
Abstract
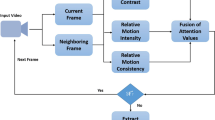
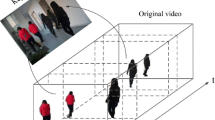
Since automatic visual semantic comprehension of video content is currently infeasible and unintelligent, key frames extracted from videos are inconsistent with human visual understanding. In this paper, a block-based self-motivated visual attention scoring mechanism named the BSVAS mechanism is proposed for extracting key frames. The approach described in this paper first reduces the dimensionality of the video by exploiting entropy as a static global characteristic measurement. Next, two block-based motion metrics are employed to express features from a spatiotemporal perspective, and a novel self-motivated strategy is applied to conduct feature fusion. Finally, a self-motivated scoring algorithm is performed to evaluate content attractiveness and frame importance to generate key frames. Experiments on gesture videos with various postures demonstrate that key frames extracted using the proposed method provide high-quality video summaries and cover the main content of the gesture videos as compared to several other excellent mechanisms in the literature.






Similar content being viewed by others

Data availability
The data that support the findings of this study are available in Dr.Sebastien Marcel-IDIAP2001 Datasets at https://www.idiap.ch/webarchives/sites/www.idiap.ch/resource/gestures/ and Cambridge Hand Gesture Dataset at https://labicvl.github.io/ges_db.htm. These data were derived from the resources available in the pubilc domain.
References
Corchs S, Fersini E, Gasparini F (2019) Ensemble learning on visual and textual data for social image emotion classification. Int J Mach Learn Cybern 10:2057–2070
Wu F, Duan J, Chen S, Ye Y, Ai P, Yang Z (2021) Multi-target recognition of bananas and automatic positioning for the inflorescence axis cutting point. Front Plant Sci 12:705021
Ding W, Hu B, Liu H, Wang X, Huang X (2020) Human posture recognition based on multiple features and rule learning. Int J Mach Learn Cybern 11:2529–2540
Hussain T, Muhammad K, Ding W, Lloret J, Baik SW, Albuquerque VHC (2021) A comprehensive survey of multi-view video summarization. Pattern Recognit 109:107567
Yan J, Gao X (2018) Pornographic video detection with mapreduce. Int J Mach Learn Cybern 9:2105–2115
Yasmin G, Chowdhury S, Nayak J, Das P, Das AK (2023) Key moment extraction for designing an agglomerative clustering algorithm-based video summarization framework. Neural Comput Appl 35(7):4881–4902
Hu W, Xie N, Li L, Zeng X, Maybank SJ (2011) A survey on visual content-based video indexing and retrieval. IEEE Trans Syst Man Cyberne Part C (Applications and Reviews) 41:797–819
Bhuyan MK, Ramaraju VV, Iwahori Y (2014) Hand gesture recognition and animation for local hand motions. Int J Mach Learn Cybern 5:607–623
Lu Z, Zhang G, Huang G, Yu Z, Pun C-M, Zhang W, Chen J, Ling W-K (2022) Video person re-identification using key frame screening with index and feature reorganization based on inter-frame relation. Int J Mach Learn Cybern 13(9):2745–2761
Tamilkodi R, Kumari GRN (2021) A novel framework for retrieval of image using weighted edge matching algorithm. Multimed Tools Appl 80:19625–19648
Lee YJ, Ghosh J, Grauman K (2012) Discovering important people and objects for egocentric video summarization. In: 2012 IEEE conference on computer vision and pattern recognition, pp 1346–1353
Li W, Qi D, Zhang C, Guo J, Yao J (2020) Video summarization based on mutual information and entropy sliding window method. Entropy 22:1–16
Hannane R, Elboushaki A, Afdel K, Nagabhushan P, Javed M (2016) An efficient method for video shot boundary detection and keyframe extraction using sift-point distribution histogram. Int J Multimed Inf Retr 5:89–104
Liu T, Kender JR (2007) Computational approaches to temporal sampling of video sequences. ACM Trans. Multimedia Comput. Commun. Appl. 3(2):7
Yuan Y, Lu Z-q, Yang Z, Jian M, Wu L, Li Z, Liu X (2021) Key frame extraction based on global motion statistics for team-sport videos. Multimed Syst 28(2):387–401
Ejaz N, Baik SW, Majeed H, Chang H, Mehmood I (2018) Multi-scale contrast and relative motion-based key frame extraction. EURASIP J Image Video Process 2018(1):40
Hannane R, Elboushaki A, Afdel K (2018) Mskvs: adaptive mean shift-based keyframe extraction for video summarization and a new objective verification approach. J Vis Commun Image Represent 55:179–200
Shi Y, Yang H, Gong M, Liu X, Xia Y (2017) A fast and robust key frame extraction method for video copyright protection. J Electr Comput Eng 2017:1–7
Tang H, Liu H, Xiao W, Sebe N (2019) Fast and robust dynamic hand gesture recognition via key frames extraction and feature fusion. Neurocomputing 331:424–433
Yu L, Cao J, Chen M, Cui X-C (2018) Key frame extraction scheme based on sliding window and features. Peer-to-Peer Netw Appl 11:1141–1152
Martins GB, Pereira DR, Almeida J, de Albuquerque VHC, Papa JP (2020) Opfsumm: on the video summarization using optimum-path forest. Multimed Tools Appl 79:11195–11211
Jadon S, Jasim M (2019) Video summarization using keyframe extraction and video skimming. arXiv:1910.04792
Ma L, Yang H, Tan X, Feng G (2018) Image keyframe-based visual-depth map establishing method. J Harbin Inst Technol 50(11):23–31
Guan G, Wang Z, Yu K, Mei S, He M, Feng DD (2012) Video summarization with global and local features. In: 2012 IEEE international conference on multimedia and expo workshops, pp 570–575
Kannan R, Ghinea G, Swaminathan S (2015) What do you wish to see? A summarization system for movies based on user preferences. Inf Process Manag 51:286–305
Kuanar SK, Ranga KB, Chowdhury AS (2015) Multi-view video summarization using bipartite matching constrained optimum-path forest clustering. IEEE Trans Multimed 17:1166–1173
Zhang Y, Jin R, Zhou Z-H (2010) Understanding bag-of-words model: a statistical framework. Int J Mach Learn Cybern 1:43–52
Shao C, Li H, Ma L (2019) Visual cognitive mechanism guided video shot segmentation. In: ICCC
Wu L, Zhang S, Jian M, Zhao Z, Wang D (2018) Shot boundary detection with spatial-temporal convolutional neural networks. In: PRCV
Lai J, Yi Y (2012) Key frame extraction based on visual attention model. J Vis Commun Image Represent 23:114–125
Traver VJ, Damen D (2022) Egocentric video summarisation via purpose-oriented frame scoring and selection. Expert Syst Appl 189:116079
Yu L, Cao J, Chen M, Cui X (2018) Key frame extraction scheme based on sliding window and features. Peer-to-Peer Netw Appl 11(5):1141–1152
Rao PC, Das MM (2012) Keyframe extraction method using contourlet transform. In: Proceedings of the 2012 international conference on electronics, communications and control. IEEE Computer Society, pp 437–440
Zhang K, Chao W-L, Sha F, Grauman K (2016) Video summarization with long short-term memory. In: ECCV
Rochan M, Ye L, Wang Y (2018) Video summarization using fully convolutional sequence networks. In: ECCV
Liu T, Meng Q, Huang J, Vlontzos A, Rueckert D, Kainz B (2022) Video summarization through reinforcement learning with a 3d spatio-temporal u-net. IEEE Trans Image Process 31:1573–1586
Zhong S-H, Wu J, Jiang J (2019) Video summarization via spatio-temporal deep architecture. Neurocomputing 332:224–235
Lei J, Luan Q, Song X, Liu X, Tao D, Song M (2019) Action parsing-driven video summarization based on reinforcement learning. IEEE Trans Circuits Syst Video Technol 29:2126–2137
Mohammad-Djafari A (2015) Entropy, information theory, information geometry and Bayesian inference in data, signal and image processing and inverse problems. Entropy 17(6):3989–4027
Rodriguez A, Laio A (2014) Clustering by fast search and find of density peaks. Science 344:1492–1496
Ejaz N, Baik S, Majeed H, Chang H, Mehmood I (2018) Multi-scale contrast and relative motion-based key frame extraction. EURASIP J Image Video Process 2018:1–11
Mahmoud R, Belgacem S, Omri MN (2021) Towards wide-scale continuous gesture recognition model for in-depth and grayscale input videos. Int J Mach Learn Cybern 12:1173–1189
Farnebäck G (2003) Two-frame motion estimation based on polynomial expansion. In: SCIA
Chang C-W, Zhong Z-Q, Liou JJ (2019) A fpga implementation of farneback optical flow by high-level synthesis. In: Proceedings of the 2019 ACM/SIGDA international symposium on field-programmable gate arrays
Kim T-K, Wong S-F, Cipolla R (2007) Tensor canonical correlation analysis for action classification. In: 2007 IEEE conference on computer vision and pattern recognition, pp 1–8
Acknowledgements
This work was funded in part by the National Key Research and Development Program of China under number 2019YFB1703600, in part by the National Natural Science Foundation of China grant under number 62076102, U1813203, and U1801262, in part by the Guangdong Natural Science Funds for Distinguished Young Scholar under number 2020B1515020041, in part by the Science and Technology Major Project of Guangzhou under number 202007030006, in part by the Science and Technology Program of Guangzhou under number 202002030250, in part by The Program for Guangdong Introducing Innovative and Entrepreneurial Teams (2019ZT08X214), in part by Guangdong-Hong Kong-Macao Greater Bay Area Center for Brain Science and Brain-Inspired Intelligence Fund (No. 2019016).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Li, Wl., Zhang, T. & Liu, X. A static video summarization approach via block-based self-motivated visual attention scoring mechanism. Int. J. Mach. Learn. & Cyber. 14, 2991–3002 (2023). https://doi.org/10.1007/s13042-023-01814-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-023-01814-9