
Abstract
The Yeşilırmak River Basin in northern Türkiye is crucial for the region’s water supply, agriculture, hydroelectric power generation, and clean drinking water. The primary goal of this study is to determine which modeling approach is most appropriate for various locations within the basin and how well meteorological data can predict river flow rates. Hydrological and meteorological forecasting both depend on the prediction of river flow rates. An artificial neural network (ANN), Univariate and Multivariate Long Short-Term Memory (LSTM) models have been utilized for streamflow forecasting. This research aims to determine the best model for several provinces in the basin area and give decision-makers a tool for reliable river flow rate estimates by combining LSTM and ANN models. According to research findings, the supervised multivariate LSTM model performed better than the unsupervised model in accuracy and precision. The sliding window methodology is suitable for estimating river flow based on meteorological datasets because it offers a primary method for reinterpreting time-series data in a supervised learning style. Compared to LSTM models, the ANN model that has been statistically optimized through experiments (DoE) design performs better in forecasting the river flow rate in the Yeşilırmak River basin (R2 = 0.98, RMSE = 0.18). The study’s findings provided prospective cognitive models for the strategic management of water resources by forecasting future data from flow monitoring stations.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Many studies have been conducted on the Yeşilırmak river basin in northern Türkiye. Türkiye ‘s Yeşilırmak River Basin is essential for the region’s water supply. It represents a lifeline for 38,730 square kilometers and several provinces (Kurunç et al. 2005). The basin is vital to agriculture, hydroelectric power generation, and providing clean drinking water to millions of people. The Yeşilırmak River’s flowing waters facilitate the development of clean and renewable energy, reducing the need for fossil fuels and reducing the impact of power generation on the environment. Several dams and power facilities capture the river’s energy, supplying electricity to local towns and provinces. This clean and sustainable energy source decreases dependency on fossil fuels and adds to Türkiye ‘s efforts to tackle climate change (Erat et al. 2021). The basin’s significance goes beyond its borders since it is a critical water supply for neighboring regions (Darama and Seyrek 2016). Numerous studies have demonstrated that univariate LSTM forecasting of river flow rate using historical data outperforms conventional models (Chen et al. 2021; Liu et al. 2021b; Silva et al. 2021). It has been discovered that the use of LSTM for forecasting is beneficial in many areas, including flood forecasting (Le et al. 2019; Ha et al. 2021), hydropower operations (Guo et al. 2021), and the creation of garbage from urban building (Huang et al. 2020).
Additionally, the relationship between climatic factors and river flow rate concerning worldwide river temperatures, river flow variations, and susceptibility to atmospheric warming has been studied (Vliet et al. 2011). Conversely, supervised extended short-term memory models have also shown to be successful in many applications. For example, structurally supervised models outperformed the LSTM model in few-shot learning and syntactic generalization in neural language models (Wilcox et al. 2020). Moreover, supervised LSTM models were applied to anomaly detection (Ergen and Kozat 2020). Conclusively, unsupervised long short-term memory (LSTM) models have demonstrated potential in several domains, including time series forecasting, driving maneuver recognition, video summarization, and voice segmentation. Nevertheless, supervised LSTM models have succeeded in language modeling, anomaly detection, and syntactic generalization. Both strategies offer advantages over the other and can be used in various situations depending on the task’s needs and the availability of labeled data.
According to research by Sagheer and Kotb (2019), unsupervised pre-training improves the model’s performance more than supervised training of a deep LSTM-based stacking autoencoder. Comparably, Maillard et al. (2019) discovered that distinct parameters are used by the fixed-branching, supervised, and unsupervised Tree-LSTM models, reflecting variations in the training strategies and model topologies. Moreover, Li and colleagues (2021) showed that semi-supervised LSTM might get outcomes identical to the supervised technique with far fewer labeled data, underscoring the possibility of unsupervised or semi-supervised methods attaining comparable performance to supervised methods.
Long Short-Term Memory (LSTM) models, both univariate and multivariate, have been extensively utilized and demonstrated efficacy in several domains, such as streamflow prediction and flood forecasting (Le et al. 2019). These models offer potential for practical applications in river flow rate forecasting since they have proven appropriate for short-term water situation forecasts (Liu et al. 2021a). Studies have shown that utilizing recent discharge measurements in univariate LSTM models can improve streamflow prediction accuracy and insights. A three-layer univariate LSTM network was employed in an urban construction waste generation research for time-series forecasting, corroborating the versatility and efficacy of univariate LSTM models across many fields (Huang et al. 2020).
On the other hand, streamflow forecasting has also investigated multivariate LSTM river flow rate forecasting using meteorological data. It is noteworthy that multivariate LSTM models have demonstrated potential in forecasting water flow. As an illustration of its potential, Silva et al. (2021) implemented a water flow forecasting study using a multivariate LSTM network on river tributaries. Wojtkiewicz et al. (2019) also noted that LSTM performed better than other models in univariate and multivariate tests. This suggests that the decision between univariate and multivariate LSTM models may rely on particular forecasting requirements and data features. These results validate that LSTM models can potentially be valuable tools for forecasting when using meteorological data (Nguyen et al. 2021). This research aims to determine the best model for six provinces in the basin area and give decision-makers a tool for reliable river flow rate estimates by comparing Long Short-Term Memory (LSTM) and artificial neural network (ANN) models. The research aims to answer questions about the efficacy of using meteorological data to estimate the river flow rate in the Yeşilırmak river basin and which modeling technique is most suited for different locations on the tributaries of the Yeşilırmak River. The findings of this study reveal that, while the ANN model has shown remarkable promise, the LSTM model is superior in forecasting river flow rates when meteorological data is also used.
Methodology
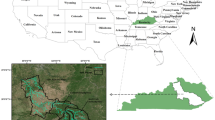
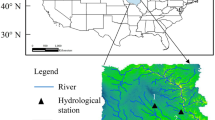
Handling this rich resource is vital to maintaining its sustainability for future generations. Figure 1 shows the observation points for the meteorological and flow rate data in six provinces in the Yeşilırmak River basin. The streamflow stations are D14A014 in Samsun, D14A024 in Amasya, D14A062 in Tokat, D14A080 in Yozgat, E14A014 Amasya, and E14A022 in Gümüşhane while the meteorological ones are Çorum, Samsun, Amasya, Tokat and Gümüşhane. The details of the stations are shown in Table 1. The closest meteorological station to the streamflow station was used to estimate streamflow data with meteorological data.

The observation points for the meteorological and flow rate data in six provinces in the Yeşilırmak River basin
This research aims to look at the ability of meteorological data to forecast river flow rate in the Yeşilırmak river basin and to find the best modeling technique for different places within the basin. We propose that combining meteorological data with LSTM and ANN models would increase the accuracy of river flow rate estimates in the Yeşilırmak river basin compared to existing time series models that do not include meteorological data.
Time series analysis is a statistical method for examining and projecting a variable’s behavior across time. Time series data are used to look for patterns, trends, and correlations in the data. They are collected regularly, such as daily, monthly, or annually (Papacharalampous et al. 2021). Time series analysis is frequently used to anticipate future variables of interest and make well-informed judgments based on previous data in various fields, including engineering, economics, finance, and environmental research. The LSTM model was implemented based on its capacity to manage seasonal data.
First, correlation analysis was used to understand the relationship between the measured values better. As a result, the association between river flow levels and meteorological data was discovered. Supplementary Figure S1, as the supporting information, shows the correlation values for the observed parameters for the six measurement locations: D14A014 Samsun, D14A024 Amasya, D14A062 Tokat, D14A080 Yozgat, E14A014 Amasya, and E14A022 Gümüşhane, respectively. Seven meteorological parameters: Solar Hour (h), Humidity (g/m3), Wind Speed (m/s), Average Temperature (℃), Maximum Temperature (℃), Minimum Temperature (℃), and Rain (mm/d), also Flow Rate (m3/s) were measured daily for all six observation points. Because the Yeşilırmak River flows through numerous provinces, flow measurements from six distinct provinces and climatic data from these provinces were used. Daily measured data spanning many years (01/09/1983–30/09/2020) were employed in the analyses. The final 20% of the data (02/05/2013–30/09/2020) was used to assess the success of the applied approaches. The correlation between meteorological indicators and river flow data is relatively low. This is true for all six observation stations. JMP-PRO was used to carry out correlation analysis and ANN implications.
In general, the process of choosing meteorological variables for AI models necessitates a thorough evaluation of various aspects, including the quality of historical data, the impact of subjective decisions on model uncertainty, the need to correct systematic biases in climate simulations (Velázquez-Zapata 2019), and the importance of precipitation as a fundamental meteorological variable in hydrological modeling (Khôi and Suetsugi 2014). The most suitable meteorological and hydrological data were selected for the developed models utilizing correlation analysis to identify any relationships or dependencies between the data. Therefore, careful selection has been made of meteorological and hydrological data that may produce the best model outcomes.
The data was subjected to a series of preprocessing steps to prepare it for deep learning models. In the literature, preprocessing steps include cleaning, sliding window, label, Piece-wise aggregate approximation / symbolic aggregate approximation, and word embedding steps (Florian et al. 2021; Naduvil-Vadukootu et al. 2017). In this research, preprocessing data includes data cleansing. In the data cleaning step, missing and contradictory data were detected. Interpolation methods corrected these data. Data transformation, feature selection, normalization, reduction, and other processes are included in data pretreatment, whereas data cleaning focuses on finding and fixing flaws in the dataset. The sliding window model was also used throughout the preprocessing stages to prepare the sequential data. The status of the data was observed using Exploratory Data Analysis methods. The relationships between pairs of variables were examined using correlation analysis to find any dependencies or correlations between them. Since the LSTM analyses were done in Matlab, the data was scaled between − 1 and 1 before being entered into the input cell using the mapminmax function, one of Matlab’s data preprocessing methods. Solar hour, humidity, wind speed, Average Temperature (Avg. T.), Maximum Temperature (Max. T.), Minimum Temperature (Min. T.), Rain, and Discharge Qt-1, Qt-2, Qt-3, Qt-4, and Qt-5 were input parameters to predict Discharge Qt.
In this study, the optimized Artificial Neural Network (ANN) architectures were created using the Design of Experiments (DoE) and consisted of two hidden layers and 20 different number combinations of activation functions at various node counts, as shown in Supplementary Table ST-1. The LSTM model was created with one 100-unit LSTM layer and one dense layer. While creating the model, the over-fitting situation was checked, and model layers were determined to be the most optimum situation.Waldner’s (2020) work covers many of the most common splitting criteria and ratios used in cross-validation. These include hold-out, block hold-out, class, and space-based stratification, and split ratios such as 67:33 and 80:20. In this study, the training and test datasets for hold-out cross-validation were divided into different ratios, such as 64:16:20 for ANN training, validation, and testing. For all LSTM models, the training and test set ratios were 80:20.
Improving the performance of Artificial neural networks (ANN) through the design of experiments (DoE)
Finding the ideal Artificial Neural Network (ANN) design requires systematically examining the links between the inputs and model outputs to maximize the performance of an ANN utilizing the Design of Experiments (DoE) (Rodriguez-Granrose et al. 2021). It is essential to identify its optimum parameters by applying DoE approaches to improve the performance of the ANN model (Khoshdel and Akbarzadeh 2016). It has been demonstrated that using DoE and Taguchi approaches to train and build ANNs may provide robust designs and statistical analyses that guarantee confidence in the best possible design (Ortiz-Rodríguez et al., 2006; Lin et al. 2011).
Moreover, utilizing DoE to optimize ANN parameters like neuron counts and activation functions might enhance the model’s accuracy and performance (Rodriguez-Granrose et al. 2021). Furthermore, it has been demonstrated that the application of Genetic Algorithms (GA) significantly enhances the performance of ANN and optimizes initial weights (Arabgol and Ko 2013; Chang et al. 2012). Furthermore, Winiczenko et al. (2016) have shown that the Response Surface Method with GA optimization of ANN topology results in a predictive model with the best mean squared error performance on validation samples. It is essential to remember that optimizing ANN parameters—like learning rate and the number of neurons in hidden layers—is vital to getting the best results from the ANN classifier (Raza et al. 2016). Supplementary Table S1, as the supporting information, shows the ideal ANN architecture combinations with the number of nodes in two layers through the twenty runs in the DoE. The two-layered ANN structure contains the hyperbolic tangent (TanH), Linear (Lin), and Gaussian (Gauss) activation functions. Twenty different ANN architectures were created for each of the six locations in the Yeşilırmak River basin.
Univariate and Multivariate Long Short-Term memory (LSTM) models
Recurrent Neural Networks (RNN) are artificial neural networks with memory units. Time series analysis makes extensive use of RNN. In applications requiring long-term learning, basic RNN topologies are inefficient. To address this issue, LSTM structures were derived from RNN structures (Hochreiter and Schmidhuber 1997). While LSTM saves information for later use, it also protects the old signal from the gradient extinction issue. This system is constructed by supplementing the simple RNN structure with an extra data stream that transmits information over time.
The fundamental RNN structure employs the values from the preceding stage in each loop step. The LSTM structure is created by including the c (transport) connection. Data is integrated into the system from the in (input) component and acquired from the out (output) part. Each block, denoted as s (state), reflects the knowledge that LSTM has learned thus far. The time value is represented by t (see Fig. 2).

The architecture of the LSTM model that was implemented for this study
In this work, we employed a single-layer 100-dimensional LSTM and a single-layer one-dimensional flatten structure in the multi-input teacherless learning RNN structure. This network was created using the Mean Absolute Error (MAE) loss function and the Adaptive Moment Estimation (ADAM) optimizer. The network was trained using 500 epochs. The hyperparameters have been fine-tuned for the best possible result.
Supervised and unsupervised LSTM
Unsupervised LSTM models have been used to identify driving movements, using a significantly smaller amount of labeled data to reach results comparable to the supervised approach (Li et al. 2021; Sagheer and Kotb 2019). Additionally, unsupervised LSTM models have been used for video summarization, where they have shown greater performance than most published supervised techniques and have surpassed other state-of-the-art unsupervised methods (Zhou et al. 2018). Furthermore, being the first models to perform well on both symbolic and acoustic representations of speech, unsupervised LSTM models have demonstrated effectiveness in speech segmentation (Elsner and Shain 2017). On the other hand, in some cases, supervised LSTM models have demonstrated better performance. Compared to the most advanced sequential LSTM language models, supervised generative models have produced the most well-known parsing findings and reduced perplexity in language modeling (Dyer et al. 2016).
The sliding window approach in time series analysis
Converting time series data into a format appropriate for supervised learning is a commonly employed approach known as the sliding window method (Derot et al. 2020; Huang et al. 2022; Peng et al. 2021). Lv et al. (2021) and Vafaeipour et al. (2014) highlight the sliding window approach for breaking down time series data into smaller pieces that can be used for statistical feature extraction or prediction. The time-series data must be reframed into a supervised learning format to anticipate river flow using meteorological data and the sliding window approach (Meng et al. 2022; Shin and Yi 2019). The sliding window approach has been integrated with a deep-learning runoff model-based meteorological forecast for a hydrological early warning system (Fuente et al. 2019). It has also been utilized in flood forecasting, which is employed to power a river routing model that generates river flow predictions several months in advance (Emerton et al. 2019).
Results
In a time series, the explanatory variables are the number of previous values to that time period represented by the given lag, and the predictor variable is the observation at a certain time. The sliding window approach refers to the process of predicting the future time step by using previous time steps. For over 37 years, the Yeşilırmak River basin recorded daily flow rates and meteorological data. The predictor variable is the observation at a specific time, and the explanatory variables are the number of prior values to that time period represented by the specified lag. For this reason, a model with a high lag correlation coefficient at a 5-day lag was used in this investigation.
In this study, the performance of ANN was significantly enhanced by methodically examining the links between inputs and outputs. The accuracy and robustness of the model improved through optimizing ANN performance via the Design of Experiments (DoE). Even in cases where trained neural networks diverge due to unpredictability in initial weights, the use of DoE and statistical analysis can result in effective optimization and confidence in the ideal design of ANN (Inohira and Yokoi 2007). Table 2 shows the results of the ANN analysis through the twenty runs in the DoE. Figure 3 shows the best fit through the ANN predictions for six observation points.



Best fit through ANN for the observation points
Long Short-Term Memory (LSTM) neural networks have been successfully applied in several domains, including streamflow modeling and flood predictions (Le et al. 2019; Feng et al. 2020; Frank et al. 2023). The relevance of meteorological data in hydrological modeling is further underscored by the fact that proper assessment of the world’s water resources depends on integrating meteorological forcing data into hydrological models (Hanasaki et al. 2008).
This research has demonstrated the effectiveness of using meteorological data to enhance river flow rate estimates using LSTM-based models. It has been discovered that including data on exogenous meteorological factors greatly enhances forecasting accuracy in LSTM models, surpassing univariate models. Figure 4 depicts the results of the univariate LSTM analysis for the flow rate prediction.



Univariate LSTM results for the observation points
Historical data-based univariate LSTM river flow rate forecasts have improved performance across six situations; however, by including more weather factors, multivariate LSTM predictions of river flow rate using meteorological data have improved and demonstrated increased predicting accuracy. These results point to the potential of LSTM models to enhance river flow rate forecasting; the selection between univariate and multivariate methods hinges on the accessibility and applicability of meteorological and historical data.
Supervised and unsupervised LSTM models have been investigated in the literature for forecasting river flow statistics using meteorological data. Applications for supervised long short-term memory (LSTM) models include real-time river water level forecasting (Silva et al. 2021), streamflow simulation (Fu et al. 2020), and flood forecasting (Le et al. 2019). These investigations have shown the effectiveness and viability of supervised LSTM models for river flow forecasting.
The sliding window approach has been effectively applied to neural network forecasting processes, where each sliding window measurement is addressed to a single input neuron. It illustrates the technique’s relevance in forecasting meteorological data (Stangalini et al., 2010). It should be noted that while using the sliding window approach, choosing the ideal time step is essential to guarantee the efficacy of the machine learning tool (Meng et al. 2022).
The sliding window approach in LSTM for supervised learning is an essential way to anticipate river flow using meteorological data. Using the value of the previous time step to predict the upcoming time step is a strategy that entails framing time-series data into a supervised learning framework (Karakish et al. 2022). The sliding window methodology provides a fundamental way to reinterpret time-series data in a supervised learning style, which makes it appropriate for forecasting river flow based on meteorological data. Supervised multivariate LSTM model results are shown in Fig. 5.



Supervised multivariate LSTM results for the observation points
The decision between supervised and unsupervised LSTM models should be based on the particular needs and features of forecasting river flow. This work shows the potential of unsupervised LSTM models in managing environmental data, which may be relevant to meteorological data used in river flow forecasting, even if it is not directly connected to river flow forecasting. Solar hour, humidity, wind speed, Average Temperature (Avg. T.), Maximum Temperature (Max. T.), Minimum Temperature (Min. T.), and Rain were input parameters to predict Discharge Qt for the unsupervised model. The unsupervised multivariate LSTM model results are shown in Fig. 6.



Unsupervised multivariate LSTM results for the observation points
Table 3 shows a comparison of the models used in terms of regression metrics: R2 and RMSE. Results underline that the supervised multivariate LSTM models have performed better than the unsupervised and univariate LSTM, considering this research. The ANN model was optimal based on its capacity to manage seasonal data for accurate river flow rate estimations.
Several statistical metrics were compared between the models’ training and testing phases’ outputs and the observed data to see if the suggested models maintained the statistical characteristics of the river flow time series. It is evident from Table 4 that the ANN model outperforms the other models in capturing the statistical characteristics of the river flow time series.
Discussion
Analyzing the relationships between inputs and outputs has significantly improved the performance of ANNs. In this study, the implemented model’s resilience and accuracy increased through the Design of Experiments (DoE) to optimize ANN performance. This cutting-edge technique was used in several recent studies, including the one by Fontana et al. (2023), which applied to the data from industrial experiments and yielded encouraging findings. Sandu et al. (2020) demonstrated how well the ANN model, DoE approach, and CAE simulation technologies work together to forecast the polymer flow length for injection-molded components. Pimentel-Mendoza et al. (2021) demonstrated integrating these two approaches in physics-related applications using DoE to build inputs for ANN training. Moreover, Khoshdel and Akbarzadeh (2016) reported an application of DoE to discover the optimal parameters of an ANN model for calculating force from the sEMG signal dataset.
Compared to LSTM models, the ANN model, which has been statistically optimized through the design of experiments (DoE), performs better. This technique produced encouraging results, making ANN the best approach for forecasting river flow compared to other approaches. We noticed a substantial weak correlation between river flow rate and the meteorological data in the Yeşilırmak basin. When historical flow data is available, supervised long short-term memory (LSTM) models can be helpful in river flow forecasting. These models can be trained to produce precise forecasts based on established input-output connections. Unsupervised LSTM models, on the other hand, could help examine and reveal hidden patterns in the river flow data, particularly in situations where the relationships between various variables are not well established.
The training strategy and performance results differ between supervised and unsupervised Long Short-Term Memory (LSTM) networks. Labeled data must be used for training for supervised LSTM networks to learn. It necessitates human assistance in supplying the appropriate input-output pairings. Unsupervised LSTM networks, on the other hand, use unlabeled data for training, enabling the model to identify patterns and structures in the input data without explicit supervision. A good set of findings was obtained when Kareem et al. (2024) applied the supervised methods for streamflow prediction.
The sliding window approach is a popular strategy for transforming time series data into a format appropriate for supervised learning. The sliding window approach has been used in meteorology to construct operational systems for seasonal hydro-meteorological forecasting. For instance, Emerton et al. (2018) created a seasonal hydro-meteorological forecasting system that combines hydrological models with seasonal meteorological predictions to produce probabilistic river flow forecasts. In conclusion, research has used supervised and unsupervised LSTM models to forecast river flow using meteorological data. While supervised LSTM models have demonstrated effectiveness in this field, taking into account this study and the relevant meteorological and river flow rate data, ANN has regularly outperformed other models.
The complexity and diversity of environmental elements, such as wind and air humidity, that influence model predictions may limit AI models’ adaptability and efficiency in areas with varying meteorological or hydrological conditions (Liu et al. 2018). This constraint may affect the model’s performance in areas with distinct climatic features, implying that the same models may not work as well in areas with significantly different climatic or hydrological characteristics.
Researchers should know the restrictions and difficulties associated with using AI models to anticipate river flow based on meteorological data. Swagatika et al. (2024) state that data availability and quality dependence are significant drawbacks. High-quality meteorological data are needed for accurate forecasting; however, these data aren’t always trustworthy or readily available. The performance of AI models may be significantly impacted by missing or erroneous data, which results in fewer accurate predictions (Sahoo et al. 2023; Srikanth et al. 2019). Forecasting accuracy is further impacted by the dynamic character of river systems and weather circumstances, which present complications that the models may not always adequately reflect. Moreover, maintaining and updating models is necessary to guarantee the accuracy and relevance of forecasts throughout time. The AI models must be routinely retrained with fresh data when climatic patterns and river dynamics change to adjust to the changing environment.
River flow prediction is critical for water resource management and decision-making. Water resource managers and policymakers may make educated decisions about water distribution, flood preparation, and reservoir management using established AI models that predict river flow based on meteorological data. These AI models have succeeded in various hydrological applications, including real-time flood forecasting, rainfall-runoff modeling, and water quality prediction. Furthermore, this study underscores the necessity for a long-term agricultural water resource management strategy in light of rising water shortages and drought.
Conclusion
This research encompasses six provinces within the Yeşilırmak River basin. These provinces span a vast region from upstream to downstream and are considered significant sites that can provide us with an understanding of all tributaries when evaluating the Yeşilırmak River’s flow rate. By utilizing long-term flow rates and climatic data, this study aims to forecast river flow rates for the future. An attempt was made to develop a model within the research parameters utilizing widely employed approaches. The ultimate objective was to ascertain the appropriate approach that can produce exact findings against hazardous scenarios like floods that may arise in the future.
First and foremost, the correlation coefficient, which indicates the strength of the association between the dependent and independent variables, was determined. The correlation study revealed a weak connection between meteorological data and flow rate. As a result, the sliding window approach, a prominent method for time series analysis, was adopted.
Even though univariate LSTM models have proven effective in various forecasting applications, such as streamflow and flood forecasting, it is crucial to consider the particular context and data properties when deciding between univariate and multivariate LSTM models for river flow rate forecasting. The findings of this study demonstrate how LSTM may be used to overcome the drawbacks of conventional models and increase predicting accuracy. Unsupervised LSTM models can reveal hidden patterns and structures within the data to help learn about intricate river flow dynamics. In contrast, supervised LSTM models are trained on labeled data to generate predictions based on established input-output correlations.
The study’s findings show that simply relying on meteorological data to forecast flow rates is impractical. The chosen unsupervised multivariate LSTM model may be worse than using the dependent variable’s mean for prediction since it fails to account for data variability. Given the current study field and data, this case clearly shows that unsupervised multivariate LSTM cannot estimate flow rate. Rigorous field observations and laboratory testing of certain factors would achieve better findings. The efficacy of the procedures employed in this study has been evaluated just for the current inquiry and may alter if more research fields and data are incorporated.
Although meteorological data have a low association with flow rate, supervised multivariate LSTM often outperforms univariate LSTM. In conclusion, the ANN model optimized through DoE mainly showed the lowest root mean square error and highest coefficient of determination when comparing the actual and predicted river flow rates.
Data availability
No datasets were generated or analysed during the current study.
References
Arabgol S, Ko H (2013) Application of artificial neural network and genetic algorithm to healthcarewaste prediction. J Artif Intell Soft Comput Res 3(4):243–250. https://doi.org/10.2478/jaiscr-2014-0017
Chang Y, Lin J, Shieh J, Abbod M (2012) Optimization the initial weights of artificial neural networks via genetic algorithm applied to hip bone fracture prediction. Adv Fuzzy Syst 2012:1–9. https://doi.org/10.1155/2012/951247
Chen Y, Gao J, Bin Z, Qian J, Pei R, Zhu H (2021) Application study of IFAS and LSTM models on runoff simulation and flood prediction in the Tokachi River basin. J Hydroinformatics 23(5):1098–1111. https://doi.org/10.2166/hydro.2021.035
Darama Y, Seyrek K (2016) Determination of watershed boundaries in Turkey by GIS based hydrological river basin coding. J Water Resour Prot 8(11):965
Derot J, Yajima H, Schmitt F (2020) Benefits of machine learning and sampling frequency on phytoplankton bloom forecasts in coastal areas. Ecol Inf 60:101174. https://doi.org/10.1016/j.ecoinf.2020.101174
Dyer C, Kuncoro A, Ballesteros M, Smith NA (2016) Recurrent neural network grammars. In: Proceedings of the 2016 Conference of the North American chapter of the Association for Computational Linguistics: Human language technologies. ACL, pp 199–209. https://doi.org/10.18653/v1/N16-1024
Elsner M, Shain C (2017) Speech segmentation with a neural encoder model of working memory. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. pp 1070–1080
Emerton R, Stephens E, Cloke H (2019) What is the most useful approach for forecasting hydrological extremes during El Niño? Environ Res Commun 1(3):031002. https://doi.org/10.1088/2515-7620/ab114e
Emerton R, Zsótér E, Arnal L, Cloke H, Muraro D, Prudhomme C, …, Pappenberger F (2018) Developing a global operational seasonal hydro-meteorological forecasting system: glofas-seasonal v1.0. Geosci Model Dev 11(8):3327–3346. https://doi.org/10.5194/gmd-11-3327-2018
Erat S, Telli A, Ozkendir OM, Demir B (2021) Turkey’s energy transition from fossil-based to renewable up to 2030: milestones, challenges and opportunities. Clean Technol Environ Policy 23:401–412
Ergen T, Kozat S (2020) Unsupervised anomaly detection with LSTM neural networks. Ieee Trans Neural Networks Learn Syst 31(8):3127–3141. https://doi.org/10.1109/tnnls.2019.2935975
Feng D, Fang K, Shen C (2020) Enhancing streamflow forecast and extracting insights using long-short term memory networks with data integration at continental scales. Water Resour Res 56(9):e2019WR026793. https://doi.org/10.1029/2019wr026793
Florian E, Sgarbossa F, Zennaro I (2021) Machine learning-based predictive maintenance: a cost-oriented model for implementation. Int J Prod Econ 236:108114. https://doi.org/10.1016/j.ijpe.2021.108114
Fontana R, Molena A, Pegoraro L, Salmaso L (2023) Design of experiments and machine learning with application to industrial experiments. Stat Pap 64:1251–1274. https://doi.org/10.1007/s00362-023-01437-w
Frank C, Rußwurm M, Fluixá-Sanmartín J, Tuia D (2023) Short-term runoff forecasting in an alpine catchment with a long short-term memory neural network. Front Water 5:1126310. https://doi.org/10.3389/frwa.2023.1126310
Fu M, Fan T, Ding Z, Salih S, Al-Ansari N, Yaseen Z (2020) Deep learning data-intelligence model based on adjusted forecasting window scale: application in daily streamflow simulation. Ieee Access 8:32632–32651. https://doi.org/10.1109/access.2020.2974406
Fuente A, Meruane V, Meruane C (2019) Hydrological early warning system based on a deep learning runoff model coupled with a meteorological forecast. Water 11(9):1808. https://doi.org/10.3390/w11091808
Guo H, Conklin M, Maurer T, Avanzi F, Richards K, Bales R (2021) Valuing enhanced hydrologic data and forecasting for informing hydropower operations. Water 13(16):2260. https://doi.org/10.3390/w13162260
Ha S, Liu D, Mu L (2021) Prediction of yangtze river streamflow based on deep learning neural network with El Niño–southern oscillation. Sci Rep 11(1):11738. https://doi.org/10.1038/s41598-021-90964-3
Hanasaki N, Kanae S, Oki T, Masuda K, Motoya K, Shirakawa N, Tanaka K (2008) An integrated model for the assessment of global water resources – part 1: model description and input meteorological forcing. Hydrol Earth Syst Sci 12(4):1007–1025. https://doi.org/10.5194/hess-12-1007-2008
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
Huang L, Cai T, Zhu Y, Zhu Y, Wang W, Sun K (2020) LSTM-based forecasting for urban construction waste generation. Sustainability 12(20):8555. https://doi.org/10.3390/su12208555
Huang G, Wang D, Du Y, Zhang Q, Bai Z, Wang C (2022) Deformation feature extraction for gnss landslide monitoring series based on robust adaptive sliding-window algorithm. Front Earth Sci 10:884500. https://doi.org/10.3389/feart.2022.884500
Inohira E, Yokoi H (2007) An optimal design method for artificial neural networks by using the design of experiments. J Adv Comput Intell Intell Inf 11(6):593–599. https://doi.org/10.20965/jaciii.2007.p0593
Karakish M, Fouz M, Elsawaf A (2022) Gait trajectory prediction on an embedded microcontroller using deep learning. Sensors 22(21):8441. https://doi.org/10.3390/s22218441
Kareem BA, Zubaidi SL, Al-Ansari N, Muhsen YR (2024) Review of recent trends in the hybridisation of preprocessing-based and parameter optimisation-based hybrid models to forecast univariate streamflow. CMES-Comput Model Eng Sci 138(1):1–41
Khôi Đ, Suetsugi T (2014) Impact of climate and land-use changes on hydrological processes and sediment yield—a case study of the be river catchment, Vietnam. Hydrol Sci J 59(5):1095–1108. https://doi.org/10.1080/02626667.2013.819433
Khoshdel V, Akbarzadeh A (2016) Application of statistical techniques and artificial neural network to estimate force from semg signals. J Artif Intell Data Min 4(2):135–141. https://doi.org/10.5829/idosi.jaidm.2016.04.02.02
Kurunç A, Yürekli K, Cevik O (2005) Performance of two stochastic approaches for forecasting water quality and streamflow data from Yeşilιrmak River, Turkey. Environ Model Softw 20(9):1195–1200
Le X, Ho H, Lee G, Jung S (2019) Application of long short-term memory (LSTM) neural network for flood forecasting. Water 11(7):1387. https://doi.org/10.3390/w11071387
Li P, Abdel-Aty M, Islam Z (2021) Driving maneuvers detection using semi-supervised long short-term memory and smartphone sensors. Transp Res Record J Transp Res Board 2675(9):1386–1397. https://doi.org/10.1177/03611981211007483
Lin TY, Ping HC, Hsu TH, Wang LC, Chen CC, Chen CF, …, Chang FC (2011) A systematic approach to the optimization of artificial neural networks. In: 2011 IEEE 3rd International Conference on Communication Software and Networks. IEEE, pp 76–79
Liu Y, Bogaardt L, Attema J, Hazeleger W (2021) Extended-range arctic sea ice forecast with convolutional long short-term memory networks. Mon Weather Rev 149(6):1673–1693
Liu Y, Wang H, Feng W, Huang H (2021) Short term real-time rolling forecast of urban river water levels based on LSTM: a case study in Fuzhou city, China. Int J Environ Res Public Health 18(17):9287
Liu L, Wang Y, You N, Liang Z, Qin D, Li S (2018) Changes in aridity and its driving factors in China during 1961–2016. Int J Climatol 39(1):50–60. https://doi.org/10.1002/joc.5781
Lv Y, Hu S, Yan T, Meng X, Zhu M, Xu R (2021) Radar target shape recognition using a gated recurrent unit based on RCS time series’ statistical features by sliding window segmentation. Iet Radar Sonar Navig 15(12):1715–1726. https://doi.org/10.1049/rsn2.12159
Maillard J, Clark S, Yogatama D (2019) Jointly learning sentence embeddings and syntax with unsupervised tree-lstms. Nat Lang Eng 25(4):433–449. https://doi.org/10.1017/s1351324919000184
Meng J, Dong Z, Shao Y, Zhu S, Wu S (2022) Monthly runoff forecasting based on interval sliding window and ensemble learning. Sustainability 15(1):100. https://doi.org/10.3390/su15010100
Naduvil-Vadukootu S, Angryk RA, Riley P (2017) Evaluating preprocessing strategies for time series prediction using deep learning architectures. In: The Thirtieth International Flairs Conference
Nguyen D, Kim J, Bae D (2021) Improving radar-based rainfall forecasts by long short-term memory network in urban basins. Water 13(6):776. https://doi.org/10.3390/w13060776
Ortiz-Rodríguez JM, Martínez-Blanco MR, Vega-Carrillo HR (2006) Robust design of artificial neural networks applying the Taguchi methodology and DoE. In: Electronics, Robotics and Automotive Mechanics Conference (CERMA’06), Vol. 2. IEEE, pp 131–136
Papacharalampous G, Tyralis H, Papalexiou SM, Langousis A, Khatami S, Volpi E, Grimaldi S (2021) Global-scale massive feature extraction from monthly hydroclimatic time series: statistical characterizations, spatial patterns and hydrological similarity. Sci Total Environ 767:144612
Peng C, Tang Z, Gui W, Chen Q, He J (2021) A bidirectional weighted boundary distance algorithm for time series similarity computation based on optimized sliding window size. J Indus Manage Optim 17(1):205–220. https://doi.org/10.3934/jimo.2019107
Pimentel-Mendoza A, Rico-Pérez L, Solis M, Villarreal-Gómez L, Vega Y, Ramírez J (2021) Application of inverse neural networks for optimal pretension of absorbable mini plate and screw system. Appl Sci 11(3):1350. https://doi.org/10.3390/app11031350
Raza S, Mokhlis H, Arof H, Naidu K, Laghari J, Khairuddin A (2016) Minimum-features‐based Ann‐Pso approach for islanding detection in distribution system. IET Renew Power Gener 10(9):1255–1263. https://doi.org/10.1049/iet-rpg.2016.0080
Rodriguez-Granrose D, Jones A, Loftus H, Tandeski T, Heaton W, Foley K, …, Silverman L (2021) Design of experiment (doe) applied to artificial neural network architecture enables rapid bioprocess improvement. Bioprocess Biosyst Eng 44(6):1301–1308. https://doi.org/10.1007/s00449-021-02529-3
Sagheer A, Kotb M (2019) Unsupervised pre-training of a deep LSTM-based stacked autoencoder for multivariate time series forecasting problems. Sci Rep 9(1):19038. https://doi.org/10.1038/s41598-019-55320-6
Sahoo BB, Panigrahi B, Nanda T, Tiwari MK, Sankalp S (2023) Multi-step ahead urban water demand forecasting using deep learning models. SN Comput Sci 4(6):752. https://doi.org/10.1007/s42979-023-02246-6
Sandu I, Susac F, Stan F, Fetecau C (2020) Prediction of polymer flow length by coupling finite element simulation with artificial neural network. Materiale Plastice 57(3):202–223. https://doi.org/10.37358/mp.20.3.5394
Shin Y, Yi C (2019) Statistical downscaling of urban-scale air temperatures using an analog model output statistics technique. Atmosphere 10(8):427. https://doi.org/10.3390/atmos10080427
Silva D, Filho A, Carvalho R, Ribeiro F, Coelho C (2021) Water flow forecasting based on river tributaries using long short-term memory ensemble model. Energies 14(22):7707. https://doi.org/10.3390/en14227707
Srikanth B, Selvarani GA, Sahoo BB (2019) Forecasting monthly discharge using machine learning techniques. Int Res J Multidiscip Technovation 1:1–6. https://doi.org/10.34256/irjmtcon1
Stangalini M, Berrilli F, Del Moro D, Piazzesi R (2010) Multiple field-of-view MCAO for a large solar telescope: LOST simulations. In: Proc. SPIE, 7736 77364H. https://doi.org/10.1117/12.856999
Swagatika S, Paul JC, Sahoo BB, Gupta SK, Singh PK (2024) Improving the forecasting accuracy of monthly runoff time series of the Brahmani River in India using a hybrid deep learning model. J Water Clim Change 15(1):139–156. https://doi.org/10.2166/wcc.2023.487
Vafaeipour M, Rahbari O, Rosen M, Fazelpour F, Ansarirad P (2014) Application of sliding window technique for prediction of wind velocity time series. Int J Energy Environ Eng 5(2–3):1–7. https://doi.org/10.1007/s40095-014-0105-5
Velázquez-Zapata J (2019) Comparing meteorological data sets in the evaluation of climate change impact on hydrological indicators: a case study on a Mexican basin. Water 11(10):2110. https://doi.org/10.3390/w11102110
Vliet M, Ludwig F, Zwolsman J, Weedon G, Kabat P (2011) Global river temperatures and sensitivity to atmospheric warming and changes in river flow. Water Resour Res 47(2). https://doi.org/10.1029/2010wr009198
Waldner F (2020) The T index: measuring the reliability of accuracy estimates obtained from non-probability samples. Remote Sens 12(15):2483. https://doi.org/10.3390/rs12152483
Wilcox E, Qian P, Futrell R, Kohita R, Levy R, Ballesteros M (2020) Structural supervision improves few-shot learning and syntactic generalization in neural language models. arXiv preprint arXiv:2010.05725. https://doi.org/10.18653/v1/2020.emnlp-main.375
Winiczenko R, Górnicki K, Kaleta A, Janaszek-Mańkowska M (2016) Optimisation of ANN topology for predicting the rehydrated apple cubes colour change using RSM and GA. Neural Comput Appl 30(6):1795–1809. https://doi.org/10.1007/s00521-016-2801-y
Wojtkiewicz J, Hosseini M, Gottumukkala R, Chambers T (2019) Hour-ahead solar irradiance forecasting using multivariate gated recurrent units. Energies 12(21):4055. https://doi.org/10.3390/en12214055
Zhou K, Qiao Y, Xiang T (2018) Deep reinforcement learning for unsupervised video summarization with diversity-representativeness reward. Proc AAAI Conf Artif Intell 32(1). https://doi.org/10.1609/aaai.v32i1.12255
Acknowledgements
Special thanks to the General Directorate of Meteorology (MGM) and State Water Works (DSI) for providing the database used in this study.
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK).
Author information
Authors and Affiliations
Contributions
Muhammed Ernur Akiner, Anil Can Guzeler, Erkan Karakoyun and Veysi Kartal contributed equally to conceptualization, methodology, validation, multiple regression analysis, investigation, resources, writing-original draft preparation, and visualization.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Additional information
Communicated by: Hassan Babaie
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Akiner, M.E., Kartal, V., Guzeler, A.C. et al. Exploring the applicability of the experiment-based ANN and LSTM models for streamflow estimation. Earth Sci Inform (2024). https://doi.org/10.1007/s12145-024-01332-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12145-024-01332-4