
Abstract
This study aims to discuss the solution methodology for a closed-loop supply chain (CLSC) network that includes the collection of used products as well as distribution of the new products. This supply chain is presented on behalf of the problems that can be solved by the proposed meta-heuristic algorithms. A mathematical model is designed for a CLSC that involves three objective functions of maximizing the profit, minimizing the total risk and shortages of products. Since three objective functions are considered, a multi-objective solution methodology can be advantageous. Therefore, several approaches have been studied and an NSGA-II algorithm is first utilized, and then the results are validated using an MOSA and MOPSO algorithms. Priority-based encoding, which is used in all the algorithms, is the core of the solution computations. To compare the performance of the meta-heuristics, random numerical instances are evaluated by four criteria involving mean ideal distance, spread of non-dominance solution, the number of Pareto solutions, and CPU time. In order to enhance the performance of the algorithms, Taguchi method is used for parameter tuning. Finally, sensitivity analyses are performed and the computational results are presented based on the sensitivity analyses in parameter tuning.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The incremental trend of industrialization demands more and more resources for producing the innovative and old-fashioned products. However, two main types of resources can be identified. Renewable resources are sources of energy that are not depleted by use, such as wind, or solar power and the like. A non-renewable resource cannot be replaced by the nature such as fossil fuels. In this study, we focus on the non-renewable resources that are noteworthy due to depleting. Considering the increase in demand for resources, these resources will be too expensive as they become less available. Consequently, many companies try to produce products that use resources supplied by the end-user. In this chain, the end-users deliver the used products to collection centers to be used for producing products in manufacturing centers (McWilliams and Siegel 2001). The process of collecting products from the end-users and recycling is called “reverse logistics” (Chen et al. 2017). A good instance for reverse logistics is the Japanese Ministry of the Environment for the automotive industry (Sudarto et al. 2016). Recent studies show a good classification for the investigated industries related to CLSC. These studies involve 69 papers between 2003 and 2015 (Govindan and Soleimani 2017). As shown in Table 1, no study is performed in the area of oil and related fields during 12 years. This reason encouraged us to make a research in this area.
Oil involves many derivatives such as kerosene, lubricant, gasoline, and tar. In this study, we concentrate on the lubricants. Engine oil that is one of the important products which is used in cars for lubrication of engine parts. Since oil is one of the expensive and non-renewable products, designing an optimized reverse logistics will be advantageous both financially and environmentally (Özceylan and Paksoy 2013).
This paper aims to design a closed-loop reverse logistics for collecting used engine oil that will be used in manufacturing centers. Most of real-world supply chain (SC) problems are complex due to high number of indices which increase the dimension of the problem and it may lead to inefficiency of routine solution approaches (Fahimnia et al. 2013). Regarding increase in the size of problem, exponential growth in complexity makes the model become NP-hard (Park et al. 2007; Jolai et al. 2011). To deal with this problem, meta-heuristic solution methodologies are applied in this study. The algorithms that have been employed in this study are NSGA-II, MOSA, and MOPSO. In order to validate the results generated by each algorithm, three meta-heuristics are used.
The paper is composed of the following sections. In “Literature review,” a comprehensive study is performed to examine earlier researches and introduce the present research path. The problem is described and the mathematical model is represented in “Problem statement” section. Meta-heuristics are presented in the “Solution methodology”. The criteria are introduced in “Performance measure.” Taguchi approach is discussed in “Parameter setting,” and finally, brief results of the study and future research recommendations are provided in “Conclusion and future research” section.
Literature review
In this section, solution methodologies for solving mathematical models are presented specifically supply chain network models which were proposed by recent researchers. Since the current work focused on the meta-heuristic solution approaches the field of the supply chain, the concerned papers are discussed as follows.
Bandyopadhyay et al. (2008)proposed a new simulated annealing (SA) called archived multi-objective simulated annealing (AMOSA). The proposed algorithm was compared with two other solution methods: (1) non-dominated sorting genetic algorithm (NSGA-II) (2) Pareto archived evolution strategy (PAES). The results showed better performance of AMOSA than NSGA-II and PAES. Mahdavi et al. (2009) designed a model for a cell formation problem in cellular manufacturing was designed for this problem. Genetic algorithm was used for solving the model. Simple and uniform crossovers as well as a heuristic mutation generate new solutions. A genetic algorithm was implemented for optimization that showed better results than other methods. Pishvaee et al. (2009) discussed a reverse logistics network. This network was formulated using a mixed integer linear programming model. Due to NP-hardness of the problem, a simulated annealing (SA) algorithm was used to solve the proposed model. Priority-based chromosome representation was used in order to encode solutions. The results of different sizes of problems showed intangible differences between exact and meta-heuristic method. Altiparmak et al. (2009) designed a SC network which was solved using a steady-state genetic algorithm (ssGA). The results obtained from ssGA were compared with some exact and heuristic algorithms which outperformed them. Lee et al. (2009) considered a reverse SC. The proposed model was solved using a hybrid genetic algorithm. A novel method is used for crossover to generate elite offsprings called weight mapping crossover (WMX). Pishvaee et al. (2010) designed a bi-objective model for a SC which involves two objective functions of maximizing responsiveness and minimizing costs. Due to insufficient search capability of genetic algorithm, a memetic algorithm is used for local search improvement. Since two objective functions are defined in their model, a multi-objective algorithm is implemented for optimizing the proposed model. Umar et al. (2012) discussed a vehicle routing problem (VRP) which was formulated as a single-objective mathematical model. Since GA was implemented for solving this problem, the priority-based method was used for genetic representation. Subramanian et al. (2013) considered a CLSC network, and then the simulated annealing algorithm was conducted in the proposed CLSC using a priority-based encoding for chromosome representation. Yang et al. (2013) considered a mixed-model assembly line which contains a multi-objective function. To solve this model, an extended version of the genetic algorithm is used, called multi-objective genetic algorithm (MOGA). Partial representation is implemented for chromosome representation. Lotfi and Tavakkoli-Moghaddam (2013) discussed a transportation problem which was solved using a genetic algorithm. New operators of crossover and mutation were proposed in their paper. The priority-based algorithm was tested against spanning-tree-based algorithm by different instances of small, medium and large-sized problems that outperformed for medium and large-sized problems. Ghasimi et al. (2014) proposed a model for a defective goods SC network with an objective function of minimizing costs. This model determines the appropriate length of each cycle based on the importance of customer lead time using just-in-time logistics. Finally, the results of CPLEX solver and the GA are compared that CPLEX showed better results. The chromosomes are displayed in a matrix representing quantity variable. Yadegari et al. (2015) implemented a memetic algorithm for an NP-hard problem of an integrated forward-reverse logistics network. Random path-based direct decoding procedure is used for the delivery and recovery path generation. Pasandideh et al. (2015) implemented two bi-objective optimization methods of NRGA and NSGA-II to solve the model for a SC network. Priority-based was used for chromosome representation. NSGA-II for outperformed NRGA in this problem. Santosa and Kresna (2015) designed a mathematical model for a warehouse location problem. Simulated annealing was used for solving the model. Quantity of variables construct the chromosome matrix. An 11% gap exists between exact and meta-heuristic methods. Since computation time is more important, SA outperforms the exact method. Liu et al. (2015) designed a multi-objective model. Two maximizing and one minimizing objective functions are used. To solve the model, a modified version of NSGA-II called I-NSGA-II is implemented which enhances diversity and convergence of the solutions. Sarrafha et al. (2015) designed a SC that was formulated as an MILP model. A multi-objective biogeography-based optimization (MOBBO) was utilized as a solution methodology. Habitat structure was used to represent the chromosome. The results of their method are compared with NSGA-II and MOSA algorithms. Kumar et al. (2015) designed a mathematical model for a reverse logistics. To solve the model, an artificial bee colony approach was utilized. Mousavi et al. (2016) discussed a bi-objective mathematical model for an inventory optimization problem. The reviewed papers are classified in Table 2, according to the implemented algorithms.
Among reviewed papers, the papers that utilized priority-based representation are classified according to the type of the proposed supply chain and its specifications in Table 3.
Based on the reviewed papers, none of the studies have been performed on the closed-loop supply chains considering multi-objective, multi-product, and multi-period models. Current paper considers a CLSC for collecting used engine oil that is multi-product, multi-period, and multi-objective. In this study, the NSGA-II, MOSA, and MOPSO multi-objective solution methods are utilized to get the optimal solution for the proposed multi-objective mathematical model.
Problem statement
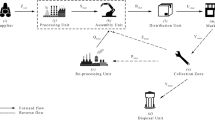
Used engine oil collection involves several layers that have been studied practically to obtain information for designing the supply chain network. The flow of collected used oil starts from vendors and continues to collection centers and then to the manufacturing centers. Two types of manufacturing centers are considered. Type one is manufacturing centers using the original oil to produce product type one; the second type is manufacturing centers that purify used engine oil and use it in the type two product. In the forward supply chain, products are distributed from manufacturing centers to distribution centers and finally to vendors. Described CLSC is presented in Fig. 1.

Illustration of the proposed closed-loop logistics
Assumptions, notations, and parameters
-
Manufacturing centers are two types. The first one is manufacturing type one that produces products type one using original oil and the second one is manufacturing type two which produces products by used engine oil.
-
Some hybrid centers are defined which function as distribution and collection centers.
-
Used engine oil is supplied by vendors and original oil is provided by the suppliers.
-
The capacity of containers that is used for transferring the used engine oil from vendors to collection centers is PO1.
-
Vehicles which transfer oil from collection centers to manufacturing centers have a capacity of PO2.
Considering the defined problem and its assumptions, a model is designed for the proposed SC. The notations, parameters, and decision variables are as follows:
Indices | |
c | Index of the first type of products; c = 1,…, C |
d | Index of the second type of products; d = 1,…, D |
r | Index of products; r = c ∪ d |
i | Index of the first type of manufacturing plants (MPs); i = 1,…, I |
j | Index of the second type of MPs; j = 1,…, J |
p | Index of MPs; p = i ∪ j |
e | Index of distribution centers (DCs); e = 1,…, E |
f | Index of collection centers (CCs); f = 1,…, F |
h | Index of hybrid (multi-purpose) centers; h = 1,…, H |
k | Index of distribution and multi-purpose centers; k = d ∪ h |
k′ | Index of collection and multi-purpose centers; k′ = c ∪ h |
v | Index of vendors; v = 1,…, V |
t | Index of periods; t = 1,…,T |
Parameters | |
C rpt | Production cost related to product r which is produced in MP p in period t |
WEI r | Weight of product r |
TC1 rpkt | Cost of shipping product r from MP p to DC k in period t |
TC2 rkvt | Cost of shipping product r from DC k to vendor v in period t |
\( TC3_{{vk^{\prime}t}} \) | Cost of shipping one unit of used engine oil from vendor v to CC k ′ in period t |
\( TC4_{{k^{\prime}pt}} \) | Cost of shipping one unit of used engine oil from CC k ′ to MP p in period t |
Cap rpt | Capacity of MP r for product p in period t |
Cap′ kt | Capacity of DC k in period t |
\( Cap_{{k^{\prime}t}}^{{\prime \prime }} \) | Number of available PO2 containers in CC k ′ in period t |
Cap ′″ vt | Capacity of vendor v to supply used oil in period t |
BE vt | Purchase cost for each PO1 container of used oil from vendor v in period t |
PP rpt | Price of product r in MP p in period t |
\( {\text{B}}_{\text{rt}} \) | Shortage cost of product r in period t |
τ r | Amount of oil to produce one unit of product r |
PO1 | Weight of small container to ship used oil from vendors to collection and hybrid centers |
PO2 | Weight of each tanker of used engine oil shipped from CC to MP |
D rvt | Demand of vendor v for product r in period t |
RI k′v | Rate of risk of supplying used oil by vendor v to CC k′ |
EC e | Establishment cost of DC of e |
EC ′ f | Establishment cost CC of f |
EC ″ h | Establishment cost of h |
M | A big number |
Decision variables | |
Q rpt | Quantity of production of product r in MP p in period t |
X rpkt | Quantity of product r shipped from MP p to DC k in period t |
Y rkvt | Quantity of product r shipped from DC k to vendor v in period t |
\( Y^{\prime}_{{vk^{\prime}t}} \) | Amount of used oil transferred from vendor v to CC k ′ in period t |
\( X^{\prime}_{{k^{\prime}pt}} \) | Amount of used oil transferred from CC k′ to MP p in period t |
L rvt | Shortage of product r for vendor v in period t |
DES e | If DC e is open 1, otherwise 0 |
CES f | If CC f is open 1, otherwise 0 |
HES h | If HC h is open 1, otherwise 0 |
Mathematical model
The first objective function (1) is maximizing total profit. It is obtained by SC costs from total incomes.
Term (2) shows incomes obtained from selling products in the forward direction of the SC network.
Terms (3) and (4) show facility establishment and production costs, respectively.
Transportation costs between facilities are obtained from term (5).
Terms (6) and (7) represent used engine oil purchase cost and forward products shortage costs, respectively.
Minimization of total risks of purchasing used oil from vendors is represented as the second objective function in Eq. (8).
Finally, minimizing the shortage of products is obtained from the third objective function in term (9).
Constraints
The number of products transferred from manufacturing centers to distribution centers should equal the quantity of production in manufacturing centers (10).
Constraints (11) present the balance of flow in distribution centers. To generate a feasible solution, it is mandatory that output from DCs be less than or equal to input to DCs.
Constraint (12) presents shortages of forward products. If the number of transferred products to vendors are less than their demands, there will be shortages of products.
The balance of flow in collection centers is specified using constraint (13).
Maximum allowed production in manufacturing centers is bounded by their capacities in term (14). Capacity is defined for each product r in each manufacturing center p in period t.
Each vendor has a certain capacity to supply used engine oil that is shown in constraint (15). This capacity is the amount of used engine oil that can be provided by each vendor in each period as the resources of producing the second type of products.
Collection centers have a capacity of processing used engine oil due to the number of the vehicle for shipment that is shown in Eq. (16).
Since products type two are produced by used engine oil, the quantity of production is specified using constraint (17).
Constraints (18)–(25) are defined to control variables to be activated when a center is open. If a center is open, the right side of the constraint can take amount.
The domain of decision variables is specified in Eq. (26).
Solution methodology
Different solution methods are utilized in order to solve problems. In case of simple problems, routine methods can be used. However, by increasing the problem size, the routine solution methods would not work efficiently (Leu and Yang 1999). In these cases, using optimization techniques that are called evolutionary techniques are advantageous. Genetic algorithm (GA), particle swarm optimization (PSO), and simulated annealing (SA) are of these methods.
In this paper, three meta-heuristic algorithms are utilized for optimization. Using different algorithms can validate the accuracy of results. Since the model involves three objective functions, using multi-objective solution methodology is necessary. Non-dominated sorting genetic algorithm (NSGA-II), multi-objective simulated annealing (MOSA), and multi-objective particle swarm optimization (MOPSO) are used for this purpose. Two encoding schemes are proposed which are priority-based and permutation encoding. In the priority-based representation, the priorities of the nodes are shown by the values in a list. According to this method, the nodes with higher values of priorities are selected earlier (Peng and Wei 2008; Taleizadeh et al. 2010). In this paper, priority-based encoding is utilized due to its compatibility with the problem.
Chromosome representation
Chromosomes are encoded using three methods: (1) encoding based on edge, (2) encoding based on vertex, and (3) encoding based on edge-and-vertex (Gen and Cheng 2000). Using the last method, sources and depots are used. When |K| is the number of sources and |J| is the number of depots, the dimension of the proposed matrix for GA representation will be |K|·|J| and the length of this matrix is |K| + |J|. The values of genes for this chromosome are between 1 and |K| + |J|. Each gene presents two kinds of values that is the locus and the allele. The locus shows the position of the value that is representative of the source or depot and the allele which is the value of the priority. Since transportation trees are generated for a set of sources and depots, the highest priority should be considered in each chromosome to select a source or depot (Altiparmak et al. 2009). These transportation problems should be solved to obtain the flow between a source and a depot. As the constrained optimization problems require constraints to be met, feasibility check is necessary. To prevent from generating infeasible solutions, using the repair mechanism is mandatory. Priority-based representation method is used to generate feasible solutions without using excessive repair mechanism (Gen and Cheng 2000). To apply priority-based encoding, stages should be clarified in the SC. The proposed SC is divided into four stages which is shown in Fig. 2. These stages are used in all the proposed algorithms such as NSGA-II, MOPSO and MOSA.

Representation of stages in the supply chain
NSGA-II
NSGA-II is a multi-objective optimization algorithm which is used to generate Pareto solutions for multi-objective models. The main procedure of NSGA-II is based on the GA that is shown in Fig. 13. Generated populations are ranked using non-dominated sorting procedure (Pasandideh et al. 2015; Safaei et al. 2017). Ranked solutions create the Pareto fronts. The crowding distance and the rank are calculated for each solution. New solutions generated by crossover and mutation operators are added to the current populations. New population is sorted and the population size is selected from these solutions (Pasandideh et al. 2015; Taleizadeh et al. 2011). Populations consist of so-called chromosomes that are the strings of values called genes. According to this definition, a chromosome is an initial solution. A chromosome is designed for each stage. The representation for each stage is shown in Fig. 3. The encoding procedure that is specified for each stage is presented in the “Appendix”.

Chromosome representation for stage 1
Crossover and mutation operators
Due to defining priorities in these chromosomes, mutation and crossover should be specified in a way that duplication will be prevented. To perform crossover, order crossover (OX) was implemented. Two cut points are determined in each chromosome. The first cut point is determined in each row and the second one is determined in each column. As shown in Fig. 4, the darker parts are selected from the first parent and the white part is selected from the second one. The rest of priorities in each row are obtained from the second parent (Pasandideh et al. 2015).

Crossover representation
In case of mutation, two positions are changed randomly for all the periods. The mutation is shown in Fig. 5.

Mutation representation
MOSA
Simulated annealing (SA) is adapted from metal annealing. In this process, the metal is heated so that its particle can move freely. As the temperature decreases, the movement will be more limited. Solutions in problems are defined as particles in the metal. A minimum temperature is defined in simulated annealing process to which the initial temperature is decreased (Bandyopadhyay et al. 2008). In higher temperatures, solutions can be changed more freely in comparison to lower temperatures. SA provides the acceptance of worse solutions with a certain probability which increases the domain of local search (Santosa and Kresna 2015). Simulated annealing generates new solutions in the neighborhood of the original solution (Altiparmak et al. 2009). Since SA is a single-objective algorithm, MOSA provides a method for generating Pareto solutions. In this method, the concept of domination is used for ranking the populations. Solutions are allocated to different fronts so that the solutions in each front are non-dominated. Solutions are selected according to their ranks (Sarrafha et al. 2015). The pseudo code of simulated annealing is represented below. SA uses local search for finding solutions. A solution is generated at random initially which is updated by neighborhood procedure. If the objective function is reduced, the current solution is changed otherwise the solutions will be retained. The iteration continues until no significant change will occur (Eglese 1990).

Neighborhood procedure
Neighborhood procedure is a mechanism which generates new solutions based on the initial solution. It works like crossover or mutation, but their procedures are not the same. To apply this procedure, some mechanisms such as swap, reversion and insertion are defined. By applying these mechanisms, new solutions are generated. In this paper, each gene contains a priority. Swap changes the positions of two positions. Reversion is a mechanism which generates new solution by reversing the positions. In the third method, called “insertion,” two positions are selected randomly. The first position is omitted and moved after that position (Sarrafha et al. 2015). The illustrations of the procedures are shown in “Appendix” Figs. 17, 18 and 19.
MOPSO
Particle swarm optimization (PSO) works with particles that is originally taken from the bird and fish movements (James and Russell 1995). PSO searches the solution space using particles that are updated in each iteration. Each particle is specified by its position and velocity. A swarm of particles is initialized randomly which will be modified according to two experiences: the local and the global best. The local best (personal best (Pbest)) is the best experience for each particle that is ever found and the global best (Gbest) is the best position among all the particles. Considering these two best sets, the velocity is computed for each particle by subtracting the local and global best from the current position (Prasanna Venkatesan and Kumanan 2012). The mechanism of updating each particle is defined by changing the velocity randomly.
Velocity update
Although the priority-based representation simplifies the optimization procedure, updating velocities may be too complex because the routine velocity formula cannot update the permutation. In formula (27), c 1 and \( {\text{c}}_{2} \) are the local and global learning coefficients.
In this study, a specific mechanism for updating the priority-based encoding approach is used which keeps the priority values exclusive. In order to create such a mechanism, the theory of vector similarity is defined. According to this theory, the solutions are considered as vectors. The vector resemblance-degree between the current and Pbest position (p i ) and the current and the Gbest position (g) specifies the way which that the current vectors (x i ) should be changed in order to obtain velocity. The vector of resemblance-degree between the current particle (vector) and Pbest is denoted by r(p i , x i ) and similarly Gbest by r(g, x i ). Vectors are specified by their magnitudes and directions. The magnitude of a vector is calculated using formula (28).
In order to calculate the vector resemblance-degree, the direction cosine between x i and Pbest or Gbest vector is calculated.
Formula (30) is used in order to specify the number of dimensions to be changed. In this formulation, “r” is a random number within [0, 1] and “w” is inertia weight parameter.
After a change occurred in a vector, velocity should be updated. The following formula calculates new velocity:
Position update
In particle swarm optimization, positions are updated considering velocities. In this study, positions take an integer value. Indeed, a permutation of integer numbers makes a string which creates the solutions. Since integer numbers compose the positions, velocities should also be an integer. The exclusive updating procedure for permutation string is presented in (32).
-
1.
Round the velocity and number of dimensions.
$$ v_{ik}^{t + 1} = \text{int} (v_{ik}^{t + 1} ),{\text{ s}}_{ik}^{t + 1} = \text{int} (s_{ik}^{t + 1} ) $$(32) -
2.
New positions of a vector are calculated according to the following procedure. Formula (33) generates values in interval [1,n]. When a value in the permutation changes from λ 1 to λ 2, another change should be done to keep the values in permutation exclusive. This change is replacing λ 2 by λ 1.
$$ x_{ik}^{t + 1} = \left\{ {\begin{array}{ll} {\frac{{x_{ik}^{t} + v_{ik}^{t + 1} }}{n}},&\quad v_{ik}^{t + 1} \ge 0 \\ \frac{{x_{ik}^{t} + v_{ik}^{t + 1} }}{n} + n,&\quad v_{ik}^{t + 1} < 0 \\ \end{array} } \right. $$(33)
The graphical presentation of the permutation position updating is shown in Fig. 6 that can be useful for better understanding of this procedure (Peng and Wei 2008).

Position update
Performance measure
There are some measures defined for evaluating multi-objective meta-heuristics algorithms. In this study, four performance metrics are considered for assessing the proposed algorithms.
Number of Pareto solutions (NPS): This measure presents the number of Pareto optimal solutions in each algorithm.
Mean ideal distance (MID): This measure examines how close the Pareto solutions and ideal point (0, 0) are.
Spread of non-dominance solution: This measure shows the diversity of Pareto solutions. The more diverse are Pareto solutions, the higher is this measure. The last metric is CPU time that measures running time of each algorithm (Karimi et al. 2010).
Parameter settings
Optimization algorithms operate using different parameters, e.g., GA uses crossover and mutation rates, number of iterations and populations, selection pressure and other parameters. Parameter setting is necessary in order to run algorithms in its best performance. In addition, it decreases the number of experiments and CPU time (Sarrafha et al. 2015). There are several parameter tuning approaches for meta-heuristics algorithms referring to the historical researches, try and error, arranging full factorial experiments, Taguchi method, response level, neural network, and meta-heuristic algorithms (prior or during the main optimization algorithm). Taguchi presents the optimized number of controllable factors. In this study, Taguchi method is utilized because it is based on the design of experiment (DOE). The purpose of the design of experiments is performing a set of tests that make meaningful changes in input variables to evaluate the impact of response variables. The response variable is obtained at the end of each experiment. A number of experiments are obtained considering how many factors and levels are defined. The total number of experiments is calculated using the formula (36).
Two strategies are defined for performing the experiments: (1) changing one factor against other fixed factors. This method is called “one factor at time (OFAT). (2) Changing some factors simultaneously, so that the impact of each factor and their interactions will be specified. The second one is the so-called “DOE”.
To simplify the computation, orthogonal arrays are designed which presents a number of experiments considering a number of factors and levels. In order to perform Taguchi analyses, two methods are recommended. First, a standardized method in which analysis of variance (ANOVA) is used. Second, using signal to noise (S/N) ratio for the same stages in the analysis. The higher this ratio is, the variance around a specific amount will be lower (Roy 2010). Three levels are defined for each parameter in each algorithm according to its characteristics that is shown in Table 4.
Ten random instances are given to compare proposed algorithms. Table 5 shows dimensions of the instances. Parameters are generated randomly according to parameter ranges defined in Table 6.
Number of runs were specified by the orthogonal arrays considering number of factors and levels. An L9 design was recommended for NSGA-II, L27 design for MOSA and L27 for MOPSO algorithm according to orthogonal arrays in Minitab software. Since ten instances were generated, 270 test problems were solved for MOSA algorithm, 90 test problems were solved for NSGA-II and 270 test problems for MOPSO. Therefore, 630 runs were totally solved for Taguchi analysis. The outputs were normalized using formula (37) which is shown in Table 7. Table 7 contains three measures of MID, NPS, and SNS. As observed, the mechanism that is used for position update of MOPSO algorithm provides a spread search of the solution space. Thus, this procedure is very useful for a wide search.
The formula (38) was utilized for calculating the scores. Since all results are normalized, test problems with minimum scores are selected.
The computations are executed on a Desktop Computer with core™ i7 3.50 GHz CPU. The scores and CPU time are computed for each algorithm, shown in Table 8. In order to compare three algorithms, performance measures “w” consisting of weighted summation of MID, NPS and SNS and CPU time were used. Both criteria of NSGA-II are minimum, so it its ranked first. Figures 7, 8, 9, and 10 show the comparison among three algorithms considering performance measures.

MID related to each algorithm

NPS related to each algorithm

SNS related to each algorithm

CPU time related to each algorithm
According to the analyses, NSGA-II is selected. Taguchi approach is conducted for parameter tuning which can enhance the performance of NSGA-II. The Taguchi analyses are performed for instances that are generated using data in Table 5. In this table, instances are classified to three types of problems: small, medium and big-size problems. Three instances are selected from Table 5, i.e. 1, 5 and 10, on behalf of all the problems. Pareto fronts of the optimal solutions for instances 1, 5 and 10 in Fig. 11 present proper diversity of the generated solutions for NSGA-II, MOSA and MOPSO.

Optimal solutions for instances 1, 5 and 10
In order to interpret results, two criteria of the mean of means and signal to noise ratio (S/N) are defined. The lower values of the mean of means and the higher S/N ratio show the better results that is shown in Fig. 12. Based on this figure, NSGA-II parameters are tuned for each instance. The tuned parameters are population, crossover rate, mutation rate, and iteration.

Mean of means and S/N ratio of instances 1, 5 and 10
Conclusion and future research
In this study, a CLSC of the used engine oil is optimized using different meta-heuristics. Optimizing small-size problems can be performed using optimization software. However, in case the dimensions of the problems increase, the new optimization tools dominate the routine optimization software. The Meta-heuristic algorithms are one of these methods that assists engineers to solve the big-size problems faster. In this paper, three meta-heuristic algorithms are utilized to optimize the proposed mathematical model. Since a multi-objective model is discussed, a multi-objective meta-heuristic should be applied in this case. The NSGA-II, MOSA and MOPSO are three algorithms implemented to deal with the multi-objective model. The feasibility control of the constraints is very essential, so it encouraged us to concentrate on the priority-based encoding and position update very carefully. In all the algorithms, a priority-based encoding is used. Instances are generated randomly to compare the capability of three algorithms. To compare three algorithms, MID, NPS, SNS, and CPU time are used as measures. Considering these criteria, NSGA-II outperformed other algorithms for the closed-loop supply chain of engine oil. This algorithm works better than other proposed algorithms for sophisticated problems such as closed-loop used engine oil logistics. Taguchi approach that is used in this study helps enhance the performance of the present algorithm and determine the best present of operational parameters.
This study could be pursued by the direction of solution methodology and parameter settings. Other algorithms can be provided to compare the performance of the proposed algorithms and other algorithms. For enthusiasts of supply chain management, there would be an option to modify the mathematical model to cover the requirement in used engine oil collection. Vehicle routing for distribution and collection part of the proposed supply chain can be complementary to the proposed mathematical model. In addition, other objective functions could be added to the present objective functions to cover real-world problems. Considering the uncertainty of real-world problems can be helpful for this purpose.
References
Altiparmak F, Gen M, Lin L, Karaoglan I (2009) A steady-state genetic algorithm for multi-product supply chain network design. Comput Ind Eng 56:521–537
Bandyopadhyay S, Saha S, Maulik U, Deb K (2008) A simulated annealing-based multiobjective optimization algorithm: AMOSA. IEEE Trans Evol Comput 12:269–283
Chen Y-W, Wang L-C, Wang A, Chen T-L (2017) A particle swarm approach for optimizing a multi-stage closed loop supply chain for the solar cell industry. Robot Comput Integr Manuf 43:111–123
Eglese R (1990) Simulated annealing: a tool for operational research. Eur J Oper Res 46:271–281
Fahimnia B, Farahani RZ, Marian R, Luong L (2013) A review and critique on integrated production–distribution planning models and techniques. J Manuf Syst 32:1–19
Gen M, Cheng R (2000) Genetic algorithms and engineering optimization, vol 7. Wiley, New York
Ghasimi SA, Ramli R, Saibani N (2014) A genetic algorithm for optimizing defective goods supply chain costs using JIT logistics and each-cycle lengths. Appl Math Model 38:1534–1547
Govindan K, Soleimani H (2017) A review of reverse logistics and closed-loop supply chains: a Journal of Cleaner Production focus. J Clean Prod 142(1):371–384
James K, Russell E (1995) Particle swarm optimization. In: Proceedings of 1995 IEEE international conference on neural networks, pp 1942–1948
Jolai F, Razmi J, Rostami N (2011) A fuzzy goal programming and meta heuristic algorithms for solving integrated production: distribution planning problem. CEJOR 19:547–569
Karimi N, Zandieh M, Karamooz HR (2010) Bi-objective group scheduling in hybrid flexible flowshop: a multi-phase approach. Expert Syst Appl 37:4024–4032
Kumar V, Liou FW, Balakrishnan SN, Kumar V (2015) Economical impact of RFID implementation in remanufacturing: a chaos-based interactive artificial bee colony approach. J Intell Manuf 26:815–830
Lee J-E, Gen M, Rhee K-G (2009) Network model and optimization of reverse logistics by hybrid genetic algorithm. Comput Ind Eng 56:951–964
Leu S-S, Yang C-H (1999) GA-based multicriteria optimal model for construction scheduling. J Constr Eng Manag 125:420–427
Liu T, Gao X, Wang L (2015) Multi-objective optimization method using an improved NSGA-II algorithm for oil–gas production process. J Taiwan Inst Chem Eng 57:42–53
Lotfi MM, Tavakkoli-Moghaddam R (2013) A genetic algorithm using priority-based encoding with new operators for fixed charge transportation problems. Appl Soft Comput 13:2711–2726
Mahdavi I, Paydar MM, Solimanpur M, Heidarzade A (2009) Genetic algorithm approach for solving a cell formation problem in cellular manufacturing. Expert Syst Appl 36:6598–6604
McWilliams A, Siegel D (2001) Corporate social responsibility: a theory of the firm perspective. Acad Manag Rev 26:117–127
Mousavi SM, Sadeghi J, Niaki STA, Tavana M (2016) A bi-objective inventory optimization model under inflation and discount using tuned Pareto-based algorithms: NSGA-II, NRGA, and MOPSO. Appl Soft Comput 43:57–72
Özceylan E, Paksoy T (2013) A mixed integer programming model for a closed-loop supply-chain network. Int J Prod Res 51:718–734
Park BJ, Choi HR, Kang MH (2007) Integration of production and distribution planning using a genetic algorithm in supply chain management. In: Melin P, Castillo O, Ramírez EG, Kacprzyk J, Pedrycz W (eds) Analysis and design of intelligent systems using soft computing techniques. Advances in Soft Computing, vol 41. Springer, Berlin, Heidelberg, pp 416–426
Pasandideh SHR, Niaki STA, Asadi K (2015a) Bi-objective optimization of a multi-product multi-period three-echelon supply chain problem under uncertain environments: NSGA-II and NRGA. Inf Sci 292:57–74
Pasandideh SHR, Niaki STA, Asadi K (2015b) Optimizing a bi-objective multi-product multi-period three echelon supply chain network with warehouse reliability. Expert Syst Appl 42:2615–2623
Peng W, Wei Y (2008) PSO for solving RCPSP. In: 2008 Chinese control and decision conference, pp 818–822
Pishvaee MS, Kianfar K, Karimi B (2009) Reverse logistics network design using simulated annealing. Int J Adv Manuf Technol 47:269–281
Pishvaee MS, Farahani RZ, Dullaert W (2010) A memetic algorithm for bi-objective integrated forward/reverse logistics network design. Comput Oper Res 37:1100–1112
Prasanna Venkatesan S, Kumanan S (2012) A multi-objective discrete particle swarm optimisation algorithm for supply chain network design. Int J Logist Syst Manag 11:375–406
Roy RK (2010) A primer on the Taguchi method. Society of Manufacturing Engineers, Dearborn
Safaei AS, Heidarpoor F, Paydar MM (2017) Group purchasing organization design: a clustering approach. Comput Appl Math 1–29
Santosa B, Kresna IGNA (2015) Simulated annealing to solve single stage capacitated warehouse location problem. Proc Manuf 4:62–70
Sarrafha K, Rahmati SHA, Niaki STA, Zaretalab A (2015) A bi-objective integrated procurement, production, and distribution problem of a multi-echelon supply chain network design: a new tuned MOEA. Comput Oper Res 54:35–51
Subramanian P, Ramkumar N, Narendran T, Ganesh K (2013) PRISM: PRIority based SiMulated annealing for a closed loop supply chain network design problem. Appl Soft Comput 13:1121–1135
Sudarto S, Takahashi K, Morikawa K, Nagasawa K (2016) The impact of capacity planning on product lifecycle for performance on sustainability dimensions in Reverse Logistics Social Responsibility. J Clean Prod 133:28–42
Taleizadeh AA, Niaki STA, Aryanezhad M-B, Tafti AF (2010) A genetic algorithm to optimize multiproduct multiconstraint inventory control systems with stochastic replenishment intervals and discount. Int J Adv Manuf Technol 51:311–323
Taleizadeh AA, Barzinpour F, Wee H-M (2011) Meta-heuristic algorithms for solving a fuzzy single-period problem. Math Comput Model 54:1273–1285
Umar U, Ariffin M, Ismail N, Tang S (2012) Priority-based genetic algorithm for conflict-free automated guided vehicle routing. Proc Eng 50:732–739
Yadegari E, Najmi H, Ghomi-Avili M, Zandieh M (2015) A flexible integrated forward/reverse logistics model with random path-based memetic algorithm. Iran J Manag Stud 8:287
Yang C, Gao J, Sun L (2013) A multi-objective genetic algorithm for mixed-model assembly line rebalancing. Comput Ind Eng 65:109–116
Author information
Authors and Affiliations
Corresponding author











Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Babaveisi, V., Paydar, M.M. & Safaei, A.S. Optimizing a multi-product closed-loop supply chain using NSGA-II, MOSA, and MOPSO meta-heuristic algorithms. J Ind Eng Int 14, 305–326 (2018). https://doi.org/10.1007/s40092-017-0217-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40092-017-0217-7