
Abstract
We examine three constructions across several languages in which a mass noun is embedded in what appears to be a count environment, but the construction as a whole remains mass. We argue that the discussed phenomena—“Q-noun” constructions like lots of water, bare measure constructions like kilos of sugar, and pluralised mass nouns in languages like Greek and Persian—all involve portioning-out of the embedded mass denotation. We provide a structural account of portioning out and propose structures that derive both mass and count portioning out. Adopting an overlap-based approach to the mass/count distinction (e.g. Landman 2011; Rothstein 2011; Khrizman et al. 2015; Landman 2016) we provide a compositional semantics for the proposed structures.
The examined phenomena all share an inference of large quantity or abundance that, we argue, cannot be reduced to the lexical meaning of the portioning-out expression, nor to a multiplicity inference contributed by plural morphology. We show that our cases of mass portioning-out involve a total order ≤ on portion size and propose to analyse the abundance inference in terms of an uninformativity-based Quantity implicature, following the analysis of the positive form (Mary is tall) in Rett’s (2015) approach to adjectival gradability.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Non-countable nominals—which cannot directly combine with numerals and/or count quantifiers such as every or several—are very widely attested in natural languages. In classifier languages like Mandarin the vast majority, if not all, of nouns are treated in this way, while number marking languages like English generally distinguish non-countable “mass nouns” from countable “count nouns.” In languages of both types, there are various syntactic strategies available to transform these non-countable nouns into countable noun phrases.Footnote 1 To begin with, measuring (exemplified in (1)) relies on standard units of measurement in order to express (not necessarily individuated) quantities of something:
-
(1)


In addition, various kinds of individuated units bearing a particular relation to the embedded noun can be made available for counting through the use of classifiers (exemplified in (2)):Footnote 2
-
(2)


Each of the classifier types in (2a)–(2c) singles out a different kind of unit. In the natural unit constructions in (2a), the noun’s denotation is conceptually individuated despite the fact that the noun remains grammatically uncountable. It is these inherent “natural units” that are picked out by the classifier (Cheng and Sybesma 1999). In the container constructions in (2b) and the portion constructions in (2c), the units are not naturally present but created by the classifier: container classifiers create individuated units by filling containers with stuff, and portion classifiers do so by dividing stuff into bits. The difference between (2b) and (2c) is that the former, but not the latter, introduces additional referents. Three vans of police doesn’t just refer to police, but also to vans; three beads of sweat, on the other hand, is just sweat.
In this paper, we will focus on the phenomenon of “portioning-out” as exemplified by (but not limited to) the constructions in (2c) above. We define the notion of a portion more explicitly as follows:
-
(3)
A portion of a substance X is a quantity of X that is individuated according to some non-inherent criterion.
Often, the specified individuated portions involve a certain shape or spatial configuration of matter, as in the case of beads, heaps, and rows. Sometimes they involve size or function, as in e.g. mouthful of bread or portion of soup (a quantity of soup that constitutes a meal for one). Sometimes only a very general individuation criterion is imposed—portion classifiers like piece, bit, or quantity facilitate reference to almost any bit of stuff that qualifies as an “individual” in the context.Footnote 3 We will subsume all these types of individuation under our notion of “portion” as long as they meet the definition in (3).
We have pointed out that portion constructions are distinct from measure constructions in that they involve individuation, not just measurement, and distinct from container constructions in that they do not introduce any additional referents. At the same time, it has often been noted (e.g. Doetjes 1997; Rothstein 2011; Partee and Borschev 2012; Khrizman et al. 2015) that portion readings—that meet the definition in (3)—are available for both measure and container constructions:
-
(4)
-
a.
John sewed the two metres of fabric neatly together.
(= metre-sized lengths of fabric)
-
b.
Fill a small and a large glass with white wine and add the two glasses of wine into the soup.
(= the contents of the two glasses)
-
a.
This means that portioning-out is at its core a type of interpretation, that cannot be reduced to a particular class of classifiers and might be expressed in a variety of ways both within and across languages. For instance, Deal (2017) relies on covert context-based portioning-out in order to account for the widespread acceptability of mass nouns in count contexts in Nez Perce:
-
(5)


We will use the observation that portioning-out is fundamentally a type of interpretation as the key to the analysis of a range of superficially distinct phenomena in terms of portioning-out.
Beyond portioning-out as a means to create a countable noun phrase out of an uncountable noun (cf. (2c)), we will also show that a systematic property of portioning-out constructions both within and across languages is that nominal denotations can also be portioned-out without becoming countable. For instance, compare (2c) to (6)–(7), (4) to (8),Footnote 4 and (5) to (9):
-
(6)
-
a.
A load / loads of water was dripping from the ceiling.
-
b.
*Three loads of water were dripping from the ceiling.
-
a.
-
(7)
You need to drink (*three) heaps of water to stay hydrated in this heat.
-
(8)


-
(9)


On the surface, (6) and (7) resemble the portion classifier constructions in (2c), but the resulting NPs are not countable, as their incompatibility with the numeral three attests. In addition, while loads of water seems plural, it agrees in the singular like a mass NP. Singular agreement and a lack of countability also characterise the Dutch example in (8), which otherwise parallels the portion construction in (4). Finally, Greek allows pluralisation of mass nouns in a way similar to Nez Perce (5), but as (9b) shows, such pluralised mass nouns are not countable (even though it is often claimed that pluralisation requires countability).
We will look at these and similar data in much more detail later on; the following is a preview of our argument and conclusions. Focusing our attention on the behaviour of (a) overt portion words (e.g. heap, lot), (b) “bare measures” (e.g. centimetres in (8)), and (c) pluralised mass nouns (‘waters’) across languages, we will show that these phenomena share a cluster of properties. First, although there are individual gaps in the paradigm, as a class these expressions/constructions show a systematic alternation between a countable use and an uncountable one. Second, these two uses are associated with different syntactic structures, as evidenced by differences in agreement, asymmetries in coordination, distinct prosodic profiles, and (in some languages) the presence of additional morphosyntactic material. Third, the uncountable constructions are all associated with an inference of abundance or large quantity that cannot be reduced to either the lexical meaning of the expressions involved or a multiplicity inference associated with plural morphology.
Our main analytical claim is that the common core of these constructions is a syntactically flexible family of portioning-out functions from mass predicates into sets of non-overlapping sums. We show that the resulting complex nominal expression may be either countable or non-countable depending on its internal syntactic structure. We will argue that in countable portioning-out constructions like (three) heaps of sand, the phrase heaps of sand is a projection of the portion expression heap; we call it a PortionP. On the semantic side, put simply, the PortionP is countable because portions are countable. In contrast, non-countable portioning-out constructions like (heaps and) heaps of sand are not PortionPs, but are headed by an operator realised by a special functional head (covert in some languages, overt in others). Semantically (again put simply), this functional element formalises the intuition that the phrase as a whole is non-countable because the substance that the portions consist of is non-countable. In this way, our proposal offers a unified account of the syntax and semantics of portions, which relies on just a few independently motivated ingredients to cover a wide range of phenomena and does not require any type-shifting or systematic lexical ambiguity.
Our syntactic and semantic analysis of portioning-out covers the first two properties from the cluster mentioned above, but it does not yet account for the inference of abundance or large quantity shared by all addressed cases of non-countable portioning-out constructions. This property has been previously observed for Greek mass plurals by Tsoulas (2009), who treats the inference as a kind of manner implicature triggered by the semantic vacuousness (under his account) of the plural morpheme. Kane et al. (2015) and Renans et al. (2018) propose that the abundance inference of mass plurals is a scalar implicature on a par with the multiplicity implicature triggered by plural number on count nouns (cf. Sauerland et al. 2005; Spector 2007). However, the parallels with the tendency of expressions like bunch, lot(s), heaps and oodles, as well as bare measures like litres, to support a similar abundance inference have not been noticed before. We will argue that abundance, in all these cases, cannot be reduced to either the lexical meaning of the noun involved or a multiplicity inference. Drawing on work on quality nouns by Tovena (2001) and Francez and Koontz-Garboden (2017), we show that non-countable portioned-out NPs are ordered in terms of portion size. We suggest that this size ordering is responsible for the abundance inference, and develop an analysis along the lines of Rett’s (2015) implicature-based account of degree constructions like Mary is tall, which support the inference that Mary’s height exceeds some contextual standard.
The paper is structured as follows. In Section 2, we discuss in detail the core data on mass portioning and establish the basic desiderata for the syntactic and semantic analysis. Section 3 focuses on the syntactic evidence and develops in some detail the syntax of portion constructions. In Section 4, we develop the semantics. In Sections 5 and 6, we zoom in on the pragmatics of the abundance inference supported by all the investigated forms of portioning-out; we present our data and analysis in Section 5 and some additional issues and suggestions for further research in Section 6. Section 7 concludes the paper.
We end this introduction with a few practical notes. We will (eventually) refer to the countable portioning-out constructions exemplified in (2c)–(5) as count portioning-out and to their non-countable counterparts (exemplified in (6)–(9)) as mass portioning-out, primarily because “count/mass” is less unwieldy than “countable/non-countable,” even though not all languages involved have a grammatical mass/count distinction. In general, we will often use “mass” as shorthand for “non-countable”; this means that, in our terminology, it is not just lexical items that have “mass” or “count” status but complex phrases as well.
We will illustrate most of our more general points using examples from English, Dutch and Greek (languages for which we have ready access to native speaker judgements). Wherever possible, we will give an English example, but we will sometimes rely on Dutch or Greek if the point can be made more clearly based on either of these languages.
2 Three cases of mass portioning-out
In this section we discuss the three main data points on mass portioning-out, namely: Q-nouns, bare measures and mass plurals.
2.1 Q-nouns
In her recent dissertation, Klockmann (2017) devotes a chapter to the puzzling behaviour of a class of semi-lexical nouns she calls Q-nouns: quantifier-like nominal expressions like lot(s), load(s), oodles, scores etc. (Klockmann’s work focuses mostly on lot/s, number, bunch and ton.) Such Q-nouns show some count noun-like behaviour in that they tend to be pluralised and sometimes occur with the indefinite determiner a. However, as (10b) shows, when a Q-noun combines with a mass noun, the phrase as a whole remains mass (that is, incompatible with numerals and determiners that presuppose countability). Similarly, (10c) and (11) shows that the number features of the NP as a whole are often determined by the embedded noun rather than the Q-noun itself:
-
(10)
-
a.
Lots of water / a lot of water
-
b.
*Three/various/each lot(s) of water
-
c.
Lots of water was/*were dripping from the ceiling.
-
a.
-
(11)


So, even though an NP like lots of water or oodles of soup appears count on the surface in that it has plural marking, it cannot actually be counted.
Given their unique properties, Klockmann treats Q-nouns as a distinct class of semi-lexical expressions. However, we would like to propose that “Q-nouns” are in fact ordinary classifiers or measure words, and the non-countable nature of the above nominal expressions is not due to any special lexical properties of the “Q-nouns” but triggered by other factors (which we will get to shortly).
First, consider the fact that most of the Q-nouns also have (or historically used to have) a countable use in which they function as a genuine portion classifier or measure word, along the lines of (1)–(2c). That is, they serve to individuate a mass referent into countable units:
-
(12)
-
a.
Today’s auction will feature various lots of furniture.
-
b.
John did three loads of laundry.
-
c.
Three scores and ten (i.e., 3 x 20 + 10 = 70)
-
d.
This factory processes 2500 tons of PET bottles every month.
-
a.
Klockmann (2017: 226) acknowledges this for lot, but takes it to be a matter of genuine lexical ambiguity. However, the data in (12) and (13)–(15) show that there are many more examples of nouns very similar to lot that alternate in this way; this suggests, deviating from Klockmann’s view, that the behaviour of lot(s) is not an idiosyncrasy, but exemplifies a more general and systematic pattern that calls for an equally systematic and compositional analysis:
-
(13)
-
a.
The geologists found several masses of Paleozoic rock.
-
b.
These Victorian hairstyles required (*several) masses of hair.
-
a.
-
(14)
-
a.
Sort the toys into three heaps.
-
b.
Drink (*three) heaps of water.
-
a.
-
(15)
-
a.
There’s only two reams of printing paper left in the supply closet.
-
b.
We need to analyse (*multiple) reams of data before we can draw any conclusions.
-
a.
The general pattern here shows a sizeable class of nouns that alternate between a countable portion classifier use (denoting a particular quantity or spatial configuration of matter) and a non-countable “Q-noun” use which is used to convey a general large quantity. (We will get back to words like ton, which show a similar alternation between Q-nouns and measure words, in the next section on what we’ll call “bare measures.”)
While we claim that Q-nouns are “just” portion classifiers and not a distinct class of nominal expressions, we reject the suggestion (which can often be found in discussions of words like lot(s) on language advice boards) that they simply involve a vague or figurative interpretation of the classifier use (‘a large quantity’). Crucially, this would fail to account for the difference in mass/count status between the two constructions, as we can easily count vague quantities:
-
(16)
You should drink three large quantities of water every day.
In addition, if (some) portion classifiers were simply ambiguous between a literal and a more figurative use, we would expect an NP like two reams of paper in (15a) to be ambiguous between a literal meaning of ‘1,000 sheets of paper’ and a figurative meaning of ‘two large quantities of paper.’ This ambiguity is not attested: when a portion classifier is used in its individuating use (as in (15a)) it is necessarily interpreted literally, and the large quantity meaning only arises when the NP is mass (as in (15b)).
Third, reducing the Q-noun interpretation of a portion classifier to a figurative interpretation does not account for the agreement facts; there is no reason why a non-literal interpretation of a plural classifier like lots would agree in the singular.
-
(17)
Large quantities of water (are/*is) dripping from the ceiling. (cf. (10b))
To sum up, the widespread availability of non-countable “Q-noun” interpretations for portion classifiers like lot, load, heap, mass, and ream shows that this alternation is not a matter of incidental lexical ambiguity, but a systematic linguistic pattern that suggests that portion classifiers and Q-nouns should be analysed as two sides of the same coin. In addition, the relation between the two cannot be a matter of literal versus figurative interpretation, since this would not explain the difference in mass/count status and agreement behaviour. In the next section, we will consider a related set of data displaying the same alternating pattern.
2.2 Bare measures
Consider the following:
-
(18)
-
a.
LITRES of drinking water were wasted.
-
b.
I spent thousands of pounds on this renovation.
-
c.
The campus was miles and miles away from the city centre.
-
a.
Unlike “ordinary” bare plurals, (e.g. Stray dogs roamed the neighbourhood), such bare measures do not simply convey multiplicity (‘more than one’). Instead, like the Q-noun interpretations of portion classifiers, they support an inference of large quantity (relative to a context). Also, like Q-noun constructions (and unlike “normal” measure phrase constructions), they are non-countable:
-
(19)
-
a.
(*A few) LITRES of drinking water were wasted.
-
b.
I spent (*three) thousands of pounds on this renovation.
-
c.
The campus was (*several/*many/*ten) miles and miles away from the city centre.
-
a.
While (19) shows that bare measure constructions are incompatible with numerals and count determiners like several and many, they happily accept neutral determiners like more, no, and the, suggesting that, like the Q-noun constructions from the previous section, these are mass NPs despite their superficial similarity to measure phrase constructions.Footnote 5
-
(20)
-
a.
And all that coal being burned adds more tons and tons of CO2 to the atmosphere, warming the planet.Footnote 6
-
b.
That means no cream, no heaps and heaps of mayonnaise, and no 4:1 ratio of oil to vinegar.Footnote 7
-
a.
The point is easier to make on the basis of Dutch, in which bare measure NPs have several properties which set them apart from true measure constructions. First, note that in Dutch, bare measure constructions pattern morphosyntactically with classifier constructions, not with measure constructions. In particular, in terms of number marking, the measure words in bare measure constructions behave like what Rothstein (2011) and Khrizman et al. (2015) (see also Chierchia 1998a) analyse as portion-shifted measure words: a type of classifier derived from a measure word, with an enriched ‘portion of this particular size’ interpretation. As already observed by Doetjes (1997), Dutch distinguishes measure and portion uses of measure words morphosyntactically: the former are never marked for number, while the latter are. (In (21), we have starred ungrammatical number marking and hashed marking that does not result in the described interpretation.)
-
(21)


The sentences in (21) represent three meanings which are all truth-conditionally distinct from each other. The measure interpretation in (21a) is true just in case I bought a length of cheesecloth measuring 3 meters. The portion interpretation in (21c) is true just in case I bought 3 meter-sized lengths of cheesecloth. Sentence (21b) has a reading corresponding to an ‘existential bare plural’ version of (21c) (which is true just in case I bought an unspecified number (n>1) of lengths of cheesecloth), but its most prominent reading by far is an abundant ‘large quantity of cheesecloth’ interpretation which is true just in case I bought lots of cheesecloth (possibly in one piece, possibly as multiple lengths).Footnote 8
The ambiguity of (21b) is reminiscent of the alternation between (countable) portion classifiers and (non-countable) Q-nouns. In line with our observations about Q-nouns, countable portion-shifted measure words always agree in number with the verb (as exemplified in (22)), while (23) shows that their abundance-conveying mass counterparts often occur with a singular verb. Example (23a) is from Broekhuis and den Dikken (2012: Ch. 4), who classify portion-shifted measures like meters as Q-nouns based on this behaviour; compare also example (8)).
-
(22)


-
(23)


In conclusion, the Dutch data (summarised in Table 1) show that in terms of both number marking and verbal agreement, bare measure constructions pattern with Q-nouns. In addition, like many Q-nouns, they have a countable counterpart which behaves like a classifier, with the interpretation ‘a particular quantity or portion of X.’
Putting the data from this and the previous section together, we conclude that we are dealing with a single class of portion expressions (including both lexical portion classifiers and portion expressions that have been derived from measure words through a portion shift, following Rothstein 2011) that systematically alternate between a countable classifier use and a non-countable ‘large quantity’ use. We will refer to these two uses as count portioning-out and mass portioning-out in the rest of the paper.
In the next section, we will discuss a third class of constructions that show the alternating pattern we have seen with portion classifiers and measure nouns, but which lack an overt portion expression. We will argue that these, too, are portioning-out constructions despite the lack of overtly expressed portion word.
2.3 Covert portioning-out and plural mass nouns
In languages like Yudja (Lima 2014a) and Nez Perce (Deal 2013, 2017), substance-denoting nouns occur productively in count contexts, where they are interpreted as ‘pieces/quantities of X.’ Other languages that systematically allow this are Yup’ik (Corbett and Mithun 1996), Ojibwe (Mathieu 2012), Old High German (Carr 1936),Footnote 9 and Blackfoot (Wiltschko 2012). Khrizman et al. (2015) and (Deal 2013, 2017) argue that such constructions involve a covert portion classifier: that is, they are structurally equivalent to portion expressions like those in (2c), but the classifier is not overtly expressed.Footnote 10,Footnote 11 We will adopt this analysis, and call this covert classifier portion following Khrizman et al. (2015) and Landman (2016).Footnote 12
-
(24)


-
(25)


Covert portioning-out plays a crucial role in accounting for a phenomenon that defies traditional wisdom on the morphosyntax and semantics of mass nouns and the mass/count distinction, namely pluralisation of mass nouns. The ban on pluralisation of mass nouns is generally a design feature of most theoretical accounts (see in particular Chierchia 1998b; Borer 2005; Heycock and Zamparelli 2005), but is in fact attested in many languages. Assuming that covert portioning-out is a feature available in some but not all languages, we can account for the surprising pluralisation facts while still leaving the wider generalisation intact. Let’s adopt for the purposes of this argument Chierchia’s (1998b) view under which mass predicates are incompatible with pluralisation because they are inherently (lexically) plural, meaning that they are closed under sum. There is, however, no reason to assume that a portioned-out mass predicate would be closed under sum; hence nothing blocks the pluralisation of a portioned-out mass noun. If portioning-out in these cases is covert, we predict plural morphology to show up on the mass noun itself (if the plural is a bound morpheme). And finally, since portion is a portion classifier, we further predict that such plural mass nouns will alternate between mass and count portion interpretations, just like the portion classifiers from Section 2.1 and the portion-shifted measure from Section 2.2.
The latter is exactly what we find crosslinguistically. We have seen above that some languages freely allow pluralisation of mass nouns with the countable interpretation ‘pieces or portions of X.’ On the other hand, languages like Greek, Persian and Indonesian allow productive pluralisation of mass nouns without turning them countable: pluralised mass nouns in these languages remain non-countable, supporting instead an inference of scatteredness and abundance.
-
(26)


-
(27)


-
(28)


-
(29)


In some languages, such as Evenki ((30) from Nedjalkov 1997), Innuttut (Gillon 2012), and Innu-Aimun ((31) from Gillon 2010), pluralised mass nouns are ambiguous between a countable portioned-out interpretation and an non-countable ‘high quantity’ one, parallel to the alternating pattern we have seen in the previous sections.
-
(30)
-
a.
se:kse ‘blood’ / se:ksel ‘a lot of blood’ (Evenki)
-
b.
singilgen ‘snow’ / singilger ‘lots of snow’
-
c.
ulle ‘meat’ / ullel ‘multiple pieces of meat’ or ‘a lot of meat’
-
a.
-
(31)


Despite the fact that plural mass nouns do not always alternate between mass and count interpretations within a single language,Footnote 13 the general crosslinguistic pattern is strongly reminiscent of the kind of alternation we saw with Q-nouns and bare measures. It is therefore natural to treat pluralisation of mass nouns along the same lines, in terms of portioning-out and structural ambiguity.
Having reached this conclusion, we now turn to a closer investigation of the syntax of our constructions of interest.
3 Syntax
In this section, we will develop a more detailed analysis of the syntax of both mass and count portioning-out before moving on to their compositional semantics in Section 4. Given that mass and count portioning-out involve the same portion expressions, and we have already argued that an analysis in terms of lexical ambiguity is unlikely, we need to account for the alternations in some other way. In Sect. 3.1, we will present evidence that mass and count portioning-out involve distinct syntactic structures despite being string-identical and in Sect. 3.2 we will propose specific derivations for each type in line with common assumptions on the way headedness/labels determine the interpretation of constructions involving multiple nominal elements.
3.1 Mass/count alternations and structural ambiguity
The four types of evidence for structural ambiguity between mass and count portioning-out that we will consider in this section involve (1) agreement, (2) coordination, (3) prosody, and (4) overt functional elements.
3.1.1 Agreement
We have seen that both Q-nouns and bare measures can agree in the singular even if they are themselves marked plural. However, it should be noted that depending on the Q-noun itself and individual speaker preference, plural agreement is possible too (the varying agreement preferences with Q-noun constructions are explored in depth in Klockmann 2017). For instance, the following examples are from two different versions of the same news item on the arrival of two pandas in a Dutch zoo:Footnote 14
-
(32)


Similar facts appear to apply in English; a simple Google search yields a similar number of hits for “there is kilos of” (254) and “there are kilos of” (323) (compare to 1860 results for “there are several kilos of” versus 0 for “there is several kilos of”).
In contrast, as we have seen, agreement is always with the portion word and never with the embedded noun in cases of count portioning-out:
-
(33)
Several heaps of sand *has/have been created for messy play.
-
(34)


The variable agreement behaviour of mass portioning-out indicates that at some point in its syntactic derivation, both nominal expressions (the singular embedded noun and the plural portion word) are accessible to the φ probe of T. In contrast, in the count portioning-out constructions, only the plural feature is accessible, resulting in obligatory plural agreement. This points to different underlying syntactic structures.
3.1.2 Coordination asymmetries
The second piece of evidence for structural differentiation involves coordination. As (35) shows, it is possible to coordinate measure phrases (35a), classifiers (35b), and mass portion expressions (35c) with another expression of the same category:
-
(35)
-
a.
I drank two litres and 500 millilitres of water.
-
b.
I drank two bottles and one mouthful of water.
-
c.
I drank tons and heaps of water.
-
a.
However, coordinations involving a combination of a mass portion expression (i.e. a Q-noun or a bare measure) with either a classifier or a measure phrase are ungrammatical:
-
(36)
*I drank \(\left \{\begin{array}{l}\text{litres and two cups}\\\text{lots and one bottle}\\\text{two buckets and oodles}\\\text{several litres and heaps}\\...\end{array}\right \}\) of water.
Note that this is not just a general ban on coordinating a bare with a non-bare NP; as (37) shows, such coordinations are fine in either order.Footnote 15
-
(37)
-
a.
John has three dogs and goldfish.
-
b.
For lunch I ate biscuits and two pieces of cake.
-
a.
Neither does the problem with coordinations like (36) seem purely semantic or pragmatic. While conjunctions of vague and precise quantities are certainly a bit odd (38), they are not ungrammatical in the same way that (36) is:
-
(38)
I drank a huge quantity and several drops of water.
We conclude from this and the contrast between (35) and (36) that (36) essentially represents a syntactic impossibility: mass portion constructions are not structurally equivalent to either measure or classifier constructions and hence cannot be coordinated with them.
3.1.3 Prosodic profile differentiation
The third piece of evidence for structural differentiation involves prosody. As we have seen ((21) and surrounding discussion), portion words (including portion-shifted measure words) can appear in bare plural classifier constructions (I bought metres of cheesecloth) with the interpretation ‘unspecified number of portions of X.’ In written form, these sentences appear identical to their mass counterparts with an abundance interpretation. However, both interpretations involve rather different stress patterns. Consider (39):
-
(39)
John distributed litres of water to the marathon runners.
As we have already seen, sentences like (39) have two possible readings. The first (count) reading is true in any situation in which John handed out litre-sized portions of water to the runners, regardless of the number of runners or portions involved. The second (mass) is true in any situation in which John handed out a huge amount of water to the runners, regardless of the size of the individual portions. The readings are truth-conditionally independent. In a situation in which a total of two runners each receive a litre bottle of water, the former is true but the latter is false. In a situation in which 200 runners each receive a cup of water from John’s tap, the latter is true but the former is false.
In spoken form, however, (39) is not ambiguous, as the two readings of litres of water are fully disambiguated by stress. For the count reading, the stress needs to fall on water; the mass reading requires stress on litres:
-
(40)
-
a.
John distributed litres of wáter to the marathon runners.
-
b.
John distributed lítres of water to the marathon runners.
-
a.
Given that stress patterns are affected by phrasal boundaries (Selkirk 1986, 1995; Truckenbrodt 1999) this strongly suggests that the ambiguity of (39) is structural, and cannot be explained in terms of e.g. a literal versus a metaphorical interpretation of litre(s).
3.1.4 Obligatory insertion of functional elements
Finally, there are languages in which mass and count portioning-out actually look distinct on the surface. German and Greek are cases in point.Footnote 16 In German, count portioning-out constructions require the classifier to be directly adjacent to the noun, without the interference of von ‘of.’ Mass portioning-out constructions, however, require the addition of von.
-
(41)


In Greek, mass portioning-out involves a definite DP following the portion word, while count portioning-out requires the noun to be bare (42):
-
(42)


All in all, there is clear evidence that the two constructions are structurally different, both in terms of category (DP vs bare N) and constituent structure. We now turn to the proposed structures.
3.2 Analysis
The proposal that we will put forward shares a number of syntactic and semantic assumptions with Rothstein (2011) and for this reason we will begin with a presentation and critique of her proposal before we present our adjustments to it.
3.2.1 Count portioning-out
Rothstein’s (2011) analysis of expressions like three glasses of wine in their individuating reading (‘three glasses filled with wine’) is in part based on Landman (2003, 2004). The structure she proposes is (43):
-
(43)


The numeral in (43) is treated as an adjective which raises to D if D is empty.Footnote 17 The evidence for the claim that numerals are adjectival is drawn from Landman (2003, 2004) and involves the following contrast:Footnote 18
-
(44)
-
a.
Fifty ferocious lions were shipped to Artis.
-
b.
# Ferocious fifty lions were shipped to Artis.
-
a.
-
(45)
-
a.
The animals in the shipment were fifty ferocious lions.
-
b.
# The animals in the shipment were ferocious fifty lions.
-
a.
-
(46)
-
a.
We shipped the fifty ferocious lions to Blijdorp, and the thirty meek lions to Artis.
-
b.
We shipped the ferocious fifty lions to Blijdorp, and the meek thirty lions to Artis.
-
a.
The crucial point here is that within the DP as in (46) the numeral three can swap places with the adjective ferocious, unlike what happens with the determinerless NPs in either argument (44) or predicate (45) position.Footnote 19 This is our first point of disagreement with Rothstein (2011). Consider first the fact that the relevant patterns are not reproducible with all adjectives, casting doubt on the evidentiary weight of the contrast in (44)–(46):
-
(47)
* We shipped the blue four cars to Blijdorp and the yellow three cars to Artis.
Second, there are no other cases of adjectives raising to D, which means this behaviour needs to be stipulated only for numerals. As (48) clearly shows, other adjectives can happily remain in situ when D is empty (or absent)—raising to D being out for surprisingly large as it is not a head—so there seems to be no reason why numerals should raise.
-
(48)
The waiter was carrying surprisingly large glasses of wine.
Furthermore, in other cases of N-to-D raising (Longobardi 1994; et seq.) Ns that raise are, all other things being equal, not compatible with determiners at least in English (compare the acceptability of (49a) with the ungrammatical (49b)):
-
(49)
-
a.
(The) two boys cycled home.
-
b.
(*The) Susan likes pizza.
-
a.
Even more importantly, it is unclear whether a radically empty D would actually be projected at all.
A more likely explanation for the reported patterns is that the numeral is the head of a functional projection within the nominal extended projection rather than an adjective. Adjective preposing is the result of focus movement within the DP, as has been argued in detail by Ntelitheos (2004) and Szendröi (2012), among others.Footnote 20,Footnote 21 The semantic claim is that numerals have the semantics of intersective adjectives. With the above in mind, we propose the following structure (53), which is a modification of Rothstein’s proposal in (43) that takes into account the points made above. We do not assume that the numeral is adjectival or raises to D; rather, it heads its own functional projection. We also assume that portion words head their own phrase (Portion Phrase) rather than an NP, reflecting their semi-lexical status (see also Section 4.2.1 for a semantic argument against treating portion words as ordinary nouns).
-
(53)


Number features (and mass/count status) percolate from Portion0 which controls number agreement on the verb; this accounts for the observation that subject-verb agreement in count portioning out is always with the portion word (see (33)–(34) and surrounding discussion).
We use dashed branches in (53) to indicate that when the PortionP is structured like a pseudopartitive, languages make different choices regarding the projection of the prepositional part of the structure. As we have already seen, Dutch and other languages do not require the overt realisation of the equivalent of of. This contrasts with full partitives (54), which can also express both count and mass portioning out and which must be accommodated by our analysis too.
-
(54)
-
a.
I drank three mouthfuls of that delicious beer.
-
b.
I drank heaps of that delicious beer.
-
a.
In general, the status of of has been a matter of debate for a considerable amount of time and a wide variety of analyses has been developed.Footnote 22 Whether, ultimately, there is a unified analysis of all instances of of, is both doubtful given of’s very high degree of grammaticisation,Footnote 23 and also perhaps undesirable for the same reason. In this paper we will adopt a dual position: pseudopartitive of acts as a (Case-assigning) preposition and does not contribute to the semantics (cf. Heim and Kratzer 1998: 61–62),Footnote 24 while partitive of is also a preposition, but one which makes a full semantic contribution:
-
(55)


In languages like English and Dutch, of behaves the same across both mass and count portioning-out (although at the end of this section we will review some evidence that the situation may be more nuanced in (British) English). English requires of in both partitives and pseudopartitives, regardless of the type of portioning-out (see e.g. (54)). Dutch only requires of in partitives while banning it from pseudopartitives; again, as (56)–(57) show, this applies to both mass (56) and count (57) portioning-out:
-
(56)


-
(57)


In contrast, in German, von ‘of’ is absent from countable pseudopartitives (as in Dutch), but required in mass pseudopartitives (see the data and discussion in Section 3.1.4). We therefore propose that (the equivalent of) of has a third possible function not associated with its prepositional incarnation: spelling out functional material that is active in mass portioning-out, but not in count portioning-out. We now turn to the syntactic details of the former.
3.2.2 Mass portioning-out
We propose that the functional material in question is an operator that mediates the surface relation between the PortionP and the DP/NP, which we call MP\(_{\text{OP}}\) (Mass Portioning operator). Morphophonologically, this operator can be realised in different ways, depending on language specific rules of lexical insertion: in German it is realised by von ‘of,’ in Greek by the definite determiner, and in Dutch, English and elsewhere it is null. The operator is merged externally to the small clause-like constituent that includes the PortionP and the NP/DP. The structure that we propose is fundamentally the same as the one proposed by Kayne (1997); Corver (1998); and den Dikken (2006).
Under this proposal, the derivation for heaps of sand runs as follows (we will not provide a full derivation for the partitive variant, which involves analogous changes compared to (55)).Footnote 25
-
(58)


PortionP moves in order to enable labelling of the constituent. Following Chomsky (2013, 2015) we assume that a constituent like [[PortionP heaps] [\(_{NP}\) sand]] fails to receive a label altogether because the heads Portion0 and N0 are equidistant from the root; as a result the labelling algorithm is unable to determine the label of the whole constituent. The only remedy is to modify the unlabellable constituent. The position of the movement is provided after the head MP\(_{\text{OP}}\) is merged.
Relevantly, the same idea has been developed for determiner spreading constructions in Greek (59) by Alexiadou and Wilder (1998a).Footnote 26
-
(59)


According to their proposal, the constituents [\(_{\text{DP}}\) the flag] and [\(_{\text{AP}}\) red] merge first, forming a predicative small clause. Subsequent raising of [\(_{\text{AP}}\) red] followed by merging of an external definite determiner yields (59). Our analysis of examples like (42a) (repeated in (60)) is in the same spirit:
-
(60)


The derivation of (59) is as follows:
-
(61)


Thus, the proposal captures our observation that mass portioning-out involves more functional material than count portioning-out,Footnote 27 in a way that is in accordance with existing proposals about the behaviour of Greek.
Another difference between mass and count portioning-out, as discussed in Section 3.1, is that (only) the former displays variable agreement patterns (in Dutch and English). This is accounted for under the present proposal. Specifically, if the structure in (58d) is to be inserted in a copular structure, and T needs to be merged next, at the point of merging T both the PortionP and the DP will be equally accessible to T’s φ-probe. This is so because labelling and movement are phase-based, and only take place once the phase head is merged (Chomsky 2008, 2013).Footnote 28 Assuming that head is C, that means that the PortionP is still in its original location when T is merged, and T will have access to both sets of ϕ-features. Schematically:
-
(62)


-
(63)


The label of the sister of T is unclear but ultimately not relevant for our purposes. Presumably it would be derived along the lines that derive the label of TP as <φ,φ>Footnote 29 by substituting the relevant features in terms of which PortionP and MP\(_{\text{OP}}\) agree (Chomsky 2013, 2015).
Inserting expletive There in Spec TP yields:
-
(64)
-
a.
There’s tons of work to do.
-
b.
There are tons of work to do.
-
a.
We also assume that the PortionP cannot move further to Spec TP (hence the necessity for an expletive) because it has reached a criterial position (Rizzi 2006, 2010, 2017). Since the portion word is not the head of the phrase but part of a specifier, it does not influence the number or mass/count status of the constituent as a whole.
We have seen that our analysis accounts for the presence of additional functional material in mass portioning out in some languages, as well as its variable agreement behaviour. The coordination and prosody data from Section 3.1 also fall out from the structure in (58).
First, the contrasts in (35)–(36) fall out directly from the fact that coordinating a DP and an MP\(_{ \text{OP}}\)P is not possible.
With respect to the stress patterns discussed in (40), Selkirk’s (2011) Match theory provides an explicit way to state the argument. Selkirk (2011: 441) proposes the following Match constraint for the identification of one of the relevant phonological domains:
-
(65)
Match phrase
A phrase in syntactic constituent structure must be matched by a corresponding prosodic constituent, call it ϕ, in phonological representation.
Stress is sensitive to ϕ and as a result, in (53) there is only one relevant phrase, PortionP, wherein the rightmost element receives primary stress (consistent with the Nuclear Stress Rule). In (58c) in contrast, the Match Phrase constraint identifies two relevant phrases, PortionP on the left and MP\(_{\text{OP}}\)P (which is also phrasal) on the right and stress is assigned accordingly.
Finally, we turn to the pluralisation strategies that we presented in Section 2.3. Given the structures proposed in (53) and (62)/(63), we obtain (66) and (67). Languages of the Ojibwe type, in which plural mass nouns receive a ‘bits or portions of X’ interpretation, have the structure in (66) available, while the structure in (67) represents languages like Greek and Persian; languages of the Evenki type, in which plural mass nouns are ambiguous, allow both structures.
-
(66)


-
(67)


Where exactly plural marking will be realised morphologically is the result of independent processes not directly relevant to the point here.
3.2.3 A note on the (c)overtness of MP\(_{\text{OP}}\)
We have claimed that MP\(_{\text{OP}}\) is covert in both Dutch and English, whereas in German it is expressed by von ‘of.’ However, there is some evidence that MP\(_{\text{OP}}\) is spelled out as of in (some varieties of) English, too. (68a)–(68b) show that, in count portioning-out, the NP sugar can be preposed either with or without the of, showing that both the NP and the of-phrase are independent constituents. However, for mass portioning-out, our British informants accepted (68c) but rejected (68d), indicating that the of-phrase is not a constituent in mass portioning-out. (Our American informants did not show this pattern; most expressed a strong dislike for all sentences in (68).)
-
(68)
-
a.
Sugar, you will need three teaspoons of for this recipe.
-
b.
Of sugar, you will need three teaspoons for this recipe.
-
c.
Sugar, you will need heaps and heaps of for this recipe.
-
d.
*Of sugar, you will need heaps and heaps for this recipe.
-
a.
This pattern is consistent with of playing a role in spelling out MP\(_{\text{OP}}\) in British English, as [MP\(_{\text{OP}}\) NP] is not a constituent in the structure in (58). This suggests that whether and how the various functional elements in our structure, including MP\(_{\text{OP}}\), are spelled out is not just language-dependent, but may also vary from one context to another. In a similar vein, consider covert mass portioning-out in Greek (e.g. (9)), which we assume has the structure in (58) but no definite determiner, suggesting that whether MP\(_{\text{OP}}\) can be spelled out or not depends on the presence of an overt portion word. We will leave such nuances in the morphological realisation of our structures of interest to future research.
4 Semantics
In this section, we propose a semantic analysis of portioning-out that is consistent with the syntax proposed in the previous section.
4.1 Background: Overlap and disjointness
We will rely on a disjointness-based approach to the mass/count distinction in order to analyse the distinction between count and mass portioning-out. While the properties of disjointness and overlap have received some attention in the mass/count literature (e.g. Bunt 1985; Gillon 1992; Bale and Barner 2009; the “built-in measure” approach to count nouns of Krifka 1989 is also a clear precursor of the present analysis), several more recent approaches to the mass/count distinction (e.g. Rothstein 2010; Landman 2011, 2016; Khrizman et al. 2015; Sutton and Filip 2016; Rothstein 2017; Landman 2020) treat disjointness as the central determinant of grammatical countability, providing an alternative to the atomicity-based framework most semanticists have relied on since Link (1983). A framework based on overlap and disjointness is particularly well-suited to analyse mass/count alternations, countable reference to substances, non-countable reference to objects, and other “grey area” phenomena without having to rely on systematic shifts between types and/or ontological domains.
Disjointness-based accounts continue the Linkian tradition of analysing nouns as denoting sets of mereological entities (atoms or sums), where the mass/count distinction follows from the formal properties of these sets and entities. However, one key difference between Link (and Chierchia 1998b, 2010) on the one hand and a disjointness-based account on the other, is that the latter does not assume that count nouns are countable because they range over atoms. Instead, both mass and count nouns are analysed in terms of predicates over mereological sums, with the difference between the two being that count nouns divide that stuff in a way that necessarily excludes any overlap, while mass nouns do not. Cats, for instance, are disjoint: the same bit of cat-stuff cannot simultaneously be part of multiple cats. As a consequence, there is only one way to divide a domain of cat-stuff such that it results in a predicate over things that are cats; this means that the cardinality of the denotation count noun cat is non-arbitrary, enabling counting.Footnote 30 In contrast, the same bit of water can be part of (possibly infinitely) many water-sums; hence, the predicate water does not provide a non-arbitrary way to divide the sums of matter in its extension and therefore no “base” of sums that “count as one.” As a result, water cannot be counted.
4.2 Portioning-out in a disjointness-based semantics
One of the advantages of a disjointness-based framework is that it enables a derivational and compositional account of countable complex NPs involving mass nouns, such as the portion constructions in (2c). Where an approach that links countability to atomicity needs to assume either a high degree of lexical ambiguity or polysemy or a system of covert inter-domain mappings (e.g. Link’s “material part” relation, or the “S-partition” and “I-partition” operators proposed in Chierchia 2010), a semantics based on overlap and disjointness allows countable reference to stuff and non-countable reference to objects without any additional ambiguity or domain-shifting. In doing so, it avoids philosophically unorthodox practices such as the breaking up of atoms into other atoms (as in Chierchia 2010), and allows us to account for equivalences like the ones in (69) without having to include in the model additional (and, in principle, arbitrary) mappings between atoms and their material parts.Footnote 31
-
(69)
-
a.
Six 20g slices of cheese
-
b.
Cheese in 6 20g slices
-
c.
120g sliced cheese
-
d.
Slices of cheese amounting to 120g
-
a.
In Khrizman et al. (2015) and Landman (2016), portioning-out of mass nouns is treated as simple intersection.Footnote 32
-
(70)
-
a.
\(\mbox{$[\!\![\mathit{slice} ]\!\!]$} = \textbf{slice}\) (the disjoint set of slice-shaped objects)
-
b.
\(\mbox{$[\!\![\mathit{cheese} ]\!\!]$} = \textbf{cheese}\) (the overlapping set of cheese-sums)
\(\mbox{$[\!\![\emph{slice of cheese} ]\!\!]$} = \textbf{slice} \cap \textbf{cheese}\) (the disjoint set of cheese-sums that are slices)
-
a.
Note that, even as we are dividing, counting up and otherwise semantically manipulating our cheese-sums, we never leave the domain of cheese; the counting of cheese-sums is enabled not because we have mapped them onto an independent atomic domain of slices, but because we have compositionally altered their overlap properties. Because slice is disjoint, the result of intersecting it with any other set is necessarily also disjoint, and hence portion constructions like slice of cheese are predicted to be countable.
Similarly, Khrizman et al. (2015) and Landman (2016) assume intersective interpretations for both portion-shifted measures and covert portioning-out constructions. For example, on its portion interpretation (e.g. We have various litres of mineral water in the fridge), the denotation of litre of water is analysed as in (71).
-
(71)
\(\mbox{$[\!\![\emph{litre of water} ]\!\!]$} = \lambda x [ \textbf{portion}(x) \wedge \textbf{water}(x) \wedge \textbf{litre}(x)=1 ]\)
So, just as slice of cheese can be analysed as a set of sums that are both cheese and slices, the relevant reading of litres of water can be analysed as a set of sums that are both water and litre-sized portions. The result, again, behaves like a count NP since portion is claimed to be disjoint:
-
(72)
In the course of the day, John drank many/several/each of these litres of mineral water.
As can be seen in (71), portion-shifting a measure construction relies on intersection with a set portion of contextually determined portions. Khrizman et al. assume that portion is also active in covert portioning-out constructions (as in the Yudja example from (24)), and can be directly intersected with the mass noun denotation to give a countable portioned-out interpretation.
4.2.1 Non-intersective portioning-out
While we also assume that counting and pluralisation of stuff-denoting nouns in languages like Yudja and Nez Perce involve covert portioning-out, we believe that there are serious conceptual and empirical problems with the treatment of portioning-out as intersective. Such a treatment relies on the notion of a contextually definable set of sums x for which it holds that x is a portion in that context. But what does that mean? It seems impossible to decide whether or not a certain sum is ‘a portion’ without knowing what is supposed to be a portion of; in other words, the meaning of portion is not just determined by the context, but depends on the extension of its complement too. In this sense portion is like part, or like a subsective adjective (skilful, former): it can be defined as a function on some other set, but it does not itself characterise a set (see also Chierchia 1998b for a very similar argument). This is reflected in its linguistic behaviour, too: words like portion are marginal at best in constructions that make the intersection explicit, such as (73).
-
(73)
-
a.
a silver ring / a ring that is silver
-
b.
delicious wine / wine that is delicious
-
c.
a portion of soup / \(^{??/}\)*a portion that is soup
-
d.
a quantity of cheese / \(^{??/}\)*cheese that is a quantity
-
a.
Moreover, Khrizman et al.’s account crucially relies on the set portion being disjoint. However, if we look more closely at the meaning of the word portion, it does not seem that it should denote a disjoint set at all. Consider a single context in which we have three bowls of soup, three pieces of buttered bread, and three single-portion tubs of ice cream. How many portions are there in the context? We might say that there are nine portions; but it is equally valid to say that there are three (three portions of a two-course meal) or perhaps six (three portions of the main course, three of the pudding). This is exactly the kind of “vertical overlap” that Landman (2011) invokes to explain why nouns like furniture are mass—yet portion crucially needs to be disjoint, otherwise intersecting it with a mass predicate would not yield a countable result.
Taken together, these two observations suggest that the analysis of portioning-out should not rely on intersectivity. We propose instead that portion expressions—including covert portion and portion-shifted measures—denote subsective functions from sets of sums to a disjoint subset of those sums. Semi-formally:
-
(74)
A portioning-out operator \(\mathcal{P}^{C}\) is a function of type 〈et,et〉 such that:
\(\mathcal{P}^{C}(X) := \{ y \in X | y \) is a contextually individuated sum with property C}
This general definition combines reference to both an extralinguistic notion of individuationFootnote 33 and an operator-specific property C that is a placeholder for any additional criteria imposed on the portions by the lexical content of the operator, such as shape (e.g. chunk, drop), size/quantity (e.g. portion-shifted measures, ream, score, bit), function (e.g. overt portion, which corresponds to a size that’s part of a meal for one), a particular spatial configuration (e.g. mass, heap), or some combination of these. C can also be absent, as in the case of neutral portion expressions like quantity, which pick out any sums that are contextually individuatedFootnote 34 without additional requirements (we assume the same holds for covert portion).
The absence or presence of an additional criterion C results in a formal distinction that we will term total versus partial portioning-out. In real-world contexts, substances always occur as part of contextually individuated quantities. It follows that, in the absence of an additional criterion C on those quantities, portioning-out necessarily involves the entire domain of the mass noun: it is total. On the other hand, if an additional criterion C is present, it is not necessarily true that all sums of a given substance will be part of a portion with property C. In these cases, portioning-out is partial: it involves only a subset of the mass noun’s domain.
-
(75)
A portioning-out operator \(\mathcal{P}^{C}\) is total iff (for any context) \(\sqcup (\mathcal{P^{C}}(X)) = \sqcup X\) and partial otherwise.
In other words, total portioning-out involves a partition of the set X (cf. Gillon 1992).
We hypothesise (although we cannot verify this intuition without further research) that covert portioning-out is always total; after all, it is unclear how any additional criteria like shape or size could be imposed on the portions in the absence of any lexical material expressing those criteria. In any case, we will assume that our general covert portioning-out operator portion is total, and equip it with the following semi-formalised denotation:
-
(76)
portion(X) := the disjoint set of sums Y such that
⊔(Y)=⊔(X)
∧∀y∈Y[y is a contextually individuated quantity of X]
For instance, portion(water) corresponds to the set of all individuated bodies of water in the context, which may include the Atlantic Ocean, the rain puddles on Main Street, and the handful of water I just scooped up to wash my face with. These portions do not overlap and together cover the entire domain of water.
4.2.2 Mass and count portioning-out
We are now in a position to put the semantics together with the syntactic structures we independently arrived at in Section 3. Count portioning-out can be dealt with pretty straightforwardly. As we have seen, the relevant structure is a PortionP headed by the portioning-out operator \(\mathcal{P}^{C}\); this PortionP may have a pseudopartitive or a partitive structure, as shown below (with examples):Footnote 35
-
(77)
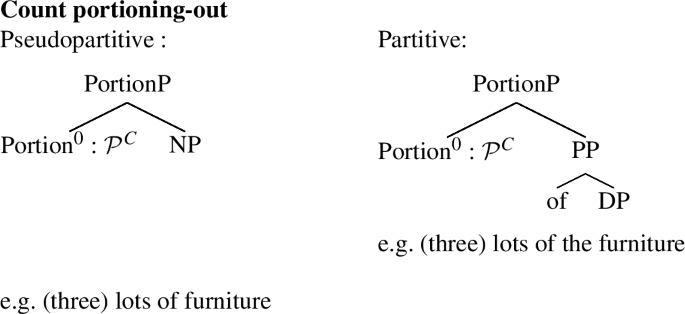

Since we have defined portioning-out operators as functions on sets of sums, we can derive the desired semantics for the first, pseudopartitive structure by simply applying \(\mathcal{P}^{C}\) to 〚NP〛. (Recall that we are assuming that the of in English pseudopartitives does not contribute to the semantics.) The partitive structure is somewhat more complex, as in order for the semantic computation to go through, the PP must denote a set of sums too. We propose that this set is made available by the application of 〚of〛 to the sum entity expressed by the embedded DP; the function of 〚of〛 in this position, then, is to access the Boolean part set of that sum, as commonly assumed in the semantic literature on partitive of (e.g. Ladusaw 1982; Hoeksema 1984; Ionin et al. 2006; a similar semantics is adopted in Barker 1998, but Barker includes only proper parts for reasons we will not get into here).
-
(78)
〚of〛(x) = {y:y⊑x}
In the case of mass portioning-out, the PortionP is in the specifier position of a phrase we have labelled MP\(_{\text{OP}}\)P, the head of which (MP\(_{\text{OP}}\)) may or may not be spelled out depending on the language and/or the construction. In (79), the structures corresponding to pseudopartitive and partitive mass portioning-out are given.Footnote 36
In (80), we provide our semantics for MP\(_{\text{OP}}\).
-
(79)


-
(80)
MP\(_{\text{OP}}(P)(\mathcal{Q}) := \{ x | x \in P \wedge \exists y [ y \in \mathcal{Q}(P) \wedge x \sqsubseteq y ] \} \)
where P is a set of sums and \(\mathcal{Q}\) a function from sets of sums to sets of sums.
(final version in (104))
In words, the result of applying MP\(_{\text{OP}}\) to a predicate P and a portioning-out operation \(\mathcal{Q}\) is the set of all sums that are both P and a Boolean part of some member of the portioned-out predicate \(\mathcal{Q}(P)\).Footnote 37
The function of MP\(_{\text{OP}}\) is to mediate between a mass predicate and the portioning-out operator, and ensure that the denotation of the phrase as a whole inherits the overlap properties of the embedded NP. For example, suppose that water = {a⊕b⊕c,a⊕b,a⊕c,b⊕c,a,b,c,...} and portion(water) = {a⊕b,c}. Then, the denotation of MP\(_{\text{OP}}\)(water)(portion) is the set {a⊕b,a,b,c,...}. In this set, the portioned-out structure is preserved in the form of partial disjointness: the set does not contain any sums x⊕y such that x is part of one portion, and y part of another. However, the set as a whole overlaps and is mass; its meaning can be paraphrased as ‘water that is part of a contextually individuated quantity.’Footnote 38
An important property of mass portioned-out predicates is that they overlap, but are not closed under sum. As we have discussed before, this means that they can be non-vacuously pluralised with Link’s star operator *. If the portioning-out is total, it follows that the result of pluralising a mass portioned-out noun is equivalent to the original mass noun denotation (since mass portioned-out predicates are divisive, i.e. closed under parthood). For example, closing the above predicate 〚MP\(_{\text{OP}}\)(portion)(water)〛 under sum gives us again our original predicate water. This formal fact sets the stage for the next part of our paper: an analysis of the “high quantity” inference of mass portioning-out in terms of implicated rather than asserted meaning.
For the sake of formal explicitness, we end this part of the paper with a full derivation of the sentence Mary spilled lots of water.
-
(81)


Note that the set defined in (81b) is equivalent to the set {x|x∈water∧∃y[y∈∗(lot(water))∧x⊑y]]}—the set of all water-sums that are part of a sum of lot-portions of water. Since this is slightly less cumbersome to write and read we will use this formula in the next section of the paper.
5 Abundance as a degree-based inference
As we have seen, all the phenomena for which an analysis in terms of mass portions seems appropriate share an inference of abundance or high quantity. In this section we will examine the abundance inference more closely. Section 5.1 focuses on the properties of the abundance inference. We will follow Tsoulas (2009); Kane et al. (2015); Renans et al. (2018) in assuming that it is an implicature, but also point out some data that appear to go against the latter two’s analysis of abundance as a scalar implicature on a par with multiplicity in count nouns. In Section 5.2 we will instead propose an alternative analysis inspired by the approach to quality nouns (e.g. courage, wisdom) in Francez and Koontz-Garboden (2017) (who build on work by Tovena 2001), combined with Rett’s (2015) implicature-based analysis of the “positive form” of gradable adjectives (e.g. Mary is tall). By assuming that mass portioning-out introduces a size ordering on portions, our analysis ties the abundance inference to the semantics of portioning-out.
5.1 A closer look at the abundance inference
Considering that, under our proposal, portioned-out mass predicates contain more semantic ingredients than ordinary mass predicates—there’s the portion operator and, usually, a plural—a natural way of accounting for the abundance inference is to build it into the semantics of either of these elements. Such approaches have been pursued by Alexiadou (2011) for mass plurals and Klockmann (2017) for Q-nouns. In the following two sections, we will examine each proposal in turn.
5.1.1 Abundance cannot be reduced to the semantics of the plural
Alexiadou (2011) locates the abundance inference in the semantics of the plural morpheme itself. She proposes that the Greek plural is ambiguous between a compositional version and a more idiosyncratic lexical one (cf. Acquaviva 2008); the abundance inference is part of the semantics of the latter type of plural. In principle, it seems that such an account could be extended more or less straightforwardly to our other cases of mass portioning-out, as these either obligatorily (bare measures) or tendentially (Q-nouns) involve pluralisation as well. However, there are both syntactic and semantic reasons not to adopt such a view. As for the first, a property of lexical plurals is that they occupy a very low syntactic position, close to the root. This “lexical” position allows them to express a more idiosyncratic operation on their complement. But both Q-nouns and bare measures involve intervening material between the mass noun and the plural, suggesting the plural expresses its “ordinary” compositional meaning here. In addition, Kane et al. (2015) provide several semantic/pragmatic arguments against Alexiadou’s lexical plural approach by showing that the abundance inference only arises in certain contexts. For example, in downward entailing and nonveridical environments, the meaning of a plural mass noun is identical to its singular equivalent.
-
(82)


This is unexpected if ‘much X’ were the literal meaning of a plural mass noun, as in that case, (82) would be true if John spilled a little water. In addition, the abundance inference from plural mass nouns can be explicitly contradicted (‘...but not much’) with a perfectly felicitous result.
Such data lead Kane et al. (2015) to conclude that the abundance inference cannot be part of the literal meaning of the plural. Instead, they argue that the patterns exemplified here are characteristic of scalar implicature. Since scalar implicature is also argued to be involved in deriving the more-than-one interpretation of plurality in count nouns (e.g. Sauerland et al. 2005; Spector 2007), it makes sense to derive abundance on mass nouns in a parallel way. Following Spector’s (2007) analysis of multiplicity in count nouns, Kane et al. assume that in Greek, singular water is enriched with the implicated meaning ‘not much water’ through pragmatic competition with the alternative much water; subsequently, the plural waters gains the meaning ‘much water’ through competition with the enriched singular. In an experimental study of Greek-speaking children and adults, Renans et al. (2018) confirm that Greek children generally fail to derive the abundance inference, which conforms to the general acquisition pattern of scalar implicatures.
At first glance, the analysis of portioning-out as proposed in this paper seems to confirm and even strengthen the intuition of Kane et al. (2015) on the parallel between abundance and multiplicity, as under our analysis, the contribution of the plural in cats and waters is fully identical (closure under sum) and the interpretation can be stated in terms of multiplicity in both cases. Thus, the enriched meaning of waters may be paraphrased as ‘water in two or more contextually individuated portions.’ Presumably, this enriched meaning can be satisfied in a context in which the water is scattered (Alexiadou 2011), but also if there is so much of it that we would hesitate to describe it as a single portion. While this analysis is tempting in its simplicity, we will argue that it is not accurate, and that the abundance inference arises independently from multiplicity. But before we move on to that argument, we will briefly evaluate a different type of semantic approach to abundance, one that locates it in the literal meaning of the portioning-out operator.
5.1.2 Abundance cannot be reduced to the meaning of the portion word
In the case of bare measures, Q-nouns like lot and perhaps shape-based portion classifiers such as blob, chunk, and slab,Footnote 39 an intuitive approach—which may be found on many an online English usage forum—is to assume that the “large quantity” interpretation simply involves a more “figurative” use of the portion word. We have already considered this option in Section 2.1 and objected that this does not account for the co-occurrence of abundance with non-countability (and, conversely, the lack of an abundance inference in countable NPs). More importantly for our present argument, it can be shown that the abundance inference also surfaces in contexts where the portion word does not express a high quantity. Consider for example the contrast in (83):
-
(83)
-
a.
I have budgeted thousands of euros for healthcare this year.
(A private citizen commenting on their family finances.)
-
b.
# I have budgeted thousands of euros for healthcare this year.
(The minister of finance introducing the national budget.)
-
a.
Note that both sentences are technically true if the budgeted amount exceeds a few thousand euros, regardless of whether that is a lot of money in the context. However, while (83a) is both true and felicitous in the context (since thousands of euros is a lot of money for a single European family to spend on medical care in a year), the same sentence is inappropriate in the context of (83b), in which a couple of thousands of euros is in fact an insignificant sum of money. In short, the reason (83b) is bad is not because it is false; it is because it wrongly implies that thousands of euros is a lot of money for a country to spend on its health budget. In sum, abundance arises because a portion word is used in a mass portioning-out construction, not because the portion word lexically expresses a large quantity.
5.1.3 Abundance cannot be reduced to multiplicity
Back to our earlier hypothesis that abundance is a type of multiplicity inference paraphrasable as (for instance) ‘water that’s part of a sum of multiple portions.’ The data in the previous subsection support the observation that plural mass portioned-out predicates carry a multiplicity inference: even though predicates like loads of laundry or Greek nera ‘waters’ are mass, they are only appropriate in a context in which multiple quantities of laundry or water can be distinguished. However, it can be shown that abundance arises independently of this multiplicity inference. If multiplicity is made explicit, as in (84), the abundance inference disappears. For instance, (84a) can be felicitously uttered by a very fiscally conservative minister of finance; (84b) does not imply that the quantity of laundry is unusually large; (84c) (unlike its bare measure counterpart) is fine in combination with the minimiser just, and so on.
-
(84)
-
a.
I have budgeted several thousands of euros for healthcare this year.
-
b.
I need to do multiple loads of laundry today; all in a normal Saturday’s work.
-
c.
John spilled just a couple of litres of water today.
-
a.
A second argument against unifying multiplicity and abundance may be derived from the observation that abundance does not always need to be interpreted as ‘a high quantity’—in the right context, it may contribute ‘a (surprisingly) small quantity,’ too. For example, in sentence (85) (from an article on the handling of sexual harassment complaints in academia), the bare measure feet away clearly implies multiplicity (i.e. a distance of more than 1 foot); in addition, it carries an inference of excessiveness or extremity but, in the particular context, it is the shortness of the distance that is excessive.
-
(85)
One stepped down, but the other, despite having been found to have violated the code, remained employed and in an office feet away for six months from one of the women who filed the complaint.Footnote 40
Similarly:
-
(86)
Yet if polls are right [the Labour party] is days away from utter collapse north of Hadrian’s Wall.Footnote 41
The same effect arises with some shape classifiers that inherently express a small quantity, such as drop:
-
(87)
Although it may take two or three weeks to get even drops of milk, the fact that the adopting mother starts to get even drops can be very reassuring.Footnote 42
The co-occurrence of these two inferences— multiple feet, days, or drops, but at the same time a particularly small distance, quantity or or amount of time—is hard to account for if we collapse abundance and multiplicity into a single quantity-related implicature, as under Kane et al.’s (2015) approach. Of course, the sentences in (86) and (87) have more pragmatic ingredients than the Greek mass plurals Kane et al. are interested in. Foot and day compete with larger alternative units of measure like yard, miles, week or month, such that upon hearing that an event is days away we will probably infer that it is less than a week away. But while such a scalar implicature might well play a role in the “reversal” of the abundance inference,Footnote 43 the abundance inference itself cannot be reduced to it. Note that these scalar implicatures are not limited to bare measures: they also arise with the full measure phrases in (88a)–(88c), but the abundance inference does not.
-
(88)
-
a.
The harasser remained in an office several feet away from one of the women who filed the complaint.
-
b.
The Labour party is a couple of days away from utter collapse north of Hadrian’s Wall.
-
c.
It may take two or three weeks for the adopting mother to get (??even) multiple drops of milk.
-
a.
So, for instance, while (88b) still supports the inference that the collapse of the Labour party is less than a week away, unlike (86) it does not imply that this is a shockingly short amount of time. This means that, just as abundance cannot be reduced to multiplicity, it cannot be reduced to a scalar implicature about the size of the measure unit either.
Let’s take stock. We have examined a few possible origins for the abundance inference (a lexical plural, the lexical contribution of the portion word, a multiplicity implicature, and a scalar implicature based on competition with alternative portion words) and argued in each case that abundance arises independently. One of the weaknesses of the approaches examined above is that most of them fail to account for the fact that abundance only arises with mass portioning-out, not with their countable equivalents. In the next section, we will provide an account of abundance that ties it to mass portioning-out.
5.2 Abundance as a tautology-based quantity implicature
5.2.1 Mass portioned-out predicates are size ordered
Tovena (2001) observes that certain abstract mass nouns in Italian and French are acceptable in contexts that are normally restricted to singular count nouns. For example:
-
(89)


Following van de Velde (1996), she identifies the relevant class of nouns as nouns denoting “intensive quantities”—nouns that are measured by intensity, not by extension (i.e. the amount of space they take up). She proposes to associate these nouns with a degree scale that provides a weak form of individuation by partitioning the domain on the basis of intensity. As weakly individuated nouns, intensive quantity nouns are compatible with certain “count” determiners like aucun and every (‘I have every confidence in his ability’); at the same time, they are mass since their structure does not distinguish any individual entities (only degrees).
Francez and Koontz-Garboden (2017) take a similar approach to what they call “property concept nouns,’ but in a way that does not rely on the rather fuzzy distinction between “intensive” and “extensive” measurement. They propose that nouns like courage and mercy are mereologically ordered in terms of (abstract) quantities, like concrete mass nouns, but in addition involve a size ordering ≤ that groups portions of the relevant quality in size-based equivalence classes. Drawing on Tovena (2001) as well as Morzycki’s (2009, 2012) work on nominal gradability, Francez and Koontz-Garboden (2017) list several tests to detect the presence of such a size ordering, which we reproduce here as given:
-
(90)
Exclamatives
-
a.
What water she drank!
Cannot mean: How much water she drank!
-
b.
What courage she has!
Does mean: How much courage she has / How courageous she is!
-
a.
The exclamative in (90a) indicates that there is something noteworthy about the water; this noteworthiness may pertain to various aspects of the water (taste, appearance, rarity...), but crucially not its quantity. In contrast, the “noteworthy quantity” interpretation is the only available interpretation for exclamatives that involve a size-ordered mass noun, such as (90b).
Secondly, unlike ordinary mass nouns, size-ordered mass nouns tend to be compatible with various classes of degree-modifying adjectives:
-
(91)
Size modification (cf. Morzycki 2009)
-
a.
*She drank major/enormous water.
-
b.
She is a major/enormous idiot.
-
c.
She has major/enormous courage.
-
a.
-
(92)
Intensifiers (cf. Morzycki 2012)
-
a.
*She drank utter/total/absolute water.
-
b.
She is an utter/total/absolute nerd.
-
c.
She has absolute conviction.
-
d.
She is a person of utter beauty.
-
a.
The same (although this is not mentioned by Francez and Koontz-Garboden) holds for evaluative (speaker attitude) modification with adjectives like incredible, astounding, or terrible, which allow a “high degree” interpretation in (93b)–(93c) but not in (93a):
-
(93)
Evaluative modification (cf. de Vries 2010)
-
a.
I’ve seen incredible/astounding water.
-
b.
He is an incredible/astounding idiot.
-
c.
He has incredible/astounding wisdom.
-
a.
Thirdly, predicates that are size-ordered enable targeting of a particular quantity with such, while in ordinary mass nouns such only triggers a subkind reading:
-
(94)
Such
-
a.
Drinking such water is bad for your health.
Cannot mean: Drinking so much water is bad for your health.
-
b.
Such wisdom is rarely seen in someone so young.
Can mean: So much wisdom is rarely seen in someone so young.
-
a.
Thus, we see that quality-denoting mass nouns like courage and wisdom involve a quantity-based ordering relation that may be targeted by expressions or constructions that normally operate on degrees.
We observe that our cases of mass portioning-out pattern with quality nouns in the tests listed above, indicating that they too involve a size ordering. (Note that the point is not that such sentences are always grammatical—for instance, the English equivalent of (96) sounds decidedly odd—but that, in contrast to the “plain” mass nouns in (63)–(67), these mass portioned-out NPs may receive a “high degree” interpretation in these contexts.)
-
(95)
English
-
a.
And, what heaps of gear you can pack in this roof top carrier!Footnote 44
-
b.
O what floods of turtle-soup; what tons of turbot and lobster-sauce must have been sacrificed to make those sinners properly miserable.Footnote 45
-
c.
If only more states (...) had realized in 1915 the truth that lay in those words, what vandalism of irreplaceable assets, what obnoxious inholdings, what miles of tawdry summer shacks along a precious seashore would have been avoided!Footnote 46
-
a.
-
(96)


-
(97)


The exclamatives in (95)–(97) do not serve to draw our attention to, say, some particularly high-quality gear or strikingly delicious lobster sauce; rather, in all examples, the exclamative expresses a high quantity of something.Footnote 47
Similarly, we find examples of modifiers like major, utter and incredible and the relevant counterparts in the other languages targeting the quantity of their mass portioned-out complements
-
(98)


-
(99)


-
(100)


And finally, mass portioned-out predicates pattern with quality nouns in allowing such to target quantities rather than subkinds.
-
(101)
English
-
a.
M. Zola went on to say that he was astonished at the extent of the outlying districts of London. He had never seen such miles of monotonous brick and mortar.Footnote 48
-
b.
Really? You wanted to post such tons of text because you don’t like this game?Footnote 49
-
c.
Why have the artistic gymnasts put on such oodles of makeup?Footnote 50
-
d.
Added to soot, such heaps of dust, mud, ash, horse-dung and other detritus littered the city’s thoroughfares that the rich were also sullied.Footnote 51
-
a.
We conclude that mass portioning-out results in a predicate that is size-ordered, just like quality nouns. Note that the same does not hold for count portioning-out: even if the sentences in (102) were grammatical, they would still lack the quantity-oriented interpretation of their mass portioned-out counterparts.Footnote 52
-
(102)
-
a.
*What several miles of depressing apartment blocks!
-
b.
*I have to do such multiple loads of laundry that I expect to be at it all day.
-
c.
*Nothing made a difference, including outright 5 years of experience.
-
a.
In the next section, we will use this observation to provide an account of the abundance inference.
5.2.2 Abundance as a “positive form” inference
We have seen that ordering a mass noun denotation by portion size leads it to display behaviour similar to gradable predicates like tall and idiot. It is well-known that, in the absence of degree morphology, such gradable predicates are interpreted as ‘X to an above-average degree’—the so-called “positive form” (103a).
-
(103)
-
a.
John is tall.
-
b.
John is 5 feet tall.
-
a.
Since gradable predicates do not always support this inference (for example, it does not follow from (103b) that John is taller than average), it is generally assumed that it is not part of the lexical meaning of the adjective. While most of the literature follows Cresswell (1976) in assuming that the positive inference is contributed by a covert morpheme (generally called pos), Rett (2015) argues in recent work that it could be derived through a pragmatic process.
There is a clear parallel between the positive inference triggered by gradable predicates and the abundance inference supported by our cases of mass portioning-out. Mass portioned-out predicates involve a size ordering that can be targeted by degree modifiers and similar environments; in the absence of any such material, they support the inference that the expressed quantity exceeds some contextual standard. We therefore propose that the abundance inference triggered by mass portioning-out should be analysed in parallel to the positive form of a gradable predicate. Since we have already seen that the abundance inference shows properties characteristic of implicature, we will base our analysis directly on Rett’s (2015) pragmatic account of positive inferences.Footnote 53
Rett proposes that both Manner and Quantity implicatures are active in the interpretation of degree constructions. In the case of the positive form, she derives the positive inference through a Quantity implicature triggered by the uninformativity of the non-enriched meaning. According to Rett, the semantics of (103a) is simply ‘John has a height’; but uttering something that is trivially true violates Grice’s maxim of Quantity (according to which our discourse contributions need to be informative to an appropriate degree). Since a cooperative speaker would not violate Quantity, the hearer infers that the intended meaning meaning is stronger than the utterance’s logical meaning. So, rather than the trivial claim that John’s height falls somewhere on the tallness scale, sentence (103a) is strengthened to the informative claim that John’s height falls on the higher end of the tallness scale. (Why not the lower end? A crucial assumption underpinning much work on degree semantics is that gradable predicates are monotone in the sense that if you are tall to degree d, you are also tall to all lower degrees \(d'< d\) (e.g. Heim 2000). This means that everyone is tall to a degree on the lower end of the tallness scale. Thus, only degrees on the higher end lead to a non-trivial result.)
In order to formalise our parallel between the positive form of gradable adjectives and the abundance inference of mass portioned-out predicates, we enrich our operator MP\(_{\text{OP}}\) with a degree scale, as follows:
-
(104)
MP\(_{\text{OP}}(P)(\mathcal{Q}) := \{ x | x \in P \wedge \exists y [ y \in \mathcal{Q}(P) \wedge x \sqsubseteq y ] \wedge \lambda d [\textbf{size}(d)(x)] \} \)
where size expresses a relation between individuals and degrees on a size scale (a tuple 〈size, D,≤〉, with size a dimension, D a set of degrees and ≤ an ordering relation)
The size scale provides a total ordering under ≤ of the portions in the predicate’s extension, but it does not affect the predicate’s membership itself, since the condition it imposes (i.e., having a size) is one that members trivially meet.Footnote 54 While the addition of the size ordering has no truth-conditional effect on the denotation of mass portioned-out predicates, it provides the compositional material required for the portioned-out noun to participate in degree modification constructions (see e.g. Morzycki 2009; de Vries 2010; Francez and Koontz-Garboden 2017 for compositional details on the analysis of gradable nouns). In the absence of degree morphology, we assume the degree argument is existentially closed, providing the basis for an uninformativity-based Quantity implicature more or less along the lines of Rett (2015).Footnote 55 The reason for the latter is precisely the fact that the addition of the size scale is trivial. If, say, John spilled any quantity of water, then the water-sum he spilled has a certain size. In order to render the addition of the size scale meaningful, then, we infer that the size of the portion of water spilled by John falls on the higher, informative end of the scale. Following standard practice, we formalise this reference to the “higher end of the scale” in terms of a contextually determined “standard degree” \(s_{\mathit{size}}\) which the portion in question is inferred to exceed.Footnote 56
-
(105)
〚John spilled waters/John spilled lots of water/John spilled litres of water〛 =
-
a.
∃x[spill(x)(j)∧x∈water∧∃y[y∈∗portion/lot/litre(water)∧x⊑y]∧∃d[size(d)(x)]]
‘There exists a sum of water that’s part of a sum of portions/lots/litres of water and was spilled by John and has a size.’
-
b.
Pragmatically strengthened interpretation: ∃x[spill(x)(j)∧x∈water∧∃y[y∈∗portion/lot/litre\((\textbf{water}) \wedge x \sqsubseteq y ] \wedge \exists d [\textbf{size}(d)(x) \wedge d > s_{\mathit{size}} ]]\)
‘There exists a sum of water that’s part of a sum of portions/lots/litres of water and was spilled by John and has an above-standard size.’
-
a.
This gives us our abundance implicature. By introducing the size scale as part of the operator MP\(_{\text{OP}}\), which is involved in mass portioning-out but not count portioning-out, we account for the observation that abundance only arises in the former case.
6 Remaining issues
In this section, we will briefly address some remaining issues and directions for further research. In Section 6.1 we will point out some ways in which the different kinds of mass portioning-out do not behave uniformly with respect to inference patterns, and discuss whether or not these observations pose a challenge to a unified analysis of these phenomena. In subsection 6.2 we return to the phenomenon of “reverse abundance” that was briefly discussed in Section 5.1.3.
6.1 Pragmatic differences between different portioning-out phenomena
While we have briefly mentioned negation in Section 5.1.1, we have not systematically discussed its effects on different forms of portioning-out. When we do, it turns out that the different forms of mass portioning-out we discussed in this paper do not all behave in the same way; nor do all of them pattern with the behaviour of gradable adjectives under negation, which we might predict on the basis of the analysis in Section 5.2. First, recall that one of the observations at the core of Kane et al.’s (2015) implicature-based approach to Greek mass plurals is that pluralised mass nouns in downward entailing environments are semantically equivalent to their singular counterparts.
-
(106)


In contrast, (107) appears to support the inference that John spilled some water (as shown by the naturalness of the continuation, in which this inference is cancelled).
-
(107)
John didn’t spill litres/oodles of water. (In fact he didn’t spill any.)
In this respect, the Q-noun and bare measure constructions pattern with the interpretation of adjectives like tall under negation:
-
(108)
John is not tall.
⇏¬[John has a height].
⇒¬[John has a height ∧ it exceeds the standard].
What (107) and (108) have in common is that, under the current assumptions, it seems to be the implicated meaning that is targeted by negation. In (108), it is not the asserted meaning (‘John has a height’) that is negated, but the positive implicature that John’s height exceeds the standard. Similarly, in (107), the negation targets the implicated meaning that the quantity of water John spilled is larger than average.
We propose that negation targets the asserted meaning in (106) but the enriched meaning in (107) and (108) because in the case of the latter two, targeting the asserted meaning violates pragmatic principles (cf. Rett 2015: 48, 128). Thus, in (108), computing a positive implicature below negation prevents a Quality violation (i.e., falsely asserting that someone could lack a height). In the case of (107), negating the asserted meaning (¬[John spilled water that was part of an oodle-sized quantity of water]) results in a meaning that could have been expressed in a much simpler way (John didn’t spill water), and hence in a Manner violation. Again, local computation of the abundance inference (¬[John spilled water that was part of an oodle-sized quantity of water ∧ it was a lot of water]) turns an utterance that would otherwise be uncooperative into one that complies with pragmatic principles.
On the other hand, pluralisation where it is not strictly necessary does not seem to count as a Manner violation; for example, I saw no boys is truth-conditionally equivalent to the strictly simpler I saw no boy, but using it does not seem to result in any pragmatic consequences (for example, it does not trigger a local computation of the multiplicity implicature ‘more than one boy’). It therefore appears that in the case of pluralised mass nouns, there is no reason to force local computation of the abundance inference in order to “save” the utterance from uncooperativity; as a consequence, negation just targets the asserted meaning.Footnote 57
The behaviour under negation is not the only difference between pluralised mass nouns on the one hand and Q-noun/bare measure constructions (and evaluative adjectives) on the other. For example, while the abundance inference of Greek mass plurals can be cancelled (Kane et al. 2015), the same does not appear to hold for other cases of mass portioning-out.
-
(109)


As van Kuppevelt (1996) and Rett (2015) discuss, whether an implicature is cancellable strongly depends on its role in the discourse: if implicated content is at issue, it behaves more like a (non-cancellable) entailment. We speculate that more marked forms are more likely to be perceived as at-issue content, at least in sentences that are uttered out of the blue. If sentences like (109b) are uttered in answer to an explicit QUD that makes it clear that the quantity of the spill is not at issue, they improve significantly:
-
(110)
Who of you spilled litres of water on the kitchen floor?
—I did, but it really wasn’t that much.
Again, we conclude that the attested pragmatic differences between different kinds of mass portioning-out have similarly pragmatic origins, and do not invalidate our unified analysis of these different phenomena.
6.2 “Reverse abundance” and scale reversal
As we have seen in Section 5.1.3, the abundance inference may be ‘reversed’ in some contexts, indicating a particularly small quantity of something rather than a particularly large one. This can be modelled fairly easily under our analysis: we simply assume that the ordering relation of the size scale is reversed in these contexts (i.e., ≥ instead of ≤). This results in portions being ordered along a “smallness scale” rather than a “largeness scale” (see e.g. Kennedy and McNally 2005); in all other respects, the derivation of the abundance inference proceeds along the lines described in Section 5.2, with uninformativity-based pragmatic strengthening to the higher end of the scale.
However, this does not explain why and how some contexts trigger such a scale reversal. In Section 5.1.3, we considered one potential factor: the choice of a small unit of measure instead of a competing larger one. Thus, in (86) (repeated here), we assume that day as a measure of time competes with scalar alternatives like week and month; from the fact that the speaker does not choose a larger measure, the hearer infers that there is an upper bound to the amount of time that separates the Labour party from utter collapse.
-
(111)
Yet if polls are right [the Labour party] is days away from utter collapse north of Hadrian’s Wall. (repeated from (86))
Perhaps, then, scale reversal is triggered by the incompatibility of this scalar implicature (an upper-bound small quantity) with the non-reversed abundance implicature (a quantity on the higher end of the scale). In cases that do not involve scalar competition between different measures or portioning operators, scale reversal may be aided by the inclusion of focus-sensitive minimisers like only, just or even (as in 87), which (combined with focus) also function to introduce a set of alternatives and, through their negation, an upper bound to the quantity. In this case, too, scale reversal reconciles the different pragmatic inferences supported by the sentence.
The idea of a reversed size ordering—a “smallness scale”—might also prove useful to the analysis of the semantics and pragmatics of the diminutive. The diminutive resembles the plural in the sense that diminutive mass nouns are obligatorily interpreted as count in some languages (such as Dutch) but remain mass in others (such as Mexican Spanish) (Wiltschko and Steriopolo 2007). In the former case, it is fairly neutral in terms of portion size (without further specification, (112) refers to a standard unit of beer, not necessarily a small one) while in the latter case it refers to a small quantity of something.
-
(112)


-
(113)


Further research will have to determine whether an analysis of mass diminutives in terms of portioning-out, along the lines argued for in this paper, fits the crosslinguistic data; in particular, whether the ‘small quantity’ inference supported by mass diminutives might feasibly be analysed in pragmatic rather than semantic terms.
7 Conclusions
In this paper we have drawn a comparison between various kinds of plural mass nouns and portion constructions in various languages. We have argued that plural mass nouns of abundance, such as attested in Greek, should be analysed on a par with overt portion constructions like English lots of soup or kilos (and kilos) of sugar. The various constructions share several formal and interpretational similarities; most strikingly, they involve “count” morphology (plurals, classifiers and/or measure words) yet lack countability.
We have proposed that the different interpretations stem from structural ambiguity. While count portioning-out constructions are analysed fairly straightforwardly as classifier constructions headed by the portion expression, mass portioning-out involves an extra operator MP\(_{\text{OP}}\), whose presence we have justified syntactically, and whose semantics involves mediating between the embedded NP and the portion word in such a way that the countability properties of the construction as a whole are inherited from the former rather than the latter. Because our analysis involves structural ambiguity, we do not have to resort to systematic lexical ambiguity (cf. Klockmann 2017 on expressions like lot, or Alexiadou 2011 on Greek mass plurals) or “figurative language” hand-waving (which leaves the countability facts unexplained).
With regard to the abundance inference supported by all our discussed cases of mass portioning-out, we depart from previous accounts in not treating it as a property of the plural. Instead, we have argued that mass portioning-out introduces a size ordering on predicates, which groups them with gradable nouns like idiot and quality-denoting abstract mass nouns like courage. The abundance inference, then, is treated as a Quantity inference rooted in the avoidance of triviality, along the lines of Rett (2015).
Notes
There are, of course, different views on the properties that force the use of classifiers in individual languages. Sudo (2016) for example suggests that in Japanese it is the nature of the numeral that forces the use of classifiers. These approaches notwithstanding, the broad point made in the text stands whether the element responsible is the numeral or the noun.
The list is non-exhaustive; for instance, Krifka (1995) also identifies “taxonomic classifiers” such as Chinese zhǒng ‘species’ and English sort. It should also be noted that the classification here—or even our primary distinction between classifying and measuring, which we adopt following Rothstein (e.g. Rothstein 2017)—is by no means universally agreed upon. For instance, in the typological literature a distinction is often made between sortal classifiers (corresponding to our “natural unit” ones) and mensural classifiers, which include our container and portion classifiers but also measure words (Aikhenvald 2003). The main purpose of our quick-and-dirty classification here is to enable us to make explicit what we mean by “portions.”
We will not make the notion of “individual” formally explicit in this paper, but we take it to be grounded in language-independent cognitive principles and rely on spatiotemporal factors such as cohesion and boundedness. The analysis we will develop can be supplemented with more explicit formalisations of individuation such as the mereotopological analysis developed in Grimm (2012).
We use a Dutch example here because Dutch conveniently makes a morphosyntactic distinction between true measure constructions and constructions in which measure words have been reinterpreted as portion classifiers (cf. 4), which means there is no doubt that this particular example involves the latter use. We will make this point in a bit more detail later. This example is from https://www.rtlnieuws.nl/nieuws/nederland/artikel/5168909/eenzame-huis-bloklandstraat-rotterdam-heleen-euwe-mike, retrieved July 2020.
Perhaps unexpectedly, however, the mass-only determiner much is out in this context. We can think of several possible explanations for this. One possibility is that much occurs lower in the nominal structure than the determiners in (20), and competes in this position with portion operators/words, so the two cannot co-occur. Supporting the hypothesis that much is in complementary distribution with other elements close to the noun, note also that much is mostly incompatible with plural marking even if the noun in question is mass (e.g. *much groceries/funds/ashes; see also Allan 1980 and Acquaviva 2008). Another option is to stipulate that Q-noun and bare measure constructions, as amalgams of both countable and non-countable nominal elements, involve some kind of feature clash where the portioned-out NP ends up being marked neither mass nor count; the result would be compatible with neutral determiners, but not with either mass-only or count-only ones. Something very similar happens when mass and count nouns are coordinated: the resulting complex NP is compatible with neither much nor many (*much/*many [biscuits and milk]).
Source: http://environmentcontext.blogspot.co.uk/2012/07/mountaintop-removal-damage-goes-beyond.html, accessed January 2018.
Source: https://www.multiculturiosity.com/arugula-salad-with-shrimp-and-grapes-6/, accessed January 2018.
While the sentence in (21b) is ambiguous in written form, the two readings have very distinct prosodic profiles; see the discussion around examples (39)–(40) for more on the ambiguity of bare measure constructions.
Carr gives few examples but notes that “[i]n OHG the plural names of substances may be used to denote things made of the substance or pieces of it where in Modern German the word Stück would be used.”
At this point we should probably clarify that we do not view cases of “packaging” coercion—e.g. English two coffees, please—as portioning-out in the sense we are interested in. The available evidence points to packaging coercion as a lexical process in which the noun itself is reanalysed as countable (see de Vries and Tsoulas 2021 for an overview of the evidence), rather than a derivational process in which the embedded noun remains mass. While the two mechanisms (packaging coercion and covert portioning-out) may both result in NPs that look like pluralised mass nouns (waters, sugars), one key difference is that coercion is contextually very restricted (mostly “restaurant talk”) whereas portioning-out is generally productive in languages that have it. See also Lima (2014b) and Deal (2017) for similar discussions of the differences between packaging coercion and reference to portions, based on Yudja and Nez Perce, respectively.
Although we will not adopt the intersective semantics of Khrizman et al. (2015) for it; we return to the compositional semantics of portioning-out shortly.
In Greek, for example, certain mass nouns can be “packaged” in restaurant contexts just as they can in English (e.g. three beers please), but as in English, this option is fairly limited and context-dependent. In contrast, the ‘bits or portions of X’ appears to be fully productive in languages like Ojibwe, Innuttut and Nez Perce, and does not require a particular context or the availability of standardised units.
Sources: https://www.nu.nl/dieren/4613739/reuzenpandas-vertrekken-vanuit-china-nederland.html (32a); https://www.sevendays.nl/nieuws/pandas-xing-ya-en-wu-wen-vliegen-naar-nederland (32b). Both sentences were originally retrieved in 2018. When preparing the final manuscript, we replaced the url for (32a) with an alternative source (accessed October 2022), the original page having disappeared. Interestingly, the url for (32b) now redirects to another website on which the sentence has been edited from er is kilo’s bamboe ‘there is kilos bamboo’ to er is heel wat bamboe ‘there is quite some bamboo.’ “Correct” number agreement in Q-noun constructions is a big prescriptivist issue in Dutch, and we suspect this may have been at play here. The Dutch speaking author of this paper herself has a marked preference for singular over plural agreement, despite the edit.
Suggesting perhaps that bare nouns too have a covert determiner.
We are very grateful to an anonymous reviewer for providing us with the German data in (41).
A reviewer points out that there is no AP in the structure in (43). We presume that Rothstein’s (2011) intention was for NumP to abbreviate something like Numeral Adjective Phrase. As we do not adopt this structure, we will not pursue this further.
These examples were first discussed by Andrews III (1983).
More generally, treating numerals as adjectives is implausible and runs counter to further available evidence: numerals except for ordinal ones cannot be intensified (50), they cannot form comparatives (51) and they behave like heads of potentially different types (Ionin and Matushansky 2018) rather than phrases hosted in specifier positions as adjectives are generally accepted to be (Cinque 2010; a.o.); witness the fact that they allow ellipsis of their complement unlike adjectives in general (52).
-
(50)
-
a.
* The very three girls ate pizza.
-
b.
The very rich girls ate pizza.
-
a.
-
(51)
-
a.
* The more three glasses are on the shelf.
-
b.
the more expensive glasses are on the shelf.
-
a.
-
(52)
-
a.
As far as ties are concerned, I always wear a blue *(one).
-
b.
As far as new ties are concerned, I bought two (*ones).
-
c.
As far as ties are concerned, I have two brown *(ones).
-
a.
Discussing this and further empirical evidence against the idea that (cardinal) numerals are adjectives would take us too far afield. We refer the reader to discussion in Huddleston and Pullum (2002) for English; and Zamparelli (2000); Lyons (1999); Alexiadou et al. (2007); amongst many others, for further crosslinguistic evidence. For further discussion of issues surrounding the grammar of numerals see Ionin and Matushansky (2006, 2018).
-
(50)
While we reject the view that numerals are adjectives, this conclusion does not necessarily mean that Landman’s (2004) adjectival theory of indefinites falls with it. Semantically, the weaker, but compatible, view that the type of numerals is that of intersective modifiers is perhaps still tenable, and is compatible with our proposed structure.
A non-exhaustive list: a dangling element that has no syntactic position proper (Aarts 1992; Rothstein 2011), a preposition (Jackendoff 1977; Selkirk 1977; Abney 1987), a type of complementiser (Kayne 2002), a D head (Kayne 1994), a K(ase) head (Bayer et al. 2001), a realisation of a predicative operator (Corver 1998), a relator, linker, or nominal copula (den Dikken 2006), all of the above, and so on.
As Huddleston and Pullum (2002: 658) put it: Of is the most highly grammaticised of all prepositions.
The dashed lines in (53) also indicate the semantic vacuity of of.
For ease of presentation, the derivation is given in a simplified form in that we do not show the phase head merging before the movement operations internal to the phase. Nothing hinges on this.
See also the discussion around (53)–(55) concerning the appearance of the optional preposition.
A reviewer suggests that the movement (Internal Merge) operations in (62) and (63) are counter-cyclic. Within the framework of phase theory that we assume this is not so. (Chomsky 2013: 42) points out that the notion of strict cyclicity dictates that syntactic objects must not be modified once they are generated. Crucially, this is not true for all syntactic objects. Phase theory seeks to identify those syntactic objects to which the condition applies (the phases, or cyclic/bounding nodes of earlier versions of the framework). Syntactic operations internal to the syntactic object with phase status (the phase), including movement, agreement, labelling and transfer happen once the phase node/head has been merged. It is in this sense and in this framework that there is no violation of the cycle in our proposal. In later work, Chomksy (Chomsky 2015) took a less strict view of the cycle and suggested that internal merge operation can (emphasis ours) take place prior to the introduction of the phase head. We do not think that this relaxation of the condition significantly affects our proposal.
This is the type of label provided to syntactic objects that contain non-minimal elements only, but where modification of the SO by internal merge is not possible.
Note that disjointness, even though it is rooted in human perception of reality, is ultimately a grammatical property; it is not a claim about the actual physical properties of the objects we perceive. For example, if two of the cats that make up the extension of cat are conjoined twins, some of their physical “stuff” might not clearly belong to one cat or the other, but that does not mean they cannot be represented as disjoint sums, just that there is some vagueness involved in the location of the boundary between the two cats; note also that no matter where we draw the line we will never end up with anything more or less than two cats. See also Chierchia (2010); Rothstein (2010); Landman (2011); Sutton and Filip (2016); Rothstein (2017) for related discussions, and Moltmann (1997) for an approach that does consider cases such as these a counterargument against a disjointness-based approach to countability, and rejects mereology in favour of an account based on “integrated wholes.”
What we mean by “arbitrary” is the following. Whatever the properties of cats are in our particular world—whether they are animals, or robots, or higher-dimensional angelic beings—it is a necessary linguistic truth that cats are made out of cat. A disjointness-based model captures this necessary truth while also leaving room for arbitrary, model-specific properties of cat (for instance, whether it is angelic in nature or not). On the other hand, in an atomicity-based model, the extensions of catcount and catmass are independent, only linked by an arbitrary mapping function. This means that in theory, nothing blocks a Linkian model in which cats are made out of dog, for instance. Of course, model-theoretic semanticists routinely dismiss non-intended models like these, but it seems to us that it would be better if their impossibility were hardwired into the system rather than stipulated. (N.B.: We are ignoring coerced examples in the vein of “stone lion” here—they are an independent challenge for both Linkian and disjointness-based approaches.)
Landman’s formalism is rather more complex, treating noun denotations as pairs of sets with potentially distinct disjointness properties. Here, we will follow the simpler version from Khrizman et al. (2015).
Note that this is not an observation about the mathematical properties of quantities, but about the linguistic behaviour of the noun quantity, as a portion expression. Thus, we can say that a bucket filled with water contains a quantity of water but not two/several/infinite quantities of water—even though that would be mathematically true. We conclude that quantity, in its use as a portioning-out operator, picks out individuated sums.
We omit of from the representation of the pseudopartitive as it is semantically inert.
We thank an anonymous reviewer for picking up on an inconsistency in an earlier version. The reviewer suggested a different approach that relied on the path-based definition of equidistance proposed by Hornstein (2008), which derives the equidistance of multiple specifiers from a higher probe (a path from a launch site to a landing site is the sequence of intervening maximal projections). Ultimately, however, there is no need for us to resort to this as raising of PortionP is motivated by syntactic considerations alone and has little effect on the compositional semantics. Also, although the path-based definition in question is successful in deriving the equidistance of multiple specifiers, it is not clear whether this should be extended to complements. Possessor raising constructions are a case in point as the possessor, not the possessee, is the one that moves out of the DP to a higher position. At any rate, much as we would like to dwell on these issues and examine them in more detail, such discussion will take us too far from our core concerns and as such we will leave it for future work.
The specification that these sums be P seems redundant given our present purposes, but is necessary to derive the appropriate results in cases where the embedded noun denotation is not closed under Boolean parthood. For example, consider an NP like lots of boys, which we want to analyse as a predicate over boys and not as a predicate over all possible bits of boy-stuff. In other words, we do not want all possible Boolean parts of our boy-lots to end up in the denotation of lots of boys, only the parts that correspond to individual boys.
It is reasonable to ask (as one anonymous reviewer did) whether it would not be equally possible to implement this approach in a more traditional atomicity-based framework, with the portioning-out operator incorporating a domain shift from non-atomic (or vague-atomic) mass stuff to an atomic domain of portions, and the MP\(_{\text{OP}}\) operator optionally shifting these portions back into their material parts. For a philosophical reason not to take this route, see footnote 33. For an empirical reason, consider again NPs like lots of boys, whose non-countability (*three lots of boys) would not follow under such an implementation; implementing mass portioning-out in the way described above entails that such constructions always end up referring in the domain of the embedded noun, and if this is atomic (e.g. boys), the result is predicted to be countable. To account for the non-countability of lots of boys, then, we need a way to refer to boys in a non-countable way, such as (only) provided by a disjointness-based implementation of mass portioning-out.
Unlike most of the portion classifiers we have discussed so far, these last three classifiers do not occur with plurals but only with mass nouns. At least some of them display the familiar alternating pattern:
-
(iii)
-
a.
If you came for slabs and slabs of meat, you came to the right place.
(Source: https://www.skyscanner.net/trip/irvine-ca/restaurants/l-l-hawaiian-barbecue, accessed February 2018.)
-
b.
Nobody likes reading chunks and chunks of text – not even me and I love reading. We like it broken up with photos, infographics, things that make us laugh out loud.
(Source: https://www.childcareexpo.co.uk/4393-2/, accessed February 2018.)
-
a.
Here, (iii-b) shows particularly clearly that chunks and chunks of text is mass despite the appearance of individuation: the author’s continuation makes it clear that, to her, chunks and chunks of text refers to a large quantity of text that is not broken up into distinct chunks. A general observation about shape-based classifiers seems to be that the more specific and well-defined the expressed shape is, the less compatible it is with mass portioning-out. Thus, #I ate cubes and cubes of cheese is distinctly odd. So, even though we argue that the lexical meaning of the portion expression is not the source of the abundance inference, it definitely plays a role in the acceptability of the expression within a mass portioning-out construction. We will leave issues like this for further research.
-
(iii)
Source: https://www.economist.com/news/britain/21650147-why-labour-partys-campaign-has-gone-surprisingly-well-meaning-mr-miliband, accessed February 2018.
Source: https://www.facebook.com/DrJackNewman/posts/315997418551311, accessed February 2018.
We will briefly return to this suggestion in Section 6.2.
Source: William Makepeace Thackeray (1840), An essay on the genius of George Cruikshank.
Source: Freeman Tilden (1962), The state parks: Their meaning in American life.
Bolinger (1972: 82) and Rett (2015) notice this fact for What a lot!; in her discussion of Bolinger’s data, Rett (2015: 167–168) speculates that lot involves a lexicalised Quantity implicature. As we hope to have shown (and show again in this section), the behaviour of lot is part of a general pattern that cannot satisfactorily be explained in terms of lexical properties of certain individual words.
Source: https://in.news.yahoo.com/dipa-karmakar-explains-why-artistic-122051924.html, accessed December 2017.
One anonymous reviewer states that they consider sentences like the ones in (102) grammatical in their dialect of English, but they do not report whether they are able to assign a “high quantity” interpretation to them. Nevertheless, this suggests that our analysis might not be universally applicable. We leave this for future research.
Rett (2015) uses the term “evaluative” for such ‘more X than average’ inferences, but we will not use this term here to avoid confusion with the evaluative modification we discussed in Section 5.2.1 (terribly tall, an astounding idiot, incredible heaps of rubbish) and use “positive inference” instead since it is most famously attested in the context of the positive form.
Providing a definition of the measure function size itself is not trivial, and we will leave it aside for now, but we assume its effect is fairly intuitive.
Note that there is not a full parallel between the process proposed by Rett for utterances like John is tall and the kind of sentences discussed here: the former are trivially true as a whole (as long as the presuppositions carried by the proper name—that is, John exists and he is a human man—are met or accommodated), while the latter involve a conjunction whose second member is trivially true if the first conjunct is. This is not a problem for our analysis as long as we assume some mechanism through which (some) implicatures can be calculated locally; Rett herself shows at length that local calculation of the positive inference of sentences such as John is tall is possible in cases where this sentence is embedded, and accounts for this within the assumptions of her theory. In Section 6.1, we discuss some cases of local implicature calculation, and include a further comparison between Rett’s sentences and our various cases of mass portioning-out.
Our present focus is on the common mechanisms underlying different forms of portioning-out; we have deliberately abstracted away from lexical differences between different portion words. However, given that our semantics for mass portioning-out essentially undoes the contribution of the portion word by re-introducing the portions’ Boolean parts into the resulting predicate, it is reasonable to ask (as one anonymous reviewer did) whether we would even be able to account for those lexical differences. Surely, while John wasted inches of precious fabric and John wasted meters of precious fabric both imply that John wasted more fabric than I believe reasonable, he wasted more fabric in the latter case. However, this does not automatically follow from our present semantics; both sentences correspond to a logical form whose first conjunct can be verified by the existence of a fabric-sum of any size. We believe this property of our semantics is actually not undesirable: clearly we do not want the truth value of John wasted tons of fabric to depend on the actual value of the measurement ton. What we need, it would seem, is a way to potentially constrain the implied portion size via the lexical meaning of the portion word, without hardwiring this into the semantics in a way that is non-defeasible. Here is a sketch of a proposal, that further extends the analogy between our cases of mass portioning-out and the semantics and pragmatics of degree predicates. The usual assumption about the latter is that the standard degree is calculated with respect to a contextually specified comparison class; thus, John (an adult man) is tall is evaluated with respect to a different standard than Mary (a toddler) is tall. The comparison class can be expressed overtly, extracted from the (extra)linguistic context, or a combination of both. In the case of mass portioning-out, which under our assumptions also involves a favourable comparison to a standard degree, it seems natural to assume that the portion word used is one of the factors influencing the members of the comparison class, and that the standard degree can be affected by the portion word in this way. From this it follows that John wasted inches of fabric is evaluated with respect to a different size standard than John wasted meters of fabric, and what counts as an “above-average” quantity in the former case is different from the latter. Addressing this hypothesis will require further research into the precise implications of mass portioning-out constructions with different portion words, which we leave for future work.
There is a non-trivial assumption here that is important to spell out, in that we are assuming that covert material is not active in fuelling Manner implicatures; in other words, markedness of form is evaluated purely based on the material that is spelled out overtly. We are not aware of any literature that explicitly addresses this issue but believe it is generally tacitly assumed in (neo-)Gricean accounts of implicature calculation.
References
Aarts, Bas. 1992. Small clauses in English: The nonverbal types. Berlin: de Gruyter.
Abney, Steven. 1987. The English noun phrase in its sentential aspect. PhD diss, MIT.
Acquaviva, P. 2008. Lexical plurals: A morphosemantic approach. Oxford studies in theoretical linguistics. London: Oxford University Press.
Aikhenvald, Alexandra. 2003. Classifiers: A typology of noun categorization devices. Oxford: Oxford University Press.
Alexiadou, Artemis. 2011. Plural mass nouns and the morpho-syntax of number. In Proceedings of the 28th West Coast Conference on Formal Linguistics, eds. Mary Byram Washburn, Katherine McKinney-Bock, Erika Varis, Ann Sawyer, and Barbara Tomaszewicz, 33–41. Somerville, Mass.: Cascadilla Press.
Alexiadou, Artemis, and Chris Wilder. 1998a. Adjectival modification and multiple determiners. In Possessors, predicates and movement in the DP, eds. Artemis Alexiadou and Chris Wilder, 303–332. Amsterdam: Benjamins.
Alexiadou, Artemis, and Chris Wilder, eds. 1998b. Possessors, predicates and movement in the DP. Amsterdam: Benjamins.
Alexiadou, Artemis, Liliane Haegeman, and Melita Stavrou. 2007. Noun phrase in the generative perspective. Vol. 71 of Studies in generative grammar. Berlin/New York: de Gruyter.
Allan, Keith. 1980. Nouns and countability. Language 56(3): 541–567.
Andrews III, Avery. 1983. A note on the constituent structure of modifiers. Linguistic Inquiry 14(4): 695–697.
Bale, Alan C., and David Barner. 2009. The interpretation of functional heads: Using comparatives to explore the mass/count distinction. Journal of Semantics 26(3): 217–252.
Barker, Chris. 1998. Partitives, double genitives, and anti-uniqueness. Natural Language and Linguistic Theory 16: 679–717.
Bayer, Josef, Markus Bader, and Michael Meng. 2001. Morphological underspecification meets oblique case: Syntactic and processing effects in German. Lingua 111(4): 465–514.
Bolinger, Dwight. 1972. Degree words. The Hague: Mouton.
Borer, Hagit. 2005. Structuring sense: In name only. Oxford: Oxford University Press.
Broekhuis, Hans, and Marcel den Dikken. 2012. Syntax of Dutch: Nouns and noun phrases, Vol. 2. Amsterdam: Amsterdam University Press.
Bunt, Harry C. 1985. Mass terms and model-theoretic semantics. Cambridge studies in linguistics. Cambridge: Cambridge University Press.
Campos, Héctor, and Melita Stavrou. 2004. Polydefinite constructions in Modern Greek and in Aromanian. In Balkan syntax and semantics, ed. Olga Mišeska Tomić, 136–173. Amsterdam: Benjamins.
Carr, Charles. 1936. Number in Old High German. The Journal of English and Germanic Philology 35(2): 214–242.
Cheng, Lisa Lai-Shen, and Rint Sybesma. 1999. Bare and not-so-bare nouns and the structure of NP. Linguistic Inquiry 30(4): 509–542.
Chierchia, Gennaro. 1998a. Plurality of mass nouns and the notion of semantic parameter. In Events and grammar, ed. Susan Rothstein. Dordrecht: Kluwer.
Chierchia, Gennaro. 1998b. Reference to kinds across languages. Natural Language Semantics 6: 339–405.
Chierchia, Gennaro. 2010. Mass nouns, vagueness and semantic variation. Synthese 174(1): 99–149.
Chomsky, Noam. 2008. On phases. In Foundational issues in linguistic theory, eds. Robert Freidin, Carlos Peregrin Otero, and Maria Luisa Zubizarreta, 133–166. Cambridge: MIT Press.
Chomsky, Noam. 2013. Problems of projection. Lingua 130: 33–49.
Chomsky, Noam. 2015. Problems of projection: Extensions. In Structures, strategies and beyond studies in honour of Adriana Belletti, eds. Elisa Di Domenico, Cornelia Hamann, and Simona Matteini, 1–16. Amsterdam: Benjamins.
Chung, Sandra. 2000. Reference to kinds in Indonesian. Natural Language Semantics 8: 157–171.
Cinque, Guglielmo. 2010. The syntax of adjectives: A comparative study. Linguistic inquiry monographs. Cambridge: MIT Press.
Corbett, Greville G., and Marianne Mithun. 1996. Associative forms in a typology of number systems: Evidence from Yup’ik. Journal of Linguistics 32(1): 1–17.
Corver, Norbert. 1998. In Predicate movement in pseudopartitive constructions, eds. Artemis Alexiadou and Chris Wilder, 215–258. Amsterdam: Benjamins.
Cresswell, Max. 1976. The semantics of degree. In Montague grammar, ed. Barbara Partee. New York: Academic Press.
Dalrymple, Mary, and Suriel Mofu. 2012. Plural semantics, reduplication, and numeral modification in Indonesian. Journal of Semantics 29(2): 229–260.
de Vries, Hanna. 2010. Evaluative degree modification of adjectives and nouns. Master’s thesis, Utrecht University.
de Vries, Hanna, and George Tsoulas. 2021. Overlap and countability in exoskeletal syntax: A best-of-both-worlds approach to the mass/count distinction. In The semantics of the count-mass distinction, eds. Francis Jeffrey Pelletier, Tibor Kiss, and Halima Husic, 305–318. Cambridge: Cambridge University Press.
Deal, Amy Rose. 2017. Countability distinctions and semantic variation. Natural Language Semantics 25(2): 125–171. https://doi.org/10.1007/s11050-017-9132-0.
Deal, Amy Rose. 2013. Apportionment and the mass-count distinction in Nez Perce. Ms., UC Santa Cruz.
den Dikken, Marcel. 2006. Relators and linkers. Cambridge: MIT Press.
Diesing, Molly. 1992. Indefinites. Cambridge: MIT Press.
Doetjes, Jenny. 1997. Quantifiers and selection: On the distribution of quantifying espressions in French, Dutch and English. HIL Dissertation #32 (Leiden).
Francez, Itamar, and Andrew Koontz-Garboden. 2017. Semantics and morphosyntactic variation: Qualities and the meaning of property concepts. Oxford: Oxford University Press.
Gillon, Brendan. 1992. Towards a common semantics for English count and mass nouns. Linguistics and Philosophy 15(6): 537–639.
Gillon, Carrie. 2010. The mass-count distinction in Innu-aimun: Implications for the meaning of plurality. In Proceedings of the 15th Workshop on Structure and Constituency in Languages of the Americas, 12–29.
Gillon, Carrie. 2012. Evidence for mass and count in Inuttut. Linguistic Variation 12: 211–246.
Grimm, Scott. 2012. Number and individuation. PhD diss, Stanford University.
Heim, Irene. 2000. Degree operators and scope. In Proceedings of SALT 10, eds. Brendan Jackson and Tanya Matthews. Vol. 10, 40–64.
Heim, Irene, and Angelika Kratzer. 1998. Semantics in generative grammar. Oxford: Blackwell.
Heycock, Caroline, and Roberto Zamparelli. 2005. Friends and colleagues: Plurality, coordination, and the DP. Natural Language Semantics 13: 201–270.
Hoeksema, Jacob. 1984. Partitives. Ms., University of Groningen.
Hornstein, Norbert. 2008. A theory of syntax: Minimal operations and universal grammar. Cambridge: Cambridge University Press. https://doi.org/10.1017/CBO9780511575129.
Huddleston, Rodney D., and Geoffrey K. Pullum. 2002. The Cambridge grammar of the English language. Cambridge: Cambridge University Press.
Ionin, Tania, and Ora Matushansky. 2006. The composition of complex cardinals. Journal of Semantics 23(4): 315–360.
Ionin, Tania, and Ora Matushansky. 2018. Cardinals: The syntax and semantics of cardinal-containing expressions. Cambridge: MIT Press.
Ionin, Tania, Ora Matushansky, and Eddy G. Ruys. 2006. Parts of speech: Toward a unified semantics for partitives. In Proceedings of NELS 36, eds. Amy Rose Deal, Christopher Davis, and Youri Zabbal, Vol. 1. Amherst: GLSA.
Jackendoff, Ray. 1977. \(\overline{\mbox{X}}\)-bar syntax. Cambridge: MIT Press.
Kadaryanto, Budi. 2010. Numeral classifiers and plural in Indonesian nominals. Master’s thesis, Utrecht University.
Kane, Frances, George Tsoulas, Raffaella Folli, Theodora Alexopoulou, and Jacopo Romoli. 2015. A scalar implicature-based account of the inference of pluralized mass (and count) nouns. In Proceedings of 51st Meeting of the Chicago Linguistic Society (CLS), 317–331. Chicago: Chicago Linguistics Society.
Kayne, Richard. 1994. The antisymmetry of syntax. Cambridge: MIT Press.
Kayne, Richard. 1997. The English complementizer of. Journal of Comparative Germanic Linguistics 1(1): 43–54.
Kayne, Richard. 2002. On some prepositions that look DP-internal: English of and French de. Catalan Journal of Linguistics 1: 71–115.
Kennedy, Christopher, and Louise McNally. 2005. Scale structure, degree modification, and the semantics of gradable predicates. Language 81(2): 345–381.
Khrizman, Keren, Fred Landman, Suzi Lima, Susan Rothstein, and Brigitta Schvarcz. 2015. Portion readings are count readings, not measure readings. In Proceedings of the 20th Amsterdam Colloquium, 197–206.
Klockmann, Heidi. 2017. The design of semi-lexicality. Utrecht: LOT Publications.
Krifka, Manfred. 1989. Nominal reference, temporal constitution and quantification in event semantics. In Semantics and contextual expressions, eds. R. Bartsch, J. van Benthem, and P. van Emde-Boas, 75–115. Dordrecht: Foris.
Krifka, Manfred. 1995. The semantics and pragmatics of polarity items. Linguistic Analysis 25: 209–257.
Ladusaw, William. 1982. Semantic constraints on the English partitive construction. In Proceedings of WCCFL 1. Stanford: Stanford University Press.
Landman, Fred. 2003. Predicate–argument mismatches and the adjectival theory of indefinites. In From NP to DP, eds. Martine Coene and Yves D’hulst Vol. 1 of The syntax and semantics of noun phrases, 211–237. Amsterdam: Benjamins.
Landman, Fred. 2004. Indefinites and the type of sets. Oxford: Blackwell Sci.
Landman, Fred. 2011. Count nouns–mass nouns–neat nouns–mess nouns. In Formal semantics and pragmatics: Discourse, context and models. The Baltic international yearbook of cognition, logic and communication, eds. Barbara H. Partee, Michael Glanzberg, and Jurgis Škilters, Vol. 6. Manhattan: New Prairie Press.
Landman, Fred. 2016. Iceberg semantics for count nouns and mass nouns: Classifiers, measures and portions. In Number: Cognitive, semantic and crosslinguistic approaches. The Baltic international yearbook of cognition, logic and communication, eds. Susan Rothstein and Jurgis Škilters, Vol. 11. Manhattan: New Prairie Press.
Landman, Fred. 2020. Iceberg semantics for mass nouns and count nouns: A new framework for Boolean semantics. Cham: Springer.
Lima, Suzi. 2014a. All notional mass nouns are count nouns in Yudja. In Proceedings of SALT 24, 534–554.
Lima, Suzi. 2014b. The grammar of individuation and counting. PhD diss, University of Massachusetts, Amherst.
Link, Godehard. 1983. The logical analysis of plurals and mass terms: A lattice-theoretical approach. In Meaning, use, and interpretation of language, eds. Rainer Bäuerle, Christoph Schwarze, and Arnim von Stechow, 302–323. Berlin: de Gruyter.
Longobardi, Giuseppe. 1994. Reference and proper names. Linguistic Inquiry 25: 609–665.
Lyons, Christopher. 1999. Definiteness. Cambridge textbooks in linguistics. Cambridge: Cambridge University Press.
Manolessou, Io. 2000. Greek noun phrase structure: A study in syntactic evolution. PhD diss, University of Cambridge.
Mathieu, Eric. 2012. Flavors of division. Linguistic Inquiry 43(4): 650–679.
Moltmann, Friederike. 1997. Parts and wholes in semantics. Oxford: Oxford University Press.
Morzycki, Marcin. 2009. Degree modification of gradable nouns: Size adjectives and adnominal degree morphemes. Natural Language Semantics 17: 175–203.
Morzycki, Marcin. 2012. The several faces of adnominal degree modification. In Proceedings of the West Coast Conference on Formal Linguistics (WCCFL) 29, eds. Jaehoon Choi, E. Alan Hogue, Jeffrey Punske, Deniz Tat, Jessamyn Schertz, and Alex Trueman, 187–195. Somerville: Cascadilla Press.
Nedjalkov, Igor. 1997. Evenki. London/New York: Routledge.
Nguyen, Dinh Hoa. 1957. Classifiers in Vietnamese. Word 13(1): 124–152.
Ntelitheos, Dimitrios. 2004. Syntax of elliptical and discontinuous nominals. Master’s thesis, University of California, Los Angeles.
Panagiotidis, Phoevos E., and Theodore Marinis. 2011. Determiner spreading as DP-predication. Studia Linguistica 65(3): 268–298.
Partee, Barbara H., and Vladimir Borschev. 2012. Sortal, relational, and functional interpretations of nouns and Russian container constructions. Journal of Semantics 29(4): 445–486.
Renans, Agata, Jacopo Romoli, Maria Margarita Makri, Lyn Tieu, Hanna de Vries, Raffaella Folli, and George Tsoulas. 2018. The abundance inference of pluralised mass nouns is an implicature: Evidence from Greek. Glossa: A Journal of General Linguistics 3(1): 103.
Rett, Jessica. 2015. The semantics of evaluativity. Oxford: Oxford University Press.
Rizzi, Luigi. 2006. On the form of chains: Criterial positions and ECP effects. In Wh-movement: Moving on, eds. Lisa Lai-Shen Cheng and Norbert Corver, 97–134. Cambridge: MIT Press.
Rizzi, Luigi. 2010. On some properties of criterial freezing. In The complementizer phrase, 17–32. London: Oxford University Press. https://doi.org/10.1093/acprof:oso/9780199584352.003.0002.
Rizzi, Luigi. 2017. Types of criterial freezing. RGG. Rivista Di Grammatica Generativa 39(1): 1–20.
Rothstein, Susan. 2010. Counting and the mass/count distinction. Journal of Semantics 27(3): 343–397.
Rothstein, Susan. 2011. Counting, measuring and the semantics of classifiers. In Formal semantics and pragmatics: Discourse, context and models. The Baltic international yearbook of cognition, logic and communication, eds. Barbara Partee, Michael Glanzberg, and Jurgis Škilters, Vol. 6. Manhattan: New Prairie Press.
Rothstein, Susan. 2017. Semantics for counting and measuring. Cambridge: Cambridge University Press.
Sauerland, Uli, Jan Anderssen, and Kazuko Yatsushiro. 2005. The plural is semantically unmarked. In Linguistic evidence, eds. S. Kesper and M. Reis, Vol. 4, 409–430. Berlin: de Gruyter.
Selkirk, Elisabeth. 1977. Some remarks on noun phrase structure. In Formal syntax, eds. Peter W. Culicover, Thomas Wasow, and Adrian Akmajan, 285–316. London: Academic Press.
Selkirk, Elisabeth. 1986. On derived domains in sentence phonology. Phonology 3: 371–405.
Selkirk, Elisabeth. 1995. The prosodic structure of function words. In University of Massachusetts occasional papers, 439–469. Amherst: GLSA.
Selkirk, Elisabeth. 2011. The syntax-phonology interface. In The handbook of phonological theory, eds. John Goldsmith, Jason Riggle, and Alan C. L. Yu, 435–484. New York: Wiley. Chap. 14.
Sharifan, Farzad, and Ahmad R. Lofti. 2003. “Rices” and “waters.” The mass-count distinction in Modern Persian. Anthropological Linguistics 45: 226–244.
Spector, Benjamin. 2007. Aspects of the pragmatics of plural morphology: On higher-order implicatures. In Presupposition and implicature in compositional semantics, eds. Uli Sauerland and Penka Stateva, 243–281. London: Palgrave Macmillan.
Sudo, Yasutada. 2016. The semantic role of classifiers in Japanese. Baltic International Yearbook of Cognition, Logic and Communication 11(1): 1–15. https://doi.org/10.4148/1944-3676.1108.
Sutton, Peter, and Hana Filip. 2016. Mass/count variation: A mereological, two-dimensional semantics. In The Baltic international yearbook of cognition, logic and communication, eds. Susan Rothstein and Jurgis Škilters. Vol. 11 of Number: Cognitive, semantic and crosslinguistic approaches. Manhattan: New Prairie Press.
Szendröi, Kriszta. 2012. Focus movement can be destressing, but it need not be. In The syntax of topic, focus, and contrast: An interface-based approach. Studies in generative grammar [SGG], 189–226. Berlin: de Gruyter.
Tovena, Lucia M. 2001. Between mass and count. In Proceedings of WCCFL 20, eds. Karine Megerdoomian and Leora Bar-el, 565–578. Somerville: Cascadilla Press.
Truckenbrodt, Hubert. 1999. On the relation between syntactic phrases and phonological phrases. Linguistic Inquiry 30(2): 219–255.
Tsoulas, George. 2009. On the grammar of number and mass terms in Greek. In MIT working papers in linguistics, eds. Claire Halpern, Jeremy Hartman, and David Hill, Vol. 57, 333–348.
van de Velde, Danièle. 1996. Le spectre nominal: Des noms de matières aux noms d’abstractions. Leuven: Peeters.
van Kuppevelt, Jan. 1996. Inferring from topics: Scalar implicatures as topic-dependent inferences. Linguistics and Philosophy 19(4): 393–443.
Wiltschko, Martina. 2012. Decomposing the mass/count distinction. Evidence from languages that lack it. In Count and mass across languages, ed. Diane Massam. London: Oxford University Press.
Wiltschko, Martina, and Olga Steriopolo. 2007. Parameters of variation in the syntax of diminutives. In Proceedings of the annual conference of the Canadian Linguistic Association. Vol. 1, 1–12.
Zamparelli, Roberto. 2000. Layers in the determiner phrase. New York: Garland.
Acknowledgements
The bulk of the work reported in this paper was undertaken thanks to the generous support of the Leverhulme Trust (grant RPG-2016-100 Pluralised mass nouns as a window to linguistic variation, G. Tsoulas, PI.). We thank first of all our colleagues in the project team: Raffaella Folli, Agata Renans, and Jacopo Romoli for discussion on the ideas presented here. We would also like to thank other colleagues and friends who commented on earlier drafts or discussed specific ideas with us, in alphabetical order: Artemis Alexiadou, Hagit Borer, Hana Filip, Kook-Hee Gil, Margarita Makri, Peter Sells, Chris Tancredi, Norman Yeo. Parts of this work have been presented at Workshop on Nominal Phrase Meaning in Berlin (January 2018), Sinn und Bedeutung 23 in Barcelona (September 2018), and the semantics group at Aoyama Gakuin (November 2018). We thank those audiences for their comments and criticism. Thanks also to the anonymous reviewers whose comments led to many improvements in the paper. Any errors are our own.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
de Vries, H., Tsoulas, G. Portions and countability: A crosslinguistic investigation. Nat Lang Linguist Theory 42, 383–435 (2024). https://doi.org/10.1007/s11049-023-09576-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11049-023-09576-3