
Abstract
Pollen-induced allergies affect a significant part of the population in developed countries. Current palynological analysis in Europe is a slow and laborious process which provides pollen information in a weekly-cycle basis. In this paper, we describe a system that allows to locate and classify, in a single step, the pollen grains present in standard glass microscope slides. Besides, processing the samples in the z-axis allows us to increase the probability of detecting grains compared to solutions based on one image per sample. Our system has been trained to recognise 11 pollen types, achieving 97.6 % success rate locating grains, of which 96.3 % are also correctly identified (0.956 macro–F1 score), and with a 2.4 % grains lost. Our results indicate that deep learning provides a robust framework to address automated identification of various pollen types, facilitating their daily measurement.
Similar content being viewed by others


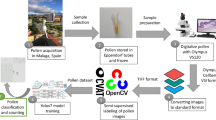
Avoid common mistakes on your manuscript.
1 Introduction
This work aims to contribute to the development of reliable automated pollen identification systems. Using deep learning techniques, we develop a multifocal pollen localisation and identification technique that improves the performance of single-image based approaches. In addition, our proposal eliminates the need for a robust microscope autofocusing algorithm because it exploits information from multiple video frames.
Accurate identification of pollen grains plays a significant role in different disciplines such as allergology [6], forensics or agriculture [33]. In allergology, measuring the daily concentration of pollen types helps to predict its daily evolution. However, the most extended estimation protocol requires human identification with an optical microscope of the pollen grains adhered to a tape from an environmental sampler [17]. This task is time-consuming, so multiple automatic image processing algorithms have been proposed in the bibliography to try to systematise the process. There are other techniques that can be used to locate and classify pollen grains, such as electron microscopy or polymerase chain reaction, but they are costly in both economic and temporal terms [33].
In light microscopy, the search and identification of pollen grains (detection) using computer vision techniques has several handicaps. Among them we can identify those associated with the visually irregular substrate used to capture grains, and others associated to the volumetric nature of pollen grains. The substrate, made with an adhesive applied on a transparent film, generates a very irregular background that makes it difficult to identify the edge of the grains in the image. Besides, the volumetric character of pollen grains requires the use of several focal planes per sample to guarantee that the location of all grains is captured.
This latter effect is illustrated in Fig. 1, where we can observe the significant variation in appearance and visibility of several pollen grains in a sample, depending on the focal plane chosen to perform detection. This effect is often ignored in automated pollen detection papers, where only one image per view is used in the process [8, 20, 24, 27, 30, 37]. This results in loss of grains when processing the sample, distorting the true pollen concentration value.

Different focal planes of the same area in a sample
The classic approach to this problem revealed considerable difficulties in automatic localisation [8, 33] and significant success rates in classification [2, 33]. For this reason, proposals based on deep learning have focused primarily on addressing the classification of segmented samples [7, 35]. However, in [11] we analysed the problem of pollen grain localisation using deep learning techniques with encouraging results, and now we address detection by extending the ideas previously developed.
For the training and test of a deep learning-based computer vision system, it is very important to have a large and representative database of the images to be learned and recognised. Published research studies in pollen classification and localisation have usually been developed with self-collected and private databases. Although there are some open datasets, none of them allow 3D pollen detection, either because they contain only segmented grains [3,4,5, 9, 13] or because they provide only one image per sample [19,20,21]. In addition, the resolution is usually low, and the edge of the grains often have artefacts due to image scaling. There are also private and non-accessible datasets associated with commercial products such as BAA500 [15] line or Classifynder [23].
In this paper we study how to address not only the classification but also the localisation of pollen grains, in a unified way, using deep learning techniques. This task required the development of a new image database that allows the study of the 3D appearance of pollen grains by the usage of several focal planes in the detection phase. To the best of our knowledge, this is the first database that enables pollen detection from more than one focal plane per sample (z-stacked images) using light microscopy.
2 Data
In this Section, we describe the characteristics of our pollen dataset (CAPI Pollen DB2). The dataset is available online at https://capi.unex.es/pollendb2.
Generally, pollen grain sizes vary in the range 8 - 100 \(\mu m\), and visually may appear as spheroidal objects. Natural samples also contain dust, debris and spores, which in some cases may also have a spherical shape. Figure 2 shows an example of the type images to be processed.

An olea sample with adhesive surface artefacts, dust particles and blurred grains due to lack of focus
This work is based on a set of slides prepared in the laboratory, where each slide contains grains of only one pollen type. This configuration facilitates the tasks of labelling the objects present in each image. Firstly, pollen slides were coloured with fuchsin according to the usual REA protocol [28]. Then, we collected from 15 to 40 video samples from each slide, depending on the variable concentration of grains present in it, in non-overlapping areas. Each sample was originally captured at 1280x1024 RGB pixels with a x40 magnification, and provides at least 21 views around a manually adjusted focus position. As a result, we have a dataset of 386 samples including 11 different pollen types, listed in Table 1. The table also reflects the number of grains contained in the dataset, both completely visible and those that appear cut in the limits of the samples.
In the test phase, our system performs inference on 21 images per sample. A cross-validation scheme would force all the focal planes of each sample to be labelled in order to allow their random selection for training or testing. This massive labelling process is unfeasible because of the time it would require. Therefore, to verify the performance of our system, we must make a reasonable distribution of the available samples between fixed training and test sets. The visual complexity of the input samples is naturally variable, so that some samples contain many grains and others just one. This way, we made an a priori distribution of the samples to try to achieve an overall proportion of 60% of the grains for the training set, and the remaining 40% for the test set and simultaneously match the complexity of both sets. Following this guideline, we sorted the samples of each type by descending grain density, and then made an alternative assignment of the samples to the training or test set. With this procedure, we ensure that both sets contain samples of similar complexity, granting 251 samples to the training set an 135 to the test set. With this allocation, we have 2038 full grains to adjust the model and 1235 to test its performance using z-stacks.
An efficient identification of the pollen grains present in a sample requires the analysis of several focal planes, to be able to detect surface ornamentation characteristic of the type of grain, if they are visible. Therefore, in the test phase, several frames of a sample should be used to perform an efficient identification. However, manual bounding box annotation is tedious, especially for images having many objects or overlapped objects [22]. Because of this, in every test sample we annotated the location of the grains but only on the focal plane where the grain border is sharpest. This strategy enables performance assessment, by allowing comparison with the ground truth boxes defined, and reduces the dataset labelling workload.
When addressing the annotations of the training set, we must try to provide different focal planes of the same grain, to include views in which differentiating surface ornamentation can be observed, at least for the types of grain where this is useful. As in the case of the samples in the test set, marking all available frames of a sample is an arduous task. In addition, by varying the focal plane we can observe little changes in the position, dimensions and sharpness of the grains, even becoming invisible in certain planes. This way, the sample ground truth annotations must be manually relocated for each image to be used in training.
The morphological changes that can be seen by varying the focal plane depend largely on the type of pollen. In order to make a database that best describes the set of pollen types to be recognised, we have used a tagging strategy that provides more training images for those samples that show greater morphological variation when changing the focal plane. The proportion of images per sample used for each type of pollen is collected in Table 2, together with the number of samples used to adjust the model and the number of grains available of each type.
3 Methods
3.1 Network models
Today, there are multiple integrated environments that facilitate the development of solutions based on deep learning models, such as TensorFlow [1], PyTorch [29] or Caffe [18]. In this work, we use the Detectron framework [12], developed using PyTorch. The design goal of Detectron is to be flexible in order to support the rapid implementation and evaluation of research projects. This framework includes, under a common configuration system, fast implementations of various state-of-the-art object detection algorithms, such as Faster R-CNN [34], RetinaNet [26] or Mask R-CNN [14].
The volumetric characteristics of the problem we are addressing require the use of multiple images per sample in detection, so the detection time is a key parameter in our study. Works based on one-stage models, such as YOLO variants [31, 32] or RetinaNet, usually report low inference times, but a typically lower mean precision. Our goal is to reach a high accuracy, so to establish a performance reference we will compare the operation of our z-stacking localisation and classification proposal using two different network models. First we will adjust a Faster R-CNN model with a Feature Pyramid Network (FPN) [25], the current ‘standard’ two-stage reference model [22]. And we will compare its results with those obtained by a RetinaNet model adjusted and tested under the same conditions, to determine if this type of network model presents a better trade-off between speed and accuracy.
The reference RetinaNet architecture uses a Feature Pyramid Network (FPN) backbone on top of a feed forward ResNet architecture [16] to generate its feature pyramid. For a stable training of deep learning models, the transfer learning technique [36] is commonly employed, which allows reusing convolution weights from a pretrained network on a large dataset. Since Detectron also allows to use a ResNet type backbone to adjust a Faster R-CNN model, we will use the original MSRA’s ResNet50 pretrained model to initialise the network models under study.

(a) Default Faster R-CNN and RetinaNet anchors with aspect ratios 1:1 (green), 1:2 (blue) and 2:1 (red). (b) Base anchor used in our proposal with aspect ratio 1:1
Both RetinaNet and Faster R-CNN algorithms use three anchor boxes with the aspect ratios shown in Fig. 3a. Rectangular anchors are useful for modelling long objects on the x or y axes, but in our case the objects to be modelled are mainly circular, and the use of rectangular anchors can worsen the detection performance with clustered pollen grains. Therefore, we configured training to use a single square anchor for adjusting both network models, as shown in Fig. 3b.
Finally, to achieve low inference times, the input images were scaled to 640x512 pixels before adjusting both models.
3.2 Network training
To adjust our models we used a GTX 1070 Ti GPU with 8GB of RAM, running in a dedicated local computer.
For both networks, the training solver was configured to use minibatch stochastic gradient descent (SGD) with 2 images per GPU and 256 ROIs per image. Hence, the number of ROIs per training minibatch was 512. We used a weight decay of 0.0001 and momentum of 0.9. Both models were trained for 60,000 iterations with an initial learning rate of 0.0025, which is multiplied by 0.1 at iteration 20,000 and again at 40,000. Therefore, 120,000 images were used during the training phase, which would equal around 206 epochs. To combat overfitting we have configured the L2 regularisation mechanism.
In the case of the Faster R-CNN model, the FPN-based RPN uses pyramid levels from 2–5 and a single square aspect ratio, with a minimum anchor size of 32 pixels. With these parameters, the training process of this model took 3 hours and 31 minutes.
In the RetinaNet model, the FPN described in [25] was used as the backbone network. We configured the model to consider a single squared anchor per location, spanning 3 sub-octave scales on Pyramid Levels 3–7. The focal loss parameters were adjusted to the recommended values in [26], and the smooth L1 loss beta for bounding box regression was set to 0.11. In this case, the adjustment of the model required 3 hours and 25 minutes.
3.3 Single vs. z-stacked samples
In a typical multiclass object detection application, performance metrics are calculated on a single image per sample, in which all present objects are visible and labelled. In our task, the use of a single image per sample could result in undetected grains for that sample, due to the invisibleness of the grain in the chosen focal plane, or the impossibility of grain classification due to its level of blur.
Image based pollen detection should consider various images included in the z-stack, which eliminates the need to determine an appropriate focal plane. However, this strategy generates handicaps when determining overlap between a detection and the stored ground truth bounding box associated to other focal plane (Fig. 4a), or when applying non-maximum suppression (NMS) algorithms to the z-stack of a sample that contains high overlapping grains visible in distant focal planes (Fig. 4b). Besides, in the classification step, the highest score class of a grain could vary when analysing the z-stack images, as Fig. 5 illustrates. Therefore, it may be necessary to add a decision algorithm, such as majority voting or based on confidence levels.

(a) Underestimation of IoU if the system selects a detection (blue) in a focal plane other than the one defined in the annotation (green). (b) Highly overlapped grains in a Dactilys sample complicates multifocal NMS

Exemplification of an undefined classification condition by using several focal planes. Green grains represent sharp objects and red grains represent blurry objects. The orange and cyan objects represent a highly overlapping grain pattern
To evaluate the impact that using multiple focal planes has on the performance, in comparison with the use of a single image, we have created a test set containing one image per sample. In this set, the image chosen for each sample is the one that contains the largest number of labelled grains in the database. In a real situation, the automatic determination of the most suitable plane is not a simple or robust task, given the high variability of the image space. Therefore, the results on this set should be understood as those that would be obtained with the best possible focal plane of each sample.
3.4 Performance assesment
In object detection, Intersection over Union (IoU) is used both to eliminate redundant detections in NMS algorithms and to measure the accuracy of a detection proposal. This parameter reaches a value of 1.0 when the proposal is perfectly overlapped with the ground truth bounding box, and a minimum value of 0.5 is usually considered a good object detection [10].
When addressing detection, a proposal is considered a success (TP, true positive) when localisation is a success and the predicted class matches that specified in the annotation. However, an error in the assigned class can still be used to estimate the total pollen concentration, so we will name this detections wrong class (WC). Finally, as is commonly accepted, a false positive (FP) accounts for background or other structures detected as grain and a false negative (FN) implies an undetected grain present in the sample.
In this work, true positive detections generated at the edges of the sample, associated with partially visible grains, are discarded and do not contribute to the success rate. Nevertheless, in order to provide a complete view of the system performance, these detections are identified as \(TP_{E}\) if they overlap with a grain present at the edge of the sample. Otherwise, are counted as a FP. Partial grains in a sample should be discarded because in sequential operation they must be suppressed by the NMS algorithm in the adjacent sample.
Under these premises, we characterise the classification performance of adjusted models through the usual definition of Precision (P), Recall (R) and an averaged F1-score. The nature of our data set makes it virtually impossible to generate a balanced test set. The randomness of a pollen grain impact on the adherent surface results in a different number of grains in each video. Given the unbalance of the dataset, a micro averaged F1-score would not provide a correct measurement of the system performance, therefore a macro or weighted averaging of F1-score should be used.
The macro averaged F1-score (\(F1_M\)) calculates the arithmetic mean of the F1-scores of each class as shown in Eq. (1), thus assigning equal importance to all classes. On the other hand, a weighted averaged F1-score (\(F1_W\)) as shown in Eq. (2) assigns a higher importance to the classes with more grains in the data set. In both equations \(N_{cls}\) is the number of classes in the experiment, \(F1_i\) is the F1-score of the i-th class, N is the total number of grains to be detected and \(N_i\) is the number of grains to be detected in the i-th class.
Both forms of F1 averaging are interesting in this case. On the one hand, pollen types with small grains tend to be more numerous and difficult to locate than large grains, which would incline us to choose the weighted version of the parameter. But on the other hand, this metric could hide an anomalous performance in some pollen types less represented in the test set. Therefore, we will use both metrics to decide which model performs more robustly. Obviously, WC detections are counted as FP when performing multi-class performance analysis.
The location correctness is expressed by the average IoU value between each bounding box generated with respect to the ground truth box stored in the database.
3.5 Managing z-stacked samples
The response of both network models after processing an image is a list of object proposals (given by bounding boxes), with an associated class and confidence score. Therefore, after processing an image of the z-stack, with a confidence cut-off of 0.75, and applying NMS to the list of detections, ideally we obtain a single proposal for each grain identifiable in the image. The NMS algorithm has been configured to rule out non-maximum score detections with an IoU overlap threshold of 0.5.
When processing the z-stack images, we obtain multiple proposals for the same grain, so a second NMS algorithm has to be applied to select the highest confidence proposal for each grain in the z-stack. However, the NMS algorithm could eliminate proposals for different grains, located in different focal planes, which appear heavily overlapped when merging the proposals on the Z axis. This result can be seen in Fig. 5, where the detection of the grain G2 with a score of 0.99 would eliminate the grain G1 detected in another plane with a lower score. To minimise this effect, we establish a more restrictive overlap threshold in the NMS algorithm, since two bounding boxes associated with the same grain in consecutive planes must be very close. As we have previously verified in localisation [11], both network models provide bounding boxes very tight to the contour of the grains, so we have raised the overlap threshold of this second NMS to 0.7.
This multi-view analysis simulates the sampling on the Z axis around a reference position made by a palynologist. After a review of the grains labelled in the database, we have concluded that using 21 focal planes around a manually selected focused position, all grains present in all samples can be located. The complete process can be seen in Fig. 6.

Complete multifocal grain detection process. The proposals generated in each focus plane are merged to obtain the final proposals, which increases the detection possibilities
4 Results and discussion
The average per-image processing time for both networks was similar: 59 ms for the Faster R-CNN model and 58 ms for the RetinaNet. In both cases, the same GPU and number of images (2863) were used to perform the detection of pollen grains.
4.1 Evaluation of the z-stacking approach
As stated in Section 2, the total number of pollen grains in the test set to be located and classified automatically is 1235. To compare the improvement in performance achieved by our z-stacking technique, we summarise the relevant results in Table 3. The table shows the results of this study for both network models, using both one image per sample and our z-stacking algorithm.
Boxes indicates the number of proposals generated by models that exceed the established score threshold after z-stack processing. True positives generated over partial border grains (\(TP_{E}\)) are shown for clarity by allowing the sum of TP, WC, FP and \(TP_E\) to match Boxes. Finally F1 scores are the metrics used to compare the experiments.
The results clearly show that both network models have high performance detecting the considered pollen types over the test set, reaching success rates that exceed 96 % of the grains manually identified. Besides, at equal network backbone, the improvement obtained when using z-stacked samples exceeds 2.4 % in terms of success rate and 2.7 % in terms of loss of grains. The low number of false positives generated in both cases is a consequence of the network’s ability to adequately model the image space and the high value required for the minimum score of the candidates.
By analysing Table 3 we can see that, under the same NMS conditions, the network with RetinaNet structure has a slightly lower weighted averaged F1-score than that obtained with the Faster R-CNN model, which we take as reference. However, the difference is greater when using the macro averaged indicator. Both models exhibit high performance indicators and practically the same inference time in our test environment, but, in view of the higher averaged F1-scores obtained by the Faster R-CNN model, we would choose the latter as the basis for the next sections.
4.2 Evaluation of multi-label classification
Table 4 shows the confusion matrix for the Faster R-CNN model over the test set. The table also details accuracy, recall rates and F1-score for the pollen types considered in this study.
The matrix shows that most of the proposals are located in the main diagonal, which indicates that, in global terms, the model shows a very good performance in the identification of the pollen types considered. Nevertheless, an evident identification error occurs when the model identifies some Avena sterilis grains as Avena sativa. The visual appearance of both types of grain is very similar under the microscope, and the model seems to favour the sativa type over the sterilis one. In any case, the low number of grains present in the available Avena sativa samples reduces the significance of this result.
4.3 Evaluation of location accuracy
The accuracy in the location of the grains is measured by expressing the IoU of the accepted proposal with the ground truth. Table 5 shows these values along with their standard deviation, both globally and for each pollen type considered in the study.
As can be seen, the average accuracy value for pollen grains is 0.91. In Section 3.3 we established that a value of 0.5 is usually considered enough for macroscopic objects. Therefore, the value obtained exceeds this threshold and validates our initial decision of requiring a high IoU when the NMS fusing algorithm is applied to the z-stack.
4.4 Discussion
A fair comparison with other works in this field is somewhat complex since not all studies address both the localisation and classification phases. Also, even if they perform full detection, the size of the test set affects performance metrics. Indeed, we can find works with excellent results for classification only, that even report F1-scores of 1.0 [7] when analysing an already segmented set of 392 pollen grains of 10 types. But when considering both tasks in an integrated system, performance falls, and the comparison of results became difficult, due not only to differences in the structure of the validation sets, but also to the lack of localisation or classification metrics. In [8] a recall of 0.819 is reported at an associated precision of 0.185 for 24 pollen types. And in an older study [27], a 0.938 recall and 0.895 precision is reported in detection for a 0.964 identification recall. Finally, in [20, 21], which addresses detection, Khanzhina et al. reported more than 96.2 mAP using a new bayesian focal loss on two datasets with single image per sample format, thus ignoring possible grains in other focal planes.
5 Conclusion
In this paper we have proposed a pollen grain detection system that increases the probability of detection by processing each sample in three dimensions. The enhancement obtained (2.4%) suggests that the use of a single image per sample underestimates the number of real grains in it. Furthermore, the z-stack processing also avoids repetitive focusing operations when scanning the slide both in x and y axes.
We have studied the ability of two deep learning based systems to carry out an efficient detection of 11 pollen types on standard slides. In both cases we have obtained very high performance rates, not only in identification of the pollen type, but also in location accuracy. Regarding the ability to identify the type of pollen grains, the model based on Faster R-CNN exhibits a slightly higher capacity, though both are very efficient for the proposed study.
This work represents an important step towards the implementation of reliable automatic systems for the estimation of specific pollen concentrations, reducing human intervention and costs. It therefore contributes to facilitate its use in allergy management. In addition, thanks to the low cost of the necessary technical equipment, integration into a palynology laboratory is straightforward.
Methods in this paper can be extended to identify other pollen types by generating systems tuned to a given work area. The development of a universal pollen detector may be difficult due to regional differences in the composition of airborne pollen.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Abadi M, Agarwal A, Barham P, Brevdo E, Chen Z, Citro C, Corrado GS, Davis A, Dean J, Devin M, Ghemawat S, Goodfellow I, Harp A, Irving G, Isard M, Jia Y, Jozefowicz R, Kaiser L, Kudlur M, Levenberg J, Mané D, Monga R, Moore S, Murray D, Olah C, Schuster M, Shlens J, Steiner B, Sutskever I, Talwar K, Tucker P, Vanhoucke V, Vasudevan V, Viégas F, Vinyals O, Warden P, Wattenberg M, Wicke M, Yu Y, Zheng X (2015) TensorFlow: Large-scale machine learning on heterogeneous systems. https://doi.org/10.5281/zenodo.4724125
Arias DG, Cirne MVM, Chire JE, Pedrini H (2017) Classification of pollen grain images based on an ensemble of classifiers. In: 2017 16th IEEE International Conference on Machine Learning and Applications. https://doi.org/10.1109/ICMLA.2017.0-153
Astolfi G, Gonçalves AB, Menezes GV, Borges FSB, Astolfi ACMN, Matsubara ET, Alvarez M, Pistori H (2020) Pollen73s: An image dataset for pollen grains classification. Ecol Inform. https://doi.org/10.1016/j.ecoinf.2020.101165
Battiato S, Ortis A, Trenta F, Ascari L, Politi M, Siniscalco C (2020) Pollen13k: A large scale microscope pollen grain image dataset. In: 2020 IEEE International Conference on Image Processing. https://doi.org/10.1109/ICIP40778.2020.9190776
Chudyk C, Castaneda H, Léger R, Yahiaoui I, Boochs F (2015) Development of an automatic pollen classification system using shape, texture and aperture features. In: LWA 2015 Workshops: KDML, FGWM, IR, and FGDB, p 65–74
D’Amato G, Cecchi L, Bonini S, Nunes C, Annesi-Maesano I, Behrendt H, Liccardi G, Popov T, Van Cauwenberge P (2007) Allergenic pollen and pollen allergy in Europe. Allergy. https://doi.org/10.1111/j.1398-9995.2007.01393.x
Daood A, Ribeiro E, Bush M (2018) Sequential recognition of pollen grain z-stacks by combining CNN and RNN. In: Brawner K, Rus V (eds) Proceedings of the Thirty-First International Florida Artificial Intelligence Research Society Conference. AAAI Press, Melbourne, p 8–13
Díaz-López E, Rincón M, Rojo J, Vaquero C, Rapp A, Salmeron-Majadas S, Pérez-Badia R (2015) Localisation of pollen grains in digitised real daily airborne samples. In: Ferrández Vicente JM, Álvarez-Sánchez JR, de la Paz López F, Toledo-Moreo FJ, Adeli H (eds) Artif. Comput Biol Med. https://doi.org/10.1007/978-3-319-18914-7_37
Duller A, Guller G, France I, Lamb H (1999) A pollen image database for evaluation of automated identification systems. Quat Newsl 89:4–9
Everingham M, Eslami SMA, Van Gool L, Williams CKI, Winn J, Zisserman A (2015) The pascal visual object classes challenge: a retrospective. Int J Comput Vis. https://doi.org/10.1007/s11263-014-0733-5
Gallardo-Caballero R, García-Orellana C, García-Manso A, González-Velasco H, Tormo-Molina R, Macías-Macías M (2019) Precise pollen grain detection in bright field microscopy using deep learning techniques. Sensors. https://doi.org/10.3390/s19163583
Girshick R, Radosavovic I, Gkioxari G, Dollár P, He K (2018) Detectron. https://github.com/facebookresearch/detectron. Accessed 20 Jan 2024
Gonçalves AB, Souza JS, Silva GGd, Cereda MP, Pott A, Naka MH, Pistori H (2016) Feature extraction and machine learning for the classification of Brazilian Savannah pollen grains. PLoS ONE. https://doi.org/10.1371/journal.pone.0157044
He K, Gkioxari G, Dollar P, Girshick R (2017) Mask R-CNN. In: The IEEE International Conference on Computer Vision. https://doi.org/10.1109/ICCV.2017.322
Heimann U, Haus J, Zuehlke D (2009) Op3 - fully automated pollen analysis and counting: The pollen monitor BAA500. In: Proceedings OPTO 2009 & IRS2 2009, pp 125–128. https://doi.org/10.5162/opto09/op3
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition. https://doi.org/10.1109/CVPR.2016.90
Hirst JM (2008) An automatic volumetric spore trap. Ann Appl Biol. https://doi.org/10.1111/j.1744-7348.1952.tb00904.x
Jia Y, Shelhamer E, Donahue J, Karayev S, Long J, Girshick R, Guadarrama S, Darrell T (2014) Caffe: Convolutional architecture for fast feature embedding. In: Proceedings of the 22nd ACM International Conference on Multimedia. Association for Computing Machinery, Orlando. https://doi.org/10.1145/2647868.2654889
Jin B, Milling M, Plaza MP, Brunner JO, Traidl-Hoffmann C, Schuller BW, Damialis A (2023) Airborne pollen grain detection from partially labelled data utilising semi-supervised learning. Sci Total Environ 891:164295. https://doi.org/10.1016/j.scitotenv.2023.164295
Khanzhina N, Filchenkov A, Minaeva N, Novoselova L, Petukhov M, Kharisova I, Pinaeva J, Zamorin G, Putin E, Zamyatina E, Shalyto A (2022) Combating data incompetence in pollen images detection and classification for pollinosis prevention. Comput Biol Med. https://doi.org/10.1016/j.compbiomed.2021.105064
Khanzhina N, Kashirin M, Filchenkov A (2023) New bayesian focal loss targeting aleatoric uncertainty estimate: Pollen image recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, p 4253–4262
Koirala A, Walsh KB, Wang Z, McCarthy C (2019) Deep learning - method overview and review of use for fruit detection and yield estimation. Comput Electron Agric. https://doi.org/10.1016/j.compag.2019.04.017
Lagerstrom R, Holt K, Arzhaeva Y, Bischof L, Haberle S, Hopf F, Lovell D (2015) Pollen Image Classification Using the Classifynder System: Algorithm Comparison and a Case Study on New Zealand Honey. Springer International Publishing, Cham, p 207–226. https://doi.org/10.1007/978-3-319-10984-8_12
Landsmeer S, Hendriks E, De Weger L, Reiber J, Stoel B (2009) Detection of pollen grains in multifocal optical microscopy images of air samples. Microsc Res Tech. https://doi.org/10.1002/jemt.20688
Lin T, Dollar P, Girshick R, He K, Hariharan B, Belongie S (2017) Feature pyramid networks for object detection. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer Society, Los Alamitos. https://doi.org/10.1109/CVPR.2017.106
Lin T, Goyal P, Girshick R, He K, Dollár P (2017) Focal loss for dense object detection. In: 2017 IEEE International Conference on Computer Vision. https://doi.org/10.1109/ICCV.2017.324
Nguyen NR, Donalson-Matasci M, Shin MC (2013) Improving pollen classification with less training effort. In: 2013 IEEE Workshop on Applications of Computer Vision. https://doi.org/10.1109/WACV.2013.6475049
Oteros J, Galán C, Alcázar P, Domínguez-Vilches E (2013) Quality control in bio-monitoring networks, Spanish Aerobiology Network. Sci Total Environ. https://doi.org/10.1016/j.scitotenv.2012.11.040
Paszke A, Gross S, Massa F, Lerer A, Bradbury J, Chanan G, Killeen T, Lin Z, Gimelshein N, Antiga L, Desmaison A, Kopf A, Yang E, DeVito Z, Raison M, Tejani A, Chilamkurthy S, Steiner B, Fang L, Bai J, Chintala S (2019) Pytorch: an imperative style, high-performance deep learning library. In: Advances in Neural Information Processing Systems, vol 32. Curran Associates, Inc., Vancouver. https://doi.org/10.5555/3454287.3455008
Ranzato M, Taylor P, House J, Flagan R, LeCun Y, Perona P (2007) Automatic recognition of biological particles in microscopic images. Pattern Recognit Lett. https://doi.org/10.1016/j.patrec.2006.06.010
Redmon J, Divvala S, Girshick R, Farhadi A (2016) You only look once: Unified, real-time object detection. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). https://doi.org/10.1109/CVPR.2016.91
Redmon J, Farhadi A (2017) Yolo9000: Better, faster, stronger. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition. https://doi.org/10.1109/CVPR.2017.690
Redondo R, Bueno G, Chung F, Nava R, Marcos JV, Cristóbal G, Rodríguez T, Gonzalez-Porto A, Pardo C, Déniz O, Escalante-Ramírez B (2015) Pollen segmentation and feature evaluation for automatic classification in bright-field microscopy. Comput Electron Agric. https://doi.org/10.1016/j.compag.2014.09.020
Ren S, He K, Girshick R, Sun J (2015) Faster R-CNN: Towards real-time object detection with region proposal networks. In: Advances in Neural Information Processing Systems. https://doi.org/10.1109/TPAMI.2016.2577031
Sevillano V, Aznarte JL (2018) Improving classification of pollen grain images of the polen23e dataset through three different applications of deep learning convolutional neural networks. PLoS ONE. https://doi.org/10.1371/journal.pone.0201807
Yosinski J, Clune J, Bengio Y, Lipson H (2014) How transferable are features in deep neural networks? In: Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2. MIT Press, Cambridge. NIPS’14. https://doi.org/10.5555/2969033.2969197
Zhao LN, Li JQ, Cheng WX, Liu SQ, Gao ZK, Xu X, Ye CH, You HL (2022) Simulation palynologists for pollinosis prevention: A progressive learning of pollen localization and classification for whole slide images. Biology 11(12). https://doi.org/10.3390/biology11121841
Funding
Open Access funding provided thanks to the CRUE-CSIC agreement with Springer Nature. This work was partly supported by “Junta de Extremadura” and “Fondo Europeo de Desarrollo Regional” under grant GR21087.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gallardo, R., García-Orellana, C.J., González-Velasco, H.M. et al. Automated multifocus pollen detection using deep learning. Multimed Tools Appl (2024). https://doi.org/10.1007/s11042-024-18450-2
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11042-024-18450-2