
Abstract
Human activity recognition (HAR) is used to support older adults to live independently in their own homes. Once activities of daily living (ADL) are recognised, gathered information will be used to identify abnormalities in comparison with the routine activities. Ambient sensors, including occupancy sensors and door entry sensors, are often used to monitor and identify different activities. Most of the current research in HAR focuses on a single-occupant environment when only one person is monitored, and their activities are categorised. The assumption that home environments are occupied by one person all the time is often not true. It is common for a resident to receive visits from family members or health care workers, representing a multi-occupancy environment. Entropy analysis is an established method for irregularity detection in many applications; however, it has been rarely applied in the context of ADL and HAR. In this paper, a novel method based on different entropy measures, including Shannon Entropy, Permutation Entropy, and Multiscale-Permutation Entropy, is employed to investigate the effectiveness of these entropy measures in identifying visitors in a home environment. This research aims to investigate whether entropy measures can be utilised to identify a visitor in a home environment, solely based on the information collected from motion detectors [e.g., passive infra-red] and door entry sensors. The entropy measures are tested and evaluated based on a dataset gathered from a real home environment. Experimental results are presented to show the effectiveness of entropy measures to identify visitors and the time of their visits without the need for employing extra wearable sensors to tag the visitors. The results obtained from the experiments show that the proposed entropy measures could be used to detect and identify a visitor in a home environment with a high degree of accuracy.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The older adult population, aged 65 or over, in developed countries, has increased dramatically over the last few decades. This is having serious effects on the healthcare sector, with the cost of their care expected to increase enormously over the coming years (Aicha et al. 2012). Moreover, the number of people living alone at home and the number of single-occupancy homes are also increasing worldwide (Gochoo et al. 2017; Tan et al. 2017). Most older adults have requirements for long-term care, and also need continuous assistance in their activities of daily living (ADLs). However, the majority of older adults prefer to remain in their own homes rather than in care homes to maintain their independence (Tan et al. 2018). Therefore, home environments equipped with an appropriate sensor network, referred to as Intelligent Environments or Smart Homes, are utilised to support older adults to live independently in their own homes. To be able to support independent living, it is essential to recognise routine ADL and distinguish any abnormality with the recognised activities. This would require accurate and reliable human activities recognition (HAR) (Aicha et al. 2012, 2017).
So far, research related to recognising ADLs has focused only on single occupancy environments, in which it is assumed that only a single person (i.e., the main resident) is present in the home (Najar et al. 2019; Hao et al. 2018; Nait Aicha et al. 2013). Nevertheless, it is very likely that the real home environments are occupied by more than one person (Singla et al. 2010; Mokhtari et al. 2018; Roy et al. 2016; Ghosh et al. 2020). For example, it is likely that older adults will receive visits from family members or healthcare workers (referred to as a multi-occupancy environment). Visiting is considered as one of the most important activities for older adults living alone at home (Hu et al. 2017). Because multi-occupancy scenarios are far more realistic, therefore, it is essential to identify human activities in the presence of visitors while visitors are not expected to wear any specialised devices to distinguish their activities (Alemdar and Ersoy 2017; Benmansour et al. 2017).
Different types of sensors are utilised to identify a visitor in a home environment. Most research works to date have considered video cameras and wearable sensors to develop HAR systems in multi-occupancy environments. Video cameras have the property of allowing the identification of different people moving around the house, but this can be considered as a violation of their privacy (Benmansour et al. 2017). In contrast, other researchers have utilised wearable sensors such as RFID to identify and detect multi-occupancy ADLs (Attal et al. 2015; Mohamed et al. 2017b; Hao et al. 2018). Such devices can provide adequate information about the locations of occupiers in a multi-occupancy home environment. Although, using wearable sensors is impractical: especially if they are used for long periods. They may forget to wear these sensors or may take them off when they become uncomfortable (Hu et al. 2017; Patel et al. 2012). Further, due to improved privacy and reduced cost of equipment, recognising human activities based on ambient sensors is a preferred option (Yang et al. 2014).
Identification of visitors in a home environment using ambient sensors is the challenge addressed in this paper. Identifying visitors and the time of the visits (such as healthcare visitors) is essential for healthcare management (Hu et al. 2017). It is important to develop a system with the ability to identify the exact time of a visit without the need for visitors to be asked to carry a tag or wearable device to identify them. This research aims to investigate whether entropy measures, including Shannon Entropy (ShEn), Permutation Entropy (PerEn), and Multiscale-Permutation Entropy (MPE), can be used to identify visitors in a home environment.
The main contributions of this paper are summarised as follows:
-
A novel entropy-based method is proposed for visitor detection in a home environment, solely based on information gathered from low-cost, non-intrusive ambient sensors.
-
The paper investigates whether entropy measures can be used as a useful measure for identifying visitors and visiting time without the need for employing extra wearable sensors to tag the visitors.
-
In this paper, the main door sensor is used along with entropy measures to confirm the time and duration of the visit.
-
Testing and evaluating the proposed entropy measures using dataset gathered from real home environments representing ADL for a multi-occupancy.
The rest of this paper is organised as follows: The related work in the context of activity recognition in multi-occupancy is presented in Sect. 2. In Sect. 3, the proposed method for identifying visitors (time of visit) in a home environment based on different entropy measures are presented. The details of different entropy measures are described in Sect. 4, followed by a description of the experimental setup and robust analysis in Sect. 5. Finally, pertinent conclusions are drawn in Sect. 6.
2 Related work
Ambient sensors such as passive infrared sensors (PIR) or door entry sensors cannot differentiate who has triggered them (Benmansour et al. 2015; Hu et al. 2017). Therefore, identifying activities in a multi-occupancy environment only based on ambient sensors has proven to be difficult, if not impossible (Alemdar and Ersoy 2017; Benmansour et al. 2017). Therefore, the use of wearable sensors, visual sensors, and video cameras has become the norm to monitor ADLs in a multi-occupancy environment (Eldib et al. 2015). However, a few studies focusing on the detection of visits in a home environment based on PIR sensors only (Aicha et al. 2012; Petersen et al. 2012; Nait Aicha et al. 2013). Several research works have been carried out on detecting and identifying multi-occupancy and monitoring activities by using different techniques and algorithms (Li et al. 2020; Lapointe et al. 2020; Tran and Zhang 2020). These techniques are classified into two main categories, which are statistical techniques and computational intelligence techniques.
Most of the research which has been conducted in the context of activity recognition in multi-occupancy has used statistical techniques, including the Hidden Markov Model (HMM) (Alemdar and Ersoy 2017; Han et al. 2004; Murphy 2012; Eldib et al. 2015), Naive Bayes Classifier (NBC) (Benmansour et al. 2016) and the conditional random field (CRF) (Hsu et al. 2010). These techniques are utilised to detect relationships between temporal data generated by the sensors and identify the pattern of the user. Aicha et al. (2014), the researchers proposed an unsupervised method for detecting visits as abnormal activity in the homes of older adults. They utilised a method based on a Markov Modulated Multidimensional non-homogeneous Poisson Process (M3P2) to model daily and weekly characteristics, as well as to distinguish between regular and irregular visits in a home environment. The results obtained from the research demonstrate that the M3P2 method performs better than the Markov Modulated Poisson Process (MMPP). They also state that the performance of M3P2 in terms of precision was 64%, while the performance of MMPP was 56%. However, the proposed model generates a high false alarm rate, which reduces the precision.
A relatively new research work by Aicha et al. (2017) has proposed a new model based on MMPP, which is an unsupervised method that models regular activity patterns and detects visits in homes of older adults living alone. The authors tested and evaluated the proposed method based on the data gathered from two apartments using different sensor networks. The researchers show that the proposed approach can detect visits in a home environment with a precision of 84.2%. The only issue, however, with this method is the difficulty in processing a large amount of low-level data such as the data gathered from ambient sensory devices. Nait Aicha et al. (2013) investigated the challenge of detecting multi-occupancy in a home environment with different sensor networks using HMM. The authors evaluated the proposed model based on data gathered from a binary sensor in a living lab. Similarly, in Aicha et al. (2012), the comparison between an NBC and an HMM in detecting a visitor in the office of a supervisor equipped with a video camera and binary sensors is investigated. Whereas these methods demonstrate a promising result, there are some constraints to the study; however, since the collected data was limited to only one room and the number of sensors used was small.
As an alternative to statistical methods, computational intelligence techniques, such as support vector machine (SVM) (Petersen et al. 2012; Hu et al. 2017), and deep convolutional neural network (DCNN) (Tan et al. 2018), are widely utilised to recognise the ADLs in a multi-occupancy environment. A study reported in Tan et al. (2018) has used a novel Red Green Blue (RGB) activity image-based on a DCNN classifier for the unobtrusive recognition of multi-occupancy activities. They have used a labelled open dataset gathered by PIR sensors and temperature sensors in a Cairo testbed, which is one of the datasets from the Centre of Advanced Studies in Adaptive Systems (CASAS) group at Washington State University (Minor et al. 2017). It is also reported that the dataset is pre-processed with a sliding window, RGB activity image conversion steps, and activity segmentation. However, the authors also suggested that further work is required to classify more intertwined and more complex activities using real-life long-term multi-occupancy activity recognition.
Petersen et al. (2012), SVM has been utilised to identify the periods where visitors are present in the home. They have used dwell time, the number of transitions between main living places (dining room, kitchen, living room, and bathroom), and the number of sensor firings as features in the SVM. The proposed model was tested and evaluated based on data gathered from only motion sensors in a living lab. However, the authors motioned that the proposed method still has some limitations. For instance, visitors in the study were only daytime visitors and they did not record overnight visits. Nevertheless, the presence of overnight visits in the home would be incredibly important to identify from both a socialisation perspective and to effectively model multiple individuals in the home. The approach, therefore, requires to be generalised for the case where visitors remain in the home overnight (Petersen et al. 2012). Likewise, the researchers in Hu et al. (2017) proposed a system based on SVM to detect visitors in the home environment using wearable devices and an ambient sensor network. They tested and evaluated the proposed method based on data gathered from a real-life healthcare system. The results obtained from the proposed method show that the method can correctly detect 58%–83% of visits in a home environment. However, the main challenge facing the authors is that the used dataset is not fully annotated.
Several other techniques are utilised to identify and detect activities in multi-occupancy environments. Recently, some research works have focused on indoor detection, either in algorithms or system developments, of a single person in a multi-occupancy environment (Nguyen et al. 2020; Shen et al. 2017; Zhao et al. 2018; Huang et al. 2016, 2019). Benmansour et al. (2017) investigated the challenge of modelling multi-occupancy activities. Specifically, they explored different models based on HMM, known as CL-HMM, to attempt to deal with cooperative activities and parallel activities in a multi-occupancy environment. The authors have tested evaluated the proposed model based on a CASAS multi-occupancy datasetFootnote 1.
Some other research works have addressed the challenge of identifying multi-occupancy activities utilising wearable sensors (Attal et al. 2015; Mohamed et al. 2017a) or video sensors (Schumitsch et al. 2005; Han et al. 2004). For example, in Mokhtari et al. (2018), bluetooth low energy (BLE) technology is used with wearable sensors for resident localisation and activity labelling in a multi-occupancy environment. The idea of the research was to automatically label the activities of multi-occupancy in a smart home, as captured by activity sensors. The BLE device is used as a tag for multi-occupancy to identify and detect activities in a home environment. The authors evaluated the proposed method based on a dataset gathered from a real home environment. The results obtained from the study show that the proposed method can achieve high accuracy, but that forgetting to wear the tag is the main issue with this method that greatly reduces the accuracy. Likewise, Wang et al. (2011), investigated the challenge of recognising multi-occupancy activities utilising wearable sensors in a home. The idea of this research was to study two probabilistic temporal models; the Coupled Hidden Markov Model (CHMM) and factorial conditional random Field (FCRF), to model and classify multi-occupancy activities. The proposed model was tested and evaluated using a dataset gathered by two subjects over two weeks. The results obtained by utilising these two models showed that CHMM performs better than FCRF. Nevertheless, the authors also highlight some limitations of the proposed study in terms of the dataset, which was collected in a mock scenario, rather than being conducted in a real home environment.
The majority of the proposed visitor detection methods in a home environment are too simplistic and thus generate a high false alarm rate. For example, without significant training, the possible observation sequences consistent with a particular activity might not be recognised utilising an HMM or SVM (Kim et al. 2009). A method with a high false-alarm rate may not be suitable for reliably detecting visitors in a home environment. In order to reduce the false-alarm rate, the user’s behaviour requires to be identified and detected accurately. This can be achieved by using an appropriate technique, such as an entropy measure, which enables analysis to detect visiting time in a home environment with a high degree of accuracy.
According to the conducted literature review, the proposed method in this paper, based on different entropy measurement analysis of data collected by ambient sensors, has not yet been applied to multi-occupancy detection. The details of why this can be considered as an important alternative method are presented in the next section.

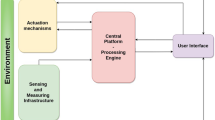
A schematic diagram of the proposed visit detection (time of visit) framework
3 Methodology
This paper proposes a method for distinguishing activities in a multi-occupancy home environment solely based on the information collected from motion detectors [e.g., passive infra-red (PIR)] and door entry sensors. Since the resident’s activity is expected to be different when there is a visitor in the same environment, the activity scenarios gathered from sensors are utilised to show normal activities (single-resident) and abnormal activities (multi-occupancy) patterns. The challenge for this study is to avoid using human tracking devices or any type of tagging sensors. Standard statistical measures such as activity count and sensors activation can be used as a measure of multiple occupants; however, they are incapable of distinguishing the level of activities and visitors. For example, our earlier work has demonstrated that the maximum sensor activation is not sufficiently reliable enough to detect the visitors (Howedi et al. 2019). Therefore, techniques such as entropy measures are showing promise in terms of indicating changes and/or disorders in a resident’s activity pattern in a home environment (Langensiepen and Lotfi 2017). Entropy can be utilised as a measure of disorder or irregularity in data. Therefore, entropy measures can be used to identify and detect a visitor in a home environment with a single occupant.
A schematic diagram of the proposed visit detection framework is shown in Fig. 1, which is composed of three processing stages.
-
In the first stage, sensor data representing ADLs in a multi-occupancy environment is gathered based on PIR motion detectors. The required numerical features to be utilised for computing the input vector sequences of the entropy measures are extracted from the raw data.
-
In the second stage, different entropy measures are applied to the extracted vector sequence from the raw data to detect the presence of a visitor in a single home environment, represented as an abnormality in the extracted activity patterns. Then, the standard deviation of entropy measures is calculated and utilised to detect and identify whether there is a visitor in the home environment.
-
In the third stage, opening and closing the main entry door to the home environment is used to confirm the time of the visit.
In the next section, the description of applied entropy measures is presented.
4 Entropy measures
The concept of entropy was proposed in the nineteenth century by Clausius (1850). It is a powerful tool to measure the degree of disorder or irregularities in a system (Rényi et al. 1961). Entropy is utilised in many fields of science, including statistical mechanics, information theory, neural networks, taxonomy, and mathematical linguistics (Borowska 2015). If the degree of randomness is low, the system will become organised, while high disorder in the data will give higher entropy values. To evaluate the relevance of entropy measures in ADL, different kinds of entropy measures, including Shannon Entropy (ShEn), Permutation Entropy (PerEn), and Multiscale-Permutation Entropy (MPE), are utilised in this paper. These three entropy measures are more relevant for measuring the complexity in time series of data gathered from an Intelligent Environment (Morabito et al. 2012). Some of the entropy measures are less relevant to the hypothesis of the research presented here. These three entropy measures are selected, and as it is shown that some entropy measures are more relevant and they perform better. An explanation of these entropy measures is briefly provided below:
4.1 Shannon entropy
Shannon Entropy (ShEn) was initially proposed by Shannon (1948) to measure the degree of uncertainty in data associated with the occurrence of the result.
For a given time series \(A=\{a(i): i=1,2,\ldots ,N\}\), the ShEn is defined as:
where \(p(a_i)\) are the probabilities of acceptance by the random variable A that takes the values \(a_i\). The entropy of variable A is a measure of the expected randomness obtained through the measurement of the values in variable A. A higher entropy value is obtained by more uncertainty in the data and is more challenging to predict (Borowska 2015).
4.2 Permutation entropy
Permutation Entropy (PerEn) was introduced by Bandt and Pompe (2002). It is based on the measure of the relative frequencies of ordinal patterns and combines the concept of Shannon Entropy with ordinal pattern analysis through estimation of the related frequencies of the ordinal patterns obtained from time-series (Morabito et al. 2012). There are two parameters, embedding dimension m and time delay \(\tau \), which must be defined to calculate the PerEn. The following is a description of the procedure for the PerEn-based algorithm as provided in Bandt and Pompe (2002).
For vector sequences, the m-dimensional delay embedding vector at time i is defined as:
where m is the embedding dimension and \(\tau \) is time delay. The vector \(A_i^m\) has a permutation \(\pi =({r_0}{r_1} \ldots {r_{m-1}})\) if it satisfies:
where \(0 \le r_i \le m-1\) and \(r_i \ne r_j\).
There are m! permutations \(\pi \) of order m, which are considered as a possible order kind of m different numbers. For each permutation \(\pi \), the relative frequency is determined by:
The permutation entropy (PerEn) of the m dimension is then defined as:
The maximum value of \(\textit{PerEn}(m)\) is \(\log (m!)\) where all possible permutations appear with the same probability. Therefore, the Normalised Permutation Entropy (NPE) is defined as:
A numerical example is provided below explaining steps required to calculate entropy measures.
4.3 Multiscale-permutation entropy
The Multiscale-Permutation Entropy (MPE) was proposed by Aziz and Arif (2005), which has been utilised as an efficient method to measure complexity over a range of scales. In MPE analysis, the entropy of the multiple coarse-grained time series at each scale is computed by the PerEn (Wu et al. 2012; Vakharia et al. 2015). The following procedure explains the MPE calculation, as described in Aziz and Arif (2005).
For a given time series \(A=\{a(i): i=1,2,\ldots ,N\}\), multiple coarse grained time series are converted by taking the mean of the data points inside non-overlapping windows of length s. The coarse grained time series \(y_j^{(s)}\) is defined by utilising the following equation:
where s represents the scale factor. The length of each coarse-grained time series is equal to the length of the original time series divided by the scale factor s.
The Permutation Entropy, as described in the previous sub-section, is calculated for each coarse-grained time series. The PerEn values for each scale factor are then plotted as a function of the scale factor. Therefore, MPE can be defined by:
4.4 Numerical example
Given a time series \(A = \{4,7,9,10,6,11,3\}\). The ShEn is calculated as:
To calculate PerEn for the same series, the parameters of the parameter m and \(\tau \) are required to be defined. Thus, the algorithm for PerEn measure is impacted by the selection of these values. When m and \(\tau \) are too small, the algorithm may not work, as there are too few distinct states. On the other hand, too large of an m and \(\tau \) is also unsuitable for detecting the dynamical changes in data. Therefore, it is motioned that the PerEn with \(m= 3\) and \(\tau = 1\) may be the most appropriate choice (Bandt and Pompe 2002; Li et al. 2013). In this research, the best results were obtained when the values of the parameters m, and \(\tau \) are 3, and 1 respectively. There will be five embedding vectors, as follows:
There are six (3!) possible permutations of dimension 3, which are denoted as:
The probability of each permutation is defined as:
The permutation entropy (PerEn) of dimension 3 is than calculated as:
The Normalised Permutation Entropy (NPE) is then calculated by:
In order to calculate MPE, firstly the coarse grained time series \(y_j^{(s)}\) is defined for the time series A as:
Then, the MPE is calculated as:
5 Experimental setup
In this section, the data source used for this work is described, followed by entropy measures that are used for visitor detection in a home environment. Finally, the results and robustness analysis are presented.
5.1 Data sources
The dataset used for this research is a dataset publicly shared through the University of California Irvine (UCI) Machine Learning Repository (Dheeru and Taniskidou 2017). For the data collection, motion sensor, pressure sensor on a sofa, a magnetic sensor on the fridge door, an electric sensor measuring microwave usage, and a main door entry sensor are used. A sample of the dataset is shown in Table 1. The motion sensors are usually utilised to track the movement of a resident representing the resident of a specific area at home. They measure infrared light radiating from objects in its field of view. Therefore, they can sense motion, and they are used to detect whether a human (or pet animal) has moved in or out of the sensors range. Placing the PIR sensors in the right location is essential to capture and monitor the resident’s movements in different areas. While the door entry sensors are utilised to detect the open and close status of the door. Due to privacy, cost issues, and ethical concerns, these sensors are the most widely used for ADL monitoring, as they allow people to live normally without feeling restrained by the technology.
The dataset comprises information regarding the ADLs performed by two users daily in their own homes. Moreover, the ADL dataset comprises 35 days of fully labelled data. It is explained by three text files. The first file is a description, which describes these data in terms of the number of rooms in the home and the number of sensors installed in the home. The second file relates to sensors events (features) and includes information in the data such as the date, start time and end time, the location of sensors in the home, and the sensor types. The final file is the activities of daily living (labels) which include activities together with the start time and the end time of each activity. The total number of data samples is 2337 samples, which representing ADLs performed by two users daily in their own homes for 35 days.
The visitor comes at 11:00 am and 7:00 pm. However, there are some variations within the times and periods of the visits. For example, on some days, the visitor comes 1 h early or late. In this investigation, only motion sensors representing the resident in an area of the home and door sensors are utilised, as these sensors track the resident’s interaction in different locations in the house. For more details about the usage of this aforementioned dataset, readers are referred to our previous work (Howedi et al. 2019).
5.2 Entropy measures for visitor detection
Once the sensor data is gathered from a home environment, the daily behaviour features for occupancy are computed. Features include the start time for entering each room in the house, the duration spent in each room, and the sensor activation per hour (transition between the rooms). The input of any entropy measure should be as a vector sequence (time series), as described earlier in Sect. 4. Therefore, to make the dataset appropriate for entropy measures, the gathered dataset is converted to a set of data points equally spaced in time, which is dependent on the calculation period of the entropy measures. ShEn, PerEn and MPE are utilised to measure the abnormality in the patterns of daily routines when the sample data is mostly representing normal activities. To obtain the entropy value, the daily activity sequence is encoded by replacing each location (room) with an odd number from 1–11 (e.g. \(\mathrm{Kitchen} = 1,\,\mathrm{bathroom} = 3,\ldots , \mathrm{corridor} = 11\)). The encoded daily activity sequence is then utilised as an input for entropy measures.
To explain the process of how the vector sequence is obtained from the dataset, a step-by-step example is provided below. Firstly, the needed numerical features to be utilised for computing the vector sequences are extracted from the dataset. Then, the daily activity sequence is encoded by replacing each location (room) with an odd number, as shown in Table 2. Finally, the features extracted from the raw data are used with the encoded daily activities as input vector sequences to the entropy measures. The entropy measures are calculated every hour, which means that there are 60 samples per hour. This period is from 15:00 to 16:00, so the vector sequence \(A_N\), which consists of a 60 sample equally spaced in time, is then defined as:
It is obvious from the given vector sequence A that the time spent in each room (duration) is represented as a repetition of the same number. The values of entropy measures will be computed every hour by repeating the same step. Once more than one sensor is activated at the same time, only the value of one sensor will be considered (i.e., the first activated sensor) to compute the input vector sequences, as shown in Table 2. For instance, given that both sensors of the bathroom and living room are active at a particular time, the first activated sensor is considered to be utilised in the vector sequence \(A_N\). The values of the parameter embedding dimension m and time delay \(\tau \), which are required to compute PerEn, are set as 3 and 1, respectively. The ShEn, PerEn, and MPE are applied to the generated data vector sequence to measure the normal/abnormal patterns and the degree of variance between the measurements in consecutive days to detect the multi-occupancy patterns. A comparison between these measures is shown in Fig. 2.

Comparison of Shannon Entropy (ShEn), Permutation Entropy (PerEn), and Multiscale-Permutation Entropy (MPE) measures based on 1-h time periods. The figure also shows that ShEn, PerEn, and MPE present similar patterns

The results obtained by applying Multiscale-Permutation Entropy (MPE) for seven days of the dataset to identify visiting time based on 1-h time periods. The figure also illustrates the standard deviation boundaries and the average value of MPE for seven days

Multiscale-Permutation Entropy (MPE) values representing the visiting time each day compared with the standard deviation: a–c there are two bumps in the multiscale-permutation entropy values, which indicate that the visitor was present twice on days 1, 3, and 5; and d the MPE values are zero (no peaks in the entropy values), which indicates non-visiting on days 2, 4, 6, and 7
After the entropy measures are calculated every hour, the average values of daily pattern and threshold, based on the standard deviation of the resident data in conjunction with different entropy measures for an interval of 24 h, are utilised to detect the visitor’s presence in the home environment, as shown in Fig. 3. The threshold value is selected based on the standard deviation that changes over time and not as a fixed value (e.g., the value of the threshold for this experiment was 0.075, changing over time as shown in Fig. 3).
5.3 Results and discussion
The proposed method is based on the hypothesis that the values of entropy measures are higher than a nominal value when a visitor is present in the home environment. Therefore, to detect the visitor in a home environment, the values of MPE for each day in Fig. 3 were compared with the upper boundaries of the standard deviation to see which days exceeded these boundaries. Figure 4 illustrates the visiting time in each day based on the values of entropy measures, according to a comparison of them with the upper standard deviation boundaries in Fig. 3.
In Fig. 4a–c it can be observed that there are two peaks in the values of entropy measure on days 1, 3, and 5, which demonstrate that the visitor’s presence was accurately detected at those times. However, Fig. 4d shows that no visitor was present on days 2, 4, 6 and 7 since there are no peaks in the entropy values (the entropy values were zero). It can be noted that the visitor came twice a day, three days a week, which means that visitor presence was detected accurately in the home environment.
To evaluate the performance of the ShEn, PerEn and MPE measures, first, the dataset is manually classified as visitor or non-visitor based on the periods of 1 h. As can be observed from Table 3, there are 8 events indicated as visitor and 160 events indicated as the normal activities of the occupancy (non-visitor). The first row shows that both PerEn and MPE measures successfully detect the visitor in 7 out of 8 events and fails for one event. However, the ShEn measure detects a visitor in 2 out of 8 and fails for 6 events. The second row demonstrates that PerEn and MPE measures successfully detect non-visitor in 160 and 159 events, respectively. In contrast, the ShEn measure detects a non-visitor in 152 of 160 and fails for 8 events.
The classification performances of ShEn, PerEn, and MPE are measured by utilising a confusion matrix. There are four possible outcomes for detecting a visitor in a home environment when represented as a multi-occupancy environment, which are defined as follows:
-
True Positive (TP): a dataset that includes a visitor, and this is correctly detected as a visitor’s presence in the home environment.
-
False Positive (FP): a dataset does not include a visitor but is incorrectly detected as the presence of a visitor in a home environment.
-
True Negative (TN): a dataset does not include the presence of a visitor, and is correctly detected as non-visitor.
-
False Negative (FN): a dataset includes the presence of a visitor but is incorrectly detected as a non-visitor.
The classification performances of ShEn, PerEn and MPE measures are evaluated using:
Precision also referred to as Positive Predictive Value (PPV).
The results presented in Table 4 represents the classification performance of ShEn, PerEn and MPE when the calculation period of entropy measures was 1 h. Clearly, the results of Sensitivity, PPV, and F-score indicate that the PerEn and MPE outperform ShEn by approximately 62%. The results related to the false positive rate demonstrate that MPE achieves a very good performance compared with ShEn and PerEn since it indicates a perfect false positive rate, which means that all the non-visitor events were detected as a non-visitor event. The PerEn and MPE also show a high detection rate, of 87.5%, whereas the ShEn measure achieves a detection rate of 25%, which means that the ShEn has a 75% false-negative rate for visitor detection.

The time confirmation of visits using a door sensor with entropy measures: a–c MPE values representing visiting times on days 1, 3, and 5, and the time is confirmed using the door sensor
5.4 Robust analysis
To evaluate the robustness of the proposed ShEn, PerEn, and MPE measures for visitor detection, the main door sensor is used along with entropy measures to confirm the visitor presence time. As the visitors enter and exit the home through the main door, the door sensor is utilised to confirm the time of visits; this will increase the performance evaluation of the proposed entropy measures. In general, the door opening or closing does not necessarily mean that a visitor is present in the home environment, as the door might be opened by the main occupant, e.g., in response to a postman or a neighbour. Thus, the presence of visitors cannot be detected only by using the main door sensor. Therefore, entropy measures are used to detect the visitor, and then the door sensor is utilised to confirm the time of the visit.
Figure 5 shows the confirmation of the visiting time each day based on entropy values and using a door sensor. The best results are obtained when the computational time of entropy measures is performed based on 1-h intervals; the door entry sensor is used to confirm the time of visits in this case. It is depicted in Fig. 5a that the main door was opened six times in one day, but the visitor came twice on that day. This means that the main occupant might have caused the other door’s events. Whilst the entropy measures can detect the visitor based on 1-h periods, they do not specify the exact time of the visit. For example, in Fig. 5c, the visitor came twice on a day 5, at around 10:00 am and 6:00 pm, without knowing the specific time of the visit. Therefore, the door sensor is used to confirm the time of the visits. On this day, it can be confirmed from the door sensor data that the visitor came at 10:00 am and stayed in the home until 10:38 am, and then came at 6:28 pm until 7:10 pm.
In summary, the entropy measures are powerful tools to detect abnormality (here, multi-occupancy) in behaviour when the sample data is mostly representing normal activities (here, single-occupancy). This also confirms the possibility that the abnormality detection by entropy measures can be confirmed with door sensors data, particularly for identifying the exact visiting times.
5.5 Comparison with existing modelling techniques
Considering the literature review carried out for this research, the most commonly utilised approaches for detecting a visitor in a home environment are SVM and MMPP. Therefore, to evaluate the proposed methods carried out in this research, the results obtained by applying ShEn, PerEn, and MPE entropy measures are compared to other approaches that achieve the same goal, such as SVM, Indoor Mobility (IM), and MMPP.
The same dataset used in this research with the same features is applied to the SVM model to detect a visitor in a home environment. Moreover, the same dataset is applied to the IM measure, which is a measure to calculate the frequency of movement from room to room in a home environment. For more details about this measure, readers are referred to Chernbumroong et al. (2014). The ShEn, PerEn, and MPE are also compared with the MMPP model proposed in another study for visitor detection in the homes of older adults living alone (Aicha et al. 2017). The authors used a dataset collected from binary sensors, which were gathered by the researchers, and they did not use any public dataset to evaluate the proposed method. The comparison between the classification performance of ShEn, PerEn, and MPE and the existing SVM, IM, and MMPP has been made for accuracy, precision, recall, and F-score, as shown in Table 5.
According to the results achieved, the PerEn and MPE entropy measures are considerably better for visitor detection in a home environment compared to other approaches. The PerEn and MPE produce an overall accuracy of 98.8% and 99.1%, respectively. This also confirms that PerEn and MPE entropy measures are suitable for visitor detection.
Based on the results presented in Table 5, it can be argued that the proposed entropy measures outperformed other the state-of-the-art approaches. It can also be confirmed that the entropy measures are considered as a new approach to detect the visitor in a home environment.
6 Conclusions
This paper has investigated a means of detecting a visitor in a single-occupancy home environment (represented as a multi-occupancy environment) based on different entropy measures using ambient sensors. The proposed method is based on the hypothesis that the values of entropy measures are higher than a nominal value when a visitor is present in the home environment, which is represented as an abnormality in behaviour when the sample data mostly represents normal activities. The threshold, based on the standard deviation of the resident data in conjunction with entropy measures (ShEn, PerEn, and MPE), is applied to detect when the visitor is present in the home environment.
When the entropy values of each day exceed the standard deviation, then the event is associated with the presence of a visitor. To evaluate the robustness of the proposed entropy measures, a door entry sensor is used along with entropy measures to confirm the time and duration of the visitor in the home environment. The experimental results show that the PerEn and MPE measures perform much better than ShEn with an overall accuracy of 98.8%, 99.1%, and 85% respectively. The conclusion drawn by this research is that the PerEn and MPE measures are shown to be the best entropy measures in detecting visitors in a home environment based on data gathered from the ambient sensor. Furthermore, it is shown that the PerEn and MPE measures outperform ShEn measure, which confirms that entropy measures could be used to detect the visitor in a home environment. This is a preferred alternative solution compared with using wearable sensors or visual cameras with associated privacy concerns.
Notes
Available from: http://ailab.eecs.wsu.edu/casas/
References
Aicha AN, Englebienne G, Kröse B (2012) How busy is my supervisor? Detecting the visits in the office of my supervisor using a sensor network. In: Proceedings of the 5th international conference on pervasive technologies related to assistive environments. ACM, p 12
Aicha AN, Englebienne G, Kröse B (2014) Modeling visit behaviour in smart homes using unsupervised learning. In: Proceedings of the 2014 ACM international joint conference on pervasive and ubiquitous computing: adjunct publication. ACM, pp 1193–1200
Aicha AN, Englebienne G, Kröse B (2017) Unsupervised visit detection in smart homes. Pervasive Mob Comput 34:157–167
Alemdar H, Ersoy C (2017) Multi-resident activity tracking and recognition in smart environments. J Ambient Intell Humaniz Comput 8(4):513–529
Attal F, Mohammed S, Dedabrishvili M, Chamroukhi F, Oukhellou L, Amirat Y (2015) Physical human activity recognition using wearable sensors. Sensors 15(12):31314–31338
Aziz W, Arif M (2005) Multiscale permutation entropy of physiological time series. In: 2005 Pakistan section multitopic conference. IEEE, pp 1–6
Bandt C, Pompe B (2002) Permutation entropy: a natural complexity measure for time series. Phys Rev Lett 88(17):174102
Benmansour A, Bouchachia A, Feham M (2015) Multioccupant activity recognition in pervasive smart home environments. ACM Comput Surv (CSUR) 48(3):1–36
Benmansour A, Bouchachia A, Feham M (2016) Multioccupant activity recognition in pervasive smart home environments. ACM Comput Surv (CSUR) 48(3):34
Benmansour A, Bouchachia A, Feham M (2017) Modeling interaction in multi-resident activities. Neurocomputing 230:133–142
Borowska M (2015) Entropy-based algorithms in the analysis of biomedical signals. Stud Log Gramm Rhetor 43(1):21–32
Chernbumroong S, Lotfi A, Langensiepen C (2014) (2014) Prediction of mobility entropy in an ambient intelligent environment. In: IEEE symposium on intelligent agents (IA). IEEE, pp 65–72
Clausius R (1850) On the motive power of heat and the laws which can be deduced therefrom regarding the theory of heat. Ann Phys 155(4):500–524
Dheeru D, Taniskidou E (2017) UCI machine learning repository. https://archive.ics.uci.edu/ml/index.php. Accessed 18 Jan 2019
Eldib M, Deboeverie F, Haerenborgh DV, Philips W, Aghajan H (2015) Detection of visitors in elderly care using a low-resolution visual sensor network. In: Proceedings of the 9th international conference on distributed smart cameras. ACM, pp 56–61
Ghosh A, Chakraborty A, Kumbhakar J, Saha M, Saha S (2020) Humansense: a framework for collective human activity identification using heterogeneous sensor grid in multi-inhabitant smart environments. Pers Ubiquitous Comput
Gochoo M, Tan TH, Jean FR, Huang SC, Kuo SY (2017) Device-free non-invasive front-door event classification algorithm for forget event detection using binary sensors in the smart house. In: IEEE international conference on systems, man, and cybernetics. IEEE, pp 405–409
Han M, Xu W, Tao H, Gong Y (2004) An algorithm for multiple object trajectory tracking. In: Proceedings of the 2004 IEEE computer society conference on computer vision and pattern recognition, 2004. CVPR 2004, vol 1. IEEE, pp I–I
Hao J, Bouzouane A, Gaboury S (2018) Recognizing multi-resident activities in non-intrusive sensor-based smart homes by formal concept analysis. Neurocomputing 318:75–89
Howedi A, Lotfi A, Pourabdollah A (2019) Exploring entropy measurements to identify multi-occupancy in activities of daily living. Entropy 21(4):416
Hsu KC, Chiang YT, Lin GY, Lu CH, Hsu JYJ, Fu LC (2010) Strategies for inference mechanism of conditional random fields for multiple-resident activity recognition in a smart home. In: International conference on industrial, engineering and other applications of applied intelligent systems. Springer, Berlin, pp 417–426
Hu R, Pham H, Buluschek P, Gatica-Perez D (2017) Elderly people living alone: detecting home visits with ambient and wearable sensing. In: Proceedings of the 2nd international workshop on multimedia for personal health and health care. ACM, pp 85–88
Huang Q, Ge Z, Lu C (2016) Occupancy estimation in smart buildings using audio-processing techniques. arXiv:160208507
Huang Q, Rodriguez K, Whetstone N, Habel S (2019) Rapid internet of Things (IoT) prototype for accurate people counting towards energy efficient buildings. ITcon 24:1–13
Kim E, Helal S, Cook D (2009) Human activity recognition and pattern discovery. IEEE Pervasive Comput 9(1):48–53
Langensiepen C, Lotfi A (2017) Uncertainty measures in an ambient intelligence environment. In: 2017 IEEE international conference on fuzzy systems (FUZZ-IEEE). IEEE, pp 1–5
Lapointe P, Chapron K, Bouchard K et al (2020) A new device to track and identify people in a multi-residents context. Procedia Comput Sci 170:403–410
Li D, Liang Z, Wang Y, Hagihira S, Sleigh JW, Li X (2013) Parameter selection in permutation entropy for an electroencephalographic measure of isoflurane anesthetic drug effect. J Clin Monit Comput 27(2):113–123
Li Q, Gravina R, Li Y, Alsamhi SH, Sun F, Fortino G (2020) Multi-user activity recognition: challenges and opportunities. Inf Fusion
Minor BD, Doppa JR, Cook DJ (2017) Learning activity predictors from sensor data: algorithms, evaluation, and applications. IEEE Trans Knowl Data Eng 29(12):2744–2757
Mohamed R, Perumal T, Sulaiman MN, Mustapha N (2017a) Multi resident complex activity recognition in smart home: a literature review. Int J Smart Home 11(6):21–32
Mohamed R, Perumal T, Sulaiman MN, Mustapha N, Manaf SA (2017b) Tracking and recognizing the activity of multi resident in smart home environments. J Telecommun Electron Comput Eng (JTEC) 9((2–11)):39–43
Mokhtari G, Anvari-Moghaddam A, Zhang Q, Karunanithi M (2018) Multi-residential activity labelling in smart homes with wearable tags using BLE technology. Sensors 18(3):908
Morabito FC, Labate D, La Foresta F, Bramanti A, Morabito G, Palamara I (2012) Multivariate multi-scale permutation entropy for complexity analysis of Alzheimer’s disease EEG. Entropy 14(7):1186–1202
Murphy KP (2012) Machine learning: a probabilistic perspective. MIT Press, Cambridge
Nait Aicha A, Englebienne G, Kröse B (2013) How lonely is your grandma? Detecting the visits to assisted living elderly from wireless sensor network data. In: Proceedings of the ACM conference on pervasive and ubiquitous computing adjunct publication, pp 1285–1294
Najar F, Bourouis S, Bouguila N, Belghith S (2019) Unsupervised learning of finite full covariance multivariate generalized gaussian mixture models for human activity recognition. Multimed Tools Appl 1–23
Nguyen D, Nguyen L, Nguyen S (2020) A novel approach of ontology-based activity segmentation and recognition using pattern discovery in multi-resident homes. In: Frontiers in intelligent computing: theory and applications. Springer, Berlin, pp 167–178
Patel S, Park H, Bonato P, Chan L, Rodgers M (2012) A review of wearable sensors and systems with application in rehabilitation. J Neuroeng Rehabilit 9(1):21
Petersen J, Larimer N, Kaye JA, Pavel M, Hayes TL (2012) SVM to detect the presence of visitors in a smart home environment. In: 2012 Annual international conference of the IEEE engineering in medicine and biology society (EMBC), pp 5850–5853
Rényi A, et al (1961) On measures of entropy and information. In: Proceedings of the fourth Berkeley symposium on mathematical statistics and probability, volume 1: contributions to the theory of statistics, The Regents of the University of California
Roy N, Misra A, Cook D (2016) Ambient and smartphone sensor assisted ADL recognition in multi-inhabitant smart environments. J Ambient Intell Humaniz Comput 7(1):1–19
Schumitsch B, Schwarz H, Wiegand T (2005) Optimization of transform coefficient selection and motion vector estimation considering interpicture dependencies in hybrid video coding. In: Image and video communications and processing 2005, International society for optics and photonics, vol 5685, pp 327–335
Shannon CE (1948) A mathematical theory of communication. Bell Syst Tech J 27(3):379–423
Shen W, Newsham G, Gunay B (2017) Leveraging existing occupancy-related data for optimal control of commercial office buildings: a review. Adv Eng Inform 33:230–242
Singla G, Cook DJ, Schmitter-Edgecombe M (2010) Recognizing independent and joint activities among multiple residents in smart environments. J Ambient Intell Humaniz Comput 1(1):57–63
Tan TH, Gochoo M, Jean FR, Huang SC, Kuo SY (2017) Front-door event classification algorithm for elderly people living alone in smart house using wireless binary sensors. IEEE Access 5:10734–10743
Tan TH, Gochoo M, Huang SC, Liu YH, Liu SH, Huang YF (2018) Multi-resident activity recognition in a smart home using RGB activity image and DCNN. IEEE Sens J 18(23):9718–9727
Tran SN, Zhang Q (2020) Towards multi-resident activity monitoring with smarter safer home platform. In: Smart assisted living. Springer, Berlin, pp 249–267
Vakharia V, Gupta V, Kankar P (2015) A multiscale permutation entropy based approach to select wavelet for fault diagnosis of ball bearings. J Vib Control 21(16):3123–3131
Wang L, Gu T, Tao X, Chen H, Lu J (2011) Recognizing multi-user activities using wearable sensors in a smart home. Pervasive Mob Comput 7(3):287–298
Wu SD, Wu PH, Wu CW, Ding JJ, Wang CC (2012) Bearing fault diagnosis based on multiscale permutation entropy and support vector machine. Entropy 14(8):1343–1356
Yang Z, Li N, Becerik-Gerber B, Orosz M (2014) A systematic approach to occupancy modeling in ambient sensor-rich buildings. Simulation 90(8):960–977
Zhao J, Frumkin N, Konrad J, Ishwar P (2018) Privacy-preserving indoor localization via active scene illumination. In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pp 1580–1589
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Howedi, A., Lotfi, A. & Pourabdollah, A. Employing entropy measures to identify visitors in multi-occupancy environments. J Ambient Intell Human Comput 13, 1093–1106 (2022). https://doi.org/10.1007/s12652-020-02824-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12652-020-02824-z