
Abstract
We examine how the patterns of inter-industry trade flows impact the transfer of information and economic shocks. We provide evidence that the intensity of transfers depends on industries’ positions within the economy. In particular, some industries occupy central positions in the flow of trade, serving as hubs. Consistent with a diversification effect, we find that these industries’ returns depend relatively more on aggregate risks than do returns of noncentral industries. Analogously, we find that the accounting performance of central industries associates more strongly with macroeconomic measures than does the accounting performance of noncentral industries. Comparing central industries to noncentral ones, we find that the stock returns and accounting performance of central industries better predict the performance of industries linked to them. This suggests that shocks to central industries propagate more strongly than shocks to other industries. Our results highlight how industries’ positions within the economy affect the transfer of information and economic shocks.


Similar content being viewed by others
Notes
Later in the introduction, we discuss why we conduct our analysis at the industry-level rather than the firm-level.
To give an analogy, miners conduct most of the activity in a coal mine, but what happens to the canary can be quite informative about conditions in the mine.
Software publishing provides another example that the notion of trade-based centrality is distinct from the bellwether effect. Based on trade data, we classify software publishing as having very low centrality. This classification may stem from the software publishers relying on labor as its primary input, as opposed to trade with other industries. Bonsall et al. (2013) classify 27 software publishers as bellwether, based on how informative their forecasts are about the overall economy.
For example, US firms are required to disclose only major customers that comprise at least 10 % of revenues. This limits disclosures to a fairly small number of large customers and provides limited ability to track the economy-wide flow of trade. According to customer and supplier links data compiled from Compustat and available on Andrea Frazzini’s website, there were 454 firms with usable sales data in 1997, the vintage of BEA data we utilize. This is a small fraction of 12,000 firms on Compustat in that year, and, according to Cohen and Frazzini (2008), the disclosed customers tend to be larger than their suppliers.
As Lucas (1977) and others argue, in highly disaggregated economies, idiosyncratic shocks will remain fairly confined. While Dupor (1999) and Horvath (1998, 2000) debate on whether sectoral shocks can transfer into aggregate fluctuations, Acemoglu et al. (2012) provide a more complete answer to this question by showing that sectoral shocks can lead to aggregate fluctuations only when there is heterogeneity in the links between sectors. With heterogeneous links, shocks to hub sectors can lead to aggregate shocks. Gabaix (2011) provides a similar model using firm-level shocks as a source of aggregate fluctuations.
Like these studies, we focus on trade flows in 1997 since this year is the approximate midpoint of our sample period. The BEA has been publishing input–output tables every five years until 2007, when the BEA published the 2007 data in December 2013, after we completed our study. However, inasmuch as the industry definitions vary in each version of these tables, it is not possible to form a consistent time series based on different versions of input–output tables. Because there are relatively minor changes between 1997 and 2002 industry classifications, we recompute our centrality measure using the 2002 data and find that the correlation between the 1997 centrality and the 2002 centrality is high at 96 %. As a robustness check we also replicate our baseline specifications using a combination of the 1997 and 2002 tables for the pre- and post-1999 periods, respectively. These replications yield qualitatively similar results.
Prior versions of the paper relied solely on the Use table and obtained similar results.
The BEA’s “special industries” category includes noncomparable imports (industry code S003), scrap, used, and secondhand goods (S004), rest of world adjustment (S006), and inventory valuation adjustment (S007). We do not include government/special industry/value added/final uses industries in the calculation of the strength measure because of the difficulties in the interpretation of certain associations (e.g., negative sales values, changes in private inventories, etc.). In the calculation of the strength measure, we include private consumption expenditures to calculate total sales numbers so that our measures gauge importance relative to overall sales, rather than strictly business-to-business sales.
In the interest of maintaining the paper’s focus, we briefly describe the eigenvector centrality measure here and refer interested readers to textbook treatments (e.g., Jackson 2008 or Newman 2010) or Borgatti (2005) for discussions of centrality metrics. The term arises because the vector c of centralities can be defined from (2) as λ c = Ac, which is an eigenvalue equation for the matrix A. Other notions of centrality, such as betweenness and closeness, pertain to shortest paths between industries and do not seem particularly relevant to our setting (See, e.g., Borgatti 2005). For example, the iron and steel industry’s economic importance likely stems more from its use in a variety of outputs than it having a short route from production to final consumption.
We obtain similar results using an alternative measure, degree centrality, which is a strength-weighted count of an industry’s neighbors, ((Σ j A ij )/(# industries − 1)). We report results for the eigenvector measure because it is more comprehensive, reflecting higher order links such as neighbors of neighbors, and because of its common use in the literature on networks. Table 1, Panel A, omits the 6th ranked industry, “monetary authorities, credit intermediation and related activities,” because we exclude financial institutions from our analyses. In other words, the 22 most central industries are those listed in Table 1, Panel A, plus “monetary authorities/credit intermediation.” For the same reason, Panel B omits “funds/trusts” and “insurance carriers.”
In particular, our analyses remain qualitatively similar when using a cutoff of 0.12, or 11 % of the distribution of industries, when using a cutoff of 0.10, or 20 % of the industries. The 0.109 cutoff classifies 22 industries as central—the 21 listed in Table 1, Panel A, plus “monetary authorities, credit intermediation and related activities,” which is ranked 6th in the trade data used to compute centrality, but we omit it from the table because we exclude financial institutions.
In some settings, such as in per share regressions, R2 can be problematic due to scale effects (e.g., Brown et al. 1999, Liu and Ohlson 2000). Scale impacts the R2 for reasons having nothing to do with the model being estimated. Our approach of using R2s from returns regressions as the dependent variable parallels its use in studies of stock return synchronicity (e.g., Morck et al. 2000; Durnev et al. 2003; Piotroski and Roulstone 2004) and earlier work such as Roll (1988). In the synchronicity tests, as in ours, the R2 has the clear interpretation as simply measuring the amount of return variation accounted for by explanatory factors.
We use industry definitions as of the end of each estimation window. Because NAICS codes became available in 1985, our estimation starts with the 1981–1985 window, and we estimate regressions for 1981–1985, 1982–1986, and so on until 2007–2011. Table 3 reports double-clustered standard errors on year and industry to control for the within-industry correlation of residuals caused by overlapping periods, and for the within-time correlation caused by the regression potentially having a better fit in some years than in others (Thompson 2011).
This controls for the fact that the market price of a stock will remain the same if the stock is not traded during a given period, which would result in a low R2.
Table 3 compares means and the overall distributions, while untabulated analysis also indicates that the percentiles of the factor loadings are roughly similar for central and noncentral industries.
In untabulated analyses, we confirm that our results are qualitatively unchanged when using OLS regressions, regressions where continuous variables are replaced with their ranks, and in an OLS regression of the log-odds ratio log(R2/(1 − R2)), similar to that used by Piotroski and Roulstone (2004). Prior work has shown that analysts tend to be industry-focused (Boni and Womack 2006; Kadan et al. 2012). If analysts find it relatively more attractive to cover central industries, this could cause the analyst coverage control variable to absorb some of the effect of centrality; however, we have been unable to devise a way to distinguish how much, if any, of the relation between analyst coverage and R2 stems from an indirect impact of centrality. Untabulated analysis shows that the coefficient on centrality is similar but slightly lower in regressions that exclude the analyst coverage control.
Our results are similar when defining industry ROA as the industry’s total earnings divided by the average of beginning and ending total industry assets, which is equivalent to using asset weights rather than market value weights to compute industry ROA.
Normalizing the weights removes any mechanical relation between centrality and the dependent variable (see expression 2).
We tested for a difference in the coefficients using a single regression where we interact all of the explanatory variables with an indicator variable that equals one for the portfolios of central linked industries. The test for the difference between the central and noncentral linked industries’ Central × Source ROA Change coefficients is not significant at conventional levels.
In the regressions for future returns, the significance of the interaction coefficient Central × Returns source is sensitive to alternative treatments. For example it loads positive and significantly when using a different cutoff for the centrality variable at 0.10 or when replacing our measure of eigenvector centrality with weighted degree centrality. Similar to the ROA cross-predictability tests, we ran the returns tests separating the linked industry portfolios into central and noncentral industries. As in Table 5, we find that centrality only has an incremental effect on concurrent returns. Similar to the ROA tests that separate the linked portfolios by centrality, the coefficient on centrality and the t statistic are larger for the portfolio of noncentral linked industries, but the difference between the coefficients is not statistically significant at conventional levels.
All industries have degrees ranging from 119 to 122 if we do not exclude weak links because every industry has some, albeit small, amount of trade with nearly every other industry.
References
Acemoglu, D., Carvalho, V. M., Ozdaglar, A., & Tahbaz-Salehi, A. (2012). The network origins of aggregate fluctuations. Econometrica, 80(5), 1977–2016.
Ahern, K. (2012). Network centrality and the cross section of stock returns. Working paper, University of Southern California.
Ahern, K., & Harford, J. (2013). The importance of industry links in merger waves. Journal of Finance, 69(2), 527–576.
Anilowski, C., Feng, M., & Skinner, D. J. (2007). Does earnings guidance affect market returns? The nature and information content of aggregate earnings guidance. Journal of Accounting and Economics, 44(1–2), 36–63.
Anjos, F., & Fracassi, C. (2012). Shopping for information? Diversification and the network of industries. Working Paper, University of Texas.
Bernard, V. L., & Thomas, J. K. (1990). Evidence that stock prices do not fully reflect the implications of current earnings for future earnings. Journal of Accounting and Economics, 13(4), 305–340.
Bonacich, P. B. (1972). Factoring and weighing approaches to status scores and clique identification. Journal of Mathematical Sociology, 2(1), 113–120.
Boni, L., & Womack, K. (2006). Analysts, industries, and price momentum. Journal of Financial and Quantitative Analysis, 41(1), 85–109.
Bonsall, S., Bozanic, Z., & Fischer, P. E. (2013). What do management earnings forecasts convey about the macroeconomy? Journal of Accounting Research, 51(2), 225–266.
Borgatti, S. (2005). Centrality and network flow. Social Networks, 27(1), 55–71.
Brown, S., Lo, K., & Lys, T. (1999). Use of R2 in accounting research: Measuring changes in value relevance over the last four decades. Journal of Accounting and Economics, 28(2), 83–115.
Clinch, G., & Sinclair, N. (1987). Intra-industry information releases: A recursive systems approach. Journal of Accounting and Economics, 9(1), 89–106.
Cohen, L., & Frazzini, A. (2008). Economic links and predictable returns. Journal of Finance, 63(4), 1977–2011.
Cready, W., & Gurun, U. (2010). Aggregate market reaction to earnings announcements. Journal of Accounting Research, 48(2), 289–334.
Dupor, B. (1999). Aggregation and irrelevance in multi-sector models. Journal of Monetary Economics, 43(2), 391–409.
Durnev, A., Morck, R., Yeung, B., & Zarowin, P. (2003). Does greater firm-specific return variation mean more or less informed stock pricing? Journal of Accounting Research, 41(5), 797–836.
Foster, G. (1981). Intra-industry information transfers associated with earnings releases. Journal of Accounting and Economics, 3(3), 201–232.
Gabaix, X. (2009). Power laws in economics and finance. Annual Review of Economics, 1, 255–293.
Gabaix, X. (2011). The granular origins of aggregate fluctuations. Econometrica, 79(3), 733–772.
Hong, H., Torous, W., & Valkanov, R. (2007). Do industries lead stock markets? Journal of Financial Economics, 83(2), 367–396.
Horvath, M. (1998). Cyclicality and sectoral linkages: Aggregate fluctuations from sectoral shocks. Review of Economic Dynamics, 1(4), 781–808.
Horvath, M. (2000). Sectoral shocks and aggregate fluctuations. Journal of Monetary Economics, 45(1), 69–106.
Jackson, M. (2008). Social and economic networks. Princeton, NJ: Princeton University Press.
Kadan, O., Madureira, L., Wang, R., & Zach, T. (2012). Analysts’ industry expertise. Journal of Accounting and Economics, 54(2–3), 95–120.
Kelly, P. J. (2005). Information efficiency and firm-specific return variation. Working Paper, New Economic School, Moscow.
Liu, J., & Ohlson, J. (2000). The Feltham–Ohlson (1995) model: Empirical implications. Journal of Accounting, Auditing and Finance, 15(3), 321–331.
Lucas, R. E. (1977). Understanding business cycles. Carnegie-Rochester Conference Series on Public Policy, 5, 7–29.
Menzly, L., & Ozbas, O. (2010). Market segmentation and cross-predictability of returns. Journal of Finance, 65(4), 1555–1580.
Montgomery, J., & Vames, S. (1998, June 23). Strike at GM could weigh down second-quarter GDP in U.S. The Wall Street Journal.
Morck, R., Yeung, B., & Yu, W. (2000). The information content of stock markets: Why do emerging markets have synchronous stock price movements? Journal of Financial Economics, 58(1–2), 215–260.
Moskowitz, T. J., & Grinblatt, M. (1999). Do industries explain momentum? Journal of Finance, 54(4), 1249–1290.
Newman, M. (2010). Networks: An introduction. Oxford: Oxford University Press.
Pandit, S., Wasley, C. E., & Zach, T. (2011). Information externalities along the supply chain: The economic determinants of suppliers’ stock price reaction to their customers’ earnings announcements. Contemporary Accounting Research, 28(4), 1304–1343.
Papke, L. E., & Wooldridge, J. M. (1996). Econometric methods for fractional response variables with an application to 401(k) plan participation rates. Journal of Applied Econometrics, 11(6), 619–632.
Piotroski, J. D., & Roulstone, D. T. (2004). The influence of analysts, institutional investors, and insiders on the incorporation of market, industry and firm-specific information into stock prices. The Accounting Review, 79(4), 119–1151.
Roll, R. (1988). R2. Journal of Finance, 43(3), 541–566.
Shepardson, D. (2009, November 24). Fixing Detroit’s automakers one year later (first of two parts); The inside story of the GM, Chrysler bailouts. The Detroit News.
Shivakumar, L. (2007). Aggregate earnings, stock market returns and macroeconomic activity: A discussion of ‘Does earnings guidance affect market returns? The nature and information content of aggregate earnings guidance’. Journal of Accounting and Economics, 44(1–2), 64–73.
Shivakumar, L. (2010). Discussion of aggregate market reaction to earnings announcements. Journal of Accounting Research, 48(2), 335–342.
Thompson, S. (2011). Simple formulas for standard errors that cluster by both firm and time. Journal of Financial Economics, 99(1), 1–10.
Acknowledgments
We thank David Aboody, Sam Bonsall, Paul Fischer (editor), Robert Freeman, Rebecca Hann (RAST discussant), Adrienna Huffman (AAA discussant), Jack Hughes, Gil Sadka, Brett Trueman, an anonymous referee, and seminar participants at Columbia University, University of Texas Austin, the 2013 Temple University Accounting Conference, the 2013 Review of Accounting Studies Conference, and the American Accounting Association 2013 Annual Meeting for helpful comments. We also thank Sam Bonsall for providing data that identify bellwether firms.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1
See Table 7.
Appendix 2: Additional details on centrality measure
This appendix provides additional discussion of the measurement of centrality. Figure 3 replicates Fig. 1 from the main body, with the exception that we use shapes other than squares to denote industries included in the discussion of this appendix. The triangle denotes “petroleum and coal products,” the pentagon denotes “employment services,” and the hexagon denotes “wholesale trade.”

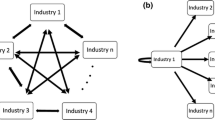
Inter-industry network based on BEA input/output tables. The inter-industry network based on the U.S. input–output matrix of 1997 provided by the BEA. Each node corresponds to an industry (based on BEA’s four-digit industry code), and each edge corresponds to a link between industries with strength (A ij ) of 3 % or more. See Sect. 2.1 for the definition of strength of the link between two industries. The triangle, pentagon, and hexagon show the petroleum and coal products, employment services, and wholesale trade industries, respectively, which we refer to in the discussion in this appendix. These three nodes, along with the square nodes, indicate industries with a centrality score above the 0.109 threshold that we use to indicate central industries, as we discuss in Sect. 3.2
A basic measure of an industry’s centrality is the raw number of industries it trades with, which is called the industry’s degree. This metric ranks wholesale trade as the most central industry, while petroleum and coal and employment services share the rank of 11th most central based on Figure B where we omit weak linkages between industries.Footnote 21 Representing the network by the matrix A, with elements A ij = A ji = 1 if industry i trades with industry j, and A ii = 0, an industry’s degree is d i = Σ j A ij .
The simple count of links fails to distinguish the relative importance of an industry’s trading partners. For example, visual inspection of Figure B suggests that employment services, the pentagon, has more highly connected trading partners than petroleum and coal, the triangle. The eigenvector centrality metric addresses this. Instead of counting links (d i = Σ j A ij ), eigenvector centrality weights the links by their importance, c i = Σ j A ij c j . With this metric, wholesale trade, the hexagon in Figure B, maintains the highest centrality. Employment services has the eighth highest rank, which exceeds the degree-based rank of 11 on account of Employment Services interacting with relatively important sectors of the economy. Petroleum and coal ranks as 36th in terms of eigenvector centrality. Because petroleum and coal plays a relatively peripheral role in this example where we do not distinguish links by strength of trade, its importance in terms of eigenvector centrality drops significantly relative to its rank in terms of degree.
The eigenvector centrality metric that we discuss in the preceding examples suffers from a shortcoming that we remedy in the measure used in our main analysis. The examples fail to account for heterogeneity in the amount of trade between industries. In our main analysis, we allow the matrix A of trade links to reflect the strength of trade. This has substantial effects on industries’ rankings. For example, petroleum and coals’ eigenvector centrality ranks as 11th, rather than 36th, while employment services drops to 16th when we account for the amount of trade they conduct with other industries.
Rights and permissions
About this article

Cite this article
Aobdia, D., Caskey, J. & Ozel, N.B. Inter-industry network structure and the cross-predictability of earnings and stock returns. Rev Account Stud 19, 1191–1224 (2014). https://doi.org/10.1007/s11142-014-9286-7
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11142-014-9286-7