
Abstract
In this paper, a method with parameter is proposed for finding the spectral radius of weakly irreducible nonnegative tensors. What is more, we prove this method has an explicit linear convergence rate for indirectly positive tensors. Interestingly, the algorithm is exactly the NQZ method (proposed by Ng, Qi and Zhou in Finding the largest eigenvalue of a non-negative tensor SIAM J Matrix Anal Appl 31:1090–1099, 2009) by taking a specific parameter. Furthermore, we give a modified NQZ method, which has an explicit linear convergence rate for nonnegative tensors and has an error bound for nonnegative tensors with a positive Perron vector. Besides, we promote an inexact power-type algorithm. Finally, some numerical results are reported.
Similar content being viewed by others


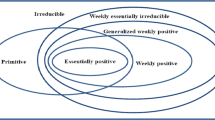
1 Introduction
Eigenvalue problems of higher order tensors have become a more and more important topic. In theory, Chang et al. generalized the Perron–Frobenius Theorem from nonnegative matrices to nonnegative tensors in [1]. Y. Yang and Q. Yang extended their results in [2, 3]. The latest result on the Perron–Frobenius Theorem is that the eigenvalues with modulus \(\rho ({\mathcal {A}})\) have the same geometric multiplicity in [4]. Some other results of nonnegative tensors were established in [5–12]. What is more, Ng, Qi, and Zhou proposed the NQZ method for finding spectral radius of a nonnegative irreducible tensor in [13]. Pearson obtained that the NQZ method would converge if the tensor with even order is essentially positive in [14]. In [15] Chang, Pearson and Zhang proved the convergence of the NQZ method for primitive tensors with any nonzero nonnegative initial vector. Zhang and Qi gave the linear convergence of the NQZ method for essentially positive tensors in [16]. Hu, Huang, and Qi [17] established the global R-linear convergence of the modified version of the NQZ method for nonnegative weakly irreducible tensors which were introduced by Friedland, Gaubert, and Han in [18]. Chen, Qi, Yang, et al showed an inexact power-type algorithm for finding spectral radius of nonnegative tensors in [19].
In this paper, we focus on a method with parameter for finding the spectral radius of weakly irreducible nonnegative tensors. What is more, the method has an explicit linear convergence rate for indirectly positive tensors. Interestingly, the algorithm is exactly the NQZ method by taking a specific parameter. Furthermore, we give a modified NQZ method, which has an explicit linear convergence rate for nonnegative tensors and has an error bound for nonnegative tensors with a positive Perron vector. Besides, we promote the inexact power-type algorithm in [19].
This paper is organized as follows. In Sect. 2, we recall some theorems and the NQZ method. And a method with parameter is proposed for finding the spectral radius of weakly irreducible nonnegative tensors. Then we prove it has an explicit linear convergence rate for indirectly positive tensors. In Sect. 3, the linear convergence rate for the method is established. In Sect. 4, a modified NQZ method is presented and the inexact power-type algorithm is promoted. In Sect. 5, we report some numerical results.
We first add a comment on the notation that is used in this paper. Vectors are written as lowercase letters \((x,y,\cdots )\), italic capitals \((A,B,\cdots )\) are for matrices, and tensors correspond to calligraphic capitals \(({\mathcal {A}}, {\mathcal {B}},\cdots )\). The entry in a tensor \({\mathcal {A}}\), \(({\mathcal {A}})_{i_1\cdots i_p,j_1\cdots j_q} = a_{i_1\cdots i_p,j_1\cdots j_q}\). \(\mathbb {R}^n_+(\mathbb {R}^n_{++})\) is for the cone \(\{x \in \mathbb {R}^n\ | x_i\geqslant (>) 0, i=1,\cdots ,n\}\). The symbol \(A >(\geqslant ,\leqslant , <) B\) denotes that \(a_{ij} >(\geqslant ,\leqslant , <) b_{ij}\) for every i, j.
2 Preliminaries
In this section, we first recall some preliminaries knowledge on nonnegative square tensors. Then a method with parameter is proposed for finding the spectral radius of weakly irreducible nonnegative tensors.
Firstly, we recall some known definitions about tensors.
Definition 2.1
(Definition of [1]) A tensor is a multidimensional array, and a real m-th order n dimensional tensor \({\mathcal {A}}\) consists of \(n^m\) real entries:
where \(i_j=1,\cdots ,n\) for \(j=1,\cdots ,m\). For any vector x and any real number m, denote \(x^{[m]} = [x^{m}_1 ,x^{m}_2 ,\cdots ,x^{m}_n ]\mathrm{^T}\). If there are a complex number \(\lambda \) and a nonzero complex vector x satisfying the following homogeneous polynomial equations:
then \(\lambda \) is called an eigenvalue of \({\mathcal {A}}\) and x the eigenvector of \({\mathcal {A}}\) associated with \(\lambda \), where \({\mathcal {A}}x^{m-1}\) is vectors, whose ith component are
Definition 2.2
(Definition 2.2 of [3]) The spectral radius of tensor \({\mathcal {A}}\) is defined as
Definition 2.3
([20]) An m-th order n dimensional tensor \({\mathcal {C}} = (c_{i_1}\cdots c_{i_m})\) is called reducible, if there exists a nonempty proper index subset \(I \subset \{1,\cdots ,n\}\) such that
If \({\mathcal {C}}\) is not reducible, then we call \({\mathcal {C}}\) irreducible.
Definition 2.4
(Definition 2.2 of [21]) For any vector \(x \in \mathbb {R}^n_+\), we define \((x^{[\frac{1}{m-1}]})_i = x_i^{\frac{1}{m-1}}\). Let \({\mathcal {A}}\) and \({\mathcal {B}}\) be two m-order n dimensional nonnegative tensors. Let \(\omega := ({\mathcal {A}}x^{m-1})^{[\frac{1}{m-1}]} \in \mathbb {R}^n_+\). We define the composite of the tensors for \(x \in \mathbb {R}_+\) to be the function (not necessarily a tensor) \(({\mathcal {B}}\circ {\mathcal {A}})x = {\mathcal {B}}\omega ^{m-1}\).
Definition 2.5
(Definition 2.3 of [21]) A nonnegative m-order n dimensional tensor \({\mathcal {A}}\) is primitive if there exists a positive integer h so that \(({\mathcal {A}} \circ {\mathcal {A}} \circ \cdots \circ {\mathcal {A}})x = {\mathcal {A}}^hx \in \mathbb {R}^n_{++} \) for any nonzero \(x \in \mathbb {R}^n_+\). Furthermore, we call the least value of such h the primitive degree.
Definition 2.6
(Definition 2.6 of [15]) An m-th order n dimensional nonnegative irreducible tensor \({\mathcal {A}}\) is called primitive if \(T_{\mathcal {A}}\) does not have a nontrivial invariant set S on \(\mathbb {R}_{+}^{n}\backslash \mathbb {R}_{++}^{n}\). (\(\{ 0 \}\) is the trivial invariant set).
Definition 2.7
(Definition 2.1 of [22]) An m-th order n dimensional tensor \({\mathcal {C}} \) is called essentially positive, if \({\mathcal {C}}x^{m-1} > 0\) for any nonzero \(x \geqslant 0\).
Definition 2.8
(Definition 2.1 of [17]) A nonnegative matrix \(M({\mathcal {A}})\) is called the majorization associated to nonnegative tensor \({\mathcal {A}}\), if the (i, j)-th element of \(M({\mathcal {A}}\)) is defined to be \(a_{ij \cdots j}\) for any \(i,j \in {1, \cdots , n}\). \({\mathcal {A}}\) is called weakly positive if \([M({\mathcal {A}} )]_{ij}>0\) for all \(i \ne j\).
Definition 2.9
(Definition 2.2 of [17]) Suppose \({\mathcal {A}}\) is an m-th order n dimensional nonnegative tensor.
-
(1)
We call a nonnegative matrix \(G({\mathcal {A}})\) the representation associated to the nonnegative tensor \({\mathcal {A}}\), if the (i, j)-th element of \(G({\mathcal {A}})\) is defined to be the summation of \({\mathcal {A}}_{\{ii_{2} \cdots i_{m}\}}\) with indices \(\{i_{2} \cdots i_{m}\}\ni j\).
-
(2)
We call the tensor \({\mathcal {A}}\) weakly reducible if its representation \(G({\mathcal {A}})\) is a reducible matrix, and weakly primitive if \(G({\mathcal {A}})\) is a primitive matrix. If \({\mathcal {A}}\) is not weakly reducible, then it is called weakly irreducible.
Definition 2.10
Suppose \({\mathcal {A}}\) is an m-th order n dimensional nonnegative tensor. We call the tensor \({\mathcal {A}}\) indirectly positive if its representation \(G({\mathcal {A}})>0\), and indirectly weakly positive if \(G({\mathcal {A}})+I>0\).
Remark
Suppose \({\mathcal {A}}\) is essentially positive tensor. It is easy to obtain \(G({\mathcal {A}})>0\) by Definition 2.8. So essentially positive tensors are indirectly positive tensors, but not vice versa. We will use one example to illustrate it.
Example 2.11
The 2nd order 3 dimensional tensor \({\mathcal {A}}\) is given by \(a(1,1,2)=1, \ a(2,1,2)=1\), and zero elsewhere. It is easy to obtain \(G({\mathcal {A}})>0\). So \({\mathcal {A}}\) is indirectly positive tensor. But \({\mathcal {A}}x^{m-1}= 0\) for \(x=(1,0) \geqslant 0\). So \({\mathcal {A}}\) is not essentially positive tensor.
Next we recall the NQZ method for an irreducible nonnegative square tensor in [13].
Algorithm 2.12
-
Step 1 Choose \(x^{(0)}>0 , x^{(0)} \in \mathbb {R}^n\). Let \(y^{(0)}= {\mathcal {A}}(x^{(0)})^{m-1}\) and set \(k=0\).
-
Step 2 Compute
$$\begin{aligned} x^{\left( k+1\right) }= & {} \left( y^{k}\right) ^{\left[ \frac{1}{m-1}\right] }\bigg / \left\| \left( y^{k}\right) ^{\left[ \frac{1}{m-1}\right] } \right\| , \quad y^{\left( k+1\right) }= {\mathcal {A}}\left( x^{\left( k+1\right) }\right) ^{m-1} , \\ {\bar{\lambda }}_{k+1}= & {} \max _{i} \left\{ \frac{y^{\left( k+1\right) }_i}{\left( x_i^{\left( k+1\right) }\right) ^{m-1}}\right\} , \ \ \ \ {\underline{\lambda }}_{k+1}= \min _{i} \left\{ \frac{y^{\left( k+1\right) }_i}{\left( x_i^{\left( k+1\right) }\right) ^{m-1}}\right\} . \end{aligned}$$ -
Step 3 If \({\bar{\lambda }}_{k+1}={\underline{\lambda }}_{k+1}\), stop. Otherwise, replace k by \(k+1\) and go to step 2.
Algorithm 2.12 has the following properties.
Lemma 2.13
(Propositions 5.1 and 5.2 of [15]) If \({\mathcal {A}}\) is primitive, then \( \{ {\bar{\lambda }}_{k} \} \) is monotonically decreasing and \( \{{\underline{\lambda }}_{k} \}\) is monotonically increasing and both of the sequences converge to \(\rho ({\mathcal {A}})\).
Lemma 2.14
([16, 23]) If \({\mathcal {A}}\) is essentially positive, then both \( \{ {\bar{\lambda }}_{k} \} \) and \( \{{\underline{\lambda }}_{k} \}\) converge linearly to \(\rho ({\mathcal {A}})\). In details, for \(k=0,1,\cdots \),
where \(\alpha _{0} = 1- \beta _{0}/{\bar{\mathbb {R}}} , \beta _{0} = \min \limits _{i,j \in \{1,2,\cdots ,n \}} a_{ij \cdots j}, \bar{\mathbb {R}}=\max \limits _i\sum \limits _{i_2,\cdots ,i_m}^na_{ii_2\cdots i_m}\).
To speed up the convergence rate of Algorithm 2.12, we present an algorithm with parameter in a different way as follows. Considering \({\underline{\lambda }}^{(k+1)}\leqslant \rho ({\mathcal {A}})\leqslant {\bar{\lambda }}^{(k+1)}\), our idea is getting \(x^{(k+1)}\) by \(x^{(k+1)}_{i}=\mu _{i}x^{(k)}_{i},i=1,\cdots ,n\), where \(\mu _{i}\) is parameter. One can get suitable algorithm by taking a specific parameter. Because there is countless viable parameters, it has plenty of room for improvement. We will give one kind of parameters, which get a faster convergence rate in some conditions.
Algorithm 2.15
-
Step 1 Choose \(x^{(0)}>0 , x^{(0)} \in \mathbb {R}^n\), \(\varepsilon >0\). \(\lambda ^{(0)}_{i}= \frac{({\mathcal {A}}(x^{(0)})^{m-1})_{i}}{(x^{(0)}_{i})^{m-1}}, \quad i=1,2,\cdots ,n\), \(y^{(0)}_{i}= (\lambda ^{(0)}_{i})^{\frac{1}{p(m-1)}}x^{(0)}_{i}\), p is a given positive integer, \(i=1,2,\cdots ,n\) and set \(k=0\).
-
Step 2 Compute
$$\begin{aligned} x^{\left( k+1\right) }= & {} y^{\left( k\right) }/ \left\| y^{\left( k\right) } \right\| , \quad \lambda ^{\left( k+1\right) }_{i}=\frac{\left( {\mathcal {A}}\left( x^{\left( k+1\right) }\right) ^{m-1}\right) _{i}}{\left( x^{\left( k+1\right) }_{i}\right) ^{m-1}}, \quad i=1,2,\cdots ,n,\\ {\bar{\lambda }}^{\left( k+1\right) }= & {} \max _{i}\{\lambda ^{\left( k+1\right) }_{i}\}, \quad {\underline{\lambda }}^{\left( k+1\right) }=\min _{i} \{\lambda ^{\left( k+1\right) }_{i}\}, \quad y^{\left( k+1\right) }_{i}=\left( \lambda ^{\left( k+1\right) }_{i}\right) ^{\frac{1}{p\left( m-1\right) }}x^{\left( k+1\right) }_{i},\\ i= & {} 1,2,\cdots ,n. \end{aligned}$$ -
Step 3 If \({\bar{\lambda }}^{(k+1)}-{\underline{\lambda }}^{(k+1)}<\varepsilon \), stop. Otherwise, replace k by \(k+1\) and go to step 2.
3 Linear Convergence Analysis for Algorithm 2.15
In this section, we prove Algorithm 2.15 has an explicit linear convergence rate for indirectly positive tensors.
Definition 3.1
([17]) If x and y are comparable, and define
then, the Hilberts projective metric d can be defined by
for \(x, y \in \mathbb {R}^{n}_{+}\backslash \{0\}\).
Definition 3.2
(Definition of [18]) Let \({{ f}}=(f_{1}\cdots f_{n})^\mathrm{T}: \mathbb {R}^{n}\rightarrow \mathbb {R}^{n}\) be a polynomial map. We assume that each \(f_{i}\) is a polynomial of degree \(d_{i} \geqslant 1\), and that the coefficient of each monomial in \(f_{i}\) is nonnegative. So \({f}: \mathbb {R}^{n}_{+}\rightarrow \mathbb {R}^{n}_{+}\). We associate with f the following digraph \(G({{ f}}) = (V, E({{ f}}))\), where \(V = \{1,\cdots ,n\}\) and \((i, j ) \in E({f})\) if the variable \(x_{j}\) effectively appears in the expression of \(f_{i}\). We call \({{ f}}\) weakly irreducible if \(G({{ f}})\) is strongly connected. To each subset \(I\in V\), is associated a part \(Q_{I} =\{x \in \mathbb {R}^{n}_{+}| x_{i} > 0 \ { \ if \ and \ only \ if} \ i\in I\) of \(\mathbb {R}^{n}_{+}\). We say that the polynomial map f is irreducible if there is no part of \(R^{n}_{+}\) that is invariant by f, except the trivial parts  and \(Q_{V}\).
and \(Q_{V}\).
Corollary 3.3
(Corollary 5.1 of [18]) Let \({{ f}}=(f_{1}\cdots f_{n})^\mathrm{T}: \mathbb {R}^{n}\rightarrow \mathbb {R}^{n}\) be a polynomial map, where each \(f_{i}\) is a homogeneous polynomial of degree \(d\geqslant 1\) with nonnegative coefficients. If the adjacency matrix of G(f) is primitive, then the sequence \(\{x^{(k)}\}\) produced by Algorithm 2.12 converges to the unique vector \(x\in \mathbb {R}^n_{++}\) satisfying \(f(x)=\rho ({\mathcal {A}})x^{[m-1]}\) and \(\sum \nolimits _{i=1}^{n} x_{i}=1\).
Theorem 3.4
(Theorem 4.1 of [17]) Suppose \({\mathcal {A}}\) is an m-th order n dimensional weakly primitive nonnegative tensor. If the sequence \(\{x^{(k)}\}\) is generated by Algorithm 2.12, then \(\{x^{(k)}\}\) converges to the unique vector \(x\in \mathbb {R}^n_{++}\) satisfying \({\mathcal {A}}x^{m-1}=\rho ({\mathcal {A}})x^{[m-1]}\) and \(\sum \nolimits _{i=1}^{n} x_{i}=1\), and there exist constant \(\theta \in (0, 1)\) and positive integer M such that
holds for all \(k\geqslant 1\).
Theorem 3.5
Suppose \({\mathcal {A}}\) is an m-th order n dimensional weakly primitive nonnegative tensor. If the sequence \(\{x^{(k)}\}\) is generated by Algorithm 2.15, then \(\{x^{(k)}\}\) converges to the unique vector \(x\in \mathbb {R}^n_{++}\) satisfying \({\mathcal {A}}x^{m-1}=\rho ({\mathcal {A}})x^{[m-1]}\) and \(\sum \nolimits _{i=1}^{n} x_{i}=1\), and there exist a constant \(\theta \in (0, 1)\) and positive integer M such that
for all \(k\geqslant 1\).
Proof
Let \(F_{\mathcal {A}}x=({\mathcal {A}}x^{m-1})\cdot x^{[(p-1)(m-1)]}\), where \(({\mathcal {A}}x^{m-1})\cdot x^{[(p-1)(m-1)]}\) is vector, whose i-th component are
Hence the convergence of sequence \(\{x^{(k)}\}\) by Algorithm 2.15 can be reached by the Corollary 3.3. Then this theorem is the same as Theorem 3.4.
Remark
Since \(\lambda ^{(k+1)}_{i}= \frac{({\mathcal {A}}(x^{(k+1)})^{m-1})_{i}}{(x^{(k+1)}_{i})^{m-1}},i=1,2,\cdots ,n\) are all homogeneous polynomials of degree 0. So they do not change for the different norms of x.
Theorem 3.6
Let \({\mathcal {A}}\) be an m-th order n dimensional weakly irreducible nonnegative tensor. Assume that \( \{{\bar{\lambda }}^{(k)}\} \) and \( \{{\underline{\lambda }}^{(k)} \}\) are two sequences generated by Algorithm 2.15. Then
where \(i_{k+1}\) and \(j_{k+1}\) satisfy \(\underline{\lambda }^{(k+1)}=\lambda ^{(k+1)}_{i_{k+1}}\), \(\bar{\lambda }^{(k+1)}=\lambda ^{(k+1)}_{j_{k+1}}\), \(p\geqslant 1\).
Proof
Suppose \(i_{k+1}\) and \(j_{k+1}\) satisfy \(\underline{\lambda }^{(k+1)}=\lambda ^{(k+1)}_{i_{k+1}}\), \(\bar{\lambda }^{(k+1)}=\lambda ^{(k+1)}_{j_{k+1}}\). Then we have
Similarly, we get
And we have
This completes the proof.
Lemma 3.7
Suppose \({\mathcal {A}}\) is an m-th order n dimensional weakly irreducible nonnegative tensor. Then in Algorithm 2.15 we have \(\frac{{\underline{\lambda }}^{(k+1)}}{{\bar{\lambda }}^{(k+1)}}\geqslant \frac{{\underline{\lambda }}^{(0)}}{{\bar{\lambda }}^{(0)}}\) and \(\exists a>0\),
Proof
Because \( \{ {\bar{\lambda }}^{(k)} \} \) is monotonically decreasing and \( \{{\underline{\lambda }}^{(k)} \}\) is monotonically increasing by Theorem 3.6. So we can get \(\frac{{\underline{\lambda }}^{(k)}}{{\bar{\lambda }}^{(k)}}\geqslant \frac{{\underline{\lambda }}^{(k-1)}}{{\bar{\lambda }}^{(k-1)}}\geqslant \cdots \geqslant \frac{{\underline{\lambda }}^{(0)}}{{\bar{\lambda }}^{(0)}}\). Suppose \(\{x^{(k)}\}\) is generated by Algorithm 2.15. Then \(x^{(k)}>0\), \(\lim _{k\rightarrow \infty }x^{(k)}>0\). Hence \(\left\{ \frac{\min \limits _{1\leqslant i\leqslant n}x^{(k)}_{i}}{\max \limits _{1\leqslant i\leqslant n}x^{(k)}_{i}}\right\} \) is convergent and \(\frac{\min \limits _{1\leqslant i\leqslant n}x^{(k)}_{i}}{\max \limits _{1\leqslant i\leqslant n}x^{(k)}_{i}}>0\), \(\lim _{k\rightarrow \infty }\frac{\min \limits _{1\leqslant i\leqslant n}x^{(k)}_{i}}{\max \limits _{1\leqslant i\leqslant n}x^{(k)}_{i}}>0\). So \(\exists a>0\), making \(a<\frac{\min \limits _{1\leqslant i\leqslant n}x^{(k)}_{i}}{\max \limits _{1\leqslant i\leqslant n}x^{(k)}_{i}}\leqslant 1\). We set \(y^{(k)}=\frac{x^{(k)}}{\Vert x^{(k)}\Vert }\), \(y^{(k)}_{t}=\min \limits _{1\leqslant i\leqslant n}y^{(k)}_{i},y^{(k)}_{s}=\max \limits _{1\leqslant i\leqslant n}x^{(k)}_{i}\). Then for any given \(q\in \{2,3,\cdots ,m\}\), we have
For \(\Vert x\Vert =\sum \nolimits _{i=1}^{n} |x_{i}|=1\) (the proof is similar for other norm ), we have
Similarly, we get
Hence we obtain
This completes the proof.
Remark
It is easy to find out that if \({\mathcal {A}}\) is indirectly positive tensor, then
Theorem 3.8
If \({\mathcal {A}}\) is indirectly positive tensor, then both \( \{{\bar{\lambda }}^{(k)}\} \) and \( \{{\underline{\lambda }}^{(k)} \}\) in Algorithm 2.15 converge linearly to \(\rho ({\mathcal {A}})\). In details, for \(k=0,1,\cdots \),
where \(\alpha =1-\frac{\beta (a_{0})^{m-1}}{p(m-1)\bar{\lambda }^{(0)}}, \beta = \min \limits _{i,j \in \{1,2,\cdots ,n \}}\{a_{ii_2\cdots i_m}+a_{jj_2\cdots j_m},a_{ii_2\cdots i_m}>0,a_{jj_2\cdots j_m}>0,i\ne j\}\),
Proof
Suppose i and j satisfy \(\bar{\lambda }^{(k+1)}=\lambda ^{(k+1)}_{i}\), \(\underline{\lambda }^{(k+1)}=\lambda ^{(k+1)}_{j}\). Because \({\mathcal {A}}\) is indirectly positive tensors. Then there exist \(i_{0}\), \(j_{0}\) such that \(x^{(k+1)}_{i_{0}}=(\bar{\lambda }^{(k)})^{\frac{1}{m-1}}x^{(k)}_{i_{0}}\), \(x^{(k+1)}_{j_{0}}=(\underline{\lambda }^{(k)})^{\frac{1}{m-1}}x^{(k)}_{j_{0}}\) and \(a_{ii_2\cdots i_m}>0,j_{0}\in \{i_2,\cdots ,i_m\}\), \(a_{jj_2\cdots j_m}>0,i_{0}\in \{j_2,\cdots ,j_m\}\). We know that
Hence by the Lemma 3.7 we have
Then both \( \{ {\bar{\lambda }}^{(k)}\} \) and \( \{{\underline{\lambda }}^{(k)} \}\) converge linearly to \(\rho ({\mathcal {A}})\).
Remark
We give the linear convergence analysis for indirectly positive tensor by this theorem. The condition of indirectly positivity is weaker than the condition of essentially positivity in Lemma 2.14. So this result is more useful in inexact algorithms. Furthermore, this theorem can be extended to find the largest singular values of a rectangular tensor.
Theorem 3.9
If \({\mathcal {A}}\) is an m-th order n dimensional nonnegative tensor with \(a_{ii\cdots ij}>0,i,j=1,\cdots ,n\), the other entries being equal to 0, then both \( \{ {\bar{\lambda }}^{(k)}\} \) and \( \{{\underline{\lambda }}^{(k)} \}\) in Algorithm 2.15 converge linearly to \(\rho ({\mathcal {A}})\). In details, for \(k=0,1,\cdots \),
where \(\alpha _{1}=1-\frac{\beta a_{0}}{p(m-1)\bar{\lambda }^{(0)}}, \ \beta _{1}= \min \limits _{i,j,i_{0},j_{0} \in \{1,2,\cdots ,n \}}\left\{ a_{ii\cdots ij_{0}}+a_{jj\cdots ji_{0}}\right\} \),
Proof
Suppose i and j satisfy \(\bar{\lambda }^{(k+1)}=\lambda ^{(k+1)}_{i}\), \(\underline{\lambda }^{(k+1)}=\lambda ^{(k+1)}_{j}\). Because \({\mathcal {A}}\) is an m-th order n dimensional nonnegative tensor with \(a_{ii\cdots ij}>0,i,j=1,\cdots ,n\). Then \({\mathcal {A}}\) is indirectly positive tensor and there exist \(i_{0}\), \(j_{0}\) such that \(x^{(k+1)}_{i_{0}}=(\bar{\lambda }^{(k)})^{\frac{1}{m-1}}x^{(k)}_{i_{0}}\), \(x^{(k+1)}_{j_{0}}=(\underline{\lambda }^{(k)})^{\frac{1}{m-1}}x^{(k)}_{j_{0}}\) and \(a_{ii\cdots ij_{0}}>0\), \(a_{jj\cdots ji_{0}}>0\). Hence by Lemma 3.7 we have
We know that
Then
where \(\beta _{1} = \min \nolimits _{i,j,i_{0},j_{0} \in \{1,2,\cdots ,n \}}\{a_{ii\cdots ij_{0}}+a_{jj\cdots ji_{0}}\}\),
Then both \( \{ {\bar{\lambda }}^{(k)}\} \) and \( \{{\underline{\lambda }}^{(k)} \}\) converge linearly to \(\rho ({\mathcal {A}})\).
Remark
We know there exists \(a>0\) but it is hard to find the explicit number. So in the complexity analysis we always use
In fact, we can compute \(a_{\varepsilon _{0}}=\frac{\min \nolimits _{i}x^{(k)}}{\max \nolimits _{i}{x^{(k)}}}\) when \(\varepsilon _{0}=10^{-2}\). Then we use “ \(a_{\varepsilon _{0}}\)” instead of “a” to give a complexity analysis when \(\varepsilon =10^{-7}\). In this way, we give the most iterations when \(\varepsilon \) is from \(10^{-2}\) to \(10^{-7}\).
In the following we give a complexity analysis.
Theorem 3.10
If \({\mathcal {A}}\) is an m-th order n dimensional nonnegative tensor with \(a_{ii\cdots ij}>0,i,j=1,\cdots ,n\), then Algorithm 2.15 terminates in at most
iterations with
Proof
By Theorem 3.8, we have for \(k=0,1,\cdots \),
In order to ensure
we only need
Then we have
This completes the proof.
Remark
Clearly, Algorithm 2.15 coincides with NQZ algorithm when p is one. We know linear convergence rate varies when p changes. One can refer the numerical results in Sect. 5 for the better choice of parameter p.
4 Linear Convergence Analysis for Algorithm 4.1
In this section, we present a modified NQZ method and we promote the inexact power-type algorithm. We find that the modified NQZ method has an explicit linear convergence rate for nonnegative tensors with any positive initial vector and this method has an error bound for nonnegative tensors with a positive Perron vector.
Because the NQZ method cannot give an explicit convergence rate for finding the spectral radius of a weakly irreducible nonnegative tensor, we present a modified NQZ method for finding the spectral radius of a weakly irreducible nonnegative tensor by a specific perturbation tensor, which can give an explicit convergence rate. Let \(\triangle {\mathcal {A}}_{0}\) be a nonnegative tensor of m-th order n dimensional with \(a_{ii\cdots ij}=1,i,j=1,\cdots ,n\), the other entries being equal to 0. The algorithm is as follows:
Algorithm 4.1
-
Step 1 Given \(x^{(0)}>0 , x^{(0)} \in \mathbb {R}^n\) and \(\varepsilon >0\). Compute \({\mathcal {B}}=\mathcal {A}+\varepsilon \triangle \mathcal {A}_{0}\), \(\lambda ^{(0)}_{i}= \frac{({\mathcal B}(x^{(0)})^{m-1})_{i}}{(x^{(0)}_{i})^{m-1}},i=1,2,\cdots ,n\), \(y^{(0)}_{i}= (\lambda ^{(0)}_{i})^{\frac{1}{m-1}}x^{(0)}_{i},i=1,2,\cdots ,n\) and set \(k=0\).
-
Step 2 Compute
$$\begin{aligned} x^{(k+1)}= & {} y^{(k)}\bigg / \left\| y^{(k)} \right\| , \quad \lambda ^{(k+1)}_{i}=\frac{\left( {\mathcal {B}}\left( x^{(k+1)}\right) ^{m-1}\right) _{i}}{\left( x^{(k+1)}_{i}\right) ^{m-1}}, \quad i=1,2,\cdots ,n,\\ {\bar{\lambda }}^{(k+1)}= & {} \max _{i}\left\{ \lambda ^{(k+1)}_{i}\right\} , \quad {\underline{\lambda }}^{(k+1)}=\min _{i} \left\{ \lambda ^{(k+1)}_{i}\right\} , \quad y^{(k+1)}_{i}=\big (\lambda ^{(k+1)}_{i}\big )^{\frac{1}{m-1}}x^{(k+1)}_{i},\\&\quad i=1,2,\cdots ,n.\\ \end{aligned}$$ -
Step 3 If \({\bar{\lambda }}^{(k+1)}-{\underline{\lambda }}^{(k+1)}<\varepsilon \), put \(\lambda =\frac{1}{2}\left( {\bar{\lambda }}^{(k+1)}+{\underline{\lambda }}^{(k+1)}+2\varepsilon -\frac{\varepsilon }{\max \nolimits _{i} \left\{ x^{(k+1)}_{i}\right\} }\right. \) \(\left. -\frac{\varepsilon }{\min \nolimits _{i} \left\{ x^{(k+1)}_{i}\right\} }\right) \). Otherwise, replace k by \(k+1\) and go to step 2.
Lemma 4.2
(Theorem 2.8 of [24]) Suppose \({\mathcal {A}}\) is an m-th order n dimensional nonnegative tensor with a positive Perron vector and \(\widetilde{\mathcal {A}}={\mathcal {A}}+\triangle {\mathcal {A}}\) is the perturbed nonnegative tensor of \({\mathcal {A}}\). Then we have
where \(\tau ({\mathcal {A}})\equiv \left\{ \min \limits _{2\leqslant k\leqslant m}\left( \frac{\max \limits _{1\leqslant i_{1},i_{k}\leqslant n}\sum \limits _{\underbrace{i_{2},\cdots ,i_{m}=1}_{\mathrm{except} \ i_{k}}}^{n}a_{i_{1},i_{2},\cdots ,i_{m}}}{\min \limits _{1\leqslant i_{1},i_{k}\leqslant n}\sum \limits _{\underbrace{i_{2},\cdots ,i_{m}=1}_{\mathrm{except} \ i_{k}}}^{n}a_{i_{1},i_{2},\cdots ,i_{m}}}\right) \right\} ^{m-1}\).
Lemma 4.3
Suppose \({\mathcal {A}}\) is an m-th order n dimensional nonnegative tensor with a positive Perron vector x and \(\widetilde{\mathcal {A}}={\mathcal {A}}+\varepsilon \triangle {\mathcal {A}}_{0}\) is the perturbed nonnegative tensor of \({\mathcal {A}}\). Then we have
where
Furthermore, if \(\Vert x\Vert _{1}=1\), then \(\frac{\varepsilon }{\max \nolimits _{i} \{x_{i}\}}\leqslant \rho (\widetilde{\mathcal {A}})-\rho ({\mathcal {A}})\leqslant \frac{\varepsilon }{\min \nolimits _{i} \{x_{i}\}}\).
Proof
Let x be the Perron vector of \({\mathcal {A}}\). Then we have
Hence
Similarly, one has
Because \(\widetilde{\mathcal {A}}\) has a positive Perron vector. Then we have \(\rho ({\mathcal {A}})\leqslant \rho (\widetilde{\mathcal {A}})\) and
Hence by Lemma 2.7 of [24], we have
where
Furthermore, if \(\Vert x\Vert _{1}=1\), then \(\frac{\varepsilon }{\max \limits _{i} \{x_{i}\}}\leqslant \rho (\widetilde{\mathcal {A}})-\rho ({\mathcal {A}})\leqslant \frac{\varepsilon }{\min \limits _{i} \{x_{i}\}}\).
Remark
Because \(\tau ({\mathcal {A}})\leqslant (\tau ({\mathcal {A}}))^{m-1}\), Lemma 4.3 is a more useful conclusion than Lemma 4.2.
Similarly, one has the following:
Lemma 4.4
Suppose \({\mathcal {A}}\) is an mth order n dimensional nonnegative tensor with a positive Perron vector and \(\widetilde{{\mathcal {A}}}={\mathcal {A}}+\varepsilon \triangle {\mathcal {A}}_{0}\) is the perturbed nonnegative tensor of \({\mathcal {A}}\). Let \(\widetilde{x}\) be positive Perron vector of \(\widetilde{\mathcal {A}}\). If \(\Vert \widetilde{x}\Vert _{1}=1\), then \(\frac{\varepsilon }{\max \nolimits _{i} \{\widetilde{x}_{i}\}}\leqslant \rho (\widetilde{\mathcal {A}})-\rho ({\mathcal {A}})\leqslant \frac{\varepsilon }{\min \nolimits _{i} \{\widetilde{x}_{i}\}}\).
Theorem 4.5
If \({\mathcal {A}}\) is an mth order n dimensional nonnegative tensor, then both \( \{ {\bar{\lambda }}^{(k)}\} \) and \( \{{\underline{\lambda }}^{(k)} \}\) in Algorithm 4.1 converge linearly to \(\rho (\mathcal {B})\), which initial value can be an arbitrary positive vector. In details, for \(k=0,1,\cdots \),
where \(\alpha _{2}=1-\frac{\beta _{2} a_{1}}{(m-1)\bar{\lambda }^{(0)}}, \ \beta _{2} = \min \limits _{i,j,i_{0},j_{0} \in \{1,2,\cdots ,n \}}\{b_{ii\cdots ij_{0}}+b_{jj\cdots ji_{0}}\}\),
Furthermore, if \({\mathcal {A}}\) has a positive Perron vector x, then
Proof
Because in Algorithm 4.1 \(\mathcal {B}={\mathcal {A}}+\varepsilon _{0}\triangle {\mathcal {A}}_{0}\) and \(\mathcal {B}\) is an m-th order n dimensional nonnegative tensor with \(a_{ii\cdots ij}\geqslant 1,i,j=1,\cdots ,n\). Then by Theorem 3.8 both \( \{ {\bar{\lambda }}^{(k)}\} \) and \( \{{\underline{\lambda }}^{(k)} \}\) in Algorithm 4.1 converge linearly to \(\rho (\mathcal {B})\). In details, for \(k=0,1,\cdots \),
where \(\alpha _{2}=1-\frac{\beta _{2} a_{1}}{(m-1)\bar{\lambda }^{(0)}},\beta _{2} = \min \limits _{i,j,i_{0},j_{0} \in \{1,2,\cdots ,n \}}\{b_{ii\cdots ij_{0}}+b_{jj\cdots ji_{0}}\}\),
And by Lemma 4.3 we have \(\frac{\varepsilon }{\max \nolimits _{i} \{x_{i}\}}\leqslant \rho (\mathcal {B})-\rho ({\mathcal {A}})\leqslant \frac{\varepsilon }{\min \nolimits _{i} \{x_{i}\}}\). Then \( \varepsilon >{\bar{\lambda }}^{(k+1)}- \rho (\mathcal {B}) \geqslant {\bar{\lambda }}^{(k+1)}- \rho ({\mathcal {A}})-\frac{\varepsilon }{\min \nolimits _{i} \{x_{i}\}}\). Hence \( \rho ({\mathcal {A}})>{\bar{\lambda }}^{(k+1)}-\frac{\varepsilon }{\min \nolimits _{i} \{x_{i}\}}- \varepsilon \). Similarly, we get \( \rho ({\mathcal {A}})<{\underline{\lambda }}^{(k+1)} -\frac{\varepsilon }{\min \nolimits _{i} \{x_{i}\}}-\varepsilon .\) This completes the proof.
Remark
By Theorem 4.5 we can find that Algorithm 4.1 has an explicit linear convergence rate for weakly irreducible nonnegative tensors and Algorithm 4.1 has an error bound for nonnegative tensors with a positive Perron vector.
Theorem 4.6
If \({\mathcal {A}}\) is an m-th order n dimensional nonnegative tensor with \(a_{ii\cdots ij}>0,i,j=1,\cdots ,n\), then Algorithm 4.1 terminates in at most
iterations with
Proof
The proof is similar to that of Theorem 3.10, so we omit it.
In the following, we promote the inexact power-type algorithm. We first recall the inexact power-type algorithm for finding spectral radius of nonnegative tensor \({\mathcal {A}}\) in [19]. Let \(\mathcal {E}\) be the all-ones m-th order n dimensional tensor.
Algorithm 4.7
-
Step 1 Take a positive sequence \(\{ \varepsilon _k \}\) such that \( \sum _{k=1}^{\infty } \varepsilon _k < \infty \). Given a \(\theta \in (0,1)\), set \(\tau _1 =\theta ,\ \ {\mathcal {A}}_1 = {\mathcal {A}}+ \tau _1 \mathcal {E} \). Choose \(x^{(0)}>0 , x^{(0)} \in \mathbb {R}^n\). Let \(y^{(0)}= {\mathcal {A}}_1 (x^{(0)})^{m-1}\). Let \(y_1^{(0)}= y^{(0)}\), \(l=1\).
-
Step 2 Compute
$$\begin{aligned} x_l^{\left( k\right) }= & {} \left( y_l^{\left( k-1\right) }\right) ^{[\frac{1}{m-1}]}\bigg / \left\| \left( y_l^{\left( k-1\right) }\right) ^{[\frac{1}{m-1}]}\right\| , \quad y_l^{\left( k\right) }= {\mathcal {A}}_l \left( x_l^{\left( k\right) }\right) ^{{m-1}},\\ {\bar{\lambda }}^l_{k}= & {} \max _i\frac{\left( y_l^{\left( k\right) }\right) _i}{\left( x_l^{\left( k\right) }\right) _i^{m-1}}, \quad \{\underline{\lambda }\}^l_{k}= \min _i\frac{\left( y_l^{\left( k\right) }\right) _i}{\left( x_l^{\left( k\right) }\right) _i^{m-1}} ,\\ \end{aligned}$$for \(k=1,2,\cdots \), until \( {\bar{\lambda }}^l_{k}- {\underline{\lambda }}^l_{k} < \varepsilon _l \), denote this k as k(l) and
$$\begin{aligned} x^{(0)}_{l+1}= x_l^{(k(l))} ,\ \ {\bar{\lambda }}^l={\bar{\lambda }}^l_{k(l)} ,\ \ {\underline{\lambda }}^l ={\underline{\lambda }}^l_{k(l)} . \end{aligned}$$ -
Step 3 \(l=l+1,\ \tau _l= \theta \tau _l,\ {\mathcal {A}}_l= {\mathcal {A}}+ \tau _l \mathcal {E} \). Set \(y^{(0)}_l={\mathcal {A}}_l (x_l^{(0)})^{m-1} \). Goto Step 2.
Remark
Let \(\mathcal {E}_{0}\) be an m-th order n dimensional nonnegative tensor with \(a_{ij\cdots j}=1,i,j=1,\cdots ,n\), the other entries being equal to 0. Because \(\rho (\mathcal {E})=n^{m-1}\), this leads to more iteration steps, while our algorithm needs less iteration steps. The proof will be given as follows.
Theorem 4.8
(Theorem 2.3 of [19]) In Algorithm 4.7, set \(\varepsilon _k = c \ \theta ^k\), where \(c > 0\) is a constant. Then for any given \(\varepsilon >0\), one may get a required approximate solution by using Algorithm 4.7 within K iteration steps, where \( K = ( \lceil \mathrm{ln}(\frac{\varepsilon }{c+C}) /\mathrm{ln} {\theta } \rceil +1) \lceil {\mathrm{ln}(\frac{c\theta }{c+(1-\theta )\rho (\mathcal {E})})}/{\mathrm{ln} d_2} \rceil \). In particular, if we choose \(c=\rho (\mathcal {E})\), then \( K = ( \lceil \mathrm{ln}(\frac{\varepsilon }{\rho (\mathcal {E})+C}) /\mathrm{ln} {\theta } \rceil +1) \lceil {\mathrm{ln}(\frac{\theta }{2-\theta })}/{\mathrm{ln} d} \rceil \), where \( d= \max \{ 1- \frac{\beta _{0}+ \theta }{\bar{\mathbb {R}}+ n^{m-1}\theta } , 1- \frac{\beta _{0}+ \theta ^L}{\bar{\mathbb {R}}+ n^{m-1}\theta ^L} \} ,\) \(L = \lceil \mathrm{ln}(\frac{\varepsilon }{c+C}) /\mathrm{ln} {\theta } \rceil +1\) is an upper bound of the outer iteration.
Let \(\mathcal {E}_{0}\) be an m-th order n dimensional nonnegative tensor with \(a_{ij\cdots j}=1,i,j=1,\cdots ,n\), the other entries being equal to 0. Take \(\mathcal {E}=\mathcal {E}_{0}\). We will prove it promote the inexact power-type algorithm.
Theorem 4.9
In Algorithm 4.7, set \(\varepsilon _k = c \ \theta ^k\), where \(c > 0\) is a constant. Then for any given \(\varepsilon >0\), one may get a required approximate solution by using Algorithm 4.7 within \(K_{1}\) iteration steps, where \( K_{1} = ( \lceil \mathrm{ln}(\frac{\varepsilon }{c+C}) /\mathrm{ln} {\theta } \rceil +1) \lceil {\mathrm{ln}(\frac{c\theta }{c+(1-\theta )\rho (\mathcal {E}_{0})})}/{\mathrm{ln} D} \rceil \). In particular, if we choose \(c=\rho (\mathcal {E}_{0})\), then \( K _{1}= ( \lceil \mathrm{ln}(\frac{\varepsilon }{\rho (\mathcal {E}_{0})+C}) /\mathrm{ln} {\theta } \rceil +1) \lceil {\mathrm{ln}(\frac{\theta }{2-\theta })}/{\mathrm{ln} D} \rceil \), where \( D= \max \{ 1- \frac{\beta _{3}+ 2\theta }{\bar{\mathbb {R}}+ n\theta } , 1- \frac{\beta _{3}+ 2\theta ^L}{\bar{\mathbb {R}}+ n\theta ^L} \} ,\) \(L = \lceil \mathrm{ln}(\frac{\varepsilon }{c+C}) /\mathrm{ln} {\theta } \rceil +1\) is an upper bound of the outer iteration.
Proof
Since \({\mathcal {A}}_{l}={\mathcal {A}}+ \tau _l \mathcal {E}_{0}\), we have \( \alpha _l = 1- \frac{\beta _{3}+ 2\theta ^l}{\bar{\mathbb {R}}+ n\theta ^l} ,\beta _{3} = \min _{i,j \in \{1,2,\cdots ,n \}}\{b_{ij\cdots j}+b_{ji\cdots i}\}\) by similar proof of Theorem 3.9. Denote
where \(L = \lceil \mathrm{ln}(\frac{\varepsilon }{c+C}) /\mathrm{ln} {\theta } \rceil +1\) is an upper bound of the outer iteration. Then we prove Theorem 4.9 by the same proof of Theorem 4.8.
Remark
Since \(\rho (\mathcal {E}_{0})=n\leqslant n^{m-1}=\rho (\mathcal {E})\) and \( \beta _{0}\leqslant \beta _{3} \), we have \( d<D \). Hence \(K< K_{1}\). Clearly, if \(\mathcal {E}=\mathcal {E}_{0}\) and \(m>1\), then Algorithm 4.7 needs less iterations.
5 Numerical Results
In this section, we give the numerical results and give a comparison for convergence rate between Algorithm 4.1 and the algorithm in [24].
When \(p=1\), Algorithm 2.15 is exact the NQZ method. Actually, for the different choices of p, Algorithm 2.15 has different performances. We state two examples to illustrate this result, and compare the performances for \(p=0.5,0.9,1,1.1,2\).
Example 5.1
We consider a 3-th order 3 dimensional nonnegative tensor \({\mathcal {A}}\) and \(\mathcal {B}\), where \(a_{132}=a_{231}=2\), \(a_{312}=1\) and \(b_{122}=b_{213}=2\), \(b_{211}=1\), \(b_{333}=3\). It can be shown that the tensor \({\mathcal {A}}\) is weakly primitive, while the tensor \(\mathcal {B}\) is weakly reducible. We can compute the spectral radius by Algorithm 2.15 for different p within \(1\,000\) iterations. we show the convergence result for each p, respectively.
p | 0.5 | 0.9 | 1 | 1.1 | 2 |
\({\mathcal {A}}-Ite\) | – | 36 | 22 | 15 | 12 |
\(\mathcal {B}-Ite\) | – | 686 | 58 | 63 | 118 |
Example 5.2
Given a 3-th order 8 dimensional nonnegative tensor \({\mathcal {A}}\), where \(a_{111}=a_{122}=a_{133}=a_{144}=a_{211}=a_{222}=a_{311}=a_{322}=a_{411}=a_{655}=a_{677}=a_{755}=a_{766}=1\), \(a_{233}=a_{333}=2\), \(a_{444}=2.5\), \(a_{455}=a_{555}=a_{566}=a_{577}=a_{588}=a_{811}=a_{855}=a_{866}=a_{877}=0.5\). We denote \(G({\mathcal {A}})\) as its representation. It is easy to see the graph of \(G({\mathcal {A}})\) that the tensor \({\mathcal {A}}\) is not indirectly positive but \({\mathcal {A}}\) is a primitive tensor, and thus we can learn that NQZ method is not global linear convergent. The experiment shows our correctness of this conclusion.
Example 5.3
We state the same example at (Example 3 [24]) to illustrate our tighter bound to compute the spectral radius of the tensor \({\mathcal {A}}\), where \(a_{122}= a_{133}=a_{211}=a_{311}=1\) and the other entries are equal to zero. The spectral radius of \({\mathcal {A}}\) is equal to \(\sqrt{2}\approx 1.414\,213\,562\,373\,095\), see [15]. It is obvious that tensor \({\mathcal {A}}\) is irreducible but not primitive. Thus the NQZ algorithm for such \({\mathcal {A}}\) will be not convergent. We use Algorithm 4.1 to test this example and use the same parameters.
We first show the result gained from (Example 22 [24]), \(\widetilde{\mathcal {A}}={\mathcal {A}}+\varepsilon \mathcal {E}\), where \(\mathcal {E}\) is a tensor with all the entries being equal to one.
\(\varepsilon \) | \(\rho (\widetilde{\mathcal {A}})-\frac{\varepsilon }{\min _{1\leqslant i\leqslant n}u_i^{m-1}}\) | \(\rho (\widetilde{\mathcal {A}})-\frac{\varepsilon }{\max _{1\leqslant i\leqslant n}u_i^{m-1}}\) | Error bound |
|---|---|---|---|
10\(^{-2}\) | 1.399 817 488 643 705 | 1.428 757 688 931 172 | 0.028 940 200 287 467 |
10\(^{-3}\) | 1.412 729 187 546 902 | 1.415 699 496 853 463 | 0.002 970 309 306 561 |
10\(^{-4}\) | 1.414 064 662 464 100 | 1.414 362 477 963 432 | 0.000 297 815 499 332 |
10\(^{-5}\) | 1.414 198 667 753 479 | 1.414 228 457 171 375 | 0.000 029 789 417 896 |
Then we state our result as follows: \(\overline{\mathcal {A}}={\mathcal {A}}+\varepsilon \triangle {\mathcal {A}}_{0}\), where \(\triangle {\mathcal {A}}_{0}\) is a nonnegative tensor of order m and dimension n with \(a_{ii\cdots ij}=1,i,j=1,\cdots ,n\), the other entries are equal to 0.
\(\varepsilon \) | \(\rho (\overline{\mathcal {A}})-\frac{\varepsilon }{\min _{1\leqslant i\leqslant n}u_i}\) | \(\rho (\overline{\mathcal {A}})-\frac{\varepsilon }{\max _{1\leqslant i\leqslant n}u_i}\) | Error bound |
|---|---|---|---|
\(10^{-2}\) | 1.411 691 223 747 498 1 | 1.416 740 234 958 303 8 | 0.005 049 011 210 805 65 |
\(10^{-3}\) | 1.413 960 041 793 559 8 | 1.414 467 148 062 405 | 0.000 507 106 268 845 227 6 |
\(10^{-4}\) | 1.414 188 190 623 875 | 1.414 238 934 550 686 3 | 0.000 050 743 926 811 349 684 |
\(10^{-5}\) | 1.414 211 026 544 121 2 | 1.414 216 100 153 698 6 | 0.000 005 073 609 577 493 887 |
It is clear that Algorithm 4.1 is more sufficient than that in [24].
What is more, we compare these two Algorithms as follows under the same error bound.
\(\varepsilon \) | Ite | \(\rho (\widetilde{\mathcal {A}})-\frac{\varepsilon }{\min _{1\leqslant i\leqslant n}u_i^{m-1}}\) | \(\rho (\widetilde{\mathcal {A}})-\frac{\varepsilon }{\max _{1\leqslant i\leqslant n}u_i^{m-1}}\) | Error bound |
|---|---|---|---|---|
\(1.702 \times 10^{-2}\) | 90 | 1.390 273 352 895 278 0 | 1.438 564 387 289 452 5 | 0.048 291 034 394 174 410 |
\(\varepsilon \) | Ite | \(\rho (\overline{\mathcal {A}})-\frac{\varepsilon }{\min _{1\leqslant i\leqslant n}u_i}\) | \(\rho (\overline{\mathcal {A}})-\frac{\varepsilon }{\max _{1\leqslant i\leqslant n}u_i}\) | Difference |
10\(^{-1}\) | 32 | 1.390 272 398 542 170 | 1.438 565 507 087 484 0 | 0.048 293 108 545 313 324 |
It is clear that our Algorithm needs less iterations.
Example 5.4
We present another example to illustrate our tighter bound to compute the spectral radius of the tensor \({\mathcal {A}}\). Let \({\mathcal {A}}\) be a 10-th order 4 dimensional nonnegative tensor, where \(a_{ij\cdots j}= \frac{1}{i},\ 1\leqslant i,j\leqslant 4,\) and the other entries are equal to zero. The spectral radius of \({\mathcal {A}}\) is equal to \(\frac{25}{12}\approx 2.083\,333\,333\,33\). We use Algorithm 4.1 to test this example and use the parameters of \(\Vert \ \Vert _{1}\).
We first show the result gained with the perturbation tensor in ([24]), \(\widetilde{\mathcal {A}}={\mathcal {A}}+\varepsilon \mathcal {E}\), where \(\mathcal {E}\) is a tensor with all the entries being equal to one, \(\varepsilon =10^{-6}\) :
\(\rho (\widetilde{\mathcal {A}})-\frac{\varepsilon }{\min _{1\leqslant i\leqslant n}\widetilde{u}_i^{m-1}}\) | \(\rho ({\mathcal {A}})\) | \(\rho (\widetilde{\mathcal {A}})-\frac{\varepsilon }{\max _{1\leqslant i\leqslant n}\widetilde{u}_i^{m-1}}\) | Error bound |
|---|---|---|---|
1.875 873 979 05 | 2.083 333 333 33 | 2.190 483 684 92 | 0.314 609 705 87 |
Then we state our result as follows: \(\overline{\mathcal {A}}={\mathcal {A}}+\varepsilon \triangle {\mathcal {A}}_{0}\), where \(\triangle {\mathcal {A}}_{0}\) is a nonnegative tensor of order m and dimension n with \(a_{ii\cdots ij}=1,i,j=1,\cdots ,n\), the other entries are equal to 0, \(\varepsilon =10^{-6} \):
\(\rho (\overline{\mathcal {A}})-\frac{\varepsilon }{\min _{1\leqslant i\leqslant n}\overline{u}_i^{m-1}}\) | \(\rho ({\mathcal {A}})\) | \(\rho (\overline{\mathcal {A}})-\frac{\varepsilon }{\max _{1\leqslant i\leqslant n}\overline{u}_i^{m-1}}\) | Error bound |
|---|---|---|---|
2.083 332 942 45 | 2.083 333 333 33 | 2.083 333 553 32 | 6.108 628 340 \(94 \times 10^{-7}\) |
It is clear that our algorithm is more efficient than that in [24].
References
Chang, K.C., Pearson, K., Zhang, T.: Perron Frobenius theorem for nonnegative tensors. Commun. Math. Sci. 6, 507–520 (2008)
Yang, Q., Yang, Y.: Further results for Perron-Frobenius theorem for nonnegative tensors II. SIAM. J. Matrix Anal. Appl. 32, 1236–1250 (2011)
Yang, Y., Yang, Q.: Further results for Perron-Frobenius theorem for nonnegative tensors. SIAM. J. Matrix Anal. Appl. 31, 2517–2530 (2010)
Li, Y., Yang, Q., Yang, Y.: A new definition of geometric multiplicity of eigenvalues of tensors and some results based on it. Front. Math. China 10(5), 1123–1146 (2015)
Chang, K.C., Qi, L., Zhang, T.: A survey on the spectral theory of nonnegative tensors. Numer. Linear Algebra Appl. 20, 891–912 (2013)
Chang, K.C., Qi, L., Zhou, G.: Singular values of a real rectangular tensor. SIAM J. Matrix Anal. Appl. 370, 284–294 (2010)
Qi, L., Sun, W., Wang, Y.: Numerical multilinear algebra and its applications. Front. Math. China 2, 501–526 (2007)
Drineas, P., Lim, L.: A Multilinear Spectral Theory of Hypergraphs and Expander Hypergraphs. Stanford University, Stanford, CA (2005)
Lim, L.H.: Multilinear pagerank: measuring higher order connectivity in linked objects. The Internet: Today and Tomorrow (2005)
Ni, Q., Qi, L., Wang, F.: An eigenvalue method for the positive definiteness identification problem. IEEE Trans. Autom. Control 53, 1096–1107 (2008)
Nussbaum, R.D.: Hilberts Projective Metric and Iterated Nonlinear Maps. Memoirs of the American Mathematical Society, Providence (1988)
Yang, Y., Yang, Q.: A note on the geometric simplicity of the spectral radius of nonnegative irreducible tensor. Front. Math. China 8(1), 129–144 (2013)
Ng, M., Qi, L., Zhou, G.: Finding the largest eigenvalue of a non-negative tensor. SIAM J. Matrix Anal. Appl. 31, 1090–1099 (2009)
Pearson, K.: Essentially positive tensors. Int. J. Algebra 4, 421–427 (2010)
Chang, K.C., Pearson, K., Zhang, T.: Primitivity, the convergence of the NQZ method, and the largest eigenvalue for nonnegative tensors. SIAM J. Matrix Anal. Appl. 32, 806–819 (2011)
Zhang, L., Qi, L.: Linear convergence of an algorithm for computing the largest eigenvalue of a nonnegative tensor. Numer. Linear Algebra Appl. 19, 830–841 (2012)
Hu, S., Huang, Z.H., Qi, L.: Strictly nonnegative tensors and nonnegative tensor partition. Sci. China Math. 57, 181–195 (2014)
Friedland, S., Gaubert, S., Han, L.: Perron-Frobenius theorem for nonnegative multilinear forms and extensions. Linear Algebra Appl. 438, 738–749 (2013)
Chen, Z., Qi, L., Yang, Q., Yang, Y.: The solution methods for the largest eigenvalue (singular value) of nonnegative tensors and convergence analysis. Linear Algebra Appl. 439(12), 3713–3733 (2013)
Lim, L.H.: Singular values and eigenvalues of tensors: a variational approach. Proceedings of the IEEE International Workshop on Computational Advances in Multi-Sensor Adaptive Processing 1, 129–132 (2005)
Pearson, K.: Primitive tensors and convergence of an iterative process for the eigenvalues of a primitive tensor. Math. Numer. Anal. arXiv:1004.2423 (2010)
Chang, K.C., Zhang, T.: Multiplicity of singular values for tensors. Commun. Math. Sci. 7, 611–625 (2009)
Yang, Y., Yang, Q., Li, Y.: An algorithm to find the spectral radius of nonnegative tensors and its convergence analysis. arXiv:1102.2668 (2011)
Li, W., Ng, M.K.: Perturbation bound for the spectral radius of a nonnegative tensor. Adv. Numer. Anal. 2014, 109525:1–109525:10 (2014)
Author information
Authors and Affiliations
Corresponding author
Additional information
Yi-Yong Li’s work was supported by the Ph.D. Candidate Research Innovation Fund of Nankai University. Qing-Zhi Yang’s work was supported by the National Natural Science Foundation of China (No. 11271206) and Doctoral Fund of Chinese Ministry of Education (No. 20120031110024).
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Li, YY., Yang, QZ. & He, X. A Method with Parameter for Solving the Spectral Radius of Nonnegative Tensor. J. Oper. Res. Soc. China 5, 3–25 (2017). https://doi.org/10.1007/s40305-016-0132-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40305-016-0132-4