
Abstract
Global warming and climate change impacts intensify hydrological cycle and consequently unprecedented drought and flood appear in different parts of the world. Meteorological drought assessments are widely evaluated by the concept of standardized precipitation index (SPI), which provides drought classification. Its application is based on the probabilistic standardization procedure, but in the literature, there is a confusion with the statistical standardization procedure. This paper provides distinctive differences between the two approaches and provides the application of a better method. As a novel approach, SPI classification is coupled with fuzzy clustering procedure, which provides drought evaluation procedure based on two variables jointly, precipitation and temperature, which is referred to as the standard precipitation-temperature index (SPTI). The final product is in the form of fuzzy c-means clustering in five clusters with exposition of annual drought membership degrees (MDs) for each cluster and resulting objective function. The application of the proposed fuzzy methodology is presented for the long-term annual precipitation and temperature records from New Jersey Statewide records.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Precipitation and temperature are the most crucial meteorological factors with their effective impacts on the extreme hydro-meteorological events including drought and flood occurrence intensity, duration, and frequency. Furthermore, their these factors are the hydrological cycle and water resources, vegetation, agricultural production, water quality, and socioeconomic development (Gao et al. 2022; Birpinar et al. 2023). As a result of global warming and climate change impacts precipitation and temperature changes cause to heavy floods and prolonged droughts (Salman et al. 2019; Ekwueme andAgunwamba, 2021).
According to IPCC (2018) report 1.5oC global warming compared to pre-industrial greenhouse gas (GHG) emission level will strengthen the impact of climate change causing dangers of unsustainable development. Malek et al. (2018) stated that since the last two decades, meteorological and hydrological researchers continuously improved the mechanism of climate change impact especially on water and agriculture sustainability. The impact of climate change is specified by increasing global warming temperature and increasing or decreasing precipitation trends, which are affected significantly by hydrological cycle intensification that escalates sustainable water resources utilization (Jones 1999; Allen and Ingram 2002; Chartres and Noble 2015). Low and high precipitation extreme event damage a certain region over short-time (floods) and long-time (drought) intervals. To mitigate drought events, scientists proposed numerous methodologies among which standardized precipitation index (SPI) is one of the most frequently used procedure in the literature (McKee et al. 1993). Trenberth et al. (2014) reviewed published papers and found conflicting results about the drought evolution under climate change impact. Van Loon (2015) concentrated on scientific definition of formulations and processes for hydrological drought assessment. The reason is thought to lie in the conceptual formulation of different drought description indices. Additionally, the usefulness of different drought indicators is discussed in drought monitoring and prediction studies. The SPI method gave way to inspiration of similar indices.
As a new index, SPI was used occasionally, but especially after 2000, it gained universal acceptance for drought classification purposes (Tsakiris and Vangelis 2005) and especially after 2010 its use has increased tremendously due to urgency of the of the World Meteorological Organization (WMO 2012) recommendation not only in meteorology domain but in the hydrology, agriculture, forestry and water related topics. SPI provides drought monitoring valuation and it is a useful method for meteorological drought classification. There are numerous drought concepts, definitions, performances and indices methodologies in the literature (Bhalme and Mooley 1980; Guttman 1998, 1999; Sirdaş and Şen 2001; Heim 2002; Redmond 2002; Mishra and Singh 2011; Vicente-Serrano et al. 2010, 2012). The methodological applications of the SPI procedure are limited to hydro-meteorological time series and regional aspects (Hayes 2000; Lloyd-Hughes and Saunders 2002; Karavitis et al. 2011). SPI procedure simplicity and accuracy sustained its super performance and extensive usage than other drought indices. For more detailed information, the drought classification studies require a combination of SPI with more supportive indices, which provide better strategy for drought relevance.
The original concept (McKee et al. 1993) has inspired the computation of new indices such as standardized runoff index (SRI) (Shukla and Wood 2008), streamflow drought index (SDI), Standardized Precipitation Evapotranspiration Index (SPEI) (Dubrovsky et al. 2009; Vicente-Serrano et al. 2010, 2012), normalized Difference Vegetation Index (NDVI) (Ji and Peters 2003), normalized soil moisture (NSM) (Dutra et al. 2008), Palmer drought severity index (PDSI) (Palmer 1965), surface water supply index (SWSI) (Shafer and Dezman 1982), standardized hydrological index (SHI) (Panu and Sharma 2009), streamflow drought index (SDI) (Hong et al. 2015; Pathak and Dodamani 2016; Udayar et al. 2019), vegetation condition index, VCI (Kogan 1990), standardized soil moisture index (SSMI) (Hao and AghaKouchak 2013), multivariate drought index (MDI) (Rajsekhar et al. 2015), improved multivariate standardized reliability and resilience index (MSRRI), reconnaissance trivariate drought index (RTDI) (Dixit and Jayakumar 2021), effective drought index (EDI) (Byun and Wilhite 1996), climatic moisture index (CMI) (Vörösmarty et al. 2005), drought hazard, exposure, and vulnerability indices (DHI, DEI, DVI) (Shiau and Hsiao 2012), and others for drought severity index definitions. Poonia et al. (2021a) mentioned unique advantages and disadvantages of each drought index.
Nkemelang et al. (2018) took into consideration precipitation and temperature extremes under 1.5 oC and 2.0 oC global warming and consequent climate change impacts. Climate extremes are bound to increase due to anthropogenic GHG emissions. SPI is combined with versions of PDSI to develop a multi-index drought (MID) by Sun et al. (2012) to improve the agricultural drought risk assessment and prediction. drought severity-areal extent-frequency (SAF) is developed by Loukas and Vasiliades (2004), and Loukas et al. (2008) to introduce and develop a method for assessing the spatial characteristics and the frequency of the drought over an area using GIS capabilities. Additionally, Liu et al. (2012) suggested the areal drought magnitude (ADM) as an aggregated index to assess spatio-temporal variation of drought magnitude. Furthermore, Mansouri Daneshvar et al. (2012) proposed a drought hazard index (DHI) produced by summing up the spatial representation of the SPI values over a certain territory. Dubrovsky et al. (2009) introduced the relative SPI (rSPI) and PDSI (rPDSI) for following a better comparison of spatial drought conditions.
Joint inputs are presented with two different indices such as a SPI-PDSI ensemble forecast for South Carolina by Huang and Carbone (2009). For experimental multi-model drought and flood forecast Sohn et al. (2012) used the SPI3 for drought and flood forecast over South Korea. Another example for joint use of input variables is achieved by the Adaptive Neural-based Fuzzy Inference System (ANFIS) by Keskin et al. (2009, 2011) to find a good potential to predict the regional meteorological drought using SPI values. Another joint input work is presented by Hannaford et al. (2011) between the regional deficiency index (RDI), a hydrological drought indicator and regional standardized precipitation index (RSPI). Multilayer linear perceptron (MLP) approach is used to combine SPI, NAOI and SOI indices for different climate forecast possibilities by RezaeianZadeh and Tabari 2012).
Gibbs and Maher (1967) proposed percent of normal (PN), and rainfall deciles (RD) concepts as preliminary measures of droughts. Six indices are suggested by different authors including RD, SPI, PDSI, cumulative precipitation anomaly (CPA) by Foley (1957), rainfall anomaly index (RAI) by van Roy (1965) and drought area index (DAI) by Bhalme and Mooley (1980). On the other hand, many indices are also studied such as RD, PN, SPI; Z-score index (ZSI) by Wu et al. (2001), effective drought index (EDI) by Byun and Wilhite (1996) and compared for their efficiency by Morid et al. (2006). Quiring and Ganesh (2010) found low correlations between the VCI and PDSI, ZSI, SPI, RD, and PN. In a study aiming to evaluate the uncertainties in the projection of future drought Burke and Brown (2008) reported that the SPI supplied much smaller global changes than indices considering the atmospheric demand for moisture. The decreasing precipitation is combined with an increase in temperatures (Tomaszkiewicz 2021), which means more droughts and more challenges for rain-fed agriculture and water supply management.
In the literature, classical drought classification methodologies such as SPI mostly consider only the evaluation of precipitation data, but drought is also associated with temperature increases. In this paper, this subject is explained in an integrated way. Especially global warming and climate change impacts cause to a warming climate, which play significant role in drought spatial extent along with changes in underlying hydro-meteorological conditions. This point has been explained in detail by Brunner et al. (2021) and Crockett and Westerling (2018).
This paper proposes joint input of precipitation-temperature couple for improvement of the one variable studies significantly. The main purpose is to support the classical SPI index by incorporating joint evaluation of precipitation and temperature and propose a novel standardized precipitation-temperature index (SPTI), which provides ability to assess more than one meteorology variable in the drought classification procedure. For this purpose, the classical SPI approach is enriched and supported by a fuzzy conceptualization through the application of fuzzy c-means methodology. The application of this methodology is furnished for New Jersey long-term annual precipitation and temperature records. This is the new, useful and the first proposal case study for New Jersey State.
Methodology
This section has three parts including proper explanation of the classical SPI approach to avoid misunderstandings in the literature; standardized precipitation-temperature index (SPTI); and fuzzy c-means cluster theoretical bases for application. The classifications in Table 1 also apply to temperature data after probabilistic standardization to the normal (Gaussian) probability distribution function (PDF). As a result, SPI and STI have the same standard normal PDF with zero mean and unit variance.
The application of fuzzy logic techniques, particularly fuzzy c-means cluster analysis, allows for more detailed interpretation of drought patterns compared to classical two-valued logic classification. This is due to the adherence of the fuzzy logic inference system, which allows the recognition of gradual transitions between drought classifications, reflecting the gradual nature of drought in hydro-meteorological events. It is possible to obtain more enlightening information about the drought phenomenon in five overlapping classes. Thus, it can be decided which drought class is more prominent numerically and linguistically in different classes in the study area.
Classical SPI
Each hydro-meteorology record has different probability distribution functions (PDFs) and thus they cannot be compared at equal footing level. In order to alleviate this non-uniform PDF situation McKee et al. (1993) suggested the equal footing PDF procedure for each record as the standardized normal (Gaussian) theoretical PDF with zero mean and unit standard deviation. For this purpose, whatever the original PDF of a hydro-meteorology record is, it is transformed to a standard normal PDF. Unfortunately, the standardization procedure is adapted by many authors as the statistical standardization, which is the subtraction from each record value the record mean and hence finding deviations from the mean and then division of each deviation values by the standard deviation of the same hydro-meteorology record. This statistical standardization procedure renders the original hydro-meteorology record to a standardized series with zero mean and unit standard deviation, but the shape of the original PDF remains the same. This is not what is meant from SPI procedure.
Another problem in the practical application of the SPI is the use of Gamma PDF as in the original paper by McKee et al. (1993), which is taken as granted by many authors in the literature without checking whether their data comply by this PDF or not. The application of the SPI procedure should include the following points.
-
1)
Original PDF identification for the data at hand, Xi (X1, X2, , , ,. Xn), among the most available PDFs in hydro-meteorology literature, which may be logarithmic normal, two- or three-parameter Gamma, Gumbel, Pearson, Weibull, exponential, etc.,
-
2)
With the location, α, scale, β, and if available, shape, γ, parameters to calculate the probability, Pi (P1, P2, , , ,. Pn), values corresponding to each data value from the identified PDF,
-
3)
Calculate SPI values, SPIi (SPI1, SPI2, , , ,. SPIn), from a standard normal (Gaussian) PDF with zero mean and unit standard deviation,
-
4)
Plot the scatter diagram of SPI values versus the number of data, which yields a time series whose values change practically between − 4 and + 4,
-
5)
Compare each scatter point or group of points with the classification limits as in Table 1 and read the verbal classification group.
The SPI classification given by McKee et al. (1993) is enriched by addition of the temperature classification of “hot” and “cold” specifications in the same table.
There are no limitations for either the SPI or SPTI methodology, provided that historical records fit an optimal probability cumulative distribution function (CDF) followed by a standardized normal (Gaussian) CDF transformation with zero mean and unit standard deviation. There is an assumption regarding the number of fuzzy sets in the SPTI calculation. In this paper, the number of clusters is considered as five, based on the number of wet (dry) clusters in Table 1. Uncertainties associated with available data are expressed by fitting the best theoretical CDF.
Novel SPTI cluster
The classical SPI and any version of it as explained in the Introduction section can be applied to a given hydro-meteorology time series record. In this section, its novel version is expanded to the assessment of two hydro-meteorology variables simultaneously for a common drought interpretation. It is not only the precipitation amounts that are the variable to assess drought situations, but in the meantime temperature also plays significant role especially with the impact of global warming that causes to climate change, which is felt more in the form of precipitation increase or decrease in a region. The proposed methodology in this section is referred to as standardized precipitation-temperature index (SPTI) and its application needs the execution of the following steps.
-
1)
Apply the procedure given for SPI in the previous sub-section separately to given precipitation and temperature records to end up with standardized index sequence for each one,
-
2)
Plot the scatter diagram of precipitation standardized indices versus temperature standardized indices,
-
3)
Divide the variation domain of each variable on the same scatter diagram vertically and horizontally with the limits shown in Table 1,
-
4)
Thus, one can interpret each scatter point according to the verbal specifications in Table 1 for precipitation and temperature values. It is possible to identify joint contribution of precipitation and temperature for drought classification.
This procedure although provides the scatter square and rectangular areas but fails to identify effective sub-group of scatter points for more refined interpretations (see Fig. 4 in subsection 3.2 SPI and SPTI). In the scatter diagram each point has the same effect on the drought classification in terms of crisp logic, where each point belongingness degree for drought description has value of 1. However, it is possible that some of the points may have less effectiveness, i.e., less than 1 membership degree for drought effect. In order to identify such cases, the scatter diagram mentioned above is subjected to fuzzy c-means procedure as in the following sub-subsection.
The classical drought assessment made with the SPI method has been further improved with the SPTI methodology, which provides joint evaluation of precipitation and temperature. These two hydro-meteorology variables are both key factors affecting drought severity based on the subclassification of classical drought indices into fuzzy sets. This approach therefore allows the identification of more reliable scenarios for drought occurrence, taking into account the combined impact of abnormal temperature increases on water demand for agricultural products. On the other hand, precipitation and temperature are two hydrometeorological factors that are effective in all kinds of water management and especially in climate change impact assessments.
Fuzzy clustering of SPTI
The fundamental science philosophical and logical bases of classical SPI depend on crisp (bivalent) logic, where the classifications in Table 1 are mutually exclusive from each other. However, instead of crisp limits between two neighboring classes, mutually inclusive limits are considered in this paper by means of fuzzy c-means clustering method application. For this purpose, there is a need for the number of clusters, which has been taken as 10 according to the crisp SPI classification in Table 1, but herein only five fuzzy clusters are considered. There are recommendations in the literature that the number of clusters should not exceed 7 (Bezdek et al. 1984; Şen 2010). It is also possible to select clusters of three or more, but generally 5 gives the clear picture. This means each one of the scatter point of SPTI will have five membership degrees (MDs), the summation of which is equal to 1. This distinction between MDs provide refined information about which clusters imply stronger drought category. Each i-th SPTI data has m cluster numbers within j-th cluster is symbolized by a MD, \({{\gamma }}_{\text{i},\text{j}}\) as the following expression.
where m is the number of clusters. The summation of MDs in each cluster must be smaller than the number of data according to the following equation.
The fuzzy c-means attach MDs to each data point in the clusters by means of the weighted average of the distance between the points and the given cluster centers, ci according to the objective function as follow (Bezdek et al. 1984).
For the minimization of this function, one can take its derivative with respect to each unknown variable leading to the following expression (Bezdek et al. 1984).
The result can be found after a series of iterations by changing automatically the cluster centers as follows.
In the light of these formulations, the following steps help to find the final cluster center and MD values after several iterations.
-
1)
Given a data series, xi = {x1, x2,. . xn}, first the number of clusters, m, must be decided as 2 < m < n – 1. In this work m = 5,
-
2)
After l number of iterations, the components of the cluster centers can be calculated from the following expression,
-
3)
Renewal of the new MDs is achieved from the previous step calculations according to the following expression.
-
4)
Iteration is stopped after the relative error between two successive objective function values is less than ±5%.
In the following window is the Matlab program software for calculating the fuzzy c-means process to determine cluster centers and the MDs for a pair of input variables.

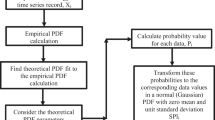
Figure 1 Shows the flowchart stages of the fuzzy c-means methodology application in this paper.
The flow chart components of the previously explained fuzzy c-means procedure is given in Fig. 1.

Fuzzy-c means calculation flow chart
Although it is generally stated that drought indices should be evaluated in the light of different time scales such as 1-month, 3-month, 6-month, 12-month, 24-month and 48-month periods. With the SPTI methodology, the same general periods can be applied like in Figs. 4 and 5. Inclusion of seasonal scales does not present the performance of the SPTI method but comparison of the two different time steps, because the application of the proposed methodology is the same except differences in data scale.
In drought analyses, monthly and seasonal temperature records, rather than daily maximum temperature values, play an important role. Because water supply problems are managed monthly and agricultural products are managed seasonally. Thus, daily minimum or maximum values are included in monthly and seasonal temperature calculations.
Data and application
The application of the methodologies explained in the previous sections is performed for annual precipitation and temperature long record durations from New Jersey State wise location, where the records are available from 1895 to 2010. New Jersey borders New York state to the north and east; On the Atlantic Ocean coast in the east, southeast and south; on the banks of the Delaware River in the west and Jersey City. Temperature differences Between the northern and southern parts there are temperature differences that reach 100 oF or higher and 0 oF or below. Annual average precipitation records range from about 40 inches along the southeast coast to 51 inches in north-central parts of the state.
Cumulative distribution functions (CDF)
The application of the empirical and theoretical CDF fit is performed for precipitation and temperature data as in Fig. 2. The precipitation and temperature theoretical cumulative distribution functions (CDFs) appeared as Pearson and logarithmic-normal types, respectively.

Empirical and theoretical PDFs
The validity of the theoretical CDFs with respect to the empirical ones is checked with Kolmogorov-Smirnov statistic test and the fits are clearly acceptable even visually. This test depends on the maximum vertical distance between the empirical and theoretical CDFs. These two CDFs must be transformed to a standard normal (Gaussian) CDF with zero mean and unit standard deviation for the classical SPI procedure application.
SPI and SPTI
The steps of classical SPI as explained in subsection are applied to the CDFs in Fig. 2 and the SPI time series are obtained as shown in Fig. 3. These time series are results of original CDFs transformations to standard normal (Gaussian) PDF with zero mean and unit standard deviation. The important point at this stage to mention is that whatever were the behavior of original time series, the same is observable in each SPI graph. The only difference is in the vertical axis variation domain, which varies between − 3 and + 3.

SPI time series for precipitation and temperature data
The joint scatter diagram of the standardized precipitation and temperature indices (SPTIs) is given in Fig. 4. Comparison of the scatter points with the classification limits in Table 1 indicates that almost at each square and rectangular areas, there are data points, but the scatter does not have any distinctive pattern except randomness.

SPTI scatter graph
Fuzzy c-means clusters
Fuzzy logic is a valuable addition as it recognizes elastic transitions between adjacent SPI classifications given in Table 1. Unfortunately, without the fuzzy logic approach, transitions between adjacent classes would be sharp and sudden, and this cannot physically occur in natural meteorological phenomena. Drought is a gradual phenomenon that cannot occur suddenly. In order to identify possible clusters in Fig. 4 holistic scatter diagram, fuzzy c-means procedure is applied with 5 cluster center requirement. Figure 5 shows the fuzzy cluster scatter points around each cluster center. In this figure, the clusters below (above) the 45o red line indicates the impact of precipitation (temperature) more than the temperature (precipitation). Cluster 1 falls almost on this line and thus indicates equivalent impact on drought event by temperature and precipitation.

Fuzzy c-means clusters
The following points are among the interpretations of the fuzzy scatter points and the positions of cluster centers.
-
1)
According to the classification in Table 1, SPI center points 1 and 2 remain within the “Moderately dry” class; cluster center 3 and 4 are in “Normal wet” class and cluster 5 has “Moderately wet” description,
-
2)
As for the STI one can deduct from the vertical classification that cluster 1 implies “Moderately cold” class, cluster 2 is within the “Normal hot” class, clusters 3 and 5 have “Normal cold” description, and finally cluster 4 is within the “Very hot” class,
-
3)
Cluster 1 means “Moderately dry” spell occurrence coupled with “Moderately cold” temperature durations,
-
4)
Joint interpretation of cluster 2 central position implies “Moderately dry” precipitation occurrences during “Normal hot” temperature durations,
-
5)
Cluster 3 has jointly “Normal wet” precipitation spells under “Normal hot” temperature spells,
-
6)
Cluster 4 precipitation and temperature joint appearance lies within the “Normal wet” and “Very hot” classes,
-
7)
Cluster 5 takes place according to “Moderate wet” spells during “Normal cold” temperature spells.
Figure 6 indicates the objective function iteration process and it is visually possible to say that the iteration can stop at number 20.

Fuzzy c-means objective function iterations
Fuzzy membership degree (MD) annual time series graphs of each cluster is presented in Fig. 7. Each graph helps identification of years with the most drought effective occurrences. The following points are worth to notice.
-
1)
Each cluster annual MD time series has not zero MDs in each year with a set of maxima (minima) in some years,
-
2)
The most critical drought couple appears in the “moderately dry” and “moderately hot” classes as it is also clear from Fig. 5 in the position of Cluster 1 center,
-
3)
In Cluster 3, there is an increasing MD trend, whereas in Cluster 4 just the opposite is valid. This cluster indicates the increase of droughts during the last 15 years as a result of “Normal wet” precipitation and “Normal cold” temperature classes,
-
4)
The maxima cluster dominance in cluster 2 indicates that “Moderately dry” precipitation occurrences take place during “Normal hot” temperature durations,

Fuzzy c-means cluster membership degrees
Discussion
Although, the methodology proposed in this paper is based on the SPI basic concept, it has been extended by incorporating joint effects of the precipitation and temperature annual records first in a crisp logical and then in fuzzy logical senses. The original drought classification numerical limits in Table 1 are crisp logic values but each class is expressed verbally at the final column by words which have fuzzy implications. Numerical limits are crisp, but the verbal expressions imply interference possibilities between the two neighboring or among all the classes, which provides the opportunity to apply fuzzy inference system (FIS) by means of fuzzy c-means drought categorization.
Each cluster with its surrounding points has drought impact MDs decreasing as went away from the cluster center. For example, the worst drought occurrences take place around the Cluster 2, where points belong to “Moderate dry” and “Moderate hot” classes, but at some points there are also “Very hot” temperature spells. In the classical SPI classification, each year value has only one description with belongingness degree of one, but in the fuzzy approach each year has five different MDs and according to these MDs, one is able to decide which cluster has the most effect on the drought type. For example, consideration of years 2000–2010 the following table yields the MD of each year in each cluster.
The conclusion that can be drawn from this table is that in New Jersey State wise precipitation and temperature records, there has not been extreme and very extreme drought conditions except in few years during the last 10-year period. Most often the drought situation is observable at Cluster 3, which implies “Normal wet” condition coupled with “Normal cold” classification. For example, in this table “Moderately dry” and “Moderately hot” implies that as for the precipitation there is moderate deficit, but temperature is hot, and thus precipitation drought is coupled by the temperature hotness.
The comparison of SPI and SPTI is clearly given in Figs. 4 and 5. In Fig. 4, the two classifications of SPI and STP have no relationship between the two indices other than a random pattern. However, in terms of SPTI, fuzzy classification provides combined classes for better evaluation. Since SPI has one dimension and SPTI has two dimensions, their numerical comparison is irrelevant. SPTI provides more valid information for the joint effectiveness of precipitation and temperature on drought impact.
Since SPI has a practical meaning, so does the proposed methodology, which considers not only a single phenomenon such as precipitation but also temperature. In practical life, people will not be able to detect drought only by rainfall or temperatures exceeding normal records. For example, although agricultural products need water, they will need more water in case of abnormal temperature increases. Thus, double evaluation of rainfall-temperature records will enable the generation of more reliable scenarios for drought occurrence.
Especially in hydro-meteorological drought evaluations, a more accurate decision can be reached by simultaneously considering temperature records instead of making decisions based only on precipitation records. Although for agricultural drought assessment there is the Standardized Precipitation Evapotranspiration Index (SPEI) which is based on precipitation and evapotranspiration considering temperature in evapotranspiration, SPTI is well suited for climate change application assessment because there are two key variables in any climate change and adaptation assessment which are precipitation and temperature.
As mentioned in the introduction, standard drought assessment procedures, such as the classical SPI and its various versions, are based on two-valued logic and therefore provide clear numerical classifications without any overlap between successive classes as in the fuzzy c-means procedure. This means a transition to the next class that is too abrupt and definitive to be acceptable in practical applications. However, SPTI has overlapping subclassifications as a result of the c-means procedure. Besides, Standardized Precipitation Evapotranspiration Index (SPEI) serves for agricultural drought assessments whereas SPTI is proposed for hydro-meteorological drought assessment. So, the aim of these two indices is different from each other. As mentioned above, SPTI is important not only for drought assessment under the joint influence of precipitation and temperature, but also for hydro-meteorological drought-type assessment under the influence of climate change.
Conclusion
In literature, there are numerous indices for the drought description of different hydro-meteorology variables among which the standardized precipitation index (SPI) is the most widely used and there are many alternatives derived from its basic conception. Most often, SPI or its derivatives are applied individually in practice to classify the drought occurrence possibility based on standard normal (Gaussian) probability distribution function (PDF). Whatever is the original PDF of a hydro-meteorological variable, it is transformed by probabilistic standardization procedure to Gaussian PDF with zero mean and standard deviation, and thus different variables can be compared on the same footing. It is mentioned in the text that there are misuses of SPI procedure that the standardization is statistical, not probabilistic and 2-parameter Gamma PDF is assumed irrespective of what is the original PDF of the hydro-meteorological variable. After drawing attention to these misuses, this paper proposes two-variable SPI version in terms of standardized precipitation temperature index (SPTI) concept and its clustral analysis by means of fuzzy c-means procedure by considering five clusters. Hence, the membership degrees (MDs) of each hydro-meteorological record is determined in this paper based on five clusters. This procedure provides precipitation and temperature combination interpretations for drought possibility effects. The fuzzy MDs of points that belong to a cluster reflect drought possibility preferences and thus comparison of these degrees among five clusters provide a wealth of information for drought interpretation by means of SPTI indices. Fuzzy c-means application with different cluster numbers than 5 is expected to yield more dynamic information about drought behavior. The necessary mathematical explanation of the fuzzy logic regarding the precipitation-temperature index is given in the text, but duration, intensity and severity are not given neither in the classical SPI approach nor in the SPTI methodology. This article proposes the SPTI methodology as an alternative to the univariate SPI procedure. Duration, intensity, frequency and severity characteristics will be discussed in the future. After what is described in this paper, the proposed SPTI methodology can be extended as future research to investigate the duration, intensity and severity of the joint behavior of the SPTI methodology.
Data availability
Data available on request from the authors.
References
Allen MR, Ingram WJ (2002) Constraints on future changes in climate and the hydrologic cycle. Nature 419(6903):228–232
Bezdek JC, Ehrlich R, Full W (1984) FCM: the fuzzy c-means clustering algorithm. Comput Geosci 10(2–3):191–203
Bhalme HN, Mooley DA (1980) Large-scale droughts/floods and monsoon circulation. Mon Weather Rev 108:1197–1211
Birpınar ME, Kızılöz B, Şişman E (2023) Classic trend analysis methods’ paradoxical results and innovative trend analysis methodology with percentile ranges. Theor Appl Climatol. https://doi.org/10.1007/s00704-023-04449-6
Brunner MI, Swain DL, Gilleland E, Wood AW (2021) Increasing importance of temperature as a contributor to the spatial extent of streamflow drought. Environ Res Lett 16:1–10
Burke EJ, Brown SJ (2008) Evaluating uncertainties in the Projection of Future Drought. J Hydrometeorol 9:292–299. https://doi.org/10.1175/2007JHM929.1
Byun HR, Wilhite DA (1996) Daily quantification of drought severity and duration. J Clim 5:1181–1201
Chartres CJ, Noble A (2015) Sustainable intensification: overcoming land and water constraints on food production. Food Secur 7:235–245. https://doi.org/10.1007/s12571-015-0425-1
Crockett JL, Westerling A (2018) Greater temperature and precipitation extremes intensify Western U.S. droughts, wildfire severity and sierra Nevada tree mortality. J Clim Vol 31:341–354
Dubrovsky M, Svoboda MD, Trnka M, Hayes MJ, Wilhite DA, Zalud Z, Hlavinka P (2009) Application of relative drought indices in assessing climate-change impacts on drought conditions in Czechia. Theoret Appl Climatol 96:155–171. https://doi.org/10.1007/s00704-008-0020-x
Dutra E, Viterbo P, Miranda PMA (2008) ERA-40 reanalysis hydrological applications in the characterization of regional drought. Geophys Res Letter 35:L19402. https://doi.org/10.1029/2008GL035381
Ekwueme BN, Agunwamba JC (2021) trend analysis and variability of air temperature and rainfall in regional river basins. civil Eng J 7:816–826. https://doi.org/10.28991/cej-2021-03091692
Foley JC (1957) Droughts in Australia: review of records from Earliest years of settlement to 1955. australian bureau meteorol bull 43:281
Gao F, Chen X, Yang W et al (2022) Statistical characteristics, trends, and variability of rainfall in Shanxi Province, China, during the period 1957–2019. Theor Appl Climatol 148:955–966. https://doi.org/10.1007/s00704-022-03924-w
Gibbs WJ, Maher JV (1967) rainfall deciles as drought indicators. bureau of meteorology bulletin no. 48. commonwealth of australia, melbourne, p 28
Guttman NB (1998) Comparing the Palmer Drought Index and the standardized precipitation index. J Am Water Resour Assoc 34(1):113–121. https://doi.org/10.1111/j.1752-1688.1998.tb05964.x
Guttman NB (1999) Accepting the standardized precipitation index: a calculation algorithm. J Am Water Resour Assoc 35(2):311–322
Hannaford J, Lloyd-Hughes B, Keef C, Parry S, Prudhomme C (2011) Examining the large-scale spatial coherence of European drought using regional indicators of precipitation and streamflow deficit. Hydrol Process 25:1146–1162
Hayes MJ (2000) Revisiting the SPI: clarifying the process. Drought Netw News 12(1):13–14
Heim RR Jr (2002) A review of Twentieth Century Drought indices used in the United States. Bull Am Meteorol Soc 83(8):1149–1165
Hong X, Guo S, Zhou Y, Xiong L (2015) Uncertainties in assessing hydrological drought using streamflow drought index for the upper Yangtze River basin. Stoch Environ Res Risk Assess 29:1235–1247
IPCC (2018) Global Warming of 1.5 ºC. Intergovernmental Panal on Climate Change. https://www.ipcc.ch/sr15/
Ji L, Peters AJ (2003) Assessing vegetation response to drought in the northern Great Plains using vegetation and drought indices. Remote Sens Environ 87:85–98
Jones JAA (1999) Climate change and sustainable water resources: placing the threat of global warming in perspective. Hydrol Sci J 44(4):541–557. https://doi.org/10.1080/02626669909492251
Karavitis CA, Alexandris S, Tsesmelis DE, Athanasopoulos G (2011) Application of the standardized precipitation index (SPI) in Greece. Water 3:787–805
Keskin ME, Terzi Ö, Taylan ED, Küçükyaman D (2009) Meteorological drought analysis using data-driven models for the Lakes District, Turkey. Hydrol Sci J 54(6):1114–1124. https://doi.org/10.1623/hysj.54.6.1114
Keskin ME, Terzi Ö, Taylan ED, Küçükyaman D (2011) Meteorological drought analysis using artificial neural networks. Sci Res Essays 6(21):4469–4477. https://doi.org/10.5897/SRE10.1022
Kogan FN (1990) Remote sensing of weather impacts on vegetation in nonhomgeneous areas. Int J Remote Sens 11:1405–1419
Liu X, Xu Z, Yu R (2012) Spatiotemporal variability of drought and the potential climatological driving factors in the Liao River basin. Hydrol Process 26:1–14. https://doi.org/10.1002/hyp.8104
Lloyd-Hughes B, Saunders MA (2002) Seasonal prediction of European spring precipitation from El Niño-southern oscillation and local sea-surface temperatures. Int J Climatol 22:1–14
Loukas A, Vasiliades L (2004) Probabilistic analysis of drought spatiotemporal characteristics in Thessaly region, Greece. Nat Hazards Earth Syst Sci 4:719–731
Loukas A, Vasiliades L, Tzabiras J (2008) Climate change effects on drought severity. Adv Geosci 17:23–29
Malek K, Adam JC, Stöckle CO, Peters RT (2018) Climate change reduces water availability for agriculture by decreasing non-evaporative irrigation losses. J Hydrol 561:444–460
Mansouri Daneshvar RM, Bagherzadeh A, Khosravi M (2012) Assessment of drought hazard impact on wheat cultivation using standardized precipitation index in Iran. Arab J Geosci. https://doi.org/10.1007/s12517-012-0695-2
McKee TB, Doesken NJ, Kliest J (1993) The relationship of drought frequency and duration to time scales. Proc. Eighth Conf. of Applied Climatology, Anaheim, CA, Amer. Meteor. Soc., 179–184
Mishra AK, Singh VP (2011) Drought modeling – a review. J Hydrol 403:157–175. https://doi.org/10.1016/j.jhydrol.2011.03.049
Morid S, Smakhtin V, Moghaddasi M (2006) Comparison of Seven Meteorological Indices for Drought Monitoring in Iran. Int J Climatol 26:971–985. https://doi.org/10.1002/joc.1264
Nkemelang T, New M, Zaroug M (2018) Temperature and precipitation extremes under current, 1.5 C and 2.0 C global warming above pre-industrial levels over Botswana, and implications for climate change vulnerability. Environ Res Lett 13(6):065016
Palmer WC (1965) Meteorological Drought, Office of Climatology. US Weather Bureau, Research Paper No. 45, Washington DC, 58 p. http://www.ncdc.noaa.gov/temp-and-precip/drought/docs/palmer.pdf
Panu US, Sharma TC (2009) Analysis of annual hydrological droughts: the case of northwest Ontario, Canada. Hydrol Sci J 54:29–42
Pathak AA, Dodamani BM (2016) Comparison of meteorological drought indices for different climatic regions of an Indian River Basin. Asia-Pacific J Atmos Sci 56:563–576i
Quiring SM, Ganesh S (2010) Evaluating the utility of the Vegetation Condition Index (VCI) for monitoring meteorological drought in Texas. Agric for Meteorol 150:330–339. https://doi.org/10.1016/j.agrformet.2009.11.015
Rajsekhar AF, Vijay P, Singh BA, Mishra AK (2015) Multivariate drought index: an information theory-based approach for integrated drought assessment. J Hydrol 526:164–182
Redmond KT (2002) The depiction of drought: a commentary. Bull Am Meteorol Soc 83:1143–1147
Rezaeian-Zadeh M, Tabari H (2012) MLP-based drought forecasting in different climatic regions. Theoret Appl Climatol 109:407–414. https://doi.org/10.1007/s00704-012-0592-3
Salman SA, Shahid S, Ismail T et al (2019) Characteristics of Annual and Seasonal trends of Rainfall and temperature in Iraq. Asia-Pacific J Atmos Sci 55:429–438. https://doi.org/10.1007/s13143-018-0073-4
Şen Z (2010) Fuzzy logic and hydrological modeling. CRC Press, Taylor and Francis Group, p 240
Shafer BA, Dezman LE (1982) Development of a Surface Water Supply Index (SWSI) to assess the severity of drought conditions in snowpack runoff areas. Proceedings of the Western Snow Conference, Colorado State University, Fort Collins, pp 164–175
Shiau JT, Hsiao Y-Y (2012) Water-deficit-based drought risk assessments in Taiwan. Nat Hazards 64:237–257. https://doi.org/10.1007/s11069-012-0239-9
Shukla S, Wood AW (2008) Use of a standardized runoff index for characterizing hydrologic drought. Geophys Res Lett 35:L02405. https://doi.org/10.1029/2007GL032487
Sirdaş S, Şen Z (2001) Application of the standardized precipitation index (SPI) to the Marmara region, Turkey. Integrated Water resources Management. IAHS Publications no 272:291–296
Sohn S-J, Tam C-Y, Ahn J-B (2012) Development of a multimodel-based seasonal prediction system for extreme droughts and floods: a case study for South Korea. Int J Climatol. https://doi.org/10.1002/joc.3464
Sun L, Mitchell SW, Davidson A (2012) Multiple drought indices for agricultural drought risk assessment on the Canadian prairies. Int J Climatol 32(11):1628–1639. https://doi.org/10.1002/joc.2385
Tomaszkiewicz MA (2021) Future Seasonal Drought conditions over the CORDEX-MENA/Arab Domain. Atmosphere 12(7). https://doi.org/10.3390/atmos12070856
Trenberth KE, Dai A, Van Der Schrier G, Jones PD, Barichivich J, Briffa KR, Sheffield J (2014) Global warming and changes in drought. Nat Clim Chang 4(1):17–22
Tsakiris G, Vangelis H (2005) Establishing a drought index incorporating evapotranspiration. Eur Water 9/10:3–11
Udayar S, Anagha B, Raja P, Kumar V, Rajan K, Jayakumar M (2019) Analysis of drought from humid, semi-arid and arid regions of India using DrinC model with different drought indices. Water Resour Manag 33:1521–1540
Van Loon AF (2015) Hydrological drought explained. Wiley Interdiscip Rev Water 2(4):359–392
Vicente-Serrano SM, Beguería S, López-Moreno A JI (2010) Multiscalar Drought Index sensitive to global warming: the standardized precipitation Evapotranspiration Index. J Clim 23:1696–1718
Vicente-Serrano SM, Beguería S, Lorenzo-Lacruz J, Camarero JJ, López-Moreno JI, Azorin-Molina C, Revuelto J, Morán-Tejeda E, Sanchez-Lorenzo (2012) Performance of Drought Indices for Ecological, Agricultural, and Hydrological Applications. Earth Interact 16:1–27
Vörösmarty CJ, Douglas EM, Green PA, Revenga C (2005) Geospatial indicators of emerging water stress: an application to Africa. Ambio 34(3):230–237
WMO (2012) Standardized Precipitation Index (M. Svoboda, M. Hayes and D. Wood). User guide. WMO-1090, Geneva, 16 pp
Wu H, Hayes MJ, Weiss A, Hu Q (2001) An evaluation of the standardized precipitation index, the China-Z Index and the statistical Z-score. Int J Climatol 21:745–758. https://doi.org/10.1002/joc.658
Funding
There is no funding for this work.
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK).
Author information
Authors and Affiliations
Contributions
This is a single author article.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable for this work.
Conflict of interest
The author has not any conflict of interest with anyone.
Additional information
Communicated by Hassan Babaie
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Şen, Z. Standard precipitation-temperature index (SPTI) drought identification by fuzzy c-means methodology. Earth Sci Inform (2024). https://doi.org/10.1007/s12145-024-01359-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12145-024-01359-7