
Abstract
This paper explores the use of chest CT scans for early detection of COVID-19 and improved patient outcomes. The proposed method employs advanced techniques, including binary cross-entropy, transfer learning, and deep convolutional neural networks, to achieve accurate results. The COVIDx dataset, which contains 104,009 chest CT images from 1,489 patients, is used for a comprehensive analysis of the virus. A sample of 13,413 images from this dataset is categorised into two groups: 7,395 CT scans of individuals with confirmed COVID-19 and 6,018 images of normal cases. The study presents pre-trained transfer learning models such as ResNet (50), VGG (19), VGG (16), and Inception V3 to enhance the DCNN for classifying the input CT images. The binary cross-entropy metric is used to compare COVID-19 cases with normal cases based on predicted probabilities for each class. Stochastic Gradient Descent and Adam optimizers are employed to address overfitting issues. The study shows that the proposed pre-trained transfer learning models achieve accuracies of 99.07%, 98.70%, 98.55%, and 96.23%, respectively, in the validation set using the Adam optimizer. Therefore, the proposed work demonstrates the effectiveness of pre-trained transfer learning models in enhancing the accuracy of DCNNs for image classification. Furthermore, this paper provides valuable insights for the development of more accurate and efficient diagnostic tools for COVID-19.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
COVID-19 has infected over 1.3 million people around the world and caused the deaths of over 106,000 cases. Inefficiency and a lack of diagnosis are two major roadblocks to regulating the progression of this disease [1,2,3]. Measures using Reverse Transcription-Polymerase Chain Reaction (RT-PCR) are used in most current assays. It takes 4–6 h to get results, which is a significant time difference when compared to COVID-19's quick spread rate. As a result, many infected cases go undetected for long periods, infecting others unintentionally [4,5,6]. Deep learning (DL) algorithms for diagnosing COVID-19 using CT scans are becoming more popular. As a result, many infected cases go undetected for long periods, infecting others unintentionally [7,8,9]. Furthermore, in nutrition during COVID-19, machine learning algorithms can be utilized to recommend a suitable diet during a pandemic [10].
The lack of COVID-19-CT scan images causes a challenge for DL models that have a risk of overfitting when trained on small datasets.
The goal of transfer learning is to use data-rich source tasks to aid the learning of a data-deficient target task for a CT-based diagnosis of COVID-19 [11, 12]. Pre-training powerful visual feature extraction DL models on large images in the source tasks and then fine-tuning the network weights on the target task's tiny dataset is a common strategy, especially in medical application [13]. We developed multiple transferring procedures and conducted a detailed analysis of the dimensions of source-target domain difference to investigate the effects of transfer learning for COVID-19 diagnosis [14, 15]. This paper proposed a pre-trained CT model with a TL approach including ResNet (50), VGG (19), VGG (16) and Inception V3 to identify and predict pneumonia from chest CT scan images. Instead of using DCNN directly in the classification process, pre-trained are used to boost the results obtained and for comprehensive analysis [16]. The Binary Cross Entropy (BCE) with its loss function is used to perform the classification procedure. Transfer learning is used to generate a pneumonia diagnosis model with chest CT scan images. Chest CT scans have been shown to aid in the early detection of COVID-19, and recent studies have explored the use of machine learning (ML) and transfer learning (TL) models for improved diagnosis [17]. TL refers to the use of pre-trained models as a starting point for training a new model, thereby allowing for better performance with limited data [18]. ML and TL models can be used to accurately classify chest CT scans as either COVID-19 positive or negative, enabling faster and more effective diagnosis. In this paper, we explore the use of advanced techniques such as Binary Cross-Entropy (BCE) and Deep Convolutional Neural Networks (DCNN), combined with TL models such as ResNet(50), VGG (19), VGG (16) and Inception V3, to classify chest CT scans of individuals with confirmed COVID-19 and normal cases [19]. We utilize the COVIDx dataset, which provides a large sample size of chest CT images from patients with COVID-19, enabling a comprehensive analysis of the virus. The proposed method achieved high accuracy rates in the validation set, indicating its potential for aiding in the diagnosis of COVID-19. The use of ML and TL models in COVID-19 diagnosis has the potential to improve patient outcomes and reduce the burden on healthcare systems, especially in resource-limited settings. The limitations of the proposed computational approach for COVID-19 detection using chest CT scans include the limited availability of CT chest samples for training and the potential for misclassification of COVID-19 cases due to similar imaging characteristics with other respiratory diseases. In terms of computational challenges, further exploration of the optimal architecture and hyperparameters for the proposed model are investigated, as well as the potential for using other imaging modalities such as X-ray or MRI for COVID-19 detection. The research contributions of this study include the use of transfer learning and binary cross-entropy loss function to improve the accuracy of COVID-19 detection and the demonstration of the potential of deep learning algorithms in medical image analysis. The potential of combining different computational methods, such as computer vision and natural language processing, for more comprehensive diagnosis and treatment of COVID-19. The contributions to this paper are summarized as follows:
-
We proposed an efficient deep learning method for aiding in the diagnosis of COVID-19 based on CT scans.
-
Using the COVID- 19 CT scan dataset to train and evaluate the DCNN model, which contains 6018 positive CT scans with COVID-19 clinical findings and 7395 negative images.
-
We apply pretrained transfer learning models (ResNet(50), VGG (19), VGG (16) and Inception V3) in the presence of Binary Cross-Entropy to evaluate, compare and boost the results obtained.
The rest of the paper is planned as follows. Section 2 presents related works, Sect. 3 presents the proposed methods, Sect. 4 conducts evaluation and experimental analysis, and Sect. 5 concludes the paper with a future direction.
2 Related works
Currently, the researchers have been striving to develop deep learning algorithms for detecting the COVID-19 virus using CT scan images since the outbreak of COVID-19 as shown in Table 1.
The table presents a summary of various studies on the application of machine learning and deep learning algorithms for the detection of COVID-19 from chest CT and Covid-19 X-Ray (CXR) images. Cherti et al. [20] used few-shot transfer learning for COVIDx CT images and achieved an accuracy of 78.35%. Chowdhury et al. [21] used the fine-tuning approach with the ECOVNet model for COVIDx CXR images and achieved an accuracy of 96.07%. Baruch et al. [22] used knowledge distillation with the adaptation of the knowledge distillation for COVIDx CT and CXR images and achieved an accuracy of 91.30%. Mei et al. [23] used a CNN model for image classification from a dataset collected from 905 patients and achieved an accuracy of 99.40%. Maheen et al. [24], used a pre-trained CNN model for image classification of COVIDx CXR images and achieved an accuracy of 98.33%. Zhang et al. [25] used a linear mixed model for image classification of CT images collected from 2,460 SARS-CoV-2-positive patients and achieved an accuracy of 90%. Harkness et al. [26] used a CNN model for pneumonia detection from COVIDx CXR images and achieved an accuracy of 88%. Sarkar et al. [27] used the COGNEX model for COVID-19 chest X-rays classification and achieved an accuracy of 93.33%. Elzeki et al. [7] used the CXRVN model for the classification of CXR images based on normal, pneumonia, and COVID-19 and achieved an accuracy of 96.70%. Elzeki et al. [8] used VGG (19) for fusion and classification of CXR images collected from 25 patients and achieved an accuracy of 99.00%. ElAraby et al. [9] used the GSEN architecture for crawling the CXR images and classification, achieving an accuracy of 95.60%. Samee et al. [28] used VGG (19) with metaheuristic optimization for CXR images and achieved an accuracy of 99.88%. Finally, the proposed study used transfer learning with DCNN and BCE classifier with ResNet (50) for COVIDx CT images and achieved an accuracy of 99.07%. The proposed study aims to develop an efficient deep learning method to aid in the diagnosis of COVID-19 based on CT scans. The study uses the COVID-19 CT scan dataset, which includes 6018 positive CT scans with COVID-19 clinical findings and 7395 negative images. The study applies pretrained transfer learning models (ResNet (50), VGG (19), VGG (16) and Inception V3) with Binary Cross-Entropy to evaluate, compare and boost the results obtained. The study is unique and efficient from the existing ones because it uses a deep learning method with transfer learning models, which are well-established models in image recognition tasks. The proposed method achieves an accuracy of 99.07%, which is higher than most of the existing methods as shown in Table 1. Table 1 presents a summary of various studies on the application of machine learning and deep learning algorithms for the detection of COVID-19 from chest CT and Covid-19 X-Ray (CXR) images. The comparison shows that the proposed study outperforms most of the existing methods in terms of accuracy. The study achieves high accuracy by using transfer learning models, which provide a robust and efficient way of learning features from images. Therefore, the proposed study is distinguished by its use of transfer learning models and its high accuracy in diagnosing COVID-19 from CT scans. The study provides a promising approach to aid in the diagnosis of COVID-19 and can potentially assist healthcare professionals in making more accurate and timely diagnoses.
3 The proposed model
The proposed work depends on using a BCE classifier with different optimizers Stochastic Gradient Decent (SGD) and Adam optimizers for the diagnosis of COVID-19. Furthermore, the proposed model depends on the idea of transfer learning from pre-trained models such as ResNet (50), VGG (19), VGG (16) and Inception V3. In this paper, we used the COVID-X dataset of chest CT-scan images. As shown in Fig. 1, some preprocessing stages are used followed by extracting the features that are used by BCE for classification tasks based on the cross-entropy loss function. Table 2 shows the training hyperparameters used while fine-tuning the pre-trained model.

The proposed architecture for CT Scan images
3.1 Preprocessing and data augmentation
The applied CT images are downsized to 224 \(\times\) 224 \(\times\) 3 in size. However, in some circumstances, getting enough information is challenging, especially in medical cases, because it is a costly and time-consuming process. Data augmentation addresses this issue by maximizing the usage of existing data while also addressing the absence of input data [18]. After the dataset has been preprocessed and partitioned, it is used in the training process to increase training data, reduce the danger of over-fitting, and improve accuracy.
3.2 Feature extraction based pre-trained DCNN architecture
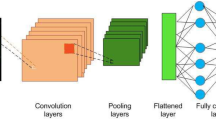
Medical image processing applications have demonstrated superior performance using Deep Neural Network (DNN) suggested models. However, due to the restricted availability of CT chest samples, training these algorithms from scratch to predict pneumonia can be challenging. To overcome this challenge, the use of pre-trained models based on transfer learning has been suggested. Transfer learning technique provides a pre-trained structure in an information base, either from the same or different domain, which enables users to solve new problems more efficiently and quickly. This technique uses a pre-trained model as the starting point for a few specified tasks, rather than relying on the traditional process of training with randomly initialized weights. Consequently, it reduces the significant computing resources required to create neural network models to address these difficulties. The use of transfer learning models in this paper has shown great promise in enhancing the accuracy and performance in predicting pneumonia, even with limited data availability. ResNet (50), VGG (19), VGG (16) and Inception V3 are the pre-trained DCNN models used in this paper as shown in Fig. 2. To enhance the classification accuracy and effectively distinguish between COVID-19 and normal cases, we propose a DCNN architecture that incorporates Transfer Learning (TL) models for feature extraction. In the proposed method, the feature extraction is performed based on pre-trained Deep Convolutional Neural Networks (DCNNs) architectures. These architectures are widely used in computer vision tasks and have achieved state-of-the-art performance on various datasets. The pre-trained models are utilized as feature extractors to capture the relevant features from the CT images. Specifically, the output of the last convolutional layer of each pre-trained model is used as a feature map for the input CT image. These feature maps are then flattened to a one-dimensional vector and fed to a fully connected layer for classification. The advantage of using pre-trained models as feature extractors is that they have learned to recognize complex features from large datasets, and this knowledge can be transferred to other related tasks with minimal training data. By leveraging these pre-trained models, the proposed method can effectively extract informative features from chest CT images, leading to improved classification performance. The extracted features are then fed into the Binary Cross-Entropy (BCE) classifier for optimal classification performance.

General Block Diagram of Proposed DCNN with Pre-Trained TL Models and BCE Classifier
3.3 Classification methods
After the features are extracted automatically using pre-trained models, BCE employs the binary cross-entropy loss function for model enhancement and overfitting reduction. The proposed architecture-based deep convolutional layer is presented in Fig. 3. The architecture contains seven convolutional layers and three max-pooling layers to produce the features. Batch normalization is utilized to make the architecture more stable and faster by centralizing and scaling the features in deep CNN networks. This is done by ignoring the connections in residual networks. Furthermore, it normalizes the pruning features, so the hyperparameter values are fine-tuned. Consequently, batch normalization normalizes the output of a previous activation layer by subtracting the batch mean and dividing it by the batch standard deviation. The remaining layers of the proposed DCNN were used to prepare the extracted features for the classification stage. The architecture of the DCNN model's layers is presented in Table 2.

The architecture layers of the proposed DCNN model
The output classifies two class labels: normal and COVID-19 cases for the applied COVIDx CT dataset. To boost the results obtained, we used BCE classifier after dropping the enrolled features and compared them with the deep transfer learning ResNet(50), VGG (19), VGG (16) and Inception V3 in the presence of binary cross-entropy.
3.4 Binary cross entropy classifier
The loss function binary cross-entropy is utilized in binary classification tasks. On many two-category tasks, it equals the average of the categorical cross-entropy loss that is calculated as in Eq. (1).
where \({\widehat{y}}_{i}\) is the i-th scalar value in the model output, \({y}_{i}\) is the corresponding target value, and the output size is the number of scalar values in the model output.
The binary cross-entropy is very convenient to train a model to solve many classification problems at the same time if each classification can be reduced to a binary choice. Table 3 displays the network's hyperparameters of the trained DCNN for Adam and SGD optimizers. We compare the Stochastic Gradient Descent (SGD) and Adaptive Moment Estimation(ADAM) optimizers set the learning rate at 0.001, the momentum at 0.9, and the batch size 64 for SGD and optimizers set the learning rate at 0.001, the momentum at 0.9, and the batch size 32 and set the learning rate at 0.001, the momentum at 0.9, and the batch size 32 for SGD and optimizers set the learning rate at 0.001 Beta1 = 0.9, Beta2 = 0.999 for Adam optimizer. The proposed model depends on performed hyperparameter tuning to optimize the performance of the deep convolutional neural networks (DCNNs). Specifically using pre-trained models like ResNet (50), VGG (19), VGG (16), and Inception V3, was employed to leverage knowledge from models trained on large datasets. This allowed the DCNNs to benefit from features learned from these models, leading to enhanced classification performance. To enhance the performance of DCNNs, the technique presented here includes carefully modifying hyperparameters such as learning rate, batch size, and number of layers. Furthermore, using pre-trained models improves classification performance by using information gathered from models trained on huge datasets. We propose a method for choosing the optimum hyperparameters for deep convolutional neural networks (DCNNs) in order to enhance their performance in this paper. We do hyperparameter tuning, which is methodically experimenting with alternative settings for important hyperparameters to identify the ideal combination. The learning rate, batch size, and number of layers are the exact hyperparameters discussed. The learning rate sets the step size at which the neural network's parameters are adjusted during training, whereas the batch size refers to the amount of data processed simultaneously in each iteration. We want to identify the values that result in the greatest model performance by modifying these hyperparameters. We want to find the optimal depth of the network that produces the greatest outcomes by methodically tweaking the number of layers. Furthermore, we use pre-trained models such as ResNet (50), VGG (19), VGG (16), and Inception V3. These models have been trained on them and have gained useful characteristics from them. We employed DCNNs to improve classification performance by leveraging transfer learning. Table 3 presents the outcomes of the hyperparameter tuning procedure, which presumably illustrates the better performance attained by the proposed model after optimizing the hyperparameters.
4 Results and discussion
This section discussed includes (i) the experimental setup, (ii) the pre-processing steps, (iii) the used dataset, (vi) the evaluation measures, (v) then the results of our proposed method. To ensure the effectiveness of our proposed model, the performance was compared with the performance of each pre-trained model individually.
4.1 Experimental setup
All the experiments were run on a laptop with a dual 8 GB GPU and 256 GB RAM. The average time of an epoch was multiplied by the number of epochs until the early stopping was used to calculate the training processing time. The remainder of this section is organized as follows. To compare them to well-known network models, we first explain image preprocessing, including contrast stretching and background removal. Finally, we show the results of scan-based categorization, which are calculated by combining patch-based scores. We compare the dataset to various pre-trained models for diagnosing cases, which are based on a variety of input data attributes.
4.2 Pre-processing
Image processing generally includes localization, segmentation, and normalization. The localization can detect the most interesting parts and highlight the patches of CT images. Segmentation is further required to extract the relevant data and reduce redundancy. The normalization of the enrolled images was performed to normalize the images in the visualization step. In this paper, augmentation processes were utilized to artificially constructs training images using a variety of processing techniques or a mix of techniques, such as random rotation, shifts, shear, and flips, among others [30]. The effects of data augmentation for the COVID-19 CT scan image database can be used to expand the dataset used. Furthermore, it is helpful to learn more data in DCNN [18].
4.3 Dataset
COVIDx CT, a benchmark CT image dataset derived from a variety of sources of CT imaging data currently comprising 104,009 images across 1489 patient cases. We used a sample of 13,413 cases that are divided into two class labels; 7395 infected COVID-19 cases and the remaining 6018 are not infected or normal cases. Figure 4 shows samples of chest CT images with COVID-19 CT cases and normal cases [31].

Example chest CT images from the COVIDx-CT dataset, (a) COVID-19 cases, and (b) Normal cases
4.4 Evaluation metrics
The evaluation metrics and CT scan image classification findings are presented in this section. Sensitivity, specificity, Precision, Negative Predictive Value (NPV), False Positive Rate (FPR), False Discovery Rate (FDR), False Negative Rate (FNR), accuracy, F1-score, and Matthews Correlation Coefficient (MCC) were all used to evaluate our model. The number of effectively classified negative and positive cases is defined as TN and TP, respectively. Furthermore, the terms FN and FP refer to the number of misclassified positive and negative instances, respectively. Where These evaluation measures were calculated using the TN, TP, FN, and FP formulas. Table 4 lists the definitions and equations for each evaluation metric. The learning curves are analysis curves that show the evaluation ratio for both the training and testing stages. Figure 5 displays the training accuracy value of the DCNN model and the loss value of the DCNN model in the case of the Adam optimizer. Figure 6 displays the validation accuracy value of the DCNN model and the Loss value of the DCNN model in the case of the Adam optimizer. Figure 7 and 8 display the training and validation curves using Stochastic Gradient Decent (SGD) optimizer.

(a) The training loss value of DCNN model, (b) The training accuracy value of DCNN model using Adam optimizer

(a) The validation loss value of DCNN model, (b) The validation accuracy value of DCNN model using Adam optimizer

(a) The training loss value of DCNN model, (b) The training accuracy value of DCNN model using SGD optimizer

(a) The validation loss value of DCNN model, (b) The validation accuracy value of DCNN model using SGD optimizer
4.5 Confusion matrix and testing accuracy
The DCNN model's performance metrics achieved the highest percentages for precision, recall, and F1 score metrics, with a percentage of accuracy compared with the model. It indicates how much the model can distinguish between classes. Figure 9 show the confusion matrix of SGD and Adam optimizer in the training stage. Furthermore, Fig. 10 investigates the cross validation of the images using both ADAM and SGD optimizers. Calculating the matrices measures is necessary for comparing the models, therefore the DCNN model achieves robustness results for CT scan image classification that are illustrated in Table 5, 6, 7 and 8.

The confusion matrixes for the training stage (a) SGD, (b) Adam

The confusion matrixes for the validation stage (a) SGD, (b) Adam
Generally, ResNet50 achieves great results in biomedical images that reflect our evaluation results. It also requires fewer computational costs by enabling the training of data with fewer data sets, so it reaches the top results in the training and testing phases with both SGD and ADAM optimizers. As investigated in Table 5, the confusion matrices for ResNet (50) in both training and validation stages achieved promising results. Furthermore, it is noted that the utilization of the Adam optimizer achieved higher accuracy than SGD in terms of accuracy in the training phase. While in the validation phase the accuracy achieved 99.07% based on the Adam optimizer compared with SGD 98.96%. Similarly, using VGG (19) the accuracy based on Adam optimized achieved higher accuracy than SGD as investigated in Table 6.
The performance of VGG (16) indicated that the accuracy of validation set using Adam optimizer achieved higher accuracy than SGD as shown in Table 7. The VGG (16) model released the last Convolutional Layer so that it would learn the specific features of the dataset. That should significantly help to improve performance. It retrains the ConvLayer of InceptionV3, but the model overfits too much to get an excellent test performance. The reason why our model does not overfit too much maybe that the VGG (16) model is not as complicated as InceptionV3 as shown in Table 8. Table 9 summarizes the achieved accuracies of the proposed ResNet (50), VGG (19), VGG (16), and Inception V3 transfer learning DCNN approaches in the training and validation phases. The proposed ResNet (50) achieved a higher performance of 99.07% in terms of accuracy. The comparison between the proposed method based on ResNet (50), VGG (19), VGG (16), and Inception (v3) transfer learning and the most recent approaches using the COVIDx dataset is shown in Fig. 11.

The comparative study between the proposed transfer learning model and the recent approaches
5 Discussion
In this work, the DCNN model is utilized to understand the most relevant features in CT images that are indicative of COVID-19. By examining the model's behavior and analyzing its internal representations, it may be possible to gain insights into the visual patterns or image characteristics that the model focuses on when making its predictions. As shown in Fig. 2, the DCNN model highlight certain regions in CT images that are consistently associated with COVID-19, such as consolidations or specific patterns of lung involvement. The models start with the preprocessing of the input images to extract the features. These features identified by the model can be interpreted by medical professionals to gain a better understanding of the disease and potentially aid in diagnosis or treatment planning. However, it is vital to emphasize that the model's conclusions should be interpreted with caution and in consultation with medical specialists. The identification of specific features or regions by the model should be regarded as a starting point for further investigation and validation by medical professionals, who have the domain expertise required to interpret the significance of these findings in the context of COVID-19 diagnosis and management. Even if the model achieves high accuracy, it is critical to examine its limitations and identify where it may stumble. DCNN models are not perfect and might have flaws or restrictions in their predictions. These constraints might be caused by a variety of variables, including the availability and quality of training data, the complexity of specific cases or situations, or the model's intrinsic biases or generalization capabilities. Furthermore, the model's performance may vary based on the severity of COVID-19 instances or the presence of comorbidities, since these variables might cause differences in the disease's visual symptoms.
Understanding training and prediction time averages helps healthcare providers efficiently allocate resources, optimize computational use, and ensure model deployment without delays or bottlenecks. ResNet (50) and BCE's success in COVID-19 detection from chest CT scans is significant due to their tailored application and results, providing valuable insights for similar applications and inspiring further research in medical image analysis.
The deployment of a COVID-19 early detection model from chest CT scans in clinical settings presents numerous challenges and considerations. The AI model's integration with existing healthcare IT systems is a significant challenge, necessitating standardized data formats and communication protocols for seamless functioning. Patient privacy and data security are crucial in COVID-19, necessitating compliance with Health Insurance Portability and Accountability Act (HIPAA) regulations, robust encryption, and access control mechanisms.
Longitudinal research on COVID-19 development in patients provide significant insights, enhance patient care, and influence public health measures; nevertheless, ethical issues and patient agreement must be prioritized. Deep convolutional neural network (DCNN) models have the potential to be used for individualized diagnoses in COVID-19. To understand patterns and characteristics related with COVID-19 infection, these models may be trained on huge datasets of CT scans. Pretrained models, which are trained on a broad dataset before being fine-tuned for a given job, might be a good place to start when constructing individualized diagnostic models. The idea of fine-tuning pretrained models for specific patients based on their medical history is exciting. The model's predictions might possibly be enhanced and adapted to each patient's unique situation by including additional patient-specific information, such as medical history, comorbidities, or past CT scans. This tailored strategy has the potential to improve diagnosis accuracy while also providing more nuanced insights into disease progression and treatment response. We strongly propose that data scientists, medical practitioners, and regulatory agencies work together to build robust and trustworthy models that can successfully contribute to tailored diagnosis and patient treatment. Collaboration with radiologists and medical experts is crucial for refining the model and its outputs in using chest CT scans for early COVID-19 detection. Radiologists and medical experts offer specialized knowledge and clinical experience, providing insights into chest CT scans and COVID-19 imaging features, enhancing the model's understanding of the disease. Radiologists can offer valuable insights into the practical challenges of implementing a model in a clinical setting, particularly in addressing integration issues with existing healthcare systems.
6 Conclusion and future work
In this paper, we propose a Deep Convolutional Neural Network (DCNN) model for the classification of COVID-19, pneumonia, and normal cases based on CT scan images. To mitigate overfitting and improve performance, we use the Binary Cross-Entropy (BCE) loss function. The proposed ResNet (50) model with Adam optimizer achieved exceptional performance in terms of various evaluation metrics, including recall, specificity, precision, negative predictive value, false-positive rate, false discovery rate, false-negative rate, accuracy, F1 score, and Matthews Correlation Coefficient. Specifically, the validation test results showed an accuracy of 99.53%, 98.62%, 98.59%, 99.54%, 0.0138, 0.0141, 0.0047, 99.07%, 99.06%, and 98.14% respectively. Our study highlights the potential benefits of transfer learning coupled with the BCE loss function. It demonstrates that the combination of these techniques leads to improved accuracy in pneumonia diagnosis and prediction while reducing the detection time. The proposed model achieved high accuracy measures in validation tests, indicating its potential for accurate diagnosis of COVID-19 and pneumonia. Future work includes expanding the dataset, testing on different types of imaging modalities, and investigating the generalizability of the proposed model on a larger population.
Data availability
References
Jinia AJ, Sunbul NB, Meert CA et al (2020) Review of Sterilization Techniques for Medical and Personal Protective Equipment Contaminated with SARS-CoV-2. IEEE Access 8:111347–111354. https://doi.org/10.1109/ACCESS.2020.3002886
He X (2020) Sample-efficient deep learning for COVID-19 diagnosis based on CT scans. IEEE transactions on medical imaging
Rodriguez Velásquez S, Jacques L, Dalal J et al (2021) The toll of COVID-19 on African children: A descriptive analysis on COVID-19-related morbidity and mortality among the pediatric population in Sub-Saharan Africa. Int J Infect Dis 110:457–465. https://doi.org/10.1016/j.ijid.2021.07.060
Tahamtan A, Ardebili A (2020) Real-time RT-PCR in COVID-19 detection: issues affecting the results. Expert Rev Mol Diagn 20:453–454
Arevalo-Rodriguez I, Buitrago-Garcia D, Simancas-Racines D et al (2020) False-negative results of initial RT-PCR assays for COVID-19: a systematic review. PLoS One 15:e0242958
van Kasteren PB, van Der Veer B, van den Brink S et al (2020) Comparison of seven commercial RT-PCR diagnostic kits for COVID-19. J Clin Virol 128:104412
Elzeki OM, Shams M, Sarhan S et al (2021) COVID-19: a new deep learning computer-aided model for classification. PeerJ Computer Science 7:e358
Elzeki OM, Abd Elfattah M, Salem H, et al (2021) A novel perceptual two layer image fusion using deep learning for imbalanced COVID-19 dataset. PeerJ Computer Science 7
ElAraby ME, Elzeki OM, Shams MY et al (2022) A novel Gray-Scale spatial exploitation learning Net for COVID-19 by crawling Internet resources. Biomed Signal Process Control 73:103441
Shams MY, Elzeki OM, Abouelmagd LM et al (2021) HANA: a healthy artificial nutrition analysis model during COVID-19 pandemic. Comput Biol Med 135:104606
Hassan E, Shams M, Hikal NA, Elmougy S (2021) Plant Seedlings Classification using Transfer Learning. In: 2021 International Conference on Electronic Engineering (ICEEM). IEEE, pp 1–7
Elmuogy S, Hikal NA, Hassan E (2021) An efficient technique for CT scan images classification of COVID-19. J Intell Fuzzy Syst 40:5225–5238
Salem H, Shams MY, Elzeki OM et al (2022) Fine-Tuning Fuzzy KNN Classifier Based on Uncertainty Membership for the Medical Diagnosis of Diabetes. Appl Sci 12:950
Shen D, Wu G, Suk H-I (2017) Deep learning in medical image analysis. Annu Rev Biomed Eng 19:221–248
Zheng C, Deng X, Fu Q, et al (2020) Deep learning-based detection for COVID-19 from chest CT using weak label. MedRxiv
Lensink K, Laradji I, Law M, et al (2020) Segmentation of pulmonary opacification in chest ct scans of covid-19 patients. arXiv preprint arXiv:200703643
Hassan E, Shams MY, Hikal NA, Elmougy S (2023) Covid-19 diagnosis-based deep learning approaches for covidx dataset: A preliminary survey. Artificial Intelligence for Disease Diagnosis and Prognosis in Smart Healthcare 107
Shams MY, Elzeki OM, Abd Elfattah M, et al (2020) Why Are Generative Adversarial Networks Vital for Deep Neural Networks? A Case Study on COVID-19 Chest X-Ray Images. In: Big Data Analytics and Artificial Intelligence Against COVID-19: Innovation Vision and Approach. Springer, pp 147–162
Hassan E, Shams MY, Hikal NA, Elmougy S (2022) The effect of choosing optimizer algorithms to improve computer vision tasks: a comparative study. Multimedia Tools and Applications 1–43
Cherti M, Jitsev J (2021) Effect of large-scale pre-training on full and few-shot transfer learning for natural and medical images. arXiv e-prints arXiv: 2106.00116
Chowdhury NK, Kabir MA, Rahman M, Rezoana N (2020) Ecovnet: An ensemble of deep convolutional neural networks based on efficientnet to detect covid-19 from chest x-rays. arXiv preprint arXiv:200911850
Baruch M, Greenberg L, Moshkowich G (2021) Fighting COVID-19 in the Dark: Methodology for Improved Inference Using Homomorphically Encrypted DNN (preprint). arXiv:211103362v1. https://doi.org/10.48550/arXiv.2111.03362
Mei X, Lee HC, Diao K yue, et al (2020) Artificial intelligence–enabled rapid diagnosis of patients with COVID-19. Nature Medicine 26:1224–1228https://doi.org/10.1038/s41591-020-0931-3
Maheen U, Malik KI, Ali G (2021) Comparative Analysis of Deep Learning Algorithms for Classification of COVID-19 X-Ray Images. 9:73–81
Zhang H tao, Zhang J song, Zhang H hua, et al (2020) Automated detection and quantification of COVID-19 pneumonia: CT imaging analysis by a deep learning-based software. European Journal of Nuclear Medicine and Molecular Imaging 47:2525–2532https://doi.org/10.1007/s00259-020-04953-1
Harkness R, Hall G, Frangi AF, et al (2021) The pitfalls of using open data to develop deep learning solutions for COVID-19 detection in chest X-rays. arXiv preprint arXiv:210908020
Sarkar A, Vandenhirtz J, Nagy J et al (2021) Identification of Images of COVID-19 from Chest X-rays Using Deep Learning: Comparing COGNEX VisionPro Deep Learning 1.0™ Software with Open Source Convolutional Neural Networks. SN Comput Sci 2:1–18. https://doi.org/10.1007/s42979-021-00496-w
Samee NA, El-Kenawy E-SM, Atteia G, et al (2022) Metaheuristic optimization through deep learning classification of COVID-19 in chest X-ray images. Computers, Materials and Continua 4193–4210
Shams M, Elzeki O, Abd Elfattah M, Hassanien A (2020) Chest x-ray images with three classes: covid-19, normal, and pneumonia, Mendeley Data v3
Hassan E, Shams M, Hikal NA, Elmougy S (2021) Plant Seedlings Classification using Transfer. In 2021 International Conference on Electronic Engineering (ICEEM), pp. 1–7. IEEE, 2021.
Gunraj H, Wang L, Wong A (2020) COVIDNet-CT: A Tailored Deep Convolutional Neural Network Design for Detection of COVID-19 Cases From Chest CT Images. Front Med 7:608525. https://doi.org/10.3389/fmed.2020.608525
Acknowledgements
We would like to thank the editor and anonymous reviewers for their helpful comments and valuable suggestions.
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
All authors take part in the discussion of the work described in this paper. Esraa Hassan, and Samir Elmougy conceived and designed the experiments; Esraa Hassan, and Noha A. Hikal performed the experiments Esraa Hassan, and Samir Elmougy analyzed the data; Mahmoud Y. Shams, Esraa Hassan, and Samir Elmougy wrote the paper.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The author declares that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hassan, E., Shams, M.Y., Hikal, N.A. et al. Detecting COVID-19 in chest CT images based on several pre-trained models. Multimed Tools Appl 83, 65267–65287 (2024). https://doi.org/10.1007/s11042-023-17990-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-17990-3