
Abstract
Smooth cycling can improve the competitiveness of bicycles. Understanding cycling speed variation during a trip reveals the infrastructure or situations which promote or prevent smooth cycling. However, research on this topic is still limited. This study analyses speed variation based on data collected in the Netherlands, using GPS-based devices, continuously recording geographical positions and thus the variation in speeds during trips. Linking GPS data to spatial data sources adds features that vary during the trip. Multilevel mixed-effects models were estimated to test the influence of factors at cyclist, trip and tracking point levels. Results show that individuals who prefer a high speed have a higher average personal speed. Longer trips and trips made by conventional electric bicycles and sport bicycles have a higher average trip speed. Tracking point level variables explain intra-trip cycling speed variations. Light-medium precipitation and tailwind increase cycling speed, while both uphill and downhill cycling is relatively slow. Cycling in natural and industrial areas is relatively fast. Intersections, turns and their adjacent roads decrease cycling speed. The higher the speed, the stronger the influence of infrastructure on speed. Separate bicycle infrastructure, such as bike tracks, streets and lanes, increase speed. These findings are useful in the areas of cycling safety, mode choice models and bicycle accessibility analysis. Furthermore, these findings provide additional evidence for smooth cycling infrastructure construction.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Cycling is emerging in countries without a strong cycling tradition and expanding in countries where the bicycle already has a solid position (Harms and Kansen 2018). Governments promote cycling for its societal and individual benefits, related to the environment, health, urban liveability and mitigating traffic congestion, while also travel satisfaction is often higher than for other modes (De Vos 2018). However, maximum cycling speeds are generally lower than for motorised transport, although short distances, particularly in urban areas, can sometimes be covered faster by bike than by car (Dill and Gliebe 2008). This means that, in most cases, cycling takes more time than driving. In addition, distances covered are typically shorter; thus in terms of travel times, the bicycle often loses out to other modes of motorised transport.
Travel time is so important because travel choices highly depend on it. In travel demand models, where travel is considered as a derived demand, travel time is assumed to involve a disutility that should be minimised (Mokhtarian et al. 2001). In evaluation studies, the value of faster travel is that it induces travel time savings (Small 2012). In accessibility studies, travel time is an essential component as well (Geurs and Van Wee 2004). Applied to cycling, it can be assumed that a smooth flow and reduction of delays will make cycling more competitive with other modes of transport (Hamilton and Wichman 2018). There are, moreover, other reasons why attention to cycling speed is important. First, higher speeds also increase accident risks (Haustein and Møller 2016; Schepers et al. 2014, 2017; Woodcock et al. 2014). Second, cycling speeds and the variety of speeds in everyday use tend to increase with the adoption of electric bicycles (Schleinitz et al. 2017). Furthermore, governments tend to build better infrastructure, such as bicycle express paths (Rayaprolu et al. 2020), enabling cyclists to increase their speeds.
Not only do maximum and average cycling speeds matter, but also variations during a trip. Cyclists prefer to cycle as smoothly as possible and to maintain their desired speed levels, taking into account safety. So, for planners, it is necessary to know to what extent speeds vary during trips. The average speed of cyclists says little about the obstacles they encounter on the route. Intra-trip speed measurement, however, provides insights into the locations where speed varies. By linking speed and characteristics of geographical positions, insights can be gained into the effect of infrastructure, urbanisation and traffic density on speed. Such insights help policymakers and road authorities to reduce or remove speed barriers.
However, remarkably little attention has been paid to the speed component of cycling in the literature (Strauss and Miranda-Moreno 2017). The research that does, typically measures speed at fixed locations (e.g. Eriksson et al. 2019; Opiela et al. 1980), or considers the average speed of an entire ride (e.g. Schantz 2017; Schleinitz et al. 2017; Stigell and Schantz 2015) or at best speeds per trip segment (El-Geneidy et al. 2007; Flügel et al. 2019; Manum et al. 2017). Only a few studies have studied the factors that influence intra-trip speed variation (Arnesen et al. 2019; Clarry et al. 2019), and they only included a limited number of influencing factors. The background for a limited number of studies is highly likely that until recently, it was hardly possible to correctly register variation in cycling speed. GPS technology solved this problem (e.g. Bohte and Maat 2009), as it allows researchers to obtain accurate information about variation in speed and related positions; through innovations in GPS technology, data quality has improved in recent years, so reliable speed measurements are now available.
The added value of this paper is that it aims to explain variations in cycling speeds on three levels. It departs from the promise that cycling speeds vary (1) between cyclists, referred to as inter-person variation, (2) between trips of the same cyclist, referred to as intra-person variation, and (3) during the trip, referred to as intra-trip variation. The cyclist represents the first level, with factors that vary between persons, such as gender, age, health condition and preferences or attitudes, explaining inter-person variation. At the second level, a person makes multiple trips, with characteristics that may vary between trips but remain stable during the trip, such as the bicycle type or trip motive (e.g. commuting, leisure), which causes intra-person variation. The factors that are assumed to influence intra-trip variation, the third level, are infrastructural features and the land use, as well as local wind conditions and precipitation circumstances. By measuring the speed continuously for each geographical position during the ride, we identify the factors that influence speeds and, consequently, the intra-trip variation in speed. For this purpose, GPS devices continuously measure the so-called tracking points, i.e. the geo-positions and the corresponding clock times. We apply a multilevel approach, in which the independence of the observations, i.e. geopositions within trips and trips per respondent, is controlled for. This allows us to identify the contribution of each level and each factor. Data was collected in the Netherlands using a survey and recording by standalone GPS devices.
The paper is structured as follows. Sect. "Literature review" discusses the empirical literature, both methods and results, followed by the methodology in Sect. "Approach" and modelling results in Sect. "Result". Sect. "Conclusion" ends with conclusions, discussions and recommendations.
Literature review
In this section, we examine how previous research collected cycling speed data, analysed speed variation, and what findings emerged from it.
Speed data collection
Speed data is collected in three ways: (1) at fixed locations, (2) by measuring the start and end time of the ride, or (3) by continuously tracking the cyclist using GPS-technology. Fixed location methods vary in degree of advance, ranging from manual approaches, which require an observer during measurement (e.g. Thompson et al. 1997), to semi-automatic methods that register automatically when a cyclist passes (Hunter et al. 2009) or use frame-by-frame video camera analysis (Ling and Wu 2004), while full automatic measurement and data extraction is the case for video cameras using computer vision (Kassim et al. 2017). These methods measure cycling speed at fixed locations over a period of time, so they only include the situation at certain locations and do not follow cyclists with their characteristics.
These shortcomings of measuring at fixed locations can be avoided by collecting data from trips, including characteristics of these trips and the corresponding cyclist. The most basic method is calculating the average cycling speed by using the departure and arrival times and the distance travelled. However, this is an inaccurate method. In many travel behaviour surveys, departure and arrival times are imprecisely measured, often relying on a posteriori estimation by the traveller (Kelly 2013; Schantz 2017). A slightly better method is to ask respondents to keep a diary, preferably filled in directly while travelling (Arentze et al. 2001). Another disadvantage is that the route and the exact distance are unknown (Sun et al. 2017). Solutions like asking routes in questionnaires (Munshi 2016), calculating the shortest route assuming that this reflects the actual route to some extent (Dissanayake and Morikawa 2002), or asking participants to draw their travel routes (Schantz 2017) are not accurate.
The breakthrough in measuring speed came with the application of GPS-based devices. A GPS receiver determines its location by measuring the time that signals from at least four satellites reach it. GPS devices record position information, i.e. latitude, longitude, altitude and time stamps, every several seconds, so they are increasingly used to track the route and speed of travellers and their vehicles. In fact, the device produces a point trace of exact time–space stamps. For each point, the exact speed can be derived (Shen and Stopher 2014), and infrastructure and environmental characteristics can be linked. Nevertheless, the satellite signal can be disturbed by environmental features, such as high buildings (Kassim et al. 2020), requiring preprocessing to remove noise. Also, detecting single trips from the raw GPS data involves intensive work and mistakes (Berjisian and Bigazzi 2022). In addition, the sample size of studies with data from GPS devices is generally relatively small. There are now a handful of studies testing the determinants of cycling speed using data from GPS devices, although they all have less than 100 participants (El-Geneidy et al. 2007; Langford et al. 2015; Parkin and Rotheram 2010; Schleinitz et al. 2018).
Standalone GPS devices require logistics, as the researcher has to distribute and collect them (Harding et al. 2021), making them difficult to deploy on a large scale; also, the respondent has to charge and carry devices with them daily. The use of smartphone tracking apps prevents these problems. They are technically similar to GPS devices; smartphones are widely available, and apps can be applied at lower costs as no extra device is needed (Romanillos et al. 2016). Studies using smartphone apps typically have larger samples; Strauss and Miranda-Moreno (2017) recruited 1000 cyclists, and Flügel (2019) had 709 participants. B-Riders is a Dutch bicycle promotional program with over 8,500 participants (Velo 2021; Romanillos et al. 2016), and the Fietstelweek (Dutch Bicycle Counting Week) collected more than a half-million trips over several years. However, also smartphone apps have drawbacks, such as using excessive power and possible privacy concerns (Kanarachos et al. 2018; Tawalbeh et al. 2016), and they are as sensitive as standalone devices to recording errors (Harding et al. 2021).
Variation in speed
GPS-based studies can be further divided into the analysis of full trips, segments and tracking points. In the full trip approach, the average speed for the entire trip is calculated (e.g. Schleinitz et al. 2018), so it is only suitable for research into the characteristics of trips and cyclists. Segment approaches divide the trip into segments based on research purposes. The segment average speed is derived from the segment distance and travel duration (El-Geneidy et al. 2007; Flügel et al. 2019; Romanillos and Gutiérrez 2020). Compared to the trip average speed, the segment speed gives additional insights into the speed variation during the trip. The division into segments is, however, often arbitrary.
The tracking point approach, however, is the most detailed in terms of 3D-geopositions and clock times, and is therefore the most accurate. Here, the speed at each tracking point is measured (Arnesen et al. 2019; Clarry et al. 2019). Since this approach is based on the travel time and distance between two tracking points, it is basically a segment approach with the shortest segments available, i.e. the segment between two tracking points. The closer the tracking points, the shorter the segments, and consequently the more detailed speed variations are recorded. In addition, environmental and infrastructure factors can be derived from spatial data sources at the tracking point level. More importantly, variables that change (almost) continuously during the ride, such as the slope, can be measured accurately. Therefore, studies using speeds at the tracking point level have the potential to reveal detailed influences of determinants on cycling speed variation. However, such studies should pay more attention to data noise than segment-based and trip-based approaches, as errors are not attenuated by average values of multiple tracking points (e.g. Arnesen et al. 2019).
Analysis methods
Early studies often used descriptive analysis to analyse cycling speed, comparing the cycling speed of different groups, such as men versus women, city bicycles versus electric bicycles and bike paths versus shared roads (e.g. Jensen et al. 2010; Lin et al. 2008). Others used OLS regression to estimate the impact of explanatory variables on speeds (Flügel et al. 2019). However, a fundamental assumption of OLS, namely independence of error terms, is unrealistic if a nested-data structure is assumed, which is the case with multiple trips per respondent, and multiple tracking points per trip (Romanillos and Gutiérrez 2020). Only a few recent studies considered the independence of observations. Clarry et al. (2019) used cycling data from 4317 trips made by 518 cyclists to analyse the determinates of cycling speed at tracking points. They assumed that tracking points and segments are not independent but share common unobserved factors influencing cycling speed. To account for these unobserved factors, they estimated three multilevel models with random intercepts, i.e. a model with point and segment levels, a model with point, segment and cyclist levels, and a model with point, segment and trip levels. These models show the existence of common unobserved factors at each level (heterogeneity) and the importance of controlling for non-dependence of observations. However, due to the absence of cyclist and bicycle characteristics, the heterogeneity of these levels has not been fully examined.
Factors determining cycling speed
Previous research has identified the effects of characteristics at different levels of aggregation, although a multilevel approach has been rare. At the level of the cyclist, it was found that men tend to cycle faster than women. This applies both to the average trip speed (Schantz 2017) as well as the speed at every segment (El-Geneidy et al. 2007; Romanillos and Gutiérrez 2020; Strauss and Miranda-Moreno 2017). Age is negatively related to the trip average cycling speed (Schantz 2017; Schleinitz et al. 2017) and the segment average speed (Romanillos and Gutiérrez 2020). Cycling experience also plays a role, as shown by the higher speeds of frequent cyclists (Poliziani et al. 2022) and those with winter cycling experience (Strauss and Miranda-Moreno 2017). However, to the best of our knowledge, preferences like risk-taking, smooth cycling and health conditions have not been investigated yet.
The trip level characteristics may vary between rides of one person but remain constant during a ride. The bicycle type influences clearly the speed, with trips using speed pedelecs and conventional electric bicycles being significantly faster than those with city bicycles (Eriksson et al. 2019; Jin et al. 2017; Lin et al. 2008; Mohamed and Bigazzi 2019; Schleinitz et al. 2018; Shan et al. 2015). Commute trips have higher speeds than non-commute trips (Broach et al. 2012; Jensen et al. 2010). Current studies also regard weather conditions as constant during a trip, although weather can change during a ride. Romanillos and Gutiérrez (2020) found that speeds are higher on sunny days than on cloudy and rainy days, and Strauss and Miranda-Moreno (2017) found a positive effect of temperature on cycling speed. By contrast, a Dutch dataset indicated a higher cycling speed (17.8 km/h) in foggy or rainy weather compared to 17 km/h for all trips (Fietstelweek 2017).
At the segment or point level, factor values depend on geo-positions. Land use usually varies during the ride and is considered as an independent characteristic or a bundle of characteristics. Cycling speeds in city centres are lower (Flügel et al. 2019; Gustafsson and Archer 2013; Schantz 2017), as higher densities of road users result in more interactions (Flügel et al. 2019; Gustafsson and Archer 2013), and higher intersection densities cause more stops and delays (Plazier et al. 2017). Infrastructure also influences cycling speeds. Separated bicycle paths protect cyclists from other traffic, allowing cyclists to cycle faster (Clarry et al. 2019; El-Geneidy et al. 2007; Flügel et al. 2019; Kassim et al. 2019; Romanillos and Gutiérrez 2020; Strauss and Miranda-Moreno 2017), although two studies found the opposite (Bernardi and Rupi 2015; Poliziani et al. 2022). Studies focusing on speeds at segments between intersections found that cycling speed at longer segments is higher than at shorter segments (Poliziani et al. 2022; Strauss and Miranda-Moreno 2017), since cyclists can more easily cycle at their desired speeds. Wide bicycle lanes (Boufous et al. 2018; Garcia et al. 2015; Li et al. 2015), a smooth surface (Manum et al. 2017; Visser 2019), and straight roads are positively related to cycling speed (Arnesen et al. 2019; Flügel et al. 2019). Intersections or traffic lights involve deceleration or stops, so trip segments (Manum et al. 2017; Strauss and Miranda-Moreno 2017) and points (Arnesen et al. 2019) close to intersections have lower speeds. Variations in slope show that cycling downhill is faster than uphill, an obvious result, while speed loss uphill is greater than speed gain downhill (Arnesen et al. 2019; Flügel et al. 2019; Parkin and Rotheram 2010). Traffic intensity and the density of bicycles appear to be negatively related to speed (Li et al. 2015; Shan et al. 2015). This influence is greater for electric bicycles than city bicycles (Jin et al. 2017). Also, the presence of pedestrians reduces cycling speed (Bernardi and Rupi 2015; Boufous et al. 2018).
Gaps and conceptual framework
Summarising Sects. "Speed data collection" to "Factors determining cycling speed", recent studies on cycling speed used data collected through GPS devices or smartphone apps. The unit of analysis for which the speed was calculated varied between the entire trip, segments within the trip, and tracking points. The latter two make it possible to analyse the intra-trip speed variation, but this has been rarely done and is considered a clear research gap. Furthermore, the influence of factors that determine speed should be distinguished on different levels: characteristics of the cyclist; characteristics of the trip, including the bicycle type; and route characteristics at different geopositions (tracking points), such as infrastructure characteristics, the environment and other traffic. The nested data structure is hardly considered in the literature, making it a second gap. Finally, except for age and gender, other cyclist characteristics, including cycling related preferences, were hardly examined.
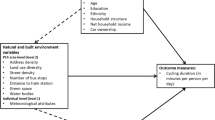
This study departs from the gaps above. Cycling speed is assumed to be determined at three levels, as shown in the conceptual model (Fig. 1). The model shows a multilevel structure and assumes that factors at each level explain a speed variation, i.e. between persons (inter-personal variation), between trips (intra-personal variation) and within trips (intra-trip variation). Both the multilevel structure and the intra-trip speed variation have hardly been applied to cycling, certainly not in combination. This study limits itself to three levels, though the bicycle used is in principle an independent level.

Conceptual model: the three-level multilevel model for cycling speed variation
Approach
Data collection
Data was collected in the Netherlands during the Covid-19 pandemic. Because random sampling or using panels was virtually impossible during the pandemic, we had to follow a less formal approach to recruit participants. Three graduate students recruited their relatives and friends for this purpose. Participants received an information letter outlining the study objectives, data pseudonymisation, and data safety. Along with the letter, they also received a standalone GPS device (Prime AT PLT) and a charging cable. They were asked to carry the GPS device, keep it in their bags or pockets, and charge it daily. The device was tested before collecting data and showed superior receiving sensitivity and high position accuracy. It records a timestamp every five seconds, including its geographical position (latitude, longitude and altitude) and speed. The respondents held this device for seven consecutive days between the end of November 2020 and the start of January 2021, and some of them also made a few trips (14%) during the Christmas and New Year holidays (23rd December to 3rd January). In addition, participants were invited to fill out a survey on their socio-demographics, bicycle ownership, cycling experience and preferences about cycling safety, smooth cycling and green areas. The changes in their cycling behaviour during the Covid-19 pandemic were also asked. 64 participants joined the study, resulting in 64 GPS data logs and 255,228 tracking points.
The sample shows an overrepresentation of students. Correspondingly, a large group of participants are young, healthy, have a high education level, a lower household income and limited access to cars. Females are also overrepresented. More than 80% of participants have commuting cycling experiences, and around half have cycled for leisure and exercise. They prefer safety, smooth cycling conditions and green areas. The Covid-19 pandemic caused a decrease in commuting cycling (work/study) and a slight increase in recreational cycling (leisure and exercise). The participants hardly intentionally avoided busy roads to reduce infection risks.
Participants cycled in 40 cities and towns, mainly in the city of Utrecht and its surrounding areas. The city of Utrecht, with a dense population of 3709 \({\text{inhabitants}}/{km}^{2}\), is centrally located in the Netherlands. It has one of the best bicycle infrastructure systems in the Netherlands (Schering et al. 2022), resulting in a high bicycle modal share. In 2019, more than 46% of trips in Utrecht were made by bicycles (Haas and Hamersma 2020). Utrecht has a maritime climate with a mild and wet winter. The average temperature in December is 3.7℃, and the average cumulative precipitation is 76 mm. However, December 2020 was relatively warm (5.5℃) and rainy (107 mm), and no ice days occurred (KNMI 2021).
Preprocessing
Raw data described all movements of the respondents during the data collection period. The preprocessing first detected bicycle trips from raw data, and then these trips were map-matched to the most likely routes.
The bicycle trip detection includes four steps, namely trip segmentation, potential bicycle trip detections, bus/tram trip removal and bicycle type confirmation. By employing trip segmentation, the raw data was split to derive separate single-mode trips (excluding walking). In a day, people may make many single-mode trips, between which they walk or participate in non-travel activities. So, a whole GPS log can be divided into single-mode trips after removing walking and non-travel activity points. We define walking points as continuous points with speeds between 1 and 7 km/h with a total distance over 50 m. Points that remain within a circular area with a 50-m radius for more than three minutes were regarded as non-travel activity points. Second, we define city or conventional electric bicycle trips as trips with average speeds between 10 and 25 km/h and the 95th percentile speed below 30 km/h. Trips with average speeds ranging from 25 to 45 km/h and the 95th percentile speed below 45 km/h were assumed to be made by sport bicycles (racing bicycles and mountain bicycles) or speed pedelecs. Conventional electric bicycles can support pedalling up to 25 km/h, while speed pedelecs support up to 45 km/h. The 95th percentile speed was used to distinguish bicycle trips from bus/tram trips, as their average speeds can be similar in urban areas. Although conventional electric bicycles and speed pedelecs may occasionally exceed their designed maximum speeds, this happens infrequently. As observed by Herteleer et al. (2022), the average 95th percentile speed for speed pedelecs trips is 40 km/h. In contrast, buses and trams have frequent stops but can maintain relatively high speeds between stops. Third, considering that buses and trams may have a similar 95th percentile speed to bicycles in some urban areas and during congestion, we further detected possible bus/tram trips with their stop positions during trips and removed these trips from the result of the previous step. A stop was assumed to be made if the speed of a point is lower than 7 km/h, at which cyclists are unlikely to maintain balance. Multiple adjacent points with speeds below 7 km/h were recognised as one stop. After excluding stops at intersections, the remaining stops were compared with the positions of bus/tram stations. Trips with a high share of stops at bus/tram stations were recognised as bus/tram trips. However, none of the trips fell into this category. Fourth, the bicycle types for all potential bicycle trips were confirmed by additional survey data, including bicycle ownership data (most participants only own one type), the usage of bicycle types for different purposes, the home address and the work/study place address. Trip purposes (commuting to work or study/leisure/others) were derived from the locations of the trip origins and destinations. This information was combined to allocate the bicycle types to each trip. Occasionally, trips initially categorised as city bicycles/conventional electric bicycle trips were reassigned as sportive bicycles, as the participant only owns a mountain bicycle.
In total, 550 bicycle trips were detected, from which 42 trips shorter than 500 m were removed, resulting in 58,979 tracking points from 508 trips made by 60 cyclists. No valid bicycle trips were recognised from the GPS data logs of four participants, and they were excluded from the analysis. Of these 508 trips, 454 are city bike trips, 24 are conventional electric bicycle trips, 30 are sportive bicycle trips and none of the trips are speed pedelec trips. Conventional electric bicycles account for 5% of all bicycle trips, lower than the Dutch average percentage of 18% (Haas and Hamersma 2020). This can be attributed to the overrepresentation of students and young cyclists in our sample, who are less likely to have electric bicycles (Boonstra et al. 2021).
Map matching is the process of finding the most likely route taken by cyclists based on tracking point locations (Romanillos and Gutiérrez 2020). Its purpose is to link the infrastructure attributes from route maps to every tracking point. The method developed by Scheider (2017) was adopted to map match tracking points to the Fietsersbond network data (2018 version). First, all road segments within a threshold distance (25 m in the present study) from tracking points were regarded as segment candidates. The match probability of a candidate decreases with its distance from tracking points. Second, the shortest path connecting segment candidates of two continuous points was found. If two continuous tracking points have 4 and 5 segment candidates respectively, there are at most 20 (4 × 5) possible paths. Similarly, shorter paths have higher match probabilities. Then, the overall match probability for a complete route was calculated by multiplying the match probabilities of its segment candidates and the paths connecting them. The route with the highest probability was chosen as the map-matched route, representing the most likely path taken by cyclists. The final step is the manual examination and correction of evident errors, which resulted in only a few corrections.
Variables
Speed and distance
Cycling speed at every tracking point is directly measured by the GPS device (the calculation method is not provided by its manual), and it can also be measured with locations and time stamps of two continuous points. In two previous studies which analysed cycling speed at tracking points, Arnesen et al. (2019) calculated speed with points’ locations and time stamps, while Clarry et al. (2019) used speed from GPS devices. However, it is uncertain which method is more accurate for our study, so speed was measured with different methods and compared.
In our study, we compared three speed measurement methods: (1) the speed reported by the GPS device, (2) by dividing the Euclidean distance between consecutive tracking points by their time interval, and (3) by dividing the network distance and time interval. The network distance is the distance between two tracking points along the map-matched route in the digital road network. It is used because most raw tracking points are not precisely located on the digital road network due to GPS inaccuracies and map abstraction, so the line connecting the points may deviate a few meters and not perfectly reflect curved routes and turns. The three speeds are denoted as \({VD}_{i}\), \({VP}_{i}\) and \({VN}_{i}\) respectively, where \(VD\) refers to the speed measured by GPS devices, \(VP\) is the speed measured by Euclidean distance, \(VN\) is the speed measured by network distance and \(i\) is the point order in a trip. The measurement of \({VP}_{i}\) and \({VN}_{i}\) is:
where \({DP}_{(i,i-1)}\) is the Euclidean distance between points \(i-1\) and \(i\), and \({T}_{(i,i-1)}\) is the duration between these two points, and
where \({DN}_{(i,i-1)}\) is the network distance between points \(i-1\) and \(i\).
Table 1 and Fig. 2 compare three ways of speed measuring. Table 1 shows that the maximum speed for \({VP}_{i}\) is 80.43 km/h, and 117.75 km/h for \({VN}_{i}\), which are impossible in daily cycling. By contrast, \({VD}_{i}\) ranges from 0 to 43 km/h, which is reasonable. Figure 2 compares one random ride as an example, showing a similar trend among the three speeds, especially at points with low or medium speeds. The main difference occurs at some points with a high speed, where \({VP}_{i}\) and \({VN}_{i}\) have evident outliers, consistent with the results in Table 1. In addition, \({VP}_{i}\), and especially \({VN}_{i}\) have several points with speed increasing by more than 20 km/h from the previous point, which is hardly achieved in daily cycling. The substantial speed increase of \({VN}_{i}\) is partially due to the map abstraction in certain turns, where curve turns are represented with two tangent lines. Therefore, tracking points at these turns have a larger network distance than the actual situation, resulting in a higher \({VN}_{i}\). In contrast, the highest speed and speed variation of \({VD}_{i}\) are reasonable. All things considered, the speed measured by GPS devices (\({VD}_{i}\)) was used in modelling.

A sample of speed calculation methods comparison
The trip length is the network distance between the first and last tracking points, equal to the sum of the network distance between each consecutive pair of tracking points within the trip.
Turn and slope
Turns were derived from the direction change of the map-matched route segments, displayed in degrees of curvature, ranging from -180° to 180°. A turn is recognised if two consecutive segments formulate an angle greater than 80° (right turn) or lesser than -80° (left turn). Points within 30 m of turns were then labelled as the part before or after right/left turns.
The road slope was calculated for each tracking point based on their altitudes and positions. Point altitudes were derived from a digital altitude map of the Netherlands (AHN 2020) based on its coordinates. First, the tangent value of the slope gradient at tracking points \(i\) (\({T}_{i}\)) was measured as:
where \({H}_{p(i,i-1)}\) is the altitude of points \(i\) minus the altitude of point \(i-1\), and \({D}_{p(i,i-1)}\) is the network distance between these two points. Then, this value was converted to a degree. Considering that roads only with a gradient exceeding 3% (1.7°) can strongly influence cycling speed (Flügel et al. 2019), slopes were categorised into uphill (slope > 2°), flat road (− 2° < = slope < = 2°), downhill (slope < − 2°).
Infrastructures and land-use
Infrastructure attributes were taken from the Fietsersbond, which includes detailed road attributes. Different bicycle lane types are distinguished. Bike tracks refer to on-road bicycle lanes that do not have a physical transition between the road space for cyclists and motorised traffic; they may have different pavements or pavement colours. Bike paths along roads are physically separated bike lanes along main roads. Solitary bike paths are routes independent from main roads. Bike streets are a relatively new road type, designed as a street where bicycles have priority; motor vehicles are allowed but have to adapt to bicycles (Olsson and Elldér, 2023). Intersection types include signalised intersections, non-signalised intersections and roundabouts; the number of legs is not considered. The parts before and after signalised/non-signalised intersections are also recognised as a separate category.
Land-use types were calculated based on tracking point locations. The dominant land-use type within the circular buffer of a tracking point was considered as its land-use type. There are 13 land-use types in Bestand Bodemgebruik 2015, and they were categorised into five types: built-up (the area in use for residents, work, shopping, cultural facilities and public amenities), semi built-up (the area with a certain amount of paving, not in use as transport area or built-up area), transport (including airports, railways, the main road network, parking lots and bus stations), industry and nature area. Different buffer radii were used to calculate the dominant land-use type, with similar outcomes; finally, a 50-m buffer was chosen.
Weather and night trip
Weather conditions, including temperature, precipitation, humidity, wind speed and wind direction, are recorded by the Royal Netherlands Meteorological Institute (KNMI) every 10 min for 33 weather stations in the study area. We took values from the nearest station. Temperature and humidity are regarded as trip-level variables since they hardly change during a short period. The temperature and humidity at the trip mid-time were regarded as the trip value. Wind and precipitation are likely to change constantly, and are point-level variables. Wind speed was classified as strong (\(> 5.5 m/s\)), light (1.5–5.5 m/s)and no wind (\(<=1.5 m/s\)), and directions as tailwind (direction difference < 67.5°), side wind (67.5° < = direction difference < = 112.5°) and headwind (direction difference > 112.5°), combining into seven categories: no wind, strong headwind, strong side-wind, strong tailwind, light headwind, light side-wind and light tailwind. Precipitation was divided into heavy rain (\(>5 mm/h\)), light to medium rain (0–5 mm/h) and no rain.
The night, the period without sunlight, was defined as the period between astronomical dusk and astronomical dawn. It changes daily. Trips that start at daytime but end at nighttime or vice versa, are allocated to the period with the longest duration.
Modelling method
Multilevel linear mixed-effects models are estimated in this study using the mixed command of Stata 17. It is a generalisation of linear regression in nested-data situations (Searle et al. 2009), allowing for the inclusion of fixed effects and random deviations (effects) other than those associated with the overall error term.
The present study uses a three-level nested data structure (cyclists, trips and points), and a three-level mixed-effect model can be expressed as:
where \({y}_{ptc}\) is cycling speed at point \(p\) in trip \(t\) of cyclist \(c\). The fixed part is \({\upbeta }_{0}+{\sum }_{g=1}^{d}{\upbeta }_{g}{{\text{x}}}_{gc}+ {\sum }_{j=1}^{b}{\upbeta }_{j}{{\text{x}}}_{jtc}+{\sum }_{i=1}^{a}{\upbeta }_{i}{{\text{x}}}_{iptc}\), which specifies the overall mean influence of \(d\) cyclist-level, \(b\) trip-level and \(a\) point-level predictors on the cycling speed. Among these parameters, \({{\text{x}}}_{gc}\) refers to the cyclist-level variables with slope \({\upbeta }_{g}\), \({{\text{x}}}_{jtc}\) refers to the trip-level variables with slope \({\upbeta }_{j}\) and \({{\text{x}}}_{iptc}\) refers to the tracking point-level variables with slope \({\upbeta }_{i}\). The random part is expressed as \({{\text{v}}}_{c}+ {{\text{u}}}_{tc}+{e}_{ptc}\) and assumed to be uncorrelated with independent variables. \({{\text{v}}}_{c} \sim N\left(0,{\sigma }_{v}^{2}\right)\) is the random effect of cyclist \(c\), and the interpretation of \({\sigma }_{v}^{2}\) is the between-cyclist variance, adjusting for the predictors. This variance therefore measures the extent to which cyclist \(c\) varies from the fixed part. \({{\text{u}}}_{tc} \sim N\left(0,{\sigma }_{u}^{2}\right)\) and \({{\text{e}}}_{ptc} \sim N\left(0,{\sigma }_{e}^{2}\right)\) have parallel interpretations.
Based on this, we first estimate a null model (Model 1) to check the speed variance components at different levels and the existence of cyclist and trip heterogeneity. Then cyclist-level and trip-level variables are added to Model 2 to explain inter-person and intra-person cycling speed variation, namely the cyclist and trip heterogeneity. Based on it, precipitation, wind, road slope and land-use are added to Model 3, and land-use is replaced by bicycle infrastructures in Model 4. These two models mainly explain intra-trip cycling speed variation. Land-use and bicycle infrastructures are modelled separately because of collinearity; for example, intersections are denser in built-up areas. Model 4 also introduces random slopes of some infrastructure variables across trips, i.e. before signalised, before left turns, before right turns, signalised intersections and pedestrian areas, since the influence of these variables is expected to vary across trips. For example, a racing bicycle may decelerate more than a city bicycle before a red light. The random slope model can help understand the differences in intra-trip speed variations between trips. Equation (5) is an example of the random slope model, allowing the coefficient of \({{\text{x}}}_{1ptc}\) to be random at the trip level:
where \({{\text{u}}}_{1tc}{\times {\text{x}}}_{1ptc}\) is a new term compared to Eq. (4). Now the grand mean slope of \({{\text{x}}}_{1ptc}\) is \({\upbeta }_{1}\), and the slope for the trip \(tc\) is \({\upbeta }_{1}+{{\text{u}}}_{1tc}\). The covariance between the trip intercept (\({\upbeta }_{0}+{{\text{u}}}_{0tc}\)) and the trip slope (\({\upbeta }_{1}+{{\text{u}}}_{1tc}\)) is also calculated. It can describe how the influence of tracking point level variables changes across trips.
Result
Sample frequency
Participants show various trip frequencies and lengths (Table 2), therefore contributing differently to the dataset. This reflects the natural variation of cyclists in cycling behaviours. Table 2 classifies participants into four groups based on their trip frequencies. Most cyclists made fewer than ten bicycle trips, and a small number of participants made up to 24 trips. The average trip length of cyclists tends to decrease with their trip frequency. So, the difference in tracking point number between cyclists is smaller than the trip frequency. Those cyclists with frequent trips show a lower speed at tracking points.
Descriptive analysis
Table 3 describes all variables included in the final models, distinguishing the cyclist, trip and tracking point levels. It reports the mean tracking point speed from the GPS device for all dummy variables. Self-evaluated health conditions, preference for separate paths for safety and preference for high speed are continuous variables, using a scale ranging from ‘strongly disagree’ to ‘strongly agree’ (1 – 5). Around 60% of participants self-report a good health condition (Fig. 3). Most cyclists prefer separate paths for safety, and even more cyclists try to maintain a high speed.

Opinions on statements about preferences and health conditions
Model outcomes
Multilevel structure
We applied multilevel mixed-effects linear regression models for cycling speeds (Table 4). The final model is constructed step by step, with the columns showing the effect of adding levels, starting with the null model (1) followed by the cyclist and the trip level (2) and the tracking point level; the latter has been divided into land use (3) and infrastructure (4). The reported coefficients represent the estimated changes in cycling speed (km/h) for a one-unit change in independent variables when holding other variables constant. For example, the coefficient of the preference for separated paths in model 2 is \(- 0.445\), meaning that cycling speeds decrease by \(0.445 km/h\) with one level of growth in this preference. Similarly, for categorical variables, \(0.891\) for light-medium rain in model 3 means that cyclists tend to cycle \(0.891\) km/h faster in light to medium rain compared to no rain. Log-likelihood (LL) and Akaike information criterion (AIC) are two parameters to compare the model fits of different models, with higher LL and lower AIC meaning a better goodness of fit. Model 1 to model 4 show increasing model fits, where the effects of the variables are fairly stable, suggesting the robustness of these models.
The null model shows variance components (Random intercept in Table 4) of the cyclist (7.864), trip (5.474) and tracking point (13.132) levels. It shows that 29.7% (\(7.864/(7.864+5.474+13.132)\) and 20.7% of the total variance in cycling speed are due to between-cyclist differences and between-trip differences respectively, while within-trip differences account for about half of the total variance (49.6%). Substantial variances at the cyclist and trip levels also illustrate the existence of cyclist heterogeneity and trip heterogeneity. With additional variables added, this variance is partially explained, and the remaining speed variance decreases as expected.
The influence of cyclist level and trip level variables
Cyclist characteristics influence the average personal speed, explaining the inter-person variation and the heterogeneity of cyclists. Two preferences significantly influence cycling speed. Cyclists who prefer high-speed cycle faster, while those who prefer separated bicycle paths because of safety concerns tend to cycle slower. Gender becomes insignificant after considering the land use and bicycle infrastructure.
Similarly, trip conditions influence the average trip speed and explain intra-person variation. Conventional electric bicycles are 3 km/h faster than city bicycles, and sport bicycles are 4 km/h faster. Longer trips tend to have a higher speed, but this effect is negligible. Dark conditions hardly influence cycling speed. Humidity and temperature have no influence.
The influence of tracking point level variables
Most tracking point level variables significantly influence intra-trip speed variation with intuitive effects. Slope, precipitation and wind are included in both Models 3 and 4. Results show that cycling uphill is \(1.7 km/h\) slower than on flat roads. Unexpectedly, cycling downhill also decreases speed by \(0.6 km/h\). Cycling during light to medium rain is \(0.9 km/h\) faster than in dry episodes, while heavy rain does not influence cycling speeds. Cycling with tailwinds and side-winds, especially the strong tailwind, is faster, while headwinds were found indifferent.
Land-use is added in Model 3, and bicycle infrastructures are added in Model 4. Compared to built-up areas, speeds are higher in natural and industrial areas, and lower in transport areas. Cycling on all types of bike lanes is faster than on residential roads; by contrast, cycling in pedestrian areas is slower. Bridges and tunnels are negatively related to speed. All three kinds of intersections decrease cycling speed, and signalised intersections have the greatest effect, reducing cycling speed by \(3.6 km/h\). Cycling before intersections and turns is over \(2 km/h\) slower, while only about \(1 km/h\) slower after the intersections/turns.
The random slope effect
The random slope for the variable “before signalised” is considered for each trip in Model 4. The covariance between the trip intercept and the trip slope of “before signalised” is \(- 2.493\), showing that the slope tends to be smaller with the increase in the trip intercept. In other words, high-speed trips decelerate more before signalised intersections. This effect also applies to signalised intersections, pedestrian areas and before/after intersections/turns, meaning their negative effects on cycling speed are stronger for trips with higher speeds. Also, the effect of after-turns and intersections is lesser than before.
Conclusion
Conclusions and discussion
This paper aims to explain variations in cycling speeds on three levels, i.e. (1) between cyclists, referred to as inter-person variation, (2) between trips of the same cyclist, referred to as intra-person variation, and (3) during the trip, referred to as intra-trip variation. The null model shows the existence of heterogeneity between the levels. About 30% of the speed variance is attributed to the heterogeneity between cyclists, 21% to the trips, and 49% to differences within trips.
The cyclist-level variables explain the variation in speed between cyclists and the heterogeneity between them. As in other studies (Boufous et al. 2018; El-Geneidy et al. 2007), women cycle more slowly than men. Remarkably, however, this difference disappears after controlling for wind, precipitation, land use and bicycle infrastructures, suggesting that women may have different route choices, and respond differently to weather, thus avoiding speed reduction. Additionally, unlike most existing studies (Schleinitz et al. 2017; Vlakveld et al. 2015), age does not influence cycling speed. A possible reason is that older people tend to use electric bicycles more often, which compensates for the decline in physical abilities. It is worth noting that the absence of an age and gender effect is also possibly due to the relatively small and less representative dataset. A novel finding is that personal preferences clearly play a role, as expressed by the correlation between the preference for separate, thus safer tracks and lower speeds, and the finding that the preference for high speed correlates with an actual higher speed.
The trip-level variables show that electric bicycles appear to be faster than city bicycles, which was also found by Schleinitz et al. (2017), Eriksson et al. (2019), Jin et al. (2017); sport bicycles are even faster, as these bicycles are designed for a high speed and often used for exercise. Contrary to previous studies suggesting an influence of temperature (Strauss and Miranda-Moreno 2017) and humidity (Liu et al. 2017) on cycling speeds and bicycle trip generation, our findings indicate that humidity and temperature did not affect cycling speed. A possible reason is that temperature and humidity varied less during the data collection period.
The tracking point level variables, measuring differences during trips, are hardly investigated in the literature, so they provide interesting, partly unexpected findings. First, the role of slopes: it appears that not only cycling uphill (see Arnesen et al. 2019; Flügel et al. 2019) reduces speed, but also downhill. This is because most slopes in the Netherlands are short, such as bridges, which often end on another road or at a junction, causing cyclists to go down carefully.
Secondly, wind effects on speeds are partly as expected: tailwinds increase cycling speed, but surprisingly, headwinds have no effect. Light to medium rain is associated with a \(0.9 km/h\) higher speed, suggesting that cyclists speed up to minimise exposure to rain, but self-selection may also play a role, namely people who choose cycling during rainy days may have better cycling abilities and so a higher speed. Heavy rain, however, does not affect cycling speed; a possible explanation could be that safety considerations discourage cyclists from cycling faster for a short exposure duration.
Third, with respect to land-use, being the landscape a cyclist crosses, we found that natural areas facilitate slightly faster cycling compared to built-up areas, as cyclists can cycle more unhindered, and decelerate and accelerate less frequently due to fewer crossings. People also ride faster in industrial areas, possibly because they are more often commuters. By contrast, cycling speeds in areas mainly used for transport are lower than in built up areas, probably due to complicated traffic conditions, including parking and bus docking.
Fourth, infrastructure characteristics play a key role in cycling speeds, and effects are largely as expected. Intersections and turns are the main barriers to cycling smoothly. Similar to other studies (Clarry et al. 2019; Strauss and Miranda-Moreno 2017), cycling speeds at intersections, especially at signalised intersections, are relatively low. Interestingly, we also find that cycling within 30 m before intersections is even slower than cycling at intersections. This is because cyclists slow down and even stop before entering an intersection, whereas they usually do not stop when passing intersections. The same effects are observed for turns. In addition, it is found that cyclists with higher speeds encounter a greater need to slow down when close to intersections and turns. This makes sense, but it also clearly shows that barriers to fast riders, for example electric bicycles, are even more of a hindrance.
Surprisingly, however, the influence of bike lane types is slightly different from existing studies (El-Geneidy et al. 2007; Flügel et al. 2019), who found that separated bike paths increase cycling speed. The highest speeds are found on bike tracks without physical separation from motorised vehicles. A possible reason is that cyclists receive pressure from other traffic (Poliziani et al. 2022), so they cycle faster to leave bike tracks quickly. Another explanation is that cyclists using bike tracks not separated from motorised vehicles are the more experienced cyclists. A third explanation is that cyclists can more easily swerve around other cyclists here. Bike streets also have higher speeds, though motorised vehicles are not excluded. They are usually located in residential areas with relatively lower traffic volume, while cyclists have priority on this road type, so they can cycle smoothly with less disturbance. Solitary bike paths are often used for leisure trips, which are partly faster if used by people with racing bikes, but also partly slower because several people cycle relaxed on such trips. In addition, cyclists with safety concerns also cycle here at a lower speed. Paths along main roads are busy, resulting in frequent interactions between cyclists. To summarise, the positive effects of separate paths are smaller than those of bike tracks and bike streets.
Implications and recommendations
Cycling speed is related to other cycling behaviours, such as safety, mode choice and cycling route choice. Insights into intra-trip speed variation are of great importance for modelling bicycle traffic. In addition, results about cycling speed variation support urban and infrastructural planning for better bicycle infrastructures (Parkin and Rotheram 2010).
Incorporating speed variations between cyclists, trips, conditions and spatial-infrastructural situations in traffic models is believed to improve the model accuracy (Romanillos and Gutiérrez 2020). For example, the inclusion of heterogeneous speeds of cyclists in bicycle congestion models successfully predicted longer delays for cyclists with high desired speeds (Paulsen et al. 2019). Paulsen and Nagel (2019) also indicated that bicycle congestion models can be further improved by considering delays at turns and intersections. However, due to an insufficient understanding of cycling speed variation along routes, traffic models often assume a constant speed (e.g. mode choice models, as shown by Ton et al. 2019) or struggle to accurately account for speed differences among infrastructures. For instance, Castro et al. (2022) modelled cycling speeds on a bicycle path with a 3% gradient with the traffic flow simulator VISSIM, but did not predict correct speed distributions, possibly because of the omission of other infrastructure characteristics influencing speeds. By including the speed differences in models, more accurate predictions can be made regarding mode choice and cycling accessibility, as the total trip time can be predicted more correctly (El-Geneidy et al. 2007). Moreover, destination and route choice can be better predicted because both depend on cycling speeds (Flügel et al. 2019).
For urban and infrastructural planners, understanding the variation of cycling speed can be used to design better cycling networks, which enable fast and smooth cycling and thus make cycling more competitive with other modes of transport. This knowledge can provide insights into ‘black spots’ where bicycle speed seriously drops. These fine-grained spatial insights enable a targeted, tailor-made approach. For example, some intelligent traffic light systems can be installed at intersections where cyclists experience long waiting times; providing more space for cyclists at intensively used segments, such as bike lanes along main roads, can prevent cyclists from reducing their speeds sharply. Moreover, it is possible to develop fast routes, which can be advised to cyclists, especially those prefer a constant and higher speed, i.e. cyclists with sporty and electric bicycles. Such routes can, for example, result from linking multiple bicycle streets.
Future research
By studying bicycle speed in a multilevel setting, using a broad dataset, this study has provided an impetus to explore bicycle speed in depth. To this end, a number of indicators and models have been developed that can be further refined in future research.
First, the present study addressed many bicycle speed influencing factors, including socio-demographics, bicycle types, bicycle infrastructure characteristics, weather conditions, etc. However, the data collected during the COVID-19 pandemic caused a small and less representative sample and limited variation in bicycle types. Although we consider this dataset to be fit for such an analysis, the small dataset may limit the generalizability of the findings to the broader population, particularly for cyclist and trip level variables. So we recommend a larger and more representative sample, to consider a richer set of variables, including different age groups, trip purposes, time of day and bicycle types, as well as their interaction effects. We also recommend to identify and control for possible confounding variables, such as the bicycle type choice across age groups, and cycling frequency and distance between genders.
Second, because cyclists might choose a residential area and cycling routes that match their cycling speed preferences, self-selection effects can easily occur, influencing the results. Moreover, the degree to which people like cycling leads to self-selection by the degree of use, type of bicycle, and destination. An avenue for future research is to explore the occurrence and impact of such self-selection effects. Such effects are usually analysed by including attitudinal data in a longitudinal model, e.g. using structural equation models (e.g. Coevering et al. 2021; Hamaker et al. 2015).
Third, it can be assumed that cyclists not only prefer a higher cycling speed but also a stable cycling speed. After all, both braking and accelerating require extra physical and mental effort and possibly increase risks. That is why additional research could focus on the extent of speed stability and where or in which situations cyclists can maintain stable speeds.
Fourth, cycling is more sensitive to weather conditions than other transportation modes, and this study reveals that weather also affects cycling speed. However, the differences in weather conditions during our observations were limited. It may even be assumed that potential cyclists will refrain from cycling when it rains, if barriers make travel times longer than strictly necessary. It therefore makes sense that some traffic lights nowadays give cyclists priority when it rains. With climate change, weather conditions tend to be more extreme and unpredictable, and the influence of weather on cycling speed is expected to increase. Consequently we advise more research into the impact of weather on cycling speeds, preferably based on year-round weather conditions.
To conclude, knowledge about cycling speed used to be almost non-existent, but with the increasing use of bicycles, the increasing stimulation of bicycle use and the greater variation in bicycle types, in particular the variety of electric bicycles, these insights are highly necessary and valuable. Based on the results of the current study, we can conclude that better cycling routes stimulate faster and smoother cycling. Any form of cycling facilities, such as cycle paths, cycle lanes and cycle tracks, can support high speeds. This also applies to the removal of speed-limiting factors. Therefore, more routes without barriers and with facilities specifically for bicycles are essential for cycling to be smooth and fast.
References
AHN: Actueel Hoogtebestand Nederland. https://www.ahn.nl (2020). (accessed)
Arentze, T., Dijst, M., Dugundji, E., Joh, C.H., Kapoen, L.L., Krygsman, S., Maat, K., Timmermans, H.: New activity diary format: design and limited empirical evidence. Transp. Res. Rec. 1768(1), 79–88 (2001). https://doi.org/10.3141/1768-10
Arnesen, P., Malmin, O.K., Dahl, E.: A forward Markov model for predicting bicycle speed. Transportation 47(5), 2415–2437 (2019). https://doi.org/10.1007/s11116-019-10021-x
Berjisian, E., Bigazzi, A.: Evaluation of methods to distinguish trips from activities in walking and cycling GPS data. Transp. Res. Part C Emerg. Technol. 137, 103588 (2022). https://doi.org/10.1016/j.trc.2022.103588
Bernardi, S., Rupi, F.: An analysis of bicycle travel speed and disturbances on off-street and on-street facilities. Transp. Res. Proc. 5, 82–94 (2015). https://doi.org/10.1016/j.trpro.2015.01.004
Bohte, W., Maat, K.: Deriving and validating trip purposes and travel modes for multi-day GPS-based travel surveys: A large-scale application in the Netherlands. Transp. Res. Part C Emerg. Technol. 17(3), 285–297 (2009). https://doi.org/10.1016/j.trc.2008.11.004
Boonstra, H.J., van den Brakel, J., Das, S., Wüst, H.: Modelling mobility trends—update including 2020 ODiN data and Covid effects. Discussion Paper. Centraal Bureau voor de Statistiek (CBS), The Hague (2021)
Boufous, S., Hatfield, J., Grzebieta, R.: The impact of environmental factors on cycling speed on shared paths. Accid. Anal. Prev. 110, 171–176 (2018). https://doi.org/10.1016/j.aap.2017.09.017
Broach, J., Dill, J., Gliebe, J.: Where do cyclists ride? A route choice model developed with revealed preference GPS data. Transp. Res. Part A Policy Pract. 46(10), 1730–1740 (2012). https://doi.org/10.1016/j.tra.2012.07.005
Castro, G.P., Johansson, F., Olstam, J.: How to model the effect of gradient on bicycle traffic in microscopic traffic simulation. Transp. Res. Rec. 2676(11), 609–620 (2022). https://doi.org/10.1177/03611981221094300
Clarry, A., Imani, A.F., Miller, E.J.: Where we ride faster? Examining cycling speed using smartphone GPS data. Sustain. Cities Soc. 49, 101594 (2019). https://doi.org/10.1016/j.scs.2019.101594
De Haas, M., Hamersma, M.: Cycling facts: new insights. Netherlands Institute for Transport Policy Analysis (KiM), The Hague (2020).
De Vos, J.: Towards happy and healthy travellers: a research agenda. J. Transp. Health 11, 80–85 (2018). https://doi.org/10.1016/j.jth.2018.10.009
Dill, J., Gliebe, J.: Understanding and measuring bicycling behaviour: a focus on travel time and route choice. Oregon Transportation Research and Education Consortium Portland (2008). https://doi.org/10.15760/trec.151
Dissanayake, D., Morikawa, T.: Household travel behavior in developing countries: nested logit model of vehicle ownership, mode choice, and trip chaining. Transp. Res. Rec. 1805(1), 45–52 (2002). https://doi.org/10.3141/1805-06
El-Geneidy, A., Krizek, K., Iacono, M.: Predicting bicycle travel speeds along different facilities using GPS data: a proof of concept model. In: paper read at 86th annual meeting of the transportation research board, at Washington DC, USA (2007)
Eriksson, J., Forsman, Å., Niska, A., Gustafsson, S., Sörensen, G.: An analysis of cyclists’ speed at combined pedestrian and cycle paths. Traffic Inj. Prev. 20(sup3), 56–61 (2019). https://doi.org/10.1080/15389588.2019.1658083
Fietstelweek.: Ruim half miljoen fietskilometers in Fietstelweek 2017. https://fietstelweek.nl/ruim-half-miljoen-fietskilometers-fiets-telweek-2017/ (in Dutch) (2017). Accessed 2021
Flügel, S., Hulleberg, N., Fyhri, A., Weber, C., Ævarsson, G.: Empirical speed models for cycling in the Oslo road network. Transportation 46(4), 1395–1419 (2019). https://doi.org/10.1007/s11116-017-9841-8
Garcia, A., Gomez, F.A., Llorca, C., Angel-Domenech, A.: Effect of width and boundary conditions on meeting maneuvers on two-way separated cycle tracks. Accid. Anal. Prev. 78, 127–137 (2015). https://doi.org/10.1016/j.aap.2015.02.019
Geurs, K.T., Van Wee, B.: Accessibility evaluation of land-use and transport strategies: review and research directions. J. Transp. Geogr. 12(2), 127–140 (2004). https://doi.org/10.1016/j.jtrangeo.2003.10.005
Go Velo.: Het B-Riders programma heet nu Go Velo! https://govelo.nl/b-riders/ (in Dutch) (2021). Accessed 2021
Gustafsson, L., Archer, J.: A naturalistic study of commuter cyclists in the greater Stockholm area. Accid. Anal. Prev. 58, 286–298 (2013). https://doi.org/10.1016/j.aap.2012.06.004
Hamaker, E.L., Kuipers, R.M., Grasman, R.P.: A critique of the cross-lagged panel model. Psychol. Methods 20(1), 102–116 (2015). https://doi.org/10.1037/a0038889
Hamilton, T.L., Wichman, C.J.: Bicycle infrastructure and traffic congestion: evidence from DC’s capital bikeshare. J. Environ. Econ. Manage. 87, 72–93 (2018). https://doi.org/10.1016/j.jeem.2017.03.007
Harding, C., Faghih Imani, A., Srikukenthiran, S., Miller, E.J., Habib, K.N.: Are we there yet? Assessing smartphone apps as full-fledged tools for activity-travel surveys. Transportation 48, 2433–2460 (2021). https://doi.org/10.1007/s11116-020-10135-7
Harms, L., Kansen, M.: Cycling facts. Netherlands Institute for Transport Policy Analysis (KiM). Prepared by the Minister van Infrastructuur en Waterstaat, The Hague (2018)
Haustein, S., Møller, M.: E-bike safety: individual-level factors and incident characteristics. J. Transp. Health 3(3), 386–394 (2016). https://doi.org/10.1016/j.jth.2016.07.001
Herteleer, B., Van den Steen, N., Vanhaverbeke, L., Cappelle, J.: Analysis of initial speed pedelec usage for commuting purposes in Flanders. Transp. Res. Interdiscip. Perspect. 14, 100589 (2022). https://doi.org/10.1016/j.trip.2022.100589
Hunter, W.W., Srinivasan, R., Martell, C.: An examination of bicycle counts and speeds associated with the installation of bike lanes in St. Petersburg, Florida. Highway Safety Research Center, University of North Carolina, Chapel Hill (2009)
Jensen, P., Rouquier, J.B., Ovtracht, N., Robardet, C.: Characterizing the speed and paths of shared bicycle use in Lyon. Transp. Res. Part D Transp. Environ. 15(8), 522–524 (2010). https://doi.org/10.1016/j.trd.2010.07.002
Jin, S., Shen, L., Liu, M., Ma, D.: Modelling speed–flow relationships for bicycle traffic flow. Proc. Inst. Civ. Eng. Transp. 170(4), 194–204 (2017). https://doi.org/10.1680/jtran.15.00115
Kanarachos, S., Christopoulos, S.R.G., Chroneos, A.: Smartphones as an integrated platform for monitoring driver behaviour: the role of sensor fusion and connectivity. Transp. Res. Part C Emerg. Technol. 95, 867–882 (2018). https://doi.org/10.1016/j.trc.2018.03.023
Kassim, A., Culley, A., McGuire, S.: Operational evaluation of advisory bike lane treatment on road user behavior in Ottawa. Canada. Transp. Res. Rec. 2673(11), 233–242 (2019). https://doi.org/10.1177/0361198119851450
Kassim, A., Tayyeb, H., Al-Falahi, M.: Critical review of cyclist speed measuring techniques. J. Transp. Eng. 7(1), 98–110 (2020). https://doi.org/10.1016/j.jtte.2019.09.001
Kassim, A., Ismail, K., Woo, S.: Modeling cyclists speed at signalized intersections: Case study from Ottawa, Canada. In: 2017 5th IEEE international conference on models and technologies for intelligent transportation systems. 639–644 (2017). https://doi.org/10.1109/MTITS.2017.8005591
Kelly, P.: Assessing the utility of wearable cameras in the measurement of walking and cycling. Oxford University, Oxford (2013)
KNMI, 2021. Month and season overviews. https://www.knmi.nl/nederland-nu/klimatologie/maand-en-seizoensoverzichten/2020/december (2021). (accessed 2023)
Langford, B.C., Chen, J., Cherry, C.R.: Risky riding: naturalistic methods comparing safety behavior from conventional bicycle riders and electric bike riders. Accid. Anal. Prev. 82, 220–226 (2015). https://doi.org/10.1016/j.aap.2015.05.016
Li, Z., Ye, M., Li, Z., Du, M.: Some operational features in bicycle traffic flow: observational study. Transp. Res. Rec. 2520(1), 18–24 (2015). https://doi.org/10.3141/2520-03
Lin, S., He, M., Tan, Y., He, M.: Comparison study on operating speeds of electric bicycles and bicycles: experience from field investigation in Kunming, China. Transp. Res. Rec. 2048(1), 52–59 (2008). https://doi.org/10.3141/2048-07
Ling, H., Wu, J.: A study on cyclist behavior at signalized intersections. IEEE Trans. Intell. Transp. Syst. 5(4), 293–299 (2004). https://doi.org/10.1109/TITS.2004.837812
Liu, C., Susilo, Y.O., Karlström, A.: Weather variability and travel behaviour–what we know and what we do not know. Transp. Rev. 37(6), 715–741 (2017). https://doi.org/10.1080/01441647.2017.1293188
Manum, B., Nordström, T., Gil, J., Nilsson, L., Marcus, L.: Modelling bikeability. In: proceedings of the 11th international space syntax symposium, Lisbon, Portugal (2017)
Mohamed, A., Bigazzi, A.: Speed and road grade dynamics of urban trips on electric and conventional bicycles. Transp. B. Transp. Dyn. 7(1), 1467–1480 (2019). https://doi.org/10.1080/21680566.2019.1630691
Mokhtarian, P.L., Salomon, I., Redmond, L.S.: Understanding the demand for travel: it’s not purely ‘derived.’ Innov. Eur. J. Soc. Sci. Res. 14(4), 355–380 (2001). https://doi.org/10.1080/13511610120106147
Munshi, T.: Built environment and mode choice relationship for commute travel in the city of Rajkot, India. Transp. Res. Part D Transp. Environ. 44, 239–253 (2016). https://doi.org/10.1016/j.trd.2015.12.005
Olsson, S.R., Elldér, E.: Are bicycle streets cyclist-friendly? Micro-environmental factors for improving perceived safety when cycling in mixed traffic. Accid. Anal. Prev. 184, 107007 (2023). https://doi.org/10.1016/j.aap.2023.107007
Opiela, K.S., Khasnabis, S., Datta, T.K.: Determination of the characteristics of bicycle traffic at urban intersections. Transp. Res. Rec. 743, 30–38 (1980)
Parkin, J., Rotheram, J.: Design speeds and acceleration characteristics of bicycle traffic for use in planning, design and appraisal. Transp. Policy 17(5), 335–341 (2010). https://doi.org/10.1016/j.tranpol.2010.03.001
Paulsen, M., Nagel, K.: Large-scale assignment of congested bicycle traffic using speed heterogeneous agents. Procedia Comput. Sci. 151, 820–825 (2019). https://doi.org/10.1016/j.procs.2019.04.112
Paulsen, M., Rasmussen, T.K., Nielsen, O.A.: Fast or forced to follow: a speed heterogeneous approach to congested multi-lane bicycle traffic simulation. Transp. Res. Part B: Methodol. 127, 72–98 (2019). https://doi.org/10.1016/j.trb.2019.07.002
Plazier, P.A., Weitkamp, G., van den Berg, A.E.: “Cycling was never so easy!” An analysis of e-bike commuters’ motives, travel behaviour and experiences using GPS-tracking and interviews. J. Transp. Geogr. 65, 25–34 (2017). https://doi.org/10.1016/j.jtrangeo.2017.09.017
Poliziani, C., Rupi, F., Schweizer, J., Saracco, M., Capuano, D.: Cyclist’s waiting time estimation at intersections, a case study with GPS traces from Bologna. Transp. Res. Proc. 62, 325–332 (2022). https://doi.org/10.1016/j.trpro.2022.02.041
Rayaprolu, H.S., Llorca, C., Moeckel, R.: Impact of bicycle highways on commuter mode choice: a scenario analysis. Environ Plan B Urban Anal City Sci 47(4), 662–677 (2020). https://doi.org/10.1177/2399808318797334
Romanillos, G., Gutiérrez, J.: Cyclists do better. Analyzing urban cycling operating speeds and accessibility. Int. J. Sustain. Transp. 14(6), 448–464 (2020). https://doi.org/10.1080/15568318.2019.1575493
Romanillos, G., Zaltz Austwick, M., Ettema, D., De Kruijf, J.: Big data and cycling. Transp. Rev. 36(1), 114–133 (2016). https://doi.org/10.1080/01441647.2015.1084067
Schantz, P.: Distance, duration, and velocity in cycle commuting: analyses of relations and determinants of velocity. Int. J. Environ. Res. Public Health 14(10), 1166 (2017). https://doi.org/10.3390/ijerph14101166
Scheider, S.: Mapmatching. https://github.com/simonscheider/mapmatching (2017). Accessed 2021
Schepers, P., Hagenzieker, M., Methorst, R., van Wee, B., Wegman, F.: A conceptual framework for road safety and mobility applied to cycling safety. Accid. Anal. Prev. 62, 331–340 (2014). https://doi.org/10.1016/j.aap.2013.03.032
Schepers, P., Twisk, D., Fishman, E., Fyhri, A., Jensen, A.: The Dutch road to a high level of cycling safety. Saf. Sci. 92, 264–273 (2017). https://doi.org/10.1016/j.ssci.2015.06.005
Schering, J., Janßen, C., Kessler, R., Dmitriyev, V., Stüven, J., Marx Gómez, J., van Dijk, E., Brouwer, W., Kamermans, A., Verweij, L., Janssen, G.: ECOSense and sniffer bike: european bike sensor applications and its potential to support the decision-making process in cycling promotion. In digital transformation for sustainability ICT-supported environmental socio-economic development. Cham: Springer International Publishing. 157–182 (2022)
Schleinitz, K., Petzoldt, T., Franke-Bartholdt, L., Krems, J., Gehlert, T.: The German naturalistic cycling study-comparing cycling speed of riders of different e-bikes and conventional bicycles. Saf. Sci. 92, 290–297 (2017). https://doi.org/10.1016/j.ssci.2015.07.027
Schleinitz, K., Petzoldt, T., Gehlert, T.: Risk compensation? The relationship between helmet use and cycling speed under naturalistic conditions. J. Safety Res. 67, 165–171 (2018). https://doi.org/10.1016/j.jsr.2018.10.006
Searle, S.R., Casella, G., McCulloch, C.E.: Variance components. Wiley, New York (2009).
Shan, X., Li, Z., Chen, X., Ye, J.: A modified cellular automaton approach for mixed bicycle traffic flow modeling. Discrete Dyn. Nat. Soc. (2015). https://doi.org/10.1155/2015/213204
Shen, L., Stopher, P.R.: Review of GPS travel survey and GPS data-processing methods. Transp. Rev. 34(3), 316–334 (2014). https://doi.org/10.1080/01441647.2014.903530
Small, K.A.: Valuation of Travel Time. Econ. Transp. 1(1–2), 2–14 (2012). https://doi.org/10.1016/j.ecotra.2012.09.002
Stigell, E., Schantz, P.: Active commuting behaviors in a Nordic metropolitan setting in relation to modality, gender, and health recommendations. Int. J. Environ. Res. Public Health 12(12), 15626–15648 (2015). https://doi.org/10.3390/ijerph121215008
Strauss, J., Miranda-Moreno, L.F.: Speed, travel time and delay for intersections and road segments in the Montreal network using cyclist smartphone GPS data. Transp. Res. Part D Transp. Environ. 57, 155–171 (2017). https://doi.org/10.1016/j.trd.2017.09.001
Sun, B., Ermagun, A., Dan, B.: Built environmental impacts on commuting mode choice and distance: evidence from Shanghai. Transp. Res. Part D Transp. Environ. 52, 441–453 (2017). https://doi.org/10.1016/j.trd.2016.06.001
Tawalbeh, L.A., Basalamah, A., Mehmood, R., Tawalbeh, H.: Greener and smarter phones for future cities: characterizing the impact of GPS signal strength on power consumption. IEEE Access 4, 858–868 (2016). https://doi.org/10.1109/ACCESS.2016.2532745
Thompson, D.C., Rebolledo, V., Thompson, R.S., Kaufman, A., Rivara, F.P.: Bike speed measurements in a recreational population: validity of self reported speed. Inj. Prev. 3(1), 43–45 (1997). https://doi.org/10.1136/ip.3.1.43
Ton, D., Duives, D.C., Cats, O., Hoogendoorn-Lanser, S., Hoogendoorn, S.P.: Cycling or walking? Determinants of mode choice in the Netherlands. Transp. Res. Part A Policy Pract. 123, 7–23 (2019). https://doi.org/10.1016/j.tra.2018.08.023
Van De Coevering, P., Maat, K., Van Wee, B.: Causes and effects between attitudes, the built environment and car kilometres: a longitudinal analysis. J. Transp. Geogr. 91, 102982 (2021)
Visser, L.A.: Built environment and cycling speed: investigating built environment influences on cycling speed in the Netherlands. Delft, the Netherlands (2019)
Vlakveld, W.P., Twisk, D., Christoph, M., Boele, M., Sikkema, R., Remy, R., Schwab, A.L.: Speed choice and mental workload of elderly cyclists on e-bikes in simple and complex traffic situations: a field experiment. Accid. Anal. Prev. 74, 97–106 (2015). https://doi.org/10.1016/j.aap.2014.10.018
Woodcock, J., Tainio, M., Cheshire, J., O’Brien, O., Goodman, A.: Health effects of the London bicycle sharing system health impact modelling study. BMJ-BRIT MED J. (2014). https://doi.org/10.1136/bmj.g425
Acknowledgements
We thank three graduate students, Maaike Kuiper, Jimme Smit and Harmke Vliek, from the interuniversity master GIMA, the Netherlands, for the data collection and initial survey data preparation. We also thank three anonymous reviewers for their valuable suggestions to improve our paper.
Author information
Authors and Affiliations
Contributions
All authors contributed to the overall study conception and design. Data analysis was performed by HY. The first draft of the manuscript was written by HY, and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yan, H., Maat, K. & van Wee, B. Cycling speed variation: a multilevel model of characteristics of cyclists, trips and route tracking points. Transportation (2024). https://doi.org/10.1007/s11116-024-10477-6
Accepted:
Published:
DOI: https://doi.org/10.1007/s11116-024-10477-6