
Abstract
Material flow control in remanufacturing is an important issue in the field of disassembly. This paper deals with the potential of autonomous material release decisions for remanufacturing systems to balance the uncertainties related to changing bottlenecks, to maximise throughput (\(TH\)) and to minimise work-in-process (\(WIP\)). The goal is to achieve the highest possible throughput rate using real-time data while keeping costs to a minimum. Unlike traditional production systems, remanufacturing must consider and handle high uncertainties in the process. Up to now, classical methods such as CONWIP, Material Requirement Planning (MRP) and Kanban have been used for material flow control. However, these methods do not perform well in a system with high variation and uncertainties such as remanufacturing as they aim to find solutions for static environments. Crucial for optimal production in stochastic environments is finding the optimum pull or release rate which can vary over time in terms of maximising \(TH\) and minimising \(WIP\). We propose a deep reinforcement learning approach that acts on the environment and can adapt to changing conditions. This ensures that changing bottlenecks are taken care of and that there is a minimum \(WIP\) in the system.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
In the age of Industry 4.0, development cycles are becoming shorter and shorter, and products are becoming more and more individualised. This poses great challenges to today's intelligent production systems. These challenges are now also arriving in remanufacturing and are increasing the uncertainties due to the increase in variability. Despite increasing challenges, the systems must be flexible and continuously adapt to changing conditions. However, this must not compromise throughput (\(TH\)) and robustness against external disturbances. Overall, this results in constantly changing production environments that production planning and control must deal with [4].
In remanufacturing, end-of-life (EOL) products are the raw material (Cores) and as a result, the remanufacturing process is subject to large uncertainties. This makes the planning of remanufacturing increasingly difficult [7]. EOL products have experienced different loads in the field, leading to significant differences in quality. Before and in the practical remanufacturing process, it is difficult to evaluate the quality of EOL products exactly. To make it even more difficult, the processing time, remanufacturing probability, random failures of cores or components and costs are uncertain under the influence of human behaviour and the environment. The uncertain quality further increases the uncertainties in processing time, reprocessing probability and cost, making it a two-fold uncertainty [38].
In general, there exist two sets of methods to control such problems: pull and push methods. All pull methods were developed with a similar goal to control the \(WIP\) in the system at a low level while having no loss of \(TH\). Pull methods set limits on \(WIP\) and observe the resulting \(TH\). In contrast, push methods try to control the \(TH\) and observe the \(WIP\) level. The big advantage of pull methods is achieving the same average \(TH\) with a lower average \(WIP\) [10]. Maximising \(TH\) and minimising \(WIP\) are conflicting goals that must be combined. Especially in systems with additional variability this can lead to major challenges. In this paper, we not only want to adapt the \(WIP\) of the remanufacturing system, but also to further optimise the pull approach.
With the help of Industry 4.0 technologies, we have the possibility to regularly readjust the \(WIP\) by changing conditions of the productions system or influence it via the pull or material release without reducing \(TH\). By observing real-time conditions, the information can be used to adjust the policy. The focus is on the development of policy architectures that make the pull approach suitable for production systems with lower volume, high product mix and high variability [5, 15, 29, 30].
An exploratory study based on simulation experiments is used to support our research. An important aspect is to maintain an optimal \(WIP\) range, which is determined based on the dynamic behaviour during the simulation. Using an innovative approach based on Deep Reinforcement Learning, we show that we can significantly reduce \(WIP\) values without reducing \(TH\). We do not need any prior information about processing time variations, failure probabilities, etc. and the system automatically adapts to the changing states.
Previous papers in this area have focused on sequencing of disassembly, production schedules for disassembly, balancing of disassembly lines or disassembly Petri nets. However, the literature does not deal with material flow control in disassembly, with predominantly manual work processes combined with the uncertainties of core quality, random failures, and highly variable processing times. Our proposed approach can be seen as an operational decision model that leads to productive use of workers and cost minimisation in disassembly. We focus on the following uncertainties in the paper:
-
(1)
The disassembly station has its own processing time per quality class. This leads to a changing bottleneck within the remanufacturing system due to the differences between the classes.
-
(2)
During disassembly, cores and components fail randomly. Different failure rates are tested, and the adaptability of the RL agent is demonstrated.
The reinforcement learning approach is compared with a pure CONWIP approach and therefor different \(WIP\) limits. The objective of this paper is the development and implementation of an autonomous and self-learning algorithm addressing material flow control with stochastic uncertainties in remanufacturing systems.
The paper is structured as follows: Sect. 2 contains a literature review. Objectives of production planning and control are identified and, in this context, literature focusing on remanufacturing and literature on reinforcement learning for material flow control are examined. The next part explains the state-of-the-art in reinforcement learning and describes the approach in general. Section 4 discusses the remanufacturing system under consideration and the uncertainties regarding the changing bottleneck. This is followed by the optimisation objective and assumptions, the state space, the action space, and the developed reward functions. The algorithm used is briefly explained in the next section and leads into the results and comparison section. The paper concludes with a summary of reinforcement learning approaches in the field of remanufacturing and ends in the conclusion.
Literature review
Production planning and control
The goal of Production planning and control (PPC) is to make the best use of available production factors, such as material, machine or work hours, as conditions change [14, 24]. Production control is responsible for the on-time delivery of the production plan. The efficient utilisation of existing capacity is crucial to competitive manufacturing that delivers on time [20].
A valuable alternative seems to be decentralised control, in which smaller units, such as workstations, workers, etc., independently take decisions based on their local knowledge. With this, the production efficiency can be improved [23], and the system is more robust as it can handle dynamics and complexity better [11]. We focus on the task of material flow control as part of production control, which can be used in combination with other autonomous units.
Material flow control in remanufacturing
The literature review [28] classifies the latest approaches in the field of disassembly planning and differentiate the approaches according to certain characteristics that have an influence on its complexity. The proposed solutions are disassembly-specific, such as disassembly priority graphs, disassembly trees, mathematical approaches to disassembly optimisation or disassembly Petri nets. Production control, as understood in this publication, describes the allocation of disassembly operations to available resources. Thus, real-world problems have a more dynamic character, such as machines can fail, completion dates or priorities can change [16], and failure rates of cores and components can change. Previous approaches in the literature aimed to find a generally optimal policy, to look in more detail at production release, e.g., of disassembly, or to adapt procedures such as Kanban to remanufacturing.
The authors of [6] investigate different disassembly release mechanisms for components by examining the effects of different delay buffers or lead times in disassembly and assembly. According to [6], the timing of the material flow through the individual stations is determined by the disassembly, the release of disassembled components and by the control of the individual workstations. In [36] they developed a technique to schedule the disassembly, so that the resources are fully utilised. The developed planning technique creates a disassembly schedule that minimises the total processing times and hence the cost of disassembly leading to an optimal process schedule. The developed algorithm was extended by a selective disassembly process plan with the aim of optimising the selection of components of a product [34, 35]. The algorithm based in the disassembly process plan was further developed to solve the problem of disassembling high-mix / low-volume batches of electronic devices. In this process, the sequence of multiple and single product batches is determined by disassembly and removal operations to minimise the idle time of machines and the production margin [33].
[17] proposes a multi-Kanban mechanism for a disassembly environment. The focus is on a disassembly line with single-variety products, different component requirements, products that have multiple precedence relationships, and random workstation failure. The performance is measured by the inventory level, the level of satisfied demand, and the customer waiting time. A simulation proved that the performance of the disassembly line using the proposed multi-Kanban mechanism outperforms the traditional push system. According to [17], the increase in efficiency must be facilitated with the help of a different control method.
[13] compared the performance of the Dynamic Kanban System for Disassembly (DKSDL) with the classical Kanban method. A number of uncertainties is listed and an approach to deal with these uncertainties dynamically is proposed [13]. found that their approach is superior to the conventional method as well as the modified Kanban system for disassembly line (MKSDL) previously developed by the authors.
[21] developed a multiple quality class approach for the end-of-life products to better deal with varying working hours to better balance the disassembly line. [2] proposed a decision support framework for disassembly systems. Specific quality criteria for electronic braking systems are defined, which classify the cores and place them in one of six quality classes. For each of these quality classes, there are specific processing times as well as information on the economic feasibility of disassembly. The publication shows that a quality-related approach leads to better compliance with the target cycle time for each quality class. In [2], the authors prioritise the decision whether further disassembly offers a benefit based on quality and economic benefit to prevent unnecessary work on the disassembly. Products that have experienced greater stress during their life cycle show a significant influence on the type and duration of disassembly work required.
Publications in the field of control methods for disassembly systems almost all exclude defective parts as well as failed processes due to the otherwise significantly increasing complexity [12]. It is generally known that in remanufacturing the variance in the quality of the cores plays a significant role with regard to the uncertainties in the disassembly process and thus an increase in failure probability [1].
In [8], the authors stated that a failure of a single disassembly process can significantly disrupt the flow within a disassembly system. A failure of components or a core would lead to difficulties, such as idling of a bottleneck workstation. By considering or observing the core conditions and the resulting parameters in the disassembly process, uncertainties can be reduced in the control phase, failures or idle times can be avoided and a higher on-time delivery can be achieved. In a production environment where cores with uncertain states are processed, a control system must be able to deal with defective operations or failures during the process steps. However, research has only addressed this problem in a limited state. The goal of fully utilising the workstations leads to unnecessary work and no productive use of resources. The knowledge of where the uncertainties are in remanufacturing should be considered in the control system.
With the increasing automation of disassembly, there will be a need for adaptive control solutions in the future [37]. A regulated workflow leads to hybrid lines being used optimally. Thus, this leads to a better productive use of labour hours. We will take these points into account in our proposal. The approach incorporates the uncertainties into its decision-making and takes appropriate action. We thus enable an increase in productivity in the form of maximised \(TH\), minimised \(WIP\) and optimum machine and worker utilisation.
Background – reinforcement learning in production flow control
The field of material flow control with reinforcement learning is still quite young. The systematic literature review [19] summarises the previous papers in the field of Deep Reinforcement Learning in Production Planning and Control. The authors divide the areas into production planning, production control, production logistics and implementation challenges. [19] only mentions one publication in connection with \(WIP\) control, see [32]. This shows that there is a need for action in this area, especially since reinforcement learning will play a major role in the future regarding the dynamic control of production systems that considers the state.
[38] used a Q-learning agent that takes care of the release in a CONWIP environment. But the Q-learning agent limit the state to discrete values and thus cannot handle continuous values. The action space is also discrete: do nothing, release a production authorisation and capture a production authorisation. Thus, [38] did not control the \(WIP\) limit but the release rate as it cannot handle continuous value from the production environment.
[32] is based on the previously published paper [27]. In their first paper, the authors chose a Deep Q-Network (DQN) agent to dynamically adjust the \(WIP\). Here, [27] considers two parallel simulations with two different agents. One agent has the goal of maximising \(TH\) regardless of the \(WIP\), like a usual push. The other agent with the goal of setting the \(WIP\) appropriately close to the critical \(WIP\) (\({w}_{0}\)) is rewarded if it has a low \(WIP\) with the same or close to the same \(TH\). This leads to a better result than the classic push method. By using this method, a \(WIP\) close to \({w}_{0}\) is achieved.
[32] extended their previous approach and replaced the DQN agent with a Proximal Policy Optimisation agent (PPO agent) and applied this approach to the same flow shop system as in [27]. The reward function is as follows:
The suffix π represents the trained policy. The maxTh is the policy where the orders are released according to their due date as in a push system. The approach was compared by simulations with other methods, i.e., statistical throughput control (STC), and achieved better results than the other agent in terms of maximising \(TH\) and minimising \(WIP\) and good results compared to the STC method.
In summary, many classic methods were used and improved by additional dynamic methods or adapted to the systems. It can be observed that deterministic processing times are often used, and random failures are not considered in remanufacturing. Mainly fixed failure rates are used. Here, we propose a different approach. Instead of choosing an agent with only the goal of maximising \(TH\) as a reference, we propose to use the observations available in actual operations and to develop the reward function based on the real measurable key performance indicators. In contrast to [32] we choose the pull or release of further material into the production system as the action space and thus control the pull signal or the material release.
We present a simulation-based control for a disassembly system including manual and automated workstations with fluctuating processing times due to different core quality and random failures of cores or components. Further, we have used a discrete-event simulation model as a digital twin to simulate the production processes that are controlled by the RL agent.
Changing bottleneck and WIP effect
Variability of the processing time leads to a changing bottleneck between different workstations. If the changing bottleneck is not considered or not included in the control of the material flow, one of the workstations will run empty because there is no more material available. On the other hand, too high release rate may result in too much material inside the remanufacturing system waiting to be processed. We focus on three KPIs in this paper: Throughput, WIP and Cycle Time, defined as follows:
-
Throughput (\(TH\)): How much material leaves the remanufacturing system per time (units/time).
-
Work-in-Process (\(WIP\)): The amount of material (units) that has been released and not yet completed.
-
Cycle time (\(CT\)): Time that passes between the release of the material and the completion of the material.
The cycle time is significantly influenced by the two parameters \(TH\) and \(WIP\) and hence results from the \(TH\) achieved and the \(WIP\) in the system. Little's Law relates the three KPIs [29]:
Little's Law can be changed to the critical \(WIP\) formula, which uses the bottleneck rate \({r}_{"constraint"}\) and raw process time \({T}_{0}\) to calculate the \({w}_{0}\) of the system under consideration [10].
The formulas (2) and (3) are difficult to apply to use cases that are stochastic [29]. The idealised production curve which shows the relation between \(TH\) and \(WIP\) can be represented as in Fig. 1.

Idealised work-in-process and throughput relation (based on [18])
Figure 1 shows the idealised existing relationship between \(TH\) and \(WIP\). The production curve shows the performance curve over the different \(WIP\) limits. From a certain point of the \(WIP\), \({w}_{o}\), a limit is reached from which the performance of a production system no longer changes significantly. This is synonymous with the realisation that above a certain \(WIP\), no interruption of work is possible [18].
In remanufacturing, however, the uncertainties that complicate the calculation of the \({w}_{0}\) or do not lead to the optimum must be considered. In the next section we propose our optimisation objective and what assumptions are made.
Disassembly and experimental setting
The considered remanufacturing system is used to test the performance of the RL agent. Here, the corresponding processing times as well as the effects of the uncertainties on key performance indicators are considered. The cores at the start of the remanufacturing system do not count towards the \(WIP\) here, as our focus is on the released cores. The simulation time is 225,000 s. The remanufacturing system is structured as shown in Fig. 2.

Remanufacturingsystem
The mean value µ and the standard deviation σ of the processing time (\(P{T}_{i}\)) at each workstation (\(W{S}_{i}\)) can be seen in the Table 1. The disassembly system consists of four workstations (\(W{S}_{i}\)) and a buffer in front of each workstation (\(Buffe{r}_{i}\)). The processing times (\(P{T}_{i}\)) are normally distributed and depend on the core quality during disassembly. With decreasing core quality (increasing index), the standard deviation and thus the fluctuations increase.
Since the processing time of \(W{S}_{3}\) cannot be predicted with certainty before the analysis at \(W{S}_{2}\), the processing time of \(W{S}_{3}\) fluctuates around the processing time of \(W{S}_{2}\). Thus, a changing bottleneck is created here between \(W{S}_{2}\) and \(W{S}_{3}\), which affects the material release. There is a risk of releasing too many cores into the disassembly creating a congestion in front of \(W{S}_{3}\) due to poor quality of the arriving cores. On the other hand, too few cores can be released, resulting in a loss of \(TH\). Not only the processing times cause difficulties, but also the random failures of cores after analysis or components during disassembly. The analysis at \(W{S}_{2}\) identifies the load on the cores during the field life and sorts out cores that are above the limit of reuse. Component damage can usually only be detected during disassembly and thus leads to failures late in the process. Failures depend on quality and differ per class. In our model, the quality of the cores can be modelled as a p-dimensional state vector:
Without loss of generality, we consider three quality classes in our simulation model. Here, 1 corresponds to very good quality and as the index increases, the quality decreases. The representation allows to classify the cores into different quality classes. The probability that a core or individual components will have to be scrapped depends on the condition q. Accordingly, the probability of remanufacturing cores and components differs in q. The probabilities may change in the process of disassembly. The general assumptions for a better understanding of the remanufacturing system are described in the assumptions and optimisation goals section below.
Material flow control in remanufacturing system
Assumptions and optimisation goals
Following the systems description above, we make the following assumptions:
-
The system is constantly supplied with material, so a shortage of raw material (in this case cores) is impossible.
-
We focus a flow shop system. Hence, the workstations are arranged in sequence and the cores must all pass through the same workstations.
-
The workstations immediately pick up the waiting material (cores or components) as soon as the current processing is completed and start the next processing (assuming the material is available in the buffer).
-
We consider a product (but can also be several that do not require a tool change) with five components that are remanufactured.
-
Cores or components are handled individually (one-piece flow), no batch production.
-
The cores are handled from the buffer according to the FIFO (first in first out) principle.
The goal is to release the material so that the production system is close to \({w}_{0}\). The release of further material here offers a direct influence on the production system and the possibility to react timely to changes in the state space. The following formulas (5) and (6) show the overall optimisation goal of the proposed material flow control:
With the help of the RL agent, it should be ensured that in a stochastic environment, important KPIs such as maximising \(TH\), minimising the average \(WIP\), a low \(CT\), a high service level and fast order processing find high importance.
In the following, the state space, action space and the reward function are discussed.
State space
In our case, the state vector has a total of five dimensions. In our simulation the sample time \(ts\), every fixed time step the agent takes an action, is 50 s. We propose to observe the following states of the environment with respect to the optimisation objective and the reward function:
-
\(WIP\) in the remanufacturing system (\(WI{P}_{reman}(t)\))
-
Average \(TH\) of the remanufacturing system per sample time (\(\overline{TH(t)}\))
-
Average Failure rate per sample time \(\overline{{n}_{core}\left(t\right)}\) at \(W{S}_{2}\) (core)
-
Average Failure rate per sample time \(\overline{{n}_{comp}(t)}\) at \(W{S}_{3}\) (component)
-
Average material release rate per sample time (\(\overline{MR(t)}\))
The average values are calculated as a cumulative value from simulation start \({t}_{0}\) to observation time \(t\) and passed on to the RL agent per sample time \(ts\). The rates are passed to the RL agent as an average value per sample time \(ts\). The \(WI{P}_{reman}(t)\) is provided as a current value and may for example have the value 4.8. As soon as the cores are disassembled into their components, the component counts towards the \(WIP\) with the value \({~}^{1}\!\left/ \!{!}_{{M}_{com{p}_{reman}}}\right.\), where \({M}_{com{p}_{reman}}\) is the number of components that are remanufactured.
Overall, all important key figures that influence the current \(WIP\) are contained in the state space. Classically, the \(WIP\) is determined at time \(t\) by the material input (\(I{N}_{mat}(t)\)), \(TH(t)\) and the starting \(WIP\) (\(WIP\left({t}_{o}\right)\)), as the following formula (7) shows:
In remanufacturing, formula (7) must be extended by two more values:
where \(I{N}_{core}(t)\) represents the input of cores, \({N}_{cores}(t)\) the number of failures of cores and \({N}_{comp}(t)\) the number of failures of components at time t. The initial \(WIP\left({t}_{0}\right)\) is set to 0, as we start with an empty disassembly line. The calculations of the individual rates are:
Using the state space, the RL agent gets the current \(WI{P}_{reman}\) and the average rates per sample time \(ts\).
Action space
The RL agent has a discrete action space. At each sample time \(ts\) it makes the decision whether to release one core or not. The discrete action space is \({A}_{1} = \{0, 1\}\). If it decides for 0, the agent does not release another core and if 1, it releases one core. This enables a core to arrive at \(W{S}_{2}\) at the necessary time and to be available there before idle time. The material flow should be coordinated with the processing rates. The action space can be seen as a pull signal.
The random failures after analysis and disassembly make this difficult, as these cannot be predicted exactly and must be compensated for accordingly. At the same time, the machining time variations further complicate material release control, as there is the risk of causing a queue before disassembly due to frequent release and poor core quality, or the risk of idling the disassembly station if no core is available. Also, there could be a puffer in front of the other workstations because of releasing to many cores.
Reward function
The reward function is the key element that is used by the agent to calculate its policy. In our case, we propose to shape the reward function into different components depending on the state of the remanufacturing system. The RL agent activates the following reward functions by fulfilling the conditions that are required at time t and the current state of the system. Figure 3 illustrates the sequence of activation. It is also possible to fall back into one of the previous reward functions as soon as the requirement for an activation point is no longer fulfilled. Also e.g., \({R}_{3}\) cannot be activated before \({R}_{2}\).

Sequence reward function and activation points
The first target is to get the average utilisation of the bottleneck or one of the changing bottlenecks above a certain transition value. Care must be taken to use a transition value aligned with the existing system. An appropriate value can be determined with the help of simulations or by means of process knowledge. The following formula (13) is used to reward increasing utilisation with a weight factor \({\omega }_{1}\):
The reward function \({R}_{1}\) thus rewards the increase of the average utilisation of the bottleneck towards 1 and thus 100%. Here, \(Uti{l}_{activate}\) is 0.3. If \(Uti{l}_{activate}\) is reached, the system activates \({a}_{{R}_{2}}\) (\({a}_{{R}_{2}}=1\)) to the next step of the reward function \({R}_{2}\). If \(Uti{l}_{activate}\) is not reached, \({a}_{{R}_{2}}\) has the value zero and \({R}_{2}\) is not activated. This first reward function is mainly important for the start-up phase. The following are the key reward functions for finding \({w}_{0}\).
After \(Uti{l}_{activate}\) has been achieved, the next goal is to bring \(\overline{MR(t)}\) and \(\overline{TH(t)}\) of the remanufacturing system into a defined range. This is important so that not too little and not too much material is released. Depending on the parameter values of the system, the limit must be adjusted. Formula (15) shows the reward for the different ranges.
If the ratio is above or below the target range at time t, it is penalised according to the distance limit. If the ratio is between Lower Limit \(LL\) (here, 0.8) and Upper Limit \(UL\) (in our case 1), the reward jumps to 2.
The next target is to get near the maximum possible or planned \(\overline{TH\left(t\right)}\) of the remanufacturing system. The maximum possible \(\overline{TH\left(t\right)}\) can be extracted from experience and simulations. In the simulation, this is measurable via the average \(TH\) of the remanufacturing system or the bottleneck workstation. However, the demand rate, if lower than the maximum \(TH\) rate, can also be used as a value. The effectivity of the remanufacturing system is measured as follows [9].
In the case of a changing bottleneck, the \(TH\) value of the entire remanufacturing system can be used. If a bottleneck has been identified or can be extracted from the long-term data, this value can be used for the planned \(TH\) value. The planned \(TH\) for the total system or in the case of an identified bottleneck can be calculated as follows:
If, for example, the agent does not release any material or releases too little, then production is not effective, and the strategy applied does not enable the maximum \(TH\). The RL agent should enable the fulfilment of the production plan by maximising \(TH\) and implement it effectively [3]. To activate the next reward function \({R}_{3}\) the RL agent must exceed a certain transition value via the release of cores. We define a transition value of 0.95. From the simulation results, the selected transition value is very suitable for the transition to \({R}_{3}\). Value \({a}_{{R}_{3}}\) is defined as:
The difficulty is that the \(\overline{TH\left(t\right)}\) value only changes after some time, depending on the length of the remanufacturing system and how many cores or components fail, the \(\overline{TH\left(t\right)}\) value in the state space will only change after the agent has performed several actions and the first core or component passes the system or the bottleneck workstation. As soon as the transition value has been reached, \({a}_{{R}_{3}}\) is set to 1 and activates \({R}_{3}\).
\({R}_{3}\) is the last function that enables finding \({w}_{0}\) of the remanufacturing system and includes the efficiency of the remanufacturing system. The function makes it possible to differentiate between various strategies, as it explicitly considers \(\overline{MR\left(t\right)}\) and \(\overline{TH\left(t\right)}\). With this part of the reward function, we measure if the agent is working at a minimum \(WIP\) level. The efficiency is calculated as follow, [9]:
With (20), the third reward function can be formulated:
With increasing \(\overline{TH\left(t\right)}\) and no increase of \(\overline{MR\left(t\right)}\), the agents receive a higher positive reward. This last formula allows to differentiate between strategies and finds the one that achieves the global optimum, maximise \(TH\) and minimise \(WIP\). The overall reward function is as follows:
As explained at the beginning of this section, the reward functions are activated in the defined order as shown in Fig. 3. The next section provides the information about the Reinforcement Learning Algorithm used in this paper.
RL algorithm—Proximal Policy Optimization (PPO)
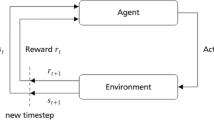
Reinforcement Learning can obtain the optimal policy by learning from the interaction with the environment. Normally the RL problem is modelled as a Markov decision process (MDP) with a tuple \(<S,A,P,R,E>\), where:
-
\(S\): set of all states
-
\(A\): set of executable actions of the agent
-
\(P\): transition distribution, \(P_{ss'}^a=P(S_{t+1}=s'\vert S_t=s,A_t=a)\)
-
\(R\): reward function, and \({r}_{t}\) represents the reward obtained after taking an action at time \(t\)
-
\(E\): set of states that have been already reached
The RL agent selects an action based on its policy, which is a probability distribution of actions under a given state. This is represented by \({\pi }_{\theta }\left({a}_{t}|{s}_{t}\right)\). The goal of the RL agent is to maximise the cumulative reward defined as:
The parameter \(\gamma\) is the discount factor to calculate the cumulative reward, where \(\gamma \in [\mathrm{0,1}]\). To find an optimal policy, RL uses a policy gradient method. It samples interactions between the agent and the environment. With that it calculates the current policy gradient directly. The current policy then can be optimised with the gradient information [31].
The optimal policy and the value of policy πθ are designed in the form of:
\({P}_{\theta }\left(\tau \right)=\prod_{t=1}^{T}{\pi }_{\theta }\left({a}_{t}|{s}_{t}\right)P\left({s}_{t+1}|{s}_{t},{a}_{t}\right)\) describes the occurrence probability of the current trajectory. \(\theta\) is the parameter of the current model. The gradient of the objective function \(L(\theta )\) is approximated as in (26) since the environment transition distribution is independent of the model parameter.
The policy gradient algorithm is divided into two steps of continuous iterative update:
-
Using \({\pi }_{\theta }\) to interact with the environment. Obtain the observed data for calculating \({\nabla }_{\theta }L(\theta )\).
-
Update \(\theta\) with the gradient. Update the learning rate \(\alpha\), where \(\theta =\theta +\alpha {\nabla }_{\theta }L(\theta )\).
We have chosen Proximal Policy Optimisation (PPO) to control the material flow. The algorithm was published by John Schulman et al. in 2017 [25]. PPO is implemented by policy gradient estimation and gradient ascent optimization [31]. The policy estimation is:
To improve the training efficiency and reuse the sampled data, PPO uses \({\uppi }_{\uptheta }\left({a}_{t}|{s}_{t}\right)/{\uppi }_{\uptheta }\left({a}_{t}|{s}_{t}\right)\) to substitute \(\mathrm{log}{\uppi }_{\uptheta }\left({a}_{t}|{s}_{t}\right)\) to support off-policy training. The clipping mechanism is added to the objective function to punish the excessive policy change when \({\uppi }_{\uptheta }\left({a}_{t}|{s}_{t}\right)/{\uppi }_{\uptheta }\left({a}_{t}|{s}_{t}\right)\) is far from 1. The final objective function is:
where \({r}_{t}\left(\theta \right)\) represents the action selection probability ratio of new and old policies.
The clip function limits the ratio between old and new to the interval \(\left[1-\epsilon ,1+\epsilon \right]\), where \(\epsilon\) is a hyperparameter. Only large changes in the direction of policy improvement are removed.
Results and comparison
Simulation scenarios
We compare our approach directly with different \(WIP\) limits to show that we can preserve \(TH\) and decrease \(WIP\) at the same time. In doing so, the RL agent should automatically adapt to the changing environment. In the CONWIP procedure, a new \(WIP\) limit would have to be determined according to the changes, which would correspond to the other conditions. We will show that the RL approach is able to control the material flow by controlling the release rate, achieving a higher \(TH\) than the classical methods. We simulated different scenarios:
-
1.
Constant failure rate (10%) at analysis (\(W{S}_{2}\)) and disassembly (\(W{S}_{3}\)) (1%) and quality-related variable processing times at disassembly (\(W{S}_{3}\)).
-
2.
Failure depending on quality class (\({Q}_{1}=1\%, {Q}_{2}=5\%, {Q}_{3}=15\%)\) and quality-related variable processing times at disassembly (\(W{S}_{3}\)).
-
3.
Failure after half processing time of the analysis workstation (\(W{S}_{2}\)).
-
a
Constant failure rate (1%) and quality-related variable processing times at disassembly (\(W{S}_{3}\)).
-
b
Quality-related failure rate (\({Q}_{1}=1\%, {Q}_{2}=5\%, {Q}_{3}=15\%)\) and quality-related variable processing times at disassembly (\(W{S}_{3}\)).
-
a
-
4.
No failures and with quality-related variables in processing times at disassembly (\(W{S}_{3}\)).
-
5.
A changing environment generating different bottlenecks between workstation \(W{S}_{2}\) and \(W{S}_{3}\).
We can observe from the results that the developed RL agent outperforms the defined CONWIP limits. The selected formulas mentioned in the reward function measure how effectively and efficiently the production system works. The TH and the material released play a key role. We simulated the RL agent and the individual WIP limits and took the cumulative reward to compare the different approaches. The RL agent performs best, as it requires less input for the maximum \(TH\) or achieves a higher \(TH\) compared to the lower WIP limits and is thus closest to the \({w}_{0}\) of the system.
The next section contains the results of the different simulations.
Comparison RL agents against fixed CONWIP
In the first scenario, we consider a constant failure rate (10%) at analysis (\(W{S}_{2}\)) and disassembly (\(W{S}_{3}\)) (1%) and quality-related variable processing times at disassembly (\(W{S}_{3}\)). Figure 4 shows the results of the simulation.

Performance methods fixed failure rate and quality-related processing time at disassembly \(W{S}_{3}\)
Figure 4 shows the cumulative reward of the individual limits and the RL agent. The selected limit of 5 is quite close to the critical WIP, but the RL agent generates a higher reward over the simulation time. The other limits are far from the \({w}_{0}\) and perform poorly overall in the selected scenario. It is easy to see that the higher the threshold is chosen, the lower the reward. This depends mainly on the fact that the higher input no longer has any influence on the \(TH\), but only reduces the reward and thus also reduces efficiency. In this case \({w}_{0}\) is between 5 and 10, with the RL agent achieving an average WIP of 5.8.
Next, we change the failure rates at disassembly (\(W{S}_{3}\)) in the scenario and define them for each quality class and keep the processing time variability at \(W{S}_{3}\). The chosen failure rates at disassembly are for \({Q}_{1}=1\%, {Q}_{2}=5\%\) and \({Q}_{3}=15\%\). The failure rate at the \(W{S}_{2}\) remains the same. Figure 5 below shows the simulation results.

Performance methods quality-related failure rates and processing time at disassembly \(W{S}_{3}\)
Figure 5 illustrates the strength of the RL agents in finding \({w}_{0}\) using the learned policy. The RL agent again achieves a higher cumulative reward than the rest of the \(WIP\) limits. As in Scenario 1, a downward trend in the higher limit values is evident. The RL agent in this case achieves an average \(WIP\) of 5.7.
In the next scenario, we change the failure point at \(W{S}_{2}\). The core fails within the analysis after half of the processing time (after 150 s) or can be used in disassembly. This can happen in remanufacturing if the cores are checked for load parameters at the beginning of the analysis and then, e.g., software modifications are made. Figure 6 shows the simulation results for this scenario.

Performance methods fixed failure rate at \(W{S}_{2}\) and \(W{S}_{3}\), quality-related processing time at \(W{S}_{3}\) and moved failure point at \(W{S}_{2}\)
This scenario changes the challenges for the RL agent. Since the RL agent must decide whether to release another core so that \(W{S}_{2}\) is supplied even in the event of a failure. Higher limits create a buffer before the analysis at \(W{S}_{2}\) and thus ensure that cores are always available. However, it can be seen from the reward function that the productivity of the limits is much worse than that of the RL agent. Also, rewarding the utilisation of the analysis does not allow for a higher reward for the higher limits. Here, the RL agent also achieves a clearer distance to CONWIP 5 and sets itself slightly apart.
The fourth scenario is dealing with the moved failure point at \(W{S}_{2}\) and with the quality-related failure rates at \(W{S}_{3}\) (\({Q}_{1}=1\%, {Q}_{2}=5\%\) and \({Q}_{3}=15\%\)). Figure 7 shows the results.

Performance methods quality-related failure rate, quality-related processing time at \(W{S}_{3}\) and moved failure point at \(W{S}_{2}\)
The RL agent performs best in all simulated scenarios so far and releases material according to \({w}_{0}\) and the corresponding challenges regarding failures. In contrast to the other limits, the RL agent can react flexibly to the respective situation. In remanufacturing, the error rates at analysis \(W{S}_{2}\) and disassembly \(W{S}_{3}\) cause the most difficulties here, as these lead to a loss of material, especially at later workstations. With a fixed limit, the newly released material takes too long to reach the required workstation in the event of a material failure.
Another simulation compares the performance of the RL agent in an environment without failures of cores and components, but with quality-related processing time fluctuations. Although this is rather unusual in remanufacturing systems, it allows to compare the agent under condition like in a flow shop production with a changing bottleneck. For example, it can be shown that the RL agent is variably adaptable to changing environments. Figure 8 shows the comparison in this scenario.

Performance methods without failures and with quality-based processing time at \(W{S}_{3}\)
The RL agent also achieves a higher reward here than the rest of the limits. Even if the RL agent achieves only a slightly higher reward than CONWIP 5, it is closer to \({w}_{0}\) and influences the efficiency of the remanufacturing system through its material release.
To demonstrate the advantages of the RL agent in terms of adaptivity, we have simulated an additional scenario in which bottlenecks alternate between \(W{S}_{2}\) and \(W{S}_{3}\) with a constant failure rate (as in the other scenarios) at each of these workstations. Table 2 shows the changing processing time at \(W{S}_{3}\).
This requires the RL agent to adapt the release so that the corresponding buffers before the bottleneck do not overflow with stock. The closer the bottleneck is to the end, the more difficult it is to utilise and supply the bottleneck with sufficient material. Figure 9 shows the results of the simulation.

Performance of the different methods in a changing environment
The extended scenario shows the potential of controlling the material flow in changing conditions with an RL agent as opposed to setting a defined limit. The agent can adjust its behaviour regarding material release as soon as it detects changes in the state space. This usually happens faster than with later adjustments by workers or planners or control software.
In the following, we will show the different plots of the simulation that reflect the adaptivity. The agent has achieved a significantly higher reward in this scenario than the other limits. The distance to CONWIP 5 is also greater and accordingly shows that CONWIP 5 releases too little material for the system in this scenario.
The key characteristic is the \(WIP\). The most important thing here is that no excessive fluctuations occur and thus a constant material flow is guaranteed by the RL agent. Figure 10 shows the \(WI{P}_{reman}\) over the simulation time \(t\).

WIP over simulation time
The \(WIP\) has a stable course over the simulation time with only a few outliers, which can, however, be caused by the failures at the individual workstations. The stability and flexibility are clearly shown by the average \(WIP\) over the simulation time as shown in Fig. 11.

Average WIP over simulation time
The average \(WI{P}_{reman}\) is from the last simulation scenario. At the beginning of the simulation, the \(WIP\) increases towards 5.8. From time 75,000 s, the processing times at \(W{S}_{3}\) change and the average \(WIP\) falls slightly towards 5.7. Thus, the average \(WIP\) falls, and the agent adapts the material release. Subsequently, the average \(WIP\) rises again from 150,000 s because the bottleneck shifts again due to the renewed adaptation of the processing times at \(W{S}_{3}\).
The agent's cumulative reward shows that the agent adapts to the changing states. The adaptation is positively rewarded. The agent achieves a high \(TH\) at the bottleneck and changes the input via the material release. Figure 12 shows the cumulative reward of the RL agent.

Cumulative Reward RL Agent over simulation time
From the individual transitions at 75,000 s and 150,000 s, we see that the agent does not get much reward at the beginning because it allows too little \(TH\) at the bottleneck and generates too much input via the release. After it adjusts the policy, it eventually gets a constant positive reward.
Figure 13 illustrates the ratio of input to output. The figure shows how the change in processing times changes the ratio of input to output. If the bottleneck is further back in the production system, the agent must release more material so that the bottleneck is constantly supplied with material. If the bottleneck is further forward in the system, the agent releases the material in longer periods of time so that the buffer in front of the bottleneck does not overflow.

Input/Output Ratio over simulation time and changing states
The transitions occur because of the changing condition at 75,000 s and 150,000 s. In addition to the input/output ratio, the average material release rate of the RL agent shows the adaptivity in Fig. 14.

Average material release rate RL Agent over simulation time
At the beginning of the simulation the RL agent releases more material, between 75,000 s and 150,000 s it decreases the material release and after 150,000 s it increases it again and releases more material per \(ts\). At the beginning, the material release rate moves towards 0.15 units/\(ts\). After the change of states, the RL agent decreases its material release, and the average value moves towards 0.165 units/\(ts\). After readjusting the environmental conditions, the RL agent adapts again and accelerates its material release rate back towards 0.15 units/\(ts\). The RL agent protects the supply with material of the changing bottlenecks, this can be seen from the buffer stocks at \(W{S}_{2}\) (Fig. 15) and \(W{S}_{3}\) (Fig. 16).

Queue analysis \(W{S}_{2}\) over simulation time \(t\)

Queue disassembly \(W{S}_{3}\) over simulation time \(t\)
The buffers are usually supplied with material so that the bottleneck can work at any time. It should be noted at figures Figs. 15 and 16 that the bottlenecks change. At the beginning and end of the simulation, \(W{S}_{3}\) is the bottleneck, while in the middle of the simulation \(W{S}_{2}\) is the bottleneck. This explains that at certain simulation times the buffer stock of the workstations drops to 0. Figure 16 shows that due to failures at \(W{S}_{2}\), the buffer stock briefly falls to 0 before \(W{S}_{3}\). At the same time, the RL agent tries to cover these failures by releasing more cores, as can be seen in Fig. 15.
With this behaviour, the RL agent receives the highest reward compared to the limits. Thus, a lower WIP risks the utilisation and material supply of the bottleneck and a higher WIP overfills the buffers with material and thus reduces the flexibility of the production system.
The RL agent has between 40–50% lower \(WIP\) compared to CONWIP 10 and CONWIP 15 in all scenarios, unlike the other limits, except \(WIP\) limit of 5. CONWIP 5 always carries the risk, which can also be seen in the reward, that the bottleneck runs empty due to the lower \(WIP\) or that there is no material at the bottleneck to process due to random failures.
The RL agent has a different material release rate in all different scenarios. This shows that the PPO agent adapts to the other states or characteristics. The PPO agent illustrates the possibilities that reinforcement learning offers in production optimisation. The adaptivity of reinforcement learning agents as well as the combination with classical methods expands the optimisation potential of multi-objective optimisation.
The next section explains areas of use of reinforcement learning in the field of remanufacturing, gives a summary and points out future areas of research.
Conclusion and further research
[22] points out that capacity control, in this case the utilisation of the production system, is an important area of research in production control and should become more important in the future. The reinforcement learning approach is a way for remanufacturing to deal with increasing complexity. The pure CONWIP approach with its simple implementation allows to compare and evaluate the RL approach. For remanufacturing, the proposed RL approach can also be used for further operational decisions, such as disassembly decisions based on various observations. The approach can also be applied to new productions or series productions that, for example, assemble the products in a flow shop with one-piece flow. Instead of assuming failure rates for cores and components as we do, the rework rate at certain workstations is considered in the series process or a defined bottleneck workstation. For production lines that can only accommodate a certain number of workpiece carriers, otherwise machine downtimes would occur, reinforcement learning can be used to determine the optimal number of workpiece carriers and control the release of the workpiece carriers according to the line conditions.
In summary, our developed approach serves as a possible solution to control the uncertainties in remanufacturing and to increase the productivity of disassembly lines. The results show an optimisation of the system and a minimisation of costs. Since setting WIP limits takes time and resources, and eventually no guarantee can be given that this is the critical WIP of the production system, our proposed approach allows for self-adaptation to changing environmental conditions. The RL agent can also be combined with different agents or control algorithms. By observing and incorporating other decisions, the RL agent can adapt its decision-making and, in contrast to supervised learning methods, continues to improve itself during production. The proposed approach can also be modified so that in case of demand uncertainties, the bottleneck rate is equal to the demand rate and the material is released accordingly.
With the help of digital twins and real-time data as well as predictions, reinforcement learning can be the next step in dealing with individualisation and increasing complexity, allowing production to increase productivity.
Data availability
All data generated or analysed during this study are included in this published article.
References
Altekin FT, Akkan C (2012) Task-failure-driven rebalancing of disassembly lines. Int J Prod Res 50:4955–4976. https://doi.org/10.1080/00207543.2011.616915
Colledani M, Battaïa O (2016) A decision support system to manage the quality of End-of-Life products in disassembly systems. CIRP Ann 65:41–44. https://doi.org/10.1016/j.cirp.2016.04.121
Drucker PF (1963) Managing for business effectiveness. Harv Bus Rev 41:53–60
ElMaraghy H, AlGeddawy T, Azab A et al (2012) Change in Manufacturing – Research and Industrial Challenges. Enabling Manufacturing Competitiveness and Economic Sustainability. Springer, Berlin, Heidelberg, pp 2–9
Fernandes NO, do Carmo-Silva S (2006) Generic POLCA—A production and materials flow control mechanism for quick response manufacturing. Int J Prod Econ 104:74–84. https://doi.org/10.1016/j.ijpe.2005.07.003
Guide VDR, Jayaraman V, Srivastava R (1999) The effect of lead time variation on the performance of disassembly release mechanisms. Comput Ind Eng 36:759–779. https://doi.org/10.1016/S0360-8352(99)00164-3
Guide VR, Kraus ME, Srivastava R (1997) Scheduling policies for remanufacturing. Int J Prod Econ 48:187–204. https://doi.org/10.1016/S0925-5273(96)00091-6
Gungor A, Gupta SM (2001) A solution approach to the disassembly line balancing problem in the presence of task failures. Int J Prod Res 39:1427–1467. https://doi.org/10.1080/00207540110052157
Heinen E (1991) Industriebetriebslehre als entscheidungsorientierte Unternehmensführung. In: Heinen E, Picot A (eds) Industriebetriebslehre. Gabler Verlag, Wiesbaden, pp 1–71
Hopp WJ, Spearman ML (2008) Factory Physics, 3rd edn. Waveland Press, United States of America
Hülsmann M (ed) (2007) Understanding autonomous cooperation and control in logistics. The impact of autonomy on management, information, communication and material flow. Springer, Berlin, Heidelberg, New York
Kim H-J, Harms R, Seliger G (2007) Automatic Control Sequence Generation for a Hybrid Disassembly System. IEEE Trans Automat Sci Eng 4:194–205. https://doi.org/10.1109/TASE.2006.880538
Kizilkaya EA, Gupta SM (2004) Modeling operational behavior of a disassembly line. In: Gupta SM (ed) Environmentally Conscious Manufacturing IV. SPIE, pp 79–93. https://doi.org/10.1117/12.580419
Lödding H (2016) Verfahren der Fertigungssteuerung. Grundlagen, Beschreibung, Konfiguration, 3rd edn. VDI-Buch. Springer Vieweg, Berlin, Heidelberg
Lödding H, Yu K-W, Wiendahl H-P (2003) Decentralized WIP-oriented manufacturing control (DEWIP). Prod Plann Control 14:42–54. https://doi.org/10.1080/0953728021000078701
Madureira A, Pereira I, Falcao D (2013) Dynamic adaptation for scheduling under rush manufacturing orders with case-based reasoning. In: International Conference on Algebraic and Symbolic Computation, pp 330–344
McGovern SM, Gupta SM (2006) Computational complexity of a reverse manufacturing line. In: Proceedings of the SPIE International Conference on Environmentally Conscious Manufacturing VI, pp 1–12. https://doi.org/10.1117/12.686371
Nyhuis P, Wiendahl H-P (2012) Logistische Kennlinien. Grundlagen, Werkzeuge und Anwendungen, 3. Aufl. 2012. VDI-Buch. Springer, Berlin, Heidelberg
Panzer M, Bender B, Gronau N (2021) Deep Reinforcement Learning In Production Planning And Control: A Systematic Literature Review. Institutionelles Repositorium der Leibniz Universität Hannover, Hannover
Pinedo ML (2018) Scheduling. Theory, algorithms, and systems, softcover reprint of the hardcover 5th edition 2016. Springer, Cham, Heidelberg, New York, Dordrecht, London
Riggs RJ, Battaïa O, Hu SJ (2015) Disassembly line balancing under high variety of end of life states using a joint precedence graph approach. J Manuf Syst 37:638–648. https://doi.org/10.1016/j.jmsy.2014.11.002
Samsonov V, Ben Hicham K, Meisen T (2022) Reinforcement Learning in Manufacturing Control: Baselines, challenges and ways forward. Eng Applic Artif Intell 112:104868 https://doi.org/10.1016/j.engappai.2022.104868
Scholz-Reiter B, Beer Cd, Freitag M et al (2008) Dynamik logistischer Systeme. In: Nyhuis P (ed) Beiträge zu einer Theorie der Logistik. Springer, Berlin, Heidelberg, pp 109–138
Schuh G (2006) Produktionsplanung und -steuerung. Grundlagen, Gestaltung und Konzepte, 3., völlig neu bearb. Aufl. VDI-Buch. Springer, Berlin
Schulman J, Wolski F, Dhariwal P et al (2017) Proximal policy optimization algorithms. https://doi.org/10.48550/arXiv.1707.06347
Silva T, Azevedo A (2019) Production flow control through the use of reinforcement learning. Procedia Manuf 38:194–202. https://doi.org/10.1016/j.promfg.2020.01.026
Slama I, Ben-Ammar O, Masmoudi F et al (2019) Disassembly scheduling problem: literature review and future research directions. IFAC-PapersOnLine 52:601–606. https://doi.org/10.1016/j.ifacol.2019.11.225
Spearman ML, Hopp WJ, Woodruff DL (1990) CONWIP: a pull alternative to kanban. Int J Prod Res 28:879–894. https://doi.org/10.1080/00207549008942761
Suri R (1998) Quick response manufacturing. A companywide approach to reducing lead times, 1st. Productivity Press/CRC Press, New York
Sutton RS, Barto AG (2018) Reinforcement Learning. An Introduction, 2 ed. Adaptive Computation and Machine Learning series. MIT Press Ltd, Massachusetts
Tomé De Andrade e Silva M, Azevedo A (2022) Self-adapting WIP parameter setting using deep reinforcement learning. Comput Oper Res 144:105854 https://doi.org/10.1016/j.cor.2022.105854
Veerakamolmal P, Gupta SM (1998) High-mix/low-volume batch of electronic equipment disassembly. Comput Ind Eng 35:65–68. https://doi.org/10.1016/S0360-8352(98)00021-7
Veerakamolmal P, Gupta SM (1998) Optimal analysis of lot-size balancing for multiproducts selective disassembly. International Journal of Flexible Automation and Integrated Manufacturing 6(3):245–269
Veerakamolmal P, Gupta SM (1999) Analysis of design efficiency for the disassembly of modular electronic products. J Electron Manuf 09:79–95. https://doi.org/10.1142/S0960313199000301
Veerakamolmal P, Gupta SM, McLean CR (1997) Disassembly process planning. In: Proceedings of the International Conference on Engineering Design and Automation, pp 18–21
Wurster M, Michel M, May MC et al (2022) Modelling and condition-based control of a flexible and hybrid disassembly system with manual and autonomous workstations using reinforcement learning. J Intell Manuf 33:575–591. https://doi.org/10.1007/s10845-021-01863-3
Xanthopoulos AS, Chnitidis G, Koulouriotis DE (2019) Reinforcement learning-based adaptive production control of pull manufacturing systems. J Ind Prod Eng 36:313–323. https://doi.org/10.1080/21681015.2019.1647301
Zhao J, Peng S, Li T et al (2019) Energy-aware fuzzy job-shop scheduling for engine remanufacturing at the multi-machine level. Front Mech Eng 14:474–488. https://doi.org/10.1007/s11465-019-0560-z
Funding
Open Access funding enabled and organized by Projekt DEAL. We acknowledge support by the German Research Foundation and the Open Access Publication Fund of TU Berlin.
Author information
Authors and Affiliations
Contributions
Felix Paschko and Steffi Knorn wrote the main manuscript text and prepared all figures and tables. Felix Paschko, Steffi Knorn, Abderrahim Krini and Markus Kemke reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interest
I declare that the authors have no competing interests as defined by Springer, or other interests that might be perceived to influence the results and/or discussion reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Paschko, F., Knorn, S., Krini, A. et al. Material flow control in Remanufacturing Systems with random failures and variable processing times. Jnl Remanufactur 13, 161–185 (2023). https://doi.org/10.1007/s13243-023-00126-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13243-023-00126-z