on Gabor filter with Genetic Algorithm optimization. Comput Industry 134: 103551-103560. https://doi.org/10.1016/j.compind.2021.103551
Guo MH, Xu TX, Liu JJ, Liu ZN, Jiang PT, Mu TJ et al (2022) Attention mechanisms in computer vision: a survey. Comput Vis Media 8(3):331–368. https://doi.org/10.1007/s41095-022-0271-y
Hu J, Shen L, Albanie S, Sun G, Wu EH (2020) Squeeze-and-excitation networks. IEEE Trans Pattern Anal Mach Intell 42(8):2011–2023. https://doi.org/10.1109/CVPR.2018.00745
Gao ZL, Xie JT, Wang QL, Li PH (2019) Global second-order pooling convolutional networks. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 3019–3028. https://doi.org/10.1109/CVPR.2019.00314
Mnih V, Heess N, Graves A, Kavukcuoglu K (2014) Recurrent models of visual attention. In: Proceedings of the 27th international conference on neural information processing systems, 2, 2204–2212. https://doi.org/10.48550/arXiv.1406.6247
Jaderberg M, Simonyan K, Zisserman A, Kavukcuoglu K (2015) Spatial transformer networks. In: Proceedings of the 28th international conference on neural information processing systems, 2: 2017– 2025. https://doi.org/10.48550/arXiv.1506.02025
Hu J, Shen L, Albanie S, Sun G, Vedaldi A (2018) Gather-excite: exploiting feature context in convolutional neural networks. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems, 9423–9433. https://doi.org/10.48550/arXiv.1810.12348
Woo S, Park J, Lee J, Kweon I (2018) CBAM: convolutional block attention module. European Conference on Computer Vision. 3–19. https://doi.org/10.1007/978-3-030-01234-2_1
Yingchao Z, Hong D, Yuanjie L, Li Y, Jianhan L (2023) Converge of coordinate attention boosted YOLOv5 model and quantum dot labeled fluorescent biosensing for rapid detection of the poultry disease. Comput Electron Agric 206:107702. https://doi.org/10.1016/j.compag.2023.107702
Hou Q, Zhou D, Feng J (2021) Coordinate attention for efficient mobile network design. IEEE/CVF Conf Computer Vision Pattern Recognit (CVPR) 2021:13708–13717. https://doi.org/10.1109/CVPR46437.2021.01350
Xue G, Liu S, Ma Y (2023) A hybrid deep learning-based fruit classification using attention model and convolution autoencoder. Complex Intell Syst 9:2209–2219. https://doi.org/10.1007/s40747-020-00192-x
Wang J, Zhang C, Yan T et al. (2022) A cross-domain fruit classification method based on lightweight attention networks and unsupervised domain adaptation. Complex Intell. Syst. https://doi.org/10.1007/s40747-022-00955-8
Sun Y, Feng J (2023) Fire and smoke precise detection method based on the attention mechanism and anchor-free mechanism. Complex Intell. Syst. https://doi.org/10.1007/s40747-023-00999-4
Chen G, Dong Z, Wang J et al (2023) Parallel temporal feature selection based on improved attention mechanism for dynamic gesture recognition. Complex Intell Syst 9:1377–1390. https://doi.org/10.1007/s40747-022-00858-8
Li D, Peng Y, Guo Y et al (2022) TAUNet: a triple-attention-based multi-modality MRI fusion U-Net for cardiac pathology segmentation. Complex Intell Syst 8:2489–2505. https://doi.org/10.1007/s40747-022-00660-6
Lin TY, Dollár P, Girshick R, He K, Hariharan B, Belongie S (2017) Feature pyramid networks for object detection. IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2117–2125. https://doi.org/10.1109/CVPR.2017.106
Liu S, Qi L, Qin H, Shi J, Jia J (2018) Path aggregation network for instance segmentation. IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). 8759–8768. https://doi.org/10.1109/CVPR.2018.00913
Tan M, Pang R, Le QV (2020) Efficientdet: Scalable and efficient object detection. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10781–10790. https://doi.org/10.1109/CVPR42600.2020.01079
Wang J, Chen K, Xu R, Liu Z et al. (2019). CARAFE: Content-Aware ReAssembly of FEatures. IEEE/CVF International Conference on Computer Vision (ICCV), 3007–3016. https://doi.org/10.1109/ICCV.2019.00310
Liu S, Qi L, Qin H, Shi J, Jia J (2018). Path aggregation network for instance segmentation. IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), 8759–8768. https://doi.org/10.1109/CVPR.2018.00913
Mingxing Tan,Quoc V. Le. (2019). EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. ArXiv, abs/1905.11946. https://doi.org/10.48550/arXiv.1905.11946
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. Adv Neural Inform Process Syst 60: 84–90. https://doi.org/10.1145/3065386.
Sifre L, Mallat S (2014) Rigid-motion scattering for texture classification. ArXiv, abs/1403.1687. https://doi.org/10.48550/arXiv.1403.1687
Sandler M, Howard A, Zhu M, Zhmoginov A, Chen L-C Mobilenetv2: Inverted residuals and linear bottlenecks. IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). 4510–4520. https://doi.org/10.1109/CVPR.2018.00474
Chen Y, Dai X, Chen D, Liu M et al. Mobileformer: Bridging mobilenet and transformer. IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). 5270–5279. https://doi.org/10.1109/CVPR52688.2022.00520
Wadekar SN, Chaurasia A (2022) MobileViTv3: mobile-friendly vision transformer with simple and effective fusion of local, global and input features. ArXiv, abs/2209.15159. https://doi.org/10.48550/arXiv.2209.15159
Chen J, Kao S-h, He H (2023) Run, don't walk: chasing higher FLOPS for faster neural networks. ArXiv, abs/2303.03667. https://doi.org/10.48550/arXiv.2303.03667
Jinwang W, Xu C, Yang W, Yu L (2021) A normalized gaussian wasserstein distance for tiny object detection. ArXiv, abs/2110.13389. https://doi.org/10.48550/arXiv.2110.13389
Song K, Yan Y (2013) A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects. Appl Surf Sci 285(21):858–864. https://doi.org/10.1016/j.apsusc.2013.09.002
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, X., Zhu, Y. A real-time and accurate convolutional neural network for fabric defect detection. Complex Intell. Syst. 10, 3371–3387 (2024). https://doi.org/10.1007/s40747-023-01317-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01317-8