
Abstract
Purpose
Unsupervised item-response theory (IRT) models such as polytomous IRT based on recursive partitioning (IRTrees) and mixture IRT (MixIRT) models can be used to assess differential item functioning (DIF) in patient-reported outcome measures (PROMs) when the covariates associated with DIF are unknown a priori. This study examines the consistency of results for IRTrees and MixIRT models.
Methods
Data were from 4478 individuals in the Alberta Provincial Project on Outcome Assessment in Coronary Heart Disease registry who received cardiac angiography in Alberta, Canada, and completed the Hospital Anxiety and Depression Scale (HADS) depression subscale items. The partial credit model (PCM) based on recursive partitioning (PCTree) and mixture PCM (MixPCM) were used to identify covariates associated with differential response patterns to HADS depression subscale items. Model covariates included demographic and clinical characteristics.
Results
The median (interquartile range) age was 64.5(15.7) years, and 3522(78.5%) patients were male. The PCTree identified 4 terminal nodes (subgroups) defined by smoking status, age, and body mass index. A 3-class PCM fits the data well. The MixPCM latent classes were defined by age, disease indication, smoking status, comorbid diabetes, congestive heart failure, and chronic obstructive pulmonary disease.
Conclusion
PCTree and MixPCM were not consistent in detecting covariates associated with differential interpretations of PROM items. Future research will use computer simulations to assess these models’ Type I error and statistical power for identifying covariates associated with DIF.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Patient-reported outcomes measures (PROMs) are multi-item questions that elicit patients’ appraisals of their health status and quality of life [1, 2]. PROMs are useful for evaluating treatment efficacy in clinical trials from a patient perspective and comparing population groups for quality improvement [3,4,5]. Comparing PROM scores among population subgroups relies on the assumption that the measurement model, which describes the relationship between the observed items and the latent construct being measured, is equivalent across these subgroups [6, 7]. This is generally of interest when PROMs are used in potentially heterogeneous populations where respondents may differ in how they interpret and respond to questions about their health and quality of life, a phenomenon known as differential item functioning (DIF). DIF arises when heterogeneity in interpretation and response to the PROM questions are associated with patient characteristics unrelated to the construct of interest being measured [8]. When DIF is ignored in PROM items, the estimated distribution of the PROM scores across population subgroups is biased. Failure to account for DIF in PROM items could affect inferences about PROM scores and their use for supporting decisions in healthcare [8,9,10]. For example, if patient subgroups consistently provide lower ratings on items of a depression PROM than other subgroups based on their socio-demographic characteristics, this could result in biased estimates of the between-group difference in PROM scores. Incorrect inferences about the meaning of the PROM scores can arise and affect clinical and health policy decisions. This, in turn, could lead to missed opportunities to address pertinent health issues for patients during routine physician visits and reduced access to mental health services.
Existing methods to test for DIF in PROM are mainly group-based methods that assume potentially relevant differences in the target populations are known a priori and can be explained by observed variables such as socio-demographics or health status [11,12,13,14,15,16]. Also, these multigroup methods evaluate DIF in PROMs items one observed variable at a time. Applying these methods to test for DIF in PROM items in heterogeneous populations where unknown or multiple interacting variables could explain DIF may become onerous with an increasing number of variables.
Unsupervised item response theory (IRT) [16,17,18,19,20,21] models, which combine IRT models with unsupervised learning methods (e.g., recursive partitioning or mixture models), are an alternative class of IRT models that overcome this limitation by identifying subgroups of patients with different patterns of DIF when patient characteristics associated with DIF are not known a priori. These models include IRT models based on the recursive partitioning method (IRTree) and mixture IRT (MixIRT) models. MixIRT model, first proposed by Rost [17], combines latent class models with an IRT modeling framework to identify latent classes across which the IRT parameters are non-invariant. MixIRT models have also been applied to test for DIF [22,23,24,25] but can be challenging to implement because of model identification issues [20]. On the other hand, IRTree models such as the Rasch trees [18], polytomous Rasch trees [19], and item-focused trees [20, 21], have been developed to identify DIF items when the variables associated with DIF are not known a priori. With these methods, there is no need to specify variables associated with DIF a priori because they are automatically detected using a data-driven approach.
To date, there has not been any investigation of the comparative performance of IRTree and MixIRT models for detecting DIF in PROMs. The aim of our study was to investigate the consistency of results for these two models. Since these two methods differ in their approach to evaluating MI, we hypothesize that these two methods will be consistent in detecting the presence of heterogeneity but will differ with respect to the number of homogeneous subgroups identified. The manuscript is organized as follows. “Methods” section describes these models and compares their statistical properties. “Numeric example” section applies these models to data from a clinical registry of patients with coronary artery disease who received cardiac angiograms. “Discussion” section discusses the methodological implications of the study findings, the strengths and limitations of the methods, and opportunities for further research.
Methods
Partial credit model
Consider a partial credit model (PCM) [26], a polytomous model commonly used for modeling ordinal data, including items comprising PROMs. Let \({Y}_{im}\) denote the \(i\) th individual’s response to the \(m\) th item. The PCM is defined as,
where \(P\left({Y}_{ijm}\ge j| {\tau }_{mj},{\theta }_{i}\right)\) is the \(i\) th individual’s probability of response \(j\)(\(j\) = 1,…,\(J\)) on the \(m\) th (\(m\) = 1,2,…,\(M\)) item, \({\tau }_{mj}\) denotes the threshold between the (j−1)th and jth category (j = 1,…, J) for the \(m\) th item, and \({\theta }_{i}\) is the \(i\) th patient’s latent factor score, which is often assumed to be distributed as \({\theta }_{i} \sim N\)(0,1). While this study considered the PCM, tree-based and mixture models can be generalized to other polytomous IRT models [27].
Tree-based partial credit model (PCTree)
The PCTree is an unsupervised latent variable model that combines the PCM and recursive partitioning to identify subgroups for which the PCM parameters differ. That is, the PCTree uses input covariates to repeatedly partition the entire sample into homogenous subgroups with respect to the model parameters. Komboz et al. [20] developed a 4-step approach for implementing a PCTree [18]:
-
1.
In Step 1, the PCM is fitted to the entire sample, and the model parameters are estimated via conditional likelihood estimation.
-
2.
In Step 2, the stability of item threshold parameters is assessed for each covariate by conducting structural change tests. Each structural change test involves ordering the contributions of each study respondent to the joint loglikelihood score function of the PCM model for each covariate. DIF is detected, for a covariate, if the ordering of the structural change test statistics for all possible cut-points on that covariate exhibits a systematic change in the individual deviations.
-
3.
In Step 3, among all model covariates, the covariate with the smallest p-value for the structural change test is selected for splitting the entire sample into two subgroups (i.e., child nodes). After a covariate has been selected for splitting, the optimal cut-point on this covariate is determined by maximizing the partitioned loglikelihood (i.e., the sum of the loglikelihoods for two separate models: one for the observations to the left and up to the cut-point, and one for the observations to the right of the cut-point), over all potential (\(r\)–1) cut points, where \(r\) is the number of possible values on a covariate. For categorical values, there are \(r\)–1 cut points.
-
4.
In Step 4, Steps 1–3 are repeated recursively in the child nodes until one of two stopping criteria is reached:
-
I.
Bonferroni correction criterion recursive partitioning of the sample stops if no further significant parameter instability exists for any covariates across all subgroups. Given that multiple structural change tests could result in an inflated familywise Type I error, a Bonferroni correction is applied to α, such that \({\alpha }{\prime}={\alpha }{\prime}/m\), where \(m\) = number of tests conducted.
-
II.
Minimum terminal node size criterion this involves pre-specifying a minimum sample size for each terminal node. A recommended simple rule of thumb is to set the minimum node size to be 10 times the average number of parameters per item.
-
I.
The mixture PCM
The mixture PCM (MixPCM) [17] aims to uncover heterogeneity by allowing model parameters to vary across two or more latent classes23 such that:
where the unconditional probability of response j to the \(m\) th item (irrespective of class membership is.
where it is assumed that \({\theta }_{i}\sim N(\mathrm{0,1})\) is the latent trait level for the \(i\) th patient i, \({\tau }_{mjc}\) denotes the threshold between the (j-1)th and jth category (j = 1,…, J) for the \(m\) th item in the \(c\) th class, and \({\pi }_{c}\) is the mixing proportion that defines the relative sizes of the latent classes, and can be explained by sample characteristics (e.g., demographic, or clinical characteristics) such that \(\sum_{c=1}^{C}{\pi }_{c}=1\).
The MixPCM is implemented using a four-step approach:
-
1.
In Step 1, a one-class PCM, which assumes no heterogeneity, is fit to the data. The tenability of the unidimensionality assumption can be assessed using exploratory factor analysis using polychoric correlation with GEOMIN rotation [28,29,30] or parallel analysis [31]. The unidimensionality assumption is considered satisfied if the ratio of the first and second eigenvalues is greater than 3. If unidimensionality is not a tenable assumption, then MixPCM is not appropriate for testing sample heterogeneity in the data. If the assumption of unidimensionality is satisfied, proceed to step 2.
-
2.
For Step 2, specify MixPCM with increasing numbers of latent classes by allowing the PCM threshold parameters to vary across the latent classes while the latent factor means and standard deviations are constrained to be equal for identifiability purposes.
-
3.
In Step 3, determine the optimal number of latent classes for the MixPCM using the Bayesian Information Criterion (BIC) [32, 33], Vuong-Lo-Mendel-Rubin likelihood ratio test (VLMR)[3, 34], bootstrap likelihood ratio test, and model entropy. The VLMR is used to compare the goodness of fit of models with k, and (k + 1) latent classes; a non-significant VLMR test (p > 0.05) prefers the model with the smaller number. Model entropy is used to assess the certainty of class membership (values > 0.8 indicate high confidence in latent class assignment [35]). For the BIC, the optimal model has the smallest BIC value.
-
4.
For the final step, the association of covariates with the estimated latent class membership is explored either via a one-step approach or a three-step approach [35, 36]. In the former, the known covariates are incorporated into the mixture IRT modeling to estimate the posterior probability of latent class membership, conditional on the covariates. The effects of the covariate on class membership are estimated simultaneously, along with the class-specific item parameters. The MixIRT modeling estimates the posterior probability of latent class membership based on the item response data in the three-step approach. In the second step, the class membership is derived based on the most probable posterior probability of class assignment. In the third step, the covariate effects on class membership are estimated using multinomial logistic regression with pseudo draws to account for imperfect classification is used to estimate the covariate effects.
Numeric example
Data source
The consistency between the MixPCM and PCTree was examined by analyzing existing population-based data. Data were from the Alberta Provincial Project for Outcome Assessment in Coronary Heart Disease (APPROACH) registry, a population-based database of all adults who received cardiac catheterization in Alberta, Canada [37]. The APPROACH registry maintains one of the most comprehensive data repositories of individuals with coronary artery disease (CAD). The registry includes detailed data on patients’ demographic and clinical characteristics. This registry was chosen because (1) it is made up of heterogeneous CAD patients with varying degrees of CAD severity, different types of treatments received, different experiences with the healthcare system, and diverse demographic and behavioral characteristics, and (2) collects both generic and cardiac-specific patient-reported HRQOL measures. The Hospital Anxiety and Depression Scale (HADS) was selected as a PROM to be investigated for potential DIF effects. Our choice of the HADS for this study was motivated by the unidimensional nature of the HADS subscales (i.e., anxiety and depression subscales) and its excellent psychometric properties for screening for depression in individuals with CAD [38, 39]. The HADS is a self-administered 14-item generic measure of psychological distress comprising two subscales: depression and anxiety [40]. The response options for the HADS items range from zero to three: higher scores indicate more severe depression and/or anxiety. We limited our attention to the depression subscale items.
The study cohort included all adult Alberta residents who (1) underwent a first cardiac catheterization between January 1, 2002, and December 31, 2017, (2) had at least 1-vessel CAD (Duke Coronary Index between 3 and 13), and (3) completed the HADS two weeks after the procedure. In addition to the HADS, data were collected on demographic characteristics (sex, age), multiple comorbid conditions, disease severity, and coronary angiography results. Ethics approval for this study was obtained from the University of Calgary Conjoint Health Research Ethics Board (REB15-1195).
Statistical analyses
Descriptive statistics were used to summarize the patient’s demographic and clinical characteristics. The assumption of the unidimensionality for the depression items of the HADS was evaluated using parallel analyses and several goodness-of-fit statistics [30, 41,42,43,44,45], including the information-weighted fit mean square error statistic (Infit MNSQ), outlier-sensitive fit statistic (Outfit MNSQ), root mean square error of approximation (RMSEA), comparative fit index (CFI), and standardized root mean square residual (SRMSR). An item with infit MNSQ or outfit MNSQ outside the 0.5–2.0 range is considered a misfit to the PCM [42].
The PCTree and MixPCM were used to identify subgroups of patients with different patterns of DIF or no DIF. Patients’ socio-demographics [sex and age (< 75 years vs\(.\ge\) 75 years)] and clinical characteristics (procedure indication, smoking status, body mass index (BMI), and comorbid conditions) were selected as covariates. Several studies have examined the presence of DIF in HADS items for patient’s demographic characteristics, such as age and sex [46,47,48]. In particular, previous studies have reported age differences in quality of life and risk of adverse health outcomes in elderly (\(\ge\) 75 years) heart disease patients compared to younger (< 75 years) patients [49,50,51]. Although there is a limited investigation of DIF in patient-reported HADS item responses with respect to their clinical and disease characteristics, these patient characteristics are known risk factors for depressive symptoms in CAD patients [51,52,53,54].
For the PCTree model, the minimum sample size for each terminal node was set at 250 as a stopping criterion for the recursive partitioning, which also allows for a sufficient sample size for within-node parameter estimation [20]. To facilitate comparability of the models, the covariates were simultaneously incorporated into the MixPCM to estimate class-specific model parameters and the effects of the covariates on latent class membership. Finally, for each method, multinomial logistic regression models were used to test the covariates (i.e., patients’ demographic and disease characteristics) associated with the identified subgroups.
The PCTree analysis and other analyses were implemented in R software [55], while the MixPCM was implemented in Mplus v8.1 [56]. Statistical significance for the analyses was set at \(\alpha\)= 0.05, except when stated otherwise.
Results
Table 1 describes the patient characteristics. Of the 4478 patients who completed the HADS, 3522 (78.7%) were male, and 815 (18.2%) were 75 years or older. The majority of patients (69.3%) had acute coronary syndrome as the clinical disease. Hypertension and hyperlipidemia were the most frequent comorbid conditions. About 75% of patients endorsed “often,” on ‘I can laugh and see the funny side of things’ and ‘I can enjoy a good book or radio or TV program’ items. In contrast, less than 5% of the patients endorsed “very seldom,” on “I can laugh and see the funny side of things”, “I look forward with enjoyment to things”, or “I can enjoy a good book or radio or TV program” (Online Table A1). Given that there were a number of sparse response categories, those categories endorsed by less than 1.5% of the sample were merged with the adjacent response categories.
The conventional one-class PCM provided a good fit for the data. Specifically, the item Infit MNSQ and Outfit MNSQ values were well within the recommended 0.5–2.0 interval (Online Table A2). Additionally, parallel analysis reveal a dominant principal factor; the ratio of the first and second principal factors was approximately 30.2 and acceptable RMSEA, CFI, and SRMSR values, suggesting that the assumption of unidimensionality of the HADS depression items was satisfied (Online Tables A2 & A3).
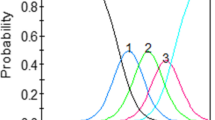
The PCTree identified four terminal nodes (i.e., subgroups) of patients defined by the interaction among smoking status, age, and BMI (Fig. 1). The entire sample was first partitioned using the smoking status variable, indicating that this was the most important variable that explained sample heterogeneity in the HADS depression subscale items. The first terminal node, which accounted for 23.7% of the sample, consisted of current smokers. The second terminal node (16.9%) included non-smokers older than 75. The third terminal node (20.8%) was comprised of older (i.e., > 75 years) non-smokers with BMI > 30.4, while the final terminal node (38.5%) consisted of patients at most 75 years and non-smoking with BMI \(\le\) 30.4. The region plots in these terminal nodes of the PCTree model in Fig. 1 show patterns of differences in the HADS items and item response categories for which patients had inconsistent patterns of responses. For example, for item #2 (“I can laugh and see the funny side of things”), the region of the second category, shaded in the second darkest gray color, was largest for patients who are smokers and lowest for non-smoking patients who are < 75 years and with a BMI > 30.422. Similarly, for item 2 (I feel cheerful), the region of the second category, shaded in the second darkest gray color, was largest for smokers and lowest for non-smoking patients < 75 years. Results from multinomial logistic regression analysis revealed that the variance inflation factors were all < 5, which indicates the absence of multicollinearity among the covariates. Significant differences exist among the terminal nodes with respect to sex, procedure indication, disease complexity, diabetes, hyperlipidemia, myocardial infarction, cerebrovascular disease, chronic obstructive pulmonary disease (COPD), and hypertension (Table 2).

IRTree model for HADS depression subscale items, N = 4478. Age = 0 (< 75 years) or 1 (\(\ge\) 75 years); smoking status = 0 (Non-smoker) or 1 (crrent smoker); BMI body mass index; Red dashed lines = items with reversed thresholds; region plots (dark and light grey regions) = regions of most probable category responses of an item. They are depicted for each item with the estimated threshold parameters of the partial credit model in the corresponding node. (Color figure online)
For the MixPCM, we fitted one-, two-, and three-class models to the data; models with more classes could not be fitted to the data due to model identification problems. A three-class model provided an optimal fit to the data based on the BIC and a VLMR test comparing two-class and three-class models (Table 3). The classes consisted of 1609 (36.0%), 2145(48.0%), and 715(16.0%) patients, respectively. The multinomial logistic regression models revealed significant differences among the classes on age, sex, smoking status, procedure indication, and comorbid conditions. Patients in class 2 had lower odds of presenting with stable angina, being current smokers, and having comorbid diabetes, prior myocardial infarction, COPD, congestive heart failure, and cerebrovascular disease than patients in class 1. Patients in class 3 had higher odds of being older (> 75 years) but lower odds of being current smokers, having COPD, and having cerebrovascular disease than patients in class 1 (Table 4).
Discussion
This study investigates the extent to which PCTree and MixPCM consistently identify patient covariates associated with different interpretations of HADS Depression items. Our analyses show that both models identified age and smoking status (i.e., whether a patient was a current smoker) as covariates associated with DIF. Overall, the PCTree model identified four subgroups of patients defined by smoking status, age, and BMI. However, MixPCM identified three latent classes defined by age, smoking status, procedure indication, and multiple comorbid conditions.
There are several similarities and notable differences in the properties of these two models and how they are operationalized to evaluate sample heterogeneity (Table 5). Both are similar concerning the underlying assumption of unidimensionality of the data, large sample size requirements, and unsupervised learning approaches for DIF detection. Unlike existing group-based methods designed to detect PROM items that exhibit DIF, these unsupervised latent variable models present a global approach for identifying individuals that exhibit DIF instead of the items that exhibit DIF. These methods are particularly of interest in routine clinical practice where PROMs data help inform clinical decisions (e.g., treatment strategies, goals of care, referral for additional services, and so on) about a patient’s care. Identifying individuals with a propensity for DIF can help clinicians contextualize each patient’s responses to PROMs, support shared decision-making, and inform the delivery of personalized disease management. However, these methods have notable differences. First, these models differ with respect to the evaluation of sample heterogeneity. The PCTree evaluates sample heterogeneity via recursive partitioning of the sample into independent homogeneous subgroups for which the PCM parameters are non-invariant using a set of covariates. MixPCM, on the other hand, evaluates sample heterogeneity by estimating the posterior probability of latent class membership for each individual so that the latent classes are non-invariant for the PCM parameters. Second, selecting the optimal number of latent classes in MixPCM is based on known goodness-of-fit statistics, whereas determining the final subgroups in PCTree depends on the likelihood ratio test used in determining optimal split across known covariates. LRT is known to be sensitive to study sample size [57]. Third, unlike the tree-based IRT model, which requires specifying a set of covariates as input variables, the MixPCM models can estimate the latent subgroups with and without specifying a set of covariates. Finally, there are notable differences in the computational requirements for implementing tree-based IRT models and mixture IRT models. Estimating latent classes from mixture IRT models can be computationally intensive as it involves sequentially fitting multiple models and assessing model fit until an optimal number of latent classes is identified. In addition, MixIRT model parameters are estimated based on numeric computation, which is prone to model convergence issues depending on the number of starting values specified. Implementing tree-based models requires only a few lines of code that are less computationally intensive.
Tree-based latent variable models, such as PCTree, are promising methods for identifying sample heterogeneity in PROMs in heterogeneous population of patients defined by multiple interacting variables. Unlike conventional group-based methods for DIF detection that require a priori specification of the variable associated with DIF, these methods can be appealing for handling population heterogeneity in PROM scores. They can be used in exploratory analyses to generate hypotheses about potential DIF variables.
Despite the strengths of these models, they are prone to the inherent limitations of unsupervised learning methods and latent variable methods from which they are derived. Specifically, tree-based models are prone to overfitting, which may lead to the detection of spurious subgroups. Bonferroni-corrected structural change tests and pre-specification of minimum terminal node size are two recommended approaches for preventing model overfitting in tree-based models. Furthermore, the accuracy of the tree-based IRT models for detecting sample heterogeneity depends, to a greater extent, on the variables included as input covariates. For example, the conclusions from the empirical analysis in this study are limited to the available demographic, clinical, and disease characteristics used as input variables. The APPROACH registry does not collect data on a history of depression, medical treatment for depression, cognitive impairment, and other important risk factors that may be associated with DIF in patient-reported HADs items. This limits the generalizability of the conclusions from this empirical study. Moreover, changing the type (i.e., ordinal, continuous, or mixed) and the number of covariates included in the model could influence the number and type of homogenous subgroups (nodes) identified.
Future research could investigate determining the optimal minimum sample size requirement for the terminal nodes across various data characteristics. Also, comparing PCTree and latent class PCM models was based on a single empirical data. Although results from simulation studies reported by Komboz et al. [20] show that PCTree exhibit comparable control of familywise Type I error as the multigroup PCM, the comparison of the Type I error of PCM and MixPCM is yet to be investigated. Future research will use computer simulations to examine the comparative performance of PCTree and MixPCM for detecting DIF in PROM items, with respect to their Type I error and statistical power, under a variety of distributional and data characteristics. Finally, the empirical comparison of these unsupervised learning methods in this study focuses on identifying homogeneous subgroups of individuals consistent patterns of responses to the HADS items and not detecting HADS items that exhibit DIF. While mixture IRT models have been extended to detect DIF and estimate DIF effect sizes in PROM items [58, 59], future research will investigate the extension of tree-based IRT models for detecting DIF PROM items.
Conclusion
In summary, this study revealed that MixPCM and PCTree models are inconsistent in identifying covariates associated with DIF in PROM items. While PCTree is an alternative methodology to the mixture IRT model for examining sample heterogeneity in PROMs items, future research is needed, including computer simulations to evaluate the Type I error and statistical power of these models for DIF detection.
Data availability
The data used for these analyses are not openly available due to reasons of sensitivity and are only available from the corresponding author upon reasonable request and with permission from the University of Calgary Conjoint Health Research Ethics Board and the APPROACH Research Group at the University of Calgary.
References
Gibbons, E., Black, N., Fallowfield, L., Newhouse, R., & Fitzpatrick, R. (2016). Patient-reported outcome measures and the evaluation of services. In Challenges, solutions and future directions in the evaluation of service innovations in health care and public health. NIHR Journals Library.
Alemayehu, D., & Cappelleri, J. C. (2012). Conceptual and analytical considerations toward the use of patient-reported outcomes in personalized medicine. American Health & Drug Benefits, 5(5), 310.
Cappelleri, J. C., & Bushmakin, A. G. (2014). Interpretation of patient-reported outcomes. Statistical Methods in Medical Research, 23(5), 460–483.
Wu, A. W., Kharrazi, H., Boulware, L. E., & Snyder, C. F. (2013). Measure once, cut twice—adding patient-reported outcome measures to the electronic health record for comparative effectiveness research. Journal of Clinical Epidemiology, 66(8), S12–S20.
Øvretveit, J., Zubkoff, L., Nelson, E. C., Frampton, S., Knudsen, J. L., & Zimlichman, E. (2017). Using patient-reported outcome measurement to improve patient care. International Journal for Quality in Health Care, 29(6), 874–879.
McHorney, C. A., & Fleishman, J. A. (2006). Assessing and understanding measurement equivalence in health outcome measures: Issues for further quantitative and qualitative inquiry. Medical Care, 44(11), S205–S210.
Schmitt, N., & Kuljanin, G. (2008). Measurement invariance: Review of practice and implications. Human Resource Management Review, 18(4), 210–222.
Haggerty, J. L., Bouharaoui, F., & Santor, D. A. (2011). Differential item functioning in primary healthcare evaluation instruments by French/English version, educational level and urban/rural location. Healthcare Policy. https://doi.org/10.12927/hcpol.2011.22692
Jones, R. N. (2019). Differential item functioning and its relevance to epidemiology. Current Epidemiology Reports, 6(2), 174–183.
Bingham, C. O., III., Noonan, V. K., Auger, C., Feldman, D. E., Ahmed, S., & Bartlett, S. J. (2017). Montreal Accord on patient-reported outcomes (PROs) use series–paper 4: Patient-reported outcomes can inform clinical decision making in chronic care. Journal of Clinical Epidemiology, 89, 136–141.
Teresi, J. A., & Fleishman, J. A. (2007). Differential item functioning and health assessment. Quality of Life Research, 16(1), 33–42.
Zumbo, B. D. (1999). A handbook on the theory and methods of differential item functioning (DIF): Logistic regression modeling as a unitary framework for binary and Likert-type (ordinal) item scores. Directorate of Human Resources Research and Evaluation Department of National Defense.
Swaminathan, H., & Rogers, H. J. (1990). Detecting differential item functioning using logistic regression procedures. Journal of Educational Measurement, 27(4), 361–370.
Wu, Q., & Lei, P.-W. (2009). Using multigroup confirmatory factor analysis to detect differential item functioning when tests are multidimensional. In Paper presented at the Annual Meeting of the National Council for Measurement in Education. San Diego.
Thissen, D., Steinberg, L., & Wainer, H. (1993). Detection of differential item functioning using the parameters of item response models. In P. W. Holland & H. Wainer (Eds.), Differential item functioning (pp. 67–113). Lawrence Erlbaum Associates Inc.
Stark, S., Chernyshenko, O. S., & Drasgow, F. (2006). Detecting differential item functioning with confirmatory factor analysis and item response theory: Toward a unified strategy. Journal of Applied Psychology, 91(6), 1292.
Rost, J. (1990). Rasch models in latent classes: An integration of two approaches to item analysis. Applied Psychological Measurement, 14(3), 271–282.
Sawatzky, R., Ratner, P. A., Kopec, J. A., & Zumbo, B. D. (2012). Latent variable mixture models: A promising approach for the validation of patient reported outcomes. Quality of Life Research, 21(4), 637–650.
Strobl, C., Kopf, J., & Zeileis, A. (2015). Rasch trees: A new method for detecting differential item functioning in the Rasch model. Psychometrika, 80(2), 289–316.
Komboz, B., Strobl, C., & Zeileis, A. (2018). Tree-based global model tests for polytomous Rasch models. Educational and Psychological Measurement, 78(1), 128–166.
Bollmann, S., Berger, M., & Tutz, G. (2018). Item-focused trees for the detection of differential item functioning in partial credit models. Educational and Psychological Measurement, 78(5), 781–804.
Sen, S., & Cohen, A. S. (2019). Applications of mixture IRT models: A literature review. Measurement: Interdisciplinary Research and Perspectives, 17(4), 177–191.
Wu, X., Sawatzky, R., Hopman, W., Mayo, N., Sajobi, T. T., Liu, J., Prior, J., Papaioannou, A., Josse, R. G., Towheed, T., & Davison, K. S. (2017). Latent variable mixture models to test for differential item functioning: A population-based analysis. Health and Quality of Life Outcomes, 15(1), 1–13.
Sawatzky, R., Russell, L. B., Sajobi, T. T., Lix, L. M., Kopec, J., & Zumbo, B. D. (2018). The use of latent variable mixture models to identify invariant items in test construction. Quality of Life Research, 27(7), 1745–1755.
Sajobi, T. T., Josephson, C. B., Sawatzky, R., Wang, M., Lawal, O., Patten, S. B., … Wiebe, S. (2021). Quality of Life in Epilepsy: Same questions, but different meaning to different people. Epilepsia, 62(9), 2094–2102.
Masters, G. (1982). A Rasch model for partial credit scoring. Psychometrika, 47, 149–174.
Choi, I.-H., Paek, I., & Cho, S.-J. (2017). The impact of various class-distinction features on model selection in the mixture Rasch model. The Journal of Experimental Education, 85(3), 411–424.
Fabrigar, L. R., Wegener, D. T., MacCallum, R. C., & Strahan, E. J. (1999). Evaluating the use of exploratory factor analysis in psychological research. Psychological Methods, 4, 272–299.
Hattie, J. (1984). Methodology review: Assessing unidimensionality of tests and items. Applied Psychological Measurement, 20, 1–14.
Slocum-Gori, S. L., & Zumbo, B. D. (2011). Assessing the unidimensionality of psychological scales: Using multiple criteria from factor analysis. Social Indicators Research, 102(3), 443–461.
Glorfeld, L. W. (1995). An improvement on Horn’s parallel analysis methodology for selecting the correct number of factors to retain. Educational and Psychological Measurement., 55(3), 377–393.
Preinerstorfer, D., & Formann, A. K. (2012). Parameter recovery and model selection in mixed Rasch models. British Journal of Mathematical and Statistical Psychology, 65(2), 251–262.
Feng, Z. D., & McCullogh, C. E. (1996). Using bootstrap likelihood ratios in finite mixture models. Journal of Royal Statistical Society., 58(3), 609–617.
Lubke, G., & Muthén, B. O. (2007). Performance of factor mixture models as a function of model size, covariate effects, and class-specific parameters. Structural Equation Modeling: A Multidisciplinary Journal, 14(1), 26–47.
Vermunt, J. K. (2010). Latent class modelling with covariates: Two improved three-step approaches. Political Analysis, 18(4), 450–469.
Asparouhov, T., & Muthén, B. (2014). Auxiliary variables in mixture modeling: Three-step approaches using M plus. Structural Equation Modeling: A Multidisciplinary Journal, 21(3), 329–341.
Ghali, W. A., & Knudtson, M. L. (2000). Overview of the Alberta Provincial Project for Outcome Assessment in Coronary Heart Disease. On behalf of the APPROACH investigators. The Canadian Journal of Cardiology, 16(10), 1225–1230.
Zigmond, A. S., & Snaith, R. P. (1983). The hospital anxiety and depression scale. Acta Psychiatrica Scandinavica, 67(6), 361–370.
Stafford, L., Berk, M., & Jackson, H. J. (2007). Validity of the hospital anxiety and depression scale and patient health questionnaire-9 to screen for depression in patients with coronary artery disease. General Hospital Psychiatry, 29(5), 417–424.
De Smedt, D., Clays, E., Doyle, F., Kotseva, K., Prugger, C., Pająk, A., … Group, E. S. (2013). Validity and reliability of three commonly used quality of life measures in a large European population of coronary heart disease patients. International Journal of Cardiology, 167(5), 2294–2299.
Smith, R. M., Schumacker, R. E., & Bush, M. J. (1995). Using item mean squares to evaluate fit to the Rasch model. Journal of Outcome Measurement, 2(1), 66–78.
Karabatsos, G. (2000). A critique of Rasch residual fit statistics. Journal of Applied Measurement, 1(2), 152–176.
Christensen, K. B., & Kreiner, S. (2012). Item fit statistics. In K. B. Christensen, S. Kreiner, & M. Mesbah (Eds.), Rasch Models in Health (pp. 83–104). Wiley.
Sharma, S., Mukherjee, S., Kumar, A., & Dillon, W. R. (2005). A simulation study to investigate the use of cutoff values for assessing model fit in covariance structure models. Journal of Business Research., 58, 935–943.
Schreiber, J. B., Nora, A., Stage, F. K., Barlow, E. A., & King, J. (2006). Reporting structural equation modeling and confirmatory factor analysis results: A review. Journal of Educational Research, 99, 323–338.
Bjorner, J. B., Kreiner, S., Ware, J. E., Damsgaard, M. T., & Bech, P. (1998). Differential item functioning in the Danish translation of the SF-36. Journal of Clinical Epidemiology, 51(11), 1189–1202.
Cameron, I. M., Crawford, J. R., Lawton, K., & Reid, I. C. (2013). Differential item functioning of the HADS and PHQ-9: An investigation of age, gender and educational background in a clinical UK primary care sample. Journal of Affective Disorders, 147(1–2), 262–268.
Cameron, I. M., Scott, N. W., Adler, M., & Reid, I. C. (2014). A comparison of three methods of assessing differential item functioning (DIF) in the hospital anxiety depression scale: Ordinal logistic regression, Rasch analysis and the Mantel Chi-square procedure. Quality of Life Research, 23, 2883–2888.
Shad, B., Ashouri, A., Hasandokht, T., Rajati, F., Salari, A., Naghshbandi, M., & Mirbolouk, F. (2017). Effect of multimorbidity on quality of life in adult with cardiovascular disease: a cross-sectional study. Health and Quality of Life Outcomes, 15(1), 1–8.
Xue, C., Bian, L., Xie, Y. S., Yin, Z. F., Xu, Z. J., Chen, Q. Z., … Wang, C. Q. (2017). Impact of smoking on health-related quality of Life after percutaneous coronary intervention treated with drug-eluting stents: a longitudinal observational study. Health and Quality of Life Outcomes, 15(1), 1–9. 36.
Sajobi, T. T., Wang, M., Awosoga, O., Santana, M., Southern, D., Liang, Z., et al. (2018). Trajectories of health-related quality of life in coronary artery disease. Circulation: Cardiovascular Quality and Outcomes, 11(3), 1–11.
Nadelmann, J., Frishman, W. H., Ooi, W. L., Tepper, D., Greenberg, S., Guzik, H., … Aronson, M. (1990). Prevalence, incidence and prognosis of recognized and unrecognized myocardial infarction in persons aged 75 years or older: the Bronx Aging Study. The American Journal of Cardiology, 66(5), 533–537.
Lye, M., & Donnellan, C. (2000). Heart disease in the elderly. Heart, 84(5), 560–566.
Graham, M. M., Norris, C. M., Galbraith, P. D., Knudtson, M. L., & Ghali, W. A. (2006). Quality of life after coronary revascularization in the elderly. European Heart Journal, 27(14), 1690–1698.
R Core Team. (2019). R: A language and environment for statistical computing. R Foundation for Statistical Computing.
Muthén, L. K., & Muthén, B. O. (2017). Mplus statistical analysis with latent variables (8th ed.). User’s Guide.
Babyak, M. A., & Green, S. B. (2010). Confirmatory factor analysis: An introduction for psychosomatic medicine researchers. Psychosomatic Medicine, 72(6), 587–597.
Zumbo, B. D. (1999). A handbook on the theory and methods of differential item functioning (DIF): Logistic regression modeling as a unitary framework for binary and Likert-type (ordinal) item scores. Directorate of Human Research and Evaluation Department of National Defense.
Karadavut, T. (2021). Characterizing the latent classes in a mixture IRT model using DIF. Applied Measurement in Education, 34(4), 301–311.
Funding
This research is supported by funding from the Canadian Institutes of Health Research Operating Grant (Grant #:438908). LML is supported by a Canada Research Chair in Methods for Electronic Health Data Quality. RS is supported by a Canada Research Chair in Patient-Reported Outcomes.
Author information
Authors and Affiliations
Contributions
TTS and LML were responsible for conceptualizing the study. TTS and RAS performed the data processing and analysis. CMN, MMG, MTJ, and SBW were responsible for data collection. TTS wrote the first draft of the manuscript, and all authors were involved in the critical revision of the previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
None of the authors have financial or non-financial interests to disclose.
Ethical approval
Ethical approval to use de-identified data from the APPROACH registry was obtained from the University of Calgary Conjoint Health Research Ethics Board (REB20-1721).
Consent to publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sajobi, T.T., Sanusi, R.A., Mayo, N.E. et al. Unsupervised item response theory models for assessing sample heterogeneity in patient-reported outcomes measures. Qual Life Res 33, 853–864 (2024). https://doi.org/10.1007/s11136-023-03560-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11136-023-03560-5