
Abstract
The Internet of Medical Things (IoMT) is a version of the Internet of Things. It is getting the attention of researchers because it can be used in a wide range of smart healthcare systems. One of the main advancements employed recently is the IoMT-cloud, which allows users to access cloud services remotely over the internet. These cloud services require an efficient task scheduling approach that satisfies the Quality of Service parameters with a low energy consumption. This paper presents an overview of the integration of IoMT and cloud computing technologies. Besides,this work proposes an efficient Extended Water Wave Optimization (EWWO) task scheduling in the IoMT Cloud for healthcare applications. EWWO algorithm performs based on its operations propagation, refraction and breaking. The proposed EWWO scheduling technique minimizes the energy consumption, makespan time, execution time and increases the resource utilization. Cloudsim simulator is used to simulate the IoMT-Cloud environment to verify the effectiveness of EWWO technique. The performance has been evaluated based on various parameters such as energy consumption, makespan time and execution time.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In Smart Healthcare, healthcare devices that are worn or implanted on or in the body make it possible to get accurate information about a patient’s health. The IoMT enables remote monitoring of a patient’s mobility, eating routine, sleep pattern, heart rate, and blood pressure using implantable and wearable sensors that are connected to the Internet and can communicate with one another. So, IoMT can be utilized to determine for sure if a patient is having a heart seizure or a fall. The demand for IoMT devices is rising not only in response to the advancement of healthcare applications and services, but also because they make life easier for people by requiring less of them to monitor their health parameters and by making it easier for them to use these cutting-edge technologies [1]. The market for IoMT is expanding, and as it gets simpler, more effective, and more efficient, so do the security flaws that go along with it. Complex cryptographic key security procedures cannot be supported by IoMT devices that run on batteries [2]. The most important areas of study right now are the ways Internet of Things (IoT) can be used in healthcare [3]. The IoMT is an important part of the healthcare business because it helps make electronic devices more accurate, consistent, and fast. The IoMT includes gadgets that can be worn or put inside the body. Heartbeat, blood sugar, and various other wellness- and fitness-related statistics are tracked via wearable medical devices. These things can be worn the same way as a jacket. During surgery, implantable medical devices like the cochlear implant are put inside the body. This is a consumer electrical device that helps people who have trouble hearing. It has a transmitter, a receiver, a speech processor, and a microphone [4, 5]. The IoMT devices that are implanted in patients gather sensitive information about physiological parameters and send it to the cloud for investigation, interpreting, and making decisions. A centralized computer system, the Cloud is a computing paradigm that facilitates speedy processing, analysis, and decision-making. On the cloud, data processing and archiving for the long term are both feasible.

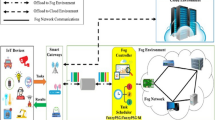
Layered Diagram of IoMT for Healthcare [2]
In Fig. 1 clearly represented the core elements of the Smart Healthcare architecture are the sensors that perform sensing and collection of data. This layer is referred to as the physical layer. Implanted medical devices (IMD) and Wearable medical devices (WMD) that are put on or inside a patient are included in this layer. These sensors’ sensing information is sent to a cloud via the IoMT’s second layer, the communication layer. Bluetooth, RFID, WiFi, LoRaWAN, Zigbee, and 5 G are just a few of the technologies that can be used to connect both IoMT devices and cloud. The cloud layer, which comprises data processing, analysis, and storage. The application layer, which is fourth layer, is responsible for securely delivering the user’s analysis of physiological parameter data.
These tasks are assigned to the asset center hubs using a suitable scheduling technique. IoMT-cloud’s core idea is that the framework breaks down client-presented tasks into certain uncontrolled tasks. As a result, one of the important advancements in IoMT-cloud computing is the scheduling of tasks in a cloud environment, which has an impact on how the computing process is carried out from beginning to end. After all sub tasks have been prepared, the approach creates asset hubs that are returned to clients [6]. A novel hybrid genetic algorithm (HGA) is proposed for task scheduling in IoMT with Cloud [7]. By comparing the new HGA method to previous studies and methods, it will be shown that it is correct. The CloudSim is used to determine out how they affect additional factors like how much time they take and how much resources they use. The suggested HGA technique’s faster execution rate of 32.57 ms made it easier to schedule tasks. By shortening the makespan of a task set and maximizing resource consumption, this work uses the Dynamic Adaptive Particle Swarm Optimization (DAPSO) algorithm to enhance the performance of the fundamental PSO algorithm [8]. Cloud computing has a task scheduling technique to schedule independent tasks. MDAPSO combines the DAPSO and Cuckoo search algorithms. Modified DAPSO and DAPSO outperform PSO in experiments.
The study recommended using dynamic algorithms with FL-BETS, a blockchain-enabled task scheduling system by Lakhan et al. [9, 10]. On distributed fog and cloud nodes, healthcare applications with hard constraints (like dates) and soft constraints (like energy use) are looked at. FL-BETS uses the least amount of time and energy possible to locate and halt privacy violations and fraud at nearby fog nodes and distant clouds so that health care deadlines can be met. EARH schedules real-time, aperiodic, autonomous jobs energy-wise [11]. The EARH uses energy-aware scheduling and rolling-horizon optimization. Two resource scaling strategies-up and down-balance work schedulability and energy savings. Our EARH beats baselines in lengthy simulations that inject random synthetic workloads and tasks from Google cloud tracelogs.
1.1 Motivation
The Internet of Medical Things (IoMT) has tremendous potential to revolutionize healthcare by improving patient outcomes, optimizing resource utilization, and reducing costs. Task scheduling plays a crucial role in maximizing the efficiency and effectiveness of IoMT systems. Healthcare often demands real-time data processing and decision-making. Task scheduling algorithms can prioritize critical tasks such as emergency alerts, patient monitoring, and diagnostic analyses, ensuring timely responses and interventions. Many IoMT devices are battery-powered or have limited energy resources. Intelligent task scheduling can reduce energy consumption by scheduling resource-intensive tasks during off-peak hours or optimizing data transmission protocols to minimize energy usage.
In this article, we develop nature inspired algorithm Extended Water Wave Optimization (EWWO) to generate efficient best optimal solution for task scheduling in a IoMT with Cloud Environment for Healthcare. The proposed techniques EWWO addressed the optimization problems and schedule the task with low energy and minimum Makespan time with satisfying Quality of Service (QoS) parameters. The major contributions of this article are listed as follows:
-
In an IoMT with cloud environment, we propose the Extended Water Wave Optimization (EWWO) technique as a system model for effectively resolving task scheduling issues.
-
We have created a mathematical representation of the scheduling of tasks problem.
-
We address the limitations of Water Wave Optimization (WWO) technique. First we used Random Opposition based learning (ROBL) to improve the diversity of population in propagation phase in WWO.
-
Second, we use the adaptive \(\omega\) for develop best management to avoid local optima problem.
-
The proposed EWWO validate the effectiveness by using cloudsim Simulator by considering energy, makespan time and Execution time.
2 Background study
This study proposes a cloud-IoT-based healthcare task scheduling method by Hassan et al. [12]. HPSOSSA (Hybrid particle swarm optimization and Salp Swarm Algorithm) combines the greatest swarm intelligence methods, Salp Swarm methodology (SSA) and particle swarm optimization (PSO). With specific parameters, the suggested model was developed using Eclipse and Cloudsim. We compared the hybrid algorithm to SSA, PSO, ACO, and proposed hybrid PSO-GA. HPSOSSA outperforms other algorithms in makespan, waiting time, and resource use, according to the experiments.
Authors [13] integrate IoT and deep learning ideas to provide data analysis and remote health monitoring. The authors provide an innovative IoT-based FoG-assisted the cloud network design that collects real-time patient health information from several IoT networks used in healthcare. The proposed architecture analyzes healthcare data and also provides patients who urgently require medical guidance with immediate relief techniques. This suggested DHNN’s effectiveness with the task-scheduling algorithm is measured, and the accuracy, precision, and sensibility are found to be 97.6%, 97.9%, and 94.9%, respectively. Deep auto-encoder’s accuracy, precision, and sensitivity are 92%, 91%, and 82.5%, compared to 96%, 97.5%, and 94% for deep CNN, respectively.
This study proposes a framework known as EEIoMT for Task Scheduling by authors [14]. This scheduling strategy balances the energy used to process other tasks while making sure that deadlines are met by finishing important work as soon as is practical. Our smart city architecture tracks heart condition at home with ECG sensors. ECG sensors continuously provide BLE information to the ESP32 micro controller for processing. The fog scheduler receives jobs and analysis results from ESP32 over Wi-Fi. By allocating every fog node a weight depending on the expected energy and latency required to complete the task, the lowest-weighted node can be selected. iFogSim2 simulated. The findings from simulations show that the proposed framework reduces energy, latency as well as and network utilization better than FNPA, LBS, and CHTM models.
The task scheduling method discussed in this research uses the moth-flame optimization technique to assign the best possible task set to nodes by Ghobaei-Arani et al. [15]. This reduces the overall amount of time required to execute tasks while still meeting the quality of service requirements of CPS applications. In the suggested method, the time it takes to do a job and move it from one place to another are seen as objective functions. The suggested method is put to the test using the iFogSim toolbox. Based on the suggested method, a simulation showed the best way to schedule jobs and give each fog node the same number of tasks. Compared to other methods, the total execution time was also cut down.
This research optimizes task scheduling with a strong genetic algorithm. The proposed approach combines heuristic and developing genetic algorithms. For algorithm accuracy analysis, authors [16] used model checking-based behavioral modeling. Linear Temporal Logic (LTL) formulas are used to determine the approach’s predicted requirements. NuSMV and PAT model checkers verify suggested behavioral models. The reachability, fairness, and deadlock-freeness of the suggested method are then assessed using the verification results. The recommended strategy surpassed the three popular heuristic algorithms plus our recently created meta-heuristics algorithm, according to simulation and statistical findings.
This study suggests using the Multi-objective Quantum-inspired Genetic Algorithm (MQGA) to streamline hybrid cloud workflow scheduling and use less energy by Hussain et al. [17]. Quantum mechanics, which studies quantum computer computation, underpins the proposed method. It utilized a qubit to represent each chromosome in order to increase population variation. It uses a type of quantum rotation gate instead of genetic operators to increase schedule convergence. In simulations, the technique decreased average energy consumption by 23.36% and the makespan by 20%.
To tackle workflow scheduling in fog computing, Salp Swarm and Particle Swarm Optimization should be used together by Ahmed et al. [18]. To lessen DDoS attacks on fog computing environments, two discrete-time systems Markov chain models are proposed. For each fog, the first Markov model calculates the network bandwidth. Based on DDoS assault intensities, the second version of the Markov model determines the usual amount of virtual machine (VMs) available per fog. Numerous simulations demonstrate that preparing for DDoS attacks in fog environments can reduce the amount of work that is offloaded to cloud servers and the amount of workflows that have deadlines that are missed.
A hybrid optimization approach splits charging chores among many chargers to reduce mobile charger (MC) distance and travel time by Srinivas and Amgoth [19]. k-medoids clusters sensors into identical-sized groupings. Wind Driven Water Wave Optimization uses sensor distance and energy to select cluster heads. Hybrid Galactic Sun Flower Optimization solves MC charging schedule. The method determines the delivery of packets ratio, lost packets level, consumption of energy, network lifespan, throughput, delay from end to end, charging latency, and MC travel distance to show scalability and efficiency. For hybrid CS-GA, 82.35% for GSA, 90.90% for NJNP, and 94.73% for FCFS-based system with varying MC speeds, the technique decreased charge delay.
Medara et al. proposed Energy-aware workflow scheduling (EASVMC) for cloud computing with VM consolidation [20]. EASVMC covers energy, resource, and VM migrations. Work scheduling and VMC comprise EASVMC. The lowest-energy virtual machine gets the longest work in the first phase. Phase two VM consolidation is NP-hard. VMC phase CPU use classifies physical hosts as normal, under-loaded, or overloaded. Virtual machines are moved to standard hosts. Virtual machines are moved to standard hosts. The meta-heuristic Water Wave Optimization (WWO) technique identified a migration technique to decrease energy consumption by improving resource usage and turning off idle hosts after migration its VMs to a suitable target host for the VMC phase. WorkflowSim used five different scientific workloads to test our method. Regardless of workload, EASVMC outperformed equal efforts.
Gu and Budati [21] developed the Energy Aware, Time, and Throughput Optimization (EATTO) heuristic from the bat approach. The goal is to maximize throughput, reduce energy consumption, and speed up computation-intensive activities without compromising QoS. To optimize performance, a multi-objective function compared all local optimal solutions to get the best global solution. The suggested EATTO algorithm is being tested against other mapping methods. EATTO consistently provides the best overall solution for the three objectives and, in most cases, the best performance for each target. The EATTO algorithm has the lowest energy consumption, execution time, and throughput.
Stavrinides and Karatza [22] use approximation computations and On heterogeneous multi-core processors, use per-core DVFS to close scheduling gaps. Input errors can potentially slow down the processing of component jobs. By sacrificing on result precision, the objective is to provide timeliness and energy savings while maintaining a respectable task result level and work execution expenses. Using QoS standards, a scheduling heuristic is contrasted with two baseline policies. Our technique outperforms other policies in simulations with promising results. Introduced various advanced scheme for healthcare applications by authors [23,24,25,26].
Table 1 shows the comparative analysis of various task-scheduling algorithms.
3 Task model
We have developed a system model for cloud task scheduling and resource provisioning. Task submission, cloud broker, and Framework are the three phases of the proposed approach.
3.1 Task submission phase
All cloud users use an interface (GUI) to submit their work in tasks set T. The task/request handler is used to receive tasks. The task handler validates the users by users’ authentication. If the user is legitimate, then the request will consider otherwise ignored. All tasks received from the task handler were clustered by the Task cluster and transmitted to the cloud broker if they were in a queue list for resource accessing and scheduling.
3.2 The phase of cloud mediator
This phase consists of three elements that provide resources and scheduling of tasks.
3.3 Task manager
The cloud broker’s Task Manager is a key component that collects tasks from the task cluster in a pipeline. The task manager accomplishes the task processing and forwards it to the Matchmaker for further consideration. The task manager will also be in charge of tracking and providing all physical and virtual resources.
3.4 Matchmaker
All virtual machines allow a single process to run as an application task on Matchmaker, an information store. The Virtual machine (VM) provides an independent platform for updating each instance by masking the information of operating instances. The quality of the matchmaker repository is updated based on VM state (Idle or Busy). According to task scheduling policies, the tasks are transmitted to Matchmaker. Then, using the task scheduling method, Matchmaker examines the accessibility of the Vms list for task scheduling.
3.5 Scheduling of tasks
By utilizing the recommended task scheduling algorithm, Matchmaker offered the mapping of the VM list utilized to efficiently conduct numerous jobs in parallel in task clusters. The jobs are scheduled and tracked by the mapping of the VM list. The suggested task scheduling technique assigns resources to VM based on the job requirements. The suggested algorithm assessed its performance by taking into account different indicators. The makespan time, energy efficiency, resource usage, the estimation cost, time required for execution, task rejection ratio, response time, throughput and deadline limitations are all reduced.
3.6 The phase of framework
In this phase, the middleware platform of the Cloud. It is one kind of software platform and sits between two clients, servers, applications, and databases. The end-user can not use it directly. In Cloud consists of cloud middleware and a cloud data center. Cloud middleware collects the resources such as processors, hosts, and memory space. The cloud middleware interacts with the cloud service provider for resource provisioners and monitors to get the resources of the Cloud. All types of resources are collected in the virtual server repositories of a cloud data center. A computational server and a storage server are two heterogeneous resources containing a virtual machine on each node. The virtual machine scheduler (IoMT) connects virtual machines to physical computers.
4 Problem statement formation
With an extensive selection of services available to users, cloud computing lately took dominance of the computer business. An enormous rise in cloud users is being brought on by cloud computing’s growing popularity. The system faces a number of difficulties as more people utilize it. In the Cloud environment, Mapping the VM list for efficient scheduling of tasks and executing the tasks scheduling algorithm is difficult. The user’s task request must be handled by the Cloud’s most delicate virtual machine. The execution time, Throughput, makespan and reaction time aspects of this effective technique can be decreased when there are time constraints. The goal of this research is to create a practical method for prioritizing and processing applications according to user needs while enhancing QoS. Consider the k different activities and p different computational skills that are divided into different Vms capabilities in the cloud data center. Based on customer requirements, cloud service providers (CSP) deliver the best resources to end users. The resource set, task set and virtual machine set are defined as follows:
The following are the possible definitions for each task \(T_{a}\)
Here, \(T_{id}\) is the identification number, \(TL_{i}\) denotes the task length in a million instructions per second, and \(D_{i}\) denotes deadline constraints of tasks. Similarly, Each \(Vm_{q}\) is described as follows:
Here, \(Vm_{type}\) denotes the virtual machine in the type of Cloud, and an integer range, \(Vm_{id}\) is a virtual machine’s id number. The VM computing cost is measured in MIPS, which stands for million instructions per second. \(Vm_{speed}\) is the VM processing speed, while \(Vm_{storage}\) is the storage capacity of each VM in the cloud.
When scheduling of tasks for resources \((R_{m})\) in Cloud, it can receive the resources immediately or need to wait up to the present task at \(R_{m}\) is computed using following equation.
\(FT_{a}\) of task set \(T_{i}\) for resource \(R_{m}\) should be less than the deadline condition of task \((\Delta (D_{i})):\)
4.1 Objective function
The fundamental objective of the recommended strategy is to enhance QoS metrics such makespan time, energy consumption, time to execution. Users of the cloud also need services that are as inexpensive as possible. As a result, we create a fitness function that takes into account deadline limitations as a QoS criterion while minimizing makespan duration, expenses, and energy. The tasks are described by the authors as follows:
4.1.1 Time to execution
A task’s execution time is the length of time that it takes the system to finish it:
Here, \(TEx_{T_{k}Vm_{q}}\) denotes the total execution time, and the average execution time is \(EEx_{T_{k}Vm_{j}}\) of \(T_{k}\) at \(Vm_{q}\) and the time of total transfer is \(TTime_{T_{k}Vm_{j}}.\)
4.1.2 Makespan time
Makespan time is the entire amount of time required to perform all tasks on a schedule, or the time required from beginning to end:
4.1.3 Energy consumption model (Ec)
Any DC has concentrated data transmission between VMs and the fundamental EC of the CPU [27]. The suggested energy model comes to the conclusion that the predicted EC during workflow execution can be decreased by implementing the bare minimum number of virtual machines on the ideal number of hosts, with minimized data movement between VMs.
5 Extended water wave optimization (EFWWO) based task scheduling algorithm
In this section, we proposed a novel hybrid scheme for task scheduling for IoMT. The standard method for optimizing water waves is used to create a model of a shallow water wave. This algorithm is based on populations, where every solution looks like a wave and the search space looks like the seafloor. How fit a wave is depends on how deep the ocean floor is, how close it is to a steady water level, and how high the water level is [28, 29]. Every solution is a different wave location in the area of the seabed. The height and length of each wave are what make it special. Wavelength is a real number that shows the search area, while wave height is an integer that shows how much energy the wave has [30]. The WWO searches with three operators: propagation, breaking, and reflection [31] (Fig. 2).

Flow diagram of EWWO scheduling in IoMT-cloud environment
5.1 WWO algorithm
Shallow water wave methods were the basis for the WWO’s development to address optimization concerns.The objective function f has a maximizing problem without losing generality. The space of optimal solution Y similar to region of seabed, and depth of seabed can be used to estimate the fitness of a point \(y \in {Y}.\) The fitness increases with distance from existing water levels f(y). The seabed’s 3-D space has been transformed into space of n-dimensional. Due to the overwhelming amount of WWO, EAs maintains the solutions population; each “wave” equivalent to a solution with height \(h \in {ZC}\) and wavelength \({\lambda } \in {RC}.\) The initial value of h is a constant (fixed) \(h_{mx}\) and \({\lambda }\) value set to 0.5. The three types of jobs that have been taken on in the process of problem-solving are propagation, refraction, and breaking [32].
5.1.1 Propagation
Every wave must precisely propagate for every generation. By altering each of the original x wave’s dimensions (d), as demonstrated below, the propagation operator creates a fresh wave \(y^{\prime }\) [28]:
Here random function measures \(ran(-1,1),\) dth dimension length \((1 \le d \le n)\) defines L(d) If a novel position is adjacent and has a prospective range, it might be anywhere within that range at random.
A fitness of the offspring wave \(y^{\prime }\) is used to estimate the propagation. When \(f(y^{\prime }) > f(y),\) the variables y and \(y^{\prime }\) are flipped, and the wave height of \(y^{\prime }\) has once more been fixed to \(h_{mx}.\) Otherwise, y is preserved along with it, but the height of h is restricted by 1 to account for the reduction in power. The following examples show how the wavelength of all waves y can be updated with each iteration:
Here, \(f_{min}\) and \(f_{max}\) are the minimum and maximum value of fitness from the present population, \(\alpha\) is reducing coefficient of wavelength. \(\gamma\) is a tiny positive integer to remove the divisible by zero.
5.1.2 Refraction
Here, the processing of wave refraction uses decreased heights to zero and uses an easier method to determine the position after the refraction process is complete:
Here \(y^{*}\) is a optimal best solution \(N(\mu ,\sigma )\) measures Gaussian arbitrary number with mean \(\mu\) and standard deviation \(\sigma .\) A novel location is an arbitrary number with an SD that is comparable to the beginning value of the difference and is approximately centered between the well-known optimal position and actual position. In order to compete with one another for difficult mathematical optimization problems, these estimations are updated. After that, \(y^{f}\) wave height is reset to \(h_{mx},\) and fix the wavelength with following equation
5.1.3 Breaking
If the wave moves to a point where the water level is less than a set amount, wave crest velocities will exceed wave celerity. The wave finally splits into parts as the peak steepens. The wave breaking job in WWO determines the optimum solution and accelerates wave breaking by performing local searching with \(y^{*}.\) A lone wave \(y^{\prime }\) is produced by the random selection of k dimension for every level d, as shown below:
Here \(\beta\) refers breaking coefficient, there is none of the optimal waves are better than \(y^{*}.\) \(y^{*}\) is remained same: otherwise \(y^{*}\) is exchanged by best fitted one from the optimal best waves.
5.2 Extended WWO
According to earlier studies, when searching is confined to a small local area, the optimum management of exploration and exploitation is crucial to completing both the global and local search processes. It is considered to be the primary problem as the distinguishing factor. It takes a lot of work to obtain optimal control between exploration and exploitation in any optimization activity. The smart method restrictions are present in the WWO algorithm. First, the random initialization of the original approach makes it challenging to ensure diversity and traversal. As a result, it can prevent the algorithm from reaching the optimum answer while lengthening the duration. Second, global exploration becomes vulnerable when initial assessments of local exploitation capabilities are deemed to be adequate. Later, WWO runs into the problem of early convergence, where the search work is stopped at a local multimodal objective function, which may upset the delicate balance between local exploitation and global exploration.
In this study, two aspects are improved in order to address these issues. The initialization approach is updated by the introduction of e opposition-based learning (OBL) first to increase population diversity.
Assuming \(Y (y_{1},y_{2},\ldots,y_{i})\) is the solution in the search range, the opposite solution \(Y^{\prime } (y^{\prime }_{1},y^{\prime }_{2},\ldots,y^{\prime }_{i})\) calculated by using below equations:
Here a and b are lower and upper bound search ranges
The Second improvement was presented adaptive \(\omega\) to improve the exploration capabilities of WWO to reduce the possibility in terminating for local optima.When local optima are switched out, this process maximizes the WWO function. The proposed adaptation \(\omega\) increases the impact of the propagation operator at the same time developing suitable management between exploration and exploitation. The primary iteration of the approach must involve exploration in order to achieve the primary goal of avoiding the trapping of local optima. However, it still poses a serious problem for a population-based heuristic method. The adaptive \(\omega\) principle is used throughout the EWWO algorithm, and the \(\omega\) is updated using the equation below. Here, we are using the dynamic adaptation strategy to switch to global optima and avoid getting stuck in local optima. The dynamic adaptation strategy modify algorithm parameters dynamically during the optimization process. The adaptive \(\omega\) principle uses Higher inertia to encourage global exploration, while lower inertia aids local exploitation.
where \(\omega _{max}\) and \(\omega _{min}\) are higher and lower wavelength coefficients, \(F_{max}\) is maximum generation value, T is current generation value and \(\omega\) is increase the exploration with highest value. if the iteration value, then \(\omega\) is decreased, this resulting the optimal exploration process. Therefore, by using exploration and exploitation develop the best management.
The proposed enhanced water wave optimization algorithm for task scheduling is discussed below.

Extended WWO
6 Results and discussion
This section describes scheduling experiments. CloudSim simulates cloud environments and tests proposed scheduling models. Model CloudSim simulators cloud environment for IaaS. New methods are used to carry out scientific workflow in an energy-efficient manner. EWWO is empirically assessed.
6.1 Simulation metrics
-
HP ProLiant ML110 G4 and G5 hosts use 117 and 135 W/s, respectively, on two hosts.
-
1 GB of data is thought to be transferred at a rate of 2.3 W of energy consumption.
-
There are four installed VMs with various CPU (in MIPS) and RAM (in MB) capacity. Scientific jobs can be scheduled in 870 MB RAM.
-
For scheduling, VMs are perpetually installed and removed. VM startup time averages 96.9 s.
-
Amazon Web Services’ average VM bandwidth is 20 MBPS (AWS).
6.2 Performance metric and simulation parameters
Time to Execute: Average time to execute per each task is computed using the Eqs. (8), (9), and (10).

Total energy consumption
Makespan Time: The time needed to accomplish the tasks. Makespan is computed using Eq. (11). Energy Consumption: The total energy consumption calculated according to energy model. For energy consumption vs. Number of tasks workflow, Fig. 3 demonstrates that the suggested EWWO approach outperformed current methods as EATTO (Energy Aware, Time, and Throughput Optimization), MQGA (Multi-objective Quantum-inspired Genetic Algorithm), DVFS (Dynamic Voltage and Frequency Scaling), and HPSOSSA (Hybrid particle swarm optimization and Salp Swarm Algorithm). The proposed algorithm was able to achieve higher energy consumption rate 2627.905 kWh, 1992.13 kWh, 1370.67 kWh, and 948.25 kWh, respectively for 1000 tasks.

Makespan time

Total execution time
For the makespan time vs. number of tasks workflow, Fig. 4 demonstrates that the proposed EWWO approach outperformed current methods like EATTO (Energy Aware, Time, and Throughput Optimization), MQGA (Multi-objective Quantum-inspired Genetic Algorithm), DVFS (Dynamic Voltage and Frequency Scaling), and HPSOSSA (Hybrid particle swarm optimization and Salp Swarm Algorithm). the proposed algorithm achieved higher makespan of 1900.42 s, 106.75 s, 102.48 s, and 92.58 s respectively, for 1000 tasks.
For the Execution time vs. Number of tasks workflow, Fig. 5 demonstrates that the proposed EWWO approach outperforms current methods like EATTO (Energy Aware, Time, and Throughput Optimization), MQGA (Multi-objective Quantum-inspired Genetic Algorithm), DVFS (Dynamic Voltage and Frequency Scaling), and HPSOSSA (Hybrid particle swarm optimization and Salp Swarm Algorithm). The proposed algorithm achieved higher result 6.21 s, 5.69 s, 2.15 s, and 1.4 s respectively for 1000 tasks.
7 Conclusion and future work
This Research article presents overview of the Internet of Medical Things (IoMT)-Cloud in general terms, with a focus on the various mechanisms that employ smart healthcare systems (SHS). The IoMT-cloud is one of the most interesting topics for students, the general public, and business. In an IoMT-cloud environment, it is important to know how to schedule tasks. Because of advances in remote communication and IoMT-cloud, problems with patients can be fixed from afar. The task scheduling test creates a model for eliminating effective loads while spreading resources for efficient QoS. The goal of this framework is to schedule tasks in the IoMT-cloud that is dynamic, clear, and different. This paper proposes an Extended Water Wave optimization (EWWO) task scheduling algorithm for efficient task scheduling. In this proposed algorithm main objective is minimize the energy consumption and provide quality of service (QoS). To achieve the goal two major modifications are made in EWWO technique to address the optimization problems. First, we use the Opposition based learning (OBL) to increase the population diversity. And Second, we use adaptive \(\omega\) to develop best management for balancing between exploitation and exploration to avoid the local optimum problem. Simulated data from the Cloudsim toolbox was utilized to validate the performance of the proposed EWWO method. The suggested EWWO work scheduling method is effective, according to the simulation findings. It outperformed EATTO (Energy Aware, Time, and Throughput Optimization), MQGA (Multi-objective Quantum-inspired Genetic Algorithm), DVFS (Dynamic Voltage and Frequency Scaling), and HPSOSSA (Hybrid particle swarm optimization and Salp Swarm Algorithm) in terms of Energy consumption, Makespan time, and Execution time. In the future, by using modern computing [33], we can extend this work to get better results.
Emerging trends in modern computing Low latency and delayed replies are just two of the real-world problems that have been solved since the invention of contemporary computing technology. It has made it easier for bright young people from all over the world to launch start-ups, given them access to enormous computer power to solve complex problems, and accelerated scientific progress. Task scheduling will give better advancements [33].
Blockchain Blockchain technology can be used for task scheduling in various ways, especially in decentralized or distributed environments where multiple parties need to coordinate tasks efficiently and securely. Blockchain technology offers a robust framework for decentralized task scheduling, enhancing transparency, security, automation, and trust among participants in collaborative environments.
Data availability
No datasets were generated or analysed during the current study.
References
Balestrieri E, De Vito L, Picariello F, Tudosa I (2019) A novel method for compressed sensing based sampling of ECG signals in medical-IoT era. In: IEEE international symposium on medical measurements and applications, IEEE Publisher, Istanbul Turkey, 2019, pp 1–6
Venkata KVV, Saraju P, Mohanty Elias K, Babu K, Bibhudutta R (2022) PUFchain 2.0: hardware-assisted robust blockchain for sustainable simultaneous device and data security in smart healthcare. SN Comput Sci 5:344
El-Shafeiy, Abohany A (2020) A new swarm intelligence framework for the Internet of Medical Things system in healthcare. In: Swarm Intelligence for Resource Management in Internet of Things. Elsevier, Amsterdam, pp 87–107
Aman AHM, Hassan WH, Sameen S, Attarbashi ZS, Alizadeh M, Abdul Latiff L (2021) IoMT amid COVID-19 pandemic: application, architecture, technology, and security. J Netw Comput Appl 174:102886
Srivastava J, Routray S, Ahmad S, Maqbool Waris M (2022) Internet of Medical Things (IoMT)-based smart healthcare system: trends and progress. Hindawi Comput Intell Neurosci 2022:7218113
Hussain A, Al-Turjman F. Applying task scheduling for IOMT-cloud business optimisation using AI. Res Sq. https://doi.org/10.21203/rs.3.rs-934310/v1
Hussain A, Al-Turjman F (2022) Hybrid genetic algorithm for IOMT-cloud task scheduling. Hindawi Wirel Commun Mob Comput 2022:6604286
Al-Maamari A, Omara FA (2015) Task scheduling using PSO algorithm in cloud computing environments. Int J Grid Distrib Comput 7:245–256
Lakhan A, Mohammed MA, Nedoma J, Martinek R, Tiwari P, Vidyarthi A, Alkhayyat A, Wang W (2022) Federated-learning based privacy preservation and fraud-enabled blockchain IoMT system for healthcare. IEEE J Biomed Health Inform 27(2):664–672
Vega MB, Saraiva AM, Simplicio MA, Albertini BC, Silva RB (2022) A systematic review of the use of blockchain in Internet of Medical Things. In: IEEE 1st global emerging technology blockchain forum: blockchain and beyond (iGETblockchain), IEEE Publisher, Santa Ana, CA, pp 1–6
Zhu X, Yang LT, Chen H, Wang J, Yin S, Liu X (2014) Real-time tasks oriented energy-aware scheduling in virtualized clouds. IEEE Trans Cloud Comput 2:168–180
Hassan KM, Abdo A, Yakoub A (2022) Enhancement of health care services based on cloud computing in IOT environment using hybrid swarm intelligence. IEEE Access 10:105877–105886
Nagarajan SM, Devarajan GG, Chatterjee P, Waleed A, Ghosh U (2021) Effective task scheduling algorithm with deep learning for Internet of Health Things (IoHT) in sustainable smart cities. Sustain Cities Soc 71:102945
Alatoun K, Matrouk K, Mohammed MA, Nedoma J, Martinek R, Zmij P (2022) A novel low-latency and energy-efficient task scheduling framework for Internet of Medical Things in an edge fog cloud system. Sensors 22(14):5327
Ghobaei-Arani M, Souri A, Safara F, Norouzi M (2020) An efficient task scheduling approach using moth-flame optimization algorithm for cyber-physical system applications in fog computing. Trans Emerg Telecommun Technol 31:e3770
Keshanchi B, Souri A, Navamipour NJ (2017) An improved genetic algorithm for task scheduling in the cloud environments using the priority queues: formal verification, simulation, and statistical testing. J Syst Softw 124:1–21
Hussain M, Wei LF, Abbas F, Rehman A, Ali M, Abdullah L (2022) A multi-objective quantum-inspired genetic algorithm for workflow healthcare application scheduling with hard and soft deadline constraints in hybrid clouds. Appl Soft Comput 128:109440
Ahmed OH, Lu J, Ahmed AM, Rahmani AM, Hosseinzadeh M, Masdari M (2020) Scheduling of scientific workflows in multi-fog environments using Markov models and a hybrid salp swarm algorithm. IEEE Access 8:189404–189422
Srinivas M, Amgoth T (2022) Delay-tolerant charging scheduling by multiple mobile chargers in wireless sensor network using hybrid GSFO. J Ambient Intell Humaniz Comput 1–17
Medara R, Singh RS, Amit (2021) Energy-aware workflow task scheduling in clouds with virtual machine consolidation using discrete water wave optimization. Simul Model Pract Theory 110:102323
Gu Y, Budati C (2020) Energy-aware workflow scheduling and optimization in clouds using bat algorithm. Future Gener Comput Syst 113:106–112
Stavrinides GL, Karatza HD (2019) An energy-efficient, QoS-aware and cost-effective scheduling approach for real-time workflow applications in cloud computing systems utilizing DVFS and approximate computations. Future Gener Comput Syst 96:216–226
Verma P, Tiwari R, Hong WC, Upadhyay S (2022) FETCH: a deep learning-based fog computing and IoT integrated environment for healthcare monitoring and diagnosis. IEEE Access 10:12548–12563
Kaur P, Harnal S, Tiwari R, Alharithi FS, Almulihi AH, Noya ID, Goyal N (2021) A hybrid convolutional neural network model for diagnosis of COVID-19 using chest X-ray images. Int J Environ Res Public Health 18(22):12191
Verma P, Tiwari R, Hong WC (2023) Secure authentication in IoT based healthcare management environment using integrated fog computing enabled blockchain system. Springer International Publishing, Berlin, pp 137–146
Thakkar M, Shah J, Verma JP, Tiwari R (2023) Smart healthcare systems: an IoT with fog computing based solution for healthcared. Springer International Publishing, Berlin, pp 63–82
Bousselmi K, Brahmi Z, Gammoudi MM (2016) Energy efficient partitioning and scheduling approach for scientific workflows in the cloud. In: IEEE international conference on services computing (SCC), IEEE Publisher, Anchorage, AK, USA, pp 146–154
Zheng Y-J (2015) Water wave optimization: a new nature-inspired metaheuristic. Comput Oper Res 55:1–11
Amer DA, Attiya G, Ziedan I, Nasr AA (2021) A new task scheduling algorithm based on water wave optimization for cloud computing. Int J Comput Appl 183:8887
Pustokhina IV, Pustokhin DA, Gupta D, Khanna A, Shankar K, Nguyen GN (2020) An effective training scheme for deep neural network in edge computing enabled Internet of Medical Things (IoMT) systems. IEEE Access 8:107112–107123
Qin S, Pi D, Shao Z, Xu Y (2021) A knowledge-based adaptive discrete water wave optimization for solving cloud workflow scheduling. IEEE Trans Cloud Comput 11(1):200–216
Xu Q, Wang L, Wang N, Hei X, Zhao L (2014) A review of opposition-based learning from 2005 to 2012. Eng Appl Artif Intell 29:1–12
Gill SS, Wu H, Patros P, Ottaviani C, Arora P, Pujol VC, Buyya R (2024) Vision and challenges. Telematics and Informatics Reports, Modern computing, p 100116
Funding
No funding was received for conducting this study.
Author information
Authors and Affiliations
Contributions
Conceptualization, B.B.; methodology and software, S.M.; validation and formal analysis, A.M.; validation and formal analysis, I.G.; investigation and resources, E.V; data curation and writing original draft preparation, M.H. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bapuram, B., Subramanian, M., Mahendran, A. et al. Extended water wave optimization (EWWO) technique: a proposed approach for task scheduling in IoMT and healthcare applications. Evol. Intel. (2024). https://doi.org/10.1007/s12065-024-00947-2
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12065-024-00947-2