
Abstract
In wireless communications, both control information and payload (user-data) are concurrently transmitted and required to be successfully recovered. This paper focuses on block-level detection, which is applicable for detecting transmitted control information, particularly when this information is selected or chosen from a finite set of information that are known at both transmitting and receiving devices. Using an orthogonal frequency division multiplexing architecture, this paper investigates and evaluates the performance of a time-domain decision criterion in comparison with a form of Maximum Likelihood (ML) estimation method. Unlike the ML method, the proposed time-domain detection technique requires no channel estimation as it uses the correlation (in the time-domain) that exists between the received and the transmitted selective information as a means of detection. In comparison with the ML method, results show that the proposed method offers improved detection performance, particularly when the control information consists of at least 16. However, the implementation of the proposed method requires a slightly increased number of mathematical computations.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Over the last few years, increased demand for high-speed downloads and the rapid growth of mobile services have led to an exponential growth in wireless data traffic. To meet mobile subscriber and internet user demands for high-speed data, wireless telecommunication bodies have proposed some high speed wireless communication standards including the 3rd Generation Partnership Project (3GPP) Long Term Evolution (LTE) standard for 4G communication systems, and IEEE 802.11 a/g within wireless local area networks (WLANs) for Wi-Fi. In these wireless systems, orthogonal frequency division multiplexing (OFDM) is the adopted physical layer technology because it is spectrally efficient, and offers some immunity to multipath fading [1–3].
In wireless communications systems, the transmitted information usually consists of two components: control information, which may be chosen from a finite set of known candidate information; and the payload (user-data), randomly generated at the transmitter. However, detection of control-data requires different decoding procedures compared with user-data. OFDM decoding schemes, which exist in the literature can involve either one-tap equalization or block-level detection. The latter is most useful for the detection of selective control information while the former is widely applied for the recovery of payload data information. In a one-tap equalization (symbol-by-symbol) decoding scheme, each OFDM subcarrier symbol is independently decoded as described in [4–7] while in a block-level decoding procedure, a group of subcarriers are collectively considered at the receiver [8]. In the case of a block-level detection, it is usually assumed that a group of subcarriers (at the receiver-end) is chosen from a fixed number of possible set (known at both transmitting and receiving terminals), as described in [8–11]. This paper studies block-level detection of selective control information in an OFDM system.
A practical application of block-level detection can be found in the determination of the modulation scheme for a given transmission scenario [12]. For instance, since the chosen modulation scheme could be 4-QAM, 16-QAM, 64-QAM or even 256-QAM, the receiver must first determine the modulation type before the subsequent user-data data decoding procedure. Hence, the control information that specifies the modulation scheme is considered as a selective control information because in this example, it can chosen from four possible values. Therefore, in practical sense, the control information for each modulation type can be encoded and transmitted on a group of subcarriers, which are known at both transmitting and receiving terminals. Then, during decoding at the receiver, the received group of subcarriers that represent the control information is compared with all the four possible candidate control information that represent each modulation type, in order to determine the modulation type that nearly correlates with or corresponds to the received control information. Another practical example of selective control information is the control format indicator (CFI), which carries key LTE system information that enables each user equipment (UE) to correctly decode the main LTE control information within the LTE physical downlink control channel. In the LTE standard, the possible CFI value is 1, 2 or 3 [8]. A detailed description of LTE control information can be found in [13]. At the receiver, an appropriate detection scheme is required to recover the transmitted selective control information. In practical systems, successful detection of the control information is usually required in order to perform subsequent recovery or detection of the transmitted payload [14].
In the literature, a Maximum Likelihood (ML) criterion is considered as the standard block-level detection approach because it is more practical and computationally efficient (in terms of hardware implementation ) compared to other methods such as successive interference cancellation (SIC) and K-best list sphere detector (K-LSD) [8]. An FPGA implementation of the ML estimation method for the detection of a critical LTE control information is described in [15]. Unfortunately, the ML estimation scheme requires channel estimation to mitigate channel fading effects. Hence, the detection performance of the ML scheme is largely dependent on the channel estimation. In practical systems, channel estimation is often achieved through the transmission of additional system resources in the form of pilot or training signals [4]. However, transmission of pilots reduces the overall spectral efficiency and a large number of pilots is often required to improve channel estimation [16]. Several forms of channel estimation exist and in practical systems, an adaptive channel estimation is usually implemented at the receiver in order to select the best channel estimation approach for different channel fading environments. In addition, channel estimation methods such as the linear minimum mean square error (L-MMSE) have very high computational complexity compared with the least squares (LS) method of channel estimation [4, 17–19]. Moreover, the L-MMSE method requires apriori knowledge of both the channel correlation and noise statistics, which may either be unavailable or further introduce practical implementation and design constraints [19, 20].
To address these practical issues (associated with the ML based detection scheme), this paper introduces an alternative scheme that eliminates the need for channel estimation during block-level detection in an OFDM receiver. The proposed detection technique is based on a time-domain decision rule that uses the correlation that exists between the transmitted and received selective information as the basis for detection. Simulations compare the performance of the conventional ML estimation approach and the proposed method in terms of: block error rate (BLER) for different block sizes; and computational complexity, with regards to the number of real multiplications (RMs) and real additions (RAs).
The paper is structured as follows. Section 2 outlines a single antenna uncoded OFDM architecture and describes an OFDM receiver that uses an ML based block-level detection approach. Section 3 describes the implementation of the proposed time-domain detection technique. Section 4 presents the simulation results and related discussions on the BLER performance of the two considered methods. It also presents comparison of the level of mathematical computations (RM and RA) required by each method. Finally, Sect. 5 highlights the main contributions of the paper.
2 OFDM architecture and ML based detection
This section describes the OFDM baseband architecture used for the investigations within this paper. It also gives an overview of the ML based estimation method for block-level detection as studied in, for example, [8].
Figure 1 shows a block diagram representation of a baseband OFDM architecture. It can be noted this architecture inserts some pilots to enable channel estimation as required by the ML estimation method. However, as will be shown later, these pilots are not used and remain passive in the proposed detection method.
2.1 Transmitter
Let \(\varvec{X}\) be an OFDM sequence of length \(N_{s}\), which is the raw input for the inverse fast Fourier transform (IFFT) stage before zero padding. Then, for \(0 \le k \le N_s-1\) where k represent a subcarrier index, \(\varvec{X}\) is written as
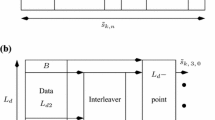
For simplicity, it is assumed that \(\varvec{X}\) consists of: a pilot sequence, \(\varvec{X_{p}}\) of size \(N_{p}\), a randomly generated data, \(\varvec{X_{d}}\) of size \(N_{d}\), and a selective sequence vector, \(\varvec{X_{c}}\) of size \(N_{c}\), such that \(N_{s} = N_{p} + N_{c} + N_{d}\). Each element of \(\varvec{X}\) is mapped to a subcarrier symbol \(\varvec{X}[k]\). Figure 2 shows an example of the considered subcarrier allocation of pilot and non-pilot subcarriers achieved through, for example, a subcarrier mapping scheme described as follows:

System model

An example of subcarrier allocation
-
1.
First, \(N_p\) pilot subcarrier symbols are inserted at every L subcarrier indices where \(L > 0\) and defines the pilot spacing. In this paper, L is set to 6, so that the pilots are mapped to \(k = \) {0, 6, 12, 18, ... }.
-
2.
Given that the selective sequence, \(\varvec{X_c}\) is chosen from a finite set \({\mathcal {S}}\), which consists of U candidate sequence vectors where \({\mathcal {S}}\) is considered to be deterministic and is known at both transmitter and the receiver. For \(1 \le u \le U\), each sequence vector in \({\mathcal {S}}\) is denoted by \(\varvec{S}_u\). Hence,
$$\begin{aligned} {\mathcal {S}}&= \Big \{\varvec{S}_1,~\varvec{S}_2,~\varvec{S}_u~\ldots ~\varvec{S}_U\Big \}. \end{aligned}$$(2)Let the \(u-\)index, \(\bar{u}\) define the index of the selected sequence vector from the set \({\mathcal {S}}\), then \(\varvec{X_c} \in {\mathcal {S}}\) i.e.,
$$\begin{aligned} \varvec{X_c}&= \varvec{S}_{\bar{u}} ~\text {where}~\varvec{S}_{\bar{u}} \in {\mathcal {S}}. \end{aligned}$$(3)Each element of \(\varvec{X_{c}}\) is then mapped to the next available \(N_c\) subcarriers in \(\varvec{X}\). As an example, \(\varvec{S}_1\), \(\varvec{S}_2\), and \(\varvec{S}_3\) may represent the control information for 4-QAM, 16-QAM and 64-QAM respectively. Hence, a block-level detection is performed at the receiver in order to determine an estimate of \(\bar{u}\). Thus, in this example, the modulation scheme (decoded at the receiver) will be 4-QAM, 16-QAM and 64-QAM respectively when the value of \(\bar{u}\) is 1, 2 or 3.
-
3.
Finally, the remaining \(N_d\) un-allocated subcarriers in \(\varvec{X}\) are assigned to each element of randomly generated modulated data \(\varvec{X_d}\).
For an equi-spaced pilot arrangement (as in Fig. 2), studies in [4, 5, 21] showed that for \(0 \le m \le N_p-1\) and \(0 \le l \le L-1\) where m and l are arbitrary indices, each subcarrier symbol \(\varvec{X}[k]\) can be represented as
After subcarrier mapping as in the standard OFDM transmitter, the OFDM sequence \(\varvec{X}\) is transformed into a time-domain OFDM signal using an IFFT to produce a time-domain OFDM signal \(\varvec{x}\) of length N where \(N > N_s\). For \(0 \le n \le N-1\), each individual sample \(\varvec{x}[n]\) within \(\varvec{x}\) is represented as
Similarly, as in standard OFDM, the length of OFDM signal \(\varvec{x}\) is further extended by a cyclic prefix (CP) as illustrated in [22]. The use of CP provides some guard interval (GI) between consecutive OFDM transmissions, and involves copying the last \(N_{\text {CP}}\) samples in \(\varvec{x}\) and placing them before the first sample in \(\varvec{x}\). CP also serves to reduce channel induced inter-symbol interference (ISI). In addition, since a multipath fading channel has a finite impulse response, the use of CP also transforms the linear convolution between the transmitted signal and the channel impulse response into a circular convolution. However, to completely mitigate channel induced ISI, the GI duration should be larger than the maximum delay spread, \(\tau _{\text {max}}\) of the multipath fading channel.
2.2 Receiver
At the receiver, CP samples are first removed. In the presence of a fading channel with impulse response \(\varvec{h}[n]\) and additive white Gaussian noise (AWGN) \(\varvec{v}[n]\), each received time-domain OFDM signal sample, \(\varvec{y}[n]\), is represented by
where \({\circledast }\) represents a linear convolution. In addition, for a fading channel that has P taps with complex-valued gains, the channel impulse response \(\varvec{h}[n]\) may be expressed as
This implies all the channel energy is concentrated within the first P components of \(\varvec{h}[n]\). The next stage involves use of the fast Fourier transform (FFT), which transforms the time-domain signal into the frequency domain to produce \(\varvec{Y}\) where
i.e.,
The terms \(\varvec{H}[k]\) and \(\varvec{V}[k]\) respectively represent the frequency domain representation of the channel and noise.
2.2.1 ML based detection
Let \(\varvec{H_c}\) and \(\varvec{V_c}\) respectively represent the sub-channel gains and AWGN components associated with the received selective sequence \(\varvec{Y_c}\) of similar size. Similarly, \(\varvec{H_p}\) and \(\varvec{V_p}\) respectively represent the sub-channel gain and AWGN components within the received pilot sequence \(\varvec{Y_p}\). Then, similar to (7), \(\varvec{Y_c}\) and \(\varvec{Y_p}\) are respectively expressed as
Let \(\hat{u}\) denote an estimate of \(\bar{u}\). Then, using the ML estimation criterion, \(\hat{u}\) is obtained from [8]
The term \(\varvec{\hat{H}_c}\) represents sub-channel estimates (associated with the received selective sequence). For a given non-pilot subcarrier index k, the sub-channel estimate at index k is determined by linear interpolation between two sub-channel pilot estimates \(\varvec{\hat{H}_p}[m]\) and \(\varvec{\hat{H}_p}[m+1]\), as described in [4–6] through
where
In terms of computational complexity and from the expression in (10), the ML method requires \(UN_c\) \(-\) complex multiplications (CM), complex additions (CA) and \(\vert \cdot \vert ^2\) operations. These operations can also be expressed in terms of RM and RA since each CM and CA operation relates to RM and RA operations through [21]
Based on the Taylor series expansion of trigonometric functions, each \(\vert \cdot \vert ^2\) will require \(\approx \) 20 RMs plus 8 RAs, as implied in [23]. In summary, the ML detection approach requires a total of \(24UN_c\) RMs and \(12UN_c\) RAs. It can be noted that similar to studies in [21, 24], these evaluations exclude both the computational and implementation complexities of channel estimation and channel interpolation procedures associated with the ML method.
3 Proposed method
Correlation is one of the most frequently applied signal processing techniques for detection, as studied in, for example, [17, 25], for channel estimation. In addition, in terms of eliminating channel fading, studies have shown that partly due to the partial elimination of the channel tap with the most energy in the time-domain, the use of a time-domain approach can produce improved performance i.e. is more robust against severe ISI compared with frequency-domain approaches [26]. The use of correlation and time-domain detection form the basis of the proposed detection scheme as it computes some form of time-domain correlation function between the received sequence \(\varvec{Y_c}\) and each candidate selective control information, \(\varvec{S}_u\). The rationale for the use of a time-domain correlation also follows a general understanding that in the presence of limited noise level, there exists an inherent correlation between \(\varvec{Y_c}\) and \(\varvec{X_c}\). This paper produces an appropriate decision rule, which will facilitate correct detection or reduce the probability of erroneous detection, particularly in the case of an OFDM system. The proposed time-domain decision rule is now described.
3.1 Time-domain decision criterion
From the discrete correlation theorem (DCT), the correlation function (CORR) of two arbitrary time-domain signals \(\varvec{a_1}\) and \(\varvec{a_2}\) (of the same size) is obtained from [27]
where \(\varvec{^{*}}\) represents the complex conjugation, and \(\varvec{A_1}\) and \(\varvec{A_2}\) are respectively the frequency domain representations of \(\varvec{a_1}\) and \(\varvec{a_2}\) i.e.,
Using the DCT, the first step in the proposed method computes a term \(\varvec{Z}_u\) from direct multiplication of \(\varvec{Y_c}\) with the complex conjugate of \(\varvec{S}_u\) i.e.,
For \(0 \le c \le N_c-1\), \(\varvec{Z}_u\) may be represented as
Alternatively, from the expression in (16), \(\varvec{Z}_u\) can also be written as
By omitting the noise terms in (18) for simplicity, the expression for \(\varvec{Z}_u\) can be re-written as
From the expression in (19), the main difference between \(\varvec{Z}_{\bar{u}}\) (when \(u = \bar{u}\)) and \(\varvec{Z}_u\), (when \(u \ne \bar{u}\)) is described by
where \(\varvec{X_c}\varvec{S^{*}}_u\) is a complex-valued number with unity magnitude since each \(\varvec{S_u}\) is assumed to have the same magnitude. It can be noted that the expression in (20) is derived from (19) by setting \(\varvec{H_c}\) to 1 since from (19), the same channel term \(\varvec{H_c}\) is common to both \(\varvec{Z}_{\bar{u}}\) (when \(u = \bar{u}\)) and \(\varvec{Z}_u\), (when \(u \ne \bar{u}\)). In addition, the condition when \(\varvec{H_c} = \) 1 shows the scenario where there is no channel fading i.e. presence of only additive noise, as will be shown later in the next section.
From the DCT, a correlation function, \(\varvec{W}_u\) can be computed from the \({\mathcal {W}}-\)point IFFT of \(\varvec{Z}_u\) where \({\mathcal {W}}\) is a power of 2 and \({\mathcal {W}} \ge N_c\) i.e. \({\mathcal {W}} = N_c\) if \(N_c\) is a power of 2, otherwise, \({\mathcal {W}} > N_c\). For \(0 \le w \le {\mathcal {W}}-1\), \(\varvec{W}_u\) is given as
where
From the definition of \(\varvec{Z}_u\) in (20), the magnitude of \(\varvec{W}_{\bar{u}}[w]\) (when \(u = \bar{u}\)) gives
Otherwise, \(0 < \Big \vert \varvec{W}_{u}[w]\Big \vert < 1\) when \(u \ne \bar{u}\). Now, using the statistical mean, the expression in (23) simply implies that
Since \(\Big \vert \varvec{W}_{u}[w]\Big \vert \) is positive-valued, then for a large value of \(N_c\), the magnitude of the correction function can be described by Rayleigh distribution, as highlighted in the Appendix.
From the expression in (24), the proposed decision criterion can be defined by
It can be seen that in the proposed method, no channel estimation is required because the time-domain correlation inherently facilitates detection even in the presence of a fading channel. However, as will be shown in the next section, one of the main limiting factors for the proposed detection method is the inaccuracy of the related decision metric for small values of \(N_c\).
4 Simulation results
This section presents comparison of both BLER performance and computational requirements between the two considered detection methods.
4.1 BLER performance
Simulations consider transmission over two well-known frequency-selective Rayleigh fading channels, namely: the extended Typical urban (ETU), with a root mean square (RMS) delay spread, \(\tau _{\text {rms}}\) of 1 \(\upmu \)s as defined in the LTE standard [28]; and the 3GPP Typical urban (3GPP-TU) channel, with \(\tau _{\text {rms}}\) of 0.5 \(\upmu \)s [29]. Tables 1 and 2 respectively show the power-delay profile of ETU and 3GPP-TU. To further understand the detection performance of each considered detection schemes, simulations also evaluate the BLER performance in the absence of a fading channel i.e. the presence of AWGN only.

BLER comparisons between the ML and the proposed estimation methods as a function of \(N_c\). a \(N_c = 8\), b \(N_c = 16\), c \(N_c = 32\) and d \(N_c = 64\)
Simulations are based on standard LTE parameters defined in Table 3 and all the transmitted information (payload and control) is QPSK modulated with U set to 8. The BLER performance of the two considered methods is investigated as a function of \(N_c\) by considering 50,000 OFDM symbol blocks for each SNR level where \(N_c\) is set to 8, 16, 32 and 64. Hence, \(N_c = {\mathcal {W}}\). For the ML scheme, simulations implement the pilot-assisted channel estimation procedures previously outlined in Sect. 2.
Figure 3a–d shows the BLER comparisons between the two considered detection methods with \(N_c\) set to 8, 16, 32 and 64 respectively. Results in Fig. 3a shows that for a small block size (\(N_c = 8\)), the ML scheme produces improved BLER performance compared with the proposed method. Results in Fig. 3 also show that with no fading channel effects, the BLER performance of the ML scheme is relatively the same even when \(N_c\) is increased. This is because as \(N_c\) is further increased, evaluation of the applied decision metric within the proposed method becomes more accurate and as a result, detection performance of the proposed method is improved compared with the ML scheme. In general, as \(N_c\) is increased, the proposed method produces improved detection performance in the form of reduced BLER. Results further show that in the presence of frequency-selective channel fading effects and due to poor channel estimation in these conditions, the ML scheme only produces minimal improvement in detection performance as \(N_c\) is increased.

Comparisons of computational complexity (number of RAs and RMs) between the ML scheme and the proposed method. a \(N_c = 8\), b \(N_c = 16\), c \(N_c = 326\) and d \(N_c = 64\)
For instance, at a BLER level of 1 %, results further show that with \(N_c\) set to 16, 32 and 64, the proposed method requires relatively smaller SNR levels compared with the ML scheme. Table 4 shows the approximate SNR level required by each considered detection method in order to achieve, for example, a target BLER level of 1 %. Results in Table 4 show that for each of the considered channel conditions and when \(N_c = 8\), the ML approach requires a relatively smaller SNR level to achieve the target BLER of 1 % compared with the proposed method. However, compared with the ML method and as \(N_c\) is increased, the proposed method requires significantly smaller SNR level to achieve the same BLER level of 1 %. It can be noted that in the ETU fading channel, the proposed method has \(\approx \)2.8 and 5.2 dB SNR gain (with respect to the ML scheme) for \(N_c\) set to 32 and 64 respectively. Similarly, in the 3GPP-TU channel and with \(N_c\) set to 32 and 64 respectively, the proposed method has \(\approx \)5.1 and 9.2 dB gain in SNR. For practical purposes, low SNR requirement of the proposed method makes it a viable and an attractive block-level detection scheme in OFDM receivers because the need for higher SNR levels for the case of the ML approach increases power consumption.

Rayleigh distribution of \(\Big \vert \varvec{W}_{u}[w]\Big \vert \). a No fading channel and b with a fading channel
4.2 Computational requirements
From the expression in (25), it can be noted that the proposed method requires approximately \(UN_c\) CMs, \(U{\mathcal {W}}\) \(\vert \cdot \vert \) computations and U IFFTs (\({\mathcal {W}}-\)point) where each IFFT requires approximately \({\mathcal {W}}/2\log _2 {\mathcal {W}}\) CMs and \({\mathcal {W}}\log _2 {\mathcal {W}}\) CAs, as indicated in [30]. As before, each complex-valued operation (i.e. CAs and CMs) can also be expressed in terms of real-valued (RM and RA) operations. Table 5 shows the approximate level of computational requirements of the ML and the proposed time-domain sequence level decision methods. However, these evaluations exclude the computational complexity of channel estimation and added system resources associated with the ML method.
Results in Table 5 show that due to the use of multiple IFFTs in the proposed method, it requires higher levels of computations compared with the ML method, particularly when the value of \(N_c\) or \({\mathcal {W}}\) is large. With \(U = 8\), Fig. 4a–d shows the graphical comparison of computational complexity (in terms of RAs and RMs) between the ML scheme and the proposed method with \(N_c\) set to 8, 16, 32 and 64 respectively. For instance, using the expressions in Table 5 and in comparison with the ML approach, the proposed method requires approximately—17, 22, 27 and 31 % extra RMs and 37, 45, 52 and 57 % extra RAs for \(N_c = 8, 16, 32\) and 64 respectively. Moreover, with advanced DSP devices, the computational complexity of IFFTs is no longer a critical issue. Hence, the proposed method is still an attractive choice, since it can produce improved detection performance compared with the ML approach and requires no channel estimation and no use of pilots.
5 Conclusions
This paper has presented and compared the detection performance of a time-domain decision technique against the conventional ML approach for block-level detection of selective control information in OFDM systems. An improved detection performance can be achieved with the proposed method compared with the ML approach. Another key benefit of the proposed method is that unlike the ML approach, it requires no channel estimation, which means no system data overhead in the form of training signals or preambles are required to be transmitted or used at the receiver. Hence, the proposed method reduces several practical implementation issues associated with channel estimation. However, without taking into account the added complexity of channel estimation associated with the ML method, the computational complexity of the proposed method is slightly higher than the ML estimation method due to the need for multiple IFFT computations. Results therefore suggest that the proposed method is a viable and an attractive detection scheme for OFDM systems.
References
Miridakis, N. I., & Vergados, D. D. (2013). A survey on the successive interference cancellation performance for single-antenna and multiple-antenna OFDM systems. IEEE Communications Surveys Tutorials, 15(1), 312–335.
Adegbite, S. A., McMeekin, S. G., & Stewart, B. G. (2014). Low-complexity data decoding using binary phase detection in SLM-OFDM systems. Electronics Letters, 50(7), 560–562.
Rahmatallah, Y., & Mohan, S. (2013). Peak-to-average power ratio reduction in OFDM systems: A survey and taxonomy. IEEE Communications Surveys Tutorials, 15(4), 1567–1592.
Coleri, S., Ergen, M., Puri, A., & Bahai, A. (2002). Channel estimation techniques based on pilot arrangement in OFDM systems. IEEE Transactions on Broadcasting, 48(3), 223–229.
Hsieh, M.-H., & Wei, C.-H. (1998). Channel estimation for OFDM systems based on comb-type pilot arrangement in frequency selective fading channels. IEEE Transactions on Consumer Electronics, 44(1), 217–225.
Rinne, J., & Renfors, M. (1996). Pilot spacing in orthogonal frequency division multiplexing systems on practical channels. IEEE Transactions on Consumer Electronics, 42(4), 959–962.
Adegbite, S., Stewart, B. G., & McMeekin, S. G. (2013). Least squares interpolation methods for LTE system channel estimation over extended ITU channels. International Journal of Information and Electronics Engineering, 3(4), 414–418.
Thiruvengadam, S. J., & Jalloul, L. M. A. (2010). Performance analysis of the 3GPP-LTE physical control channels. EURASIP Journal on Wireless Communications and Networking, 2010, 1–10.
Damen, M., El Gamal, H., & Caire, G. (2003). On maximum-likelihood detection and the search for the closest lattice point. IEEE Transactions on Information Theory, 49(10), 2389–2402.
Su, K., Berenguer, I., Wassell, I., & Wang, X. (2009). Efficient maximum-likelihood decoding of spherical lattice codes. IEEE Transactions on Communications, 57(8), 2290–2300.
Pan, J., Ma, W.-K., & Jalden, J. (2014). MIMO detection by Lagrangian dual maximum-likelihood relaxation: Reinterpreting regularized lattice decoding. IEEE Transactions on Signal Processing, 62(2), 511–524.
Agilent Technologies. (2009). LTE and the evolution to 4G wireless: Design and measurement challenges. John Wiley & Sons.
3GPP Technical Specification (TS) 36.211 v12.0.0. (2013). Evolved universal terrestrial radio access (E-UTRA); physical channels and modulation (Release 12).
Dahlman, E., Parkvall, S., & Skold, J. (2011). 4G: LTE/LTE-advanced for mobile broadband. Academic Press.
Abbas, S., Thiruvengadam, S. J., & Susithra, S. (2014). Novel receiver architecture for LTE-A downlink physical control format indicator channel with diversity. VLSI Design, 2014, 7.
Ozdemir, M., & Arslan, H. (2007). Channel estimation for wireless OFDM systems. IEEE Communications Surveys Tutorials, 9(2), 18–48.
Edfors, O., Sandell, M., van de Beek, J.-J., Wilson, S., & Borjesson, P. (1998). OFDM channel estimation by singular value decomposition. IEEE Transactions on Communications, 46(7), 931–939.
Morelli, M., & Mengali, U. (2001). A comparison of pilot-aided channel estimation methods for OFDM systems. IEEE Transactions on Signal Processing, 49(12), 3065–3073.
Hung, K.-C., & Lin, D. W. (2010). Pilot-based LMMSE channel estimation for OFDM systems with power-delay profile approximation. IEEE Transactions on Vehicular Technology, 59(1), 150–159.
Liu, Y., Tan, Z., Hu, H., Cimini, L., & Li, G. (2014). Channel estimation for OFDM. IEEE Communications Surveys Tutorials, 16(4), 1891–1908.
Hong, E., Kim, H., Yang, K., & Har, D. (2013). Pilot-aided side information detection in SLM-based OFDM systems. IEEE Transactions on Wireless Communications, 12(7), 3140–3147.
Peled, A., & Ruiz, A. (1980). Frequency domain data transmission using reduced computational complexity algorithms. In IEEE international conference on acoustics, speech, and signal processing, ICASSP ’80 (Vol. 5, pp. 964–967).
Stein, J. Y. (2000). Digital signal processing: A computer science perspective. Wiley.
Park, J., Hong, E., & Har, D. (2011). Low complexity data decoding for SLM-based OFDM systems without side information. IEEE Communications Letters, 15(6), 611–613.
Zhu, M., Awoseyila, A., & Evans, B. (2011). Low-complexity time-domain channel estimation for OFDM systems. Electronics Letters, 47(1), 60–62.
Minn, H., & Bhargava, V. (2000). An investigation into time-domain approach for OFDM channel estimation. IEEE Transactions on Broadcasting, 46(4), 240–248.
Davis, J. M., Gravagne, I. A., & Marks, R. J. (2010). Time scale discrete Fourier transforms. 2010 42nd Southeastern Symposium on System Theory (SSST), pp. 102–110.
3GPP Technical Specification (TS) 36.101 v12.0.0. (2013). Evolved universal terrestrial radio access (E-UTRA); user equipment (UE) radio transmission and reception (Release 12).
ETSI Technical Report (TR) 125.943 v11.0.0. (2012). Universal mobile telecommunications system (UMTS); deployment aspects (Release 11).
Bianchi, T., Piva, A., & Barni, M. (2008). Comparison of different FFT implementations in the encrypted domain. 2008 16th European Signal Processing Conference, pp. 1–5.
Jiang, T., Guizani, M., Chen, H.-H., Xiang, W., & Wu, Y. (2008). Derivation of PAPR distribution for OFDM wireless systems based on extreme value theory. IEEE Transactions on Wireless Communications, 7(4), 1298–1305.
Walck, C. (2007). Handbook on statistical distributions for experimentalists. Internal Report (SUF-PFY/96-01). Sweden: University of Stockholm.
Author information
Authors and Affiliations
Corresponding author
Appendix: Rayleigh PDF of \(\Big \vert \varvec{W}_u[w]\Big \vert \)
Appendix: Rayleigh PDF of \(\Big \vert \varvec{W}_u[w]\Big \vert \)
Using the Rayleigh distribution, this section describes the rationale behind the use of the proposed decision metric. The magnitude of each correlation function \(\Big \vert \varvec{W}_u[w]\Big \vert \) can be represented by a Rayleigh probability density function (PDF) since it is positive valued and is obtained from the magnitudes of a Gaussian distributed complex numbers [31]. By letting \(x = \Big \vert \varvec{W}_u[w]\Big \vert \), the PDF of x is represented as [32]
where \(\varTheta \) is the scale parameter of the Rayleigh distribution, which is a measure of the spread of the distribution. The value of \(\varTheta \) also indicates the mode of the distribution i.e. the point (the value of x) at which the PDF, \(\varvec{F}( x )\) is maximum [32]. As a function of \(\varTheta \), the mean of x, \(\varvec{E}(x)\) is defined by [32]
From the expression for \(\varvec{E}(x)\), it seems there is a linear relationship between \(\varTheta \) and \(\varvec{E}(x)\). Hence, as previously claimed and with regards to the proposed decision method, the corresponding value of \(\varTheta \) for the PDF of \(\Big \vert \varvec{W}_u[w]\Big \vert \) is expected to be smaller in the case of correct decision compared with the case of incorrect decision. For instance, with \(N_c = 32\) and SNR set to 6 dB, Fig. 5a, b respectively shows examples of resulting Rayleigh PDF of \(\Big \vert \varvec{W}_u[w]\Big \vert \) in the absence of channel fading and with ETU fading channel. These PDF curves clearly indicate that whenever there is a perfect or correct detection, the value of \(\varTheta \) is smaller than that when there is an incorrect decision. Therefore, amongst all the U correlation functions, the one that possesses the minimum or the lowest mean value gives correct decision.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Adegbite, S.A., McMeekin, S.G. & Stewart, B.G. A selective control information detection scheme for OFDM receivers. Telecommun Syst 64, 31–41 (2017). https://doi.org/10.1007/s11235-016-0154-6
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11235-016-0154-6