
Abstract
This paper aims to improve the channel estimation (CE) in the indoor visible light communication (VLC) system. We propose a system that depends on a comparison between Deep Neural Networks (DNN) and Kalman Filter (KF) algorithm for two optical modulation techniques; asymmetrically clipped optical-orthogonal frequency-division multiplexing (ACO-OFDM) and direct current optical-orthogonal frequency division multiplexing (DCO-OFDM). The channel estimation can be evaluated by changing the rate of errors in the received bits, where increased error means a performance decrease of the system and vice versa. Receiving less errors at the receiver indicates improved channel estimation and system performance. Thus, the main aim of our proposal is decreasing the error rate by using different estimators. Using the simulation results with the metric parameter of bit error rate (BER) aims to determine the improvement ratio between different systems. The proposed model is trained with OFDM signal samples with labels, where the labels represent the received signal after applying OFDM travelling across the medium. At a BER = 10–3 with DCO-OFDM, the DNN outperforms KF with 1.6 dB (7.6%) at the bit energy per noise \(({{\varvec{E}}}_{{\varvec{b}}}/{{\varvec{N}}}_{{\varvec{o}}})\) axis. Also, for ACO-OFDM at BER = 10–3, the DNN achieves better results than KF by about 1.3 dB (8.12%) at the \(({{\varvec{E}}}_{{\varvec{b}}}/{{\varvec{N}}}_{{\varvec{o}}}).\) At different values of M in QAM, the DNN outperforms KF for ACO-OFDM by average improvement of ~ 1 dB (~ 11.5%).
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Recently, VLC and the technology of intriguing applied visibled light for both data transfer and illumination. PWM, PPM, OOK, and OFDM are some of the modulation techniques utilized in VLC systems [Moustafa H. Aly 2021]. The optical transmission data through channel is represented as a power and so, it cannot have any negative values. To grantee that, OFDM applied in DCO-OFDM and ACO-OFDM are used in this research. For measuring the performance of the channel estimation to indoor VLC system. Both of BER and \(({E}_{b}/{N}_{o})\) are used to assess the channel estimate system's performance.
The KF is considered as an optimal estimator and can be used for different applications, like channel estimation as in Shawky et al. (2018a, b), positioning and localization systems (Shawky et al. 2020, 2021). Authors in Shawky et al. (2018a, b) performed a comparison between KF, least square (LS) and minimum mean square error (MMSE) methods using both ACO-OFDM and DCO-OFDM, showing that KF outperforms both LS and MMSE. Also, when using ACO-OFDM, the BER is improved than that in of DCO-OFDM. The improved percentage for using KF with DCO-OFDM is nearly 4.3% and for using KF with ACO-OFDM is about 5.6%, that mean using ACO-OFDM outperforms DCO-OFDM by 1.3% improving in CE for indoor VLC. In [E. B. Bektas and E. Panayirci 2021], channel sparsity is exploited to VLC and DCO-OFDM in attendance of the noise clipping. The simulation results illustate the converges of algorithm in the top of two iterations and that leads to enhance MSE and BER performance, outperforming CE algorithms, having no clipping noise mitigation capability. To deal with severe channel defects, a deep learning equalisation approach was developed in Miao et al. (2021). The proposed approach used twoice subnets for replacing the demodulation module for the conventional system to learn the nonlinearity of channel and the symbol de-mapping relation of the training data by utilizing the replicating of the block-by-block signal processing block in OFDM. The output demonstrates the addresses of the proposed system of the overall channel impairments efficiently and recovers the input with enhance BER performance.
In Wu et al. (2020), the authors introduced enhancing CE for indoor VLC by applying deep learning utilizing DNN to improve CE by fewer pilots. The results validated the feasibility of DNN-based CE.
Some learning methods, including Channel State Information positioning (Wang et al. 2016), equalization of the channel (Chen et al. 1990), and CE (Wu et al. 2020), have also shown to be effective in VCL fields. The authors of Zhang et al. (2018) presented a CE strategy based on a fast and flexible de-noising convolutional neural network (FFDNet), which considered the response of both time and frequency of a fast fade channel like a 2D image.
In our work, we applied several techniques to enhance CE like neural network with deep learning utilized KF for DCO-OFDM and ACO-OFDM. BER is used to assess performance. The findings show that deep learning approaches could be used to learn and assess channel properties, develop a model to help recovering distorted signals, and replace standard CE. The obtained results reveal that deep learning makes exploration potential to enhance CE.
The reminder of this paper is arranged as follows. Section 2 describes the DCO-OFDM and ACO-OFDM system models. The DNN algorithm is explained in Sect. 3. In Sect. 4, the system results are displayed and discussed. Finally, the work conclusion is shown in Sect. 5.
2 System model
2.1 DCO-OFDM
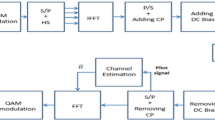
The DCO-OFDM block diagram is shown in Fig. 1. The modulation of the input signal is done using the quadrature amplitude modulation (QAM) technique and the Hermitian symmetry (HS) is used as in Shawky et al. (2018a, b) to get real values after QAM. To obtain a time domain signal inverse fast Fourier transform (IFFT) block is used with N subcarriers. To avoid a cyclic prefix and intersymbol interference, we applied OFDM. For cancelling negative signal, add the bias shift the signal to be all in positive values. The optical signal is transmitted through the channel. At the receiver, a line of sight (LoS) received signal is detected by the photodiode.

Block diagram of the DCO-OFDM system
Inverse operations of the transmitter are done at the receiver. First remove DC bias and then remove CP. The output of pilot signals is used to estimate the channel by different techniques. FFT is used to return back to frequency domain. The output of QAM demodulation is used to obtain the output bit stream. The CE is applied for recovering the received data. CE is depending on utilizing known symbols at receiver that is known by pilot.
2.2 ACO-OFDM
The ACO-OFDM diagram is shown in Fig. 2. As described in DCO-OFDM. HS, IFFT and CP are used to get non-negative symbols, convert to time domain and to avoid ISI. ACO-OFDM includes the input of odd signal that helps in clipping the non-negative signal without effect on its amplitude and the distortion (Wang et al. 2015; Dissanayake et al. 2013) (Fig. 3).

Block diagram of the ACO-OFDM system

Block diagram shows the algorithm for Kalman filter
2.3 Kalman filter algorithm
As described in [2], the KF is depending on the autoregressive which is used to channel model easily. In the KF, the coefficients \({h}_{k}\) of the channel are modeled using the AR dynamic process (Shawky et al. 2018a, b)
where k represents the OFDM symbol, \({\alpha }_{n}\) is the correlation time of the channel with respect to \({k}^{th}\) and \({(k+1)}^{th}\) OFDM symbols for the nth sub-carrier and \({v}_{k,n}\) is a Gaussian white noise.
First, consider only an AR model, where the channel response can be expressed as state x as following algorithm (Jain et al. 2014; Wang et al. 1996).
Predict step:
Prediction state
Measurement formula
Prediction covariance
Update step:
Compute Kalman gain as
Updated estimate with \({z}_{k}\)
Updated the error covariance:
where \({X}_{k}\) is the estimateion state at \((k)\). \({P}_{k}\) is a matrix of the covariance error (a measure of the estimation that ocuurs at the estimation state). \({A}_{k}\) is the transition state model. \({H}_{k}\) is a model of the observation, \({Q}_{k}\) is process noise covariance, and \({R}_{k}\) is the observation noise covariance.
3 Channel estimation deep learning based methods
The CE techniques are necessary for enhanced recovering data in receiver side.
3.1 DNN model
The number of layers in a neural network is referred to as deep. DNNs have more than one hidden layer, whereas shallow neural networks only have one. It is assumed that observations are the results of interactions between many causes, and that boken down into some layers, signifying the multi-layered abstraction of observed values.
The train is offline in this paper, but the implementation is online. The model is trained using both of OFDM samples and the labels. As illustrated in Fig. 4, the internal layer of neural for DNN is separated to three kinds: input layer, hidden layer, and output layer.

Deep neural network
The intermediate layers are connected for the point of the \({i}^{th}\) layer and should be concatenacted with any point of the \({i+1}^{th}\) layer. The active and linear operations are done by the forward propagation via the matrix the input value vector, the bias vector, and the weight coefficient (w). The input layer is started firstly, then, calculate the backward layer, and output layer to gain the final result. The propagation forwarded is calculated:
where \(l\) means the \({l}^{th}\) layer, \(i\) represents the \({i}^{th}\) point of the layer, and f(.) is the fuction of activation. The loss function is mandatory in the backpropagation to evaluate the change between the output calculations using the actual a sample of training output and the training sample, while the results from the calculation of a sample of the training utilizing the algorithm of the forward propagation and can utilize \({L}_{2}\) like the loss function [16].

where  ) is the predicte parameter and Y(k) is the controlling parameter in this case of symbols transmission. The following formula is anticipated to be minimized for each sample
) is the predicte parameter and Y(k) is the controlling parameter in this case of symbols transmission. The following formula is anticipated to be minimized for each sample
Neural network layers will make estimations. As a result, the standard regression problem gradient descent method cannot be utilized to decrease the loss function, and the estimation error must be addressed and optimized layer after layer. The backpropagation algorithm optimizes estimation for a neural network multi-layer. First, each layer prediction error is used as a vector (l) and is written as (Qiu et al. 2019)
The activation function must be nonlinear since the outcomes from each layer are a linear function of the top layer. The neural network output no longer has to be a linear combination of inputs when a nonlinear function is used as an activation function, and it can approximate any function. Tanh and Rectified linear activation unit (Relu) (Sharma et al. 2017) are the activation functions, which are defined as
where \(S\) is convolutional data, Relu is a popular function activation for the deep neural networks that is becoming increasingly rapidly. The Tanh activation function appears to be a Sigmoid at first appearance, and is utilized in the final layer to transfer the value of the input to an output.
3.2 DNN model training
The input of external node uses an activation function to determine the output, which helps with de-linearization. The bias may be seen like a specific input as additive radio noise; the input correlates to the weight, that is the related relevance for the input received usinfg this node; the bias is a particular input such like additive radio noise.
Our proposed model has seven levels, five of which are hidden layers. Each layer has 256, 500, 500, 120, 120, 60, and 16 neurons. There is a relation between the neurons number and the data vector length for both the input and output. Neurons number in the network input layer is \(n=1024\), that is OFDM subcarriers. As transmitted data, a random binary integer \({b}_{i}\) is generated, which is then can be moduated with m-mod to become 128 complex values, that are the training signal. The label corresponds to the \({b}_{i}\)-generated constellation point. The \({L}_{2}\) loss, which is used to train the model, describes the input and the label difference.
We employ the Relu function as an function activation in the intermediate layers, and the Tanh function in the output layer to get the output in the interval 0, 1. The dropout is defined into the training to avoid over-fitting. When we train a batch of training data, we delete the hidden layer neurons randomly and partially, then use the neural network to cancel the hidden layer to accept the training data, and then utilize this network to cancel a portion of the neurons to complete a round of parameter update. First, restoring the DNN model is done in the connected form then, the data training batch, following which the coefficients of particular hidden layer neurons can be adjusted. When we train a batch of training data, we delete the hidden layer neurons randomly and partially, then use the neural network to cancel the hidden layer to accept the training data, and then utilize this network to cancel a portion of the neurons to complete a round of parameter update. First, restoring the DNN model is done in the connected form then, the data training batch, following which the coefficients of particular hidden layer neurons can be adjusted.
Moreover, the batch size is set to be 32 and the maximum pool size is adjusted to be 4 × 4 with stride 4 × 4. Furtheromre, the number of epoch is set to be 50. These parameters are utilized to achieve the best perfromance. The procedure and findings are summarized in Table 1.
As a future work, we can use the optimization in DNN to decrease the error rate to reach the optimum error. The main control factor in this case is the hyper-paramter (HP) which is a machine learning parameter that must be fixed before the training process begins. As a result, unlike the value of parameters (e.g., weights) that may be taught during the training process, HPs (e.g., learning rate, batch size, and number of hidden nodes) cannot be learned during the learning process. HPs can affect the quality of the model produced by the training process as well as the algorithm time and memory requirements (Mai et al. 2019).
4 Results and discussion
According to the system models of ACO-OFDM and DCO-OFDM for indoor VLC system, shown in Figs. 1 and 2, our simulations use the KF algorithm and DNN model. In empty room with dimensions (5 × 5 × 3) m3 for LOS channel response, Additive White Gaussian Noise (AWGN) is added to the signal through the wireless channel. An LED is used in transmitter and a photodiode is used in receiver with air as an indoor optical channel. The the photodiode should be with high sensitivity. Hence, we have chosen avalanch photodiode to be used where is characterized by a greater level of sensitivity, high performance and fast response time.
Figure 5 illustrates the performance of the CE for both DNN and KF using ACO-OFDM and DCO-OFDM modulation techniques. BER and \({E}_{b}/{N}_{o}\) axes are units of measuring the performance. Using 1024 OFDM subcarriers and M = 128 for QAM modulation, the results confirm that ACO-OFDM outperforms DCO-OFDM for both DNN and KF. The DNN achieves better results than KF for ACO-OFDM and DCO-OFDM. At BER = 10–3 with ACO-OFDM, the DNN outperform 1.3 dB (8.12%) for \({E}_{b}/{N}_{o}\) axis than KF, and at BER = 10–3 with DCO-OFDM, DNN outperforms 1.6 dB (7.6%) for \({E}_{b}/{N}_{o}\) axis than KF.

Comparison between DNN and KF for DCO-OFDM and ACO-OFDM modulation techniques
In [2], there is a comparison between LS, MMSE and KF for different values of M and KF outperforms both of LS and MMSE. Here, we perform a comparison between different values of the constellation M = 16, 32, 64 and 128 for QAM modulation between KF and DNN. Figure 6 illustrates this comparison for ACO-OFDM between DNN and KF. The DNN achieves better results than KF for different constellation values. At BER = 10–3, there is an improvement for DNN over KF by ~ 1 dB (~ 11.5%) for \({E}_{b}/{N}_{o}\) axis for M = 16, 32, 64 and 128.

Comparison between DNN and KF for ACO-OFDM modulation techniques for different QAM, M = 16, 32, 64 and 128
5 Conclusion
This paper aims to improve the CE using DNN and KF with different modulation techniques ACO-OFDM and DCO-OFDM, our results improve the performance of VLC system. There is a positive relationship between improving the CE and decreasing BER that declares the importance of choosing BER as a metric parameter in the simulations. Comparing DNN and KF for ACO-OFDM and DCO-OFDM, in both ACO-OFDM and DCO-OFDM modulation techniques, the DNN achieves better results over KF by about 8.12% and 7.6%, respectively. Using the QAM modulation technique with different values of M, again, the DNN outperforms KF for ACO-OFDM by average improvement about 11.5%. As a future work, we can use the optimization in DNN to decrease the error rate to reach the optimum error.
References
Aly, M.H.: Visible light communications illuminates the future. J. Adv. Comput. Eng. (ACE) 1(2), 33–36 (2021)
Bektas, E. B., Panayirci, E.: Sparse Channel estimation for DCO-OFDM VLC systems in the presence of clipping noise. Research Square, pp. 1–15, June (2021)
Chen, S., Gibson, G.J., Cowan, C.F.N.: Adaptive channel equalisation using a polynomial-perceptron structure. IEE Proc. I-Commun. Speech vis. 137(5), 257–264 (1990)
Dissanayake, S.D., Armstrong, J.: Comparison of ACO-OFDM, DCO-OFDM and ADO-OFDM in IM/DD systems. J. Lightwave Technol. 31(7), 1063–1072 (2013)
Jain, R.: Kalman filter based channel estimation. Int. J. Eng. Res. Technol. 3(4), 277–282 (2014)
Mai, L., Koliousis, A., Li, G., Brabete, A.O., Pietzuch, P.: Taming hyper-parameters in deep learning systems. ACM SIGOPS Op. Syst. Rev. 53(1), 52–58 (2019)
Miao, P., Yin, W., Peng, H., Yao, Y.: Study of the performance of deep learning-based channel equalization for indoor visible light communication systems. Photonics 8(10), 1–16 (2021)
Qiu, T., Shi, X., Wang, J., Li, Y., Qu, S., Cheng, Q., Cui, T., Sui, S.: Deep learning: a rapid and efficient route to automatic metasurface design. Adv. Sci. 6(12), 190–196 (2019)
Sharma, S., Sharma, S., Athaiya, A.: Activation functions in neural networks. Towards Data Sci. 6(12), 310–316 (2017)
Shawky, E., El-Shimy, M., Mokhtar, A., El-Badawy, E.-S.A., Shalaby, H.M.H.: Improving the visible light communication localization system using Kalman filtering with averaging. J. Opt. Soc. Am. B 37(11), A130–A138 (2020)
Shawky, E. and Amer, A. E. F.: Averaging indoor localization system, adaptive filtering - recent advances and practical implementation. Book Chapter, Wenping Cao and Qian Zhang, IntechOpen, pp. 121–140, (2021)
Shawky, E., El-Shimy, M. A., Shalaby, H. M. H., Mokhtar, A., and El-Badawy, E.-S. A.: Kalman filtering for VLC channel estimation of ACO-OFDM systems. In: Proc. Asia communications and photonics conference (ACP 2018a), pp. 1–3, Hangzhou, China, 26–29 (2018a)
Shawky, E., El-Shimy, M. A., Shalaby, H. M. H., Mokhtar, A., El-Badawy, E.-S. A. and Srivastava, A.: Optical channel estimation based on Kalman filtering for VLC systems adopting DCO-OFDM. In: Proc. 20th Int. Conf. Transparent Optical Networks (ICTON 2018b), Paper We.P.13 (1–4), Bucharest, Romania, 1–5 July (2018b)
Wang, H.S., Chang, P.C.: On verifying the first-order Markovian assumption for a Rayleigh fading channel model. IEEE Trans. Veh. Tech. 45(2), 353–357 (1996)
Wang, Q., Qian, C., Guo, X., Wang, Z., Cunningham, D.G., White, I.H.: Layered ACO-OFDM for intensity-modulated direct-detection optical wireless transmission. Opt. Expr. 23, 12382–12393 (2015)
Wang, X., Gao, L., Mao, S., Pandey, S.: CSI-based fingerprinting for indoor localization: a deep learning approach. IEEE Trans. Veh. Technol. 66(1), 763–776 (2016)
Wu, X., Huang, Z., Ji, Y.: Deep neural network method for channel estimation in visible light communication. Opt. Commun. 462, 12527 (2020)
Zhang, K., Zuo, W., Zhang, L.: FFDNet: toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 27(9), 4608–4622 (2018)
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB). The authors have not disclosed any funding.
Author information
Authors and Affiliations
Contributions
We are enclosing herewith a manuscript entitled “Enhanced Deep Learning Based Channel Estimation for Indoor VLC Systems” for publication in Optical and Quantum Electronics Journal. With the submission of this manuscript I would like to undertake that: All authors of this research paper have directly participated in the planning, execution, or analysis of this study; All authors of this paper have read and approved the final version submitted; The contents of this manuscript have not been copyrighted or published previously; The contents of this manuscript are not now under consideration for publication elsewhere; The contents of this manuscript will not be copyrighted, submitted, or published elsewhere, while acceptance by the Journal is under consideration; There are no directly related manuscripts or abstracts, published or unpublished, by any authors of this paper.
Corresponding author
Ethics declarations
Conflict of interest
The authors have not disclosed any competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Salama, W.M., Aly, M.H. & Amer, E.S. Enhanced deep learning based channel estimation for indoor VLC systems. Opt Quant Electron 54, 535 (2022). https://doi.org/10.1007/s11082-022-03904-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11082-022-03904-4