
Abstract
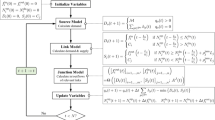
We propose two classes of algorithms for achieving the user equilibrium in simulation-based dynamic traffic assignment with special attention given to the interactions between travel information and route choice behavior. A driver is assumed to perform day-to-day route choice repeatedly and experience payoffs with unknown noise. The driver adaptively changes his/her action in accordance with the payoffs that are initially unknown and must be estimated over time due to noisy observations. To solve this problem, we develop a multi-agent version of Q-learning to estimate the payoff functions using novel forms of the ε−greedy learning policy. We apply this Q-learning scheme for the simulation-based DTA in which traffic flow and travel times of routes in the traffic network are generated by a microscopic traffic simulator based on cellular automaton. Finally, we provide simulation examples to show convergence of our algorithms to Nash equilibrium and effectiveness of the best-route provision services.














Similar content being viewed by others


References
Treiber, M., Kesting, A.: Traffic Flow Dynamics. Springer-Verlag, Berlin, Heidelberg (2013)
Miyagi, T., Peque, G.: Informed user algorithm that converge to a pure Nash equilibrium in traffic games. Procedia Soc. Behav. Sci. 54, 438–449 (2012)
Miyagi, T., Peque, G., Fukumoto, J.: Adaptive learning algorithms for traffic games with naive users. Procedia Soc. Behav. Sci. 80, 806–817 (2013)
Chapman, A.C., Leslie, D.S., Rogers, A., Jennings, N.R.: Convergent learning algorithms for unknown rewards games. SIAM J. Control. Optim. 5(4), 3154–3180 (2013)
Cominetti, R., Melo, E., Sorin, S.: A payoff-based learning procedure and its application to traffic games. Games Econ. Behav. 70, 71–83 (2010)
Leslie, D., Collins, E.: Individual Q-learning in normal form games. SIAM J. Control. Optim. 44(2), 495–514 (2005)
Leslie, D., Collins, E.: Generalized weakened fictitious play. Games Econ. Behav. 56, 285–298 (2006)
Marden, J., Young, P., Arslan, G., Shamma, J.S.: Payoff–based dynamics for multi–player weakly acyclic games. SIAM J. Control. Optim. 48(1), 373–396 (2009)
Young, P.: Learning by trial and error. Games Econ. Behav. 65, 626–643 (2009)
Miyagi, T.: A reinforcement learning model with endogenously determined learning-efficiency parameters, The Proceedins of CIS/SIS Conference, Keio University (2004)
Miyagi, T.: Stochastic fictitious play, reinforcement learning and the user equilibrium in transportation networks. A Paper Presented at the IVth Meeting on “Mathematics in Transport”, University College London (2005)
Miyagi, T.: Multi-agent learning models for route choices in transportation networks: An integrated approach of regret-based strategy and reinforcement learning. Proceedings of the 11th International Conference on Travel Behavior Research, Kyoto (2006)
Miyagi, T., Ishiguro, M.: Modelling of route choice behaviours of car-drivers under imperfect travel information. Urban Transp. 14, 551–560 (2008), WIT Press
Gawron, C.: Continuous limit of the Nagel–Schreckenberg–model. Phys. Rev. E. 54, 3707 (1996)
Nagel, K., Schreckenberg, M.: A cellular automaton model for freeway traffic. J. Phys. I France. 2, 2221–2229 (1992)
Rosenthal, R.: A class of games possessing pure-strategy Nash equilibria. Int. J. Game Theory. 2, 65–67 (1973)
Monderer, D., Shapley, L.: Potential games. Games Econ. Behav. 14, 124–143 (1996)
Beckmann, M.J., McGuire, C.B., Winsten, C.B.: Studies in the Economics of Transportation. Yale University Press (1956)
Singh, S.P., Jaakola, T., Littman, M.L., Szepesvari, C.: Convergence results for single-step on-policy reinforcement-learning algorithm. Mach. Learn. 38(3), 287–308 (2000)
Acknowledgments
This research is supported by MEXT Grants-in-Aid for Scientific Research, No. 26420511, for the term 2014-2016.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Peque, G., Miyagi, T. & Kurauchi, F. Adaptive Learning Algorithms for Simulation-Based Dynamic Traffic User Equilibrium. Int. J. ITS Res. 16, 215–226 (2018). https://doi.org/10.1007/s13177-017-0150-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13177-017-0150-6