
Abstract
We derive price limits as decision aids for identifying favorable and unfavorable contracts from the perspective of a selling firm in face of uncertain outcomes. The analysis is based on the concept of almost stochastic dominance to incorporate incomplete information about the decision-maker’s preferences. The main challenges to use this concept in practice are to define and limit the required preference information and to demonstrate the performance of the resulting price limits. We propose price limits that are suitable for a wide range of applications, in particular services. While their information requirements vary, all price limits refer to the same type of aggregate information about marginal utilities and risk aversion. In the scenario with the lowest requirements, the preference information shrinks to a single number which is easy to approximate and to communicate. A comprehensive numerical study featuring fixed-price contracts shows that the incomplete preference information may lead to substantial improvements of the price limits over the situation of no preference information. We also discuss determinants and caveats of these improvements. For instance, the improvements increase with decreases of the decision-maker’s risk sensitivity and may differ substantially in magnitude between the lower and the upper price limit.
Similar content being viewed by others


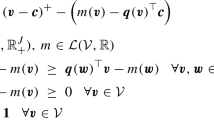
Avoid common mistakes on your manuscript.
1 Introduction
Common wisdom has it that a profit-maximizing firm should not sell a product or service at a price below cost. Accordingly, the cost forms a lower price limit (or price floor) for selling the product or service and thereby may serve, e.g., as a reservation price in an auction or as a decision criterion during sales negotiations (Myerson 1981; Phillips et al. 2015). More generally, a price limit indicates whether it is favorable for the decision-maker (DM) to accept or reject a given sales contract. Provided that the price limit reflects the DM’s preferences, it is possible to decide on contract offers merely by comparing the offered price with the price limit, i.e., without further preference information and without actually submitting the contract to the DM for decision. Therefore, price limits reduce complexity and facilitate decision-making.
The decision-facilitating role of price limits is not restricted to centralized decision-making, but extends to delegation. According to Phillips et al. (2015), a common approach to delegating the pricing authority is based on lower price limits in the form of list prices combined with maximum discounts. Prices and discounts are established by headquarters (or sales management), i.e., by the DM, and are used to restrict the sales representatives’ discretion when negotiating prices with the customers. While the sales representatives are free to settle on prices above the lower limit, prices below the limit are subject to approval by headquarters. Vudali and Atherton (2012) describes such rules for the example of Yahoo!.
This possibility under decentralized pricing of having prices approved by the DM suggests that there are prices that are favorable from the DM’s perspective, although they fall short of the price limit. This imperfection of price limits applies equally to centralized pricing and can be explained by insufficient customization of the price limits to the specifics of the contract (Phillips et al. 2015). Such specifics include the order quantity, shipping terms, future profits from follow-up deals, and lost profits due to scarce capacity or product cannibalization. Yet another source of imperfection arises from uncertainty of the goods and services to be provided. With risky economic outcomes, in turn, the DM’s risk preferences come into play, and the price limits may not fully reflect these preferences. Therefore, risky outcomes and risk preferences are the starting point for our analysis.
Price limits are prone to not fully reflect the DM’s preferences if they are derived from incomplete preference information. This problem could be avoided by directly eliciting the price limits from the DM. However, this is time-consuming due to the diversity of possible contract specifics, group decisions, and preferences changing over time. A more efficient approach is to elicit preferences as a von Neumann–Morgenstern utility function and to compute price limits from it based on expected utility theory (Farquhar 1984; Keeney and Raiffa 1976, §§ 4, 10). But, as explained by Armbruster and Delage (2015), these assessment methods only produce approximations of the true utility function. Moreover, the utility function may still change over time. Consequently, it is realistic to assume that the preference information from which price limits are derived is incomplete. This directly leads to the questions of what kind of preference information is available or should be gathered and how it can be translated into price limits.
In the event that no relevant preference information is available, it is possible to derive price limits from the well-known concept of first-degree stochastic dominance (FSD).Footnote 1 This approach is parsimonious and robust, but the resulting price limits are typically poor. We illustrate this by means of the following example.
Suppose a firm sold a piece of technical equipment to a customer. This equipment may require maintenance or repair to remain functional. The firm considers to offer carrying out these works under two different contract modes. Under transaction-based pricing, the customer commissions the firm to service the equipment if necessary and pays 200 for the service provided. Let the probability of service provision be 0.1. There is no service and thus no payment if the service is not necessary. Alternatively, the firm may offer a fixed-price contract covering any service during the considered period of time. Here, the customer pays an upfront fee, \(\pi \), on entering the contract while not knowing whether the service will be necessary.
Assuming the firm’s costs for carrying out the service are 100, Table 1 shows the profit distributions the firm faces under the two types of contracts. Given the customer offers to pay a fixed price of \(\pi \), the firm has to decide whether it will enter the fixed-price contract or stick to transaction-based pricing. If the DM was known to be risk neutral, as an example of complete information, the price limit for entering the fixed-price contract would be 20. This number or the information that the DM is risk neutral could be handed down to the sales representative to make the decision on every \(\pi \) offered by the customer.
The left-hand side of Fig. 1 depicts the profits from Table 1 in terms of cumulative distribution functions (cdfs) for a fixed price of \(\pi =60\). This price is clearly above the indifference price of 20, so a risk-neutral DM would switch to the fixed-price contract. However, without the DM’s specific indifference price or without the information that the DM is risk neutral, the sales representative cannot say whether the DM prefers the fixed-price contract. He could if the cdf for the fixed-price contract was completely below the cdf for transaction-based pricing as postulated by the definition of FSD. This is not the case for a fixed price of 60 as indicated by the two outer gray areas. It would be the case for a price of 100 and above; this is depicted on the right-hand side of Fig. 1. Hence, the lower price limit for accepting the fixed-price contract derived from FSD is 100.
Likewise, the sales representative cannot say whether the DM wants to stick to transaction-based pricing and therefore reject the fixed-price contract for a fixed price of 60. This is because the cdf for transaction-based pricing does not completely lie below that for the fixed-price contract as indicated by the inner gray area. It would for a price of 0 (or below). Therefore, the upper price limit (or price ceiling) derived from FSD for rejecting the fixed-price contract is 0.
The decision on any fixed price in between the price limits of 0 and 100 depends on the specific risk preference of the DM. If relevant preference information is not available, as is the case under FSD, the sales representative is not able to make the decision for such intermediate prices safely and has to submit it to the DM. Thus, the facilitating role of price limits is restricted to fixed prices up to 0 and from 100.

Cdfs of introductory example
From this example, we learn that FSD only incorporates little preference information and thereby considers a large class of possible utility functions. The corresponding price limits allow for robust decisions to accept or reject a given contract. The flip side of the coin is that such price limits may include a wide range of prices where there is no support for making the decision easier. By and large, this also applies to second-degree stochastic dominance (SSD) which focuses on risk-averse DMs. Therefore, we turn from stochastic dominance (SD) to almost stochastic dominance (ASD), which exploits additional, albeit still incomplete, preference information, to make the class of considered utility functions and thereby the range of intermediate prices smaller.
The main contributions of our paper are the following.
-
1.
We present for the first time price limits that are derived from incomplete information about the DM’s preferences by means of ASD (Propositions 1–2). Since ASD refers to prospects with constant outcome supports, the main challenges of its application to pricing are (a) to account for supports that vary with the price (Sect. 5.4) and (b) to reduce the information requirements with respect to the largest allowed violation of SD (Sect. 5.5).
The second of our incomplete information scenarios (Sect. 5.5) appears to be particularly applicable in business practice for several reasons. First, the information requirement boils down to a single number which may be approximated from past decisions taken by the DM or even from experimental studies in the literature. Second, it is possible to apply the same number to other decision problems, so it is not necessary to determine this number for each decision problem separately. Third, the achieved improvements of the price limits over those based on SD are substantial, which leads us to the second main contribution.
-
2.
Based on a comprehensive numerical study referring to fixed-price contracts, we demonstrate that the application of ASD, instead of SD, may lead to substantial improvements of the price limits (Sect. 6). This underlines the relevance of our first main contribution. We also discuss determinants and caveats of these improvements. For instance, the improvements increase with decreases of the DM’s risk sensitivity and may differ substantially in magnitude between the lower and the upper price limit.
The remainder of the paper begins with a review of the related literature (Sect. 2). Then, we introduce the model in Sect. 3 including the decision problem, the two-stage decision process, the information scenarios, and the example case of fixed-price contracts which generalizes the introductory example and is used throughout the paper. Section 4 provides the definition of price limits and a characterization in terms of the best price limits based on complete preference information. It also contains the no information scenario which helps to shape the information requirements under incomplete preference information as discussed in Sect. 5 and serves as a lower benchmark for the performance analysis in Sect. 6. The proofs of our results are included in the text or in Appendix 5.
2 Related literature
The interpretation of costs as price limits can be found, among others, in Horngren et al. (2015, §§ 11, 13) and Mas-Colell et al. (1995, § 5). A major challenge is to determine the costs relevant for the considered decision, which is the domain of managerial accounting. See, for example, Horngren et al. (2015, § 11) for a general discussion of relevant costs, Göx and Wagenhofer (2007) for price limits under capacity constraints, and Küpper (2009) and Reichelstein and Rohlfing-Bastian (2015) for long-term price limits. The integration of the DM’s risk preferences and incomplete information about them in the price limits is neglected in the management accounting literature. This is also true for the literature on the delegation of the pricing authority, where it is argued that an upward distortion of the lower price limit may have a favorable effect on the competition on oligopolistic markets or on the sales representative’s effort (e.g., Bhardwaj 2001; Joseph 2001).
The incompleteness of the preference information requires consideration of a set of risk utility functions rather than a unique utility function. This nonuniqueness of considered utility functions parallels expected utility theory without the completeness axiom (e.g., Aumann 1962; Dubra et al. 2004). Accordingly, depending on the decision alternatives, it may not be possible to rank two alternatives, and hence both of them are efficient, i.e., nondominated. A commonality of the approaches to incomplete preference information is thus the identification of inefficient alternatives (e.g., Weber 1987).
A well-known instrument to identify dominated alternatives under incomplete preference information is SD. See, for example, Levy (1992) and Levy and Leshno (2000) for surveys of the methodological results and their applications. The application closest to ours is option pricing (e.g., Constantinides and Perrakis 2007; Levy 1985). SD is appropriate for that application for it considers large sets of utility functions and thereby reflects a large number of presumably diverse investors. By contrast, the DM in our context is an individual or a board which makes the set of relevant utility functions smaller than that under option pricing. Therefore, we focus on ASD to be able to consider smaller sets of utility functions and thereby to get better price limits.
Almost first-degree stochastic dominance (AFSD) was introduced by Leshno and Levy (2002) and refers to information about marginal utility. Under risk aversion, there are two different approaches to almost second-degree stochastic dominance (ASSD), namely Tsetlin et al. (2015) and Tzeng et al. (2013). We make use of the latter approach for it exhibits the hierarchy property, i.e., ASSD follows from AFSD. It is thus possible to use the same preference information for both AFSD and ASSD and to do without information about higher-order derivatives of the utility functions. Moreover, experimental evidence referring to AFSD as found in Levy et al. (2010) can equally be used for ASSD. The ASSD approaches in Leshno and Levy (2002) and Levy et al. (2010) are not valid as shown by Tsetlin et al. (2015) and Tzeng et al. (2013).
3 Model
3.1 Decision problem
We take the perspective of a firm, with the DM considering to accept or reject a given contract for the supply of goods or services to a customer at price \(\pi \). Our focus is not on optimal prices, rather on favorable prices. Examples can be found in the area of contract manufacturing and service contracts where contracts are often highly customized. For instance, imagine a firm constructing equipment, machines, plants, buildings, or ships on custom order, or providing maintenance and repair services for such objects as featured in the introductory example.
The firm’s profits x from the contract are described by cdf \(F_\pi \). The index \(\pi \) indicates the dependence on the sales price. The firm’s profits under the given status quo alternative, i.e., when not entering the contract represented by \(F_\pi \), are captured by cdf S. The DM thus chooses between the contract \(F_\pi \) and the status quo S. Focusing on the price \(\pi \), one can restate this decision problem as the question of whether \(\pi \) is high enough so that \(F_\pi \) is preferred over S, or whether it is low enough so that S is preferred over \(F_\pi \).
Our main assumption on \(F_\pi \) is that increasing prices are favorable. More specifically,
meaning that \(F_{\pi _2}\) dominates \(F_{\pi _1}\) by a strict form of FSD.
This assumption seems obvious due to the positive income effect: higher prices are, ceteris paribus, always favorable for the selling firm; one would even expect statewise dominance. However, even for the considered decision to enter into a given contract, the ceteris paribus condition does not need to hold perfectly. As an example, think of a machine that is maintained and repaired by the firm at a fixed price, but operated by the customer. In this situation, a higher fixed price might make the customer take less care when operating the machine, which, in turn, bears on the costs for maintenance and repair incurred by the firm. Another example is that higher prices may impair the firm’s profits from follow-up deals.
In view of the industrial and service context of the pricing problem considered in this paper, it is very plausible to assume that the profit distributions \(F_\pi \) and S are given, all the more considering the growing possibilities of data collection and remote monitoring in the course of Industry 4.0 (Internet of Things). In case there are only scenarios of possible profit distributions, these can be compounded into a single distribution as described by French (1986, § 2).
The decision problem is illustrated by the following example case which generalizes the introductory example.
3.2 Example case
In the example case, the contract under consideration states that the firm provides the specified goods or services at a fixed price, independent of the actual goods and services provided and costs incurred. A day-to-day example capturing the basic idea of such a fixed-price contract are free refills for beverages. In an industrial context, one might consider maintenance and repair services for servitized equipment. The status quo is either no contract at all or an agreement stating that the goods or services are billed as they are provided. In terms of the process model by Oliva and Kallenberg (2003), this situation reflects a manufacturer offering industrial services and switching from transaction-based pricing (stage 2) to relationship-based pricing (stage 3).
To model the uncertain financial consequences, we assume that there are two events. In one event, the firm has to provide the contracted goods or services resulting in costs c. The probability of this event is p. In the other, the firm does not have to provide the contracted goods or services and thus does not incur costs c. One might think of a machine that fails with probability p and has to be repaired at costs c, or it does not fail and thus does not need repair. In both events, the firm charges the fixed price \(\pi \). Fixed costs are neglected. This explains the first line of the decision matrix in Table 2.
An alternative to the fixed-price contract is no contract at all. In this case, the firm’s profit is zero, and we would set \(m=0\) in the second line of the decision matrix. By contrast, \(m>0\) describes a firm that considers converting an existing cost-plus contract into a fixed-price contract. To see this, interpret m as the profit markup on the costs c when supplying the same goods or services as under the fixed-price contract.
In terms of cdfs, the fixed-price contract and the status quo are given by
3.3 Two-stage decision process
The two-stage decision process that is immanent in the concept of price limits can be described in our context as follows. In the first stage, contracts are screened by means of the given price limits \(\overline{\pi }\) and \(\underline{\pi }\). Contracts with high prices, \(\pi \ge \underline{\pi }\), are accepted and those with low prices, \(\pi \le \overline{\pi }\), are declined. As the price limits are derived from incomplete information about the DM’s preferences, the DM is involved in the screening stage only as much as is necessary for collecting this information. Given the price limits, the screening happens without consulting the DM. Only contracts with intermediate prices proceed to the second stage, where they are submitted to the DM for decision.
The screening stage facilitates decision-making by avoiding the full-fledged decision in the second stage and thereby reduces the complexity of the decision. The tighter the price limits, the more contracts can be decided during screening. Furthermore, it is possible to relieve the DM by delegating the screening and, provided the communication of the (incomplete) preference information, the calculation of the price limits.
Our focus is on the screening stage. The challenge is to find the lowest lower price limit and the highest upper price limit subject to two constraints. First, contracts must not be accepted or declined mistakenly from the DM’s perspective. Second, the price limits must be determined only on the basis of the available information about the DM’s preferences.
3.4 Relevant utility functions
The DM’s preferences are represented by the set D of risk utility functions defined over the firm’s profits. The utility functions in D are referred to as the relevant utility functions. There are several cases and interpretations of D. The case that D is a singleton, i.e., \(D=\{u\}\), can be interpreted in two ways. First, the DM might be a single individual, and u represents this person’s preferences. Second, the DM might be a board, and u is the group utility function of its members. The case that D comprises more than one utility function, say, \(D=\{u_1, \ldots , u_n\}\), comports with an individual DM whose preferences are unstable. More specifically, the DM’s preferences may change over time, and each utility function reflects one of the n periods of time. Alternatively, each utility function may represent one of n board members. In this event, we leave open the question of how the individual preferences aggregate.
Given the relevant utility functions D, we can more precisely state the above requirement that there must be no false acceptance or false rejection of a contract in the screening stage: \(\pi \ge \underline{\pi }\) only if \({{\,\mathrm{E}\,}}_{F_\pi }(u) \ge {{\,\mathrm{E}\,}}_S(u)\) for all \(u \in D\), and \(\pi \le \overline{\pi }\) only if \({{\,\mathrm{E}\,}}_S(u) \ge {{\,\mathrm{E}\,}}_{F_\pi }(u)\) for all \(u \in D\), where \({{\,\mathrm{E}\,}}_{F_\pi }(u)\) and \({{\,\mathrm{E}\,}}_S(u)\) denote the expected utilities. If D happens to represent individual board members, these conditions translate the axiom of Pareto efficiency from social choice theory (e.g., Arrow 1963, § 8) into our context.
3.5 Information scenarios
The analysis comprises four scenarios of the available preference information. Under Complete Information (index “C”), the set D is completely known. This scenario serves as an upper benchmark. The opposite is the No Information scenario (index “N”), where we cannot say whether a given utility function is relevant. This scenario serves as a lower benchmark. In addition to these best and worst case scenarios, there are two intermediate scenarios of Incomplete Information (indices “I1” and “I2”), on which we elaborate in Sect. 5.2.
In addition, we distinguish between the situation where it is known that the DM is risk averse (index “a”), i.e., all relevant utility functions are known to be concave, and the situation where this information is not available (no index).
3.6 Further assumptions
The set of all utility functions is U with \( U \equiv \{ u:\inf \{ u^{\prime}(x)\} > 0\} \) and \(D \subseteq U\). The set of utility functions reflecting risk aversion is denoted by \(U_a\), i.e., \(U_{a} \equiv \{ u \in U:u^{\prime\prime}(x) \le 0\}\). To avoid trivial situations and technical problems, we assume that \(F_\pi (x)\) is continuous in \(\pi \). As a consequence, an increase in the price leads to a continuous increase in the expected utility, \({{\,\mathrm{E}\,}}_{F_\pi }(u)\), and thus also in the expected value, \({{\,\mathrm{E}\,}}_{F_\pi }\). Moreover, we assume that there exists a price \(\pi \) such that \(F_\pi (x) \le S(x)\) for all x and \(F_\pi (x) < S(x)\) for at least one x. Analogously, let there exist a price such that \(S(x) \le F_\pi (x)\) for all x and \(S(x) < F_\pi (x)\) for at least one x. Finally, \(F_\pi \) and S are thought of as being defined on finite supports. The convex hull of these supports is referred to as the distributions’ joint support \([\underline{x}, \overline{x}]\).
3.7 Example case continued
In the example case introduced in Sect. 3.2, the joint support of the cdfs of the fixed-price contract, \(F_\pi \), and the status quo, S, is
The relevant utility functions are assumed to be \(D = \{u_1, u_2\}\) with \(u_1\) reflecting risk neutrality. The other utility function reflects risk aversion and is defined as \(u_2(x) \equiv 22\!-\!22\exp (-23 r x \!\cdot \! 10^{-6})\) if \(x \le 0\) and \(23 \!-\!23\exp (- 22 r x \!\cdot \! 10^{-6})\) otherwise. The specification of \(u_2\) is based on a study by Pennings and Smidts (2003), who fit piecewise exponential utility functions to their experimental evidence. We refer to their findings and assume an average shape of this type of utility function with parameter \(r >0\) measuring risk sensitivity.Footnote 2 We thus take a representative from the class of concave utility functions. In Appendix 4, we conduct our analysis without the restriction to risk aversion when adding three utility functions that are representative for convex shapes, S shapes, and reversed S shapes.
4 Complete and No Information
4.1 Definition and characterization of price limits
The requirement that contracts must neither be accepted nor rejected mistakenly implies the following definition of price limits.
Definition 1
The price \(\underline{\pi }\) is a lower price limit for accepting the contract if and only if the contract is preferred for all relevant utility functions for all prices higher than \(\underline{\pi }\), i.e., \({{\,\mathrm{E}\,}}_{F_\pi }(u) \ge {{\,\mathrm{E}\,}}_S(u)\) for all \(\pi \ge \underline{\pi }\) and all \(u \in D\). Analogously, \(\overline{\pi }\) is an upper price limit for rejecting the contract if and only if \({{\,\mathrm{E}\,}}_{F_\pi }(u) \le {{\,\mathrm{E}\,}}_S(u)\) for all \(\pi \le \overline{\pi }\) and all \(u \in D\).
It is important to realize that price limits are not unique. This is because we are going to derive several price limits which refer to different information scenarios with respect to the DM’s preferences, but to the same decision problem. In particular, a price exceeding (falling short of) a lower (upper) price limit is itself a lower (upper) price limit. However, the tighter the price limits, i.e., the smaller the range \([\overline{\pi }, \underline{\pi }]\), the more useful is the screening stage.
For a given utility function, the contract \(F_\pi \) and the status quo S can be ranked by the corresponding expected utilities \({{\,\mathrm{E}\,}}_{F_\pi }(u)\) and \({{\,\mathrm{E}\,}}_S(u)\). By the assumptions on \(F_\pi \) and u, the price solving \({{\,\mathrm{E}\,}}_{F_\pi }(u)={{\,\mathrm{E}\,}}_S(u)\) is unique. Denote this indifference price by \(\pi _u\). In light of Definition 1, \(\pi _u\) is both a lower price limit and an upper price limit, provided there is no other relevant utility function. In this case, it is even the best lower and the best upper price limit because there is no lower price limit below and no upper price limit above it. In the event that u reflects risk neutrality, we write \(\pi _n\) where appropriate. On the basis of the indifference prices for each single utility function, it is straightforward to characterize price limits for all relevant utility functions.
Lemma 1
The price \(\underline{\pi }\) is a lower price limit if and only if \(\underline{\pi } \ge \underline{\pi }_C\) . The price \(\underline{\pi }_C \equiv \sup \{\pi _u : u \in D \}\) is the best lower price limit, since there is no smaller lower price limit. Analogously, \(\overline{\pi }\) is an upper price limit if and only if \(\overline{\pi } \le \overline{\pi }_C\) with \(\overline{\pi }_C \equiv \inf \{\pi _u : u \in D \}\) as the best upper price limit.
The best price limits are the extreme indifference prices across the relevant utility functions. If these price limits were known, the two-stage decision process for the example case with \(r=258\), \(c=m=100\), and \(p=0.1\) would look as follows. Contracts with prices of at least \(\underline{\pi }_C=20.89=\max \{20, 20.89\}=\max \{\pi _{u_1}, \pi _{u_2}\}\), would be accepted in the screening stage, while contracts with prices of at most \(\overline{\pi }_C=20=\min \{20, 20.89\}=\min \{\pi _{u_1}, \pi _{u_2}\}\) would be rejected.Footnote 3 Contracts with intermediate prices would proceed to the second stage.
4.2 No Information
Under the No Information scenario, there is no information available other than that the DM is risk averse or not. We thus have no information about marginal utilities which distinguishes this scenario from the Incomplete Information scenarios.
The lack of information makes it necessary to consider all utility functions in U or \(U_a\), not only those in D. We would therefore like to substitute the set D for U or \(U_a\) in Lemma 1. But the actual calculation of the price limits proves to be an arduous task due to the infinite number of utility functions. However, with FSD and SSD it is possible to derive the price limits from the cdfs without reference to the individual utility functions.Footnote 4
Lemma 2
Under No Information, the best lower price limit is \(\underline{\pi }_N \equiv \min \left\{ \pi : F_\pi (x) \le S(x) \; \text { for \; all }\; x \right\} \). This means that \(\underline{\pi }_N\) exhibits two properties: (1) \(\underline{\pi }_N\) is a lower price limit, i.e., \(\underline{\pi }_N \ge \underline{\pi }_C\), and (2) there is no \(\underline{\pi } < \underline{\pi }_N\) such that \({{\,\mathrm{E}\,}}_{F_\pi }(u) \ge {{\,\mathrm{E}\,}}_S(u)\) for all \(\pi \ge \underline{\pi }\) and for all \(u \in U\). Analogous properties hold for the upper price limit \(\overline{\pi }_N \equiv \max \left\{ \pi : S(x) \le F_\pi (x) \; \text { for \; all } \; x \right\} \). The corresponding best price limits under risk aversion are \(\underline{\pi }_{N, a} \equiv \min \left\{ \pi : \int _{\underline{x}}^x [ F_\pi (t) \!-\! S(t) ] {\text{d}}t \le 0 \; \text { for \; all } \; x \right\} \) and \(\overline{\pi }_{N, a} \equiv \max \left\{ \pi : \int _{\underline{x}}^x [ S(t) \!-\! F_\pi (t) ] {\text{d}}t \le 0 \; \text { for \; all } \; x \right\}. \)
The aim of exploiting information about the relevant risk preferences is to increase the number of contracts that are accepted or rejected in the screening stage by decreasing the lower limit from \(\underline{\pi }_N\) and \(\underline{\pi }_{N, a}\) toward \(\underline{\pi }_C\) and increasing the upper limit from \(\overline{\pi }_N\) and \(\overline{\pi }_{N, a}\) toward \(\overline{\pi }_C\). In the example case with \(r=258\), \(c=m=100\), and \(p=0.1\), the best price limits under No Information are \([\overline{\pi }_N, \underline{\pi }_N]=[0, 100]\) and \([\overline{\pi }_{N, a}, \underline{\pi }_{N, a}]=[11.11, 100]\), while the best price limits are \([\overline{\pi }_C, \underline{\pi }_C]=[20, 20.89]\); see Appendix 1 for formulas of \(\underline{\pi }_N\), \(\underline{\pi }_{N, a}\), \(\overline{\pi }_N\), and \(\overline{\pi }_{N, a}\). This suggests the high potential benefit of further preference information.
5 Incomplete Information
5.1 Almost stochastic dominance
We briefly recap those parts from Leshno and Levy (2002) and Tsetlin et al. (2015) that are relevant for our analysis.
Let F and G denote the cdfs with joint support \([\underline{x}, \overline{x}]\) that represent the two risky prospects to choose from. v (F, G) measures the violation of FSD of F over G as the area between F and G for which the FSD condition is violated relative to the total area enclosed between F and G. With \(V \equiv \{x \!\in \! [\underline{x}, \overline{x}] : F(x) \!>\! G(x)\}\) as the outcomes for which the FSD condition is violated, we thus have
provided \(F\not =G\); for \(F=G\), we set \(v(F, G)=0\). The set of considered utility functions is defined as
for \(\epsilon \in [0, 0.5]\). The higher the parameter \(\epsilon \), the more sufficiently curved and thus risk-sensitive utility functions are excluded from consideration, and eventually only linear utility functions remain.
The following AFSD result stems from Leshno and Levy (2002, Theorem 1).
AFSD
F dominates G by \(\epsilon \)-AFSD, i.e., \(v(F, G) \le \epsilon \), if and only if F is preferred over G for all utility functions in \(U(\epsilon )\), i.e., \({{\,\mathrm{E}\,}}_F(u) \ge {{\,\mathrm{E}\,}}_G(u)\) for all u in \(U(\epsilon )\).
The corresponding result under risk aversion is due to Tsetlin et al (2015, Theorem 2). It is based on the violation measure defined as
for \(F\not =G\) and \(v_a(F, G)\equiv 0\) for \(F=G\). The numerator of the violation measure is the maximum violation of the SSD condition. The structure of \(v_a\) resembles that of v which can be restated as \(\left (\int _{V} [F(x)\!-\!G(x)] {\text{d}}x\right )/\left (2 \int _{V} [F(x)\!-\!G(x)] {\text{d}}x + {{\,\mathrm{E}\,}}_F \!-\! {{\,\mathrm{E}\,}}_G\right )\). The restriction to risk-averse utility functions is accomplished by focusing on the concave utility functions in \(U(\epsilon )\), i.e., \(U_a(\epsilon ) \equiv U(\epsilon ) \cap U_a\).
ASSD
F dominates G by \(\epsilon \)-ASSD, i.e., \({{\,\mathrm{E}\,}}_F \ge {{\,\mathrm{E}\,}}_G\) and \(v_a(F, G) \le \epsilon \), if and only if F is preferred over G for all utility functions in \(U_a(\epsilon )\), i.e., \({{\,\mathrm{E}\,}}_F(u) \ge {{\,\mathrm{E}\,}}_G(u)\) for all u in \(U_a(\epsilon )\).
In terms of generalized almost stochastic dominance (GASSD) as proposed by Tsetlin et al. (2015), \(\epsilon \)-ASSD is a shorthand for \((\epsilon _1, \epsilon _2)\)-GASSD with \(\epsilon _1=\epsilon \) and \(\epsilon _2=0\). \(\epsilon _2=0\) means that there is no restriction on the second derivative of the utility functions, so the same preference information about marginal utility is used for both AFSD and ASSD.
\(\epsilon \)-AFSD is a generalization of FSD because both concepts coincide for \(\epsilon =0\); the same holds for \(\epsilon \)-ASSD and SSD. Finally, \(\epsilon \)-ASSD is implied by \(\epsilon \)-AFSD (hierarchy property) as \(U_a(\epsilon ) \subseteq U(\epsilon )\). For the violation measures, this means \(v_a(F, G) \le v(F, G)\).
5.2 Largest allowed violation
The price limits under Incomplete Information are based on AFSD and ASSD, so the sets of considered utility functions are \(U(\epsilon )\) and \(U_a(\epsilon )\). We thus have to specify parameter \(\epsilon \) in accordance with the set of relevant utility functions, D. As both sets refer to the same condition on marginal utilities, see (3), \(\epsilon \) must satisfy \(D \subseteq U(\epsilon )\); otherwise, ASD risks to produce results that do not comply with all relevant utility functions. This calls for sufficiently small values of \(\epsilon \). We thus might set \(\epsilon \) to zero. But this would not improve the price limits upon No Information, because ASD then coincides with SD. Hence, \(\epsilon >0\) is needed. In fact, the higher the value of \(\epsilon \), the more utility functions are excluded from consideration and the narrower the price limits become. Consequently, we search for the highest value of \(\epsilon \) such that \(D \subseteq U(\epsilon )\). This particular value of \(\epsilon \) is denoted by \(\epsilon _D\).
It can be determined in two steps. First, concentrate on a given relevant utility function u and define
which can be restated as \(\epsilon _u = \rho /(1\!+\!\rho )\) with \(\rho \equiv \inf _{x \in [\underline{x}, \overline{x}]} \{u^{\prime}(x)\}/\sup _{x \in [\underline{x}, \overline{x}]} \{u^{\prime}(x)\}\). Second, take the lowest of the \(\epsilon _u\) values among D:
Parameter \(\epsilon _u\) can be interpreted as the largest allowed violation of FSD such that the preference for F over G follows from AFSD for utility function u. That is, \(\epsilon _u\) is the maximal value of \(\epsilon \) such that \(v(F, G) \le \epsilon \) \(\Leftrightarrow {{\,\mathrm{E}\,}}_F(\tilde{u}) \ge {{\,\mathrm{E}\,}}_G(\tilde{u})\) for all \(\tilde{u} \in U(\epsilon )\) \(\Rightarrow {{\,\mathrm{E}\,}}_F(u) \ge {{\,\mathrm{E}\,}}_G(u)\). This does not mean that F is never preferred over G for u if the actual FSD violation is higher than \(\epsilon _u\), i.e., \(v(F, G) > \epsilon _u\), but that we know by AFSD that it is preferred if the violation is lower. Since an analogous interpretation holds under risk aversion, we refer to \(\epsilon _u\) as the largest violation of SD allowed for utility function u.
Parameter \(\epsilon _D\) can be interpreted in like manner: it is the largest allowed violation of SD such that the preference for F over G follows from ASD for all relevant utility functions. We thus speak of \(\epsilon _D\) as the largest violation of SD allowed for the DM or, briefly, as the largest allowed violation.
The knowledge of \(\epsilon _D\) allows us to reduce the set of considered utility functions from U to \(U(\epsilon _D)\) and from \(U_a\) to \(U_a(\epsilon _D)\). Provided \(\epsilon _D>0\), we thus have more information about the relevant utility functions than under No Information. For \(\epsilon _D < 0.5\), in turn, we have less information than under Complete Information, because the set of considered utility functions, \(U(\epsilon _D)\) or \(U_a(\epsilon _D)\), is larger than the set of relevant utility functions, D. Parameter \(\epsilon _D\) thus carries incomplete information about the relevant risk preferences.
5.3 Scenarios
The information scenario, where the largest allowed violation \(\epsilon _D\) is known, is denoted by Incomplete Information I1. The analysis of this scenario is to be found in Sect. 5.4.
A closer look at the definitions of \(\epsilon _u\) and \(\epsilon _D\) in (4) and (5) reveals their dependence on the joint support \([\underline{x}, \overline{x}]\). The joint support, in turn, varies with the price \(\pi \) when it comes to the decision between the contract \(F_\pi \) and the status quo S, meaning that both \(\epsilon _u\) and \(\epsilon _D\) are functions of the price \(\pi \). This can also be seen from the joint support in the example case given in (2). In general, the varying support, combined with the curvatures of the utility functions, produce various functional forms of \(\epsilon _u\) and a piecewise definition of \(\epsilon _D\); they do not even need to be continuous.
The elicitation of \(\epsilon _D\) from the DM may prove costly due to the varying joint support. Two measures reduce these costs. First, it is futile to assess \(\epsilon _D\) for prices that are already covered by the No Information scenario. This is why we concentrate on the price ranges \([\overline{\pi }_N, \underline{\pi }_N]\) and \([\overline{\pi }_{N, a}, \underline{\pi }_{N, a}]\) for all Incomplete Information scenarios. Second, it is possible to reduce the accuracy of the assessment by using a lower bound of the largest allowed violation \(\epsilon _D\) over the considered price range. This is done to arrive at the Incomplete Information I2 scenario. See Sect. 5.5 for the analysis and further discussion of this scenario.
In Appendix 2, we elaborate on how to elicit the largest allowed violation from the DM. The actual application of these approaches goes beyond the scope of our paper.
5.4 Incomplete Information I 1
Here, we assume that the information available about the relevant risk preferences D is \(\epsilon _D\) as a function of the price \(\pi \) over the range \([\overline{\pi }_{N}, \underline{\pi }_{N}]\); under risk aversion, the range reduces to \([\overline{\pi }_{{N,a}} ,\underline{\pi } _{{N,a}} ]\).
Proposition 1
The price \( \underline{\pi } _{{{I}_{1} }} \equiv \inf \left\{ {\pi \in \left[ {\pi _{n} ,\underline{\pi } _{N} } \right]:v(F_{\pi } ,S) \le \epsilon_{D} (\pi )} \right\} \) is a lower price limit, and \(\overline{\pi }_{{{I}_{1} }} \equiv \sup \left\{ {\pi \in \left[ {\overline{\pi }_{N} ,\pi _{n} } \right]:v(S,F_{\pi } ) \le \epsilon_{D} (\pi )} \right\}\) is an upper price limit. The corresponding price limits under risk aversion are \(\overline{\pi }_{{{I}_{1} ,a}} \equiv \inf \big\{ {\pi \in \left[ {\pi _{n} ,\overline{\pi }_{{N,a}} } \right]:v_{a} (F_{\pi } ,S) \le \epsilon_{D} (\pi )} \big\}\) and \(\overline{\pi }_{{{I}_{1} ,a}} \equiv \sup \big\{ {\pi \in \left[ {\overline{\pi }_{{N,a}} ,\pi _{n} } \right]:v_{a} (S,F_{\pi } ) \le \epsilon_{D} (\pi )} \big\}\).
The proposition seems evident: the price limits result from the lowest and the highest price such that the actual violation is allowed for all relevant utility functions. These limits lie between those under No Information, i.e., \(\underline{\pi }_{N}\) and \(\overline{\pi }_{N}\), and that under risk neutrality, i.e., \(\pi_{n}\). But, there is a caveat. In general, the violations v and \(v_{a}\) on the one hand and the largest allowed violation \(\epsilon_{D}(\pi )\) on the other may intersect more than once. Suppose, for instance, that \(v(F_{\pi } ,S)\) and \(\epsilon_{D}(\pi )\) intersect at prices \(\pi_{1}\), \(\pi_{2}\), and \(\pi_{3}\) with \(\pi _{1} < \pi _{2} < \pi _{3}\) and \(v(F_{\pi } ,S) > \epsilon_{D} (\pi )\) for \(\pi < \pi _{1}\). The violation thus does not exceed the largest allowed level, \(v(F_{\pi } ,S) \le \epsilon_{D} (\pi )\), for prices \(\pi \in [\pi _{1} ,\pi _{2} ]\) and \( \pi \ge \pi _{3} \); but it does so for \(\pi < \pi _{1}\) and \(\pi \in (\pi _{2} ,\pi _{3} )\). Nevertheless, Proposition 1 tells us to take \(\pi_{1}\) rather than \(\pi_{3}\) as a lower price limit.
This puzzle can be explained as follows. For \(\pi = \pi _{1}\), we know that the violation \(v(F_{\pi } ,S)\) is allowed by all utility functions in \(U(\epsilon_{D}(\pi ))\) and thereby by all relevant utility functions because D is always a subset of \(U(\epsilon_{D}(\pi ))\). Hence, it is safe to enter the contract for \( \pi = \pi _{1} \). Since higher prices are preferred over lower ones, see assumption (1), a higher price is even more favorable. Consequently, the excessive violations for \(\pi \in (\pi _{2} ,\pi _{3} )\) are irrelevant. Put differently, from \(v(F_{\pi^{\prime}}, S) > \epsilon_{D}(\pi^{\prime})\) for some \(\pi ^{\prime } \in (\pi _{2} ,\pi _{3} )\), we conclude that there might be utility functions in \(U(\epsilon_{D}(\pi^{\prime}))\) that do no support the choice of the contract. However, by \(v(F_\pi , S)=\epsilon_{D}(\pi )\) for \(\pi = \pi _{1}\) and the fact that higher prices are preferred over lower ones, we know that none of these utility functions are found in \(U(\epsilon_{D}(\pi _1))\) and thus in D.
It should be noted that the price limits in Proposition 1 are not the best conceivable given the information carried by the entire function \(\epsilon_{D}\), because AFSD only uses the information carried by a single point of \(\epsilon_{D}\). We elaborate on this point in Appendix 3.
5.5 Incomplete Information I 2
For this information scenario, we assume that only lower bounds on the largest allowed violation \(\epsilon_{D}(\pi )\) over the price ranges \([\overline{\pi }_{N}, \underline{\pi }_{N}]\) and \([\overline{\pi }_{N, a}, \underline{\pi }_{N, a}]\) are known.
Proposition 2
The price \(\underline{\pi }_{{{I}_{2} }} \equiv \inf \left\{ \pi \in \left[ \pi _n, \underline{\pi }_N\right] : v(F_\pi , S) \le \underline{\epsilon }_D \right\} \) is a lower price limit, and \(\overline{\pi }_{{{I}_{2} }} \equiv \sup \left\{ \pi \in \left[ \overline{\pi }_N, \pi _n\right] : v(S, F_\pi ) \le \underline{\epsilon }_D \right\} \) is an upper price limit. The corresponding price limits under risk aversion are \(\underline{\pi }_{{{I}_{2} ,a}} \equiv \inf \left\{ \pi \in \left[ \pi _n, \underline{\pi }_{N, a}\right] : v_a(F_\pi , S) \le \underline{\epsilon }_{D, a} \right\} \) and \(\overline{\pi }_{{{I}_{2} ,a}} \equiv \sup \left\{ \pi \in \left[ \overline{\pi }_{N, a}, \pi _n\right] : v_a(S, F_\pi ) \le \underline{\epsilon }_{D, a} \right\} \) . The constants \(\underline{\epsilon }_D\) and \(\underline{\epsilon }_{D, a}\) are lower bounds on \(\epsilon _D(\pi )\) over \([\overline{\pi }_{N}, \underline{\pi }_{N}]\) and \([\overline{\pi }_{{N,a}} ,\underline{\pi } _{{N,a}} ]\) , respectively.
This proposition follows from Proposition 1 because the analysis of Incomplete Information I1 does not impose restrictions on the form of \(\epsilon_{D}\). In particular, \(\epsilon_{D}\) might be constant. Consequently, we may substitute \(\epsilon_{D}(\pi )\) in Proposition 1 for any nonnegative constant not exceeding \(\epsilon_{D}(\pi )\) for any price \(\pi\) from \([\overline{\pi }_{N}, \underline{\pi }_{N}]\) and \([\overline{\pi }_{{N,a}} ,\underline{\pi } _{{N,a}} ]\), respectively, to arrive at price limits under Incomplete Information I2. Moreover, analogous to Proposition 1 under Incomplete Information I1, Proposition 2 does not give the best conceivable price limits under Incomplete Information I2. See again Appendix 3 for more details.
For a motivation of this information scenario, realize that \(\underline{\epsilon }_{D}\) and \(\underline{\epsilon }_{{D,a}}\) do not react to the price \(\pi\). They are therefore easier to assess than the function \(\epsilon_{D}(\pi )\). They are also easier to communicate in a setting where the determination of the price limits is delegated. Choosing values of \(\underline{\epsilon }_{D}\) and \(\underline{\epsilon }_{{D,a}}\) that apply to several different contracts leads to a further simplification. One might even want to do without a preference assessment and rely on experimental evidence from the literature. Following Levy et al. (2010, Table 7), this would lead to values of \(\underline{\epsilon }_{D}\) and \(\underline{\epsilon }_{{D,a}}\) between 0.03 and 0.27. To our minds, this information scenario is the most relevant one for business practice.
To be more explicit, remember that the price limits under Incomplete Information I1 are based on the largest allowed violation \(\epsilon_{D}(\pi )\). The dependency on the price \(\pi\) implies that \(\epsilon_{D}(\pi )\) has to be assessed according to (5) for a whole set of prices, namely for \([\overline{\pi }_{N}, \underline{\pi }_{N}]\) and \([\overline{\pi }_{{N, a}}, \underline{\pi }_{{N, a}}]\), respectively. As different prices bring about different joint supports \([\underline{x}, \overline{x}]\), the assessment of \(\epsilon_{D}(\pi )\) may prove to be a tedious task, although it refers only to marginal utilities.
By contrast, a lower bound on \(\epsilon_{D}(\pi )\) is easily found by determining the largest allowed violation for a single profit range, rather than for a set of ranges, provided this range covers all joint supports resulting from varying the price between the No Information price limits. This means that the support used to evaluate \(\epsilon_{D}\) according to (5) is not a specific joint support \([\underline{x}, \overline{x}]\), but a (convex) superset of all considered joint supports, i.e., a superset of \(\cup _{\pi \in [\overline{\pi }_{N}, \underline{\pi }_{N}]} [\underline{x}, \overline{x}]\) or \(\cup _{\pi \in [\overline{\pi }_{{N, a}}, \underline{\pi }_{{N, a}}]} [\underline{x}, \overline{x}]\), respectively.
This approach exploits the following result which is driven by the fact that the supremum (infimum) of a function increases (decreases) in reaction to an extension of the considered range.
Lemma 3
Let \([\underline{X}, \overline{X}]\) be a superset of the joint support of contract \(F_{\pi}\) and status quo S, i.e., \([\underline{X}, \overline{X}] \supseteq [\underline{x}, \overline{x}]\). Then, \(\inf \{ 1/(1 + \rho ):u \in D\}\) with \(\rho \equiv \sup _{x \in [\underline{X}, \overline{X}]} \{u^{\prime}(x)\} \big / \inf _{x \in [\underline{X}, \overline{X}]} \{u^{\prime}(x)\}\) is a lower bound on \(\epsilon_{D}(\pi )\) over the considered range of prices \(\pi \).
Hence, if we take a profit range \([\underline{X} ,\overline{X}]\) covering \(\cup _{{\pi \in [\overline{\pi }_{N} ,\underline{\pi } _{N} ]}} [\underline{x} ,\overline{x}]\), the \(\epsilon\) value given in Lemma 3 forms a lower bound on \(\epsilon_{D}(\pi )\) over the price range \([\overline{\pi }_{N} ,\underline{\pi } _{N} ]\). Analogously, \([\underline{X}, \overline{X}] \supseteq \bigcup _{\pi \in [\overline{\pi }_{N, a}, \underline{\pi }_{N, a}]} [\underline{x}, \overline{x}]\) leads to a lower bound on \(\epsilon_{D}(\pi )\) over the price range \([\overline{\pi }_{{N,a}} ,\underline{\pi } _{{N,a}} ]\).
Take the example case with \(c = m = 100\) and \(p = 0.1\) as an illustration. The best price limits under No Information without risk aversion are \(\overline{\pi }_{N} = 0\) and \(\underline{\pi }_{N} = 100\), so the range of considered prices is [0, 100]. Each price from this range translates into a joint support according to (2). For \(\pi = 0\), for example, the joint support covers profits from \(\underline{x} = - 100\) to \(\overline{x}=100\), and the corresponding profit range for \(\pi =100\) is [0, 100]. The smallest superset of all such profit ranges is \([-100, 100] = \bigcup _{\pi \in [\overline{\pi }_N, \underline{\pi }_N]} [\underline{x}, \overline{x}]\) where \(-100=\underline{x}|_{\pi =\overline{\pi }_{N}}\) and \(100=\overline{x}|_{\pi =\underline{\pi }_{N}}\). It covers all joint supports considered for \(c = m = 100\) and \(p = 0.1\). For \(r = 258\), the largest allowed violation for this profit range is 0.238, which results from evaluating (5) for the profit range \([ - 100,100]\). \(\underline{\epsilon }_{D}=0.238\) is thus a lower bound on \(\epsilon_{D}(\pi )\) over [0, 100]. Accordingly, neither \(\epsilon_{D}(0)=0.238\) nor \(\epsilon_{D}(100)=0.362\) falls short of this bound.
6 Performance
6.1 Information about largest allowed violation
The information about the largest allowed violation becomes better across the scenarios starting from No Information via Incomplete Information I2 to Incomplete Information I1. It also improves in higher values of \(\underline{\epsilon }_D\) and \(\underline{\epsilon }_{D, a}\) used for Incomplete Information I2. As can be concluded from the definitions, this is reflected by improvements of the respective price limits.
Lemma 4
The better the information about the largest violation of stochastic dominance allowed for the relevant utility functions, the better are the price limits:
-
1.
the lower price limits \(\underline{\pi }_{{{I}_{2} }}\) and \(\underline{\pi }_{{{I}_{2} ,a}}\) decrease and the upper price limits \(\overline{\pi }_{{{I}_{2} }}\) and \(\overline{\pi }_{{{I}_{2} ,a}}\) increase in the levels of \(\underline{\epsilon }_D\) and \(\underline{\epsilon }_{D, a}\) , respectively;
-
2.
the price limits satisfy \(\overline{\pi }_N \le \overline{\pi }_{{{I}_{2} }} \le \overline{\pi }_{{{I}_{1} }} \le \overline{\pi }_C \le \underline{\pi }_C \le \underline{\pi }_{{{I}_{1} }} \le \underline{\pi }_{{{I}_{2} }} \le \underline{\pi }_N\) and \(\overline{\pi }_{N, a} \le \overline{\pi }_{{{I}_{2} ,a}} \le \overline{\pi }_{{{I}_{1} ,a}} \le \overline{\pi }_C \le \underline{\pi }_C \le \underline{\pi }_{{{I}_{1} ,a}} \le \underline{\pi }_{{{I}_{2} ,a}} \le \underline{\pi }_{N, a}\).
The first part of the lemma is driven by the monotonicity of the violations \(v(F_\pi , S)\), \(v(S, F_\pi )\), \(v_a(F_\pi , S)\), and \(v_a(S, F_\pi )\) in the price \(\pi \), which results from assumption (1). To illustrate this part of the lemma, refer to the example case under Incomplete Information I2. There, the price limits \(\underline{\pi }_{{{I}_{2} }}\) and \(\overline{\pi }_{{{I}_{2} }}\) can be stated as \(\underline{\pi }_N \!-\! 2 ( \underline{\pi }_N \!-\! \pi _n ) \underline{\epsilon }_D\) and \(\overline{\pi }_N \!+\! 2 ( \pi _n\!-\! \overline{\pi }_N ) \underline{\epsilon }_D\), respectively, provided that probability p equals 0.5. The price limits clearly improve, i.e., the range between them decreases, as \(\underline{\epsilon }_D\) increases. The idea is that the better \(\underline{\epsilon }_D\) approximates \(\epsilon _D(\pi )\), i.e., the higher \(\underline{\epsilon }_D\), the smaller is the set of utility functions considered under AFSD for which the price limits hold. The idea of shrinking the set of considered utility functions to better approximate the relevant utility functions equally applies to the second part of the lemma.
6.2 Performance under risk aversion
In light of these intuitive relations, we are interested by how much the price limits improve under Incomplete Information. To make the analysis more accessible, we refer to the numerical example given in Table 3 which is based on the example case as presented in Sects. 3.2 and 3.7. The r values represent increasing degrees of risk sensitivity, and the values of the margin m are chosen such that they vary around the costs \(c=100\). The numerical example refers to the situation where it is known that the DM is risk averse, because we use the same example in Sect. 6.3 to analyze the effect of this information on the performance of the price limits. See Appendix 4 for a corresponding numerical example without risk aversion.
For Version 1 of Incomplete Information I2, we proceed as described in Sect. 5.5 when determining the level of the allowed violation, \(\underline{\epsilon }_{D, a}\), by eliminating the effect of the price, while \(\underline{\epsilon }_{D, a}\) still depends on m and p. The \(\underline{\epsilon }_{D, a}\) values are thus driven by both the DM’s preferences and the decision problem, i.e., by the risk sensitivity r as well as by m and p. Version 2 goes one step further and eliminates the influence of m and p in addition to that of the price \(\pi \). This is done by extending the considered profit range to \([-99, 200]\), so the same value of \(\underline{\epsilon }_{D, a}\) can be used for all decision problems satisfying \(c=100\), \(m \in [0, 200]\), and \(p \in [0.01, 0.5]\) and thus for all problems included in Table 3.Footnote 5 As a consequence, the differences in the \(\underline{\epsilon }_{D, a}\) values given for Version 2 are not driven by the decision problem anymore, but only by the DM’s risk sensitivity. The specific values of r are chosen such that the \(\underline{\epsilon }_{D, a}\) values under Version 2 of Incomplete Information I2 match with Levy et al (2010, Table 7).Footnote 6
Here, we focus on the \(\Pi \) columns, while the \(\Gamma \) columns are discussed in Sect. 6.3. \(\Pi _C\), \(\Pi _{{{I}_{1} ,a}}\), and \(\Pi _{{{I}_{2} ,a}}\) give the reduction of the range enclosed by the upper and the lower price limit relative to No Information without the information of risk aversion, i.e., \(\Pi _C \equiv 1 \!-\! \frac{\underline{\pi }_C - \overline{\pi }_C}{\underline{\pi }_N - \overline{\pi }_N}\), \(\Pi _{{{I}_{1} ,a}} \equiv 1 - \frac{{\underline{\pi } _{{{I}_{1} ,a}} - \overline{\pi }_{{{I}_{1} ,a}} }}{{\underline{\pi } _{N} - \overline{\pi }_{N} }}\), and \( \Pi _{{{I}_{2} ,a}} \equiv 1 - \frac{{\underline{\pi } _{{{I}_{2} ,a}} - \overline{\pi }_{{{I}_{2} ,a}} }}{{\underline{\pi } _{N} - \overline{\pi }_{N} }} \). This performance measure is not defined if the best price limits under No Information are the same. This happens when \(c = m\) in conjunction with \(p = 0.5\), so this setting is omitted.
In addition to a confirmation of Lemma 4, we make the following observations from Table 3.
Observation 1
Incomplete preference information can lead to substantial improvements of the price limits.
For the intermediate risk sensitivity, i.e., \(r = 258\), the price limits are narrowed on average by at least 76%, which makes up for more than 79% of the maximum performance given by the performance under Complete Information. Overall, the improvements vary between 59.2 and 99.6% for Incomplete Information I1 and between 30.9 and 99.1% for Incomplete Information I2.
Observation 2
The weaker the DM’s risk sensitivity, the higher the performance of the price limits under Incomplete Information.
To make this observation, fix the values of m and p, concentrate on one of the Incomplete Information scenarios, and then decrease the value of r from 519 via 258 to 147. For example, under Incomplete Information \(I_{2}\) (Version 2) with \(m = 100\) and \(p = 0.1\), this yields performances of 30.9, 67.6, and 83.2%.
For an explanation, realize that a weaker risk sensitivity means less pronounced curvatures of the risk-averse utility function \(u_{2}\) and thereby a higher level of the largest allowed violation \(\epsilon_{D} (\pi )\) and of its approximation \(\underline{\epsilon}_{{D,a}} \). The violations \(v_{a} (F_{\pi } ,S)\) and \(v_{a} (S,F_{\pi } )\), in turn, are monotonic functions of the price \(\pi\): the first violation decreases with \(\pi\), while the latter increases. Therefore, the increases in \(\epsilon_{D} (\pi )\) and \(\underline{\epsilon}_{{D,a}} \) translate into tighter and thus better performing price limits.
From the table, the increasing effect of decreasing the risk sensitivity on the largest allowed violation can be observed only for \(\underline{\epsilon}_{{D,a}} \) because the function \(\epsilon_{D} (\pi )\) is not shown. To see the effect for \(\epsilon_{D} (\pi )\), we first observe that the largest allowed violation for the relevant utility functions \(D = \{ u_{1} ,u_{2} \}\) is driven by utility function \(u_{2}\), i.e., \(\epsilon_{D} (\pi ) = \epsilon_{{u_{2} }}\), since \(u_{1}\) reflects risk neutrality which implies \(\epsilon_{{u_{1} }} = 0.5\). For \(u_{2}\), the largest allowed violation according to (4) is \(\epsilon_{{u_{2} }} = \rho /(1 + \rho)\) with \(\rho = u_{2}^{\prime } (\overline{x})/u_{2}^{\prime } (\underline{x} )\) as the ratio of the smallest to the largest slope of the utility function over the support \([\underline{x} ,\overline{x}]\). Decreasing the risk sensitivity r makes the positive slope ratio \(\rho\) increase, so that the largest allowed violation \(\epsilon_{{u_{2} }}\) also increases. For \(\underline{x} < 0 < \overline{x}\), for example, \(\rho\) amounts to \( \exp [r \cdot (23\underline{x} - 22\overline{x}) \cdot 10^{{ - 6}} ] \), and its derivative with respect to r, i.e., \(\rho \cdot (23\underline{x} - 22\overline{x}) \cdot 10^{{ - 6}}\), is negative.
Observation 2 can be generalized in two ways.
Lemma 5
Observation 2 applies to any decision problem. It also holds if the relevant utility functions D comprise at least one exponential utility function of the form \(c_{1} - c_{1} \exp ( - c_{2} rx) + c_{3}\) if \(x \le x_{0}\) and \(c_{2} - c_{2} \exp ( - c_{1} rx) + c_{3}\) otherwise with \(c_{1} ,c_{2} ,r > 0\) and at least one of the risk sensitivity parameters r is reduced.
The first part of the lemma means that Observation 2 does not depend on the specific choices \(F_{\pi }\) and S. This is due to assumption (1) which implies that the violation measures are monotonic in the price. The second part generalizes the form and number of exponential utility functions. With respect to the form, the direction of the effect of the risk sensitivity on the largest allowed violation described above for the specific utility function \(u_{2}\) is the same for any utility function of the same type. For \(\underline{x} < x_{0} < \overline{x} \), for example, \(\rho\) amounts to \(\exp [r \cdot (c_{2} \underline{x} - c_{1} \overline{x})] \) and its derivative with respect to r to \(\rho \cdot (c_{2} \underline{x} - c_{1} \overline{x}), \) which is still negative. With respect to the number of exponential utility functions, we realize that increasing the allowed violation for any relevant utility function, i.e., increasing \(\epsilon_{u}\) according to (4), increases the allowed violation for all relevant utility functions, i.e., increases \(\epsilon_{D}\) according to (5).
Observation 3
The weaker the DM’s risk sensitivity, the better is the performance of the price limits under Incomplete Information I2 compared to Incomplete Information I1.
Take \(m = 100\) and \( p = 0.1 \) as an example. For high risk sensitivity, i.e., \(r = 519\), performance drops by 9.3 percentage points when switching from Incomplete Information I1 to Incomplete Information I2 (Version 1). The corresponding performance loss for \(r = 258\) is smaller, namely 2.0 points, and that for \(r = 147\) only amounts to 0.7 points. The performance losses when switching from Incomplete Information I1 to Incomplete Information I2 (Version 2) show the same pattern.
The observation is driven by the dependence of the largest allowed violation on the price: the weaker the risk sensitivity, the less does \(\epsilon_{D} (\pi )\) react to changes in \(\pi\) and the better does its approximation in the form of the constant \(\underline{\epsilon}_{{D,a}}\) become.
However, the diminishing distance between \(\epsilon_{D} (\pi ) \) and \(\underline{\epsilon}_{{D,a}}\) is not the only effect to take into account. From the explanation of the previous observation, we know that weaker risk sensitivity also means that the largest allowed violation rises. In view of Propositions 1 and 2, this means that the section of the violation measure that becomes relevant for determining the price limit shifts. If this new section of the violation measure exhibits a lower slope, the shift causes the price limits to diverge and thereby counteracts the converging effect of the converging largest allowed violations. Therefore, Observation 3 does not hold in general.
Observation 4
The effect of incomplete preference information on the price limits may differ substantially in magnitude between the lower and the upper price limit.
The performance measures only give the aggregate effect from both price limits. That is why Observation 4 cannot readily be made from Table 3. For \(m=0\), this problem can be overcome by first referring to the best upper price limit under No Information which equals the indifference price under risk neutrality, i.e., \(\overline{\pi }_{N, a} = \pi _n\); see (6) in Appendix 1. This means that the upper price limit is unaffected by the information about the largest allowed violation. Hence, all performance figures given in Table 3 for \(m=0\) are solely driven by improvements of the lower price limit rather than the upper price limit.
6.3 Performance gain from the information of risk aversion
Finally, we look at the performance gain from the additional information that the DM is risk averse. Due to this information it is valid to use the price limits \(\underline{\pi }_{X, a}\) and \(\overline{\pi }_{X, a}\) with \( X \in \{ N,{I}_{1} ,{I}_{2} \}\) instead of \(\underline{\pi }_X\) and \(\overline{\pi }_X\) with \( X \in \{ N,{I}_{1} ,{I}_{2} \}\). At the same time, this describes the switch from FSD and AFSD to SSD and ASSD.
The types of information carried by the largest allowed violation on the one hand and risk aversion on the other are different. This section helps to disentangle and quantify the effects of both types of information on the performance of the price limits. It raises the awareness for the different kinds and effects of preference information and provides implications for the elicitation of the DM’s preferences. For instance, it suggests testing for risk aversion when the information on the largest allowed violation is weak.
The following result confirms the idea of Lemma 4 that more preference information leads to better price limits. Here, it is the information that the DM is risk averse. The lemma is driven by the hierarchy between AFSD and ASSD.
Lemma 6
The price limits improve with the additional information that the DM is risk averse: the price limits satisfy \(\overline{\pi }_X \le \overline{\pi }_{X, a} \le \underline{\pi }_{X, a} \le \underline{\pi }_{X}\) for all \( X \in \{ N,{I}_{1} ,{I}_{2} \}\).
In Table 3, the corresponding performance gain is measured by \(\Gamma _X \equiv \frac{\Pi _{X, a} - \Pi _X}{\Pi _{X, a}}\) with \(X \in \{{I}_{1} ,{I}_{2} \}\). The performance \(\Pi _X\) is the counterpart of \(\Pi _{X, a}\) and thus gives the reduction of the range enclosed by the upper and the lower price limit relative to No Information without the restriction to risk aversion, i.e., \(\Pi _X \equiv 1 \!-\! \frac{\underline{\pi }_X - \overline{\pi }_X}{\underline{\pi }_N - \overline{\pi }_N}\) with \( X \in \{{I}_{1} ,{I}_{2} \}\). That is, \(\Gamma _X \!\cdot \! 100\)% (not percentage points) of the \(\Pi _{{{I}_{1} ,a}}\) and \(\Pi _{{{I}_{2} ,a}}\) performances are due to the information of risk aversion. For \(r=258\), \(m=100\), and \(p=0.1\), for instance, 22.4% of the performance of 81% under Incomplete Information I2 (Version 1) go back to switching from AFSD to ASSD.
Observation 5
Under Incomplete Information, the performance gained from the additional information of risk aversion may exceed the initial performance without that information.
This observation can be made from \(\Gamma _{{{I}_{1} }}\) and \(\Gamma _{{{I}_{2} }}\) values exceeding 50%, which is equivalent to \(\Pi _{X, a} \!-\! \Pi _X > \Pi _X\) for \(X \in \{{I}_{1} ,{I}_{2} \}\). We also observe that the weaker the information about the largest violation, the more likely it is. This is addressed by the following observation.
Observation 6
The higher the DM’s risk sensitivity and the weaker the information about the largest violation of stochastic dominance allowed for the relevant utility functions, the higher is the performance gained from the information of risk aversion.
To observe the effect of the DM’s risk sensitivity, stick to one of the Incomplete Information scenarios and compare the \(\Gamma \) values across the risk sensitivities for given values of m and p. This part of Observation 6 relates to Observation 2: the higher the risk sensitivity, the lower is the largest allowed violation \(\epsilon _D\) and its approximations \(\underline{\epsilon }_D\) and \(\underline{\epsilon }_{D, a}\), and the more important is the other piece of information, namely the information of risk aversion.
The effect of weaker information about the largest allowed violation can be seen from Table 3 by realizing that the \(\Gamma \) values deteriorate when switching from Incomplete Information I2 (Version 2) via Incomplete Information I2 (Version 1) to Incomplete Information I1. However, this effect does not always occur.
The common intuition behind both parts of Observation 6 is that the two pieces of which the incomplete preference information consists, namely the information about the largest allowed violation and the information about risk aversion, are substitutes in terms of their effect on the price limits’ performance.
7 Conclusion
The purpose of our research is to exploit preference information to improve the price limits’ screening power. The approach where the information is carried by a single number seems particularly promising for business practice due to its simplicity and effectiveness.
However, the relevance of our research depends on the considered market: the higher the pricing pressure, the more relevant are our results. That is, markets with low profit margins call for tight price limits. Otherwise, it is likely that contracts cannot be decided upon in the screening stage and have to be passed on to the DM for decision, which makes the screening stage obsolete.
A second factor for the relevance of exploiting preference information is the size of the considered contracts. Small contracts, i.e., those associated with low revenues and costs, lead to price limits under no preference information that only include a narrow range of prices. In this case, price limits based on expected values serve as good approximations of the price limits derived from incomplete or even complete preference information. However, the larger the considered contracts, the worse does this approximation become. Summing up, our research is most beneficial when pricing pressure is high and contracts are large.
Notes
We take rounded values of the mean Arrow–Pratt measures \(c_l\) and \(c_g\) given in Table 3 to calibrate the relation between the loss domain and the gain domain. The remaining parameters are chosen such that the utility function is continuously differentiable.
Numerical results are rounded where appropriate.
Cdf F dominates G by SSD if and only if \(\int _{-\infty }^x [F(t)\!-\!G(t)]{\text{d}}t \le 0\) for all x. SSD is equivalent to the fact that F is preferred over G for any (nondecreasing) concave utility function, i.e., \({{\,\mathrm{E}\,}}_F(u) \ge {{\,\mathrm{E}\,}}_G(u)\) for all \(u \in U_a\) (Hadar and Russel 1969; Hanoch and Levy 1969).
The profit range results from (2) and (6)–(7). The lowest profit is \(-99=\min \{1 \!-\!100, 0\}=\min \{\overline{\pi }_{N, a}\!-\!c,0\}\) since the lowest value of \(\overline{\pi }_{N, a}\) is 1 which obtains for \(m=0\) and \(p = 0.01\). The highest profit is \(200=\max \{150, 200\}=\max \{\underline{\pi }_{N, a}, m\},\) because the highest value of \(\underline{\pi }_{N, a}\) amounting to 150 results from \(p=0.5\) combined with the highest margin \(m=200\).
Accordingly, it can be shown that \(\underline{\pi }_{{{I}_{1} }} \ge \sup \{\pi _u : u \in U_{{{I}_{1} }}\}\) and \(\overline{\pi }_{{{I}_{1} }} \le \inf \{\pi _u : u \in U_{{{I}_{1} }}\}\). The proof is identical to the second part of the proof of Proposition 1; the only modification needed is to substitute \(\underline{\pi }_C\) for \(\sup \{\pi _u : u \in U_{{{I}_{1} }}\}\) and \(\overline{\pi }_C\) for \(\inf \{\pi _u : u \in U_{{{I}_{1} }}\}\).
References
Armbruster, B., and E. Delage. 2015. Decision making under uncertainty when preference information is incomplete. Management Science 61 (1): 111–128.
Arrow, K.J. 1963. Social choice and individual values, 2nd ed. New York: Wiley.
Aumann, R.J. 1962. Utility theory without the completeness axiom. Econometrica 30: 445–462.
Bali, T.G., K.O. Demirtas, H. Levy, and A. Wolf. 2009. Bonds versus stocks: Investors’ age and risk taking. Journal of Monetary Economics 56: 817–830.
Bali, T.G., S.J. Brown, and K.O. Demirtas. 2013. Do hedge funds outperform stocks and bonds? Management Science 59 (8): 1887–1903.
Bhardwaj, P. 2001. Delegating pricing decisions. Marketing Science 20 (2): 143–169.
Constantinides, G.M., and S. Perrakis. 2007. Stochastic dominance bounds on American option prices in markets with frictions. Review of Finance 11 (1): 71–115.
Dubra, J., F. Maccheroni, and E.A. Ok. 2004. Expected utility theory without the completeness axiom. Journal of Economic Theory 115 (1): 118–133.
Farquhar, P.H. 1984. Utility assessment methods. Management Science 30 (11): 1283–1300.
French, S. 1986. Decision theory: An introduction to the mathematics of rationality. New York: Halsted Press.
Göx, R.F., and A. Wagenhofer. 2007. Economic research on management accounting. In Issues in management accounting, 3rd ed, ed. T. Hopper, D. Northcott, and R. Scapens, 399–424. Englewood Cliffs: Prentice-Hall.
Hadar, J., and W.R. Russel. 1969. Rules for ordering uncertain prospects. The American Economic Review 59 (1): 25–34.
Hanoch, G., and H. Levy. 1969. The efficiency analysis of choices involving risk. The Review of Economic Studies 36 (3): 335–346.
Horngren, C.T., S.M. Datar, and M.V. Rajan. 2015. Cost accounting: A managerial emphasis, 15th ed. Boston: Pearson.
Joseph, K. 2001. On the optimality of delegating pricing authority to the sales force. Journal of Marketing 65 (1): 62–70.
Keeney, R.L., and H. Raiffa. 1976. Decisions with Multiple Objectives: Preferences and Value Tradeoffs. Chichester, New York, Brisbane, Toronto, Singapore: John Wiley & Sons.
Küpper, H.U. 2009. Investment-based cost accounting as a fundamental basis of decision-oriented management accounting. Abacus 45 (2): 249–274.
Leshno, M., and H. Levy. 2002. Preferred by “all” and preferred by “most” decision makers: Almost stochastic dominance. Management Science 48 (8): 1074–1085.
Levy, H. 1985. Upper and lower bounds of put and call option value: Stochastic dominance approach. The Journal of Finance 40 (4): 1197–1217.
Levy, H. 1992. Stochastic dominance and expected utility: Survey and analysis. Management Science 38 (4): 555–593.
Levy, H., and M. Leshno. 2000. Decision-making under uncertainty: Stochastic dominance. In The current state of business disciplines, vol. 3, ed. S.B. Dahiya, 1377–1408. Rohtak: Spellbound Publications.
Levy, H., M. Leshno, and B. Leibovitch. 2010. Economically relevant preferences for all observed epsilon. Annals of Operations Research 176: 153–178.
Mas-Colell, A., M.D. Whinston, and J.R. Green. 1995. Microecomic Theory. New York: Oxford University Press.
Myerson, R.B. 1981. Optimal auction design. Mathematics of Operations Research 6 (1): 58–73.
Oliva, R., and R. Kallenberg. 2003. Managing the transition from products to services. International Journal of Service Industry Management 14 (2): 160–172.
Pennings, J.M.E., and A. Smidts. 2003. The shape of utility functions and organizational behavior. Management Science 49 (9): 1251–1263.
Phillips, R., A.S. Simsek, and G. van Ryzin. 2015. The effectiveness of field price discretion: Empirical evidence from auto lending. Management Science 61 (8): 1741–1759.
Reichelstein, S., and A. Rohlfing-Bastian. 2015. Levelized product cost concept and decision relevance. The Accounting Review 90 (4): 1653–1682.
Tsetlin, I., R.L. Winkler, R.J. Huang, and L.Y. Tzeng. 2015. Generalized almost stochastic dominance. Operations Research 63 (2): 363–377.
Tzeng, L.Y., R.J. Huang, and P.T. Shih. 2013. Revisiting almost second-degree stochastic dominance. Management Science 59 (5): 1250–1254.
Vudali, M., and A. Atherton. 2012. Pricing of on-line display advertising. In The Oxford handbook of pricing management, ed. Ö. Özer, and R. Phillips, 121–137. Oxford: Oxford University Press.
Weber, M. 1987. Decision making with incomplete information. European Journal of Operational Research 28 (1): 44–57.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1: Violation measures and price limits in the example case
Under No Information, the best price limits are
and
with \(\pi_n = p \!\cdot\! (c\!+\!m).\)
The AFSD violation measure is given by
with \(\alpha \equiv p \!\cdot \! \bigl [ (c \!-\! \pi )^+ \!+\! (m \!-\! \pi )^+ \bigr ] \!+\! (2p \!-\! 1)^+ \bigl [ \pi \!-\! (\pi \!-\! c)^+ \!-\! (\pi \!-\! m)^+ \bigr ]\) as the area between \(F_\pi \) and S where the FSD condition is violated and \(x^+ \equiv \max \{x, 0\}\). For the reverse relation, we may exploit \(v(S, F_\pi ) = 1 \!-\! v(F_\pi , S)\) unless \(\underline{\pi }_N=\overline{\pi }_N=\pi _n\), in which case the violation measure is \(v(S, F_\pi )=0\) if \(\pi \le \pi _n\) and 1 otherwise.
The ASSD violation measure reads \(v_a(F_\pi , S) = \frac{\alpha - \beta }{2 (\alpha \!-\! \beta ) + {{\,\mathrm{E}\,}}_{F_\pi }-{{\,\mathrm{E}\,}}_S}\) if \(\pi _n \le \pi < \underline{\pi }_{N, a}\) and 0 if \(\underline{\pi }_{N, a} \le \pi \) with
For the reverse relation, we have \(v_a(S, F_\pi ) = 0\) if \(\pi \le \overline{\pi }_{N, a}\) and \(\frac{{\alpha ^{\prime} - \beta ^{\prime}}}{{2(\alpha ^{\prime} - \beta ^{\prime}) + {\mathrm{E}}_{S} - {\mathrm{E}}_{{F_{\pi } }} }}\) if \(\overline{\pi }_{N, a} < \pi \le \pi _n\) with \(\alpha ^{\prime} \equiv \alpha - ({\mathrm{E}}_{S} - {\mathrm{E}}_{{F_{\pi } }} )\) as the area between S and \(F_\pi \) where the FSD condition is violated and
Appendix 2: Elicitation of the largest allowed violation
The first method to elicit the largest allowed violation \(\epsilon _D\) from the DM is to assess the relevant utility functions and to estimate the highest ratio of marginal utilities. It is important that the assessment of utility functions typically results in a set of possible functions. Hence, we are not in the situation of complete preference information even if utility functions are assessed. The second method is to infer \(\epsilon _D\) from observed actual violations allowed by the DM. This is the method used by Levy et al. (2010). A caveat concerning this method is that \(\epsilon _D\) is the largest violation allowed irrespective of the specific prospects under consideration. Hence, many observations have to be taken into account to find a good estimate of the largest violation allowed for all pairs of prospects sharing the same given joint support.
The second method is tied to a specific joint support of profits and therefore is more appropriate for Incomplete Information I2 where, as demonstrated in Sect. 5.5, the lower bound on \(\epsilon _D\) is derived for a constant joint support. By contrast, the first method seems appropriate for the estimation of \(\epsilon _D\) as well as of a lower bound on it, i.e., for both Incomplete Information scenarios, because the same family of utility functions can be used for estimations referring to different joint supports of profits.
Appendix 3: Best price limits under Incomplete Information
In general, the price limits given in Propositions 1 and 2 are not the best limits under Incomplete Information, as they do not fully exploit the available information. To see this for the example of Incomplete Information 1 and AFSD, first realize that, for a given price, the largest violation allowed for any given relevant utility function is not smaller than that allowed for all relevant utility functions, i.e., \(\epsilon _u(\pi ) \ge \epsilon _D(\pi )\) for all \(u \in D\). Hence, we learn that the set of relevant utility functions is a subset of \(U(\epsilon _D(\pi ))\):
Second, this kind of information is available for a whole range of prices, namely \([\overline{\pi }_N, \underline{\pi }_N]\). This allows us to reduce the set of considered utility functions to
The corresponding lower and upper price limits are \(\sup \{\pi _u : u \in U_{{{I}_{1} }}\}\) and \(\inf \{\pi _u : u \in U_{{{I}_{1} }}\}\). We would like to determine them by means of AFSD as we apply FSD to determine the best price limits under No Information. Yet, this is not possible. The reason is that AFSD only uses the information carried by a single point of \(\epsilon _D\), whereas \(U_{{{I}_{1} }}\) is derived from the information carried by all points of which \(\epsilon _D\) consists. Put differently, the price limits given in Proposition 1 correspond to the level of (8), but the price limits corresponding to the level of (9) are better.Footnote 7
Appendix 4: Performance without risk aversion
Here, we provide performance data for the example case described in Sects. 3.2 and 3.7 for a situation where the DM is not risk averse. The lack of risk aversion is reflected by the extension of the set of relevant utility functions to \(D = \{u_1, u_2, u_3, u_4, u_5\}\) with
and
The functional forms and parameter values are again based on Pennings and Smidts (2003).
The extension of the set of relevant utility functions and the switch from SSD and ASSD to FSD and AFSD change the performances given in Table 3 to those in Table 4. Table 4 immediately confirms Lemma 4 and Observations 1–3. Observation 4 also applies as the following example shows. For \(c=m=100\) and \(p=0.1\), the price limits under No Information are \([\overline{\pi }_N, \underline{\pi }_N] = [0, 100]\). They shrink to \([\overline{\pi }_{{{I}_{2} }}, \underline{\pi }_{{{I}_{2} }}] = [0.77, 89]\) for \(\underline{\epsilon }_D=0.03\), to [4.25, 58.48] for \(\underline{\epsilon }_D=0.151\), and to [8.54, 40.1] for \(\underline{\epsilon }_D=0.272\). Hence, the effect of the preference information on the lower price limit is much higher than on the upper price limit.
Appendix 5: Proofs
We present the proofs of Lemmas 1 and 2 and of Proposition 1; the other proofs are integrated into the text or given in the literature. Due to the analogy between FSD and SSD and between AFSD and ASSD, the proofs concentrate on FSD and AFSD where applicable.
Proof of Lemma 1
The “If” part follows from the fact that \(\pi \ge \pi _u\) implies \({{\,\mathrm{E}\,}}_{F_\pi }(u) \ge {{\,\mathrm{E}\,}}_S(u)\). To see the “Only if” part realize that, for any \(\pi <\underline{\pi }_C\), there is a utility function \(u \in D\) such that \(\pi <\pi _u\), which implies \({{\,\mathrm{E}\,}}_{F_{\pi }}(u) < {{\,\mathrm{E}\,}}_S(u)\). Hence, \(\pi \) cannot be a lower price limit, and \(\underline{\pi }_C\) is the smallest lower price limit. The supremum in the definition of \(\underline{\pi }_C\) is necessary, instead of the maximum, because D might not be finite. The proof for the upper price limit is analogous. \(\square \)
Proof of Lemma 2
The sets over which the minimum and the maximum are taken and the second property of the price limits stem from FSD; the minimum and the maximum exist due to the continuity assumption on \(F_\pi (x)\). The first property follows from \(\underline{\pi }_N = \sup \{\pi _u : u \in U\}\) and \(\overline{\pi }_N = \inf \{\pi _u : u \in U\}\) in conjunction with \(U \supseteq D\). The first property follows from \(\underline{\pi }_N = \sup \{\pi _u : u \in U\}\) and \(\overline{\pi }_N = \inf \{\pi _u : u \in U\}\) in conjunction with \(U \supseteq D\).
It remains to show that the minimum and the maximum exist. Concentrating on the lower price limit, define \(\underline{\pi } \equiv \inf \left\{ \pi : F_\pi (x) \le S(x) \; \text { for \; all } \; x \right\} \) and assume that \(\min \left\{ \pi : F_\pi (x) \le S(x) \; \text { for \; all } \; x \right\} \) does not exist. Then there exists some \(x^{\prime}\) such that \(F_{\underline{\pi }}(x^{\prime})>S(x^{\prime})\). For \(x^{\prime}\), in turn, there is some \(\pi^{\prime}>\underline{\pi }\) such that \(F_{\underline{\pi }}(x^{\prime}) \ge F_{\pi^{\prime}}(x^{\prime}) >S(^{\prime})\) because \(F_\pi (x)\) is assumed to be a nonincreasing, continuous function of \(\pi \) for all x. Thus, \(\underline{\pi }\) cannot be equal to \(\inf \left\{ \pi : F_\pi (x) \le S(x) \; \text { for \; all } \; x \right\} \). \(\square \)
Proof of Proposition 1
We only give the proof for the lower price limit as it is analogous to that for the upper price limit. First we prove that \(\underline{\pi }_{{{I}_{1} }}\) exists and then that it is a lower price limit according to Lemma 1.
We prove the existence of \(\underline{\pi }_{{{I}_{1} }}\) by showing that \(v(F_{\underline{\pi }_N}, S)=0\), so the set over which the infimum is taken is nonempty. We know that \({{\,\mathrm{E}\,}}_{F_\pi }(u) \ge {{\,\mathrm{E}\,}}_S(u)\) for all \(u \in U\) if \(\pi \ge \underline{\pi }_N\). \({{\,\mathrm{E}\,}}_{F_\pi }(u) \ge {{\,\mathrm{E}\,}}_S(u)\) for all \(u \in U\) implies FSD of \(F_\pi \) over S, i.e., \(v(F_\pi , S)=0\). Consequently, \(v(F_\pi , S)=0\) for \(\pi \ge \underline{\pi }_N\).
Now, we prove that \(\underline{\pi }_{{{I}_{1} }}\) is a lower price limit, i.e., \(\underline{\pi }_{{{I}_{1} }} \ge \underline{\pi }_C\), by proving that \(\underline{\pi }_{{{I}_{1} }} < \underline{\pi }_C\) is false. \(\underline{\pi }_{{{I}_{1} }}, \underline{\pi }_{C} \in \left[ \overline{\pi }_{N}, \underline{\pi }_{N}\right] \) is true by the definition of \(\underline{\pi }_{{{I}_{1} }}\) and Lemmas 1 and 2. Hence, the assumption \(\underline{\pi }_{{{I}_{1} }} < \underline{\pi }_{C}\) implies \(\overline{\pi }_{N} < \underline{\pi }_{N}\), \(\overline{\pi }_{N} < \underline{\pi }_{C}\), and \(\underline{\pi }_{{{I}_{1} }} < \underline{\pi }_{N}\). Realize that, for all prices \(\pi^{\prime} \in \left( \underline{\pi }_{{{I}_{1} }}, \underline{\pi }_{N}\right] \), there exists \(\pi^{{\prime}{\prime}} \in \left[ \underline{\pi }_{{{I}_{1} }}, \pi^{\prime}\right) \) such that \(v(F_{\pi^{{\prime}{\prime}}}, S) \le \epsilon_{D}(\pi^{{\prime}{\prime}})\). This property is obvious for \(\underline{\pi }_{{{I}_{1} }} = \min \left\{ \pi \in \left[ \overline{\pi }_{N}, \underline{\pi }_{N}\right] : v(F_\pi , S) \le \epsilon_{D}(\pi ) \right\} \), but it also holds when the minimum does not exist. With \(\pi^{\prime}=\underline{\pi }_{C}\), we get \(\overline{\pi }_{N} \le \underline{\pi }_{{{I}_{1} }} \le \pi^{{\prime}{\prime}} < \underline{\pi }_{C} \le \underline{\pi }_{N}\). From AFSD we know that \({\mathrm{E}}_{{F_{\pi^{{\prime}{\prime}}} }}(u) \ge {\mathrm{E}}_{S} (u)\) for all \(u \in U(\epsilon_{D}(\pi^{{\prime}{\prime}}))\). Equivalently, we have \(\pi^{{\prime}{\prime}} \ge \sup \{\pi _{u} : u \in U(\epsilon_{D}(\pi^{{\prime}{\prime}}))\}\). Keeping in mind that \(\underline{\pi }_{C}\) is defined as \(\sup \{ \pi _{u} :u \in D\}\), it must be true that \(\pi^{{\prime}{\prime}} \ge \underline{\pi }_{C}\) because \(D \subseteq U(\epsilon_{D} (\pi^{{\prime}{\prime}} ))\). This contradicts \( \pi^{{\prime}{\prime}} < \underline{\pi }_{C} \) following from our initial assumption \(\underline{\pi } _{{{I}_{1} }} < \underline{\pi }_{C}\). Hence, the assumption must be false. \(\square\)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Jahnke, H., Martini, J.T. & Wiens, T. Price limits under incomplete preference information based on almost stochastic dominance. Bus Res 12, 241–269 (2019). https://doi.org/10.1007/s40685-018-0082-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40685-018-0082-2