
Abstract
In data analysis, change point problems correspond to abrupt changes in stochastic mechanisms generating data. The detection of change points is a relevant problem in the analysis and prediction of time series. In this paper, we consider a class of conjugate prior distributions obtained from conditional specification methodology for solving this problem. We illustrate the application of such distributions in Bayesian change point detection analysis with Poisson processes. We obtain the posterior distribution of model parameters using general bivariate distribution with gamma conditionals. Simulation from the posterior are readily implemented using a Gibbs sampling algorithm. The Gibbs sampling is implemented even when using conditional densities that are incompatible or only compatible with an improper joint density. The application of such methods will be demonstrated using examples of simulated and real data.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Data science, as an interdisciplinary field, plays a pivotal role in extracting knowledge and insights from complex and large-scale datasets. It encompasses a wide range of techniques, methodologies, and tools to analyse and interpret data, enabling evidence-based decision making and driving innovation across various domains [1,2,3,4].
Data science involves the integration of statistical analysis, machine learning, data mining, and visualization techniques to extract actionable insights from data. It encompasses the entire data lifecycle, including data collection, cleaning, integration, transformation, modeling, and interpretation. By applying rigorous statistical methods and computational algorithms, Data Scientists can uncover patterns, trends, and correlations within data, enabling organizations to make data-driven decisions and gain a competitive advantage [5, 6].
The rise of big data has presented both opportunities and challenges in the field of Data Science. On one hand, Big Data offers vast amounts of information that can uncover valuable insights and patterns. On the other hand, the sheer volume, velocity, and variety of data pose significant computational and analytical challenges, which means traditional statistical methods may not be scalable or efficient enough to handle such data [7,8,9,10].
The application of statistical methods in data science provides the foundation for understanding data patterns, making inferences, and predicting outcomes. By using statistical techniques, meaningful insights, robust models, and informed decisions based on data-driven evidence can be extracted [6, 11,12,13,14].
Within the scope of data science and statistics, change point detection serves as a pivotal tool for identifying shifts or transitions in data patterns. By effectively detecting change points, Data Scientists can gain profound insights into anomalies, events, or structural transformations embedded within the data [15].
The application of change point detection methods, including Bayesian approaches, holds significant importance in data science. Bayesian change point detection employs Bayesian inference principles to estimate the posterior probability of change points by incorporating prior knowledge and updating it based on observed data. Such a framework offers a flexible and robust approach to detecting change points, and its applicability extends across diverse domains such as genetics, environmental monitoring, finance, and quality control.
Change points are defined as abrupt variations in the generative parameters of a data sequence. The detection of change points is a relevant problem in the analysis and prediction of time series. The application can be found in copy number variation detection [16], air quality control [17] and signal processing [18].
Among the methods available, the Bayesian approach is particularly appealing because it automatically captures the trade-off between model complexity (number of change points) and model fit. It also allows one to express uncertainty about the number and location of change points.
In this paper, we propose a novel approach for detecting change points in a Poisson process. We introduce conditionally specified priors and derive the posterior distribution of model parameters using the general bivariate distribution with gamma conditionals. Such prior distribution have also been used in the comparison of gamma scale parameters [19] and the estimation of incomplete data [20]. Although these prior distributions have been extensively used in Bayesian analysis for classical distributions such as the normal distribution, Pareto distribution, and linear regression [21], their application in the context of Poisson processes is novel.
The remainder of this is organised as follows. Section 2 includes a short review on change point techniques and the motivation. Section 3 provides design of our proposed model. Section 4 we introduce the general bivariate distribution with gamma conditionals as the prior distribution for the parameters of a Poisson change point model and discuss the full Bayesian analysis of the change point problem. The application of our methodology is illustrated using simulated and real data sets in Sect. 5. Finally, Sect. 6 concludes the paper and suggests future extensions to our proposed approach.
2 Time Series Change Point Detection Techniques
Analysing time series data is crucial in various domains such as finance, economics, environmental science, and healthcare as it allows for the detection of underlying patterns, trends, and anomalies. In this context, change point detection techniques play a vital role in identifying points in a time series where the statistical properties significantly change.
Change point detection methods aim to pinpoint abrupt or gradual shifts in the underlying characteristics of a time series, which may indicate changes in mean, variance, distribution, or other structural properties. Detecting change points is essential for understanding system behavior, forecasting future trends, and detecting unusual events or anomalies.
Numerous change point detection methods have been developed, each with its strengths and assumptions. Classic techniques include cumulative sum methods, likelihood ratio tests, and sequential analysis methods. More advanced approaches leverage Bayesian inference, nonparametric methods, and machine learning algorithms to detect change points in complex and high-dimensional time series data.
Chen and Gupta [22, 23] conducted a detailed study of parametric models for change point analysis, exploring the univariate and multivariate normal cases, regression models, exponential-type models, and models with discrete data, from both classical and Bayesian perspectives. They also presented applications in genetics, medicine, and finance.
The use of Bayesian techniques in these types of models is extensively studied in [24]. One popular Bayesian change point detection method is the Bayesian Online Change point Detection algorithm proposed by [25], which provides a probabilistic framework for online change point detection and has been widely applied in signal processing, finance, and environmental monitoring. Bootstrap techniques have also been used by various authors to estimate these types of problems, as highlighted by [26].
Modern machine learning approaches, such as deep learning models, have shown promise in change point detection. For instance, [27] present a Long Short-Term Memory based model for detecting change points in multivariate time series data, demonstrating its effectiveness in identifying shifts in complex temporal patterns. In another study [28] reviewed models for the detection of change points in time series, including supervised and unsupervised algorithms proposed in the literature, and propose suitable criteria for comparing these algorithms.
In time series trend analysis, [29] propose a solution for change point detection, assessing four methods: wild binary segmentation, E-agglomerative algorithms, iterative robust detection methods, and Bayesian analysis.
In this study, we propose a Bayesian approach for detecting change points in a Poisson process. Unlike previous studies, we assume that the parameters of the Poisson process before and after the change are jointly distributed. Therefore, we propose a joint conjugate prior distribution based on the conditional specification methodology and introduce the application of conditionally specified prior distributions in change point detection problems. The general aspects of conditional specification can be found in [30]. The following section provides the details of obtaining the proposed prior distribution.
3 Motivation and Design of the Model
The general ideal of the conditional specification methodology can be described as follows. Suppose \(x_i\), for \(i = 1, \dots , n\), be n independently distributed random variables with probability distribution functions of \(f(\theta _i)\), where \(\theta _i \in \Theta \subset {\mathbb {R}}^n\) and let likelihood function be denoted as
Our interest lies in specifying a class of conjugate prior distributions such that the conditional distribution of \(\theta _i|\theta _{-i}\) belongs to the family class of \(f(\theta _i|\theta _{-i})\), where \(\theta _{-i} = (\theta _1, \dots , \theta _{i-1}, \theta _{i+1}, \dots , \theta _n)\).
We consider a candidate family of prior distributions for \(\theta _1, \dots , \theta _n\) such that, for each i, the conditional density of \(\theta _i\) given \(\theta _{-i}\) belongs to the family \(f_i\). We will show that the posterior distribution will be in the same family and will also be conditionally specified, resulting in a broad and flexible conjugate prior family for \(\theta _1, \dots , \theta _n\).
Simulation from the posterior will be readily implemented using a Gibbs sampling algorithm. The Gibbs sampling can be implemented even when using conditional densities that are incompatible or only compatible with an improper joint density [31].
Now, let \(X_i\) be a Poisson random variable where \(i = 1, \dots , T\). Assume that the change point occurs at time k such that
and
where \(\lambda >0\), \(\alpha >0\) and \(k\in \{1,2,\dots ,n\}\) are unknown parameters and \(X\sim {{{\mathcal {P}}}}o(\lambda )\) denotes a Poisson distribution with parameter \(\lambda \). In can be seen if \(k=n\), then \(\lambda = \alpha \) and we do not have change. Thus, the likelihood function takes the form,
Our goal is to obtain a conjugate prior for \(\lambda \) and \(\alpha \) in a way that if \(\alpha \) is known, a conjugate prior for \(\lambda \) is a gamma distribution, and if \(\lambda \) is known, the conjugate prior for \(\alpha \) is again a gamma distribution. Consequently, we have conjugate prior distributions for each parameter conditioned on the other parameter.
In order to obtain a bivariate conjugate distribution for \(\lambda \) and \(\alpha \), we will have to obtain the most general bivariate distribution whose conditional distributions are gamma. The class of distributions whose conditionals are gamma has been obtained in [30].
Let us assume the likelihood in Eq. (1) only depends on parameters \(\alpha \) and \(\lambda \). We assume parameter k is known. According to the Theorem 1 in [32], the most general bivariate distribution with all conditionals of \(\lambda \) given \(\alpha \) and, of \(\alpha \) given \(\lambda \), being gamma distribution has the following form
which is a conjugate prior for the family of likelihood given in (1). A bivariate distribution with joint pdf (2) will known as (general bivariate distribution with gamma conditionals) which is denoted by \((\lambda ,\alpha )\sim \mathcal{GBGC}(\varvec{m})\).
As can be seen in (2), the new class of distributions depends on eight parameters with the following conditional distributions are
It can be seen that the conditional distributions of the proposed conjugate prior also conjugate distributions for the parameters \(\lambda \) and \(\alpha \). Moreover, it is important to note that the model incorporates informative priors, allowing the incorporation of prior knowledge about the parameters. Lastly, due to the specific construction of the model, both conditional distributions follow a gamma distribution, which facilitates their estimation using Gibbs sampling algorithm. The conditional parameters in (3)–(4) are given by,
In order to ensure that this prior distribution is proper, the hyperparameters must satisfy the following list of constraints,
Note that for a gamma random variable Y with the probability function,
the expected value and variance are \(E(Y)=\frac{a}{p}\) and \(var(Y)=\frac{a}{p^2}\), respectively.
3.1 A Relevant Submodel
Consider the bivariate continuous distribution with joint pdf,
where \(r,s,m_1,m_2>0\) and \(\phi \ge 0\), which is a submodel of (2) with a new parameterization (see [30]). A random variable with joint probability density function (8) will be denoted by,
The conditional distributions are:
The marginal distributions of (8) are given by,
and
The normalizing constant is given by,
where U(a, b, z) denotes the hypergeometric function, which is defined by (\(a,z>0\)),
[33].
The raw moments of the marginal distributions (12) and (13) are given by,
and
respectively.
4 Bayesian Analysis with GBGC Prior
Let us assign the joint distribution of \(\lambda \) and \(\alpha \)
as a prior distribution and incorporate Eq. (2) with (1). Thus, we obtain the following posterior distribution
where the hyperparameters vector \(\varvec{m}^{(0)}\) is updated to \(\varvec{m}^{*}\) using the expression in Table 1. Note that only four of the eight parameters are updated by data. The rest of the parameters do no change. However, the existence of these parameters permits more flexibility when we select the prior distribution.
Now, if we consider the submodel
and we combine with (2) we obtain
where the parameters are updated according to Table 2
4.1 Parameter Estimation
In the conditional context, Gibbs sampling is a natural estimation methodology. The idea in Gibbs sampling is to generate posterior samples by sweeping through each variable (or block of variables) to sample from its conditional distribution with the remaining variables fixed to their current values. Assume that we are interested in approximating the posterior moments of a given function of \(\lambda \) and \(\alpha \), say \(\delta (\lambda ,\alpha )\).
Then, to approximate \(E(\delta (\lambda ,\theta )|x)\), we generate random values
using the conditional gamma distributions,
where the expressions for obtaining \(m_{ij}\) are given in Table 1 and \(m_0\) is the number of iterations before burn-in. Thus, we have the estimator,
At each iteration l, for \(l = 1, \dots , M\), the following steps are repeated:
-
(1)
Set \(l = 0\) and initial values as \(\lambda ^{(0)}, \alpha ^{(0)}\) and \(k^{(0)}\).
-
(2)
Repeat for \(l = 1, \dots , M\)
-
(a)
Draw \(\lambda ^{(l)}|(\alpha ^{(l-1)}, k^{(l-1)})\) from \({{{\mathcal {G}}}}a(a_1(\alpha )^{(l-1)}, b_1(\alpha )^{(l-1)};k^{(l-1)})\).
-
(b)
sample from \(\alpha ^{(l)}|(\lambda ^{(l)}, k^{(l-1)})\) from \({{{\mathcal {G}}}}a(a_2(\lambda ^{(l)}), b_2(\lambda ^{(l)});k^{(l-1)})\).
-
(c)
sample from \(k^{(l)}|(\lambda ^{(l)}, \alpha ^{(l)})\) from \(\pi (k|\lambda ^{(l)}, \alpha ^{(l)})\).
-
(a)
where \(\pi (k|\lambda ^{(l)}, \alpha ^{(l)})\) is the conditional posterior distribution of k given in (20). Let us assume \(k\sim unif\{1,n\}\) then k can be updated using its posterior conditional distribution
where \(m^{\text{ th }}\) iteration, for \(m = 1, \dots , M\), and \(S_k\) is \(\sum _{i = 1}^{k} x_i\) [34]. As a previous step, we must elicit the hyperparameters \(m_{ij}\) using the methods proposed in Sect. 4.2.
4.2 Hyperparameter Elicitation
This section provides a brief description of eliciting hyperparameters. Similar to Arnold01, we consider inconsistency in the prior information provided by the expert or experts. This will allow us to assume a sample space for the conditional conjugate space rather than exactly one value that agrees with the prior information elicited from our expert or experts.
Let \(\mu \), \(\sigma ^2\), \(\mu '\) and \(\sigma '^2\) denote the conditional mean and variance of \(\lambda |\alpha \) and \(\alpha |\lambda \), respectively. We assume a series of \(\alpha _1, \dots , \alpha _{m_1}\) and \(\lambda _1, \dots , \lambda _{m_2}\) based on the experts’ information are available. This results in a system of equations will allow us to obtain a realisation of hyperparametrs.
In order to satisfy conditions in Eq. (6) sequential quadratic programming using nloptr [35] in R was used to solve the above system of equations and elicit hyperparameters. Sequential Quadratic Programming (SQP) is one of the most successful methods for the numerical solution of constrained nonlinear optimization problems. It relies on a profound theoretical foundation and provides powerful algorithmic tools for the solution of large-scale technologically relevant problems.
5 Numerical Experiments
The numerical experiments is designed as follows. The method will be applied to sets of simulated data and real data. The simulation study investigated the performance of the model under three cases: 1. all parameters of the model are fixed, 2. varying k, 3. varying n and k. In all examples, 100 sets of data are simulated and number of iterations are 20,000. Based on Gelman-Rubin convergence diagnostics [36, 37], chains were considered to be converging after 5000 iterations, in all simulations. The accuracy of parameter estimates using root mean square error (RMSE).
The real data application will use the well known mine data available in R.
5.1 Simulation Study
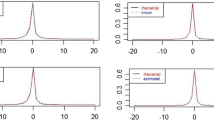
Trace plots and marginal posterior density of model parameters for the full model and the submodel are presented in.
From Table 2, it can be seen that model is not generally affected by the number of observations and where the change happens.
Finally, we extended the simulation study to sets of MC simulation studies for \(N = 10000\) and obtained the RMSE for the parameters of the model. In order to present the convergence diagnostics, we selected Figs. 3 and 4 as examples of the Gelman-Rubin convergence diagnostics plots which confirm the convergence after 5000 burn-in [38].
5.1.1 Case 1: \(n = 200, k = 100, \lambda = 1\) and \(\alpha = 3\)
Case 1 simulates data from a model with \(\lambda = 1, \alpha = 3, n = 200\) and \(k = 100\). A realisation of the conditional posterior distributions of model parameters was obtained using Gibbs sampler, and graphical presentation of the results including trace plots, marginal posterior densities and Gelman–Rubin diagnostics plot are given in Figs. 6–4.
It can be seen for both models the posterior mean of parameters are close to true values. However, the posterior variance for parameters \(\lambda \) and \(\alpha \) were small.

Monte Carlo simulation results of the full model

Monte Carlo simulation results of the sub-model

Gelman–Rubin diagnostics plots and statistics for parameters a \(\lambda \), b \(\alpha \) and c k of the full model with \(n = 200\) and \(k = 100\). The Gibbs sampler converges after 5000 iterations

Gelman–Rubin diagnostics plots and statistics for parameters a \(\lambda \), b \(\alpha \) and c k of the sub-model model with \(n = 200\) and \(k = 100\). The Gibbs sampler converges after 5000 iterations
5.1.2 Case 2: \(n = 200, \lambda = 1\), \(\alpha = 3\) and \(k = 50, 100, 150\)
The simulation study was extended where \(\lambda \), \(\alpha \) and n are fixed with values of 1, 3 and 200, respectively and k varies at 25%, 50% and 75% of the total number of observations. This will allow us to assess the performance of the model based on where the change happens.
Results for this case are summarised in Table 3. It can be seen k has hardly been affected by the position of change. However, the estimation of parameters \(\lambda \) and \(\alpha \) was less accurate when the location of change was at the 25% of the total sample size for both full- and sub-model.
5.1.3 Case 3: \(\lambda = 1\) and \(\alpha = 3\), varying n and k
In the final case we assessed the effect of sample size on the parameter estimation, in addition to the location of change. Data was simulated with values of \(n = 50, 100\) and 150. Tables 4 and 5 provide summarise performance of full- and sub-models using RMSE.
5.2 Real Data: Coal Mine Example
The coal mine example adopted from [39]. The data was downloaded from the boot library in R [40]. The data set provided the dates of 191 explosions in coal mines which resulted in 10 or more fatalities between March 15, 1851 and March 22, 1962.

Mine data adopted from Davison and Hinkley (1997) illustrates number of explosions with more than 10 mortalities from 1851 to 1962
Let the number of explosions with more than 10 mortalities, X such that
The full model was only fitted to the data. In order to solve the system of equations in (6)–(5) elicit hyperparameters, we assumed the following values for the conditional expected mean and variances
Therefore, under the general model hyperparameters can be elicited as illustrated in Table 6.
Table 7 provides a summary of the posterior mean, standard deviation and \(95\%\) credible intervals (CI) of the model parameters. The results are compared with a basic model where we assume \(\lambda \) and \(\alpha \) are independently distributed with non-informative gamma priors. It can be seen that although both models have close posterior means, the proposed model offers smaller standard deviation and a narrower \(95\%\) CI.

Mine data Gibbs sampler chain results, where a, c and e are the chain convergence plots for the parameters \(\lambda \),\(\alpha \) amd k
Trace plots and marginal density plots are presented in Fig. 6. Finally, the posterior mean of the model parameters were added to the coal mine data along with the estimated change point and presented in Fig. 7. It can be seen that the number of explosions resulting in 10 or more mortalities have decreased around year 40 which is 1891.

Mine data along with the posterior mean of \(\lambda \) and \(\alpha \) presented in yellow
6 Conclusions
In this paper, we presented a novel approach for estimating change point problems by using a broad class of conjugate prior distributions derived from a conditional specification methodology. While previous research extensively demonstrated the application of such prior distributions in problems involving continuous distributions, our contribution lied in exploring their effectiveness in the context of discrete distributions, specifically the Poisson process.
We conducted a comprehensive simulation study and applied the proposed methodology to real mine data. Through Gelman-Rubin diagnostics, we confirmed the convergence of the Gibbs sampler after a burn-in period of 5000 iterations. The simulation results revealed that parameter estimates exhibit smaller error when the change point, denoted as k, is closer to half of the total data points n. We compared the results obtained using our methodology with those of a basic model assuming independent parameters with non-informative priors. The findings demonstrated that our proposed approach yields significantly smaller estimation errors.
Furthermore, our methodology holds potential for extension to estimate multiple change points. Additionally, the introduction of a bivariate Poisson process poses new challenges that warrant further investigation and refinement of our proposed methodology. Overall, our research contributes to the advancement of change point analysis and provides valuable insights for improving the estimation accuracy in various application domains.
Data availability
The author confirms that all data analysed during in this paper can be either simulated from a Poisson process with given parameters in this article or is available from the boot library in R.
Code availability
Pseudo Gibbs sampler code has been provided at the end of the paper.
References
Hastie T, Tibshirani R, Friedman JH, Friedman JH (2009) The elements of statistical learning: data mining, inference and prediction, vol 2. Springer, Berlin
Shi Y, Tian Y, Kou G, Peng Y, Li J (2011) Optimization based data mining: theory and applications. Springer, Berlin
Tien JM (2017) Internet of things, real-time decision making, and artificial intelligence. Ann Data Sci 4:149–178
Olhede SC, Wolfe PJ (2018) The future of statistics and data science. Statist Prob Lett 136:46–50
Louis D, Shi Y (2007) Introduction to business data mining, vol 10. McGraw-Hill/Irwin, New York
Shi Y (2022) Advances in big data analytics: theory, algorithm and practice. Springer, Singapore
Irizarry RA (2019) Introduction to data science. Chapman and Hall-CRC Press, Boca Raton
Agresti A, Kateri M (2021) Foundations of statistics for data scientists: with R and Python. Chapman and Hall-CRC Press, Boca Raton
Bruce P, Bruce A, Gedeck P (2020) Practical statistics for data scientists: 50+ essential concepts using R and Python. O’Reilly Media
Mishra S, Datta-Gupta A (2017) Applied statistical modeling and data analytics: a practical guide for the petroleum geosciences. Elsevier, New York
Olson DL, Shi Y (2007) Introduction to business data mining. McGraw-Hill/Irwin, New York
Shi Y, Tian YJ, Kou G, Peng Y, Li JP (2011) Optimization based data mining: theory and applications. Springer, Berlin
Tien JM (2017) Internet of things, real-time decision making, and artificial intelligence. Ann Data Sci 4(2):149–178
Chen M, Mao S, Liu Y (2014) Big data: a survey. Mobile Netw Appl 19:171–209
Killick R, Fearnhead P, Eckley IA (2012) Optimal detection of changepoints with a linear computational cost. J Am Stat Assoc 107(500):1590–1598
Zhang L, Jia S, Yang M, Yao X, Li C, Sun J, Huang Y et al (2014) Detection of copy number variations and their effects in Chinese bulls. BMC Genom 15:1
Carslaw DC, Ropkins K, Bell MC (2006) Change-point detection of gaseous and particulate traffic-related pollutants at a roadside location. Environ Sci Technol 40(22):6912–6918
Sluss D, Bingham C, Burr M, Bott ED, Riley EA, Reid PJ (2009) Temperature-dependent fluorescence intermittency for single molecules of violamine r in poly (vinyl alcohol). J Mater Chem 19(40):7561–7566
Arnold BC, Castillo E, Sarabia JM (1998) The use of conditionally conjugate priors in the study of ratios of gamma scale parameters. Comput Stat Data Anal 27(2):125–139
Sarabia JM, Shahtahmassebi G (2017) Bayesian estimation of incomplete data using conditionally specified models. Commun Stat Simul Comput 46:3419–3435
Arnold BC, Castillo E, Sarabia JM (1998) Bayesian analysis for classical distributions using conditionally specified priors. Sankhyā Indian J Stat Ser B 228–245
Chen J, Gupta AK (2012) Parametric statistical change point analysis: with applications to genetics, medicine, and finance, 2nd edn. Birkhäuser, Boston
Chen J, Gupta AK (2001) On change point detection and estimation. Commun Stat Simul Comput 30(3):665–697
Barry D, Hartigan JA (1993) A Bayesian analysis for change point problems. J Am Stat Assoc 88(421):309–319
Adams RP, MacKay DJC (2007) Bayesian online change point detection. arXiv:0710.3742
Antoch J, Husková M, Veraverbeke N (1995) Change-point problem and bootstrap. J Nonparametr Stat 5(2):123–144
Malhotra P, Vig L, Shroff G, Agarwal P, et al (2015) Long short term memory networks for anomaly detection in time series. In: ESANN, p 89
Aminikhanghahi S, Cook DJ (2017) A survey of methods for time series change point detection. Knowl Inf Syst 51(2):339–367
Sharma S, Swayne DA, Obimbo C (2016) Trend analysis and change point techniques: a survey. Energy Ecol Environ 1:123–130
Arnold BC, Castillo E, Sarabia JM (2001) Conditionally specified distributions: an introduction (with discussion). Stat Sci 16:249–274
Hobert JP, Casella G (1996) The effect of improper prior on gibbs sampling in hierarchical linear mixed models. J Am Stat Assoc 91:1481–1473
Arnold BC, Castillo E, Sarabia JM (1999) Conditional specification of statistical models. Springer Series in Statistics. Springer, New York
Abramowitz M, Stegun I (1964) Handbook of mathematical functions. Government Publishing Office, Washington, DC
Rizzo ML (2007) Statistical computing with R. Chapman and Hall/CRC, New York
Johnson SG (2007) The NLopt nonlinear-optimization package. http://github.com/stevengj/nlopt
Gelman A, Rubin DB (1992) Inference from iterative simulation using multiple sequences. Stat Sci 7(4):457–472
Brooks SP, Gelman A (1998) General methods for monitoring convergence of iterative simulations. J Comput Graph Stat 7(4):434–455
Plummer M, Best N, Cowles K, Vines K (2006) Coda: convergence diagnosis and output analysis for mcmc. R News 6:7–11
Hand David J, Daly Fergus, McConway K, Lunn D, Ostrowski E (1993) A handbook of small data sets
Canty A, Ripley B (2017) boot: Bootstrap r (s-plus) functions. R package version 1(3–20):2017
Acknowledgements
We are grateful for the constructive suggestions provided by editors and reviewers, which have improved our paper. The second author gratefully acknowledge financial support from Grant No. PID2019-105986GB-C22 by MCIN/AEI/10.13039/501100011033.
Funding
The second author gratefully acknowledge financial support from Grant No. PID2019-105986GB-C22 by MCIN/AEI/10.13039/501100011033.
Author information
Authors and Affiliations
Contributions
GS and JS equally contributed to writing this article. JS contribution was towards the thoeretical concept and drivations. GS contributed in computational part and coding.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical Approval
All authors approved this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 Posterior Conditional Distributions
Let \(X_i\) be a Poisson random variable where \(i = 1, \dots , T\). Assume that the change point occurs at time k such that
and
where \(\lambda >0\), \(\alpha >0\) and \(k\in \{1,2,\dots ,n\}\) are parameters of interest. The likelihood function can be written as:
We assign a bivariate gamma prior distribution to the joint distribution of \((\lambda , \alpha )\) with the following form:
Thus the joint posterior distribution of \((\lambda , \alpha )|(x, k)\) can be obtain as:
1.2 Pseudo Code: Gibbs Sampler

Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shahtahmassebi, G., Sarabia, J.M. Bayesian Analysis of Change Point Problems Using Conditionally Specified Priors. Ann. Data. Sci. (2023). https://doi.org/10.1007/s40745-023-00484-2
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40745-023-00484-2