
Abstract
The study of relations between cities has long been a major focus in urban research. For decades, this field has grown integrating contributions from many disciplines. But today, the field appears rather fragmented. This study analyses the body of literature that has developed over the last 23 years to identify schools of thought on interurban relationships and to see to what extent these interact with each other. It does so by innovatively employing bibliometric analysis to the study of systems of cities, which allows a bottom-up identification of five schools of thought: one predominantly focusing on the regional or intra-metropolitan scale and centred on concepts of polycentricity; one addressing the global scale with a focus on world city networks; one employing simulation and complexity theories to understand behaviour of agents building the urban system bottom-up; one rooted in (new) economic geography and focusing on growth and decline in the urban system; and, one seeking regularities with respect to city size distributions. The conceptual, methodological and empirical aspects of these different schools are discussed by means of a ‘semantic map’ derived from the vocabulary of titles and abstracts of papers. The coupling of the semantic map with the citation networks of these schools of thought confirms the increasing fragmentation of the field over the last decades. However, in the most recent years, the different schools of thought start to interact slightly more. The desirability and feasibility of a move from multidisciplinarity to interdisciplinarity in urban systems research needs further exploration.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Cities do not function in isolation, but are organised in systems of cities characterised by strong interdependencies that develop at the scale of a large region, a nation, a continent or even at the global scale (Pumain 2011). A large literature on interrelated cities has developed since the end of the nineteenth century. Early contributions include work observing the regularities in the size distribution of cities in countries (Auerbach 1913; Gibrat 1931; Zipf 1949) as well as the formulation of central place theory (Christaller 1933). These contributions provided the basis for an upsurge of work on intercity relationships in the 1960s and 1970s, addressing many aspects of a system of cities such as the size, location and specialisation of cities as well as the uneven circulation of people, goods and information among them (Berry 1964; Bourne and Simmons 1978; Pred 1977). The definition of a ‘system of cities’ by Allan Pred (1977, p.13) is still valid today: “a national or regional set of cities that are interdependent in such a way that any significant change in the economic activities, occupational structure, total income or population of one member city will directly or indirectly bring about some modification in the economic activities, occupational structure, total income or population of one or more other set members”. Nowadays, this definition can also be extended to global urban systems because of long-distance interrelationships between cities, particularly those at the top of national urban hierarchies becoming more common.
Since the 1990s the literature on systems of cities has developed further and expanded, but the current landscape of research appears rather fragmented. Increasingly the term ‘paradigm change’ is used by researchers willing to position themselves in opposition with ‘classical’ approaches. For example, Friedmann (1995) talked about a ‘world city paradigm’, by which he meant an encompassing approach of different aspects of intercity relations at the global scale, which tended to be studied separately. Also Capello (2000) and Meijers (2007) suggested a ‘paradigm change’, claiming that the classical Central Place model was unable to describe contemporary trends in the pattern of intercity relations. More recently, Batty (2013) wrote about the rise of a ‘new paradigm’ in the conception of cities. Building on previous works that consider cities as emerging from the multitude of interactions between individuals, he underlines that processes of centralised decision-making such as planning and governing have a limited influence on cities. These different theoretical positions have an important impact on the research approach. While some studies focus more on stakeholders (Alderson and Beckfield 2004; Sassen 1991), others look at the emergent properties of a system of cities by considering the basic interactions between urban agents, for instance in a simulation framework (Sanders et al. 1997) or in the methodological individualism of economics (Fujita et al. 1999). There are also different positions regarding the scale at which the most important urban processes take place. For some researchers, in the context of globalisation, the global scale has become most determinant (Taylor and Derudder 2015). For others, the erosion of national borders in this context puts the regional scale at the centre of economic processes (Kloosterman and Musterd 2001; Parr 2014). Somewhere in between these scales is a research stream stressing the importance of the national scale given its determining influence on many structures and parameters that experience strong path dependencies (Pumain 1997; Bretagnolle and Franc 2017). Differences in ontological and epistemological perspectives translate into wildly varying objectives of research, ranging from identifying universal laws of urbanisation (Bettencourt et al. 2007) to much more policy oriented studies (Meijers and Romein 2003). This variety in objectives partly relates to the disciplinary background and sources of influence of the researchers. While theoretical and quantitative geographers and physicians will look for basic mechanisms, planners will aim to give policy recommendations. As the field exploring relationships between cities has received contributions and influences from many different disciplines such as geography, regional science, sociology, economics, physics and the interdisciplinary movement of complexity theories, it seems that increasingly separate approaches or subfields have emerged.
This paper aims to answer the following questions: How did the system of cities literature evolve over the last two decades? Which different schools of thought can be distinguished and what are their defining elements? And, to what extent do these schools interact? Assessing interdisciplinarity in this research field is all the more important given the frequent calls for interdisciplinarity in urban systems research (Pflieger and Rozenblat 2010), and because there is clear evidence that innovation in geography – still the main discipline addressing systems of cities - is fostered by collaborations among disciplines (Ducruet and Beauguitte 2013).
This study of the evolution of the urban systems literature does not take the form of a classical literature review paper. Rather it adopts a bibliometric approach to analyse a set of 1491 papers on intercity relationships from 1995 onward. The main advantage of this method is that certain bias in reviewing the literature can be avoided, such as a too narrow disciplinary point of departure. Indeed, during our readings, we noticed that certain studies were ignoring entire parts of the field. By limiting human intervention on the collection of the set of papers, we intend to overcome this bias and show the diversity of the field and its complex internal structure. This does not mean that our approach can replace extensive readings, at the contrary, but it allows to get a ‘bird’s eye view’ for further exploration. Our approach is inspired by the hyper-network approach, which combines the analysis of semantic and citation networks. This approach has for instance been applied recently to the papers of a journal (Raimbault 2017), or to the classification of a large set of patents (Bergeaud et al. 2017). The approach entails a two-step approach. First, following Chavalarias and Cointet (2013) who define scientific fields “as sets of ‘keywords’ delineating a research area”, a semantic network based on co-occurrences of words in the titles and abstracts of the set of papers is extracted. This allows then to identify the different subfields or schools of thought on systems of cities. Second, the pattern of citations of the papers developed within these schools are analysed to understand the connections between the different subfields.
The following section presents and discusses the bibliometric method as a way to undertake a literature review, as well as the delineation procedure that is needed to select a relevant corpus of texts (section 2). In the subsequent section, we present the content-analysis based on the vocabulary of the papers and how differences in vocabulary allow to identify different schools of thought. In addition, we explore the relations between these different schools of thought by analysing the evolution of citation patterns (section 3). The last section concludes and discusses the implications of our findings (section 4).
2 Bibliometric Analysis and Corpus Delineation
2.1 Bibliometric Analysis in Social Science
Citation networks do not only reveal intellectual connections, but also the social organization of science (Leydesdorff 1998). This dimension of science stands central when studying the formation of concepts but can be enriched by the analysis of the text related to the production of knowledge (Callon et al. 1983). Words have a central place in science because scientists are first of all readers and writers (Latour and Woolgar 2013). Consequently, to study the evolution of a notion such as systems of cities, we can, in addition to exploring citation patterns, also study the semantic network extracted from the set of papers. Using a mixed approach combining citation and text analysis such as the recently developed hyper-network framework allows characterising a corpus more precisely (Raimbault 2017). The semantic network can be obtained through text mining techniques applied to titles and abstracts of the studied papers. Hence, the first step of this research is to extract the vocabulary of scientific publications on system of cities to see which concepts are generally associated with each other. Chavalarias and Cointet (2013) have shown that the vocabulary of publications can be used to study the evolution of a scientific field. Rather than using predefined categories, this approach allows a “bottom-up” reconstruction of science. The basic hypothesis behind co-word analysis is that two words co-occurring often within individual papers will have a great probability of being strongly related (Chavalarias and Cointet 2013). After this semantic analysis, a citation network analysis can be used to see whether papers with a similar approach are embedded in very homogeneous clusters or not, and/or whether there are exchanges between different schools of thought.
The Scopus database indexes most social science journals and was therefore chosen as point of departure for defining the body of literature to analyse. This implies that we focus on papers published after 1994, because the Scopus database does not systematically provide information preceding this date. The content analysis has been processed and visualised with VOS-viewer (Van Eck and Waltman 2011), a computer program that was developed at the Centre for Science and Technology Studies of Leiden University and that is freely available.Footnote 1 For the creation of the citation network and the creation of a hybrid citation-semantic network we relied on R and notably the igraph package (Csardi and Nepusz 2006).
Although our approach can lead to new insights on the systems of cities literature, the approach also has a number of limitations. First of all, we cannot claim that we are dealing with an all-encompassing, exhaustive set of papers on systems of cities for several reasons other than the absence of pre-1995 papers. As this field is predominantly enriched by social scientists, many contributions, notably some of them published in books are missing. According to Hicks (1999) social scientists publish more in books than natural scientists, resulting in a smaller coverage of the outputs of social science disciplines in journal-based bibliometric databases. However, according to a more recent case study on research outputs in Flanders (Engels et al. 2012) the number of book publications remains rather stable in social science, but their share is diminishing because of the increase in journal publications. Even if Scopus sometimes includes book chapters, we have to accept that some contributions are missing. Moreover, there is a big chance that papers published in English are overrepresented in our corpus because we did the query in this language. Somewhat alleviating the problem is the fact that the Scopus database indexes most of the non-English literature with an English title and abstract. In addition, the focus on just one language avoids the tricky issue of the translation of scientific concepts. Nonetheless, we do think that analysing a large corpus of publications can bring new insights to the field because it covers a very significant part of the scientific production in the given period. The fact that the set of publications was collected by predominantly using a key-word strategy rather than by just climbing up or going down the chain of citations allows to avoid the teleological bias of classical literature reviews. This approach, of course, does not replace the fundamental work of extensive readings but allows framing the literature in a novel way.
2.2 Delineating the Corpus
The collection of the corpus of relevant publications on systems of cities is a very important and sensitive step because it potentially has a strong influence on the outcomes of the analysis. There is no consensus on the best approach to delineate a scientific field and collect related publications. In practice, three main strategies tend to be used: the key-words strategy (van Meeteren et al. 2015) where the set is obtained by collecting all the papers mentioning some chosen key-words; the journal-level strategy (Leydesdorff and Zhou 2007; Liu 2005) that supposes that specific scientific areas are covered by a limited number of journals; and, the citation-based strategy (Waltman and van Eck 2012) which supposes that scientific fields can be conceived as clusters of individual publications citing each other. According to (Zitt 2015) “mixed strategies with learning processes, adaptive queries and multistep protocols, with possible combination of supervised and automatic stages” are welcomed in bibliometric studies and information retrieval. This is especially the case with interdisciplinary fields that are not necessarily institutionalised such as the system of cities literature. For example, previous analysis of the ‘urban studies’ literature have been based on mixed journal-level/key-words strategies (Kamalski and Kirby 2012; Wang et al. 2012).
Social sciences and humanities often deal with complex notions that can have multiple meanings and expressions. This is also the case here: the most common expressions used in the studies of a set of interdependent cities are “system of cities”, “urban system”, “city-system”, “urban network” and “city network”. Some research included in this study, particularly those dealing with city size distributions, has no explicit mention of intercity relationships but focuses on stock data. However, we do not draw a clear line between those studies and the studies that adopted a more relational approach, as both approaches overlap, intersect and complement each other. This comes forward in the original formulation of the ‘Zipf law’ that is supposed to describe “the relative population sizes of the communities of the total system”, which would be the result of the two opposite forces of diversification and unification: “the actual location of the population will depend upon the extent to which persons are moved to materials and materials to persons in a given system” (Zipf 1949, p. 352). This model supposes an underlying relational conception of cities that exchange materials but also migrants (p. 359). In fact, many classics have associated the form of the size-distribution of cities with the level of integration of the system (Vapnarsky 1969; Pred 1977). This applies also to work employing scaling laws, as most of them compare cities belonging to a coherent geographical entity that can be considered a system.
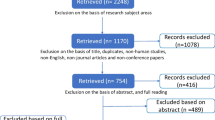
A particularly ambiguous expression of intercity relationships is ‘urban system’. In the late 1970s, Allan Pred (1977, p. 219) was already underlining the “inconsistent connotation” of the ‘urban system’ term that was used in connection to both an individual city and to a set of cities. This explains why during our first attempts of corpus delineation we were confronted with a vast array of papers addressing intra-urban infrastructure networks (water, electricity, roads) and the urban metabolism (a research stream focusing on the material flow analysis of a city). Since these generally had nothing to say about inter-urban relations, we adopted a multistep process with adaptive queries, refined after each iteration and mixed with the analysis of citation patterns. The different steps taken are schematised in Fig. 1 and are described below.

The algorithm of the delineation procedure
We first mined the references of existing literature reviews (Ducruet and Lugo 2013; van Meeteren 2016; Pumain 2006) to select relevant keywords on the subject. This first step allowed identifying a large spectrum of the field because they cover different aspects of the literature. We then added other terms based on our knowledge of the subject.
(1) TITLE-ABS-KEY("city system*" OR "urban system*" OR "system* of cities" OR "city network*" OR "urban network*" OR "network* of cities" OR "settlement system*" OR "system* of settlements" OR "central place system*" OR "megaregion*" OR "polycentric urban region*" OR "urban hierarch*") AND PUBYEAR > 1994
The first query resulted in a set of 7218 documents. We visualised them as citation networks where publications are nodes and citations are edges. It returned a ‘Saturn’ type of configuration with a big connected graph of publications in the centre and a ring of unconnected publications surrounding this centre. We took a random sample of 100 publications from the outer-ring to read their title and abstract. The vast majority of them were not about our subject so we decided to keep only the biggest connected graph in the centre. We then took a random sample of 100 publications in this graph and read their title and abstract. The first counting resulted in 36 relevant publications and 64 irrelevant ones. Following (Milanez et al. 2016) we decided to exclude some publications with an iterative cleaning procedure that excluded papers containing certain keywords that are not relevant in for our field, by adding them in the query with the “AND NOT” operator. After each iteration when new words were added to the query, we checked random samples of 100 papers that were part of the biggest connected graph to ensure that they were rightly kept and a similar sample of the papers that were now excluded (ending up in the ‘ring of Saturn’) to check whether this was fair. When, after several iterations, we established that 95% of the papers in these samples were correctly included or dismissed, we considered our set as sufficiently adequate to scrutinize further. The final query is the following:
(2) TITLE-ABS-KEY("city system*" OR "urban system*" OR "system* of cities" OR "city network*" OR "urban network*" OR "network* of cities" OR "settlement system*" OR "system* of settlements" OR "central place system*" OR "megaregion*" OR "polycentric urban region*" OR "urban hierarch*" AND NOT "dispute settlement system*" AND NOT "traffic control" AND NOT "urban metabolism*" AND NOT "urban ecosystem*" AND NOT "parking*" AND NOT "smart cit*" AND NOT "urban traffic" AND NOT "space syntax" AND NOT "flood*" AND NOT "land use change*" AND NOT "urban ecology" AND NOT "hazard*" AND NOT "emergy" AND NOT "sewage" AND NOT "nitrogen" AND NOT "sensors" AND NOT "mobile landscapes" AND NOT "radial major roads" AND NOT "carbon metabolic network" AND NOT "route perception" AND NOT "waste" AND NOT "healthy cities") AND PUBYEAR > 1994
This query returns a set of 5331 papers. After extracting the biggest connected graph in the centre and excluding the ‘ring of Saturn’, we ended up with a set of 1436 publications. During the manual check of the excluded publications, we observed that some of them should have been included based on their title and abstract. Most of them were publications citing the classical urban systems literature but not the contemporary one. We then designed a ‘security net’ for these cases. We based it on the ‘referencing structure function’ (Zitt and Bassecoulard 2006), which is the “fraction of the literature which can be retrieved under two interplaying constraints: a minimum threshold on citation scores for the cited repertoire Y, and a minimum closeness of the article with this repertoire, measured by the number X of references in common with this repertoire.” We used Y = 15 for English literature and Y = 8 for non-English literature, considering that a non-English paper cited 8 times in the corpus is as least as important as an English paper cited 15 times. We kept only the references published before 1995 as ‘classical urban systems literature’. For the number of references in common, we set X > 1 because these very central studies are often cited by works outside or at the border of our field. We assume that a text citing at least two of them will be relevant for our study. These publications cited by the biggest connected graph can be considered as ‘urban systems classics’.
In the Scopus database, the same reference can reappear with several slightly different spellings, making the citation score of some references artificially low because they are separated in several entries. To give an example, Allan Pred’s City-systems in advanced economies (Pred 1977) appears in 11 different forms, all of them with a citation score below 12. For each single entry in our data, we extracted a sequence made up of the Author’s names, the title of the reference, the year of publication, the Journal, the issue and the page numbers and measured the Levenshtein distance between them. This string metric gives the number of characters that have to be deleted, added or substituted to go from a sequence to another. This operation allowed us to identify when the same publication was listed several times with a slightly different spelling, and aggregated their citation score together. We manually sorted them to keep only texts about cities and not general social science or statistical books (Table 1).
Then we extracted from the excluded papers all the texts citing at least two of these ‘urban system classics’ to add them to the final set. This operation allowed reintroducing 55 relevant texts into the final set, leading to a total of 1491 publications. Figure 2 describes the set of papers and book chapters. The production of publications related to systems of cities increased globally over the period, especially from 2010 onwards, with a peak in 2014. The data collection has been realised in October 2017, which explain the low score for the year 2017. The indexation of publications can sometimes take several months. But we decided to keep 2017 incomplete to grasp very contemporaneous trends. In terms of languages, English is largely dominant; recall that its importance was probably increased by the use of an English query. French, Chinese, Spanish and German are also important languages in the literature.

Year repartition and languages of the set of papers and book chapters
3 Analysing the System of Cities Literature
3.1 The Vocabulary of the Urban System Literature
Having finalised our set of relevant papers, we now turn to the analysis of the vocabulary of these papers to identify schools of thought with text mining techniques. We first did a graph of co-occurrences of keywords using VOSviewer based on the title and abstract of the 1491 publications in our set. This software allows to work on noun phrases rather than simple words. It means that the words that are used systematically together will be a single node in the graph (i.e. “cellular automata”, “world city”). Phrases need to have an occurrence score O ≥ 10 to be in the graph (to keep the Figure readable). The software computes a relevance score T, which corresponds to a tf-idf score for each noun phrase (van Eck and Waltman 2014). A tf-idf score is a statistic that signals the importance of a term in a collection of documents. It returns a high score for the very specific terms, and a low score for the stop-words and also the standard wording of the scientific literature (i.e. “this paper analyses”, “interesting result”). We kept the 60% of the noun phrases with the highest score T. We deleted terms with O ≥ 40 and T < 0.7 because these two thresholds allowed us to remove the ‘hubs’ in the co-occurrence network that are not specific to the different subfields and break the community structure (i.e. “size”, “urban growth”, “actor”, etc.). VOS-viewer assigns the nodes to a cluster using a variant of the modularity function with a resolution parameter γ that allow to play with the level of detail of the clustering (Waltman et al. 2010). A high value of γ will result in a large number of clusters. Choosing the level of resolution when performing a clustering algorithm often requires taking an ad hoc decision in a trade-off between level of precision and necessity of simplification. This is the stage where the knowledge of the field plays an important role. With γ = 1, we identified five meaningful clusters that we describe below. The number of terms in different clusters varies from 45 for the smallest to 116 for the largest. The result of the text mining and the cluster analysis can be seen in Fig. 3. In this visualization, the size of the nodes corresponds to the number of occurrences O of the terms in the corpus. The placing of these nodes is based on their co-occurrences, with terms that co-occur generally being located closer. The 20 most representative terms for each cluster can be found in Table 2, and gives a first description of what these clusters are about. Their relative importance have been calculated with a score I, which is the product of their number of occurrences O and their relevance score T.

‘Semantic map’ of co-occurrences of the vocabulary of urban system research
Below, we will refer to the clusters with the following labels: REG or ‘regional systems’ stands for the first cluster due to the importance of the regional scale in its vocabulary, WCN for the second cluster as acronym for ‘world city network’, SIM for the third cluster with a vocabulary around the notions of ‘simulation and complexity’, ECON for the fourth cluster, which deals with ‘economic geography’ and the branch of urban economics known as ‘new economic geography’, and finally CSD for the fifth cluster refers to ‘city size distribution’, the main focus of interest.
The vocabulary used in studies of intercity relationships reveals many aspects of the different research approaches. We decided to focus especially on five aspects: the urban agents identified, the geographical scope, the methodology, some thematic aspects and the terms that reveal influence from other disciplines. We placed the 20 most prominent words for each cluster into these categories in Table 2.
Here, we describe the five clusters in more detail. REG is articulated around the notions of “polycentricity” and “polycentric urban regions”. Words referring to agents include “policy maker” and the “planner”, revealing a top-down approach, but also “commuting”, that suggests the opposite. The paper by Verhetsel et al., Assessing Daily Urban Systems (DUS) in Belgium: a network approach based on commuting flows, with special attention to gender and income differences (unpublished) fits in this tradition. Indeed, several studies on polycentricity use commuting data (De Goei et al. 2010; Burger et al. 2014) to study the patterns of relations between cities, revealing a bottom-up approach. The words that illustrate the topics of this field seem fairly similar, with many concepts referring to the ambition of urban policies and strategies: “competitiveness”, “complementarity”, “spatial development”, “deconcentration”, “implementation”, “cooperation”, “urban sustainability”. The regional spatial scale is at the centre of the research agenda with “regional development”, “regional economy”, “province” and “metropolitan region” and also the high occurrence of “Randstad”, the classic example of a polycentric urban region in the Netherlands, is consistent with this observation. Yet, also “national urban system” is present in this cluster. Except for “Russia” and “Japan”, most of the geographical toponyms that can be found refer to Europe: “Netherlands”, “Italy”, “European city”, “Barcelona”, “western Europe”. Finally, the co-word analysis does not reveal a shared methodological basis of this field and no interdisciplinary dimension.
WCN corresponds to the research on world cities and world city networks. The urban agents at the centre of this approach are private transnational firms (“firm”, “advanced producer services”, “company”, “office network”). These agents are associated with modern capitalism terms (“globalization”, “finance”, “foreign direct investment”). The geographical scope of most research in this cluster is either the global scale indicated by terms such as “global scale”, “global urban hierarchy”, “global urban network” and “world economy”, or the local scale of the cities making up this world city network, as indicated by the numerous city names that correspond to major centres of the global economy (“London”, “New York”, “Shanghai”, “Tokyo”, “Hong Kong”, “Beijing”, “Paris”, “Moscow” and “Amsterdam”). The profusion of place names revealed by the co-word analysis indicates clearly the strong empirical nature of this cluster of research. From a methodological point of view, the presence of “ranking” indicates the prevalence of benchmarking studies as an outcome of this approach. One can also note the presence of “interlocking network model”, which is the model allowing to build a network from the observation of multiple office locations of firms, which is extensively used by researchers working on world cities (many of them gathered in the Globalisation and World Cities research network) (Derudder et al. 2010; Taylor and Derudder 2015). “Network analysis” also appears in this cluster, strongly related to the notion of “connectivity”. These words refer to graph theory, an area of mathematics use to study graphs, which are models of relations between objects. This type of abstraction has been used frequently by researchers working on world cities to analyse corporate networks (Neal 2008) or airplane networks (Zhang et al. 2016). Graph theory has been imported by geographers and regional scientists since the 1960s (Kansky 1963; Haggett and Chorley 1969), but recently, spatial scientists have started to use models popular in the interdisciplinary field of network sciences such as scale-free or small-words networks (see Neal ZP, Is the urban world small? The evidence for small world structure in urban networks (unpublished), for a meta-analysis of studies using this last model). However, according to our analysis, the WCN cluster does not manifest strong interdisciplinarity.
The SIM cluster is organised around the terms “simulation” and “complex urban systems”. The basic entities studied by those employing this approach are clearly identifiable (“agent”, “household”, “individual”). The interest for parameters set at the micro scale and elementary interactions between individuals is very visible in the vocabulary with terms such as “behaviour”, “choice” and “decision”. Among all the words of the cluster, only one geographic name appears: “South Africa”. There are no other mentions of cities or regions which indicates that this approach is theoretical rather than empirical. The presence of “central place theory” in the graph, one of the most widespread theoretical models of a system of cities is also consistent with this orientation. Methods and tools are at the centre of this approach as the profusion of terms related to modelling and simulation shows. One can see two different methods of simulation: “multi agent system” on the one hand, and “cellular automata” on the other. These methods are associated with a particular terminology: “rule”, “scenario” and “prediction”. All these terms show clearly the interdisciplinary background of this research line, parallel to the computational turn in social science. According to Sanders (2014) this simulation field draws its main inspiration from physics, with the works on dissipative structures and synergetic, and from computer science and artificial intelligence that notably created the tools such as cellular automata and agent based models. Studies using these two types of simulation are both represented in our corpus (see for example Batty 2001; Bretagnolle and Pumain 2010). But simulation is not the only methodological framework represented in this vocabulary. References to network science are also visible in the cluster given the “complex network” and “graph” terms. The words that reveal the thematic interest are “urban dynamic”, “spatial interaction” and “transportation network”, which confirm that this cluster covers a significant part of the research program of the theoretical and quantitative geography.
ECON manifests the vocabulary of (new) economic geography. Words related to agents are “migrant”, “worker”, “human capital”, showing an interest for individuals considered as economic agents. This focus on the micro-scale is corroborated by the frequent co-occurrence of “census” and “census data” with vocabulary of this cluster. In terms of scope, the cluster seems to study mainly Northern America with the inclusion of “United States” and “Canada” as geographical keywords. The very high I score of “county”, a common administrative and political division used in the US as well as in some provinces in Canada confirms this territorial focus. The words that reveal the thematic dimension of the cluster are “population growth”, “urban population”, “economic growth” and “urban function”, referring to the economic dynamics of cities. The co-word analysis also reveals mention of several levels of the urban hierarchy from “primate city” and “large metropolitan area” to “small city” and “rural areas”. The vocabulary of this cluster shows clearly that some papers of the corpus are characterised by the vocabulary of economics with “cost”, “wage”, “amenity” and “human capital”. This is further confirmed by the presence of “new economic geography” in the cluster.
The fifth cluster (CSD) gathers the vocabulary of studies dealing with aspects associated with city size. As expected, cities are the main unit of analysis, as aggregate of urban dwellers (“population size”, “city size”). The fact that the word “law” is the most representative of the cluster indicates the search for common laws or regularities with respect to city size distributions. This cluster presents numerous terms related to mathematical formalization such as “Zipf” (for the Zipf’s law), “Gibrat” (for the Gibrat’s law), “power law”, “scaling law”, “exponent” and “growth rate”. This interest for regularities is also visible with the mention of the “gravity model”, one of the most widespread models in spatial analysis. From a thematic point of view, the “hierarchical structure” and “size distribution” seems at the core of the research agenda, but also the evolution of these structures (“urban evolution”, “population growth”). In terms of territorial scope, several toponyms referring to China as well as “Brazil” and “Mexico” appear, showing that the field is not only theoretic but also deals with case studies. In terms of interdisciplinarity, along with the influence of physics (“entropy”), one can see the influence of the field of complex systems with “complex system”, “fractal dimension” and “self” (probably reflecting self-organisation and self-similarity).
This analysis allows to distinguish five different lexical fields in urban systems research. Strong differences in terms of methods, scope, thematic focus, main agents identified and influences from other disciplines have become manifest, which warrants to talk about five schools of thought. But some links can already be discerned. Both the SIM and CSD clusters refer to the interdisciplinary field of complexity theories. Moreover, the CSD and ECON clusters seem to focus both on demographic features of cities. There is a clear geographical spread in attention for these different subfields as shown in Table 3.
Sizable academic communities like those of the U.S.A. and China contribute to all subfields, but they are particularly dominant in the CSD and ECON clusters, followed by SIM where also France is a significant contributor. More than 60% of the WCN contributions derive from just four countries: the U.K., U.S.A., China and comparatively tiny Belgium. The Netherlands is the largest contributor to the REG subfield, which probably reflects its polycentric urban system and the fact that its main metropolitan area, the Randstad has been a classic research laboratory for polycentricity. Also Spain is an unusual suspect for the REG subfield.
3.2 Vocabulary and Citation Patterns
We now turn to exploring the relationships between the five schools of thought as they were identified through the co-word analysis. In order to analyse the evolution of these relations, we assign the papers (and occasional book chapter) to one of these schools, using a simple scoring method. Given the 5 lists of words (Table 2) corresponding to the schools of thought described above, we calculated the number of occurrences of words from each category in the title and abstract of individual texts. As the number of words for each school was unequal, we took the 40 most representative words for each school (based on the calculation of the I score as explained in 3.1) to make sure that papers have an equal chance of being assigned to the different schools. For example, if a paper mentioned 20 terms belonging to the SIM school, and 5 terms from the WCN school, it will be considered as belonging to the former. The result of this tagging process can be found in Fig. 4, and it also informs about the citation patterns between individual publications. The fact that the WCN, REG, and CSD schools are clearly clustered together shows the presence of dense citation networks within these schools. The more dispersed distribution of the SIM and especially the ECON schools suggests that these schools are less internally coherent, at least in terms of citations. In the case of ECON, we use the term “school of thought” because we identified a community in terms of disciplinary influence and thematic focus, however, the publications belonging to this school are so scattered that they do not seem to be united by a single research approach. It probably shows that the approaches of urban economists (the ‘new economic geography’) and the economic geographers approach have not been integrated much.

Citation network of publications, labelled according to the schools of thought in urban systems research
In a next step, we filtered our network in order to obtain snapshots for 5 different periods (1995–1999, 2000–2004, 2005–2009, 2010–2014 and 2015–2017). For each period we computed an insularity index S (1) to analyse whether the schools are self-referencing or drawing inspiration from others in a particular period (after van Meeteren et al. 2015). This index corresponds to the share of citations within the school or subfield divided by the total number of citations. Given the fact that the literature does not disappear from one year to another, we take into account cited publications from previous periods.
Where \( {S_{C_a}}^t \) is the insularity index S of the subfield Ca at time t and v being a publication. The value of this score ranges between 0 and 1. A score close to 0 means that the papers of a subfield do not cite each other but cite other subfields, while a score close to 1 means that the subfield is very strongly inward-looking. Table 4 shows the evolution of this index and of the size of the different clusters (measured by the number of papers).
Two of the schools of thought manifest a grossly similar pattern: first a sharp increase of the insularity score, after which it remains relatively stable at a high insularity level. This holds for the REG and WCN schools addressing polycentric regions and world city networks respectively (and grossly speaking). REG scores 0.38 in the beginning of our study period (0.38), peaks during the period 2000–2004, and remains rather stable (between 0.51 and 0.55) the following periods. It is the only school that draws less inspiration from other fields and becomes more internally coherent in the most recent period of analysis. The insularity score of the WCN school is initially quite low for the period 1995–1999, probably reflecting that this school was in its initial stage of development, but its insularity score skyrockets in the following five years. It reaches its maximum between 2010 and 2014, with 80% of the citations remaining within the same school of thought. This suggests that a very coherent body of work emerges, but also that it does not draw a lot of inspiration from other schools of thought. It seems quite ‘closed’. The pattern for the CSD school of thought (with a particular focus on city size distributions) is to some extent similar given the rapid increase (even from zero in the first period) and relatively high insularity score, but the increase happens later, and the insularity score drops quite substantially in the most recent period. The latter suggests that it is drawing more inspiration from other fields than before. We interpret these profiles of sharp increase followed by relative stability of the REG, WCN and also CSD schools of thought as the structuration and perpetuation of a clear research program organised after the publication of important seminal studies formulating a research agenda, presenting new models or methodology or giving new empirical results leading to a new approach. In the case of the WCN literature, these papers include those of Beaverstock et al. (2000) and Taylor (2001). For the REG subfield, the most central papers are those of Kloosterman and Musterd (2001) who sketched a research agenda for Polycentric Urban Regions (PURs), and the papers of Parr (2004) and Davoudi (2003) offering a critical reflection on the concept of PUR. In the case of CSD, the study of the size distribution of cities and of the link between urban size and functions is definitely not new in geography and economics. These questions have been debate for many years (see for example Vapnarsky 1969) and was often featured in urban geography readers (Bourne and Simmons 1978; Pred 1977). However, in the mid-2000s, these research questions experienced a revival of scholarly interest with the import of scaling laws from natural science into urban studies following the publication of the seminal studies by Pumain and Guerois (2004) and Bettencourt et al. (2007). In our set, the number of papers related to this subfield increased a lot from one period to another. This has led to numerous studies on how the diverse properties of cities are changing with population, for instance addressing patent numbers, the selling of gas, road length, occupational structure, congestion, crime, etc. Nowadays, this subfield is still very dynamic and animated by a debate about the statistical validity and explanatory power of these relations (Arcaute et al. 2015; Cottineau et al. 2017; Depersin and Barthelemy 2018). The SIM school (on simulation and complexity) and ECON (economic geography) papers follow quite different trends. SIM had a higher insularity score in the beginning (0.62), but decreases over the period to reach a 0.23 score in the period 2015–2017, which is the lowest score of all the subfields in this period. This means that the SIM cluster of papers appears to be the most open to other subfields. ECON starts as one of the lowest (0.15) and fluctuates then between middle values (from 0.24 to 0.43). The final value of 0.24 suggests that it is also a rather open school of thought. The low insularity values for SIM and ECON are consistent with the rather dispersed structure of these schools of thought as presented in Fig. 4. The relatively low scores can be interpreted as a greater openness of these subfields, or at least as being less structured around a very specific debate or coherent research agenda.
The relations between the different subfields are visualised in Fig. 5. In this figure, all the papers from the same subfield have been aggregated into a single node, as well as their out-citations. Between 1995 and 1999, patterns of citations between the different subfields are quite equally distributed. REG cites equally itself and ECON, WCN cites all the others, SIM is connected to WCN and ECON, and CSD cites the SIM school of thought but not itself, clearly showing that it originates in the latter. It is from the period 2000–2004 that internal citation starts taking the biggest share of citations. In terms of external citations, the distribution is also quite equal. It is really from 2005 that our data starts to show preferred relations between subfields. For the period 2005–2009, most of the external citations of REG and ECON go to WCN, and this tendency is confirmed the following period, as well as for 2015–2017. WCN is also the most cited subfield by SIM and CSD. Among the literature on interurban relationships, the research on world cities/world city networks is clearly the one that received the most attention. In return, this subfield seems to pay some attention to REG and ECON for the three last periods, and to the SIM school of thought in the most recent period. The SIM school pays attention to the research on city size (CSD), but this is less so the other way around. They have a common interest in complex systems theories, as was already emerging from our analysis of the vocabulary of those two subfields. Finally, REG and ECON also manifest a common interest, especially for the period 2015–2017 where most of the external citations of ECON go to REG.

Evolution of the citation patterns between the subfields
4 Conclusion and Discussion
This paper presented the first bibliometric analysis of the research addressing relationships between cities, also referred to as ‘urban systems’ research. The analysis of the vocabulary in the papers led to the bottom-up identification of five clusters of terms corresponding to different schools of thought that have emerged over the last 23 years. Even though these schools manifest very different approaches, they can be split into two overarching groups. On the one hand, the research on world cities and on polycentric urban regions deals with quite specific objects of research. The former explores the top of the urban hierarchy by looking at global networks (mainly corporate networks and some transportation networks), while the latter studies very specific, polycentric settlement systems, characterised by the proximity of several small and medium-sized cities. These two fields depart from what they consider an existing reality and try to simplify it in order to understand it. To do so, they use models and heuristics, but the starting point is an empirical one. On the other hand, the theoretical and quantitative geography using notably simulation methods and the research cluster on city size distributions are both more interested in identifying general laws and mechanisms. They depart from hypotheses about causalities and try to explain or reproduce regularities presumably present in reality. According to its vocabulary and its central position in the co-word analysis, the subfield dealing with economic geography seems in between. The emphasis on rather abstract or generalised notions such as “cost”, “wage”, and “worker” would place it in the latter overarching group, but its strong focus on North America would include it in the former.
The bibliometric method developed in this paper has proven its capacity to study a set of publications by exploring both their content and their patterns in citations. First, the multi-step delineation procedure with adaptive queries and learning process allowed to collect a set of papers and book chapters with a minimum of noise and can be applied to other scholarly fields. The main advantage of this way of approaching literature is to limit the bias in the selection of the corpus by allowing for the possibility to include texts that are not known nor targeted a priori. The mapping of terms revealed effectively the different schools of thought addressing systems of cities. Again, using methods such as co-word analysis allows a bottom-up reconstruction of the different approaches in urban systems research, limiting the influence of predefined ideas of the field. Studying the vocabulary of papers proved to be a novel and adequate way to assess the primary units of analysis, the geographical scope, the methodologies and the thematic foci of different schools of thought, as well as several epistemological dimensions of each of them. Finally, the hypernetwork approach, which combines semantic and citations networks from papers appears an efficient way of exploring the communication between different schools of thought.
Despite the small recent signs of openness, increasing fragmentation appears to be the main tendency over the last two decades. Three out of five schools of thought (REG, WCN and CSD) witnessed a quick and very substantial increase of their insularity score. All three schools of thought have had more that 50% of internal citations since 2005. It has to be noted that the very last period is characterised by a small average decrease of this insularity index, suggesting more integration between most schools of thought. But this is still insufficient evidence for a move from multidisciplinarity to interdisciplinarity in urban system research. Although such a move is generally propagated in science, it remains a question for further debate and research whether this is desirable in urban systems research, and whether it would bring us new insights. If the answer is confirmative, the next question is how to achieve this. As our analysis revealed, the quite strong ontological and epistemological differences between some of the schools of thought identified here do not necessarily allow for an easy generation, modification and recombination of ideas and approaches. Yet, we hope that our analysis urges others to explore this potential.
References
Alderson AS, Beckfield J (2004) Power and position in the World City system. Am J Sociol 109:811–851. https://doi.org/10.1086/378930
Arcaute E, Hatna E, Ferguson P et al (2015) Constructing cities, deconstructing scaling laws. J R Soc Interf 12:20140745
Auerbach F (1913) Das Gesetz der Bevölkerungskonzentration. Petermanns Geogr Mitteilungen 59:74–76
Batty M (2013) The new science of cities. MIT Press
Batty M (2001) Polynucleated urban landscapes. Urban Stud 38:635–655. https://doi.org/10.1080/00420980120035268
Beaverstock JV, Smith RG, Taylor PJ (2000) World-City network: a new Metageography? Ann Assoc Am Geogr 90:123–134. https://doi.org/10.1111/0004-5608.00188
Bergeaud A, Potiron Y, Raimbault J, Gao Z-K (2017) Classifying patents based on their semantic content. PLOS ONE 12(4):e0176310
Berry BJL (1964) Cities as systems within systems of cities. Pap Reg Sci 13:147–163. https://doi.org/10.1111/j.1435-5597.1964.tb01283.x
Bettencourt LMA, Lobo J, Helbing D et al (2007) Growth, innovation, scaling, and the pace of life in cities. Proc Natl Acad Sci 104:7301–7306. https://doi.org/10.1073/pnas.0610172104
Bourne LS, Simmons JW (1978) Systems of cities: readings on structure, growth, and policy. Oxford University Press
Bretagnolle A, Franc A (2017) Emergence of an integrated city-system in France (XVIIth–XIXth centuries): evidence from toolset in graph theory. Hist Methods J Quant Interdiscip Hist 50:49–65. https://doi.org/10.1080/01615440.2016.1237915
Bretagnolle A, Pumain D (2010) Simulating urban networks through multiscalar space-time dynamics: Europe and the United States, 17th-20th centuries. Urban Stud 47:2819–2839. https://doi.org/10.1177/0042098010377366
Burger MJ, van der KB, Wall RS (2014) Polycentricity and the Multiplexity of urban networks. Eur Plan Stud 22:816–840. https://doi.org/10.1080/09654313.2013.771619
Callon M, Courtial J-P, Turner WA, Bauin S (1983) From translations to problematic networks: an introduction to co-word analysis. Soc Sci Inf 22:191–235. https://doi.org/10.1177/053901883022002003
Capello R (2000) The City network paradigm: measuring urban network externalities. Urban Stud 37:1925–1945. https://doi.org/10.1080/713707232
Chavalarias D, Cointet J-P (2013) Phylomemetic patterns in science evolution—the rise and fall of scientific fields. PLoS One 8:e54847. https://doi.org/10.1371/journal.pone.0054847
Christaller W (1933) Die zentralen Orte in Süddeutschland: Eine ökonomisch-geographische Untersuchung über die Gesetzmässigkeit der Verbreitung und Entwicklung der Siedlungen mit städtischen Funktionen. University Microfilms
Cottineau C, Hatna E, Arcaute E, Batty M (2017) Diverse cities or the systematic paradox of urban scaling Laws. Comput Environ Urban Syst 63:80–94. https://doi.org/10.1016/j.compenvurbsys.2016.04.006
Csardi G, Nepusz T (2006) The igraph software package for complex network research. InterJournal Complex Syst 1695:1–9
Davoudi S (2003) EUROPEAN BRIEFING: Polycentricity in European spatial planning: from an analytical tool to a normative agenda. Eur Plan Stud 11:979–999. https://doi.org/10.1080/0965431032000146169
De Goei B, Burger MJ, Van Oort FG, Kitson M (2010) Functional polycentrism and urban network development in the greater south east, United Kingdom: evidence from commuting patterns, 1981–2001. Reg Stud 44:1149–1170. https://doi.org/10.1080/00343400903365102
Depersin J, Barthelemy M (2018) From global scaling to the dynamics of individual cities. Proc Natl Acad Sci 201718690. doi: https://doi.org/10.1073/pnas.1718690115
Derudder B, Taylor P, Ni P et al (2010) Pathways of change: shifting Connectivities in the World City network, 2000—08. Urban Stud 47:1861–1877. https://doi.org/10.1177/0042098010372682
Ducruet C, Beauguitte L (2013) Spatial science and network science: review and outcomes of a complex relationship. Netw Spat Econ 14:297–316. https://doi.org/10.1007/s11067-013-9222-6
Ducruet C, Lugo I (2013) Cities and transport networks in shipping and logistics research. Asian J Shipp Logist 29:145–166. https://doi.org/10.1016/j.ajsl.2013.08.002
Engels TCE, Ossenblok TLB, Spruyt EHJ (2012) Changing publication patterns in the social sciences and humanities, 2000–2009. Scientometrics 93:373–390. https://doi.org/10.1007/s11192-012-0680-2
Friedmann J (1995) Where we stand: a decade of world city research. In: World cities in a world-system, Cambridge University Press. Cambridge, pp 21–46
Fujita M, Krugman P, Mori T (1999) On the evolution of hierarchical urban systems1. Eur Econ Rev 43:209–251. https://doi.org/10.1016/S0014-2921(98)00066-X
Gibrat R (1931) Les inégalités économiques. Recueil Sirey
Haggett P, Chorley RJ (1969) Network analysis in geography. Edward Arnold
Hicks D (1999) The difficulty of achieving full coverage of international social science literature and the bibliometric consequences. Scientometrics 44:193–215. https://doi.org/10.1007/BF02457380
Kamalski J, Kirby A (2012) Bibliometrics and urban knowledge transfer. Cities 29. Supplement 2:S3–S8. https://doi.org/10.1016/j.cities.2012.06.012
Kansky KJ (1963) Structure of transportation networks: relationships between network geometry and regional characteristics. University of Chicago
Kloosterman RC, Musterd S (2001) The polycentric urban region: towards a research agenda. Urban Stud 38:623–633. https://doi.org/10.1080/00420980120035259
Latour B, Woolgar S (2013) Laboratory life: the construction of scientific facts. Princeton University Press
Leydesdorff L (1998) Theories of citation? Scientometrics 43:5–25. https://doi.org/10.1007/BF02458391
Leydesdorff L, Zhou P (2007) Nanotechnology as a field of science: its delineation in terms of journals and patents. Scientometrics 70:693–713. https://doi.org/10.1007/s11192-007-0308-0
Liu Z (2005) Visualizing the intellectual structure in urban studies: a journal co-citation analysis (1992-2002). Scientometrics 62:385–402
Meijers E (2007) From central place to network model: theory and evidence of a paradigm change. Tijdschr Voor Econ En Soc Geogr 98:245–259
Meijers E, Romein A (2003) Realizing potential: building regional organizing capacity in polycentric urban regions. Eur Urban Reg Stud 10:173–186. https://doi.org/10.1177/0969776403010002005
Milanez DH, Noyons E, de Faria LIL (2016) A delineating procedure to retrieve relevant publication data in research areas: the case of nanocellulose. Scientometrics 107:627–643. https://doi.org/10.1007/s11192-016-1922-5
Neal ZP (2008) The duality of world cities and firms: comparing networks, hierarchies, and inequalities in the global economy. Glob Netw 8:94–115. https://doi.org/10.1111/j.1471-0374.2008.00187.x
Parr J (2004) The polycentric urban region: a closer inspection. Reg Stud 38:231–240. https://doi.org/10.1080/003434042000211114
Parr JB (2014) The regional economy, spatial structure and regional Urban Systems. Reg Stud 48:1926–1938. https://doi.org/10.1080/00343404.2013.799759
Pflieger G, Rozenblat C (2010) Introduction. Urban networks and network theory: the City as the connector of multiple networks. Urban Stud 47:2723–2735. https://doi.org/10.1177/0042098010377368
Pred A (1977) City Systems in Advanced Economies: past growth, present processes, and future development options. Wiley
Pumain D (2011) Systems of Cities and Levels of organisation. In: Bourgine P, Lesne A (eds) Morphogenesis. Springer, Berlin Heidelberg, pp 225–249
Pumain D (1997) Pour Une théorie évolutive des villes. Espace Géographique 26:119–134. https://doi.org/10.3406/spgeo.1997.1063
Pumain D (2006) Hierarchy in natural and social sciences. Springer, Dordrecht, the Netherlands
Pumain D, Guerois M (2004) Scaling laws in urban systems. St Fe Inst Work Pap 4
Raimbault J (2017) Exploration of an Interdisciplinary Scientific Landscape. ArXiv171200805 Cs
Sanders L (2014) Trois décennies de modélisation des systèmes de villes : sources d’inspiration, concepts, formalisations, Three decades of modeling systems of cities : sources of inspiration, concepts, formalization. Rev D’Économie Régionale Urbaine décembre:833–856
Sanders L, Pumain D, Mathian H et al (1997) SIMPOP: a multiagent system for the study of urbanism. Environ Plan B Plan Des 24:287–305. https://doi.org/10.1068/b240287
Sassen S (1991) The Global City: New York, London, Tokyo. Princeton University Press
Taylor PJ (2001) Specification of the world city network. Geogr Anal 33:181–194
Taylor PJ, Derudder B (2015) World City network: a global urban analysis. Routledge
Van Eck NJ, Waltman L (2011) Text mining and visualization using VOSviewer. ArXiv Prepr ArXiv11092058
van Eck NJ, Waltman L (2014) Visualizing bibliometric networks. In: Ding Y, Rousseau R, Wolfram D (eds) Measuring scholarly impact. Springer International Publishing, Cham, pp 285–320
van Meeteren M (2016) From polycentricity to renovated urban systems theory: explaining Belgian settlement geographies. Ghent University
van Meeteren M, Poorthuis A, Derudder B, Witlox F (2015) Pacifying Babel’s tower: a scientometric analysis of polycentricity in urban research. Urban Stud 0042098015573455. doi: https://doi.org/10.1177/0042098015573455
Vapnarsky CA (1969) On rank-size distributions of cities: an ecological approach. Econ Dev Cult Change 17:584–595
Waltman L, van Eck NJ (2012) A new methodology for constructing a publication-level classification system of science. J Am Soc Inf Sci Technol 63:2378–2392. https://doi.org/10.1002/asi.22748
Waltman L, van Eck NJ, Noyons ECM (2010) A unified approach to mapping and clustering of bibliometric networks. ArXiv10061032 Phys
Wang H, He Q, Liu X et al (2012) Global urbanization research from 1991 to 2009: a systematic research review. Landsc Urban Plan 104:299–309. https://doi.org/10.1016/j.landurbplan.2011.11.006
Zhang S, Derudder B, Witlox F (2016) Dynamics in the European air transport network, 2003–9: an explanatory framework drawing on stochastic actor-based modeling. Netw Spat Econ 16:643–663. https://doi.org/10.1007/s11067-015-9292-8
Zipf GK (1949) Human behavior and the principle of least effort: an introduction to human ecology. Addison-Wesley Press
Zitt M (2015) Meso-level retrieval: IR-bibliometrics interplay and hybrid citation-words methods in scientific fields delineation. Scientometrics 102:2223–2245. https://doi.org/10.1007/s11192-014-1482-5
Zitt M, Bassecoulard E (2006) Delineating complex scientific fields by an hybrid lexical-citation method: an application to nanosciences. Inf Process Manag 42:1513–1531. https://doi.org/10.1016/j.ipm.2006.03.016
Acknowledgements
The authors would like to thank Bijan Ranjbar-Sahraei from the AIDA project for his valuable advice on the bibliometric method. This work was funded through a VIDI grant (452-14-004) provided by the Netherlands Organisation for Scientific Research (NWO).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Peris, A., Meijers, E. & van Ham, M. The Evolution of the Systems of Cities Literature Since 1995: Schools of Thought and their Interaction. Netw Spat Econ 18, 533–554 (2018). https://doi.org/10.1007/s11067-018-9410-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11067-018-9410-5