
Abstract
With the explosive growth of academic writing, it is difficult for researchers to find significant papers in their area of interest. In this paper, we propose a pipeline model, named collective topical PageRank, to evaluate the topic-dependent impact of scientific papers. First, we fit the model to a correlation topic model based on the textual content of papers to extract scientific topics and correlations. Then, we present a modified PageRank algorithm, which incorporates the venue, the correlations of the scientific topics, and the publication year of each paper into a random walk to evaluate the paper’s topic-dependent academic impact. Our experiments showed that the model can effectively identify significant papers as well as venues for each scientific topic, recommend papers for further reading or citing, explore the evolution of scientific topics, and calculate the venues’ dynamic topic-dependent academic impact.







Similar content being viewed by others


Notes
References
Bethard, S., & Dan, J. (2010). Who should i cite: Learning literature search models from citation behavior. In ACM conference on information and knowledge management, CIKM 2010, Toronto: Ontario, Canada, October (pp. 609–618).
Blei, D. M., Jordan, M. I., Griffiths, T. L., & Tenenbaum, J. B. (2003a). Hierarchical topic models and the nested Chinese restaurant process. In International conference on neural information processing systems (pp. 17–24).
Blei, D. M., Lafferty, J. D., Blei, D. M., & Lafferty, J. D. (2007). Correction: A correlated topic model of science. Annals of Applied Statistics, 1(2), 634–634.
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003b). Latent Dirichlet allocation. Journal of Machine Learning Research, 3, 993–1022.
Ding, Y. (2011). Topic-based PageRank on author cocitation networks. New York: Wiley.
Erosheva, E., Fienberg, S., & Lafferty, J. (2004). Mixed-membership models of scientific publications. Proceedings of the National Academy of Sciences, 101(suppl 1), 5220–5227.
Fujii, A. (2007). Enhancing patent retrieval by citation analysis. In Proceedings of the 30th annual international ACM SIGIR conference on research and development in information retrieval, ACM (pp. 793–794).
Garfield, E. (2006). Citation indexes for science: A new dimension in documentation through association of ideas. International Journal of Epidemiology, 35(5), 1123–1127.
Gori, M., & Pucci, A. (2007). Research paper recommender systems: A random-walk based approach. In IEEE/WIC/ACM international conference on web intelligence (pp. 778–781).
Griffiths, T. L., & Steyvers, M. (2004). Finding scientific topics. Proceedings of the National Academy of Sciences of the United States of America, 101(1), 5228.
Gross, P. L. K., & Gross, E. M. (1927). College libraries and chemical education. Science, 66(1713), 385–389.
Gyngyi, Z., Garcia-Molina, H., & Pedersen, J. (2004). Combating web spam with trustrank. In Thirtieth international conference on very large data bases (pp. 576–587).
Haveliwala, T. H. (2003). Topic-sensitive pagerank: A context-sensitive ranking algorithm for web search. IEEE Transactions on Knowledge and Data Engineering, 15(4), 784–796.
Jardine, J. G., & Teufel, S. (2014). Topical PageRank: A model of scientific expertise for bibliographic search. In EACL (pp. 501–510).
MacLean, M., Davies, C., Lewison, G., & Anderson, J. (1998). Evaluating the research activity and impact of funding agencies. Research Evaluation, 7(1), 7–16.
Meij, E., & De Rijke, M. (2007). Using prior information derived from citations in literature search. In Large scale semantic access to content (text, image, video, and sound) (pp. 665–670). Le centre de Hautes etudes Internationales D’Informatique Documentaire.
Page, L., Brin, S., Motwani, R., & Winograd, T. (1999). The PageRank citation ranking: Bringing order to the web, Technical report. Stanford InfoLab.
Pal, S. K., & Narayan, B. L. (2005). A web surfer model incorporating topic continuity. IEEE Transactions on Knowledge and Data Engineering, 17(5), 726–729.
Richardson, M., & Domingos, P. (2002). The intelligent surfer: Probabilistic combination of link and content information in pagerank. In Nips (pp. 1441–1448).
Steyvers, M., Smyth, P., Rosen-Zvi, M., & Griffiths, T. (2004). Probabilistic author-topic models for information discovery. In Tenth ACM SIGKDD international conference on knowledge discovery and data mining (pp. 306–315).
Tang, J., Jin, R., & Zhang, J. (2008a). A topic modeling approach and its integration into the random walk framework for academic search. In Eighth IEEE International Conference on Data Mining (pp. 1055–1060).
Tang, J., Zhang, J., Yao, L., Li, J., Zhang, L., & Su, Z. (2008b). Arnetminer: Extraction and mining of academic social networks. In ACM SIGKDD international conference on knowledge discovery and data mining (pp. 990–998).
Walker, D., Xie, H., Yan, K.-K., & Maslov, S. (2007). Ranking scientific publications using a model of network traffic. Journal of Statistical Mechanics: Theory and Experiment, 2007(06), P06010.
Wang, X., Zhai, C., & Roth, D. (2013). Understanding evolution of research themes: A probabilistic generative model for citations. In Proceedings of the 19th ACM SIGKDD international conference on knowledge discovery and data mining, ACM (pp. 1115–1123).
Wu, B., Goel, V., & Davison, B. D. (2006). Topical trustrank: Using topicality to combat web spam. In International conference on world wide web (pp. 63–72).
Yan, E. (2014). Topic-based pagerank: Toward a topic-level scientific evaluation. Scientometrics, 100(2), 407–437.
Yang, Z., Tang, J., Zhang, J., Li, J., & Gao, B. (2009). Topic-level random walk through probabilistic model. In Proceedings of joint international conferences on advances in data and web management, APWeb/WAIM 2009, Suzhou, China, April 2–4 (pp. 162–173).
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Grant Nos. 61602202 and 61603146), the Natural Science Foundation of Jiangsu Province, China (Grant Nos. BK20160427 and BK20160428), Top-notch Academic Programs Project of Jiangsu Higher Education Institutions, the Social Key Research and Development Project of Huaian, Jiangsu, China (Grant No. HAS2015020).
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1: Decrease the preference for older papers
The original PageRank and most of its modifications set the parameter \(\alpha\) to be 0.1 or 0.15 empirically to weight the contribution of the bias probability, which makes them suffer from bias where older papers are favored. The TPM takes a linear age-taper strategy to address this limit, while our CTPM uses another way to address the bias problem. Taking into account that parameter \(\alpha\) determines the contribution proportions of random choice and transition choosing, the CTPM adjusts \(\alpha\) dynamically according to the papers age. Since new papers have fewer opportunities to be cited than older papers, the CTPM gives newer papers a higher value of \(\alpha\) to indicate that the newer papers should have a high probability to be chosen using random choosing. In addition, we made the following assumptions about the influence of the age of the papers. (1) Researchers prefer up-to-date papers which were published in the last 3 years, so the age-taper of the papers in the last 3 years should be slow. (2) For papers whose ages vary from 4 to 10 years, the age-taper is approximatively linear. (3) If papers are older than 10 years, the age-taper will be slow again. For example, a 20-year old paper has nearly the same timeliness as a 15-year old paper. We applied a Gaussian decay function to make the age-taper agree with the above assumptions. The dynamic is set to
where \(g_{d}\) is the age of the paper d; h is the bandwidth parameter to control the age-taper rate. We experimented h with different values and found an appropriate setting of 10. The age-taper curve for \(h=10\) is illustrated in Fig. 8.

The Gaussian age-taper of the CTPM
According to Eq. (20), a new paper would be chosen mainly by random choice. In particular, the latest paper with an age of 0 years would be chosen completely at random, since it has no chance to be cited.
Appendix 2: A simple example to illustrate our algorithm
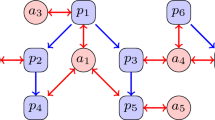
To explain our algorithm more clearly, here, we include an example for illustration. Figure 9 shows a citing network with 4 papers, \(d_{1}\), \(d_{2}\), \(d_{3}\), and \(d_{4}\). Paper \(d_{2}\) is cited by both \(d_{1}\) and \(d_{3}\), and \(d_{3}\) cites both \(d_{4}\) and \(d_{2}\). Here, we describe the calculation of \({\mathrm{TRP}}^{1}(d_{2}|k)\) in detail. The first step is to calculate the Gaussian decay factor of \(d_{2}\); we obtain \(\alpha _{2}\) easily from Eq. 20. Then we need to calculate the \({\mathrm{TRP}}^{0}(d_{2}|k)\). It is also very simple to use the equation \(\frac{r_{d_{2},k}}{r_{d_{1},k}+r_{d_{2},k}+r_{d_{3},k}+r_{d_{4},k}}\). After we initialize \({\mathrm{TPR}}\) for all the papers, we calculate the average value of topic-dependent scores of papers for \(v_{1}\) and \(v_{2}\), respectively, which are denoted as \({{\mathrm{avg}}}_{v_{1}} = \dfrac{{\mathrm{TRP}}^{0}(d_{1}|k)+{\mathrm{TRP}}^{0}(d_{2}|k)}{2}\) and \({{\mathrm{avg}}}_{v_{2}} = \dfrac{{\mathrm{TRP}}^{0}(d_{3}|k)+{\mathrm{TRP}}^{0}(d_{4}|k)}{2}\). Then the initial topic-dependent scores of \(v_{1}\) and \(v_{2}\) are \(V^{0}(v_{1}|k)=\dfrac{{{\mathrm{avg}}}_{v_{1}}}{{{\mathrm{avg}}}_{v_{1}}+{{\mathrm{avg}}}_{v_{2}}}\) and \(V^{0}(v_{2}|k)=\dfrac{{{\mathrm{avg}}}_{v_{2}}}{{{\mathrm{avg}}}_{v_{1}}+{{\mathrm{avg}}}_{v_{2}}}\). So far, we have finished the initialization work and will enter the first iteration. For \(d_{2}\), the bias probability is calculated by the following equation:
In our algorithm, the most complicated step is the calculation of the transition probabilities. For \(d_{2}\), there are 2 papers \(d_{1}\) and \(d_{3}\) citing it, thus the transition probabilities \(T(d_{2}|d_{1},k)\) and \(T(d_{2}|d_{3},k)\) will be greater than 0 and others will be 0. The calculation of \(T^{1}(d_{2}|d_{3},k)\) requires 3 steps to complete. The first step is obtaining \(T^{'}(d_{2}|d_{3},k)\), which can be calculated using Eq. 8 and considering \(L_{d_{3}} = \{d_{2},d_{4}\}\):
The second step is obtaining \(T^{''}(d_{2}|d_{3},k)\). Because \(C_{d_{2}}=\{d_{1},d_{3}\}\), it can be calculated using Eq. 9:
In the last step, we calculate \(T^{1}(d_{2}|d_{3},k)\) as follows according to Eq. 10:
where the calculation of \(T^{''}(d_{4}|d_{3},k)\) is similar to \(T^{''}(d_{2}|d_{3},k)\). The calculation of another transition probability \(T^{1}(d_{2}|d_{1},k)\) follows the same process of \(T^{1}(d_{2}|d_{3},k)\). Once we have calculated \(\alpha _{2}\), \(B^{1}(d_{2}|k)\), \(T^{1}(d_{2}|d_{3},k)\) and \(T^{1}(d_{2}|d_{3},k)\), the \({\mathrm{TRP}}^{1}(d_{2}|k)\) can be obtained easily with Eq. 4, which is defined as follows:

A citing network with 4 papers. \(d_{1}\) and \(d_{2}\) are published in the venue \(v_{1}\), \(d_{3}\) and \(d_{4}\) are published in the venue \(v_{2}\)
Rights and permissions
About this article

Cite this article
Zhang, Y., Ma, J., Wang, Z. et al. Collective topical PageRank: a model to evaluate the topic-dependent academic impact of scientific papers. Scientometrics 114, 1345–1372 (2018). https://doi.org/10.1007/s11192-017-2626-1
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-017-2626-1