
Abstract
Great progress has been made in the domain of multi-agent reinforcement learning in recent years. Most work concentrates on solving a single task by learning the cooperative behaviors of agents. However, many real-world problems are normally composed of a set of subtasks in which the execution order follows a certain procedure. Cooperative behaviors should be learned on the premise that agents are first allocated to those subtasks. In this paper, we propose a hierarchical framework for learning the dynamic allocation of agents among subtasks, as well as cooperative behaviors. We design networks corresponding to agents and subnetworks, respectively, which constitute the whole hierarchical network. For the upper layer, a novel allocation learning mechanism is devised to map an agent network to a subtask network. Each agent network could only be assigned to only one subtask network at each time step. For the lower layer, an action learning module is designed to compute appropriate actions for each agent with the allocation result. The agent networks together with the subtask networks are updated by a common reward obtained from the environment. To evaluate the effectiveness of our framework, we conduct experiments in two challenging environments, i.e., Google Research Football and SAVETHECITY. Empirical results show that our framework achieves much better performance than other recent methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Multi-agent reinforcement learning (MARL) has attracted much attention, and different methods, like VDN [1], RODE [2], and QTRAN [3], have been proposed. However, most existing works treat problems as a whole task and directly learn the cooperative behaviors of agents. In fact, many real-world problems are composed of a series of subtasks with a specific execution procedure. For example, fire-fighting [4] involves subtasks like water supply and fire control. Firefighters need be distributed to subtasks, and then, they collaborate to accomplish all subtasks in accordance with the fire-fighting procedure. There are two key problems in multi-agent multi-subtask games. One is that agents should be dynamically assigned to subtasks. The other one is that how the policy of each subtask is learned with dynamically assigned agents.
Finding a good allocation scheme is not easy for multi-agent multi-subtask game. First, the state of a game is dynamically changed with time going on. The allocation scheme should be adjusted according to the change of states. Second, the strategy of opponents always changes which also poses challenges to the allocation. Finally, the allocation should consider the coordination of agents among different subtasks. Further, the policy for finishing the subtask with dynamic assigned agents in dynamic antagonistic environment also poses great challenges.
Regarding the agent allocation problem, traditional combinatorial methods will not work in such dynamic environment. Instead, different learning-based methods have been studied for allocation problems in various domains. For example, the work in [5] proposes a heterogeneous DDPG-based method to alleviate the spatio-temporal mismatch between the supply and demand distributions of vehicles and passengers. The work in [6] proposes an RL-based intelligent resource allocation algorithm to minimize the energy consumption of each user subject to the latency requirement. Such allocation only considers states of environment. Behaviors of agents are not taken into account, and there are no confrontations between two opposing parties in those environments. Moreover, following along with the agent allocation, we also need to decide which action should be taken for each agent. It makes the problem even harder. A natural idea is to use hierarchical learning methods. In fact there are indeed some recent works taking such methods. However, they either use rules for certain parts of the hierarchical structure or ignore the cooperation of agents among different subtasks. The details will be explained in the third part of the related work.
In this paper, we propose a hierarchical multi-agent allocation-action learning (MAAAL) framework for multi-subtask games. Subtasks are normally executed following a certain procedure, which could be organized by Behavior Tree (BT), a widely used tool for decomposing tasks. The main idea of this method is to use two types of networks, i.e., agent networks and subtask networks, to learn in a hierarchical way. An allocation mechanism is designed to map an agent network to a subtask network, and then, the action of each agent is computed by the subtask network. Each agent network can only be assigned to one subtask network, and multiple agents could share one subtask network. In this way, agents belong to one subtask network will cooperate to finish this subtask. Specifically, at the upper level, we encode the observations of each agent using the agent network, resulting in a vector, which is then multiplied with the encoded subtask information. The output indicates the subtask network to which each agent network should be assigned, corresponding to the subtask with the highest Q value. At the low layer, the subtask network calculates the Q values for all possible actions of each agent and select the action with the highest Q value as the final action for each agent. Moreover, to enhance cooperative behaviors, a total Q value, denoted as \(Q_\mathrm{{tot}}\), is computed based on selected Q values from subtasks, similar to the mechanism in QMIX [7]. Once the allocation results and actions are computed, subtasks are executed following the control procedure of BT. In summary, our main contributions are listed below:
-
We devise a hierarchical learning framework, which is composed of agent networks, subtask networks, and the allocation mechanism. It could automatically learn the allocation of agents and the subtask policy simultaneously.
-
We design an agent allocation learning mechanism, which could dynamically assign each agent network to a certain subtask network based on agent observations and game states through encoding, achieving dynamic allocation of agents to subtasks.
-
For the subtask policy learning, the action of each agent is computed by the corresponding subtask network. Q values of actions of all agents are combined to enhance the cooperative behaviors of agents in different subtasks.
Related work
In this section, we first investigate related studies on multi-agent multi-task games and the research progress in this field. Then, we give a literature review for solving the allocation problem with reinforcement learning, and point out the differences from ours. For both agent allocation and subtask policy learning, we present some recent works and show how they deal with such problems. Finally, we summarize all related works and show how we contribute to minimize the research gap.
Multiple agents for multiple tasks The work [8] makes a formal analysis of the taxonomy of agent-task allocation in multi-robot systems. Based on that, the problem we studied belongs to the class of ST-MR-IA (single-task agent, multi-agent tasks, instantaneous allocation). The whole problem is composed of a set of subtasks and each agent can only execute a certain subtask. The work [9] models such problem as Markov Decision Process (MDP), which allows the utilization of learning and planning-based methods. The work [10] develops a game theory-based method for simple agent-task allocation problems. The work [11] proposes a real-world multi-task allocation approach for mobile crowd sensing based on multi-agent reinforcement learning, which considers heterogeneity and enables independent learning to optimize task quality. These works give some theoretical analysis on multi-agent multi-task problems, and develops some methods for simple applications. The learning of agent allocation does not take into account.
Reinforcement learning methods for allocation problems Reinforcement learning-based methods have been studied for different allocation problems. The work in [12] presents a PPO-based method for mapping tasks to workers with time constraints. The work in [13] proposes a general method, i.e., structure2vec, for solving combinatorial optimization problems that can be formulated over graphs. However, those problems can be explicitly formulated and the state space is simpler compared to games. Another main related research aspect is the resource allocation in distributed systems with reinforcement learning [14]. The work in [15] utilizes neural networks to capture desired resource management for hybrid workloads in a distributed computing environment, which coordinates overall cluster-level resource allocation. The work in [16] proposes the use of graph neural networks which are used to represent the various relations within different resources and orders. Moreover, some complex real-life allocation problems under different scenarios are studied with reinforcement learning [17]. However, these works differ from ours in that the allocation does not consider behaviors of agents, which presents a significant challenge for learning how to dynamic assign agents and accomplish tasks collaboratively.
Hierarchical allocation learning Hierarchical methods for learning both agent allocation and agent action start to attract attention in recent years. The work [9] introduces the decomposition of the simultaneous task setting into task allocation and task execution levels. The task allocation problem is solved by search algorithms, and task execution is solved by coordinated reinforcement learning. The work [4] proposes a hierarchical method to learn both high-level subtask allocation policy and low-level agent policies. The high-level policy considers the states of all subtasks as input to estimate values for different allocations. The low-level polices depend only on the relevant subtask states to reduce the state space and improve learning efficiency. However, this fails to fully consider the information provided by agent observations during the allocation process. Another issue is that the actions of agents in a subtask are learned by treating agents in other subtasks as the environment which may bring difficulties in learning the cooperative behaviors of all agents. In contrast, our method takes into account both the current state of the subtasks and the agent observations when seeking the optimal allocation, and by computing the total Q value for the subtasks and enhancing cooperation among agents. The work [18] proposes a coach-player framework that learns a centralized controller in the higher layer, which then broadcasts strategies periodically to coordinate players in the lower layer. Its purpose is to alleviate the problem of partial observability during decentralized execution. This is different from our method, our purpose is to assign different agents to perform different subtasks to improve the execution efficiency of subtasks.
In summary, multi-agent multi-task problems have attracted increasing attention in recent years. Early studies in this topic mainly concentrate on general definition and theoretical analysis. We consider to develop learning methods for complex multi-agent multi-task problems with confrontation between two opposite parties, which will greatly promote the piratical usage of the study in this field. Meanwhile, different from studies that solely solving agent allocation or subtask policy learning, we aim to solve the two problems in a hierarchical way, which would obtain better performance. Further, different from other hierarchical methods, we design mechanisms to strengthen cooperations of among agents, both inter- and intra-subtasks.
Background
Behavior trees
Formally, a BT is a directed tree structure consisting of root, child, parent, and leaf nodes. The leaf nodes are called execution nodes, while other nodes are called control flow nodes. In the classical formulation, the control flow nodes are divided into three categories, i.e., Sequence, Fallback, and Parallel. The Sequence node returns Success state when all child nodes get Success. the Fallback node returns Failure state when all children fail. The Parallel node ticks all child nodes simultaneously and returns Success if N children return Success. It returns Failure if \( M-N+1 \) children return Failure, and it returns Running otherwise, where M is the number of children. The execution nodes are divided into two types, i.e., Condition and Action. The action node returns Success when the action is executed and Failure when the action fails. The condition node corresponds to a proposition, which will return Success or Failure depending on if the proposition holds or not.

The hierarchical multi-agent allocation-action learning framework for the multi-subtask game
Periodically, the execution of a BT starts from the root node. A tick signal is generated and then propagated through the tree branches according to each node type [19]. A node is executed if, and only if, it receives the tick. The child node immediately returns Running to the parent, if its execution is underway, Success if it has achieved its goal, or Failure otherwise. Suppose there are M subtasks in a BT. At each tick time t, the BT gets a state \(S_t\) from the environment. A tick signal is generated and activates the execution process of BT. The set of agents associated with task m is denoted by \({\mathcal N}_m^t\), which will be dynamically changed with time going on.
Multi-agent reinforcement learning
The theoretic foundation of multi-agent reinforcement learning is the Markov Decision Process, which could be represented by the tuple \(\left\langle \mathcal {N}, \mathcal {S}, \mathcal {A}, R, P\right\rangle \), where \(\mathcal {N}=\{1,2, \ldots , N\}\) is the set of agents. \(\mathcal {S}=\left\{ S^{t}\right\} _{t=0}^{T}\) is the environment state where \(S^{t}\) is the state at time t and T is the maximum time steps. \(\mathcal {A} = \{A_i\}_{i=0}^{N}\) represents the action space for all agents. \(R: \mathcal {S} \times \mathcal {A} \rightarrow \mathcal {R}\) is the reward function. \( \mathcal {P}=\{P_{ss'}^a\mid s,s' \in \mathcal {S},a\in \mathcal {A}\} \) is the state transition function, and \(P_{ss'}^a\) gives the probability from state s to state \(s'\) if the action a is taken
For multi-agent games, a popular solution approach is the value-decomposition-based MARL algorithms [1, 7, 20]. Each agent i is associated with a neural network, which is used to compute the individual value \(Q_{i}\) based on its observation. During the training process, the global state-action value \(Q_\mathrm{{t o t}}\) is computed as a function of \(Q_{i}\) of all agents. At present time, different algorithms are proposed to study the relation between \(Q_\mathrm{{t o t}}\) and \(Q_{i}\). The whole neural network is updated by the TD-loss, which is shown as (1).
Method
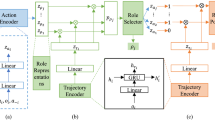
In this section, we present a novel hierarchical multi-agent allocation-action learning (MAAAL) framework for multiple subtasks in games. The whole framework is shown in Fig. 1. The left part illustrates the set of subtasks, which are organized by a BT. It shows the number of subtasks with the execution order in the game. The right part shows the learning framework. In the upper layer, each agent is associated with an agent network, which is used to encode the observation as \(w_i\). The allocation learning module is used to connect the agent network to a subtask network, with encoded observation \(w_i\) and encoded status of subtasks \(v_1,v_2,...,v_M\). In the lower layer, the output of each subtask network is the action space for each agent. Q values are computed for the selection of proper action for each agent. Note that \(Q_\mathrm{{tot}}\) is computed over all Q values which is used to enhance the cooperative behaviors of all agents.
The allocation learning
The allocation learning mechanism is used to connect an agent network to a subtask network, i.e., assigning each agent to a certain subtask. The agent network encodes the observation of agent \(o_i\) to a vector \(w_i\), which is then used as the input for the allocation learning module. \(w_i\) is disposed by another MLP module, of which the output is multiplied by the encode subtask status vectors \(v_i, i=1,2, \dots , M\). The subtask information refers to the running status, for example, the number of agents included in the subtask. The outputs are Q values of all possible choices of subtasks, i.e., \(\hat{Q}_1,\hat{Q}_2,...,\hat{Q}_M\). They are obtained by the multiplication of \(W={w_1,w_2,\dots ,w_N}\) and \(V={v_1,v_2,\dots ,v_M}\). The subtask selection during the training follows the \(\epsilon -\)greedy principle [21]. The index with the maximal Q value corresponds to the subtask that the agent network should be assigned. Once an agent i is assigned to subtask m, the encoded observation vector \(w_i\) will be passed to the input of the subtask network \(m, m\in \Lambda \). In this way, each agent could be associated with a certain subtask. For the training of the subtask allocation, the loss for this part \(L_1\) at each decision time t is computed following Eq. (2), where \(r^t\) is the global reward. (2) is analogous to the standard TD-loss of (1)
The action learning
The action learning is used to select a proper action \(a \in \mathcal A\) for an agent among all possible actions. Suppose agent i is assigned to the subtask network m, then the encoded vector \(w_i\) is used as the input. The output of the subtask network is the vector of Q values of all actions for agent i, i.e., \(\bar{Q}^i_1,\bar{Q}^i_2,...,\bar{Q}^i_{|A|}\). Note that there is a masking module for each subtask network, which is used to mask invalid actions through a const vector \(u_m\). The masking vector \(u_m\) includes some constraints information defined by subtask m. For example, in cooperative soccer games, it is clear that the two subtasks of defense and offense should compute different actions, so that the respective subtasks can be completed. With the masking module, the Q value of actions for agent i under subtask m is computed as \(Q_i = \bar{Q}^i*u_m\). To combine Q values of all agents, we introduce a neural network f to compute \(Q_\mathrm{{tot}}\), i.e., \(Q_\mathrm{{tot}} = f(Q^1_{a_1},Q^2_{a_2},...,Q^N_{a_N})\). \(a_i\) is the action selected by agent i following the \(\epsilon -\)greedy principle. The loss for the action learning is computed following Eq. (3):

MAAAL training procedure
Overall training procedure
Finally, we describe how allocation learning and action learning work together in our framework. We define the overall loss as \(L=L_1+L_2\) to update the whole neural network. Note that \(L_1\) is only used to update the agent network and the network in the allocation learning module, and this can be realized by detaching it from other networks. The overall training procedure is shown as Algorithm 1. Given a BT with a set of subtasks and a set of agents, the algorithm could generate an optimized hierarchical allocation-action policy. Each episode represents a game round, and K represents the maximum training episodes. For each episode, we reset the environment system and BT parameters. When a game is not over, steps 5–6 collect the observation of agent and the subtask status to encode different vectors. Then, in steps 7–8 allocate agents to accommodate the subtask. After completing the subtask allocation for each agent, obtain the specific action of each agent through the subtask network (steps 9–10). Step 11 executes actions and obtains the next state and the global reward, and the samples are stored in the buffer, shown as step 12. Finally, the keyword “UPDATE” in step 13 is used to control the frequency of updating the neural networks.
Experiments
In this section, we examine the performance of the proposed method on two challenging environments, i.e., Google Research Football (GRF) [22] and SAVETHECITY [4]. We aim to answer three questions in the following experiments: (1) Is the proposed method effective in different multi-agent multi-subtask problems? (2) Can the proposed agent allocation mechanism effectively assign agents to subtasks dynamically? (3) How does each component of the proposed hierarchical framework affect the final performance respectively?
Scenarios

Two scenarios with different number of subtasks for GRF
Google Research Football (GRF) The GRF simulates a complete football game with two teams and a ball. We consider the full game scenario in which 11 players play against 11 players. In the game, we must balance short-term control tasks, such as passing, dribbling, and shooting with long-term strategic planning. Each player has a discrete action space whose dimension is 19, including moving in eight directions, sliding, shooting, and so on. The observation contains the positions and moving directions of own agents, opposing agents, the ball, etc. To evaluate our proposed framework, we divide the football ground into two zones, i.e., Back-field and Front-field, with different subtasks assigned to each area. We construct two different BTs with different numbers of subtasks, i.e., \(10\_\mathrm{{subtasks}}\_\mathrm{{BT}}\) and \(6\_\mathrm{{subtasks}}\_\mathrm{{BT}}\), which are shown in Fig. 2. Each BT includes two parts, i.e., Back-field and Front-field. For the scenario \(10\_\mathrm{{subtasks}}\_\mathrm{{BT}}\) (Fig. 2a), each part includes five subtasks corresponding to the players’ defensive and offensive areas. The left-side and right-side defensive subtasks are a pair of parallel subtasks defending the central area of the Back-field, while the left-corner, right-corner, and penalty area are another set of parallel subtasks defending the goal area, with their parent nodes executed sequentially in each part. The Front-field part includes five subtasks corresponding to the players’ offensive area on the left-side, right-side, left-corner, right-corner, and penalty, executed in parallel, with their parent nodes executed sequentially in each part. The setting of subtasks in scenario \(6\_\mathrm{{subtasks}}\_\mathrm{{BT}}\) is similar to that in scenario \(10\_\mathrm{{subtasks}}\_\mathrm{{BT}}\), with differences in the partition of areas, as seen in Fig. 2b.

Left is a snapshot of 16a_16b scenario. Right is the structure of a BT organization subtasks, where the number represents the index of the building
SAVETHECITY is inspired by the classical Dec-POMDP task i.e., Factored Fire-fighting [23], where several firefighters must cooperate to put out independent fires. N agents and \(N+1\) buildings are randomly generated on a 16x16 grid map. Buildings randomly catch fire, reducing their health. The agents’ goal is to extinguish fires and repair buildings until they are fully restored. Agents can contribute to any subtask instead of having fixed locations, requiring learned subtask allocation. Furthermore, agents must physically navigate between buildings through low-level actions instead of just selecting buildings. Additionally, multiple agent types with different capabilities are introduced. The subtask allocation must learn to match agents to suitable capabilities based on their strengths. For example, firefighter (red) are best at extinguishing fires, builder (blue) excel at repairing, and generalist (green) move faster and can enhance other agents’ weak capabilities if at the same building. Agents are rewarded for increasing building health, completing buildings, extinguishing fires, etc. They are penalized for buildings being destroyed or losing health. An episode is successful if no buildings are burnt down (Fig. 3).
Baselines We make extensive comparisons for the proposed MAAAL framework with the following baselines. Fixed-BT: The action of each player is generated by the rules inside the GRF platform. QMIX: It is a classical multi-agent reinforcement learning method, and we use it to learn actions of all players without the hierarchical structure. COPA: As explained in the related work, it uses a different hierarchical structure for the multi-subtask game. ALMA: It uses a similar hierarchical structure to ours; however, the design of allocation and action learning mechanisms are different.
All the experiments are conducted on a computer with an i7-11700F CPU, RTX3060, and 32 G RAM. And we set the discount factor \( \gamma = 0.99 \). The optimization is conducted using Adam with a learning rate \( 5 \times 10^{-4} \).
Performance in GRF
Comparison of the training performance In this subsection, we compare the training performance of the MAAAL framework with the baselines on the two scenarios. For each scenario, we adopt the MAAAL framework to train each part of the BT tree, i.e., Front-field and Back-field, respectively. The training curves are shown in Fig. 4, in which the horizontal axis represents the training episodes, and the vertical axis represents the win rate. For all curves, we can see that MAAAL achieves the best performance over all scenarios.

Training performance comparison on two GRF scenarios
Figure 4a and b shows the performance of all methods for Front-field and Back-field in scenario \(10\_\mathrm{{subtasks}}\_\mathrm{{BT}}\). In Front-field, compared to the Fixed-BT, MAAAL improves the win rate by about 40%, while ALMA and COPA improve by about 28% and 18%, respectively. The same trend could be observed for the Back-field. As we can see, the performance of Fixed-BT is better than MAAAL at the beginning, owing to the learning algorithm needs time to explore the unknown environment. The win rate of MAAAL gradually increases as the train goes on, and ultimately outperforms Fixed-BT with the least number of training episodes among all learning-based methods. MAAAL needs around 2.8 million episodes in Fig. 4a, while ALMA and COPA need around 4.5 million and 5.2 million episodes to be better than Fixed-BT in Fig. 4b. It is interesting to see that QMIX has the worst performance among all learning-based methods due to the less hierarchical structure. In Fig. 4a, QMIX performs even worse than Fixed-BT, since it is quite hard to learn cooperative behaviors of agents without partition of subtasks.
We conduct the same experiments for scenario \(6\_\mathrm{{subtasks}}\_\mathrm{{BT}}\) which has less number of subtasks. The results are shown in Fig. 4a and b. As we can see, similar conclusions are also held. Compared to the Front-field case in scenario \(10\_\mathrm{{subtasks}}\_\mathrm{{BT}}\), it takes longer episodes for MAAAL, COPA, and ALMA to outperform Fixed-BT, which are 3.1 million, 5.1 million and 6 million, respectively. The reason is that fewer subtasks mean that learning-based methods need to explore more possibilities of cooperative behaviors. Another notification is that MAAAL performs slightly better in this scenario than in scenario \(10\_\mathrm{{subtasks}}\_\mathrm{{BT}}\). The reason is that fewer subtasks make agent allocation easier. Meanwhile, cooperation behaviors could be learned among more agents. However, this does not mean that the fewer the number of subtasks, the better the final performance. QMIX is a special example corresponding to the case with only one subtask.
Comparison of the evaluating performance We further investigate the impact of MAAAL, ALMA, COPA, and QMIX on the overall performance of the 11vs11 full game. We take two criteria, i.e., win score and loss score, to measure the performance of all methods. In a game, the win score refers to the number of scoring a goal, while the loss score refers to the number of conceding one to the opposing team. We run the game around 100 matches with the trained model. The results for all methods under two scenarios are shown in Table 1.
As we can see, learning-based methods could improve the win score of the full game compared to Fixed-BT for all cases in the two scenarios. For example, in Front-field of scenario \(10\_\mathrm{{subtasks}}\_\mathrm{{BT}}\), MAAAL, ALMA, and COPA increase the win score by about 4.02, 1.65, and 1.38 compared with Fixed-BT. The learning methods also reduce the loss score, in Back-field of scenario \(10\_\mathrm{{subtasks}}\_\mathrm{{BT}}\), and MAAAL, ALMA, and COPA decrease the loss score by about 1.64, 1.03, and 0.59. We can find that MAAAL delivers the best performance for reducing the loss score and increasing the win score. The most significant case is the Front-field in scenario \(6\_\mathrm{{subtasks}}\_\mathrm{{BT}}\), and MAAAL improves the win score by around 4.22, which is much bigger than other learning based methods, i.e., ALMA, COPA, and QMIX, which are 1.47, 1.36, and 0.22, respectively. Again, QMIX performs the worst overall learning based methods, for example, in Back-field of scenario \(10\_\mathrm{{subtasks}}\_\mathrm{{BT}}\) and \(6\_\mathrm{{subtasks}}\_\mathrm{{BT}}\), QMIX decreases the average loss score by about 0.26, while MAAAL, ALMA, and COPA are on average 1.69, 1.05, and 0.54. It is interesting to see that the win score is improved more significatively for Front-field than that for Back-field. The loss score is reduced more significatively for the Back-field than that for the Front-field. For example, in scenario \(10\_\mathrm{{subtasks}}\_\mathrm{{BT}}\), MAAAL improves the win score by 4.02 for Front-field while 2.09 for Back-field. The loss score is reduced by 0.31 for Front-field, while 1.64 for Back-field. The reason is that the responsibility of players in the Front-field is scoring the goal, while the responsibility of the Back-field players is to prevent the opponent team goal.

Performance comparison on SAVETHECITY tasks
Performance in SAVETHECITY
We apply a BT to organize the entire SAVETHECITY task, as shown in Fig. 3 (right). Each building consists of a firefight subtask and a repair subtask, with different precondition nodes to determine whether the building is on fire and requires repair. Agents are rewarded for successfully extinguishing fires and repairing buildings, while they are penalized when buildings are destroyed or their health deteriorates. We consider two scenarios: 7a_7b and 16a_16b.
The results are shown in Fig. 5. As we can see, MAAAL achieves the best performance in both scenarios. The success rate of MAAAL gradually increases during the training process, eventually surpassing all other baseline methods, and requires the fewest training episodes to outperform Fixed-BT. Compared with QMIX, we find that the hierarchical approaches significantly enhance learning performance. MAAAL and ALMA outperform COPA, since COPA does not consider the learning of allocation from agents to subtasks. Additionally, the performance of all methods decreases as the number of subtasks and agents increases. MAAAL drops by about 24%, while ALMA, COPA, and QMIX drop by about 43%, 44%, and 50%, respectively, which illustrates the scalability of MAAAL in complex scenarios.
Ablation studies
In this subsection, we conduct ablation experiments to illustrate the effectiveness of each component in the framework MAAAL. We provide rule-based realizations for the allocation learning and the action learning component, respectively. The framework with rule-based allocation is named as R-AL and the framework with rule-based action computing is named as R-AC. In addition, we removes the allocation learning module and statically assigns agents to perform different subtasks, which is named as S-AC. Figure 6 shows the comparison results between the GRF scenario \(10\_\mathrm{{subtasks}}\_\mathrm{{BT}}\) and SAVETHECITY 16a_16b. As we can see, both R-AL, R-AC and S-AC are worse than MAAAL, which verifies that each component of MAAAL is important for its performance. Compared with R-AC, R-AL achieves higher performance, which indicates that action learning has a greater impact than allocation learning on the performance of MAAAL. Furthermore, MAAAL is far superior to S-AC, which further proves the importance of agent dynamic allocation.
Results’ demonstration
Finally, we conduct a case study to demonstrate the learning result for Back-field case in scenario \(10\_\mathrm{{subtasks}}\_\mathrm{{BT}}\). We take two snapshots which are shown in Fig. 7. The allocation of agents among subtasks is shown at the bottom and visualizations are shown at the top. We use the hierarchical learning framework to allocate 10 players (excluding goalkeeper) to five different subtask areas. In the first graph, players 1 and 2 are allocated to the penalty area to perform defensive subtasks, The 5 players are allocated to the right-side area, and other players are allocated to the left-side area. When the opponent player gets the ball in the penalty area, players 3 and 4 are newly assigned to the penalty area; see the second graph. In addition, we observe that Player 1 is approaching the goal area, and Player 3 is approaching Player 2, which indicates that action learning enables the agent to make more effective actions.

Ablation results for \(10\_\mathrm{{subtasks}}\_\mathrm{{BT}}\) in GRF and for SAVETHECITY

A case demonstration
Conclusion
In this paper, we study the multi-agent multi-task problem that agents should cooperate to complete a set of subtasks. We propose a hierarchical learning framework, including allocation learning and action learning, which could allocate agents to different subtasks as well as compute the action for each agent in real time. We provide a way of computing the loss for each part of the framework and describe the whole training procedure. We conduct experiments on the GRF full game and SAVETHECITY, and the empirical results show that the overall performance is significantly improved by introducing hierarchical learning methods, i.e., for certain scenarios, reduce the loss score by around 77% on average compared to baseline, the win score improved by 164%. In the future, it would be interesting to investigate the application of the proposed method on more multi-agent multi-task problem, such as robotics systems, multi-player games, multi-drone systems. A possible research direction would be optimizing more types of resources, and extend the applications to large-scale games.
Data Availability
All data generated or analyzed during this study are included in this published article.
References
Sunehag P, Lever G, Gruslys A, Czarnecki WM, Zambaldi V, Jaderberg M, Lanctot M, Sonnerat N, Leibo JZ, Tuyls K et al (2017) Value-decomposition networks for cooperative multi-agent learning. arXiv preprint arXiv:1706.05296
Wang T, Gupta T, Mahajan A, Peng B, Whiteson S, Zhang C (2020) Rode: learning roles to decompose multi-agent tasks. arXiv preprint arXiv:2010.01523
Son K, Kim D, Kang WJ, Hostallero DE, Yi Y (2019) Qtran: learning to factorize with transformation for cooperative multi-agent reinforcement learning. In: International conference on machine learning. PMLR , pp 5887–5896
Iqbal S, Costales R Sha F (2022) Alma: hierarchical learning for composite multi-agent tasks. arXiv preprint arXiv:2205.14205
Liu C, Chen C-X, Chen C (2021) Meta: a city-wide taxi repositioning framework based on multi-agent reinforcement learning. IEEE Trans Intell Transp Syst 23:13890–13895
Chen X, Liu G (2021) Energy-efficient task offloading and resource allocation via deep reinforcement learning for augmented reality in mobile edge networks. IEEE Internet Things J 8(13):10843–10856
Rashid T, Samvelyan M, Schroeder C, Farquhar G, Foerster J, Whiteson S (2018) Qmix: monotonic value function factorisation for deep multi-agent reinforcement learning. In: International conference on machine learning. PMLR, pp 4295–4304
Gerkey BP, Matarić MJ (2004) A formal analysis and taxonomy of task allocation in multi-robot systems. Int J Robot Res 23:939–954
Proper S, Tadepalli P (2009) Solving multiagent assignment Markov decision processes. In: Proceedings of The 8th international conference on autonomous agents and multiagent systems-volume 1. pp 681–688
Dai W, Lu H, Xiao J, Zheng Z (2019) Task allocation without communication based on incomplete information game theory for multi-robot systems. J Intell Robot Syst 94:841–856
Han J, Zhang Z, Wu X (2020) A real-world-oriented multi-task allocation approach based on multi-agent reinforcement learning in mobile crowd sensing. Information 11(2):101
Pathan S, Shrivastava V (2021) Reinforcement learning for assignment problem with time constraints. arXiv preprint arXiv:2106.02856
Ma Q, Ge S, He D, Thaker D, Drori I (2019) Combinatorial optimization by graph pointer networks and hierarchical reinforcement learning. arXiv preprint arXiv:1911.04936
Wang J, Zhao L, Liu J, Kato N (2019) Smart resource allocation for mobile edge computing: a deep reinforcement learning approach. IEEE Trans Emerg Top Comput 9(3):1529–1541
Liu Z, Zhang H, Rao B, Wang L (2018) A reinforcement learning based resource management approach for time-critical workloads in distributed computing environment. In: 2018 IEEE international conference on big data (Big Data). IEEE, pp 252–261
Hameed MSA, Schwung A (2020) Reinforcement learning on job shop scheduling problems using graph networks. arXiv preprint arXiv:2009.03836
Bitsakos C, Konstantinou I, Koziris N (2018) Derp: a deep reinforcement learning cloud system for elastic resource provisioning. In: 2018 IEEE international conference on cloud computing technology and science (CloudCom). IEEE, pp 21–29
Liu B, Liu Q, Stone P, Garg A, Zhu Y, Anandkumar A (2021) Coach-player multi-agent reinforcement learning for dynamic team composition. In: International conference on machine learning. PMLR, pp 6860–6870
Iovino M, Scukins E, Styrud J, Ögren P, Smith C (2022) A survey of behavior trees in robotics and AI. Robot Auton Syst 154:104096
Yang Y, Hao J, Liao B, Shao K, Chen G, Liu W, Tang H (2020) Qatten: a general framework for cooperative multiagent reinforcement learning. arXiv preprint arXiv:2002.03939
Tokic M, Palm G (2011) Value-difference based exploration: adaptive control between epsilon-greedy and softmax. In: Annual conference on artificial intelligence. Springer, pp 335–346
Kurach K, Raichuk A, Stańczyk P, Zając M, Bachem O, Espeholt L, Riquelme C, Vincent D, Michalski M, Bousquet O et al (2020) Google research football: a novel reinforcement learning environment. In: Proceedings of the AAAI conference on artificial intelligence, vol 34. pp 4501–4510
Oliehoek FA, Spaan MT, Vlassis N, Whiteson S (2008) Exploiting locality of interaction in factored dec-pomdps. In: International joint conference on autonomous agents and multi-agent systems, pp 517–524
Acknowledgements
This work was financially supported by the National Natural Science Foundation of China Youth Science Foundation under Grant Nos. 61902425 and 62102444.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, X., Li, Y., Zhang, J. et al. A hierarchical multi-agent allocation-action learning framework for multi-subtask games. Complex Intell. Syst. 10, 1985–1995 (2024). https://doi.org/10.1007/s40747-023-01255-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01255-5