
Abstract
Introduction
Propensity score (PS) matching is widely used in medical record studies to create balanced treatment groups, but relies on prior knowledge of confounding factors. High-dimensional PS (hdPS) is a semi-automated algorithm that selects variables with the highest potential for confounding from medical databases. The objective of this study was to evaluate performance of hdPS and PS when used to compare antihypertensive therapies in the UK clinical practice research datalink (CPRD) GOLD database.
Methods
Patients initiating antihypertensive treatment with either monotherapy or bitherapy were extracted from the CPRD GOLD database. Simulated datasets were generated using plasmode simulations with a marginal hazard ratio (HRm) of 1.29 for bitherapy versus monotherapy for reaching blood pressure control at 3 months. Either 16 or 36 known covariates were forced into the PS and hdPS models, and 200 additional variables were automatically selected for hdPS. Sensitivity analyses were conducted to assess the impact of removing known confounders from the database on hdPS performance.
Results
With 36 known covariates, the estimated HRm (RMSE) was 1.31 (0.05) for hdPS and 1.30 (0.04) for PS matching; the crude HR was 0.68 (0.61). Using 16 known covariates, the estimated HRm (RMSE) was 1.23 (0.10) and 1.09 (0.20) for hdPS and PS, respectively. Performance of hdPS was not compromised when known confounders were removed from the database.
Results on Real Data
With 49 investigator-selected covariates, the HR was 1.18 (95% CI 1.10; 1.26) for PS and 1.33 (95% CI 1.22; 1.46) for hdPS. Both methods yielded the same conclusion, suggesting superiority of bitherapy over monotherapy for time to blood pressure control.
Conclusion
HdPS can identify proxies for missing confounders, thereby having an advantage over PS in case of unobserved covariates. Both PS and hdPS showed superiority of bitherapy over monotherapy for reaching blood pressure control.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
A previously published real-world study [1] used standard PS matching on CPRD database to compare efficacy on blood pressure control of antihypertensive monotherapy versus bitherapy. However, high-dimensional PS method is said to be more performant than standard PS method in handling confounding bias from unknown or unmeasured confounders, and thus may provide more accurate results. |
The primary objective of this study was to evaluate if high-dimensional PS method outperformed standard PS method when comparing antihypertensive therapies on CPRD GOLD database. |
In all the simulation scenarii, high-dimensional PS equaled or outperformed standard PS method in handling confounding bias in CPRD GOLD database. On real data, both methods showed superiority of bitherapy over monotherapy for reaching blood pressure control. |
High-dimensional PS is a valid method to use in CPRD GOLD database to compare antihypertensive therapies and should be preferred to standard PS method when there is limited knowledge or report of confounding variables. |
Introduction
Randomized clinical trials (RCT) are often considered the gold standard of evidence-based medicine since they provide a scientifically rigorous framework to compare treatment effect between treatment groups with similar baseline characteristics. Randomization ensures that treatment groups are balanced, both in terms of known and unknown confounding factors. Nevertheless, RCTs have some limitations, including high cost, limited long-term follow-up, and lack of generalizability to the overall patient population, which is typically more heterogeneous than the study population [2].
Observational studies based on medical claims or administrative databases use real-world data that is representative of the general population and covers extended time periods. In contrast to RCTs, therapy assignment results from decisions made by the treating physician considering patient characteristics and preferences, which can lead to imbalance in baseline characteristics and confound inference of a potential treatment effect. Statistical methods, such as propensity score (PS) matching, have been employed to control for confounding in observational studies and create well-balanced treatment cohorts in terms of baseline characteristics [3,4,5]. Using these techniques, real-world data becomes amenable to hypothesis testing and to estimating treatment effects. Observational studies, in combination with PS matching, have been conducted to assess the generalizability of RCT results into clinical practice, evaluate long-term safety of new therapies, or to generate comparator arms for single-arm studies where randomization is jeopardized either due to ethical reasons or challenges in patient enrollment [1, 6,7,8,9].
From a statistical perspective, PS denotes the probability of being assigned to a given treatment group under a prespecified set of baseline characteristics [3]. In randomized clinical trials employing a 1:1 randomization ratio, PS is 0.5 for all participants, i.e., the chance of being assigned to either treatment group is 50%, regardless of baseline characteristics. In case of real-world data, the PS distribution differs between treatment groups as patient characteristics inherently impact treatment choice. In the standard PS approach, covariates are identified on the basis of clinical knowledge and used to estimate the PS to create patient cohorts with well-balanced baseline characteristics [10,11,12]. However, unknown or unobserved confounders may be neglected, and this may lead to residual bias [13].
Alternative algorithms, such as high-dimensional PS (hdPS), aim at reducing residual bias by introducing a large number of additional covariates through a semi-automated selection process [13]. HdPS identifies covariates with the highest confounding potential among variables stored in electronic healthcare databases. The method does not require prior knowledge of the correlation between variable and outcome because it automatically estimates the strength of correlation. It is thought that in doing so, hdPS can identify and select proxies for confounders, thereby reducing imbalance between treatment groups even if some confounding variables are unknown or unmeasured [13, 14].
Several studies were carried out to compare hdPS versus standard PS. Schneeweiss et al. evaluated hdPS and standard PS in three cohorts of older adults enrolled in Medicare and the Pennsylvania Pharmaceutical Assistance Contract for the Elderly [14]. Compared with standard PS, hdPS moved the estimated treatment effect closer to that expected on the basis of evidence from RCTs, suggesting that hdPS removes residual bias more efficiently than PS alone. Li et al. compared covariate regression, PS, and hdPS regression in a sample of patients treated with inhaled corticosteroids or leukotriene antagonists for asthma control [15]. Several healthcare databases were included and analyzed separately because of inherent differences in the patient population. No marked difference in estimated hazard ratios was observed for hdPS, PS, and covariate regression. Results were not in agreement with RCT data, which may reflect true differences in real-world effectiveness. Austin et al. used information collected from either administrative databases or clinical records [13]. Performance of hdPS and conventional PS was evaluated across several patient cohorts and treatment options; a retrospective chart review study in the same patient population was used as internal benchmark. Results showed that neither hdPS nor expert-based PS, using administrative data only, managed to balance all clinically important covariates. In terms of hazard ratios, hdPS performed well in some settings, while in others the method yielded qualitatively different results compared with the benchmark.
While this list of studies is not exhaustive, they highlight that choice of healthcare database and internal standard may be critical in the evaluation of hdPS performance. Until recently, there has been no well-defined benchmark to evaluate the ability of different methods to remove confounding from real-world datasets [13, 16]. RCT results are not adequate as a comparator since study populations are usually homogeneous and not representative of real-world data populations. Well-designed observational studies could serve as internal standard as demonstrated by Austin et al. [13], but such studies are not always available. Fully artificial datasets are not appropriate since they lack the complexity and quantity of data included in real world data [16]. A potential solution to this problem has been proposed by Franklin et al. who developed plasmode simulations. Plasmode simulations generate datasets that keep the complexity and association of all baseline characteristics contained in the original medical records datasets, but simulate expected outcomes under a prespecified treatment effect [17].
The primary objective of this study was to evaluate performance of hdPS and PS when used in conjunction with the clinical practice research datalink (CPRD) GOLD database by using plasmode simulation. A previously published real-world study applying PS matching to patients receiving different antihypertensive treatment options was emulated [1]. The goal of this study was to compare efficacy between bitherapy or monotherapy in achieving blood pressure control at 3 months after treatment initiation using PS matching.
Treatment effect was prespecified and used in the plasmode simulations. Since hazard ratios simulated within the plasmode framework are conditional on the set of covariates used in the model, we developed a method that provides the corresponding marginal hazard ratios [18, 19]. The latter can directly be compared with those obtained within the PS and hdPS framework. The impact of hdPS input parameters on estimated hazard ratios was assessed, both for the simulated and real-world datasets.
Methods
Data Sources
The CPRD GOLD database is a real-world database collecting anonymized patient data from general practitioner (GP) practices across the UK. Data can be linked to other healthcare databases, including the hospital episodes statistics (HES) and the Office for National Statistics (ONS) [20, 21]. The latter was used to censor patients at the time of their death.
Information is stored into different panels, including clinical, tests, referral, immunization, therapy, patient, and practice. Using these panels, information regarding symptoms, exams and laboratory tests, procedures, and diagnosis can be recorded (Table 1). The GPs enter relevant information using prespecified read codes for all medical information and British National Formulary (BNF) codes for prescriptions. Read codes follow a hierarchical pattern with each additional digit providing more granularity. In this study, four digits were kept to balance a relevant level of clinical detail with the number of records that would be disregarded because of insufficient precision. A time-window of 1 year prior to the index date was used to extract all baseline characteristics, except for diagnosis, which included the entire recorded period prior to the index date. Regarding the BNF codes, six digits were used to extract prescription medicines. This is the prevailing number of digits used in the BNF, grouping prescriptions by indication, and commonly used in other studies of this kind [22, 23]. Hospitalization data were divided into two dimensions: diagnoses, using the International Classification of Diseases version 10.0 (ICD-10) and procedures, using the Office of Population Censuses and Surveys (OPCS 4th version) for acts and procedures carried out during hospitalization.
This study protocol (number 21_000484) was approved by the Research Data Governance (RDG), formerly known as the Independent Scientific Advisory Committee (ISAC), of the Medicines and Healthcare products Regulatory Agency (MHRA) in the UK. ISAC, now called RDG, is a non-statutory expert advisory body providing scientific and ethical approval on research requests to access data provided by CPRD.
PS Matched Cohort Reference Study
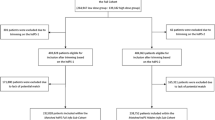
A retrospective cohort study using the UK CPRD GOLD database in conjunction with PS matching served as reference for evaluating the hdPS algorithm [1]. The objective of this reference study was to compare efficacy of initiating bitherapy versus monotherapy in a primary hypertensive population. The primary endpoint was time to occurrence of first blood pressure control [1]. Patients were eligible if they initiated either bitherapy or monotherapy between 1 January 2006 and 31 December 2014 and had no antihypertensive prescription during the previous 6 months. Antihypertensive classes considered were angiotensin converting enzyme inhibitor, angiotensin receptor blockers, calcium channel blocker, thiazide and thiazide‐like diuretics (TZD), and/or beta blockers [1].
Medical, prescription, and hospitalization records were extracted from CPRD GOLD, linked with data from the HES and the Office for National Statistics. PS was calculated using a logistic regression model including covariates that were selected on the basis of their known confounding potential. These investigator-selected covariates included demographic and life-style variables, medical history, and pharmacological therapy, as well as laboratory tests (Supplementary Table S1 and Supplementary Fig. S1). PS matching was applied to balance clinical and baseline characteristics between two patient cohorts. Patients were matched in a 1 bitherapy:2 monotherapy ratio using greedy matching with a caliper of 0.2 for the standard deviation (SD) of the logit PS [1, 24]
Results of this previous study suggested that patients starting with bitherapy were more promptly achieving blood pressure control compared with patients initiating monotherapy [hazard ratio 1.17, 95% confidence interval (CI) 1.09–1.26].
High-Dimensional PS
hdPS is a semi-automated algorithm that identifies variables with the highest potential for confounding among all variables available in medical records databases. Details of the algorithm have been described elsewhere [14] and a brief summary is provided hereafter.
In a first step, dimensions are defined to match information stored in the underlying healthcare database. Each dimension is treated separately since the prevalence of variables therein may vary, e.g., diagnosis typically occurs once, while tests can be prescribed several times.
In a second step, n variables with prevalence closest to 50% are kept. The choice of n is arbitrary since it aims only at reducing the computational burden. In this study, n was set to 10,000 on recommendation from the experts of the method [14].
Then, for each variable, the recurrence pattern is determined and Bross’ formula is applied to rank recurrence indicators created according to their multiplicative bias, also referred to as confounding bias [25]. Once the variables are ranked, the top k variables are selected. The choice of k should be sufficiently large to include all important confounders, but not too high to avoid overfitting [15]. In our study, multiplicative bias values indicated that setting k to 200 was sufficient to include all variables with a potential of confounding, while preventing overfitting. A lower value of k was evaluated in sensitivity analyses to test the performances of hdPS when a smaller number of automatic variables are included.
Finally, investigator-selected covariates are forced manually, in addition to the k variables identified by the hdPS algorithm. Typically, these are covariates that would be included for conventional PS, and should at a minimum include demographic variables [14]. Here, several sets of investigator-selected covariates from the reference study, containing an increased number of variables, were created to test the impact of the number and nature of investigator-selected covariates on the performance of hdPS. In addition to the native study set including 49 variables, two sets were created: the large set (n = 36) included demographics, essential variables (e.g., body mass index, history of hypertension), number of antihypertensive drugs, time variables (e.g., time since diagnosis of hypertension, time since diagnosis of diabetes, etc.), and test variables (e.g., lipid profile, cholesterol, glomerular filtration rate, etc.). The small set (n = 16) only included demographics, essential variables, and number of drugs (Table S1 and Fig. S1 ).
Plasmode Simulation
hdPS and PS were applied to both simulated and real datasets to compare their performance.
Simulated datasets preserving the empirical distribution of baseline characteristics and associations between covariates were generated using the plasmode methodology [17]. In this approach, the patient population of interest is extracted from the healthcare record database. In a first step, a Cox proportional hazards model was used on the real dataset to estimate associations between the covariates and the time-to-event outcome (Eq. 1):
where λY(t) is the hazard function at time t for the outcome Y, βZ is the observed treatment coefficient, and βX is the association between selected confounders X with the outcome. A total of 74 covariates, including demographic, clinical, medical history, therapy, and healthcare resource use information (Fig. S1 and Table 1), were defined as confounders for the simulated datasets. Time-to-event functions for both survival and censoring events were estimated.
In the next step, the treatment coefficient βZ was modified to define the desired treatment effect. In addition, the strength of association or confounding between covariates and outcome was inflated in the base case scenario by multiplying βX by α = 3 to increase confounding bias.
A total of 1000 cohorts with n = 54,523 patients were then generated by applying the previously defined survival and censoring functions to create new time-to-event and censoring variables. In the simulated datasets obtained, original information regarding covariates and treatment is kept, which allows to preserve real associations between variables while knowing the true treatment effect (conditional hazard ratio).
The above method allows estimating the hazard ratio conditional on the covariates used in the plasmode simulation model. However, it is the marginal hazard ratio that is required for comparison with the hazard ratio obtained with the univariate Cox model after PS matching. Hazard ratios are non-collapsible by nature, meaning that their conditional and marginal values differ, except when hazard ratio (HR) = 1 [18]. Therefore, the conditional hazard ratio used in plasmode simulation has to be converted to a marginal hazard ratio to serve as an internal standard for assessment of the treatment effect estimates after matching [18]. To derive the marginal hazard ratio from plasmode simulations, the entire patient dataset was generated twice, once assuming that all patients received treatment (X = 1) and once that they all received control (X = 0), creating by design two perfectly balanced cohorts. A univariate Cox model was then applied to these two cohorts to estimate the simulated marginal hazard ratio [18, 19].
Statistical and Sensitivity Analyses
Analyses on Simulated Data
Plasmode datasets were generated as described above. In the base case scenario, α was set to 3 and the conditional hazard ratio was set to 1.5, leading to an estimated marginal hazard ratio of 1.29. In sensitivity analyses, several combinations of different parameters were used with the conditional (and marginal) hazard ratio set to 1.0, and α to 1, to study the impact of these parameters on results. For each set of parameters, 1000 datasets were generated.
PS and hdPS matching were then applied on each simulated dataset. In the base case scenario, the large (n = 36) and the small (n = 16) sets of investigator-selected covariates were used both for PS and hdPS matching. In the hdPS matching, an additional k = 200 automatically selected covariates were added, and a sensitivity analysis was performed with only k = 50 automatically selected covariates. Additional sensitivity analyses were run by (a) removing test and time sets from the pool of variables available to the hdPS algorithm, (b) removing potential instrumental variables, and (c) redefining dimensions by using the CPRD GOLD panels [22], rather than dimensions based on variable type.
Removing test and time variables from the pool of available variables creates a test-environment that is blinded to these variables. This test-environment allows evaluating whether hdPS successfully identifies proxies for unobserved variables, one of the acclaimed premises of the hdPS algorithm [13]. Removal of instrumental variables from hdPS matching was recommended by the authors of the original hdPS algorithm. Instrumental variables correlate with exposure, but not with outcome. These variables should be excluded from the PS matching because they may increase standard error and bias results [14]. To do so, the relative risks of exposure (rrce) and outcome (rrcd) were evaluated for each variable, and the latter was excluded if the absolute value of log rrce was > 1.5 and the absolute value of log rrcd was < 0.5 (Table S2). Finally, the way variables and dimensions are defined upfront may impact performance of the hdPS algorithm. In the base case scenario, we selected ten dimensions on the basis of the type of information contained in the variables, which can be inferred from the first digit in the read codes. An alternative is to use CPRD GOLD panels as dimensions, as done elsewhere [22].
Finally, a univariate Cox proportional hazard model with robust variance estimator was used to calculate the marginal treatment effect in patient cohorts obtained after conventional PS and hdPS matching on the simulated plasmode datasets [26]. HdPS included all covariates used in PS plus additional variables selected with the semi-automated algorithm, as described above.
Analyses on Real Data
For the application of PS and hdPS to the real dataset, the 49 investigator-selected covariates that were used in the reference study were forced in PS and hdPS models, and 200 additional variables were selected via the hdPS algorithm [1]. Sensitivity analyses have been performed on the number of investigator-selected covariates, which were varied from 6 (i.e., only demographics) to 36 (i.e., large set).
To assess whether matched cohorts are well balanced with respect to baseline characteristics, the absolute standard differences (ASD) for each covariate was computed. A covariate with an ASD < 0.1 is usually considered balanced. For hdPS, calculation and presentation of ASD for all covariates is impractical; therefore, only the variables (n = 49) included in the reference study were considered (Fig. S1).
Kaplan–Meier survival analysis was carried out to estimate survival curves and to derive survival at 3 months for both treatment cohorts. The survival probability represents the probability of patients not having reached blood pressure control at a given time. Finally, a univariate Cox proportional hazard model was used to estimate the hazard ratio for reaching blood pressure control at 3 months for the patient cohorts resulting after hdPS or PS matching.
Results
Simulated Plasmode Datasets
Both PS and hdPS matching generated two treatment cohorts that were well equilibrated with respect to baseline characteristics.
In the base case scenario, PS and hdPS adjusted on the large set of investigator-selected covariates (n = 36) yielded marginal hazard ratios (Root Mean Square Error (RMSE)) of 1.31 (0.05) and 1.30 (0.04), respectively, close to the actual marginal hazard ratio of 1.29 (Table 2, Fig. 1). In comparison, the crude Cox proportional hazard model using the full, unmatched patient cohorts yielded a hazard ratio (RMSE) of 0.68 (0.61), favoring monotherapy over bitherapy.

Plasmode simulation results. hdPS, high-dimensional propensity score; HR, hazard ratio; HRc, conditional hazard ratio; PS, propensity score; RMSE, root mean square error;
Using the small set of investigator-selected covariates (n = 16), hdPS performed better than PS with an estimated HR (RMSE) of 1.23 (0.10) compared with 1.09 (0.20) for PS (Table 2, Fig. 1). Keeping the small set of covariates and removing test and time variables from the pool of available covariates to create a blinded test-environment, did not diminish performance of hdPS [HRm (RMSE) = 1.23 (0.10)], suggesting that the method was able to choose proxy variables in the dataset for these unknown/unmeasured covariates (Table 2). Selecting fewer variables (k = 50) during the hdPS algorithm moved the estimated marginal hazard ratio further away from the true hazard ratio, but still favored bitherapy over monotherapy HR (RMSE) = 1.18 (0.12) (Table S3). Excluding instrumental variables from hdPS matching tended to lower the estimated marginal hazard ratio [HR (RMSE) = 1.21 (0.11)] as well (Table S3). Using CPRD GOLD panels as dimensions had little impact on results with HR (RMSE) = 1.23 (0.08) (Table S3).
Root mean square errors (RMSE) were in general comparable between hdPS and PS and tended to be higher when only the small set of investigator-selected covariates was selected (Table 2). This could be related to improved matching when more known covariates are included, leading to less variability in patient cohorts across simulations. Another issue that may influence results is the size of treatment cohorts; the latter shows larger variability after hdPS matching compared with PS matching. Furthermore, additional variables included in hdPS matching could lead to better discrimination between patients in the two treatment groups and the exclusion of a higher proportion of patients that could not be matched. Indeed, the number of patients in the hdPS matched cohorts varied between approximately 5000 and 7500 patients compared with approximately 8500 to 9800 matched patients after PS matching (Fig. S2).
Real Dataset
After application of selection criteria, 54,523 patients were included in reference study, with 51,267 started on monotherapy and 3256 started on bitherapy [1].
Receiver operating characteristics (ROC) curves were calculated for exposure with the PS and hdPS models adjusted on the 49 investigator-selected covariates of the reference study. The area under the ROC curve was higher after hdPS matching compared with PS matching (0.913 versus 0.847). This result suggests that hdPS predicts treatment exposure more precisely compared with PS. However, it does not imply that hdPS has better control of confounding [27,28,29]. The latter depends on the ability of the algorithm to generate well-balanced matched cohorts on all confounders. There must be sufficient overlap between the PS distributions of the treatment cohorts to create matched cohorts. Visual inspection of the PS distributions shows that there is sufficient overlap for both PS and hdPS to proceed with the matching procedure (Fig. S3), although the overlap is slightly lower for the hdPS approach, as expected.
A total of 2821 bitherapy patients were matched to 5642 monotherapy patients with PS calculated on the 49 investigator-selected variables, whereas 1651 bitherapy patients were matched to 3302 monotherapy patients with hdPS (i.e., adding 200 automatic variables). Characteristics of full and matched cohorts are given in Tables S4, S5, and S6. The mean ASD over the 49 investigator-selected covariates was 0.02 after PS matching. It was slightly higher after hdPS matching, i.e., 0.05. In sensitivity analyses, with the small set of covariates (n = 16), the mean ASD was also higher with hdPS matching than with PS matching (0.05 versus 0.04). On the contrary, when only the demographics variables were forced, the mean ASD was higher with PS matching (0.10) than with hdPS matching (0.06).
Median follow-up, i.e., time at which 50% of patients have been censored, was comparable between the two cohorts (116 versus 120 days for the hdPS and PS matched cohorts, respectively). With hdPS matching, Kaplan–Meier survival curves showed a 26% chance for reaching blood pressure control at 3 months in the monotherapy cohort compared with a 30% chance in the bitherapy cohort (Table 3). The corresponding probabilities for PS matching were 24% and 26% with monotherapy and bitherapy, respectively (Table 3). The hazard ratio for treatment effect of bitherapy versus monotherapy, calculated with the univariate Cox proportional hazard model, was 1.18 (95% CI 1.10, 1.26) for PS and 1.33 (95% CI 1.22, 1.46) for hdPS. The estimated treatment effect was higher with hdPS compared with PS. Both methods yielded the same conclusion, suggesting superiority of bitherapy over monotherapy for time-to blood pressure control.
Finally, the effect of adding more investigator-selected covariates to the PS and hdPS models on the estimated HR (sensitivity analyses) is visually depicted in Fig. 2. The crude hazard ratio is smaller than 1, suggesting that monotherapy is superior to bitherapy in achieving blood pressure control. When adjusting via PS matching for demographic variables, the hazard ratio slightly increases but still favors monotherapy. Only when including essential and number of drugs variables to PS matching, the estimated hazard ratios is higher than 1, favoring bitherapy over monotherapy. The hazard ratio estimated with hdPS is > 1 in all cases, even when only demographic variables are forced into the model, suggesting that hdPS can find proxies for missing confounders. In this given example, the estimated hazard ratio increases for both PS and hdPS as more investigator-selected covariates are included.

Impact of forced covariates on hazard ratio estimation for PS and hdPS. CI, confidence interval; hdPS, high-dimensional propensity score; HR, hazard ratio; PS, propensity score
Discussion
The performance of hdPS versus PS was evaluated using simulated plasmode datasets with the advantage of complex data structure and known treatment effect as internal references. HdPS and PS performed similarly when a large set of known confounding factors were included in their estimation. However, hdPS outperformed PS when only a limited set of investigator-selected variables (n = 16) was forced.
One of the claimed benefits of hdPS consists in finding proxies for unknown or unobserved confounders among variables recorded in medical record databases [13, 14, 27]. Only few studies have systematically assessed this aspect [30,31,32]. In this study, the performance of hdPS was not compromised when certain known confounders were withdrawn from the pool of variables available to the hdPS algorithm, suggesting that the hdPS algorithm is robust under conditions where important confounders are unobserved in the dataset. Also, when only few investigator-selected variables were forced into the model, hdPS could identify unknown confounders, suggesting that the algorithm is able to identify confounders that would otherwise have been overlooked with the conventional PS approach. Thus, hdPS should be seen as a complement to standard PS.
A similar experiment was carried out by Toh et al. to assess the effect of unknown variables on the performance of hdPS [27]. The authors calculated odds ratios (OR) for upper gastrointestinal bleeding in patients initiating traditional non-steroidal antiinflammatory drugs (NSAIDs) compared with selective Cox-2 inhibitors using hdPS or PS matching. Both methods correctly predicted a lower risk of gastrointestinal bleeding with Cox-2 inhibitors compared with traditional NSAIDs. Importantly, in the study by Toh et al., the OR estimated with hdPS was robust, even when only demographic variables were forced into the hdPS model. Austin et al. created an experimental set-up reminiscent of testing the capacity of identifying unobserved confounders. The authors compared different matching strategies, using either clinical information or administrative healthcare databases [13]. Neither PS nor hdPS matching using information from administrative databases only were able to balance all clinically important covariates across cohorts, indicating that the method was unable to identify sufficient proxies for unobserved confounders in the administrative database. Of note, performance of hdPS was little affected when expert-selected covariates were omitted. Taken together, these results suggest that the number of investigator-selected covariates forced into hdPS has only a small impact on performance. In addition, the clinical situation and nature of the healthcare databases can affect results. The authors of the original hdPS algorithm have pointed out that the method may miss potential confounders in situations when the outcome of interest is rare. In these clinical situations, the number of events might be insufficient to detect a true association between covariates, exposure, and outcome [14]. In addition, the content of healthcare databases may limit the performance of hdPS if too many covariates are missing. In this case, the capacity of the hdPS algorithm of finding proxies for unknown or unobserved variables could be compromised [15].
Performance of hdPS is generally assessed by two distinct approaches: (a) calculating the balance between cohorts in terms of covariates [15, 16, 33, 34] and/or (b) comparing estimates of treatment effect with an internal standard [16]. Previous studies generally focused on the balance of important confounders after the matching procedure using ASD. Even though this measure can be useful for model selection for a given matching algorithm [35], comparison of ASD resulting from hdPS versus PS is of limited interest because the variables used to estimate these quantities are not the same. Here, mean ASD of the 49 investigator-selected covariates was higher after hdPS matching compared with PS matching. This result can be explained by the fact that the hdPS algorithm tries to optimize the balance across a larger set of covariates (n > 200), and this may reduce the balance in the subset of variables for which ASD was calculated [36]. The purpose of matching on hdPS is not only achieving balance among known confounders, but also balancing other unknown/unobserved confounders in the dataset, which ultimately should improve the quality of treatment effect estimates.
Several studies have assessed hdPS performance by comparing estimated hazard or odd ratios against a reference taken either from RCT data, meta-analyses, or observational studies [12,13,14]. However, the lack of a well-defined gold standard leads to a methodological dead-end [13, 16]. Recently, Franklin et al. developed a hybrid method, called plasmode simulations, which combines the complexity of baseline variables contained in real-world datasets with simulated time-to-event functions that generate outcomes on the basis of a known treatment effect [17].
The strength of our study is the use of plasmode simulations as an internal standard and the derivation of marginal hazard ratios from these simulated datasets. This sets a solid mathematical framework to compare PS and hdPS derived hazard ratios to an internal gold standard and allows evaluating systematically the performance of either algorithm. Besides the impact of the number of investigator-selected variables on hdPS performance, we have also analyzed the effect of decreasing the number of automatically selected variables (decreased accuracy in estimating HR), definition of dimensions (little impact), and inclusion/exclusion of instrumental variables (decreased accuracy in estimating HR). Decreasing the number of automatically selected variables to k = 50 worsens the treatment effect prediction. Even though bitherapy is still predicted to be superior to monotherapy, the estimated HR is lower than the true HR, and closer to the crude HR estimate. This suggests that there remains some confounding bias in the matched samples. The second observation is in line with other studies that analyzed the effect of modifying granularity of read-codes or dimensions—these changes had little impact on results [14, 27]. Exclusion of instrumental variables slightly worsened the estimated hazard ratios in our example. Instrumental variables were identified automatically on the basis of a previously published algorithm [14]. Additional research is needed to define the best way of excluding instrumental variables without detriment to the quality of the model. One possibility could be to exclude instrumental variables from PS model, but include them in the final outcome model.
This study has several limitations. Considering the base case scenario employing a large set of investigator-selected variables, the lack of a marked benefit of hdPS over PS in balancing treatment cohorts, and predict treatment effect casts doubt on the usefulness of hdPS in this scenario. However, it should be noted that PS matching has been optimized extensively for the reference study, and that most confounding variables (n = 36) were used in the PS matching procedure. The simulated datasets were based on a Cox linear model with 74 covariates, including those used for PS matching. It is hypothesized that the 36 covariates were sufficient to control most of the confounding, thereby limiting the potential for improvement by hdPS.
Second, we have only used one reference study to test performance of hdPS. It would be useful to apply plasmode simulations to other clinical situations. In addition, using other healthcare databases might be of value to determine the role of the underlying medical records database on results. While our study suggests that information stored in the CPRD GOLD database is suited for the hdPS algorithm, this result cannot be generalized to other databases.
Third, the hdPS method has originally been developed for binary information and tailored to the format of medical claims databases. In its current form, the algorithm cannot automatically select continuous variables, which need to be added manually during the procedure.
It was argued that in clinical research, all analyses should be prespecified in a manner that is agnostic to treatment outcome [4]. The hdPS algorithm violates this principle, since it uses outcome data to select confounders. However, the procedure is automated with no iterative fine tuning to improve its predictive capacity. The automated character of the hdPS algorithm could be exploited for clinical settings where little is known about confounding factors. HdPS may reveal variables that correlate with treatment or outcome. These potential confounders may then be subject to evaluation in prospective studies to test and validate hypothetical associations and outcome predictors and help with elucidating disease mechanisms.
HdPS could be generalized to handle continuous variables and/or considering correlation between covariates. Lasso regression after hdPS selection has been used to reduce multicollinearity and overfitting, but this method only handles the relationship with treatment [37, 38]. Other methods could be evaluated that consider associations between variables and both treatment and outcome. In this study, we used matching algorithms to create balanced cohorts with the caveat that some patients will be excluded during the matching procedure. Alternative methods such as inverse probability of treatment weighting or adjusted regression analysis may mitigate the risk of excluding a large proportion of patients [15, 39]. Considering multiple outcomes in the selection procedure might be interesting in the context of diseases with heterogeneous clinical presentation that require inclusion of multiple endpoints to determine treatment effect. Finally, our study emphasizes the fact that conditional and marginal hazard ratios differ; therefore, attention should be paid in any comparison including hazard ratios.
Conclusions
HdPS improves propensity score matching in simulation scenarii where few confounding variables were known or observed, thanks to the fact that it can identify proxies for missing confounders. In these situations, treatment effect estimated with hdPS was more accurate than that obtained with conventional PS in our plasmode simulations. In addition, the simulation results demonstrated that the CPRD GOLD database is suited for using hdPS in the clinical setting of hypertension. When using the real CPRD GOLD data, both PS and hdPS showed superiority of bitherapy therapy over monotherapy for reaching blood pressure control. Future studies should explore the application of hdPS to other healthcare databases and a more diverse set of clinical situations.
References
Marinier K, Macouillard P, de Champvallins M, Deltour N, Poulter N, Mancia G. Effectiveness of bitherapy therapy versus monotherapy as initial regimen in hypertension: a propensity score-matched cohort study in the UK Clinical Practice Research Datalink. Pharmacoepidemiol Drug Saf. 2019;28(12):1572–82. https://doi.org/10.1002/pds.4884.
Frieden TR. Evidence for health decision making—beyond randomized, controlled trials. N Engl J Med. 2017;377(5):465–75. https://doi.org/10.1056/nejmra1614394.
Rosenbaum PR, Rubin DB. The central role of the propensity score in observational studies for causal effects. Matched Sampl Causal Eff. 2006;1083:170–84. https://doi.org/10.1017/CBO9780511810725.016.
Rubin DB. The design versus the analysis of observational studies for causal effects: parallels with the design of randomized trials. Stat Med. 2022;26:20–36.
D’Agostino RJ. Propensity score methods for bias reduction in the comparison oa treatment to a non-randomized control group. Stat Med. 1998;17(19):2265–81.
Weinhandl E, Gilbertson D, Collins A, Foley R. Relative safety of peginesatide and epoetin alfa. Pharmacoepidemiol Drug Saf. 2014;23(10):1003–11. https://doi.org/10.1002/PDS.3655.
de Botton S, et al. Improved survival with enasidenib versus standard of care in relapsed/refractory acute myeloid leukemia associated with IDH2 mutations using historical data and propensity score matching analysis. Cancer Med. 2021;10(18):6336–43. https://doi.org/10.1002/CAM4.4182.
Eisler L, Lenke L, Sun L, Li G, Kim M. Do antifibrinolytic agents reduce the risk of blood transfusion in children undergoing spinal fusion? A propensity score-matched comparison using a national database. Spine (Phila PA 1976). 2020;45(15):1055–1061. https://doi.org/10.1097/BRS.0000000000003455.
Rambaldi A, et al. Blinatumomab compared with standard of care for the treatment of adult patients with relapsed/refractory Philadelphia chromosome–positive B-precursor acute lymphoblastic leukemia. Cancer. 2020;126(2):304–10. https://doi.org/10.1002/cncr.32558.
Elze MC, et al. Comparison of propensity score methods and covariate adjustment: evaluation in 4 cardiovascular studies. J Am Coll Cardiol. 2017;69(3):345–57. https://doi.org/10.1016/j.jacc.2016.10.060.
Austin PC. An introduction to propensity score methods for reducing the effects of confounding in observational studies. Multivar Behav Res. 2011;46(3):399–424. https://doi.org/10.1080/00273171.2011.568786.
Ellis AR, et al. Investigating differences in treatment effect estimates between propensity score matching and weighting: a demonstration using STAR*D trial data. Pharmacoepidemiol Drug Saf. 2017;22(2):138–44. https://doi.org/10.1002/pds.3396.
Austin PC, Wu CF, Lee DS, Tu JV. Comparing the high-dimensional propensity score for use with administrative data with propensity scores derived from high-quality clinical data. Stat Methods Med Res. 2020;29(2):568–88. https://doi.org/10.1177/0962280219842362.
Schneeweiss S, Rassen JA, Glynn RJ, Avorn J, Mogun H, Brookhart MA. High-dimensional propensity score adjustment in studies of treatment effects using health care claims data. Epidemiology. 2009;20(4):512–22. https://doi.org/10.1097/EDE.0b013e3181a663cc.High-dimensional.
Li L, Vollmer WM, Butler MG, Wu P, Kharbanda EO, Wu AC. A comparison of confounding adjustment methods for assessment of asthma controller medication effectiveness. Am J Epidemiol. 2014;179(5):648–59. https://doi.org/10.1093/aje/kwt323.
Guertin JR, Rahme E, Dormuth CR, Lelorier J. Head to head comparison of the propensity score and the high-dimensional propensity score matching methods. BMC Med Res Methodol. 2016;16(1):8–11. https://doi.org/10.1186/s12874-016-0119-1.
Franklin JM, Schneeweiss S, Polinski JM, Rassen JA. Plasmode simulation for the evaluation of pharmacoepidemiologic methods in complex healthcare databases. Comput Stat Data Anal. 2014;72:219–26. https://doi.org/10.1016/j.csda.2013.10.018.Plasmode.
Daniel R, Zhang J, Farewell D. Making apples from oranges: comparing noncollapsible effect estimators and their standard errors after adjustment for different covariate sets. Biometrical J. 2021;63(3):528–57. https://doi.org/10.1002/bimj.201900297.
Austin PC, Stafford J. The performance of two data-generation processes for data with specified marginal treatment odds ratios. Commun Stat Simul Comput. 2008;37(6):1039–51. https://doi.org/10.1080/03610910801942430.
National Health Service (NHS). Hospital Episode Statistics (HES). https://digital.nhs.uk/data-and-information/data-tools-and-services/data-services/hospital-episode-statistics.
Office for National Statistics (ONS). Births, deaths and marriages; 2020. https://www.ons.gov.uk/peoplepopulationandcommunity/birthsdeathsandmarriages.
Tazare J, Smeeth L, Evans SJW, Williamson E, Douglas IJ. Implementing high-dimensional propensity score principles to improve confounder adjustment in UK electronic health records. Pharmacoepidemiol Drug Saf. 2020;29(11):1373–81. https://doi.org/10.1002/pds.5121.
National Health System (NHS). BNF classification and pseudo classification used by the NHS prescription services; 2017. https://www.nhsbsa.nhs.uk/sites/default/files/2017-04/BNF_Classification_Booklet-2017_0.pdf.
Austin PC. The use of propensity score methods with survival or time-to-event outcomes: reporting measures of effect similar to those used in randomized experiments. Stat Med. 2014;33(7):1242–58. https://doi.org/10.1002/sim.5984.
Bross IDJ. Spurious effects from an extraneous variable. J Chronic Dis. 1966;19(6):637–47. https://doi.org/10.1016/0021-9681(66)90062-2.
Lin DY, Wei LJ. The robust inference for the cox proportional hazards model. J Am Stat Assoc. 1989;84(408):1074. https://doi.org/10.2307/2290085.
Toh S, García Rodríguez LA, Hernán MA. Confounding adjustment via a semi-automated high-dimensional propensity score algorithm: an application to electronic medical records. Pharmacoepidemiol Drug Saf. 2011;20(8):849–857. https://doi.org/10.1002/pds.2152.
Weitzen S, Lapane KL, Toledano AY, Hume AL, Mor V. Weaknesses of goodness-of-fit tests for evaluating propensity score models: the case of the omitted confounder. Pharmacoepidemiol Drug Saf. 2005;14(4):227–38. https://doi.org/10.1002/PDS.986.
Brookhart M, Schneeweiss S, Rothman K, Glynn R, Avorn J, Stürmer T. Variable selection for propensity score models. Am J Epidemiol. 2006;163(12):1149–56.
Schneeweiss S. Automated data-adaptive analytics for electronic healthcare data to study causal treatment effects. Clin Epidemiol. 2018;10:771–88. https://doi.org/10.2147/CLEP.S166545.
Wyss R, Schneeweiss S, van der Laan M, Lendle SD, Ju C, Franklin JM. Using super learner prediction modeling to improve high-dimensional propensity score estimation. Epidemiology. 2018;29:96–106.
Guertin JR, Rahme E, LeLorier J. Performance of the high-dimensional propensity score in adjusting for unmeasured confounders. Eur J Clin Pharmacol. 2016;72(12):1497–505. https://doi.org/10.1007/s00228-016-2118-x.
Austin PC. The relative ability of different propensity score methods to balance measured covariates between treated and untreated subjects in observational studies. Med Decis Making. 2009;29(6):661–77. https://doi.org/10.1177/0272989X09341755.
Austin PC. Balance diagnostics for comparing the distribution of baseline covariates between treatment groups in propensity-score matched samples. Stat Med. 2009;28:3083–3107. https://doi.org/10.1002/sim.3697.
Belitser S, Martens E, Pestman W, Groenwold R, de Boer A, Klungel O. Measuring balance and model selection in propensity score methods. Pharmacoepidemiol Drug Saf. 2011;20(11):1115–29. https://doi.org/10.1002/PDS.2188.
Wyss R, Schneeweiss S, Van Der Laan M, Lendle SD, Ju C, Franklin JM. Using super learner prediction modeling to improve high-dimensional propensity score estimation. Epidemiology. 2018;29(1):96–106. https://doi.org/10.1097/EDE.0000000000000762.
Tian Y, Schuemie MJ, Suchard MA. Evaluating large-scale propensity score performance through real-world and synthetic data experiments. Int J Epidemiol. 2018;47(6):2005–14. https://doi.org/10.1093/ije/dyy120.
Schneeweiss S, Eddings W, Glynn RJ, Patorno E, Rassen J, Franklin JM. Variable selection for confounding adjustment in high-dimensional covariate spaces when analyzing healthcare databases. Epidemiology. 2017;28:237–48. https://doi.org/10.1097/EDE.0000000000000581.
Allan V, et al. Propensity score matching and inverse probability of treatment weighting to address confounding by indication in comparative effectiveness research of oral anticoagulants. J Comp Eff Res. 2020;9(9):603–14. https://doi.org/10.2217/cer-2020-0013.
Acknowledgements
We thank Lucile Offredo and Karine Marinier (Servier) for programming, advice and discussion, and Katrin Spiegel, on behalf of Springer Healthcare France, for medical writing assistance.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Funding
This study was funded by Institut de Recherches Internationales Servier (IRIS), including time spent by the authors and contributors, database license, software license, article writing, and the journal’s rapid service fee.
Medical Writing and Editorial Assistance
Medical writing support was provided by Katrin Spiegel (Springer Healthcare France) and editorial support was provided by Sarah Novack (Springer Healthcare France).
Author Contributions
Authors had full access to the data in the study and take full responsibility for the integrity and accuracy of the data. Concept and design was carried out by all authors. Acquisition, analysis, or interpretation of data was performed by all authors. Drafting of the manuscript was performed by all authors. Critical revision for intellectual content was performed by all authors. Statistical analysis was performed by Jade Vadel.
Disclosures
Virginie Simon is an employee of Institut de Recherches Internationales Servier (IRIS). Jade Vadel’s affiliation changed from Institut de Recherches Internationales Servier (IRIS) to IQVIA during the completion of the manuscript.
Compliance with Ethics Guidelines
The study protocol was approved by the Independent Scientific Advisory Committee (ISAC) of the Medicines and Healthcare products Regulatory Agency in the UK. ISAC is a non-statutory expert advisory body providing scientific and ethic approval on research requests to access data provided by CPRD.
Data Availability
Please contact the authors for further information. Datasets used for this study are propriety of the Medicines and Healthcare products Regulatory Agency (MHRA) and are not publicly available.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License, which permits any non-commercial use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc/4.0/.
About this article

Cite this article
Simon, V., Vadel, J. Evaluating the Performance of High-Dimensional Propensity Scores Compared with Standard Propensity Scores for Comparing Antihypertensive Therapies in the CPRD GOLD Database. Cardiol Ther 12, 393–408 (2023). https://doi.org/10.1007/s40119-023-00316-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40119-023-00316-7