
Abstract
This proof of concept (PoC) assesses the ability of machine learning (ML) classifiers to predict the presence of a stenosis in a three vessel arterial system consisting of the abdominal aorta bifurcating into the two common iliacs. A virtual patient database (VPD) is created using one-dimensional pulse wave propagation model of haemodynamics. Four different machine learning (ML) methods are used to train and test a series of classifiers—both binary and multiclass—to distinguish between healthy and unhealthy virtual patients (VPs) using different combinations of pressure and flow-rate measurements. It is found that the ML classifiers achieve specificities larger than 80% and sensitivities ranging from 50 to 75%. The most balanced classifier also achieves an area under the receiver operative characteristic curve of 0.75, outperforming approximately 20 methods used in clinical practice, and thus placing the method as moderately accurate. Other important observations from this study are that (i) few measurements can provide similar classification accuracies compared to the case when more/all the measurements are used; (ii) some measurements are more informative than others for classification; and (iii) a modification of standard methods can result in detection of not only the presence of stenosis, but also the stenosed vessel.

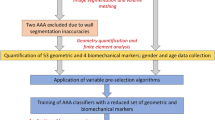
An overview of methodology fo the creation of virtual patients and their classification
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
While there are many forms of arterial disease, one of the most common is stenosis, which refers to the narrowing of an arterial vessel. This is normally caused by a build up of fatty deposits, known as atherosclerosis. Stenosis can be be categorised into several sub-diseases depending on its location. Three of the most common forms of stenosis are peripheral artery disease (PAD), carotid artery stenosis, and subclavian artery stenosis (SS). The prevalence of PAD and SS have been recorded to vary between 1.9 and 18.83% within different demographics [14, 45], while carotid artery stenosis has been recorded to affect 3.8% of men and 2.7% of women [28].
Current methods for the detection of arterial disease are primarily based on imaging techniques [25, 27, 37, 49], and so are often impractical for large-scale screening, expensive, or both. If a new inexpensive and non-invasive method for the detection of stenosis is found, the cost effectiveness of large-scale screening could be improved making both continuous monitoring and screening feasible. One such alternative is to use easily acquirable pressure and flow-rate measurements at accessible peripheral locations within the circulatory system and use them for diagnosis. It is known from the principles of fluid mechanics that if the cross-sectional area of a vessel is changed, the pressure and flow-rate profiles of fluid passing through that vessel will also change [11, 31, 44, 50]. Applying this to arterial disease, the inclusion of a stenosis within a patients arterial network may create detectable biomarkers within the pressure and flow-rate profiles of blood. This precise hypothesis is explored in this study.
A previous study [44] has explored the use of physics-based models of pulsewave propagation to predict the presence of an aneurysm, another common form of arterial disease, using flow-rate measurements. Its use for disease detection is, however, limited by the the need for patient specific parameters. If a consistent and significant biomarker of arterial disease is found within pressure and flow-rate profiles, irrespective of a patients individual arterial network, it would be possible to predict the presence of a stenosis using only these measurements. This would allow for inexpensive and non-invasive screening of patients for arterial disease. As opposed to a mechanistic approach to such an inverse problem, this study explores a pure data-driven machine learning approach for finding such biomarkers.
It is likely that the indicative biomarkers of arterial disease held within pressure and flow-rate profiles consist of micro inter- and intra-measurement details. Discovery of these biomarkers through a traditional hypothesis driven scientific method [53] and a classical inverse problems approach is difficult. If a large database of pressure and flow-rate measurements taken from patients of known arterial health is available, it maybe possible for a machine learning (ML) classifier to be trained to not only discover but also exploit any biomarkers within the pressure and flow-rate profiles. In the past, ML has been used for a variety of diagnostic medical applications [24] with applications such as detection of irregularities in heart valves [10], arrhythmia [47], and sleep apnea [22] from recorded time domain data. Other applications include estimation of pulse wave velocity from radial pressure wave measurements [20]; automatic detection, segmentation, and classification of abdominal aneurysms in computer tomography (CT) images [17]; and prediction of aneurysm severity growth from CT images [18]. The wide application and success of ML methods in medical applications motivates exploration of their use for stenosis detection.
The aim of this proof of concept (PoC) study is to carry out an initial investigation into the potential of using ML classification algorithms to predict the presence of stenosis, using haemodynamics measurements. While two previous studies [9, 54] have investigated the potential of aneurysm classification, no comparable work has been completed for stenosis to the authors’ knowledge. In [9], a seven-parameter synthetic dataset is constructed and deep-learning methods are tested on it for binary detection of abdominal aortic aneurysm (AAA), yielding accuracies of ≈ 99.9% from three pressure measurements. A sensitivity of 86.8 % and a specificity of 86.3% for early detection of AAA from photoplethysmogram pulse waves is reported in [54], which used a synthetic dataset created by varying six cardiovascular variables. Extending these ideas to exploring detection of stenosis, this study will investigate (i) the potential for stenosis (which are expected to have a more localised affect than aneurysm) classification, and (ii) the ability to classify when using a database created with significantly more variability (25 parameters varied in this study, compared to seven and six parameters in [9] and [54], respectively).
To train and test such ML classifiers, a large database of measurements taken from patients of known arterial health is required. As opposed to using measurements from a real population, which are unavailable, a synthetic virtual patient database (VPD), similar to that presented in [56], is created through the use of a physics-based model of pulse wave propagation. To create the VPD, a priori distributions are first constructed for the parameters describing the arterial networks of virtual patients (VPs) across the resulting VPD. Random realisations are then sampled from these distributions, and the physics-based model is solved to obtain the corresponding pressure and flow-rate profiles. Finally, “Hard” filters, i.e. the direct imposition of bounds on the ranges of pressure profiles, are applied to the VPD to reduce the occurrence of physiologically unrealistic VPs.
This virtual population is then used to train and test a series of ML classifiers to detect arterial disease, and test their performance. Focus is on assessing feasibility and uncovering behaviours and patterns in the performance of classification methods, rather than optimisation and creation of increasingly complex ML models for maximum accuracy. Understanding the behaviour of classifiers will allow subsequent, more complex, studies to leverage on these observations.
In what follows, first the design of the VPD—its motivation, physics-based model, the arterial network, its parameterisation, probability distributions, and filters—is presented. This is followed by the ML setup, its relation to the size of the VPD required, brief description of the ML methods and metrics to quantify their performance. Finally, the results and analysis of the ML methods performance are presented, with a focus on uncovering why some ML methods perform better than others and which measurements (and their combinations) are more informative.
2 Virtual patient database
2.1 Motivation
To train and test ML classifiers a large database of haemodynamics measurements taken from a comprehensive cohort of patients is required. The corresponding correct arterial health of these patients is also required. As opposed to using measurements taken from real patients, VPs are created using a physics-based model of pulse wave propagation. This VP approach has several advantages:
-
1.
Expense: creating VPs is relatively inexpensive. The primary cost associated with the creation of VPs is computational, and thus negligible in comparison to data acquisition in a real population.
-
2.
Class imbalance: creating VPs allows for the control of the distribution of different diseased states. For example, in a real population the rate of arterial disease can vary between 1 and 20%. During the creation of VPs, however, 50% diseased patients can be created to ensure a balanced dataset.
-
3.
Measurement availability: using VPs allows for measurements of pressure and flow-rate to be taken at any location within the arterial system. This allows for an a priori assessment of ML classifiers using all possible combinations of pressure and flow-rate measurements.
While there are limitations to the measurements that can be non-invasively and inexpensively obtained for a clinical application, pressure and flow-rate measurements throughout the arterial network are useful as they allow the impact of measurement location on performance to be investigated. This benefit is particularly important for this PoC where feasibility of the ML approach is being assessed. A primary purpose of this study is to gain an understanding of the patterns between the measurements and classification accuracy.
2.2 Physics-based model of pulse wave propagation
To compute the pressure and flow-rate waveforms associated with VPs, a physics-based model of one-dimensional pulse wave propagation is adopted [4]. By considering each vessel within the network to be a deforming tube, a system of two governing equations can be derived. These equations represent conservation of mass and momentum balance with the assumption that blood is incompressible and that the tube walls are impermeable. The system of equations is (see [2] for details):
where P(x,t), U(x,t), and A(x,t) represent the pressure, flow velocity, and arterial cross-sectional area, respectively, at spatial coordinate x and time t; ρ and μ represent the density and the dynamic viscosity of blood, respectively; and f represents the frictional force per unit length described as follows
where ζ is a constant that depends on the velocity profile across the arterial cross-section. To close this system of equations, a mechanical model of the displacement of the vessel walls [4] is included:
with
where Pext represents the external pressure, Pd represents the diastolic blood pressure, Ad represents the diastolic area of the vessel, E represents the vessel wall’s Young’s modulus, and h represents the vessel wall’s thickness. This system of equations has been previously used and tested extensively [2, 4, 13, 29, 34, 38]. Such one-dimensional models have been shown to obtain good accuracies in predicting global haemodynamics in the presence of both stenoses and aneurysms when compared against more complex and detailed 3D simulations [5, 19], against in vitro measurements [19], and against in-vivo clinical measurements [8]. These studies support the idea that the 1D models provide a good balance between accuracy and computational costs, and are able to capture global changes in haemodynamics, thus making them a suitable choice for machine learning applications. While local flow-features are not captured in the one-dimensional formulation, which leads to a loss of 3D flow features such as vortices and recirculation zones, the motivation of this study is to detect changes in global haemodynamics and biomarkers in space-averaged flow-features (pressure and flow-rate waveforms), which are naturally included in the 1D formulation and more likely to be available as clinical measurements. Another limitation of the 1D formulation is that vessel cross-sectional areas directly are the variables. Thus, the effects of how the cross-section areas change because of disease (radially symmetric or asymmetric variations) are not considered in the 1D model. For an initial exploratory study, the advantages of the 1D model in terms of computational costs are deemed to outweigh these limitations.
2.3 Arterial network
In this study, the network of interest is the abdominal aorta bifurcating into the two common iliacs. A pre-existing model for this is taken as a reference network from [4]. This is shown in Fig. 1, where the three vessels (abdominal aorta and the two iliacs) are represented in 1D while suitable boundary conditions are imposed at the inlet and the outlets.

The inlet and outlet boundary conditions to the model. The relation of the model to the aortic bifurcation is also shown through comparison to an angiogram (reprinted from [7] with permission from Elsevier)
At the inlet a time varying volumetric flow-rate is prescribed. The terminal outlets are coupled to three element Windkessel models [55], which replicate the effect of peripheral arteries. Each Windkessel model, as shown in Fig. 2, consists of two resistors, R1 and R2, which represent the viscous resistances of the large arteries and the micro-vascular system, respectively, and a capacitor C, which represents the compliance of large arteries.

The configuration of a three element Windkessel model: Q1D and P1D represent the volumetric flow-rate and pressure, respectively, at the terminal boundary of the 1D system
2.4 Numerical scheme
With the specification of the network mechanical parameters and the boundary conditions, the model of Section 2.2 is solved to compute the pressure and flow-rate waveforms across the network. The system of equations is numerically solved using a discontinuous Galerkin scheme, see [2] for details. This scheme is implemented in an in-house code written in Python/NumPy [15, 51], and has been successfully validated against benchmarks [4], and against a 3D model of blood flow through stenosed arterial vessels [5].
2.5 Parameterisation of the arterial network
This section presents the parameterisation of the arterial network for the creation of VPs. Once parameterised, the network parameters can be randomly sampled to create VPs. The inlet volumetric flow-rate profile, Qinlet(t), is described using a Fourier series (FS) representation:
where an and bn represent the n th sine and cosine FS coefficients, respectively; N represents the truncation order; and ω = 2π/T, with T as the time period of the cardiac cycle. It is found that the time domain inlet flow-rate profile of [4] can be described to a high level of precision using a FS truncated at the 5th order. Thus, the time domain inlet flow-rate profile is described by:
requiring specification of 11 coefficients.
Since the three vessel segments in the network are short, It is assumed that the properties of all the three vessels are constant along their lengths. To impose geometric and mechanical symmetry on the lower extremities, the two common iliac arteries are assumed to share identical properties. This symmetry, however, is not extended to the terminal Windkessel model parameters. The parameterisation of the network thus requires specification of the following 25 parameters:
-
Six geometric properties: the two common iliac arteries require specification of a single length, a reference area, and a wall thickness. These three properties are also required for the aorta.
-
Two mechanical properties: Young’s modulus of the aorta and the common iliacs need to be specified.
-
Six terminal boundary parameters: each of the Windkessel models requires two resistances and a compliance.
-
11 FS coefficients: the time domain inlet flow-rate profile is described using a FS truncated at the 5th order.
For an ML classifier to be trained to distinguish between healthy and unhealthy patients, examples of both classifications are required within the VPD. A parameterisation must, therefore, be chosen to describe stenosed arterial vessels. For simplicity, all VPs are limited to having a maximum of one diseased vessel. To create a change in the reference area of a diseased vessel a normalised map of each vessel’s area is produced. Both the length and cross-sectional area of the vessel is normalised between 0 and 1. This map, for a 60% stenosis, is shown in Fig. 3, where the x-axis represents the reference position along the length of the vessel and the y-axis represents the reference cross-sectional area. For healthy vessels the normalised reference cross-sectional area is constant and equal to 1. For unhealthy vessels, a cosine curve is used to create a change in area. This cosine curve is scaled using three parameters to create variation in location and severity of disease between patients. These parameters are the severity \(\mathcal {S}\), the start location b, and the end location e of the disease. The normalised cross-sectional area An of a diseased vessel at a normalised spatial location xn is described as:

An example of a 60% stenosis with a start location of b = 0.2 and an end location of e = 0.8
Thus, in addition to the 25 parameters for the description of a healthy subject, three more parameters are required for specification of disease. Random realisations of these parameters are sampled and the physics-based model of pulse wave propagation is solved to produce each VP. Examples of pressure and flow-rate profiles taken from one healthy subject and corresponding subjects with 80% stenoses in the aorta and the first iliac are shown in Fig. 4. The probability distributions of the VP parameters are described next.

Example pressure and flow-rate profiles at the inlet of the aorta and outlet of the first iliac for (i) healthy subject (solid), (ii) corresponding subject with 80% stenosis in the aorta (dashed), and (iii) corresponding subject with 80% stenosis in the first iliac (dotted)
2.6 Probability distributions
Ideally the distribution of both arterial network parameters and the resulting pressure and flow-rate profiles should be representative of those measured in a real population. Since one-dimensional arterial network parameters are generally either expensive and invasive to obtain or non-physical (so cannot be directly measured), their exact distributions are not known. Thus, a priori distributions are assumed for both healthy and diseased virtual subjects, as described next.
2.6.1 Healthy subjects
A priori distributions are assumed for the arterial network parameters, based on values reported in literature [4]. It is assumed that across a large population, all parameters required to describe VPs arterial networks, excluding the disease parameters, are independent and normally distributed. The mean value for each of these parameters is taken from [4] and the standard deviation is set to be 20% of the mean, as summarised in Table 1. VPs are assigned disease so that the VPD consists of an expected 50% healthy patients, and there is an expected equal number of aortic, first iliac, and second iliac stenosis VPs.
2.6.2 Diseased patients
In addition to the parameters described for healthy patients above, a diseased patient is characterised by three more parameters—disease severity, start location, and end location—which are assigned uniform distributions based on physical constraints. A fourth parameter, the reference location of the disease (represented by r), is introduced. This parameter is included to impose a minimum stenosis length of 10% of the vessel length. The four parameters are sequentially sampled from uniform distributions within the following bounds:
The assumption that all arterial network parameters are independent and normally distributed is likely physiologically incorrect. To correct for this assumption, post simulation filters are applied to discard non-physiological patients. This is described next.
2.7 Post simulation filter
Through random sampling, there is a chance that VPs are assigned combinations of arterial network parameters that result in physiologically unrealistic pressures and flow-rate profiles. Thus, to remove these VPs from the VPD, a post simulation filter is applied. “Hard filters” are applied to VPs, i.e. ranges within which pressure profiles must fall are directly imposed. Based on literature reported ranges [46], a more conservative version is adopted to allow for the full range of possible pressure waveforms to be expressed in the VPD. The three conditions of the the post simulation filter are:
where Pinlet represents the vector describing the time domain pressure profile at the inlet of the system. Using the VPD created through the methodology described above, the ability of ML classifiers to distinguish between healthy and unhealthy VPs is assessed, as outlined next.
2.8 Representation of measurements
The output of the pulse wave propagation model is the pressure and flow-rate at all temporal and spatial locations. While, these vectors of pressure or flow-rate at any spatial location (for example p = [p(t0),p(t0 + Δt),p(t0 + 2Δt),⋯ ,p(t0 + kΔt)]) can be used directly as a measurement input to the ML algorithms, its dimensionality is quite large. Furthermore, as severity of stenosis increases, resulting in additional nonlinearities in the model, the time step Δt for a stable solution can become very small. As pressure and flow-rate profiles are periodic, it seems natural to represent the time domain haemodynamic profiles using a FS representation. Using this representation allows the pressure and flow-rate profiles to be described to a high level of completeness in significantly fewer dimensions. Since the input FS coefficients differ by several orders of magnitude between measurements and VPs, they are individually transformed to have zero-mean and unit-variance through the widely used Z-score standardisation [32]. The transformed inputs are subsequently used as inputs to the ML algorithms.
With the above stated method of network parameterisation, its sampling, and measurement representation, the ML setup is described next.
3 Machine learning setup
3.1 Test/train split
The VPD is split into two parts: testing set and training set. The training set is used for learning in the ML algorithms and is set to two-thirds of the size of the VPD. The remaining one-third of the VPs comprise the testing set, which is used to assess the accuracy of the ML algorithms on previously unseen data, i.e. the data not used while training. The ML algorithms are briefly described next.
3.2 Machine learning algorithms
A model mapping a vector of input measurements, x, to a discrete output classification, y, can be described as:
with,
where \(\boldsymbol {\mathcal {C}}\) represents the set describing all possible classifications, and \(\mathcal {C}^{(j)}\) represents the j th possible classification. In the context of this study, the measured inputs x and output classification y represent the haemodynamics measurements taken from VPs and the corresponding health of those VPs, respectively. The following four ML methods are used in this study.
3.2.1 Logistic regression (LR)
The LR classifier [16, 48] is a probabilistic binary classification method. Given that patients belong to one of the two classifications, i.e. \(\boldsymbol {\mathcal {C}} = \{\mathcal {C}^{(1)}, \mathcal {C}^{(2)}\}\), the true binary responses τi are assigned to all subjects in the training set:
To predict the binary health of a patient an activation function is used. A general equation for an activation function h(xi,𝜃) can be written as:
where \(\text {p}\left (\hat {\tau }_{i}=1 \mid \boldsymbol {x}_{i}, \boldsymbol {\theta }\right )\) represents the predicted probability that the i th VP belongs to \(\mathcal {C}^{(1)}\), given that the patient specific input measurements xi have been observed, and that the vector of measurement specific weightings are described by 𝜃. Typical choices for h(xi,𝜃) are the the sigmoid and tanh functions. The sigmoid function is shown below:
To obtain optimal measurement specific weightings 𝜃, the logistic regression algorithm is trained by minimising the mean error between the predicted probability of VPs producing a positive binary response and the known correct classification across the training set, i.e.:
with
where L(𝜃,Xtrain,τtrain) represents the average cost, in this case computed as a log loss, across the training set; Xtrain and τtrain represent the matrix of input measurements and the vector of the known correct binary classifications for all the m VPs in the training set, respectively; xi and τi represents the vector of input measurements and the known correct binary classification corresponding to the ith VP, respectively; and 𝜃 represents the measurement specific weightings.
The numerical minimisation can be carried out using many algorithms such as gradient descent, gradient descent with momentum [36], Nesterov accelerated gradient (NAG) [33], Adadelta [57], and Adam method [23]. Post training, the obtained weightings can be used to predict the health classification of new unseen VPs, i.e. VPs within the test set, by Eq. 14 through application of a threshold \({\mathscr{B}}\), often referred to as the decision boundary, to the predicted probabilities as follows:
where \(\hat {y}_{i}\) represents the predicted health classification of the new unseen test VP, \(\text {p}\left (\hat {\tau }_{i}=1 \mid \boldsymbol {x}_{i}, \boldsymbol {\theta }\right )\) represents the predicted probability returned by the activation function through Eq. 14, and \({\mathscr{B}}\) represents a chosen decision boundary.
The remaining three methods are not described in great detail here. Their descriptions can be found in the references below. LR is described in more detail above as it is later modified for the application in this study.
3.2.2 Naive Bayes (NB)
An NB classifier [40, 41] is a probabilistic multiclass method. An NB classifier creates a conditional probability model, through the use of Bayes theorem, that predicts the probability of a VP belonging to each classification, given the measured pressure and flow-rate profiles.
3.2.3 Support vector machine (SVM)
An SVM classifier is a non-probabilistic binary classification method [21]. An SVM method finds an optimum partition between positive and negative binary outcomes through a high-order feature space by maximising the distance between the partition and the nearest instances of both binary outcomes. It is common for SVM classifiers to map the input measurements to a higher order feature space, typically through the use of an input kernel.
3.2.4 Random forest (RF) classification method
An RF classification method is a non-probabilistic multiclass classification method [6, 26]. An RF method is an ensemble method, combining the predictions returned by a series of weak decision tree classifiers through the use of a bootstrap aggregation method. Each decision tree within the ensemble is created by repeatedly splitting the training data into subsets, based on an evaluation criteria, to maximise the homogeneity of the subsets.
3.2.5 Motivation for the chosen ML classifiers
Two characteristics that can be used to distinguish between different ML methods are if they are capable of producing linear or non-linear partitions between different classifications, and if they return a probabilistic or non-probabilistic output prediction. These four ML methods are chosen as they encompass all four combinations of classifier characteristic behaviours, as shown in Table 2. Another attractive feature of these methods is that they all require very little problem specific optimisation. Before ML classifiers are trained and tested using these four different methods, preliminary tests are carried out using the LR method. LR is used for these initial tests as it is computationally inexpensive. Once an initial understanding of the VPD has been gained, further classifiers are trained using the other three ML classification methods. The methodologies and considerations required to use the VPD to train and test ML classifiers are explained next.
3.3 Required size of the VPD
An important consideration in the creation of VPD is its size—how many virtual patients are sufficient for the ML algorithms to be applied? Here, a priori evaluation of the required size of the VPD is presented, while a posteriori analysis is found in Section 4.1. A common rule of thumb in ML is that to train a classifier at least 10 examples of each possible classification are required per input dimension, known as events per variable or EPV [52]. While pressure and flow-rate measurements can be obtained at any location within the arterial network, measurements are limited to the inlet and two outlets of the system, shown in Fig. 1 by P1, Q1, P2, Q2, P3, and Q3 respectively. This results in the maximum number of input dimensions to be 66 (each measurement is described by 11 FS coefficients and all six measurements taken). A minimum EPV of any one health classification is chosen to be 12 in this study, in order to be on the conservative side of the rule of 10. Two-thirds of VPs within the VPD are used for training the classifiers, and the remaining one third are used for testing. From this, it is calculated that the VPD requires 1188 (3/2 × 12 × 66) VPs with disease in each of the three vessels. Since a balanced dataset is desired, the number of healthy patients required are 3564 (1118 × 3). This results in the EPV of 36 for healthy subjects.
3.4 Classifier configurations
The objectives and configurations of classifiers can be split into two general categories. These two categories are binary classifiers and multiclass classifiers. Binary ML classifiers are trained to predict the outcome of Eq. 10 when the output classification may belong to one of two possible outcomes, i.e. \(\boldsymbol {\mathcal {C}} = \{\mathcal {C}^{(1)}, \mathcal {C}^{(2)}\}\). In contrast, when more than two classes are present, multiclass classifiers are necessary.
3.4.1 Binary classifiers
Binary classifiers are created using one of two different configurations.
3.4.1.1 Individual vessel binary configuration
The first configuration of binary classifiers are individual vessel binary classifiers (IVBCs). The purpose of IVBCs is to predict if there is a stenosis present within a particular vessel of a VP’s arterial network. When creating IVBCs, an arterial vessel of interest must be isolated, and VPs with disease present within this vessel are assigned to the first discrete output classification, \(\mathcal {C}^{(1)}\). All other VPs are assigned to the second discrete output classification, \(\mathcal {C}^{(2)}\). The assignment of true state classifications to VPs when creating IVBCs is described by:
where yi represents the true state classification of the i th VP, and a represents the arterial vessel for which the binary health is being predicted.
3.4.1.2 Entire network binary configuration
The second configuration of binary classifiers are entire network binary classifiers (ENBCs). The purpose of ENBCs is to predict the health of a VP’s entire arterial network, i.e. irrespective of the vessel in which the disease is located. When creating ENBCs, VPs with no disease present within their arterial network are assigned to the first class, \(\mathcal {C}^{(1)}\), while all other VPs are assigned to the second discrete output classification, \(\mathcal {C}^{(2)}\). The assignment of true state classifications to VPs when creating ENBCs is described by:
Multiclass ML classifiers are discussed next.
3.4.2 Multiclass classifiers
Multiclass classifiers predict the outcome of Eq. 10 when the output may belong to more than two different classifications. The purpose of multiclass classifiers is to predict if there is a stenosis present within a VP’s arterial network, and if so which vessel does that disease occur within. Thus four different classifications exist:
where \(\mathcal {C}^{(1)}\), \(\mathcal {C}^{(2)}\), \(\mathcal {C}^{(3)}\), and \(\mathcal {C}^{(4)}\) represent no disease present; and disease present within the aorta, the first iliac, and the second iliac respectively. It is found through analysis of binary classification behaviours (Section 4.3) that LR and SVM classifiers consistently achieve higher accuracy classification than NB and RF classifiers. Thus, multiclass classifiers are only created using these two methods. However, LR and SVM methods are both inherently binary—only naturally capable of distinguishing between two classes. In order to be used as multiclass classifiers, they can be adopted through strategies such as one-versus-all [39] and one-versus-one [42]. These are described next.
3.4.2.1 One-versus-all (OVA)
An OVA strategy [39] trains multiple instances of binary classifiers, each designed to predict the probability of a separate classification problem. These probabilities are then combined to make a multiclass prediction.
In our problem, the OVA strategy trains four instances of a binary classifiers. Each binary classifier prescribes a correct binary health classification of 1 to all VPs belonging to the corresponding possible classification. All other patients, irrespective of which of the other three classifications they belong too, are assigned a correct binary health classification of 0:
where \(\tau ^{(j)}_{i}\) represents the correct binary health classification of the i th VP for the j th instance of a binary classifier. To assign a predicted multiclass classification to a new subject, the predicted probability of producing a positive binary response (\(y_{i} = \mathcal {C}^{(j)}\)) is found for all the four binary classifiers. The classification that corresponds to the highest predicted probability is then selected as the multiclass prediction.
3.4.2.2 One-versus-one (OVO)
An OVO strategy [42] creates binary classifiers for all the pairs of the classes. Thus, if n total classes exist, then n(n − 1)/2 binary classifiers are created. The most frequent class predicted among these binary classifiers is then used as the multiclass prediction.
In our problem, the OVO strategy creates six instances of a binary classifier. Each binary classifier is designed to distinguish between two different classes. Thus, the binary classifier created to distinguish between classifications \(\mathcal {C}^{(j)}\) and \(\mathcal {C}^{(k)}\) uses:
When predicting the classification of an unseen test VP, a voting scheme is applied. The input measurements taken from the test VPs are passed through each of the six instances of a binary classifier, and the predicted classifications recorded. The classification that occurs most frequently is selected as the multiclass prediction.
It is found that while both LR classifiers employing an OVA method and SVM classifiers employing an OVO method achieve high aortic, first iliac, and second iliac classification accuracy, they produce very low healthy VP classification accuracy (see Section 4.5). To rectify the low healthy VP classification accuracies a custom probabilistic configuration is developed, as described next.
3.4.2.3 Custom probabilistic configuration (CPC)
The CPC method assigns all VPs a health classification corresponding to ‘no disease’ before running any binary classifiers. This strategy treats ‘no disease present’ as the opposite to the three other possible classifications a VP may belong to. The binary classifiers employed in CPC are identical to OVA, except that the classifier for ‘no disease’ is omitted. Thus, as opposed to four binary classifiers in the OVA strategy, this strategy uses only three binary classifiers—each pertaining to diseased aorta, first iliac, and second iliac, respectively. The assignment of true state binary outcomes to VPs for the three binary classifiers are:
Note that j = 1 for ‘no disease’ classification is not included. To predict a multiclass classification for test VPs, the vessel that produces the highest probability of being diseased among the three binary classifiers is first found. The default multiclass classification is ‘no disease’ unless the highest probability of disease occurring is greater than a prescribed threshold (decision boundary), in which case the test VP is predicted to have disease in the arterial vessel with this highest probability, i.e.
where \(\text {p}\left (\hat {\tau }^{(j)}_{i}=1 \mid \boldsymbol {x}_{i}, \boldsymbol {\theta }^{(j)}\right )\) represents the probability of the i th VP being predicted to produce a positive binary response for the j th instance of a classifier within the ensemble; xi represent the vector of measurements for the test patient, 𝜃(j) represent the measurement specific weightings for the j th classifier; and \({\mathscr{B}}\) represents the threshold (decision boundary).
As opposed to the classical OVA, where the classification with highest predicted probability, irrespective of the magnitude of this probability, is chosen, CPC requires a minimum certainty of disease being present to be met before the default hypothesis ‘no disease’ can be overridden. It is not possible to create multiclass classifiers in this manner using non-probabilistic methods, such as SVM.
3.5 Quantification of results
Two different methods are used to quantify and compare the results of different classifiers. The first, also the most intuitive, of these is to compute the sensitivity and specificity of classification across the test set. Determination of whether a VP is classified correctly or incorrectly can be achieved by comparison against the true states, see Table 3. The proportion of VPs belonging to a classification that are correctly classified, i.e. the sensitivity (Se), is computed using the equation Se =TP/(TP+FN), while the proportion of VPs not belonging to a classification that are correctly classified, i.e. the specificity (Sp), is compute using the equation Sp=TN/(TN+FP). The relationships between the TP, FN, FP, TN, Se, and Sp with respect to the class \(\mathcal {C}^{(j)}\) are shown in Fig. 5.

Computation of sensitivity, specificity, recall, and precision are shown above. TP: true positive; FN: false negative; FP: false positive; and TN: true negative
In the case of multiclass classifiers, assessment of the accuracy of classification requires provision of the sensitivity and specificity corresponding to each classification. In our case, there are four classes, thus requiring specification of eight different numbers (four sensitivities and four specificities). While quantifying the accuracy of ML classifiers through the sensitivity and specificity of each classification is simple and easily understood, the description of results through two different numbers per classification can make comparison of different classifiers difficult.
A more complex, however easier to compare, method for quantifying the accuracy of ML classifiers is the F score [43]. The F score produces a single quantitative score allowing for easy comparison. Higher values of F score imply a better classification. To calculate the F score, the precision (\(\mathcal {P}\)) and recall (\(\mathcal {R}\)) of each discrete classification are calculated. A visual explanation of the F score, precision, and recall is shown in Fig. 5. Precision is the proportion of patients predicted to belong to a classification, who do in fact belong to that classification. The recall is the portion of patients belonging to a classification who are correctly classified, thus identical to sensitivity. The F score combines the precision and recall as follows:
where \(\mathcal {P}\) represents the precision, \(\mathcal {R}\) represents the recall, and δ represents a hyper parameter. Values of δ above 1 give preference to recall, while values under 1 give preference to precision. Although there is a preference to recall in the proposed application of the classifiers, δ = 1 is used to get a general sense of classifier performance without any bias. As δ = 1 is used, the F score is referred to as the F1 score and is, thus, essentially the harmonic mean of precision and recall.
While the F1 score balances the affect of precision and recall, it does not balance the affect of the sensitivity and specificity. Given a situation in which there is an equal number of healthy and unhealthy VPs, an ENBC which correctly predicts the health of 80% of healthy VPs (\(\mathcal {R}=S_{e}=0.8\)) and 20% of unhealthy VPs (Sp = 0.2) will achieve an F1 score of 0.61. An ENBC that correctly predicts the health of 20% of healthy VPs (\(\mathcal {R}=S_{e}=0.2\)) and 80% of unhealthy VPs (Sp = 0.8), however, will achieve an F1 score of 0.28, despite the fact that the total number of VPs who have been correctly classified is unchanged. This highlights the importance of using both the F1 score and the sensitivities/specificities in combination.
4 Results and discussion
4.1 Empirical evaluation VPD size
While an estimation to the adequacy of the VPD size has been made by calculating the EPV, this can be checked more thoroughly by training and testing a series of classifiers with successively increasing number of VPs. This assessment is made for the case with the largest input dimensionality, i.e. when all the six measurements—three pressure and three flow-rate profiles—at all the three measurement locations are used (see Fig. 1).
To minimise the lowest number of VPs belonging to a single classification, classifiers must be trained to predict the health of each vessel individual. As the VPD has been created so that there is an equal number of healthy and unhealthy VPs, for any given number of available VPs an ENBC will have half of the number of available VPs belonging to \(\mathcal {C}^{(1)}\) and half belonging to \(\mathcal {C}^{(2)}\). On the contrary, three series of IVBCs are created (as described in Section 3.4.1), each predicting the health of a different vessel. This results in each instance of an IVBC having 5/6 of the available VPs belonging to a negative binary classification, however only 1/6 of the number of available VPs belonging to a positive binary classification. By empirically showing there is an adequate number of VPs to train and test classifiers in this extreme situation, it is reasonable to assume there is an adequate number of VPs to train and test ENBCs.
Due to the class imbalance present, i.e. there are significantly more VPs belonging to \(\mathcal {C}^{(2)}\) than \(\mathcal {C}^{(1)}\), a weighting w is applied to the cost of VPs belonging to \(\mathcal {C}^{(1)}\) when training IVBCs. Without this weighting, the IVBCs are biased towards VPs belonging to \(\mathcal {C}^{(2)}\). The weighting applied to the cost of the prediction of VPs belonging to \(\mathcal {C}^{(1)}\) for each classifier is calculated by assigning a ratio r to the effective number of VPs belonging to classifications \(\mathcal {C}^{(1)}\) and \(\mathcal {C}^{(2)}\):
where m(1) and m(2) represent the number of VPs belonging to classes \(\mathcal {C}^{(1)}\) and \(\mathcal {C}^{(2)}\), respectively. The corresponding cost (loss) function is modified from Eq. 16 to include the weight w as
When r = 1 is used, VPs belonging to \(\mathcal {C}^{(1)}\) and \(\mathcal {C}^{(2)}\) have the potential to contribute equally to the total cost of prediction across the training set. If r > 1 is used, bias is given towards VPs belonging to \(\mathcal {C}^{(1)}\), and r < 1 gives bias towards VPs belonging to \(\mathcal {C}^{(2)}\). Unless stated otherwise, r = 1 is used.
For successively increasing number of VPs, five instances of each of the three IVBCs corresponding to disease in the three vessels are trained and tested. Each of these instances uses a different random subset of VPs for training and testing the classifier. The average performance of these five instances is then computed, thus minimising the effect of test-train split. This is referred to as five-fold validation. The average F1 scores achieved across the training and test sets, over the five-folds, with increasing numbers of VPs are shown in Fig. 6.

Analysis of the adequacy of VPD size when using pressure and flow-rate measurements at all the three locations: training and test F1 scores with successively increasing VPD size
Figure 6 shows that both training and test accuracies are low when a small proportion of the VPD is made available to ML classifiers. This suggests that the classifiers being trained are underfitting the training data, i.e. low variance but high bias. The classifiers trained can neither fit the training data nor generalise to the test data. As the number of available VPs increases, the behaviour of classifiers differs between the aorta and two common iliacs. In the case of the aorta, the training accuracy remains relatively constant, while the test accuracy increases. In the case of the two common iliac classifiers, both the training and test accuracy increase. These behaviours suggest the classifiers are fitting the training data better, and as a consequence are better able to classify test patients. Initially, between 1000 and 5000 available VPs, the changes made to the partition between VPs belonging to \(\mathcal {C}^{(1)}\) and \(\mathcal {C}^{(2)}\) through the input measurement space are significant, and so there are large jumps in change to the training and test accuracies. As the number of available VPs continuous to increase, the partition between healthy and unhealthy patients through the input measurement space begins to converge to an optimum solution. This causes the changes to the training and test accuracies to reduce, and eventually flatten off. Figure 6 suggests that beyond 7000 VPs the VPD contains enough VPs to train and test ML classifiers. This is shown by the fact that the training and test accuracies of each vessel are consistent for the final several numbers of available VPs, and so the partitions between healthy and unhealthy patients are no longer changing.
4.2 VPD characteristics
The stenosis characteristics in the VPD are visualised by considering the distributions of the severity \(\mathcal {S}\) and the location of the stenosis (b + e)/2. These distributions are shown in Fig. 7a and b, respectively. The severity is uniformly distributed within the range considered, and the location (b + e)/2 shows a Gaussian-like distribution centred at the middle of each vessel.

Distributions (histograms) of primary disease attributes in the VPD
4.3 ENBC results
The architecture of LR, NB, and SVM classifiers can all be considered to be problem independent. While these three algorithms are able to undergo varying levels of problem specific optimisation, the underlying structure of the classifier cannot be changed. In the case of SVM classifiers, the classifier is optimisation for a specific problem by choosing a kernel to map the input measurements to a higher order feature space. Unless otherwise stated, all SVM classifiers use a radial basis function kernel. In the case of NB classifiers, the classifier is optimisation to a specific problem by choosing the distribution of input measurements across the dataset. Here, for NB, it is assumed that all input measurements are normally distributed across the dataset.
The architecture of RF classifiers, however, is dependent on the specific problem. The number of trees within the ensemble and the maximum depth of each tree can be optimised for a specific problem. To fit the RF classifiers, a basic grid search is carried out. The hyperparameters describing the architecture that produces the highest F1 score are empirically found, and this combination of hyperparameters is then used for all further classifiers trained and tested.
There are 63 possible combinations of input measurements that can be provided to the ML classifiers from the three locations at which pressure and flow-rate are measured. A combination search is performed—for every combination of input measurements, an ENBC is trained and then subsequently tested using each of the four different classification methods. The average F1 score, sensitivity, and specificity of healthy classification accuracy for each input measurement combination and classification method across five-folds are recorded. Combinations of interest are then further analysed. The full tables of results are shown in Appendix A. The F1 score achieved by each ML method and combination of input measurements are visually shown in Fig. 8.

The F1 scores achieved by the ENBCs employing the NB, LR, SVM, and RF methods for all the combinations of the input measurements. The bottom legend shows the measurements used in black squares
4.3.1 Like-for-like input measurement comparison
To gain a better understanding of how much difference in F1 score can be considered insignificant, classifiers that should theoretically achieve identical accuracies are compared. Exploiting the symmetrical structure of the arterial network (see Fig. 1), classifiers that use symmetric measurements can be identified. These are referred to as like-for-like measurements; two examples of such measurements are shown in Fig. 9. Any discrepancy between the F1 scores achieved by classifiers trained using like-for-like input measurement combinations is therefore introduced due to training and statistical errors.

Two examples of like for like input measurements
There are 24 possible cases of like-for-like input measurement pairs. The discrepancy in the F1 score achieved by the two classifiers within each of these pairs is computed when using each of the four different classification methods. It is found that NB classifiers show significantly greater magnitudes in the discrepancies of F1 scores produced than any of the three other methods. The maximum discrepancy in F1 scores produced when using an NB method is equal to 0.18. This large discrepancy points to something beyond statistical and training errors and is, therefore, most likely related to the unsuitability of the NB method to our problem. It is therefore decided to exclude the results achieved by the NB method from all subsequent analysis. The histograms of the discrepancies in the F1 score between like for like input measurement combinations produced when using the remaining three ML methods are shown in Fig. 10.

Histograms of the discrepancy between the F1 scores of ‘like for like’ ENBCs
Figure 10 shows that the discrepancy in F1 scores between like-for-like input measurement combinations follow a very similar pattern for both the LR and RF classification methods. For both of these methods it can be seen that the majority of the 24 like-for-like input measurement combinations produce a discrepancy in F1 score of less than 0.005. There is then a clear exponential decay in the number of occurrences as the F1 score discrepancy increases. Twenty of the 24 LR pairs, and 16 of the 24 RF pairs achieved a discrepancy of less than 0.01. When looking at the F1 discrepancies of SVM classifiers, there appears to be no real decay in the number of occurrences as the F1 discrepancy increases, and instead a relatively constant number of SVM pairs produce F1 discrepancies between 0 and 0.025.
The maximum discrepancy in F1 scores between like-for-like input measurement combinations is equal to 0.0231. This discrepancy in F1 score is measured between two pairs of input measurements when using an SVM method. The firsts of these two pairs is (Q3, P3) and (Q2, P2). When training a SVM classifier using (Q3, P3) the sensitivity and specificity is equal to 0.71 and 0.51 respectively. When training an SVM classifier using (Q2, P2) the sensitivity and specificity is equal to 0.74 and 0.47 respectively. The second pair of input measurements producing a discrepancy in F1 score of 0.0231 is (Q3, P1) and (Q2, P1). When training SVM classifiers using (Q3, P1) and (Q2, P1), the sensitivities and specificities are equal to 0.76 and 0.50; and 0.8 and 0.46 respectively. It can be seen that in the case of both pairs of input measurements highlighted above, while there are some differences in the sensitivities and specificities produced, the differences in accuracies are relatively low and the behaviours of each of the two classifiers are relatively consistent.
From Fig. 10 and the aforementioned analysis, a difference in F1 score of more than 0.01 between two LR, SVM, or RF classifiers trained using different input measurements can be considered to be significant and likely due to the behaviour of the classifiers. It is important to remember, however, that a difference in F1 score of approximately 0.025 is required to fully rule out the possibility that patterns are due to training or statistical errors.
4.3.2 Effect of the number of input measurements
Appendix A and Fig. 8 show that there is a correlation between the number of input measurements used in the ML classifiers and the F1 score. To investigate this further the average F1 score achieved by all the classifiers using one to six input measurements is found for each of the three different classification methods. The maximum and minimum F1 scores are also recorded and shown in Fig. 11. It can be seen that as the number of input measurements increases, the average F1 score achieved by all classification methods also increases. The increase in F1 score is most noticeable for the SVM method. For the LR and RF classification methods, the average F1 score achieved when using 1 input measurement is approximately 0.5, representing naive classification (Se + Sp = 1). The average F1 score achieved by SVM classifiers trained using 1 input measurement is marginally better than naive classification. This finding that the average F1 score increases as the number of input measurements increases is expected as the discriminatory information increases, on average, as more measurements are made available.

The average, maximum, and minimum F1 score achieved by all the ENBCs against the numbers of input measurements. The central markers represent the average score achieved, while the error bars indicate the upper and lower limits. The combination of input measurements that produces the highest F1 score is identified in text for the SVM method
Observing the range of maximum to minimum F1 scores in Fig. 11 it can be seen that as the number of input measurements increases, the range of F1 scores decreases. An interesting pattern to note is that while the average and minimum F1 score achieved increases when increasing the number of input measurements between four and six, the maximum remains relatively constant. The maximum and minimum F1 scores are shown in Table 4, along with the corresponding sensitivities and specificities. Table 4 shows that the maximum accuracy of classifications—assessed by F1 scores, sensitivities, and specificities—varies insignificantly between four, five, and six measurements. Thus, the analysis points that similar levels of accuracies can be achieved by using only four measurements compared to the case when all six measurements are used, but one must be judicious in the choice of the four measurements.
4.3.3 Importance of inlet pressure and flow-split
A further pattern noticed within the tables in Appendix A and Fig. 8 is that classifiers trained using P1 generally perform better than those that do not use P1. To analyse this further, the F1 scores of classifiers trained with and without P1 are separated and plotted in Fig. 12. For LR and SVM classifiers, a clear improvement of ΔF1 ≈ 0.05 is observed when P1 is included. This behaviour is expected, in part due to design. There are a total of 32 combinations of input measurements that include P1, and 31 combinations of input measurements that exclude P1. The classifier trained using all six input measurements, and five of the six classifiers trained using five input measurements contain P1. Only one classifier trained using five input measurements does not include P1. It has previously been shown in Fig. 11 that, generally, classifiers trained using more input measurements achieve higher accuracy classification results. There is, therefore, some expected skewing towards higher F1 scores in favour of classifiers trained with P1. This expected behaviour is further amplified by the fact that only one combination of input measurements consists of a single input measurement and contains P1. This compares to five combinations that consist of a single input measurement and exclude P1. This results in an expectation of more low scoring classifiers without P1.

The histograms of the F1 scores achieved by the ENBCs that include P1 (upper), and exclude P1 (lower)
Figure 12 shows that in the case of LR, only 11 of the 32 classifiers trained using P1 achieve an F1 score of less than 0.54. This compares to all 31 LR classifiers trained without P1 achieving an F1 score of less than 0.54. In the case of SVM classifiers, only 1 combination of input measurements containing P1 achieves an F1 score of less than 0.54. This compares to 5 combinations of input measurements that do not contain P1 that achieved an F1 score of less than 0.54. When the threshold for comparison is increased to 0.6 it is found that 20 of the 32 SVM classifiers trained with P1 exceed this threshold, compared to 14 of the 31 trained without P1 exceeding this threshold. Similar analysis shows that the inclusion or exclusion of Q1 produces similar patterns and behaviours in the F1 scores produced. Thus, measurements of pressure and flow-rate at the inlet of the system appear to be particularly informative in differentiating between healthy and unhealthy patients.
Another observation can be made by observing the highest scoring SVM classifiers in Fig. 11. The best performing classifiers include P1 and a combination to determine the flow-split between the left and the right iliacs. For example, when three measurements are used, the best combination is (Q3,Q1,P1), which would enable the flow split to be known through mass conservation (note that compliance of the arteries is relatively small) in addition to P1. This observations bears similarity to the classical inverse problem analysis presented in [35], where the authors show that in order to find the parameters of any arterial network, the inlet pressure and flow-splits to all the outlets should be known.
4.3.4 Linear vs non-linear partitions
Comparing the results achieved by LR and SVM classifiers in all previous analyses, it can be seen that SVM classifiers consistently achieve higher accuracy results than the LR classifiers. When using all the six input measurements, the LR and SVM classifiers achieve sensitivities and specificities of 0.73 and 0.52; and 0.80 and 0.57, respectively. Similarly, the F1 scores for LR and SVM classifiers are 0.58 and 0.65, respectively. All SVM classifiers trained up to this point have mapped the input measurements provided to a higher order feature space through the use of radial basis function kernel. The fact that the accuracy of SVM classifiers are consistently higher than LR classifiers suggests that the partition between healthy and unhealthy VPs through the pressure and flow-rate measurement space is likely non-linear. To test the hypothesis that the increase in accuracy seen in SVM classifiers is due to this higher order mapping, an SVM classifier is trained and tested with a linear kernel. It is found that an SVM classifier trained using all the six pressure and flow-rate measurements and a linear kernel produces an average sensitivity and specificity of 0.85 and 0.42 respectively over five-folds of the VPD. This corresponds to an F1 score of 0.53. The corresponding F1 scores for LR and radial basis function SVM are 0.58 and 0.65, respectively. The non-linear SVM outperforms the linear SVM and LR (also linear), thus demonstrating that a non-linear mapping is beneficial in discerning between healthy and diseased states.
4.3.5 Effect of disease severity
Here the effect of disease severity on the accuracy of classification is investigated. This analysis is performed using an SVM classifier employing an RBF kernel and an LR classifier, both using pressure and flow-rate measurements at all the three locations.
A scatter plot of the predicted probability returned by the LR classifier against the severity of disease (i.e. diseased VPs) for false negatives and true positives is shown in Fig. 13 (left), while a histogram of the predicted probabilities for all the healthy VPs (i.e. zero severity) is shown in Fig. 13 (right). Contrary to intuitive reasoning, which suggests that higher severity of stenosis should be easier to detect, no trends are observed in Fig. 13, with classification accuracy being independent of the severity. This suggests that the variability in the pressure and flow-rate waveforms induced by the boundary conditions representing physiology before and after the anatomical network (see Fig. 1) is large and can overshadow the variability induced by stenosis severity alone.

Logistic Regression: predicted probability of disease against stenosis severity for diseased patients (left) and histogram of predicted probability of disease for healthy subjects (right). TP: true positive; FN: false negative; FP: false positive; and TN: true negative
Since the SVM classifiers do not predict a probability of disease, but a direct classification of healthy of diseased subject, histograms of the distributions of true positives and false negatives across the range of severities for diseased subjects are considered to assess the effect of stenosis severity. These are shown in Fig. 14. For the healthy subjects, 224 false positives and 1044 true negatives are recorded. Similarly to the LR results above, the SVM results do not show a strong trend of severity affecting classifier performance.

SVM with an RBF kernel: histograms of true positives (TP) and false negatives (FN) against stenosis severity
4.4 IVBC results
Following an identical procedure to that employed for the ENBC combination search, three IVBC combination searches—one for disease classification in each of the three vessels—are performed using the LR and SVM methods. It is chosen to limit the IVBC combination searches to these two classification methods due to the higher computational expense, and the fact that these two methods have shown consistently higher accuracy results. The full tables of results for the IVBC combination search are presented in Appendix B. The average, minimum, and maximum F1 score achieved when using one to six input measurements are shown in Fig. 15. There is a good agreement between the overall behaviour seen across the IVBC and ENBC (as shown in Fig. 11) combination searches. These similarities include:
-
The average and minimum F1 score achieved continuously increases when increasing the number of input measurements from one to six.
-
The maximum F1 score initially increases rapidly and reaches an asymptotic limit between two and four input measurements.
-
The SVM method consistently produces higher accuracy results than the LR method.

The average, maximum, and minimum F1 score achieved by all the IVBCs when providing different numbers of input measurements to detect disease in each of the three vessels. The central markers represent the average score achieved, while the error bars indicate the upper and lower limits
For the SVM configurations corresponding to maximum F1 scores, the sensitivities, specificities, and the combination of measurements is shown in Table 5. It shows that the combinations of input measurements that produce the highest F1 scores in the two common iliacs are not only identical, but also symmetrical (with the same input measurements being taken from the right and left sides). While the combinations of input measurements that produce the highest F1 scores differ from the ENBC results (see Table 4), a similarity between the two is that the best performing classifiers include a pressure measurement and a combination to determine the flow-split. In Section 4.3.3, it is hypothesised that the combination of pressure at the inlet and flow-split may be particularly informative. Table 5, however, seems to suggest that it may be the pressure within the diseased vessel and the flow-split that best captures the presence of a stenosis.
Comparing Tables 4 and 5 also shows that IVBCs, owing to their more granular characterisation of diseases states, lead to higher F1 scores, sensitivities, and specificities, relative to the ENBCs. Neither of them are, however, good at pointing to the precise vessel that is diseased in the network. Note that even if an IVBC classifier has perfect accuracy it does not lead to knowledge of precise diseased vessel; for example, the aortic IVBC classifier only determines whether disease is in aorta, and considers both healthy and diseased iliac vessel patients together in one class (see Section 3.4.1). When knowledge of not only the presence of disease but also the precise location is required, multiclass classifiers are necessary, and their results are presented next.
4.5 Multiclass analysis
Results of the multiclass configurations are presented here. Unlike ENBC and IVBC classifier results presented above, here the goal is also to determine which vessel the disease is located in. Due to the increased computational expense, a full combination search is not carried out for multiclass classifiers. Instead multiclass classifiers are trained and tested using the measurements of pressure and flow-rate at all the three available locations.
Initially, multiclass classifiers are created using LR employing an OVA method (see Section 3.4.2.1) and SVM employing an OVO method (see Section 3.4.2.2). While these initial classifiers produced high accuracy for aortic, first iliac, and second iliac disease classification, it is found that the sensitivity corresponding to the classification of VPs with ‘no disease’ present is consistently close to 0. A multiclass classifier is, therefore, created using LR employing a CPC method, as outlined in Section 3.4.2.3. The results of the OVA, OVO, and the CPC classifiers are shown in Table 6.
Table 6 shows that for OVA the sensitivities and specificities for the first and second iliac are equivalent. For aorta, the specificity is relatively higher but comes at a compromise of reduced sensitivity. Finally, the healthy classification sensitivity is poor, almost close to zero. Similar behaviour is observed for OVO with almost all classification accuracies lower when compared to OVA. Thus, OVA outperforms OVO in all cases and is thus superior for this application. When comparing OVA against CPC, the highest improvement is seen for the sensitivity of healthy classification, an increase to \(\sim \)50% compared in CPC compared to \(\sim \)0% in OVA. For the aorta and iliacs, a rebalancing of sensitivities and specificities is observed in relation to OVA—an increase in sensitivity is accompanied by a decrease in specificity, with their averages relatively unchanged. Overall, Table 6 shows that the CPC achieves its purpose of improving the classification accuracy for healthy (‘no disease’) class without significantly compromising other classification accuracies.
When creating CPC multiclass classifiers, preference can be given to healthy or unhealthy VPs by adjusting the decision boundary \({\mathscr{B}}\) in Eq. 24 —i.e. the certainty required to override the default classification that a VP has no disease present. Reducing the certainty required to change the classification a VP is assigned to, i.e. lowering the decision boundary, creates bias towards unhealthy VPs as the CPC classifier is more willing to override the default classification that a VP is healthy. Increasing the decision boundary will require more certainty to classify a VP as diseased, giving bias toward healthy VPs, as the CPC is less willing to override the default classification that a VP is healthy.
To analyse the aforementioned affect of the decision boundary used on the classification of VPs, receiver operating characteristic (ROC) curves [1] are plotted. ROC curves are obtained by plotting the true positive rates against the false positive rates of each classification when different decision boundaries are applied. By recording a series of discrete true-positive/false-positive points for various decision boundaries, a curve is fitted that shows the characteristics of the accuracy of each classification across all possible decision boundaries. A complete ROC curve must start at the point representing a true positive and false positive rate of 0, i.e. no VPs are predicted to belong to the classification being examined, and must end at the point representing a true positive and false positive rate of 1, i.e. all VPs are predicted to belong to the discrete classification being examined. A naive classifier, achieving an accuracy of 50%, will produce a straight line between these two points, and so the area under the curve (AUC) is equal to 0.5. A perfect classifier ascends vertically along the the y-axis between the points (0, 0) and (0, 1), then transverses the x-axis between the points (0, 1) and (1, 1). This will result in a perfect AUC score of 1. The point (0, 1) represents a perfect classifier, as 100% of positive VPs are correctly classification, while 0% of negative patients are incorrectly classified.
Within the context of the multiclass CPC, when a decision boundary of 1 is applied, all VPs are classified as healthy, and so the ROC curves of aortic disease, first iliac disease, and second iliac disease classification all begin at the true positive and false positive position (0, 0). When a decision boundary of 1 is applied, the true positive and false positive position of healthy classification is (1, 1), i.e. all VPs are being assigned to the classification of no disease present. When the decision boundary is set to be 0 all VPs are classified as having disease in one of the three vessels, and so the healthy classification will reach the point (0, 0). A complete ROC curve can, therefore, be obtained for healthy classification accuracy. When the decision boundary is set to be 0, while all VPs are classified as having disease in one of the three vessels, this does not necessarily ensure that the true positive and false positive classification accuracy is equal to 1 for disease classification in each individual vessel. Complete ROC curves can, therefore, not be plotted for aortic, first iliac, and second iliac disease classification. The ROC curve of healthy VP classification accuracy is plotted against the reported true positive and false positive rates of 193 current general screening methods, recorded in [30] and [3], and is shown in Fig. 16. Note that the general screening methods in this Figure are not necessarily all cardiovascular related, i.e. this analysis does not compare the results achieved here to current directly comparable methods for identical configuration. Instead, it shows a comparison of the results achieved against the general landscape of clinically used methods for screening.

The ROC curve of healthy VP classification within the CPC ensemble trained and tested using pressure and flow-rate measurements at all the three measurement locations. The accuracy of classification is compared to current general screening methods (shown in red) [1]
Figure 16 shows that the ROC curve of healthy VP classification follows a desirable profile. The AUC of the ROC curve is computed 0.75. An AUC of between 0.7 and 0.9 can be considered as moderate accuracy [12]. The overall correct classification of healthy VPs by the CPC outperforms approximately 20 of the current methods.
The ROC curve of classifiers created in this PoC study can not be fairly compared to current screening methods, as the affects of simplifications such as only using a simple three vessel system, and limiting the number of diseased vessels to one are not understood. However, Fig. 16 provides some indication of how the results achieved in this PoC study compare to currently used screening methods. Overall, the results, despite simplifications and assumptions used in this study, are encouraging and point towards the potential of increased classification accuracies when larger networks and more sophisticated ML or deep learning algorithms are used.
5 Conclusions
This is the first-of-its-kind PoC study exploring ML application to detection of stenosis in arterial networks. The key conclusion is that ML methods are appropriate for detection of arterial disease, as demonstrated in the three-vessel network. The most balanced classifier, the CPC, achieves specificities larger than 80% and sensitivities ranging from 50–75%. The AUC under the ROC for this classifier is 0.75, which outperforms approximately 20 of the current methods used in clinical practice for various types of screening (see Section 4.5). This observation, motivates further exploration of more sophisticated ML and deep learning methods on virtual databases created on larger networks. This can facilitate home monitoring of disease and/or larger-scale, cost-effective, screening programmes.
Among the four ML methods considered, it is shown that LR and SVM perform significantly better than NB and RF, with the further advantage that these require little to no problem-specific optimisation. While this conclusion may be specific to the network considered, the results show that non-linear classification methods, such as the SVM with radial basis functions, perform better than linear classification methods for arterial disease detection. Finally, it is demonstrated that the standard methods can be modified in a custom probabilistic configuration to not only detect the presence of stenosis in the network, but also identify the diseased vessel.
This study also presents a methodological framework to both create the virtual patient database and assess that it is of adequate size for the ML applications. The conclusion from ML classifier performance is that all measurements are not equally informative (or the classifiers are not able to extract the information equally from all the measurements), and that similar classification accuracies can be achieved by using fewer measurements as long as the measurements are chosen judiciously. For example, the spread of F1 scores for a given number of measurements in Fig. 11 (also see Table 4) shows that the best performing classifier with only three measurements outperforms the worst performing classifiers with four and five measurements. In this context of which measurements are more informative, for the arterial network considered, the importance of inlet pressure, inlet flow-rate, and flow-split at the bifurcation is highlighted.
6 Limitations and future work
Several simplifications and assumptions are made during both the creation of the VPD and the training and testing of ML classifiers. These are likely to affect the classification accuracies achieved within this study. Some of these major limitations are:
-
The arterial network, containing only three vessels, is small. It is not clear whether this aids or hinders classification. On the one hand, due to small nature of the network, the signals are less diffused, and on the other hand specific features which may be result of unique reflections in certain anatomical locations is not accounted for. However, the small arterial network does allow for a preliminary analysis which, with encouraging results, points towards exploration in larger networks.
-
The distributions of all arterial network parameters, excluding disease conditions, across the VPD are described using independent distributions. These simple distributions ignore the complex inter-parameter relationships likely seen within real arterial networks. The simplification of the distribution of arterial network parameters likely results in a wider range of pressure and flow-rate profiles across the VPD, making distinction between healthy and unhealthy VPs more difficult. This may be potentially solved by first determining the probability distributions through an inverse problem approach, for example Markov chain monte carlo.
-
This study is completed without significant consideration for clinical requirements. For example which measurements are really obtainable easily, and what range of stenosis severities should a ML classifier be able to detect? These questions are best explored on a larger network.
-
The pressure and flow-rate profiles are free of noise and other measurement errors. A straightforward inclusion of additive Gaussian white noise to the measurements is likely to not result in any significant changes as the representation of the measurements is based on Fourier series. With truncation of the Fourier series at low orders, such a representation will filter-out most of the added noise. A careful investigation of the errors in the measurements, including biases, is thus needed to make the results more robust. This should be performed while considering the nature and magnitude of errors in the measurement devices used in the clinic and also procedural errors which may include biases.
References
Akobeng AK (2007) Understanding diagnostic tests 3: receiver operating characteristic curves. Acta Paediatr 96(5):644–647
Alastruey J, Parker KH, Sherwin SJ et al (2012) Arterial pulse wave haemodynamics. In: 11th international conference on pressure surges, pp 401–442
Alberg AJ, Park JW, Hager BW et al (2004) The use of verall accuracy to evaluate the validity of screening or diagnostic tests. J Gen Intern Med 19(5p1):460–465
Boileau E, Nithiarasu P, Blanco PJ et al (2015) A benchmark study of numerical schemes for one-dimensional arterial blood flow modelling. Int J Numer Methods Biomed Eng 31(10):e02732. https://doi.org/10.1002/cnm.2732
Etienne B, Pant S, Roobottom C, et al. (2018) Estimating the accuracy of a reduced-order model for the calculation of fractional flow reserve (FFR). Int J Numer Methods Biomed Eng 34(1):e2908
Breiman L (2001) Random forests. Mach Learn 45(1):5–32
Burnham SJ, Jaques P, Burnham C.B (1992) Noninvasive detection of iliac artery stenosis in the presence of superficial femoral artery obstruction. J Vasc Surg 16(3):445–452
Carson JM, Pant S, Roobottom C et al (2019) Non-invasive coronary CT angiography-derived fractional flow reserve: a benchmark study comparing the diagnostic performance of four different computational methodologies. Int J Numer Methods Biomed Eng 35(10):e3235
Chakshu NK, Sazonov I, Nithiarasu P (2020) Towards enabling a cardiovascular digital twin for human systemic circulation using inverse analysis. In: Biomechanics and modeling in mechanobiology, pp 1–17
Çomak E, rslan A, Türkoğlu İ (2007) A decision support system based on support vector machines for diagnosis of the heart valve diseases. Comput Biol Med 37(1):21–27
Donohue TJ, Kern MJ, Aguirre FV et al (1993) Assessing the hemodynamic significance of coronary artery stenosis: analysis of translesional pressure-flow velocity relations in patients. J Am Coll Cardiol 22(2):449–458
Fischer JE, Bachmann LM, Jaeschke R (2003) A readers’ guide to the interpretation of diagnostic test properties: clinical example of sepsis. Intensive Care Med 29(7):1043–1051
Formaggia L, Lamponi D, Quarteroni A (2003) One-dimensional models for blood flow in arteries. J Eng Math 47(3-4):251–276
Fowkes FGR, Rudan D, Rudan I et al (2013) Comparison of global estimates of prevalence and risk factors for peripheral artery disease in 2000 and 2010: a systematic review and analysis. Lancet 382 (9901):1329–1340
Harris CR, Millman KJ, van der Walt SJ et al (2020) Array programming with NumPy. Nature 585(7825):357–362. https://doi.org/10.1038/s41586-020-2649-2
Hilbe JM (2009) Logistic regression models. CRC Press, Boca Raton
Hong HA, Sheikh UU (2016) Automatic detection, segmentation and classification of abdominal aortic aneurysm using deep learning. In: 2016 IEEE 12th international colloquium on signal processing & its applications (CSPA). IEEE, pp 242–246
Jiang Z, Do HN, Choi J et al (2020) A deep learning approach to predict abdominal aortic aneurysm expansion using longitudinal data. Front Phys 7:235
Jin W, Alastruey J (2021) Arterial pulse wave propagation across stenoses and aneurysms: assessment of one-dimensional simulations against three-dimensional simulations and in vitro measurements. J R S Interface 18(177):20200881
Jin W, Chowienczyk P, Alastruey J (2020) Estimating pulse wave velocity from the radial pressure wave using machine learning algorithms. In: medRxiv
Kecman V (2005) Support vector machines–an introduction. In: Support vector machines: theory and applications. Springer, pp 1–47
Khandoker AH, Palaniswami M, Karmakar CK (2009) Support vector machines for automated recognition of obstructive sleep apnea syndrome from ECG recordings. IEEE Trans Inf Technol Biomed 13(1):37–48
Kingma DP, Ba J (2014) Adam: a method for stochastic optimization. arXiv:1412.6980
Kononenko I (2001) Machine learning for medical diagnosis: history, state of the art and perspective. Artif Intell Med 23(1):89–109
Leopold GR, Goldberger LE, Bernstein EF (1972) Ultrasonic detection and evaluation of abdominal aortic aneurysms. Surgery 72(6):939–945
Liaw A, Wiener M (2002) Classification and regression by randomForest. R News 2(3):18–22
Litt AW, Eidelman EM, Pinto RS et al (1991) Diagnosis of carotid artery stenosis: comparison of 2DFT time-of-flight MR angiography with contrast angiography in 50 patients. Am J Neuroradiol 12 (1):149–154
Mathiesen EB, Joakimsen O, Bønaa KH (2001) Prevalence of and risk factors associated with carotid artery stenosis: the Tromsø Study. Cerebrovasc Dis 12(1):44–51
Matthys KS, Alastruey J, Peiró J et al (2007) Pulse wave propagation in a model human arterial network: assessment of 1-D numerical simulations against in vitro measurements. J Biomech 40(15):3476–3486
Maxim LD, Niebo R, Utell MJ (2014) Screening tests: a review with examples. Inhal Toxicol 26(13):811–828
May AG, Deweese JA, Rob CG (1963) Hemodynamic effects of arterial stenosis. Surgery 53(4):513–524
Mohamad IB, Usman D (2013) Standardization and its effects on K-means clustering algorithm. Res J Appl Sci Eng Technol 6(17):3299–3303
Nesterov YE (1983) A method for solving the convex programming problem with convergence rate O (1/k 2). In: Dokl. Akad. Nauk SSSR, vol 269, pp 543–547
Olufsen MS, Peskin CS, Kim WY et al (2000) Numerical simulation and experimental validation of blood flow in arteries with structured-tree outflow conditions. Ann Biomed Eng 28(11):1281–1299
Pant S, Fabrèges B, Gerbeau J-F, Vignon-Clementel IE et al (2014) A methodological paradigm for patient-specific multi-scale CFD simulations: from clinical measurements to parameter estimates for individual analysis. Int J Numer Methods Biomed Eng 30(12):1614–1648
Qian N (1999) On the momentum term in gradient descent learning algorithms. Neural Netw 12 (1):145–151
Quill DS, Colgan MP, Sumner DS (1989) Ultrasonic screening for the detection of abdominal aortic aneurysms. Surg Clin N Am 69(4):713–720
Reymond P, Merenda F, Perren F et al (2009) Validation of a one-dimensional model of the systemic arterial tree. Am J Physiol-Heart Circ Physiol 297(1):H208–H222
Rifkin R, Klautau A (2004) In defense of one-vs-all classification. J Mach Learn Res 5:101–141
Rish I et al (2001) An empirical study of the naive Bayes classifier. In: IJCAI 2001 workshop on empirical methods in artificial intelligence, vol 3, pp 41–46
Rish I, Hellerstein J, Thathachar J (2001) An analysis of data characteristics that affect naive Bayes performance. IBM TJ Watson Res Center 30:1–8
Rocha A, Goldenstein SK (2013) Multiclass from binary: expanding one-versus-all, one-versus-one and ecoc-based approaches. IEEE Trans Neural Netw Learn Syst 25(2):289–302
Sasaki Y (2007) The truth of the F-measure. In: Teach tutor mater
Sazonov I, Khir AW, Hacham WS et al (2017) A novel method for non-invasively detecting the severity and location of aortic aneurysms. Biomech Model Mechanobiol 16(4):1225–1242
Shadman R, Criqui MH, Bundens WP et al (2004) Subclavian artery stenosis: prevalence, risk factors, and association with cardiovascular diseases. J Am Coll Cardiol 44(3):618–623
Sonesson B, Dias N, Malina M et al (2003) Intra-aneurysm pressure measurements in successfully excluded abdominal aortic aneurysm after endovascular repair. J Vasc Surg 37(4):733–738
Song MH, Lee J, Cho SP et al (2005) Support vector machine based arrhythmia classification using reduced features. Int J Control Autom Syst 3(4):571–579
Sperandei S (2014) Understanding logistic regression analysis. Biochemia Medica: Biochemia Medica 24(1):12–18
Titi M, George C, Bhattacharya D et al (2007) Comparison of carotid Doppler ultrasound and computerised tomographic angiography in the evaluation of carotid artery stenosis. Surgeon 5(3):132–136
Ujiie H, Tachi H, Hiramatsu O et al (1999) Effects of size and shape (aspect ratio) on the hemodynamics of saccular aneurysms: a possible index for surgical treatment of intracranial aneurysms. Neurosurgery 45(1):119–130
Van Rossum G, Drake FL (2009) Python 3 reference manual. Scotts Valley, CA: CreateSpace. ISBN: 1441412697
Vittinghoff E, McCulloch CE (2007) Relaxing the rule of ten events per variable in logistic and Cox regression. Am J Epidemiol 165(6):710–718
Voit EO (2019) Perspective: Dimensions of the scientific method. PLoS Comput Biol 15(9):e1007279
Wang T, Jin W, Liang F et al (2021) Machine learning-based pulse wave analysis for early detection of abdominal aortic aneurysms using in silico pulse waves. Symmetry 13(5):804
Westerhof N, Lankhaar J-W, Westerhof BE (2009) The arterial windkessel. Med Biol Eng Comput 47(2):131–141
Willemet M, Chowienczyk P, Alastruey J (2015) A database of virtual healthy subjects to assess the accuracy of foot-to-foot pulse wave velocities for estimation of aortic stiffness. Am J Physiol-Heart Circ Physiol 309(4):H663–H675
Zeiler MD (2012) ADADELTA: an adaptive learning rate method. arXiv:1212.5701
Funding
This work is supported by an Engineering and Physical Science Research Council studentship ref. EP/N509553/1 and an Engineering and Physical Science Research Council grant ref. EP/R010811/1.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: ENBC combination search results
The F1 scores, sensitivities, and specificities achieved by ENBC classifiers when employing each of the four classification methods are shown in Tables 7, 8, and 9.
Appendix B: IVBC combination search results
The F1 scores, sensitivities, and specificities achieved by IVBC classifiers when employing each of the two classification methods are shown in Tables 10, 11, and 12.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jones, G., Parr, J., Nithiarasu, P. et al. A proof of concept study for machine learning application to stenosis detection. Med Biol Eng Comput 59, 2085–2114 (2021). https://doi.org/10.1007/s11517-021-02424-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11517-021-02424-9