
Abstract
This paper presents a typology of tonal exponence. Couched within an Abstractive Word-and-Paradigm approach to morphology, the present study builds on previous studies on exponence typology and morphological organization by extending it to the study of tone. About half the languages of the world have tone systems, and tone is an important dimension in the morphologies of numerous languages. Tone is therefore a necessary part of a comprehensive typology of exponence. This paper shows that like segmental exponents, tonal exponents may be involved in a diversity of form-function mappings, but they also pose unique challenges due to their autosegmental nature. This study aims to advance our understanding of the role of tone in the organization of morphological systems by addressing deviations from form-function isomorphism, polyfunctionality, morphomic distributions, paradigmatic layers, and inflectional class organization. It is argued that the attested diversity of form-function mappings constitutes an empirical argument for a paradigm-based view of morphology, where the attested diversity is taken at face value and the range of encoding strategies are treated as equivalent, as opposed to choosing form-function isomorphism as the theoretical ‘ideal’.
Similar content being viewed by others


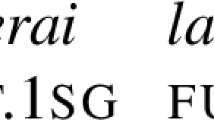
Avoid common mistakes on your manuscript.
1 Introduction
The study of exponence typology has revealed a great diversity in the way languages encode grammatical information on words (Caballero & Harris, 2012; Carroll, 2022; Harris, 2017; Matthews, 1974/1991). From the exponence types originally proposed by Matthews (1974/1991) to the complex networks of exponence relations laid out by Carroll (2022), we know that languages vary greatly in the extent to which they exhibit complexity of exponence, i.e. deviations from form-function isomorphism. Carroll (2022) argues for a typological-functional approach in which exponence is conceptualized as informativeness, where the informativeness of a given exponent for morphosyntactic properties emerges from its distribution across a morphological paradigm. This notion of exponence as informativeness is in line with paradigmatic approaches to morphological analysis (e.g. Blevins, 2016), which are concerned with how inflected word forms are embedded in relational systems. Under such an approach, the objects of study are patterns within and across paradigms of which speakers may make use, e.g. to extract information about the grammatical properties of a word form given a specific formative.
The present paper aims to extend the study of exponence typology to the study of morphological tone, and as such, this paper makes three key contributions: Firstly, while exponence typology (e.g. Carroll, 2022) has focused largely on segmental morphology, the present paper aims to extend this typology by tackling the unique challenges posed by suprasegmental morphology, focusing on tonal exponence specifically. About half the languages of the world have tone systems (Hyman, 2011, p. 198), and tone is an important dimension in the morphologies of numerous languages (see e.g. Palancar & Léonard, 2016), and therefore a necessary part of a comprehensive typology of exponence.
Secondly, the present paper aims to advance our understanding of the typology of tone by incorporating the insights from exponence typology. A first step towards a typology of morphological tone under a paradigmatic perspective was presented by Palancar (2016). The present paper builds on this approach by laying out a more comprehensive set of form-function mappings and interactions between tonal and non-tonal formatives. It provides a fine-grained taxonomy for language-particular as well as cross-linguistic analysis of tonal exponence, informed by recent advances in exponence typology.
Finally, the broader goal of this work is to show how the attested diversity pose a challenge for morphological theory. The paper presents a comprehensive taxonomy of strategies for encoding grammatical information on words, and shows that none of these strategies is more or less basic or “natural” than another. The present work is thus grounded in a theoretical approach to morphology that is paradigm-based and abstractive in nature (Blevins, 2006), and shows how this approach provides a unified way of capturing the attested diversity in morphological organization, without giving any single encoding strategy a special theoretical status.
1.1 An illustrative example
In this paper, we will explore the cross-linguistic diversity in how tonal formatives may map onto meaning, either alone or in conjunction with non-tonal formatives. As a starting point, consider the Somali data in Table 1. Here, an acute accent é indicates a High tone; Low tones are left unmarked. These examples illustrate that TAM marking can be tonal (a) or segmental (b-c) or both (d-e). The examples in (d-e) show that the progressive is marked by the suffix -ay co-occurring with a High tone on the final mora of the stem.
To tackle these kinds of form-function mappings and more, the present paper explores how the research in exponence typology applies to the typology of morphological tone. It will be shown that like segmental exponents, tonal exponents may be involved in a diversity of exponence relations correlative with their informativeness about morphosyntactic properties. This is illustrated with a rich typology with examples from a set of diverse languages. I show that conceptualizing morphological exponence as informativeness provides us with the tools for conducting more fine-grained analyses of morphological tone, both within and across languages. It allows us to analyze the role of tone in morphological organization in a non-aprioristic way, and demonstrate that no single exponence strategy has a special theoretical status as more ‘basic’ than the others.
1.2 A note on transcription conventions
The present paper discusses data from a variety of different languages, and follows the transcription conventions used in the original sources (unless indicated otherwise). In most cases, these follow the IPA conventions of using diacritics on the tone-bearing segment, e.g. é for a High tone and è for a Low tone. Deviations from these conventions will be commented on and explained along the way.
1.3 Outline of paper
This paper is organized as follows: Sect. 2 introduces exponence typology and illustrates five basic exponence types discussed in the literature, which have motivated paradigm-based and abstractive approaches to morphology, discussed in Sect. 3. Section 4 moves on to tonal exponence, and presents examples illustrating how tone may be involved in any of the five basic exponence types. Section 5 provides a more nuanced picture by discussing various types of co-exponence and overlap of information. Section 6 introduces the complexity that arises when there are different types of polyfunctional exponence and morphomic distributions. Section 7 adds another dimension of complexity to the picture, namely inflectional classes. Section 8 concludes.
2 Background: exponence typology
In the tradition of Matthews (1974/1991), the term exponence refers to the form-function mappings that emerge from the distribution of formatives within and across morphological paradigms. The starting point for the present paper is the five-way typology of exponence types listed in Table 2 (based on Matthews, 1974/1991; see also Carroll, 2016).Footnote 1
The five types are diagrammed in Table 3, where formatives are represented with a μ, and morphosyntactic properties are represented with a P. The different types will be illustrated in turn below.
We will begin by considering the simplest type of exponence, in which there is a one-to-one mapping between form and function—what Matthews (1974/1991) refers to as simple exponence. This is illustrated here with Turkish nominal morphology: as the examples in Table 4 show, case and number in Turkish are marked separately and in a compositional way, by dedicated suffixes (e.g. plural -ler and accusative -i).
This simple one-to-one mapping between form and function is embodied in the traditional structuralist notion of the morpheme (e.g. Bloomfield, 1933). In the event that simple exponence emerges from the contrasts within a paradigm, the paradigm is organized in a “morphemic” way. However, this is only one of many possible form-function mappings attested cross-linguistically. Arkadiev and Gardani (2020) contrasts the Turkish data in Table 4 with the Lithuanian data in Table 5 (see also Plank (1991) for a similar comparison between Turkish and Latin). In both languages, there are two number values and six case values, yielding twelve word forms in total. But unlike Turkish, Lithuanian case and number are expressed together, such that there is only one suffix per word form. For example, the suffix -us marks both the plural and the accusative, and this suffix cannot be segmented further. In this case, there is cumulative exponence, that is, a one-to-many mapping between form (e.g. -us) and function (e.g. plural and accusative).
The opposite of cumulative exponence is multiple exponence (which is the term used by contemporary authors for Matthews’ extended exponence), which involves a many-to-one mapping between form and function. It has been defined as “the occurrence of multiple realizations of a single feature, bundle of features, or derivational category in more than one position in a domain” (Caballero & Harris, 2012; see also Harris, 2017, p. 9). An example from Archi is provided in (1). Here, there are three possessive pronouns, all showing gender agreement (class II). The first (d-is ‘my’) has an agreement prefix, the second (ɑtːo-r ‘yours’) has an agreement suffix, and the third (d-isso-r ‘mine’) has both; this final example in (1b) is an instance of multiple exponence.
-
(1)
Multiple exponence in Archi (Nakh-Daghestanian)


Multiple exponence has been controversial because it was predicted by some not to exist; for example, Halle and Marantz (1993, p. 138) claim that “there is no ‘multiple exponence’ of features from a single syntactic or morphological node”. Harris (2017) provides a thorough overview of the literature and on what sorts of phenomena would count as “true” multiple exponence. The main criterion she sets up for identifying convincing cases of multiple exponence is that both exponents need to be attested independently of each other (Harris, 2017, pp. 17–20), as in the Archi example in (1) above. In contrast, circumfixes are typically not considered to be instances of multiple exponence, if both components of a circumfix, though not realized adjacently, always co-occur and are not attested independently of each other; Harris (2017, pp. 17–20) uses the term “bipartite morpheme” for data of this kind.
The final two types of exponence discussed here involve mappings with zero. In the case of zero exponence, the absence of form is meaningful. This can be illustrated by returning to the Turkish data in Table 4. Every inflectional value except the singular and the nominative has a dedicated suffix; this means, in turn, that the absence of a plural suffix -ler indicates that the word form is singular, and the absence of a case suffix indicates that the word form is nominative.
The concept of “zero morphemes”, is, as Trommer puts it, “one of the ideologically most loaded subjects in theoretical morphology” (Trommer, 2012, p. 326). For a discussion of ‘zero markers’ and ‘zero exponence’ in different morphological frameworks, see Blevins (2016, pp. 56–57), who argues that “the appeal to ‘zeros’ can be seen as a means of compensating for the rigidly syntagmatic character of the Post-Bloomfieldian model, which has no provision for any type of paradigmatic comparison or deduction” (Blevins, 2016, p. 56). For the present purposes, zero exponence is conceptualized paradigmatically as resulting from contrasts between forms in the system.
Empty exponents, or empty morphs, are pieces of form that do not realize any morphosyntactic properties, but instead mark different types of morphological constructions. An example of this is the semantically empty linking elements found in compounds in many languages (see e.g. Bauer, 2012). One example of such a language is German, for which the linking elements -n- and -s- are illustrated in Table 6.
Blevins (2016, pp. 54–55) explains that while the -n- in Spinne-n-netz ‘spider web’ is formally identical to the plural -n in Spinnen ‘spiders’, it occurs in the compound regardless of the number inflection of the compound. The -s- in Liebe-s-brief ‘love letter’ is formally identical to two inflectional markers in German, but it cannot be an instance of either, because *Liebes is not a possible form: first, while there is a plural marker -s, Liebe is an abstract noun without a plural form (and the corresponding count noun interpretation would have a plural form in -en). Second, while there is a genitive marker -s, Liebe is a noun of the feminine gender, whose singular forms lack case suffixes (the genitive form is simply Liebe). A similar discussion is found in Bauer (2012, pp. 346), who provides the example Liebe-s-lied ‘love song’ and concludes that the linking element here “is thus simply that, and cannot be related to any other inflectional form”.
While the defining property of an empty exponent is that it is semantically empty, the present work focuses on cases in which such markers also satisfy a second criterion: the distribution of the markers is not conditioned by extramorphological (phonological, semantic or syntactic) factors. We therefore leave aside cases in which e.g. phonological analyses are possible, such as the augmentative syllable found in many Bantu languages that require a word or stem to be at least two syllables (e.g. Ndebele yi- as in yi-dl-a ‘eat!’; Hyman et al., 2009, pp. 8–9).
Although linking elements and related phenomena, such as the theme vowels in Romance (see e.g. Blevins, 2016, p. 53) typically are considered semantically empty, Blevins (2016, p. 55) points out that they do serve a function in the context of the system they are embedded in: for example, linking elements convey information about construction type.
The form-function mappings in Table 2 are not intended to form an exhaustive list; combinations of these exponence types are possible, and exponence relations can get quite complex. For this reason, complexity of exponence is considered a distinct dimension of morphological complexity (Anderson, 2015; Stump, 2017; Arkadiev & Gardani, 2020), and is one of the ways in which languages exhibit cross-linguistic diversity in their organization. An illustrative case is found in the verbal morphology of Komnzo (Yam; Southern New Guinea); the example illustrated in Fig. 1 shows the form-function mappings found in the word-form yfathwroth ‘they hold him away’.

Complexity of exponence in Komnzo (Yam; Southern New Guinea) (figure reproduced from Döhler, 2019, p. 178)
This verb form contains five formatives: y-, fath, -wr, -o, and -th. The only one-to-one mapping in this verb is between the form -o and the function andative. The other formatives are all mapped to multiple functions, and conversely, several functions (e.g., the imperfective) are marked by multiple formatives.
The degree to which languages exhibit such complexity of exponence is a parameter of cross-linguistic variation, and thus in and of itself constitutes a topic within morphological typology as well as a challenge for morphological theory across frameworks. While we could have imagined that all languages organized their words in an isomorphic way, with one-to-one mappings between forms and functions, and where stems and exponents combine in a compositional way (i.e. a “morphemic” organization), the picture that emerges when considering cross-linguistic variation is much more diverse. This diversity in morphological organization is among the empirical facts that have motived paradigm-based and abstractive approaches to morphological analysis, which will be discussed in more detail in the next section.
3 Guiding assumptions
3.1 Abstractivist word-and-paradigm morphology
In order to tackle the attested diversity in form-function mappings, a morphological framework is needed which is compatible with the attested non-isomorphism. As discussed by Matthews (1974/1991), non-isomorphism is among the empirical facts which motivated a Word-and-Paradigm approach to morphology. The present paper adopts Word-and-Paradigm in the sense of Blevins (2016). Within this framework, there is no expectation for one-to-one mappings between the formatives and the morphosyntactic properties they mark. There is still a correlation between the individual properties and the formatives, but it is not expected to be one-to-one or morphemic in nature, and “this looser property-form correlation is termed (morphological) exponence” (Blevins, 2016, p. 52).
The one-to-one mapping of simple exponence (discussed in Sect. 2) corresponds to the structuralist concept of a “morpheme”, but within the Word-and-Paradigm framework, there is nothing normative about this particular mapping (Blevins, 2016, p. 53). What we see cross-linguistically is great diversity in how grammatical information is encoded on words. Instead of analyzing some encoding strategies as “deviations” from an a priori given morphemic or agglutinative “ideal”, the Word-and-Paradigm approach provides a unified framework for the attested diversity in morphological organization.
In a Word-and-Paradigm model, words are the minimal meaningful elements of grammatical systems. The objects of morphological analysis are the fully inflected word forms and how they are embedded into a larger relational system. Under an abstractive approach to Word-and-Paradigm morphology (in the sense of Blevins, 2006), stems and exponents are understood as abstractions over a lexicon of word forms which exhibit a network organization which may differ widely across languages (see e.g. Sims, 2020, who demonstrates this with graph-theoretic tools). As abstractive approaches assume surface patterns as the unit of comparison, they are arguably to be preferred for linguistic typology; they allow for a non-aprioristic approach to morphological analysis, as there is no expectation of compositionality or a direct correspondence between forms and functions. In this sense, an abstractive approach allows each system to be described on its own terms.
An abstractive approach to morphological analysis contrasts with constructive approaches, in which surface word forms are built from sub-word units, and where morphological analysis proceeds by segmenting word forms, classifying the resulting sub-word units (e.g. morphemes), and proposing rules for reassembling the word forms (see Blevins, 2006, 2016 for more on the abstractive-constructive distinction). Within constructive approaches, words represent the output of morphological derivations, and therefore have no status as permanent lexical units. The derivation of a given form has no access to ‘paradigmatic’ information about other word forms. Thus the relations between full surface forms is not considered the object of study, and some even dismiss paradigms as epiphenomena (e.g. Embick & Marantz, 2008).
Abstractivist paradigm-based approaches were the response to developing a general theory of exponence types for segmental exponence. The present article exploits the flexibility of this independently needed approach to suprasegmental phenomena (in conjunction with segmental phenomena). In the present paper, inflectional paradigms are considered to be objects of linguistic analysis that allow us to explore cross-linguistic variation at the level of morphological organization (see e.g. Ackerman & Malouf, 2013 for arguments and discussion). Irrespective of the informing perspective of this article, it should be recognized that any theory of tone and exponence would need to address the diversity of phenomena presented here.
3.2 Exponence as informativeness
In recent years, the foundation laid by Matthews (1974/1991) has been built on in several works on exponence typology (Caballero & Harris, 2012; Harris, 2017; Carroll, 2022), which have advanced our understanding of the possible ways in which languages organize their morphological systems. Carroll (2022) conceptualizes exponence as the informativeness of a given formative for a given inflectional category (e.g. case or number), and defines this informally as “what information does a language learner or hearer have about the (grammatical) meaning of a word given this formative” (p. 6). Consider the examples in Table 7.
To illustrate the notion of informativeness, Carroll (2022, p. 10) notes that multiple formatives within a given inflected word-form in Table 7 may be informative for case: for example, the singular forms exhibit stem alternations, where  is found in the absolutive case, and
is found in the absolutive case, and  is found in all non-absolutive or ‘oblique’ case forms. The oblique singular forms are also characterized by a stem formant -iri, and thus both
is found in all non-absolutive or ‘oblique’ case forms. The oblique singular forms are also characterized by a stem formant -iri, and thus both  and -iri provide the information that the word-form is in one of the oblique cases. There may additionally be a dedicated case marker, e.g. -n for the genitive.
and -iri provide the information that the word-form is in one of the oblique cases. There may additionally be a dedicated case marker, e.g. -n for the genitive.
Furthermore, the stem alternant  and the oblique stem formant -iri are also informative for number, as they are only found in the singular cells of the paradigm. The plural forms have two oblique stem formants: -čaj, which is only found in the ergative, and -če, which is found in the non-absolutive and non-ergative forms. In addition, there is a dedicated plural marker -ur, which itself is informative for number, but not case (given that it is found in all case forms across the plural cells).
and the oblique stem formant -iri are also informative for number, as they are only found in the singular cells of the paradigm. The plural forms have two oblique stem formants: -čaj, which is only found in the ergative, and -če, which is found in the non-absolutive and non-ergative forms. In addition, there is a dedicated plural marker -ur, which itself is informative for number, but not case (given that it is found in all case forms across the plural cells).
Thus the organization of Archi case paradigms shows that complexity of exponence is a type of attested morphological organization, and points to the need for paradigmatic contrast in morphological analysis. The lack of form-function isomorphism allows us to illustrate the usefulness of conceptualizing exponence in a functional way as informativeness, emerging from the distributions of the different formatives across the paradigm. Informativeness allows for the determining of exponence mappings unambiguously for a given language, and is therefore well suited to typological studies.
4 Tonal exponence
The study of exponence typology has taught us that “[l]anguages abound in relations between form and content that are complex in the basic sense of violating the most natural way of expressing the one by the other” (Anderson, 2015). That is, form-function isomorphism is only one of many attested strategies for encoding grammatical information on words, and while our theoretical expectations may lead us to conceptualize isomorphism as more ‘natural’ or ‘basic’, an examination of the rich diversity found in natural languages reveals a far more complex situation.
Section 2 presented five basic exponence types, and the aim of the present section is to show the same diversity in exponence relations illustrated with tonal formatives. The present work takes inspiration from previous studies of grammatical tone that have shown that tonal morphology can do anything that non-tonal morphology can do (Hyman, 2016, p. 16), e.g. mark any morphosyntactic category, such as case, number, and TAM (Monich, 2020). Here, I will take a different perspective and extend this line of inquiry to the study of exponence typology, and demonstrate that like segmental exponents, tonal exponents may be involved in a large range of form-function mappings. However, they also pose unique challenges due to their autosegmental nature (see e.g. Hyman, 2011 on this point from a phonological perspective). The next subsections illustrate how tonal and non-tonal formatives may be distributed across morphological paradigms and interact in complex ways.
4.1 Phonological considerations
Before we begin our exploration of how tonal formatives map onto meaning, we will discuss aspects of their phonological realization. Let us first consider a case in which tone is a phonological property of grammatical markers. In Northern Otomi (Oto-Manguean, Mexico), tone is used to contrast different inflectional markers in the same way it is used to distinguish different lexical items; this is illustrated with the word pair in (2) and the grammatical markers dá/da and gí/gi in (3) (Palancar, 2016, p. 113; High tones are marked with an acute accent, Low tones are left unmarked).
-
(2)
Tone distinguishing lexemes in Otomi (Oto-Manguean, Mexico)


-
(3)
Tone distinguishing grammatical markers in Otomi (Oto-Manguean, Mexico)


The data in (3) are not examples of tonal exponence, but rather a case where the grammatical formatives themselves have tone inherently, just as they have both a consonant and a vowel inherently. In Palancar’s (2016) terminology, tone is simply a phonological property of the grammatical markers, a mechanism to keep the markers phonologically distinctive.
Tonal exponents are different from segmental exponents in that they need a host to be realized (the same is true of other subsegmental exponents, such as morphological labialization, palatalization and nasalization; see e.g. Akinlabi, 2011). This host may be a stem or another segmental formative. An example of this is provided in (4): a tonal associative marker is realized on the first of two nouns in an associative construction in Central Igbo (Igboid, Nigeria).
-
(4)


An example of a tonal exponent associating to another grammatical marker is the High tone marking a third person possessor in Otomi: this High tone associates phonologically to the mora immediately preceding the possessed noun (Palancar, 2016, p. 114). This mora may belong to a determiner, as in (5a), or a preposition, as in (5b).Footnote 2
-
(5)
A tonal exponent associating to grammatical markers in Otomi (Oto-Manguean, Mexico)


Tonal exponents may also co-occur with non-tonal exponents to express a single morphosyntactic function (see e.g. Rolle, 2018, pp. 33–34). Consider the Hausa data in Table 8. Each word has a lexical tone pattern (listed to the left), but in the ventive forms (to the right), the verbs take a distinct ventive tone pattern, which is all High regardless of the noun’s lexical tone. In addition, there is a ventive suffix -óː.
In Hausa, the High tone realized over the verb is a component of the ventive marking. But in this case, tone is not the sole exponent of grammatical information, but rather, a co-exponent of it, together with the segmental form -óː (which itself bears a High tone). There are different ways of analyzing data of this kind depending on one’s framework (see e.g. Inkelas & Zoll, 2007 and Trommer, 2024); from the perspective of informativeness taken here, what matters is that both the stem tone and the suffix provide the information that the verb is in the ventive form.
The Hausa example is relatively straightforward in that the information provided by the tonal formative is the same as the information provided by the segmental formative, but we return to the issue of co-exponence in Sect. 5, where I show that in such cases, multiple form-function mappings are possible.
The data discussed in the present section illustrate that we need to distinguish between tonal association and tonal exponence; while association is about the phonological mapping between tones and tone-bearing units, exponence is about how forms map onto meaning. The schematic representations in Fig. 2 may make these different patterns clearer. These figures illustrate three different situations of a tone being phonologically associated to some segmental formative. T indicates a tonal exponent (a single tone or a tonal melody), V indicates a vowel (or any other Tone-Bearing Unit), P indicates a grammatical (e.g. morphosyntactic) property, the black lines indicate the phonological mapping between tonal and non-tonal formatives, and the thick, gray lines indicate the mapping between forms and functions. In addition, subscript indices indicate which forms (Ts and Vs) are mapped onto which functions (Ps). These figures combine the notation for form-function mappings with the tools of autosegmental phonology (Goldsmith, 1976) by representing the tones on their own tier, independently of the vowels and consonants. However, unlike the typical use of autosegmental representations, this formalization is not intended as an analysis of how words can be built incrementally, but to represent the formatives of inflected word forms and how they map onto meaning.

Tonal association. (a) Tone as a phonological property of a grammatical marker. (b) A tonal exponent realized on another exponent. (c) Tone as a co-exponent realized on another exponent
In Fig. 2 (a), the tonal and segmental formatives are simply a part of the same unit. In (b), the tonal exponent and its host mark different grammatical information. In (c), there is a segmental formative Vi expressing property Pi which has its own inherent tone Ti, but in addition, there is a tonal co-exponent Ti realized on another host Vj, which itself conveys a different property Pj.
To summarize, we need to distinguish between tonal association (how tones map onto form) and tonal exponence (how tones map onto meaning), and whether tone is the sole exponent of a grammatical meaning or a co-exponent of grammatical meaning. With this in mind, we now move on to the question of how tones may be involved in different exponence types.
4.2 Tones involved in simple exponence
As explained in Sect. 2, simple exponence refers to cases in which there is a one-to-one relationship between form and function. Locative marking in Jamsay, illustrated in Table 9, is an example of this type.
The bare stems in Table 9 have one of two lexical tone melodies, High or Low-High, spread out over either one or two syllables, yielding the four surface tone patterns H, HH,  and LH (where the joining bar represents a contour tone over a single syllable). When comparing the lexical tones to the corresponding locative tone patterns, we see that there is an extra Low tone at the end of the locative forms. This Low tone is thus the exponent of the locative function.Footnote 3
and LH (where the joining bar represents a contour tone over a single syllable). When comparing the lexical tones to the corresponding locative tone patterns, we see that there is an extra Low tone at the end of the locative forms. This Low tone is thus the exponent of the locative function.Footnote 3
In the case of tonal alternations on stems, there are at least two ways of conceptualizing the data, depending on one’s perspective. We can think of them as stem alternations, or as “tonal affixes” that are concatenated with lexical tones on a tonal tier. In some cases there are clear arguments for one analysis over the other, and in the Jamsay case, the fact that the Low tone exponent occurs on the right edge and combines with the lexical tone warrants an analysis of this marker as a tonal suffix.
From an abstractive perspective, the distinction is not as important as exponents are considered to be emergent properties of paradigmatic contrasts. However, the patterns that motivate the distinction are interesting from both a diachronic and a synchronic perspective; we would expect alternations of the kind in Table 9 when a tonal exponent is the result of tonal stability after the loss of an affix that also had segmental material. Whether or not speakers analyze the patterns in this way is a question for psycholinguistics, but regardless, the distinction between tonal affixes and tonal stem formants is a useful one to keep in mind for the tone analyst.
The formalization in Fig. 3 illustrates simple exponence as exemplified by the locative form of ‘hand’ in Jamsay.

Simple exponence in Jamsay: L tone marking the locative
The locative Low tone in Jamsay is additive in that it combines with the lexical tones; tonal exponents may also be replacive (Welmers, 1973, pp. 132–133) and overwrite lexical tones. For example, the imperative forms of verbs in Hausa are formed by replacing lexical tones; this is illustrated in Table 10, which shows that verbs with different lexical tones (to the left) all neutralize to a Low-High tonal melody in the imperative (to the right). The Low-High melody associates to tone-bearing units from right to left, with the Low tone being multiply linked if there are more than two syllables.
While the Jamsay example in Table 9 illustrated simple exponence with a single tone, the Hausa data in Table 10 illustrate a case in which the tonal formative consists of two tones (Low and High). This is still a case of a one-to-one relationship between form and function, but the form here is a tonal melody {LH} rather than a single tone (in this sense, tones are like segments: for example, the English suffix -ity is a single exponent although it has three segments; in the same way, the imperative LH marker in Hausa is a single tonal formative consisting of two tones). The resulting form-function mapping is illustrated in Fig. 4.

A {LH} melody marking the imperative in Hausa
4.3 Tones involved in cumulative exponence
Table 11 illustrates verbal morphology in Iau (Lakes Plain, West Papua), where each tone pattern marks two functions, and the tone patterns cannot be decomposed into one tone (or tonal melody) per function. This is an example of cumulative exponence (e.g. Mid tone for durative and resultative). Figure 5 gives a representation of the resulting one-to-many mapping between form and functions.

Cumulative exponence in Iau: M tone marking durative and resultative
Because the tone patterns in Table 11 cannot be decomposed further, they also provide examples of tonal melodies as single pieces of form mapping onto multiple functions. For example, {HLM} is a single tonal formative marking durative and telic. If one tentatively segments {HLM} into, say, a telic H tone and a durative LM tone, this would not make any predictions beyond this paradigm cell (while all telic forms begin in a High tone, it is not the case that all durative forms end in a LM tone). Figure 6 captures the resulting form-function mapping.

Cumulative exponence in Iau: a {HLM} melody marking durative and telic
Judging from the data in Bateman (1990), there is no evidence for individual morphemes, e.g. a punctual morpheme or a telic morpheme. Under the present terminology, the aspect tone patterns in Table 11 are thus true examples of cumulative exponence rather than fused forms.Footnote 4
4.4 Tones involved in multiple exponence
We now turn to examples of multiple exponence. Consider the data in Table 12, which illustrate a subset of case marking strategies in Rere.
In Table 12 (a), the accusative case is marked by a suffix (which consists of a vowel and a High tone: -á), while in (b), it is marked by a tone change (HL to LL). Both types are examples of simple exponence, the second type involving tone only. However, in (c), both case marking strategies co-occur, an instance of multiple exponence (where both realizations are found within the word). The formalization in Fig. 7 captures the resulting many-to-one mapping between form and function; here, there are two exponents that redundantly provide the information that this word form is in the accusative case.

Multiple exponence in Rere: L tone and -á marking the accusative
To distinguish multiple exponence from other types of co-exponence, I follow Harris (2017, pp. 7–23) in using the heuristic that each exponent needs to be attested independently of each other (see also Sect. 2). While in isolation, the example in Fig. 7 could have been analyzed as a single exponent (perhaps /- /, where
/, where  indicates a floating Low tone that docks onto the stem and replaces the lexical tone), it is the fact that each exponent (the Low tone and the suffix -á) is attested independently of each other that makes this a case of multiple exponence.
indicates a floating Low tone that docks onto the stem and replaces the lexical tone), it is the fact that each exponent (the Low tone and the suffix -á) is attested independently of each other that makes this a case of multiple exponence.
The Rere case marking system is more complex than what is indicated here (see Quint & Allassonnière-Tang, 2022), and will be returned to in Sect. 6 on polyfunctionality. For the present purposes, the data in Fig. 7 serves to illustrate an example of a many-to-one mapping between form and function within an inflected word-form. For more examples of tonal and non-tonal formatives interacting in a relationship of multiple exponence, see Fedden (2016); Harris (2017, pp. 71–87). In Sect. 5, we will turn to other types of co-exponence.Footnote 5
4.5 Toneless as zero exponence
As discussed in Sect. 2, zero exponence refers to cases in which the absence of form is meaningful. This can be understood paradigmatically: for example, in the English word pair cat–cats, a paradigmatic contrast occurs in which the absence of the plural suffix -s in the form cat indicates that the word form cat is singular.
The present section explores a parallel between zero exponence and the concept of tonelessness. In a language with a tone system, there may be a difference between the number of phonetic surface tones and the number of phonological tones. For example, there are several possible analyses to consider for a system with a set of two surface tones High and Low, where the analytical choice depends on whether one or both tones are active in the phonology (i.e. being referenced by phonological rules): the phonological contrast may be one of High vs. Low (e.g. Aghem; Hyman, 1987), or it may be High vs. toneless (∅) (e.g. Haya; Hyman & Byarushengo, 1984), or Low vs. ∅ (e.g. Engenni; Hyman, 2000). For overviews and discussion, see e.g. Hyman (2000); Yip (2002, ch. 2).
Tonelessness as a phenomenon opens up the possibility of a paradigmatic contrast between word-forms that have tones versus those that lack them altogether, in which case we can consider tonelessness as a form of zero exponence. This idea necessitates a higher level of abstraction than what is found when the paradigmatic contrast involve the presence or absence of a segmental affix, as the absence of tone does not entail the absence of pitch. As Hyman points out, “it is not always clear whether the non-H tone of a two-level system should be analyzed as /L/ or /∅/. In addition, different phonologists have taken the position that there should be full specification in underlying representations” (Hyman, 2009, p. 224). Furthermore, a pitch difference involved in a paradigmatic contrast is informative regardless of the phonological objects proposed by the analyst. With these caveats in mind, the goal of the present section is to explore what tonelessness as zero exponence might look like, if tonelessness is taken to exist. This will be illustrated by the case marking system of Somali (Cushitic, Horn of Africa).
Somali is analyzed as having a tone system in which the tone-bearing unit is the mora, and where moras are either High-toned (H) or toneless (∅, realized with low pitch) (Hyman, 1981). Further, it is analyzed as having a case system of the type marked nominative (Mous, 2012), in which nouns marked for the nominative case contrasts with an unmarked base form (called the absolute case in Cushitic studies, dating back to Moreno, 1939). The examples in Table 13 illustrate absolute and nominative forms of four nouns; a High tone is marked by an acute accent (á) and the absence of tone is left unmarked.
As illustrated in Table 13 (a-b), a subset of nouns are toneless in the nominative form, while the absolute case form has a High tone. The data in (c-d) illustrate that a subset of nouns have a nominative suffix -i, demonstrating that nominative forms are marked.Footnote 6 The nominative forms in Table (a-b) thus exhibit the tonal equivalent of zero exponence, where the absence of tone is meaningful and marks a grammatical function. This can be formalized as in Fig. 8; note that the ∅ symbol here simply is meant to capture the paradigmatic contrast between the absolute and nominative forms, rather than to indicate the presence of a (silent) object. The figure is meant to capture that the absence of a High tone is informative; it indicates that this word-form is in the nominative case.Footnote 7

Toneless as zero exponence in Somali
Toneless moras in Somali are realized with low pitch, and the analysis of the Somali tone contrast as privative (High vs. ∅) rather than High vs. Low is ultimately an analytical matter rather than an empirical one; the main motivation for the privative analysis is that the whole system can be described by referring to the distribution of the High tone only (Hyman, 1981); i.e., the Low tone is not involved in any phonological processes. Somali is thus ambiguous in this sense, and may be analyzed as having underlyingly toneless units that are realized with low pitch due to Low tones being filled in by the phonology, in which case the surface paradigmatic contrast is between High and Low, not High and toneless. As mentioned above, the goal of this section is not to discuss whether analyses in terms of tonelessness are necessary, but what tonelessness as zero exponence looks like, if tonelessness is taken to exist.
4.6 Tones as empty exponents (construction markers)
An example of empty exponents is the linking elements found in compounds in many languages, as introduced in Sect. 2 above. These are pieces of form that do not realize morphosyntactic properties, but rather mark construction type.
The examples in Table 14 illustrate that in Urban East Norwegian, such linking elements can be segmental and/or tonal. Following Kristoffersen (1992), there are several types: -s- (a), a High tone realized on the first element of the compound (b), -s- and a High tone (c), or -ə- with a High tone (d) (the High tones combine with Low tones to create Falling tones, indicated with a circumflex: ê). They contrast with compounds with no linking element, as in (e). Yet other compounds show variable behavior and are acceptable both with and without a linking element, as in (f).Footnote 8
A formalization of the one-to-zero mapping between form and function found with the tonal linking element exemplified in Table 14 (b) is provided in Fig. 9. This figure is meant to capture that empty exponents do not mark any morphosyntactic properties. From the perspective of informativeness, however, formatives are never truly empty; they may provide lexical, derivational, or inflectional information. In this case, the ‘linking tones’ mark that these words are compounds, and the linking tones are thus informative for the morphological construction involved.

A High tone as a morphosyntactically empty exponent in Norwegian
The example in Table 14 (c) above includes two linking elements that are attested independently of each other, namely the -s- and the High tone. This is thus a case of tone being an empty co-exponent, i.e. it does not realize any morphosyntactic properties, but marks the construction type together with a non-tonal formative, in a relationship of multiple exponence.
Under Kristoffersen’s (1992) analysis of compounds, the linking elements are “morphemes” introduced by rules. A few notes on this analysis are in order here. First, the fact that the linking elements lack meaning suggests that they are not morphemes in the traditional sense. They are also not exponents of morphosyntactic properties; rather, they are markers of the construction type. Second, the distribution of the linking elements in Norwegian is complex, and like in other Germanic systems that have them (see e.g. Krott et al., 2001 for Dutch; Krott et al., 2007 for German), it is nontrivial to predict which compounds get a linking element, and if so, which one. Because of this, Kristoffersen (1992, p. 50) regards them as being lexically marked. He proposes morphological rules that introduce the linking elements, and these rules apply to lexical items that are marked for having those rules applying to them (p. 51–53). This seems circular, and one might, on a conceptual basis, question the usefulness of proposing a rule-based analysis of something that is of a fundamentally probabilistic character.
It is the lack of function that is definitional for empty exponents, so we can imagine a case in which we have linking elements whose distribution is predictable. In fact, the tone patterns (or “tonal accents”) of compounds across Scandinavian varies in this respect. In some dialects, including Urban East Norwegian, compounds show variable accent assignment. In other dialects, including Central Swedish, all compounds receive Accent 2, regardless of the presence or absence and type of segmental linking element. In such cases, the surface tone pattern can be analyzed as prosodic and post-lexical assignment of Accent 2 (see e.g. Riad, 2006). However, from the perspective taken here, the possibility of a phonological analysis does not preclude a morphological analysis; even in cases where constructional markers are predictable by independent factors, they are still also informative for construction type.
4.7 Section summary
The present section has demonstrated that tone can be involved in all exponence types introduced in Sect. 2: simple exponence, cumulative exponence, multiple exponence, zero exponence, and empty exponence. We have seen that there are many ways in which tonal formatives may indicate grammatical information: through form-function isomorphism or different types of deviations from it; either alone or in conjunction with non-tonal formatives. While this five-way typology served well as a starting point, these exponence relations do not capture the full picture. We now move beyond these five main types and consider more complex form-function mappings.
5 Verbose exponence and overlapping distributions
Carroll (2022) proposes the term verbose exponence to refer to cases in which multiple formatives are sensitive to some common information. There are many possible types of overlap between the information provided by different formatives within a given word; the term verbose exponence is thus an umbrella term for many different exponence types. In this section, we will explore some of this diversity, including types of overlapping exponence and distributed exponence. In the typology presented by Carroll (2022), only segmental morphology is included, and inflected word-forms are explicitly treated as sequences of formatives, provided as a list or set (Carroll, 2022, pp. 3–4). The present paper builds on this work by extending it to the study of tonal exponence, which cannot readily be analyzed as belonging to a sequence of formatives due to its autosegmental nature. In what follows, we will explore the interplay between tonal and non-tonal formatives. In Sect. 5.1, we will explore different types of co-exponence. In Sect. 5.2, we will discuss overlap of information, and in Sect. 5.3, we turn to distributed exponence.
5.1 Types of co-exponence
We have seen that tone can be the sole exponent, or a co-exponent of morphosyntactic properties alongside non-tonal ones. It is worth clarifying the possible relationships between co-exponents in more detail, and here, we will focus on three dimensions: whether or not the formatives involved provide the same information, whether or not they are attested independently of each other, and whether or not they are realized adjacently to each other.
Examples of tonal and non-tonal exponents co-occuring include the High tone and the suffix -ay marking the progressive in Somali (Table 1; e.g. keén-ay-aa ‘bring (present progressive)’), or the High tone and the suffix -óː marking the ventive in Hausa (Table 8; e.g. gángár-óː ‘roll down (ventive)’). In these cases, the tonal formative provides the same information as the non-tonal formative, and we can consider them to be co-exponents.
Under a constructive approach to morphological analysis, one could analyze the High tone of the Somali progressive as being triggered by the progressive suffix -ay, and the High tone of the Hausa ventive as being triggered by the ventive suffix -óː. In this sense, these examples are conceptually different from the example of multiple exponence in Rere, which were illustrated in Table 12 (e.g. kwòrtò-á ‘rich person (accusative)’), where both the tonal and non-tonal accusative exponent (Low tone and -á) are attested independently of each other. These data do not straightforwardly lend themselves to an analysis in which one formative is triggered by the other. It is for this reason that we in Sect. 2 introduced the heuristic that the formatives involved in a relationship of co-exponence need to be attested independently of each other for the example to count as “true” instances of multiple exponence.
Tones are famous for their autosegmental nature and—as Hyman (2016, p. 16) puts it—their “ability to wander”. Thus it is not uncommon for a tonal exponent to end up on a different marker than its segmental co-exponent. For example, the data in (6) illustrate High tone shifting in Giryama. The verb forms with a 1sg subject in (6a) have a prefix ni- and no tone, while the verb forms with a 3sg subject in (6b) have a prefix a- and a High tone. The High tone is realized on the penultimate mora of the phrase, which means that unless the verb is phrase-final, the High tone ends up on a different word. Although realized non-adjacently, the two components of the 3sg subject marker always co-occur in expressing 3sg subject in this TAM, and so this example would not count as multiple exponence based on the heuristic used above. From a perspective of informativeness, however, this is a clear example of a tonal and non-tonal exponent providing the same information.
-
(6)
Person marking in Giryama (Bantu; Kenya)


To summarize, tonal and non-tonal formatives may function as co-exponents and provide the same information, they may or may not be attested independently of each other, and may or may not be realized adjacently to each other. The next sections discusses examples where co-exponents provide overlapping, but not identical information.
5.2 Subset of information
When a morphosyntactic property is marked by multiple formatives, but one or more of those forms also mark other properties, there may be different types of overlap between the information provided by the formatives involved. Different types of overlap and its relationship to redundancy have been discussed in the literature (Caballero & Harris, 2012; Caballero & Inkelas, 2013; Caballero & Kapatsinski, 2015; Carroll, 2022; Harris, 2017); here, we will focus on what is called partially superfluous multiple exponence by Caballero and Harris (2012) or subset verbose exponence by Carroll (2022), in which there is at least one formative which does not make any unique semantic or syntactic contribution to the inflected word form.
For an example of a case in which the information provided by a tonal formative is a subset of the information provided by another formative, consider the data in Table 15.
Here, all first and second person forms (regardless of number) are marked by a final High tone, while third person forms are marked by a penultimate High tone. In this case, tone is the exponent of person (a final High tone marking first or second person, and a penultimate High marking third person), although it is not the only exponent of person: the prefixes mark person as well as number.Footnote 9
Third person is marked twice on the 3pl form: once on the prefix (which also indicates number), and once through the penultimate High tone. This is indicated in the representation in Fig. 10. The High tone has a superscript which indicates its location (penultimate) to capture that the meaning does not just result from its form (High tone), but also where the tone associates. This is a case of partially superfluous multiple exponence; both the prefix and the tone marks third person, but the prefix also provides additional information about number (i.e. plural).Footnote 10

Subset exponence in Chimwiini
5.3 Distributed exponence
Distributed exponence involves multiple markers co-occurring, and is therefore reminiscent of multiple exponence, but it differs from it in that “more than one formative is required to provide a fully specified reading of a feature or category” (Carroll, 2022, p. 2). Distributed exponence is found e.g. throughout the Yam family, in languages such as Ngkolmpu (Carroll, 2016) and Komnzo (Döhler, 2019). An example is provided in Table 16, which illustrates number marking in Nen.
The formatives involved in Table 16 are informative for the category number, but information from multiple formatives are required to disambiguate potential readings: for example, yä- indicates that the word form is either dual or plural, and -ngr indicates that the wordform is either singular or plural. When the two formatives co-occur in (c), they disambiguate each other’s function: together, they indicate plural. We can abstract over these data as in Table 17; this table indicates the distribution of four formatives (A, B, C, and D) across a paradigm with four cells and four morphosyntactic properties (P1-4). Given the formatives’ distribution, each one is ambiguous on its own, but has its function disambiguated by the other formative within the same word.
A case of tone involved in distributed exponence is found in the TAM system of Rere, illustrated by the verb bubl- ‘wrestle’ in Table 18. These verb forms have the same structure, which involves a noun class marker (kwʊ-), an auxiliary (m or  ), and the verb root suffixed by a final vowel (-
), and the verb root suffixed by a final vowel (- or -í). There are two types of auxiliaries illustrated here: m in (a-b), and a floating High tone
or -í). There are two types of auxiliaries illustrated here: m in (a-b), and a floating High tone  in (c-d), which associates to the noun class marker kwʊ- (cl). The
in (c-d), which associates to the noun class marker kwʊ- (cl). The  indicates that the verb form is either the conditional or the imperfective (a set of meanings which cannot be unified as a semantically natural class). On its own, the
indicates that the verb form is either the conditional or the imperfective (a set of meanings which cannot be unified as a semantically natural class). On its own, the  is thus ambiguous, but in combination with the final vowel (FV) -
is thus ambiguous, but in combination with the final vowel (FV) - it indicates conditional, and with the final vowel -í it indicates imperfective. The meaning of the final vowels is also underdetermined as they have other functions elsewhere; when they are used in verb forms which contain the perfect marker m, they mark the distinction between remote and recent.Footnote 11,Footnote 12
it indicates conditional, and with the final vowel -í it indicates imperfective. The meaning of the final vowels is also underdetermined as they have other functions elsewhere; when they are used in verb forms which contain the perfect marker m, they mark the distinction between remote and recent.Footnote 11,Footnote 12
To represent distributed exponence, I will combine conventions developed for related, but different phenomena in other languages, and modify them slightly to fit the phenomenon under consideration here. First, the polyfunctionality of each marker can be captured by the use of the logic operator ∨ (see Stump, 2014, p. 84), that is, we can gloss the  as ipfv∨cond, the suffix -
as ipfv∨cond, the suffix - as rem∨cond, and the suffix -í as ipfv∨rec. Second, we need a way to capture the dependency between these formatives, that is, the fact that they disambiguate each other’s function by co-occurring within the same word.Footnote 13 In order to do this, I adopt the conventions developed by Carter (2023) for the analysis of polyfunctional markers in Ket: dependency arrows represent the information that the formatives provide about each other, and strikeout indicates which function is ruled out. This is illustrated in Fig. 11, a representation of (d) in Table 18. While Carter (2023) focuses on unidirectional relationships between different markers, the relationship in the case of distributed exponence is bidirectional. The modification used here to capture this is simply to use a bidirectional arrow. While these conventions have been developed for segmental morphology, they are extended here to tonal morphology, and we need a multidimensional diagram in which we can capture the autosegmental nature of the tonal exponents. As in previous figures in this paper, I have used color coding to distinguish between associations between tones and TBUs (in black) and form-function mappings (in gray).
as rem∨cond, and the suffix -í as ipfv∨rec. Second, we need a way to capture the dependency between these formatives, that is, the fact that they disambiguate each other’s function by co-occurring within the same word.Footnote 13 In order to do this, I adopt the conventions developed by Carter (2023) for the analysis of polyfunctional markers in Ket: dependency arrows represent the information that the formatives provide about each other, and strikeout indicates which function is ruled out. This is illustrated in Fig. 11, a representation of (d) in Table 18. While Carter (2023) focuses on unidirectional relationships between different markers, the relationship in the case of distributed exponence is bidirectional. The modification used here to capture this is simply to use a bidirectional arrow. While these conventions have been developed for segmental morphology, they are extended here to tonal morphology, and we need a multidimensional diagram in which we can capture the autosegmental nature of the tonal exponents. As in previous figures in this paper, I have used color coding to distinguish between associations between tones and TBUs (in black) and form-function mappings (in gray).

Distributed exponence in Rere
In this example, tone is a co-exponent alongside segmental ones. One question that arises is whether multiple tonal exponents may co-occur in a relationship of distributed exponence. I am not aware of any such examples, but if it exists, it would surface as tonal melodies which would be decomposable into independent components that are polyfunctional on their own, but disambiguate each other’s functions.
5.4 Section summary
This section explored the interplay between tonal and non-tonal co-exponents, ranging from cases in which they contribute the same information and always co-occur, to cases of subset exponence and distributed exponence. The latter case always involves a type of polyfunctionality, and we turn to polyfunctional exponence next.Footnote 14
6 Polyfunctionality and morphomic distributions
The present section moves further beyond the exponence types addressed to far and explores in depth a topic briefly introduced in Sect. 5, namely cases in which one or more exponents are polyfunctional. There are different types of polyfunctional exponence (see e.g. Stump, 2014), which may interact with other types of exponence in complex ways. Here, we will discuss morphomic distributions as well as the distinction between polyfunctionality within and across paradigms.
To the extent that these phenomena have been discussed in previous typologies of grammatical tone, they have received different labels, e.g. Paradigmatic Grammatical Tone (Rolle, 2018) or morphological tone (Palancar, 2016). However, the phenomena in question have clear parallels in non-tonal morphology (e.g. polyfunctionality and morphomic distributions) and there is thus a body of literature to engage with and build off of when analyzing their tonal equivalents. In this section, I will aim to do just that, as well as provide a more fine-grained typology of the different interactions that may occur when polyfunctional tones interact with non-tonal formatives in different ways.
Although the aim of the present paper is exploratory, and no claims of frequency of distributions are made, it is worth asking whether the phenomena discussed in this section are rare—given their infrequent mentioning in previous literature on tone—or simply unreported, perhaps because our theories do not lead us to expect them.Footnote 15
6.1 Tonal morphomes
Among the types of polyfunctional exponence discussed by Stump (2014) is one involving morphomes, which refers to cases in which a given form is associated with a set of functions that do not form a natural class. Morphomes are particularly interesting because they tap into one of the major differences between morphological theories: they have been argued to constitute patterns not motivated by phonology, syntax, or semantics, and thus to be examples of morphology by itself (Aronoff, 1994). The existence of morphomes therefore pose a challenge for frameworks that adopt an architecture of grammar in which there is no autonomous morphology, e.g. most frameworks growing out of the Chomskyan tradition (see Luís & Bermúdez-Otero, 2016 for discussion and analyses across different frameworks). In his typology of morphomes, Herce (2020) finds this phenomenon in 30 genetically independent stocks across the world, and concludes that it “cannot be dismissed lightly as an accidental quirk of a few languages” (Herce, 2020, p. 359). If tone can do anything that non-tonal morphology can do (Hyman, 2016, p. 16), we would expect it to be able to show morphomic distributions as well, and indeed this is the case.
An example of tones being polyfunctional and exhibiting morphomic distributions within a paradigm is found in Tlatepuzco Chinantec. Consider the data in Table 19. Here, tone is marked by superscript numbers 1 (High), 2 (Mid) and 3 (Low); numbers 31 and 32 indicate contour tones (High rising and Mid rising, respectively). The prefix ka3- marks past tense, and the root húʔ ‘bend’ is marked tonally for person. The pronouns distinguish six person/number values, but the stem húʔ only shows three forms (3, 31, and 2).Footnote 16
The tones 3 (Low) and 31 (High rising) are both polyfunctional within this paradigm because they can be associated with different person/number values: for example, the stem has tone 3 in the 1sg, 2sg, and 2pl forms. This distribution is morphomic because it cannot be captured as a natural class to the exclusion of the morphosyntactic property sets associated with the remaining paradigm cells (1pl.incl/excl and 3). Additionally, the distribution of tonal formatives are different in other aspectual forms. There are three aspectual stems from which all aspect forms are built, namely the present, future, and completive (for example, the past tense forms in Table 19 are built on the completive stem forms, with a past tense prefix ka3-; see (Baerman & Palancar, 2014, p. 47) for additional details). Table 20 illustrates the stem tone alternations of ‘bend’ for all three aspectual stems.Footnote 17
This is a case of tonal polyfunctionality leading to syncretism, i.e. a case in which multiple paradigm cells have identical word-forms (ka3-húʔ3 is found in three paradigm cells).Footnote 18 However, syncretism is not a necessary outcome when polyfunctionality is involved. The next section presents cases in which polyfunctional markers have their function disambiguated by other exponents occurring within the same word-form.
6.2 Tonal morphomes as co-exponents
Tones may exhibit morphomic distributions yet have their function disambiguated by other formatives. One example comes from Choguita Rarámuri, as documented and analyzed by Caballero and German (2021). The examples in Table 21 illustrate different forms of the verb biʔw -a ‘to clean’ (where -a is a transitivizer suffix), and shows that it receives Low tone in one set of forms (called neutral constructions), and High-Low tone in another set of forms (called shifting constructions).Footnote 19
Caballero and German (2021, p. 167) argue that the distinction between the two sets of verb forms in Table 21 is morphomic because whether a given construction belongs to one set or the other is “determined not by morphosyntactic inflectional features nor by any semantic or phonological principles but rather by purely morphological properties”. Although the distribution of tone is morphomic, the inflected word-forms are distinguished from each other straightforwardly by the presence of suffixes.
We can compare this to a slightly more complex system. In Modo (Central Sudanic, Sudan), verbs index the person and number values of subjects through a combination of tonal and non-tonal formatives. The final syllable of a verb root has a lexical tone, either High or Low, while the tone of the initial syllable hosts an inflectional tone (Andersen, 1981, pp. 42–45); this is illustrated in Table 22 with the verb ubà ‘to sing’, which has a lexical Low tone, and in Table 23 with the verb edí ‘to be’, which has a lexical High tone.
A schematized version of the inflectional formatives in Tables 22–23 is provided in Table 24; this shows that the person and number of the subject are marked through a combination of affixes and tonal formatives.
If we first look solely at the tonal formatives, we see that the High tone is found in the paradigm cells listed in (7a), and the Low tone is found in the paradigm cells listed in (7b). Neither can be captured as a natural class—that is, there is no way of unifying 1sg, 2sg and 2pl to the exclusion of 1pl, 3sg and 3pl—and thus the distributions of these formatives are morphomic.
-
(7)
The morphomic distribution of the tonal formatives
-
a.
High tone: 1sg, 2sg, 2pl
-
b.
Low tone: 1pl, 3sg, 3pl
-
a.
From a phonological perspective, inflectional and lexical tones combine in a straightforward way (e.g. inflectional High + lexical Low →[HL]), and Hyman uses the Modo data as an example of a case in which “segmenting the tones by morpheme is straightforward” (Hyman, 2016, p. 19). Here, I would like to revise this observation and say that segmenting the tones by lexical tone and morphomic tone is straightforward. What is interesting about the Modo data in my opinion, is how the relatively simple set of formatives in Table 24 come together to exhibit a high degree of complexity of exponence. We will therefore look at these complexities in a little more detail.
If a stem tone formative co-occurs with a non-tonal one within the same word form, its function can be disambiguated, as each segmental affix shows a limited distibution across the paradigm and thus has a clear function: m- means 1sg, d- means 1pl, and -ké means 2pl. This is thus a case of a tonal morphome functioning as a co-exponent with a non-tonal formative, where the information provided by the tonal morphome is both ambiguous and redundant, and its ambiguity is resolved by the non-tonal formative. This is illustrated by the schematization in Fig. 12.

A non-tonal formative disambiguating the function of a tonal morphome
In contrast, the lack of a prefix is informative for person, but ambiguous: it tells us that the verb form is in either the second or third person. This ambiguity of person value introduced by the lack of an overt person/number marker is resolved by the tonal exponent: for example, a Low tone exponent indicates that the verb form is either 1pl or third person, and the only person value shared by the lack of a prefix and the presence of a Low tone is third person. Thus in combination, the two formatives resolve each other’s function; that is, this is a case of distributed exponence (although one of the formatives in question is zero). This is schematized in Fig. 13, which also indicates that the third person form is unmarked for number.

Distributed exponence in Modo
Morphomic tones may also co-occur with other morphomes. A case in point is the ‘Melodic Tone’ in Bantu (see Odden & Bickmore, 2014 and papers therein). While the details differ somewhat across Bantu languages, the Melodic Tones form a part of the verbal inflection system, and typically occur in a set of TAM forms which do not form a natural class. A Melodic Tone may be the sole exponent of a given TAM value in some word-forms, and in other cases, there may be other exponents as well. An illustrative example is found in Cilungu, a Bantu language spoken in Zambia and Tanzania. The Cilungu verbal template is provided in (8). This shows that TAM markers can occur both before and after the root. Additionally, there is a final vowel whose quality (-a or -e) differ across TAM forms.Footnote 20
-
(8)
Verbal template of Cilungu (Rolle & Bickmore, 2022, p. 200)
[V SM (NEG) TAM [MS (OM) [STEM ROOT (DERIV) TAM FV ]]]
Melodic tones are introduced in a subset of TAM forms. The example in (9) illustrates the Yesterday Past Progressive, which is characterized by a prefix á- (whose tone spreads one mora to the right), a suffix -ang, and the final vowel -a, in addition to a Melodic High on the final mora. Rolle and Bickmore (2022) formalize this tone as  F (a floating High tone with its location indicated through a superscript F for Final).
F (a floating High tone with its location indicated through a superscript F for Final).
-
(9)


The location of the melodic High depends on TAM. The example in (10) illustrate the Remote Perfect, which is characterized by a prefix a-, a final vowel -a, and a Melodic High which associates to the second mora of the stem and the following moras up until the final one, indicated as  2-F (additionally, the tone of the subject marker spreads once to the right).
2-F (additionally, the tone of the subject marker spreads once to the right).
-
(10)


Rolle and Bickmore (2022) present an overview of TAM exponents and show that they are distributed across paradigm cells which do not form a natural class: “It is not possible to associate an individual grammatical tone pattern with a consistent semantic meaning by itself in the absence of segmental co-exponents” (Rolle & Bickmore, 2022, p. 204).
This is a descriptive generalization that does not follow from any specific theoretical assumptions, but can be accommodated by making some, such as acknowledging a morphomic layer (Aronoff, 1994, pp. 22–29) in the architecture of the grammar. The distribution of TAM tone in Cilungu is morphomic, and like the Rarámuri and Modo data above, there are other exponents (different affixes) that disambiguate the meaning of the construction as a whole. These exponents may themselves be morphomic, and the meaning of the verb form may be distributed across multiple formatives. A case in point is the final vowels. The final vowel is -e if there is a suffix -il (in the Far Past, the Far Past 2, the Yesterday Past, the Recent Past, and the Perfect), and in the Subjunctive (Rolle & Bickmore, 2022, p. 205). There is nothing to unify this set of functions to the exclusion of the remaining ones, in which the final vowel is -a.
Downing and Mtenje (2017, p. 208) points out that the issue of where in the grammar the grammatical tone patterns are represented “has, surprisingly, received no attention in the literature on Bantu morphosyntax, as far as we know, and relatively little attention in the phonology literature analyzing grammatical tone patterns”. Bickmore (2022) considers different options under “a model where the morpho-syntax precedes and feeds a phonology component” (p. 2) and discusses some of the complications stemming from the long list of TAM forms that would need to be referenced by different rules. One fruitful avenue of exploration for such data might be a model that contains a morphomic layer (as proposed by Aronoff, 1994, pp. 22–29).
6.3 Polyfunctionality within and across paradigms
It is useful to distinguish between polyfunctionality within a paradigm, which is what we have focused on so far in the present section, and polyfunctionality across paradigms. Consider the examples of tonal case marking in Rere provided in Table 25, which illustrates tonal polyfunctionality across paradigms of different (classes of) lexemes. Note that this is a subset of many case marking strategies: others were introduced in Sect. 4.4 (see also Quint & Allassonnière-Tang, 2022).
These data illustrate that the three tone patterns High-High, High-Low, and Low-Low are found on nominative forms as well as on accusative forms. For each noun in Table 25, its tone pattern illustrates simple exponence within the inflected word form—e.g. Low-Low for the accusative in (a)—but when comparing across word forms, the tone patterns themselves are polyfunctional, and mark different functions on different nouns. Thus it is not the case that one can identify a single accusative tone pattern, or a single nominative tone pattern. Moreover, the complexities of the data (as laid out in more detail by Quint & Allassonnière-Tang, 2022) cannot readily be accounted for as predictable realizations of a single underlying form, e.g. by separating inflectional and lexical tones.
Another example comes from Chinantec. In Sect. 6.1, we introduced aspect and person marking in Tlatepuzco Chinantec. The distribution of tonal formatives of the verb húʔ ‘bend’ was given in Table 20, and schematized forms are provided in Table 26. The paradigmatic structure found with the verb ‘bend’ is one of many possible patterns; verb lexemes fall into different classes with respect to the distribution of tonal formatives. In Table 27 and Table 28, the stem tone distribution associated with two other verb classes are illustrated.
These data illustrate that in Chinantec, tone is polyfunctional both within and across paradigms. Consider the distribution of tone 3, for example. Tone 3 is found in the first person singular and second person forms of the completive in Table 26. In Table 27, tone 3 is found in the first person singular and third person cells of the completive, as well as the third person future cell. In Table 28, tone 3 is found in the second person completive, and the third person future. It is not the case that we can assign a consistent function to tone 3 or any other tone, or for that matter, a consistent tone to any given morphosyntactic property set (such as the first person singular completive). In fact, Baerman and Palancar (2014) show that all tones—1, 2, 3, 31 and 32—are used for all possible property sets.Footnote 21
While the examples discussed previously in the present paper have illustrated different types of exponence relations within single word-forms, and is the result of analyzing how information is indicated through patterns in morphological paradigms of single lexemes (or a single class of lexemes), the Rere and Chinantec data in the present section illustrates that another dimension of complexity is added when considering paradigms of multiple lexemes. Such lexemes may fall into different inflectional classes, and the role of tone in the organization of inflectional classes will be discussed further in Sect. 7.
6.4 Section summary
In the present section, we further expanded the five-way typology introduced in Sect. 2 to discuss a series of more complex deviations from form-function isomorphism, including different kinds of polyfunctionality and morphomic distributions. I aimed to extend the study of these morphological phenomena to the study of tone, and to illustrate a rich set of interactions between tonal and non-tonal formatives. Next, we introduce an additional layer of complexity, namely the one added in languages with inflectional class systems.
7 Inflectional classes and paradigmatic layers
An inflectional class is defined as “a set of lexemes whose members each select the same set of inflectional realizations” (Aronoff, 1994, p. 64); a language has multiple inflectional classes when there is more than one realization for a given morphosyntactic property set. Such systems thus present us with another kind of deviation from form-function isomorphism; so far, we have focused on the internal organization of words by looking at the organization of paradigms of single lexemes (or classes of lexemes); we now turn to comparisons across such classes. As we will see, inflectional formatives are not just informative for morphosyntactic properties in such cases, but also for inflectional class membership.
7.1 Inflectional classes distinguished by tone
For the present purposes, we will adhere to a strict interpretation of the term inflectional class, where it is reserved for cases in which class membership (and thus the realizations of the exponents in question) is not determined by any independent factors, such as phonological, semantic, or syntactic ones. In such cases, the classes are only relevant for the morphology and no other components of the grammar, and this is an instance of morphology by itself in the sense of Aronoff (1994). As Corbett puts it: “If there were outside motivation, this might allow an analysis in terms of sub-categories, each with a single type of inflection, and hence no need for inflectional classes” (Corbett, 2009, p. 6). For example, if a lexeme’s inflectional realizations can be predicted by its phonological properties, there is no need to postulate inflectional classes. Even when inflectional classes cannot be categorically predicted based on extramorphological factors, there may still be partial and gradient motivation for the classes, usually related to their diachronic origin (see Beniamine & Bonami, 2023 for a recent overview).
An example of a language with inflectional classes distinguished by tone is Gulmancema (Niger-Congo, Gur; Burkina Faso). In this language, tone marks tense-aspect (perfective, imperfective, and aorist). Which tone performs which function differs across lexemes independent of any phonological, syntactic or semantic factors, and verbs fall into 80 inflectional classes (Baerman et al., 2023, based on Naba, 1994). Some of these classes are distinguished solely by their tone patterns, others by their affixes as well. Examples of the former are illustrated in Table 29, and we will return to the latter below.
There is a three-way tone contrast between a High tone, a Low tone, and a Low tone which assimilates to a preceding High tone, labeled as L2. These combine on bisyllabic verb stems to the tone patterns HH, HL, LL, LH, L2H, or L2L.Footnote 22
Baerman et al. (2017, pp. 22–23) discuss whether it is possible to derive these tone patterns from the underlying tones of the roots combined with inflectional tone, and argue that the answer is ‘no’. They first propose a provisional analysis of the first three verbs to illustrate what this might have looked like: in each of these verbs, the initial tone is the same throughout the paradigm, while the final tone is either High in the perfective and Low in the imperfective/aorist or vice versa. While this could have been analyzed as resulting from three different lexical tone patterns combining with a rule of tonal polarity (switching the final tone of the perfective to form the imperfective and aorist, or vice versa), this cannot account for the remaining types. In ‘grill’, ‘read’, and ‘roll’, the aorist patterns with the perfective instead of the imperfective; in ‘rinse mouth’, the final tone is the same across all aspect forms. Furthermore, in the last two verbs in the table, the initial tone alternates, a pattern not seen with the other verbs. In conclusion, “[n]o system of rules will derive the variety of patterns from a single underlying tonal configuration, so there is no way to tease apart lexical and inflectional tone. We thus have inflectional classes determined by tone” (Baerman et al., 2017, p. 23).
Some terminological discussion is in order here, as the term tonal class has been used in different ways by different authors; Palancar (2016) uses it in the sense of inflectional classes determined by tone (however, the examples provided are languages in which tonal and non-tonal formatives interact in inflectional classes; we will return to this below). When there are inflectional classes determined by tone, different classes of words have different tonal realizations for morphosyntactic property sets, and one cannot derive the variety of patterns from a single underlying tonal configuration (root tone plus inflectional tone). In the Bantu literature, tone class refers to a division of verbs based on the analysis of the underlying tone of the verb root, typically /H/ vs. /L/ (or /H/ vs. Ø, or /L/ vs. Ø); see e.g. the overview in Marlo (2013). It is useful to distinguish between cases in which verbs have different underlying root tones and cases of inflectional classes made by tone, in which there is no “underlying tone”. While underlying root tones and inflectional tones may interact in complex ways, as in many Bantu languages, this is, at least conceptually, a different phenomenon from systems in which one cannot predict the surface tones from the underlying (lexical) tone and the inflectional tone.
7.2 Inflectional classes distinguished by both tonal and non-tonal formatives
Inflectional classes may be distinguished by tonal formatives alone, or a combination of tonal and non-tonal formatives. The Gulmancema verbs illustrated in Table 29 represent only a subset of inflectional classes in this language. Others are distinguished by suffixes as well, and these are exemplified in Table 30. The suffixes involved are -ni, -di, -li and -gi, and while -gi only ever occurs in the imperfective, the other suffixes can occur in any paradigm cell and are thus polyfunctional.Footnote 23
When laying out a typology of the paradigmatic structure of inflectional classes, Baerman et al. (2017, pp. 100–116) distinguish between allomorphic classes (which are distinguished based on the shape of the exponents in question) and distributional classes (which are distinguished by the distribution of the exponents). They provide the Gulmancema data in Table 30 as an example of a system in which the two combine: the different inflectional classes are distinguished by the shape of the suffix in question (-ni, -di, -li, -gi, or none) as well as the distribution of the suffix (if any) across the paradigm—the three suffixes -ni, -di and -li occur in three different distributions: in the imperfective, the perfective, or the perfective as well as the aorist.
The distribution and shape of the suffixes are independent of the tone patterns associated with the paradigm cells. This is illustrated in Table 31, which shows two different verbs with the same suffix, but different stem tone patterns, and in Table 32, which shows two different verbs with different suffixes, but the same tone pattern. Finally, Table 33 shows two different verbs with the same suffix and the same stem tone patterns, but with the suffix showing different distributions. In Gulmancema, the tonal formatives seem to operate independently from the segmental ones, and the next section explores this type of system further.
7.3 Paradigmatic layers and morphological organization
Previous research on inflectional class typology has taught us that when there is distributed or multiple exponence, the possibility arises that different formatives may vary independently of each other, such that a single lexeme simultaneously belongs to multiple inflectional classes (Baerman, 2013), giving rise to multiple paradigmatic layers (Brown & Hippisley, 2012). For example, Russian nouns fall into a set of inflectional classes based on the form of case and number suffixes, but in addition, they fall into a separate set of classes based on their stress patterns. Given that the two classes partly cross-cut each other, they have been analyzed as two independent layers of morphological organization (Brown & Hippisley, 2012; Parker & Sims, 2020). Other examples include segmental affixes and inflectional stress in Greek nouns (Sims, 2015, Chap. 5) as well as prosodic structure, stem augments, and suffixes in verbs in Pitjantjatjara (Pama-Nyungan; Australia) (Wilmoth & Mansfield, 2021).
If tone can do anything that non-tonal morphology can do (Hyman, 2016, p. 16), we would expect them to be able to form independent paradigmatic layers as well, and indeed this is the case. Morphological systems in which there are both tonal and non-tonal paradigmatic layers are particularly pervasive across Oto-Manguean, as discussed by e.g. Palancar (2016), Baerman (2014), and different authors contributing to the special issue of Amerindia on inflectional class complexity across Oto-Manguean (Baerman et al., 2019). For example, Woodbury (2019) shows that in the Chatino languages, tonal and non-tonal marking of aspect/mood form two different paradigmatic layers that vary independently of each other. Each verb thus belongs to two inflectional classes at once, one based on tone patterns, and one based on prefix patterns. Outside of Oto-Manguean, a complex example of a system with tonal and non-tonal paradigmatic layers is found in Asama (Northern Ryukyuan, Japonic; Japan) as documented and analyzed by Lévêque and Pellard (2023). For reasons of space, I will focus on one type of system which illustrates the basic principles, namely Chiquihuitlán Mazatec (Oto-Manguean; Mexico), as analyzed by Ackerman and Malouf (2013), based on Jamieson (1982).
In Chiquihuitlán Mazatec, verbs are inflected for aspect and person along three dimensions: tones, final vowels, and stem formatives. An example is provided in Table 34, showing a partial paradigm for ‘remember’. Tones are marked by superscript numbers (from 1 = High to 4 = Low).
Each verb simultaneously belongs to three different inflectional classes distinguished by tones, final vowels and stem formatives, respectively. There are six tonal classes, ten final vowel classes, and 18 stem formative classes. The available tone patterns, final vowels, and stem formatives yield 6 × 10 × 18 = 1080 logically possible combinations (or “meta-classes”). Of these, only 109 are reported to be attested, and some of these classes have more members than others. Still, Ackerman and Malouf (2013, p. 448) show that there is little predictability among the classes: “knowing the class membership in one dimension does little to help predict the class membership in another”, i.e. they form independent paradigmatic layers.
Ackerman and Malouf (2013) further show that despite the high morphological complexity of Mazatec, with little form-function isomorphism both within and across paradigms, inflected word forms are organized by a network of implicational relations that license reliable inferences between them. We will not recapitulate all the details of their analysis here, but we will make a few remarks on the organizations of the tonal layer based on Table 35, which provides schematized tone patterns of the different tonal classes.
The paradigms are organized in such a way that the tones found in a given cell provide some information about the tones found in other cells. For example, the 1pl and 2pl tone patterns are informative for each other such that the 1pl tones are the same as the 2pl tones except there is an additional tone 4 at the end. Moreover, the tone patterns found in class C are only ever found in class C, so knowing any form of a verb in this class (e.g. the 1sg form with its 1-43 tone) uniquely identifies this inflectional class, which allows one to predict the remaining forms. Although both class A, B2, and D2 have tone 3-1 in the 1sg cell, they have different tone patterns in the 2sg cell (3-1, 2-2, and 3-2, respectively), so knowing both forms serves to disambiguate and is diagnostic of tone class membership.
Mazatec is an example of a language in which tone functions as a co-exponent of morphosyntactic properties alongside non-tonal ones (stem formatives and final vowels), where tonal and non-tonal formatives form separate sets of inflectional classes. That is, the tonal exponents form their own independent paradigmatic layer. Looking at the data in terms of informativeness, the tonal (and non-tonal) formatives are informative for morphosyntactic properties, but also for inflectional class, such that knowing the tones of one inflected verb form reduces the uncertainty when predicting an unknown form of the same verb. The Mazatec case thus provides a clear example of what we have seen throughout the paper, namely the importance of morphological organization in analysis.
7.4 Section summary
The goal of the present section was to illustrate the morphological role of tone in the organization of inflectional classes, and to demonstrate how tonal and non-tonal formatives may interact. This has shown yet another way in which attested morphological systems deviate from form-function isomorphism in the way they are organized, namely across paradigms (of different lexemes or classes of lexemes), not just within them. In such systems, exponents can be analyzed not only in terms of their informativeness for morphosyntactic properties, but also for their informativeness about inflectional class membership.
8 Concluding remarks
This paper has built on previous work on the typology of morphological tone under a paradigmatic perspective (Palancar, 2016) by incorporating insights from exponence typology (e.g. Carroll, 2022) as well as from the study of polyfunctionality (e.g. Stump, 2014), morphomes (e.g. Herce, 2020), and inflectional class typology and paradigmatic layers (e.g. Baerman, 2013; Parker & Sims, 2020). Previous research on exponence typology has shown the usefulness of thinking about exponence as information encoding, where the informativeness of different formatives emerges from patterns of distributions across paradigms. This allows us to capture the many form-function mappings that are found cross-linguistically in a non-aprioristic way, as opposed to describing natural language data as deviations from an isomorphic “ideal”. While this has previously been shown for segments (Carroll, 2022), the present paper has extended this typology and incorporated suprasegmental morphology, specifically morphological tone. Conceptualizing tone this way and demonstrating the diversity of ways in which tonal formatives may be distributed across morphological paradigms has allowed us to deepen our understanding of the role of tone in the organization of morphological systems. This way, we have embedded the study of morphological tone within a broader study of morphological organization.
I have aimed to develop a precise typology of tonal exponence, and have shown that when analyzing the morphological role of tone, several aspects need to be considered: whether the tonal exponent is a single tone or a tonal melody, whether tone is the sole exponent of a morphosyntactic property or one of multiple exponents, and how each tonal and/or non-tonal exponent map onto grammatical meaning. Table 36 provides a summary of the exponence types presented in this paper, with references to the relevant examples. What emerges from the attested diversity is a taxonomy of morphological organization, based on paradigmatic contrasts. With this taxonomy, we have established an empirical argument for a paradigm-based view of morphology (Blevins, 2016), where we take the attested diversity at face value and treat the range of encoding strategies as equivalent, as opposed to choosing form-function isomorphism as the theoretical ‘ideal’.
In the present paper, I have taken an abstractive approach to morphological analysis (Blevins, 2006), and conceptualized tonal exponents as abstractions emerging from patterns across paradigms. In such an approach, there is no inherent expectation that words will be structured in a compositional way, with the meaning of the word being equal to the sum of its parts. Inspired by Carroll’s (2022) conceptualization of exponence as informativeness of a given formative for morphosyntactic properties, I have been able to lay out the attested types of tone-function mappings in a non-aprioristic way. It is my hope that the approach developed here will prove fruitful for future description of the tonal morphology of particular languages, for cross-linguistic comparison of the role of tone in morphological organization, and for different theories of exponence and morphological complexity.
Most previous works on the typology of morphological or grammatical tone take a constructive approach to morphological analysis, and is concerned with providing rules for building inflected word forms, thus focusing on topics relevant to this conceptualization of morphology, such as cyclicity and dominance effects (Rolle, 2018), whether to conceptualize grammatical tone as item-based or process-based (Sande, 2023), or how to analyze replacive tone as concatenative morphology (Trommer, 2024). A bold claim made within Concatenativist approaches to morphology is that “Morphology = Concatenation + Phonology” (e.g. Trommer, 2024). For example, Bye and Svenonius (2012) propose that all non-concatenative morphology is epiphenomenal, and can be analyzed as the surface result of an underlying concatenation of phonological content in a linear order which directly reflects syntactic hierarchy. With respect to tonal morphology, the authors illustrate this with the locative Low tone in Jamsay (discussed here in 4.2). But as we have seen in the present paper, the tonal locative marking in Jamsay illustrates just one of many attested roles that tones may play in the organization of morphological systems cross-linguistically. A challenge for the constructive approach to morphological analysis is to develop a unified account of the diversity of phenomena addressed in this paper, i.e. non-isomorphic form-function mappings, different possible overlaps between the information provided by a tonal formative and its co-exponent(s), the role of tone in inflectional class organization, and paradigmatic layers.
The present work has discussed a range of deviations from form-function isomorphism both within and across paradigms. This opens up several questions for future research: what is the frequency of the different exponence types across languages, and what might explain this? How do the different exponence types develop within different morphological systems? Are they all diachronically stable?
Thinking about exponence as informativeness helps us understand the diversity of ways in which languages organize their morphologies. It lays out the design space which morphological typology will have to explain, and opens up new questions for learning, processing, and diachrony.
Notes
The conventions of interlinear glossing are faced with a challenge when there are patterns of the kind in (5): here, I simply follow the glossing convention used by Palancar (2016). In the present paper, starting in Sect. 4.2, I develop a different approach to capturing attested form-function mappings that is intended to do justice to the multidimensional nature of data of this kind.
The difference between Table 9 (a) and (b) can be captured as follows: in (a), there are two tones associating to one Tone-Bearing Unit (TBU), hence the resulting falling tone. In (b), there are two tones and two TBUs, and the output [H.HL] is simplified to [H.L].
Hyman and Leben (2020) refers to the data in Table 11 as portmanteau tonal melodies. However, when Hockett proposed the term portmanteau morph in his paper “Problems of Morphemic Analysis” (Hockett, 1947), it was intended to capture cases in which two (or more) independently attested morphemes are realized as one form. He provided an example from French, where à ‘to’ and le ‘the (masc.)’ do not combine to à le, but rather the single form au ‘to the (masc.)’. It is useful to distinguish cases like the French example au, in which the two exponents à and le are independently attested, from cases such as the Iau data in Table 11, in which there is only ever one form, but it always realizes two functions, i.e. there is cumulative exponence (see Matthews, 1972, pp. 65–72 for discussion).
One question that arises is whether purely tonal multiple exponence is possible, i.e. whether there are cases in which multiple tonal exponents attested independently of each other may co-occur within the same word. I am not aware of any such examples, but that does not mean it does not exist. Some Bantu languages have TAM forms to which two High tones are assigned (e.g. the simple infinitive in Ikorovere Makua; Cheng & Kisseberth, 1979). To my knowledge, however, the two High tones always co-occur and therefore would not meet the criterion set in Sect. 2, where we said that each exponent needs to be attested independently of each other to be a true case of multiple exponence.
The present work is concerned with identifying the form-function mappings that arise from paradigmatic relationships between inflected word-forms, but it is worth mentioning that a constructive analysis (in the sense of Blevins, 2006) of case marking in Somali is made by Green and Lampitelli (2022). They propose a process of subtractive grammatical tone, or grammatically conditioned High tone deletion (one of the types of grammatical tone as defined by Rolle, 2018, p. 2).
Here, I assume Kristoffersen’s (2000) phonological analysis: there is a tone contrast on syllables with primary stress. The Low tone is a part of the stress realization system, while the High tone may be lexically associated to stems, sponsored by an affix, or mark construction types, such as compounds (for alternative analyses, see e.g. Kaldhol & Köhnlein, 2021; Lahiri et al., 2005; Wetterlin & Lahiri, 2012). In the Scandinavian philological tradition, the Low tone is indicated with a superscript 1 (for “Accent 1”), and the High tone is indicated with a superscript 2 (“Accent 2”) (see e.g. Kristoffersen, 2000).
Note that these generalizations hold for subject marking in the past and present tenses in Chimwiini; other TAM forms have a consistent tone pattern (either final High or penultimate High) across person/number combinations (Kisseberth & Imam Abasheikh, 2011). Therefore, the tone patterns are informative for TAM as well, a fact we abstract away from here.
The tonal person distinction is redundant only in the parts of the paradigm in which there is a prefix that marks both person and number. In the 2sg and 3sg forms, however, there are no overt person/number prefixes. This is thus a case of zero exponence, which we have conceptualized paradigmatically in the present paper (i.e. as emerging from the contrast between different forms in the paradigm). The lack of a person marker here indicates either 2sg or 3sg, but the ambiguity of person value introduced by the lack of an overt person/number marker is resolved by the tonal exponent.
A potential alternative analysis would be that the
 marks the Irrealis, in which case only the meaning of the suffixes are underdetermined, and is disambiguated by the auxiliary they combine with. However, this analysis does not make predictions beyond these forms as other TAM forms typically associated with Irrealis cross-linguistically (e.g. the imperative or interrogative) are not marked with a
marks the Irrealis, in which case only the meaning of the suffixes are underdetermined, and is disambiguated by the auxiliary they combine with. However, this analysis does not make predictions beyond these forms as other TAM forms typically associated with Irrealis cross-linguistically (e.g. the imperative or interrogative) are not marked with a  in Rere.
in Rere.Note that the examples in Table 18 illustrate periphrastic expressions rather than synthetic forms. Given that the morphosyntactic property set associated with each periphrastic verb form is distributed among its parts, I treat these as instances of periphrasis as inflection, following e.g. Ackerman and Stump (2004) (see also Ackerman et al., 2011; Bonami, 2015; Brown et al., 2012).
It is not the case that any combination of the two polyfunctional markers are possible (e.g. conditional and recent), and this is simply a fact about the Rere TAM morphology; the remote/recent distinction is only found in the perfect forms, and elsewhere, the same suffixes are co-opted to indicate a different distinction.
All of the examples explored in the present paper involve tonal and/or segmental formatives and their interactions. However, tonal formatives may also co-occur with other suprasegmental formatives in different types of form-function mappings. A case in point is Dinka, in which singular-plural distinctions may be conveyed by tone alone, vowel length alone, or a combination of suprasegmental and/or segmental distinctions (tone, vowel length, voice quality, vowel quality, consonantal changes) (Ladd et al., 2009). This is beyond the scope of the present paper, but a complete typology would incorporate such examples as well, laying out how different suprasegmental formatives may interact in their informativeness for grammatical properties.
The patterns cannot be phonologically predicted. Even if the fact that tone 31 always precedes 1 can be derived phonologically, the other forms cannot be: tone 2 on the pronominal can be preceded by either 2 or 3, and tone 3 on the root can be followed by either 2 or 32.
Further complicating the system in Chinantec is that verb lexemes fall into different classes with respect to the distribution of tonal formatives. We will return to this in Sect. 6.3.
Note that the potential ambiguity introduced by the syncretism is avoided by the presence of pronouns.
The neutral/shifting distinction refers to how these morphological constructions affect stress patterns in lexically unstressed roots; this particular verb is lexically stressed and so there are no stress shifts. The Rarámuri system exhibits complex interactions between stress and tone, which for reasons of space will be left out here. The interested reader is referred to Caballero and German (2021) for details.
In (8), V = verb, SM = subject marker, TAM = tense/aspect/mood, MS = macro-stem, OM = object marker, NEG = negative, DERIV = derivational suffixes, FV = final vowel.
The lack of form-function isomorphism in Tlatepuzco Chinantec is striking, but as Baerman and Palancar (2014) point out, this does not mean that the distribution of tone is completely random; in fact, “only” 70 different paradigm types are attested, which allows them to investigate interpredictability between forms. We will return to this way of analyzing morphological organization in Sect. 7.3.
The behavior of L2 may warrant an analysis in terms of tonelessness, that is, the TBUs in question may be underlyingly unspecified for tone, and realized with low pitch unless preceded by a High tone, in which case that High tone spreads onto the toneless TBU.
The tone on the suffixes does not seem to be predictable by the segmental shape of the prefixes (for example, there is both -dí and -dì), or by independent factors such as the tone pattern of the stem (both High- and Low-toned suffixes are found after stems ending in any tone), so the tone patterns can be analyzed as being properties of the paradigm cells and the associated word forms holistically, as opposed to be being inherent parts of the suffixes.
 marks the Irrealis, in which case only the meaning of the suffixes are underdetermined, and is disambiguated by the auxiliary they combine with. However, this analysis does not make predictions beyond these forms as other TAM forms typically associated with Irrealis cross-linguistically (e.g. the imperative or interrogative) are not marked with a
marks the Irrealis, in which case only the meaning of the suffixes are underdetermined, and is disambiguated by the auxiliary they combine with. However, this analysis does not make predictions beyond these forms as other TAM forms typically associated with Irrealis cross-linguistically (e.g. the imperative or interrogative) are not marked with a  in Rere.
in Rere.References
Ackerman, F., & Malouf, R. (2013). Morphological organization: The low conditional entropy conjecture. Language, 89(3), 429–464.
Ackerman, F., & Stump, G. T. (2004). Paradigms and periphrastic expression: A study in realization-based lexicalism. In A. Spencer & L. Sadler (Eds.), Projecting syntax (pp. 111–158). Stanford: CSLI.
Ackerman, F., Stump, G. T., & Webelhuth, G. (2011). Lexicalism, periphrasis, and implicative morphology. In R. Borsley & K. Börjars (Eds.), Non-transformational syntax: Formal and explicit models of grammar (pp. 325–358). New York: Wiley.
Akinlabi, A. (2011). Featural affixes. In M. van Oostendorp, C. J. Ewen, E. Hume, & K. Rice (Eds.), The Blackwell companion to phonology, New York: Wiley.
Andersen, T. (1981). A grammar of Modo: A preliminary sketch. Aalborg: University Centre of Aalborg.
Anderson, S. R. (2015). Dimensions of morphological complexity. In M. Baerman, D. Brown, & G. G. Corbett (Eds.), Understanding and measuring morphological complexity (pp. 11–26). Oxford: Oxford University Press.
Andrzejewski, B. W. (1964). The declension of Somali nouns, London: School of Oriental and African Studies, University of London.
Arkadiev, P., & Gardani, F. (2020). Introduction: Complexities in morphology. In P. Arkadiev & F. Gardani (Eds.), The complexities of morphology (pp. 1–20). Oxford: Oxford University Press.
Aronoff (1994). Morphology by itself: Stems and inflectional classes. Cambridge: The MIT Press.
Baerman, M. (2013). Inflection class interactions. In N. Hathout, F. Montermini, & J. Tseng (Eds.), Morphology in Toulouse, Munich: LINCOM.
Baerman, M. (2014). Inflectional class interactions in Otomanguean. In J. L. Léonard & A. Kihm (Eds.), Patterns in Mesoamerican morphology (pp. 15–25). Michel Houdiard Éditeur.
Baerman, M., & Palancar, E. L. (2014). The organization of Chinantec tone paradigms. In Carnets de Grammaire 22: Proceedings of Les Décembrettes, 8th international conference on morphology (pp. 46–59). Toulouse: CLLE-ERSS.
Baerman, M., Brown, D., & Corbett, G. G. (2017). Morphological complexity. Cambridge: Cambridge University Press.
Baerman, M., Palancar, E., & Feist, T. (2019). Inflectional class complexity in the Oto-Manguean languages. Amerindia, 41, 1–18.
Baerman, M., Brown, D., Evans, R., Corbett, G. G., Cahill, L., & Beniamine, S. (2023). Surrey morphological complexity database. University of Surrey. https://doi.org/10.15126/SMG.23/1.
Bateman, J. (1990). Iau segmental and tonal phonology. In Miscellaneous studies of Indonesian and other languages (Vol. 10, pp. 29–42).
Bauer, L. (2012). Typology of compounds. In R. Lieber & P. S̆tekauer (Eds.), The Oxford handbook of compounding, Oxford: Oxford University Press.
Beniamine, S., & Bonami, O. (2023). Inflection class systems. In P. Ackema, S. Bendjaballah, E. Bonet, & A. Fábregas (Eds.), The Wiley Blackwell companion to morphology.
Bickmore, L. (2007). Cilungu phonology. Stanford: CSLI Publications.
Bickmore, L. (2014). Cilungu tone melodies: A descriptive and comparative study. Africana Linguistica, 20(1), 39–62.
Bickmore, L. (2022). Factors influencing the presence and realization of melodic tones in Bantu. In The 53rd Annual Conference on African Linguistics. La Jolla: University of California San Diego.
Blevins, J. P. (2006). Word-based morphology. Journal of Linguistics, 42(3), 531–573.
Blevins, J. P. (2016). Word and paradigm morphology. Oxford: Oxford University Press.
Bloomfield, L. (1933). Language. New York: Henry Holt and Company.
Bonami, O. (2015). Periphrasis as collocation. Morphology, 25, 63–110.
Brown, D., & Hippisley, A. (2012). Network morphology: A defaults-based theory of word structure. Cambridge: Cambridge University Press.
Brown, D., Chumakina, M., Corbett, G., Popova, G., & Spencer, A. (2012). Defining ‘periphrasis’: Key notions. Morphology, 22, 233–275.
Bye, P., & Svenonius, P. (2012). Non-concatenative morphology as epiphenomenon. In J. Trommer (Ed.), The morphology and phonology of exponence (pp. 444–512). Oxford: Oxford University Press.
Caballero, G., & German, A. (2021). Grammatical tone patterns in Choguita Rarámuri (Tarahumara). International Journal of American Linguistics, 87(2), 149–178.
Caballero, G., & Harris, A. C. (2012). A working typology of multiple exponence. In F. Kiefer, M. Ladányi, & P. Siptár (Eds.), Current issues in morphological theory: (Ir)regularity, analogy and frequency (pp. 163–188). Amsterdam: Benjamins.
Caballero, G., & Inkelas, S. (2013). Word construction: Tracing an optimal path through the lexicon. Morphology, 23(2), 103–143.
Caballero, G., & Kapatsinski, V. (2015). Perceptual functionality of morphological redundancy in Choguita Rarámuri (Tarahumara). Language, Cognition and Neuroscience, 30(9), 1134–1143.
Carroll, M. J. (2016). The Ngkolmpu Language, with special reference to distributed exponence. PhD thesis, Australian National University.
Carroll, M. J. (2022). Verbose exponence: Integrating the typologies of multiple and distributed exponence. Morphology, 32, 1–24.
Carter, M. (2023). Polyfunctional argument markers in Ket: Implicative structure within the word. Morphology, 33(2), 67–113.
Cheng, C.-C., & Kisseberth, C. W. (1979). Ikorovere Makua Tonology (Part 1). Studies in the Linguistic Sciences, 9(1).
Chumakina, M., Bond, O., & Corbett, G. G. (2016). Essentials of Archi grammar. In O. Bond, G. G. Corbett, M. Chumakina, & D. Brown (Eds.), Archi: Complexities of agreement in cross-theoretical perspective (pp. 17–42). Oxford: Oxford University Press.
Corbett, G. G. (2009). Canonical inflectional classes. In F. Montermini, G. Boyé, & J. Tseng (Eds.), Selected proceedings of the 6th Décembrettes: Morphology in Bordeaux (pp. 1–11). Sommerville: Cascadilla Proceedings Project.
Döhler, C. (2019). A grammar of Komnzo. Language Science Press.
Downing, L. J., & Mtenje, A. (2017). The phonology of Chichewa. Oxford: Oxford University Press.
Embick, D., & Marantz, A. (2008). Architecture and blocking. Linguistic Inquiry, 39(1), 1–53.
Evans, N. (2015). Inflection in Nen. In M. Baerman (Ed.), The Oxford handbook of inflection (pp. 543–576). Oxford: Oxford University Press.
Fedden, S. (2016). Tonal inflection in Mian. In E. L. Palancar & J. L. Léonard (Eds.), Tone and inflection: New facts and new perspectives (pp. 67–82). Berlin: De Gruyter Mouton.
Goldsmith, J. A. (1976). Autosegmental phonology. Cambridge: Massachusetts Institute of Technology.
Green, C. R., & Lampitelli, N. (2022). Conditions on complex exponence: A case study of the Somali subject marker. Phonological Data and Analysis, 4(4), 1–31.
Halle, M., & Marantz, A. (1993). Distributed morphology and the pieces of inflection. In K. Hale & S. J. Keyser (Eds.), The view from building 20: Essays in linguistics in honor of Sylvain Bromberger (pp. 111–176). Cambridge: MIT Press.
Harris, A. C. (2017). Multiple exponence. Oxford: Oxford University Press.
Heath, J. (2008). A grammar of Jamsay. Berlin: Mouton De Gruyter.
Herce, B. (2020). A typological approach to the morphome. PhD thesis, University of Surrey.
Hockett, C. F. (1947). Problems of morphemic analysis. Language, 23, 321–343).
Hyman, L. M. (1981). Tonal accent in Somali. Studies in African Linguistics, 12(2), 169–203.
Hyman, L. M. (1987). Downstep deletion in Aghem. In D. Odden (Ed.), Current approaches to African linguistics (Vol. 4). Dordrecht: Foris.
Hyman, L. M. (2000). Privative tone in Bantu. In Symposium on tone. Tokyo: ILCAA.
Hyman, L. M. (2009). How (not) to do phonological typology: The case of pitch-accent. Language Sciences, 31(2), 213–238.
Hyman, L. M. (2011). Tone: Is it different? In J. Goldsmith, J. Riggle, & A. C. L. Yu (Eds.), The handbook of phonological theory (2nd ed., pp. 197–239). Oxford: Blackwell.
Hyman, L. M. (2016). Morphological tonal assignments in conflict: Who wins?. In E. L. Palancar & J. L. Léonard (Eds.), Tone and inflection: New facts and new perspectives (pp. 15–39). Berlin/Boston: De Gruyter Mouton.
Hyman, L. M., & Leben, W. R. (2020). Tone systems. In C. Gussenhoven & A. Chen (Eds.), The Oxford handbook of language prosody, Oxford: Oxford University Press.
Hyman, L. M., & Byarushengo, E. R. (1984). A model of Haya tonology. In G. Nickerson Clements & J. Goldsmith (Eds.), Autosegmental studies in Bantu tone, Dordrecht: Foris.
Hyman, L. M., & Schuh, R. G. (1974). Universals of tone rules: Evidence from West Africa. Linguistic Inquiry, 5(1), 81–115.
Hyman, L. M., Inkelas, S., & Sibanda, G. (2009). Morphosyntactic correspondence in Bantu reduplication. In The nature of the word: Essays in honor of Paul Kiparsky (pp. 273–309). Cambridge: MIT Press.
Inkelas, S., & Zoll, C. (2007). Is grammar dependence real? A comparison between cophonological and indexed constraint approaches to morphologically conditioned phonology. Linguistics, 45(1). https://doi.org/10.1515/ling.2007.004.
Jamieson, C. A. (1982). Conflated subsystems marking person and aspect in Chiquihuitlán Mazatec verbs. International Journal of American Linguistics, 48(2), 139–167.
Kaldhol, N. H., & Johnsen, S. S. (2021). Grammaticalization in Somali and the development of morphological tone. Proceedings of the Linguistic Society of America, 6(1), 587–599.
Kaldhol, N. H., & Köhnlein, B. (2021). North germanic tonal accent is equipollent and metrical: Evidence from compounding. In R. Bennett, R. Bibbs, M. Loren Brinkerhoff, M. J. Kaplan, S. Rich, A. Rysling, N. Van Handel, & M. Wax Cavallaro (Eds.), Proceedings of the 2020 Annual Meeting on Phonology.
Kisseberth, C. W., & Imam Abasheikh, M. (2011). Chimwiini phonological phrasing revisited. Lingua, 121(13), 1987–2013.
Kristoffersen, G. (1992). Tonelag i sammensatte ord i østnorsk. Norsk lingvistisk tidsskrift, 10(2), 39–65.
Kristoffersen, G. (2000). The phonology of Norwegian. Oxford: Oxford University Press.
Krott, A., Baayen, R. H., & Schreuder, R. (2001). Analogy in morphology: Modeling the choice of linking morphemes in Dutch. Linguistics, 39(1), 51–93.
Krott, A., Schreuder, R., Baayen, R. H., & Dressler, W. U. (2007). Analogical effects on linking elements in German compound words. Language and Cognitive Processes, 22(1), 25–57.
Ladd, D. R., Remijsen, B., & Manyang, C. A. (2009). On the distinction between regular and irregular inflectional morphology: Evidence from Dinka. Language, 659–670.
Lahiri, A., Wetterlin, A., & Jönsson-Steiner, E. (2005). Lexical specification of tone in North Germanic. Nordic Journal of Linguistics, 28(1), 61–96.
Lévêque, D., & Pellard, T. (2023). The implicative structure of Asama verb paradigms: A quantitative study of segmental and suprasegmental alternations. Morphology, 33(3), 261–286.
Lewis, G. (2001). Turkish grammar. Oxford: Oxford University Press.
Luís, A., & Bermúdez-Otero, R. (2016). The morphome debate. Oxford: Oxford University Press.
Marlo, M. (2013). Verb tone in Bantu languages: Micro-typological patterns and research methods. Africana Linguistica, 19(1), 137–234.
Matthews, P. H. (1972). Inflectional morphology: A theoretical study based on aspects of Latin verb conjugations. Cambridge: Cambridge University Press.
Matthews, P. H. (1974/1991). Morphology. Cambridge: Cambridge University Press.
Merrifield, W. R., & Anderson, A. E. (2007). Diccionario Chinanteco de la diáspora del pueblo antiguo de San Pedro Tlatepuzco, Oaxaca (2nd ed.). Serie de vocabularios y diccionarios indígenas “Mariano Silva y Aceves” 39 Mexico: Summer Linguistic Institute.
Monich, I. (2020). Morphology and Tone. Oxford Research Encyclopedia of Linguistics.
Moreno, M. M. (1939). Grammatica teorico-pratica della lingua galla. Milan: A. Mondadori.
Mous, M. (2012). Cushitic. In Z. Frajzyngier & E. Shay (Eds.), The Afroasiatic languages (pp. 342–422). Cambridge: Cambridge University Press.
Naba, J.-C. (1994). Le Gulmancema: Essai des systématisation. Köln: Rüdiger Köppe Verlag.
Newman, P. (1986). Tone and affixation in Hausa. Studies in African Linguistics, 17(3).
Newman, P. (2000). The Hausa language: An encyclopedic reference grammar. New Haven: Yale University Press.
Odden, D., & Bickmore, L. (2014). Melodic tone in Bantu: Overview. Africana Linguistica, 20(1), 3–13.
Palancar, E. L. (2016). A typology of tone and inflection: A view from the Oto-Manguean languages of Mexico. In E. L. Palancar & J. L. Léonard (Eds.), Tone and inflection: New facts and new perspectives (pp. 109–139). Berlin/Boston: De Gruyter Mouton.
Palancar, E. L., & Léonard, J. L., eds. (2016). Tone and inflection: New facts and new perspectives. Berlin/Boston: De Gruyter Mouton.
Parker, J., & Sims, A. D. (2020). Irregularity, paradigmatic layers, and the complexity of inflection class systems: A study of Russian nouns. In P. Arkadiev & F. Gardani (Eds.), The complexities of morphology (pp. 23–51). Oxford: Oxford University Press.
Plank, F. (1991). Of abundance and scantiness in inflection: A typological prelude. In F. Plank (Ed.), Empirical approaches to language typology 9. Paradigms: The economy of inflection (pp. 1–40). Berlin: Mouton de Gruyter.
Quint, N., & Allassonnière-Tang, M. (2022). Inferring case paradigms in Koalib with computational classifiers. Corpus Linguistics and Linguistic Theory, 19(2), 237–269.
Riad, T. (2006). Scandinavian accent typology. STUF - Sprachtypologie und Universalienforschung, 59(1), 36–55.
Rolle, N. R. (2018). Grammatical tone: Typology and theory. PhD thesis, University of California Berkeley.
Rolle, N., & Bickmore, L. (2022). Outward-sensitive phonologically-conditioned suppletive allomorphy vs. first-last tone harmony in Cilungu. Morphology, 32(2), 197–247.
Rose, S. (2021). Tone of person marking in Rere (Koalib). ICU LINC African Linguistics.
Sande, H. (2023). Is grammatical tone item-based or process-based? Phonology, 39(3), 399–442.
Sims, A. D. (2015). Inflectional defectiveness. Cambridge: Cambridge University Press.
Sims, A. D. (2020). Inflectional networks: Graph-theoretic tools for inflectional typology. In Proceedings of the society for computation in linguistics (Vol. 3, pp. 88–98).
Stump, G. (2014). Polyfunctionality and inflectional economy. Linguistic Issues in Language Technology, 11, 73–93.
Stump, G. (2017). The nature and dimensions of complexity in morphology. Annual Review of Linguistics, 3, 65–83.
Thornton, A. M. (2019). Overabundance: A canonical typology. In F. Rainer, F. Gardani, W. U. Dressler, & H. C. Luschütszky (Eds.), Studies in morphology 5. Competition in inflection and word-formation (pp. 223–258). Berlin: Springer.
Trommer, J. (2012). Zero exponence. In J. Trommer (Ed.), The morphology and phonology of exponence (pp. 343–371). Oxford: Oxford University Press.
Trommer, J. (2024). The concatenative structure of tonal overwriting. Linguistic Inquiry, 55(1), 95–151.
Volk, E. (2011). Mijikenda tonology. PhD thesis, Tel-Aviv University.
Welmers, W. E. (1973). African language structures. Berkeley: University of California Press.
Wetterlin, A., & Lahiri, A. (2012). Tonal alternations in Norwegian compounds. The Linguistic Review, 29, 279–320.
Wilmoth, S., & Mansfield, J. (2021). Inflectional predictability and prosodic morphology in Pitjantjatjara and Yankunytjatjara. Morphology, 31(4), 355–381.
Woodbury, A. (2019). Conjugational double-classification: The separate life cycles of prefix classes vs. tone ablaut classes in aspect/mood inflection in the Chatino languages of Oaxaca, Mexico. Amerindia, 41, 75–120.
Yip, M. (2002). Tone. Cambridge: Cambridge University Press.
Acknowledgements
The author would like to thank Sharon Rose, Farrell Ackerman, Gabriela Caballero, Sarah Creel, two anonymous referees and the editor for useful comments on previous drafts of this paper. The work has also benefited from discussions with Enrique Palancar, Mae Carroll, Justin McIntosh, Andrea Sims, Björn Köhnlein, Sverre Stausland Johnsen, Hans-Olav Enger, Torben Andersen, and the audience at the 14th Conference of the Association of Linguistic Typology. Any mistakes left are my own.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing Interests
The author declares no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Abbreviations
Abbreviations
Abbreviations in this paper follow the Leipzig Glossing Rules, with the following additions.
- cpl:
-
Completive
- fv:
-
Final vowel
- om:
-
Object marker
- rec:
-
Recent
- sm:
-
Subject marker
- ss:
-
Secondary stem
- tel:
-
Telic
- II:
-
Class II
- H:
-
High tone
- L:
-
Low tone
- M:
-
Mid tone
- S:
-
Superhigh tone
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kaldhol, N.H. A Typology of Tonal Exponence. Morphology (2024). https://doi.org/10.1007/s11525-024-09427-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11525-024-09427-w