
Abstract
This study breaks new ground by developing a multi-hazard vulnerability map for the Tensift watershed and the Haouz plain in the Moroccan High Atlas area. The unique juxtaposition of flat and mountainous terrain in this area increases sensitivity to natural hazards, making it an ideal location for this research. Previous extreme events in this region have underscored the urgent need for proactive mitigation strategies, especially as these hazards increasingly intersect with human activities, including agriculture and infrastructure development. In this study six advanced machine learning (ML) models were used to comprehensively assess the combined probability of three significant natural hazards: flooding, gully erosion, and landslides. These models rely on causal factors derived from reputable sources, including geology, topography, meteorology, human activities, and hydrology. The research's rigorous validation process, which includes metrics such as specificity, precision, sensitivity, and accuracy, underlines the robust performance of all six models. The validation process involved comparing the model's predictions with actual hazard occurrences over a specific period. According to the outcomes in terms of the area under curve (AUC), the XGBoost model emerged as the most predictive, with remarkable AUC values of 93.41% for landslides, 91.07% for gully erosion and 93.78% for flooding. Based on the overall findings of this study, a multi-hazard risk map was created using the relationship between flood risk, gully erosion, and landslides in a geographic information system (GIS) architecture. The innovative approach presented in this work, which combined ML algorithms with geographical data, demonstrates the power of these tools in sustainable land management and the protection of communities and their assets in the Moroccan High Atlas and regions with similar topographical, geological, and meteorological conditions that are vulnerable to the aforementioned risks.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Numerous research projects have highlighted the undeniable increase in the frequency of natural disasters worldwide, predominantly caused by changes in climate (Pei et al. 2023; Zhang et al. 2023). Therefore, protection against natural disasters has become an absolute priority, and forecasting and prevention measures are still among the steps that need to be taken to move towards good planning (Bashir et al. 2024a, b; Yousefi et al. 2020). Creating thematic data to map catastrophe susceptibility is still among the most crucial methods for foreseeing and managing natural risks (Khan et al. 2020; Youssef et al. 2023). These maps are essential in natural risk management and developing risk reduction strategies. They make it possible to visualize and classify at-risk areas, identify vulnerable populations and infrastructures, and better understand the risk factors specific to each region.
However, most current research into natural hazards is limited to the analysis of individual risks (Bammou et al. 2024b; Razavi-Termeh et al. 2023). These studies, which focus on particular threats, generally consider risks as independent phenomena without considering the combined degree of vulnerability of relationships between several risks (Panahi et al. 2020; Yousefi et al. 2020). Thus, assessing and looking into the interactions between different risks is fundamental. Various hazard investigations are crucial, as they allow us to find far more significant concentrations of harm and risk than studies focusing on a single type of hazard (Hillier et al. 2020). For this kind of research, the geographical distribution of natural hazards in the area has to be reevaluated. This strategy aids in lowering the likelihood of occurrence and the possibility of cumulative risks brought on by the interplay of several hazards, such as landslides, financial losses, and fatalities (Bammou et al. 2024d; Sestras et al. 2023; Stalhandske et al. 2024). By mapping vulnerability holistically and considering the complex interactions between natural hazards, it is possible to predict, prevent, and proactively manage threats to communities and the environment.
Multi-hazard vulnerability mapping is a method that aims to consider multiple types of threats simultaneously at each location. It makes it possible to assess the complex spatial relationships between different high-risk events, including the possibility for these events to occur concurrently or cumulatively, as well as any potential interactions between them (Aksha et al. 2020; Ming et al. 2022). According to Bammou et al. (2024a, b, c, d), the Tensift catchment consists of well-correlated risk zones with certain common conditioning factors, such as increased water erosion risk from runoff-induced flooding and landslides from heavy rainfall and flooding. Multi-hazard mapping is a powerful tool for understanding better and managing the complex risks that threaten communities (Lombardo et al. 2020; Saunders and Kilvington 2016).
Various techniques have been used to model multiple hazards, such as using two decision aids, namely the sequential Monte Carlo technique and a decision aid (Guo et al. 2020; Zhao et al. 2024). Another method combines empirical data with deterministic, equation-based (i.e., theoretical) discoveries (Bout et al. 2018; Mondini et al. 2023). Furthermore, a method integrating multi-criteria analysis and geographic information systems (GIS) has been applied to produce successful outcomes, as demonstrated by Lyu and Yin (2023), Sestras et al. (2023). Recently, a lot of research has employed the integration of machine learning methods, including Boosted Regression Tree (BRT), Generalized Additive Model (GAM), Random Forest (RF), and Support Vector Machine (SVM) for risk prediction (Bammou et al. 2024a; Kohansarbaz et al. 2022; Ye et al. 2020).
The development of a multi-hazard map using ML models is based on the study of the leading natural hazards in the study area, namely gullying, landslides, and flooding (Bammou et al. 2023). The production of such a map is essential for a good understanding of the association of these risks. This study, therefore, compared the effectiveness and accuracy of different machine learning models, such as SVM, RF, ANN, KNN, DT and XGBoost, in producing risk maps for the Tensift catchment and the Haouz plain.
This would be a pioneering study in the scientific literature that combines three natural hazards: landslide, gully erosion and flood risks together to construct. This work uses state-of-the-art ML models to develop a novel multi-hazard assessment strategy to understand the interrelationships and assess the dangers of landslides, gully erosion, and floods. This study aims to answer the research questions: Why is a multi-hazard assessment necessary rather than a single-hazard approach, and what are the benefits? The findings of this research are helpful for researchers, authorities, developers, and decision-makers involved in land management and risk mitigation strategies in the Moroccan High Atlas and regions across the globe with similar topographical, geological, and meteorological conditions.
Material and methods
Study area
The High Atlas in Marrakech is formed by three primary geological formations, according to Duclaux (2005): (1) the Permo-Triassic is the most common formation in the east. The highest peaks of the Atlas are located in the central region, home to (2) Precambrian igneous and metamorphic rocks. The western area is home to (3) primary and secondary limestone formations, most of which have limited permeability, continuous surface runoff, and the potential to develop significant runoff after heavy rainfall. It often occurs in conjunction with Ordovician and Precambrian shales.
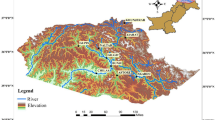
The central Moroccan region around Marrakesh is home to the Tensift watershed. Its 20,000 km2 surface consists mainly of two zones that behave differently hydrologically as illustrated by Fig. 1. With an elevation gain of over 4000 m, the Atlas Mountains' southern slopes receive a substantial amount of precipitation and snowfall (up to 600 mm/year) in the catchment region. These mountains act as a "water tower" for the large, semi-arid Haouz plain, which is situated downstream and receives 250 mm of precipitation annually. More specifically, irrigation covers a sizable portion of the 2000 km3 Haouz plain.

The Haouz Plain and the Tensift watershed are study areas
Numerous lithological and structural elements and a varied and erratic hydrological behavior driven by geomorphological and climatic conditions define the research region. They give rise to various threats, such as the floods in Ourika on August 17, 1995, and October 28, 1999, which destroyed 142 structures that regularly caused severe damage, caused 200 fatalities, and flooded over 300 ha of arable land. More recently, on July 18, 2023, they also caused significant damage in Moulay Brahim. The landslides in this area, especially along the Tizi N'tichka national route, which links Ouarzazate and Marrakech, and the village of Ijoukak, where a dramatic landslide occurred in July 2019 that killed over 20 people due to the landslide and gully erosion, were also documented by the Hydraulic Agency of the Tensift Basin (ABHT).
Multi-hazard inventory
Compiling an inventory is a crucial step in assessing the hazard. Based on GPS-based field surveys, regional and national statistics from many sources, including the Tensift Hydraulic Basin Agency (ABHT) and analysis of Google Earth imagery of vulnerable areas in mountainous regions, the comprehensive A list of gully erosion, floods, and landslides in the Tensift watershed is available given by Fig. 2. The inventory maps were created using this information, and 620 gully erosion sites, 1291 landslide sites, and 762 inundation sites as of Fig. 1. The training and validation sites for each hazard class in the inventory map were selected by random selection. In the literature, the percentage ratio of 70/30% is frequently utilized for training and validation datasets (Bammou et al. 2024a; Hong et al. 2016; Pourghasemi and Rahmati 2018) and it is being continued in this study as well. This study applies this percentage ratio by integrating binary codings (0, 1), i.e., values associated with landslide-relevant and non-landslide-relevant pixels. The landslide inventory map was then converted into raster data at a resolution of thirty meters (30 m).

Photographs of the three hazards in the Tensift catchment collected in the field. 1a, 1b and 1c Flooding; 2a, 2b and 2c gully erosion; 3a and 3b landslides. NB: their locations are shown in Fig. 1
Data collection
The creation of the landslide susceptibility grids was based on different data sources. Table 1 shows a description of the other media used.
Multi-hazard conditioning factors (MCFs)
Multi-hazard conditioning factors (MCFs) was also conducted to determine the most pertinent criteria for each risk category. Table 2 and Fig. 3 provide a quick overview of the rasters and data layers of topography, climate, hydrology, vegetation, land use, and geology that were constructed using GIS software.


a Slope in °, b aspect, c elevation, d rainfall, e TWI, f NDVI, g drainage density, h lithology, i LULC, j LS factor, k distance to rivers, l SPI, m TRI, n geomorphons, o factor K, p HSG, q distance to roads, r soil type, s flow accumulation, t profile curvature, u distance to faults, v curvature, w valley depth, x TPI and y plan curvature
These include 25 conditioning factors, namely slope given in Fig. 3a, aspect given by Fig. 4b, elevation given by Fig. 3c, and precipitation given in Fig. 3d, which were generated from data from 14 precipitation stations provided by ABHT for the period 1992 to 2020. The Topographic Moisture Index (TWI) illustrated in Fig. 3e was calculated using Eq. (1). Normalised Differential Vegetation Index (NDVI) illustrated by Fig. 3f was determined using Eq. (2).

Flowchart of the methodology developed for this study
Other parameters such as drainage density (Fig. 3g), lithology (Fig. 3h) which includes 32 facies was derived from a 1:500,000 scale geological map of Marrakech, LULC (Fig. 3i), which was generated from Sentinel-2 images with 10 m resolution from 2022, LS factor (Eq. (3) and Fig. 3j) is one of the critical elements in the RUSLE equation, along with the distances to faults (Fig. 3u) and rivers (Fig. 3k), developed using spatial analyst Euclidean distance tool, SPI illustrated by Fig. 3l was calculated using Eq. (6), TRI illustrated by Fig. 3m was calculated using Eq. (4), geomorphons (Fig. 3n), factor K illustrated by Fig. 3o was calculated using Eq. (5), HSG (Fig. 3p), distance to roads (Fig. 3q), soil type (Fig. 3r), river accumulation (Fig. 3s), profile curvature (Fig. 3t), curvature (Fig. 3v), valley depth (Fig. 3w), TPI (Fig. 3x) and plan curvature (Fig. 3y). At a resolution of thirty (30 m) meters, the topographic variables were extracted using the digital elevation model (DEM).
Each layer shown in Fig. 3 was standardized to a pixel resolution of 30 m*30 m using software GIS in the WGS 84/UTM zone 29N projection system. Many factor sets were employed to generate the maps of hazard sensitivity, as indicated in Table 1: following the removal of two components, there are 13 factors for floods, 17 for gully erosion, and 14 for landslides.
-
As: drainage area of the upstream,
-
Β: slope degree (Nellemann and Reynolds 1997).
$$\text{TRI}=\text{Y}{\left[{\sum ({\text{X}}_{\text{ij}}-{\text{X}}_{00})}^{2}\right]}^\frac{1}{2}$$(2) -
xii: each pixel's height next to (0, 0). roughened areas with steep slopes have positive TRI values, whereas regions with zero gradient have zero TRI values (Jones and Vaughan 2010).
$$\text{NDVI}=\frac{\text{B}8-\text{B}4}{\text{B}8+\text{B}4}$$(3) -
B8 = NIR and B4 = RED.
$${\text{LS }} = \, \left( {{\text{m }} + { 1}} \right) \, \times \, \left[ {{\text{As}}/{22}} \right] \, \times \, \left[ {{\text{sin}}\beta /0.0{896}} \right]$$(4) -
As: upstream drainage area.
-
β: slope degree.
$${\text{K }} = {\text{ f}}_{{{\text{csand}}}} \, *{\text{f}}_{{\text{cl-si}}} \, *{\text{ f}}_{{{\text{orgc}}}} \, *{\text{ f}}_{{{\text{hisand}}}}$$(5) -
ƒcsand: portion of soils that have a lot of gritty sand.
-
ƒcl-si: portion of soils with a high percentage of clay to silt.
-
ƒorgc: portion of soils that contain a lot of organic carbon.
-
ƒhisand: portion of very high sand-content soils.
$${\text{SPI }} = {\text{ As }} \times {\text{ tan}}\beta$$(6) -
As: upstream drainage area.
-
β: slope degree.
Selection of multi-hazard factors
The present study used six predictive models to improve ML prediction of susceptibility to floods, landslides, and water erosion. These models were subjected to several statistical tests to identify solid and linear correlations between the various components. These tests, which included variance inflation factor (VIF) calculated using Eq. (7) and correlation matrix analysis (CM), were used to identify and exclude the non-significant components, tolerance (TOL) calculated using Eq. (8), and mutual information (MI) calculated using Eq. (9). Low MI values indicated a minor effect and led to eliminating the causes producing flooding, landslides, and gully erosion. The MI analysis demonstrated the relevance of these components.
-
j: affects landslide susceptibility (LS), flood susceptibility (FS), and gully erosion susceptibility (GES).
-
n: subclass of LS, FS, and GES impact factors.
-
Toli: j tolerance.
-
VIFj: j inflation factor.
-
MI (n; j): n and j data exchange.
-
R: the propensity of j's regression coefficient on all other predisposition components.
-
H(n): conditional entropy for n given the landslide, flooded, and eroded zone j. is the entropy of n − H(n/j).
Using Eq. (10), the normalized frequency ratio (NFR) was calculated, the basis for the model's application and the optimal analysis of the factors that affected LS, FS, and GES. This approach is the most widely recommended method for standardizing the significance regarding the variety of data used as input for the different factors (Mao et al. 2021; Youssef et al. 2023). Therefore, to define the link between the factors affecting LS, FS, and GES and the susceptible locations, the frequency ratio (FR) derived from Eq. (11) was allocated to the subclass of factors impacting LS, FS, and GES, as similar to the approach followed by Masoud et al. (2022). Afterwards, Eq. (10) was used to standardize the data. This led to the transformation of each map into an NFR of 1 for high LS, FS, and GES and 0 for low LS, FS, and GES.
-
n: is the category of variables affecting the likelihood of landslides, floods, and gully erosion.
-
FRn: n frequency ratio
-
NFRn: n normalized frequency ratio
-
Wn: n is the number of risk sample points.
-
Wt: points in the overall risk sample.
-
Pn: n number of pixels
-
Pt: total amount of all pixels
The determining factors Jenks' natural break approach was utilized to analyze the maps and classify LS, FS, and GES into subclasses (Sarker 2021).
Methodology flowchart
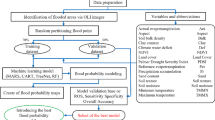
The current study was carried out in five different phases. Phase 1 involved the identification of the three natural hazards dealt with in this study to collect exhaustive data on various events from other sources; Phase 2 involved the differentiation of the different events based on an in-depth analysis of the published literature; Phase 3 dealt with the modelling of the various types of hazard using six ML models; phase 4 involved the validation of the models and the selection of the most appropriate model for each hazard. Finally, in phase 5, a multi-hazard susceptibility map (MHSM) was created by integrating the model with the best AUC for each type of hazard. Figure 4 illustrates the overall methodology of this research.
The methodology employed in this research is robust, multifaceted, and based on several key elements. Firstly, it begins with carefully curating high-quality data to ensure its reliability and relevance to the study objectives. Secondly, rigorous validation techniques are applied to assess the accuracy and integrity of the data collected, thereby enhancing the credibility of subsequent analyses. In addition, the methodology recognizes the importance of carefully selecting and prioritizing conditioning factors and using diverse inventories from reputable sources by integrating multiple data sets of varying spatial and temporal dimensions. Finally, the systematic comparison of different machine learning models is an integral part of the methodology, ensuring a rigorous evaluation is employed to select the best-performing model.
Methods of validation
For the six models developed using different performance measures, such as specificity (Eq. 12), precision (Eq. 15), sensitivity (Eq. 13), F1 score (Eq. 16), and accuracy (Eq. 14), the outcomes of the suggested approach were validated. The performance indices are deemed significant if there is a geographic correlation between the areas that represent the risks of flooding, landslides, and gully erosion and the measured stable regions and the predicted risk areas of indicated risks (Costache 2019; Costache and Tien Bui 2020).
While TP (true positives), TN (true negatives), FP (false positives), and FN (false negatives).
The investigation also used the ROC (receiver operating characteristic) curve, another widely utilized metric. The most popular ROC curve calculates the prediction models' accuracy (AUC) by analyzing the area under the curve (Eq. 17). Additionally, mean absolute error (MAE) (Eq. 19) and root mean square error (RMSE) (Eq. 18) were used to map the vulnerability to landslides, floods, and gully erosion. Numerous scholarly research have made use of both of these types of indexes.
where TP stands for the real positive, TN for the actual negative, and P and N, respectively, are the total numbers of pixels with and without torrential events.
n: is the total number of samples in the learning or testing phase, Xpredicted: the projected value from the susceptibility models (landslides, floods, and gully erosion), Factual: the observed value.
Results
Factor selection and multicollinearity
The Pearson correlation analysis between fifteen influencing factors (LULC, soil type, topographic wetness index, precipitation, elevation, slope, river accumulation, TPI, SPI, elevation, plan curvature, HSG, and aspect) and flood risk is shown in Fig. 5A. In contrast, Fig. 5B illustrates the Pearson analysis between eighteen influencing variables (drainage density, aspect, LS-factor, lithology, drainage density, K-factor, TPI, TWI, precipitation, distance to rivers, curvature, elevation, slope, NDVI, LULC, and TRI) for gully erosion risk. The following factors were considered for the landslide risk shown in Fig. 5C: soil type, proximity to rivers, topographic position index (TPI), topographic wetness index (TWI), and linkage to faults.

The conditioning factors for A flood, B gully erosion, and C landslide were studied using the variance inflation factor (VIF) and tolerance (TOL) multicollinearity
To ensure the complexity of the input variables investigated in this study, the findings of the tolerance and inflation coefficients of variance (VIF) indicate a Tol value between 0.12 and 0.97 for HSG and TWI, respectively, and between 1.02 and 8.02 for TWI and 8.02 for HSG at the lowest VIF value as illustrated by Fig. 5A. Among the fifteen indicators taken into consideration in this study, The Tol and VIF criteria led to the exclusion of TWI and SPI from additional inquiry. Subsequently, the MI of the remaining thirteen elements (distance to the river) to 0.013 (HSG) is computed and produces positive results as described by Fig. 6A. Thus, the most significant aspect is the distance to the river, which is followed by slope (MI = 0.159), height (MI = 0.245), and backwater (MI = 0.183).

Analysis of conditioning components' multicollinearity using the correlation matrix for A flood, B gully erosion, and C landslide
Figure 6 showed that the LS factor and slope for the gully erosion risk had the most substantial positive correlation (0.69). Elevation and slope, drainage density and gully depth, TWI and gramophone, SPI and gramophone, SPI and LS factor, precipitation, elevation, slope, and TRI all showed significant linear connections. Figure 5B illustrates the results of the tolerance and variance information factors (VIF) used in this study to test the overlap of the forage influencing factors. For Geomorphone and TWI, respectively, the Tol value falls between 0.15 and 0.94, and the maximum VIF value for Geomorphones is 6.35, while the minimum value for TWI is 1.05. The gramophone component was removed from the 18 variables utilized in this analysis because of Tol and VIF constraints. The MI of the parameters displayed in Fig. 6B is then calculated, and the findings show positive values in the range of 0.261 (slope) to 0.029 (aspect). As a result, slope is the most significant factor, followed by lithology (MI = 0.213), TPI (MI = 0.226), and LS (MI = 0.227).
A significant linear relationship was found between the following variables: NDVI and precipitation, elevation and slope, lithology and elevation, slope and lithology, and slope and lithology and the distance between roads and rivers. The results for landslide risk indicate that the highest positive correlation value (0.63) was a correlation between road mileage and height. The findings of the tolerance and variance information factors (VIF), which were utilized in this study to examine the multicollinearity of the forage-affecting variables, show that the LULC values and elevation range from 0.30 to 0.92 in terms of Tol and that the values of LULC and elevation range from 1.08 to 3.30 on the maximum VIF value (Fig. 5C). The MI of the remaining 14 components (Fig. 7B) indicates positive values between 0.132 (inclination) to 0.021 (LULC). Thus, the slope is the most significant component, followed by the following: height (MI = 0.120), lithology (MI = 0.118), road distance (MI = 0.095), and fault distance (MI = 0.091).

The importance of selected hazard predictive factors for A flood, B gully erosion, and C landslide
Six machine learning models were applied to generate sensitivity maps for floods (Fig. 8A), gully erosion (Fig. 8B), and landslides (Fig. 8C) based on risk predictions using independent variables and the actual risk condition using dependent variables. Based on the Jenks classifier for natural breaks (Jenks and Caspall 1971). Five classifications were applied to each sensitivity map: very low, low, moderate, high, and very high. Maps showing the flood sensitivity of the Tensift watershed and the Haouz plain were created using the SVM, RF, KNN, DT, ANN, and XGBoost models (Fig. 8A(a–g)). Furthermore, gully erosion sensitivity maps were created for the same watershed using the same models (Fig. 8B(a–g)). Finally, landslide sensitivity maps were produced using the same models (Fig. 8C(a–g)).



Susceptibility maps for A flooding, B gully erosion, and C landslide, predicted by the (a) SVM, (b) RF, (e) DT, (d) KNN, (g) XGBoost, and (f) ANN models
Validation of models
The AUC curves for the six machine learning models that were utilized to develop the models for landslides, floods, and gully erosion are shown in Fig. 9. The results show that the AUCs for the different flood vulnerability models range from 90.69 to 96.21% in the training phase and from 87.56 to 93.78% in the testing phase, corresponding to high to extremely high performance. The XGBoost, RF, KNN, DT, ANN, and SVM models achieved AUCs of (96.21%), (94.32%), (94.32%), (93.38%), (91.01%) and (90. 01%) in the training phase and AUCs of (93.78%), (93.71%), (90.53%), (90.67%), (87.56%) and (92.02%) in the test phase (Fig. 9A), for gully erosion the results show an AUC that varies from 96.71 to 72.84% in the training phase and from 91.07 to 78.60% in the test phase, for landslides, the results show an AUC that varies from 94.57 to 70.03% in the training phase and from 93.41 to 70.03% in the test phase.

ROC curve analysis of different models of A flooding, B gully erosion, and C landslide for training and validation data
The effectiveness of the chosen XGBoost FS, GES, and LS prediction models throughout the training and validation stages is displayed in Tables 4 and 5. Along with the effectiveness of the training data used (30%) and test data used (70%), the following metrics are evaluated by adhering to the approaches of (Bammou et al. 2024d): Pr (precision), Se (sensitivity), Sp (specificity), Ac (accuracy), F1 score, FPR (false positive rate), MAE (mean absolute error), RMSE (root mean square error), and AUC-ROC (area under the receiver operating characteristic curve).
The XGBoost model performed exceptionally well for all training data, as evidenced by the following values: (Pr = 0.95), (Se = 0.97), (Sp = 0.95), (Ac = 0.97), (Recall = 0.96), (F1 score = 0.95), (MAE = 0.04), and RMSE (values = 0. 19) for the risk of flooding; (Pr = 0.99), (Se = 0.94), (Sp = 0.99), (Ac = 0.96), (Recall = 0.95), (F1 score = 0.97), (FPR = 0.009), (MAE = 0.03) and RMSE (values = 0. 12) for the risk of gully erosion; and lastly, (Pr = 0.97), (Se = 0.98), (Sp = 0.96), (Ac = 0.97), (Recall = 0.98), (F1 score = 0.98), (FPR = 0.03), (MAE = 0.05) and RMSE (values = 0.23) for the risk of landslides, as shown by Tables 3 and 4.
For all test data, the XGBoost model performed excellently, as confirmed by the values (Pr = 0.93), (Se = 0.94), (Sp = 0.93), (Ac = 0.94), (Recall = 0.92), (F1 score = 0.92), (FPR = 0.07), (MAE = 0.06) and RMSE (values = 0.25) for the flood risk, the values (Pr = 0.94), (Se = 0.90), (Sp = 0.93), (Ac = 0.91), (Recall = 0.90), (F1 score = 0.92), (FPR = 0.07), (MAE = 0.03) and RMSE (values = 0.118) for gully erosion risk and lastly the values (Pr = 0.93), (Se = 0.95), (Sp = 0.92), (Ac = 0.93), (Recall = 0.95), (F1 score = 0.94), (FPR = 0.08), (MAE = 0.06) and RMSE (values = 0.25) for the risk of landslides as described by Table 5.
Multi-hazard maps
The multi-hazard map was produced by constructing and evaluating three separate hazard susceptibility maps, each correlated with a distinct hazard (FL, GES, and LS). Using the XGBoost model, this development was based on the link between independent factors, i.e., hazard indicators, and dependent variables, i.e., locations at risk of flooding, gully erosion, and landslides. The three vulnerability maps (flooding, gully erosion, and landslides) were then integrated into Software GIS to create the comprehensive multi-hazard risk map shown in Fig. 10.

A multi-hazard risk map was developed using the most potent XGBoost model
As illustrated by Fig. 11, the results indicate that the research region is separated into seven vulnerability groups. The region is exposed to various risks to the extent of around 71.03%, with the percentage breakdown as follows: 36.05% of the total area is made up of gully erosion (GES), 16.92% of floods (FS), 10.59% of landslides and gully erosion (GES-LS), 6.54% of floods and gully erosion (FS-GES), 0.56% of landslides (LS), 0.33% of floods and landslides (FS-LS), and 0.31% of floods, gully erosion, and landslides (FL-GES-LS).

Percentages of various hazard types in the research region
Discussion
A range of modelling techniques can significantly enhance the understanding of risk management. In a semi-arid area prone to many hazards such as flooding, gully erosion, landslides, and, more recently, earthquakes, such as the catastrophic earthquake of September 8, 2023, in the research region, there has been an acceleration in the establishment of landslide hazard zones.
This study investigated three natural hazards in the Tensift watershed, a region in the Moroccan High Atlas with mountain and lowland characteristics. The aim was to perform multi-hazard modelling to understand the relationships and to assess the susceptibility to landslides, gully erosions and flood risks in the study area. To this end, six ML models were used to study flooding, gully erosion, and landslides: DT, RF, SVM, KNN, ANN, and XGBoost. The analysis of (CM), (TOL), (VIF), and (MI) led to the conclusion that the selected factors can influence flooding, gully erosion, and landslides in the Tensift catchment. To evaluate the models' success, training datasets, validation, and evaluation metrics were employed to assess the ML models' performance. Accuracy, precision, recall, F1 score, mean absolute error (MAE), root mean square error (RMSE), and area under the receiver characteristic curve (AUC-ROC) are examples of standard measurements. The XGBoost model for the three hazards showed an average accuracy of (AUC = 95.83%) and (AUC = 92.75%) in the training and test phases, respectively.
The spatial prediction of FS is dependent on several affecting variables. Due to their collinearity with other factors, which reduced the prediction's efficacy, TWI and SPI were eliminated from this study's original set of fifteen components. Additionally, MI claims that the most crucial element is the distance to the river. According to the spatial prediction results of (Al-Areeq et al. 2022; Meliho et al. 2022) regarding FS, the most critical areas at a given distance from the river were considered very vulnerable to high-density floods. Since the Haouz Plain is located at low elevations, the findings of the present study are being validated by the previous scientific literature, notably (Meliho et al. 2022), which shows that high susceptibility is connected with elevation, slope, TPI, and TRI in Tensift rivers and sub-catchments, especially the Ourika, Zat, and Rheraya sub-catchments.
The key variables influencing gully erosion in the research region for the spatial prediction of GES indicate that geological factors, represented by lithology and topographic factors, such as slope, LS factor, and TPI, are more significant than other variables. This fact is primarily in line with the findings of (Baiddah et al. 2023) for lithology and the LS variables in the Chichaoua sub-basin; his work also highlights the importance of additional elements like altitude and proximity to rivers. Selecting a mixed zone, which compares altitude values by combining a lowland, a mountainous zone, and the study zone's broad area, can help to understand this divergence.
The combination of exceptionally highly friable lithologies, such as Tertiary clays and sediments and Neogene phosphate marls, with high altitudes and little vegetation, especially on steep slopes and in areas where the vegetation cover is damaged, favors the occurrence and development of this type of erosion (Arabameri et al. 2020; Bammou et al. 2024c). Lastly, spatial prediction of LS findings demonstrates that the following five factors—slope gradient, height, lithology, proximity to highways, and proximity to rivers—are critical in determining the likelihood of landslides. Unstable soils migrate along slopes due to the constant action of gravity and the slope gradient and elevation variables. Steeper hills are more likely to cause landslides. In addition to affecting slope stability, excavation activities related to the building or extension of road networks can raise the danger of landslides in locations near highways. Another critical factor in landslides is the proximity to rivers. The stability of slopes next to rivers is threatened by bank and gully erosion, raising the possibility of landslides in these locations.
Compared to the other six models, the XGBoost model is more accurate primarily because it uses all base learners' prediction outcomes, improving its recognition rate and generalization capacity. When determining and preserving the optimal path of action, several techniques will be employed to address missing values that may have occurred on other nodes. XGBoost adds a regular term to the objective function and allows custom loss functions, but it also minimizes the learning model and avoids overfitting, which accelerates learning. Because of this, the XGBoost model ultimately produces improved simulation results, and the XGBoost-based method is practical and efficient for mapping the susceptibility of landslides, floods, and gully erosion.
The use of the XGBoost algorithm, which has shown excellent predictive capabilities in this study, has many advantages. One notable advantage is its simple implementation, which does not require prior data preprocessing and its built-in mechanisms for handling missing data. In addition, the ensembled algorithm employs bias reduction techniques by sequentially combining multiple weak learners to improve the quality of predictions iteratively (Bashir et al. 2024a, b; Benzougagh et al. 2024; Zounemat-Kermani et al. 2021). This approach effectively mitigates the significant biases that often occur in ML models. In addition, XGBoost prioritizes features in the training phase that contribute to improved prediction accuracy to increase computational efficiency. This feature can be beneficial in reducing data attributes and efficiently managing large data sets.
It is essential to know that the presence of one danger can cause the occurrence of another. For example, knowledge of multiple hazards, their interrelationships, linkages, and cascading effects can increase awareness of their processes and the best methods to prevent and reduce catastrophic losses while supporting good land management (Godschall et al. 2020; Msabi and Makonyo 2021; Ouallali et al. 2024). The resulting maps provide essential information to prepare and monitor existing and future anthropogenic activities.
Conclusion
The research has substantially contributed to the knowledge of how vulnerable Morocco's Northern and High Atlas areas are to different threats. Due to their distinct geography and dense population, these mountainous areas face an intricate web of natural threats. The primary goal was to give decision-makers the necessary information to identify and demarcate high-risk zones. This research yields a thorough multi-hazard vulnerability map incorporating these three main natural risks.
This map divides the research area into six danger zones, accounting for 71.03% of the area. Three zones are linked to specific hazards: the landslide risk zone (0.56%), which is situated in steep, high-altitude Tensift sub-basins; the erosion risk zone (36.05%), which is concentrated along major rivers like the R'dat, Zat, and Ourika; and the flood risk zone (16.92%), which primarily affects the Haouz plains and certain tributaries of the High Atlas.
Additionally, the study showed that there are three zones—the flood and landslide hazard zone (0.33%), the flood and gully erosion hazard zone (6.54%), and the landslide and gully erosion hazard zone (10.59%)—where two types of risks overlap. Surprisingly, the High Atlas has multi-hazard zones, especially in the Ourika and N'fis catchments, which comprise 0.31% of the study area and are impacted by all three hazards: landslides, gully erosion, and floods.
The XGBoost machine learning model demonstrated exceptional dependability and yielded precise forecasts for several categories of hazards. Our multi-hazard map was the result, and it achieved an impressive average of (AUC = 95.83%) during the training phase and (AUC = 92.75%) during the testing phase. The multi-hazard analysis is essential for sustainable growth in these hilly and flood-prone areas as infrastructure and urban and rural development continue to rise. Based on the multi-hazard risk map, policy recommendations for sustainable land management and hazard mitigation could be proposed in the context of the High Atlas landscape. Developing strategies for increasing public awareness and education about these hazards and the importance of sustainable land management could also contribute to a more comprehensive understanding of multi-hazard assessments and more effective land management and hazard mitigation.
Albeit it is a pioneering study in the field of multi-hazard assessment, this study has a few identified limitations that could be rectified in future research studies. Firstly, the study's geographical focus might limit the results' applicability to other regions with different topographical, geological, and meteorological conditions. Conducting similar studies in the future in various geographical areas could validate the applicability of the models and allow for comparison of the results. The ML models used in this study rely on causal factors derived from reputable and trusted sources. Future studies could incorporate real-time or dynamic data into ML models to study the reflection of changing conditions and enhance prediction accuracy. Lastly, this study does not extensively acknowledge how the changes in anthropogenic activities could impact the three aforementioned hazards. It is highly encouraged to encapsulate in-depth studies on how the changes in anthropogenic activities such as urbanization, deforestation, and land use dynamics could impact landslides, soil erosion and flood risks could get incorporated into ML models.
Availability of data and materials
All data used in this research were described within the manuscript.
References
Aksha SK, Resler LM, Juran L, Carstensen LW Jr (2020) A geospatial analysis of multi-hazard risk in Dharan, Nepal. Geomat Nat Hazards Risk 11(1):88–111. https://doi.org/10.1080/19475705.2019.1710580
Al-Areeq AM, Abba S, Yassin MA, Benaafi M, Ghaleb M, Aljundi IH (2022) Computational machine learning approach for flood susceptibility assessment integrated with remote sensing and GIS techniques from Jeddah, Saudi Arabia. Remote Sens 14(21):5515. https://doi.org/10.3390/rs14215515
Arabameri A, Saha S, Roy J, Chen W, Blaschke T, Tien Bui D (2020) Landslide susceptibility evaluation and management using different machine learning methods in the Gallicash River Watershed, Iran. Remote Sens 12(3):475. https://doi.org/10.3390/rs12030475
Baiddah A, Krimissa S, Hajji S, Ismaili M, Abdelrahman K, El Bouzekraoui M et al (2023) Head-cut gully erosion susceptibility mapping in semi-arid region using machine learning methods: insight from the High Atlas, Morocco. Front Earth Sci 11:1184038. https://doi.org/10.3389/feart.2023.1184038
Bammou Y, Benzougagh B, Bensaid A, Igmoullan B, Al-Quraishi AMF (2023) Mapping of current and future soil erosion risk in a semi-arid context (haouz plain-Marrakech) based on CMIP6 climate models, the analytical hierarchy process (AHP) and RUSLE. Model Earth Syst Environ. https://doi.org/10.1007/s40808-023-01845-9
Bammou Y, Benzougagh B, Abdessalam O, Brahim I, Kader S, Spalevic V et al (2024a) Machine learning models for gully erosion susceptibility assessment in the Tensift catchment, Haouz Plain, Morocco for sustainable development. J Afr Earth Sci 213:105229. https://doi.org/10.1016/j.jafrearsci.2024.105229
Bammou Y, Benzougagh B, Bensaid A, Igmoullan B, Al-Quraishi AMF (2024b) Mapping of current and future soil erosion risk in a semi-arid context (haouz plain-Marrakech) based on CMIP6 climate models, the analytical hierarchy process (AHP) and RUSLE. Model Earth Syst Environ 10(1):1501–1514. https://doi.org/10.1007/s40808-023-01845-9
Bammou Y, Benzougagh B, Igmoullan B, Al-Quraishi AMF, Ghaib FA, Kader S (2024c) Assessing soil erosion vulnerability in semi-arid Haouz Plain, Marrakech, Morocco: land cover, socio-spatial mutations, and climatic variations. In: Al-Quraishi AMF, Mustafa YT (eds) Natural resources deterioration in MENA Region: land degradation, soil erosion, and desertification. Springer International Publishing, Cham, pp 113–133. https://doi.org/10.1007/978-3-031-58315-5_7
Bammou Y, Benzougagh B, Igmoullan B, Ouallali A, Kader S, Spalevic V et al (2024d) Optimizing flood susceptibility assessment in semi-arid regions using ensemble algorithms: a case study of Moroccan High Atlas. Nat Hazards. https://doi.org/10.1007/s11069-024-06550-z
Bashir O, Bangroo SA, Shafai SS, Senesi N, Kader S, Alamri S (2024a) Geostatistical modeling approach for studying total soil nitrogen and phosphorus under various land uses of North-Western Himalayas. Eco Inform 80:102520. https://doi.org/10.1016/j.ecoinf.2024.102520
Bashir O, Bangroo SA, Shafai SS, Senesi N, Naikoo NB, Kader S, Jaufer L (2024b) Unlocking the potential of soil potassium: geostatistical approaches for understanding spatial variations in Northwestern Himalayas. Eco Inform 81:102592. https://doi.org/10.1016/j.ecoinf.2024.102592
Benzougagh B, Al-Quraishi AMF, Bammou Y, Kader S, El Brahimi M, Sadkaoui D, Ladel L (2024) Spectral Angle Mapper Approach (SAM) for land degradation mapping: a case study of the Oued Lahdar Watershed in the Pre-Rif Region (Morocco). In: Al-Quraishi AMF, Mustafa YT (eds) Natural Resources deterioration in MENA Region: land degradation, soil erosion, and desertification. Springer International Publishing, Cham, pp 15–35. https://doi.org/10.1007/978-3-031-58315-5_2
Bout B, Lombardo L, van Westen CJ, Jetten VG (2018) Integration of two-phase solid fluid equations in a catchment model for flashfloods, debris flows and shallow slope failures. Environ Model Softw 105:1–16. https://doi.org/10.1016/j.envsoft.2018.03.017
Costache R (2019) Flash-Flood Potential assessment in the upper and middle sector of Prahova river catchment (Romania). A comparative approach between four hybrid models. Sci Total Environ 659:1115–1134. https://doi.org/10.1016/j.scitotenv.2018.12.397
Costache R, Tien Bui D (2020) Identification of areas prone to flash-flood phenomena using multiple-criteria decision-making, bivariate statistics, machine learning and their ensembles. Sci Total Environ 712:136492. https://doi.org/10.1016/j.scitotenv.2019.136492
Duclaux A (2005) Modélisation hydrologique de 5 Bassins Versants du Haut-Atlas Marocain avec SWAT (Soil and Water Assessment Tool). Mémoire du diplôme d'Ingénieur Agronome de l'Institut National Agronomique de Paris-Grignon. p 53
Godschall S, Smith V, Hubler J, Kremer P (2020) A decision process for optimizing multi-hazard shelter location using global data. Sustainability 12(15):6252. https://doi.org/10.3390/su12156252
Guo Z, Chen L, Yin K, Shrestha DP, Zhang L (2020) Quantitative risk assessment of slow-moving landslides from the viewpoint of decision-making: a case study of the Three Gorges Reservoir in China. Eng Geol 273:105667. https://doi.org/10.1016/j.enggeo.2020.105667
Hillier JK, Matthews T, Wilby RL, Murphy C (2020) Multi-hazard dependencies can increase or decrease risk. Nat Clim Change 10(7):595–598. https://doi.org/10.1038/s41558-020-0832-y
Hong H, Pourghasemi HR, Pourtaghi ZS (2016) Landslide susceptibility assessment in Lianhua County (China): a comparison between a random forest data mining technique and bivariate and multivariate statistical models. Geomorphology 259:105–118. https://doi.org/10.1016/j.geomorph.2016.02.012
Jenks GF, Caspall FC (1971) Error on choroplethic maps: definition, measurement, reduction. Ann Assoc Am Geogr 61(2):217–244. https://doi.org/10.1111/j.1467-8306.1971.tb00779.x
Jones HG, Vaughan RA (2010) Remote sensing of vegetation: principles, techniques, and applications. Oxford University Press, Oxford
Khan A, Gupta S, Gupta SK (2020) Multi-hazard disaster studies: monitoring, detection, recovery, and management, based on emerging technologies and optimal techniques. Int J Disaster Risk Reduct 47:101642. https://doi.org/10.1016/j.ijdrr.2020.101642
Kohansarbaz A, Kohansarbaz A, Shabanlou S, Yosefvand F, Rajabi A (2022) Modelling flood susceptibility in northern Iran: application of five well-known machine-learning models. Irrig Drain 71(5):1332–1350. https://doi.org/10.1002/ird.2745
Lombardo L, Tanyas H, Nicu IC (2020) Spatial modeling of multi-hazard threat to cultural heritage sites. Eng Geol 277:105776. https://doi.org/10.1016/j.enggeo.2020.105776
Lyu H-M, Yin Z-Y (2023) An improved MCDM combined with GIS for risk assessment of multi-hazards in Hong Kong. Sustain Cities Soc 91:104427. https://doi.org/10.1016/j.scs.2023.104427
Mao W, Xu C, Yang Y (2021) Investigation on strength degradation of sandy soil subjected to concentrated particle erosion. Environ Earth Sci 81(1):1. https://doi.org/10.1007/s12665-021-10123-9
Masoud AM, Pham QB, Alezabawy AK, El-Magd SAA (2022) Efficiency of geospatial technology and multi-criteria decision analysis for groundwater potential mapping in a semi-arid region. Water 14(6):882. https://doi.org/10.3390/w14060882
Meliho M, Khattabi A, Driss Z, Orlando CA (2022) Spatial prediction of flood-susceptible zones in the Ourika watershed of Morocco using machine learning algorithms. Appl Comput Inform. https://doi.org/10.1108/ACI-09-2021-0264
Ming X, Liang Q, Dawson R, Xia X, Hou J (2022) A quantitative multi-hazard risk assessment framework for compound flooding considering hazard inter-dependencies and interactions. J Hydrol 607:127477. https://doi.org/10.1016/j.jhydrol.2022.127477
Mondini AC, Guzzetti F, Melillo M (2023) Deep learning forecast of rainfall-induced shallow landslides. Nat Commun 14(1):2466. https://doi.org/10.1038/s41467-023-38135-y
Msabi MM, Makonyo M (2021) Flood susceptibility mapping using GIS and multi-criteria decision analysis: a case of Dodoma region, central Tanzania. Remote Sens Appl Soc Environ 21:100445. https://doi.org/10.1016/j.rsase.2020.100445
Nellemann C, Reynolds PE (1997) Predicting Late Winter Distribution of Muskoxen Using an Index of Terrain Ruggedness. Arctic Alpine Res 29(3):334–338. https://doi.org/10.2307/1552148
Ouallali A, Kader S, Bammou Y, Aqnouy M, Courba S, Beroho M et al (2024) Assessment of the erosion and outflow intensity in the Rif Region under different land use and land cover scenarios. Land. https://doi.org/10.3390/land13020141
Panahi M, Gayen A, Pourghasemi HR, Rezaie F, Lee S (2020) Spatial prediction of landslide susceptibility using hybrid support vector regression (SVR) and the adaptive neuro-fuzzy inference system (ANFIS) with various metaheuristic algorithms. Sci Total Environ 741:139937. https://doi.org/10.1016/j.scitotenv.2020.139937
Pei Y, Qiu H, Yang D, Liu Z, Ma S, Li J et al (2023) Increasing landslide activity in the Taxkorgan River Basin (eastern Pamirs Plateau, China) driven by climate change. CATENA 223:106911. https://doi.org/10.1016/j.catena.2023.106911
Pourghasemi HR, Rahmati O (2018) Prediction of the landslide susceptibility: which algorithm, which precision? CATENA 162:177–192. https://doi.org/10.1016/j.catena.2017.11.022
Razavi-Termeh SV, Hatamiafkoueieh J, Sadeghi-Niaraki A, Choi S-M, Al-Kindi KM (2023) A GIS-based multi-objective evolutionary algorithm for landslide susceptibility mapping. Stoch Environ Res Risk Assess. https://doi.org/10.1007/s00477-023-02562-6
Sarker IH (2021) Machine learning: algorithms, real-world applications and research directions. SN Comput Sci 2(3):160. https://doi.org/10.1007/s42979-021-00592-x
Saunders WSA, Kilvington M (2016) Innovative land use planning for natural hazard risk reduction: a consequence-driven approach from New Zealand. Int J Disaster Risk Reduct 18:244–255. https://doi.org/10.1016/j.ijdrr.2016.07.002
Sestras P, Mircea S, Roșca S, Bilașco Ș, Sălăgean T, Dragomir LO et al (2023) GIS based soil erosion assessment using the USLE model for efficient land management: a case study in an area with diverse pedo-geomorphological and bioclimatic characteristics. Notulae Botanicae Horti Agrobotanici Cluj-Napoca 51(3):13263–13263. https://doi.org/10.15835/nbha51313263
Stalhandske Z, Steinmann CB, Meiler S, Sauer IJ, Vogt T, Bresch DN, Kropf CM (2024) Global multi-hazard risk assessment in a changing climate. Sci Rep 14(1):5875. https://doi.org/10.1038/s41598-024-55775-2
Ye T, Liu W, Mu Q, Zong S, Li Y, Shi P (2020) Quantifying livestock vulnerability to snow disasters in the Tibetan Plateau: comparing different modeling techniques for prediction. Int J Disaster Risk Reduct 48:101578. https://doi.org/10.1016/j.ijdrr.2020.101578
Yousefi S, Pourghasemi HR, Emami SN, Pouyan S, Eskandari S, Tiefenbacher JP (2020) A machine learning framework for multi-hazards modeling and mapping in a mountainous area. Sci Rep 10(1):12144. https://doi.org/10.1038/s41598-020-69233-2
Youssef B, Bouskri I, Brahim B, Kader S, Brahim I, Abdelkrim B, Spalević V (2023) The contribution of the frequency ratio model and the prediction rate for the analysis of landslide risk in the Tizi N’tichka area on the national road (RN9) linking Marrakech and Ouarzazate. CATENA 232:107464. https://doi.org/10.1016/j.catena.2023.107464
Zhang T, Wang W, An B, Wei L (2023) Enhanced glacial lake activity threatens numerous communities and infrastructure in the Third Pole. Nat Commun 14(1):8250. https://doi.org/10.1038/s41467-023-44123-z
Zhao T, Peng H, Xu L, Sun P (2024) Statistical landslide susceptibility assessment using Bayesian logistic regression and Markov Chain Monte Carlo (MCMC) simulation with consideration of model class selection. Georisk Assess Manag Risk Eng Syst Geohazards 18(1):211–227. https://doi.org/10.1080/17499518.2023.2288600
Zounemat-Kermani M, Batelaan O, Fadaee M, Hinkelmann R (2021) Ensemble machine learning paradigms in hydrology: a review. J Hydrol 598:126266. https://doi.org/10.1016/j.jhydrol.2021.126266
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions No funding was received for this research project.
Author information
Authors and Affiliations
Contributions
Conceived and designed the studies—Youssef Bammou, Brahim Benzougagh, Brahim Igmoullan, Shuraik Kader, and Velibor Spalevic. Performed the analysis—Youssef Bammou, Brahim Benzougagh, Brahim Igmoullan, Abdessalam Ouallali, Shuraik Kader, Velibor Spalevic, Paul Sestras, and Alban Kuriqi. Analyzed and interpreted the data—Youssef Bammou, Brahim Benzougagh, Brahim Igmoullan, Abdessalam Ouallali, Shuraik Kader, Velibor Spalevic, Paul Sestras, and Alban Kuriqi. Contributed materials, analysis tools, or data—Youssef Bammou, Brahim Benzougagh, Brahim Igmoullan, Abdessalam Ouallali, Shuraik Kader, and Velibor Spalevic. Authored the paper—Youssef Bammou, Brahim Benzougagh, Brahim Igmoullan, Abdessalam Ouallali, Shuraik Kader, Velibor Spalevic, Paul Sestras, and Alban Kuriqi. Internal reviewers – Brahim Benzougagh, Shuraik Kader, Velibor Spalevic, Paul Sestras, and Alban Kuriqi. Project administration – Brahim Benzougagh, Velibor Spalevic, and Alban Kuriqi. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Ethical approval
Not applicable.
Consent to participate
Not applicable.
Consent to publish
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bammou, Y., Benzougagh, B., Igmoullan, B. et al. Spatial Mapping for Multi-Hazard Land Management in Sparsely Vegetated Watersheds Using Machine Learning Algorithms. Environ Earth Sci 83, 447 (2024). https://doi.org/10.1007/s12665-024-11741-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12665-024-11741-9