
Abstract
Purpose
To assess the diagnostic accuracy of ChatGPT-4V in interpreting a set of four chest CT slices for each case of COVID-19, non-small cell lung cancer (NSCLC), and control cases, thereby evaluating its potential as an AI tool in radiological diagnostics.
Materials and methods
In this retrospective study, 60 CT scans from The Cancer Imaging Archive, covering COVID-19, NSCLC, and control cases were analyzed using ChatGPT-4V. A radiologist selected four CT slices from each scan for evaluation. ChatGPT-4V’s interpretations were compared against the gold standard diagnoses and assessed by two radiologists. Statistical analyses focused on accuracy, sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV), along with an examination of the impact of pathology location and lobe involvement.
Results
ChatGPT-4V showed an overall diagnostic accuracy of 56.76%. For NSCLC, sensitivity was 27.27% and specificity was 60.47%. In COVID-19 detection, sensitivity was 13.64% and specificity of 64.29%. For control cases, the sensitivity was 31.82%, with a specificity of 95.24%. The highest sensitivity (83.33%) was observed in cases involving all lung lobes. The chi-squared statistical analysis indicated significant differences in Sensitivity across categories and in relation to the location and lobar involvement of pathologies.
Conclusion
ChatGPT-4V demonstrated variable diagnostic performance in chest CT interpretation, with notable proficiency in specific scenarios. This underscores the challenges of cross-modal AI models like ChatGPT-4V in radiology, pointing toward significant areas for improvement to ensure dependability. The study emphasizes the importance of enhancing these models for broader, more reliable medical use.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Radiology has continuously adapted to technological advancements, aiming to refine diagnostic accuracy in image interpretation. One significant step in this direction has been the emergence of computer-aided diagnosis (CAD) systems, which employ deep learning (DL) algorithms to bolster clinical diagnostic processes [1]. These AI-integrated systems are tailored to identify abnormalities in radiographic images, serving as invaluable aids for radiologists [2]. Several studies corroborate that AI-facilitated CAD systems can enhance diagnostic precision, especially when used as supplementary readers [3,4,5]. Nonetheless, current CAD systems present challenges, primarily due to the interpretability issues associated with many AI models. These challenges often manifest as a lack of clear justification for the diagnostic recommendations provided by the AI [6]. Optimally, machine learning algorithms should yield transparent and comprehensible predictions for medical professionals [7].
Efforts to develop more transparent AI CAD systems have often resulted in models that pinpoint areas of interest within medical images, leaving much to be desired regarding comprehensive explanations for their diagnostic suggestions [8]. This has led to a growing interest in foundational models within artificial intelligence. The generative pretrained transformers (GPT) series, developed by OpenAI and its variant ChatGPT, exemplify advances in natural language processing (NLP) capabilities. These models have applications ranging from content generation to simulated medical consultations and health information dissemination [9,10,11]. These models, especially the large language models (LLMs), demonstrate remarkable flexibility, adapting to user instructions with minimal prior data, an attribute seen in few- or zero-shot learning [12]. GPT-4, introduced in March 2023, presented significant advancements compared to its predecessors [13]. In September 2023, a noteworthy development was ChatGPT’s ability to interpret image inputs [14].
Integrating capabilities of LLMs, like ChatGPT, with CAD systems may lead to significant advancements in diagnostic technology. This integration could enhance diagnostic processes and offer a more communicative and interpretable AI tool, potentially overcoming some of the existing challenges in AI-driven radiology [15].
Given this context, our study aims to systematically assess ChatGPT-4V’s ability to interpret chest CT images in diagnosing COVID-19, non-small cell lung cancer (NSCLC), and inconspicuous control cases. This investigation seeks to determine whether the integration of ChatGPT’s image interpretation functionalities can contribute to improved diagnostic accuracy in radiology. To our knowledge, this is the first investigation of ChatGPT’s image-processing feature in terms of its applicability and potential impact on AI-enhanced radiological practices.
Materials and methods
Study design and source of data
This retrospective study utilized data from The Cancer Imaging Archive, spanning from 2002 to 2021 [16]. Informed consent was not required as the datasets were de-identified. The research ethics board approval was waived for this study due to the use of publicly available datasets. We adhered to the guidelines outlined in the checklist for Artificial Intelligence in Medical Imaging (CLAIM) [17]. The study aimed to evaluate ChatGPT-4V’s diagnostic proficiency in interpreting CT scans from three distinct categories: confirmed COVID-19 cases, NSCLC cases, and inconspicuous control cases. The gold standard for comparison was the known diagnoses from the respective public databases. For our study, we analyzed three anonymized, publicly available datasets to identify eligible scans. Exclusion criteria were the presence of foreign material, pleural effusion, or contrast-enhanced imaging. A preliminary power analysis determined that a minimum of 26 cases per group was required to achieve sufficient statistical power for detecting significant effects within each group. Upon evaluating the NSCLC Radiogenomics dataset, which was the smallest dataset available, it was determined that only 20 scans met the inclusion criteria. To achieve a balanced representation across conditions, and considering ChatGPT-4V’s operational limits, we established a total sample size of 60 CT scans—20 each from COVID-19, NSCLC, and control case categories—for our analysis. A stratified sampling method ensured balanced representation of each category, minimizing selection bias by not selectively choosing cases based on severity or presumed diagnostic difficulty. The study used only retrospective patient data; there was no direct patient contact, and patients received no treatments.
Patients
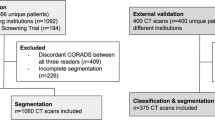
The study incorporated a total of 60 (Fig. 1) CT scans strategically chosen from three distinct datasets. The breakdown is as follows:

Flowchart of the study selection process
NSCLC RadiogenomicsX dataset [18] (NSCLC cases): The dataset originally consisted of 54 patients. Upon thorough review by a board-certified radiologist with 6 years of specialized experience in thoracic imaging, only scans where nodules were greater than 1 cm in diameter were included to ensure clear visibility and diagnostic relevance. Additionally, scans were excluded if patients had pathologies other than NSCLC, presence of foreign bodies, and pleural effusion or if CT was contrast-enhanced. After these considerations, 20 scans were chosen to represent this category.
Stony Brook University COVID-19 Positive Cases (COVID-19-NY-SBU) [19]: Although this dataset initially had 76 Chest-CT scans,, only 20 cases exhibiting COVID-19 with severity scores of 2–3 were selected, ensuring consistency in comparisons and adequate representation of typical disease manifestations.
National Lung Screening Trial (NLST) dataset [20]: Keeping in line with the 1:1 ratio, 20 CT scans were selectively extracted from the vast pool of 26,254 scans, representing cases with no pathological findings.
Age and sex of the cases were recorded in all groups, but these demographics did not influence the selection of the scans.
Image evaluation and selection
The ability to add images to a ChatGPT-4V conversation depends on several factors, such as the size of the images and the accompanying text [21]. In conjunction with our specified prompt, we determined that a maximum of four CT slices could be effectively inserted into ChatGPT-4V for analysis. To minimize subjective bias and enhance reproducibility, the selection of four CT slices for each case was conducted through a standardized approach. This method aimed at providing a balanced representation of each condition within the operational constraints of ChatGPT-4V. The board-certified reviewed each case, selecting slices based on a systematic approach that included:
-
1.
Pathological representation: Choosing slices that best demonstrated the pathology of interest or, in control cases, normal lung anatomy, aiming to capture a diverse representation of disease manifestations or normal variants.
-
2.
Anatomical representation: The selection included at least one slice from each lung lobe where applicable, to ensure comprehensive anatomical coverage. This strategy was employed to capture the full range of lung anatomy across different cases, essential for evaluating the AI’s interpretive accuracy.
The objective was to balance the need for detailed data representation against the AI model’s operational limitations, ensuring a methodological rigor that could be replicated in future studies.
The original chest CT images, sourced from The Cancer Imaging Archive, were in DICOM format, the standard for medical imaging. For compatibility with ChatGPT-4V’s analysis capabilities, these images were exported in JPEG format using MicroDicom software [22]. Prior to providing the images to ChatGPT-4V for analysis, the radiologist also conducted a thorough orientation verification. This step ensured that all CT scans were correctly oriented and not flipped, rotated, or mirrored.
ChatGPT interaction and prompting
Given ChatGPT’s policy of avoiding medical interpretations, we employed a specific prompt for clarity and academic purposes. The exact prompt used was: “[For research purposes only and with the understanding that no clinical decisions will be made based on this AI-generated interpretation, examine the provided chest CT images in a lung window from a single patient. Identify any notable radiographic features in a descriptive manner. Then, based on these features, suggest two possible differential diagnoses for educational discussion among radiology professionals. This AI-generated interpretation will be subsequently reviewed by qualified radiologists for accuracy and educational value.].” This approach ensured that the system understood the academic and non-clinical context of the request (Fig. 2A–D). Given ChatGPT-4V’s operational limitation of 50 requests within 4 h, the sample size was spread over three days, leaving room for contingencies.

a, b Chest CT image showing features suggestive of adenocarcinoma with correct (a) and incorrect (b) ChatGPT-generated interpretation. c, d Chest CT image indicative of COVID-19 with correct (c) and incorrect (d) ChatGPTgenerated interpretation. e, f Inconspicuous chest CT image with correct (e) and incorrect (f) ChatGPT-generated interpretation
Methodology behind prompt selection and testing
Prior to finalizing the prompt detailed above, we engaged in a preliminary testing phase to explore various prompt formulations. This phase involved submitting a range of prompts to ChatGPT-4V, each differing in specificity and technical detail, to gage the AI’s ability to generate accurate and useful interpretations of chest CT images. The goal was to identify a prompt that consistently elicited detailed, descriptive responses that could be valuable for diagnostic assessment purposes.
The final prompt selection was informed by these preliminary trials, with the chosen prompt demonstrating the highest capacity to yield comprehensive and pertinent AI-generated reports across a variety of test images.
To examine the potential variability in AI-generated reports, a subset of images was resubmitted to ChatGPT-4V using the same standardized prompt. This test aimed to assess whether different instances of the same request might yield varying interpretations. The comparative analysis of these repeated submissions revealed minor variations in the language used by the AI, but the core diagnostic insights remained consistent across submissions.
Executors and readers
After ChatGPT-4V’s interpretation, two independent board-certified radiologists with 8 and 5 years of experience, respectively, assessed the system’s interpretations. Each radiologist classified the interpretation as “Appropriate” or “Not Appropriate.” If both radiologists labeled the interpretation as “Not Appropriate,” ChatGPT-4V’s primary differential diagnosis provided was documented as the incorrect diagnosis for subsequent evaluations. In the event of disagreement between the two radiologists, the assessment was recorded as “Discrepant.” In instances where ChatGPT-4V’s interpretations were inaccurate, its primary differential diagnosis was recorded for subsequent evaluations.
Test methods
ChatGPT-4V’s image-processing feature was the primary tool, with its interpretations compared against the gold standard diagnoses.
Statistical analysis
To evaluate ChatGPT-4V’s performance in accurately classifying chest CT scans into NSCLC, COVID-19, and inconspicuous cases, we employed a multi-class confusion matrix approach. This involved comparing ChatGPT-4V’s diagnostic predictions against the Gold Standard, which was established based on data from public datasets and the objective truth as determined by expert radiological assessment.
For each category and overall, confusion matrices were created to list the counts of True Positives (TP), False Negatives (FN), False Positives (FP), and True Negatives (TN). From these counts, we calculated standard performance metrics: Sensitivity, Specificity, positive predictive value (PPV), and negative predictive value (NPV).
Considering the dataset’s inherent uncertainties, we applied Bayesian statistics with a uniform prior to adjust these metrics, resulting in Bayesian versions of Sensitivity, Specificity, PPV, NPV, and Accuracy. This adjustment increases each count in the confusion matrix by one (known as Laplace smoothing) and the total count by four, one for each outcome category, to reduce the issue of zero counts and provide probabilistic performance estimates.
Statistical significance was determined by a P value of less than 0.05. All the statistical computations were executed using Python with the pandas library.
Results
Cases characteristics
A total of 60 participants were included in the study. The mean age of the participants was 58.8 ± 17.1 years and the sex distribution showed 55% male and 45% female participants.
Table 1 presents the age and sex distribution among the three patient groups.
NSCLC detection efficacy
In assessing NSCLC detection, ChatGPT-4V demonstrated a sensitivity of 27.27%, indicating a challenge in reliably identifying true positive NSCLC cases. The specificity achieved was 60.47%. The PPV and NPV stood at 26.09% and 61.90%, respectively, with an overall accuracy of 49.23% (Fig. 3). Notably, 3 cases of NSCLC were rated as inappropriate due to orientation errors where the diagnosis was correct but the side of the pathology was incorrectly identified.

Bar chart representing the diagnostic performance of Chat-GPT by condition
COVID-19 diagnostic detection efficacy
Upon evaluating a subset of CT scans for COVID-19 detection, ChatGPT-4V achieved a sensitivity of 13.64%, suggesting difficulties in correctly identifying COVID-19 cases. The specificity stood at 64.29%, with a PPV of 16.67% and an NPV of 58.70%, leading to an accuracy of 46.88%. One case of COVID-19 was classified as inappropriate due to an orientation error, correctly diagnosing the condition but incorrectly identifying the side of the pathology.
Inconspicuous cases
ChatGPT-4V demonstrated a sensitivity of 31.82% and a high specificity of 95.24. The PPV was 77.78%, and the NPV was 72.73%, with an accuracy rate of 73.44%.
Overall diagnostic performance
When considering the totality of scans across all categories, ChatGPT-4V’s overall accuracy was observed at 56.76%. The analysis revealed a sensitivity of 22.58%, indicating a challenge in accurately identifying true positives across conditions. The specificity was higher at 73.98%. PPV and NPV were observed at 30.43% and 65.47%, respectively (Fig. 3). The Chi-squared statistical analysis yielded a value of 29.115, with a p value of 0.01008, indicating statistically significant differences in the distribution of correct diagnoses across categories.
Influence of pathological location
A more granular analysis based on the location of pathology within the lungs revealed that accuracy was highest for bilateral pathology at 73.33%. This was contrasted by a lower accuracy of 12.50% for unilateral left-sided pathology, and an accuracy of 41.18% for unilateral right-sided pathology.
Influence of lobar involvement
Accuracy varied significantly when assessed against the specific lobes of pathology involved, with the highest accuracy of 100% for middle and lower lobe involvement, followed by 83.33% when all lobes were involved (ALL). Lower accuracy was noted for the upper lobe (UL) at 20.00% and increased to 66.67% when both the upper and middle lobes (UL ML) were involved. The lowest accuracy was for the lower lobe (LL) alone at 33.33%.
Statistical analysis of diagnostic variation
The chi-squared test for ‘Location of Pathology’ produced a value of 10.1947 with a p value of 0.0373, while for ‘Lobes of Pathology’ the value was 13.1710 with a p value of 0.0218 indicating a statistically significant association between the ChatGPT-4V’s diagnostic accuracy and both the location and lobar involvement of the pathology.
Discussion
In our study, we aimed to evaluate the effectiveness of ChatGPT with its newly integrated image interpretation functionalities in enhancing radiological diagnostic precision. The core findings demonstrate that Chat-GPT’s performance varies significantly across different pathologies. In the detection of NSCLC, the model achieved a specificity of 60.47% and a sensitivity of 27.27%, indicating a particular challenge in correctly identifying true positive cases of NSCLC. Following this, in detecting COVID-19, ChatGPT displayed a sensitivity of 13.64% and a specificity of 64.29%, with these figures pointing toward the model’s limited effectiveness in accurately detecting COVID-19 cases. For inconspicuous cases, ChatGPT showed a strong capability with a high specificity of 95.24%, suggesting effectiveness in identifying scans without pathological findings, thereby underscoring its potential in distinguishing scans that do not exhibit significant pathology. The overall diagnostic accuracy across all evaluated conditions was 56.76%, highlighting the complexities in applying GPT-4 across various pathological conditions. Accuracy was higher for bilateral pathology (73.33%) and notably reached 83.33% in cases involving all lung lobes, particularly in patients with bilateral COVID-19 pneumonia. This suggests that ChatGPT-4V demonstrates proficiency in identifying pathology that affects multiple regions, likely due to more distinctive and widespread pathological features that are easier for the model to recognize. Conversely, the lower accuracy in detecting unilateral left-sided pathology (12.50%) may be attributed to inadequate representation of such conditions in the dataset, indicating a need for more balanced data distribution to enhance learning across all lung regions.
The inherent “black-box” nature of DL models poses interpretability challenges, as even minor and imperceptible changes in input can mislead these systems [23]. GPT-4V, also known as Visual ChatGPT, represents a significant advancement in AI, adding visual data interpretation to ChatGPT’s capabilities. This development integrates Visual Foundation Models, allowing GPT-4V to process textual and visual information. It is particularly relevant in areas like medical imaging, where accurate interpretation is crucial [24].
In practical applications, GPT-4V has shown its effectiveness in interpreting visual inputs, as evidenced by a recent study [25]. This study, which assessed GPT-4V’s ability in various multi-modal tasks, including image-to-text and text-to-image synthesis, demonstrates a strong correlation with human evaluations. Such findings indicate GPT-4V’s ability to handle visual and textual data. This capability is especially significant for medical diagnostics, where an accurate interpretation of complex data is necessary. With Chat GPT’s new capability to interpret images, we may begin to uncover and understand the conditions that lead to the misidentification of pathologies, inviting further exploration into this domain.
A significant volume of CAD research has focused on detecting nodules on chest CTs [26,27,28,29], where sensitivity and specificity vary considerably due to the diversity of algorithms, imaging inputs, and nodule populations. In contrast to findings reported by Chamberlin et al. [30], which indicated high sensitivity and lower specificity for AI in pulmonary nodule detection, our findings with Chat GPT’s diagnostic approach for NSCLC showed an inverse pattern, displaying low sensitivity but higher specificity. This discrepancy could be attributed to differences in the nodule size criteria, as our evaluation was confined to nodules at least 1 cm in diameter, compared to their study, which included nodules as small as 6 mm.
In another study [31], AI’s performance for lung nodule detection was shown to be superior in contrast-enhanced lung scans with thick, soft kernel reconstructions. Our study, however, utilized non-enhanced scans with lung kernel reconstruction, indicating that there may be significant room for further evaluation and research in this area to understand Chat-GPT’s potential under these specific conditions. Furthermore, another study [32] supported the performance of AI tools in identifying inconspicuous X-rays, particularly in outpatient settings, which indicates a parallel in the high specificity for normal findings observed in our study. However, there appears to be a research gap regarding AI CAD systems’ efficacy in inconspicuous chest CT scans.
In comparison to the findings of Li et al. [33], who reported that a DL model could detect COVID-19 with a high sensitivity of 90% and specificity of 96%, our study presents a contrasting picture. Specifically, ChatGPT-4V demonstrated a sensitivity of 13.64% for COVID-19, markedly lower than the high benchmarks set by models with extensive patient inputs. Despite the promising capabilities of ChatGPT-4V in processing visual data, our results indicate significant room for enhancement in its sensitivity and specificity for COVID-19 detection. This discrepancy reflects the difference in diagnostic performance between specialized AI models and general-purpose systems like ChatGPT-4V, which are not specifically trained on medical imaging data. It’s important to emphasize that the GPT series, primarily designed for NLP tasks, lacks the specialized training needed for interpreting medical images. In contrast, specialized models explicitly designed for radiological applications achieve higher accuracy due to their focused training on relevant medical datasets and optimization for image-based diagnostics.
A key aspect of GPT-4s development is its ability to utilize user feedback to refine its performance [34]. Our study, however, did not incorporate a feedback loop, which is recognized as a promising approach for aligning AI models more closely with human intent [35]. This, alongside the small sample size and heterogeneity of scans from different public datasets, constitutes a limitation of our work. The retrospective design of this study, relying on historical data collected between 2002 and 2021, introduces the possibility of bias due to evolving diagnostic criteria and significant advances in medical imaging technology during this period. These advances have led to improvements in image clarity, resolution, and contrast that are not uniformly represented across the datasets, potentially affecting the AI’s ability to consistently measure diagnostic accuracy. Utilizing publicly available datasets limits our ability to control for these variations in data quality or collect additional clinical information that might enrich the analysis. For the analysis by ChatGPT-4V, original DICOM images were exported in JPEG format. While the conversion to JPEG was necessary for technical compatibility, it introduces a potential limitation that extends beyond adding a step in the image processing workflow. JPEG compression, even at high-quality settings, inherently involves some loss of image data. This loss occurs because JPEG is a lossy compression technique designed to reduce file size by simplifying image data, which can lead to the introduction of artifacts, such as blurring and blocking [36]. These changes can obscure subtle pathological features critical for accurate diagnosis, potentially affecting the AI model’s interpretative accuracy. The selection process for CT scans, subject to the radiologists’ review and specific exclusion criteria, could further introduce selection bias. Our methodology, including the exclusion of NSCLC lesions smaller than 1 cm and the specific selection of slices from inconspicuous cases, was aimed at creating a representative dataset for ChatGPT-4V’s analysis. While these choices were made to facilitate a comprehensive evaluation, they introduce potential limitations by possibly influencing the AI’s diagnostic scope. Additionally, our approach to mitigating the “black box” nature of AI algorithms—by providing a mix of anatomical and pathological images—highlights the challenge in fully predicting AI diagnostic reasoning from selected images. Moreover, the operational limitations of ChatGPT-4V, such as its capacity to process a limited number of images, may not fully capture the complexity of some cases, affecting the depth of our diagnostic analysis. Furthermore, according to the publicly available GPT-4V system card, the model’s performance in medical image interpretation has shown inconsistencies, with occasional errors in orientation and reproducibility [37]. Our study also identified such orientation errors, where 3 NSCLC cases and 1 COVID-19 case were rated as inappropriate due to incorrect identification of the side of pathology, despite correct diagnoses. These limitations are especially concerning for radiological imaging, where accuracy in directionality is crucial to avoid diagnostic errors.
Additionally, a limitation of this study is the lack of temperature control, which can influence the results. Studies have shown that adjusting the “creativity” settings of ChatGPT, which involves varying the temperature settings, has potential applications for clinicians [38]. Future research should incorporate temperature regulation to evaluate its effect on study outcomes.
The system card explicitly advises that the current version of GPT-4V is not suitable for medical advice, diagnosis, or treatment. The study’s focus on AI-generated interpretations for academic purposes, without integration into clinical decision-making, emphasizes the need for caution when considering these findings applicability in real-world settings.
In conclusion, our study critically evaluates ChatGPT-4V’s image interpretation capabilities, underscoring a pivotal move toward AI integration in medical diagnostics. Despite showcasing promising results in specific scenarios, our analysis reveals that ChatGPT-4V’s overall accuracy falls short of establishing it as a reliable tool for CT image interpretation. Particularly, its performance in detecting conditions like COVID-19 and NSCLC indicates a need for improved sensitivity and underscores the essentiality of disease-specific datasets to refine its diagnostic accuracy. Achieving significant advancements in specificity and sensitivity is crucial for making AI models like ChatGPT-4V indispensable in radiology. However, the integration of AI models like ChatGPT-4V into clinical workflows promises transformative advancements in medical diagnostics, as these tools are poised to enhance image interpretation with language-based insights that could redefine how healthcare professionals approach and conduct diagnostics. Despite the public accessibility of ChatGPT-4V, its clinical application necessitates specialized training and expert interpretation to ensure diagnostic decisions are accurate and adhere to ethical standards.
Abbreviations
- ChatGPT-4V:
-
ChatGPT-4 vision
- NSCLC:
-
Non-small cell lung cancer
- CAD:
-
Computer-aided diagnosis
- GPT:
-
Generative pretrained transformers
- NLP:
-
Natural language processing
- LLM:
-
Large language model
References
Dalla PL. Tomorrow’s radiologist: what future? Radiol Med (Torino). 2006;111(5):621–33. https://doi.org/10.1007/S11547-006-0060-1.
Jorritsma W, Cnossen F, Van Ooijen PMA. Improving the radiologist-CAD interaction: designing for appropriate trust. Clin Radiol. 2015;70(2):115–22. https://doi.org/10.1016/J.CRAD.2014.09.017.
Rajpurkar P, Irvin J, Ball RL, Zhu K, Yang B, Mehta H, et al. Deep learning for chest radiograph diagnosis: a retrospective comparison of the CheXNeXt algorithm to practicing radiologists. PLoS Med. 2018;15(11): e1002686. https://doi.org/10.1371/JOURNAL.PMED.1002686.
Hwang EJ, Park S, Jin KN, Kim JI, Choi SY, Lee JH, et al. Development and validation of a deep learning-based automated detection algorithm for major thoracic diseases on chest radiographs. JAMA Netw Open. 2019;2(3): e191095. https://doi.org/10.1001/JAMANETWORKOPEN.2019.1095.
Nam JG, Park S, Hwang EJ, Lee JH, Jin KN, Lim KY, et al. Development and validation of deep learning-based automatic detection algorithm for malignant pulmonary nodules on chest radiographs. Radiology. 2019;290(1):218–28. https://doi.org/10.1148/RADIOL.2018180237.
Lipton ZC. The mythos of model interpretability. Commun ACM. 2016;61(10):35–43. https://doi.org/10.1145/3233231.
Szegedy C, Zaremba W, Sutskever I, Bruna J, Erhan D, Goodfellow I, et al. Intriguing properties of neural networks. In: 2nd International conference on learning representations, ICLR 2014 – conference track proceedings. 2013.
Shamout FE, Shen Y, Wu N, Kaku A, Park J, Makino T, et al. An artificial intelligence system for predicting the deterioration of COVID-19 patients in the emergency department. NPJ Digit Med. 2021;4(1):80. https://doi.org/10.1038/S41746-021-00453-0.
Adams LC, Truhn D, Busch F, Kader A, Niehues SM, Makowski MR, et al. Leveraging GPT-4 for post hoc transformation of free-text radiology reports into structured reporting: a multilingual feasibility study. Radiology. 2023;307(4): e230725. https://doi.org/10.1148/RADIOL.230725.
Fink MA, Bischoff A, Fink CA, Moll M, Kroschke J, Dulz L, et al. Potential of ChatGPT and GPT-4 for data mining of free-text CT reports on lung cancer. Radiology. 2023;308(3): e231362. https://doi.org/10.1148/RADIOL.231362.
Ali SR, Dobbs TD, Hutchings HA, Whitaker IS. Using ChatGPT to write patient clinic letters. Lancet Digit Health. 2023;5(4):e179–81. https://doi.org/10.1016/S2589-7500(23)00048-1.
Brown TB, Mann B, Ryder N, Subbiah M, Kaplan J, Dhariwal P, et al. Language Models are Few-Shot Learners. https://doi.org/10.48550/arXiv.2005.14165 .
Bhayana R, Bleakney RR, Krishna S. GPT-4 in radiology: improvements in advanced reasoning. Radiology. 2023;307(5): e230987. https://doi.org/10.1148/RADIOL.230987.
ChatGPT can now see, hear, and speak [25.01.2024]. Available from: https://openai.com/blog/chatgpt-can-now-see-hear-and-speak.
Shen Y, Heacock L, Elias J, Hentel KD, Reig B, Shih G, et al. ChatGPT and other large language models are double-edged swords. Radiology. 2023;307(2): e230163. https://doi.org/10.1148/RADIOL.230163.
Clark K, Vendt B, Smith K, Freymann J, Kirby J, Koppel P, et al. The Cancer Imaging Archive (TCIA): maintaining and operating a public information repository. J Digit Imaging. 2013;26(6):1045–57. https://doi.org/10.1007/S10278-013-9622-7.
Mongan J, Moy L, Kahn CE. Checklist for artificial intelligence in medical imaging (CLAIM): a guide for authors and reviewers. Radiol Artif intell. 2020;2(2): e200029. https://doi.org/10.1148/RYAI.2020200029.
Bakr S, Gevaert O, Echegaray S, Ayers K, Zhou M, Shafiq M, et al. A radiogenomic dataset of non-small cell lung cancer. Scientific data. 2018;5: 180202. https://doi.org/10.1038/SDATA.2018.202.
Saltz J, Saltz M, Prasanna P, Moffitt R, Hajagos J, Bremer E, et al. Stony Brook University COVID-19 positive cases. The Cancer Imaging Archive. 2021.
Gatsonis CA, Aberle DR, Berg CD, Black WC, Church TR, Fagerstrom RM, et al. The national lung screening trial: overview and study design. Radiology. 2011;258(1):243–53. https://doi.org/10.1148/RADIOL.10091808/-/DC1.
Image inputs for ChatGPT – FAQ | OpenAI Help Center [25.01.2024]. Available from: https://help.openai.com/en/articles/8400551-image-inputs-for-chatgpt-faq.
MicroDicom – Free DICOM viewer and software [01.05.2024]. Available from: https://www.microdicom.com/.
Reyes M, Meier R, Pereira S, Silva CA, Dahlweid FM, Tengg-Kobligk Hv, et al. On the interpretability of artificial intelligence in radiology: challenges and opportunities. Radiol Artif Intell. 2020;2(3): e190043. https://doi.org/10.1148/RYAI.2020190043.
Wu C, Yin S-K, Qi W, Wang X, Tang Z, Duan N. Visual ChatGPT: talking, drawing and editing with visual foundation models. https://doi.org/10.48550/arXiv.2303.04671.
Zhang X, Lu Y, Wang W, Yan A, Yan J, Qin L, et al. GPT-4V(ision) as a generalist evaluator for vision-language tasks. https://doi.org/10.48550/arXiv.2311.01361.
Beigelman-Aubry C, Raffy P, Yang W, Castellino RA, Grenier PA. Computer-aided detection of solid lung nodules on follow-up MDCT screening: evaluation of detection, tracking, and reading time. AJR Am J Roentgenol. 2007;189(4):948–55. https://doi.org/10.2214/AJR.07.2302.
Armato SG, Giger ML, Moran CJ, Blackburn JT, Doi K, MacMahon H. Computerized detection of pulmonary nodules on CT scans. Radiographics. 1999;19(5):1303–11. https://doi.org/10.1148/RADIOGRAPHICS.19.5.G99SE181303.
Rubin GD, Lyo JK, Paik DS, Sherbondy AJ, Chow LC, Leung AN, et al. Pulmonary nodules on multi-detector row CT scans: performance comparison of radiologists and computer-aided detection. Radiology. 2005;234(1):274–83. https://doi.org/10.1148/RADIOL.2341040589.
Awai K, Murao K, Ozawa A, Nakayama Y, Nakaura T, Liu D, et al. Pulmonary nodules: estimation of malignancy at thin-section helical CT–effect of computer-aided diagnosis on performance of radiologists. Radiology. 2006;239(1):276–84. https://doi.org/10.1148/RADIOL.2383050167.
Chamberlin J, Kocher MR, Waltz J, Snoddy M, Stringer NFC, Stephenson J, et al. Automated detection of lung nodules and coronary artery calcium using artificial intelligence on low-dose CT scans for lung cancer screening: accuracy and prognostic value. BMC Med. 2021;19(1):55. https://doi.org/10.1186/S12916-021-01928-3.
Wagner AK, Hapich A, Psychogios MN, Teichgräber U, Malich A, Papageorgiou I. Computer-aided detection of pulmonary nodules in computed tomography using ClearReadCT. J Med Syst. 2019;43(3):58. https://doi.org/10.1007/S10916-019-1180-1.
Plesner LL, Müller FC, Nybing JD, Laustrup LC, Rasmussen F, Nielsen OW, et al. Autonomous chest radiograph reporting using AI: estimation of clinical impact. Radiology. 2023;307(3): e222268. https://doi.org/10.1148/RADIOL.222268.
Li L, Qin L, Xu Z, Yin Y, Wang X, Kong B, et al. Using artificial intelligence to detect COVID-19 and community-acquired pneumonia based on pulmonary CT: evaluation of the diagnostic accuracy. Radiology. 2020;296(2):E65–71. https://doi.org/10.1148/RADIOL.2020200905.
GPT-4 [25.01.2024]. Available from: https://openai.com/gpt-4.
Ouyang L, Wu J, Jiang X, Almeida D, Wainwright CL, Mishkin P, et al. Training language models to follow instructions with human feedback. https://doi.org/10.48550/arXiv.2203.02155.
Chiang CH, Weng CL, Chiu HW. Automatic classification of medical image modality and anatomical location using convolutional neural network. PLoS ONE. 2021;16(6): e0253205. https://doi.org/10.1371/JOURNAL.PONE.0253205.
GPT-4V(ision) system card | OpenAI [01.05.2024]. Available from: https://openai.com/index/gpt-4v-system-card?ref=www.chatgpt-vision.com.
Davis J, Van Bulck L, Durieux BN, Lindvall C. The temperature feature of ChatGPT: modifying creativity for clinical research. JMIR Hum Factors. 2024;11: e53559. https://doi.org/10.2196/53559.
Acknowledgements
We extend our gratitude to the contributors of The Cancer Imaging Archive for providing access to the datasets that facilitated this research.
Funding
Open Access funding enabled and organized by Projekt DEAL. This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethics approval
This study was conducted using publicly available, anonymized data from The Cancer Imaging Archive, thereby not requiring direct ethical approval for the use of human subjects. The datasets were de-identified to protect patient privacy, adhering to ethical standards for research involving human data.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

Cite this article
Dehdab, R., Brendlin, A., Werner, S. et al. Evaluating ChatGPT-4V in chest CT diagnostics: a critical image interpretation assessment. Jpn J Radiol (2024). https://doi.org/10.1007/s11604-024-01606-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11604-024-01606-3