
Abstract
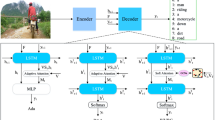
Image captioning is a challenging task that aims to generate a natural description for an image. The word prediction is dependent on local linguistic contexts and fine-grained visual information and is also guided by previous linguistic tokens. However, current captioning works do not fully utilize local visual and linguistic information, generating coarse or incorrect descriptions. Also, captioning decoders have less recently focused on convolutional neural network (CNN), which has the advantage in extracting features. To solve these problems, we propose a local representation-enhanced recurrent convolutional network (Lore-RCN). Specifically, we propose a visual convolutional network to obtain enhanced local linguistic context, which incorporates selected local visual information and models short-term neighboring. Furthermore, we propose a linguistic convolutional network to obtain enhanced linguistic representation, which models long- and short-term correlations explicitly to leverage guiding information from previous linguistic tokens. Experiments conducted on COCO and Flickr30k datasets have verified the superiority of our proposed recurrent CNN-based model.



Similar content being viewed by others


Availability of data and materials
Data are available from the authors upon request.
References
Anderson P, Fernando B, Johnson M, et al (2016) Spice: semantic propositional image caption evaluation. In: European conference on computer vision. Springer, 382–398
Anderson P, He X, Buehler C, et al (2018) Bottom-up and top-down attention for image captioning and visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 6077–6086
Aneja J, Deshpande A, Schwing AG (2018) Convolutional image captioning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 5561–5570
Banerjee S, Lavie A (2005) Meteor: an automatic metric for mt evaluation with improved correlation with human judgments. In: Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, 65–72
Chen L, Zhang H, Xiao J, et al (2017) Sca-cnn: spatial and channel-wise attention in convolutional networks for image captioning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 5659–5667
Chen R, Li Z, Zhang D (2019) Adaptive joint attention with reinforcement training for convolutional image caption. In: International workshop on human brain and artificial intelligence. Springer, 235–247
Cornia M, Stefanini M, Baraldi L, et al (2020) Meshed-memory transformer for image captioning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 10,578–10,587
Dorfer M, Schlüter J, Vall A et al (2018) End-to-end cross-modality retrieval with cca projections and pairwise ranking loss. Int J Multimed Inf Retrieval 7(2):117–128
Gao L, Li X, Song J et al (2019) Hierarchical lstms with adaptive attention for visual captioning. IEEE Trans Pattern Anal Mach Intell 42:1112–1131
Gu J, Wang G, Cai J, et al (2017) An empirical study of language cnn for image captioning. In: Proceedings of the IEEE international conference on computer vision, 1222–1231
Huang L, Wang W, Chen J, et al (2019) Attention on attention for image captioning. In: Proceedings of the IEEE/CVF international conference on computer vision, 4634–4643
Huang L, Wang W, Xia Y, et al (2019) Adaptively aligned image captioning via adaptive attention time. arXiv:1909.09060
Ji J, Xu C, Zhang X et al (2020) Spatio-temporal memory attention for image captioning. IEEE Trans Image Process 29:7615–7628
Jiang W, Ma L, Jiang YG, et al (2018) Recurrent fusion network for image captioning. In: Proceedings of the European conference on computer vision (ECCV), 499–515
Jin T, Li Y, Zhang Z (2019) Recurrent convolutional video captioning with global and local attention. Neurocomputing 370:118–127
Karpathy A, Fei-Fei L (2015) Deep visual-semantic alignments for generating image descriptions. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 3128–3137
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. Adv Neural Inf Process Syst 25:1097–1105
Lan H, Zhang P (2022) Learning and Integrating Multi-Level Matching Features for Image-Text Retrieval. IEEE Signal Process Lett 29:374–378. https://doi.org/10.1109/LSP.2021.3135825
Li G, Zhu L, Liu P, et al (2019) Entangled transformer for image captioning. In: 2019 IEEE/CVF international conference on computer vision (ICCV), 8927–8936. https://doi.org/10.1109/ICCV.2019.00902
Lin CY (2004) Rouge: a package for automatic evaluation of summaries. In: Text summarization branches out, 74–81
Lin TY, Maire M, Belongie S, et al (2014) Microsoft coco: common objects in context. In: European conference on computer vision. Springer, 740–755
Lu J, Xiong C, Parikh D, et al (2017) Knowing when to look: adaptive attention via a visual sentinel for image captioning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 375–383
Pan Y, Yao T, Li Y, et al (2020) X-linear attention networks for image captioning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Papineni K, Roukos S, Ward T, et al (2002) Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 311–318
Qin Y, Du J, Zhang Y, et al (2019) Look back and predict forward in image captioning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 8367–8375
Ren S, He K, Girshick R et al (2015) Faster r-cnn: towards real-time object detection with region proposal networks. Adv Neural Inf Process Syst 28:91–99
Sharma P, Ding N, Goodman S, et al (2018) Conceptual captions: a cleaned, hypernymed, image alt-text dataset for automatic image captioning. In: Proceedings of the 56th annual meeting of the association for computational linguistics (Volume 1: Long Papers), 2556–2565
Vedantam R, Lawrence Zitnick C, Parikh D (2015) Cider: consensus-based image description evaluation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 4566–4575
Vinyals O, Toshev A, Bengio S, et al (2015) Show and tell: a neural image caption generator. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 3156–3164
Wang C, Gu X (2021) Image captioning with adaptive incremental global context attention. Appl Intell. https://doi.org/10.1007/s10489-021-02734-3
Wang L, Bai Z, Zhang Y, et al (2020) Show, recall, and tell: Image captioning with recall mechanism. In: Proceedings of the AAAI conference on artificial intelligence, 12,176–12,183
Wang Q, Chan AB (2018) Cnn+ cnn: convolutional decoders for image captioning. arXiv:1805.09019
Wang W, Chen Z, Hu H (2019) Hierarchical attention network for image captioning. In: Proceedings of the AAAI conference on artificial intelligence, 8957–8964
Wang Y, Sun X, Li X et al (2021) Reasoning like humans: on dynamic attention prior in image captioning. Knowl-Based Syst 228(107):313
Wei H, Li Z, Huang F et al (2021) Integrating scene semantic knowledge into image captioning. ACM Trans Multimed Comput Commun Appl 17:2. https://doi.org/10.1145/3439734
Wu A, Han Y, Yang Y et al (2019) Convolutional reconstruction-to-sequence for video captioning. IEEE Trans Circuits Syst Video Technol 30(11):4299–4308
Wu J, Hu H, Wu Y (2018) Image captioning via semantic guidance attention and consensus selection strategy. ACM Trans Multimed Comput Commun Appl (TOMM) 14(4):1–19
Xiao H, Xu J, Shi J (2020) Exploring diverse and fine-grained caption for video by incorporating convolutional architecture into lstm-based model. Pattern Recognit Lett 129:173–180
Xu K, Ba J, Kiros R, et al (2015) Show, attend and tell: neural image caption generation with visual attention. In: International conference on machine learning, PMLR, 2048–2057
Yang L, Tang K, Yang J, et al (2017) Dense captioning with joint inference and visual context. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 2193–2202
Yang L, Wang H, Tang P et al (2020) Captionnet: a tailor-made recurrent neural network for generating image descriptions. IEEE Trans Multimed 23:835–845
Yao T, Pan Y, Li Y, et al (2018) Exploring visual relationship for image captioning. In: Proceedings of the European conference on computer vision (ECCV), 684–699
You Q, Jin H, Wang Z, et al (2016) Image captioning with semantic attention. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 4651–4659
Young P, Lai A, Hodosh M et al (2014) From image descriptions to visual denotations: new similarity metrics for semantic inference over event descriptions. Trans Assoc Comput Linguist 2:67–78
Funding
This work was supported by the National Key R&D Program of China (2019YFC1521204).
Author information
Authors and Affiliations
Contributions
Xiaoyi Wang made the main contributions as regards the conception of work, the experimental work, the data analysis, and writing the paper. Jun Huang is the corresponding author.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethics approval
This paper contains no cases of studies with human participants performed by any of the authors
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Code availability
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Wang, X., Huang, J. A local representation-enhanced recurrent convolutional network for image captioning. Int J Multimed Info Retr 11, 149–157 (2022). https://doi.org/10.1007/s13735-022-00231-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13735-022-00231-y