
Abstract
The Internet-of-things (IoT) plays a significant role in healthcare monitoring, where the IoT Cloud integration introduces many new opportunities for real-time remote monitoring of the patient. Task scheduling is one of the major challenges in cloud environment. Solving that problem reduces delay, missed tasks, and failure rate, and increases the guarantee ratio. This paper proposes a new task scheduling and allocation technique: Prioritized Sorted Task-Based Allocation (PSTBA) for healthcare monitoring implemented in IoT cloud-based architecture. The proposed technique selects the best virtual machine to execute the health task considering multiple factors such as; the wait time of the VM and the Expected processing time (EPT) of the task as well as its criticality. An extensive simulation study is conducted using the CloudSim simulator to evaluate the performance of the proposed technique. The proposed technique is compared to the Sorted Task-Based Allocation (STBA) and FCFS techniques and it reduces the delay by 13.7% and 80.2%, the failure rate by 21% and 37.5%, and increases the guarantee ratio by 2.2% and 4.5% compared to STBA and FCFS, respectively. In analyzing the critical health tasks, the proposed PSTBA has also reduced the critical health tasks missed ratio by 15.7% and 50.9% compared to STBA and FCFS, respectively. The simulation results demonstrate that PSTBA is more effective than the STBA and FCFS techniques in terms of delay, missed critical tasks, guarantee ratio, and failure rate.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Healthcare is considered one of the most important applications for IoT. In many countries, the aging population and the elevation of chronic diseases lead to significant challenges in healthcare systems. Challenges include the high cost of in-patient care in conventional hospitals and clinics [1] as well as the time wasted in hospitals manually managing and maintaining patients’ health data, case history, diagnostics, medication, and billing. In addition, human errors occurring due to manual processing affects patient’s life [2]. Consequently, there is a need to monitor a patient's health status outside the hospital, in his environment, or everywhere. Internet of things (IoT) technology can overcome these challenges [3, 4]. IoT system consists of sensors and circuits that have the ability to gather data from any object, process, store, and transmit over the network [5, 6]. The use of IoT for Remote Patient Monitoring (IoT-RPM) enables monitoring of chronic conditions (not real-time critical) in addition to being utilized to detect acute medical conditions (real-time critical) and generate alarms in real-time [7,8,9]. IoT-RPM provides the patient the ability to self-manage his disease, access care remotely, and receive assistance in emergency cases through an IoT mobile devices like smartphones, smart cars, etc. [10,11,12]. An overview of telemedicine's real-time remote health monitoring systems is introduced by Kalid et al. [13].
Recently, IoT-RPM systems utilize Cloud environment where the IoT generates huge amounts of data that can overwhelm storage systems and data analytics applications since IoT things have constrained capabilities of computing and storage resources. Whereas cloud computing environment with its unlimited capabilities of processing, storage, and virtual resources can help in solving this issue [14, 15].
The National Institute of Standards and Technology (NIST) has defined cloud computing as “A model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction” [16]. A literature reviews about cloud computing in healthcare sector as well as their challenges across countries over a period of the health industry is introduced in [17,18,19,20].
Cloud is composed of datacenters, hosts, resources, virtual machines (VMs), etc. Datacenters manage several hosts or physical machines. Hosts are consisting of a large number of VMs that act as processing nodes [21]. Cloud computing handles a variety of virtualized resources, which make task scheduling very complex specially in healthcare domain [22,23,24].
Task scheduling refers to the process of assigning various tasks to different VMs as per the task’s requirement at that time [25], and the task is defined as a piece of work that must be finished within a certain time [26]. There are two categories of task scheduling techniques: static and dynamic. In static scheduling, allocation to various resources occurs at compile time where the information of the tasks and the cloud resources is known before the execution. While in dynamic scheduling, allocation occurs at runtime where there is no prior knowledge about the submitted tasks before the time of their submission to make a scheduling decision [27, 28]. In dynamic scheduling, the tasks are ordered and allocated during the execution of the system according to their priorities.
In this research, we propose a dynamic task scheduling technique to schedule the healthcare tasks in IoT Cloud-based architecture for remote patient monitoring (RPM) in a heterogeneous environment. The proposed technique is Prioritized Sorted Task-Based Allocation (PSTBA) that considers the critical tasks that must be carried out and meet its Max.ResponseTime so that the patient's life is not jeopardized and catastrophic conditions do not occur. To attain an efficient and effective task scheduling and allocation technique for healthcare in cloud, we must consider many quality of services (QoS) parameters to enhance the system performance. The QoS parameters included are execution time, deadline, cost, makespan, failure rate, guarantee ratio, and delay. Based on QoS parameters a task is selected for the execution on a picked VM, which increases the resource utilization and the throughput of the overall system.
The primary contributions of this paper are summarized as follows:
-
A scheduling and allocation technique is proposed to reduce the delay and meet the Max.ResponseTime of healthcare tasks with focusing on the types of healthcare tasks.
-
A simulation-based performance evaluation study for the proposed scheduling technique is conducted, and the simulation results are analyzed and discussed.
The following layout is used to organize the remaining sections of this research: Sect. 2 provides a thorough review of writing regarding the task scheduling based on cloud environment. Section 3 describes the IoT Cloud-based architecture for RPM, while Sect. 4 depicts the scheduling and allocation technique implemented in the core of this architecture. Section 5 illustrates the scenario in evaluating the proposed solution, while the analysis of the obtained results is discussed in Sect. 6. Finally, Sect. 7 concludes the paper and provides insights into future research.
2 Related work
This section presents several papers about task scheduling in cloud environments. Because the task scheduling problem itself is NP-complete, the researchers have proposed many techniques. A literature survey about task scheduling techniques in cloud computing was introduced by Arunarani et al. [27] and Houssein et al.[29].
In [23], the authors introduced a patient health monitoring system (PHMS) to remotely monitor the patient's vital indicators(i.e. blood pressure, body temperature, heart rate (ECG)). This system is composed of two modules; firstly, they developed a scheduling algorithm based on real-time IoT-based healthcare task orchestration architecture, then they introduced an optimization module based on objective function to diminish task idle time for enhancing the performance of Particle Swarm Optimization (PSO) scheduling algorithm. The authors used the Libelium e-Health toolkit for monitoring the patient’s health status. The outcomes revealed that the proposed system with the optimized scheduling algorithm is more effective and reduces the tasks starvation rate and failure rate than others. Although they didn't concern about the cost per execution, energy consumption, execution time, and the makespan.
In [30], the authors introduced a healthcare system and load balancing model in cloud environment based on a Sparrow Search Algorithm (SSA). The SSA helps in selection the best virtual machine based on its fitness value. The idea of this paper is to allocate the task that has a high million instructions to the best virtual machine that has a high fitness value. The performance of the proposed algorithm is simulated by using the toolkit package of CloudSim. The authors measure the processing time, makespan, and degree of imbalance among VMs, and the outcome results are accepted. But they did not regard the type of healthcare tasks (critical or non-critical) and the latency parameter that is particularly important in healthcare applications. In addition to the proposed algorithm consume large time for evaluation the repeated fitness function for large complex problems.
Another research in [24], offered a new task scheduling called Hybrid Moth Flame Optimization HMFO for cloud computing incorporated in the Internet of Health Things (IoHT) environment based on a deep neural network for e-healthcare system. The proposed algorithm schedules tasks in real-time based on training it with the Google cluster dataset used to learn the instances of how to schedule the tasks in cloud environment. The CloudSim package was used to test and simulate the proposed algorithm. The performance metrics measured are cost, response time, and average run time. The proposed approach has reduced cost and run time than other methods. However, it offered an increased response rate and it didn't measure the delay and the throughput as well as the selection of the task didn't depend on its prority.
In [31], the authors proposed two task scheduling algorithms; called threshold-based task scheduling algorithm (TBTS) and service level agreement-based load balancing algorithm (SLA-LB). Where the mapping of tasks to virtual machines is based on calculating the execution time matrix and the threshold in the first algorithm and the requirement of clients (i.e. deadline and budget) and load balance in the second algorithm. Simulation results of two proposed algorithms performed with benchmark datasets. The measured parameters are makespan, gain-penalty cost, and VM utilization but they didn't take into consideration delay, failure rate, and guarantee ratio.
Another algorithm proposed in [32] is based on task duplication and priority list technologies. The tasks are represented as a Directed Acyclic Graph (DAG) where some parent tasks of the current task may be duplicated by using the virtual machine’s timeslot. The algorithm is based on computing the priority of each task, the communication latency between two tasks, and mapping the task to a virtual machine that has the earliest execution time. The simulation is performed with the CloudSim toolkit package. The algorithm computes the scheduling length ratio and load balancing as the performance analysis but still, the algorithm did not measure other metrics like delay, throughput, and execution cost.
The work [33] proposed a task scheduling named Chaotic Artificial Immune Optimization Algorithm for resource allocation (CAIOA-RS) in an IoT-based cloud computing environment. The proposed method modifies the traditional Artificial Immune Optimization Algorithm (AIOA) by integrating it with Chaotic maps to improve its performance and solve the problems of resource allocation in cloud. The experimental results were simulated with the CloudSim tool and the measured parameters are makespan, throughput, memory utilization, and CPU utilization but they didn't regard the delay.
In [34], the algorithm BSufferage for task scheduling was proposed, which augments the performance of the traditional Sufferage algorithm. The main idea of the introduced method computes the required time for tasks to execute on virtual machines, record the time in which the virtual machine is available, and then compute the expected computation time. After that, they sort the completion time on all virtual machines, find three minimum values and compute the standard deviation of the difference between the completion time and the minimum. The proposed algorithm is modeled by CloudSim platform. The measured parameters are throughput, turnaround time, and load balancing. BSufferage algorithm can attain better results than Sufferage, Min-Min, and Max–Min algorithms. But the algorithm didn't measure the latency, cost, and makespan.
The work [35], developed a mobility-aware allocation and scheduling technique as well as an efficient cloud-fog framework for healthcare. The presented protocol assists the movement of the patient using an adaptive Received Signal Strength (RSS) based handoff system. The presented framework enables dynamic sharing of healthcare tasks between processing nodes either fog or cloud devices using the execution of the introduced scheduling and allocation approach. The performance of the offered approach was simulated in iFogSim model. The outcomes of this experiment proved that the proposed approach is more effective than the state of art techniques in terms of missed task range, makespan, network load, and energy consumption.
In [36], the paper proposed a Fog-Cloud Internet of Healthcare Things (IoHT) architecture where healthcare data will be forwarded to the cloud/fog layer depending on the type of traffic. The Fog layer processes the collected data until it is offloaded the data to the cloud. The authors adapted the Particle Swarm Optimization (PSO) algorithm to load balance and schedule the data traffic to different devices of fog/cloud layers. The proposed method showed acceptable results when compared with Random and FCFS algorithms. Whereas, the measured parameters are latency, throughput, and delivery ratio, the algorithm didn't measure other metrics like makespan and execution cost.
The research [37] proposed a static task scheduling algorithm for Fog computing in the health monitoring area. It gives priority to tasks based on their importance rather than their length. This research offered a method called Tasks Classification and Virtual machines Categorization (TCVC) based on task importance. The author classified tasks into three classes; importance tasks, medium importance tasks, and low importance tasks based on the patient's health status. The performance of this method was measured by applying it to the MAX–MIN scheduling algorithm. The measured parameters are average execution time, average waiting time, and average finish time. The performance of the proposed method implemented in the CloudSim simulator was compared with Max–Min, FCFS, and SJF showing acceptable results. The proposed method didn't take into consideration the makespan, latency, and processing cost, and it is not concerned with dynamic scheduling that is more adequate for real-time scheduling techniques.
Another work [38] proposed a Max–Min Ant System (MMAS) metaheuristic approach which is different from the static task graph scheduling in homogeneous environments. Its idea is to duly manage the priority values of tasks so that the most optimal task order can be achieved. The proposed approach is estimated with the conventional algorithms and the only measured parameter is normalized schedule length.
In [39], the authors proposed a new model for the optimal selection of VMs for healthcare services in the cloud environment by adopting Parallel Particle Swarm Optimization (PPSO). They used neural network and linear regression techniques to implement the prediction model of chronic kidney diseases. The parameters measured are total execution time, accuracy, and system efficiency but they didn't consider makespan, delay and throughput measurements.
In [40], a Sorted Task-Based Allocation (STBA) algorithm is proposed for independent scheduling tasks in a heterogeneous cloud system to minimize the makespan and increase resource utilization. The authers opted to sort all tasks based on their length in decreasing order, and give priority for the higher task length to be executed on the higher speed of virtual machine. They described and give simple examples on calculating expected time to complete (ETC) matrix and allocating tasks dynamically. The evaluation and testing of the proposed algorithm were simulated in the CloudSim toolkit package. The selection of task depends only on its length and they didn't regard the priority for tasks and the only measured metric is the makespan.
The study of [41] proposed a real-time task scheduling technique in the cloud environment where the tasks are sort based on their deadlines; if a task misses its deadlines, it is rejected. Another work in [42] proposed a task scheduling algorithm that distributes the load among all virtual machines where it is assign the virtual machines to the tasks according to the power factor. While in [43], the authors suggested a task scheduling algorithm based on calculating the total processing power of the available resources and the total requested processing power by the users' tasks to reduce the makespan and the price of execution.
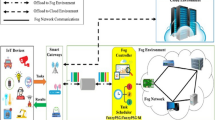
3 IoT Cloud-based architecture for RPM
Figure 1 demonstrates IoT Cloud-based architecture for the proposed PSTBA technique. Initially, users of medical services submit their tasks represented as {T1, T2, T3, T4, ……..Tn} to cloud. The task manager checks their validity and hands the valid ones over to the scheduler. These tasks are mapped to Virtual Machines represented as {VM1, VM2, VM3, VM4, … VMm}, on physical hosts housed in data centers.

IoT Cloud-based architecture for RPM
IoT Cloud-based architecture for RPM is composed of three layers:
Things layer: It consists of various IoT devices, for example, environmental sensors such as temperature, location, camera, etc., and biomedical sensors such as blood pressure, EEG, heart rate, body temperature, and respiration rate. This layer monitors the patient's health status, generates the healthcare data, and sends it to the upper layer through Bluetooth or WiFi.
Data collector layer: It is responsible for connecting the patients with the internet. This layer comprises a mobile phone or smartwatch responsible for collecting the healthcare data generated from the sensors and devices monitoring the patient's health status. These collected data are then transmitted to cloud through the Internet.
Cloud layer: consists of the following four modules:
-
1.
Task Manager: Receives all tasks from the data collection layer, where a set of independent tasks are submitted to the task manager. These tasks are classified based on their criticality, then sorted descendingly based on their length.
-
2.
Task Scheduler: It is responsible for scheduling and mapping the sorted tasks to the available VMs based on the proposed technique PSTBA.
-
3.
VM Manager: Monitor the VM resources.
-
4.
Data storage: In this layer, there is a permanent data storage for storing the patient data and results to be available for the stakeholders (patients, doctors, etc.).
4 Proposed task scheduling and allocation technique for RPM
This section presents the proposed Prioritized Sorted Task-Based Allocation (PSTBA) technique adapted from [40]. It is a task scheduling and allocation technique implemented in IoT Cloud-based environment for remote patient monitoring. The main goal of the PSTBA technique is to meet the Max.ResponseTime, minimize the delay, balance the load, minimize the number of missed critical tasks, and maximize the throughput. To achieve this, we give priority for healthcare tasks based on its criticality then order tasks based on their length in decreasing order, where the task with higher priority and higher task length is allocated to the higher capacity of VM.
4.1 The system model:
Assuming n is a set of heterogeneous independent static tasks where no new tasks are coming in during PSTBA execution, no precedence constraints or inter-task communication, and have different computational requirements. These tasks are submitted to the Task Manager module. Each task consists of a set of parameters Task = {ID,Priority, Length, MaxResponseTime}, where ID is the identification number. Priority refers to the type of task based on its importance such that a critical task with high priority has a priority value of 1, the crucial medium task has a priority value of 2, and a general task has low priority has a priority value of 3. Critical tasks are latency-sensitive, involve real-time analysis, and can send notifications or alerts, Important tasks require timely and correct access to information, and General tasks are tolerable [37]. Length is the number of instructions of a task in MI (Million Instructions). Max.ResponseTime is the maximum amount of time required by the system to respond to a patient's task [44].
Furthermore, when a set of m virtual machines be hosted in physical machines, these VMs are heterogeneous and vary in their computing capabilities. Each VM has multiple properties such as the rate of CPU processing in MIPS (Million Instructions Per Second), size of memory RAM, storage, bandwidth capacity, and cost of CPU usage.
A Pseudo-code for PSTBA execution steps is shown in algorithm 1 as follows:
-
1.
We assign each healthcare task a priority as in Table 1, where the value 1 is a higher priority, then 2 is a medium priority, and finally 3 is a low priority.
-
2.
Classifying input healthcare tasks based on their priority into three queues. Critical tasks are sent to the high priority queue, important tasks to the medium priority queue, and general tasks to the low priority queue.
-
3.
Sorting the healthcare tasks in each queue in a descending order based on their length.
-
4.
For allocation process, the Expected Processing Time (EPT) matrix for each task (i) on all VMs is calculated starting with high priority tasks queue first then medium followed by low priority tasks queue. EPT matrix size is equal to the number of tasks multiplied by the number of VMs according to Eq. (1), where EPT of one task varies from one VM to another based on VM's capacity.
$${\text{EPT}}(i,j) = \frac{{{\text{Task}}\_{\text{Length}}(i)}}{{{\text{Computing}}\_{\text{Capacity}}\_of\_VM(j)}}$$(1)where i index is set over the current task and j is set over the current VM.
-
5.
Assigning a task to the VM that has the least waiting time and least expected processing time (EPT) for that task. Allocation of tasks starts with the highest priority first, then medium, and finally the lowest because critical tasks require to meet their Max.ResponseTime. While with low priority tasks the delay is tolerable. Task allocation and mapping occurs based on EPT and wait time of VM (wt(j)). Wait time is the duration the task waits until the VM finishes the execution of the previous task namely the VM is busy. It is calculated as in Eq. (2).
$$wt\left( j \right) = {\text{ EPT}}\left( {k,j} \right)$$(2)where wt(j) is the wait time for the virtual machine’s availability and it is updated continuously and k is index of the task that preceded the task i and executed on the same VM.
The Expected Time to Complete (ETC) as a result of the allocation of task(i) over VM(j) is given by equation (3).

5 Performance evaluation
This section presents the performance of the proposed technique PSTBA and evaluates the performance metrics. We also compare the performance of the proposed technique PSTBA against different task scheduling techniques: First Come First Served (FCFS) [45] and STBA [40]. For fair comparison we have already implemented FCFS and STBA on the same environment setup of PSTBA. In the FCFS technique, the tasks are executed based on their arrival time, where the task that arrived first is served first. The second technique is the Sorted Task-Based Allocation (STBA) [40], where the tasks to be scheduled are initially sorted based on their length only but we take into our consideration the priority and length. Tables 2, 3, and 4 list the simulation parameters for tasks, data centers, and virtual machines. In Table 4 we assume using 20 VMs with the same Instruction Set Architecture (ISA) and different computing capability. CloudSim simulator [46] is used to carry out and analyze the proposed technique. It is a simulation toolkit that enables large-scale cloud computing applications to model and simulate.
We run and evaluate three different scenarios: (1) Studying the effect of varying the task counts from 100 to 700 with fixing VM count to 20. (2) Investigating the effect of varying VM counts from 10 to 70 by fixing the task count to 400. We measure the performance metrics makespan, guarantee ratio, failure rate, delay, and processing cost for both scenarios. (3) We focus on critical task analysis with varying task counts and VM counts. Hence, we measure the number of critical tasks missed their Max.ResponseTime and the substantial delay. For all scenarios, the number of critical tasks is 40% of the total number of tasks, while important and general tasks each is 30%. The results of the experiments are averaged over ten simulation runs.
The metrics used to evaluate the performance are defined and calculated as follows:
-
(1)
Makespan: It is the maximum ETC of all virtual machines [47] and it is calculated as in Eq. (4)
where ETC(j) is the total expected time to complete all tasks allocated to that VM, and m is the total number of VM.
$${\text{Makespan}} = {\text{Max}}\left( {{\text{ETC}}\left( j \right)} \right), j = 1,2,3, \ldots ,m$$(4) -
(2)
Cost of Processing: The total cost of processing (TCost) [48] is calculated as in Eq. (5)
$${\text{TCost}} = \sum\nolimits_{j = 1}^{m} {\left( {{\text{ETC}}\left( j \right)} \right)*{\text{Cost}}_{{{\text{CPU}}}} }$$(5)\(\sum\nolimits_{j = 1}^{m} {\left( {{\text{ETC}}\left( j \right)} \right)}\) is the sum of the total expected time to complete all tasks on all VMs, and \({\text{Cost}}_{{{\text{CPU}}}}\) is the processing cost per time unit and is equal to 1$, so the total cost of processing is equal to the total expected time.
-
(3)
Guarantee Ratio: This is the ratio between the number of tasks completing their execution and meeting their Max.ResponseTime (Throughput) to the total number of tasks [41].
$${\text{Guarantee Ratio}} = \frac{{{\text{Throughput}}}}{{{\text{Total No}}{\text{.of Tasks}}}}$$(6) -
(4)
Failure Rate: This is the ratio between the number of tasks that missed their Max.ResponseTime (Tasks Missed RT) and the total number of tasks.
$${\text{Failure Rate}} = \frac{{{\text{Tasks Missed }}R \, T}}{{{\text{Total No}}{\text{. of Tasks}}}}$$(7)The task (Ti) time if [49]:
$${\text{CompletionTime}}\left( {T_{i} } \right) \, > \, \left( {{\text{Max}}.{\text{ResponseTime}}\left( {T_{i} } \right) \, + {\text{ StartTime}}\left( {T_{i} } \right)} \right).$$(8) -
(5)
Delay: This is the sum of the times that exceeded the Max.ResponseTime for all the tasks [49].
$${\text{Delay }}\left( {T_{i} } \right) \, = {\text{ CompletionTime}}\left( {T_{i} } \right) \, {-} \, \left( {{\text{Max}}.{\text{ResponseTime}}\left( {T_{i} } \right) \, + {\text{ StartTime}}\left( {T_{i} } \right)} \right)$$(9)$${\text{Delay}} = \sum\limits_{i = 1}^{n} {{\text{Delay}}(T_{i} )}$$(10)where StartTime(Ti) is the task's release time, and n is the number of tasks that missed their Max.ResponseTime.
6 Analysis of results
6.1 Scenario 1: Varying number of tasks
When varying the number of tasks and fixing the number of VMs to 20, the following results are reported:
Makespan: Fig. 2a demonstrates the effect of varying the number of tasks on makespan. The makespan is increased with increasing the number of tasks. The value of makespan of STBA and PSTBA is less than that in the FCFS technique. Because the execution time of any task differs from one VM to other based on VM's capacity, so the makespan differs according to the different methodologies used. There is no significant difference that can be noticed in makespan when comparing PSTBA and STBA. For instance, when the number of tasks is 400, the makespan of PSTBA, STBA, and FCFS is 266 s, 266.5 s, and 463.9 s, respectively. Then the PSTBA executes faster than FCFS by 74.4%.

Effect of a varying number of tasks on a Makespan, b Delay, c Guarantee Ratio, d Failure Rate, and e Cost of Processing
PSTBA achieves a better result than STBA and FCFS, because the FCFS technique schedules tasks according to arrival sequence, where it executes the arrived task on the first free VM. For example, a more extended task may be executed on a low-capacity VM, resulting in a longer completion time and, as a result, missing its Max.ResponseTime. Hence increase the delay, failure rate, and cost of processing and decrease the guarantee ratio. But with STBA and PSTBA there is a difference in sorting the tasks, where with STBA the allocation of the task is based on its length only and the task with higher length is assigned to the higher capacity VM. While the PSTBA allocates and schedules the task based on its priority and length, where the task with higher priority and higher length is executed first. In addition, the higher task length is mapped to the VM with higher computing capacity, which speeds up the execution and allows the task to meet its Max.ResponseTime. Hence decreases the delay, the failure rate, and cost of processing and increases the guarantee ratio as in Fig. 2b–d.
Delay: One of the critical parameters used in measuring the performance of the proposed technique PSTBA is the delay. The delay is increased with increasing the number of tasks, as shown in Fig. 2b. The delay in the case of PSTBA is less than that in the case of STBA and FCFS techniques. For instance, when the number of tasks is 400, the delay in the case of PSTBA does not exceed 3 s, whereas it exceeds 3.48 and 5.5 s in STBA and FCFS, respectively. So that PSTBA reduces the delay by 13.7% and 80.2% more than STBA and FCFS techniques.
Guarantee ratio: This ratio decreases with increasing the number of tasks, as shown in Fig. 2c. It is worth noting that the guarantee ratio of the PSTBA strategy is greater than that of STBA and FCFS. For instance, when the number of tasks is 400, the Guarantee ratio of PSTBA, STBA, and FCFS are 0.92, 0.90, and 0.88, respectively. PSTBA has a 2.2% more Guarantee ratio than STBA and 4.5% more than the FCFS technique.
Failure rate: The effect of increasing the number of tasks on the failure rate is shown in Fig. 2d. The failure rate increases with the increase in the number of tasks for the implemented scheduling technique. It can also be noted that the failure rate of the PSTBA technique is less than the STBA and FCFS techniques. For instance, when the number of tasks is 400, the Failure rate of PSTBA, STBA, and FCFS is 0.08, 0.097, and 0.11, respectively. Indeed, PSTBA has a 21% less failure rate than STBA and 37.5% less than the FCFS technique.
Cost of processing: Fig. 2e demonstrates the influence of changing the number of tasks on the cost of processing. As the execution time of any task varies from one VM to other based on VM's capacity, the cost differs according to the different methodologies used. As noticed, the cost of processing increases with increasing the number of tasks. The cost in the case of STBA and PSTB is less than that of FCFS, and there is a slight difference between STBA and PSTBA in the cost of processing. For instance, when the number of tasks is 400, the cost of processing for PSTBA, STBA, and FCFS are 5303.6$, 5303.2$, and 5954.6$, respectively. Remarkably, the PSTBA has 12.3% less cost of processing than the FCFS technique.
6.2 Scenario 2: varying number of VMs
With varying the number of VMs and fixing the number of tasks to 400, the following results are reported:
Makespan: Fig. 3a demonstrates the effect of varying the number of VMs on makespan. The makespan is decreasing with increasing the number of VMs because there are more available resources for execution the tasks. The value of makespan in the case of STBA and PSTBA is less than that of the FCFS technique. No significant difference in makespan was detected between PSTBA and STBA. For instance, when VMs are 40, the makespan of PSTBA, STBA, and FCFS is 134.5 s, 134.6 s, and 232 s, respectively. The PSTBA executes faster than the FCFS by 72.5%.

Effect of a varying number of VMs on a Makespan, b Delay, c Guarantee Ratio, d Failure Rate, and e Cost of Processing
Delay: The delay decreases with increasing the number of VMs, as shown in Fig. 3b. The delay in PSTBA is less than that in STBA and FCFS techniques. For instance, when the number of VMs is 40, the delay of PSTBA, STBA and FCFS are 627 ms, 697.3 ms, and 1303.4 ms, respectively. Consequently, PSTBA has 11.2% less delay than STBA and 108% less than FCFS techniques.
Guarantee ratio: As in Fig. 3c, the Guarantee ratio increases with increasing the number of VMs. It is worth noting that the guarantee ratio of the PSTBA technique is greater than that of STBA and FCFS. For instance, when the number of VMs is 40, the Guarantee ratio of PSTBA, STBA, and FCFS are 0.96, 0.95, and 0.94, respectively. Then PSTBA has a 1% higher guarantee ratio than STBA and 2% higher than the FCFS technique.
Failure rate: Fig. 3d shows the effect of increasing the number of VMs on the failure rate. The Failure rate decreases with increasing the number of VMs for three implemented scheduling techniques. As noticed, the Failure rate of the PSTBA technique is less than the STBA FCFS techniques. For instance, when the number of VMs is 40, the Failure rate of PSTBA, STBA, and FCFS are 0.037, 0.042, and 0.056, respectively. Consequently, PSTBA has a 13.5% less failure rate than STBA and 51.3% less than FCFS techniques.
Cost of Processing: Fig. 3e depicts the effect of changing the number of VMs on the cost of processing. As noticed, the cost of processing decreases with increasing the number of VMs, and the costs of PSTBA and STBA are less than that in FCFS. No improvement is reported in cost for PSTBA compared to STBA. For instance, with VMs equal to 40, the cost of processing for PSTBA, STBA, and FCFS are 5286.9$, 5286.6$, and 5954.6$, respectively. Then PSTBA has 12.6% less cost of processing than the FCFS technique. Also, with a VM number equal to 70, PSTBA has a slightly higher cost than STBA. It is worth noting that enhancing the failure rate comes at expense of slightly higher cost.
6.3 Scenario 3: critical task analysis
This scenario evaluates the ratio of missed critical tasks, the significant delay with varying tasks, and the number of VMs. The number of critical tasks is set to 40% of the total number of tasks.
Critical tasks missed ratio: As depicted in Fig. 4a, the number of critical tasks missed increases with increasing the number of tasks. It is noticed that the critical tasks missed ratio in the case of PSTBA is less than that in STBA and FCFS. For instance, when the number of tasks is 400, the average number of critical tasks missed by PSTBA, STBA, and FCFS are 15.9, 18.4, and 24, respectively. PSTBA has 15.7% fewer critical tasks missed than STBA and 50.9% less than FCFS techniques. In Fig. 5a demonstrates the number of critical tasks missed by changing the number of VMs. It is noticed that the PSTBA has 17% and 58.5% less critical tasks missed than STBA and FCFS techniques at VMs number is 40.

Effect of varying the number of tasks on a Missed Critical Tasks and b Delay

Effect of varying the number of VMs on a Missed Critical Tasks and b Delay
Delay: Fig. 4b and 5b show the delay of critical tasks missed with varying numbers of tasks and VMs. It can be noticed in Fig. 4b that the delay increases with increasing the number of tasks, and in Fig. 5b the delay decreases with the increase in the number of VMs. In both cases; the delay of PSTBA is less than that in STBA and FCFS techniques. When scheduling 400 tasks, the PSTBA reduces the delay of critical tasks by 18% and 32.3% more than the STBA and FCFS. While in the case of increasing the VMs number, the proposed technique reduces the delay by 16% and 113.7% than STBA and FCFS at VMs number 40.
PSTBA achieves better results than STBA since it initially classifies tasks based on their priorities. Then sorts the healthcare tasks based on their length in descending order. Starting the allocation procedure with the highest priority tasks (the critical tasks) regardless of their lengths, helps in protecting patient life. In addition, assigning the task with maximum length to the VM with higher capacity that meets Max.ResponseTime, reduces the delay, failure rate, and the average number of missed critical tasks and increases the throughput.
7 Conclusion and future work
This paper proposes a new task scheduling and allocation technique called Prioritized Sorted Task-Based Allocation (PSTBA). The proposed technique aims to decrease the delay, meets Max.ResponseTime, minimizes the number of missed critical tasks, and maximizes the throughput. The proposed technique is implemented in the CloudSim simulation environment. Different experiments with different scenarios are conducted for measuring the performance metrics: makespan, delay, missed critical tasks, guarantee ratio, failure rate, and cost of processing.
Also, it focuses on analyzing the performance of critical tasks in terms of the number of missed critical tasks and delays. The results of the PSTBA technique outperform FCFS and STBA techniques at a large number of assigned tasks and a limited number of VMs. At varying the VMs number, the proposed technique reduces the delay and the average number of missed critical tasks by 16% and 17% than STBA at VM number 40. While in the case of increasing the task number, the PSTBA reduces the delay of critical tasks by 18% and reduces the average number of missed critical tasks by 15.7% than the STBA at tasks number 400.
Future work will focus on evaluating the performance of the proposed scheduling technique in IoT cloud-fog-based architecture in the healthcare domain.
Data availability
The data used to support the findings of this study are available from the first or the corresponding author upon request.
References
Kraemer FA, Braten AE, Tamkittikhun N, Palma D (2017) Fog computing in healthcare-a review and discussion. IEEE Access 5(May):9206–9222. https://doi.org/10.1109/ACCESS.2017.2704100
Vishnu S, Jino Ramson SR, Jegan R (2020) Internet of medical things (IoMT)-an overview. In: ICDCS 2020–2020 5th International Conference on Devices, Circuits Systems, no. March, pp. 101–104. https://doi.org/10.1109/ICDCS48716.2020.243558.
Bhuiyan MN, Rahman MM, Billah MM, Saha D (2021) Internet of things (IoT): a review of its enabling technologies in healthcare applications, standards protocols, security, and market opportunities. IEEE Internet Things J 8(13):10474–10498. https://doi.org/10.1109/JIOT.2021.3062630
Huang J, Wu X, Huang W, Wu X, Wang S (2021) Internet of things in health management systems: A review. Int J Commun Syst. https://doi.org/10.1002/dac.4683
Jino Ramson SR, Vishnu S, Shanmugam M (2020) Applications of internet of things (IoT)-an overview. In: ICDCS 2020–2020 5th international conference devices, circuits system, no. March, pp. 92–95, 2020. https://doi.org/10.1109/ICDCS48716.2020.243556.
Javaid M, Khan IH (2021) Internet of things (IoT) enabled healthcare helps to take the challenges of COVID-19 Pandemic. J Oral Biol Craniofacial Res 11(2):209–214. https://doi.org/10.1016/j.jobcr.2021.01.015
M. Rockwood, V. Joshi, K. Sullivan, and R. Goubran (2014) Using a real-time operating system for multitasking in remote patient monitoring. In: 2014 IEEE International Symposium on Medical Measurement and Applications and Proceedings. https://doi.org/10.1109/MeMeA.2014.6860109
Islam K, Alam F, Zahid AI, Khan MM, Inamabbasi M (2022) Internet of things- ( IoT- ) based real-time vital physiological parameter monitoring system for remote asthma patients. wireless commun. and mobile computing, 22 pages. https://doi.org/10.1155/2022/1191434.
Islam M, Rahaman A, Islam R (2020) Development of smart healthcare monitoring system in IoT environment. SN Comp Sci 1:185. https://doi.org/10.1007/s42979-020-00195-y
Singh AK, Firoz N, Tripathi A, Singh KK, Choudhary P, Vashist PC (2020). Internet of Things From Hype to Reality. https://doi.org/10.1016/b978-0-12-821326-1.00007-3
Surantha N, Atmaja P, David, Wicaksono M (2021) A review of wearable internet-of-things device for healthcare. Procedia Comput. Sci. 179(2020):939–943. https://doi.org/10.1016/j.procs.2021.01.083
Rahaman A, Islam M, Islam R, Sadi MS, Nooruddin S (2020) Developing IoT based smart health monitoring systems : a review. Revue d ’ Intell Artif 33(6):435–440
Kalid N, Zaidan AA, Zaidan BB, Salman OH, Hashim M, Muzammil H (2018) Based real time remote health monitoring systems a review on patients prioritization and related ‘big data’ using body sensors information and communication technology. J Med Syst. https://doi.org/10.1007/s10916-017-0883-4
Babu SM, Lakshmi AJ, Rao BT (2015) A study on cloud based internet of things: cloudIoT. Proceedings of 2015 Global Conference on Communication Technologies (GCCT 2015).
Botta A, De Donato W, Persico V, Pescapé A (2016) Integration of cloud computing and Internet of Things: A survey”. Futur Gener Comput Syst 56:684–700. https://doi.org/10.1016/j.future.2015.09.021
“N I S T SP 500‐291 C l o u d C o m p u t i n g S t a n d a r d s R o a d m a p”.
Narkhede BE, Raut RD, Narwane VS, Gardas BB (2020) Cloud computing in healthcare – a vision. Challenges Future Directions. 34(1):1–39
Dang LM, Piran J, .Han D, Min K, Moon H (2019) A survey on internet of things and cloud computing for healthcare. pp. 1–49. doi: https://doi.org/10.3390/electronics8070768.
Darwish A, Hassanien AE, Elhoseny M, Sangaiah AK, Muhammad K (2019) The impact of the hybrid platform of internet of things and cloud computing on healthcare systems: opportunities, challenges, and open problems. J Ambient Intell Humaniz Comput 10(10):4151–4166. https://doi.org/10.1007/s12652-017-0659-1
Thar MA, Carl B, Asim M, Kolivand H, Fahim M, Waraich A (2019) Remote health monitoring of elderly through wearable sensors. pp. 24681–24706.
Elhoseny M, Abdelaziz A, Salama AS, Riad AM, Muhammad K, Sangaiah AK (2018) A hybrid model of Internet of Things and cloud computing to manage big data in health services applications. Futur Gener Comput Syst 86:1383–1394. https://doi.org/10.1016/j.future.2018.03.005
Nagarajan SM, Deverajan GG, Chatterjee P, Alnumay W, Ghosh U (2021) Effective task scheduling algorithm with deep learning for Internet of Health Things (IoHT) in sustainable smart cities. Sustain. Cities Soc. 71(1):102945. https://doi.org/10.1016/j.scs.2021.102945
Iqbal N, Imran S, Ahmad RA, Kim DH (2021) A scheduling mechanism based on optimization using IOT-tasks orchestration for efficient patient health monitoring. Sensors 21(16):1–29. https://doi.org/10.3390/s21165430
Arivazhagan N et al (2022) Cloud-internet of health things (IOHT) task scheduling using hybrid moth flame optimization with deep neural network algorithm for e healthcare systems. Sci Program. https://doi.org/10.1155/2022/4100352
Aburukba RO, Alikarrar M, Landolsi T, El-fakih K (2019) Scheduling Internet of Things requests to minimize latency in hybrid fog-cloud computing. Futur Gener Comput Syst. https://doi.org/10.1016/j.future.2019.09.039
Mathew T, Sekaran KC, Jose J (2014) Study and analysis of various task scheduling algorithms in the cloud computing environment. Proc. 2014 Int. Conf. Adv. Comput. Commun Informatics, ICACCI 2014:658–664. https://doi.org/10.1109/ICACCI.2014.6968517
Arunarani AR, Manjula D, Sugumaran V (2019) Task scheduling techniques in cloud computing: A literature survey. Futur Gener Comput Syst 91:407–415. https://doi.org/10.1016/j.future.2018.09.014
Hosseinioun P, Kheirabadi M, Kamel Tabbakh SR, Ghaemi R (2022) aTask scheduling approaches in fog computing: A survey. Trans Emerg Telecommun Technol 33(3):1–11. https://doi.org/10.1002/ett.3792
Houssein EH, Gad AG, Wazery YM, Suganthan PN (2021) Task scheduling in cloud computing based on meta-heuristics: review, taxonomy, open challenges, and future trends. Swarm Evol. Comput. 62(October 2020):100841. https://doi.org/10.1016/j.swevo.2021.100841
Abdulhammed OY (2022) Load balancing of IoT tasks in the cloud computing by using sparrow search algorithm. J Supercomput 78(3):3266–3287. https://doi.org/10.1007/s11227-021-03989-w
Lavanya M, Shanthi B, Saravanan S (2020) Multi objective task scheduling algorithm based on SLA and processing time suitable for cloud environment. Comput. Commun. 151(May 2019):183–195. https://doi.org/10.1016/j.comcom.2019.12.050
Geng X, Yu L, Bao J, Fu G (2019) A task scheduling algorithm based on priority list and task duplication in cloud computing environment. Web Intell 17(2):121–129. https://doi.org/10.3233/WEB-190406
R. Joshua Samuel Raj, et al (2022) Evolutionary algorithm based task scheduling in iot enabled cloud environment. Comput Mater Contin 71(1):1095–1109. https://doi.org/10.32604/cmc.2022.021859
Shi Y, Suo K, Hodge J, Mohandoss DP, Kemp S (2021) Towards optimizing task scheduling process in cloud environment. In: 2021 IEEE 11th Annual Computing and Communication Workshop CCWC 2021, pp. 81–87. https://doi.org/10.1109/CCWC51732.2021.9376146
Abdelmoneem RM, Benslimane A, Shaaban E (2020) Mobility-aware task scheduling in cloud-Fog IoT-based healthcare architectures. Comput. Networks 179(June):107348. https://doi.org/10.1016/j.comnet.2020.107348
Chudhary R, Sharma S (2021) Fog-cloud assisted framework for heterogeneous internet of healthcare things. Procedia Comput Sci 184(2019):194–201. https://doi.org/10.1016/j.procs.2021.03.030
Aladwani T (2019) Scheduling IoT Healthcare Tasks in Fog Computing Based on their Importance. Procedia Comput Sci 163:560–569. https://doi.org/10.1016/j.procs.2019.12.138
Boveiri HR, Khayami R, Elhoseny M, Gunasekaran M (2019) An efficient Swarm-Intelligence approach for task scheduling in cloud-based internet of things applications. J Ambient Intell Humaniz Comput 10(9):3469–3479. https://doi.org/10.1007/s12652-018-1071-1
Abdelaziz A, Elhoseny M, Salama AS, Riad AM (2018) A machine learning model for improving healthcare services on cloud computing environment. Meas J Int Meas Confed 119:117–128. https://doi.org/10.1016/j.measurement.2018.01.022
Mishra SK, Khan MA, Sahoo B, Jena SK (2017) Time efficient task allocation in cloud computing environment. In: 2017 2nd International Conference for Convergence in Technology, vol 2017, pp 715–720. doi:https://doi.org/10.1109/I2CT.2017.8226222.
Sahoo S, Nawaz S, Mishra SK, Sahoo B (2016) Execution of real time task on cloud environment. In: 12th IEEE International Conference Electronics, Energy, Environment, Communication, Computer, Control (E3-C3), INDICON 2015, no. December. https://doi.org/10.1109/INDICON.2015.7443778.
Kumar N, Sharma S (2017) Task scheduling algorithm in cloud computing based on power factor. Int J Innov Res Sci Eng. Technol, (6):12973–12980. doi: https://doi.org/10.11897/SP.J.1016.2018.01360.
Ibrahim E, El-Bahnasawy NA, Omara FA (2016) Task scheduling algorithm in cloud computing environment based on cloud pricing models. Proc. - 2016 World Symp Comput Appl Res WSCAR 2016:65–71. https://doi.org/10.1109/WSCAR.2016.20
Alizadeh MR, Khajehvand V, Rahmani AM, Akbari E (2020) Task scheduling approaches in fog computing: A systematic review. Int J Commun Syst 33(16):1–36. https://doi.org/10.1002/dac.4583
Kaur A (2018) Different task scheduling algorithms in cloud computing. Int J Latest Trends Eng Technol 9(3):217–223. https://doi.org/10.21172/1.93.37
Calheiros1 RN, Ranjan RN, Beloglazov A, De Rose CAF, Buyya R (2011) CloudSim: a toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithm. Softw. Pract. Exper. pp 23–50. https://doi.org/10.1002/spe.995.
Ali SA, Alam M (2016) A relative study of task scheduling algorithms in cloud computing environment. In: 2016 2nd International Conference on Contemporary Computing and Informatics (ic3i) pp. 105–111.
Alworafi MA, Dhari A, Al-hashmi A (2017) Cost-aware task scheduling in cloud computing environment. no. May. https://doi.org/10.5815/ijcnis.2017.05.07.
Abdelmoneem RM, Benslimane A, Shaaban E, Abdelhamid S, Ghoneim S (2019) A cloud-fog based architecture for IoT applications dedicated to healthcare. In: IEEE International Confrence on Communication., vol. 2019-May. doi:https://doi.org/10.1109/ICC.2019.8761092.
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
The authors declare that they have no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Elshahed, E.M., Abdelmoneem, R.M., Shaaban, E. et al. Prioritized scheduling technique for healthcare tasks in cloud computing. J Supercomput 79, 4895–4916 (2023). https://doi.org/10.1007/s11227-022-04823-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-022-04823-7