
Abstract
Monitoring for cloud is the key technology to know the status and the availability of the resources and services present in the current infrastructure. However, cloud monitoring faces a lot of challenges due to inefficient monitoring capability and enormous resource consumption. We study the adaptive monitoring for cloud computing platform, and focus on the problem of balancing monitoring capability and resource consumption. We proposed HSACMA, a hierarchical scalable adaptive monitoring architecture, that (1) monitors the physical and virtual infrastructure at the infrastructure layer, the middleware running at the platform layer, and the application services at the application layer; (2) achieves the scalability of the monitoring based on microservices; and (3) adaptively adjusts the monitoring interval and data transmission strategy according to the running state of the cloud computing system. Moreover, we study a case of real production system deployed and running on the cloud computing platform called CloudStack, to verify the effectiveness of applying our architecture in practice. The results show that HSACMA can guarantee the accuracy and real-time performance of monitoring and reduces resource consumption.
Similar content being viewed by others

1 Introduction
Cloud computing is a new type of computing and service model, which is based on technologies such as distributed computing (Thain et al. 2005), grid computing (Berman and Fox 2003), parallel computing (Chen 2011), and virtualization (Barham et al. 2003). It establishes a sharing pool of computing resources to provide users with a wide range of cloud services for computing, storage, database, analytic, application, deployment, and so on in a pay-as-you-go style. According to NIST (Mell and Grance 2011), cloud computing can provide three different service models: Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS).
In the cloud computing platform, the application system has strict requirements for performance, such as Integrated Disaster Reduction Application System (IDRAS) (Wang et al. 2017), and it has a series of Web components with independent functions. When the disaster occurs, the system visualizes the risk and loss of natural disasters from two dimensions of space and time in the shortest possible time, and provides direct information for the disaster management. However, the diversity of applications and the dynamic nature of the deployment environment often lead to the failure of the cloud computing system (Patterson 2002), which will affect the normal disaster management. Cloud monitoring is used to measure the resources usage of the cloud computing platform in real time and provide visual performance monitoring data. It can enable operation and maintenance managers (O&M managers) to understand system performance at the first time and grasp the running state of the entire system in time, and even accurately discover performance issues and locate the causes of the issues, so as to take effective measures, optimizing system performance. Therefore, it is necessary to monitor the cloud computing platform.
Currently, three issues that must be considered in the cloud monitoring architecture are (1) in the cloud computing platform, different resources are distributed at different layers. Each layer of resources will have an impact on the performance of the system during its running. Monitoring resources at a certain layer alone cannot fully demonstrate the performance characteristics of the system. Therefore, monitoring needs to adopt a multi-layered monitoring method to monitor the resources of the three layers of the cloud computing platform. (2) In the cloud computing platform, the load changes dynamically, resources can be added or removed at any time, and the type and quantity of resources are also increasing. All of these make the resources in the cloud computing platform dynamic, diverse, and huge-scale. In addition, cloud computing platforms also vary in scale. It can be a small private cloud computing platform built in the lab environment of this paper, such as CloudStack, or a large cloud computing platform in the world, such as Amazon EC2. Therefore, monitoring needs to meet the demands of rapid changes in resources and different scale cloud computing platforms. (3) Monitoring a cloud computing platform may require a large number of monitoring services and eventually generate a large amount of monitoring data. And the transmission of these data will occupy a lot of network bandwidth, resulting in greater communication overhead, and may cause network congestion. In this case, the monitoring information cannot be synchronized in real time, which may even affect the normal use of the cloud computing platform and reduce the quality of service (QoS). Therefore, it is necessary to minimize the impact of the monitoring on application services, system resources, and network bandwidth in the cloud computing platform.
In this paper, we propose HSACMA, a hierarchical scalable adaptive cloud monitoring architecture that (1) uses microservices to construct a monitoring system, which provides different monitoring services for monitoring resources at different layers in the cloud computing platform and satisfies the demands of rapid changes in resources and different scale cloud computing platforms, and (2) uses PCA algorithm to analyze performance state of the virtual machine node, according to which dynamically adjusts monitoring interval and employs push&pull hybrid model as data transmission strategy. A case study shows that our monitoring system can effectively monitor cloud computing platform and have small system overhead.
This paper is organized as follows. In Section 1, we introduce the research background of this paper. In Section 2, we explain our cloud monitoring architecture, including the architecture overview, and its hierarchy, scalability, and adaptability. In Section 3, we discuss the technology implementation of the cloud monitoring architecture. Our experimental evaluation and case study are presented in Section 4. We discuss the threats to validity in Section 5. Section 6 summarizes the related work. We conclude our work in Section 7.
2 Cloud monitoring architecture
In order to balance the monitoring capability and the monitoring overhead, we propose a monitoring architecture which has the characteristics of hierarchy, scalability, and adaptability.
2.1 Architecture overview
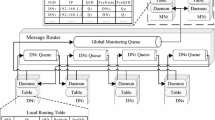
When monitoring the cloud computing platform, it is necessary to consider (1) the architecture of the cloud computing platform; (2) the scalability of the monitoring system; and (3) the impact of the monitoring system on the application services, system resources, and network bandwidth. For these problems, we propose a hierarchical scalable adaptive cloud monitoring architecture as shown in Fig. 1.

Cloud monitoring architecture
The left part of Fig. 1 is the cloud computing platform, which includes three layers: IaaS, PaaS, and SaaS. The IaaS layer includes the physical and virtual infrastructure such as server, storage, and network. The PaaS layer has the middleware required by the software running environment. The SaaS layer provides a variety of running application services. The right part of Fig. 1 is the cloud monitoring architecture proposed in this paper. The architecture provides three layers of monitoring services for the three layers of the cloud computing platform, including Infrastructure Data Collection Service (IDC) at the IaaS layer; Global Monitoring Management Service (GMM), Middleware Data Collection Service (MDC), Data Processing Service (DP), and Global Data Storage Service (GDS) at the PaaS layer; and Local Monitoring Management Service (LMM), Application Data Collection Service (ADC), and Local Data Storage Service (LDS) at the SaaS layer.
Figure 2 shows the monitoring process for the cloud computing platform, it is divided into the following steps (the adaptive mechanism denoted by bold lines):
-
(1)
GMM sends the relevant monitoring information of the monitored resources on each virtual machine node to LMM;
-
(2)
LMM receives the configuration information from GMM, and starts: (2a) IDC, (2b) MDC, and (2c) ADC;
-
(3)
LDS stores the performance data monitored by (3a) IDC, (3b) MDC, and (3c) ADC;
-
(4)
LDS transmits the monitored data to DP for data preprocessing;
-
(5)
DP transmits the monitored data to GDS for unified storage management according to the data transmission strategy;
-
(6)
GMM obtains performance data from GDS;
-
(7)
Through the evaluation and analysis of monitored performance data, the new data collection strategy, including monitoring interval adjustment and data transmission strategy, is obtained;
-
(8)
The new data collection strategy is transmitted to LMM;
-
(9)
Each data collection service is triggered to collect the performance data using the new collection strategy: (9a) adjust infrastructure monitoring, (9b) adjust middleware monitoring, and (9c) adjust application monitoring;
-
(10)
The new data transmission strategy is applied to data transmission between LDS and GDS.

Cloud monitoring process
2.2 Hierarchy of cloud monitoring architecture
Due to the variety of monitoring data, monitoring should follow a hierarchical approach based on the three main layers of the cloud computing. In SaaS layer, the high-level metrics (Jain 1991; Bezemer and Zaidman 2014) such as response time and throughput are specific to the application both in nature and in technique for collecting them. They are important for getting a general idea of the performance state of the system. However, the application monitoring data are not always enough to identify misbehaving operation and more importantly to identify performance issues (Katsaros et al. 2012). The low-level metrics, e.g., CPU, memory, network, and disk parameters (so-called performance counters (Berrendorf and Mohr 1998), in IaaS layer provide information on the resource usage for each application component deployed in the virtual environment. They are important for pinpointing the right place of the performance issues. The aggregation of these two monitoring sources in PaaS layer allows for an efficient and holistic management as well as rapid enforcement of recovery policies for assuring the required QoS level. In that context, the proposed monitoring solution spans across the three-tier structure of cloud computing, having multiple services and components residing on the IaaS, PaaS, and SaaS.
2.2.1 IaaS layer
Infrastructure Data Collection Service (IDC): This component is responsible for collecting the basic performance data of each virtual machine node at the IaaS layer. These data are mainly the performance metrics related to operating system, which are used to detect the performance at system level. The IaaS layer virtualizes physical infrastructure such as server, storage, and network to provide users with resources such as computing, storage, and network in the form of services. So from the perspective of the cloud computing platform users, each virtual machine is an independent node.
2.2.2 PaaS layer
Global Monitoring Management Service (GMM): It is the core service of the cloud monitoring architecture. It is responsible for managing each monitoring service and configuring all the monitored resources in the cloud computing platform. The XML (Kimelfeld and Senellart 2013) configuration for the monitored resources on each monitored virtual machine node is shown in Table 1.
Middleware Data Collection Service (MDC): Different MDCs are used to monitor different middleware to achieve performance data collection. PaaS is the middle layer of the cloud computing platform, which provides customized software development and deployment middleware platforms for users based on user customization. The performance metrics of the middleware products at the PaaS layer will be collected according to the configuration file from LMM and the arrived data will be distributed to LDSs for analysis and storage.
Data Processing Service (DP): It provides some data computing framework. Before LDS transfers data to GDS, DP processes the data, for example, to obtain data that can support performance issue identification (Wang and Ying 2018) and diagnosis (Wang and Ying 2020) while the SaaS software is running. The processed data is integrated according to transactions, that is, each transaction is associated with its average response time, service interface throughput, database connection status, middleware status, operating system hints, CPU/memory/network resource status, and other related information.
Global Data Storage Service (GDS): It provides a persistent data storage service interface that receives performance data from each virtual machine node stored in LDS. Performance data is transmitted between GDS and LDS based on a data transmission strategy that can intelligently switch the push and pull modes. GDS persists the received performance data in the database for unified storage and management, and provides a query interface of historical and real-time performance data for data visualization.
2.2.3 SaaS layer
Local Monitoring Management Service (LMM): LMM is deployed on each virtual machine node and receives the configuration information from GMM for monitoring the virtual machine node. LMM manages the resources about the monitored virtual machine node, including the data collection service name, the data collection method, the type and name of monitored resource, the monitoring interval, the collected performance metrics, and the data transmission strategy. In addition, it is responsible for starting infrastructure monitoring, middleware monitoring, and application service monitoring.
Application Data Collection Service (ADC): ADC collects two performance metrics, response time and throughput. Response time is the end-to-end time that a task spends to traverse a certain path within the system (Cortellessa et al. 2011). It includes server processing time and network transmission time (Smith and Williams2002). Average response time (Wang et al. 2017) reflects the user expectation on time that software responds to request. The longer the average response time, the slower the service processes requests, the lower the performance. It can give an overall impression of system performance (Bezemer and Zaidman 2014). Throughput (Smith and Williams 2002) measures the number of requests processed per unit time. It is used to express the ability of service to process requests, and is an important performance metric to measure the system’s processing ability.
Local Data Storage Service (LDS): LDS takes a virtual machine as a unit. The performance data collected by IDC, MDC, and ADC are first transmitted to LDS for temporary storage. LDS formats performance data at different layers, and then chooses data transmission strategy between it and GDS through performance evaluation, which transfers performance data to GDS in push mode or pull mode for storage.
2.3 Scalability of cloud monitoring architecture
Cloud monitoring architecture in this paper uses a series of microservices to develop the monitoring application, each of which runs in its own process and communicates through a lightweight protocol. These services are built based on business functions and can be deployed independently on one or more servers. So the biggest advantage of the cloud monitoring architecture based on microservices is its scalability. As shown in Fig. 1, each microservice in the architecture has its own business logic, which performs specific functions and is independent of each other.
The scalability of the cloud monitoring includes horizontal scalability and vertical scalability.
Horizontal scalability refers to the extension of functionality, such as adding new monitoring metrics, adding new monitoring processes, and supporting new monitoring environment. The monitored resources on the cloud computing platform are dynamic. When new resources are added, such as the newly deployed application service X, it is better to monitor the service without modifying the original monitoring system. To monitor the service X, we can register it through GMM, the registration configuration information as shown in Table 1, and then send its configuration information to LMM of the virtual machine node where the service is deployed to start monitoring service X.
Vertical scalability refers to improving system performance and scaling up user support without changing functionality. When a certain type of resource in the cloud computing platform is huge, it is not enough to monitor the performance state only through the data collection service instance of the resource. Because the microservices architecture makes different services independent of each other, we can dynamically expand the number of monitoring service instances according to the size of monitored resources to meet the monitoring requirements and improve the monitoring efficiency. At the same time, when we want to modify the processing power or mode of a service, we can perform extended maintenance by rewriting the service without making any changes to other services. In addition, when monitoring on a single virtual machine node, if the monitoring service on this node fails, the monitoring services on other nodes will not be affected, and the monitoring system can still operate normally, thus ensuring the reliability.
2.4 Adaptability of cloud monitoring architecture
In this paper, we adjust the monitoring interval and choose the appropriate data transmission strategy to push or pull the monitoring data by evaluating the performance of the system. In this way, we can provide appropriate monitoring information to meet the accuracy and consistency requirements of the monitoring system and reduce resource consumption.
2.4.1 Performance evaluation
In cloud computing platform, application services are deployed on several different virtual machine nodes. We use principal component analysis (PCA) (Mackiewicz and Ratajczak 1993) to obtain the weight coefficient of each service that affects node performance. PCA reduces the p related metrics to q (q ≤ p) principal component metrics, which can express the information of the original p metrics. It can abstract several metrics into a few principal components and form eigenvectors as the direction of data distribution. Generally, there is a linear relationship between metrics (Jiang et al. 2006), and PCA can express the linear correlation well through eigenvectors. When the system performance is in a normal state, the linear correlation between the metric values will be stable, and the main direction of the eigenvector of the monitoring data set will also be stable. Conversely, when the system performance is in an abnormal state, the linear relationship between the metric values will change, and the main direction of the eigenvector of the monitoring data set will also change. So in this paper, PCA is used to express the linear correlation of service response times, which represents the performance state of the system. The calculation process is shown in Algorithm 1.

2.4.2 Monitoring interval adjustment
We use PCA to characterize the system performance based on the service response time and dynamically adjust the monitoring interval according to the system performance. The monitoring interval refers to the time interval between two adjacent collection tasks. When the performance of the monitored system changes greatly, the monitoring interval is shortened, and the running state of the system is closely tracked, thereby improving the accuracy and timeliness of the performance analysis. Conversely, when the performance of the monitored system changes less, the monitoring interval is extended, reducing monitoring overhead. Since the probability of performance anomaly is relatively small during the entire system running, the dynamic adjustment of monitoring interval can reduce monitoring overhead, which is important for scalable monitoring in the cloud computing environment.
When the service response time changes, the performance of virtual machine node also changes. As shown in Eq. (1), Δy represents the impact of the M services on the node performance, Δti represents the response time change rate of service Si, where \({\Delta } t_{i}=\frac {|t_{i}-RS_{i}|}{MAX_{i}-MIN_{i}}(i=1,2{\ldots } M)\), ti represents the response time, RSi represents the average response time, and MAXi and MINi represent the maximum and minimum response time respectively.
We adjust the monitoring interval of IaaS layer and PaaS layer in real time based on the observed Δy in the response time. The monitoring interval Mon_Interval is adjusted according to Eq. (2). The maximum monitoring interval is set as Mon_Interval_Max, the minimum monitoring interval is set as Mon_Interval_Min, and the adjustment parameters are set as λ and 𝜖.
When Δy = α, Mon_Interval = Mon_Interval_Max, when Δy =β, Mon_Interval = Mon_Inter val_Min, and the values of λ and 𝜖 can be calculated from the given α, β, Mon_Interval_Min and Mon_Interval_Max. When Δy is less than α, the performance change of virtual machine node is small, at this time monitoring system only needs less performance data, and data collection services perform the collection tasks at the monitoring interval of Mon_Interval_Max; when Δy is larger than β, the performance of virtual machine node changes greatly, then monitoring system requires a lot of performance data to analyze this change, and data collection services carry out the collection tasks at the monitoring interval of Mon_Interval_Min; when Δy is greater than α and less than β, we dynamically adjust monitoring interval according to the change of Δy, if Δy increases, Mon_Interval calculated by Eq. (2) decreases, then the monitoring interval is reduced to collect more performance data. When the system is stable, Δy decreases, Mon_Interval increases, and the performance data that needs to be collected reduces.
2.4.3 Data transmission strategy adjustment
There are two basic methods for communications between producers and consumers: the push mode and the pull mode (Zanikolas and Sakellariou 2005). In the push mode, the server actively “pushes” the information to the client. For example, in our monitoring system, LDS actively pushes the performance data collected by each data collection service to GDS. Once the collected performance data changes, LDS will transmit it to GDS for storage, so the data real-time is high, but frequent data transmission will increase the network overhead of the system. In the pull mode, the client actively “pulls” the information from the server. For example, in our monitoring system, GDS periodically sends the query request to LDS to obtain the monitoring information of resources. In this mode, the communication overhead is small, but the periodic query strategy may fail to obtain the critical load changes of the monitored virtual machine node in the query interval, resulting in poor data real-time. Therefore, we adopt push&pull hybrid model, which switches the above two modes in real time according to the system performance. This can ensure real-time synchronization of monitoring information and reduces communication overhead.
Data change degree (DCD) in Eq. (3) describes the degree of change between the current status of the real monitoring data from Collector and the status persisted in corresponding Receiver. Each status message contains a timestamp that records the time at which a LDS collects status information.
In Eq. (3), tcol denotes the closest timestamp in Collector prior to time t, and trecv denotes the closest timestamp in Receiver prior to time t. We have tcol > trecv, because the data update in Collector is always prior to the data update in Receiver. Col(tcol) represents the value of the resource status in the Collector at time tcol, Recv(trecv) represents the value maintained in the Receiver at time trecv, and MAX and MIN are the maximal and minimal values of this resource status, respectively.
Data real-time tolerance (DRT) describes how tolerant the monitoring system is to the real-time of data. A small DRT indicates that the monitoring system has strict real-time requirement. Oppositely, a large DRT indicates that the monitoring system is prepared to tolerate non-real-time. DRT is calculated by Eq. (4) as follows:
The smaller the Δy, the smaller the change of the node performance, the less information the monitoring system needs to monitor, the greater the tolerance of the monitoring system to the data real-time, and vice versa. Therefore, we alter DRT based on the change of node performance, and determine the data transmission strategy according to the value of DRT, as shown in Eq. (5).
When DCD ≤ DRT, it indicates that the data change degree is less than or equal to the data real-time tolerance of the monitoring system, so we increase the pull interval, and vice versa. Instead of simply adding or subtracting a fixed value to alter the pull interval, we dynamically adjust it according to the change of running status, as shown in Eq. (6); the pull interval at time t is determined based on the last pull interval and the node performance change Δy. STEP represents the predefined increment of the pull intervals.
3 Cloud monitoring architecture implementation
In order to apply the proposed monitoring architecture to the actual cloud environment, its system is designed, and each module in the system is implemented technically.
3.1 System design
The system for the proposed cloud computing architecture is designed according to the process of performance data collection, performance data transmission, performance data processing, and performance data storage. Figure 3 is the overall architectural solution for hierarchical scalable adaptive cloud monitoring system.

Cloud monitoring system
The system architecture adopts the idea of modularization. It consists of four modules: collection module, transmission module, processing module, and storage module, and the function of each module is described as follows:
(1) Collection module. This module is responsible for real-time data collection in the cloud computing platform. As the performance data is multi-sourced and heterogeneous, different collection services collect the data generated by different objects.
(2) Transmission module. The module transmits performance data in push or pull mode according to the data transmission strategy. The strategy is adjusted according to the system performance, which is evaluated based on the dynamic change of the service response time.
(3) Processing module. In this module, one is data-intensive computing applied to analyze massive raw data to obtain the required information. The other is stream computing applied to deal with every coming data in real time, aiming at quickly discovering system performance exceptions.
(4) Storage module. This module includes two kinds of storage systems. One is raw data storage, which stores historical data orderly and permanently for future data mining and analyzing. The other is result data storage, which supports data-intensive computing to satisfy the demands of various roles and provides them with rapid access to data for analysis, evaluation or diagnosis.
3.2 Collection module
In the cloud computing platform, hardware metrics are distributed at the IaaS layer, middleware metrics are distributed at the PaaS layer, and application service metrics are distributed at the SaaS layer. These metrics and their descriptions are shown in Table 2. For the performance metrics at different layers, different data collection services employ different monitoring techniques to collect them, as shown in Table 3.
At the IaaS layer, we collect node-level performance metrics from CPU, memory, disk, and network. For physical infrastructure, we obtain performance data by calling the API interface of the cloud computing platform; for virtual machine, we use the local resource monitoring library, System Information Gatherer and Report (Sigar) (Reddy and Rajamani 2015), to get the related performance metrics.
At the PaaS layer, there are many middleware (such as database server and Web server) that provide interfaces for monitoring and management. We obtain performance metrics of these middleware through different JXM interfaces. For example, the number of MySQL server running threads is obtained through MySQL performance query service, and the size of free JVM, the total number of Tomcat requests, the number of Tomcat threads, and other parameters are acquired through Tomcat performance monitoring service.
At the SaaS layer, ADC invokes the performance monitoring interface to collect the performance metrics related to application services. These services are released by Java Web application based on Service-Oriented Architecture (SOA) (Papazoglou and Heuvel 2007) and deployed on the cloud computing platform. In this paper, Aspect-Oriented Programming (AOP) (Kiczales 1996) is used to process the requests of SaaS service to obtain the high-level metric.
3.3 Transmission module
Data transmission strategy adopts push&pull hybrid model, which is composed of ACMA-push algorithm and ACMA-pull algorithm. Algorithms 2 and 3 show details of the ACMA-push and ACMA-pull algorithms.


ACMA-push algorithm runs at the Collector and ACMA-pull algorithm runs at the Receiver simultaneously. The two algorithms make the monitoring system intelligently switch between push and pull actions according to DCD and DRT. We analyze the algorithms from four aspects:
(1) To prevent the push and pull actions running concurrently in the same period, the two action identifiers, isPulled and isPushed, are set to be mutually exclusive, which may further reduce updating times. If the pull action occurs, the push action is prohibited in the corresponding time interval, and vice versa. Thus, when DRT equals to 0, all pull actions are invalid and the push&pull hybrid model degenerates to pure push mode. Similarly, when DRT equals to 1, all push actions are disabled, and the push&pull hybrid model degenerates to pure pull mode. Also, isPulled and isPushed should be controlled by synchronization operation to avoid inconsistency when concurrently reading or writing.
(2) When the value of DRT is relatively small, the push mode is dominant. As shown in Algorithm 2, because the condition at line 7 is easily to be met, push actions are frequently triggered. On the other side, at line 14 of Algorithm 3, the value of pull_interval is also constantly updated. When pull_interval becomes very small (line 15 of Algorithm 3), PULL_INTERV AL_MIN will prevent it from infinitely decreasing. In most cases, push action runs before pull action. Hence, the push action dominates the model. An extreme case is that the data status of Collector changes little, so push action is not triggered for a long time, but the push&pull hybrid model still pulls data from the Collector with PULL_INTERV AL_MAX.
(3) When the value of DRT is relatively large, the pull mode is dominant. Since the condition of line 7 in Algorithm 2 is difficult to achieve, push action is rarely triggered. However, the ACMA-pull algorithm adjusts its pull interval (lines 10–16 of Algorithm 3) according to the status changes. When the condition of line 12 in Algorithm 3 is satisfied, the algorithm will try to increase pull_interval, that is, to reduce network bandwidth by reducing the number of data transmission. In this case, the pull action becomes dominant. The extreme case is that when pull_interval becomes very large, a dramatic status change occurs during the very large pull interval. The push action is triggered at this moment to push the abnormal status to Receiver.
(4) When the value of DRT is relatively moderate, none of the push and pull actions is dominant. This situation is just between the above two cases, and both push and pull actions occur frequently.
In transmission module, we use message queue Kafka to implement the push&pull hybrid model of ACMA-push algorithm and ACMA-pull algorithm for performance data transmission. Kafka MQ serves as a data buffer, Flume’s KafkaSink component (producer) publishes/pushes data to broker, and Spark Streaming’s KafkaInputDStream (consumer) subscribes/pulls the data from broker.
3.4 Processing module
Different layers of data collection services use different monitoring techniques to collect resources at different layers of cloud computing platform. The formats of the original performance data collected by these data collection services are different. The JavaScript Object Notation (JSON) (Liu et al. 2014) format shown in Table 4 is used to define the format of the collected performance data.
After the performance data collected by each data collection service is formatted, the performance data collected on each virtual machine needs to be integrated. The aggregation pseudocode is shown in Algorithm 4.

In processing module, we use the Spark Streaming framework (Karau et al. 2015) to process monitoring data. KafkaInputDStream (also known as Kafka connector) reads data from Kafka MQ, the data is divided into Discretized Stream (DStream) according to batch size (such as 1 min). Each DStream is transmitted into Resilient Distributed Dataset (RDD) in the Spark Streaming, and each RDD will generate a Spark Job for processing. Spark Streaming provides some basic data statistics interfaces. In this paper, we use its total, mean, and percentage functions. For the window operation of Spark Streaming, we use its incremental method to improve the efficiency of statistics. The final processing results are aggregated into database.
3.5 Storage module
In this paper, database MySQL (Schwartz et al. 2012) is used to store the monitoring performance data. The database table structure of MySQL is shown in Fig. 4. Table vmInfo stores information about virtual machine nodes, including unique identifier vmId, name, node creating time, and node type. Table resourceStatusItem stores the performance metrics, including cloudtype of the cloud computing platform to which the resource belongs, its value range is {iaas, paas, saas}, type of monitored resource, its value can be {CPU, memory, disk, Tomcat, MySQL, Webservice,…}, timeStamp of data monitoring, and properties has three fields: {key, value, valueType}, where key is the monitored resource name, value indicates the metric value, and valueType is the metric unit. Table resourceConfigurationItem stores the health status of the operating system of the virtual machine node. Since the health status information of operating system does not change much over a long period of time, it is stored separately from the performance metrics that change in real time.

Monitoring data storage database table
4 Experiment and case study
In order to validate the effectiveness of the cloud monitoring architecture proposed in this paper, we conduct an experimental evaluation and case study in a real cloud computing environment.
4.1 Case overview
The hardware environment configuration for the cloud computing platform CloudStack is shown in Table 5, including a blade chassis, a management node server and 6 computing node, and a 10Gb ISCSI storage. The management server running system is Centos 6.5, the LAN IP address is 192.168. 185.1, and the computing node is virtualized with virtualization technology XenServer. The CloudStack version is Apache CloudStack 4.7.
On CloudStack, we deployed the real production system (IDRAS) introduced in Section 1. It was implemented in Java and deployed on multiple virtual machine nodes. We apply the cloud monitoring architecture HSACMA to the cloud computing platform CloudStack where the application system IDRAS is located. As shown in Fig. 5, we monitor the resources at all layers of IaaS, PaaS, and SaaS.

Application case of the cloud monitoring architecture
In this application case, the resources that need to be monitored include virtual machine nodes A-F at the IaaS layer, MySQL, Tomcat, KafkaMQ, and FileZilla middleware at the PaaS layer, image register service, data process service, business operation management service, information extraction service, and other services at the SaaS layer. When monitoring, information about the resources to be monitored is registered to GMM according to the configuration in Table 1. LMM on each virtual machine node receives the configuration information from GMM; starts IDC to collect the CPU, memory, disk, and network usage of the virtual machine node; starts MDC to collect the number of MySQL threads, Tomcat’s JVM free memory, the total number of requests, etc.; and starts ADC to acquire response time and throughput of application service. LDS receives the performance data monitored on the virtual machine nodes, and transmits them to GDS for unified storage and management according to data transmission strategy.
4.2 Data visualization
We take virtual machine node A and the business operation management (BOM) service deployed on it as example. We monitor node A and its middleware resources and BOM service. For example, a service S in BOM is invoked with average service request interval of 100ms. The execution timestamp is 2017-9-23 10:28:16. The monitoring results are shown in Table 6.
The monitoring system provides the data display function to visualize the monitoring results so as to facilitate the O&M managers to view and analyze the data and take timely measures to solve the performance issues. As can be seen from Fig. 5, we added monitoring data visualization module and alert module in the monitoring system. Without modifying the original monitoring system, the new function module can be accessed through the performance data query interface provided by GMM to achieve the horizontal scalability of the monitoring system. In monitoring data visualization module, O&M managers can check the usage of resources in the cloud computing platform through the resource display interface of the monitoring system. In alert module, they can set the thresholds for monitored resources.
As can be seen from Fig. 6, the cloud monitoring architecture proposed in this paper can effectively monitor the cloud computing platform. By comprehensively monitoring the resources at the IaaS, PaaS, and SaaS layers to obtain various performance data, O&M managers can accurately grasp the running status of the system and quickly adjust the resource supply strategy so as to guide the load balancing and optimize the system performance.

Data visualization of the cloud computing platform. This figure shows performance data at the IaaS, PaaS, and SaaS layers monitored by our cloud monitoring architecture. a Health status of node A at IaaS layer; b CPU utilization, memory utilization, disk read/write rate, network send/receive rate of node A at IaaS layer; c No. of MySQL threads, size of free JVM, total No. of Tomcat requests, No. of Tomcat threads at Paas layer; d Response time and throughput of service S at SaaS layer
4.3 Adaptability evaluation
In the cloud computing environment, the load changes dynamically. We simulate the change of load to verify that HSACMA can adapt to the dynamic change of load. In other words, although the number of concurrent changes constantly during the normal operation of the system, our monitoring is still able to work effectively. The number of concurrent requests increases from 0 to 200, with a step size of 2. Each concurrent number lasts for 5 min and the experiment lasts for 500 min.
The response time of each service on virtual machine node A changes with the increase of load requests, and Δy is calculated by Algorithm 2. The threshold TH is set to 0.85, which results in 3 principal components. The change of Δy under different service load requests is shown in Fig. 7.

Δy changes with load concurrent requests
4.3.1 Monitoring interval adjustment
The monitoring interval is adjusted according to the change of node performance Δy, which is computed by Eq. (2). In the experiment, Mon_Interval_Max is set to 60s, Mon_Interval_Min is set to 5s, α = 0.2, β = 0.8, then λ = 1.53, 𝜖 = − 13.33. The monitoring interval Mon_Interval changes with Δy, as shown in Fig. 8a. When Δy < 0.2, Mon_Interval is Mon_Interval_Max, that is, 60s; when Δy > 0.8, Mon_Interval is Mon_Interval_Min, that is, 5s; when 0.2 < Δy < 0.8, Mon_Interval is adjusted according to the change of Δy.

Adjustment of the monitoring interval according to Δy. When 0.2 < Δy < 0.8, monitoring interval is adjusted according to the change of Δy. a Monitoring interval changes with Δy; b Adjustment of monitoring interval
Due to the long experimental period, in order to more clearly display the adaptive adjustment process of Mon_Interval changing with Δy, we take a short period of time for analysis, as shown in Fig. 8b. It is observed that before 240s, Δy < 0.2, data is collected in every 60s; within 140–155s, Δy > 0.8, data is collected in every 5s; in the rest of the time period, Mon_Interval will be dynamically adjusted according to the change of Δy, and it will increase or decrease with Δy.
4.3.2 Data transmission strategy adjustment
According to Eq. (4), we calculate DRT, which is negatively correlated to the node performance Δy. In the experiment for the data transmission, we set Mon_Interval to a fixed value of 10s, so that the relationship between the update in the push/pull actions and the value of DRT can be seen more obviously. In Algorithm 3, the initial pull interval is set to 50s, PULL_INTERV AL_MAX is set to 120s, PULL_INTERV AL_MIN is set to 30s, the value of pull_interval is adjusted according to Eq. (6), and STEP is set to 1.
As it can be seen from Fig. 9, both the push action and the pull action are related to DRT. When DRT increases, the total number of updates reduces. In the course of the experiment, the decrease rate of the number of push actions is much faster than the increase rate of the number of pull actions. When the number of push actions decreases, the proportion of the pull actions in the total number of updates increases. When DRT = 0, the push&pull hybrid model turns to the push mode. When DRT is small, e.g., 0.1 to 0.2, the push action is dominant. When DRT is moderate, such as 0.4 to 0.6, the number of push actions is almost equal to the number of pull actions. When DRT is large, such as 0.7 to 0.8, the pull action is dominant. When DRT = 1, the push&pull hybrid model only operates pull actions.

Data update times at different DRT. Push action update times decrease as DRT increases, pull action update times increase as DRT increases; The total update times are reduced. a Push/pull action update times; b Total update times.
4.3.3 Monitoring capability evaluation
For the monitoring system, the longer the monitoring interval and the pull action period are, the smaller the monitoring overhead will be. The experimental results of Figs. 8 and 9 show that our adaptive monitoring can reduce the number of data updates. But in this case, can we collect enough performance data? We take the data updates of CPU utilization as example. The virtual machine node A is monitored, and the performance data obtained is transmitted to GDS for storage. Figure 10 shows the comparison results on the original CPU utilization and actual collected CPU utilization with our adaptive monitoring strategy. It reveals that the collection data with adaptability is able to capture the main change trend of the original monitoring data. Specially, the collection data with adaptive monitoring captures most of the peaks of the original monitoring data. Figure 10 demonstrates that adaptive monitoring strategy is effective in capturing the mutations of monitored values as well as reducing the number of data updates.

Data updates comparison between original CPU utilization and actual collected CPU utilization
Our approach analyzes the metric of the service on the virtual machine node through PCA, and obtains the response time weight of each service to describe the running status of the system. According to the real-time change of the system status, the monitoring interval and the data transmission strategy are adaptively adjusted. The above analysis and experimental comparison show that our approach can ensure the sufficiency of monitoring data and meet the accuracy and real-time of monitoring (Appendix Table 7).
4.4 Monitoring overhead analysis
In order to analyze the overhead of the monitoring, we evaluate its impact on the service performance, CPU resource, and network bandwidth.
We compare the response time of service S on virtual machine node A with monitoring and without monitoring. As the requests increase from 1 to 200, the response time of the service increases gradually, as shown in Fig. 11a. When the requests are greater than 100, the response time of the service increases abruptly. Correspondingly, the CPU utilization shown in Fig. 12a rises to 90%, which indicates that node A cannot handle so many requests at the same time. The fact is that the performance bottleneck of node A results in a dramatic change in the response time of service S. Figure 11b shows that the service response time caused by monitoring is about 1 to 10ms, revealing its impact on service performance is very small (1% or less).

Impact of monitoring on service performance. a Service response time comparison with and without monitoring; b Service response time overhead with monitoring

CPU consumption of monitoring. a CPU utilization comparison with and without monitoring; b CPU utilization overhead with monitoring
Then, we compare the CPU utilization of virtual machine node A with monitoring and without monitoring as the load concurrent requests of the service change from 1 to 200, as shown in Fig. 12. The CPU is consumed by the monitoring as shown in Fig. 12b. It can be seen that the CPU occupied by the monitoring is basically about 1%. Therefore, our monitoring consumes few system resource.
Finally, we compare the network send rate of virtual machine node A with monitoring and without monitoring. Service S invoked during the experiment needs to return the result to user after querying in the database according to the user’s request. With the increase of the requests, whether there is monitoring or not, the network send rate will increase. Meanwhile, the performance fluctuation of the node increases, the monitoring interval of data collection service will decrease, the collected performance data will increase, and the push data in the data transmission process will also increase. Therefore, the network bandwidth occupied by transmitting performance data shows a rising trend, but it is basically less than 5%, as shown in Fig. 13. So the network bandwidth occupied by our monitoring is still relatively small.

Network bandwidth occupied by monitoring. a Network bandwidth comparison with and without monitoring; b Network bandwidth overhead with monitoring
The above experimental results show that the performance overhead of our monitoring method itself is very small, which reduces the impact on system performance, CPU resource, and network bandwidth as much as possible.
5 Threats to validity
In order to validate the functionality and the performance of the proposed monitoring mechanism, we selected the case study of a real production application (IDRAS). The application is deployed on the virtual infrastructure while the whole operation is managed through the service platform (Wang et al. 2017; Wang et al.2019). The monitoring mechanism must be able to operate in the frame of this distributed application deployment (Gogouvitis et al. 2012). However, we only collected data from one subject system; the generality of the proposed approach should be further evaluated. In the future, we will compare our approach with a baseline approach in existing work and explore whether it can be applied to a variety of systems.
In this paper, monitoring metrics are selected by monitoring strategies formulated by cloud computing platform administrators or application developers. There are many resources to monitor at all layers of cloud computing system, which will cause huge monitoring overhead. Reducing the monitoring object is an important way to improve the monitoring efficiency. Different metrics in the system have different expressiveness to the running state, and the metrics that best reflect the performance state of applications in cloud computing platform can be selected from many metrics.
The work in this paper is mainly focused on the collection, transmission, processing, and storage of performance data of cloud computing platform, and the analysis of performance data is mainly focused on how to adjust the monitoring process. In addition, we take virtual machine node as a unit to collect the performance data. In order to be of system-wide use, the performance data can be collected from the running system to construct the feature matrix. An interesting direction is to investigate how to conduct correlation analysis between different metrics for performance issue identification and diagnosis.
6 Related work
At present, both industry and academia have done a lot of research and development work on cloud monitoring.
In industry, several cloud management platforms own specialized monitoring tools. The best known examples are CloudWatchFootnote 1 for Amazon EC2, CloudMonixFootnote 2 for Microsoft Azure, and CeilometerFootnote 3 for Openstack. Apart from commercial monitoring tools, there are several representative prototypes of cloud monitoring system that are not restricted to a certain platform. For example. Nagios (Barth 2008) is an integrated system for monitoring large-scale data centers. It is designed to collect and manage runtime measurements from dispersed sensors. Ganglia (Massie et al. 2004) is another important monitoring tool for enterprise data centers. NewRelicFootnote 4 is a popular system for application performance management. It focuses on collecting performance-related metrics. Nimsoft (Tasquier et al. 2012) can monitor different cloud platforms, such as Amazon EC2, Microsoft Azure, and Google App Engine, to provide users with a unified operation and maintenance management.
In academia, research efforts have focused on developing monitoring techniques, platforms, and frameworks for clouds. A significant number of new approaches and improvements in monitoring architectures that collect, transmit, process, and store the data have been developed. In the following, we group these recent works into five categories: (1) cloud monitoring architecture, (2) monitoring data collection, (3) monitoring data delivery, (4) monitoring data processing, and (5) monitoring data storage.
- (1) Cloud monitoring architecture:
-
For example, Povedano-Molina et al. (8) proposed a distributed cloud platform resource management monitoring framework DARGOS to monitor the physical infrastructure resources and virtual resources of multi-tenant cloud platform. But the framework cannot meet the scalability requirement of monitoring services in large application scenarios. Konig et al. (2012) proposed a hierarchical monitoring architecture based on distributed monitors, which can monitor large-scale systems in real time and has strong scalability to meet the analysis needs. Andreozzi et al. (2005) proposed a grid system monitoring service GridICE to provide users with fault monitoring reports, service-level agreement violations, and user-defined event mechanisms. Meng and Ling (2013) proposed a monitoring model called MaaS (Monitoring as a Service), which supports the function requirements for traditional state monitoring and the non-functional requirements for performance enhancement, and provides status monitoring services to users.
- (2) Monitoring data collection:
-
For instance, Han et al. (2009) proposed a RESTful approach to monitor and manage cloud infrastructures, where the monitored entities in the cloud platform are modeled with REST in a tree structure. However, this approach only focuses on monitoring the cloud infrastructure, and the platforms, applications, and interactions are not covered. Thus, Shao et al. (2010) proposed a more universal runtime model for cloud monitoring (RMCM). All the raw monitoring data gathered by different monitoring techniques can be organized by this model and it presents an intuitive view of a running cloud.
- (3) Monitoring data transmission:
-
For example, Chieu et al. (2009) proposed a push-based approach to scale web applications by installing an agent in the web application and triggering up-scale or down-scale operations. This work focuses only on monitoring web server resource usage at the service level. Huang and Wang (2010) proposed a user-oriented resource monitoring model named Push&Pull (P&P) for cloud computing, which employs both push model and pull model, and switches the two models intelligently according to users’ requirements and monitored resources’ status. But it does not consider the distribution of monitoring resources in the cloud platform and the scalability of the monitoring method.
For monitoring data transmission, the messaging system is of great importance for achieving high efficiency. Many kinds of messaging systems have been used in cloud monitoring systems to transmit data efficiently. For instance, Amazon CloudWatchFootnote 5 and CloudStatusFootnote 6 use simple queue services, Google Cloud Platform StatusFootnote 7 uses its own messaging system, Nimsoft uses its own messaging bus, and mOSAIC (Rak et al. 2011) uses AMQP as its messaging system.
- (4) Monitoring data processing:
-
Monitoring applications often involves processing a massive amount of data from a possibly huge number of data sources. Big data processing methods and technical support platforms can be adopted to effectively complete data processing tasks. The data processing tasks involve many aspects, such as data formatting, integration, denoising, and computing. For example, the real-time calculation of data will be used for statistical measurement of the obtained data. There are several mainstream real-time computing frameworks. Storm (Jones 2013) is an open-source, low-latency data stream processing system. Real-time processing of data can be implemented by API interface provided by Storm framework. Spark is a distributed lightweight general-purpose computing framework. It is an engine that can process PB-level big data at high speed based on in-memory computing.
- (5) Monitoring data storage:
-
For example, HBase (George 2011) and MySQL are the mainstream big data storage technologies. HBase is a column-oriented NoSQL database, which is actually a key value database. MySQL is an open-source relational database management system (RDBMS), which stores data in different tables. Wang et al. (2014) proposed an approach to indexing and querying observational data in log-structured storage. Based on key traits of observational data, they designed a novel index approach called the CR-index (Continuous Range Index), which provides fast query performance without compromising write throughput.
To monitor the cloud computing platform, it is necessary to reduce the monitoring overhead of the system in the normal running state and improve the real-time monitoring of the system under the abnormal state. This requires a targeted, multi-layered, scalable, and adaptive cloud monitoring system to efficiently collect and organize the resources in the cloud computing platform.
Our previous work (Chen et al. 2017) proposed a hierarchical and scalable monitoring architecture for clouds (SHMA). Due to the diversity of entities in SHMA, multiple common monitoring techniques are introduced for cloud monitoring in Chen et al. (2017) . In this paper, we used the similar architecture to acquire the status of monitored entities at different layers of cloud resources. We also employ these techniques in SHMA to implement various monitoring facilities for cloud computing platform, but the monitored entities have a broader scope in HSACMA in this paper; we use PCA to evaluate the virtual machine performance, based on which to dynamically adjust the monitoring interval and the data transmission strategy. Further, we employ push&pull hybrid model based on data change degree (DCD) and Data Real-time Tolerance (DRT) as our adaptive data transmission strategy.
7 Conclusion
In this paper, we proposed HSACMA, a hierarchical scalable adaptive monitoring architecture for cloud computing platform, which solves the dynamic, diverse, and huge-scale problems of the monitoring resources at IaaS layer, PaaS layer, and SaaS layer of cloud computing platform. HSACMA uses microservices architecture to implement scalable and independent service components in the monitoring system. In addition, we dynamically adjust the monitoring interval and data transmission strategy to solve the problem of balancing monitoring capability and resource consumption. We design and implement the adaptive monitoring system according to the proposed cloud monitoring architecture. And we use a case of real production system (IDRAS) on the cloud computing platform (CloudStack) to evaluate our approach. Through the analysis of monitoring results and monitoring overhead, it is shown that the proposed monitoring approach is hierarchical, scalable, and adaptive, which can effectively monitor the cloud and reduce the monitoring overhead.
References
Andreozzi, S., Bortoli, N.D., Fantinel, S., Ghiselli, A., Rubini, G.L., Tortone, G., & Vistoli, M.C. (2005). Gridice: a monitoring service for grid systems. Future Generation Computer Systems, 21(4), 559–571.
Barham, P., Dragovic, B., Fraser, K., Hand, S., Harris, T., Ho, A., Neugebauer, R., Pratt, I., & Warfield, A. (2003). Xen and the art of virtualization. In Nineteenth Acm Symposium on Operating Systems Principles (pp. 164–177).
Barth, W. (2008). Nagios: system and network monitoring.
Berman, F., & Fox, G. (2003). Grid computing: making the global infrastructure a reality. John Wiley & Sons, 2, 945–962.
Berrendorf, R., & Mohr, B. (1998). PCL - the performance counter library: a common interface to access hardware performance counters on microprocessors.
Bezemer, C.P., & Zaidman, A. (2014). Performance optimization of deployed software-as-a-service applications. Journal of Systems & Software, 87(1), 87–103.
Chen, G.L. (2011). Parallel computing: structures, algorithms, programming publisher Higher Education Press.
Chen, L., Ying, S., & Jia, X.Y. (2017). Shma: monitoring architecture for clouds. Computer Science, 44(1), 7–12.
Chieu, T.C., Mohindra, A., Karve, A.A., & Segal, A. (2009). Dynamic scaling of web applications in a virtualized cloud computing environment. In IEEE International Conference on E-business Engineering.
Cortellessa, V., Marco, A.D., & Inverardi, P. (2011). Model-based software performance analysis.
George, L. (2011). HBase: the definitive guide O’Reilly Media, Inc.
Gogouvitis, S., Konstanteli, K., Waldschmidt, S., Kousiouris, G., Katsaros, G., Menychtas, A., Kyriazis, D., & Varvarigou, T. (2012). Workflow management for soft real-time interactive applications in virtualized environments. Future generation computer systems, 28, 193–209.
Han, H., Kim, S.G., Jung, H., Yeom, H.Y., Yoon, C., Park, J.W., & Lee, Y. (2009). A restful approach to the management of cloud infrastructure.
Huang, H., & Wang, L. (2010). P&P: a combined push-pull model for resource monitoring in cloud computing environment. In IEEE International Conference on Cloud Computing (pp. 260–267).
Jain, R. (1991). The art of computer systems performance analysis (techniques for experimental design, measurement, simulation, and modeling).
Jiang, G., Chen, H., & Yoshihira, K. (2006). Modeling and tracking of transaction flow dynamics for fault detection in complex systems. IEEE Transactions on Dependable & Secure Computing, 3(4), 312–326.
Jones, M.T. (2013). Process real-time big data with Twitter Storm.
Karau, H., Konwinski, A., Wendell, P., & Zaharia, M. (2015). Learning Spark: lightning-fast big data analytics.
Katsaros, G., Kousiouris, G., Gogouvitis, S.V., Kyriazis, D., Menychtas, A., & Varvarigou, T. (2012). A self-adaptive hierarchical monitoring mechanism for clouds. Journal of Systems & Software, 84(10), 1029–1041.
Kiczales, G. (1996). Aspect-oriented programming.
Kimelfeld, B., & Senellart, P. (2013). Probabilistic XML: models and complexity.
Konig, B., Alcaraz Calero, J., & Kirschnick, J. (2012). Elastic monitoring framework for cloud infrastructures. Iet Communications, 6 (10), 1306–1315.
Liu, Z.H., Hammerschmidt, B., & Mcmahon, D. (2014). JSON data management: supporting schema-less development in RDBMS. In International Conference on Management of Data (SIGMOD). ACM (pp. 1247–1258).
Mackiewicz, A., & Ratajczak, W. (1993). Principal components analysis (PCA). Computers & Geosciences, 19(3), 303–342.
Massie, M.L., Chun, B.N., & Culler, D.E. (2004). The ganglia distributed monitoring system: design, implementation, and experience. Parallel Computing, 30(7), 817–840.
Mell, P., & Grance, T. (2011). The NIST definition of cloud computing. National Institute of Standards & Technology.
Meng, S., & Ling, L. (2013). Enhanced monitoring-as-a-service for effective cloud management. IEEE Transactions on Computers, 62(9), 1705–1720.
Papazoglou, M.P., & Heuvel, W.J.V.D. (2007). Service oriented architectures: approaches, technologies and research issues. Vldb Journal, 16(3), 389–415.
Patterson, D.A. (2002). A simple way to estimate the cost of downtime.
Povedano-Molina, J., Lopez-Vega, J.M., Lopez-Soler, J.M., Corradi, A., & Foschini, L. (8). DARGOS: a highly adaptable and scalable monitoring architecture for multi-tenant clouds. Future Generation Computer Systems, 29, 2041–2056.
Rak, M., Venticinque, S., Mahr, T., Echevarria, G., & Esnal, G. (2011). Cloud application monitoring: the mosaic approach. In IEEE Third International Conference on Cloud Computing Technology and Science (pp. 758–763).
Reddy, P.V.V., & Rajamani, L. (2015). Performance comparison of different operating systems in the private cloud with KVM hypervisor using SIGAR framework. In International Conference on Communication, Information & Computing Technology (pp. 1–6).
Schwartz, B., Zaitsev, P., & Tkachenko, V. (2012). High performance MySQL: optimization, backups, and replication. O’Reilly Media, Inc.
Shao, J., Wei, H., Wang, Q., & Mei, H. (2010). A runtime model based monitoring approach for cloud.
Smith, C.U., & Williams, L.G. (2002). Performance solutions: a practical guide to creating responsive, scalable software. IEEE Software, 20(5), 103–103.
Tasquier, L., Venticinque, S., Aversa, R., & Martino, B.D. (2012). Agent based application tools for cloud provisioning and management.
Thain, D., Tannenbaum, T., & Livny, M. (2005). Distributed computing in practice: the condor experience: Research articles, (Vol. 17.
Wang, R., & Ying, S. (2018). SaaS software performance issue identification using HMRF-MAP framework. Software: Practice and Experience, 48(11), 2000–2018.
Wang, R., & Ying, S. (2020). SaaS software performance issues diagnosis using ICA and RBM. Concurrency and Computation: Practice and Experience, 32(14), e5729.
Wang, R., Ying, S., & Jia, X. (2019). Log data modeling and acquisition in supporting SaaS software performance issue diagnosis. International Journal of Software Engineering and Knowledge Engineering, 29(9), 1245–1277.
Wang, R., Ying, S., Sun, C., Wan, H., Zhang, H., & Jia, X. (2017). Model construction and data management of running log in supporting SaaS software performance analysis. In International Conference on Software Engineering and Knowledge Engineering (pp. 149–154).
Wang, S., Maier, D., & Ooi, B.C. (2014). Lightweight indexing of observational data in log-structured storage. Proceedings of the Vldb Endowment, 7(7), 529–540.
Zanikolas, S., & Sakellariou, R. (2005). A taxonomy of grid monitoring systems. Future Generation Computer Systems, 21(1), 163–188.
Funding
This work is supported in part by the grants of the National Natural Science Foundation of China (Grant Nos. 61672392 and 61373038) and National Key Research and Development Program of China (No. 2016YFC1202204).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Rights and permissions
About this article

Cite this article
Wang, R., Ying, S., Li, M. et al. HSACMA: a hierarchical scalable adaptive cloud monitoring architecture. Software Qual J 28, 1379–1410 (2020). https://doi.org/10.1007/s11219-020-09524-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11219-020-09524-z