
Abstract
In recent years, especially children and adolescents have shown increased interest in social media, making them a potential risk group for cyberbullying. Cyberbullying posts spread very quickly, often taking a long time to be deleted and sometimes remaining online indefinitely. Cyberbullying can have severe mental, psychological, and emotional effects on children and adolescents, and in extreme cases, it can lead to suicide. Turkey is among the top 10 countries with the highest number of children who are victims of cyberbullying. However, there are very few studies conducted in the Turkish language on this topic. This study aims to identify cyberbullying in Turkish Twitter posts. The Multi-Layer Detection (MLP) based model was evaluated using a dataset of 5000 tweets. The model was trained using both social media features and textual features extracted from the dataset. Textual features were obtained using various feature extraction methods such as Bag of Words (BOW), Term Frequency-Inverse Term Frequency (TF-IDF), Hashing Vectorizer, N-gram, and word embedding. These features were utilized in training the model, and their effectiveness was evaluated. The experiments revealed that the features obtained from TF-IDF and unigram methods significantly improved the model’s performance. Subsequently, unnecessary features were eliminated using the Chi-Square feature selection method. The proposed model achieved a higher accuracy of 93.2% compared to machine learning (ML) methods used in previous studies on the same dataset. Additionally, the proposed model was compared with popular deep learning models in the literature, such as LSTM, BLSTM, and CNN, demonstrating promising results.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Social media platforms have provided a foundation for people to express their thoughts freely [1]. Alongside the conveniences and advantages that social media platforms offer, excessive and uncontrolled use can also bring about problems [2]. In recent years, bullying behavior has evolved with the increase in social media usage, transitioning traditional bullying to the virtual environment [3]. However, cyberbullying, which is more challenging to define and address than traditional bullying, may have more severe consequences [4]. Especially children and adolescents’ interest in social media makes them a potential risk group for cyberbullying. Cyberbullying is defined as deliberate, repetitive, and malicious behavior intended to harm individuals through information and communication technologies by an individual or group [5, 6]. Cyberbullying can cause mental, psychological, and emotional problems in children and adolescents, and in extreme cases, it can even lead to suicide [7].
In studies conducted in Turkey, cases of cyberbullying have been mostly observed among primary, secondary, and high school students. It has been found that 17% of students were victims, 10.5% were bullies, and 35.2% were both bullies and victims [8]. While the rate of cyberbullying among children in Turkey was 5% in 2011, this rate reached 20% in 2018, indicating a growing problem. Turkey is among the ten countries with the highest number of children exposed to cyberbullying globally [9].
Despite this situation, very few studies have been conducted in the literature on the detection of cyberbullying in the Turkish language. Therefore, this study aims to contribute to the existing literature by creating a deep learning model that utilizes both textual features and social media features to detect and prevent cyberbullying in Turkish posts.
The contributions of this paper include:
-
Proposing a new model based on feature fusion for cyberbullying detection.
-
Presenting benchmark results of the proposed model for comparison with state-of-the-art models.
-
Providing a semi-synthetic dataset that overcomes the limitations of existing Turkish language cyberbullying detection datasets.
-
Incorporating the unique details of each natural language into the cyberbullying model introduces too much complexity. Considering this situation, we aim to contribute to the studies in the literature since there are very few cyberbullying detection studies in the Turkish language.
2 Related works
The first study on the detection of cyberbullying was conducted by Yin et al. [10]. They employed N-gram, TF-IDF, and linear kernel classifier methods to identify malicious content. Experiments were carried out on three distinct datasets acquired from MySpace, Slashdot, and Kongregate platforms. It was observed that performance improved when sentiment contextual features were combined with TF-IDF. The highest F1 performance (0.45) was achieved in the Kongregate dataset by using TF-IDF and contextual features together. Although the results were not sufficient, they were encouraging for further studies in this field. Dadvar et al. [11] emphasized the importance of handling the written language used by cyberbullies according to the gender of the bully. In their study, they classified gender using the support vector machines method, which increased the success rate in detecting cyberbullying. In another study [12], user-oriented features such as age and previous comments were added to enhance the success rate. The dataset used contained 54,050 comments, with only 12% of them containing cyberbullying. Ptaszynski et al. [13] pintroduced a new model for cyberbullying detection, where sentence patterns were extracted using an approach based on a brute-force search algorithm, and the extracted patterns were classified. The dataset included data provided by the Human Rights Center, and it was reported that the proposed model outperformed previous methods. Dadvar et al. [14] utilized three different datasets obtained from Wikipedia, Twitter, and Formspring platforms in their study. While 31% of the dataset obtained from the Twitter platform included cyberbullying, only 7% of the dataset obtained from Formspring platforms contained cyberbullying. Training operations were conducted by combining DNN and transfer learning. It has been demonstrated that the proposed models are adaptable and transferable to any dataset by performing tests on YouTube. The proposed model achieved a 0.76 F1 score, outperforming machine learning methods with a 0.64 F1 score in the YouTube dataset for cyberbullying detection.
Iwendi et al. [15] performed a performance analysis using four different deep learning algorithms: Bidirectional Long Short-Term Memory (BLSTM), Gated Recurrent Units (GRU), Long Short-Term Memory (LSTM), and Recurrent Neural Network (RNN). They used the Kaggle dataset, which includes data from Instagram, Facebook, and Twitter. Preprocessing operations such as text cleaning, tokenization, stemming, and lemmatization were performed. According to the experimental results, the BLSTM method achieved an F1 score of 88 and an accuracy of 82.18%. Perera et al. [16] utilized textual and sentimental features through the TF-IDF and SVM method. They used 1000 texts obtained from the Twitter platform as the dataset, with 70% reserved for training and 30% for testing. The proposed model achieved an accuracy of 74.50% and an F1 score of 74%.
Kao et al. [17] employed the Binary Random Forest method to detect cyberbullying using a dataset obtained from Instagram and ask.fm. Only textual features were considered, with only 12% of the 13350 data being cyberbullying data.
Cheng et al. [18] proposed a new cyberbullying detection framework, XBully, which considered both text and user information. The dataset contained 2210 data points from Instagram, with 30% of the dataset containing cyberbullying.
Gomez et al. [19] used a dataset consisting of 18776 comments collected from YouTube, with 34.4% involving cyberbullying. Two machine learning approaches, NB and SVM, were proposed for cyberbullying detection, considering only textual features.
Salawu et al. [20] proposed a series of transformer-based deep learning models that yielded impressive results. They used a dataset containing 62587 tweets obtained from the Twitter platform, with 82.8% involving cyberbullying.
Murshed et al. [21] proposed a new method by combining Elman-type Recurrent Neural Networks (RNN) with the optimized Dolphin Echolocation Algorithm (DEA). A dataset containing 10000 tweets obtained from the Twitter platform was used, with 35% including cyberbullying. Classification was carried out solely through text content.
Dey and Das [22] proposed a hybridized neural network-based sentiment analysis framework using a modified TF-IDF approach. They achieved accuracy values of 84.4%, 75.0%, 62.9%, 62.1%, 80.3%, 76.9%, and 89.2% in datasets obtained from Amazon, ETSY, Big Basket, Facebook, Financial News, Twitter, and Wine platforms, respectively. In their next study [23], they performed sentiment analysis with a Hybridized Deep Neural Network consisting of CNN and LSTM, achieving accuracy values of 89%, 81.9%, 67.9%, 64.6%, 83.2%, 79.8%, and 91.3% in datasets obtained from Amazon, ETSY, Big Basket, Facebook, Finance, Twitter, and Wine platforms, respectively.
These presented studies were generally carried out for the detection of cyberbullying in English. The first study for the Turkish language in the detection of cyberbullying was conducted by Ozel et al. [24]. Fifty percent of the 900 tweets in the dataset contained cyberbullying content. Cyberbullying was detected using various machine learning methods such as TF-IDF, C4.5, NB, SVM, and kNN. The classification was based on textual features, and according to the test results, NB showed the best performance with a 79% F1 score.
Bozyigit et al. [25] designed various artificial neural network models using a dataset consisting of 3000 Twitter posts. Eighty percent of this dataset was reserved for training, 10% for validation, and the remaining 10% for testing. Cyberbullying was detected using textual features, and the best-performing artificial neural network model achieved a 91% F1-score.
In another study [26], cyberbullying was determined using various machine learning methods by combining textual features and social media features selected according to the chi-square test. The dataset consisted of 5000 Twitter posts, with 90% reserved for training. The success rate when social media features were used in combination with textual features was higher than when using only textual features. The highest performance was achieved by AdaBoost with 90.1% accuracy. A summary of the studies examined in the literature is provided in Table 1. In this study, cyberbullying was detected using textual features and social media features together. The proposed deep learning model in this study yielded better results with an accuracy rate of 93.2% compared to the previous study specific to this dataset.
When examining studies on cyberbullying detection and classification in detail, it becomes evident that machine learning (ML)-based approaches utilizing different feature selection methods are widely employed. However, it has been observed that deep learning models demonstrate superior performance in terms of accuracy when trained with a sufficient amount of data. Nevertheless, the computational complexity of deep learning-based approaches is higher, potentially hindering their effectiveness in processing larger datasets. Furthermore, it is worth noting that the models proposed in most studies solely classify based on text content without incorporating information about social media or users. Moreover, many studies exhibit high levels of class imbalance, which can lead to biased decisions favoring the majority class and neglecting the minority class. Additionally, it is noteworthy that the majority of cyberbullying detection systems in the literature are designed for English. Given that every language has distinct structures and expressions, what may be harmless in one language could be offensive in another. Integrating the unique characteristics of each natural language into a cyberbullying model would introduce excessive complexity. Consequently, a model developed in one language may not be suitable for application in another language. Considering this scenario, it is apparent that very few studies in the literature have focused on the detection of cyberbullying in the Turkish language.

Proposed model of cyberbullying detection
In light of the aforementioned limitations, a new model for cyberbullying detection is presented herein, employing a simple deep learning model with reduced complexity and a balanced dataset that incorporates fusion features. Additionally, a semi-synthetic dataset was generated using BERT-based data augmentation, thereby overcoming the limitations associated with existing Turkish language cyberbullying detection datasets. The deep learning model produced in this study yielded better results with an accuracy rate of 93.2% compared to the previous study specific to this dataset.
3 Material and Method
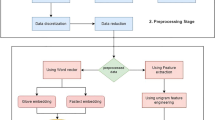
In this study, the proposed method for detecting of Turkish cyberbullying posts is shown in Fig. 1. In the method, both textual features and social media features such as SlangWords, Retweets, Favorites, Hashtags, Medias, Mentions, SenderAccountYears, SenderFavorites, SenderStatues, SenderFollowings, SenderFollowers were used [26]. The steps followed in the method are listed below:
-
The dataset was loaded from the Mendeley Datastore.
-
Preprocessing steps such as tokenization, text cleaning, and stop words removal were performed.
-
80% of the dataset was reserved for training, 10% for validation and 10% for testing.
-
Feature engineering tasks including normalization, feature extraction, and feature selection were conducted.
-
Various feature extraction methods were employed, and their performances were evaluated. The most successful feature extraction method (TF-IDF and unigram) was selected.
-
A deep learning model based on MLP was designed and trained using the extracted features.
-
The performance of the MLP model was evaluated using test data, and performance measures derived from the confusion matrix were assessed.
-
State-of-the-art deep learning models (CNN, LSTM, and BLSTM) were compared with the proposed model.
-
A comparison was made between the proposed model, the previous study using the same dataset, and other studies on Turkish cyberbullying detection in the literature.
As seen in Fig. 1, the dataset comprising Twitter posts was loaded from the Mendeley Data repository. To enhance the success rate on the dataset, the tokenization process was initially applied to the posts. In the subsequent step, text cleaning was performed, which involved removing numerical characters and punctuation marks from the texts and converting characters to lowercase. Subsequently, stop words were eliminated. Given the varying intervals at which digital social media features change in the preprocessed dataset, the minimum-maximum normalization process was employed to mitigate potential adverse effects on model performance. Following this, the posts were transformed into vectors using different feature extraction methods. The performances of these feature extraction methods were assessed, and the most effective one was selected. Prior to feeding these extracted features into the DL model, unnecessary features were eliminated using the Chi-Square feature selection method. The DL model was then formulated and trained using the obtained features. Model performance was evaluated using precision, sensitivity, specificity, F1-score, accuracy, and AUC performance metrics through the prediction process with the test data. Finally, the proposed model was compared with previous studies in the literature and state-of-the-art deep learning models..
3.1 Dataset
In this study, the dataset presented by Bozyiğit et al. [26] was utilized. The dataset comprises 5000 Twitter posts. Upon analysis of the dataset, it was observed that there were no unlabeled or missing data. Half of the posts in this dataset were labeled as true (containing cyberbullying), while the other half were labeled as false (not containing cyberbullying). Fig. 2 illustrates that the dataset exhibits a balanced distribution. A balanced dataset prevents bias towards any class during model training.

Class-wise dataset distribution
3.2 Pre-processing
To achieve more successful results with the dataset used in the study, several preprocessing steps such as splitting and cleaning should be applied before utilizing the data. Initially, the tokenization process was applied to the texts in the dataset. In the second stage, the text cleaning process was performed, during which numerical characters and punctuation marks were removed from the texts. Additionally, all characters were converted to lowercase. Finally, the stop words removal process was applied.
3.2.1 Tokenization
First, the process of separating the texts in the dataset into tokens was carried out. This process is used to obtain words, alphabetic or alphanumeric characters and other meaningful expressions in the text. Tokenization is basically the process of breaking a text into smaller parts such as individual words or terms [27]. Each of these small pieces is called a token. These tokens can be words, numerical expressions, and punctuation marks. Tokenization is an important preprocessing step in NLP tasks because it provides a structured representation of text data that can be easily processed by machine learning algorithms. It enables the extraction of meaningful features from text, such as word frequencies, n-grams, or syntactic structures, which are then used as input to models for various NLP tasks. Overall, tokenization is a fundamental step in NLP and text processing pipelines, enabling raw text to be converted into a structured format suitable for further analysis and modeling. Tokenization is the first step in cleaning text from noise. In this study, the tokenization process was carried out using the Python NLTK library. No filtering was applied in the tokenization process
3.2.2 Text cleaning
Text cleaning, also known as text preprocessing, is the process of preparing raw text data for analysis or modeling by removing noise, irrelevant information, or inconsistencies. It involves a series of steps to standardize, normalize, and improve the quality of text data.
Normalization involves converting text into a consistent format by standardizing elements such as punctuation and abbreviations. This ensures that similar words or phrases are treated the same during analysis. Converting all text to lowercase or removing punctuation can help standardize the text. Writing a word in lowercase or uppercase does not change the meaning of that word.
Removal of special characters and symbols: Special characters, symbols, and punctuation marks that do not contribute to the semantic meaning of the text are removed.
Processing of numerical data: Depending on the task, numerical data may need to be handled differently. But in sentiment analysis, numeric values may not contribute to sentiment and can be removed with a placeholder.
Stemming and Lemmatization: Stemming and lemmatization are techniques used to reduce words to their base or stem forms. This helps combine variations of words and reduce word size. However, stemming preprocessing was not applied in this study because Turkish is an agglutinative language [26]. Due to the structure of the Turkish language, the stemming process would change the meaning of the words. Therefore, the stemming procedure was not suitable for this study.
Text cleaning is essential to improve the quality and consistency of text data, which improves the performance of downstream tasks such as text classification, sentiment analysis, information retrieval, and machine translation. By removing noise and standardizing text, text cleaning helps uncover meaningful patterns and insights from data.
3.2.3 Stop words removal
As the third and final preprocessing step, stop words have been removed. Turkish stop words do not affect the meaning of the sentence. Since stop words are expressions that do not add meaning to the sentence, similar to numerical expressions and punctuation marks, processing these expressions will not provide any benefit in the detection of cyberbullying. Therefore, these expressions have been removed from the text. As a result of this preprocessing, the meaningless expressions in the dataset were eliminated and the noise and feature size were reduced.
3.3 Feature engineering
First, the minimum-maximum normalization process was applied because the digital social media features in the dataset were in different ranges. Then, using different feature extraction methods, features were obtained to feed the deep learning model. The obtained features were combined or used separately, and the most successful feature extraction methods were selected. Finally, the Chi-Square feature selection method was employed to select the best features for the detection of cyberbullying.
3.3.1 Normalization
Considering the social media features in the dataset, each feature changes at different intervals. Since this difference can adversely affect the performance of the model when the features obtained from the feature extraction process are applied in the deep learning model, the normalization process has been applied. With the minimum-maximum [28] normalization process, social media features are stabilized in a certain range. The calculation of the normalization value v is given in (1). In (1), minA represents the minimum value of a social media feature and maxA represents the maximum value of a social media feature.
3.3.2 Feature extraction
In text classification studies, the texts whose class is to be determined need to be converted into a form that the computer can understand, that is, into a digital form. Feature extraction allows the creation of a new feature space by applying a transformation operation based on some criteria. In this study, the performances of different feature extraction methods were examined.
3.3.3 Bag of words
The Bag of Words (BOW) method divides a text into individual words. Each generated word is treated as a feature. Then, the frequency of occurrence of each feature in the whole text is assigned as the value of the feature. In other words, a “bag” is created regardless of the order or context of all the words in the text, and then the count of how many times each word occurs in that bag is taken. In this study, the BoW method for term-counting is utilized. The CountVectorizer class from Python’s scikit-learn library is employed, which converts a collection of text documents into a term count matrix.
While BoW has its limitations, it contributes to model performance in several ways:
Simplicity and efficiency: BoW is a simple and effective method for converting text data into numerical vectors that machine learning algorithms can process. This simplicity makes BoW easy and computationally efficient to implement.
Feature extraction: BoW represents text data as numerical vectors, making it easy to extract relevant features from text for use in machine learning models. These features capture the presence or absence of words and their frequencies, allowing the model to learn patterns and relationships in text data.
Dimensionality reduction: BoW helps reduce dimensionality by encoding text data into a fixed-length vector representation. This reduction in dimensionality can avoid the curse of dimensionality and improve the efficiency of machine learning algorithms.
Generalization: Despite its simplicity, BoW can capture important information about the underlying semantics of the text. It preserves information about word frequencies and co-occurrences while ignoring the order of words in the text. This allows machine learning models to generalize from training data to unseen data, making BoW particularly useful for tasks such as document classification and sentiment analysis.
Robustness to noise: BoW is robust to noisy text data and changes in word order or grammar. This robustness makes BoW suitable for processing text data from different sources with varying levels of quality and consistency.
Compatibility with a variety of algorithms: BoW can be used as input to a wide variety of machine learning algorithms, including linear models (e.g., logistic regression), tree-based models (e.g., decision trees, random forests), and neural networks.
Overall, although BoW has limitations such as the inability to capture semantic relationships between words and sensitivity to word size, it remains a valuable and widely used technique in NLP due to its simplicity, efficiency, and effectiveness in contributing to model performance.
3.3.4 Term frequency to inverse document frequency
In order for texts to be understood by deep learning models, they must be ex- pressed in numbers. This is a fundamental step in the machine learning process for analyzing documents [29]. The basic structure that makes up the texts is the words. To express a text with vectors, words can be represented with metrics such as the Term Frequency to Inverse Document Frequency (TF-IDF). The TF-IDF value indicates how important a word is in the text. The TF-IDF value is calculated according to equation (2, 3, 4) (2, 3, 4) [30].
Term frequency (TF) represents the selected term divided by the total number of terms found in the text. Inverse Document Frequency (IDF) shows how many of the texts contain the search term. It is calculated as the logarithm of the total number of texts divided by the number of texts containing the term. By multiplying these two values, the TF-IDF value is obtained. Where t is the word(term), d is the document and D is the dataset. f(t,d) is the number of times the word t occurs in the dth document; \({\left| d\epsilon D:t\epsilon d \right| }\) expression is the information on how many of the documents that make up the D collection contain the word t [31]. TF-IDF is a numerical measure of how relevant any word in a document is to the document [32].
It contributes to TF-IDF’s model performance in several ways:
Weighting: TF-IDF assigns weights to words across the entire corpus based on their importance in a document. It considers not only the frequency of a term in a document but also how unique that term is across the entire corpus. This helps to give more importance to words that occur frequently in a document but are rare throughout the corpus.
Normalization: TF-IDF normalizes the weights of words, making them comparable across different documents.
Dimensionality Reduction: Like BOW, TF-IDF reduces the dimensionality of text data by representing documents as vectors.
Feature representation: TF-IDF provides a more nuanced feature representation of text data. It captures the importance of words in a document while considering their distribution across corpora. This can lead to better discrimination between documents in classification tasks.
Improved Performance: By considering both frequency and rarity of terms, TF-IDF generally leads to better model performance compared to simple BOW representations. Versatility: Similar to BOW, its flexibility and effectiveness make it a widely used technique in many NLP applications.
Overall, TF-IDF contributes to model performance by providing a more informative and discriminatory representation of text data compared to simple word counts, thereby increasing the ability of machine learning models to extract meaningful patterns and insights from textual information.
3.3.5 Word embedding
Word embedding methods are techniques that express vector representations of words. Word2Vec is an unsupervised learning and neural network-based word representation method developed by Google that aims to represent words in vector space. Similar to weight learning, word vectors are learned, and relationships such as similarities or contrasts between words are expressed mathematically. In other words, it involves calculating the vector distance between words.
In general, word embeddings contribute to model performance by providing semantic representations of words that capture contextual information, enable efficient representation learning, and facilitate transfer learning across tasks and domains in natural language processing.
3.3.6 Hashing
Hashing is another method that can be used to extract features from text. Similar to CountVectorizer, but instead of creating a word bag to match words to indexes, it uses a hash function to convert words directly into numeric indexes. The hashing method is faster than other methods when extracting features from the text. Additionally, it requires less memory usage, which is another advantage. However, when different words are mapped to the same index, it can cause collisions. In this case, since information loss occurs, the performance of the model may be adversely affected.
Hashing methods are computationally efficient, allowing for faster feature extraction and model training compared to other methods. They require less memory than traditional methods by mapping features to a fixed-size space. This can be useful for models with limited memory resources or when working with large datasets.
While hashing methods provide various benefits, they also have limitations. A common challenge is the potential for hash collisions, where different features match the same hash value, leading to information loss. Additionally, because hashing methods rely on randomization, the resulting feature representations may not be interpretable or easily reversible. Despite these limitations, hashing methods remain a valuable tool for dimensionality reduction and feature engineering in machine learning and NLP tasks.
3.3.7 Feature selection
After the feature extraction step, a large number of features are obtained. Unnecessary features within this set can negatively affect the performance of the deep learning model as they increase the size of the feature set. The chi-square test is a statistical method used to determine whether there is a significant relationship between two categorical variables. Calculation of Chi-Square value is given in (5). Where, O and E represent observed and expected values, respectively.
When the two events, feature occurrence and class occurrence, are independent, the observed count approaches the expected count, resulting in a small chi-square score. The chi-square method is used to determine the best features by identifying the features on which the class is most dependent. The chi-square value for each feature is calculated and sorted in descending order of the chi-square values. The higher the chi-square value, the more dependent the class is on the feature, and the more important the feature is in determining the class [33]. Therefore, features with higher Chi-square scores should be selected for model training. In this study, the 500 features with the highest chi-square scores were selected.
Effect of the chi-square test method on noise reduction and model accuracy:
-
1.
Identifying relevant features: The chi-square test evaluates the relationship between each feature and the target variable. Features with low chi-square statistics are considered less relevant, while those with high chi-square statistics are deemed relevant. Selecting features with high chi-square statistics allows us to focus on those most likely to provide useful information to the model.
-
2.
Removal of irrelevant features: Features that are not significantly related to the target variable may introduce noise into the model, increasing its complexity without offering meaningful predictive power. This can lead to overfitting and decreased generalization performance. By using the chi-square test, noise in the data is reduced, enhancing the model’s ability to generalize to unseen data.
-
3.
Reduced dimensionality: The chi-square test reduces the dimensionality of the feature space by retaining only the most relevant features. In high-dimensional feature spaces, as the number of features increases relative to the number of observations, the model’s performance may deteriorate. The chi-square test addresses the issue of dimensionality, thereby enhancing the model’s efficiency.
-
4.
Improved model performance: Feature selection using the chi-square test, by focusing on the most relevant features and discarding irrelevant ones, can result in improved model performance. A shorter feature set helps the model capture underlying data patterns more effectively, leading to enhanced prediction accuracy and generalization to new data. Additionally, it enables shorter training times and faster inference speeds, which are particularly beneficial in applications with limited computational resources or requiring real-time predictions.
3.4 Deep learning model
The Multi-Layer Perceptron (MLP) has emerged as a result of studies aimed at solving the XOR Problem. MLP works particularly well in classification and generalization situations. After the preprocessing and feature engineering steps, noise is removed, and dense layers in the proposed model are fed with selected important features. The structure of the MLP model is presented in Fig. 3. As seen in the figure, the model consists of 3 dense layers and 3 dropout layers. Each dense layer contains RELU as the activation function. The dropout process is applied between dense layers. The first dense layer consists of 128 nodes, with a dropout rate of 0.25. The second dense layer consists of 64 nodes, followed by a dropout layer with a dropout rate of 0.25. The third dense layer consists of 32 nodes, with a dropout layer following it with a dropout rate of 0.5. Finally, the classification process is applied using softmax.

MLP structure
3.5 Synthetic data
BERT-based data augmentation is a widely used technique in machine learning to artificially increase the size of a training dataset by creating modified versions of existing data samples. This can help improve model performance by providing more diverse inputs during training. First, text conversion is performed. This phase involves transforming the original text data using techniques such as BERT-based data augmentation, synonym substitution, word insertion, word deletion, and word replacement. These transformations are applied to create new, slightly modified versions of the original text. Once the text is converted, it is passed through the pre-trained BERT model to obtain contextualized word embeddings. BERT captures rich contextual information about each word in a sentence, which helps create meaningful augmented examples.
BERT-based data augmentation can help create various training samples by generating variations of the original data. This is especially useful in situations where having a diverse dataset is crucial for text classification, sentiment analysis, and model generalization. BERT-based data augmentation can be considered effective in a variety of natural language processing tasks, especially when the original dataset is limited in size or lacks diversity. By exposing the model to a wider range of input variations during training, it helps make the model more robust and less prone to overfitting. Since Turkish language cyberbullying datasets are scarce in the literature and the size of the dataset is limited, the aim is to fill this gap by generating synthetic data. This also contributes to the generalization of the proposed model.
4 Experimental results
This study was conducted using the Python programming language. During the evaluation process of the designed model, 80% of the dataset consisting of 5000 Twitter posts was allocated for training, 10% for validation, and the remaining 10% for testing. Preprocessing was applied to the dataset to enhance the performance of the model. Social media features and textual features of the Twitter posts were processed using feature engineering and then utilized in the deep learning model. During training, the batch size was set to 256, and the number of epochs was set to 50. The training process of the model was terminated using early stopping criteria when there was no significant change in the model’s performance. The trial and error method was employed to determine the batch size and other parameters such as the number of nodes in the dense layer and the dropout rate. Various feature extraction methods were used to obtain features for feeding into the deep learning model. These obtained features were then either combined or used separately.
4.1 Performance Analysis
The proposed model’s performance is evaluated based on performance metrics such as precision, sensitivity, specificity, F1 score, and accuracy obtained from the confusion matrix. Table 2 illustrates the success rates of feature extraction methods according to these criteria. The features extracted using various methods listed in the table were selected using the chi-square method, and the top 500 features were chosen. These selected features were then employed in the designed MLP model, and their performance was assessed.
4.1.1 Accuracy analysis
Accuracy is a metric used to evaluate the performance of the model, representing the proportion of correctly classified examples among all examples in the dataset. Mathematically, accuracy is calculated as the number of correct predictions divided by the total number of predictions. The number of correct predictions includes true positives (correctly predicted positives) and true negatives (correctly predicted negatives) in a binary classification problem.
As observed in the table, the lowest accuracy value is obtained with the word embedding method, resulting in an accuracy value of 69.2. This may be because this method only utilizes text features. Conversely, the highest accuracy value is achieved using a hybrid of TF-IDF and unigram methods, with an accuracy value of 93.2. When the TF-IDF method is employed alone, the accuracy value reaches 92.4. Combining features obtained from TF-IDF and BOW methods in the deep learning model yields an accuracy value of 91.4, while using BOW alone results in an accuracy value of 91.2. Notably, the accuracy value obtained by TF-IDF and the bigram method is lower than that obtained by using TF-IDF and unigram methods together. In general, unigram hybrid methods outperform bigram hybrid methods.
Comparing with methods in the previous study using the same dataset, the proposed model achieves a higher accuracy value than other methods. Specifically, the training, validation, and testing accuracy of the proposed model are 94.4%, 89.8%, and 93.2%, respectively. In previous studies, popular deep learning models CNN, LSTM, BLSTM, and pre-trained Bert model for the detection of cyberbullying exhibit accuracy values of 81.6, 82.8, 83.8, and 80.9, respectively. The proposed model was validated by generating synthetic data to mitigate bias and ensure its generalizability. The achieved accuracy value of 92.2 is promising, indicating the robustness and generalizability of the proposed model.
4.1.2 Specificity analysis
Specificity, also known as the true negative rate or selectivity, is a metric used to evaluate the performance of a binary classification model. It measures the proportion of true negatives correctly identified by the model, indicating whether tweets that are not cyberbullying are correctly identified.
Mathematically, specificity is calculated as follows:
Where: True Negatives (TN): The number of samples that are actually negative (belong to the negative class) and are correctly classified as negative by the model. False Positives (FP): The number of samples that were actually negative but were incorrectly classified as positive by the model.
Among the feature extraction methods, the method with the highest specificity value is the TF-IDF method, yielding a specificity value of 92. Additionally, the TF-IDF and unigram hybrid method exhibits a high specificity value of 90.8. Conversely, the word embedding method yields the lowest specificity value. The TF-IDF and TF-IDF unigram hybrid method are identified as the most effective in detecting non-cyberbullying tweets. However, the hashing and TF-IDF bigram hybrid method achieve lower specificity values compared to other methods, with specificity values of 82.8 and 82.4, respectively.
4.1.3 Sensitivity (Recall) analysis
Sensitivity, also known as true positive rate (TPR) or recall, is a metric used to evaluate the performance of a binary classification model. It measures the proportion of true positive cases correctly identified by the model. Mathematically, sensitivity is calculated as follows:
True Positives (TP): The number of samples that are actually positive (belong to the positive class) and are correctly classified as positive by the model. False Negatives (FN): The number of samples that were actually positive but were incorrectly classified as negative by the model. Among the feature extraction methods, the method with the highest sensitivity value is the TF-IDF and unigram hybrid method. The sensitivity value of the TF-IDF and unigram hybrid method is 95.6. In other words, tweets containing cyberbullying were best obtained using the TF-IDF and unigram methods. After this method, the BOW method showed the best performance. The sensitivity value obtained with the BOW method is 94. The method with the lowest sensitivity value is the word embedding method. The sensitivity value of hashing and word embedding methods is 87.2 and 75.2 respectively. Generally speaking, the sensitivity value of all feature extraction methods is higher than the specificity value. It can be said that the model detects tweets containing cyberbullying better. As seen in Table 3, when compared to the methods in the previous study using the same dataset, the proposed model achieved a higher sensitivity value than other methods.
4.1.4 Precision analysis
Precision is a metric used to evaluate the performance of a classification model, especially in binary classification settings. It measures the proportion of true positive predictions among all positive predictions made by the model. Mathematically, precision is calculated as follows:
True Positives (TP): The number of samples that are actually positive (belong to the positive class) and are correctly classified as positive by the model. False Positives (FP): The number of samples that were actually negative but were incorrectly classified as positive by the model. Precision provides information regarding the reliability of positive predictions made by the model. Considering the precision values, the two feature extraction methods that show the highest values are TF-IDF and TF-IDF unigram hybrid method. The precision values of TF-IDF and TF-IDF unigram hybrid methods are 92.06 and 91.22, respectively. The lowest precision values were obtained by word embedding and hashing feature extraction methods. The precision values of the word embedding and hashing methods are 67.14 and 83.52, respectively. As seen in Table 3, when compared to the methods in the previous study using the same dataset, the proposed model achieved a higher precision value than other methods.
4.1.5 F1-Score analysis
F1 score is a metric used to evaluate the performance of a classification model, especially in binary classification environments. It provides a balance between the two metrics by combining both precision and recall into a single value. The F1 score is calculated as the harmonic mean of precision and recall:
When examining the F1 scores of the feature extraction methods, the method with the highest F1 score is the TF-IDF and unigram hybrid method. When the feature was extracted using the TF-IDF and unigram hybrid method, the model reached a 93.36 F1-score value. Additionally, TF-IDF and TF-IDF BOW hybrid methods also achieved high F1 scores: 92.43 and 91.55, respectively. The features obtained by word embedding and hashing methods reached the lowest F1 score values when used in the model. The F1 score values of the hash and word embedding methods are 85.32 and 70.94, respectively. As seen in Table 3, when compared to the methods in the previous study using the same dataset, the proposed model achieved a higher F1 score value than the other methods. As shown in Table 5, the proposed model is the model with the highest F1-score in cyberbullying detection studies in the Turkish language.
4.1.6 Performance analysis in terms of training
Considering the training time, the model with the least training time is the recommended deep learning model. The training time of the proposed deep learning model is 9.14 seconds. BLSTM training time is 159.22 seconds, LSTM training time is 88.92 seconds, and CNN model training time is 44.19 seconds. The model with the longest training time is the pre-trained BERT model, which took approximately 600 seconds. Based on the training times, it can be concluded that the proposed model is the most promising model. As shown in Table 4, due to the dimensional expansion of the dataset using synthetic data, the training time was completed in a short period of 27 seconds, indicating the effectiveness of the proposed model in handling larger datasets. Given the higher computational complexity of deep learning models, they may not be as effective in processing large datasets. Therefore, employing simpler deep learning models with fewer parameters could be more advantageous.
When examining Table 2 overall, it’s evident that the specificity values are lower than the sensitivity values. Across all methods, it can be inferred that posts containing cyberbullying are better detected than those that do not. The TF-IDF, TF-IDF+unigram, and TF-IDF+BOW methods exhibit the top three performances. Combining and utilizing features obtained from different methods has yielded promising outcomes. The TF-IDF+unigram method boasts the highest F1-score and accuracy value. The confusion matrix derived from the MLP+TF-IDF+unigram framework is illustrated in Fig. 4. As depicted in Fig. 4, 239 out of 250 cyberbullying-positive instances were correctly identified, while 227 out of 250 cyberbullying-negative instances were accurately classified. Referring to the table, the sensitivity value stands at 95.6%, and the specificity value is 90.8%. Hence, it can be inferred that the model effectively detects posts containing cyberbullying. The ROC curve, based on the experimental results, is presented in Fig. 5, with an AUC value of 0.932. The model’s F1-score and accuracy value were determined as 93.36% and 93.2%, respectively, with similar values across all three criteria.

Confusion matrix obtained with the proposed model

Roc curve of proposed model
In this study, an MLP-based model for detecting cyberbullying in Turkish Twitter posts was evaluated using the dataset presented by [26]. A comparison of the ML models tested on the same dataset and the proposed model is provided in Table 3. It’s evident from Table 3 that the proposed deep learning model outperformed machine learning methods in the previous study for the same dataset, achieving a success rate of 93.2%.
In this study, simple deep learning models designed with preprocessing steps for detecting cyberbullying in Turkish texts were evaluated using the dataset presented by [26]. Table 3 provides a comparison of the ML models tested on the same dataset and the proposed model. It’s evident from the table that the deep learning model designed within the scope of this study outperformed methods used in the previous study for this dataset [26], achieving a success rate of 92.8%.

LSTM training/validation accuracy and loss graphs

BLSTM training/validation accuracy and loss graphs

CNN training/validation accuracy and loss graphs
Previous studies employed popular deep learning models such as CNN, LSTM, and BLSTM for cyberbullying detection. A comparison of these state-of-the-art deep learning models with the proposed model is presented in Table 4. Training/validation accuracy and loss graphs of LSTM, BLSTM, CNN, BERT, and the proposed model are depicted in Figs. 6, 7, 8, 9, 10 and 11, respectively. As observed in the figures, the training process of all deep learning models was terminated via early stopping when there was no significant change in performance. Notably, the proposed model exhibited higher performance than other deep learning models, achieving training accuracy, validation, and testing accuracy rates of 94.4%, 89.8%, and 93.2%, respectively.

BERT training/validation accuracy and loss graphs

Proposed Model (MLP) training/validation accuracy and loss graphs

Proposed Model (MLP with synthetic data) training/validation accuracy and loss graphs
5 Discussion
In recent years, the growing interest of children and adolescents in social media has made them a potential risk group for cyberbullying. Cyberbullying poses a significant threat, leading to mental, psychological, and emotional issues, and in severe cases, even suicide. To address this problem, cyberbullying detection studies are conducted worldwide. However, most of these studies focus on the English language. Despite Turkey being among the top ten countries with the highest number of children who fall victim to cyberbullying, there is a notable scarcity of research on the Turkish language. In this study, we designed an MLP-based model to detect cyberbullying in Turkish social media text. The model was trained and tested using a dataset comprising 5000 Twitter posts.
When compared to methods used in a previous study with the same dataset, the proposed model demonstrated superior performance with an accuracy of 93.2%. This study indicates that a simple deep learning model yields better results in cyberbullying detection than machine learning models. Additionally, the proposed model was evaluated against state-of-the-art deep learning models, outperforming them as well. Table 5 provides a comparison of cyberbullying detection studies on Turkish posts, where the proposed model achieved the highest performance (93.36%) among all models in the literature. Due to the dimensional expansion of the dataset using synthetic data, the training time was completed in a short period of 27 seconds, indicating the effectiveness of the proposed model in handling larger datasets. Given the higher computational complexity of deep learning models, they may not be as effective in processing large datasets. Therefore, employing simpler deep learning models with fewer parameters could be more advantageous.
In this study, both social media features and textual features are utilized. It is hypothesized that incorporating additional features such as user-based or sentiment-based features will enhance the model’s accuracy. Therefore, future plans involve augmenting the existing features employed by the proposed model with user-based and sentiment-based features. Additionally, there is intent to evaluate the proposed model on data from other social media platforms.
In this study, both social media features and post text content features are combined. It is believed that incorporating additional useful features will enhance the model’s accuracy. Future plans for this study include utilizing the proposed model in conjunction with word embedding, training it on Twitter data, and subsequently testing it on other social media platforms.
6 Conclusion
In recent years, children and adolescents have shown a growing interest in social media, making them a potential risk group for cyberbullying. Cyberbullying can lead to various mental, psychological, and emotional problems in this demographic, and in extreme cases, it can even result in suicide. Despite Turkey being among the top ten countries with a high number of children victimized by cyberbullying, there are very few studies conducted in Turkish. This study addresses this gap by designing an MLP-based model to detect cyberbullying in Turkish social media text. Unlike many previous studies, this research integrates social media features with textual features extracted from various methods. This holistic approach aims to contribute to existing literature on cyberbullying detection.
Data Availability
The data can be accessed at https://data.mendeley.com/datasets/xf9ck7ntbs/1
References
Sharma A, Kabra A, Jain M (2022) Ceasing hate with MoH: Hate Speech Detection in Hindi-English code-switched language. Inf Process Manag 59(1):102760
Pamungkas EW, Basile V, Patti V (2021) A joint learning approach with knowledge injection for zero-shot cross-lingual hate speech detection. Inf Process Manag 58(4):102544
Ptaszynski M, Masui F, Nitta T, Hatakeyama S, Kimura Y, Rzepka R, Araki K (2016) Sustainable cyberbullying detection with category-maximized relevance of harmful phrases and double-filtered automatic optimization. International Journal of Child-Computer Interaction 8:15–30
Kocoń J, Figas A, Gruza M, Puchalska D, Kajdanowicz T, Kazienko P (2021) Offensive, aggressive, and hate speech analysis: From data-centric to human-centered approach. Inf Process Manag 58(5):102643
Belsey B (2005) Cyberbullying: An emerging threat to the “always on’’ generation. Recuperado el 5(5):2010
Hinduja S, Patchin JW (2013) Social influences on cyberbullying behaviors among middle and high school students. Int J Adolesc 42(5):711–722
Hosseinmardi H, Ghasemianlangroodi A, Han R, Lv Q, Mishra S (2014) Towards understanding cyberbullying behavior in a semi-anonymous social network. In 2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2014), pp 244–252
Peker A (2015) Analyzing the risk factors predicting the cyberbullying status of secondary school students. Egitim ve Bilim, 40(181)
Cook S (2022) Cyberbullying facts and statistics for 2018 – 2022. https://www.comparitech.com/internetproviders/cyberbullying-statistics/. 10 Feb 2022
Yin D, Xue Z, Hong L, Davison BD, Kontostathis A, Edwards L (2009) Detection of harassment on web 2.0. Proceedings of the Content Analysis in the WEB 2:1–7
Dadvar M, Jong FD, Ordelman R, Trieschnigg D (2012) Improved cyberbullying detection using gender information. In: Proceedings of the twelfth dutch-belgian information retrieval workshop (DIR 2012). University of Ghent
Dadvar M, Trieschnigg D, Jong FD (2014) Experts and machines against bullies: A hybrid approach to detect cyberbullies. Springer, In Canadian conference on artificial intelligence, pp 275–281
Ptaszynski M, Masui F, Kimura Y, Rzepka R, Araki K (2015) Extracting patterns of harmful expressions for cyberbullying detection. In Proceedings of 7th language & technology conference: Human language technologies as a challenge for computer science and linguistics (LTC’15), The First Workshop on Processing Emotions, Decisions and Opinions, pp 370–375
Dadvar M, Eckert K (2018) Cyberbullying detection in social networks using deep learning based models; a reproducibility study. arXiv:1812.08046
Iwendi C, Srivastava G, Khan S, Maddikunta PKR (2020) Cyberbullying detection solutions based on deep learning architectures. Multimedia Systems, pp 1–14
Perera A, Fernando P (2021) Accurate Cyberbullying Detection and Prevention on Social Media. Procedia Comput Sci 181:605–611
Kao HT, Yan S, Huang D, Bartley N, Hosseinmardi H, Ferrara E (2019) Understanding cyberbullying on Instagram and Ask. Fm via social role detection. In Companion proceedings of the 2019 world wide web conference pp. 183–188
Cheng L, Li J, Silva YN, Hall DL, Liu H (2019) Xbully: Cyberbullying detection within a multi-modal context. In: Proceedings of the twelfth acm international conference on web search and data mining, pp 339–347
Gomez CE, Sztainberg MO, Trana RE (2022) Curating cyberbullying datasets: A human-AI collaborative approach. Int J Bullying Prev 4(1):35–46
Salawu S, Lumsden J, He Y (2021) large-scale English multi-label Twitter dataset for cyberbullying and online abuse detection. In: The 5th workshop on online abuse and harms. Association for Computational Linguistics, pp 146–156
Murshed BAH, Abawajy J, Mallappa S, Saif MAN, Al-Ariki HDE (2022) DEA-RNN: A hybrid deep learning approach for cyberbullying detection in Twitter social media platform. IEEE Access 10:25857–25871
Dey RK, Das AK (2023) Modified term frequency-inverse document frequency based deep hybrid framework for sentiment analysis. Multimed Tools Appl 82(21):32967–32990
Dey RK, Das AK (2024) Neighbour adjusted dispersive flies optimization based deep hybrid sentiment analysis framework. Multimedia Tools and Applications, pp 1–24
Özel SA, Saraç E, Akdemir S, Aksu H (2017) Detection of cyberbullying on social media messages in Turkish. In: 2017 International conference on computer science and engineering (UBMK), IEEE, pp 366–370
Bozyiğit A; Utku S, Nasiboğlu E (2019) Cyberbullying detection by using artificial neural network models. In: 2019 4th International conference on computer science and engineering (UBMK), IEEE, pp 520–524
Bozyiğit A, Utku S, Nasibov E (2021) Cyberbullying detection: Utilizing social media features. Expert Syst Appl 179:115001
Eronen J, Ptaszynski M, Masui F, Smywiński-Pohl A, Leliwa G, Wroczynski M (2021) Improving classifier training efficiency for automatic cyberbullying detection with Feature Density. Inf Process Manag 58(5):102616
Al Shalabi L, Shaaban Z, Kasasbeh B (2006) Data mining: A preprocessing engine. J Comput Sci 2(9):735–739
Dey RK, Das AK (2022) A simple strategy for handling ‘not’can improve the performance of sentiment analysis. International conference on computational intelligence in pattern recognition. Singapore, Springer Nature Singapore, pp 255–267
Alshammari SM, Nielsen RD (2018) Less is more: with a 280-character limit, Twitter provides a valuable source for detecting self-reported flu cases. In: Proceedings of the 2018 international conference on computing and Big Data, pp 1–6
Meng J, Zheng Z, Tao G, Liu X (2016) User-specific rating prediction for mobile applications via weight-based matrix factorization. In: 2016 IEEE international conference on web services (ICWS), IEEE, pp 728–731
Chia ZL, Ptaszynski M, Masui F, Leliwa G, Wroczynski M (2021) Machine Learning and feature engineering-based study into sarcasm and irony classification with application to cyberbullying detection. Inf Process Manag 58(4):102600
Venkatesh B, Anuradha J (2019) A hybrid feature selection approach for handling a high- dimensional data. In: Innovations in computer science and engineering. Springer, pp 365–373
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK).
Author information
Authors and Affiliations
Contributions
M.Y. and C.O.A. designed the study; M.Y. performed the study; C.O.A. analyzed the data; and M.Y. and C.O.A. wrote the paper. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflicts of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Aliyeva, Ç.O., Yağanoğlu, M. Deep learning approach to detect cyberbullying on twitter. Multimed Tools Appl (2024). https://doi.org/10.1007/s11042-024-19869-3
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11042-024-19869-3