
Abstract
Most link prediction methods return estimates of the connection probability of missing edges in a graph. Such output can be used to rank the missing edges from most to least likely to be a true edge, but does not directly provide a classification into true and nonexistent. In this work, we consider the problem of identifying a set of true edges with a control of the false discovery rate (FDR). We propose a novel method based on high-level ideas from the literature on conformal inference. The graph structure induces intricate dependence in the data, which we carefully take into account, as this makes the setup different from the usual setup in conformal inference, where data exchangeability is assumed. The FDR control is empirically demonstrated for both simulated and real data.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
1.1 Problem and aim
Graphs (or networks) denote data objects that consist of links (edges) between entities (nodes). Real-world examples are ubiquitous and include social networks, computer networks, food webs, molecules, etc. A fundamental problem in network analysis is link prediction (Lu and Zhou 2011), where the goal is to identify missing links in a partially observed graph. Biological networks such as protein–protein interaction networks (Kovács et al. 2019) or food webs (Terry and Lewis 2020) are typical examples of incomplete networks: because experimental discovery of interactions is costly, many interactions remain unrecorded. Link prediction can be used to identify promising pairs of nodes for subsequent experimental evaluations. Other applications include friend or product recommendation (Li and Chen 2013), or identification of relationships between terrorists (Clauset et al. 2008).
In this work, we consider a link prediction problem, where a graph with a set of vertices \(V = \{1, \dots , n \}\) and a set of edges E is only partially observed: namely, we observe a sample of node pairs recorded as interacting (true edges) and a sample of pairs recorded as non-interacting (false edges). The graph can be directed or undirected and self-loops are allowed. The two observed samples of node pairs make up only a part of the set of all pairs \(V \times V\), and the non-observed pairs correspond to missing information, where it is not known whether there is an edge or not. The aim is to identify the true edges among the pairs of nodes for which the interaction status has not been recorded.
There exists a variety of approaches for link prediction, and they are mainly divided according to two viewpoints. In Ben-Hur and Noble (2005); Bleakley et al. (2007); Li and Chen (2013); Zhang et al. (2018), link prediction is treated as a classification problem. That is, examples are constructed by associating the label 1 (or 0) with all true (or false) edges. Then, a classifier is learned by using either a data representation for each edge (Zhang et al. 2018), or kernels (Ben-Hur and Noble 2005; Bleakley et al. 2007; Li and Chen 2013). Another line of research views link prediction rather as an estimation issue, namely as the problem of estimating the true matrix of the probabilities of connection between node pairs. In this line, Tabouy et al. (2020) consider maximum likelihood (ML) estimation for the Stochastic block model (SBM) with missing links and propose a variational approach for a variety of missing data patterns. Gaucher et al. (2021) study a low-rank model and a technique based on matrix completion tools, which is also robust to outliers. Mukherjee and Chakrabarti (2019) give an algorithm for graphon estimation in a missing data setup. Li et al. (2023) study a special case of missing data setup called egocentric or star sampling, where observations are generated by sampling a subset of nodes randomly and then recording all of their connections, and Zhao et al. (2017) consider the case where the recording of true/false edges can be erroneous. Minimax results are derived in Gao et al. (2016) for a least squares estimator in the SBM under a uniform and known missing data pattern and in Gaucher and Klopp (2021) for the ML estimator under a more general setting.
Concretely, the output of all of these methods are scores for all missing edges, ranking them from most likely to least likely to interact. Such an output is satisfying when the application constrains the number of pairs of vertices to be declared as true edges to be fixed, as in e-recommendation, where we could have to recommend the top 3 best products most likely to interest the consumer. Alternatively, other practical cases may instead require a classification of the missing edges into true and false edges together with a control of the amount of edges that are wrongly declared as true (false positives). Putting the emphasis on false positives is appropriate in many contexts. For instance, in the reconstruction of biological networks, the edges that are classified as true are then tested experimentally in a costly process, which makes it desirable for the user to avoid false positives in the selection step. This is increasingly true for real-world networks that are in general very sparse. The decision of declaring a missing pair as a false edge can be viewed as a type of abstention option: Based on the data, we do not have enough evidence to confidently predict it as a true edge.
How to build a reliable classification procedure? Using an ad hoc rule like declaring as true edges, the node pairs with a connection probability above the 50% threshold may lead to a high number of false positives since a) probabilities may not be estimated correctly and b) even if they were, the probability of making a mistake may still be high if there are many node pairs with moderately elevated connection probability.
In this work, we consider the goal of identifying a subset of the missing pairs of nodes for which we can confidently predict the presence of an edge, with a guarantee on the number of edges that are falsely predicted as true. Our problem can be viewed as finding the appropriate threshold (not 50%) for the connection probabilities such that the number of false positives remains below a prescribed level. The optimal threshold depends on the problem itself. In simple settings, a low threshold may be satisfactory, as for instance when most connected triplets are indeed triangles. However, on a graph with much stochasticity, the exact prediction of links is a very uncertain endeavor.
The problem is formalized in terms of controlling the false discovery rate (FDR), defined as the average proportion of errors among the pairs of vertices declared to be true edges (proportion of false discoveries). More precisely, the goal is to develop a procedure such that the FDR is below a user-specified level \(\alpha \), which is an error margin that represents the acceptance level for the proportion of false edges in the selection. The interpretation for the user is clear: if, for instance, \(\alpha \) is set to 5% and the method returns a set of 100 node pairs, then the number of nonexistent edges in this set is expected to be at most 5.
1.2 Approach
We propose a method that takes as input the partially observed graph and, using an off-the-shelf link prediction method, returns a set of node pairs with an FDR control at level \(\alpha \). The method can be seen as a general wrapper that transforms any link prediction technique into an FDR-controlling procedure. Crucially, even when the quality of the link predictor is not particularly good, our method provides control of the FDR.
Our approach relies on conformal inference (Vovk et al. 2005; Balasubramanian et al. 2014), a statistical framework that provides generic tools to rigorously estimate uncertainty for off-the-shelf ML algorithms in various tasks. In particular, conformal prediction (Angelopoulos and Bates 2021; Lei and Wasserman 2014; Romano et al. 2019, 2020; Tibshirani et al. 2019) enables to build model-free confidence intervals for the output of any ML algorithm, even “black-box,” valid in finite samples without any assumptions on the data distribution besides exchangeability of the observations. Another important application of conformal inference is nonparametric hypothesis testing, via the so-called conformal p-value (Vovk et al. 2005; Balasubramanian et al. 2014; Bates et al. 2023). Considering a standard testing problem \(H_0 :X \sim P_0\) for some multivariate observation X and reference distribution \(P_0\), conformal p-values measure statistical significance by comparing the test statistic, or score, to a reference set, consisting of values of the score function on observations drawn from \(P_0\). Crucially, computing a conformal p-value only requires to have at hand a sample from \(P_0\), rather than knowing the distribution explicitly. Under the exchangeability of the reference scores with the test score when the null hypothesis is true, conformal p-values enable to build valid tests in various contexts, such as FDR control in novelty detection (Bates et al. 2023; Yang et al. 2021; Marandon et al. 2024; Liang rt al. 2022), binary classification (Rava et al. 2021; Jin and Candès 2023), or two-sample testing (Hu and Lei 2023).
We propose to use this high-level idea of comparing a score to a set of reference scores representing the null hypothesis being tested, in order to properly threshold the link prediction probabilities for FDR control. In our link prediction setup, the connection probability for a pair of nodes (i, j) can be seen as a score indicating the relevance of an edge between i and j. The aforementioned score comparison then turns into a comparison of the connection probability for a non-observed pair of nodes to connection probabilities of pairs that are known to be nonexistent edges. However, the setup is markedly different from the previous literature, making this transposition challenging. In particular, the graph structure makes the scores dependent on each other in an intricate way, which requires to build the scores with care.
Contributions. The contributions of this work are summarized as follows:
-
We introduce a novel method to control the FDR in link prediction (Sect. 3), which extends ideas from the conformal inference literature to graph-structured data. The proposed method acts as a wrapper that transforms any off-the-shelf link prediction (LP) technique into an FDR-controlling procedure for link prediction. It is designed to provide FDR control regardless of the difficulty of the setting and of the quality of the chosen LP technique. Moreover, the ability to use any LP technique of choice, including the state-of-the-art, makes it flexible and powerful.
-
Extensive numerical experimentsFootnote 1 (Sect. 4) assess the excellent performance of the approach and demonstrate its usefulness compared to the state-of-the-art.
1.3 Relation to previous work
Error rate control in statistical learning. Error rate control has notably been considered in novelty detection (Bates et al. 2023; Yang et al. 2021; Marandon et al. 2024; Liang rt al. 2022), binary classification (Geifman and El-Yaniv 2017; Angelopoulos et al. 2021; Rava et al. 2021; Jin and Candès 2023), clustering (Marandon et al. 2022) and graph inference (Rebafka et al. 2022). The setting closest to ours is that of binary classification, in the sense that here the goal is to classify non-observed pairs of nodes as a “true” or “false” edge, given that we observe part of both true edges and nonexistent edges. In this line, some approaches (e.g., Zhang et al., 2018) view link prediction as a binary classification problem. These approaches use the graph structure to produce edge embeddings, i.e., data objects representing an edge, that are fed to a classifier as learning examples along with labels corresponding to existence or nonexistence. The methods introduced in Geifman and El-Yaniv (2017); Angelopoulos et al. (2021); Rava et al. (2021); Jin and Candès (2023) in the context of general binary classification all provide finite-sample guarantees, but the approaches and the type of guarantees vary. To be more precise, the algorithms in Rava et al. (2021); Jin and Candès (2023) control the FDR and are very close to the conformal-based approach of Bates et al. (2023), whereas Geifman and El-Yaniv (2017); Angelopoulos et al. (2021) consider controlling the mis-classification error for a single new point and use certain bounds of the empirical risk with respect to the true risk.
However, these approaches cannot be applied in our situation because here data examples are based on the graph structure and thus depend on each other in a complex way. In particular, we do not have i.i.d. data examples as assumed in the classical binary classification setting. In this regard, our method is related to the work of Marandon et al. (2024) that extends the conformal novelty detection method of Bates et al. (2023) to the case where the learner is not previously trained, but uses the test sample to output scores which makes the scores dependent. This is similar to our problem in the sense that here we aim to calibrate connection probabilities that depend on each other through the graph structure.
Conformal inference applied to graph data A few recent works (Huang et al. 2023; Lunde et al. 2023) have considered the application of conformal prediction to graph data. However, conformal prediction is concerned with constructing prediction sets, rather than error rate control as considered here. Moreover, in these works, the prediction task concerns the nodes: Huang et al. (2023) considers node classification, while Lunde et al. (2023) studies prediction of node covariates (also called network-assisted regression). By contrast, in our work, the prediction task concerns the edges, and therefore, the specific dependency issue that arises differs from Huang et al. (2023); Lunde et al. (2023). Finally, Luo et al. (2023) employed conformal p-values to detect anomalous edges in a graph. However, their method relies on edge-exchangeability, which is a restrictive assumption, and the guarantee is only for a single edge.
Conformal inference for missing data problems. Link prediction can be seen as a type of missing data problem where the goal is to give a prediction for missing values, rather than with missing values. The latter setting was addressed within conformal prediction in Zaffran et al. (2023) for a regression task with missing values in the covariates and in Shao and Zhang (2023) for a particular task called matrix prediction. A concurrent work by Gui et al. (2023) investigated conformal prediction for the matrix completion task, in which the aim is to fill in a matrix that has missing values. In particular, the method proposed therein is shown to provide coverage in a general missing data setup where the entries of the sampling matrix are either i.i.d. Bernoullis variables or known independent Bernoullis variables. Gui et al. (2023) also cover the case where the sampling is unknown and non-uniform by providing error bounds for a weighted version of their method, based on tools from conformal prediction under covariate shift (Tibshirani et al. 2019). However, as outlined previously, conformal prediction is a different aim from the one considered here, which is FDR control.
Link with multiple testing. The FDR criterion is a staple of multiple testing, where recent works on knockoffs and conformal p-values (Barber and Candès 2015; Weinstein et al. 2017; Bates et al. 2023; Yang et al. 2021; Marandon et al. 2024) have provided model-free procedures that come with an FDR control guarantee in finite samples. However in this work, while we do use tools of Bates et al. (2023), our setting does not strictly conform to a known multiple testing framework such as the p-value framework (Benjamini and Hochberg 1995) (the hypotheses being random) or the empirical Bayes framework (Efron et al. 2001; Sun and Cai 2007) (the number of hypotheses being itself random). Hence, previous theory in that area cannot be applied.
2 Problem setup

Illustration of the learning problem. The left panel shows the true complete graph \(A^*\), which is not observed. The right panel describes our observation: the true edges (1, 2), (1, 4), (2, 3), (2, 5), (3, 5) are observed, along with the nonexistent edges (1, 3),(1, 5), (4, 5) but the information concerning the pairs (2, 4) and (3, 4) is missing. We aim to decide for (2, 4) and (3, 4) whether there is a true edge or not
Let \(A^* = (A^*_{i,j})_{1 \le i,j \le n}\) be the adjacency matrix of the true complete graph \(\mathcal {G}\), \(X \in {{\,\mathrm{\mathbb {R}}\,}}^{n \times d}\) a matrix of node covariates (if available), and \(\Omega = (\Omega _{i,j})_{1 \le i,j \le n}\) the sampling matrix such that \(\Omega _{i,j} = 1\) if the interaction status (true/false) of (i, j) is observed, and 0 otherwise. We denote by A the observed adjacency matrix with \(A_{i,j} = \Omega _{i,j} A^*_{i,j}\). Thus, \(A_{i,j}=1\) indicates that there is an observed true edge between i and j, whereas \(A_{i,j}=0\) indicates either the observed lack of an edge or an unreported edge. The sampling matrix \(\Omega \) is assumed to be observed, so that it is known which zero-entries \(A_{i,j}=0\) correspond to observed false edges and which ones correspond to missing information. The general setting is illustrated in Fig. 1. We denote by P the joint distribution of \(Z^* = (A^*, X, \Omega )\), Z the observation \((A, X, \Omega )\) and \(\mathcal {Z}\) the observation space.
We next lay out our specific modeling assumptions regarding P. In this work, we make assumptions on the generation of the sampling matrix only. We start by reviewing the main settings encountered in the literature in this regard. As outlined in Tabouy et al. (2020), most works on link prediction do not explicitly model the sampling matrix \(\Omega \). To fill this gap, Tabouy et al. (2020) provided a formal taxonomy of missing data patterns in networks by adapting the theory developed in Little and Rubin (2019), dividing them into three cases:
-
Missing completely at random (MCAR): \(\Omega \) is independent from \(A^*\).
-
Missing at random (MAR): \(\Omega \) is independent from the value of \(A^*\) on the unobserved part of the network.
-
Missing not at random (MNAR): when the setting is neither MCAR nor MAR.
Tabouy et al. (2020) give several examples for each case. For instance, the MCAR assumption trivially includes the setting of random-dyad sampling where entries of \(A^*\) are missing uniformly at random, that is considered in Gao et al. (2016) and is also well-studied in the matrix completion literature (Candes and Recht 2009; Candes and Plan 2010; Chatterjee 2015). In the specific context of link prediction, another typical MCAR sampling pattern is star (or egocentric) sampling (Li et al. 2023) that consists in randomly selecting a subset of the nodes and observing the corresponding row of \(A^*\). A particular type of MNAR sampling is studied in Gaucher et al. (2021) where the sampling only depends on latent structure (e.g., node communities).
In this work, we consider a type of MNAR sampling called double standard sampling (Tabouy et al. 2020; Sportisse et al. 2020), in which the entries of \(\Omega \) are independently generated as:
for some unknown sampling rates \(w_0, w_1\). This amounts to consider that true edges together with false edges are missing uniformly at random at a certain status-specific rate, and can be seen as a straightforward generalization of random-dyad sampling that is more relevant for practical applications. Indeed, detecting interactions is typically more of interest rather than the detecting of non-interactions; hence, one can expect that in general true edges have more chance of being reported than false edges.
We are interested in classifying the unobserved node pairs \(\{ (i,j) \; :\; \Omega _{i,j} = 0\}\) into true edges and false edges, or in other words, selecting a set of unobserved node pairs to be declared as true edges, based on the observed graph structure. In order to be consistent with the notation of the conformal inference literature, we use the following notations:
-
We denote by \({{\,\mathrm{\mathcal {D}_{\text {test}}}\,}}(Z)=\{ (i,j) \; :\; \Omega _{i,j} = 0\}\) the set of non-sampled (or missing) node pairs and by \(\mathcal {D}(Z)=\{ (i,j) \; :\; \Omega _{i,j} = 1\}\) the set of sampled pairs, with \({{\,\mathrm{\mathcal {D}^0}\,}}= \{ (i,j) \in \mathcal {D}\; :\; A^*_{i,j} = 0 \}\) the set of observed nonexistent edges and \({{\,\mathrm{\mathcal {D}^1}\,}}= \{ (i,j) \in \mathcal {D}\; :\; A^*_{i,j} = 1 \}\) the set of observed true edges. We refer to \({{\,\mathrm{\mathcal {D}_{\text {test}}}\,}}(Z)\) as the test set.
-
We denote by \(\mathcal {H}_0 = \{(i,j) \; :\; \Omega _{i,j} = 0, A^*_{i,j} = 0 \} \) the (unobserved) set of false edges in the test set and \(\mathcal {H}_1 = \{(i,j) \; :\; \Omega _{i,j} = 0, A^*_{i,j} = 1 \}\) the (unobserved) set of true edges in the test set.
The notations are illustrated in Fig. 2.

Illustration of the notations introduced in Sect. 2. The test edges \({{\,\mathrm{\mathcal {D}_{\text {test}}}\,}}\) (left panel) are divided into two subsets (unobserved): true edges \(\mathcal {H}_1\), and false edges \(\mathcal {H}_0\) (right panel)
In our framework, a selection procedure is a (measurable) function \(R=R(Z)\) that returns a subset of \({{\,\mathrm{\mathcal {D}_{\text {test}}}\,}}\) corresponding to the indices (i, j) where an edge is declared. The aim is to design a procedure R close to \(\mathcal {H}_1\), or equivalently, with \(R\cap \mathcal {H}_0\) (false discoveries) as small as possible. For any such procedure R, the false discovery rate (FDR) of R is defined as the average of the false discovery proportion (FDP) of R under the model parameter \(P\in \mathcal {P}\), that is,
Similarly, the true discovery rate (TDR) is defined as the average of the true discovery proportion (TDP), that is,
Our aim is to build a procedure R that controls the FDR while having a TDR (measuring the power of the procedure) as large as possible.
Remark 1
In some applications, missingness can also be present in the covariate matrix X. While we do not explicitly consider this setup here, our method can readily be applied and control the FDR over the detected edges with missingness in X as long as the distributional assumption on \(\Omega \vert A^*, X\) holds.
3 Methodology
3.1 Review of conformal p-values for out-of-distribution testing
We first provide a general overview of conformal p-values in the classical setting of out-of-distribution testing, in which the problem is to test the null hypothesis that a data point \(Z_{n+1}\) is drawn from the same (unknown) distribution \(P_0\) as an i.i.d. data sample \(Z_1, \dots , Z_n\). A conformal p-value (Haroush et al. 2022; Bates et al. 2023) is a nonparametric approach that relies on reducing each multivariate observation \(Z_i\) to a univariate non-conformity score (or score for short) \(S_{i} = g(Z_i) \in {{\,\mathrm{\mathbb {R}}\,}}\) that measures the conformity to the data sample \((Z_j)_{1 \le j \le n}\), to evaluate the statistical evidence of being an outlier:
In words, the conformal p-value amounts to the rank of the test score \(S_{n+1}\) among the scores of the data sample. If \((Z_j)_{1 \le j \le n+1}\) is i.i.d. when \(Z_{n+1} \sim P_0\) and the scoring function g is fixed, then p is uniformly distributed under the null and hence yields a valid test. In practice, to use a learned score function, one splits the data sample \((Z_j)_{1 \le j \le n}\) into two subsets, a training sample \({{\,\mathrm{\mathcal {D}_{\text {train}}}\,}}= \{Z_1,\ldots ,Z_k\}\) and a calibration sample \({{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}= \{Z_{k+1},\ldots , Z_n\}\). The training sample \({{\,\mathrm{\mathcal {D}_{\text {train}}}\,}}\) is used to learn the score (e.g., using one-class classifiers), whereas the calibration sample \({{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}\) is used to compute the p-value. (Hence, n is replaced by \(n-k\) in the above equation). More generally, the core idea is that the validity holds as soon as we have exchangeability of the scores \(S_i\) under the null. Moreover, in the multiple testing case, conformal p-values can be employed for FDR control when plugged into the Benjamini–Hochberg (BH) procedure (Benjamini and Hochberg 1995) (Bates et al. 2023; Liang rt al. 2022; Marandon et al. 2024).
3.2 Conformal link prediction
Let \(g: \mathcal {Z}\rightarrow {{\,\mathrm{\mathbb {R}}\,}}^{n \times n}\) be a scoring function that takes as input an observation \(z \in \mathcal {Z}\), which is a tuple consisting of an adjacency matrix, a covariate matrix, and a sampling matrix as described in Sect. 2, and returns a score matrix \((S_{i,j})_{1 \le i,j \le n} \in {{\,\mathrm{\mathbb {R}}\,}}^{n \times n}\), with \(S_{i,j}\) estimating how likely it is that i is connected to j. A scoring function amounts to a link prediction algorithm (also returning in general an indicator of the relevance of an edge between i and j for any pair of nodes (i, j)), and in the sequel, we use the two terms exchangeably. The score does not have to be in [0, 1]: for instance, \(S_{i,j}\) can be the number of common neighbors between i and j.

Conformal link prediction
To obtain a set of edges with FDR below \(\alpha \), we borrow from the literature on conformal p-values (Bates et al. 2023; Marandon et al. 2022) to formulate the following idea: some of the observed false edges can be used as a reference set, by comparing the score for a node pair in the test set to scores computed on false edges to determine if it is likely to be a false positive. Effectively, we will declare as edges the pairs that have a test score higher than a cut-off \(\hat{t}\) computed from the calibration set and depending on the level \(\alpha \). In detail, the steps are as follows:
-
1.
Build a reference set \({{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}\) of false edges by sampling uniformly without replacement from the set of observed false edges \({{\,\mathrm{\mathcal {D}^0}\,}}\)
-
2.
Run an off-the-shelf LP algorithm g on the “masked” observation \(Z_{\text {train}}=(A,X,{{\,\mathrm{\Omega _{\text {train}}}\,}})\), where \(({{\,\mathrm{\Omega _{\text {train}}}\,}})_{i,j}= 0\) if \((i,j) \in {{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}\) and \(\Omega _{i,j}\) otherwise.
-
3.
Compute the scores for the reference set, and for the test set, \(S_{i,j} = g(Z_{\text {train}})_{i,j}\) for \((i,j) \in {{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}\cup {{\,\mathrm{\mathcal {D}_{\text {test}}}\,}}\);
-
4.
Compute the conformal p-values \((p_{(i,j)})_{(i,j) \in {{\,\mathrm{\mathcal {D}_{\text {test}}}\,}}}\) given by
$$\begin{aligned} p_{(i,j)} = \frac{1}{\vert {{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}\vert +1} \left( 1 + \sum _{(u,v) \in {{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}} {{\,\mathrm{\mathbb {1}}\,}}\{S_{(i,j)} \le S_{(u,v)} \} \right) , \quad (i,j) \in {{\,\mathrm{\mathcal {D}_{\text {test}}}\,}}; \end{aligned}$$(1) -
5.
Declare as true edges the node pairs in the test set that are in the rejection set returned by the BH procedure applied to the p-values \((p_{(i,j)})_{(i,j) \in {{\,\mathrm{\mathcal {D}_{\text {test}}}\,}}}\).
The procedure is summarized in Algorithm 1. We now review each step one by one in order to provide the intuition behind the proposed procedure. Step 1 builds a reference set of false edges that are sampled in such a way as to imitate the missingness of false edges in the test set, i.e., the sampling of \(\mathcal {H}_0\). Step 2 runs an off-the-shelf LP algorithm g on \(Z_{\text {train}}\) (instead of Z) so as to treat the edge examples (i, j) in the reference set \({{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}\) as unreported information when learning the score, which is necessary to avoid biasing the comparison of the test scores to the reference scores. Otherwise, the scoring g may use the knowledge that the node pairs in the reference set are false edges and produce an overfitted score for those. Together with Step 1, this is crucial to fabricate good reference scores that are representative of the scores of false edges in the test set. Finally, the remaining steps correspond exactly to the conformal procedure of Bates et al. (2023) for out-of-distribution testing, and we refer the reader to Sect. 3.1 and to Bates et al. (2023) for more details.
Remark 2
This type of procedure is designed to control the FDR at level \(\frac{ \vert \mathcal {H}_0 \vert }{\vert {{\,\mathrm{\mathcal {D}_{\text {test}}}\,}}\vert } \alpha < \alpha \). To maximize power, we recommend to apply the procedure at level \(\alpha / {{\hat{\pi }}}_0\) where \({{\hat{\pi }}}_0 \in ]0,1[\) is an estimate of \(\frac{ \vert \mathcal {H}_0 \vert }{\vert {{\,\mathrm{\mathcal {D}_{\text {test}}}\,}}\vert }\). In particular, tools from the multiple testing literature on the estimation of the proportion of null hypotheses may be employed, e.g., by using Storey’s estimator (Marandon et al. 2024).
Remark 3
Many LP algorithms (e.g., Zhang et al., 2018) are not trained on the entire set of observed edges \(\mathcal {D}\) but on a subset \({{\,\mathrm{\mathcal {D}_{\text {train}}}\,}}\subset \mathcal {D}\) with a 50–50% distribution of true and false edges. As most real-world networks are sparse, typically all observed edges \({{\,\mathrm{\mathcal {D}^1}\,}}\) are used for training and a randomly chosen subset of false edges in \({{\,\mathrm{\mathcal {D}^0}\,}}\) of the same size as \({{\,\mathrm{\mathcal {D}^1}\,}}\). Then, the reference set \({{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}\) is naturally chosen among the false edges in \({{\,\mathrm{\mathcal {D}^0}\,}}\) that are not used in \({{\,\mathrm{\mathcal {D}_{\text {train}}}\,}}\) for learning the predictor. Consequently, in practice choosing a reference set \({{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}\) does not diminish the amount of data on which the predictor is learned.
Remark 4
The sample size of the reference set \({{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}\) must be large enough to ensure a good power, as pointed out in previous work using conformal p-values in the novelty detection context (Mary and Roquain 2022; Marandon et al. 2024; Yang et al. 2021). In particular, Mary and Roquain (2022) give a power result under the condition that \(\vert {{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}\vert \gtrsim \vert {{\,\mathrm{\mathcal {D}_{\text {test}}}\,}}\vert / (k\alpha )\), where k is the number of “detectable” novelties. Consequently, our recommendation is to choose \(\vert {{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}\vert \) of the order of \(\vert {{\,\mathrm{\mathcal {D}_{\text {test}}}\,}}\vert / \alpha \); this choice works reasonably well in our numerical experiments.
3.3 Link with conformal out-of-distribution testing
In this section, we explicit the output of typical link prediction methods, to write each score \(S_{i,j}\) as a (learned) function of an edge embedding representing the information that is observed about the pair (i, j). This allows to reframe our approach as using the procedure of Bates et al. (2023) (see Sect. 3.1) on data objects that have a non-exchangeable dependence structure.
For simplicity of presentation, in this section, we consider an undirected graph without node covariates. Link prediction methods output a matrix of predictions/scores \((g (Z)_{i,j})_{1 \le i,j \le n}\), where the prediction for i and j can be written in general as
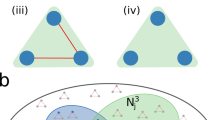
for a real-valued measurable function h and a given fixed \(K \in \{1, \dots , n \}\) and where \(A^k_{i, \cdot }\) is defined as the i-th row of \(A^k\). In the (3), the r.v. \(W_{i,j}\) can be thought of as the “K-hop neighborhood” of (i, j). It represents an embedding for the node pair (i, j) that describes a pattern of connection around i and j. If the graph has some structure, it should be observed that the pattern differs when i and j are connected compared to when they are not. Moreover, there should be some similarity between the patterns observed for true edges, as compared to false edges. Figure 3 gives an illustration in the case of a graph with community structure. When there is an edge between i and j (Fig. 3a), i and j are involved in a same group of nodes that is densely connected (community). Conversely, when there is no edge between them (Fig. 3b), i and j belong to separate groups of densely connected nodes that share few links between them.

Example of K-hop (K=2) neighborhood of (i, j) (in color), for when a i and j are connected and b i and j are not connected
For instance, in the case of the common neighbors (CN) heuristic (Lu and Zhou 2011), we have that \(g(Z)_{i,j}= A_{i, \cdot }^T A_{j, \cdot }\). Alternatively, when considering supervised approaches such as binary classification-based (Zhang et al. 2018; Bleakley et al. 2007), maximum likelihood-based (Kipf and Welling 2016; Tabouy et al. 2020) or matrix completion-based (Li et al. 2023; Gaucher et al. 2021), the link prediction function can be written as the minimizer of an empirical risk (ERM):
with \(\mathcal {L}: [0,1] \times \{0,1\} \rightarrow {{\,\mathrm{\mathbb {R}}\,}}\) a loss function and \(\mathcal {F}\) a function class. In (4), \(h(W_{i,j}) \) is an estimate of the probability that there is an edge between i and j, and the error term \(\mathcal {L}[ h(W_{i,j}), A_{i,j} ]\) quantifies the difference between the prediction \(h(W_{i,j})\) and the true \(A_{i,j} \). The ERM formulation for the aforementioned supervised approaches can be justified as follows:
-
Binary classification approaches (Zhang et al. 2018; Bleakley et al. 2007): In that case, the ERM formulation (4) is obvious. For instance, for SEAL (Zhang et al. 2018), \(g(Z)_{i,j}\) is given by a GNN that takes as input the K-hop subgraph around (i, j), excluding the edge between (i, j) if there is one observed, and augmented with node features that describe the distance of each node in the subgraph to i and to j. The parameters of the GNN are fitted by minimizing the cross-entropy loss over a set \({{\,\mathrm{\mathcal {D}_{\text {train}}}\,}}\subset \mathcal {D}\) of observed true/false edges. In practice, \({{\,\mathrm{\mathcal {D}_{\text {train}}}\,}}\) is subsampled from \(\mathcal {D}\) in order to have a \(50\%--50\%\) partitioning between true and false edges.
-
Maximum likelihood approaches (Kipf and Welling 2016; Tabouy et al. 2020): Maximum likelihood approaches aim to optimize a lower bound on the likelihood (ELBO). This lower bound is an expectation, and therefore, using Monte Carlo approximation, we end up with a function of the form (4). For instance, for VGAE (Kipf and Welling 2016), \(g(Z)_{i,j}\) is given by the scalar product \(H_i^T H_j\) where \(H_u\) is a node embedding for node u, the embedding matrix \(H \in {{\,\mathrm{\mathbb {R}}\,}}^{n \times n}\) being the output of a GNN. It follows that \(H_u = \phi \left( A_{u, \cdot }, A^2_{u, \cdot }, \dots , A^L_{u, \cdot }\right) \) for some function \(\phi \), with L the number of layers of the GNN.
-
Matrix completion (Li et al. 2023; Gaucher et al. 2021): For example, for Li et al. (2023), one can rewrite the estimated probability matrix \(\hat{P}\) as \(\hat{P} = {{\,\textrm{argmin}\,}}_{P} \{ \sum _{(u,v) \in \mathcal {D}} (A_{u,v} - P_{u,v})^2, P = A_{in}^T\Theta A_{in}, \; \text {rank}(\Theta ) \le r\}\) where \(A_{in}\) is the sub-matrix of A consisting only of the observed entries. Hence, in that case, \(g(Z)_{i,j}\) is of the form (4) with \(h(W_{i,j})=\phi (A_{i, \cdot }, A_{j, \cdot })\) for some function \(\phi \).
In this view, our procedure proceeds by learning a binary classification rule for a set of examples indexed by \({{\,\mathrm{\mathcal {D}_{\text {train}}}\,}}= \mathcal {D}\backslash {{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}\), each learning example consisting of an edge embedding and its “label” (true/false), and then using a reference set of false edges examples indexed by \({{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}\) to properly calibrate the edge probabilities for \({{\,\mathrm{\mathcal {D}_{\text {test}}}\,}}\). As such, it boils down to the approach proposed by Bates et al. (2023) for FDR control except for a supervised context and with non-exchangeable data objects. Sampling \({{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}\) in a manner that mimics the missingness for false edges and learning on the edge examples indexed by \(\mathcal {D}\backslash {{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}\) allows to control the FDR despite this dependence. Figure 4 provides a high-level sketch.

Sketch of the procedure proposed in this work
4 Numerical experiments
In this section, we study the performance of our method (Algorithm 1) both on simulated data (Sect. 4.1) and on a real dataset (Sect. 4.2). We consider two choices for the scoring function g: the GNN-based method of (Zhang et al. 2018) called SEAL and the common neighbors (CN) heuristic, yielding the procedures CN-conf and SEAL-conf. SEAL is used with a hop number of 2, for the GNN, we use GIN (Xu et al. 2019) with three layers and 32 neurons, and we train for 10 epochs with a learning rate of 0, 001. In addition, following Remark 2, we consider a version of our method where Algorithm 1 is applied at level \( \alpha / {{\hat{\pi }}}_0\), with \({{\hat{\pi }}}_0\) a suitable estimator of \(\vert \mathcal {H}_0 \vert / \vert {{\,\mathrm{\mathcal {D}_{\text {test}}}\,}}\vert \). Specifically, following Marandon et al. (2024), we use Storey’s estimator (Storey et al. 2004) given by \({{\hat{\pi }}}_0 =(1-\lambda )^{-1}\left( 1+ \sum _{(i,j) \in {{\,\mathrm{\mathcal {D}_{\text {test}}}\,}}} {{\,\mathrm{\mathbb {1}}\,}}\{p_{i,j} \ge \lambda \} \right) \) with \(\lambda =1/2\), which gives the procedures CN-conf-storey and SEAL-conf-storey. Finally, we compare the performance of our methods to a “naive" procedure for FDR control (called fixed threshold procedure hereafter) in which we select in R(Z) the edges \((i,j) \in {{\,\mathrm{\mathcal {D}_{\text {test}}}\,}}\) for which \(g(Z)_{i,j} \ge 1-\alpha \). (Here, we assume that \(g \in [0,1]\), otherwise, scores are normalized into [0, 1] by standardizing the values and applying the sigmoid function.) Combined with either SEAL or CN, this yields the procedures CN-fixed and SEAL-fixed. If the probabilities \(g(Z)_{i,j}\) are poorly estimated, these fixed threshold procedures are expected to not control the FDR at level \(\alpha \) in general.
4.1 Simulated data
In this section, we evaluate our method by generating the true graph \(A^*\) from two popular random graph models: the Stochastic block model and the graphon model (Matias and Robin 2014).
4.1.1 Stochastic block model

Illustration of the SBM model considered in Sect. 4.1. Nodes represent classes, edges indicate connection patterns between classes
To start with, \(A^*\) is generated from a Stochastic block model:
with \(Q=5\) classes, mixture proportions \(\pi = (1/5, \dots 1/5)\), and connectivity matrix \(\gamma \) given by
In this model, the graph \(A^*\) displays a variety of connection patterns including community structure and hubs, see Fig. 5 for an illustration. The overall difficulty of the problem resides within two distinct statistical tasks: learning the edge link probabilities (i.e., the score), and the multiple testing issue of controlling the false discovery rate with a given test statistic. The main quantities that govern the difficulty of the learning problem are the density of the graph \(\rho = n^{-2}{{\,\mathrm{\mathbb {E}}\,}}(\sum _{i,j} A^*_{i,j}) = \sum _{q,l} \gamma _{q,l}\) and the number of nodes n (Gaucher and Klopp 2021). For the FDR control, the difficulty mainly depends on the signal-to-noise ratio \(\text {SNR} = p / \epsilon \) as well as the proportion of true edges to false edges within the test set \(\vert \mathcal {H}_1 \vert / \vert \mathcal {H}_0 \vert = \frac{(1-w_1) \rho }{(1-w_0)(1-\rho )}\) and the number of observed false edges \(w_0(1-\rho )\). Indeed, the higher the SNR, the more true edges display different connection patterns as compared to false edges, whereas increasing the proportion of true edges to false edges within the test set and the calibration sample size improves the estimation of the false discovery rate in Algorithm 1, see Remark 4.
Hence, in order to study the performance of the methods in various conditions, we vary the number of nodes n, the SNR \(p/ \epsilon \), and the connectivity parameter p (controlling the density \(\rho \) for a fixed SNR and a fixed number of nodes n). In each setting, we construct samples \(\mathcal {D}(Z)\) and test samples \({{\,\mathrm{\mathcal {D}_{\text {test}}}\,}}(Z)\) by removing at random \(1-w_1 = 10\%\) of the true edges, and \(1-w_0\%\) of the false edges such as to have that \(\vert \mathcal {H}_0 \vert / \vert \mathcal {H}_1 \vert = 50\%\), and we use \(\vert {{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}\vert = \max \left( \vert \mathcal {D}^0 \vert - \vert \mathcal {D}^1 \vert , 5000\right) \) in Algorithm 1. The FDR and TDR of the different methods are evaluated by using 100 Monte Carlo replications. The results are displayed in Fig. 6 for 1) \(p=0.5, p/\epsilon =10\), 2) \(p=0.5, p/\epsilon =5\), and 3) \(p=0.2, p/\epsilon =10\), with \(n \in \{50, 100, 200 \}\).
In this SBM, for any parameter values, the connection probabilities cannot be consistently well estimated by a CN heuristic, as some classes have a low probability of connection within their class while being well connected with other classes: For nodes that belong to these groups, it occurs that they share neighbors despite not being connected. Hence, in the case that CN is used, the fixed procedure fails to control the FDR in Fig. 6. By contrast, our conformal procedures displays a FDR that is below or close to \(\alpha \) across all level values, for all choices of scoring function and for all model configurations.
However, in some model configurations (when \(p =0.2\) or SNR \(= 5\)), the power is near zero for any scoring function across all values of \(\alpha \) and n.
Moreover, even in the more favorable setting where \(p=0.5\) and SNR \(=10\), the power decreases as n increases if \(\alpha \) is low enough (\(\alpha \le 0.2\)). The issue is that the FDR control problem is intrinsically difficult for a model such as the SBM. To illustrate, consider an oracle setting where the true classes \((C_i)_{1\le i \le n}\) and model parameters are known. In that case, a natural strategy is to declare edges using for each test pair (i, j), the probability \(\P (A^*_{i,j}=1 \vert (C_i)_{1\le i \le n} )\), and if \(p > \epsilon \), then the pairs that are most likely to be connected are pairs that are in the same class. However, within a class, all pairs have the same likelihood of being connected \(\P (A^*_{i,j}=1 \vert (C_i)_{1\le i \le n} ) \) and so if \(\alpha < p\), it is impossible to control the FDR at \(\alpha \) based on a thresholding of \(\P (A^*_{i,j}=1 \vert (C_i)_{1\le i \le n} )\), unless one applies a trivial decision rule that declares any node pair as non-interacting. On principle, one can get a finer test statistic than \(\P (A^*_{i,j}=1 \vert (C_i)_{1\le i \le n} )\) by using the observation A, but if the sampling is homogeneous for true and false edges, respectively, as is assumed here, A does not give much more information about the location of true and false edges within a class. Thus, when n increases, the learned scores concentrate around the oracle probabilities \(\P (A^*_{i,j}=1 \vert (C_i)_{1\le i \le n} )\), entailing that if \(\alpha \) is too low, we get near-zero power. When n is small, the probability estimates are more noisy, and the margin of error \(\alpha \) may be fully utilized by the conformal procedures, which could explain the better power observed here—however, the variance of the FDP naturally increases as n decreases. Nonetheless, across all settings, the most powerful procedure among the ones that control the FDR is a conformal method.

FDR (left panel) and TDR (right panel) as a function of the nominal level \(\alpha \). The bands indicate the standard deviation
4.1.2 Graphon
Next, \(A^*\) is generated using a graphon model:
We construct samples \(\mathcal {D}(Z)\) and test samples \({{\,\mathrm{\mathcal {D}_{\text {test}}}\,}}(Z)\) and choose \(\vert {{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}\vert \) as in the previous section. The FDR and TDR of the methods are shown in Fig. 7 for \(\sigma =0.01, a=2\) and for \(\sigma =0.1, a=0.5\), with \(n \in \{50, 100, 200 \}\). In this model, compared to Sect. 4.1.1, the CN heuristic is not necessarily a poor predictor: by transitivity, the graphon function implies that the more neighbors two nodes have in common, the more likely it is that they are connected.
In the case that \(\sigma =0.01\) and \(a=2\), all procedures control the FDR for all n and \(\alpha \) values. However, our conformal procedures are the most powerful by a margin. In the more difficult setup where \(\sigma =0.1\) and \(a=0.5\), the FDR of the fixed procedure is inflated: across all values of n in the case of CN and for small n (\(n=50\)) in the case of SEAL. By contrast, our conformal procedures control the FDR across all values of n in this setup also, with equal or higher power than the fixed procedure when its FDR is below the nominal level. Finally, for all procedures the power improves when n increases; however, the gain is more substantial for the conformal methods.

FDR (left panel) and TDR (right panel) as a function of the nominal level \(\alpha \). The bands indicate the standard deviation
4.2 Real data
We evaluate our method on a real dataset: a food web network (Christian and Luczkovich 1999) downloaded from the Web of Life Repository (https://www.web-of-life.es/). A food web is a network of feeding interactions in an ecological community, in which nodes are species and two species are connected if one eats the other. Food web analysis delivers important insights into the workings of an ecosystem. However, documenting species interaction is in practice labor-intensive, and the resources for such investigations are finite; hence, food webs are typically incomplete.
In this dataset, there are in total 48 species and 221 interactions recorded between them. We consider a directed and bipartite representation where a set of predators connect to a set of preys: if a species plays both roles (i.e., eats certain species and also gets eaten by others), then we associate with it two separate nodes, one in the predator set and one in the prey set. We thus obtain a network of 81 nodes and 221 edges (see Fig. 8). In the corresponding adjacency matrix, there is by construction a zero entry for any node pair (i, j) where i is a prey or both i and j are predators; hence, we remove these node pairs from the set of negative edges \(\{(i,j) :A^*_{i,j} =0 \}\) in the sequel.

Food web network of Christian and Luczkovich (1999) with a bipartite representation: prey nodes are colored in blue and predator nodes are colored in yellow
We construct samples \(\mathcal {D}(Z)\) and test samples \({{\,\mathrm{\mathcal {D}_{\text {test}}}\,}}(Z)\) by considering the dataset at hand as the complete network \(A^*\) and by generating the missingness, encoded by \(\Omega \), using double standard sampling with \(w_1=10\%\) and \(w_0\) chosen such that \(\vert \mathcal {H}_0 \vert / \vert \mathcal {H}_1 \vert = 50\%\), and use \(\vert {{\,\mathrm{\mathcal {D}_{\text {cal}}}\,}}\vert = \max ( \vert \mathcal {D}^0 \vert - \vert \mathcal {D}^1 \vert , 5000)\) for the conformal methods. As in the simulations, we apply the methods using two different link prediction models, the CN heuristic and the SEAL algorithm. The performance of each method is then evaluated by computing the FDP and TDP with respect to the ground truth, and the FDR and TDR are computed by using 100 Monte Carlo replications. The FDR and TDR of the methods are shown in Fig. 9 for varying \(\alpha \).
When the CN heuristic is used as link prediction model, the proportion of falsely detected edges that are returned by the fixed threshold procedure is well above the target margin of error \(\alpha \). Such a result is well-expected since this particular heuristic is not suitable to estimate edge probabilities in bipartite networks: nodes of a given type (prey/predator) will often have many neighbors in common, yet they share no connections with each other. Hence, in this instance, the heuristic does not accurately model how connections are made, and the estimation of edge probabilities is very poor, whereas the fixed procedure relies on the model being correct to declare an unobserved node pair as interacting. Conversely, as a link prediction model, the SEAL method is not only learning-based, but is also expressive enough that it can learn various connection patterns. Hence, we observe here that when using SEAL to model and learn the edge probabilities, the FDR of the fixed threshold procedure is kept below \(\alpha \). By contrast, our conformal procedures control the FDR at \(\alpha \) regardless of the link prediction model used. Moreover, they uniformly improve upon the fixed procedure in terms of power: even when the fixed threshold procedure has an FDR under the nominal level, the proportion of true edges identified by our conformal procedures is much higher. In particular, when using a link prediction model that is suited to the characteristics of the network at hand, our conformal procedures are able to identify a significant amount of the interactions that were masked in the input data.

FDR (left panel) and TDR (right panel) as a function of the nominal level \(\alpha \), for the food web dataset described in Sect. 4.2. The bands indicate the standard deviation
5 Discussion
We have proposed a novel method that calibrates the output of any link prediction technique for FDR control, using recent ideas from the conformal inference literature. In a nutshell, our method acts as a wrapper that allows to transform an off-the-shelf link prediction technique into a procedure that controls the proportion of falsely detected edges at a user-defined level. Importantly, our proposed method is model-free: no assumptions are made regarding the distribution of the complete graph, and the control is provided regardless of the quality of the link prediction model. However, the power of the procedure depends on the quality of the chosen link prediction model and the intrinsic difficulty of the problem (in other words, how much connection patterns differ between true and false edges). Hence, in order to maximize the number of detected edges, the chosen link prediction model should be carefully tailored to the characteristics of the network at hand.
In this work, it is assumed that the sampling matrix is generated by sampling at random true and false edges at an unknown rate, respectively. However, this type of sampling does not include certain practical sampling designs such as egocentric sampling (Li et al. 2023). On the other hand, the key of the method is to sample the calibration node pairs in a manner that mimics the missingness of the false edges in the test set; therefore, if the sampling mechanism is complicated but its parameters are known, the control can be still provided as long as the sampling of the calibration sample is adapted.
An important topic in conformal inference is the question of conditional guarantees, that is, achieving error guarantees that hold conditionally on some component of the data. For instance, in classical conformal prediction, a large body of work (Foygel et al. 2021; Romano et al. 2020, 2019) studies the aim of obtaining valid prediction sets conditional on the features of a new test point, while a few others (Löfström et al. 2015; Sadinle et al. 2019) are rather interested in conditioning on the label. In the outlier detection context, Bates et al. (2023) consider guarantees conditional on the calibration data. In our case, let us note that the control can be considered as conditional on the complete graph \(A^*\): indeed, the calibration node pairs are actually sampled in a manner that mimics the missingness of the false edges conditionally on \(A^*\). Hence, the randomness of the problem resides in the sampling matrix. However, defining a relevant variable to further condition on is not clear here, since the observed data have a complex dependence structure.
Finally, some related scenarios of interest are settings where some true/false edges are erroneously observed or where the sampling matrix is not observed (Zhao et al. 2017). Investigating the extension of the method for these cases represents an interesting avenue of research for future work.
Notes
We publicly release the code of these experiments at https://github.com/arianemarandon/linkpredconf. We have also included a Jupyter notebook that illustrates the use of our procedure.
References
Angelopoulos AN, Bates S (2021). A gentle introduction to conformal prediction and distribution-free uncertainty quantification. arXiv preprint arXiv:2107.07511
Angelopoulos AN, Bates S, Candès EJ, Jordan MI, Lei L (2021). Learn then test: calibrating predictive algorithms to achieve risk control. arXiv preprint arXiv:2110.01052
Balasubramanian V, Ho S-S, Vovk V (2014) Conformal prediction for reliable machine learning: theory, adaptations and applications. Newnes
Barber RF, Candès EJ (2015) Controlling the false discovery rate via knockoffs. Annals Stat 43(5):2055–2085
Bates S, Candès E, Lei L, Romano Y, Sesia M (2023) Testing for outliers with conformal p-values. Annals Stat 51(1):149–178
Ben-Hur A, Noble W S (2005) Kernel methods for predicting protein-protein interactions. In: Proceedings Thirteenth International Conference on Intelligent Systems for Molecular Biology 2005, Detroit, MI, USA
Benjamini Y, Hochberg Y (1995) Controlling the false discovery rate: a practical and powerful approach to multiple testing. J Roy Stat Soc Ser B 57(1):289–300
Bleakley K, Biau G, Vert J-P (2007) Supervised reconstruction of biological networks with local models. Bioinformatics 23(13):i57–i65
Candes E, Recht B (2009) Exact matrix completion via convex optimization. Found Comput Math 9(6):717
Candes EJ, Plan Y (2010) Matrix completion with noise. Proc IEEE 98(6):925–936
Chatterjee S (2015) Matrix estimation by universal singular value thresholding. Annals Stat 43(1):177–214
Christian RR, Luczkovich JJ (1999) Organizing and understanding a winter’s seagrass foodweb network through effective trophic levels. Ecol Model 117(1):99–124
Clauset A, Moore C, Newman ME (2008) Hierarchical structure and the prediction of missing links in networks. Nature 453(7191):98–101
Efron B, Tibshirani R, Storey JD, Tusher V (2001) Empirical Bayes analysis of a microarray experiment. J American Stat Assoc 96(456):1151–1160
Foygel Barber R, Candes EJ, Ramdas A, Tibshirani RJ (2021) The limits of distribution-free conditional predictive inference. Inf Inf: J IMA 10(2):455–482
Gao C, Lu Y, Ma Z, Zhou HH (2016) Optimal estimation and completion of matrices with biclustering structures. J Mach Learn Res 17(1):5602–5630
Gaucher S, Klopp O (2021) Maximum likelihood estimation of sparse networks with missing observations. J Stat Plan Inf 215:299–329
Gaucher S, Klopp O, Robin G (2021) Outlier detection in networks with missing links. Comput Stat Data Anal 164:107308
Geifman Y, El-Yaniv R (2017) Selective classification for deep neural networks. In: Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, pages 4885–4894, Red Hook, NY, USA
Gui Y, Barber R, Ma C (2023) Conformalized matrix completion. Adv Neural Inf Process Syst 36:4820–4844
Haroush M, Frostig T, Heller R, Soudry D (2022) A statistical framework for efficient out of distribution detection in deep neural networks. In: The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event
Hu X, Lei J (2023) A two-sample conditional distribution test using conformal prediction and weighted rank sum. J American Stat Assoc, pages 1–19
Huang K, Jin Y, Candes E, Leskovec J (2023) Uncertainty quantification over graph with conformalized graph neural networks. In: Oh A, Neumann T, Globerson A, Saenko K, Hardt M, Levine S (eds) Advances in Neural Information Processing Systems, vol 36. Curran Associates Inc, pp 26699–26721
Jin Y, Candès EJ (2023) Selection by prediction with conformal p-values. J Mach Learn Res 24(244):1–41
Kipf TN, Welling M (2016) Variational graph auto-encoders. NIPS Workshop on Bayesian Deep Learning
Kovács IA, Luck K, Spirohn K, Wang Y, Pollis C, Schlabach S, Bian W, Kim D-K, Kishore N, Hao T, Calderwood MA, Vidal M, Barabási A-L (2019) Network-based prediction of protein interactions. Nat Commun 10(1):1240
Lei J, Wasserman L (2014) Distribution-free prediction bands for non-parametric regression. J Royal Stat Soc Series B: Stat Methodol 76(1):71–96
Li T, Wu Y-J, Levina E, Zhu J (2023) Link prediction for egocentrically sampled networks. J Comput Graph Stat 32(4):1296–1319
Li X, Chen H (2013) Recommendation as link prediction in bipartite graphs: a graph kernel-based machine learning approach. Decis Supp Syst 54(2):880–890
Liang Z, Sesia M, Sun W (2022) Integrative conformal p-values for powerful out-of-distribution testing with labeled outliers. arXiv preprint arXiv:2208.11111
Little RJ, Rubin DB (2019) Statistical analysis with missing data, vol 793. John Wiley & Sons, New Jersey, USA
Löfström T, Boström H, Linusson H, Johansson U (2015) Bias reduction through conditional conformal prediction. Int Data Anal 19(6):1355–1375
Lu L, Zhou T (2011) Link prediction in complex networks: a survey. Phys A: Stat Mech Appl 390(6):1150–1170
Lunde R, Levina E, Zhu J (2023) Conformal prediction for network-assisted regression. arXiv preprint arXiv:2302.10095
Luo R, Nettasinghe B, Krishnamurthy V (2023) Anomalous edge detection in edge exchangeable social network models. In: Conformal and Probabilistic Prediction with Applications, pages 287–310. PMLR
Marandon A, Lei L, Mary D, Roquain E (2024) Adaptive novelty detection with false discovery rate guarantee. Annals Stat 52(1):157–183
Marandon A, Rebafka T, Roquain E, Sokolovska N (2022) False clustering rate control in mixture models. arXiv preprint arXiv:2203.02597
Mary D, Roquain E (2022) Semi-supervised multiple testing. Electron J Stat 16(2):4926–4981
Matias C, Robin S (2014) Modeling heterogeneity in random graphs through latent space models: a selective review. ESAIM Proc Surv 47:55–74
Mukherjee S. S, Chakrabarti S (2019) Graphon estimation from partially observed network data. CoRR, abs/1906.00494
Rava B, Sun W, James G. M, Tong X (2021) A burden shared is a burden halved: A fairness-adjusted approach to classification. arXiv preprint arXiv:2110.05720
Rebafka T, Roquain É, Villers F (2022) Powerful multiple testing of paired null hypotheses using a latent graph model. Electron J Stat 16(1):2796–2858
Romano Y, Patterson E, Candes E (2019) Conformalized quantile regression. Advances in neural information processing systems, 32
Romano Y, Sesia M, Candes E (2020) Classification with valid and adaptive coverage. Adv Neural Inf Process Syst 33:3581–3591
Sadinle M, Lei J, Wasserman L (2019) Least ambiguous set-valued classifiers with bounded error levels. J American Stat Assoc 114(525):223–234
Shao M, Zhang Y (2023) Distribution-free matrix prediction under arbitrary missing pattern. arXiv preprint arXiv:2305.11640
Sportisse A, Boyer C, Josse J (2020) Imputation and low-rank estimation with missing not at random data. Stat Comput 30(6):1629–1643
Storey JD, Taylor JE, Siegmund D (2004) Strong control, conservative point estimation and simultaneous conservative consistency of false discovery rates: a unified approach. J R Stat Soc Ser B Stat Methodol 66(1):187–205
Sun W, Cai TT (2007) Oracle and adaptive compound decision rules for false discovery rate control. J American Stat Assoc 102(479):901–912
Tabouy T, Barbillon P, Chiquet J (2020) Variational inference for stochastic block models from sampled data. J American Stat Assoc 115(529):455–466
Terry JCD, Lewis OT (2020) Finding missing links in interaction networks. Ecology 101(7):e03047
Tibshirani R. J, Foygel Barber R, Candes E, Ramdas A (2019) Conformal prediction under covariate shift. Advances in neural information processing systems, 32
Vovk V, Gammerman A, Shafer G (2005) Algorithmic learning in a random world, vol 29. Springer, New York, USA
Weinstein A, Barber R, Candes E (2017) A power and prediction analysis for knockoffs with lasso statistics. arXiv preprint arXiv:1712.06465
Xu K, Hu W, Leskovec J, Jegelka S (2019) How powerful are graph neural networks? In: 7th International Conference on Learning Representations, ICLR, New Orleans, LA, USA
Yang C-Y, Lei L, Ho N, Fithian W (2021) Bonus: Multiple multivariate testing with a data-adaptivetest statistic. arXiv preprint arXiv:2106.15743
Zaffran M, Dieuleveut A, Josse J, Romano Y (2023) Conformal prediction with missing values. In: International Conference on Machine Learning, pages 40578–40604. PMLR
Zhang M, Chen Y (2018) Link prediction based on graph neural networks. In: Advances in Neural Information Processing Systems, pages 5165–5175
Zhao Y, Wu Y-J, Levina E, Zhu J (2017) Link prediction for partially observed networks. J Comput Graph Stat 26(3):725–733
Acknowledgements
The authors would like to thank Tabea Rebafka, Etienne Roquain, Nataliya Sokolovska, Gilles Blanchard, Guillermo Durand and Romain Perier for their constructive feedbacks. A. Marandon has been supported by a grant from Région Île-de-France (“DIM Math Innov”).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Marandon, A. Conformal link prediction for false discovery rate control. TEST (2024). https://doi.org/10.1007/s11749-024-00934-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11749-024-00934-w