
Abstract
The economic implications from the COVID-19 crisis are not like anything people have ever experienced. As predictions indicated, it is not until the year 2025 may the global economy recover to the ideal situation as it was in 2020. Regions lacked of developing category is among the mostly affected regions, because the category includes weakly and averagely potential power. For supporting the decision of economic system recovery scientifically and accurately under the stress of COVID-19, one feasible solution is to assess the regional economic restorability by taking into account a variety of indicators, such as development foundation, industrial structure, labor forces, financial support and government's ability. This is a typical multi-criteria decision-making (MCDM) problem with quantitative and qualitative criteria/indicator. To solve this problem, in this paper, an investigation is conducted to obtain 14 indicators affecting regional economic restorability, which form an indicator system. The interval type-2 fuzzy set (IT2FS) is an effective tool to express experts’ subjective preference values (PVs) in the process of decision-making. First, some formulas are developed to convert quantitative PVs to IT2FSs. Second, an improved interval type-2 fuzzy ORESTE (IT2F-ORESTE) method based on distance and likelihood are developed to assess the regional economic restorability. Third, a case study is given to illustrate the method. Then, robust ranking results are acquired by performing a sensitivity analysis. Finally, some comparative analyses with other methods are conducted to demonstrate that the developed IT2F-ORESTE method can supporting the decision of economic system recovery scientifically and accurately.
Similar content being viewed by others

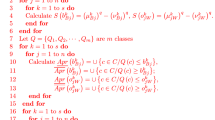
Introduction
The COVID-19 outbreak in 2020, as a major public health emergency, has brought heavy disaster to people around the world. COVID-19 pandemic is considered to be the notorious economic shock arising throughout the year 2020. The economic implications from the COVID-19 crisis are not like anything people have ever experienced. As predictions indicated, it is not until the year 2025 may the global economy recover to the ideal situation as it was in 2020 [1]. As a result, although the negative effects of the deadly CODIV-19 pandemic are still presented currently, the regional economic recovery phase must be projected to start due to the fact that regional economic development has plummeted to historic bottom [2,3,4,5,6]. Specially, regions lacked of developing category is among the mostly affected regions, because the category includes weakly and averagely potential power [7,8,9].
Quantitative research on the impact of major public health events on economic system can provide scientific support for improving the regional economic restorability. Existing studies have analyzed the economic impact of major public health events at different scales and industrial sectors, but there is still an issue that needs to be discussed:
-
(1)
There are few studies on the economic impact of epidemics at the scale and level. What’s more, there are as yet no studies in the associated field of the assessment of regional economic restorability (RER) under the stress of COVID-19.
In this study, RER can be considered as a multi-criteria (indicators) decision-making (MCDM) problem which a number of regions should be ranked based on several special indicators. Studies form China, Japan researched on establishing assessment indicator systems for major natural disaster or public health emergencies, such as earthquake [10], flood damage [11], SARS [12], etc., and then implemented in the prioritization of regions.
Those assessment indicator systems contain specific indicators for reflecting the comprehensive strength of regional economy. At the same time, each indicator is assigned a certain number to confirm its relative significance. Obviously, those systems are good at processing quantitative information, however, it still has some drawbacks. On one hand, those systems are limited in pay close attention to comprehensive indicators, which make the final ranking results less practical and effective in determining the priority for regions; on the other hand, those indicators are mostly qualitative with a great deal of fuzzy and imprecise information, but the MCDM methods mentioned earlier are not able to process qualitative information. The type-1 fuzzy set (T1FS) theory [13] represent the qualitative indicator values with membership function (MF). MFs of T1FS are crisp number and have two-dimensional NFs. Nevertheless, in the real assessment of RER, owing to more complexity and uncertainty, the preference values of most indicator, such as location advantages, foreign trade dependence, diversification of industrial structure, industrial clusters competitiveness and Internet economy development environment, etc., cannot be represented sufficiently by T1FS. Because it is unreasonable to apply an accurate membership degree for an uncertain item. In such circumstances, Type-2 fuzzy set (T2FS) [13] are developed based on T1FS which could cover more complexity and uncertainty by three-dimensional MFs. That is, T2FS can more easily express vagueness and imprecision than T1FS. Whereas, the computation of T2FS is commonly complex, and the corresponding amounts of computation are very large. As a consequence, interval type-2 fuzzy set (IT2FS) is the most extensively utilized, membership degree of IT2FS take the form of crisp intervals, which make the calculations related to IT2FS. Furtherly, many studies of IT2FS have detected that IT2FS is a very helpful tool for quantifying the ambiguous nature of linguistic variables. In this regard, the IT2FS is a suitable tool when their fuzz MF cannot be defined easily for fuzzy system.
Although MCDM methods with IT2FSs have been widely applied to many fields [14,15,16], there are few studies on assessment of RER applying interval type-2 fuzzy MCDM (IT2F-MCDM) methods. In the meantime, as a result of effectiveness, many IT2F-MCDM methods have also been developed, which are mostly the utility value-based methods, such as the interval type-2 fuzzy aggregate operators [14,15,16], the interval type-2 fuzzy TOPSIS (IT2F-TOPSIS) method [17], the interval type-2 fuzzy VIKOR (IT2F-VIKOR) method [18], and the interval type-2 fuzzy MULTIMOORA (IT2F- MULTIMOORA) method [19]. However, the existing IT2F-MCDM methods have some crucial drawbacks:
-
(2)
The above IT2F-MCDM methods only focus on the preference interrelations and the indifference interrelations between alternatives. And the incomparable interrelations are neglected which occurs objectively. For instance, when a comparison of economic restorability according to diversification of industrial structure (\(\tilde{C}_{1}\)) and industrial clusters competitiveness (\(\tilde{C}_{2}\)) is given between regions (\(X_{1}\) and \(X_{2}\)), if in region \(X_{1}\) the preference value (PV) of \(\tilde{C}_{1}\) is “Very unimportant” but the PV of \(\tilde{C}_{2}\) is “Very important”, and if in region \(X_{2}\) the preference value (PV) of \(\tilde{C}_{1}\) is “Very important” but the PV of \(\tilde{C}_{2}\) is “Very unimportant”, then these two regions cannot be regarded simply indifference interrelation based on the corresponding aggregated results.
-
(3)
The existing IT2F-MCDM methods can merely solve the decision-making problems that the PVs are represented as IT2FSs but cannot solve the real problems that an unspecified number of the PVs are in crisp numbers. But in reality, the cases involve generally both quantitative indicators and qualitative indicators, and under the most circumstances the quantitative indicator PVs are easy to acquire.
The ORESTE method, developed originally by Roubens [20], is an ordinary outranking method and does not need to be concerned with crisp indicator weights. Compared with the existing MCDM methods, the ORESTE method not only can determine the utility values of alternatives but also can capture the preference interrelations, incomparability interrelations and the indifference interrelations between alternatives. Moreover, a large number of researchers have developed some extended forms of the OREST method, such as probabilistic hesitant fuzzy ORESTE method [21], hesitant fuzzy linguistic ORESTE method [22], interval type-2 fuzzy ORESTE (IT2F-ORESTE) method [23]. Although the IT2F-ORESTE method can overcome the above drawback (2), it still has some other drawbacks:
-
(4)
Most of the distance measures (DMs) for IT2FS are generalizations of the distances applied in the crisp sets, using the membership function to take place of the characteristic function, such as the normalized Hamming DM and the normalized Euclidean DM. Heidarzade et al. [24] illustrated that these two DMs are not suitable for IT2FS and require extensive computations.
-
(5)
The likelihood of IT2FSs has not been combined with the IT2F-MCDM methods. The measure of preference information (PI) has always been a hot button for IT2F-MCDM method improvement. Different measures of IT2FSs have a critical impact on the ordering of schemes on account of different information they conveyed. For instance, the similarity of IT2FSs can detail the general interrelation between PI [25], and the entropy of IT2FSs can detail the uncertainty of PI [26]. Compared to similarity and entropy, the likelihood of IT2FSs can detail the binary interrelation of PI. Besides, it still has some wonderful properties such as transmission and complementation.
Therefore, it is worthwhile developing a feasible IT2F-ORESTE solution to a significance problem in economic management field, namely, assessment of RER. First, the Delphi approach is applied to construct a comprehensive indicator system for RER based on the interview with 35 magisterial and accomplished experts from regional economic field, government management field, medical care and public health field. The IT2FSs provided by experts are applied to express fuzzy and imprecise information. Then, an improved IT2F-ORESTE method is developed to solve the RER assessment problem with both qualitative and quantitative indicator. The main contributions of this paper are summarized as follows:
-
For supporting the decision of economic system recovery scientifically and accurately, on the basis of the development foundation, industrial structure, labor forces, financial support and government's ability, etc., RER of different regions under the stress of COVID-19 are determined. Thus, the drawback (1) is overcome.
-
Some formulas are developed to convert quantitative PVs to IT2FSs for combining the quantitative and qualitative indicator information. In this case, drawback (3) is overcome.
-
The vertex method for DM is extended to encompass IT2FSs. The extended vertex method is an efficient simple formula that requires few computations in contrast to other DMs. This overcomes drawback (4) of existing DMs.
-
An improved IT2F-ORESTE method based on the DM and likelihood of IT2FS is developed to deal with the RER assessment problem. Thus, the drawback (2) and (5) are overcome.
-
Also, a comprehensive discussion between the improved IT2F-ORESTE method, the traditional ORESTE method and two representative IT2F-MCDM methods, including IT2F-TOPSIS method, IT2F-VIKOR method, and IT2F-MULTIMOORA method, are developed to demonstrate the validity and reliability of the improved IT2F-ORESTE method. In addition, the case study presents a helpful reference for government departments to improve the RER.
The structure of this paper is briefly introduced as follows. “Literature reviews” constructs an assessment indicator system of RER under the stress of COVID-19. “Preliminaries” reviews some relative principal theory of IT2FS and the classic ORESTE method. “Assessment of RER under the stress of COVID-19 using the new IT2F-ORESTE method based on distance and likelihood” develops a new IT2F-ORESTE method based on distance measure and likelihood. “A case study: the assessment of RER of cities under the stress of COVID-19 epidemic” proposes a case study of the assessment of RER of Shandong Province under the stress COVID-19 epidemic. Moreover, sensitivity and comparative analyses are conducted. “Conclusions” provides the conclusions and recommendations for future study.
Literature reviews
Indicator system and selection of MCDM method are the essential issues of assessment of RER. Thus, the literature in this section includes restorability assessment, indicator system and ORESTE method.
Assessment of restorability
On account of the newly increased popularity of restorability in various research disciplines, some assessment methods of restorability have been proposed. Moslehi and Reddy [27] proposed a new performance-based method for characterizing and assessing resilience of multi-functional demand-side engineered systems. Liu et al. [28] presented a planning-oriented resilience assessment framework to develop quantitative resilience indices from both the system and component perspectives. Zarei et al. [29] presented a framework for resilience assessment in process systems using a fuzzy hybrid MCDM model. Abbasnejadfard et al. [30] developed a novel deterministic and probabilistic resilience assessment measures for engineering and infrastructure systems based on the economic impacts. Rezvani et al. [31] built an enhancing urban resilience evaluation system through automated rational and consistent decision-making simulations. In this study, assessment of regional economic restorability can be considered as a MCDM problem. Although MCDM methods have been widely applied to restorability assessment fields, there are few studies on assessment of RER.
Assessment indicator system of RER under the stress of COVID-19
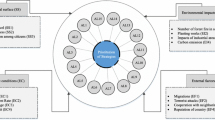
First of all, “assessment”, “regional economic”, “restorability”, “resilience”, “major public emergencies” are taken as keywords to search the relevant literatures in Web of Science, Science Direct, Springer Databases, Wiley Online Library and CNKI (Time is up to June 30, 2022). A great deal of literature works regarding the indicator system for RER were reviewed, which are displayed in Table 1. Clearly, assessment of RER is basis of a series of qualitative and quantitative criteria. Whereas, under the stress of COVID-19, many researchers consider the assessment indicator system should contain specific indicators for reflecting the comprehensive strength of regional economy. At present, in the context of COVID-19, government departments are required to formulate the economic promotion policies according to the RER. On this basis, the related 23 indicators from the relevant literatures are picked out. Furtherly, these indicators are divided into five dimensions from the perspectives of social and economic, which contain development foundation (\(\tilde{T}_{1}\)), industrial structure (\(\tilde{T}_{2}\)), labor forces (\(\tilde{T}_{3}\)), financial support (\(\tilde{T}_{4}\)) and government's ability (\(\tilde{T}_{5}\)) displayed in Table 1.
OREST method
The ORESTE method is an ordinary outranking method to deal with MCDM problems. The most interesting part of ORESTE method is to separate preference, indifference and incomparability relations of alternatives through the conflict analysis, which makes the results more easily accepted by the decision-makers. At present, a large number of researchers have developed some extended forms of the OREST method. Li et al. [21] proposed an ORESTE method for MCDM with probabilistic hesitant fuzzy. Li et al. [22] prioritized the elective surgery patient admission in a Chinese public tertiary hospital using the hesitant fuzzy linguistic ORESTE method. Zheng et al. [23] developed an extended IT2F-ORESTE method for risk analysis in FMEA. Liao et al. [54] presented a new hesitant fuzzy linguistic ORESTE method for hybrid MCDM. Luo et al. [55] proposed a likelihood-based hybrid ORESTE method for evaluating the thermal comfort in underground mines. Wang et al. [56] proposed a double hierarchy hesitant fuzzy linguistic ORESTE method. Wang et al. [57] developed an interval 2-Tuple linguistic Fine-Kinney model for risk analysis based on extended ORESTE method with cumulative prospect theory. Liang et al. [58] proposed a hesitant Pythagorean fuzzy ORESTE method to determine the risk priority of the failure modes.
These previous studies indicate that the ORESTE method has been successfully utilized to address the priority calculation problem. Consequently, in this study, it is worthwhile developing the classic ORESTE method and extending it into the interval type-2 fuzzy context to deal with the complexity MCDM problems with both qualitative and quantitative criteria and the weights being unknown.
Preliminaries
In following subsection, some concepts, operational laws, likelihood of IT2FS, PA operator of IT2FS, and the classic ORESTE method are briefly reviewed.
IT2FS
Definition 1
[14] Let \(E\) be the universe of discourse, a T2FS \(A\) can be denoted as follows:
where \(\mu_{\rm A} \left( {\varepsilon ,\sigma } \right)\) is called type-2 MF, \(0 \le \mu_{\rm A} \left( {\varepsilon ,\sigma } \right) \le 1\) for each \(\varepsilon\) and \(\sigma\). In addition, the T2FS \(A\) also can be denoted as follows:
where \(J_{\varepsilon } \subseteq \left[ {0,1} \right]\) is the primary membership at \(\varepsilon\) and \(\int_{{\sigma \in J_{\varepsilon } }} {\mu_{A} \left( {\varepsilon ,\sigma } \right)} /\sigma\) is the second membership at \(\varepsilon\). For discrete spaces, \(\int {}\) is replaced by \(\sum {}\).
Definition 2
[14] Let \(A\) be a T2FS in the universe of discourse \(E\), if all \(\mu \left( {\varepsilon ,\sigma } \right) = 1\), then \(A\) is called an IT2FS, represented as follows:
Apparently, IT2FS \(A\) in \(E\) is totally determined by the footprint of uncertainty (FOU) which can be denoted:
Generally, due to the calculations on IT2FSs are more complex, some simplified forms can be utilized to denote IT2FSs. In here, we utilize trapezoidal IT2FS to process GSS problems.
Definition 3
[14] Let \(\tilde{A}^{L}\) and \(\tilde{A}^{U}\) be two generalized trapezoidal fuzzy numbers, where the height of a generalized FM is positioned in \(\left[ {0,1} \right]\). Let \(h_{{\tilde{A}}}^{L}\) and \(h_{{\tilde{A}}}^{U}\) be the heights of \(\tilde{A}^{L}\) and \(\tilde{A}^{U}\), respectively. An IT2FS \(\tilde{A}\) (as shown in Fig. 1) in the universe of discourse \(E\) can be defined:
where \(\tilde{A}^{L}\) and \(\tilde{A}^{U}\) are type-1 fuzzy sets,\(\alpha_{1}^{L} \le \alpha_{2}^{L} \le \alpha_{3}^{L} \le \alpha_{4}^{L}\),\(\alpha_{1}^{U} \le \alpha_{2}^{U} \le \alpha_{3}^{U} \le \alpha_{4}^{U}\), \(\alpha_{1}^{U} \le \alpha_{1}^{L}\), \(\alpha_{4}^{L} \le \alpha_{4}^{U}\) and \(0 \le h_{{\tilde{A}}}^{L} \le h_{{\tilde{A}}}^{U} \le 1\). The lower MF \(\tilde{A}^{L} \left( \varepsilon \right)\) and upper MF \(\tilde{A}^{U} \left( \varepsilon \right)\) are defined as follows:

Definition 4
[15, 16] Let \(\tilde{A}_{1} = \Bigl( \tilde{A}_{1}^{L} ,\tilde{A}_{1}^{U} \Bigr) = \Bigl[ \Bigl( \alpha_{11}^{L} ,\alpha_{12}^{L} ,\alpha_{13}^{L} ,\alpha_{14}^{L} ;h_{{\tilde{A}}}^{L} \Bigr),\Bigl( \alpha_{11}^{U} ,\alpha_{12}^{U} ,\alpha_{13}^{U} ,\alpha_{14}^{U} ;h_{{\tilde{A}}}^{U} \Bigr) \Bigr]\) and \(\tilde{A}_{2} = \left( {\tilde{A}_{2}^{L} ,\tilde{A}_{2}^{U} } \right) = \left[ {\left( {\alpha_{21}^{L} ,\alpha_{22}^{L} ,\alpha_{23}^{L} ,\alpha_{24}^{L} ;h_{{\tilde{A}_{2} }}^{L} } \right),\left( {\alpha_{21}^{U} ,\alpha_{22}^{U} ,\alpha_{23}^{U} ,\alpha_{24}^{U} ;h_{{\tilde{A}_{2} }}^{U} } \right)} \right]\) be any two IT2FSs, then the operational laws between \(\tilde{A}_{1}\) and \(\tilde{A}_{2}\) are defined as follows:
Definition 5
[59] Let \(\tilde{A}_{1} = \left( {\tilde{A}_{1}^{L} ,\tilde{A}_{1}^{U} } \right) = \Big[ \Big( \alpha_{11}^{L} ,\alpha_{12}^{L} ,\alpha_{13}^{L} ,\alpha_{14}^{L} ;h_{{\tilde{A}_{1} }}^{L} \Big),\Big( \alpha_{11}^{U} ,\alpha_{12}^{U} ,\alpha_{13}^{U} ,\alpha_{14}^{U} ;h_{{\tilde{A}_{1} }}^{U} \Big) \Big]\) and \(\tilde{A}_{2} = \left( {\tilde{A}_{2}^{L} ,\tilde{A}_{2}^{U} } \right) = \left[ {\left( {\alpha_{21}^{L} ,\alpha_{22}^{L} ,\alpha_{23}^{L} ,\alpha_{24}^{L} ;h_{{\tilde{A}_{2} }}^{L} } \right),\left( {\alpha_{21}^{U} ,\alpha_{22}^{U} ,\alpha_{23}^{U} ,\alpha_{24}^{U} ;h_{{\tilde{A}_{2} }}^{U} } \right)} \right]\) be two any IT2FSs, then the distance measure based on the extend vertex method between \(\tilde{A}_{1}\) and \(\tilde{A}_{2}\) are defined as follows:
Likelihood of IT2FS
In this section, a framework of the likelihood of IT2FSs based on the upper likelihood and the lower likelihood are proposed in the following definition.
Definition 6
[60] Let \(\tilde{A}_{1} = \left( {\tilde{A}_{1}^{L} ,\tilde{A}_{1}^{U} } \right) = \Big[ \Big( \alpha_{11}^{L} ,\alpha_{12}^{L} ,\alpha_{13}^{L} ,\alpha_{14}^{L} ;h_{{\tilde{A}_{1} }}^{L} \Big),\Big( \alpha_{11}^{U} ,\alpha_{12}^{U} ,\alpha_{13}^{U} ,\alpha_{14}^{U} ;h_{{\tilde{A}_{1} }}^{U} \Big) \Big]\) and \(\tilde{A}_{2} = \left( {\tilde{A}_{2}^{L} ,\tilde{A}_{2}^{U} } \right) = \left[ {\left( {\alpha_{21}^{L} ,\alpha_{22}^{L} ,\alpha_{23}^{L} ,\alpha_{24}^{L} ;h_{{\tilde{A}_{2} }}^{L} } \right),\left( {\alpha_{21}^{U} ,\alpha_{22}^{U} ,\alpha_{23}^{U} ,\alpha_{24}^{U} ;h_{{\tilde{A}_{2} }}^{U} } \right)} \right]\) be two any IT2FSs. Assume that at least one of \(h_{{\tilde{\rm A}_{1} }}^{L} \ne h_{{\tilde{\rm A}_{2} }}^{U}\), \(\alpha_{14}^{L} \ne \alpha_{11}^{L}\), \(\alpha_{24}^{U} \ne \alpha_{21}^{U}\), and \(\alpha_{1\zeta }^{L} \ne \alpha_{2\zeta }^{U}\) holds, and at least one of \(h_{{\tilde{A}_{1} }}^{U} \ne h_{{\tilde{A}_{2} }}^{L}\), \(\alpha_{14}^{U} \ne \alpha_{11}^{U}\), \(\alpha_{24}^{L} \ne \alpha_{21}^{L}\), and \(\alpha_{1\zeta }^{U} \ne \alpha_{2\zeta }^{L}\) holds, where \(\zeta = \left\{ {1,2,3,4} \right\}\). The upper likelihood \(I^{ + } \left( {\tilde{A}_{1} \ge \tilde{A}_{2} } \right)\) of an IT2FS binary relation (BR) \(\tilde{A}_{1} \ge \tilde{A}_{2}\) can be defined by:
The lower likelihood \(I^{ - } \left( {\tilde{A}_{1} \ge \tilde{A}_{2} } \right)\) of an IT2FS BR \(\tilde{A}_{1} \ge \tilde{A}_{2}\) can be defined by:
The likelihood \(I\left( {\tilde{A}_{1} \ge \tilde{A}_{2} } \right)\) of an IT2FS BR \(\tilde{A}_{1} \ge \tilde{A}_{2}\) can be defined by:
Definition 7
[61] Let \(\tilde{A}_{1} = \left( {\tilde{A}_{1}^{L} ,\tilde{A}_{1}^{U} } \right)\) and \(\tilde{A}_{2} = \left( {\tilde{A}_{2}^{L} ,\tilde{A}_{2}^{U} } \right)\) be two any IT2FSs. Based on the likelihood, the comparison rules between \(\tilde{A}_{1}\) and \(\tilde{A}_{2}\) can be defined by:
-
(1)
if \(I\left( {\tilde{A}_{1} \ge \tilde{A}_{2} } \right) = 1\), then \(\tilde{A}_{1}\) is strictly preferred to \(\tilde{A}_{2}\), denoted by \(\tilde{A}_{1} \succ_{S} \tilde{A}_{2}\);
-
(2)
if \(0.5 < I\left( {\tilde{A}_{1} \ge \tilde{A}_{2} } \right) < 1\), then \(\tilde{A}_{1}\) is weakly preferred to \(\tilde{A}_{2}\), denoted by \(\tilde{A}_{1} \succ_{W} \tilde{A}_{2}\);
-
(3)
if \(I\left( {\tilde{A}_{1} \ge \tilde{A}_{2} } \right) = 0.5\), then \(\tilde{A}_{1}\) is indifferent to \(\tilde{A}_{2}\), denoted by \(\tilde{A}_{1} \sim \tilde{A}_{2}\).
Power average operator of IT2FS
Power average operator, developed firstly by Yager [62], can be often seen as an effective technique to aggregate individual preference information. Then, the power average operator of IT2FS is developed in the following section.
Definition 7
[23] Assume that \(\tilde{A}_{\xi } = \left( {\tilde{A}_{\xi }^{L} ,\tilde{A}_{\xi }^{U} } \right) = \left[ {\left( {\alpha_{\xi 1}^{L} ,\alpha_{\xi 2}^{L} ,\alpha_{\xi 3}^{L} ,\alpha_{\xi 4}^{L} ;h_{{\tilde{A}_{\xi } }}^{L} } \right),\left( {\alpha_{\xi 1}^{U} ,\alpha_{\xi 2}^{U} ,\alpha_{\xi 3}^{U} ,\alpha_{\xi 4}^{U} ;h_{{\tilde{A}_{\xi } }}^{U} } \right)} \right]\), \(\left( {\xi = 1,2, \ldots M} \right)\) be a collection of IT2FSs. Then, the collective value of interval type-2 fuzzy power average (IT2FPA) operator is still an IT2FS, and
By literature [23], the IT2FPA operator has some desirable properties, for example, idempotence, boundedness and monotonicity.
The traditional ORESTE method
In this section, the traditional ORESTE method, developed initially by Roubens [20], is one of the most effective and reliable ranking methods for handing MCDM problems. The specific procedures of this method are presented as follows:
Step 1: Aggregate global preference scores (GPS).
Assume that \(R_{j}\) is the original ranking of the important degree of criterion \(C_{j} \left( {j = 1,2, \cdots ,n} \right)\) and \(R_{j} \left( {X_{i} } \right)\) is the original ranking of the preference value of alternative \(X_{i} \left( {i = 1,2, \cdots ,m} \right)\) under criterion \(C_{j}\). Then, the GPS can be aggregated with
where \(\eta \in \left[ {0,1} \right]\) is the coefficient to declare the importance between \(R_{j}\) and \(R_{j} \left( {X_{i} } \right)\).
Step 2: Establish the global weak ranking (WR).
Based on Eq. (15), compute the global weak ranking \(R\left( {X_{ij} } \right)\).
Step 3: Compute the weak ranking of \(X_{i} \left( {i = 1,2, \cdots ,m} \right)\).
Step 4: Obtain the preference intensity (PI).
The average PI of \(X_{i}\) over \(X_{\kappa }\) can be defined as:
The net PI of \(X_{i}\) over \(X_{\kappa }\) can be defined as:
Step 5: Construct the preference/indifference/incomparability (PIR) structure.
-
(1)
If \(\left| {P\left( {X_{i} ,X_{\kappa } } \right)} \right| \le \mu\),
-
(2)
If \(\left| {P\left( {X_{i} ,X_{\kappa } } \right)} \right| > \mu\),
$$ {\text{Then}}\,\left\{ {\begin{array}{*{20}c} {X_{i} \, P \, X_{\kappa } ,{\text{ if }}\frac{{\min \left( {P\left( {X_{i} ,X_{\kappa } } \right),P\left( {X_{\kappa } ,X_{i} } \right)} \right)}}{{\left| {\Delta P\left( {X_{i} ,X_{\kappa } } \right)} \right|}} < \vartheta {\text{ and }}P\left( {X_{i} ,X_{\kappa } } \right) > P\left( {X_{\kappa } ,X_{i} } \right)} \\ {X_{\kappa } \, P \, X_{i} ,{\text{ if }}\frac{{\min \left( {P\left( {X_{i} ,X_{\kappa } } \right),P\left( {X_{\kappa } ,X_{i} } \right)} \right)}}{{\left| {\Delta P\left( {X_{i} ,X_{\kappa } } \right)} \right|}} < \vartheta {\text{ and }}P\left( {X_{i} ,X_{\kappa } } \right) < P\left( {X_{\kappa } ,X_{i} } \right)} \\ {X_{i} \, R \, X_{\kappa } ,{\text{ if }}\frac{{\min \left( {P\left( {X_{i} ,X_{\kappa } } \right),P\left( {X_{\kappa } ,X_{i} } \right)} \right)}}{{\left| {\Delta P\left( {X_{i} ,X_{\kappa } } \right)} \right|}} \ge \vartheta \, } \\ \end{array} } \right., $$(20)
where \(\mu\), \(\theta\), \(\vartheta\) are three predefined thresholds [53].
Step 6: Determine the strong ranking based on the weak ranking and PIR.
Assessment of RER under the stress of COVID-19 using the new IT2F-ORESTE method based on distance and likelihood
Construct the indicator system for RER under the stress of COVID-19 by Delphi method
In this section, the Delphi approach is applied to construct a comprehensive indicator system for RER based on the interview with 35 magisterial and accomplished experts (20 experts from the regional economic field, 10 experts from government management field, 5 experts from medical care and public health field). These experts are invited to conduct questionnaire surveys on the indicators. The Delphi method are applied to construct the indicator system for RER under the stress of COVID-19. The questionnaire surveys with the above 35 experts are directed in following three rounds:
In the first round, the adaptability of the indicators (0 is no and 1 is yes) are appraised by experts. Then, the indicators with a score below 0.50 are removed, which contains Location advantages (\(\tilde{C}_{2}\)), Scientific and technological innovation talent resources allocation efficiency (\(\tilde{C}_{12}\)), Per capita fiscal expenditure (\(\tilde{C}_{16}\)).
In the second round, the Likert 5 scale are applied to evaluated the relative significance of every indicator (on a scale of 1, 3, 5, 7, and 9, respectively, which displays it is greatly unimportant, a little unimportant, medium, a little important, greatly important). The indicators with final score below 5.5 are removed. That is, the indicators deleted in the second round include Internet economy development environment (\(\tilde{C}_{10}\)), Small and medium-sized enterprises develop vitality (\(\tilde{C}_{11}\)), Scientific and technological innovation talent resources allocation efficiency (\(\tilde{C}_{12}\)), Optimization of financial structure (\(\tilde{C}_{17}\)), Government financial self-sufficient capacity (\(\tilde{C}_{23}\)). By means of inquiring experts, the remaining secondary indicator of Labor forces (\(\tilde{T}_{3}\)) is incorporated into Government's ability (\(\tilde{T}_{5}\)). Then, an adjusted indicator system is acquired.
In the third round, experts have no objection to the constructed indicator system.
Through three rounds of survey, the indicator system, which includes 4 first-level indicators and 15 s-level indicators, are finally obtained, shown in Fig. 2.

Indicator system for RER under the stress of COVID-19
The proposed IT2F-ORESTE method
This section develops the IT2F-ORESTE method based on distance measure and likelihood to deal with the assessment problem of RER under COVID-19 epidemic stress in which the preference values of alternatives are denoted by IT2FSs or crisp numbers and the weights of criteria are unknown.
The basic notations are shown in Table 2.
Assume that \(X = \left\{ {X_{i} \left| {i = 1,2, \cdots ,m} \right.} \right\}\) is a set of alternatives (regionals), \(C = \left\{ {C_{j} \left| {j = 1,2, \cdots ,n} \right.} \right\}\) is a set of criteria (assessment indicators of RER), \(\omega = \left\{ {\omega_{j} \left| {j = 1,2, \cdots ,n} \right.} \right\}\) is a set of criteria weights and \(E = \left\{ {E_{l} \left| {l = 1,2, \cdots ,q} \right.} \right\}\) is a set of experts. Assume that there are \(\delta\) (\(0 \le \delta \le n\)) quantitative indicators and \(n - \delta\) qualitative indicators. The proposed IT2F-ORESTE method contains three phases:
Phase I: Collect assessment indicator information of RER
In general, indicator system includes both the quantitative indicator (such as per capita GDP, fixed asset investment, total retail sales of consumer goods) and qualitative indicator (such as industrial transformation and upgrading capacity, business environment, financial support), in which the preference values of the quantitative indicator can be dimensionless and the preference values of the qualitative indicator cannot be quantified as crisp number [63].
The quantitative indicator information is obtained by investigation or estimation, while the qualitative indicator information is the experts’ subjective evaluation based on their experience, knowledge or ability. For solving the assessment problem with quantitative and qualitative indicator information in the same environments, next a transformation function that converts quantitative indicator information to the IT2FSs is developed.
Definition 8
Let \(B = \left\{ {b_{j} \left| {j = 1,2, \cdots ,n} \right.} \right\}\) be a crisp number set. \(b^{ - } = \min \left\{ {b_{j} \left| {j = 1,2, \cdots ,n} \right.} \right\}\), \(b^{ + } = \max \left\{ {b_{j} \left| {j = 1,2, \cdots ,n} \right.} \right\}\). Then, \(b_{j}\) corresponding linguistic terms (LTs) and IT2FSs are denoted as follows (Table 3):
Example 1
In 2020, the GDP of Qindao, Jinan, Yantai, Weifang, Linyi of Shandong province of China are 12,400.56, 10,140.91, 7816.42, 5872.20, 4805.25 (Unit:100 million RMB), respectively. The Crisp number interval are \(\left[ {4805.25,5890.25} \right)\), \(\left[ {5890.25,6975.25} \right)\), \(\left[ {6975.25,8060.25} \right)\), \(\left[ {8060.25,9145.25} \right)\), \(\big[ 9145.25,10230.25 \big)\), \(\left[ {10230.25,11315.25} \right)\), \(\left[ {11315.25,12400.56} \right]\), respectively. Then, indicator information of the GDP of Qindao corresponding linguistic terms and IT2FSs are \(\left\{ {{\text{Very strong }}\left( {{\text{VS}}} \right)} \right\}\) and [(0.9,1,1,1;1), (0.95,1,1,1;0.9)], respectively. Indicator information of the GDP of Qindao corresponding linguistic terms and IT2FSs are {Extremely Strong (ES)} and [(0.9,1,1,1;1), (0.95,1,1,1;0.9)], respectively, and so on.
Step 1: Convert \(\delta\) (\(0 \le \delta \le n\)) quantitative indicator information obtained by investigation to the LTs based on the definition 8.
Step 2: Establish the initial decision matrix.
The initial decision matrix \(\overline{D}_{l}\) including LTs converted by definition 8 and LTs given by expert \(E_{l}\) is established as follows:
where \(b_{ij}\) (\(i = = 1,2, \cdots m,j = 1,2, \cdots ,\delta\)) denotes the converted linguistic indicator value, and \(L_{ij}\) (\(i = = 1,2, \cdots m,j = \delta + 1,\delta + 2, \cdots ,n\)) denotes the linguistic indicator value given by experts.
Step 3: Normalize the linguistic decision matrix \(\overline{D}_{l}\).
In general, the decision matrix \(\overline{D}_{l}\) should be normalized before solving the real assessment problems, except that all the assessment indicators have the same form. In this step, based on Table 4 and Fig. 3, the decision matrix \(\overline{D}_{l}\) is normalized by utilizing the following equation:

The MF of IT2FSs for LTs
Step 4: Convert the normalized LTs into the corresponding IT2FSs, which can be represented by:
where \(\tilde{\tilde{A}}_{ij}\) (\(i = 1,2, \cdots m,j = 1,2, \cdots ,n\)) denotes the corresponding IT2FSs.
Step 5: Aggregate the converted IT2FSs by the weighted average (WA) operator. If the weights of the experts are not given, a general solution is that \(w_{l} = {\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 q}}\right.\kern-\nulldelimiterspace} \!\lower0.7ex\hbox{$q$}}\), \(\left( {l = 1,2, \cdots ,q} \right)\), then the IT2FS-WA operator can be defined as:
Phase II: Determinate the weight of indicator
The weights of indicators can have a significant impact on the assessment results. Nevertheless, it is hard to denote accurately the weights of indicators by using crisp number or LTs in the complex environments. In contrast, experts can make pairwise comparisons among indicators. In a more ideal situation, the preference degree (PD) between two indicators can be accurately measured by LTs. Therefore, in this paper, the preference relations (PRs) based on the IT2FSs are constructed to obtain the weights of indicators.
Step 6: Establish the PRs matrix with LTs.
Experts are invited to give the PDs between two indicators by LTs. Next, their LTs are converted into IT2FSs. Then, the converted IT2FSs are aggregated by WA operator. That is, the PRs matrix with IT2FSs is established as:
where \(\tilde{A}_{ij}^{\omega }\) (\(i = 1,2, \cdots n,j = 1,2, \cdots ,n\)) denotes the corresponding IT2FSs and represents the PD of indicator \(C_{j} \left( {j = 1,2, \cdots ,n} \right)\) for \(C_{i} \left( {i = 1,2, \cdots ,n} \right)\). In particular, \(\tilde{A}_{11}^{\omega } = \tilde{A}_{22}^{\omega } = \cdots = \tilde{A}_{nn}^{\omega } = \left[ {\left( {1,1,1,1;1} \right),\left( {1,1,1,1;0.9} \right)} \right]\).
Step 7: Compute the PDs of one indicator over the others.
The PD of indicator \(C_{j} \left( {j = 1,2, \cdots ,n} \right)\) over the others can be computed by collecting the all elements (except \(C_{jj}\)) in the \(i\) th row of matrix \(\tilde{A}^{\omega }\) based on the IT2FPA operator (Eq. (26)).
Step 8: Compute the weight of indicator.
Based on the likelihood of two PDs between two indicators \(I\left( {\tilde{A}_{i}^{\omega } \ge \tilde{A}_{j}^{\omega } } \right)\), the weight of indicator \(C_{i} \left( {i = 1,2, \cdots ,n} \right)\) can be computed as:
Phase III: Obtain the ranking result
The traditional ORESTE method denotes the decision-making information only by using general ranking [64]. Nevertheless, the downside of this method is a loss of much valuable information, which may obtain an unreasonable result. In order to further improve the drawbacks of this method, the distance measure based on the extend vertex method are applied to establish GPS function since it encompasses more preference information on the PR between the indicators and the PR between the alternatives than general ranking.
Step 9: Calculate the GPS \(\tilde{G}\left( {A_{ij} } \right)\) of alternative \(X_{i}\) with respect to the indicator \(C_{j}\).
The maximum IT2FS \(\tilde{A}_{{_{j} }}^{ + }\) of \(X_{i}\) with respect to the \(C_{j}\) are defined as follows:
The weight of the most significant indicator \(C_{j}\) are defined as follows:
Based on the extend vertex method, let the distance measure \(d\left( {\tilde{A}_{ij} ,\tilde{A}_{{_{j} }}^{ + } } \right)\) replace the \(R_{j} \left( {X_{i} } \right)\) and let the distance measure \(d\left( {\omega_{j} ,\omega^{ + } } \right)\) replace \(R_{j}\).
Then, the GPS \(\tilde{G}\left( {X_{ij} } \right)\) can be calculated as follows:
where \(\rho \in \left[ {0,1} \right]\) is the coefficient to declare the importance between \(d\left( {\tilde{A}_{ij} ,\tilde{A}_{{_{j} }}^{ + } } \right)\) and \(d\left( {\omega_{j} ,\omega^{ + } } \right)\). Obviously, the smaller \(\tilde{G}\left( {X_{ij} } \right)\) is, the closer \(\tilde{A}_{ij}\) is to \(\tilde{A}_{{_{j} }}^{ + }\) and the better \(\tilde{A}_{ij}\) should be.
Step 10: Establish the global WR.
The average PD of the alternative \(X_{i}\) can be defined as follows:
Then, the WR can be obtained as follows:
If \(\tilde{\tilde{R}}\left( {X_{i} } \right) - \tilde{\tilde{R}}\left( {X_{\kappa } } \right) < 0\), \(X_{i} \, P \, X_{\kappa }\);
If \(\tilde{\tilde{R}}\left( {X_{i} } \right) - \tilde{\tilde{R}}\left( {X_{\kappa } } \right) = 0\), \(X_{i} \, I \, X_{\kappa }\).
Step 11: Construct the PIR structure of alternatives \(X_{i} \left( {i = 1,2, \cdots ,m} \right)\).
-
(1)
Calculate the PIs.
The PI of \(X_{i}\) over \(X_{\kappa }\) with respect to \(C_{j}\) can be defined as follows:
The average PI of \(X_{i}\) over \(X_{\kappa }\) with respect to \(C_{j}\) can be defined as:
The net PI of \(X_{i}\) over \(X_{\kappa }\) can be defined as:
-
(2)
Determine the preference threshold (PT) and the indifference threshold (IT).
The PT \(\varepsilon\) can be defined as follows:
The IT \(\lambda\) can be defined as follows:
where \(\gamma\) is PI indifference threshold that \(\gamma = \sqrt \rho * \left( {{\upsilon \mathord{\left/ {\vphantom {\upsilon 6}} \right. \kern-\nulldelimiterspace} 6}} \right)\) with \(\upsilon\) being the minimal difference between LTs that sustain the indifference relation. The quantitative value of \(\upsilon\) can be obtained on the basis of the real circumstances.
-
(3)
Construct the PIR structure.
Based on the PT \(\varepsilon\) and IT \(\lambda\), the PIR structure is determined as follows:
Step 12: Obtain the strong ranking based on the WR and the PIR structure.
The developed IT2F-ORESTE method is an improved assessment method of RER under COVID-19 epidemic stress in which the preference values of alternatives are denoted by IT2FSs or crisp numbers and the weights of criteria are represented by IT2FSs. Compared with the forthcoming assessment method, the developed IT2F-ORESTE method can handle the indicator weights that are denoted as IT2FSs, which can to a great extent information loss in time of converting fuzzy weights into crisp number weights. What’s more, PIR structure is applied to distinguish the specific relationships between alternatives. Surprisingly, the incomparable relation that forthcoming assessment method are neglected is taken into consideration. For understanding the developed IT2F-ORESTE method better, the flowchart of this method is shown in Fig. 4.

The flowchart of the developed new IT2F-ORESTE method
A case study: the assessment of RER of cities under the stress of COVID-19 epidemic
In this section, the developed IT2F-ORESTE method with distance measure and likelihood is applied to assess the RER of cities under the stress of COVID-19 epidemic.
Case description
The COVID-19, as an on-going global pandemic continually spreading across the world, has led to a truly worldwide crisis. An increasing number of scholars and government officials have begun to put more emphasis on the geographically uneven impact and consequences of this pandemic. Different regions, in particular, are definitely discovered to possess a wide variation with regard to the efficacy of region policy/measure to contain it, and subsequent socio-economic consequences. Traditional regional structural advantages might lose advantages for economic resilience under the stress of COVID-19 epidemic. As an example, evidence has revealed that cities with dense market clustering and workforce base, or with wider global interconnections in supply chain have exhibited higher economic vulnerability.
Suppose RER of five cities, including \(X_{1}\), \(X_{2}\), \(X_{3}\), \(X_{4}\), \(X_{5}\), are assessed under COVID-19 epidemic stress. In the indicator system shown as Fig. 2, the indicator \(C_{1}\) is quantitative indicator with known data while the others are qualitative ones with unknown data. The weights of these indicators are unknown. Five experts (\(E_{1}\), \(E_{2}\) and \(E_{3}\) from the regional economic field, \(E_{4}\) from government management field, \(E_{5}\) from medical care and public health field) are invited to give the initial preference value of indicator. The PDs between two indicators are represented by LTs. \(\omega = \left\{ {\omega_{j} \left| {j = 1,2, \cdots ,n} \right.} \right\}\) is a set of criteria weights. Let L1 = {Extremely weak (EW), Very weak (VW), Weak (W), Medium (M), Strong (S), Very strong (VS), Extremely strong (ES)} be a LTs for assessing the qualitative indicators. Let L2 = {Very unimportant (VN), Quite unimportant (QN), Unimportant (U), Medium (M), Important (I), Quite important (QI), Very important (VI)} be a LTs for assessing the PDs between two indicators.
Solving the case by the developed IT2F-ORESTE method
Phase I: Collect assessment indicator information of RER
Step 1: Convert quantitative indicator information obtained by investigation to the LTs based on the definition 8.
Quantitative indicator values are from the corresponding city statistical yearbook of 2020. The regional GDP (\(C_{1}\)) of each city can be converted into the LTs, shown in Table 5 (\(C_{1}\) is the benefit indicator).
Step 2: Establish the initial linguistic decision matrix.
The evaluations on the cities over the 14 indicators given by the 5 experts are shown in Tables 25, 26, 27, 28, 29 (see the Appendix).
Step 3: Normalize the decision matrix \(\overline{D}_{l}\).
In this decision matrixes, each indicator corresponds to benefit type, and thus, it is not necessary to perform the normalization.
Step 4: Convert the normalized LTs into the corresponding IT2FSs.
Step 5: Aggregate the converted IT2FSs by the WA operator. In this case, the weights of the experts are not given, it is supposed that \(w_{l} = {\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 5}}\right.\kern-\nulldelimiterspace} \!\lower0.7ex\hbox{$5$}}\), \(\left( {l = 1,2, \cdots ,5} \right)\), then:
\(\begin{aligned}\tilde{A}_{11} &= \left[ {\left( {0.90,1.00,1.00,1.00;1} \right),}\right.\\ &\left.{\left( {0.95,1.00,1.00,1.00;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{12} &= \left[ {\left( {0.78,0.94,0.94,1.00;1} \right),}\right.\\ &\left.{\left( {0.86,0.94,0.94,0.91;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{13} &= \left[ {\left( {0.34,0.54,0.54,0.74;1} \right),}\right.\\ &\left.{\left( {0.44,0.54,0.54,0.64;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{14} &= \left[ {\left( {0.70,0.88,0.88,0.98;1} \right),}\right.\\ &\left.{\left( {0.79,0.88,0.88,0.93;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{15} &= \left[ {\left( {0.62,0.82,0.82,0.94;1} \right),}\right.\\ &\left.{\left( {0.72,0.82,0.82,0.88;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{16} &= \left[ {\left( {0.74,0.90,0.90,0.98;1} \right),}\right.\\ &\left.{\left( {0.82,0.90,0.90,0.94;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{17} &= \left[ {\left( {0.46,0.66,0.66,0.84;1} \right),}\right.\\ &\left.{\left( {0.56,0.66,0.66,0.75;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{18} &= \left[ {\left( {0.50,0.70,0.70,0.88;1} \right),}\right.\\ &\left.{\left( {0.60,0.70,0.70,0.79;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{19} &= \left[ {\left( {0.62,0.82,0.82,0.96;1} \right),}\right.\\ &\left.{\left( {0.72,0.82,0.82,0.89;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{110} &= \left[ {\left( {0.54,0.74,0.74,0.88;1} \right),}\right.\\ &\left.{\left( {0.64,0.74,0.74,0.81;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{111} &= \left[ {\left( {0.18,0.38,0.38,0.58;1} \right),}\right.\\ &\left.{\left( {0.28,0.38,0.38,0.48;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{112} &= \left[ {\left( {0.38,0.58,0.58,0.78;1} \right),}\right.\\ &\left.{\left( {0.48,0.58,0.58,0.68;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{113} &= \left[ {\left( {0.22,0.42,0.42,0.62;1} \right),}\right.\\ &\left.{\left( {0.32,0.42,0.42,0.52;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{114} &= \left[ {\left( {0.62,0.80,0.80,0.94;1} \right),}\right.\\ &\left.{\left( {0.71,0.80,0.80,0.87;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{21} &= \left[ {\left( {0.50,0.70,0.70,0.90;1} \right),}\right.\\ &\left.{\left( {0.60,0.70,0.70,0.80;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{22} &= \left[ {\left( {0.38,0.58,0.58,0.78;1} \right),}\right.\\ &\left.{\left( {0.48,0.58,0.58,0.68;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{23} &= \left[ {\left( {0.42,0.62,0.62,0.82;1} \right),}\right.\\ &\left.{\left( {0.52,0.62,0.62,0.72;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{24} &= \left[ {\left( {0.46,0.66,0.66,0.84;1} \right),}\right.\\ &\left.{\left( {0.56,0.66,0.66,0.75;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{25} &= \left[ {\left( {0.38,0.58,0.58,0.78;1} \right),}\right.\\ &\left.{\left( {0.48,0.58,0.58,0.68;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{26} &= \left[ {\left( {0.38,0.58,0.58,0.78;1} \right),}\right.\\ &\left.{\left( {0.48,0.58,0.58,0.68;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{27} &= \left[ {\left( {0.62,0.82,0.82,0.96;1} \right),}\right.\\ &\left.{\left( {0.72,0.82,0.82,0.89;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{28} &= \left[ {\left( {0.58,0.78,0.78,0.94;1} \right),}\right.\\ &\left.{\left( {0.68,0.78,0.78,0.86;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{29} &= \left[ {\left( {0.50,0.70,0.70,0.88;1} \right),}\right.\\ &\left.{\left( {0.60,0.70,0.70,0.79;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{210} &= \left[ {\left( {0.62,0.82,0.82,0.94;1} \right),}\right.\\ &\left.{\left( {0.72,0.82,0.82,0.88;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{211} &= \left[ {\left( {0.34,0.54,0.54,0.74;1} \right),}\right.\\ &\left.{\left( {0.44,0.54,0.54,0.64;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{212} &= \left[ {\left( {0.50,0.70,0.70,0.90;1} \right),}\right.\\ &\left.{\left( {0.60,0.70,0.70,0.80;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{213} &= \left[ {\left( {0.42,0.62,0.62,0.82;1} \right),}\right.\\ &\left.{\left( {0.52,0.62,0.62,0.72;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{214} &= \left[ {\left( {0.58,0.78,0.78,0.92;1} \right),}\right.\\ &\left.{\left( {0.68,0.78,0.78,0.85;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{31} &= \left[ {\left( {0.10,0.30,0.30,0.50;1} \right),}\right.\\ &\left.{\left( {0.20,0.30,0.30,0.40;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{32} &= \left[ {\left( {0.58,0.78,0.78,0.94;1} \right),}\right.\\ &\left.{\left( {0.68,0.78,0.78,0.86;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{33} &= \left[ {\left( {0.18,0.38,0.38,0.58;1} \right),}\right.\\ &\left.{\left( {0.28,0.38,0.38,0.48;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{34} &= \left[ {\left( {0.50,0.70,0.70,0.86;1} \right),}\right.\\ &\left.{\left( {0.60,0.70,0.70,0.78;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{35} &= \left[ {\left( {0.34,0.54,0.54,0.72;1} \right),}\right.\\ &\left.{\left( {0.44,0.54,0.54,0.63;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{36} &= \left[ {\left( {0.38,0.58,0.58,0.78;1} \right),}\right.\\ &\left.{\left( {0.48,0.58,0.58,0.68;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{37} &= \left[ {\left( {0.50,0.70,0.70,0.90;1} \right),}\right.\\ &\left.{\left( {0.60,0.70,0.70,0.80;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{38} &= \left[ {\left( {0.38,0.58,0.58,0.78;1} \right),}\right.\\ &\left.{\left( {0.48,0.58,0.58,0.68;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{39} &= \left[ {\left( {0.22,0.42,0.42,0.62;1} \right),}\right.\\ &\left.{\left( {0.32,0.42,0.42,0.52;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{310} &= \left[ {\left( {0.34,0.54,0.54,0.74;1} \right),}\right.\\ &\left.{\left( {0.44,0.54,0.54,0.64;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{311} &= \left[ {\left( {0.58,0.78,0.78,0.94;1} \right),}\right.\\ &\left.{\left( {0.68,0.78,0.78,0.86;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{312} &= \left[ {\left( {0.42,0.62,0.62,0.82;1} \right),}\right.\\ &\left.{\left( {0.52,0.62,0.62,0.72;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{313} &= \left[ {\left( {0.54,0.74,0.74,0.92;1} \right),}\right.\\ &\left.{\left( {0.64,0.74,0.74,0.83;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{314} &= \left[ {\left( {0.58,0.78,0.78,0.94;1} \right),}\right.\\ &\left.{\left( {0.68,0.78,0.78,0.86;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{41}& = \left[ {\left( {0.00,0.00,0.00,0.10;1} \right),}\right.\\ &\left.{\left( {0.00,0.00,0.00,0.50;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{42} &= \left[ {\left( {0.46,0.66,0.66,0.86;1} \right),}\right.\\ &\left.{\left( {0.56,0.66,0.66,0.76;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{43} &= \left[ {\left( {0.34,0.54,0.54,0.74;1} \right),}\right.\\ &\left.{\left( {0.44,0.54,0.54,0.64;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{44} &= \left[ {\left( {0.42,0.62,0.62,0.80;1} \right),}\right.\\ &\left.{\left( {0.52,0.62,0.62,0.71;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{45} &= \left[ {\left( {0.20,0.38,0.38,0.58;1} \right),}\right.\\ &\left.{\left( {0.29,0.38,0.38,0.48;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{46} &= \left[ {\left( {0.22,0.42,0.42,0.62;1} \right),}\right.\\ &\left.{\left( {0.32,0.42,0.42,0.52;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{47} &= \left[ {\left( {0.58,0.78,0.78,0.92;1} \right),}\right.\\ &\left.{\left( {0.68,0.78,0.78,0.85;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{48} &= \left[ {\left( {0.50,0.70,0.70,0.88;1} \right),}\right.\\ &\left.{\left( {0.60,0.70,0.70,0.79;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{49} &= \left[ {\left( {0.22,0.42,0.42,0.62;1} \right),}\right.\\ &\left.{\left( {0.32,0.42,0.42,0.52;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{410} &= \left[ {\left( {0.42,0.62,0.62,0.80;1} \right),}\right.\\ &\left.{\left( {0.52,0.62,0.62,0.71;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{411} &= \left[ {\left( {0.62,0.82,0.82,0.94;1} \right),}\right.\\ &\left.{\left( {0.72,0.82,0.82,0.88;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{412} &= \left[ {\left( {0.54,0.74,0.74,0.92;1} \right),}\right.\\ &\left.{\left( {0.64,0.74,0.74,0.83;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{413} &= \left[ {\left( {0.58,0.78,0.78,0.94;1} \right),}\right.\\ &\left.{\left( {0.68,0.78,0.78,0.86;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{414} &= \left[ {\left( {0.46,0.66,0.66,0.86;1} \right),}\right.\\ &\left.{\left( {0.56,0.66,0.66,0.76;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{51} &= \left[ {\left( {0.00,0.00,0.00,0.10;1} \right),}\right.\\ &\left.{\left( {0.00,0.00,0.00,0.50;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{52} &= \left[ {\left( {0.38,0.58,0.58,0.78;1} \right),}\right.\\ &\left.{\left( {0.48,0.58,0.58,0.68;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{53} &= \left[ {\left( {0.40,0.58,0.58,0.74;1} \right),}\right.\\ &\left.{\left( {0.49,0.58,0.58,0.66;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{54} &= \left[ {\left( {0.54,0.74,0.74,0.88;1} \right),}\right.\\ &\left.{\left( {0.64,0.74,0.74,0.81;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{55} &= \left[ {\left( {0.46,0.66,0.66,0.86;1} \right),}\right.\\ &\left.{\left( {0.56,0.66,0.66,0.76;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{56} &= \left[ {\left( {0.38,0.58,0.58,0.78;1} \right),}\right.\\ &\left.{\left( {0.48,0.58,0.58,0.68;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{57} &= \left[ {\left( {0.08,0.26,0.26,0.46;1} \right),}\right.\\ &\left.{\left( {0.17,0.26,0.26,0.36;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{58} &= \left[ {\left( {0.42,0.62,0.62,0.82;1} \right),}\right.\\ &\left.{\left( {0.52,0.62,0.62,0.72;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{59} &= \left[ {\left( {0.16,0.34,0.34,0.54;1} \right),}\right.\\ &\left.{\left( {0.25,0.34,0.34,0.44;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{510} &= \left[ {\left( {0.38,0.58,0.58,0.76;1} \right),}\right.\\ &\left.{\left( {0.48,0.58,0.58,0.67;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{511} &= \left[ {\left( {0.66,0.86,0.86,0.98;1} \right),}\right.\\ &\left.{\left( {0.76,0.86,0.86,0.92;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{512} &= \left[ {\left( {0.58,0.78,0.78,0.94;1} \right),}\right.\\ &\left.{\left( {0.68,0.78,0.78,0.86;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{513} &= \left[ {\left( {0.66,0.86,0.86,0.98;1} \right),}\right.\\ &\left.{\left( {0.76,0.86,0.86,0.92;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{514} &= \left[ {\left( {0.14,0.30,0.30,0.50;1} \right),}\right.\\ &\left.{\left( {0.22,0.30,0.30,0.40;0.9} \right)} \right]\end{aligned}\).
Phase II: Determinate the weights of indicator
In this case, the PDs between any two indicators are measured by LTs, and the PRs based on the IT2FSs are constructed to get the weights of indicators.
Step 6: Establish the PRs matrix with LTs.
The same five experts are invited to give the PDs between two indicators by LTs. In particular, the LT \(O = \left[ {\left( {1,1,1,1;1} \right),\left( {1,1,1,1;0.9} \right)} \right]\). The initial linguistic PRs matrixes are shown in Tables 30, 31, 32, 33, 34 (see the Appendix).
Next, their LTs are converted into IT2FSs, and the converted IT2FSs are aggregated by WA operator. In this case, the weights of the experts are not given, and it is supposed that \(w_{l} = {\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 5}}\right.\kern-\nulldelimiterspace} \!\lower0.7ex\hbox{$5$}}\), \(\left( {l = 1,2, \cdots ,5} \right)\). Then, the PRs matrix with IT2FSs can be obtained:
\(\begin{aligned}\tilde{A}_{12}^{\omega }& = \left[ {\left( {0.40,0.56,0.56,0.70;1} \right),}\right. \\ & \left.{\left( {0.48,0.56,0.56,0.63;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{13}^{\omega }& = \left[ {\left( {0.20,0.36,0.36,0.54;1} \right),}\right. \\ & \left.{\left( {0.28,0.36,0.36,0.45;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{14}^{\omega }& = \left[ {\left( {0.36,0.54,0.54,0.72;1} \right),}\right. \\ & \left.{\left( {0.45,0.54,0.54,0.63;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{15}^{\omega }& = \left[ {\left( {0.12,0.26,0.26,0.46;1} \right),}\right. \\ & \left.{\left( {0.19,0.26,0.26,0.36;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{16}^{\omega }& = \left[ {\left( {0.54,0.72,0.72,0.86;1} \right),}\right. \\ & \left.{\left( {0.63,0.72,0.72,0.79;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{17}^{\omega }& = \left[ {\left( {0.44,0.60,0.60,0.76;1} \right),}\right. \\ & \left.{\left( {0.52,0.60,0.60,0.68;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{18}^{\omega }& = \left[ {\left( {0.54,0.70,0.70,0.82;1} \right),}\right. \\ & \left.{\left( {0.62,0.70,0.70,0.76;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{19}^{\omega }& = \left[ {\left( {0.22,0.36,0.36,0.54;1} \right),}\right. \\ & \left.{\left( {0.29,0.36,0.36,0.45;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{110}^{\omega }& = \left[ {\left( {0.28,0.46,0.46,0.64;1} \right),}\right. \\ & \left.{\left( {0.37,0.46,0.46,0.55;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{111}^{\omega }& = \left[ {\left( {0.42,0.60,0.60,0.76;1} \right),}\right. \\ & \left.{\left( {0.51,0.60,0.60,0.68;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{112}^{\omega }& = \left[ {\left( {0.42,0.62,0.62,0.80;1} \right),}\right. \\ & \left.{\left( {0.52,0.62,0.62,0.71;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{113}^{\omega }& = \left[ {\left( {0.50,0.68,0.68,0.84;1} \right),}\right. \\ & \left.{\left( {0.59,0.68,0.68,0.76;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{114}^{\omega }& = \left[ {\left( {0.46,0.62,0.62,0.74;1} \right),}\right. \\ & \left.{\left( {0.54,0.62,0.62,0.68;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{21}^{\omega }& = \left[ {\left( {0.30,0.44,0.44,0.60;1} \right),}\right. \\ & \left.{\left( {0.37,0.44,0.44,0.52;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{22}^{\omega }& = \left[ {\left( {1,1,1,1;1} \right),}\right. \\ & \left.{\left( {1,1,1,1;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{23}^{\omega }& = \left[ {\left( {0.34,0.54,0.54,0.74;1} \right),}\right. \\ & \left.{\left( {0.44,0.54,0.54,0.64;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{24}^{\omega }& = \left[ {\left( {0.28,0.44,0.44,0.62;1} \right),}\right. \\ & \left.{\left( {0.36,0.44,0.44,0.53;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{25}^{\omega }& = \left[ {\left( {0.38,0.58,0.58,0.78;1} \right),}\right. \\ & \left.{\left( {0.48,0.58,0.58,0.68;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{26}^{\omega }& = \left[ {\left( {0.44,0.58,0.58,0.70;1} \right),}\right. \\ & \left.{\left( {0.51,0.58,0.58,0.64;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{27}^{\omega }& = \left[ {\left( {0.50,0.60,0.60,0.68;1} \right),}\right. \\ & \left.{\left( {0.55,0.60,0.60,0.64;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{28}^{\omega }& = \left[ {\left( {0.46,0.66,0.66,0.82;1} \right),}\right. \\ & \left.{\left( {0.56,0.66,0.66,0.74;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{29}^{\omega }& = \left[ {\left( {0.36,0.54,0.54,0.72;1} \right),}\right. \\ & \left.{\left( {0.45,0.54,0.54,0.63;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{210}^{\omega }& = \left[ {\left( {0.32,0.50,0.50,0.68;1} \right),}\right. \\ & \left.{\left( {0.41,0.50,0.50,0.59;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{211}^{\omega }& = \left[ {\left( {0.38,0.58,0.58,0.76;1} \right),}\right. \\ & \left.{\left( {0.48,0.58,0.58,0.67;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{212}^{\omega }& = \left[ {\left( {0.18,0.32,0.32,0.48;1} \right),}\right. \\ & \left.{\left( {0.25,0.32,0.32,0.40;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{213}^{\omega }& = \left[ {\left( {0.44,0.60,0.60,0.76;1} \right),}\right. \\ & \left.{\left( {0.52,0.60,0.60,0.68;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{214}^{\omega }& = \left[ {\left( {0.26,0.42,0.42,0.60;1} \right),}\right. \\ & \left.{\left( {0.34,0.42,0.42,0.51;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{31}^{\omega }& = \left[ {\left( {0.38,0.56,0.56,0.72;1} \right),}\right. \\ & \left.{\left( {0.47,0.56,0.56,0.64;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{32}^{\omega }& = \left[ {\left( {0.26,0.46,0.46,0.66;1} \right),}\right. \\ & \left.{\left( {0.36,0.46,0.46,0.56;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{33}^{\omega }& = \left[ {\left( {1,1,1,1;1} \right),}\right. \\ & \left.{\left( {1,1,1,1;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{34}^{\omega }& = \left[ {\left( {0.26,0.40,0.40,0.56;1} \right),}\right. \\ & \left.{\left( {0.33,0.40,0.40,0.48;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{35}^{\omega }& = \left[ {\left( {0.30,0.44,0.44,0.60;1} \right),}\right. \\ & \left.{\left( {0.37,0.44,0.44,0.52;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{36}^{\omega }& = \left[ {\left( {0.46,0.66,0.66,0.82;1} \right),}\right. \\ & \left.{\left( {0.56,0.66,0.66,0.74;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{37}^{\omega }& = \left[ {\left( {0.54,0.72,0.72,0.88;1} \right),}\right. \\ & \left.{\left( {0.63,0.72,0.72,0.80;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{38}^{\omega }& = \left[ {\left( {0.48,0.62,0.62,0.74;1} \right),}\right. \\ & \left.{\left( {0.55,0.62,0.62,0.68;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{39}^{\omega }& = \left[ {\left( {0.28,0.46,0.46,0.64;1} \right),}\right. \\ & \left.{\left( {0.37,0.46,0.46,0.55;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{310}^{\omega }& = \left[ {\left( {0.38,0.52,0.52,0.66;1} \right),}\right. \\ & \left.{\left( {0.45,0.52,0.52,0.59;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{311}^{\omega }& = \left[ {\left( {0.38,0.56,0.56,0.72;1} \right),}\right. \\ & \left.{\left( {0.47,0.56,0.56,0.64;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{312}^{\omega }& = \left[ {\left( {0.50,0.70,0.70,0.88;1} \right),}\right. \\ & \left.{\left( {0.60,0.70,0.70,0.79;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{313}^{\omega }& = \left[ {\left( {0.38,0.56,0.56,0.72;1} \right),}\right. \\ & \left.{\left( {0.47,0.56,0.56,0.64;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{314}^{\omega }& = \left[ {\left( {0.38,0.52,0.52,0.68;1} \right),}\right. \\ & \left.{\left( {0.45,0.52,0.52,0.60;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{41}^{\omega }& = \left[ {\left( {0.28,0.46,0.46,0.64;1} \right),}\right. \\ & \left.{\left( {0.37,0.46,0.46,0.55;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{42}^{\omega }& = \left[ {\left( {0.38,0.56,0.56,0.72;1} \right),}\right. \\ & \left.{\left( {0.47,0.56,0.56,0.64;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{43}^{\omega }& = \left[ {\left( {0.44,0.60,0.60,0.74;1} \right),}\right. \\ & \left.{\left( {0.52,0.60,0.60,0.67;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{44}^{\omega }& = \left[ {\left( {1,1,1,1;1} \right),}\right. \\ & \left.{\left( {1,1,1,1;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{45}^{\omega }& = \left[ {\left( {0.58,0.78,0.78,0.92;1} \right),}\right. \\ & \left.{\left( {0.68,0.78,0.78,0.85;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{46}^{\omega }& = \left[ {\left( {0.30,0.46,0.46,0.64;1} \right),}\right. \\ & \left.{\left( {0.38,0.46,0.46,0.55;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{47}^{\omega }& = \left[ {\left( {0.20,0.38,0.38,0.58;1} \right),}\right. \\ & \left.{\left( {0.29,0.38,0.38,0.48;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{48}^{\omega }& = \left[ {\left( {0.40,0.56,0.56,0.72;1} \right),}\right. \\ & \left.{\left( {0.48,0.56,0.56,0.64;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{49}^{\omega }& = \left[ {\left( {0.54,0.74,0.74,0.88;1} \right),}\right. \\ & \left.{\left( {0.64,0.74,0.74,0.81;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{410}^{\omega }& = \left[ {\left( {0.36,0.54,0.54,0.72;1} \right),}\right. \\ & \left.{\left( {0.45,0.54,0.54,0.63;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{411}^{\omega }& = \left[ {\left( {0.36,0.50,0.50,0.64;1} \right),}\right. \\ & \left.{\left( {0.43,0.50,0.50,0.57;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{412}^{\omega }& = \left[ {\left( {0.52,0.68,0.68,0.82;1} \right),}\right. \\ & \left.{\left( {0.60,0.68,0.68,0.75;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{413}^{\omega }& = \left[ {\left( {0.62,0.80,0.80,0.92;1} \right),}\right. \\ & \left.{\left( {0.71,0.80,0.80,0.86;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{414}^{\omega }& = \left[ {\left( {0.30,0.42,0.42,0.56;1} \right),}\right. \\ & \left.{\left( {0.36,0.42,0.42,0.49;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{51}^{\omega }& = \left[ {\left( {0.46,0.66,0.66,0.80;1} \right),}\right. \\ & \left.{\left( {0.56,0.66,0.66,0.73;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{52}^{\omega }& = \left[ {\left( {0.22,0.42,0.42,0.62;1} \right),}\right. \\ & \left.{\left( {0.32,0.42,0.42,0.52;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{53}^{\omega }& = \left[ {\left( {0.40,0.56,0.56,0.70;1} \right),}\right. \\ & \left.{\left( {0.48,0.56,0.56,0.63;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{54}^{\omega }& = \left[ {\left( {0.08,0.22,0.22,0.42;1} \right),}\right. \\ & \left.{\left( {0.15,0.22,0.22,0.32;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{55}^{\omega }& = \left[ {\left( {1,1,1,1;1} \right),}\right. \\ & \left.{\left( {1,1,1,1;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{56}^{\omega }& = \left[ {\left( {0.50,0.68,0.68,0.82;1} \right),}\right. \\ & \left.{\left( {0.59,0.68,0.68,0.75;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{57}^{\omega }& = \left[ {\left( {0.32,0.48,0.48,0.64;1} \right),}\right. \\ & \left.{\left( {0.36,0.48,0.48,0.56;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{58}^{\omega }& = \left[ {\left( {0.36,0.54,0.54,0.72;1} \right),}\right. \\ & \left.{\left( {0.45,0.54,0.54,0.63;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{59}^{\omega }& = \left[ {\left( {0.16,0.32,0.32,0.50;1} \right),}\right. \\ & \left.{\left( {0.24,0.32,0.32,0.41;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{510}^{\omega }& = \left[ {\left( {0.32,0.48,0.48,0.64;1} \right),}\right. \\ & \left.{\left( {0.40,0.48,0.48,0.56;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{511}^{\omega }& = \left[ {\left( {0.34,0.46,0.46,0.60;1} \right),}\right. \\ & \left.{\left( {0.40,0.46,0.46,0.53;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{512}^{\omega }& = \left[ {\left( {0.24,0.42,0.42,0.62;1} \right),}\right. \\ & \left.{\left( {0.33,0.42,0.42,0.52;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{513}^{\omega }& = \left[ {\left( {0.40,0.56,0.56,0.70;1} \right),}\right. \\ & \left.{\left( {0.48,0.56,0.56,0.63;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{514}^{\omega }& = \left[ {\left( {0.22,0.42,0.42,0.62;1} \right),}\right. \\ & \left.{\left( {0.32,0.42,0.42,0.52;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{61}^{\omega }& = \left[ {\left( {0.14,0.28,0.28,0.46;1} \right),}\right. \\ & \left.{\left( {0.21,0.28,0.28,0.37;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{62}^{\omega }& = \left[ {\left( {0.30,0.42,0.42,0.56;1} \right),}\right.\\ & \left.{42\left( {0.36,0.,0.42,0.49;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{63}^{\omega }& = \left[ {\left( {0.18,0.34,0.34,0.54;1} \right),}\right. \\ & \left.{\left( {0.26,0.34,0.34,0.44;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{64}^{\omega }& = \left[ {\left( {0.36,0.54,0.54,0.70;1} \right),}\right. \\ & \left.{\left( {0.45,0.54,0.54,0.62;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{65}^{\omega }& = \left[ {\left( {0.18,0.32,0.32,0.50;1} \right),}\right. \\ & \left.{\left( {0.25,0.32,0.32,0.41;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{66}^{\omega }& = \left[ {\left( {1,1,1,1;1} \right),}\right. \\ & \left.{\left( {1,1,1,1;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{67}^{\omega }& = \left[ {\left( {0.44,0.62,0.62,0.78;1} \right),}\right. \\ & \left.{\left( {0.53,0.62,0.62,0.70;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{68}^{\omega }& = \left[ {\left( {0.44,0.60,0.60,0.74;1} \right),}\right. \\ & \left.{\left( {0.52,0.60,0.60,0.67;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{69}^{\omega }& = \left[ {\left( {0.52,0.66,0.66,0.78;1} \right),}\right. \\ & \left.{\left( {0.59,0.66,0.66,0.72;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{610}^{\omega }& = \left[ {\left( {0.30,0.44,0.44,0.60;1} \right),}\right. \\ & \left.{\left( {0.37,0.44,0.44,0.52;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{611}^{\omega }& = \left[ {\left( {0.28,0.44,0.44,0.60;1} \right),}\right. \\ & \left.{\left( {0.36,0.44,0.44,0.52;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{612}^{\omega }& = \left[ {\left( {0.36,0.54,0.54,0.72;1} \right),}\right. \\ & \left.{\left( {0.45,0.54,0.54,0.63;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{613}^{\omega }& = \left[ {\left( {0.42,0.62,0.62,0.80;1} \right),}\right. \\ & \left.{\left( {0.52,0.62,0.62,0.71;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{614}^{\omega }& = \left[ {\left( {0.44,0.62,0.62,0.78;1} \right),}\right. \\ & \left.{\left( {0.53,0.62,0.62,0.70;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{71}^{\omega }& = \left[ {\left( {0.22,0.34,0.34,0.48;1} \right),}\right. \\ & \left.{\left( {0.28,0.34,0.34,0.41;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{72}^{\omega }& = \left[ {\left( {0.32,0.40,0.40,0.50;1} \right),}\right. \\ & \left.{\left( {0.36,0.40,0.40,0.54;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{73}^{\omega }& = \left[ {\left( {0.12,0.28,0.28,0.46;1} \right),}\right. \\ & \left.{\left( {0.20,0.28,0.28,0.37;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{74}^{\omega }& = \left[ {\left( {0.42,0.62,0.62,0.80;1} \right),}\right. \\ & \left.{\left( {0.52,0.62,0.62,0.71;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{75}^{\omega }& = \left[ {\left( {0.36,0.52,0.52,0.68;1} \right),}\right. \\ & \left.{\left( {0.44,0.52,0.52,0.60;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{76}^{\omega }& = \left[ {\left( {0.22,0.38,0.38,0.56;1} \right),}\right. \\ & \left.{\left( {0.30,0.38,0.38,0.47;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{77}^{\omega }& = \left[ {\left( {1,1,1,1;1} \right),}\right. \\ & \left.{\left( {1,1,1,1;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{78}^{\omega }& = \left[ {\left( {0.54,0.72,0.72,0.86;1} \right),}\right. \\ & \left.{\left( {0.63,0.72,0.72,0.79;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{79}^{\omega }& = \left[ {\left( {0.42,0.62,0.62,0.80;1} \right),}\right. \\ & \left.{\left( {0.52,0.62,0.62,0.71;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{710}^{\omega }& = \left[ {\left( {0.36,0.54,0.54,0.72;1} \right),}\right. \\ & \left.{\left( {0.45,0.54,0.54,0.63;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{711}^{\omega }& = \left[ {\left( {0.46,0.64,0.64,0.78;1} \right),}\right. \\ & \left.{\left( {0.55,0.64,0.64,0.71;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{712}^{\omega }& = \left[ {\left( {0.20,0.32,0.32,0.50;1} \right),}\right. \\ & \left.{\left( {0.26,0.32,0.32,0.41;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{713}^{\omega }& = \left[ {\left( {0.30,0.50,0.50,0.70;1} \right),}\right. \\ & \left.{\left( {0.40,0.50,0.50,0.60;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{714}^{\omega }& = \left[ {\left( {0.42,0.58,0.58,0.70;1} \right),}\right. \\ & \left.{\left( {0.50,0.58,0.58,0.64;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{81}^{\omega }& = \left[ {\left( {0.36,0.50,0.50,0.64;1} \right),}\right. \\ & \left.{\left( {0.43,0.50,0.50,0.57;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{82}^{\omega }& = \left[ {\left( {0.18,0.34,0.34,0.54;1} \right),}\right. \\ & \left.{\left( {0.26,0.34,0.34,0.44;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{83}^{\omega }& = \left[ {\left( {0.26,0.38,0.38,0.52;1} \right),}\right. \\ & \left.{\left( {0.32,0.38,0.38,0.54;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{84}^{\omega }& = \left[ {\left( {0.28,0.44,0.44,0.60;1} \right),}\right. \\ & \left.{\left( {0.36,0.44,0.44,0.52;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{85}^{\omega }& = \left[ {\left( {0.28,0.46,0.46,0.64;1} \right),}\right. \\ & \left.{\left( {0.37,0.46,0.46,0.55;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{86}^{\omega }& = \left[ {\left( {0.26,0.40,0.40,0.56;1} \right),}\right. \\ & \left.{\left( {0.33,0.40,0.40,0.48;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{87}^{\omega }& = \left[ {\left( {0.14,0.28,0.28,0.46;1} \right),}\right. \\ & \left.{\left( {0.21,0.28,0.28,0.37;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{88}^{\omega }& = \left[ {\left( {1,1,1,1;1} \right),}\right. \\ & \left.{\left( {1,1,1,1;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{89}^{\omega }& = \left[ {\left( {0.20,0.38,0.38,0.58;1} \right),}\right. \\ & \left.{\left( {0.29,0.38,0.38,0.48;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{810}^{\omega }& = \left[ {\left( {0.28,0.46,0.46,0.66;1} \right),}\right. \\ & \left.{\left( {0.37,0.46,0.46,0.56;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{811}^{\omega }& = \left[ {\left( {0.36,0.42,0.42,0.50;1} \right),}\right. \\ & \left.{\left( {0.39,0.42,0.42,0.46;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{812}^{\omega }& = \left[ {\left( {0.30,0.42,0.42,0.58;1} \right),}\right. \\ & \left.{\left( {0.36,0.42,0.42,0.50;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{813}^{\omega }& = \left[ {\left( {0.16,0.32,0.32,0.50;1} \right),}\right. \\ & \left.{\left( {0.24,0.32,0.32,0.41;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{814}^{\omega }& = \left[ {\left( {0.26,0.46,0.46,0.66;1} \right),}\right. \\ & \left.{\left( {0.36,0.46,0.46,0.56;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{91}^{\omega }& = \left[ {\left( {0.28,0.46,0.46,0.64;1} \right),}\right. \\ & \left.{\left( {0.37,0.46,0.46,0.55;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{92}^{\omega }& = \left[ {\left( {0.28,0.46,0.46,0.64;1} \right),}\right. \\ & \left.{\left( {0.37,0.46,0.46,0.55;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{93}^{\omega }& = \left[ {\left( {0.28,0.46,0.46,0.64;1} \right),}\right. \\ & \left.{\left( {0.37,0.46,0.46,0.55;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{94}^{\omega }& = \left[ {\left( {0.12,0.26,0.26,0.46;1} \right),}\right. \\ & \left.{\left( {0.19,0.26,0.26,0.36;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{95}^{\omega }& = \left[ {\left( {0.40,0.54,0.54,0.68;1} \right),}\right. \\ & \left.{\left( {0.47,0.54,0.54,0.61;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{96}^{\omega }& = \left[ {\left( {0.22,0.34,0.34,0.48;1} \right),}\right. \\ & \left.{\left( {0.28,0.34,0.34,0.41;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{97}^{\omega }& = \left[ {\left( {0.20,0.38,0.38,0.58;1} \right),}\right. \\ & \left.{\left( {0.29,0.38,0.38,0.48;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{98}^{\omega }& = \left[ {\left( {0.42,0.62,0.62,0.80;1} \right),}\right. \\ & \left.{\left( {0.52,0.62,0.62,0.71;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{99}^{\omega }& = \left[ {\left( {1,1,1,1;1} \right),}\right. \\ & \left.{\left( {1,1,1,1;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{910}^{\omega }& = \left[ {\left( {0.32,0.48,0.48,0.64;1} \right),}\right. \\ & \left.{\left( {0.40,0.48,0.48,0.56;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{911}^{\omega }& = \left[ {\left( {0.46,0.66,0.66,0.82;1} \right),}\right. \\ & \left.{\left( {0.56,0.66,0.66,0.74;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{912}^{\omega }& = \left[ {\left( {0.48,0.66,0.66,0.82;1} \right),}\right. \\ & \left.{\left( {0.57,0.66,0.66,0.74;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{913}^{\omega }& = \left[ {\left( {0.20,0.38,0.38,0.58;1} \right),}\right. \\ & \left.{\left( {0.29,0.38,0.38,0.48;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{914}^{\omega }& = \left[ {\left( {0.32,0.50,0.50,0.70;1} \right),}\right. \\ & \left.{\left( {0.41,0.50,0.50,0.60;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{101}^{\omega }& = \left[ {\left( {0.36,0.52,0.52,0.68;1} \right),}\right. \\ & \left.{\left( {0.44,0.52,0.52,0.60;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{102}^{\omega }& = \left[ {\left( {0.32,0.50,0.50,0.68;1} \right),}\right. \\ & \left.{\left( {0.41,0.50,0.50,0.59;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{103}^{\omega }& = \left[ {\left( {0.34,0.48,0.48,0.62;1} \right),}\right. \\ & \left.{\left( {0.41,0.48,0.48,0.55;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{104}^{\omega }& = \left[ {\left( {0.28,0.46,0.46,0.64;1} \right),}\right. \\ & \left.{\left( {0.37,0.46,0.46,0.55;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{105}^{\omega }& = \left[ {\left( {0.36,0.52,0.52,0.68;1} \right),}\right. \\ & \left.{\left( {0.44,0.52,0.52,0.60;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{106}^{\omega }& = \left[ {\left( {0.40,0.56,0.56,0.70;1} \right),}\right. \\ & \left.{\left( {0.48,0.56,0.56,0.63;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{107}^{\omega }& = \left[ {\left( {0.24,0.42,0.42,0.62;1} \right),}\right. \\ & \left.{\left( {0.33,0.42,0.42,0.52;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{108}^{\omega }& = \left[ {\left( {0.34,0.54,0.54,0.72;1} \right),}\right. \\ & \left.{\left( {0.44,0.54,0.54,0.63;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{109}^{\omega }& = \left[ {\left( {0.36,0.52,0.52,0.68;1} \right),}\right. \\ & \left.{\left( {0.44,0.52,0.52,0.60;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{1010}^{\omega }& = \left[ {\left( {1,1,1,1;1} \right),}\right. \\ & \left.{\left( {1,1,1,1;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{1011}^{\omega }& = \left[ {\left( {0.44,0.62,0.62,0.80;1} \right),}\right. \\ & \left.{\left( {0.53,0.62,0.62,0.71;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{1012}^{\omega }& = \left[ {\left( {0.54,0.72,0.72,0.86;1} \right),}\right. \\ & \left.{\left( {0.63,0.72,0.72,0.79;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{1013}^{\omega }& = \left[ {\left( {0.44,0.60,0.60,0.74;1} \right),}\right. \\ & \left.{\left( {0.52,0.60,0.60,0.67;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{1014}^{\omega }& = \left[ {\left( {0.26,0.46,0.46,0.66;1} \right),}\right. \\ & \left.{\left( {0.36,0.46,0.46,0.56;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{111}^{\omega }& = \left[ {\left( {0.38,0.58,0.58,0.76;1} \right),}\right. \\ & \left.{\left( {0.48,0.58,0.58,0.67;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{112}^{\omega }& = \left[ {\left( {0.24,0.42,0.42,0.62;1} \right),}\right. \\ & \left.{\left( {0.33,0.42,0.42,0.52;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{113}^{\omega }& = \left[ {\left( {0.28,0.44,0.44,0.62;1} \right),}\right. \\ & \left.{\left( {0.36,0.44,0.44,0.53;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{114}^{\omega }& = \left[ {\left( {0.36,0.50,0.50,0.64;1} \right),}\right. \\ & \left.{\left( {0.43,0.50,0.50,0.57;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{115}^{\omega }& = \left[ {\left( {0.40,0.54,0.54,0.66;1} \right),}\right. \\ & \left.{\left( {0.47,0.54,0.54,0.60;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{116}^{\omega }& = \left[ {\left( {0.40,0.56,0.56,0.72;1} \right),}\right. \\ & \left.{\left( {0.48,0.56,0.56,0.64;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{117}^{\omega }& = \left[ {\left( {0.26,0.40,0.40,0.56;1} \right),}\right. \\ & \left.{\left( {0.33,0.40,0.40,0.48;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{118}^{\omega }& = \left[ {\left( {0.50,0.58,0.58,0.64;1} \right),}\right. \\ & \left.{\left( {0.54,0.58,0.58,0.61;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{119}^{\omega }& = \left[ {\left( {0.18,0.34,0.34,0.54;1} \right),}\right. \\ & \left.{\left( {0.26,0.34,0.34,0.44;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{1110}^{\omega }& = \left[ {\left( {0.20,0.38,0.38,0.56;1} \right),}\right. \\ & \left.{\left( {0.29,0.38,0.38,0.47;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{1111}^{\omega }& = \left[ {\left( {1,1,1,1;1} \right),}\right. \\ & \left.{\left( {1,1,1,1;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{1112}^{\omega }& = \left[ {\left( {0.48,0.64,0.64,0.78;1} \right),}\right. \\ & \left.{\left( {0.56,0.64,0.64,0.71;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{1113}^{\omega }& = \left[ {\left( {0.30,0.50,0.50,0.70;1} \right),}\right. \\ & \left.{\left( {0.40,0.50,0.50,0.60;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{1114}^{\omega }& = \left[ {\left( {0.54,0.72,0.72,0.84;1} \right),}\right. \\ & \left.{\left( {0.63,0.72,0.72,0.78;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{121}^{\omega }& = \left[ {\left( {0.20,0.38,0.38,0.58;1} \right),}\right. \\ & \left.{\left( {0.29,0.38,0.38,0.48;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{122}^{\omega }& = \left[ {\left( {0.52,0.68,0.68,0.82;1} \right),}\right. \\ & \left.{\left( {0.60,0.68,0.68,0.75;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{123}^{\omega }& = \left[ {\left( {0.12,0.30,0.30,0.50;1} \right),}\right. \\ & \left.{\left( {0.21,0.30,0.30,0.40;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{124}^{\omega }& = \left[ {\left( {0.18,0.32,0.32,0.48;1} \right),}\right. \\ & \left.{\left( {0.25,0.32,0.32,0.40;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{125}^{\omega }& = \left[ {\left( {0.38,0.58,0.58,0.76;1} \right),}\right. \\ & \left.{\left( {0.48,0.58,0.58,0.67;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{126}^{\omega }& = \left[ {\left( {0.28,0.46,0.46,0.64;1} \right),}\right. \\ & \left.{\left( {0.37,0.46,0.46,0.55;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{127}^{\omega }& = \left[ {\left( {0.50,0.68,0.68,0.80;1} \right),}\right. \\ & \left.{\left( {0.59,0.68,0.68,0.74;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{128}^{\omega }& = \left[ {\left( {0.42,0.58,0.58,0.70;1} \right),}\right. \\ & \left.{\left( {0.50,0.58,0.58,0.64;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{129}^{\omega }& = \left[ {\left( {0.18,0.34,0.34,0.52;1} \right),}\right. \\ & \left.{\left( {0.26,0.34,0.34,0.43;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{1210}^{\omega }& = \left[ {\left( {0.14,0.28,0.28,0.46;1} \right),}\right. \\ & \left.{\left( {0.21,0.28,0.28,0.37;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{1211}^{\omega }& = \left[ {\left( {0.22,0.36,0.36,0.52;1} \right),}\right. \\ & \left.{\left( {0.29,0.36,0.36,0.44;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{1212}^{\omega }& = \left[ {\left( {1,1,1,1;1} \right),}\right. \\ & \left.{\left( {1,1,1,1;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{1213}^{\omega }& = \left[ {\left( {0.30,0.44,0.44,0.60;1} \right),}\right. \\ & \left.{\left( {0.37,0.44,0.44,0.52;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{1214}^{\omega }& = \left[ {\left( {0.54,0.72,0.72,0.88;1} \right),}\right. \\ & \left.{\left( {0.62,0.72,0.72,0.80;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{131}^{\omega }& = \left[ {\left( {0.16,0.32,0.32,0.50;1} \right),}\right. \\ & \left.{\left( {0.24,0.32,0.32,0.41;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{132}^{\omega }& = \left[ {\left( {0.24,0.40,0.40,0.56;1} \right),}\right. \\ & \left.{\left( {0.32,0.40,0.40,0.48;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{133}^{\omega }& = \left[ {\left( {0.28,0.44,0.44,0.62;1} \right),}\right. \\ & \left.{\left( {0.36,0.44,0.44,0.53;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{134}^{\omega }& = \left[ {\left( {0.08,0.20,0.20,0.38;1} \right),}\right. \\ & \left.{\left( {0.14,0.20,0.20,0.29;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{135}^{\omega }& = \left[ {\left( {0.30,0.44,0.44,0.60;1} \right),}\right. \\ & \left.{\left( {0.37,0.44,0.44,0.52;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{136}^{\omega }& = \left[ {\left( {0.20,0.38,0.38,0.58;1} \right),}\right. \\ & \left.{\left( {0.29,0.38,0.38,0.48;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{137}^{\omega }& = \left[ {\left( {0.30,0.50,0.50,0.70;1} \right),}\right. \\ & \left.{\left( {0.40,0.50,0.50,0.60;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{138}^{\omega }& = \left[ {\left( {0.50,0.68,0.68,0.84;1} \right),}\right. \\ & \left.{\left( {0.59,0.68,0.68,0.76;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{139}^{\omega }& = \left[ {\left( {0.42,0.62,0.62,0.80;1} \right),}\right. \\ & \left.{\left( {0.52,0.62,0.62,0.71;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{1310}^{\omega }& = \left[ {\left( {0.26,0.40,0.40,0.56;1} \right),}\right. \\ & \left.{\left( {0.33,0.40,0.40,0.48;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{1311}^{\omega }& = \left[ {\left( {0.30,0.50,0.50,0.70;1} \right),}\right. \\ & \left.{\left( {0.40,0.50,0.50,0.60;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{1312}^{\omega }& = \left[ {\left( {0.40,0.56,0.56,0.70;1} \right),}\right. \\ & \left.{\left( {0.48,0.56,0.56,0.63;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{1313}^{\omega }& = \left[ {\left( {1,1,1,1;1} \right),}\right. \\ & \left.{\left( {1,1,1,1;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{1314}^{\omega }& = \left[ {\left( {0.22,0.36,0.36,0.54;1} \right),}\right. \\ & \left.{\left( {0.29,0.36,0.36,0.45;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{141}^{\omega }& = \left[ {\left( {0.26,0.38,0.38,0.54;1} \right),}\right. \\ & \left.{\left( {0.32,0.38,0.38,0.55;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{142}^{\omega }& = \left[ {\left( {0.40,0.58,0.58,0.74;1} \right),}\right. \\ & \left.{\left( {0.49,0.58,0.58,0.66;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{143}^{\omega }& = \left[ {\left( {0.32,0.48,0.48,0.62;1} \right),}\right. \\ & \left.{\left( {0.40,0.48,0.48,0.55;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{144}^{\omega }& = \left[ {\left( {0.44,0.58,0.58,0.70;1} \right),}\right. \\ & \left.{\left( {0.51,0.58,0.58,0.64;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{145}^{\omega }& = \left[ {\left( {0.38,0.58,0.58,0.78;1} \right),}\right. \\ & \left.{\left( {0.48,0.58,0.58,0.68;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{146}^{\omega }& = \left[ {\left( {0.22,0.38,0.38,0.56;1} \right),}\right. \\ & \left.{\left( {0.30,0.38,0.38,0.47;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{147}^{\omega }& = \left[ {\left( {0.30,0.42,0.42,0.58;1} \right),}\right. \\ & \left.{\left( {0.36,0.42,0.42,0.50;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{148}^{\omega }& = \left[ {\left( {0.34,0.54,0.54,0.74;1} \right),}\right. \\ & \left.{\left( {0.44,0.54,0.54,0.64;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{149}^{\omega }& = \left[ {\left( {0.30,0.50,0.50,0.68;1} \right),}\right. \\ & \left.{\left( {0.40,0.50,0.50,0.59;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{1410}^{\omega }& = \left[ {\left( {0.34,0.54,0.54,0.74;1} \right),}\right. \\ & \left.{\left( {0.44,0.54,0.54,0.64;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{1411}^{\omega }& = \left[ {\left( {0.16,0.28,0.28,0.46;1} \right),}\right. \\ & \left.{\left( {0.22,0.28,0.28,0.37;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{1412}^{\omega }& = \left[ {\left( {0.12,0.28,0.28,0.46;1} \right),}\right. \\ & \left.{\left( {0.20,0.28,0.28,0.37;0.9} \right)} \right]\end{aligned}\).
\(\begin{aligned}\tilde{A}_{1413}^{\omega }& = \left[ {\left( {0.46,0.64,0.64,0.78;1} \right),}\right. \\ & \left.{\left( {0.55,0.64,0.64,0.71;0.9} \right)} \right]\end{aligned}\);
\(\begin{aligned}\tilde{A}_{1414}^{\omega }& = \left[ {\left( {1,1,1,1;1} \right),}\right. \\ & \left.{\left( {1,1,1,1;0.9} \right)} \right]\end{aligned}\).
Step 7: Compute the PDs of one indicator over the others.
The PD of indicator \(C_{j} \left( {j = 1,2, \cdots ,14} \right)\) over the others can be computed by collecting the all elements (except \(C_{jj}\)) in the \(i\) th row of matrix \(\tilde{A}^{\omega }\) based on the Eq. (26).
Step 8: Compute the weight of indicator.
Based on Eq. (13), the likelihood matrix of the indicator preference is obtained which shown in Table 6.
Based on the likelihood of two PDs between two indicators \(I\left( {\tilde{A}_{i}^{\omega } \ge \tilde{A}_{j}^{\omega } } \right)\), the weight of indicator \(C_{i} \left( {i = 1,2, \cdots ,14} \right)\) can be computed by applying Eq. (27) as shown in Table 7.
Phase III: Obtain the ranking result
Step 9: Calculate the GPS \(\tilde{G}\left( {A_{ij} } \right)\) of alternative \(X_{i}\) with respect to the indicator \(C_{j}\).
By applying Eq. (28), the maximum IT2FS \(\tilde{A}_{{_{j} }}^{ + }\) of alternative \(X_{i}\) with respect to the indicator \(C_{j}\) can be acquired. And by applying Eq. (29), the weight of the most significant indicator \(C_{j}\) can be acquired. By applying Eq. (10), the \(d\left( {\tilde{A}_{ij} ,\tilde{A}_{{_{j} }}^{ + } } \right)\) can be acquired, which shown in Table 8. At the same time, the \(d\left( {\omega_{j} ,\omega^{ + } } \right)\) can also be acquired, which shown in Table 9.
Without losing of generality, suppose \(\rho = 0.5\). Then, by applying Eq. (30), the GPS \(\tilde{G}\left( {X_{ij} } \right)\) can be calculated, which shown in Table 10.
Step 10: Establish the global WR.
By applying Eq. (31), the average PD of the alternative \(X_{i}\) can be defined as follows:
\(\tilde{\tilde{R}}\left( {X_{1} } \right) = 0.0919\), \(\tilde{\tilde{R}}\left( {X_{2} } \right) = 0.1210\), \(\tilde{\tilde{R}}\left( {X_{3} } \right) = 0.1657\), \(\tilde{\tilde{R}}\left( {X_{4} } \right) = 0.1899\), \(\tilde{\tilde{R}}\left( {X_{5} } \right) = 0.2129\).
Then, the WR can be obtained as follows: \(X_{1} \succ X_{2} \succ X_{3} \succ \, X_{4} \succ X_{5}\).
Step 11: Construct the PIR structure of alternatives \(X_{i} \left( {i = 1,2, \cdots ,5} \right)\).
-
(1)
Calculate the PIs.
By applying Eq. (32) and Eq. (33), the average PI of \(X_{i}\) over \(X_{\kappa }\) with respect to \(C_{j}\) can be obtained, which shown in Table 11.
By applying Eq. (34), the net PI of \(X_{i}\) over \(X_{\kappa }\) with respect to \(C_{j}\) can be acquired, which shown in Table 12.
-
(2)
Determine the preference threshold (PT) and the indifference threshold (IT).
Without loss of generality, let \(\upsilon = 0.9\), based on the distance between two adjacent interval type-2 fuzzy numbers shown in Table 3, then \(\gamma \in \left[ {0,0.105} \right]\). Let \(\gamma = 0.02\), by applying Eq. (35) and Eq. (36), then \(\varepsilon = 0.00143\),\(\lambda = 0.01\).
Step 12: Obtain the strong ranking based on the WR and the PIR structure.
The rank of RER of cities under the stress of COVID-19 are obtained as: \(X_{1} \succ X_{2} \succ X_{3} \succ \, X_{4} \succ X_{5}\). Obviously, the strong ranking result is the same as the weak ranking.
-
(3)
Construct the PIR structure.
Based on the PT \(\varepsilon\) and IT \(\lambda\), the PIR structure is determined as shown in Table 13.
Based on the weight of each indicator in Table 5, the four most significance indicator are epidemic prevention and control efforts (\(\tilde{C}_{11}\)), intensity of credit support (\(\tilde{C}_{8}\)), industrial clusters competitiveness (\(\tilde{C}_{6}\)) and industrial chain system (\(\tilde{C}_{5}\)). By means of inquiring experts, this result is consistent with real case. Because epidemic prevention and control is the foundation and guarantee for the rapid recovery of regional economy. The epidemic has interrupted the business plans of enterprises and made them face difficulties in capital turnover. Credit support is an important means to maintain the normal operation of enterprises. At the same time, the impact of COVID-19 on regional economic development is typical of external shocks, so the more stable the industrial chain, the stronger the competitiveness of industrial clusters, the stronger the ability of regional economy to resist external shocks. At present, based on perfect industrial chain and strong industrial cluster competitiveness, city \(X_{1}\) has the highest level of regional economic development. Therefore, the ranking result accords with reality.
More importantly, the above ranking result can provide some valuable reference information for government departments at all levels with targeted operation. They can formulate targeted economic recovery policies according to the regional economic recovery capacity of each city.
Exploration of effects of parameters \(\gamma\), \(\varepsilon\) and \(\lambda\) on final ranking results for this case
Furthermore, for exploring the effects of the parameters \(\gamma\), \(\varepsilon\) and \(\lambda\) on ranking results in this real case, based on the range of \(\gamma \in \left[ {0,0.105} \right]\), distinct parameter \(\gamma\) can be assigned to acquire the parameters \(\varepsilon\) and \(\lambda\) in five scenarios, and the corresponding results are shown in Table 14.
By applying the developed IT2F-ORESTE method, the PIR structure between cities can be acquired according with the three thresholds (\(\gamma\), \(\varepsilon\) and \(\lambda\)). In five different scenarios, the cities ranking based on the corresponding PIR structure all remain \(X_{1} \succ X_{2} \succ X_{3} \succ \, X_{4} \succ X_{5}\). Though with the gradual increase of \(\gamma\), the values of \(\varepsilon\) and \(\lambda\) change accordingly, the ranking results demonstrate a better degree of stability. That is, in this case (n = 14), the values of parameters \(\gamma\), \(\varepsilon\) and \(\lambda\) may have no important effect on the ranking result.
Comparison analyses with the traditional ORESTE method
In this section, the case is solved by the traditional ORESTE method and the comparison are made with the IT2F-ORESTE method to demonstrate the superiority of the developed new method.
Step 1: Aggregate global preference scores (GPS).
Assume that \(R_{j}\) is the original ranking of the important degree of criterion \(C_{j} \left( {j = 1,2, \cdots ,14} \right)\) and \(R_{j} \left( {X_{i} } \right)\) is the original ranking of the preference value of alternative \(X_{i} \left( {i = 1,2, \cdots ,5} \right)\) under criterion \(C_{j}\). The results are shown in Table 15.
Let \(\eta = 0.5\), the GPS can be aggregated by applying Eq. (15), and which is shown in Table 16.
Step 2: Establish the global weak ranking (WR).
Based on the Eq. (15), compute the global weak ranking \(R\left( {X_{ij} } \right)\).
Step 3: Compute the weak ranking of \(X_{i} \big( i = 1,2, \cdots ,5 \big)\).
Based on the Eq. (16), \(\tilde{R}\left( {X_{1} } \right) = 81.5379\), \(\tilde{R}\left( {X_{2} } \right) = 78.6293\), \(\tilde{R}\left( {X_{3} } \right) = 85.5630\), \(\tilde{R}\left( {X_{4} } \right) = 84.0396\), \(\tilde{R}\left( {X_{5} } \right) = 83.5090\).
Then, the WR can be obtained as follows:
Step 4: Obtain the preference intensity (PI).
By applying Eq. (17), the average PI of \(X_{i}\) over \(X_{\kappa }\) with respect to \(C_{j}\) can be obtained, which shown in Table 17.
By applying Eq. (18), the net PI of \(X_{i}\) over \(X_{\kappa }\) with respect to \(C_{j}\) can be acquired, which shown in Table 18.
Step 5: Construct the preference/indifference/incomparability (PIR) structure.
Let \(\mu = 0.001\), \(\theta = 0.2\) and \(\vartheta = 4\), based on Eq. (19) and Eq. (20), the PIR structure is determined as shown in Table 19.
Step 6: Determine the strong ranking based on the weak ranking and PIR.
The WR can be obtained as follows:
Actually, it is intuitive to see the ranking result based on the IT2F-OREST method is coordinate with the real situation, and the ranking result based on the traditional ORESTE method is contrary to the real situation. Therefore, the developed IT2F-OREST method is more reliable. In theory, compared with the traditional OREST method, the developed IT2F-OREST method has the following four advantages:
-
(1)
The decision matrixes obtained by applying the developed IT2F-OREST method can gather as much evaluation information as possible from experts by taking advantage of IT2FS. But the traditional OREST method matrix is simply expressed by ranking and it is very hard for experts to reach a consensus on the rankings.
-
(2)
Comparing with the traditional OREST method, which the ranking is simply based on the distance measure, the developed IT2F-OREST method can more effectively reflect the conflicts between IT2FSs by the distance measure and likelihood measure.
-
(3)
Comparing with the traditional OREST method, the developed IT2F-OREST method is more reasonable and reliable by developing the PI indifference threshold \(\mu\) based on the IT2FS indifference threshold.
-
(4)
About the calculation process, the developed IT2F-OREST method is more practical and flexible than the traditional OREST method. Because when a new alternative is added, the traditional OREST method have to re-adjust the ranking and recalculate the preference scores of all the alternatives but the developed IT2F-OREST method simply needs to calculate the preference scores of the added new alternative.
Comparison analyses with the other interval type-2 fuzzy MCDM method
Next, for demonstrating in further detail, the superiority of the developed IT2F-OREST method, Mathew et al.’ IT2F- TOPSIS method [17], Wu et al.’ IT2F- VIKOR method [18], as well as Wang et al.’ IT2F-MULTIMOORA method [19] are applied to solve the above-mentioned case of RER under COVID-19 epidemic stress. For guaranteeing the consistency of all the above-mentioned MADM methods, the distance measure based on Eq. (10) are applying to obtain the distance between the IT2FSs.
Comparing with the IT2F-TOPSIS method
TOPSIS method is a more popular MADM method based on the utility value theory [17]. First, based on Eq. (10), the negative ideal separation matrix is built by computing \(d\left( {\tilde{A}_{ij} ,\tilde{A}_{{_{j} }}^{ - } } \right)\), where \(\tilde{A}_{{_{j} }}^{ - }\) is the worst \(\tilde{A}_{ij}\), which is shown in Table 20. In addition, the positive ideal separation matrix has been built, which is the same as Tables 8.
Next, compute the relative closeness \(R_{1} \left( {X_{i} } \right)\) based on Eq. (38).
The detailed numerical results derived by the IT2F-TOPSIS method is shown in Table 21.
In final, rank the cities based on the \(R_{1} \left( {X_{i} } \right)\) and get \(X_{1} \succ X_{2} \succ X_{3} \succ \, X_{4} \succ X_{5}\).
Though the ranking result based on the IT2F-TOPSIS method is the same as the developed IT2F-OREST, the IT2F-TOPSIS method lose sight of the PIR relations. That is to say, the IT2F-TOPSIS method cannot takes into consideration their relationships flexibly, but in the developed IT2F-OREST method, some errors in the process of evaluation can be noticed by applying different thresholds. Generally, as the threshold changes, the difference between indicators may become smaller and smaller. In addition, in the IT2F-TOPSIS method, the relationships are strictly examined by the preference scores. If only the preference scores are the same, there is only indifference relationships, and if the preference are not same, there is a preference relationship.
Comparing with the IT2F-VIKOR method
VIKOR method as a classic MADM method to integrating utility values is widely recognized [18]. However, it has to be centered on the compromise solution. Let \(\psi = 0.5\) denotes the strategy of the maximum group utility. Next, compute the relative closeness \(R_{2} \left( {X_{i} } \right)\) based on Eq. (39).
The detailed numerical results derived by the IT2F-VIKOR method is shown in Table 22.
In final, rank the cities based on the \(R_{2} \left( {X_{i} } \right)\) and get \(X_{5} \succ X_{4} \succ X_{3} \succ \, X_{1} \succ X_{2}\).
Obviously, the ranking result based on the IT2F-VIKOR method is the exact opposite of the ranking result based on the developed IT2F-OREST method. Compared with the new method, IT2F-VIKOR method widens the differences between two cities by regret measure and only divides the relationships into PI relation. In addition, it is difficult to obtain the strategy of the maximum group utility reasonably, but in real case, it has essential effect toward the ranking result.
Comparing with the IT2F-MULTIMOORA method
The MULTIMOORA method is a multiple objectives optimization method, which contains the ratio system, the reference point method and the full multiplicative form method [19].
First, based on Eq. (40) and the aggregate results in the step 5 of Phase I (“Solving the case by the developed IT2F-ORESTE method”), the normalization decision matrix is constructed.
In which, the parameter \(g_{j} = \sqrt {\sum\nolimits_{i = 1}^{5} {\sum\nolimits_{\xi = 1}^{4} {\left( {\alpha_{ij\xi }^{L} } \right)^{2} + \sum\nolimits_{i = 1}^{5} {\sum\nolimits_{\xi = 1}^{4} {\left( {\alpha_{ij\xi }^{U} } \right)^{2} } } } } }\).
Second, because of each indicator corresponds to benefit type, based on the Eq. (41), the ration of each city can be calculated:
The numerical results are:
Based on the definition 7, the ranking result is: \(X_{1} \succ X_{2} \succ X_{3} \succ \, X_{4} \succ X_{5}\).
Third, by using the data in Tables 5 and 11, based on Eq. (42), the reference point can be calculated:
The numerical results are:
\(\Re_{2} \left( {X_{1} } \right) = 0.0711\),\(\Re_{2} \left( {X_{2} } \right) = 0.2100\),\(\Re_{2} \left( {X_{3} } \right) = 0.3766\),\(\Re_{2} \left( {X_{4} } \right) = 0.4082\),\(\Re_{2} \left( {X_{5} } \right) = 1.0141\).
And the ranking result is: \(X_{5} \succ X_{4} \succ X_{3} \succ \, X_{2} \succ X_{1}\).
Next, based on the Eq. (43), the full multiplicative form method can be calculated:
where \(\prod\nolimits_{j = 1}^{\vartheta } {\left( {\overline{\tilde{A}}_{ij} } \right)^{{\omega_{j} }} }\) is the product of the weighted normalized scores of all benefit criteria and \(\prod\nolimits_{j = \vartheta + 1}^{14} {\left( {\overline{\tilde{A}}_{ij} } \right)^{{\omega_{j} }} }\) is the product of the weighted normalized scores of all cost criteria.
The numerical results are:
Based on the definition 7, the ranking result is: \(X_{1} \succ X_{2} \succ X_{3} \succ \, X_{4} \succ X_{5}\).
Finally, by applying the above three method, the comprehensive ranking result under the IT2F-MULTIMOORA method is shown in Table 23, that is: \(X_{1} \succ X_{2} \succ X_{3} \succ \, X_{4} \succ X_{5}\).
The IT2F-MULTIMOORA method takes into consideration the ranking results of three methods synthetically. However, this synthetical method has no more detailed division as the developed IT2F-OREST method. Most importantly, if the three methods obtain completely different ranking results, it will be very hard to obtain the ultimate reasonable ranking result.
Comparison summary
Based on the above analyses, compared with the other three interval type-2 fuzzy MCDM methods, the developed IT2F-OREST method has the following special superiorities:
-
(1)
The developed IT2F-OREST method can give a detailed ranking result by using the PIR relationships among cities. Compared with above three methods, it can not only provide preference relationships, but also provide incomparable relationships and indifference relationships, which can reduce information distortion in the calculation and evaluation process. The results obtained by this method are more reliable and reasonable.
-
(2)
The application strategies obtained by the developed IT2F-OREST method are more realistic and practical. The ranking results can change with different thresholds. Therefore, decision maker can adjust the parameters based on the real situation and physical truth to obtain the comprehensive ranking results.
-
(3)
The preference index of each pair of alternatives is computed based on the likelihood of IT2FSs. In this method, the ranking results are acquired based on the comprehensive pairwise comparison of all alternatives, making them more precise and persuasive. In addition, the IT2F-OREST method are developed by applying the extended vertex method for distance measure, which is a simple expression that needs few calculations.
-
(4)
In addition, the developed IT2F-OREST method can solve the MCDM problems with the quantitative and qualitative indicators and the weights of indicators are unknown.
In detail, the comparisons over these methods are simplified as shown in Table 24.
Practical implications
For improving the regional economic restorability, some valuable practical implications based on the above evaluation results are suggested as follows:
-
(1)
The administrative department should speed up the improvement of the emergency support system, take the emergency supplies support as an important part, and establish a corresponding reserve of emergency supplies. Relevant working mechanisms and emergency plans should be formulated in accordance with the principle of centralized management and unified allocation, and effectively improve emergency response capabilities.
-
(2)
After the COVID-19 outbreak is effectively contained, it is important to resume work and production in a timely manner to promote stable economic and social development. On one hand, the production order should be restored in different areas by zoning and grading, on the other hand, the resumption of work and production across the industrial chain need to be promoted.
-
(3)
The government should encourage commercial banks to speed up innovation and upgrading of financial services, and make full use of technologies such as big data, blockchain and artificial intelligence to speed up digital transformation. On the supply side, the supervision council will guide financial institutions to increase credit supply and provide greater support to the real economy, especially to enterprises heavily affected by the epidemic. On the demand side, the administration need to effectively expand domestic demand and make up for the shortage of external demand to help enterprises, especially foreign trade enterprises, effectively cope with the impact of the epidemic.
Conclusions
COVID-19 pandemic is considered to be the notorious economic shock arising throughout the year 2020. As a result, although the negative effects of the deadly CODIV-19 pandemic are still presented currently, the regional economic recovery phase must be projected to start due to the fact that regional economic development has plummeted to historic bottom. Quantitative research on the impact of major public health events on economic system can provide scientific support for improving the RER. In this paper, by developing an improved IT2F-ORESTE method based on the DM and likelihood of IT2FS, RER of different regions under the stress of COVID-19 are determined. First, some formulas are developed to convert quantitative PVs to IT2FSs for combining the quantitative and qualitative indicator information. Then, the vertex method for DM is extended to encompass IT2FSs. Furthermore, a comprehensive discussion between the improved IT2F-ORESTE method, the traditional ORESTE method and two representative IT2F-MCDM methods, are developed to demonstrate the validity and reliability of the improved IT2F-ORESTE method. The case study presents a helpful reference for government departments to improve the RER.
The main contribution of this study to the current RER problem is the development of an improved IT2F-ORESTE method based on the DM and likelihood of IT2FS for dealing with RER assessment problem. Compared with current ORESTE method, the proposed method has some desirable capabilities for addressing MCDM-based RER problem. First, the proposed IT2F-OREST method can not only provide preference relationships, but also provide incomparable relationships and indifference relationships, which can reduce information distortion in the calculation and evaluation process. And it is developed by applying the extended vertex method for distance measure, which is a simple expression that needs few calculations. Second, decision maker can adjust the parameters based on the real situation and physical truth to obtain the comprehensive ranking results. More importantly, the proposed method can solve the MCDM problems with the quantitative and qualitative indicators and the weights of indicators are unknown.
There more or less are limitations existed in this study, which need to be remedied in the future. The optimum solution acquired by the proposed IT2F-ORESTE method may be inferior under certain criteria. In the future, the following aspects are worthy of further study. First, whether there are other meaningful indicators under more complex environments that can be included to improve indicator system is worthy of investigation. Second, in the process of evaluation, different experts may provide different ranking results, the consensus process among experts is a meaningful issue. Some recently developed consensus optimization models can be introduced to improve the performance of method. Last but not least, for improving reliability and accuracy, some other meaningful ORESTE method with different fuzzy information forms can be used to resolve RER problem [65, 66]. Third, the application scopes of the improved IT2F-ORESTE method will be extended further to include economic—ecological complex system restorability, regional economic competitiveness, enterprise sustainable development ability, etc.
Data availability
The authors confirm that the data supporting the findings of this study are available within the article.
References
Paul SK, Chowdhury P, Moktadir M, Lau KH (2021) Supply chain recovery challenges in the wake of COVID-19 pandemic. J Bus Res 136:316–329
Abdulkareem K, Mohammed M, Salim A et al (2021) Realizing an effective COVID-19 diagnosis system based on machine learning and iot in smart hospital environment. IEEE Internet Things J 8(21):15919–15928
Cui C, Li B, Liu W (2022) The selection of COVID-19 epidemic prevention and control programs based on group decision-making. Complex Intell Syst 8:1653–1662
Dogan O, Tiwari S, Jabbar M, Guggari S (2021) A systematic review on AI/ML approaches against COVID-19 outbreak. Complex Intell Syst 7:2655–2678
AiZhongZhou HTZ (2022) The real economic costs of COVID-19: Insights from electricity consumption data in Hunan Province, China. Energy Econ 105:105747
Maxim R, Dmitry L, Jennifer B, Anand N (2022) Adapting supply chain operations in anticipation of and during the COVID-19 pandemic. Omega 110:102635
Tadeusz S (2022) Stochastic optimization of supply chain resilience under ripple effect: a COVID-19 pandemic related study. Omega 109:102596
Altay B, Okumus A, Mercangoz B (2022) An intelligent approach for analyzing the impacts of the COVID-19 pandemic on marketing mix elements (7Ps) of the on-demand grocery delivery service. Complex Intell Syst 8:129–140
Ciravegna L, Michailova S (2022) Why the world economy needs, but will not get, more globalization in the post-COVID-19 decade. J Int Bus Stud 53:172–186
Tokui J, Kawasaki K, Miyagawa T (2017) The economic impact of supply chain disruptions from the Great East-Japan earthquake. Jpn World Econ 41:59–70
Petit-Boix A, Sevigne-Itoiz E, Rojas-Gutierrez L et al (2017) Floods and consequential life cycle assessment: Integrating flood damage into the environmental assessment of stormwater best management practices. J Clean Prod 162(20):601–608
Elbe S (2007) Our epidemiological footprint: The circulation of avian flu, SARS, and HIV/AIDS in the world economy. Rev Int Polit Econ 15(1):116–130
Zadeh L (1975) The concept of a linguistic variable and its application to approximate reasoning-I. Inf Sci 8(3):199–249
Liu P, Gao H, Ma J (2019) Novel green supplier selection method by combining quality function deployment with partitioned Bonferroni mean operator in interval type-2 fuzzy environment. Inf Sci 490:292–316
Liu P, Gao H (2020) A novel green supplier selection method based on the interval type-2 fuzzy prioritized Choquet Bonferroni means. IEEE-CAA J Autom 8(9):1549–1566
Zhang H, Gao H, Liu P (2019) Type-2 fuzzy multi-attribute group decision-making for logistics services providers selection by combining QFD with partitioned Heronian mean operator. Complexity 2019:6727259
Meniz B (2021) An advanced TOPSIS method with new fuzzy metric based on interval type-2 fuzzy sets. Expert Syst Appl 186:1–14
Wu Q, Zhou L, Chen Y et al (2019) An integrated approach to green supplier selection based on the interval type-2 fuzzy best-worst and extended VIKOR methods. Inf Sci 502:394–417
Liang D, Linda BE, Wang M, Xu Z (2022) Hospital health-care delivery quality evaluation in Ghana: an integrated medical triangular fuzzy MULTIMOORA approach. Inf Sci 605:99–118
Roubens M (1982) Preference relations an actions and criteria in multicriteria decision making. Eur J Oper Res 10(1):51–55
Li J, Chen T, Niu L, Wang Z (2020) An ORESTE approach for multi-criteria decision-making with probabilistic hesitant fuzzy. Int J Mach Learn Cyb 11:1591–1609
Li J, Luo L, Wu X, Liao C, Liao H (2019) W. Shen, Prioritizing the elective surgery patient admission in a Chinese public tertiary hospital using the hesitant fuzzy linguistic ORESTE method. Appl Soft Comput 78:407–419
Zheng Q, Liu X, Wang W (2021) An extended interval type-2 fuzzy ORESTE method for risk analysis in FMEA. Int J Fuzzy Syst 23:1379–1395
Heidarzade A, Mahdavi Z, Mahdavi-Amiri N (2016) Supplier selection using a clustering method based on a new distance for interval type-2 fuzzy sets: a case study. Appl Soft comput 38:213–231
Cherif S, Baklouti N, Hagras H, Alini M (2021) Novel intuitionistic based interval type-2 fuzzy similarity measures with application to clustering. IEEE T Fuzzy Syst 30(5):1260–1271
Pan X, Wang Y, He S (2021) The evidential reasoning approach for renewable energy resources evaluation under interval type-2 fuzzy uncertainty. Inf Sci 576:432–453
Moslehi S, Reddy T (2018) Sustainability of integrated energy systems: a performance-based resilience assessment methodology. Appl Energy 228:487–498
Liu X, Hou K, Jia H et al (2020) A Planning-oriented resilience assessment framework for transmission systems under typhoon disasters. IEEE Trans Smart Grid 11(6):5431–5441
Zarei E, Ramavandi B, Darabi A, Omidvar M (2021) A framework for resilience assessment in process systems using a fuzzy hybrid MCDM model. J Loss Prevent Proc 69:104375
Abbasnejadfard M, Bastami M, Abbasnejadfard M, Borzoo S (2022) Novel deterministic and probabilistic resilience assessment measures for engineering and infrastructure systems based on the economic impacts. Int J Disaster Risk Reduct 75:102956
Rezvani S, Almeida N, Falcao M, Duarte M (2022) Enhancing urban resilience evaluation systems through automated rational and consistent decision-making simulations. Sustain Cities Soc 78:103612
Ortega-Bastida J, Gallego AJ, Rico-Juan JR, Albarran P (2021) A multimodal approach for regional GDP prediction using social media activity and historical information. Appl Soft Comput 111:107693
Song M, Zhu S, Wang J, Zhao J (2020) Share green growth: regional evaluation of green output performance in China. Int J Prod Econ 219:152–163
Shaheer N, Li S, Priem R (2020) Revisiting location in a digital age: how can lead markets accelerate the internationalization of mobile apps? J Int Mark 28(4):21–40
Rocchetta S, Mina A, Lee C, Kogler D (2022) Technological knowledge spaces and the resilience of European regions. J Econ Geogr 22(1):27–51
Mena C, Karatzas A, Hansen C (2022) International trade resilience and the Covid-19 pandemic. J Bus Res 138:77–91
Pretorius O, Drewes E, Aswegen M, Malan G (2021) A policy approach towards achieving regional economic resilience in developing countries: evidence from the SADC. Sustainability 13(5):2674
Wu GL, Feng Q, Wang ZF (2021) A structural estimation of the return to infrastructure investment in China. J Dev Econ 152:1–18
Yan J, Tsinopoulos C, Xiong Y (2021) Unpacking the impact of innovation ambidexterity on export performance: microfoundations and infrastructure investment. Int Bus Rev 30(1):101766
Yan Y, He M, Song L (2021) Evaluation of regional industrial cluster innovation capability based on particle swarm clustering algorithm and multi-objective optimization. Complex Intell Syst. https://doi.org/10.1007/s40747-021-00521-8
Luan B, Zou H, Chen S, Huang J (2021) The effect of industrial structure adjustment on China’s energy intensity: evidence from linear and nonlinear analysis. Energy 218:1–15
Wang Y, Hu H, Dai W, Burns K (2021) Evaluation of industrial green development and industrial green competitiveness: evidence from Chinese urban agglomerations. Ecol Indic 124:1–20
Montasser GE, Charfeddine L, Benhamed A (2022) COVID-19, cryptocurrencies bubbles and digital market efficiency: sensitivity and similarity analysis. Financ Res Lett 46:102362
Hossain M (2021) The effect of the Covid-19 on sharing economy activities. J Clean Prod 280(1):1–9
Jinil Persis D, Venkatesh VG, Raja Sreedaran V et al (2021) Modelling and analysing the impact of circular economy; Internet of Things and ethical business practices in the VUCA world: evidence from the food processing industry. J Clean Prod 301:126871
Markovic S, Koporcic N, Arslanagic-Kalajdzic M et al (2021) Business-to-business open innovation: COVID-19 lessons for small and medium-sized enterprises from emerging markets. Technol Forecast Soc 170:1–5
Korsgaard S, Hurt R, Townsend D, Ingstrup M (2020) COVID-19 and the importance of space in entrepreneurship research and policy. Int Small Bus J 38(8):697–710
Zhao C, Xue Y, Niu T (2021) Research on the risk of unbalanced distribution of scientific and technological talents in China. Fresenius Environ Bull 30(8):9980–9985
Teresiene D, Keliuotyte-Staniuleniene G, Kanapickiene R (2021) Sustainable economic growth support through credit transmission channel and financial stability: in the context of the COVID-19 pandemic. Sustainability 13(5):1–34
Liu Y, Zhang Y, Fang H, Chen X (2022) SMEs’ line of credit under the COVID-19: evidence from China. Small Bus Econ 58:807–828
Makin AJ, Layton A (2021) The global fiscal response to COVID-19: Risks and repercussions. Econ Anal Policy 69:340–349
Ahundjanov B, Akhundjanov SB, Okhunjanov BB (2020) Information search and financial markets under COVID-19. Entropy 22(7):1–18
Wu X, Huang Y, Gao J (2022) Impact of industrial agglomeration on new-type urbanization: evidence from Pearl River Delta urban agglomeration of China. Int Rev Econ Finance 77:312–325
Liao HC, Wu XL, Xu JP et al (2018) A new hesitant fuzzy linguistic ORESTE method for hybrid multi-criteria decision making. IEEE Trans Fuzzy Syst 26(6):3793–3807
Luo S, Liang W, Zhao G (2020) Likelihood-based hybrid ORESTE method for evaluating the thermal comfort in underground mines. Appl Soft Comput 87:105983
Wang X, Gou X, Xu Z (2020) Assessment of traffic congestion with ORESTE method under double hierarchy hesitant fuzzy linguistic environment. Appl Soft Comput 86:105864
Wang W, Ding L, Liu X, Liu S (2022) An interval 2-Tuple linguistic Fine-Kinney model for risk analysis based on extended ORESTE method with cumulative prospect theory. Inf Fusion 78:40–56
Liang D, Li F (2022) Risk assessment in failure mode and effect analysis: improved ORESTE method with hesitant pythagorean fuzzy information. IEEE Trans Eng Manag. https://doi.org/10.1109/TEM.2021.3073373
Sharaf IM (2020) An interval type-2 fuzzy TOPSIS using the extended vertex method for MAGDM. SN Appl Sci 2(87):1–15
Chen TY (2015) An interval type-2 fuzzy PROMETHEE method using a likelihood-based outranking comparison approach. Inf Fus 25:105–120
Yu SM, Wang J, Wang JQ (2017) An interval type-2 Fuzzy likelihood-based MABAC approach and its application in selecting hotels on a tourism website. Int J Fuzzy Syst 19(1):47–61
Yager RR (2001) The power average operator. IEEE Trans Syst Man Cybern A 31(6):724–731
Santos L, Osiro L, Lima R (2017) A model based on 2-tuple fuzzy linguistic representation and analytic hierarchy process for supplier segmentation using qualitative and quantitative criteria. Expert Syst Appl 79:53–64
Oastijn H, Leysen J (1989) Constructing an outranking relation with ORESTE. Math Compu Model 12(10–11):1255–1268
Tolga A, Parlak I, Castillo O (2020) Finite-interval-valued type-2 Gaussian fuzzy numbers applied to fuzzy TODIM in a healthcare problem. Eng Appl Artif Intell 87:103352
Mittal K, Jain A, Vaisla K et al (2020) A comprehensive review on type-2 fuzzy logic applications: past, present and future. Eng Appl Artif Intell 95:103916
Acknowledgements
This paper is supported by the National Natural Science Foundation of China (No. 71771140), Project of cultural masters and “the four kinds of a batch” talents, Major bidding projects of National Social Science Fund of China (No. 19ZDA080), Humanities and Social Sciences General Research Program of the Ministry of Education (22YJC630025) and Funds of Humanity and Society Science Project of Shandong Province (No. 2020-NDJJ-02).
Author information
Authors and Affiliations
Contributions
HG: conceptualization, formal analysis, methodology, resources, validation, writing—original draft. PL: conceptualization, formal analysis, methodology, funding acquisition, writing—review and editing. HZ: methodology, formal analysis, resources, visualization, supervision, writing—review and editing.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Research involving human participants and/or animals
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
See Tables 25, 26, 27, 28, 29, 30, 31, 32, 33, 34.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, H., Gao, H. & Liu, P. Assessment of regional economic restorability under the stress of COVID-19 using the new interval type-2 fuzzy ORESTE method. Complex Intell. Syst. 9, 4025–4060 (2023). https://doi.org/10.1007/s40747-022-00928-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-022-00928-x