
Abstract
Big Data is characterized by large volumes of highly dynamical data and is used for discovering hidden trends and correlations. However, as more data is collected, previous pieces of information can be put together to facilitate linkage of private records. In this context, when protecting the privacy of data subjects, the same attributes that are to be protected may be used for further re-identification, that is, sensitive attributes may be used as quasi-identifiers. For example, in high-dimensional data such as recommendations, transaction records or geo-located data, previously published transactions and locations may be used to uncover further private transactions and locations. In this paper, we propose a k-anonymization algorithm and a metric for privacy in databases in which all the attributes are quasi-identifiers as well as sensitive attributes. We apply our algorithm on high dimensional datasets for model-based and memory-based collaborative filtering, and use the metric to perform privacy comparisons between different methods of protection such as k-anonymity and differential privacy. We show the applicability of our method by performing tests on the large and sparse dataset (MovieLens 20M) of 20 million ratings that 138,493 users gave to 27,278 movies.




Similar content being viewed by others
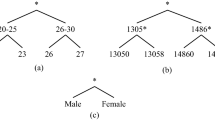
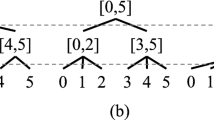

References
Aggarwal CC (2005) On k-anonymity and the curse of dimensionality. In: Proceedings of the 31st International Conference on Very Large Data Bases, VLDB ’05, pp 901–909. VLDB Endowment. ISBN 1-59593-154-6
Aggarwal CC, Hinneburg A, Keim DA (2001) On the surprising behavior of distance metrics in high dimensional space. In Jan Van den Bussche and Victor Vianu, editors, Database Theory– ICDT 2001, pp 420–434. Springer, Berlin, Heidelberg. ISBN 978-3-540-44503-6
Beyer K, Goldstein J, Ramakrishnan R, Shaft U (1999) When is “nearest neighbor” meaningful? In Catriel B, Peter B (eds) Database theory—ICDT’99, pp 217–235. Springer, Berlin, Heidelberg. ISBN 978-3-540-49257-3
Brickell J, Shmatikov V (2008) The cost of privacy: destruction of data-mining utility in anonymized data publishing. In: Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’08, pp 70–78, New York, NY, USA. ACM. ISBN 978-1-60558-193-4. https://doi.org/10.1145/1401890.1401904
Byun J-W, Sohn Y, Bertino E, Li N (2006) Secure anonymization for incremental datasets. In: Willem J, Milan P (eds) Secure data management, pages 48–63. Springer, Berlin, Heidelberg. ISBN 978-3-540-38987-3
Calandrino JA, Kilzer A, Narayanan A, Felten EW, Shmatikov V (2011) “you might also like:” privacy risks of collaborative filtering. In: 2011 IEEE symposium on security and privacy, pp 231–246. https://doi.org/10.1109/SP.2011.40
Campan A, Truta TM (2009) Data and structural k-anonymity in social networks. In: Francesco B, Elena F, Wei J, Bradley M (eds) Privacy, security, and trust in KDD, pp 33–54. Springer, Berlin, Heidelberg. ISBN 978-3-642-01718-6
Casas-Roma J, Herrera-Joancomartí J, Torra V (2017) A survey of graph-modification techniques for privacy-preserving on networks. Artif Intell Rev 47(3):341–366. https://doi.org/10.1007/s10462-016-9484-8 (ISSN 1573-7462)
Casino F, Domingo-Ferrer J, Patsakis C, Puig D, Solanas A (2015) A k-anonymous approach to privacy preserving collaborative filtering. J Comput Syst Sci 81(6):1000–1011. https://doi.org/10.1016/j.jcss.2014.12.013 (ISSN 0022-0000. Special issue on optimisation, security, privacy and trust in e-business systems)
Chang C-C, Thompson B, Wang H(W), Yao D (2010) Towards publishing recommendation data with predictive anonymization. In: Proceedings of the 5th ACM symposium on information, computer and communications security, ASIACCS ’10, pp 24–35, New York. ACM. ISBN 978-1-60558-936-7. https://doi.org/10.1145/1755688.1755693
Chris C, Tamir T (2013) On syntactic anonymity and differential privacy. Trans Data Privacy 6(2):161–183
de Montjoye Y-A, Hidalgo CA, Verleysen M, Blondel VD (2013) Unique in the crowd: the privacy bounds of human mobility. Sci Rep 2013:3
Domingo-FJ Torra V (2005) Ordinal, continuous and heterogeneous k-anonymity through microaggregation. Data Min Knowl Discov 11(2):195–212. https://doi.org/10.1007/s10618-005-0007-5 (ISSN 1573-756X)
Dwork C, McSherry F, Nissim K, Smith A (2006) Calibrating noise to sensitivity in private data analysis. In: Shai H, Tal R (eds) Theory of cryptography, pp 265–284. Springer, Berlin, Heidelberg. (ISBN 978-3-540-32732-5)
Hajian S, Tassa T, Bonchi F (2015) Individual privacy in social influence networks. Soc Netw Anal Min 6(1):2. https://doi.org/10.1007/s13278-015-0312-y (ISSN 1869-5469)
Harper FM, Konstan JA (2015) The movielens datasets: history and context. ACM Trans Interact Intell Syst 5(4):19:1–19:19. https://doi.org/10.1145/2827872 (ISSN 2160-6455)
Ji S, Mittal P, Beyah R (2017) Graph data anonymization, de-anonymization attacks, and de-anonymizability quantification: a survey. IEEE Commun Surv Tutor 19(2):1305–1326. https://doi.org/10.1109/COMST.2016.2633620 (Secondquarter ISSN 1553-877X)
Kasiviswanathan SP Nissim K, Raskhodnikova S, Smith A (2013) Analyzing graphs with node differential privacy. In: Proceedings of the 10th theory of cryptography conference on theory of cryptography, TCC’13, pp 457–476. Springer, Berlin, Heidelberg. ISBN 978-3-642-36593-5
Koren Y (2010) Factor in the neighbors: scalable and accurate collaborative filtering. ACM Trans Knowl Discov Data 4(1):1:1–1:24. https://doi.org/10.1145/1644873.1644874 (ISSN 1556-4681)
Koren Y, Bell R, Volinsky C (2009) Matrix factorization techniques for recommender systems. Computer 42(8):30–37. https://doi.org/10.1109/MC.2009.263 (ISSN 0018-9162)
Lemire D, Maclachlan A (2007) Slope one predictors for online rating-based collaborative filtering. CoRR, arXiv:abs/cs/0702144
Li N, Li T, Venkatasubramanian S (2007) t-closeness: privacy beyond k-anonymity and l-diversity. In: 2007 IEEE 23rd international conference on data engineering, pp 106–115. https://doi.org/10.1109/ICDE.2007.367856
Luo X, Zhou M, Xia Y, Zhu Q (2014) An efficient non-negative matrix-factorization-based approach to collaborative filtering for recommender systems. IEEE Trans Ind Informatics 10(2):1273–1284. https://doi.org/10.1109/TII.2014.2308433 (ISSN 1551-3203)
Machanavajjhala A, Gehrke J, Kifer D, Venkitasubramaniam M (2006) L-diversity: privacy beyond k-anonymity. In: 22nd international conference on data engineering (ICDE’06), pp 24. https://doi.org/10.1109/ICDE.2006.1
McSherry F, Mironov I (2009) Differentially private recommender systems: Building privacy into the netflix prize contenders. In: Proceedings of the 15th ACM SIGKDD international conference on knowledge discovery and data mining, KDD ’09, pp 627–636, New York, NY, USA. ACM. ISBN 978-1-60558-495-9. https://doi.org/10.1145/1557019.1557090
McSherry F, Talwar K (2007) Mechanism design via differential privacy. In :48th annual IEEE symposium on foundations of computer science (FOCS’07), pp 94–103. https://doi.org/10.1109/FOCS.2007.66
Narayanan A, Shmatikov V (2008) Robust de-anonymization of large sparse datasets. In: 2008 IEEE symposium on security and privacy (sp 2008), pp 111–125. https://doi.org/10.1109/SP.2008.33
Navarro-Arribas G, Torra V, Erola A, Castellà-Roca J (2012) User k-anonymity for privacy preserving data mining of query logs. Inf Process Manag 48(3):476–487 (ISSN 0306-4573. Soft Approaches to IA on the Web)
Nettleton DF, Salas J (2016) A data driven anonymization system for information rich online social network graphs. Expert Syst Appl 55:87–105. https://doi.org/10.1016/j.eswa.2016.02.004 (ISSN 0957-4174)
Nicolas H (2017) Surprise, a Python library for recommender systems. http://surpriselib.com
Ohm P (2010) Broken promises of privacy: responding to the surprising failure of anonymization. UCLA Law Rev 57:9–12
Ramakrishnan N, Keller BJ, Mirza BJ, Grama AY, Karypis G (2001) Privacy risks in recommender systems. IEEE Internet Comput 5(6):54–63. https://doi.org/10.1109/4236.968832 (ISSN 1089-7801)
Ros-Martín M, Salas J, Casas-Roma J (2018) Scalable non-deterministic clustering-based k-anonymization for rich networks. Int J Inf Secur. https://doi.org/10.1007/s10207-018-0409-1 (ISSN 1615-5270)
Salas J, Domingo-Ferrer J (2018) Some basics on privacy techniques, anonymization and their big data challenges. Math Comput Sci 12(3):263–274. https://doi.org/10.1007/s11786-018-0344-6 (ISSN 1661-8289)
Salas J, Torra V (2018) A general algorithm for k-anonymity on dynamic databases. In: Joaquin G-A, Jordi H-J, Giovanni L, Ruben R (eds) Data privacy management, cryptocurrencies and blockchain technology, pp 407–414, Cham. Springer International Publishing (ISBN 978-3-030-00305-0)
Samarati P (2001) Protecting respondents identities in microdata release. IEEE Trans Knowl Data Eng 13(6):1010–1027. https://doi.org/10.1109/69.971193 (ISSN 1041-4347)
Samarati P, Sweeney L (1998) Generalizing data to provide anonymity when disclosing information (abstract). In: Proceedings of the seventeenth ACM SIGACT-SIGMOD-SIGART symposium on principles of database systems, PODS ’98, pp 188, New York, NY, USA. ACM. ISBN 0-89791-996-3. https://doi.org/10.1145/275487.275508
Sweeney L (2002) k-anonymity: a model for protecting privacy. Int J Uncertain Fuzziness Knowl Based Syst 10(05):557–570. https://doi.org/10.1142/S0218488502001648
Tassa T, Cohen DJ (2013) Anonymization of centralized and distributed social networks by sequential clustering. IEEE Trans Knowl Data Eng 25(2):311–324. https://doi.org/10.1109/TKDE.2011.232 (ISSN 1041-4347)
Torra V (2017) Data privacy: foundations, new developments and the big data challenge. Springer, New York
Wei R, Tian H, Shen H (2018) Improving k-anonymity based privacy preservation for collaborative filtering. Comput Electr Eng 67:509–519. https://doi.org/10.1016/j.compeleceng.2018.02.017 (ISSN 0045-7906)
Zhou B, Pei J, Luk WS (2008) A brief survey on anonymization techniques for privacy preserving publishing of social network data. SIGKDD Explor Newsl 10(2):12–22. https://doi.org/10.1145/1540276.1540279 (ISSN 1931-0145)
Acknowledgements
This work was partially supported by the Spanish Government under grants RTI2018-095094-B-C22 “CONSENT” and TIN2014-57364-C2-2-R “SMARTGLACIS”, and the UOC postdoctoral fellowship program. We acknowledge Alex Dotor for coding in Java the original algorithm in Python, both accessible on demand.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Salas, J. Sanitizing and measuring privacy of large sparse datasets for recommender systems. J Ambient Intell Human Comput 14, 15073–15084 (2023). https://doi.org/10.1007/s12652-019-01391-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12652-019-01391-2