
Abstract
The algorithms underpinning information retrieval shape its outcomes and have epistemological, social and political consequences. On the one hand, the Web search algorithms place a specific actor—the Web librarian (cataloguer), the document’s creator, the expert (“authority”), the user or the service provider (developer and operator of a search engine)—in the position of a decision-maker. Each of them has distinctive criteria of relevance in information retrieval. On the other hand, the application of those criteria determines what information the user receives. Content-based search places emphasis on the contents of retrievable documents whereas collaborative search shifts the focus of attention to opinions of experts and other users. The outcomes of content-based and collaborative searches diverge as a result. Depending on the information provided to the user, the development of her knowledge and socialization proceeds differently. A plea for customized Web search is made. It is argued that the user should be given an opportunity for selecting a combination of content-based and collaborative search that matches her interests and the context of a search query.
Similar content being viewed by others
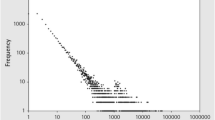

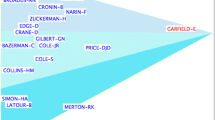
Notes
As of January 2021, https://www.internetlivestats.com/total-number-of-websites/.
The expression “raw data” implies that data are given. It ignores that “data produce and are produced by the operations of knowledge production more broadly”, always being “already cooked” in this sense (Gitelman 2013, p. 3; see also Haider and Sundin 2019, p. 59). Therefore, it is more appropriate to view data as being derived from “the operations of knowledge production” in the past and feeding a new cycle of knowledge production. Such approach, however, requires consideration of causal sequences in their entirety. Since the nineteenth century scholarly inquiries proceed by “closing” causal sequencies and separating causes and effects in an analytical manner (Veblen 1998; Peirce 1992, pp. 197–217). It is in this sense only that data, information and knowledge form a closed causal sequence.
Videos and images are searched using textual descriptions attached to them.
The journal “discusses instruments of methodology… Quality and Quantity is an interdisciplinary journal which systematically correlates disciplines such as data and information sciences with the other humanities and social sciences” (https://www.springer.com/journal/11135/aims-and-scope).
The association between the disciplinary origin of a cited source and the author’s judgment about its relevance to the discussion of the Web librarian’s role would be statistically significant, were the sample of cited sources random: χ2 = 14.831, p < 0.001.
The association between the discipline and the author’s judgment of relevance would be statistically significant in this case too: χ2 = 8.549, p = 0.014.
The underlying idea is that words occurring in all documents—“the”, “a”, “we”—do not help differentiate between them. By contrast, if a word has a high frequency in a few documents, this information tells us more about the degree of their similarity.
The source of a document, i.e. the website at which it is posted, should not be confused with the document’s creator. PageRank allows measuring the reputation of the source saying much less and in an indirect manner about the creator’s reputation.
Here one can find the other link to pragmatism in information retrieval, in addition to the discussion of closure versus opening of causal sequences in American pragmatism mentioned in footnote 2.
Google Quality Rater Guidelines are not made public by Google. However, their copies are available at several websites and meet the criteria of sufficient quality outlined in these guidelines.
See endnote 7.
The search was conducted using Google.com on February 8, 2021 (with no quotation marks).
As of January 2021 (https://gs.statcounter.com/search-engine-market-share).
Google currently blocks search requests made by users of Tor, a software enabling them to communicate anonymously. Anonymous communication invalidates the user’s clickthrough and geolocation data.
References
Amini, R., Sabourin, C., De Koninck, J.: Word associations contribute to machine learning in automatic scoring of degree of emotional tones in dream reports. Conscious. Cognit. 20(4), 1570–1576 (2011)
Bakhtin, M.: Problemy poetiki Dostoevskogo, 4th edn. [Problems of Dostoevsky’s Poetics]. Sovetskaya Rossiia, Moscow (1979)
Barabási, A.-L.: Linked. Perseus, Cambridge (2002)
Barabási, A.-L.: Network science. Cambridge University Press, Cambridge (2016)
Berman, J.J.: Principles of big data: preparing, sharing, and analyzing complex information. Morgan Kaufmann, Waltham (2013)
Bernard, R.H.: Social research methods: qualitative and quantitative approaches, 2nd edn. Sage, Thousand Oaks (2013)
Bilić, P.: Search algorithms, hidden labour and information control. Big Data Soc. 3(1), 1–9 (2016)
Brier, A., Hopp, B.: Computer assisted text analysis in the social sciences. Qual. Quant. 45(1), 103–128 (2011)
Brin, S., Motwani, R., Page, L., Winograd, T.: What can you do with a web in your pocket? Bull. IEEE Comput. Soc. Techn. Comm. Data Eng. 21(2), 37–47 (1998)
Bruggeman, J., Traag, V.A., Uitermark, J.: Detecting communities through network data. Am. Soc. Rev. 77(6), 1050–1063 (2012)
Bryman, A., Bell, E.: Social Research Methods, 5th Canadian edn. Oxford University Press, Don Mills (2019)
Burrell, J.: How the machine “thinks”: understanding opacity in machine learning algorithms. Big Data Soc. 3(1), 1–12 (2016)
Business Insider: Inktomi Corporation Formed by UC Berkeley Scientists to Bring Parallel Processing Power to Commercial Internet Applications. Business Insider May 20 (1996). https://tech-insider.org/internet/research/1996/0520.html.
Collins, R.: The sociology of philosophies: a global theory of intellectual change. The Belknap Press, Cambridge (1998)
DiMaggio, P., Nag, M., Blei, D.: Exploiting affinities between topic modeling and the sociological perspective on culture: application to newspaper coverage of U.S. Government arts funding. Poetics 41(6), 570–606 (2013)
Evangelopoulos, N., Zhang, X., Prybutok, V.R.: Latent semantic analysis: five methodological recommendations. Eur. J. Inf. Syst. 21(1), 70–86 (2012)
Evans, J.A., Aceves, P.: Machine translation: mining text for social theory. Ann. Rev. Sociol. 42, 21–50 (2016)
Evans, M., McIntosh, W., Lin, J., Cates, C.: Recounting the courts? applying automated content analysis to enhance empirical legal research. J. Empir Legal Stud. 4(4), 1007–1039 (2007)
Fortunato, S., Flammini, A., Menczer, F., Vespignani, A.: Topical interests and the mitigation of search engine bias. PNAS: Proceedings of the National Academy of Sciences of the United States of America 103(34), 12684–12689 (2006)
Foucault, M.: The Government of self and others: lectures at the Collège de France, 1982–1983. Picador/Palgrave Macmillan, New York (2011a)
Foucault, M.: The courage of truth (The Government of self and others II): lectures at the Collège de France, 1983–1984. Palgrave Macmillan, Basingstoke and New York (2011b)
Frank, R.H., Cook, P.J.: The winner-take-all society: how more and more Americans compete for ever fewer and bigger prizes, encouraging economic waste, income inequality, and an impoverished cultural life. The Free Press, New York (1995)
Gitelman, L. (ed.): “Raw Data” is an Oxymoron. The MIT Press, Cambridge, MA (2013)
Goodfellow, I., Bengio, Y., Courville, A.: Deep Learning. MIT Press, Cambridge, MA (2016)
Google: Google Quality Rater Guidelines, December 5, 2019. https://static.googleusercontent.com/media/guidelines.raterhub.com/en//searchqualityevaluatorguidelines.pdf.
Grosser, B.: What do metrics want? how quantification prescribes social interaction on facebook. Comput. Cult. J. Softw. Stud. (2014)
Grossman, D.A., Frieder, O.: Information retrieval: algorithms and Heuristics, 2nd edn. Springer, Dordrecht (2004)
Haider, J., Sundin, O.: Invisible search and online search engines: the ubiquity of search in everyday life. Routledge, Abingdon (2019)
Haykin, S.: Neural networks and learning machines, 3rd edn. Pearson/Prentice Hall, Upper Saddle River (2009)
Hesse, B.W., Moser, R.P., Riley, W.T.: From big data to knowledge in the social sciences. Ann. Am. Acad. Pol. Soc. Sci. 659(1), 16–32 (2015)
Hjørland, B.: The foundation of the concept of relevance. J. Am. Soc. Inform. Sci. Technol. 61(2), 217–237 (2010)
Hogeraad, R., McKenzie, D.P., Péladeau, N.: Force and influence in content analysis: the production of new social knowledge. Qual. Quant. 37(3), 221–238 (2003)
Huang, L., Milne, D., Frank, E., Witten, I.H.: Learning a concept-based document similarity measure. J. Am. Soc. Inform. Sci. Technol. 63(8), 1593–1608 (2012)
Jeanneney, J.N.: Google and the myth of universal knowledge: a view from Europe. The University of Chicago Press, Chicago (2007)
Jiang, Z., Lu, C.: A latent semantic analysis based method of getting the Category Attribute of Words. In: 2009 International Conference on Electronic Computer Technology, Macau, China, February 20–22, pp. 141–146 (2009)
Jurafsky, D., Martin, J.H.: Speech and Language Processing, draft of the 3rd edn. Pearson-Prentice Hall, Upper Saddle River, NJ (n.d.) https://web.stanford.edu/~jurafsky/slp3/
Keynes, J.M.: The general theory of employment, interest and money. BN Publishing, Milton Keynes (2008)
Khan, F.H., Qamar, U., Bashir, S.: A semi-supervised approach to sentiment analysis using revised sentiment strength based on SentiWordNet. Knowl. Inf. Syst. 51(3), 851–872 (2017)
Krippendorff, K.: Content analysis: an introduction to its methodology, 2nd edn. Sage, Thousand Oaks (2004)
Lakoff, G., Johnson, M.: Metaphors we live by. The University of Chicago Press, Chicago (1980)
Lewandowski, D.: Why we need an independent index of the web. In: König, R., Rasch, M. (eds.) Society of the query reader: reflections on web search, pp. 50–58. Institute of Network Cultures, Amsterdam (2014)
Li, P., Yamada, S.: A Movie Recommender System Based on Inductive Learning. In: Proceedings of the 2004 IEEE Conference on Cybernetics and Intelligent Systems, pp. 318–323 (2004)
Lu, C., Park, J.-R., Hu, X.: User tags versus expert-assigned subject terms: A comparison of LibraryThing tags and Library of Congress Subject Headings. J. Inf. Sci. 36(6), 763–779 (2010)
Malia, M.: Russia under western eyes: from the bronze horseman to the Lenin Mausoleum. The Belknap Press, Cambridge (1999)
Mannens, E., et al.: Automatic news recommendations via aggregated profiling. Multimed. Tools Appl. 63(2), 407–425 (2013)
McQuillan, D.: Algorithmic paranoia and the convivial alternative. Big Data Soc. 3(2), 1–12 (2016)
Mendes, L.H., Quiñonez-Skinner, J., Skaggs, D.: Subjecting the catalog to tagging. Libr. Hi Tech 27(1), 30–41 (2009)
Merton, R.K.: The Thomas theorem and the Matthew effect. Soc. Forces 74(2), 379–424 (1995)
Michel, J.-B., et al.: Quantitative analysis of culture using millions of digitized books. Science 331(6041), 176–182 (2011)
Morriss, P.: Power: a philosophical analysis. St. Martin’s Press, New York (1987)
Munster, A.: Nerves of data: the neurological turn in/against networked media. In: Computational Culture: A Journal of Software Studies (2011)
Nirkhi, S.: Potential use of artificial neural network in data mining. In: The 2nd International Conference on Computer and Automation Engineering, Vol. 2, pp.339–343 (2010)
North, D.C.: Structure and change in economic history. Norton, New York (1981)
Peirce, C.S.: Reasoning and the logic of things: the cambridge conferences lectures of 1898. Harvard University Press, Cambridge (1992)
Oleinik, A.: What are neural networks not good at? On artificial creativity. Big Data & Society 6(1) (2019)
Oleinik, A.: Knowledge and networking: on communication in the social sciences. Routledge, London (2016)
Oleinik, A.: Mixing quantitative and qualitative content analysis: triangulation at work. Qual. Quant. 45(4), 859–873 (2011)
Oleinik, A., Kirdina-Chandler, S., Popova, I., Shatalova, T.: On academic reading: citation patterns and beyond. Scientometrics 113(1), 417–435 (2017)
Pirmann, C.: Tags in the catalogue: insights from a usability study of LibraryThing for libraries. Libr. Trends 62(1), 234–247 (2012)
Rogers, R.: Aestheticizing google critique: a 20-year retrospective. Big Data Soc 5(1), 1–13 (2018)
Rolla, P.J.: User tags versus subject headings: can user-supplied data improve subject access to library collections? Libr. Resour. Tech. Serv. 53(3), 174–184 (2009)
Salganik, M.J., Dodds, P.S., Watts, D.J.: Experimental study of inequality and unpredictability in an artificial cultural market. Nature 311(5762), 854–856 (2006)
Salton, G., McGill, M.J.: Introduction to modern information retrieval. McGraw-Hill, New York (1983)
Saracevic, T.: Relevance: a review of and a framework for the thinking on the notion in information science. J. Am. Soc. Inf. Sci. 26(6), 321–343 (1975)
SearchMetrics: Rebooting Ranking Factors Google.com. San Mateo, CA: SearchMetrics (2016)
Soroka, S.: Reliability and validity in automated content analysis. In: Hart, R.P. (ed.) Communication and Language Analysis in the Corporate World, pp. 352–363. IGI Global, Hershey, PA (2014)
Steele, T.: The new cooperative cataloging. Libr. Hi Tech 27(1), 68–77 (2009)
Sundin, O., Haider, J., Andersson, C., Carlsson, H., Kjellberg, S.: The search-ification of everyday life and the mundane-ification of search. J. Document 73(2), 224–243 (2017)
Swedberg, R.: Principles of economic sociology. Princeton University Press, Princeton (2003)
Thelwall, M., Kousha, K.: Goodreads: a social network site for book readers. J. Am. Soc. Inf. Sci. 68(4), 972–983 (2017)
Thorsrud, L.A.: Words are the new numbers: A newsy coincident index of business cycles. Working Paper 21/2016. Norges Bank Research (2016)
Yom-Tov, E., Dumais, S., Guo, Q.: Promoting civil discourse through search engine diversity. Soc. Sci. Comput. Rev. 32(2), 145–154 (2014)
Vaidya, P., Harinarayana, N.S.: The comparative and analytical study of LibraryThing tags. Knowl. Organ. 43(1), 35–43 (2016)
Vee, A.: Text, speech, machine: metaphors for computer code in the law. In: Computational Culture: A Journal of Software Studies (2012)
Veblen, T.: Why is economics not an evolutionary science? Camb. J. Econom. 22(4), 403–414 (1998)
Voorbij, H.: The value of LibraryThing tags for academic libraries. Online. Inf. Rev. 36(2), 196–217 (2012)
Waller, V.: Not just information: who searches for what on the search engine google? J. Am. Soc. Inform. Sci. Technol. 62(4), 761–775 (2011)
Wang, X., Tao, T., Sun, J.-T., Shakery, A., Zhai, C.: DirichletRank: Solving the Zero-One Gap Problem of PageRank. ACM Trans. Inf. Syst. 26(2):1–29 Article 10 (2008)
Weber, M.: Economy and society: an outline of interpretative sociology. Bedminster Press, New York (1968)
Weigang, L., Zheng, J.: Using W-Entropy rank as a unified reference for search engines and blogging websites. In: José, C., Karl-Heinz, K. (eds.) Web information systems and technologies, 8th international conference, WEBIST 2012, Porto, Portugal, April 18–21, 2012, Revised Selected Papers, pp. 252–266. Springer-Verlag, Berlin (2013)
White, M.D., Marsh, E.E.: Content Analysis: A Flexible Methodology. Libr. Trends 55(1), 22–45 (2006)
Witten, I.H., Frank, E., Hall, M.A., Pal, C.J.: Data mining: practical machine learning tools and techniques, 4th edn. Morgan Kaufmann, Cambridge (2017)
Yang, Q.: A novel recommendation system based on semantics and context awareness. Computing 100(8), 809–823 (2018)
Zhai, C.X., Massung, S.: Text data management and analysis: a practical introduction to information retrieval and text mining. ACM Books and Morgan & Claypool, San Rafael, CA (2016)
Zhang, S., Medo, M., Lü, L., Mariani, M.S.: The long-term impact of ranking algorithms in growing networks. Inf. Sci. 488, 257–271 (2019)
Acknowledgements
The author is grateful to two anonymous reviewers of Quality & Quantity for their constrictive critique.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Oleinik, A. Relevance in Web search: between content, authority and popularity. Qual Quant 56, 173–194 (2022). https://doi.org/10.1007/s11135-021-01125-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11135-021-01125-7