
Abstract
The replicability crisis refers to the apparent failures to replicate both important and typical positive experimental claims in psychological science and biomedicine, failures which have gained increasing attention in the past decade. In order to provide evidence that there is a replicability crisis in the first place, scientists have developed various measures of replication that help quantify or “count” whether one study replicates another. In this nontechnical essay, I critically examine five types of replication measures used in the landmark article “Estimating the reproducibility of psychological science” (Open Science Collaboration, Science, 349, ac4716, 2015) based on the following techniques: subjective assessment, null hypothesis significance testing, comparing effect sizes, comparing the original effect size with the replication confidence interval, and meta-analysis. The first four, I argue, remain unsatisfactory for a variety of conceptual or formal reasons, even taking into account various improvements. By contrast, at least one version of the meta-analytic measure does not suffer from these problems. It differs from the others in rejecting dichotomous conclusions, the assumption that one study replicates another or not simpliciter. I defend it from other recent criticisms, concluding however that it is not a panacea for all the multifarious problems that the crisis has highlighted.
Similar content being viewed by others
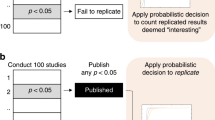

Notes
Depending on the discipline and context in which they are used, terms derived from “replicable” and “reproducible” can be synonymous or not (Fidler and Wilcox 2018, §1). In this essay, these terms will not mark distinct concepts, although I will attempt to use only terms derived from “replicable”; I am in particular only concerned here with the kind, adumbrated above, sometimes known as direct replication (Schmidt 2009). (See, e.g., Nosek and Errington (2020) or Machery (2020) for alternative definitions and typologies.) However, I am not concerned here so much with the minutiae of its definition as with the techniques for measuring it; see the end of this Section 1 for further remarks thereon.
One of my conclusions, discussed in Section 8, will be that the dichotomous terms of “success” and “failure” are inapt for measuring replication.
To be clear, my critique’s focus is the replication measures, not OSC’s particular employment of them or their conclusions about psychological science.
Good experimental design in these sorts of contexts dictates the comparison of the effect of the culturing condition on yields with some sample of stem cells left untreated, the so-called control group. I have omitted these details, which do not make any difference to the present illustration of classical statistical testing and estimation, for simplicity of presentation.
It’s important to remind ourselves that this probability is not that for any particular interval so produced to contain the true effect size, as would be for a Bayesian posterior interval. In classical statistical testing, statements like that are not even elements of the event space.
This entailment would not obtain if one understood human bias as deviation from scientific consensus regardless of how that consensus was reached. It is an assumption, albeit one that seems to be widely held and sometimes only implicitly in the scientific and philosophical literature concerning objectivity, replicability, and reproducibility, that a scientific community’s methods for reaching consensus make a difference to whether those methods are objective. See, for example, Reiss and Sprenger (2017 §§4–5) and references therein.
This is not a criticism of their project. Again, they aim to account for the significance of replication successes and failures, not how one measures replication.
To be clear, OSC do not take this position; as far as I know, it is a novel, if extreme, way of defending the use of NHST.
Semantic theories of vagueness are more popularly applied to the usual sorites cases philosophers analyze, in part because they take seriously the idea that vagueness is a semantical phenomenon of natural language. By contrast, here the goal of explicating “rejection” as a technical concept within the theory of NHST is not beholden to everyday linguistic activity. For similar reasons, ideal language approaches and those that take “rejection” as incoherent or vacuous are not apropos. (For more on these approaches to sorites paradoxes, see Hyde et al. (2018, §3) .)
But see Douglas (2009, pp. 104–5) for some general considerations.
Simonsohn (2015) proposes another defense: calculate the effect size at which the original study has power of 0.33. Then, have the attempted replication test the hypothesis that the effect size is at least this large, or alternately check whether the attempted replication’s confidence interval contains that effect size. Rejection (or the confidence interval’s failure to contain the original point estimate) signifies a failure of replication. Simonsohn (2015, p. 565) requires that the replication have power of 0.8 at that effect size, which typically demands a sample size of about 2.5 times the original. Besides various ad hoc components, this proposal introduces two new parameters whose exact values are arbitrary and so only exacerbates the first problem with NHST. It also suffers from the asymmetry problem that befalls confidence interval-based measures of replication, which I describe in Section 6.2.
Thus, Bayes factors for simple statistical hypotheses are just likelihood ratios; they do not require any information about the prior probability for the hypotheses being compared. Consequently, likelihoodists, who focus on this ratio and eschew prior probabilities when it comes to statistical inference and evidence (Hacking 1965; Edwards 1972; Royall 1997), can adopt the same procedure. The second of my two criticisms in the subsequent paragraphs does not depend on these priors either, so it applies equally to the likelihoodist.
Actually, Etz and Vanderkerckhove (2016) employ a more complicating weighting system, using what they call “mitigated” Bayes factors, based on different scenarios for publication bias, the phenomenon that the results of published studies are not representative of studies performed.
There may be other Bayesian ways of construing an NHST replication measure. For instance, by using the techniques of prior elicitation, researchers could construct a justified prior representing the beliefs of a relevant scientist (or an average from a group of relevant scientists) as well as their preferences that determine a threshold for the Bayes factors. However, except in the simplest cases, these techniques themselves involve modeling choices and idealizations, variations on which can significantly alter the priors and preferences represented (Stefan et al. 2020). Thus it is not clear that using prior elicitation in practice avoids problems of arbitrariness.
In addition to the criticisms I’ve described, Simonsohn (2015, p. 561) makes two further criticisms of measuring replication via NHST. Both amount to the fact that NHST does not depend on the similarity of the studies’ estimates of effect size. For example, an original study with a large estimated effect size could be replicated “successfully,” according to a NHST replication measure, by a study with a small estimated effect size. Like the criticisms I’ve described, a defender of NHST could claim that these criticisms beg the question because they presume different conceptions of what the results of a study are. But these criticisms are equally well explained in the unified way I have suggested: NHST does not adequately capture what the results of a study are, and so no viable replication measure can be based on it alone.
An important qualification: Although OSC do use this method, they do not highlight it to describe a replication rate for any particular psychological effect. Instead, because OSC are interested in aggregate rates of replication in social and cognitive psychology, they compute paired difference significance tests (both t and Wilcoxon signed rank) that compare the estimated standardized effect sizes (in terms of correlation coefficients) found in nearly one hundred original studies with those estimated standardized effect sizes found in attempted replications of those studies. In a word, this test is of the hypothesis that there is no difference in the effect size for the aggregate of replication attempts in comparison with their paired originals. (Their test rejected this hypothesis, finding that the replication effect sizes were in aggregate smaller than the originals). However, the underlying idea in this application is quite analogous to that when applied to individual replication attempts.
Simonsohn (2015, p. 561) suggests another related problem, that effect size comparisons answer the question of “whether the effect of interest is smaller than previously documented … rather than whether a detectable effect exists.” But this problem implausibly presupposes that the point estimates are not a part of the results that must be sufficiently similar in a replication.
There is also a Bayesian version of CIs, called credible intervals. However, the same problems arise for credible intervals as CIs because these problems depend on features of intervals common to both. (Cf. similar comments by Simonsohn (2015, p. 567) .)
There is also a Bayesian version of a prediction interval, but as I described in the previous footnote, switching to Bayesian methods doesn’t preclude any of the problems with interval-based replication measures.
OSC (2015, p. 4) were only able to employ this technique with 75 of the original 100 studies they examined because limitations in the reported statistics of the remaining 25 studies precluded the necessary meta-analytic calculations.
Braver et al. (2014) work in psychology, but are not the first to suggest meta-analysis for their discipline. Schmidt (1996, 1992), for instance, has advocated it as a general methodology for “cumulative knowledge” in psychology and only more recently suggesting it as a partial solution for some of the problems of the replication crisis (Schmidt and Oh 2016).
Other objections do not carry over. The third problem for effect size comparisons—that they do not plausibly test whether the results of two studies are the same (Section 5.2)—does not carry over because the comparison between the results of a previous study and that of a meta-analysis no longer aims to explicate such a comparison of sameness. Instead, it tests whether the addition of the results of a new study to one’s total evidence changes how the total evidence bears on hypotheses of interest. The asymmetry problem for confidence interval-based measures (Section 6.2)—that as a relation between studies they are not symmetric, hence do not capture sameness of results—does not apply for similar reasons.
It may be possible to delineate admissible measures of replication by starting with and defending this negative conclusion as an assumption instead. Investigating this possibility, however, must await another occasion.
References
Anderson, C.J., Bahník, Š., Barnett-Cowan, M., Bosco, F.A., Chandler, J., Chartier, C.R., Cheung, F., Christopherson, C.D., Cordes, A., Cremata, E.J., Della Penna, N., Estel, V., Fedor, A., Fitneva, S.A., Frank, M.C., Grange, J.A., Hartshorne, J. K., Hasselman, F., Henninger, F., van der Hulst, M., Jonas, K.J., Lai, C.K., Levitan, C.A., Miller, J.K., Moore, K.S., Meixner, J.M., Munafò, M. R., Neijenhuijs, K.I., Nilsonne, G., Nosek, B.A., Plessow, F., Prenoveau, J.M., Ricker, A.A., Schmidt, K., Spies, J.R., Stieger, S., Strohminger, N., Sullivan, G.B., van Aert, R.C.M., van Assen, M.A.L.M., Vanpaemel, W., Vianello, M., Voracek, M., & Zuni, K. (2016). Response to comment on “Estimating the reproducibility of psychological science”. Science, 351(6277), 1037–c.
Baker, M. (2016). 1,500 scientists lift the lid on reproducibility. Nature, 533(7604), 452–454.
Begley, C.G., & Ellis, L.M. (2012). Raise standards for preclinical cancer research: Drug development. Nature, 483(7391), 531–533.
Braver, S.L., Thoemmes, F.J., & Rosenthal, R. (2014). Continuously cumulating meta-analysis and replicability. Perspectives on Psychological Science, 9(3), 333–342.
Camerer, C.F., Dreber, A., Holzmeister, F., Ho, T.-H., Huber, J., Johannesson, M., Kirchler, M., Nave, G., Nosek, B.A., Pfeiffer, T., Altmejd, A., Buttrick, N., Chan, T., Chen, Y., Forsell, E., Gampa, A., Heikensten, E., Hummer, L., Imai, T., Isaksson, S., Manfredi, D., Rose, J., Wagenmakers, E.-J., & Wu, H. (2018). Evaluating the replicability of social science experiments in Nature and Science between 2010 and 2015. Nature Human Behaviour, 2(9), 637–644.
Carter, E.C., Schönbrodt, F.D., Gervais, W.M., & Hilgard, J. (2019). Correcting for bias in psychology: A comparison of meta-analytic methods. Advances in Methods and Practices in Psychological Science, 2(2), 115–144.
Cox, D.R., & Hinkley, D. (1974). Theoretical statistics. London: Chapman and Hall.
Cumming, G. (2013). Understanding the new statistics: Effect sizes, confidence intervals and meta-analysis. London: Routledge.
Douglas, H.E. (2009). Science, policy and the value-free ideal. Pittsburgh: University of Pittsburgh Press.
Dreber, A., Pfeiffer, T., Almenberg, J., Isaksson, S., Wilson, B., Chen, Y., Nosek, B.A., & Johannesson, M. (2015). Using prediction markets to estimate the reproducibility of scientific research. Proceedings of the National Academy of Sciences, 112(50), 15343–15347.
Earp, B.D., & Trafimow, D. (2015). Replication, falsification, and the crisis of confidence in social psychology. Frontiers in Psychology, 6, 621.
Edwards, A. (1972). Likelihood. Cambridge: Cambridge University Press.
Ellis, P.D. (2010). The essential guide to effect sizes: Statistical power, meta-analysis and the interpretation of research results. Cambridge: Cambridge University Press.
Etz, A., & Vanderkerckhove, J. (2016). A Bayesian perspective on the reproducibility project: Psychology. PLOS ONE, 11(2), e0149794.
Fidler, F., & Wilcox, J. (2018). Reproducibility of scientific results. In Zalta, E.N. (Ed.) The Stanford Encyclopedia of Philosophy. Metaphysics Research Lab, Stanford University, winter 2018 edition.
Fletcher, S.C., & Mayo-Wilson, C. (2021). Evidence in classical statistics. Written for Routledge Handbook of Evidence, Maria Lasonen-Aarnio and Clayton Littlejohn, eds.
Forsell, E., Viganola, D., Pfeiffer, T., Almenberg, J., Wilson, B., Chen, Y., Nosek, B.A., Johannesson, M., & Dreber, A. (2019). Predicting replication outcomes in the Many Labs 2 study. Journal of Economic Psychology, 75, 102117.
Gilbert, D.T., King, G., Pettigrew, S., & Wilson, T.D. (2016). Comment on “Estimating the reproducibility of psychological science”. Science, 351 (6277), 1037–b.
Graff, D. (2000). Shifting sands: An interest-relative theory of vagueness. Philosophical Topics, 28(1), 45–81.
Graff Fara, D. (2008). Profiling interest-relativity. Analysis, 68 (4), 326–35.
Hacking, I. (1965). The logic of statistical inference. Cambridge: Cambridge University Press.
Harlow, L.L., Mulaik, S.A., Steiger, J.H, & editors. (1997). What if there were no significance tests? Lawrence Erlbaum Associates.
Holman, B. (2019). In defense of meta-analysis. Synthese, 196 (8), 3189–3211.
Hyde, D., Raffman, D., & Sorites paradox. (2018). In Zalta, E.N. (Ed.) The Stanford Encyclopedia of Philosophy. Metaphysics Research Lab, Stanford University, summer 2018 edition.
Joint Committee for Guides in Metrology (JCGM). (2012). International vocabulary of metrology — Basic and general concepts and associated terms (VIM), 3rd edition. https://www.bipm.org/en/publications/guides/vim.html.
Jukola, S. (2015). Meta-analysis, ideals of objectivity, and the reliability of medical knowledge. Science & Technology Studies, 28(3), 101–120.
Kahneman, D., & Klein, G. (2009). Conditions for intuitive expertise: A failure to disagree. American Psychologist, 64(6), 515–526.
Klein, R.A., Ratliff, K.A., Vianello, M., Adams, R.B., Bahník, v., Bernstein, M.J., Bocian, K., Brandt, M.J., Brooks, B., Brumbaugh, C.C., Cemalcilar, Z., Chandler, J., Cheong, W., Davis, W.E., Devos, T., Eisner, M., Frankowska, N., Furrow, D., Galliani, E.M., Hasselman, F., Hicks, J.A., Hovermale, J.F., Hunt, S.J., Huntsinger, J.R., IJzerman, H., John, M.-S., Joy-Gaba, J.A., Barry Kappes, H., Krueger, L.E., Kurtz, J., Levitan, C.A., Mallett, R.K., Morris, W.L., Nelson, A.J., Nier, J.A., Packard, G., Pilati, R., Rutchick, A.M., Schmidt, K., Skorinko, J.L., Smith, R., Steiner, T.G., Storbeck, J., Van Swol, L.M., Thompson, D., van’t Veer, A.E., Ann Vaughn, L., Vranka, M., Wichman, A.L., Woodzicka, J.A., & Nosek, B.A. (2014). Investigating variation in replicability. Social Psychology, 45 (3), 142–152.
Kline, R. (2004). Beyond significance testing: Reforming data analysis methods in behavioral research. Washington, D.C: American Psychological Association.
Kvarven, A., Strømland, E., & Johannesson, M. (2020). Comparing meta-analyses and preregistered multiple-laboratory replication projects. Nature Human Behaviour, 4(4), 423–434.
Lakens, D., Adolfi, F.G., Albers, C.J., Anvari, F., Apps, M.A., Argamon, S.E., Baguley, T., Becker, R.B., Benning, S.D., Bradford, D.E., & et al. (2018). Justify your alpha. Nature Human Behaviour, 2(3), 168.
Larrick, R.P., & Feiler, D.C. (2015). Expertise in decision making. In Keren, G., & Wu, G. (Eds.) The Wiley Blackwell handbook of judgment and decision making (pp. 696–721). West Sussex: Wiley.
Lipsey, M.W., & Wilson, D.B. (2001). Practical meta-analysis. Thousand Oaks, CA: SAGE.
Machery, E. (2020). What is a replication? Philosophy of Science, 87(4), 545–567.
Mayo, D., & Spanos, A. (2004). Methodology in practice: Statistical misspecification testing. Philosophy of Science, 71(5), 1007–1025.
McCloskey, D.N., & Ziliak, S.T. (2008). The cult of statistical significance: How the standard error costs us jobs, justice and lives. Ann Arbor: University of Michigan Press.
Morrison, D., Henkel, R., & editors. (1970). The significance test controversy. London: Aldine Publishing.
Nosek, B.A., & Errington, T.M. (2017). Reproducibility in cancer biology: Making sense of replications. eLife, 6, e23383.
Nosek, B.A., & Errington, T.M. (2020). What is replication? PLoS Biology, 18(3), e3000691.
Nozick, R. (1981). Philosophical explanations. Cambridge: Cambridge University Press.
Open Science Collaboration (OSC). (2015). Estimating the reproducibility of psychological science. Science, 349(6251), ac4716.
Patel, R., & Alahmad, A.J. (2016). Growth-factor reduced Matrigel source influences stem cell derived brain microvascular endothelial cell barrier properties. Fluids Barriers CNS, 13(6), 1–7.
Patil, P., Peng, R.D., & Leek, J.T. (2016). What should researchers expect when they replicate studies? A statistical view of replicability in psychological science. Perspectives on Psychological Science, 11(4), 539–544.
Reiss, J., & Sprenger, J. (2017). Scientific objectivity. In Zalta, E.N. (Ed.) The Stanford Encyclopedia of Philosophy. Metaphysics Research Lab. Stanford University, winter 2017 edition.
Romero, F. (2016). Can the behavioral sciences self-correct? A social epistemic study. Studies in History and Philosophy of Science, 60, 55–69.
Romero, F. (2017). Novelty vs. replicability: Virtues and vices in the reward system of science. Philosophy of Science, 84(5), 1031–1043.
Romero, F. (2019). Philosophy of science and the replicability crisis. Philosophy Compass, 14(11), e12633.
Rosenthal, R. (1991). Meta-analytic procedures for social research. Beverly Hills, CA,: Sage. Revised edition.
Rosnow, R.L., & Rosenthal, R. (1989). Statistical procedures and the justification of knowledge in psychological science. American Psychologist, 44(10), 1276–1284.
Royall, R. (1997). Scientific evidence: a likelihood paradigm. London: Chapman and Hall.
Schmidt, F.L. (1992). What do data really mean? Research findings, meta-analysis, and cumulative knowledge in psychology. American Psychologist, 27 (10), 1173–1181.
Schmidt, F.L. (1996). Statistical significance testing and cumulative knowledge in psychology: Implications for training of researchers. Psychological Methods, 1(2), 115–129.
Schmidt, F.L., & Hunter, J.E. (2015). Methods of meta-analysis: Correcting error and bias in research findings, 3rd edn. Thousand Oaks, CA: Sage.
Schmidt, F.L., & Oh, I.-S. (2016). The crisis of confidence in research findings in psychology: Is lack of replication the real problem? Or is it something else? Archives of Scientific Psychology, 4(1), 32–37.
Schmidt, S. (2009). Shall we really do it again? The powerful concept of replication is neglected in the social sciences. Review of General Psychology, 13(2), 90–100.
Shanteau, J. (1992). The psychology of experts: An alternative view. In Wright, G., & Bolger, F. (Eds.) Expertise and decision support (pp. 11–23). New York: Plenum Press.
Simonsohn, U. (2015). Small telescopes: Detectability and the evaluation of replication results. Psychological Science, 26(5), 559–569.
Stefan, A.M., Evans, N.J., & Wagenmakers, E.-J. (2020). Practical challenges and methodological flexibility in prior elicitation. Psychological Methods. https://doi.org/10.1037/met0000354.
Stegenga, J. (2011). Is meta-analysis the platinum standard of evidence? Studies in History and Philosophy of Biological and Biomedical Sciences, 42(4), 497–507.
van Aert, R.C.M., Wicherts, J.M., & van Assen, M.A.L.M. (2016). Conducting meta-analyses based on p values: Reservations and recommendations for applying p-uniform and p-curve. Perspectives on Psychological Science, 11(5), 713–729.
Wolfers, J., & Zitzewitz, E. (2006). Interpreting prediction market prices as probabilities. Technical report, National Bureau of Economic Research.
Acknowledgements
Thanks to Katie Creel, Dan Malinsky, Conor Mayo-Wilson, Tom Sterkenburg, Kino Zhao, and two reviewers for comments on a previous version.
Funding
This essay was written in part with the support of a Visiting Fellowship at the University of Pittsburgh’s Center for Philosophy of Science and a Single Semester Leave from the University of Minnesota, Twin Cities.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article belongs to the Topical Collection: Philosophical Perspectives on the Replicability Crisis
Guest Editors: Mattia Andreoletti, Jan Sprenger
Rights and permissions
About this article

Cite this article
Fletcher, S.C. How (not) to measure replication. Euro Jnl Phil Sci 11, 57 (2021). https://doi.org/10.1007/s13194-021-00377-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13194-021-00377-2