
Abstract
Facial expression recognition is a fine-grained task because different emotions have subtle facial movements. This paper proposes to learn inter-class optical flow difference using generative adversarial networks (GANs) for facial expression recognition. Initially, the proposed method employs a GAN to produce inter-class optical flow images from the difference between the static fully expressive samples and neutral expression samples. Such inter-class optical flow difference is used to highlight the displacement of facial parts between the neutral facial images and fully expressive facial images, which can avoid the disadvantage that the optical flow change between adjacent frames of the same video expression image is not obvious. Then, the proposed method designs four-channel convolutional neural networks (CNNs) to learn high-level optical flow features from the produced inter-class optical flow images, and high-level static appearance features from the fully expressive facial images, respectively. Finally, a decision-level fusion strategy is adopted to implement facial expression classification. The proposed method is validated on two public facial expression databases, BAUM_1a, SAMM and AFEW5.0, demonstrating its promising performance.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
With the development of human-computer interaction (HCI), facial expression recognition is becoming increasingly important because it makes human-computer interaction more natural [16]. Facial feature extraction is a key step in a facial expression recognition system [31]. So far, the representative facial features are the static geometry appearance [10, 20, 22, 29]. The static geometry appearance is popularly employed to recognize facial expressions since it contains valuable information for expression detection and can effectively characterize expressions [18]. Extracting dynamic optical flow images for facial expression recognition, as a supplement to the static geometry appearance, is a challenging problem.
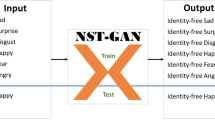
To improve the effect of facial expression recognition, the optical flow features of facial images, which can well describe the regional difference between two different facial expression images, will provide an insight. The inter-class optical flow images from the difference between the static fully expressive samples and neutral samples, are able to emphasize the dynamic expression variation (displacement) of facial parts between the neutral facial images and the fully expressive facial images. A comparison of the neutral expression with other expressions is shown in Fig. 1.

A comparison of the neutral expression with other expressions
Motivated by the good properties of inter-class optical flow images, this paper proposes to employ generative adversarial networks (GANs) [9] to produce inter-class dynamic optical flow images, as a supplement to the static appearance images, so as to further enhance the discriminative power of feature representations. Our method can effectively distinguish the changes between the static fully expressive samples and neutral samples, thereby significantly improving the performance of facial expression recognition. The inter-class optical flow images and the static appearance images are separately fed into the designed convolutional neural networks (CNNs) to learn high-level feature representations. Then, the classification results based on them are fused on decision-level for facial expression recognition.
The main contributions of this paper are as follows:
-
(1).
We propose to employ a GAN to produce inter-class optical flow images so as to highlight the dynamical facial parts changing from the neutral facial image to the fully expressive facial image. To the best of our knowledge, this work is the first to employ a GAN to learn inter-class optical flow difference for facial expression recognition.
-
(2).
We design four-channel convolutional neural networks (CNNs) to learn high-level optical flow features from the produced optical flow images and the static appearance features from the fully expressive facial images, respectively.
-
(3).
The proposed method is verified on two public databases, BAUM_1a, SAMM and AFEW5.0, showing its effectiveness.
2 Related work
Facial expression recognition aims to perceive user’s emotional changes which are very useful for a lot of application scenarios, like monitoring patient’s status [1], enhancing spatial perception [2], and making decisions faster in emergency situations [24]. The main methods of facial expression recognition usually utilize the static appearance and optical flow information from facial images. Static appearance images are popularly employed to recognize facial expressions and achieve good recognition performance [7]. The static appearance of the mouth and eyes is employed to recognize smiling [3]. The static appearance of the nose is employed to recognize the facial expression of disgust [28]. The spatial emotional region is employed to recognize facial expressions by a new action-unit attention mechanism [21]. Dhall A et al. [8] employs local binary pattern-three orthogonal planes (LBP-TOP), pyramid of histogram of gradients (PHOG) and local phase quantisation (LPQ) to recognize facial expression. Kayaoglu et al. [11] presents a multimodal categorical emotion recognition method based on key frame selection from video. Yao A et al. [37] presents a pair-wise learning strategy to learn the AU-aware features Zhalehpour S et al. [38] employs the static appearance images to recognize facial expressions. Knor et al. [12] presents a lightweight Dual-Stream Shallow Network (DSSN) to learn deep micro-expression features. Pan H et al. [26] employs low-level descriptors of static appearance images to recognize facial expressions. Li et al. [23] adopts two methods (Branches [19] and ApexME [14]) by using MiE-X pre-training to improve the facial expression recognition accuracy. The gray-level co-occurrence matrix is adopted to represent facial images and achieves the expected recognition results [13]. Although static appearance images can achieve promising recognition results, fusing the optical flow information can mine more contextual and deeper information for facial expression recognition.
At present, numerical studies have focused on fusing optical flow images with other features to improve recognition performance [33]. Pan X et al. [27] employs the static appearance images and intra-class optical flow images of adjacent frames to identify facial expressions. Zhang S et al. proposes a hybrid deep learning model to apply for facial expression recognition [39]. Action units (AUs) are widely employed to represent the main facial appearance region changes in the mouth and eyes. It is necessary to guide our method to focus on optical flow information for facial expression recognition. Weighted spatial and optical flow features are employed to classify facial expressions and outperform state-of-the-art methods on CASME II and SMIC-HS [34]. The spatial and optical flow features are learned simultaneously and play a significant role in facial expression recognition [36]. The apex frame of the frequency domain is detected and employed to recognize micro-expressions [16]. The frequency domain is adopted to yield high-level features by the learnable multiplication kernel for facial expression recognition [32]. The optical flow features are extracted and combined with facial landmarks to recognize facial expression. In this way, these methods achieve competitive facial expression recognition performance [15].
From the above-mentioned previous works, we can see that it is feasible to fuse optical flow information with other features for improving facial expression recognition performance. However, identifying subtle facial movements between different facial expressions is still a challenging problem. Many researchers adopt the intra-class optical flow information between the fully expressive (peak) frame and the neural frame from the same sample for facial expression recognition [4, 40]. Nevertheless, few researchers focus on employing inter-class optical flow information that reflect the difference between the static fully expressive samples and neutral samples for facial expression for improving facial expression classification. Therefore, this paper proposes to employ a generative adversarial networks (GAN) to learn inter-class optical flow difference between the static fully expressive samples and neutral samples, and then the learned optical flow difference are combined with the learned static appearance features from the fully expressive facial images to further recognize facial expressions on decision-level.
3 The proposed method
The framework of the proposed method is shown in Fig. 2. It has three key steps:
-
(1).
Generating inter-class optical flow images with a GAN;
-
(2).
Designing four-channel CNNs to learn high-level optical flow features from the produced optical flow images and the static appearance features from the fully expressive facial images, respectively;
-
(3).
Implementing decision-level fusion for final expression classification.

The framework of the proposed method for facial expression recognition
It is known that all facial images have the labels of facial expressions in the training datasets. In this case, we can produce the inter-class optical flow images between the static fully expressive samples and neutral samples in the training datasets. However, it is noted that in real-world application scenarios the labels of facial expression images from the testing datasets are not available. In this case, the labels of facial expression images from the training datasets are only obtained. Therefore, we cannot directly obtain inter-class optical flow images between the static fully expressive samples and neutral samples in the testing datasets. To solve this problem, generative adversarial networks (GANs) [9] are designed to generate inter-class optical flow images between the static fully expressive samples and neutral samples. The inter-class optical flow images between the fully expressive image (such as joy) and the neutral facial images have more displacement information, reflecting he dynamic expression variation (displacement) of facial parts between the neutral facial images and the fully expressive facial images. A four-channel CNN structure is designed to recognize facial expression categories of inter-class optical flow images and static appearance images simultaneously. Considering the complementarity between the dynamic inter-class optical flow images and the static appearance facial image for facial expression classification, a decision-level fusion strategy is designed to integrate four-channel based classification results for final facial expression recognition.
3.1 Generating inter-class optical flow images with a GAN
The facial action coding system (FACS) shows that the movements of key regions are the most important clues for facial expression recognition [5]. Thus, neutral facial expression can be used as the reference point for a comparison with other fully expressive categories. The displacement variation between neutral expression images and other fully expressive images is employed to reflect the dynamic expression variation. This can be embodied by producing inter-class optical flow images, which is similar to inter-class optical flow images for facial expression classification. Due to the influence of possibly existing noise from the input image, it is necessary to perform noise reduction when extracting inter-class optical flow images. To reduce the impact of noise, FaceNet is employed to preprocess and crop face images [30].
To generate inter-class optical flow images between neutral expression images and other fully expressive facial expression images, GANs [9] may provide a possible solution. GANs can be used to directly generate inter-class optical flow images based on the target facial expression images and neutral facial expression images. The discrimination of optical flow feature in different facial expressions is expanded by the proposed GAN, which is compared with neutral expression. It avoids the disadvantage that the optical flow change between adjacent frames of the same video expression image is not obvious. The design of a GAN is shown in Fig. 3.

The illustration of the used cycle-GAN for generating inter-class optical flow images
In detail, a facial image x (static appearance images) is fed into a network K (Generator) to generate an inter-class optical flow image relative to neutral expression image y (optical flow images). Similarly, y is fed into the network R (Generator) to generate the facial image x. Given the training samples \( {\left\{{x}_i\right\}}_{i=1}^N\in X \)and\( {\left\{{y}_i\right\}}_{i=1}^N\in Y \), in this work we used the cycle-GAN [42] to learn two mapping functions: K : X → Y, and R : Y → X. DX and DY are two adversarial discriminators. Here, DX aims to identify between the facial image x and the translated imageR(y). Similarly, DY aims to distinguish between the image y and the translatedK(x). For the mapping function K : X → Yand its discriminator DY, the adversarial loss is defined as:
where E represents Expectation.
Likewise, for the mapping function R : Y → X and its discriminator DX, the adversarial loss is defined as:
Suppose that the learned mapping functions are cycle-consistent, the cycle consistency loss is defined as:
Then, the full objection function is defined as:
where λ aims to control the related importance of the used two objective functions. The parameters that minimize the total loss of formula (4) are obtained by using the facial expression training dataset. Therefore, we can calculate the inter-class optical flow image related to the neutral expression image according to the input facial image with a GAN, as shown in Fig. 3. The input facial image size is 299 × 299 × 3.
In the generative adversarial network training process, the template of inter-class optical flow images related to the neutral expression images is achieved based on the BAUM_1a facial expression dataset [38], because the facial expression images of the BAUM_1a dataset are very standardized and comprehensive. In detail, the template of inter-class optical flow images related to the neutral expression images is computed by formula (5). Here, \( {M}_p^l \) represents the inter-class optical flow image related to the neutral expression image. It also represents the l-th type of facial expression, such as joy. \( {S}_{c,j}^{(l)} \) denotes the l-th type of facial image, N represents the neutral expression image, and \( {S}_{d,j}^{(l)} \) represents the number of facial images belonging to the l-th facial expression.
3.2 Designing four-channel CNNs for high-level feature learning
Different softmax loss with CNNs may bring about different classification performance [35]. It is noted that the basic L1-contrained softmax loss makes the learned features prone to be separable, rather than discriminative for classification. By contrast, L2-constrained softmax loss is able to increase the discriminative power of the learned features, thereby increasing the classification performance. Motivated by diverse properties of L1 and L2-contrained softmax loss on classification tasks, we design four-channel CNNs (CNN-1, CNN-2, CNN-3, CNN-4) for high-level feature learning, as shown in Fig. 2. Every channel of the proposed framework has the same CNN structure, which has 17 convolution layers, 5 max-pooling layers, and 1 fully connected (FC) layer. Among four-channel CNNs, CNN-1 and CNN-3 employ the basic L1-contrained softmax loss, whereas CNN-2 and CNN-4 adopt the L2-contrained softmax loss. In Fig. 2, CNN-1 and CNN-2 are used to learn high-level appearance features from the static fully expressive facial images. By contrast, CNN-3 and CNN-4 are leveraged to learn high-level inter-class optical flow difference from the produced inter-class optical flow images. In this case, there may exist the complementarity among the learned different features with the designed four-channel CNNs (CNN-1, CNN-2, CNN-3, CNN-4) on facial expression classification tasks. The key step of a CNN is to implement the convolution operation with convolution layers. The goal of convolution layers is to learn more representative emotional features. The convolution layer consists of several convolution kernels. The process of convolution calculation is shown in formula (6).
where f refers to the input image, and ∅ denotes the convolution kernel. The size of the convolution kernel is 3 × 3. The goal of max-pooling layers is to reduce the emotional feature dimension. The FC layer is employed to classify emotions. The output of each channel CNN is a 1 × 7 vector. The size of maximum pooling is 2 × 2. The input image size is 48 × 48 × 1. The proposed framework employs two independent CNNs to classify face images and two other independent CNNs to classify inter-class optical flow images simultaneously. In this way, four classification results for the input image are obtained.
The illustrations of training process with different CNNs on BAUM_1a, SAMM and AFEW5.0 are shown in Figs. 4, 5 and 6 respectively. Horizontal coordinate means the number of training epoch. Vertical coordinate means the loss values. The acceptable convergence results are obtained in the range of 1000 steps during training on the three database sets.

The illustrations of training process with different CNNs on BAUM_1a

The illustrations of training process with different CNNs on SAMM

The illustrations of training process with different CNNs on AFEW5.0
3.3 Decision-level fusion
Considering the complementarity among the learned features of the designed four-channel CNNs (CNN-1, CNN-2, CNN-3, CNN-4) on facial expression classification tasks, integrating their obtained results of four-channel CNNs may provide better performance [17]. To this end, a decision–level fusion strategy is adopted to improve the performance of facial expression recognition. This is shown in formula (7).
where Aoptical and Boptical separately represent the classification scores of CNN-3 and CNN-4 from the produced inter-class optical flow images. Cstatic and Dstatic individually represent the classification scores of CNN-1 and CNN-2 from the static appearance images. w1, w2, w3, w4 are the weights of decision makers, which satisfy formula (8). We seek every w in the range of [0,1] with an interval of 0.1 satisfying formula (8) and find that w1 = 0.1, w2 = 0.1, w3 = 0.4 and w4 = 0.4 give the best performance on facial expression recognition tasks. Once the optimal weight values of w1, w2, w3, w4 are fixed, we perform the maximization operations on the total fused classification scores to obtain the final class. In this way, the proposed method combines different learned features with certain consistency and complementarity to improve facial expression recognition performance.
4 Experimental studies
The proposed method is evaluated on three public datasets. The experimental implementation details and analysis are shown in this section.
4.1 Datasets
BAUM_1a [38]: There are 31 persons acting in 1222 video clips in the BAUM_1a dataset. It includes videos of contempt, joy, fear, anger, sadness, surprise, disgust and other facial expressions. In this wok, the middle frame of each video from BAUM_1a Dataset is employed as a facial image sample for facial expression recognition. In addition, we focus on six basic expressions: surprise, sadness, joy, disgust, fear, and anger, thereby producing 521 samples for experiments. Some facial images of BAUM_1a are shown in Fig. 7.

Some facial images of BAUM_1a
SAMM [6]: There are 32 persons acting in 159 video clips in the SAMM dataset. It has videos of joy, fear, anger, sadness, surprise, disgust, contempt, and other facial expressions. In this work, 11,816 images on the SAMM are used to evaluate the proposed method, including six basic expressions: surprise, sadness, joy, disgust, fear, and anger. Some facial images of SAMM are shown in Fig. 8.

Some facial images of SAMM
AFEW5.0 [8]: It is divided three parts, which are training, validation and testing. The training part has 723 samples. The valid part has 383 samples. The testing part has 539 samples. It includes videos of neutral, joy, fear, anger, sadness, surprise and disgust. Some facial images of AFEW5.0 are shown in Fig. 9.

Some facial images of AFEW5.0
4.2 Experimental results and analysis
The well-known leave-one-subject-out (LOSO) cross-validation strategy is employed for subject-independent experiments. The respective recognition accuracies of the inter-class optical flow images and static appearance images are shown in Table 1.
Table 1 shows that static appearance images play a major role in facial expression recognition, whereas the role of inter-class optical flow images in facial expression recognition is smaller than static appearance images. In particular, the inter-class optical flow images provide an accuracy of 46.70% on BAUM_1a, 55.30% on SAMM and 27.84% on AFEW5.0 respectively. The static appearance images separately give an accuracy of 52.80% on BAUM_1a, 57.60% on SAMM and 30.12% on AFEW5.0. Fusing the inter-class optical flow images and the static appearance images can significantly improve facial expression recognition performance. In detail, our proposed method individually obtains an accuracy of 56.98% on BAUM_1a, 60.20% on SAMM and 44.72% on AFEW5.0. This shows the effectiveness of integrating the inter-class optical flow images and the static appearance images. Besides, it is noted that AFEW5.0 collected image data on the lighting conditions in the wild which is mostly close to the real-world scenarios, whereas BAUM_1a and SAMM obtained image data on hand-designed experimental lighting conditions. That is why the reported performance on AFEW5.0 dataset is lower than the reported results on other datasets.
Figures 10, 11 and 12 separately describe the confusion matrix of recognition results of each expression on these datasets.

The confusion matrix of recognition results on the BAUM_1a database

The confusion matrix of recognition results on the SAMM database

The confusion matrix of recognition results on the AFEW5.0 database
Evaluation metrics, such as Precision, Recall, Accuracy, F1-score are adopted in this paper. They are defined as follows:
where TP represents True Positive, FP represents False Positive, TN represents True Negative and FN represents False Negative.
Tables 2, 3 and 4 separately show the performance measures for every expression on these datasets.
As shown in Figs. 10, 11 and 12 and Tables 2, 3 and 4, we can see that “fear” is more difficult to classify than other expressions on BAUM_1a, SAMM and AFEW5.0. This may be attributed to that fear is easily confused with other expressions such as sadness or anger on these datasets.
4.3 Performance comparison with state-of-the-art methods
To show the effectiveness of the proposed method, we compared our obtained results with state-of-the-art methods. The proposed method gains an improvement of 3.38%, 1.74% and 0.25% on the BAUM_1a dataset, SAMM dataset and AFEW5.0 database, respectively, compared with the state-of-the-art methods, as shown in Table 5, 6 and 7.
Note that Knor et al., [12] present a lightweight Dual-Stream Shallow Network (DSSN) to learn deep micro-expression features. Pan H et al., [26] employed low-level descriptors of static appearance images to recognize facial expressions in SAMM. Li et al., [23] adopted two methods [14, 19] by using MiE-X pre-training to improve the accuracy on SAMM. A comparison of results is shown in Table 5.
Zhalehpour S et al., [38] also employed the static appearance images to recognize facial expressions in BAUM_1a. Pan X et al., [27] employed the static appearance images and intra-class optical flow images of adjacent frames to identify facial expressions in BAUM_1a. Zhang S et al. [39] propose a hybrid deep learning model to apply for facial expression recognition. Comparison of results as shown in Table 6.
AFEW5.0 is one of the databases for video and image based emotion recognition challenges in the wild 2015. Dhall A et al., [8] describes the baselines, data and protocols for the challenges. The testing part of AFEW has no label, we compared with the validate part, Kayaoglu et al., [11] employed the Minimum Sparse Reconstruction of key static appearance images to identify facial expressions in AFEW5.0. Yao A et al. [37] presents a pair-wise learning strategy to learn the AU-aware features in AFEW5.0, comparison of results as shown in Table 7.
5 Conclusions and future work
This paper proposes a new facial expression recognition method, which learns inter-class optical flow difference with a designed GAN. Such inter-class optical flow difference aims to emphasize the displacement of facial parts between the neutral facial images and fully expressive facial images. The GAN produces inter-class optical flow images so as to highlight the dynamical facial parts changing. The designed four-channel convolutional neural networks (CNNs) can learn high-level optical flow features from the produced optical flow images and the static appearance features from the fully expressive facial images, respectively. From the above-mentioned experiments on the SAMM, BAUM_1a and AFEW5.0 datasets, we conclude that integrating the inter-class optical flow images and the static appearance images yield promising performance on facial expression recognition tasks.
In future, it is meaningful to explore the performance of advanced and effective shallow CNNs [25] on facial expression recognition owing to the limited samples. In addition, it is a research direction to investigate the performance of our method on cross-database micro-expression recognition tasks [41]. It will also be interesting to design a more comprehensive deep learning framework to further promote facial expression recognition performance.
Data availability
The data used to support the findings of this study are available from http://baum1.bahcesehir.edu.tr/ (BAUM_1a dataset) and http://goo.gl/SJmoti (SAMM dataset).
References
Breve B, Caruccio L, Cirillo S, Deufemia V, Polese G (2021) Visual ECG analysis in real-world scenarios. In proceedings of 27th International DMS Conference on Visualization and Visual Languages(DMSVIVA 2021), Virtual, Pittsburgh, PA, United states, 29–30 June 2021; pp. 46–54. https://doi.org/10.18293/DMSVIVA2021-008
Breve B, Cirillo S, Cuofano M, Desiato D (2022) Enhancing spatial perception through sound: mapping human movements into MIDI. Multim Tools Appl 81(1):73–94. https://doi.org/10.1007/s11042-021-11077-7
Calvo M, Fernández-Martín A, Nummenmaa L (2012) Perceptual, categorical, and affective processing of ambiguous smiling facial expressions. Cognition 125(3):373–393. https://doi.org/10.1016/j.cognition.2012.07.021
Chen J, Xu R, Liu L (2018) Deep peak-neutral difference feature for facial expression recognition. Multim Tools Appl 2018(22):29871–29887. https://doi.org/10.1007/s11042-018-5909-5
Clark E, Kessinger J, Duncan S, Bell M, Lahne J, Gallagher D, O’Keefe S (2020) The facial action coding system for characterization of human affective response to consumer product-based stimuli: a systematic review. Front Psychol 11:1–21. https://doi.org/10.3389/fpsyg.2020.00920
Davison A, Lansley C, Costen N, Tan K, Yap M (2018) SAMM: a spontaneous Micro-facial movement dataset. IEEE Trans Affect Comput 9(1):116–129. https://doi.org/10.1109/TAFFC.2016.2573832
Deriso D, Susskind J, Tanaka J, Winkielman P, Herrington J, Schultz R, Bartlett M (2012) Exploring the facial expression perception-production link using real-time automated facial expression recognition. In proceedings of 12th European conference on computer vision(ECCV 2012), Florence, Italy, 7-13 October 2012; pp. 270-279. https://doi.org/10.1007/978-3-642-33868-7_27
Dhall A, Ramana Murthy OV, Goecke R, Joshi J, Gedeon T (2015) Video and image based Emotion recognition challenges in the wild: EmotiW 2015. In Proceedings of the 2015 ACM International Conference on Multimodal Interaction (ICMI 2015), Seattle, WA, United states, 9–13 November, 2015; pp. 423–426. https://doi.org/10.1145/2818346.2829994
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2014) Generative adversarial nets. In Proceedings of 28th Annual Conference on Neural Information Processing Systems(NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. https://proceedings.neurips.cc/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3Paper.pdf
Kamarol S, Jaward M, Parkkinen J, Parthiban R (2016) Spatiotemporal feature extraction for facial expression recognition. IET Image Process 10(7):534–541. https://doi.org/10.1049/iet-ipr.2015.0519
Kayaoglu M, Erdem CE (2015) Affect Recognition using Key Frame Selection based on Minimum Sparse Reconstruction. In Proceedings of the 2015 ACM International Conference on Multimodal Interaction (ICMI 2015), Seattle, WA, United states, 9–13 November, 2015; pp. 519–524. https://doi.org/10.1145/2818346.2830594
Khor H, See J, Liong S, Phan RCW, Lin W (2019) Dual-stream Shallow Networks for Facial Micro-expression Recognition. In Proceedings - International Conference on Image Processing (ICIP2019), Taipei, Taiwan, China, 22–25 September, 2019; pp. 36–40. https://doi.org/10.1109/ICIP.2019.8802965
Kommineni J, Mandala S, Sunar M, Chakravarthy P (2021) Accurate computing of facial expression recognition using a hybrid feature extraction technique. J Supercomput 77:5019–5044. https://doi.org/10.1007/s11227-020-03468-8
Li Y, Huang X (2018) Zhao G (2018) can Micro-expression be recognized based on single apex frame? In proceedings of 2018 IEEE international conference on image processing (ICIP 2018), Athens. Greece 7-10:3094–3098. https://doi.org/10.1109/ICIP.2018.8451376
Li Q, Yu J, Kurihara T, Zhang H, Zhan S (2020) Deep convolutional neural network with optical flow for facial micro-expression recognition. J Circuits Syst Comput 29(1):2050006:1–2050006:205000618. https://doi.org/10.1142/S0218126620500061
Li Y, Huang X, Zhao G (2021) Joint local and global information learning with single apex frame detection for micro-expression recognition. IEEE trans. Image Process 30:249–263. https://doi.org/10.1109/tip.2020.3035042
Li Q, Gkoumas D, Lioma C, Melucci M (2021) Quantum-inspired multimodal fusion for video sentiment analysis. Inf Fusion 65:58–71. https://doi.org/10.1016/j.inffus.2020.08.006
Liang L, Lang C, Li Y, Feng S, Zhao J (2021) Fine-grained facial expression recognition in the wild. IEEE trans. Inf. Forensics Secur 16:482–494. https://doi.org/10.1109/tifs.2020.3007327
Liu Y, Du H, Zheng L, Gedeon T (2019) A neural Micro-expression recognizer. In proceedings of 14th IEEE international conference on automatic face and gesture recognition (FG 2019), Lille, France, 14-18 may 2019; pp. 1-4. https://doi.org/10.1109/FG.2019.8756583
Liu C, Hirota K, Wang B, Dai Y, Jia Z (2020) Two-Channel feature extraction convolutional neural network for facial expression recognition. J Adv Comput Intell Inf 24(6):792–801. https://doi.org/10.20965/jaciii.2020.p0792
Liu D, Ouyang X, Xu S, Zhou P, He K, Wen S (2020) SAANet: Siamese action-units attention network for improving dynamic facial expression recognition. Neurocomputing 413:145–157. https://doi.org/10.1016/j.neucom.2020.06.062
Liu C, Hirota K, Ma J, Jia Z, Dai Y (2021) Facial expression recognition using hybrid features of pixel and geometry. IEEE Access 9:18876–18889. https://doi.org/10.1109/ACCESS.2021.3054332
Liu Y, Wang Z, Gedeon T, Zheng L(2021) Action Units That Constitute Trainable Micro-expressions (and A Large-scale Synthetic Dataset) https://arxiv.org/abs/2112.01730. Accessed 28 Jan 2022
Lopez-Fuentes L, van de Weijer J, González Hidalgo M, Skinnemoen H, Bagdanov AD (2018) Review on computer vision techniques in emergency situations. Multim Tools Appl 77(13):17069–17107. https://doi.org/10.1007/s11042-017-5276-7
Miao S, Xu H, Han Z, Zhu Y (2019) Recognizing facial expressions using a shallow convolutional neural network. IEEE Access 7:78000–78011. https://doi.org/10.1109/ACCESS.2019.2921220
Pan H, Xie L, Lv Z, Li J, Wang Z (2020) Hierarchical support vector machine for facial micro-expression recognition. Multim. Tools Appl. 79(3):31451–31465. https://doi.org/10.1007/s11042-020-09475-4
Pan X, Zhang S, Guo W, Zhao X, Chuang Y, Chen Y, Zhang H (2020) Video-based facial expression recognition using deep temporal–spatial networks. IETE Tech Rev 37(4):402–409. https://doi.org/10.1080/02564602.2019.1645620
Pochedly J, Widen S, Russell J (2012) What emotion does the “facial expression of disgust” express? Emotion 12(6):1315–1319. https://doi.org/10.1037/a0027998
Sadeghi H, Raie A (2019) Human vision inspired feature extraction for facial expression recognition. Multim Tools Appl 78(21):30335–30353. https://doi.org/10.1007/s11042-019-07863-z
Schroff F, Kalenichenko D, Philbin J (2015) FaceNet: a unified embedding for face recognition and clustering. In proceedings of IEEE conference on computer vision and pattern recognition(CVPR 2015), Boston, MA, United States, 7-12 June 2015; pp. 815-823. https://doi.org/10.1109/CVPR.2015.7298682
See J, Yap MH, Li J, Hong X, Wang S (2019) MEGC 2019 - the second facial Micro-expressions grand challenge. In proceedings of 14th IEEE international conference on automatic face and gesture recognition(FG 2019), Lille, France, 14-18 may 2019; pp.1-5. https://doi.org/10.1109/FG.2019.8756611
Tang Y, Zhang X, Hu X, Wang S, Wang H (2021) Facial expression recognition using frequency neural network. IEEE Trans Image Process 30:444–457. https://doi.org/10.1109/tip.2020.3037467
Verburg M, Menkovski V (2019) Micro-expression detection in long videos using optical flow and recurrent neural networks. In proceedings of 14th IEEE international conference on automatic face and gesture recognition(FG 2019), Lille, France, 14-18 may 2019; pp. 1-6. https://doi.org/10.1109/FG.2019.8756588
Wang L, Xiao H, Luo S, Zhang J, Liu X (2019) A weighted feature extraction method based on temporal accumulation of optical flow for micro-expression recognition. Signal Process Image Commun 78:246–253. https://doi.org/10.1016/j.image.2019.07.011
Wang X, Zhang S, Wang S, Fu T, Mei T (2020) Mis-classified vector guided Softmax loss for face recognition. In proceedings of 34th AAAI conference on artificial intelligence (AAAI2020), New York, USA, 7-12 February, 2020; pp. 12241-12248. https://doi.org/10.1609/aaai.v34i07.6906
Wu C, Guo F (2021) TSNN: three-stream combining 2d and 3d convolutional neural network for micro-expression recognition. IEEJ Trans Electr Electron Eng 16:98–107. https://doi.org/10.1002/tee.23272
Yao A, Shao J, Ma N, Chen Y (2015) Capturing au-aware facial features and their latent relations for emotion recognition in the wild. In proceedings of the 2015 ACM international conference on multimodal interaction (ICMI 2015), Seattle, WA, United States, 9-13 November, 2015; pp. 451-458. https://doi.org/10.1145/2818346.2830585
Zhalehpour S, Onder O, Akhtar Z, Erdem C (2017) BAUM-1: a spontaneous audio-visual face database of affective and mental states. IEEE Trans Affect Comput 8(3): 300–313. https://doi.org/10.1109/TAFFC.2016.2553038
Zhang S, Pan X, Cui Y, Zhao X, Liu L (2019) Learning affective video features for facial expression recognition via hybrid deep learning. IEEE Access 7:32297–32304. https://doi.org/10.1109/ACCESS.2019.2901521
Zhao X, Liang X, Liu L, Li T, Han Y, Vasconcelos N, Yan S (2016) Peak-piloted deep network for facial expression recognition. In proceedings of 14th European conference on computer vision (ECCV 2016), Amsterdam, Netherlands 8-16 October, 2016; pp. 425-442. https://doi.org/10.1007/978-3-319-46475-6_27
Zhou L, Mao Q, Xue L (2019) Dual-inception network for cross-database Micro-expression recognition. In proceedings of 14th IEEE international conference on automatic face and gesture recognition(FG 2019), Lille, France, 14-18 may 2019; pp.1-5. https://doi.org/10.1109/FG.2019.8756579
Zhu J, Park T, Isola P, Efros A (2017) Unpaired image-to-image translation using cycle-consistent adversarial networks. In proceedings of 2017 IEEE international conference on computer vision (ICCV 2017), Venice, Italy, 22-29 October 2017; pp. 2242-2251. https://doi.org/10.1109/ICCV.2017.244
Acknowledgments
The authors are grateful to the Institute of Big Data and Artificial Intelligence in Medicine, Taizhou University, for providing computing resources.
Funding
This research was funded by the Humanities and Social Science Project of the Chinese Ministry of Education (20YJAZH033), the Key Projects of Zhejiang Province’s Educational Science Planning (2021SB081), the Zhejiang Provincial Public Welfare Project of China (LGF19F020009), the National Natural Science Foundation of China (61976149), the Zhejiang Provincial National Science Foundation of China (LZ20F020002) and Research Project of Education Department of Zhejiang Province (Y202045617).
Author information
Authors and Affiliations
Contributions
Conceptualization, W.G. and X.Z.; methodology, W.G. and X.P.; software, X.P.; validation, W.G., S.Z. and X.P.; resources, X.Z.; writing—original draft preparation, W.G. and X.P.; writing—review and editing, X.Z. and S.Z.; funding acquisition, X.Z. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflicts of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Guo, W., Zhao, X., Zhang, S. et al. Learning inter-class optical flow difference using generative adversarial networks for facial expression recognition. Multimed Tools Appl 82, 10099–10116 (2023). https://doi.org/10.1007/s11042-022-13360-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-022-13360-7