
Abstract
Rock mechanical properties play a crucial role in fracturing design, wellbore stability and in situ stresses estimation. Conventionally, there are two ways to estimate Young’s modulus, either by conducting compressional tests on core plug samples or by calculating it from well log parameters. The first method is costly, time-consuming and does not provide a continuous profile. In contrast, the second method provides a continuous profile, however, it requires the availability of acoustic velocities and usually gives estimations that differ from the experimental ones. In this paper, a different approach is proposed based on the drilling operational data such as weight on bit and penetration rate. To investigate this approach, two machine learning techniques were used, artificial neural network (ANN) and support vector machine (SVM). A total of 2288 data points were employed to develop the model, while another 1667 hidden data points were used later to validate the built models. These data cover different types of formations carbonate, sandstone and shale. The two methods used yielded a good match between the measured and predicted Young’s modulus with correlation coefficients above 0.90, and average absolute percentage errors were less than 15%. For instance, the correlation coefficients for ANN ranged between 0.92 and 0.97 for the training and testing data, respectively. A new empirical correlation was developed based on the optimized ANN model that can be used with different datasets. According to these results, the estimation of elastic moduli from drilling parameters is promising and this approach could be investigated for other rock mechanical parameters.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The ability of a matter to revert from strain induced by external stresses is known as elasticity, and rock elastic characteristics such as Young’s modulus and Poisson’s ratio are geomechanical parameters that characterize the stress–strain relationship (Fjar et al. 2008). Young’s modulus (E) is an indicator of stiffness and stands for the strain (\(\varepsilon \)) to stress (\(\sigma \)) ratio as in Hook’s law (Eq. 1):
where E and \(\sigma \) are in the same unit.
The design of hydraulic fracturing, wellbore stability and the estimation of the in situ stresses are all influenced by rock elastic characteristics (Hammah et al. 2006; Kumar 1976; Labudovic 1984; Nes et al. 2005). Young’s modulus could be determined from experimental tests on rock samples (static) or indirectly derived from well logs (dynamic) using shear and compressional wave velocities using Eq. 2 (Barree et al. 2009).
where \({E}_{\mathrm{dyn}}\) is the dynamic Young’s modulus (in GPa), the compressional and shear wave velocities (in km/s) are donated by Vp and Vs, respectively, while the bulk density (in g/cm3) is donated by ρ.
A continuous profile can be presented using dynamic properties, however, the measurements of static and dynamic parameters differ considerably. Many publications presented empirical models to estimate static elastic values from dynamic parameters because core tests are costly and cannot produce a continuous profile. The models that correlate the static with the dynamic properties are presented in Table A1 in the Appendix A Part of the equations presented in Table A1 were derived with relatively small numbers of samples or for a certain type of rock. They also require the knowledge of dynamic elastic properties which is not always guaranteed.
Artificial intelligence (AI) approaches are increasingly being used to create models in various sectors of petroleum engineering. Different correlations for reservoir fluid properties have been developed using AI tools, namely PVT fluid properties (Khaksar Manshad et al. 2016), petrophysical properties (Moussa et al. 2018), drilling fluid properties (Abdelgawad et al. 2019), enhanced oil recovery (Van and Chon 2018) and geomechanical properties (Elkatatny 2018). Young’s modulus was not an exception, various correlations were created using AI, as shown in Table 1. Different techniques were used to develop the presented models such as functional network (FN), adaptive neuro-fuzzy inference system (ANFIS), alternating conditional expectation (ACE) and fuzzy logic (FL).
These models in Table 1 need the acoustic log data, which may not always be available. In contrast, drilling data are easier and earlier to be available. In addition, the drilling data have been reported to be successfully utilized to generate synthetic logs for acoustic wave velocity and bulk density (Gowida et al. 2020; Gowida and Elkatatny 2020). Moreover, the use of drilling parameters in abnormal pressure zones detection and formation pressure estimation is an old technique (Jorden and Shirley 1966; Rehm and McClendon 1971). In this paper, a complete workflow to obtain a continuous static Young’s modulus profile using drilling operational parameters is presented using different AI techniques.
Methodology
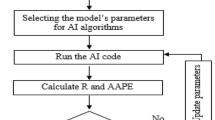
Workflow
In this study, the following steps have been followed to utilize the drilling data to build a continuous profile of static Young’s modulus. Information from two wells including drilling operational records, static and dynamic Young’s modulus has been collected. Correlation between static and dynamic Young’s modulus has been built using machine learning methods and presented in a previous publication (Elkatatny et al. 2019). Then, this correlation has been used to fill the gap between the static values, and a continuous profile of static Young’s modulus is obtained. Afterward, this continuous profile, together with the corresponding drilling parameters for the first well, has been employed to construct the model applying two AI techniques. The machine learning algorithms were blinded to the dataset of the second well, which was then utilized to validate the created model.
Data description
Data from two vertical wells drilled have been used in this study. The lithology of these two wells contains sandstone, shale and limestone. Well-1 has over 2280 data points that were utilized for models’ construction, with 70% of this dataset being used for training and the remaining for testing. The machine learning algorithms were blinded to 1667 data points from Well-2, which were then utilized to evaluate the created model. Any data point consists of six drilling records that are used as inputs, in addition to Young’s modulus that is set as the intended output. The following drilling parameters were gathered from field data and used in the creation of this model:
-
– Drilling rate of penetration ROP
-
– Weight on bit WOB
-
– Drill pipe pressure SPP
-
– Torque
-
– Drilling fluid pumping rate
-
– Rotary speed RPM
Data analysis
Using MATLAB code, the datasets were cleansed of noise and outliers before being fed into the machine learning methods. Data points that contain any value that is away from the mean of the data with three times the standard deviation were considered as an outlier using a built-in keyword in MATLAB. The outliers detection criteria are described in Fig. 1, out of 4307 data points, 352 points were considered as outliers.

Outliers’ detection
Table 2 shows the quantitative analysis of the training dataset used to create the models. As shown by the histogram in Fig. 2, Young’s modulus has a distributed range of values between 0.5 and 7.15 Mpsi.

Young’s modulus histogram
Machine learning algorithms
In this work, two AI algorithms were used, artificial neural network (ANN) and support vector machine (SVM). ANN is a popular machine learning method that mimics the brain’s neurons that could be utilized in clustering, classification or regression (Aggarwal and Agarwal 2014; Chen et al. 2019). ANN contains various parameters such as neurons, activation functions, layers and learning functions (Abdulraheem et al. 2009). Many successful implementations of ANN in the oil sector have been reported (Elkatatny et al. 2017, 2016; Field et al. 2019; Shokooh Saljooghi and Hezarkhani 2015; Tariq et al. 2016).
SVM was introduced in the 1960s as a linear classifier and modified in the 1990s for nonlinear problems by using kernel function (Boser et al. 1992; Cortes and Vapnik 1995). Kernel function was proposed by Aizerman et al. (Aizerman et al. 1964), and there are different kernels such as homogenous and inhomogeneous polynomial, Gaussian and hyperbolic tangent. SVM was applied successfully in petroleum-related problems for regression problems (Abdelgawad et al. 2019; Elkatatny et al. 2016; Elkatatny and Mahmoud 2018; Mahmoud et al. 2020) and classification problems (Aibing et al. 2012; Heinze and Al-Baiyat 2012; Li et al. 2004; Olatunji and Micheal 2017; Zhao et al. 2005).
Evaluation criterion
The models were built using SVM and ANN. These methods use 70% of Well-1 data points to develop the models, and the remaining to test internally, for numerous rounds before selecting the best fit, while Well-2 data were employed as additional validation for the optimized models.
To establish the appropriate tuning parameters inside the algorithms, different runs were performed in each technique. In SVM models, two kernel functions, different values for kernel options, epsilon and regularization were tested. In ANN models, neurons quantity, training and transfer functions were optimized.
Two statistical measures, the correlation coefficient (R) and the average absolute percentage error (AAPE), were utilized to evaluate all of these models’ trials. Equations 3 and 4 are used to determine R and AAPE, respectively:
where N is the size of dataset, \({E}_{\mathrm{given}}\) and \({E}_{\mathrm{Predicted}}\) are, respectively, the measured and the AI-predicted Young’s modulus values.
Results and discussion
Using dataset from Well-1, different machine learning methods were employed to train and test the models. Dataset from Well-2 was utilized for model validation after it had been constructed. This section presents the results obtained using each method and the comparison between them. Additionally, a model that could be used for different datasets is presented as a white box.
Artificial neural network
Several numbers of neurons, training and activation functions have been tested to assure the optimum outcomes from ANN. Using this technique, good results have been obtained. The correlation coefficients for training and testing were 0.97 and 0.92, respectively, while the AAPE values were between 10 and 15%. The given and ANN-predicted Young’s modulus are compared in Fig. 3.

ANN-predicted and actual Young’s modulus cross-plots for a training b and testing
Support vector machine
Different trials have been applied using SVM with changing some tuning parameters inside the algorithm, such as kernel function and regularization. The best results were achieved using the Gaussian kernel function. It’s noticeable that this method outperformed the ANN in training, however, its performance in testing was lower. The R values for training and testing were 0.996 and 0.891, respectively, while the AAPE values were 1% and 15% in the same sequence. Figure 4 presents a comparison between the actual and the SVM-predicted Young’s modulus.

SVM-predicted and actual Young’s modulus cross-plots for a training and b testing
Models’ validation
The dataset of Well-2 was completely hidden during the model’s construction phase. After the best model has been achieved in each method in terms of R and AAPE of training and testing, the models have been tested with this dataset. Figure 5 shows the actual and predicted profiles for Young’s modulus in Well-2.

Trend comparison of the actual Young’s modulus against the prediction of a ANN b SVM for validation dataset (Well-2)
Models’ comparison
In comparison between the models built by ANN and SVM, it could be noticed that while SVM has better results in the training, ANN has better accuracy in the other datasets, which indicates a better-generalized model. Table 3 shows a comparison of the results obtained by the two machine learning methods in terms of coefficient of determination (R2), average absolute relative error and root-mean-square error (RMSE).
Different parameters’ combinations have been tested to ensure optimum fit. Table 4 displays ANN and SVM parameters that yielded the best matches between the predictions and actual values.
New empirical equation for Young’s modulus
When considering all datasets, ANN provided the best fit as presented in the previous section. Equation 5 represents the ANN-based model, whereas Table A2 in the Appendix A gives the weights and biases of the model. This model has been obtained using the tangent sigmoid transfer function.
Conclusions
In this paper, building a continuous static Young’s modulus profile in a real time from the drilling parameters has been investigated by utilizing two machine learning tools. In light of the workflow and tests that have been provided, this study could be concluded with the following statements:
-
Two methods were investigated and resulted in good predictions for Young’s modulus with correlation coefficients all above 0.9.
-
ANN yielded results with correlation coefficients range between 0.92 and 0.97 for training, testing and validation, while SVM outperformed the ANN in training but with lower performance in testing and validation.
-
New empirical correlation for Young’s modulus was developed based on the optimized ANN model. This correlation has been tested with the validation dataset and yielded a 0.93 correlation coefficient.
Based on the findings of this work, which demonstrate the possibility to construct a continuous static Young’s modulus profile from operational drilling parameters, it is recommended that the same approach be investigated for the prediction of other geomechanical characteristics.
References
Abdelgawad K, Elkatatny S, Moussa T, Mahmoud M, Patil S (2019) Real-time determination of rheological properties of spud drilling fluids using a hybrid artificial intelligence technique. J Energy Resour Technol. https://doi.org/10.1115/1.4042233
Abdulraheem A, Ahmed M, Vantala A, Parvez T (2009) Prediction of rock mechanical parameters for hydrocarbon reservoirs using different artificial intelligence techniques. SPE Saudi Arab Sect Tech Symp. https://doi.org/10.2118/126094-MS
Aggarwal A, Agarwal S (2014) ANN powered virtual well testing. Offshore Technol Conf. https://doi.org/10.4043/24981-MS
Aibing L, Guang Z, Peiliang H, Zhengyu L, Yanbo Y, Ping Z (2012) Prediction of rockburst classification by SVM method. ISRM Reg Symp—7th Asian Rock Mech Symp, Paper No. ISRM-ARMS7-2012-130
Aizerman MA, Braverman EM, Rozonoer LI (1964) Theoretical foundations of the potential function method in pattern recognition. Autom Remote Control 25:821–837
Al-anazi BD, Algarni MT, Tale M, Almushiqeh I (2011) Prediction of poisson’s ratio and young’s modulus for hydrocarbon reservoirs using alternating conditional expectation algorithm. SPE Middle East Oil Gas Show Conf. https://doi.org/10.2118/138841-MS
Ameen MS, Smart BGD, Somerville JM, Hammilton S, Naji NA (2009) Predicting rock mechanical properties of carbonates from wireline logs (a case study: Arab-D reservoir, Ghawar field, Saudi Arabia). Mar Pet Geol 26:430–444. https://doi.org/10.1016/j.marpetgeo.2009.01.017
Asef MR, Farrokhrouz M (2017) A semi-empirical relation between static and dynamic elastic modulus. J Pet Sci Eng 157:359–363. https://doi.org/10.1016/j.petrol.2017.06.055
Barree RD, Gilbert JV, Conway M (2009) Stress and rock property profiling for unconventional reservoir stimulation. SPE Hydraul Fract Technol Conf. https://doi.org/10.2118/118703-MS
Boser BE, Guyon IM, Vapnik VN (1992) A training algorithm for optimal margin classifiers. In: Proceedings of the fifth annual workshop on computational learning theory—COLT ’92. ACM Press, New York, USA, pp 144–152. https://doi.org/10.1145/130385.130401
Bradford IDR, Fuller J, Thompson PJ, Walsgrove TR (1998) Benefits of assessing the solids production risk in a north sea reservoir using elastoplastic modelling. SPE/ISRM Rock Mech Pet Eng. https://doi.org/10.2118/47360-MS
Brotons V, Tomás R, Ivorra S, Grediaga A (2014) Relationship between static and dynamic elastic modulus of calcarenite heated at different temperatures: the San Julián’s stone. Bull Eng Geol Environ 73:791–799. https://doi.org/10.1007/s10064-014-0583-y
Brotons V, Tomás R, Ivorra S, Grediaga A, Martínez-Martínez J, Benavente D, Gómez-Heras M (2016) Improved correlation between the static and dynamic elastic modulus of different types of rocks. Mater Struct 49:3021–3037. https://doi.org/10.1617/s11527-015-0702-7
Canady WJ (2011) A method for full-range young’s modulus correction. North Am Unconv Gas Conf Exhib. https://doi.org/10.2118/143604-MS
Chen Y-Y, Lin Y-H, Kung C-C, Chung M-H, Yen I-H (2019) Design and Implementation of cloud analytics-assisted smart power meters considering advanced artificial intelligence as edge analytics in demand-side management for smart homes. Sensors 19:2047. https://doi.org/10.3390/s19092047
Christaras B, Auger F, Mosse E (1994) Determination of the moduli of elasticity of rocks. Comparison of the ultrasonic velocity and mechanical resonance frequency methods with direct static methods. Mater Struct 27:222–228. https://doi.org/10.1007/BF02473036
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20:273–297. https://doi.org/10.1007/BFb0026683
Eissa EA, Kazi A (1988) Relation between static and dynamic Young’s moduli of rocks. Int J Rock Mech Min Sci Geomech Abstr 25:479–482. https://doi.org/10.1016/0148-9062(88)90987-4
Elkatatny S (2018) Application of Artificial intelligence techniques to estimate the static poisson’s ratio based on wireline log data. J Energy Resour Technol. https://doi.org/10.1115/1.4039613
Elkatatny S, Mahmoud M (2018) Development of a new correlation for bubble point pressure in oil reservoirs using artificial intelligent technique. Arab J Sci Eng 43:2491–2500. https://doi.org/10.1007/s13369-017-2589-9
Elkatatny S, Tariq Z, Mahmoud M, Abdulazeez A, Mohamed IM (2016) application of artificial intelligent techniques to determine sonic time from well logs. 50th U.S. Rock Mech Symp 11. Paper Number: ARMA-2016-755
Elkatatny S, Tariq Z, Mahmoud MA, Al-AbdulJabbar A (2017) Optimization of rate of penetration using artificial intelligent techniques. 51st U.S. Rock Mech Symp Paper Number: ARMA-2017-0429
Elkatatny S, Tariq Z, Mahmoud M, Abdulraheem A, Mohamed I (2019) An integrated approach for estimating static Young ’s modulus using artificial intelligence tools. Neural Comput Appl 31:4123–4135. https://doi.org/10.1007/s00521-018-3344-1
Feng C, Wang Z, Deng X, Fu J, Shi Y, Zhang H, Mao Z (2019) A new empirical method based on piecewise linear model to predict static Poisson’s ratio via well logs. J Pet Sci Eng 175:1–8. https://doi.org/10.1016/j.petrol.2018.11.062
Field A, Abdulaziz AM, Mahdi HA, Sayyouh MH (2019) Prediction of reservoir quality using well logs and seismic attributes analysis with an arti fi cial neural network : a case study from Farrud. J Appl Geophys 161:239–254. https://doi.org/10.1016/j.jappgeo.2018.09.013
Fjar E, Holt RM, Raaen AM, Horsrud P (2008) Petroleum related rock mechanics, vol 53. Elsevier Science
Ghafoori M, Rastegarnia A, Lashkaripour GR (2018) Estimation of static parameters based on dynamical and physical properties in limestone rocks. J African Earth Sci 137:22–31. https://doi.org/10.1016/j.jafrearsci.2017.09.008
Gowida A, Elkatatny S (2020) Prediction of sonic wave transit times from drilling parameters while horizontal drilling in carbonate rocks using neural networks. Petrophysics 61:482–494
Gowida A, Elkatatny S, Al-afnan S, Abdulraheem A (2020) new computational artificial intelligence models for generating synthetic formation bulk density logs while drilling. Sustainability 12:686. https://doi.org/10.3390/su12020686
Hammah R, Curran J, Yacoub T (2006) The influence of Young’s modulus on stress modelling results. Golden rocks 2006, 41st U.S. Symp Rock Mech. Paper Number: ARMA-06-995
Heerden WL (1987) General relations between static and dynamic moduli of rocks. Int J Rock Mech Min Sci Geomech Abstr 24:381–385. https://doi.org/10.1016/0148-9062(87)92262-5
Heinze L, Al-Baiyat IA (2012) Implementing artificial neural networks and support vector machines in stuck pipe prediction. SPE Kuwait Int Pet Conf Exhib. https://doi.org/10.2118/163370-MS
Horsrud P (2001) Estimating mechanical properties of shale from empirical correlations. SPE Drill Complet 16:68–73. https://doi.org/10.2118/56017-PA
Jorden JR, Shirley OJ (1966) Application of drilling performance data to overpressure detection. J Pet Technol 18:1387–1394. https://doi.org/10.2118/1407-PA
Karagianni A, Karoutzos G, Ktena S, Vagenas N, Vlachopoulos I, Sabatakakis N, Koukis G (2017) ELASTIC PROPERTIES OF ROCKS. Bull Geol Soc Greece 43:1165. https://doi.org/10.12681/bgsg.11291
Khaksar Manshad A, Rostami H, Moein Hosseini S, Rezaei H (2016) Application of artificial neural network-particle swarm optimization algorithm for prediction of gas condensate dew point pressure and comparison with gaussian processes regression-particle swarm optimization algorithm. J Energy Resour Technol. https://doi.org/10.1115/1.4032226
King MS (1983) Static and dynamic elastic properties of rocks from the canadian shield. Int J Rock Mech Min Sci Geomech Abstr 20:237–241. https://doi.org/10.1016/0148-9062(83)90004-9
Kumar J (1976) The effect of poisson’s ratio on rock properties. SPE Annu Fall Tech Conf Exhib. https://doi.org/10.2118/6094-MS
Labudovic V (1984) The effect of poisson’s ratio on fracture height. J Pet Technol 36:287–290. https://doi.org/10.2118/10307-PA
Lacy LL (1997) Dynamic rock mechanics testing for optimized fracture designs. SPE Annu Tech Conf Exhib. https://doi.org/10.2118/38716-MS
Lashkaripour GR (2002) Predicting mechanical properties of mudrock from index parameters. Bull Eng Geol Environ 61:73–77. https://doi.org/10.1007/s100640100116
Li J, Castagna J, Li D, Bian X (2004) Reservoir prediction via SVM pattern recognition. 2004 SEG Annu Meet. Paper Number: SEG-2004-0425
Mahmoud AA, Elkatatny S, Ali A, Abdulraheem A, Abouelresh M (2020) Estimation of the total organic carbon using functional neural networks and support vector machine. International Petroleum Technology Conference. Paper Number: IPTC-19659-MS. https://doi.org/10.2523/IPTC-19659-MS
Mahmoud AA, Elkatatny S, Ali A, Moussa T (2019) Estimation of static young’s modulus for sandstone formation using artificial neural networks. Energies 12:2125. https://doi.org/10.3390/en12112125
Mahmoud M, Elkatatny S, Ramadan E, Abdulraheem A (2016) Development of lithology-based static Young’s modulus correlations from log data based on data clustering technique. J Pet Sci Eng 146:10–20. https://doi.org/10.1016/j.petrol.2016.04.011
Martínez-Martínez J, Benavente D, García-del-Cura MAA (2012) Comparison of the static and dynamic elastic modulus in carbonate rocks. Bull Eng Geol Environ 71:263–268. https://doi.org/10.1007/s10064-011-0399-y
Moussa T, Elkatatny S, Mahmoud M, Abdulraheem A (2018) Development of new permeability formulation from well log data using artificial intelligence approaches. J Energy Resour Technol. https://doi.org/10.1115/1.4039270
Najibi AR, Ghafoori M, Lashkaripour GR, Asef MR, Reza A, Ghafoori M, Reza G (2015) Empirical relations between strength and static and dynamic elastic properties of Asmari and Sarvak limestones, two main oil reservoirs in Iran. J Pet Sci Eng 126:78–82. https://doi.org/10.1016/j.petrol.2014.12.010
Nes O-M, Fjær E, Tronvoll J, Kristiansen TG, Horsrud P (2005) Drilling time reduction through an integrated rock mechanics analysis. SPE/IADC Drill Conf. https://doi.org/10.2118/92531-MS
Ohen HA (2003) Calibrated wireline mechanical rock properties model for predicting and preventing wellbore collapse and sanding. SPE Eur Form Damage Conf. https://doi.org/10.2118/82236-MS
Olatunji OO, Micheal O (2017) Prediction of sand production from oil and gas reservoirs in the niger delta using support vector machines SVMs: a binary classification approach. SPE Niger Annu Int Conf Exhib. https://doi.org/10.2118/189118-MS
Rehm B, McClendon R (1971) Measurement of formation pressure from drilling data. Fall Meet Soc Pet Eng AIME. https://doi.org/10.2118/3601-MS
Sharifi J, Mirzakhanian M, Mondol NH (2017) Proposed relationships between dynamic and static Young modulus of a weak carbonate reservoir using laboratory tests. 4th Int Work Rock Phys, pp 27–29. https://www.ntnu.edu/documents/1269440143/1274882131/69.pdf/a283e58d-a8c2-4d88-8bec-8801c8d1d00c
Shokooh Saljooghi B, Hezarkhani A (2015) A new approach to improve permeability prediction of petroleum reservoirs using neural network adaptive wavelet (wavenet). J Pet Sci Eng 133:851–861
Tariq Z, Elkatatny S, Mahmoud M, Abdulraheem A, Fahd K (2016) A New artificial intelligence based empirical correlation to predict sonic travel time. Int Pet Technol Conf. https://doi.org/10.2523/IPTC-19005-MS
Tariq Z, Elkatatny S, Mahmoud MA, Abdulraheem A, Abdelwahab AZ, Woldeamanuel M (2017) Estimation of rock mechanical parameters using artificial intelligence tools. 51st U.S. Rock Mech Symp 11. Paper Number: ARMA-2017-0301
Van SL, Chon BH (2018) Effective prediction and management of a CO2 flooding process for enhancing oil recovery using artificial neural networks. J Energy Resour Technol. https://doi.org/10.1115/1.4038054
Zhao B, Zhou H, Hilterman F (2005) Fizz and gas separation with SVM classification. 2005 SEG Annu Meet. Paper Number: SEG-2005-0297
Funding
No funding was received for conducting this study.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflict of interest to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Siddig, O., Elkatatny, S. Workflow to build a continuous static elastic moduli profile from the drilling data using artificial intelligence techniques. J Petrol Explor Prod Technol 11, 3713–3722 (2021). https://doi.org/10.1007/s13202-021-01274-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13202-021-01274-3