
Abstract
Climate projections at fine spatial resolutions are required to conduct accurate risk assessment for critical infrastructure and design adaptation planning. Generating these projections using advanced Earth system models (ESM) requires significant computational resources. To address this issue, various statistical downscaling techniques have been introduced to generate fine-resolution data from coarse-resolution simulations. In this study, we evaluate and compare five deep learning-based downscaling techniques, namely, super-resolution convolutional neural networks, fast super-resolution convolutional neural network ESM, efficient sub-pixel convolutional neural network, enhanced deep residual network (EDRN), and super-resolution generative adversarial network (SRGAN). These techniques are applied to a dataset generated by the Energy Exascale Earth System Model (E3SM), focusing on key surface variables such as surface temperature, shortwave heat flux, and longwave heat flux. Models are trained and validated using paired fine-resolution (0.25\(^{\circ }\)) and coarse-resolution (1\(^{\circ }\)) monthly data obtained from a 9-year simulation. Next, blind testing is performed using monthly data obtained from two different years outside of the training and validation set. To evaluate the efficiency of each technique, different statistical metrics are used, including mean squared error (MSE), peak signal-to-noise ratio (PSNR), structural similarity index measure (SSIM), and learned perceptual image patch similarity (LPIPS). The results show that EDRN outperforms other algorithms in terms of PSNR, SSIM, and MSE, but struggles to capture fine-scale features in the data. In contrast, SRGAN, a generative model that uses perceptual loss, excels in capturing fine details at boundaries and internal structures, resulting in lower LPIPS than other methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Understanding the changes in climate patterns and their impact on society is of great importance. Rising temperatures, increasing sea-level, and escalating frequency of extreme weather events make many aspects of our society vulnerable. These vulnerabilities extend to our health, urban infrastructure, natural resources, energy systems, and transportation systems (Nicholls and Cazenave 2010; Trenberth 2012; Vandal et al. 2017; Davarpanah et al. 2023). Therefore, to conduct a risk assessment and design adaptation planning, future local and regional projections of climate change are of greater importance (Venetsanou et al. 2019; Mahjour et al. 2024). Earth System Models (ESMs) represent physics-based numerical models that currently run on massive supercomputers (Vandal et al. 2017). These models simulate Earth’s past climate and project future scenarios, considering changes in atmospheric greenhouse gas emissions (Passarella et al. 2022; Vandal et al. 2017).
The ESMs, however, typically work at coarse horizontal resolutions, around 1\(^{\circ }\) to 3\(^{\circ }\), which can lead to inaccuracies in representing crucial physical processes, such as extreme precipitation (Vandal et al. 2017; Schmidt 2010; Passarella et al. 2022; Kharin et al. 2007). Recent progress has allowed global ESMs to operate at higher horizontal resolutions, for example, 0.25\(^{\circ }\)and 0.125\(^{\circ }\) for extended durations (Hurrell et al. 2013; E3SM Project 2018; Hohenegger et al. 2023). This development has demonstrated improvements in the simulation of regional average climate conditions and extreme events (Mahajan et al. 2015), but at a high computational cost. To address the computational challenge, downscaling techniques, such as statistical downscaling and dynamical modeling, have been employed in the literature to generate fine-resolution ESM data (Passarella et al. 2022; Vandal et al. 2017).
Statistical downscaling is a technique used to convert coarse-resolution (CR) climate data into fine-resolution (FR) projections by incorporating observational data through the application of statistical methods (Passarella et al. 2022). Statistical downscaling involves two categories for spatial downscaling: (i) regression models, and (ii) weather classification. Regression models include automatic statistical downscaling (Hessami et al. 2008), Bayesian model averaging (Zhang and Yan, 2015), expanded downscaling (Bürger 1996; Bürger and Chen 2005), and bias-corrected spatial disaggregation (BCSD) (Thrasher et al. 2012). On the other hand, weather classification includes methods such as nearest-neighbor estimates (Hidalgo et al. 2008) and hierarchical Bayesian inference models (Manor and Berkovic 2015). Recently, regression-based statistical downscaling has been extended to include machine learning techniques, such as neural networks (Park et al. 2022; Oyama et al. 2023; Kumar et al. 2023; Vu et al. 2016), quantile regression neural networks (Cannon 2011), and support vector machines (Ghosh 2010), for statistical downscaling. These techniques demonstrate superior performance compared to conventional statistical downscaling methods (Passarella et al. 2022; Oyama et al. 2023). In addition to machine learning techniques, computer vision-based statistical downscaling techniques known as super-resolution have emerged (Vandal et al. 2017).
These super-resolution methods generalize patterns across fine-resolution and show to learn local-scale patterns more efficiently than other statistical downscaling techniques (Park et al. 2022; Vandal et al. 2017). Vandal et al. (2017) introduced the augmented stacked super-solution convolutional neural networks (SRCNN), which downscaled climate and ESM-based simulations based on observational and topographical data across the continental United States. The method outperforms BCSD, artificial neural networks, Lasso, and SVM in the downscaling task. The stacked SRCNN outperformed in terms of bias, correlation, and RMSE with values of 0.022 mm/day, 0.914, and 2.529 mm/day. Furthermore, Passarella et al. (2022) proposed a fast SRCNN ESM (FSRCNN-ESM) that surpasses augmented stacked SRCNN and FSRCNN models in downscaling features such as surface temperature, surface radiative fluxes, and precipitation in ESM data over North America. The FSRCNN-ESM model demonstrated better \(L_1\) and \(L_2\) error metrics, quantifying the reconstruction skill compared to the stacked FSRCNN, with the majority of samples in the testing dataset having \(L_1\) error less than 10% and \(L_2\) error less than 1%.
Other studies include using super-resolution generative adversarial networks (SRGAN), which enhances the resolution of coarse 100-km climate data by a factor of 50 for wind velocity and 25X for solar radiance data (Stengel et al. 2020). The semivariograms of ground truth data exhibit an initial variance jump (nugget) due to cloud cover discontinuities. While bicubic interpolation and CNN super-resolution fail to capture the nugget for solar radiance data, SRGAN reproduces it by learning small-scale texture and discontinuity data (Stengel et al. 2020). Advancements in this domain include physics-informed SRGAN (Oyama et al. 2023), which integrates climatologically important physical information such as pressure and topography into the network to achieve significant downscaling of temperature and precipitation data by a factor of 50 (Oyama et al. 2023). The results showed that physics-informed SRGAN in comparison to the cumulative distribution function-based downscaling method achieved 3.6 times better accuracy for the average mean square error value on 12 sites (Oyama et al. 2023). Kumar et al. (2023) employed SRGAN and compared it with other deep learning approaches such as stacked SRCNN (Vandal et al. 2017), UNET (Serifi et al. 2021), and ConvLSTM (Harilal et al. 2021) for downscaling precipitation data. Their findings highlight the superiority of SRGAN, showcasing a correlation coefficient of 0.8806, while UNET, ConvLSTM, and DeepSD exhibited values of 0.8399, 0.8311, and 0.8037, respectively (Kumar et al. 2023).
The literature shows promising areas where CNN-based deep learning has been employed to downscale ESM data (Passarella et al. 2022; Park et al. 2022; Vandal et al. 2017). However, there is a lack of systematic comparison of state-of-the-art super-resolution techniques on E3SM data, considering the entire globe. In this study, our objective is to address this shortcoming by exploring five downscaling methods, namely, SRCNN (Dong et al. 2014), FSRCNN-ESM (Passarella et al. 2022), efficient sub-pixel convolutional neural networks (ESPCNN) (Talab et al. 2019), enhanced deep residual networks (EDRN) (Lim et al. 2017) and SRGAN (Ledig et al. 2017). The five models in this study are selected based on a literature review of CNN-based super-resolution algorithms (Passarella et al. 2022; Oyama et al. 2023; Park et al. 2022; Soltanmohammadi and Faroughi 2023). SRCNN is selected because it represents a fundamental version of the CNN-based superresolution technique (Dong et al. 2014). FSRCNN-ESM is selected because it was shown to achieve higher accuracy for E3SM data downscaling compared to the stacked SRCNN family (Passarella et al. 2022). ESPCNN is chosen for its lightweight nature and faster training time, as highlighted in (Talab et al. 2019). Furthermore, the selection of EDRN (Lim et al. 2017) and SRGAN (Ledig et al. 2017) is motivated by their deeper architectures, allowing us to analyze their performance compared to previous models. The overarching goal is to employ the vanilla architectures of these selected models and to conduct a comprehensive comparison of their efficacy in downscaling E3SM datasets.
We conduct a comparison of these techniques to assess their performance on an ESM dataset named Energy Exascale Earth Systems Model (E3SM) (E3SM Project 2018). Our focus is on key surface variables including surface temperature (TS), shortwave heat flux (FSNS), and longwave heat flux (FLNS) over the entire globe. We allocate 80% of the sliced first 9 years of ESM simulation data (with monthly interval) for training, reserving the remaining 20% for validation. Additionally, we employ blind testing on two distinct years outside of the training and validation sets. To facilitate model comparison, we employ evaluation metrics including absolute point error (APE) (Faroughi et al. 2022), peak-signal-to-noise ratio (PSNR) (Deng 2018), structural similarity index measure (SSIM) (Dosselmann and Yang 2011), learned perceptual image patch similarity (LPIPS) (Zhang et al. 2018), and mean squared error (MSE).
Earth exascale earth systems model (E3SM) data
In this study, we employed the monthly output information derived from a 30-year period within the 1950-control simulation, utilizing the global fine-resolution (0.25\(^{\circ }\)) setup of the Energy Exascale Earth Systems Model (E3SM) (E3SM Project 2018). The selection of E3SM compared to other earth system models is attributed to its open accessibility through the Earth System Grid Federation (ESGF) distributed archives (E3SM Project 2018). The E3SM simulation data undergo bilinear interpolation from their original non-orthogonal cubed-sphere grid to a regular 0.25\(^{\circ }\) \(\times \) 0.25\(^{\circ }\) longitude-latitude grid, resulting in the interpolated model data known as E3SM-FR (Passarella et al. 2022). To generate the corresponding coarse-resolution input data, the fine-resolution data is further interpolated onto a 1\(^\circ \) \(\times \) 1\(^\circ \) grid using a bicubic (BC) method (Passarella et al. 2022). This interpolation process removes fine-scale details present in the original fine-resolution data, creating coarse-resolution profiles. When applying deep learning techniques to gridded E3SM data, each grid point is treated as an image pixel. The E3SM fine-resolution data is organized into an image with dimensions of 720 \(\times \) 1440 pixels, while the corresponding coarse-resolution data has dimensions of 180 \(\times \) 360 pixels. The global data are then divided into 18 slices, and within each slice, the coarse-resolution images measure 60 \(\times \) 60 pixels, while the fine-resolution images measure 240 \(\times \) 240 pixels. We select surface temperature, shortwave heat flux, and longwave heat flux to evaluate the super-resolution models. As depicted in Fig. 1, the total number of datasets used for the study is calculated as follows: 11 (years) \(\times \) 12 (months), \(\times \) 3 (variables) , \(\times \) 18 (slices). In this study, all three variables are collectively incorporated by normalizing each of them and saving them as an RGB image. This normalization process ensures that the variables are brought to a standardized scale, enabling the use of a multi-channel network during training, thus enhancing the regeneration process. The total dataset is divided into training, validation, and blind testing sets. The training dataset consists of 80% of the total dataset for the first 9 years, while the remaining 20% is used for the validation set. For blind testing, we consider two distinctive sets corresponding to two randomly selected years (15\(^{th}\) and 19\(^{th}\) year), focusing on the surface variables surface temperature, shortwave heat flux, and longwave heat flux.

Schematic procedure of data pre-processing for the super-resolution technique. Panels (a), (b), and (c) show surface temperature, shortwave heat flux, and longwave heat flux, respectively, for the first month of year 1 obtained from the global fine-resolution configuration of E3SM. It indicates the division of each month into 18 distinct sections, as visually represented. Each FR month comprises a matrix of dimensions 720 by 1440. Through the division into 18 segments, each section transforms into a 240 by 240 matrix, subsequently converted as a 240 by 240 image
Methodologies
This section provides an overview of the five architectures used in our study: super-resolution convolutional neural networks (SRCNN), fast super-resolution convolutional neural network earth system model (FSRCNN-ESM), efficient sub-pixel convolutional neural network (ESPCNN), enhanced deep residual network (EDRN) (Lim et al. 2017), and super-resolution generative adversarial network (SRGAN). The SRCNN model uses bicubic interpolation as input and features a shallow architecture (Soltanmohammadi and Faroughi 2023; Dong et al. 2014). In contrast, both the FSRCNN and ESPCNN techniques use the coarse-resolution images as input (Passarella et al. 2022; Talab et al. 2019). The EDRN takes coarse-resolution as input and model employs a deep architecture and incorporates skip connections to retain important features from earlier layers (Soltanmohammadi and Faroughi 2023; Lim et al. 2017). The SRGAN architecture consists of a generator and a discriminator, where the generator generates a fine-resolution using the coarse-resolution input (Soltanmohammadi and Faroughi 2023; Ledig et al. 2017). The algorithms and their architectures are detailed in Appendix A, and the evaluation metrics used to assess the models’ performance are described in Appendix B.
Computational experiments
Training and validation
The training process is carried out using an NVIDIA RTX A6000 GPU with 47.5 GB of dedicated GPU memory (vRAM). Additionally, the computer used for training is equipped with an Intel (R) Xeon (R) W7-3455 processor and boasts 512 GB of RAM capacity. Detailed information on the number of parameters and the time required for training each algorithm can be found in Table 1. The super-resolution generative adversarial network model has the most trainable parameters with 2,039,939 numbers and the longest training time (41.10X compared to SRCNN). This is because the discriminator network in SRGAN compares two RGB images sized \(240\times 240\). The efficient sub-pixel convolutional neural network model is the most computationally efficient, with a training time relative to SRCNN of 0.64X, despite having more trainable parameters than SRCNN and FSRCNN-ESM. This is due to the efficient training approach used in ESPCNN, as discussed by Shi et al. (2016).
Table 2 presents the evaluation metrics associated with the performance of each algorithm on the training set. The results show a clear trend: PSNR increases from bicubic interpolation to EDRN, with SRGAN exhibiting the lowest PSNR values. In contrast, the SSIM values do not show a clear pattern throughout the dataset, although SRGAN has the lowest SSIM. Furthermore, the mean square error shows an inverse trend, decreasing from bicubic interpolation to enhanced deep residual network, with SRGAN having a value slightly higher than bicubic interpolation but lower than the other methods. Lower PSNR and SSIM for SRGAN have been reported previously (Ledig et al. 2017), however, these are not accurate measures of super-resolution. While PSNR and SSIM may decrease, the fine-scale resolution of the generated images often improves. Therefore, using additional metrics, such as LPIPS, is important to assess the performance of different algorithms. Learned perceptual image patch similarity measures perceptual similarity between images and is a more accurate measure of image resolution than peak-signal-to-noise-ratio and structural similarity index measure. In this regard, LPIPS decreases from 0.297 to 0.234 from bicubic interpolation to SRGAN, indicating that SRGAN generates more accurate fine-resolution images than the other models. Table 2 shows the evaluation metrics for each algorithm tested using the validation set. The results are similar to those for the training set, indicating that the models do not overfit the training dataset. Table 2 has been deliberately included to present training and validation results. Our objective is to provide a comprehensive analysis for understanding the models’ performance across training and validation phases. Next, we will evaluate the performance of each algorithm on the blind testing dataset.

Comparison between generated fine-resolution using SRCNN, FSRCNN-ESM, and ESPCNN compared to bicubic interpolation and ground truth for the zoomed-in cross-section of net longwave flux
Blind testing
SRCNN, FSRCNN and ESPCNN
SRCNN takes the bicubic interpolation image as input and generates a fine-resolution using three convolutional layers. For blind testing, we randomly consider a zoom in section for the longwave heat flux of fall (December) from first blind testing set. This results focuses on a zoomed-in cross-section of the longwave heat flux for North America to assess the fine-scale resolution of the generated fine-resolution profile, as depicted in Fig. 2. The results show that SRCNN outperforms bicubic interpolation in terms of evaluation metrics with LPIPS of 0.197 compared to 0.209 for bicubic interpolation. Furthermore, SRCNN is capable of reproducing the boundary of the zoomed-in cross-section; however, it faces a challenge recovering the internal structure and strong gradients of the selected cross-section for longwave heat flux.
FSRCNN-ESM uses the coarse-resolution image as input, unlike SRCNN, which uses the bicubic interpolated image. It is an improved extension of FSRCNN, where the model after the deconvolutional step employs an additional SRCNN-like convolutional layer to enhance accuracy. During blind testing, similar to SRCNN we focus on a zoomed in section in the fall (December) from the first set of blind test, considering the surface variable longwave heat flux. Figure 2 provides a zoomed-in cross-section of longwave heat flux to assess the fine-scale details generated by FSRCNN-ESM. The outcomes indicate that FSRCNN-ESM surpasses bicubic interpolation and SRCNN in terms of evaluation metrics i.e., LPIPS and is capable of generating boundaries for the zoomed-in longwave heat flux cross-section, but similar to SRCNN, it has limitations in generating internal structure and strong gradients of the longwave heat flux cross-section.
An efficient sub-pixel convolutional neural network, similar to FSRCNN-ESM, uses a coarse-resolution image as input but utilizes an efficient sub-pixel convolutional layer for super-resolution. We evaluated ESPCNN using the cross section in the fall (December) from the first set of blind test, considering the longwave heat flux. The results show that ESPCNN is capable of generating fine-resolution images in E3SM data, similar to FSRCNN-ESM, SRCNN and FSRCNN, as shown in Fig. 2. It is evident that, compared to bicubic interpolation, SRCNN and FSRCNN-ESM the boundaries are slightly sharper and the internal structure is somewhat clearer, leading to improvements LPIPS. However, due to its limited architectural depth, ESPCNN cannot produce an accurate internal structure and fine details in the E3SM data, resulting in a blurriness similar to that seen in FSRCNN-ESM and SRCNN.
EDRN
An enhanced deep residual network, an in-depth residual network designed for the super-resolution task. Figure 3 (a) shows the coarse-resolution, super-resolution generated using EDRN, ground truth images, and error images for the features of surface temperature, shortwave heat flux, and longwave heat flux during the spring (March) from the first set of blind testing data. The results show that the EDRN accurately reconstructs fine-resolution images, preserving gradients, and closely resembling the internal E3SM data structure, all while maintaining a low absolute point error. EDRN faces the greatest challenge in reconstructing longwave heat flux as seen in terms of LPIPS 0.238 compared to 0.231 and 0.179 for shortwave heat flux and surface temperature. Hence, to assess the fine-scale details, we highlight a zoomed-in cross-section in Fig. 3(b). Compared to bicubic interpolation, EDRN enhances PSNR, and SSIM and reduces LPIPS for the zoomed-in cross-section. However, it falls short of fully reconstructing fine-scale features of E3SM data, although it excels in generating boundaries with strong gradients due to its complex and deeper architecture compared to SRCNN, FSRCNN-ESM, and ESPCNN.

Comparison of the EDRN performances for generating fine-resolution E3SM data. Panel (a) compares the generated fine-resolution surface variables from EDRN with the global fine-resolution configuration of the E3SM. The top row shows the surface temperature, while the second and third rows show the shortwave heat flux and the longwave heat flux, respectively. For each row, the left column displays the coarse-resolution surface variable, followed by the EDRN-generated fine-resolution surface variable, the ground truth fine-resolution surface variable from E3SM, and the absolute point error between the generated and ground truth fine-resolution surface variables. Panel (b) compares the coarse-resolution, bicubic interpolation, EDRN-generated, and ground truth images of a net longwave flux cross-section
SRGAN
Super-Resolution Generative Adversarial Network, with a more complex architecture than EDRN, comprises a generator and discriminator. Figure 4(a) shows coarse-resolution, super-resolution generated using SRGAN, ground truth, and error images for surface temperature, shortwave heat flux, and longwave heat flux features during the summer (August) month of the first blind testing set. The results show that SRGAN can capture boundaries with strong gradients and fine-scale details in internal structures with minimal absolute point error, as is evident in the error images for the surface variables surface temperature, shortwave heat flux, and longwave heat flux in Fig. 4(a). Moreover, Fig. 4(b) displays a zoomed-in cross-section of longwave heat flux similar to that of EDRN, indicating SRGAN’s accuracy in capturing boundaries, internal structure, and fine-scale details, despite a low SSIM value. Here, the choice of LPIPS as an evaluation metric for SRGAN is justified because it is designed to capture the perpetual similarity between ground truth and generated fine-resolution images, while PSNR, SSIM rely on mean squared error and structural similarity. For example, the average PSNR value for SRGAN, presented in Table 2 for training and validation phases and Table 3 for blind testing, is lower than that of bicubic interpolation. However, there are instances, as shown in Fig. 4(b), where there is a noticeable increase in PSNR.

Comparison of the SRGAN performances for generating fine-resolution E3SM data. Panel (a) compares the generated fine-resolution surface variables from SRGAN with the global fine-resolution configuration of the E3SM. The top row shows the surface temperature, while the second and third rows show the shortwave heat flux and the longwave heat flux, respectively. For each row, the left column displays the coarse- resolution surface variable, followed by the SRGAN-generated fine-resolution surface variable, the ground truth fine-resolution surface variable from E3SM, and the absolute point error between the generated and ground truth fine-resolution surface variables. Panel (b) compares the coarse-resolution, bicubic interpolation, SRGAN-generated, and ground truth images of a net longwave flux cross-section
Model comparison

A comparison of various algorithms employed in this study for reconstructing fine-resolution from coarse-resolution images in the blind test reveals a consistent trend of decreasing learned perceptual image patch similarity values from bicubic interpolation to SRGAN. This trend shows that SRGAN achieves more accurate reconstruction compared to all other algorithms

A comparison of various algorithms employed in this study to reconstruct fine-resolution cross-section of surface temperature. The trend indicates that SRGAN could reconstruct the perpetual features with higher accuracy compared to all other algorithms
In the final analysis, we conduct a comparison of all five models to assess their effectiveness in generating fine-resolution E3SM data. Figure 5 shows a comparison of the different algorithms for the longwave heat flux feature in the summer (August) from the first blind test set. Based on the evaluation metrics, the PSNR and SSIM values increase from bicubic interpolation to EDRN, with SRGAN having the lowest structural similarity index measure and PSNR values just above bicubic interpolation. However, SRGAN has the lowest LPIPS value, which indicates its superior performance in generating fine-resolution images compared to other models. Furthermore, Fig. 6 shows the zoomed-in cross-section comparison of all the models for the spring (February) in the first blind testing dataset. A similar trend could be observed, except for FSRCNN-ESM performing better than ESPCN in terms of LPIPS and PSNR. This is because both algorithms have very close values for the evaluation metrics. Additionally, in terms of learned perceptual image patch similarity, there is a significant drop from 0.291 for bicubic interpolation to 0.198 for SRGAN, which explains SRGAN’s capability to generate boundaries with strong gradients, internal structures, and fine-scale details of the surface variable.

A comparison of the mean squared error (MSE) between the fine-resolution predictions and the ground truth along the edge of the white square. The values of location represent positions on the white square, starting from the top-left as the initial point and proceeding through the square, with the last 800 points ending back at the top-left. Panel (a) illustrates the surface temperature (TS), Panel (b) displays the shortwave heat flux (FSNS), and Panel (c) shows the longwave heat flux (FLNS)

Violin plots for the evaluation metrics. Panels (a) to (d) depict the peak-signal-to-noise-ratio, structural similarity index measure, learned perceptual image patch similarity, and mean squared error values, respectively, obtained from all five super-resolution models, including bicubic interpolation. The \(\mu \) is used to denote the mean value
To understand the rationale behind the lower values of structural similarity index measure and PSNR, we present Fig. 7, which displays the mean square error between the ground truth and the generated fine-resolution images using all algorithms employed in this study along the edges of the white square. It is evident that the mean square error for SRGAN slightly surpasses that of the bicubic interpolation for surface temperature, but it remains lower than that of all the other algorithms. The shortwave heat flux surface variable has the lowest MSE. There is an exception in the case of longwave heat flux, where the mean square error for SRGAN performed second best after EDRN. For the majority of the features, we see that SRGAN has a higher mean square error because SRGAN’s loss function is based on perceptual similarity rather than statistical pixel-wise metrics, such as mean square error. Therefore, SRGAN generates fine-resolution images that are more perceptually realistic, even though they have lower PSNR, SSIM, and MSE values. Additionally, to analyze the trend in the evaluation metrics, we plot the values in the violin plot. Figure 8(a) shows that the high-density distribution of PSNR for bicubic interpolation ranges from 15 to 35 dB. In contrast, the distribution for SRCNN is more compact and lies in the upper bound, with PSNR values ranging from 18 to 30 dB. This indicates that the SRCNN results have a more concentrated peak-signal-to-noise-ratio distribution. Furthermore, SRCNN shows a higher mean PSNR of 24.59 dB, compared to 24.13 dB for bicubic interpolation. Similarly, performance in terms of PSNR increases from FSRCNN-ESM to EDRN, with a high-density distribution of PSNR values for EDRN ranging from 18 dB to 36 dB and a mean PSNR value of 25.52, indicating improved performance compared to other algorithms. Note that SRGAN has a high density distribution for PSNR in the lower bound compared to other models, leading to the lowest mean value compared to all other algorithms.
In Fig. 8(b), structural similarity index measure shows a high-density distribution ranging from 0.69 to 0.98, with a mean value of 0.87 for bicubic interpolation. Applying SRCNN results in a more compact distribution, ranging from 0.73 to 0.93, with a reduced mean value of 0.83. For FSRCNN, the values range from 0.75 to 0.95, with a mean value of 0.87. For ESPCN, the values range from 0.75 to 0.97, with a mean value of 0.87. There is an improvement in the range for EDRN, i.e., from 0.82 to 0.99, accompanied by an improvement in the mean, reaching 0.90. EDRN shows a compact, upper-bound, high-density distribution for SSIM values, demonstrating superior performance compared to all other algorithms. Similarly to PSNR, structural similarity index measure in the SRGAN has a high density distribution in lower range values compared to other models, further leading to the lowest mean SSIM value compared to all other algorithms. Figure 8(c) shows the LPIPS value distribution for each algorithm. The results indicate a decreasing trend in the high-density distribution of data, becoming lower and more compact from bicubic interpolation to SRGAN. This trend is also reflected in the mean values of LPIPS, which decrease from 0.258 to 0.193 from the bicubic interpolation to SRGAN. This suggests that SRGAN outperforms other algorithms. The LPIPS evaluation metric is more important compared to peak-signal-to-noise-ratio and structural similarity index measure, as it considers perceptual similarity compared to statistical image metrics. Figure 8(d) shows the inverse trend of PSNR, i.e., mean square error decreases from bicubic interpolation to EDRN, with SRGAN having the lowest mean square error.
Finally, when comparing Tables 2 (training and validation) and 3 (blind testing), we observe that the blind testing dataset yields better results for all evaluation metrics across all models, including bicubic interpolation. To validate the results obtained from the blind test, we apply all the models to a second blind test dataset, as shown in Table 3. The results show a pattern similar to that of the first set of blind tests. Therefore, it can be confirmed that all the models demonstrated superior performance, in terms of metrics, for blind testing datasets compared to the training and evaluation datasets. This trend could be attributed to the lower number of data points in the blind testing set compared to the training and evaluation datasets. Furthermore, for the blind test, a similar trend could be observed as in the training and evaluation datasets, wherein EDRN achieved the maximum peak signal-to-noise ratio and structural similarity index measure, along with the lowest mean square error, while SRGAN achieved the lowest learned perceptual image patch similarity.
Our results show that vanilla super-resolution techniques provide useful prediction, but may face challenges in predicting fine-resolution features and high-gradient regions due to their pure statistical nature not incorporating known physical laws behind the data (Oyama et al. 2023; Faroughi et al. 2022). The most effective super-resolution vanilla techniques, e.g., EDRN and SRGAN, provide better predictions in those regions but are computationally expensive, creating a trade-off between accuracy and computational cost. Current research mainly aims to address these challenges by improving the accuracy of super-resolution techniques by incorporating contextual and physical information into the input array (Oyama et al. 2023; Passarella et al. 2022), modifying architecture such as activation functions (Sitzmann et al. 2020; Dupont et al. 2021), and utilizing advanced learning techniques such as model compression (Cheng et al. 2018; Choudhary et al. 2020), and transfer learning (Tan et al. 2018; Zhang et al. 2017) to reduce computational cost. Future research can incorporate all these advances into a united framework that offers high accuracy in capturing fine-resolution details at a low computational cost. Using such a framework, it will be possible to generate accurate E3SM projections at very fine resolutions, which are necessary to address the complexities posed by climate change and help plan adaptation and critical decision-making processes.
Conclusions
We investigated the application of super-resolution deep learning techniques to downscale the Energy Exascale Earth Systems Model (E3SM) data, generating fine-resolution data using their coarse-resolution simulation counterparts. We compared five super-resolution methods, including super-resolution convolutional neural networks (SRCCNN), fast super-resolution convolutional neural network ESM (FSRCNN-ESM), efficient sub-pixel convolutional neural networks (ESPCN), enhanced deep residual networks (EDRN), and super-resolution generative adversarial networks (SRGAN). We compared the accuracy of each method to produce fine-resolution data using several statistical criteria, such as PSNR, SSIM, and LPIPS. In general, these models can provide finer-resolution E3SM data that better captures the finer features than bicubic interpolation, although we found different performance trends for each model. In terms of PSNR and SSIM, EDRN outperformed all other methods, while SRGAN excelled in LPIPS. The SRCNN technique generates fine-resolution data with low PSNR and SSIM. This is because SRCNN uses a bicubic image as input instead of a coarse-resolution image and has a shallow architecture compared to other methods. In contrast, FSRCNN-ESM and ESPCNN, which take coarse-resolution images as input, produce fine-resolution with PSNR and SSIM better than that of SRCNN. EDRN, which uses a residual network, was able to accurately reconstruct the internal structure and regenerate strong gradients, as evidenced by a 1.39 dB and 1.57 dB improvement in PSRN in the first and second blind testing datasets compared to bicubic interpolation. However, it was unable to properly preserve the fine-scale details of the E3SM data. In contrast, SRGAN was able to reproduce both fine-scale details at boundaries and the internal structure of the E3SM data, but at a higher computational cost (14X more compared to EDRN and 41X more compared to SRCNN). Despite the visual closeness of SRGAN’s outputs to ground truth images, the PSNR and SSIM metrics were not reflective of their true performance. However, the LPIPS metric accurately highlighted this important aspect of the effectiveness of SRGAN, showing a 25% improvement compared to bicubic interpolation and a 7% improvement compared to EDRN for both sets of blind testing data. Future research could focus on unified frameworks incorporating physical information, architecture modifications (e.g., activation functions), and advanced learning techniques like model compression and transfer learning to achieve high accuracy in capturing fine-resolution details at a low computational cost.
Data Availibility
No datasets were generated or analysed during the current study.
Code Availibility
The code is available at https://bitbucket.org/gilab2022/e3sm_superresolution_dl/src/main/.
References
Bürger G (1996) Expanded downscaling for generating local weather scenarios. Clim Res 7:111–128
Bürger G, Chen Y (2005) Regression-based downscaling of spatial variability for hydrologic applications. J Hydrol 311:299–317
Cannon AJ (2011) Quantile regression neural networks: implementation in r and application to precipitation downscaling. Comput & Geosci 37:1277–1284
Cheng Y, Wang D, Zhou P, Zhang T (2018) Model compression and acceleration for deep neural networks: the principles, progress, and challenges. IEEE Signal Process Mag 35:126–136
Choudhary T, Mishra V, Goswami A, Sarangapani J (2020) A comprehensive survey on model compression and acceleration. Artif Intell Rev 53:5113–5155
Davarpanah A, Babaie H, Dhakal N (2023) Semantic modeling of climate change impacts on the implementation of the un sustainable development goals related to poverty, hunger, water, and energy. Earth Sci Inform 16:929–943
Deng X (2018) Enhancing image quality via style transfer for single image super-resolution. IEEE Signal Process Lett 25:571–575
Ding B, Qian H, Zhou J, (2018) Activation functions and their characteristics in deep neural networks. In: 2018 Chinese control and decision conference (CCDC), IEEE, pp 1836–1841
Dong C, Loy CC, He K, Tang X (2014) Learning a deep convolutional network for image super-resolution. In: European conference on computer vision, Springer, pp 184–199. https://doi.org/10.1007/978-3-319-10593-2_13
Dosselmann R, Yang XD (2011) A comprehensive assessment of the structural similarity index. Signal, Image and Video Processing 5:81–91. https://doi.org/10.1007/s11760-009-0144-1
Dupont E, Goliński A, Alizadeh M, Teh YW, Doucet A (2021) Coin: compression with implicit neural representations. arXiv:2103.03123
E3SM Project D (2018) Energy exascale earth system model v1.0. [Computer Software]. https://doi.org/10.11578/E3SM/dc.20180418.36
Faroughi SA, Datta P, Mahjour SK, Faroughi S (2022) Physics-informed neural networks with periodic activation functions for solute transport in heterogeneous porous media. arXiv:2212.08965
Ghosh S (2010) Svm-pgsl coupled approach for statistical downscaling to predict rainfall from gcm output. J Geophys Res Atmos 115
Harilal N, Singh M, Bhatia U (2021) Augmented convolutional lstms for generation of high-resolution climate change projections. IEEE Access 9, pp 25208–25218
Hessami M, Gachon P, Ouarda TB, St-Hilaire A (2008) Automated regression-based statistical downscaling tool. Environ Model & Softw 23:813–834
Hidalgo HG, Dettinger MD, Cayan DR (2008) Downscaling with constructed analogues: daily precipitation and temperature fields over the united states. California Energy Comm PIER Final Project Rep CEC-500-2007-123
Hohenegger C, Korn P, Linardakis L, Redler R, Schnur R, Adamidis P, Bao J, Bastin S, Behravesh M, Bergemann M et al (2023). Icon-sapphire: simulating the components of the earth system and their interactions at kilometer and subkilometer scales. Geosci Model Develop 16:779–811
Hurrell JW, Holland MM, Gent PR, Ghan S, Kay JE, Kushner PJ, Lamarque JF, Large WG, Lawrence D, Lindsay K et al (2013) The community earth system model: a framework for collaborative research. Bull Am Meteorol Soc 94:1339–1360
Kharin VV, Zwiers FW, Zhang X, Hegerl GC (2007) Changes in temperature and precipitation extremes in the ipcc ensemble of global coupled model simulations. J Climate 20:1419–1444
Kumar B, Atey K, Singh BB, Chattopadhyay R, Acharya N, Singh M, Nanjundiah RS, Rao SA (2023) On the modern deep learning approaches for precipitation downscaling. Earth Sci Inform 16:1459–1472
Ledig C, Theis L, Huszár F, Caballero J, Cunningham A, Acosta A, Aitken A, Tejani A, Totz J, Wang Z et al (2017) Photo-realistic single image super-resolution using a generative adversarial network. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4681–4690
Li Y, Sixou B, Peyrin F (2021) A review of the deep learning methods for medical images super resolution problems. Irbm 42:120–133. https://doi.org/10.1016/j.irbm.2020.08.004
Lim B, Son S, Kim H, Nah S, Mu Lee K (2017) Enhanced deep residual networks for single image super-resolution. In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pp 136–144
Mahajan S, Evans KJ, Branstetter M, Anantharaj V, Leifeld JK (2015) Fidelity of precipitation extremes in high resolution global climate simulations. Procedia Comput Sci 51:2178–2187
Mahjour SK, Liguori G, Faroughi SA (2024) Selection of representative general circulation models under climatic uncertainty for western north america. J Water and Clim Chang
Manor A, Berkovic S (2015) Bayesian inference aided analog downscaling for near-surface winds in complex terrain. Atmos Res 164:27–36
Nicholls RJ, Cazenave A (2010) Sea-level rise and its impact on coastal zones. Science 328:1517–1520
Oyama N, Ishizaki NN, Koide S, Yoshida H (2023) Deep generative model super-resolves spatially correlated multiregional climate data. Sci Rep 13:5992
Park S, Singh K, Nellikkattil A, Zeller E, Mai TD, Cha M (2022) Downscaling earth system models with deep learning. In: Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining, pp 3733–3742
Passarella LS, Mahajan S, Pal A, Norman MR (2022) Reconstructing high resolution esm data through a novel fast super resolution convolutional neural network (fsrcnn). Geophys Res Lett 49:e2021GL097571. https://doi.org/10.1029/2021GL097571
Schmidt G (2010) The real holes in climate science. Nature 463:21
Serifi A, Günther T, Ban N (2021) Spatio-temporal downscaling of climate data using convolutional and error-predicting neural networks. Front Clim 3:656479
Shi W, Caballero J, Huszár F, Totz J, Aitken AP, Bishop R, Rueckert D, Wang Z (2016) Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1874–1883
Sitzmann V, Martel J, Bergman A, Lindell D, Wetzstein G (2020) Implicit neural representations with periodic activation functions. Adv Neural Inform Process Syst 33:7462–7473
Soltanmohammadi R, Faroughi SA (2023) A comparative analysis of super-resolution techniques for enhancing micro-ct images of carbonate rocks. Appl Comput Geosci p 100143
Stengel K, Glaws A, Hettinger D, King RN (2020) Adversarial super-resolution of climatological wind and solar data. Proceedings of the national academy of sciences 117:16805–16815
Talab MA, Awang S, Najim SAdM (2019) Super-low resolution face recognition using integrated efficient sub-pixel convolutional neural network (espcn) and convolutional neural network (cnn). In: 2019 IEEE international conference on automatic control and intelligent systems (I2CACIS), IEEE, pp 331–335. https://doi.org/10.1109/I2CACIS.2019.8825083
Tan C, Sun F, Kong T, Zhang W, Yang C, Liu C (2018) A survey on deep transfer learning. In: Artificial neural networks and machine learning–ICANN 2018: 27th international conference on artificial neural networks, Rhodes, Greece, October 4–7, 2018. Proceedings, Part III 27, Springer, pp 270–279
Thrasher B, Maurer EP, McKellar C, Duffy PB (2012) Bias correcting climate model simulated daily temperature extremes with quantile mapping. Hydrol Earth Syst Sci 16, pp 3309–3314
Trenberth KE (2012) Framing the way to relate climate extremes to climate change. Clim Chang 115:283–290
Vandal T, Kodra E, Ganguly S, Michaelis A, Nemani R, Ganguly AR (2017) Deepsd: generating high resolution climate change projections through single image super-resolution. In: Proceedings of the 23rd acm sigkdd international conference on knowledge discovery and data mining, pp 1663–1672
Venetsanou P, Anagnostopoulou C, Loukas A, Lazoglou G, Voudouris K (2019) Minimizing the uncertainties of rcms climate data by using spatio-temporal geostatistical modeling. Earth Sci Inform 12:183–196
Vu MT, Aribarg T, Supratid S, Raghavan SV, Liong SY (2016) Statistical downscaling rainfall using artificial neural network: significantly wetter Bangkok? Theor Appl Climatol 126:453–467
Zhan R, Isola P, Efros AA, Shechtman E, Wang O (2018) The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 586–595
Zhang X, Yan X (2015) A new statistical precipitation downscaling method with bayesian model averaging: a case study in china. Clim Dyn 45:2541–2555
Zhang Y, An M et al (2017) Deep learning-and transfer learning-based super resolution reconstruction from single medical image. J Healthcare Eng 2017
Funding
S.A.F. would like to acknowledge support from the Department of Energy’s Biological and Environmental Research (BER) program (award no. DE-SC0023044).
Author information
Authors and Affiliations
Contributions
Nikhil M. Pawar: Implementation of the models, Analyzing Data, Writing - Review & Editing. Ramin Soltanmohammadi: Data Preparation. Seyed Kouroush Mahjour : Data Preparation, Writing - Review & Editing. Salah A. Faroughi: Conceptualization, Supervision, Funding acquisition, Writing - Review & Editing. All authors have read and agreed to the contributions of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Communicated by: H. Babaie.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix:methodology
SRCNN model
The super-resolution convolutional neural network (SRCNN) architecture, as shown in Fig. 9 consists of three convolutional layers: patch extraction and representation, nonlinear mapping, and reconstruction (Dong et al. 2014). Prior to this, the CR image is upscaled to the desired size using BC interpolation, after which it is fed into these three convolutional layers. In the patch extraction step, patches are extracted from the coarse-resolution image and transformed into high-dimensional vectors, forming feature maps. Nonlinear mapping then converts these vectors into another set of high-dimensional vectors, representing fine-resolution patches. Finally, the reconstruction layer combines these fine-resolution patchwise representations to produce the final fine-resolution image. The first convolutional layer has 64 filters and a \(9\times 9\) kernel size; the second convolutional layer has 32 filters and a \(1\times 1\) kernel size; and the final convolutional layer has 3 filters with a \(5\times 5\) kernel size, which constructs the FR image of the surface variable with a size of \(240\times 240\). The Adam optimizer is used as the optimization algorithm, while MSE is employed as the loss function for the model.

A schematic illustration of the SRCNN architecture. The architecture takes a bicubic interpolated image of the surface variable as input and then generates a fine-resolution image of the surface variable
FSRCNN-ESM model
The fast super-resolution convolutional neural network earth system model (FSRCNN-ESM) (Passarella et al. 2022) consists of four conv blocks, one deconvolutional layer, and three convolutional layers, as shown in Fig. 10. The FSRCNN-ESM is an extension of the FSRCNN (Passarella et al. 2022) designed to improve the accuracy of image reconstruction for ESM data. In the FSRCNN-ESM architecture, the first conv block consists of a convolutional layer with 64 filters, \(5\times 5\) kernel size, and the ReLU activation function. The second conv block has a convolutional layer with 32 filters, a \(1\times 1\) kernel size, and a ReLU activation function. The third and fourth Conv blocks each consist of a convolutional layer with 12 filters, \(3\times 3\)kernel size. Following these, there is a deconvolutional layer with 64 filters and \(3\times 3\) kernel size, and then another convolutional layer with 32 filters and \(3\times 3\) kernel size. Lastly, the final convolutional layer has 3 filters with a \(3\times 3\) kernel size, which constructs the FR image of the surface variable with a size of \(240\times 240\). The Adam optimizer is used as the optimization algorithm, while MSE is employed as the loss function for the model.

A schematic of the FSRCNN-ESM architecture. The architecture takes a coarse-resolution image of the surface variable as input and then generates a fine-resolution image of the surface variable
ESPCNN model
Efficient sub-pixel convolutional neural network (ESPCNN) consists of four hidden convolutional layers, followed by a depth-to-space (sub-pixel) layer (Shi et al. 2016). The coarse-resolution image is used as the input. The information is then passed through the first convolutional layer with a kernel size of \(5\times 5\), which comprises 64 filters. The second layer is equipped with 64 filters and a \(3\times 3\) kernel size. This is followed by the third layer with 32 filters and \(3\times 3\) kernel size. The final layer has a kernel size of \(3\times 3\) and \(r^2 \times c\) filters, where ’c’ represents the number of channels in the fine-resolution image and ’r’ signifies the upscaling ratio. Throughout all four convolutional layers, the SAME padding, orthogonal kernel initializer, and ReLU activation function are employed. Subsequently, the information is forwarded to the sub-pixel layer, which generates an FR image with an upscaling ratio of 4. The optimization algorithm employed is the Adam optimizer, and the loss function for this model is the MSE.

A schematic of the ESPCNN architecture. The architecture takes a coarse-resolution image of the surface variable as input and then generates a fine-resolution image of the surface variable
EDRN model
The enhanced deep residual network (EDRN) architecture is an extension of the super-resolution residual networks (SRResNet), sharing the same architecture as SRResNet but with a notable difference in the residual block (Lim et al. 2017). The difference lies in the absence of a batch normalization layer after each convolutional layer in the residual block. The EDRN produces better SR images with enhanced PSNR and SSIM due to this update. The model we used, as shown in Fig. 12, takes a CR image with an input size of \(60\times 60\) pixels. The first convolutional layer consists of a linear activation function, 64 filters, and a kernel size of \(3\times 3\). The padding for all Conv layers is set to “SAME.” The architecture of the residual block is depicted in Fig. 12. The EDRN model contains 16 iterations of this residual block. Each Conv layer within the residual block has 64 filters and a kernel size of \(3\times 3\). The output of the residual block is then followed by a Conv layer with 64 filters and a \(3\times 3\)-sized kernel. The output of this layer and the output of the first Conv layer are concatenated. The next block is an upsampling block consisting of four layers. The Conv layers in the upsampling block have 256 filters and a kernel size of 3x3. The depth-to-space (sub-pixel) layers, similar to the ESPCN model, are used with an upscale factor of 2. The loss function utilized for the model is mean absolute error, and the Adam optimizer is used.

A schematic of the EDRN architecture. The architecture takes a coarse-resolution image of the surface variable as input and then generates a fine-resolution image of the surface variable
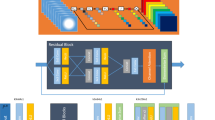
SRGAN model
The super-resolution generative adversarial network (SRGAN) architecture consists of a generator and a discriminator, as schematically shown in Fig. 13. This architecture is an extension of generative adversarial networks designed for the super-resolution task. The generator takes a CR image of the surface variable with an input size of \(60\times 60\) pixels and generates a fine-resolution image of the surface variable with an output size of \(240\times 240\) pixels. On the other hand, the discriminator takes both the generated FR image and the ground truth image of the surface variable and tries to determine the similarity between them.
In SRGAN, the generator begins with a \(60\times 60\) CR input, which goes through a convolutional layer (Conv2D) with 64 filters, a kernel size of \(9\times 9\), and SAME padding with PReLU (Ding et al. 2018) as an activation function. Following this initial layer, there are 16 residual blocks, each containing a Conv2D layer with 64 filters and a \(3\times 3\) kernel size, along with batch normalization and a PReLU activation function. The information then proceeds through another Conv2D layer and batch normalization, maintaining the same configuration. In each residual block, the element-wise sum operation combines the input with the output of that block. The output of these 16 repeating residual blocks is then merged with the result of the first PReLU layer, followed by a Conv2D layer with 64 filters and a \(3\times 3\) sized kernel, along with batch normalization. Subsequently, the resulting tensor is processed by the next two upscale blocks, each consisting of a Conv2D layer with 256 filters and a \(3\times 3\) kernel, followed by an upsampling layer and parametric activation function. Finally, we have the last Conv2D layer with 3 filters and a kernel size of \(9\times 9\) that generates an FR image of the size \(240\times 240\).
The discriminator in SRGAN evaluates the similarity between the generated FR image and the ground truth FR image to gauge their similarity. In this study, the discriminator is structured with a Conv2D layer with a kernel size of \(3\times 3\) 64 filters and a stride of 1. This is followed by an activation function, LReLU (Ding et al. 2018), with an alpha value set to 0.2. Subsequently, seven discriminator blocks are included in the architecture. Each discriminator block comprises a Conv2D layer, a batch normalization layer, and an activation function employing LReLU. While the kernel size remains fixed at \(3\times 3\), however, there are variations in the number of channels and stride. After the seventh discriminator block, the output undergoes a flattening operation. The resulting data is then passed into a dense layer consisting of 1024 neurons and utilizing a LReLU activation function. The final layer is a single-unit dense layer employing a sigmoid activation function. The overall SRGAN loss is defined as Ledig et al. (2017),
where \(\mathcal {L}_{cl}\) and \(\mathcal {L}_{al}\) represent the content and adversarial loss. The content loss is derived from the VGG-19 network (Ledig et al. 2017) and is computed as the MSE between the features of the generated CR profile and the features of the corresponding ground truth profile extracted from the network. The adversarial loss is derived from the discriminator network, which is calculated as a binary cross-entropy between the predicted probability of the discriminator and the target label. For additional detail, refer to Ledig et al. (2017); Li et al. (2021).

A schematic of the SRGAN architecture. Panel (a) depicts the architecture of the generator, which takes the coarse-resolution image of the surface variable as input and generates the fine-resolution image of the surface variable. Panel (b) illustrates the discriminator architecture, which takes both the fine-resolution and the ground truth images of the surface variable and attempts to distinguish between them
B. Appendix: evaluation metrics
To assess the effectiveness of our proposed framework, we employ a range of statistical metrics. We begin with the Absolute Point Error (APE), denoted as E(x, y) (Faroughi et al. 2022), which is defined as follows:
The APE measures the point-wise difference between the reconstructed and ground truth profiles, where \(X_{1}\) represents the reconstructed profile and \(X_{2}\) is the ground truth profile.
Next, we utilize the Mean Squared Error (MSE) (Passarella et al. 2022), defined as:
Here, the MSE computes the average squared difference between corresponding data points in the reconstructed and ground truth profiles, where N is the total number of grids or pixels in an image.
Another metric in our evaluation toolbox is the Peak Signal-to-Noise Ratio (PSNR) (Deng 2018), given by:
PSNR measures the ratio between the maximum possible signal power and the power of noise that affects the fidelity of the representation. It is expressed in decibels (dB).
Additionally, we employ the Structural Similarity Index Measure (SSIM) (Dosselmann and Yang 2011), defined as:
in the SSIM formula, \(\mu _{x_1}\) and \(\mu _{x_2}\) represent the mean values of the reconstructed and ground truth profiles, \(\sigma _{x_1}^2\) and \(\sigma _{x_2}^2\) are the variances, \(\sigma _{{x_1}{x_2}}\) is the covariance, and \(c_1\) and \(c_2\) are small constants included for numerical stability. SSIM captures differences in structure, luminance, and contrast between profiles.
Finally, we incorporate the Learned Perceptual Image Patch Similarity (LPIPS) metric (Zhang et al. 2018; Soltanmohammadi and Faroughi 2023), which is given by:
here, \(\phi _j\) represents feature maps from the j-th layer of a pre-trained deep neural network, \(w_j\) are the applied weights for each layer, M is the number of overlapping patches extracted from the profiles, K is the number of layers considered, and p is typically set to 2 for Euclidean distance. LPIPS leverages a deep neural network trained to mimic human perception of image similarity, allowing it to capture fine-grained perceptual differences between profiles by comparing their feature representations at multiple network layers. This enables a more comprehensive measure of profile similarity.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Pawar, N.M., Soltanmohammadi, R., Mahjour, S.K. et al. ESM data downscaling: a comparison of super-resolution deep learning models. Earth Sci Inform (2024). https://doi.org/10.1007/s12145-024-01357-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12145-024-01357-9